Лекция 1. Начальные сведения о программах на языке Pascal
Алгоритм и программа
Наш курс посвящен изучению не только языка Pascal, но и некоторых алгоритмов, решающих наиболее известные задачи программирования, поэтому начнем мы со знакомства с некоторыми основополагающими понятиями.
Алгоритм - это последовательность действий, которые необходимо выполнить, чтобы решить поставленную задачу.
Программа же представляет собой набор команд на языке, понятном исполнителю, реализующий некоторый алгоритм. В нашем случае исполнителем является компьютер, а языком программирования будет язык высокого уровня Pascal. К сожалению, любой язык высокого уровня удобен только человеку, пишущему или отлаживающему программу, но совершенно непонятен компьютеру. Программа на таком языке называется исходным текстом и хранится во внешнем файле с расширением .pas.
Для перевода программы на язык низкого уровня, понятный исполнителю-компьютеру, существуют специальные программы-переводчики - компиляторы. Результатом работы компилятора (иными словами, результатом процесса компиляции) является исполняемый код, который записывается в файл с расширением .exe.
Свойства алгоритма
Любой алгоритм должен обладать следующими свойствами:
- массовостью ( алгоритм должен уметь решать не одну конкретную задачу, а целый класс однотипных задач);
- результативностью ( алгоритм должен выдавать результат своей работы);
- определенностью (на каждом шаге выполнения алгоритма исполнитель должен точно знать, какой шаг будет следующим).
Эти же свойства присущи и программам, реализующим алгоритмы. Если же хотя бы одно из них оказывается невыполненным, программа полностью теряет смысл.
Компиляция, отладка и тестирование
Никто не станет спорить с тем, что неграмотно написанный текст очень сложно, а порой и вовсе невозможно правильно перевести на другой язык. Это верно для естественных языков, это верно и для языков программирования. Но если переводчик-человек иногда может как-то догадаться, что же именно хотел сказать автор неграмотного текста, то программе-переводчику такое не по силам. Любой компилятор требует, чтобы программа, подаваемая ему для перевода, была абсолютно правильно составлена.
В языке программирования, как и в любом другом языке, существуют синтаксис - правила записи его конструкций - и семантика - смысл его конструкций. Компилятор проверяет только синтаксис. Поиском же семантических ошибок занимается программист в процессе тестирования и отладки своей программы
Отладка - это поиск и исправление ошибок в программе. Тестирование - это составление специальных наборов входных и выходных данных (тестов), а затем исполнение программы и проверка полученных результатов в поисках возможных семантических или логических ошибок.
Чтобы уменьшить затраты времени и сил на отладку, нужно писать синтаксически и логически правильные программы. Технологиям написания надежных программ, их тестирования и отладки будет посвящена последняя лекция нашего курса.
Средства разработки программ
Существует довольно большое количество средств написания программ на языке Pascal, позволяющих составлять, компилировать, исполнять и отлаживать программы на этом удобном языке структурного программирования1). Самыми известными сегодня являются Turbo Pascal (он же Borland Pascal), Object Pascal (не путать с Delphi) и Free Pascal. Их различные, в том числе и бесплатные, версии можно найти в Сети. Для определенности мы будем опираться на самую распространенную (хотя и не во всем соответствующую стандартам ISO) реализацию - Turbo Pascal.
Итак, в составе среды разработчика Turbo Pascal имеются:
- текстовый редактор, в котором можно набирать тексты программ ;
- компилятор, превращающий исходные тексты в исполняемый код ;
- отладчик, помогающий обнаруживать и исправлять ошибки в программе
Из многочисленных возможностей, предоставляемых средой Turbo Pascal, мы упомянем лишь самые важные - те, без которых написание программ становится совсем уж затруднительным.
- Нажатие клавиш F1, Alt+F1, Ctrl+F1 открывает экранную подсказку.
- Нажатие клавиши F2 позволяет сохранить исходный текст программы.
- Нажатие клавиши F3 открывает диалог выбора нужного файла (по умолчанию, отображаются только файлы с расширением .pas).
- Нажатие клавиши Alt+F5 показывает консоль (см. п. "Ввод и вывод: консоль" ниже) с результатами работы программы.
- Нажатие клавиши Ctrl+F9 начинает процесс выполнения программы. Если она еще не была откомпилирована, предварительно будет вызван компилятор
- Клавиши F7 и F8 обеспечивают трассировку - пошаговое выполнение программы, позволяющее проследить за процессом ее выполнения.
- Дополнительное окно Debug/Watch показывает текущее состояние выбранных переменных.
Более подробно о возможностях среды Turbo Pascal можно узнать в любом руководстве по ее использованию (в том числе и во встроенном Help).
Структура Pascal-программы
Для того чтобы Pasсal-компилятор правильно понял, какие именно действия от него ожидаются, ваша программа должна быть оформлена в полном соответствии с синтаксисом (правилами построения программ ) этого языка.
Приступим же к изучению этих правил.
Любая Pascal-программа может состоять из следующих блоков (напомним, что квадратными скобками здесь и далее помечены необязательные части):
program <имя_программы>;
[ uses <имена_подключаемых_модулей>;] (см. лекцию 13)
[ label <список_меток>;]
(см. п. "Метки и безусловный переход" ниже)
[ const <имя_константы> = <значение_константы>;]
(см. п. "Константы" ниже)
[ type <имя_типа> = <определение_типа>;] (см. лекцию 2)
[ var <имя_переменной> : <тип_переменной>;]
(см. п. "Переменные и типы данных" ниже)
[ procedure <имя_процедуры> <описание_процедуры>;]
(см. лекцию 8)
[ function <имя_функции> <описание_функции>;]
begin {начало основного тела программы}
<операторы>
end. (* конец основного тела программы *)Сразу же необходимо сделать важную оговорку: поздние версии компиляторов языка Pascal уже не требуют указывать название программы, то есть строку
program <имя_программы>;
проще говоря, можно опустить. Но это возможно только в том случае, если вся программа содержится в одном модуле-файле. Если же программа состоит из нескольких самостоятельных кусков - модулей (см. лекцию 13), то каждый из них должен иметь заголовок (program или unit).
Любой из перечисленных необязательных разделов может встречаться в тексте программы более одного раза, их общая последовательность также может меняться, но при этом всегда должно выполняться главное правило языка Pascal: прежде чем объект будет использован, он должен быть объявлен и описан.
Внешний вид исходного текста программы
Компиляторы языка Pascal не различают строчные и прописные буквы, а пробельные символы игнорируют, поэтому текст программы можно структурировать так, чтобы читать и отлаживать его было наиболее удобно.
Например, операторы каждого логически единого блока программы стоит записывать с небольшим отступом от левого края экрана, и чем глубже вложенность блока, тем шире должны быть отступы перед входящими в него операторами. Этому правилу подчиняются все примеры, приводимые в курсе наших лекций2). Кроме того, встроенный редактор среды Turbo Pascal автоматически выравнивает левые края строк. И еще один полезный совет: для облегчения отладки программы не следует записывать на одну строку несколько операторов.
Комментарии
Помимо отступов, большие логически замкнутые блоки программы удобно разделять строками-комментариями, содержащими информацию о смысле последующего блока. Комментарий - это строка (или несколько строк) из произвольных символов, заключенная в фигурные скобки:
{ комментарий }Другой вариант оформления комментария:
(* комментарий *)
Внутри самого комментария символы } или *) встречаться не должны.
Во время компилирования программы комментарии игнорируются. Следовательно, их можно добавлять в любом месте программы. Можно даже разорвать оператор вставкой комментария. Кроме того, все, что находится после ключевого слова end., завершающего текст программы, компилятор тоже воспринимает как комментарий.
Директивы компилятора
Строка, начинающаяся символами {$, является не комментарием, а директивой компилятора - специальной командой, от которой зависит процесс компиляции и выполнения программы. Директивы мы будем рассматривать в тех разделах, к которым они относятся "по смыслу".
Например, строка {$I-,Q+} отключает контроль правильности ввода-вывода, но включает контроль переполнения при вычислениях.
Идентификаторы
Имена, даваемые программным объектам ( константам, типам, переменным, функциям и процедурам, да и всей программе целиком) называются идентификаторами. Они могут состоять только из цифр, латинских букв и знака "_" (подчеркивание). Однако цифра не может начинать имя. Идентификаторы могут иметь любую длину, но если у двух имен первые 63 символа совпадают, то такие имена считаются идентичными.
Вы можете давать программным объектам любые имена, но необходимо, чтобы они отличались от зарезервированных слов, используемых языком Pascal, потому что компилятор все равно не примет переменные с "чужими" именами.
Приведем список наиболее часто встречающихся зарезервированных слов:
and goto set array implementation shl begin in shr case interface string const label then div mod text do nil to downto not type else of unit end or until file pointer uses far procedure var for program while forward record with function repeat xor
Переменные и типы данных
Переменная - это программный объект, значение которого может изменяться в процессе работы программы.
Тип данных - это характеристика диапазона значений, которые могут принимать переменные, относящиеся к этому типу данных.
Все используемые в программе переменные должны быть описаны в специальном разделе var по следующему шаблону:
var <имя_переменной_1> [, <имя_переменной_2, _>] : <имя_типа_1>; <имя_переменной_3> [, <имя_переменной_4, _>] : <имя_типа_2>;
Язык Pascal обладает большим набором разнообразных типов данных, однако сейчас мы укажем лишь некоторые из них. Обо всех же типах данных мы поговорим в следующей лекции, там же приведем и различные примеры описания переменных
Константы
Константа - это объект, значение которого известно еще до начала работы программы.
Константы необходимы для оформления наглядных программ, незаменимы при использовании в тексте программы многократно повторяемых значений, удобны в случае необходимости изменения этих значений сразу во всей программе.
В языке Pascal существует три вида констант:
- неименованные константы (цифры и числа, символы и строки, множества);
- именованные нетипизированные константы ;
- именованные типизированные константы.
Неименованные константы
Неименованные константы не имеют имен, и потому их не нужно описывать.
Тип неименованной константы определяется автоматически, по умолчанию:
- любая последовательность цифр (возможно, предваряемая знаком "-" или "+" или разбиваемая одной точкой) воспринимается компилятором как неименованная константа - число (целое или вещественное);
- любая последовательность символов, заключенная в апострофы, воспринимается как неименованная константа - строка (см. лекцию 5);
- любая последовательность целых чисел1) либо символов через запятую, обрамленная квадратными скобками, воспринимается как неименованная константа - множество (см. лекцию 5).
Кроме того, существуют две специальные константы true и false, относящиеся к логическому типу данных.
Примерами использования неименованных констант могут послужить следующие операторы:
int1 := -10; real2 := 12.075 + х; char3 := 'z'; string4 := 'abc' + string44; set5 := [1,3,5] * set55; boolean6 := true;
Нетипизированные константы
Именованные константы, как следует из их названия, должны иметь имя. Стало быть, эти имена необходимо сообщить компилятору, то есть описать в специальном разделе const.
Если не указывать тип константы, то по ее внешнему виду компилятор сам определит, к какому (базовому) типу ее отнести. Любую уже описанную константу можно использовать при объявлении других констант, переменных и типов данных. Вот несколько примеров описания нетипизированных именованных констант:
const n = -10; m = 1000000000; mmm = n*100; x = 2.5; c = 'z'; s = 'string'; b = true;
Типизированные константы
Типизированные именованные константы представляют собой переменные (!) с начальным значением, которое к моменту старта программы уже известно. Следовательно, во-первых, типизированные константы нельзя использовать для определения других констант, типов данных и переменных, а во-вторых, их значения можно изменять в процессе работы программы.
Описание типизированных констант производится по следующему шаблону:
const <имя_константы> : <тип_константы> = <начальное_значение>;
Из приведенных ниже примеров видно, как это сделать:
const n: integer = -10; x: real = 2.5; c: char = 'z'; b: boolean = true;
Примеры типизированных констант других типов мы будем приводить по мере изучения соответствующих типов данных.
Простейшие операторы
Перейдем теперь к изучению операторов - специальных конструкций языка Pascal.
Если говорить строго, то оператором называется (минимальная) структурно законченная единица программы.
Важно! Все операторы языка Pascal должны заканчиваться знаком ";" (точка с запятой), и ни один оператор не может разрываться этим знаком. Единственная возможность не ставить после оператора ";" появляется в том случае, когда сразу за этим оператором следует ключевое слово end.
К простейшим операторам языка Pascal относятся:
- a:= b; - присваивание переменной а значения переменной b. В правой части присваивания может находиться переменная, константа, арифметическое выражение или вызов функции.
- ; - пустой оператор, который можно вставлять куда угодно, а также вычеркивать откуда угодно, поскольку на целостность программы это никак не влияет.
- Операторные скобки, превращающие несколько операторов в один:
begin <несколько операторов> end;
Везде далее, где в записи конструкций языка Pascal мы будем использовать обозначение <один_оператор>, его следует понимать как "один оператор или несколько операторов, заключенные в операторные скобки begin - end".
Метки и безусловный переход
Метка помечает какое-либо место в тексте программы. Метками могут быть числа от 0 до 9999 или идентификаторы, которые в этом случае уже нельзя использовать для каких-либо иных нужд. Все метки должны быть описаны в специальном разделе label:
label <список_всех_меток_через_запятую>;
Меткой может быть помечен любой оператор программы
<метка>: <оператор>;
Любая метка может встретиться в тексте программы только один раз. Используются метки только операторами безусловного перехода goto:
goto <метка>;
Это означает, что сразу после оператора goto будет выполнен не следующий за ним оператор (как это происходит в обычном случае), а тот оператор, который помечен соответствующей меткой.
В принципе, передавать управление можно вперед и назад по тексту программы, внутрь составных операторов и наружу и т.п. Исключением являются только процедуры и функции (см. лекцию 8): внутрь них и наружу безусловные переходы невозможны.
Вообще же использование безусловных переходов в структурном и надежном программировании считается "дурным тоном". Поэтому мы настоятельно советуем нашим читателям воздерживаться от употребления операторов goto. Язык Pascal обладает достаточным количеством структурных конструкций и возможностей, позволяющих достичь хороших результатов надежными средствами.
Ввод и вывод: консоль
Как мы уже говорили, любой алгоритм должен быть результативным. В общем случае это означает, что он должен сообщать результат своей работы потребителю: пользователю-человеку или другой программе (например, программе управления принтером). Мы не будем описывать здесь внутренние автоматические процессы, использующие сигналы непрерывно функционирующих программ, а сосредоточим внимание на взаимодействии программы и человека, то есть на процессах ввода информации с клавиатуры и вывода ее на экран.
В программировании существует специальное понятие консоль, которое обозначает клавиатуру при вводе и монитор при выводе.
Ввод с консоли
Для того чтобы получить данные, вводимые пользователем вручную (то есть с консоли ), применяются команды
read(<список_ввода>) и readln(<список_ввода>).
Первая из этих команд считывает все предложенные ей данные, оставляя курсор в конце последней строки ввода, а вторая - сразу после окончания ввода переводит курсор на начало следующей строки. В остальном же их действия полностью совпадают.
Список ввода - это последовательность имен переменных, разделенных запятыми. Например, при помощи команды
readln(k,x,c,s); {k:byte; x:real; c:char; s:string}программа может получить с клавиатуры данные сразу для четырех переменных, относящихся к различным типам данных.
Вводимые значения необходимо разделять пробелами, а завершать ввод - нажатием клавиши Enter. Ввод данных заканчивается в тот момент, когда последняя переменная из списка ввода получила свое значение. Следовательно, вводя данные при помощи приведенной выше команды, вы можете нажать Enter четыре раза - после каждой из вводимых переменных, - либо же только один раз, предварительно введя все четыре переменные в одну строчку (обязательно нужно разделить их пробелами).
Типы вводимых значений должны совпадать с типами указанных переменных, иначе возникает ошибка. Поэтому нужно внимательно следить за правильностью вводимых данных.
Вообще, вводить с клавиатуры можно только данные базовых типов (за исключением логического). Если же программе все-таки необходимо получить с консоли значение для boolean-величины, придется действовать более хитро: вводить оговоренный символ, а уже на его основе присваивать логической переменной соответствующее значение. Например1):
repeat
writeln('Согласны ли Вы с этим утверждением? y - да, n - нет');
readln(c); {c:char}
case c of
'y': b:= true;
'n': b:= false;
else writeln('Ошибка!');
end;
until (c='n')or(c='y');Второе исключение: строки, хотя они и не являются базовым типом, вводить тоже разрешается. Признаком окончания ввода строки является нажатие клавиши Enter, поэтому все следующие за нею переменные необходимо вводить с новой строчки.
Вывод на консоль
Сделаем одно важное замечание: ожидая от человека ввода с клавиатуры, не нужно полагать, что он окажется ясновидящим и просто по мерцанию курсора на черном экране догадается, какого типа переменная нужна ожидающей программе. Старайтесь всегда придерживаться правила: "лысый" ввод недопустим! Перед тем как считывать что-либо с консоли, необходимо сообщить пользователю, что именно он должен ввести: смысл вводимой информации, тип данных, максимальное и минимальное допустимые значения и т.п.
Примером неплохого приглашения служит, скажем, такая строчка:
Введите два вещественных числа (0.1<x,y<1000000) - длины катетов.
Впрочем, и ее можно улучшить, сообщив пользователю не только допустимый диапазон ввода, но и ожидаемую точность (количество знаков после запятой).
Средства, позволяющие организовать выдачу информации на экран, мы здесь и рассмотрим.
Для того чтобы вывести на экран какое-либо сообщение, воспользуйтесь процедурой write(< список_вывода >) или writeln(<список_вывода>).
Первая из них, напечатав на экране все, о чем ее просили, оставит курсор в конце выведенной строки, а вторая переведет его в начало следующей строчки.
Список вывода может состоять из нескольких переменных, записанных через запятую; все эти переменные должны иметь тип либо базовый2), либо строчный. Например, writeln(a,b,c);
Форматный вывод
Если для вывода информации воспользоваться командой, приведенной в конце предыдущего пункта, то выводимые символы окажутся "слепленными". Чтобы этого не случилось, нужно либо позаботиться о пробелах между выводимыми переменными:
writeln(a,' ',b,' ',c);
либо задать для всех (или хотя бы для некоторых) переменных формат вывода:
writeln(a:5,b,c:20:5);
Первое число после знака ":" обозначает количество позиций, выделяемых под всю переменную, а второе - под дробную часть числа. Десятичная точка тоже считается отдельным символом.
Если число длиннее, чем отведенное под него пространство, количество позиций будет автоматически увеличено. Если же выводимое число короче заданного формата, то спереди к нему припишутся несколько пробелов. Таким образом можно производить вывод красивыми ровными столбиками, а также следить за тем, чтобы переменные не сливались.
Например, если a = 25, b = 'x', а c = 10.5, то после выполнения команды writeln(a:5,' ',b,c:10:5) на экране или в файле будет записано следующее (подчерки в данном случае служат лишь для визуализации пробелов):
_ _ _25_x_ _10.50000
Особенно важен формат при выводе вещественных переменных. К примеру, если не указать формат, то число 10.5 будет выведено как 1.0500000000Е+0001. Такой формат называется записью с плавающей точкой.
Если же задать только общую длину вещественного числа, не указывая длину дробной части, то оно будет занимать на экране заданное количество символов (в случае надобности, спереди будет добавлено соответствующее количество пробелов), но при этом останется в формате плавающей точки. Минимальной длиной для вывода вещественных чисел является 10 (при формате _x.xE+yyyy). Первая позиция зарезервирована под знак "-".
Необходимо помнить, что в случае недостаточной длины вывода число будет автоматически округлено, например (подчерк служит для визуализации пробела):
| Оператор форматного вывода | Результат вывода на экран |
|---|---|
| write (125.2367:10); | _1.3E+0002 |
| write (125.2367:11); | _1.25E+0002 |
| write (125.2367:12); | _1.252E+0002 |
| write (125.2367:13); | _1.2524E+0002 |
| write (125.2367:14); | _1.25237E+0002 |
| write (125.2367:15); | _1.252367E+0002 |
| write (125.2367:16); | _1.2523670E+0002 |
Пример простейшей программы на языке Pascal
program start;
var s: string;
begin
write('Пожалуйста, введите Ваше имя: ');
readln(s);
writeln('Мы рады Вас приветствовать, ',s,'!');
end.Во время работы этой программы на экране появится примерно следующее:
Пожалуйста, введите Ваше имя: Иван Иваныч Мы рады Вас приветствовать, Иван Иваныч!
Лекция 2. Типы данных и операции
Типы данных языка Pascal
Компиляторы языка Pascal требуют, чтобы сведения об объеме памяти, необходимой для работы программы, были предоставлены до начала ее работы. Для этого в разделе описания переменных ( var ) нужно перечислить все переменные, используемые в программе. Кроме того, необходимо также сообщить компилятору, сколько памяти каждая из этих переменных будет занимать. А еще было бы неплохо заранее условиться о различных операциях, применимых к тем или иным переменным...
Все это можно сообщить программе, просто указав тип будущей переменной. Имея информацию о типе переменной, компилятор "понимает", сколько байт необходимо отвести под нее, какие действия с ней можно производить и в каких конструкциях она может участвовать.
Для удобства программистов в языке Pascal существует множество стандартных типов данных и плюс к тому возможность создавать новые типы.
Конструируя новые типы данных на основе уже имеющихся (стандартных или опять-таки определенных самим программистом), нужно помнить, что любое здание должно строиться на хорошем фундаменте. Поэтому сейчас мы и поговорим об этом "фундаменте".
На основании базовых типов данных строятся все остальные типы языка Pascal, которые так и называются: конструируемые.
Разделение на базовые и конструируемые типы данных в языке Pascal показано в таблице:
| Базовые типы данных | Дискретные типы данных | Арифметические типы данных | Адресные типы данных | Структурированные типы данных | ||
|---|---|---|---|---|---|---|
| Целые | Вещественные | |||||
Логическийboolean | Символьный
(литерный)char | shortint byte integer word longint | real single double extended comp | Нетипизированный указательpointer | ||
| Конструируемые типы | Перечисляемыйweek = (su, mo, tu, we, th, fr,sa); | Типизированный указатель^<тип> | Массив array | |||
| Строка string | ||||||
| Запись record | ||||||
Интервал (диапазон)budni = mo..fr; | Файлtext file | |||||
| Процедурный | ||||||
| Объектный1) | ||||||
| Типы данных, конструируемые программистом | ||||||
Типы данных, конструируемые программистом, описываются в разделе type по следующему шаблону:
type <имя_типа> = <описание_типа>;
Например:
type lat_bukvy = 'a'..'z','A'..'Z';
Базовые типы данных являются стандартными, поэтому нет нужды описывать их в разделе type. Однако при желании это тоже можно сделать, например, дав длинным определениям короткие имена. Скажем, введя новый тип данных
type int = integer;
можно немного сократить текст программы.
Стандартные конструируемые типы также можно не описывать в разделе type. Однако в некоторых случаях это все равно приходится делать из-за требований синтаксиса. Например, в списке параметров процедур или функций конструкторы типов использовать нельзя (см. лекцию 8).
Порядковые типы данных
Среди базовых типов данных особо выделяются порядковые типы. Такое название можно обосновать двояко:
- Каждому элементу порядкового типа может быть сопоставлен уникальный (порядковый) номер. Нумерация значений начинается с нуля. Исключение - типы данных shortint, integer и longint. Их нумерация совпадает со значениями элементов.
- Кроме того, на элементах любого порядкового типа определен порядок (в математическом смысле этого слова), который напрямую зависит от нумерации. Таким образом, для любых двух элементов порядкового типа можно точно сказать, который из них меньше, а который - больше2).
Стандартные подпрограммы, обрабатывающие порядковые типы данных
Только для величин порядковых типов определены следующие функции и процедуры:
- Функция ord(x) возвращает порядковый номер значения переменной x (относительно того типа, к которому принадлежит переменная х).
- Функция pred(x) возвращает значение, предшествующее х (к первому элементу типа неприменима).
- Функция succ(x) возвращает значение, следующее за х (к последнему элементу типа неприменима).
- Процедура inc(x) возвращает значение, следующее за х (для арифметических типов данных это эквивалентно оператору x:=x+1).
- Процедура inc(x,k) возвращает k-е значение, следующее за х (для арифметических типов данных это эквивалентно оператору x:=x+k).
- Процедура dec(x) возвращает значение, предшествующее х (для арифметических типов данных это эквивалентно оператору x:=x-1).
- Процедура dec(x,k) возвращает k-e значение, предшествующее х (для арифметических типов данных это эквивалентно оператору x:=x-k).
На первый взгляд кажется, будто результат применения процедуры inc(x) полностью совпадает с результатом применения функции succ(x). Однако разница между ними проявляется на границах допустимого диапазона. Функция succ(x) неприменима к максимальному элементу типа, а вот процедура inc(x) не выдаст никакой ошибки, но, действуя по правилам машинного сложения, прибавит очередную единицу к номеру элемента. Номер, конечно же, выйдет за пределы диапазона и за счет усечения превратится в номер минимального значения диапазона. Получается, что процедуры inc() и dec() воспринимают любой порядковый тип словно бы "замкнутым в кольцо": сразу после последнего вновь идет первое значение.
Поясним все сказанное на примере. Для типа данных
type sixteen = 0..15;
попытка прибавить 1 к числу 15 приведет к следующему результату:
+ 1 1 1 1 1
Начальная единица будет отсечена, и потому получится, что inc(15)=0.
Аналогичная ситуация на нижней границе допустимого диапазона произвольного порядкового типа данных наблюдается для процедуры dec(x) и функции pred(x):
dec(min_element)= max_element
Типы данных, относящиеся к порядковым
Опишем теперь порядковые типы данных более подробно.
- Логический тип boolean имеет два значения: false и true, и для них выполняются следующие равенства:
ord(false)=0, ord(true)=1, false<true, pred(true)=false, succ(false)=true, inc(true)=false, inc(false)=true, dec(true)=false, dec(false)=true.
- В символьный тип char входит 256 символов расширенной таблицы ASCII (например, 'a', 'b', 'я', '7', '#'). Номер символа, возвращаемый функцией ord(), совпадает с номером этого символа в таблице ASCII.
- Целочисленные типы данных сведем в таблицу:
- Перечисляемые3) типы данных задаются в разделе type явным перечислением их элементов. Например:Напомним, что для этого типа данных:
type week =(sun,mon,tue,wed,thu,fri,sat) 0 1 2 3 4 5 6inc(sat) = sun, dec(sun) = sat.
- Интервальные типы данных задаются только границами своего диапазона. Например:
type month = 1..12; budni = mon..fri;
- Программист может создавать и собственные типы данных, являющиеся комбинацией нескольких стандартных типов. Например:
type valid_for_identifiers = 'a'..'z','A'..'Z','_','0'..'9';
Этот тип состоит из объединения нескольких интервалов, причем в данном случае изменен порядок латинских букв: если в стандартном типе char 'A' < 'a', то здесь, наоборот, 'a' < 'A'. Для величин этого типа выполняются следующие равенства:
inc('z')='A'; dec('0')='_', pred('9')='8'; ord('b')= 2.Вещественные типы данных
Напомним, что эти типы данных являются арифметическими, но не порядковыми.
| Тип | Количество байтов | Диапазон (абсолютной величины) |
|---|---|---|
single real double extended comp | 4 6 8 10 8 | 1.5*10-45..3.4*1038 2.9*10-39..1.7*1038 5.0*10-324..1.7*10308 3.4*10-4932..1.1*104932 -263+1..263-1 |
Конструируемые типы данных
Эти типы данных (вместе с определенными для них операциями) мы будем рассматривать далее на протяжении нескольких лекций:
Лекция 3. Массивы
Лекция 5. Строки и множества
Лекции 6 и 7. Файлы
Лекция 7. Записи
Лекция 8. Процедурный тип данных
Лекция 10. Указатели
Операции и выражения
Арифметические операции
Как мы уже упоминали, для каждого типа данных определены действия, применимые к его значениям. Например, если переменная относится к порядковому типу данных, то она может фигурировать в качестве аргумента стандартных функций ord(), pred() и succ() (см. п. "Совместимость типов данных" ниже). А к вещественным типам эти функции применить невозможно.
Итак, поговорим теперь об операциях - стандартных действиях, разрешенных для переменных того или иного базового типа данных. Основу будут составлять арифметические операции, но, конечно же, мы не забудем и о логическом типе данных (операции, определенные для значений символьного типа, будут подробно рассмотрены в лекции 5).
Замечание: Все перечисленные ниже операции (за исключением унарных '-' и not) требуют двух операндов.
- Логические операции (and, or, not, xor) применимы только к значениям типа boolean. Их результатом также служат величины типа boolean. Приведем таблицы значений для этих операций:
- Операции сравнения (=, <>, >, <, <=, >=) применимы ко всем базовым типам. Их результатами также являются значения типа boolean.
- Операции целочисленной арифметики применимы, как легко догадаться, только к целым типам. Их результат - целое число, тип которого зависит от типов операндов.
a div b - деление а на b нацело (не нужно, наверное, напоминать, что деление на 0 запрещено, поэтому в таких случаях операция выдает ошибку). Результат будет принадлежать к типу данных, общему для тех типов, к которым принадлежат операнды. Например, (shortint div byte = integer). Пояснить это можно так: integer - это минимальный тип, подмножествами которого являются одновременно и byte, и shortint.
a mod b - взятие остатка при делении а на b нацело. Тип результата, как и в предыдущем случае, определяется типами операндов, а 0 является запрещенным значением для b. В отличие от математической операции mod, результатом которой всегда является неотрицательное число, знак результата "программистской" операции mod определяется знаком ее первого операнда. Таким образом, если в математике (-2 mod 5)=3, то у нас (-2 mod 5)= -2.
a shl k - сдвиг значения а на k битов влево (это эквивалентно умножению значения переменной а на 2k). Результат операции будет иметь тот же тип, что и первый ее операнд (а).
a shr k - сдвиг значения а на k битов вправо (это эквивалентно делению значения переменной а на 2k нацело). Результат операции будет иметь тот же тип, что и первый ее операнд (а).
and,or,not,xor - операции двоичной арифметики, работающие с битами двоичного представления целых чисел, по тем же правилам, что и соответствующие им логические операции.
- Операции общей арифметики (+, -, *, /) применимы ко всем арифметическим типам. Их результат принадлежит к типу данных, общему для обоих операндов (исключение составляет только операция дробного деления /, результат которой всегда относится к вещественному типу данных).
Другие операции
Помимо арифметических, существуют и другие операции, специфичные для значений некоторых стандартных типов данных языка Pascal. Эти операции мы рассмотрим в соответствующих разделах:
#, in, +, *, [] : см. лекцию 5 @, ^ : см. лекцию 10
Стандартные арифметические функции
К арифметическим операциям примыкают и стандартные арифметические функции. Их список с кратким описанием мы приводим в таблице.
| Описание | Тип аргумента | Тип результата1) | |
|---|---|---|---|
| abs(x) | Абсолютное значение (модуль) числа | Арифметический | Совпадает с типом аргумента |
| arctan(x) | Арктангенс (в радианах) | Арифметический | Вещественный |
| cos(x) | Косинус (в радианах) | Арифметический | Вещественный |
| exp(x) | Экспонента (ex) | Арифметический | Вещественный |
| frac(x) | Взятие дробной части числа | Арифметический | Вещественный |
| int(x) | Взятие целой части числа | Арифметический | Вещественный |
| ln(x) | Натуральный логарифм (по основанию e) | Арифметический | Вещественный |
| odd(x) | Проверка нечетности числа | Целый | boolean |
| pi | Значение числа | - | Вещественный |
| round(x) | Округление к ближайшему целому | Арифметический | Целый |
| trunc(x) | Округление "вниз" - к ближайшему меньшему целому | Арифметический | Целый |
| sin(x) | Синус (в радианах) | Арифметический | Вещественный |
| sqr(x) | Возведение в квадрат | Арифметический | Вещественный |
| sqrt(x) | Извлечение квадратного корня | Арифметический | Вещественный |
Арифметические выражения
Все арифметические операции можно сочетать друг с другом - конечно, с учетом допустимых для их операндов типов данных.
В роли операндов любой операции могут выступать переменные, константы, вызовы функций или выражения, построенные на основе других операций. Все вместе и называется выражением. Определение выражения через выражение не должно вас смущать, ведь рекурсивное задание конструкций вообще свойственно программированию (см. лекцию 9).
Примеры арифметических выражений:
(x<0) and (y>0) - выражение, результат которого принадлежит к типу boolean;
z shl abs(k) - вторым операндом является вызов стандартной функции;
(x mod k) + min(a,b) + trunc(z) - сочетание арифметических операций и вызовов функций;
odd(round(x/abs(x))) - "многоэтажное" выражение.
Полнота вычислений
В общем случае вычисление сложного логического выражения прекращается в тот момент, когда его окончательное значение становится понятным (например, true or (b<0)). Зачастую такой подход позволяет заметно сэкономить на выполнении "лишних" действий. Скажем, если есть некоторая сложно вычислимая функция my_func, вызов которой входит в состав выражения
if (x<=0) and my_func(z+12),
то для случая, когда x положительно, этих сложных вычислений можно избежать.
Однако включение директивы {$B+} принудит компилятор завершить эти вычисления даже в таком случае. Ее выключение {$B-} вернет обычную схему вычислений.
Порядок вычислений
Если в выражении расставлены скобки, то вычисления производятся в порядке, известном всем еще с начальной школы: чем меньше глубина вложенности скобок, тем позже вычисляется заключенная в них операция. Если же скобок нет, то сначала вычисляются значения операций с более высоким приоритетом, затем - с менее высоким. Несколько подряд идущих операций одного приоритета вычисляются в последовательности "слева направо".
| Операции | Приоритет | |
|---|---|---|
| Унарные2) операции | +, -, not, @, ^, # | Первый(высший) |
| Операции, эквивалентные умножению | *, /, div, mod, and, shl, shr | Второй |
| Операции, эквивалентные сложению | +,-, or, xor | Третий |
| Операции сравнения | =, <>, >, <, <=, >=, in | Четвертый |
Замечание: Вызов любой функции имеет более высокий приоритет, чем все внешние относительно этого вызова операции. Выражения, являющиеся аргументами вызываемой функции, вычисляются в момент вызова (см. лекцию 8).
Примеры выражений (с указанием последовательности вычислений) для целых чисел:
a + b * c / d (результат принадлежит к вещест- 3 1 2 венному типу данных); a * not b or c * d = 0 (результат принадлежит к логиче- 2 1 4 3 5 скому типу данных); -min(a + b, 0) * (a + 1) (результат принадлежит к целочис- 3 2 1 5 4 ленному типу данных).
Совместимость типов данных
В общем случае при выполнении арифметических (и любых других) операций компилятору требуется, чтобы типы операндов совпадали: нельзя, например, сложить массив и множество, нельзя передать вещественное число функции, ожидающей целый аргумент, и т.п.
В то же время, любая процедура или функция, написанная в расчете на вещественные значения, сможет работать и с целыми числами.
Правила, по которым различные типы данных считаются взаимозаменяемыми, мы приводим ниже.
Эквивалентность
Эквивалентность - это наиболее высокий уровень соответствия типов. Она требуется при действиях с указателями (см. лекцию 10), а также при вызовах подпрограмм. "А как же тогда быть с оговоркой, сделанной двумя абзацами выше?" - спросите вы. Мы не станем сейчас описывать механизм передачи аргументов процедурам и функциям, поясним лишь, что эквивалентность типов требуется только для параметров-переменных (см. лекцию 8).
Итак, два типа - Т1 и Т2 - будут эквивалентными, если верен хотя бы один вариант из перечисленных ниже:
- Т1 и Т2 совпадают;
- Т1 и Т2 определены в одном объявлении типа;
- Т1 эквивалентен некоторому типу Т3, который эквивалентен типу Т2.
Поясним это на примере:
type T2 = T1; T3 = T1; T4,T5 = T2;
Здесь эквивалентными будут Т1 и Т2; Т1 и Т3; Т1 и Т4; Т1 и Т5; Т4 и Т5. А вот Т2 и Т3 - не эквивалентны!
Совместимость
Совместимость типов требуется при конструировании выражений, а также при вызовах подпрограмм (для параметров-значений). Совместимость означает, что для переменных этих типов возможна операция присваивания - хотя во время этой операции присваиваемое значение может измениться: произойдет неявное приведение типов данных (см. п. "Приведение типов данных" ниже).
Два типа Т1 и Т2 будут совместимыми, если верен хотя бы один вариант из перечисленных ниже:
- Т1 и Т2 эквивалентны (в том числе совпадают);
- Т1 и Т2 - оба целочисленные или оба вещественные;
- Т1 и Т2 являются подмножествами одного типа;
- Т1 является некоторым подмножеством Т2;
- Т1 - строка, а Т2 - символ (см. лекцию 5);
- Т1 - это тип pointer, а Т2 - типизированный указатель (см. лекцию 10);
- Т1 и Т2 - оба процедурные, с одинаковым количеством попарно эквивалентных параметров, а для функций - с эквивалентными типами результатов (см. лекцию 8).
Совместимость по присваиванию
В отличие от простой совместимости, совместимость по присваиванию гарантирует, что в тех случаях, когда производится какое-либо присваивание (используется запись вида a:=b; или происходит передача значений в подпрограмму1) или из нее и т.п.), не произойдет никаких изменений присваиваемого значения.
Два типа данных Т1 и Т2 называются совместимыми по присваиванию, если выполняется хотя бы один вариант из перечисленных ниже:
- Т1 и Т2 эквивалентны, но не файлы2) ;
- Т1 и Т2 совместимы, причем Т2 - некоторое подмножество в Т1;
- Т1 - вещественный тип, а Т2 - целый.
Приведение типов данных
Неявное приведение типов данных
Как мы упомянули в п. "Арифметические операции" выше, тип результата арифметических операций (а следовательно, и выражений) может отличаться от типов исходных операндов. Например, при "дробном" делении ( / ) одного целого числа на другое целое в ответе все равно получается вещественное. Такое изменение типа данных называется неявным приведением типов.
Если в некоторой операции присваивания участвуют два типа данных совместимых, но не совместимых по присваиванию, то тип присваиваемого выражения автоматически заменяется на подходящий. Это тоже неявное приведение. Причем в этих случаях могут возникать изменения значений. Скажем, если выполнить такую последовательность операторов
a:= 10; {a: byte}
a:= -a;
writeln(a);то на экране мы увидим не -10, а 246 (246 = 256 - 10).
Неявным образом осуществляется и приведение при несоответствии типов переменной-счетчика и границ в циклах for (см. лекцию 3).
Неявное приведение типов данных можно отключить, если указать директиву компилятора {$R+}, которая принуждает компилятор всегда проверять границы и диапазоны. Если эта директива включена, то во всех ситуациях, в которых по умолчанию достаточно совместимости типов данных, будет необходима их эквивалентность.
По умолчанию такая проверка отключена, поэтому во всем дальнейшем изложении (если, конечно, явно не оговорено противное) мы будем считать, что эта директива находится в выключенном состоянии {$R-}.
Явное приведение типов данных
Тип значения можно изменить и явным способом: просто указав новый тип выражения, например: a:= byte(b). В этом случае переменной а будет присвоено значение, полученное новой интерпретацией значения переменной b. Скажем, если b имеет тип shortint и значение -23, то в a запишется 233 (= 256 - 23).
Приводить явным образом можно и типы, различающиеся по длине. Тогда значение может измениться в соответствии с новым типом. Скажем, если преобразовать тип longint в тип integer, то возможны потери из-за отсечения первых двух байтов исходного числа. Например, результатом попытки преобразовать число 100 000 к типу integer станет число 31 072, а к типу word - число 34 464.
Функции, изменяющие тип данных
В заключение мы приведем список стандартных функций, аргумент и результат которых принадлежат к совершенно различным типам данных:
trunc3): real -> integer; round: real -> integer; val4): string -> byte/integer/real; chr5): byte -> char; ord: <порядковый_тип> -> longint;
Лекция 3. Ветвления. Массивы. Циклы
Операторы ветвления
К операторам, позволяющим из нескольких возможных вариантов выполнения программы (ветвей) выбрать только один, относятся if и case.
Условный оператор if
Оператор if выбирает между двумя вариантами развития событий:
if <условие> then <один_оператор> [else <один_оператор>];
Обратите внимание, что перед словом else (когда оно присутствует, конечно же) символ ";" не ставится - ведь это разорвало бы оператор на две части.
Условный оператор if работает следующим образом:
- Сначала вычисляется значение <условия> - это может быть любое выражение, возвращающее значение типа boolean.
- Затем, если в результате получена "истина" (true), то выполняется оператор, стоящий после ключевого слова then, а если "ложь" (false) - без дополнительных проверок выполняется оператор, стоящий после ключевого слова else. Если же else-ветвь отсутствует, то не выполняется ничего.
Что же произойдет, если написать несколько вложенных операторов if?
В случае, когда каждый оператор if имеет собственную else-ветвь, все будет в порядке. А вот если некоторые из них этой ветви не имеют, может возникнуть ошибка. Компилятор языка Pascal всегда считает, что else относится к самому ближнему оператору if. Таким образом, если написать
if i>0 then if s>2 then s:= 1 else s:= -1;
подразумевая, что else-ветвь относится к внешнему оператору if, то компилятор все равно воспримет эту запись как
if i>0 then if s>2
then s:= 1
else s:= -1
else;Ясно, что таким образом правильного результата получить не удастся.
Для того чтобы избежать подобных ошибок, стоит всегда (или по крайней мере при наличии нескольких вложенных условных операторов) указывать оба ключевых слова, даже если одна из ветвей будет пустовать. Так вы застрахуетесь от одной из частых "ошибок по невнимательности", которые очень сложно найти в процессе отладки программы.
Итак, исходный вариант нужно переписать следующим образом:
if i>0 then if s>2
then s:=1
else
else s:=-1;либо так:
if i>0 then begin if s>2
then s:=1
end
else s:=-1;Вообще же, если есть возможность переписать несколько вложенных условных операторов как один оператор выбора, это стоит сделать.
Оператор выбора case
Оператор case позволяет сделать выбор между несколькими вариантами:
case <переключатель> of <список_констант> : <один_оператор>; [<список_констант> : <один_оператор>;] [<список_констант> : <один_оператор>;] [else <один_оператор>;] end;
Замечание: Обратите внимание, что после else двоеточие не ставится.
Существуют дополнительные правила, относящиеся к структуре этого оператора:
- Переключатель должен относиться только к порядковому типу данных, но не к типу longint.
- Переключатель может быть переменной или выражением.
- Список констант может задаваться как явным перечислением, так и интервалом или их объединением.
- Повторение констант не допускается.
- Тип переключателя и типы всех констант должны быть совместимыми1).
Пример оператора выбора:
case symbol(* :char *) of
'a'..'z', 'A'..'Z' : writeln('Это латинская буква');
'а'..'я', 'А'..'Я' : writeln('Это русская буква');
'0'..'9' : writeln('Это цифра');
' ',#10,#13,#26 : writeln('Это пробельный символ');
else writeln('Это служебный символ');
end;Выполнение оператора case происходит следующим образом:
- вычисляется значение переключателя;
- полученный результат проверяется на принадлежность к тому или иному списку констант;
- если такой список найден, то дальнейшие проверки уже не производятся, а выполняется оператор, соответствующий выбранной ветви, после чего управление передается оператору, следующему за ключевым словом end, которое закрывает всю конструкцию case.
- если подходящего списка констант нет, то выполняется оператор, стоящий за ключевым словом else. Если else-ветви нет, то не выполняется ничего.
Иллюстрация if и case
В качестве примера, иллюстрирующего использование операторов ветвления, приведем несколько различных реализаций функции sgn(x)2) - знак числа х. Из математики известно, что эта функция имеет следующие значения:
sgn(x) = -1, если x < 0; sgn(x) = 0, если x = 0; sgn(x) = 1, если x > 0.
Реализовать эту функцию для случая, когда х вещественное, можно следующими способами (при условии, что x:real; sgn: -1..1;):
- Это так называемая реализация "в лоб". Здесь нет никаких хитростей и никаких попыток оптимизации: даже если сработает первый вариант, второй и третий все равно будут проверены, невзирая на то, что результат уже получен.
if x=0 then sgn:= 0; if x<0 then sgn:= -1; if x>0 then sgn:= 1;
- Этот вариант свободен от излишних проверок в случае, если значение переменной не положительно.Эту реализацию следует признать более эффективной, чем предыдущая
if x=0 then sgn:= 0 else if x<0 then sgn:= -1 else sgn:= 1;
- Еще одна попытка сократить текст программы. Здесь используется стандартная функция abs(), которая возвращает абсолютное значение аргумента. Проблема в данном случае состоит в том, что "/" - деление дробное, но ведь нам необходим целый, а не вещественный ответ! "Давайте воспользуемся стандартной функцией округления", - скорее всего, скажет внимательный читатель.
if x=0 then sgn:=0 else sgn:=x/abs(x);
- И действительно, исправленный вариант будет выдавать верный результат.
if x=0 then sgn:=0 else sgn:=round(x/abs(x));
- А вот еще один (правда, несколько неестественный) способ с использованием оператора выбора. Вся хитрость этого варианта в том, что выбирающий ветви переключатель обязан принадлежать к перечислимому типу, именно поэтому пришлось заменить "х" на "х = 0". Напомним, что эта операция сравнения выдает результат логического типа boolean, и именно логические константы true и false фигурируют в качестве меток выбора.
case x=0 of true: sgn:=0; false: sgn:=round(x/abs(x)); end;
Конечно же, мы перебрали далеко не все возможные способы реализации функции sgn(x) (ведь сколько людей, столько и способов выражать свои мысли - хоть в литературе, хоть в программировании). Однако уже на этом простеньком примере видно, что способов запрограммировать желаемое всегда больше, чем один, и вряд ли самое простое решение будет и оптимальным.
Массивы
Теперь мы приступаем к изучению массива - наиболее широко используемого структурированного типа данных, предназначенного для хранения нескольких однотипных элементов.
Описание массива
Для того чтобы задать массив, необходимо в разделе описания переменных (var) указать его размеры и тип его компонент.
Общий вид описания (одномерного) массива:
array[<тип_индексов> ]1) of <тип_компонент>;
Чаще всего это трактуется так:
array[<левая_граница>..<правая_граница>] of <тип_компонент>;
Например, одномерный ( линейный) массив, состоящий не более чем из 10 целых чисел, можно описать следующим образом:
var a1: array [1..10] of integer;
Нумерация
Нумерация компонент массива не обязана начинаться с 1 или с 0 - вы можете описывать массив, пронумерованный любыми целыми числами. Необходимо лишь, чтобы номер последней компоненты был больше, чем номер первой:
var a1: array [-5..4] of integer;
Собственно говоря, нумеровать компоненты массива можно не только целыми числами. Любой порядковый тип данных (перечислимый, интервальный, символьный, логический, а также произвольный тип, созданный на их основе) имеет право выступать в роли нумератора. Таким образом, допустимы следующие описания массивов:
type char = 'a','c'..'z'; (- отсутствует символ "b")
var a1: array[char] of integer; - 25 компонент
a2: array [char] of integer; - 256 целых компонент
a3: array [shortint] of real; - 256 вещественных компонент
Общий размер массива не должен превосходить 65 520 байт. Следовательно, попытка задать массив a4:array[integer]of byte ; не увенчается успехом, поскольку тип integer покрывает 65 535 различных элементов. А про тип longint в данном случае лучше и вовсе не вспоминать.
Тип компонент массива может быть любым:
var a4: array[10..20] of real; - массив из компонент простого типа
a5: array[0..100] of record1; - массив из записей2)
a6: array[-10..10] of ^string; - массив из указателей3) на строки
a7: array[-1..1] of file; - массив из имен файловых переменных4)
a8: array[1..100] of array[1..100] of char; - двумерный массив (массив векторов)
Для краткости и удобства многомерные массивы можно описывать и более простым способом:
var a9: array[1..10,1..20] of real; - двумерный массив 10 х 20
a10: array[boolean, -1..1,char, -10..10] of word; - четырехмерный массив 2 х 3 х 256 х 21
Общее ограничение на размер массива - не более 65 520 байт - сохраняется и для многомерных массивов. Количество компонент многомерного массива вычисляется как произведение всех его "измерений". Таким образом, в массиве а9 содержится 200 компонент, а в массиве а10 - 32 256 компонент.
Описание переменных размерностей
Если ваша программа должна обрабатывать матрицы5) переменных размерностей (скажем, N по горизонтали и М по вертикали), то вы столкнетесь с проблемой изначального задания массива, ведь в разделе var не допускается использование переменных. Следовательно, самый логичный, казалось бы, вариант
var m,n: integer;
a: array[1..m,1..n] of real;придется отбросить.
Если на этапе написания программы ничего нельзя сказать о предполагаемом размере входных данных, то не остается ничего другого, как воспользоваться техникой динамически распределяемой памяти (см. лекцию 10).
Предположим, однако, что вам известны максимальные границы, в которые могут попасть индексы обрабатываемого массива. Скажем, N и М заведомо не могут превосходить 100. Тогда можно выделить место под наибольший возможный массив, а реально работать только с малой его частью:
const nnn=100;
var a: array[1..nnn,1..nnn] of real;
m,n: integer;Обращение к компонентам массива
Массивы относятся к структурам прямого доступа. Это означает, что возможно напрямую (не перебирая предварительно все предшествующие компоненты) обратиться к любой интересующей нас компоненте массива.
Доступ к компонентам линейного массива осуществляется так6):
<имя_массива>[<индекс_компоненты>]
а многомерного - так:
<имя_массива>[<индекс>,_,<индекс>]
Правила употребления индексов при обращении к компонентам массива таковы:
- Индекс компоненты может быть константой, переменной или выражением, куда входят операции и вызовы функций.
- Тип каждого индекса должен быть совместим с типом, объявленным в описании массива именно для соответствующего "измерения"; менять индексы местами нельзя.
- Количество индексов не должно превышать количество "измерений" массива. Попытка обратиться к линейному массиву как к многомерному обязательно вызовет ошибку. А вот обратная ситуация вполне возможна: например, если вы описали N-мерный массив, то его можно воспринимать как линейный массив, состоящий из (N-1)-мерных массивов.
Примеры использования компонент массива:
a2['z']:= a2['z']+1; a3[-10]:= 2.5; a3[i+j]:= a9[i,j]; a10[x>0,sgn(x),'!',abs(k*5)]:= 0;
Задание массива константой
Для того чтобы не вводить массивы вручную во время отладки программы (особенно если они имеют большую размерность), можно пользоваться не только файлами7). Существует и более простой способ, когда входные данные задаются прямо в тексте программы при помощи типизированных констант.
Если массив линейный (вектор), то начальные значения для компонент этого вектора задаются через запятую, а сам вектор заключается в круглые скобки.
Многомерный массив также можно рассматривать как линейный, предполагая, что его компонентами служат другие массивы. Таким образом, для системы вложенных векторов действует то же правило задания типизированной константы: каждый вектор ограничивается снаружи круглыми скобками.
Исключение составляют только массивы, компонентами которых являются величины типа char. Такие массивы можно задавать проще: строкой8) символов.
Примеры задания массивов типизированными константами:
type mass = array[1..3,1..2] of byte;
const a: array[-1..1] of byte = (0,0,0); {линейный}
b: mass = ((1,2),(3,4),(5,6)); {двумерный}
s: array[0..9] of char = '0123456789';
Замечание: Невозможно задать неименованную или нетипизированную константу, относящуюся к типу данных array.
Операторы циклов
Для того чтобы обработать несколько однотипных элементов, совершить несколько одинаковых действий и т.п., разумно воспользоваться оператором цикла - любым из четырех, который наилучшим образом подходит к поставленной задаче.
Оператор цикла повторяет некоторую последовательность операторов заданное число раз, которое может быть определено и динамически - уже во время работы программы.
Замечание: Алгоритмы, построенные только с использованием циклов, называются итеративными1) - от слова итерация, которое обозначает повторяемую последовательность действий.
for-to и for-downto
В случае когда количество однотипных действий заранее известно (например, необходимо обработать все компоненты массива), стоит отдать предпочтение циклу с параметром ( for ).
Инкрементный цикл с параметром
Общий вид оператора for-to:
for i:= first to last do <оператор>;
Счетчик i (переменная), нижняя граница first (переменная, константа или выражение) и верхняя граница last (переменная, константа или выражение) должны относиться к эквивалентным порядковым типам данных. Если тип нижней или верхней границы не эквивалентен типу счетчика, а лишь совместим с ним, то осуществляется неявное приведение: значение границы преобразуется к типу счетчика, в результате чего возможны ошибки.
Цикл for-to работает следующим образом:
- вычисляется значение верхней границы last;
- переменной i присваивается значение нижней границы first;
- производится проверка того, что i<=last;
- если это так, то выполняется <оператор> ;
- значение переменной i увеличивается на единицу;
- пункты 3-5, составляющие одну итерацию цикла, выполняются до тех пор, пока i не станет строго больше, чем last; как только это произошло, выполнение цикла прекращается, а управление передается следующему за ним оператору.
Из этой последовательности действий можно понять, какое количество раз отработает цикл for-to в каждом из трех случаев:
- first < last: цикл будет работать last-first+1 раз;
- first = last: цикл отработает ровно один раз;
- first > last: цикл вообще не будет работать.
После окончания работы цикла переменная-счетчик может потерять свое значение2). Таким образом, нельзя с уверенностью утверждать, что после того, как цикл завершил работу, обязательно окажется, что i=last+1. Поэтому попытки использовать переменную-счетчик сразу после завершения цикла (без присваивания ей какого-либо нового значения) могут привести к непредсказуемому поведению программы при отладке.
Декрементный цикл с параметром
Существует аналогичный вариант цикла for, который позволяет производить обработку не от меньшего к большему, а в противоположном направлении:
for i:= first downto last do <оператор>;
Счетчик i (переменная), верхняя граница first (переменная, константа или выражение) и нижняя граница last (переменная, константа или выражение) должны иметь эквивалентные порядковые типы. Если тип нижней или верхней границы не эквивалентен типу счетчика, а лишь совместим с ним, то осуществляется неявное приведение типов.
Цикл for-downto работает следующим образом:
- переменной i присваивается значение first ;
- производится проверка того, что i>=last ;
- если это так, то выполняется <оператор> ;
- значение переменной i уменьшается на единицу;
- пункты 2-4 выполняются до тех пор, пока i не станет меньше, чем last ; как только это произошло, выполнение цикла прекращается, а управление передается следующему за ним оператору.
Если при этом
- first < last, то цикл вообще не будет работать;
- first = last, то цикл отработает один раз;
- first > last, то цикл будет работать first-last+1 раз.
Замечание о неопределенности значения счетчика после окончания работы цикла справедливо и в этом случае.
while и repeat-until
Если заранее неизвестно, сколько раз необходимо выполнить тело цикла, то удобнее всего пользоваться циклом с предусловием (while) или циклом с постусловием (repeat-until).
Общий вид этих операторов таков:
while <условие_1> do <оператор>; repeat <операторы> until <условие_2>;
Условие окончания цикла может быть выражено переменной, константой или выражением, имеющим логический тип.
Замечание: Обратите внимание, что на каждой итерации циклы for и while выполняют только по одному оператору (либо группу операторов, заключенную в операторные скобки begin-end и потому воспринимаемую как единый составной оператор). В отличие от них, цикл repeat-until позволяет выполнить сразу несколько операторов: ключевые слова repeat и until сами служат операторными скобками.
Так же, как циклы for-to и for-downto, циклы while и repeat-until можно назвать в некотором смысле противоположными друг другу.
Последовательности действий при выполнении этих циклов таковы:
| Для while: | Для repeat-until: |
|---|---|
| 1. Проверяется, истинно ли <условие_1>. | 1. Выполняются <операторы>. |
| 2. Если это так, то выполняется <оператор>. | 2. Проверяется, ложно ли <условие_2> |
| 3. Пункты 1 и 2 выполняются до тех пор, пока <условие_1> не станет ложным. | 3. Пункты 1 и 2 выполняются до тех пор, пока <условие_2> не станет истинным. |
Таким образом, если <условие_1> изначально ложно, то цикл while не выполнится ни разу. Если же <условие_2> изначально истинно, то цикл repeat-until выполнится один раз.
break и continue
Существует возможность3) прервать выполнение цикла (или одной его итерации), не дождавшись конца его (или ее) работы.
break прерывает работу всего цикла и передает управление на следующий за ним оператор.
continue прерывает работу текущей итерации цикла и передает управление следующей итерации (цикл repeat-until ) или на предшествующую ей проверку (циклы for-to, for-downto, while ).
Замечание: При прерывании работы циклов for-to и for-downto с помощью функции break переменная цикла (счетчик) сохраняет свое текущее значение, не "портится".
Оператор безусловного перехода goto
Возвращаясь к сказанному об операторе goto4), необходимо отметить, что при всей его нежелательности все-таки существует ситуация, когда предпочтительно использовать именно этот оператор - как с точки зрения структурированности текста программы, так и с точки зрения логики ее построения, и уж тем более с точки зрения уменьшения трудозатрат программиста. Эта ситуация - необходимость передачи управления изнутри нескольких вложенных циклов на самый верхний уровень.
Дело в том, что процедуры break и continue прерывают только один цикл - тот, в теле которого они содержатся. Поэтому в упомянутой выше ситуации пришлось бы заметно усложнить текст программы, вводя много дополнительных прерываний. А один оператор goto способен заменить их все.
Сравните, например, два программно-эквивалентных отрывка:
write('Матрица '); write('Матрица ');
for i:=1 to n do for i:=1 to n do
begin for j:=1 to m do
flag:=false; if a[i,j]>a[i,i]
for j:=1 to m do then begin
if a[i,j]>a[i,i] write('не ');
then begin flag:=true; goto 1;
write('не '); end;
break; 1: writeln('обладает
end свойством
if flag then break; диагонального
end; преобладания.');
writeln('обладает свойством
диагонального
преобладания.');Пример использования циклов
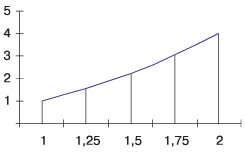
Задача. Вычислить интеграл в заданных границах a и b для некоторой гладкой функции f от одной переменной (с заданной точностью).
Алгоритм. Метод последовательных приближений, которым мы воспользуемся для решения этой задачи, состоит в многократном вычислении интеграла со все возрастающей точностью, - до тех пор, пока два последовательных результата не станут различаться менее чем на заданное число (скажем, eps = 0,001). Количество приближений нам заранее неизвестно (оно зависит от задаваемой точности), поэтому здесь годится только цикл с условием (любой из них).
Вычислять одно текущее значение для интеграла мы будем с помощью метода прямоугольников: разобьем отрезок [a,b] на несколько мелких частей, каждую из них дополним (или урежем - в зависимости от наклона графика функции на данном участке) до прямоугольника, а затем просуммируем получившиеся площади. Количество шагов нам известно, поэтому здесь удобнее всего воспользоваться циклом с параметром.
На нашем рисунке изображена функция f(x) = x2 (на отрезке [1,2]). Каждая из криволинейных трапеций будет урезана (сверху) до прямоугольника: высотой каждого из них послужит значение функции на левом конце участка. График станет "ступенчатым".
Реализация
step:= 1; h:= b-a; s_nov:= f(a)*h; repeat s_star:= s_nov; s_nov:= 0; step:= step*2; h:= h/2; for i:= 1 to step do s_nov:= s_nov+f(a+(step-1)*h); s_nov:= s_nov*h; until abs(s_nov - s_star)<= eps; writeln(s_nov);
Вывод массива, удобный для пользователя
Задача. Распечатать двумерный массив размерности MxN удобным для пользователя способом. (Известно, что массив содержит только целые числа из промежутка [0..100].)
Алгоритм. Понятно, что если весь массив мы вытянем в одну строчку (или, того хуже, в один столбик), то хороших слов в свой адрес мы от пользователя не дождемся. Именно поэтому нам нужно вывести массив построчно, отражая его структуру.
Реализация
for i:= 1 to n do begin for j:= 1 to m do write(a[i,j]:4); writeln; end;
Лекция 4. Сортировки массивов
Задача сортировки
Эта лекция посвящена сугубо алгоритмической проблеме упорядочения данных.
Необходимость отсортировать какие-либо величины возникает в программировании очень часто. К примеру, входные данные подаются "вперемешку", а вашей программе удобнее обрабатывать упорядоченную последовательность. Существуют ситуации, когда предварительная сортировка данных позволяет сократить содержательную часть алгоритма в разы, а время его работы - в десятки раз.
Однако верно и обратное. Сколь бы хорошим и эффективным ни был выбранный вами алгоритм, но если в качестве подзадачи он использует "плохую" сортировку, то вся работа по его оптимизации оказывается бесполезной. Неудачно реализованная сортировка входных данных способна заметно понизить эффективность алгоритма в целом.
Методы упорядочения подразделяются на внутренние (обрабатывающие массивы) и внешние (занимающиеся только файлами )1).
Эту лекцию мы посвятим только внутренним сортировкам. Их важная особенность состоит в том, что эти алгоритмы не требуют дополнительной памяти: вся работа по упорядочению производится внутри одного и того же массива.
Простые сортировки
К простым внутренним сортировкам относят методы, сложность которых пропорциональна квадрату размерности входных данных. Иными словами, при сортировке массива, состоящего из N компонент, такие алгоритмы будут выполнять С*N2 действий, где С - некоторая константа.
Количество действий, необходимых для упорядочения некоторой последовательности данных, конечно же, зависит не только от длины этой последовательности, но и от ее структуры. Например, если на вход подается уже упорядоченная последовательность (о чем программа, понятно, не знает), то количество действий будет значительно меньше, чем в случае перемешанных входных данных.
Как правило, сложность алгоритмов подсчитывают раздельно по количеству сравнений и по количеству перемещений данных в памяти (пересылок), поскольку выполнение этих операций занимает различное время. Однако точные значения удается найти редко, поэтому для оценки алгоритмов ограничиваются лишь понятием "пропорционально", которое не учитывает конкретные значения констант, входящих в итоговую формулу. Общую же эффективность алгоритма обычно оценивают "в среднем": как среднее арифметическое от сложности алгоритма "в лучшем случае" и "в худшем случае", то есть (Eff_best + Eff_worst)/2.
Сортировка простыми вставками
Самый простой способ сортировки2), который приходит в голову, - это упорядочение данных по мере их поступления. В этом случае при вводе каждого нового значения можно опираться на тот факт, что все предыдущие элементы уже образуют отсортированную последовательность.
Алгоритм ПрВст
- Первый элемент записать "не раздумывая".
- Пока не закончится последовательность вводимых данных, для каждого нового ее элемента выполнять следующие действия:
- начав с конца уже существующей упорядоченной последовательности, все ее элементы, которые больше, чем вновь вводимый элемент, сдвинуть на 1 шаг назад;
- записать новый элемент на освободившееся место.
При этом, разумеется, можно прочитать все вводимые элементы одновременно, записать их в массив, а потом "воображать", что каждый очередной элемент был введен только что. На суть и структуру алгоритма это не повлияет.
Реализация алгоритма ПрВст
for i:= 2 to N do
if a[i-1]>a[i] then {*}
begin x:= a[i];
j:= i-1;
while (j>0)and(a[j]>x) do {**}
begin a[j+1]:= a[j];
j:= j-1;
end;
a[j+1]:= x;
end;Метод прямых вставок с барьером (ПрВстБар)
Для того чтобы сократить количество сравнений, производимых нашей программой, дополним сортируемый массив нулевой компонентой (это следует сделать в разделе описаний var) и будем записывать в нее поочередно каждый вставляемый элемент (сравните строки {*} и {**} в приведенных вариантах программы). В тех случаях, когда вставляемое значение окажется меньше, чем a[1], компонента a[0] будет работать как "барьер", не дающий индексу j выйти за нижнюю границу массива. Кроме того, компонента a[0] может заменить собою и дополнительную переменную х:
for i:= 2 to N do
if a[i-1]>a[i] then
begin a[0]:= a[i]; {*}
j:= i-1;
while a[j]>a[0] do {**}
begin a[j+1]:= a[j];
j:= j-1;
end;
a[j+1]:= a[0];
end;Эффективность алгоритма ПрВстБар
Понятно, что для этой сортировки наилучшим будет случай, когда на вход подается уже упорядоченная последовательность данных. Тогда алгоритм ПрВстБар совершит N-1 сравнение и 0 пересылок данных.
В худшем же случае - когда входная последовательность упорядочена "наоборот" - сравнений будет уже (N+1)*N/2, а пересылок (N-1)*(N+3). Таким образом, этот алгоритм имеет сложность ~N2 (читается "порядка эн квадрат") по обоим параметрам.
Пример сортировки
Предположим, что нужно отсортировать следующий набор чисел:
5 3 4 3 6 2 1
Выполняя алгоритм ПрВстБар, мы получим такие результаты (подчеркнута уже отсортированная часть массива, полужирным выделена сдвигаемая последовательность, а квадратиком выделен вставляемый элемент):
Состояние массива Сдвиги Сравнения Пересылки данных
0 шаг: 5343621 1 шаг: 5343621 1 1+ 13) 1+ 24) 2 шаг:543621 1 1+1 1+2 3 шаг:
53621 2 2+1 2+2 4 шаг:
5621 0 1 0 5 шаг:
621 5 5+1 5+2 6 шаг:
61 6 6+1 6+2 Результат:
6
Сортировка бинарными вставками
Сортировку простыми вставками можно немного улучшить: поиск "подходящего места" в упорядоченной последовательности можно вести более экономичным способом, который называется Двоичный поиск в упорядоченной последовательности. Он напоминает детскую игру "больше-меньше": после каждого сравнения обрабатываемая последовательность сокращается в два раза.
Пусть, к примеру, нужно найти место для элемента 7 в таком массиве:
[2 4 6 8 10 12 14 16 18]
Найдем средний элемент этой последовательности (10) и сравним с ним семерку. После этого все, что больше 10 (да и саму десятку тоже), можно смело исключить из дальнейшего рассмотрения:
[2 4 6 8] 10 12 14 16 18
Снова возьмем середину в отмеченном куске последовательности, чтобы сравнить ее с семеркой. Однако здесь нас поджидает небольшая проблема: точной середины у новой последовательности нет, поэтому нужно решить, который из двух центральных элементов станет этой "серединой". От того, к какому краю будет смещаться выбор в таких "симметричных" случаях, зависит окончательная реализация нашего алгоритма. Давайте договоримся, что новой "серединой" последовательности всегда будет становиться левый центральный элемент. Это соответствует вычислению номера "середины" по формуле
nomer_sred:= (nomer_lev + nomer_prav)div 2
Итак, отсечем половину последовательности:
2 4 [6 8] 10 12 14 16 18
И снова:
2 4 6 [8] 10 12 14 16 18 2 4 6][8 10 12 14 16 18
Таким образом, мы нашли в исходной последовательности место, "подходящее" для нового элемента. Если бы в той же самой последовательности нужно было найти позицию не для семерки, а для девятки, то последовательность границ рассматриваемых промежутков была бы такой:
[2 4 6 8] 10 12 14 16 18 2 4 [6 8] 10 12 14 16 18 2 4 6 [8] 10 12 14 16 18 2 4 6 8][10 12 14 16 18
Из приведенных примеров уже видно, что поиск ведется до тех пор, пока левая граница не окажется правее(!) правой границы. Кроме того, по завершении этого поиска последней левой границей окажется как раз тот элемент, на котором необходимо закончить сдвиг "хвоста" последовательности.
Будет ли такой алгоритм универсальным? Давайте проверим, что же произойдет, если мы станем искать позицию не для семерки или девятки, а для единицы:
[2 4 6 8] 10 12 14 16 18 [2] 4 6 8 10 12 14 16 18 ][2 4 6 8 10 12 14 16 18
Как видим, правая граница становится неопределенной - выходит за пределы массива. Будет ли этот факт иметь какие-либо неприятные последствия? Очевидно, нет, поскольку нас интересует не правая, а левая граница.
"А что будет, если мы захотим добавить 21?" - спросит особо въедливый читатель. Проверим это:
2 4 6 8 10 [12 14 16 18] 2 4 6 8 10 12 14 [16 18] 2 4 6 8 10 12 14 16 [18] 2 4 6 8 10 12 14 16 18][
Кажется, будто все плохо: левая граница вышла за пределы массива; непонятно, что нужно сдвигать...
Вспомним, однако, что в реальности на (N+1)-й позиции как раз и находится вставляемый элемент (21). Таким образом, если левая граница вышла за рассматриваемый диапазон, получается, что ничего сдвигать не нужно. Вообще же такие действия выглядят явно лишними, поэтому от них стоит застраховаться, введя одну дополнительную проверку в текст алгоритма.
Реализация алгоритма БинВст
for i:= 2 to n do
if a[i-1]>a[i] then
begin x:= a[i];
left:= 1;
right:= n-1;
repeat
sred:= (left+right) div 2;
if a[sred]<x then left:= sred+1
else right:= sred-1;
until left>right;
for j:= i-1 downto left do a[j+1]:= a[j];
a[left]:= x;
end;Эффективность алгоритма БинВст
Теперь на каждом шаге выполняется не N, а log N проверок5), что уже значительно лучше (для примера, сравните 1000 и 10 = log 1024). Следовательно, всего будет совершено N*log N сравнений. Впрочем, улучшение это не слишком значительное, ведь по количеству пересылок наш алгоритм по-прежнему имеет сложность "порядка N2".
Сортировка простым выбором
Попробуем теперь сократить количество пересылок элементов.
Алгоритм ПрВыб
На каждом шаге (всего их будет ровно N-1) будем производить такие действия:
- найдем минимум среди всех еще не упорядоченных элементов;
- поменяем его местами с первым "по очереди" не отсортированным элементом. Мы надеемся, что читателям очевидно, почему к концу работы этого алгоритма последний (N-й) элемент массива автоматически окажется максимальным.
Реализация ПрВыб
for i:= 1 to n-1 do
begin min_ind:= i;
for j:= i+1 to n do
if a[j]<=a[min_ind] {***}
then min_ind:= j;
if min_ind<>i
then begin
x:= a[i];
a[i]:= a[min_ind];
a[min_ind]:= x;
end;
end;Эффективность алгоритма ПрВыб
В лучшем случае (если исходная последовательность уже упорядочена), алгоритм ПрВыб произведет (N-1)*(N+2)/2 сравнений и 0 пересылок данных. В остальных же случаях количество сравнений останется прежним, а вот количество пересылок элементов массива будет равным 3*(N-1).
Таким образом, алгоритм ПрВыб имеет квадратичную сложность (~N2) по сравнениям и линейную (~N) - по пересылкам.
Замечание. Если перед вами поставлена задача отсортировать строки двумерного массива (размерности NxN) по значениям его первого столбца, то сложность алгоритма ПрВыб, модифицированного для решения этой задачи, будет квадратичной (N2 сравнений и N2 пересылок), а алгоритма БинВст - кубической (N*log N сравнений и N3 пересылок). Комментарии, как говорится, излишни.
Пример сортировки
Предположим, что нужно отсортировать тот же набор чисел, при помощи которого мы иллюстрировали метод сортировки простыми вставками:
5 3 4 3 6 2 1
Теперь мы будем придерживаться алгоритма ПрВыб (подчеркнута несортированная часть массива, а квадратиком выделен ее минимальный элемент):
1 шаг: 5343621 2 шаг:3 шаг: 1
{***}6) 4 шаг: 12
{ничего не делаем} 5 шаг: 123
6 шаг: 1233
результат: 12334
Сортировка простыми обменами
Рассмотренными сортировками, конечно же, не исчерпываются все возможные методы упорядочения массивов.
Существуют, например, алгоритмы, основанные на обмене двух соседних элементов: Пузырьковая и Шейкерная сортировки. Обе имеют сложность порядка N2, однако и по скорости работы на любых входных данных, и по простоте реализации они проигрывают другим простым сортировкам. Поэтому мы настойчиво советуем читателю не прельщаться красивыми названиями, за которыми не стоит никакой особенной выгоды.
Тем же, кто все-таки желает ознакомиться с обменными сортировками, а также с подробными данными по сравнению различных сортировок, мы рекомендуем труды Д. Кнута7) или Н. Вирта8).
Улучшенные сортировки
В отличие от простых сортировок, имеющих сложность ~N2, к улучшенным сортировкам относятся алгоритмы с общей сложностью ~N*logN.
Необходимо, однако, отметить, что на небольших наборах сортируемых данных (N<100) эффективность быстрых сортировок не столь очевидна: выигрыш становится заметным только при больших N. Следовательно, если необходимо отсортировать маленький набор данных, то выгоднее взять одну из простых сортировок.
Сортировка Шелла
Эта сортировка1) базируется на уже известном нам алгоритме простых вставок ПрВст. Смысл ее состоит в раздельной сортировке методом ПрВст нескольких частей, на которые разбивается исходный массив. Эти разбиения помогают сократить количество пересылок: для того, чтобы освободить "правильное" место для очередного элемента, приходится уже сдвигать меньшее количество элементов.
Алгоритм УлШелл
На каждом шаге (пусть переменная t хранит номер этого шага) нужно произвести следующие действия:
- вычленить все подпоследовательности, расстояние между элементами которых составляет kt;
- каждую из этих подпоследовательностей отсортировать методом ПрВст.
Нахождение убывающей последовательности расстояний kt, kt-1..., k1 составляет главную проблему этого алгоритма. Многочисленные исследования позволили выявить ее обязательные свойства:
- k1 = 1;
- для всех t kt > kt-1;
- желательно также, чтобы все kt не были кратными друг другу (для того, чтобы не повторялась обработка ранее отсортированных элементов).
Дональд Кнут предлагает две "хорошие" последовательности расстояний:
1, 4, 13, 40, 121, _ (kt = 1+3*kt-1) 1, 3, 7, 15, 31, _ (kt = 1+2*kt-1 = 2t -1)
Первая из них подходит для сортировок достаточно длинных массивов, вторая же более удобна для коротких. Поэтому мы остановимся именно на ней (желающим запрограммировать первый вариант предоставляется возможность самостоятельно внести необходимые изменения в текст реализации алгоритма).
Как же определить начальное значение для t (а вместе с ним, естественно, и для kt)?
Можно, конечно, шаг за шагом проверять, возможно ли вычленить из сортируемого массива подпоследовательность (хотя бы длины 2) с расстояниями 1, 3, 7, 15 и т.д. между ее элементами. Однако такой способ довольно неэффективен. Мы поступим иначе, ведь у нас есть формула для вычисления kt = 2t -1.
Итак, длина нашего массива (N) должна попадать в такие границы:
kt <= N -1 < kt+1
или, что то же самое,
2t <= N < 2t+1
Прологарифмируем эти неравенства (по основанию 2):
t <= log N < t+1
Таким образом, стало ясно, что t можно вычислить по следующей формуле:
t = trunc(log N))
К сожалению, язык Pascal предоставляет возможность логарифмировать только по основанию е (натуральный логарифм). Поэтому нам придется вспомнить знакомое из курса средней школы правило "превращения" логарифмов:
logmx =logzx/logzm
В нашем случае m = 2, z = e. Таким образом, для начального t получаем:
t:= trunc(ln(N)/ln(2)).
Однако при таком t часть подпоследовательностей будет иметь длину 2, а часть - и вовсе 1. Сортировать такие подпоследовательности незачем, поэтому стоит сразу же отступить еще на 1 шаг:
t:= trunc(ln(N)/ln(2))-1
Расстояние между элементами в любой подпоследовательности вычисляется так:
k:= (1 shl t)-1; {k= 2t-1}Количество подпоследовательностей будет равно в точности k. В самом деле, каждый из первых k элементов служит началом для очередной подпоследовательности. А дальше, начиная с (k+1)-го, все элементы уже являются членами некоторой, ранее появившейся подпоследовательности, значит, никакая новая подпоследовательность не сможет начаться в середине массива.
Сколько же элементов будет входить в каждую подпоследовательность? Ответ таков: если длину всей сортируемой последовательности (N) можно разделить на шаг k без остатка, тогда все подпоследовательности будут иметь одинаковую длину, а именно:
s:= N div k;
Если же N не делится на шаг k нацело, то первые р подпоследовательностей будут длиннее на 1. Количество таких "удлиненных" подпоследовательностей совпадает с длиной "хвоста" - остатка от деления N на шаг k:
P:= N mod k;
Реализация алгоритма УлШелл
Ради большей наглядности мы пожертвовали эффективностью и воспользовались алгоритмом ПрВст, а не ПрВстБар или БинВст. Дотошному же читателю предоставляется возможность самостоятельно улучшить предлагаемую реализацию:
program shell_sort;
const n=18;
a:array[1..n] of integer
=(18,17,16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1);
var ii,m,x,s,p,t,k,r,i,j: integer;
begin
t:= trunc(ln(n)/ln(2));
repeat
t:= t-1;
k:= (1 shl t)-1;
p:= n mod k;
s:= n div k;
if p=0 then p:= k
else s:= s+1;
writeln(k,'-сортировка');
for i:= 1 to k do {берем и длинные, и короткие подпоследовательности}
begin
if i= p+1 then s:= s-1; (для коротких - уменьшаем длину}
for j:= 1 to s-1 do {метод ПрВст с шагом k}
if a[i+(j-1)*k]>a[i+j*k]
then begin x:= a[i+j*k];
m:= i+(j-1)*k;
while (m>0) and (a[m]>x) do
begin a[m+k]:= a[m];
m:= m-k;
end;
a[m+k]:= x;
end;
for ii:= 1 to n do write(a[ii],' ');
writeln;
end;
until k=1;
end.Результат работы
7-сортировки
4 17 16 15 14 13 12 11 10 9 8 7 6 5 18 3 2 1 4 3 16 15 14 13 12 11 10 9 8 7 6 5 18 17 2 1 4 3 2 15 14 13 12 11 10 9 8 7 6 5 18 17 16 1 4 3 2 1 14 13 12 11 10 9 8 7 6 5 18 17 16 15 4 3 2 1 7 13 12 11 10 9 8 14 6 5 18 17 16 15 4 3 2 1 7 6 12 11 10 9 8 14 13 5 18 17 16 15 4 3 2 1 7 6 5 11 10 9 8 14 13 12 18 17 16 15
3-сортировки
1 3 2 4 7 6 5 11 10 9 8 14 13 12 18 17 16 15 1 3 2 4 7 6 5 8 10 9 11 14 13 12 18 17 16 15 1 3 2 4 7 6 5 8 10 9 11 14 13 12 15 17 16 18
1-сортировка
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Эффективность алгоритма УлШелл
Довольно сложными методами, в изложение которых мы не будем углубляться, показано, что алгоритм Шелла имеет сложность ~N3/2. И хотя это несколько хуже, чем N*logN, все-таки эта сортировка относится к улучшенным.
Пример сравнения сортировок: Вновь возьмем последовательность, для сортировки которой методом простых вставок ПрВст потребовалось 15 сдвигов (25 пересылок и 20 сравнений):
5 3 4 3 6 2 1
Теперь применим к ней метод Шелла.
Здесь N = 7, поэтому:
t= trunc(log 7) = 2
k= 22-1 = 3 {начнем с 3-сортировки}
p= 7 mod 3 = 1 {кол-во длинных подпоследовательностей}
s= (7 div 3)+1 = 3 {длина длинной подпоследовательности}- 3-сортировки:Всего 4 сдвига: 10 пересылок, 8 сравнений Итог 3-сортировок: 1 3 2 3 6 4 5
5 3 1 -> 1 3 5 {3 сдвига: 7 пересылок, 5 сравнений} 3 6 -> 3 6 {0 сдвигов: 0 пересылок, 1 сравнение} 4 2 -> 2 4 {1 сдвиг: 3 пересылки, 2 сравнения} - 1-сортировка:
Состояние массива Сдвиги Сравнения Пересылки данных 0 шаг: 1323645 1 шаг: 1323645 0 1 0 2 шаг:
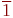 323645 1 1+1 1+2
3 шаг:
323645 1 1+1 1+2
3 шаг: 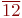 33645 0 1 0
4 шаг:
33645 0 1 0
4 шаг:  3645 0 1 0
5 шаг:
3645 0 1 0
5 шаг:  645 1 1+1 1+2
6 шаг:
645 1 1+1 1+2
6 шаг:  65 1 1+1 1+2
результат: 6
65 1 1+1 1+2
результат: 6 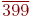
При сортировке методом Шелла в сумме получилось 7 сдвигов (19 пересылок и 17 сравнений). Выигрыш по сравнению с методом простых вставок составляет 53% (24% экономится на пересылках и 15% - на сравнениях )2). Если вместо метода простых вставок ПрВст использовать метод бинарных вставок БинВст, то выигрыш по количеству сравнений будет ощутимее.
Кроме того, не нужно забывать, что в нашем примере последовательность очень коротка: N = 7. Для больших N (скажем, N = 10000) преимущество метода Шелла станет еще заметнее.
Пирамидальная сортировка
Попытаемся теперь усовершенствовать другой рассмотренный выше простой алгоритм: сортировку простым выбором ПрВыб.
Р. Флойд предложил перестроить линейный массив в пирамиду - своеобразное бинарное дерево, - а затем искать минимум только среди тех элементов, которые находятся непосредственно "под" текущим вставляемым.
Просеивание
Для начала необходимо перестроить исходный массив так, чтобы он превратился в пирамиду, где каждый элемент "опирается" на два меньших. Этот процесс назвали просеиванием, потому что он очень напоминает процесс разделения некоторой смеси (камней, монет, т.п.) на фракции в соответствии с размерам частиц: на нескольких грохотах3) последовательно задерживаются сначала крупные, а затем все более мелкие частицы.
Итак, будем рассматривать наш линейный массив как пирамидальную структуру:
Видно, что любой элемент a[i] (1<=i<=N div 2) "опирается" на элементы a[2*i] и a[2*i+1]. И в каждой такой тройке максимальный элемент должен находится "сверху". Конечно, исходный массив может и не удовлетворять этому свойству, поэтому его потребуется немного перестроить.
Начнем процесс просеивания "снизу". Половина элементов (с ((N div 2)+1)-го по N-й) являются основанием пирамиды, их просеивать не нужно. А для всех остальных элементов (двигаясь от конца массива к началу) мы будем проверять тройки a[i], a[2*i] и a[2*i+1] и перемещать максимум "наверх" - в элемент a[i].
При этом, если в результате одного перемещения нарушается пирамидальность в другой (ниже лежащей) тройке элементов, там снова необходимо "навести порядок" - и так до самого "низа" пирамиды:
for i:= (N div 2)downto 1 do
begin j:= i;
while j<=(N div 2) do
begin k:= 2*j;
if (k+1<=N) and (a[k]<a[k+1])
then k:= k+1;
if a[k]>a[j]
then begin x:= a[j];
a[j]:= a[k];
a[k]:= x;
j:= k
end
else break
end
end;Пример результата просеивания
Возьмем массив [1,7,5,4,9,8,12,11,2,10,3,6] (N = 12).
Его исходное состояние таково (серым цветом выделено "основание" пирамиды, не требующее просеивания):
После первых трех просеиваний (a[6], a[5], a[4]) получим такую картину (здесь и далее серым цветом выделяем участников просеивания):
Просеивание двух следующих элементов (a[3] и a[2]) тоже не вызовет вопросов - для каждого из них будет достаточно только одного шага:
А вот для просеивания последнего элемента (a[1]) понадобится целых три шага:
Итак, мы превратили исходный массив в пирамиду: в любой тройке a[i], a[2*i] и a[2*i+1] максимум находится "сверху".
Алгоритм УлПир
Для того чтобы отсортировать массив методом Пирамиды, необходимо выполнить такую последовательность действий:
0-й шаг: Превратить исходный массив в пирамиду (с помощью просеивания).
1-й шаг: Для N-1 элементов, начиная с последнего, производить следующие действия:
- поменять местами очередной "рабочий" элемент с первым;
- просеять (новый) первый элемент, не затрагивая, однако, уже отсортированный хвост последовательности (элементы с i-го по N-й).
Реализация алгоритма УлПир
Часть программы, реализующую нулевой шаг алгоритма УлПир, мы привели в пункте "Просеивание", поэтому здесь ограничимся только реализацией основного шага 1:
for i:= N downto 2 do begin x:= a[1]; a[1]:= a[i]; a[i]:= x; j:= 1; while j<=((i-1)div 2) do begin k:= 2*j; if (k+1<=i-1) and (a[k]<a[k+1]) then k:= k+1; if a[k]>a[j] then begin x:= a[j]; a[j]:= a[k]; a[k]:= x; j:= k end else break end end;
Пример. Продолжим сортировку массива, для которого мы уже построили пирамиду: [12,11,8,7,10,6,5,4,2,9,3,1]. С целью экономии места мы не будем далее прорисовывать структуру пирамиды, оставляя это несложное упражнение читателям. Подчеркивание будет отмечать элементы, участвовавшие в просеивании, а полужирный шрифт - элементы, исключенные из дальнейшей обработки:
1) Меняем местами a[1] и a[12]: [1,11,8,7,10,6,5,4,2,9,3,12]; 2) Просеиваем элемент a[1], получаем: [11,10,8,7,9,6,5,4,2,1,3,12]; 3) Меняем местами a[1] и a[11]: [3,10,8,7,9,6,5,4,2,1,11,12]; 4) Просеиваем a[1], получаем: [10,9,8,7,3,6,5,4,2,1,11,12]; 5) Меняем местами a[1] и a[10]: [1,9,8,7,3,6,5,4,2,10,11,12]; 6) Просеиваем элемент a[1]: [9,7,8,4,3,6,5,1,2,10,11,12]; 7) Меняем местами a[1] и a[9]: [2,7,8,4,3,6,5,1,9,10,11,12]; 8) Просеиваем элемент a[1]: [8,7,6,4,3,2,5,1,9,10,11,12]; 9) Меняем местами a[1] и a[8]: [1,7,6,4,3,2,5,8,9,10,11,12]; 10) Просеиваем элемент a[1]: [7,4,6,1,3,2,5,8,9,10,11,12]; 11) Меняем местами a[1] и a[7]: [5,4,6,1,3,2,7,8,9,10,11,12]; 12) Просеиваем элемент a[1]: [6,4,5,1,3,2,7,8,9,10,11,12]; 13) Меняем местами a[1] и a[6]: [2,4,5,1,3,6,7,8,9,10,11,12]; 14) Просеиваем элемент a[1]: [5,4,2,1,3,6,7,8,9,10,11,12]; 15) Меняем местами a[1] и a[5]: [3,4,2,1,5,6,7,8,9,10,11,12]; 16) Просеиваем элемент a[1]: [4,3,2,1,5,6,7,8,9,10,11,12]; 17) Меняем местами a[1] и a[4]: [1,3,2,4,5,6,7,8,9,10,11,12]; 18) Просеиваем элемент a[1]: [3,1,2,4,5,6,7,8,9,10,11,12]; 19) Меняем местами a[1] и a[3]: [2,1,3,4,5,6,7,8,9,10,11,12]; 20) Просеивать уже ничего не нужно; 21) Меняем местами a[1] и a[2]: [1,2,3,4,5,6,7,8,9,10,11,12]; 22) Просеивать ничего не нужно, сортировка закончена.
Эффективность алгоритма УлПир
Пирамидальная сортировка хорошо работает с большими массивами, однако на маленьких примерах (N<20) выгода от ее применения может быть не слишком очевидна.
В среднем этот алгоритм имеет сложность, пропорциональную N*log N.
Быстрая сортировка
Существует еще один метод улучшенной сортировки, имеющий среднюю сложность порядка N*log N: так называемая Быстрая сортировка4). Этот алгоритм является усовершенствованием обменных сортировок. Его реализация наиболее удобна в рекурсивном варианте, поэтому мы вернемся к ее изучению после того, как познакомимся с рекурсивными процедурами и функциями (см. лекцию 9).
Лекция 5. Символы и строки. Множества
Символы и строки
Две предыдущие лекции были посвящены произвольным массивам. Перейдем теперь к изучению массивов специального вида - линейных массивов, состоящих только из символов, - строк. Кроме того, сами символы мы тоже не обойдем вниманием.
Описание строк
В разделе var строки описываются следующим образом1):
var <имя_строки>: string[[<длина>]] 2)
Максимальная длина строки - 255 символов. Нумеруются ее компоненты начиная с 0, но этот нулевой байт хранит длину строки.
Если <длина> не указана, то считается, что в строке 255 символов. Поэтому для экономии памяти следует по возможности точно указывать длину используемых строк.
Примеры описаний:
var s1: string[10]; (*строка длиной 10 символов*) s2: string; (*строка длиной 255 символов*)
Необходимо отметить, что один символ и строка длиной в один3) символ
var c: char; s: string[1];
совершенно не эквивалентны друг другу. Вне зависимости от своей реальной длины, строка относится к конструируемым структурированным типам данных, а не к базовым порядковым (см. лекцию 2).
Символ-константа и строка-константа
Неименованные константы
В тексте программы на языке Pascal последовательность любых символов, заключенная в апострофы, воспринимается как символ или строка. Например:
c:='z'; {c: char}
s:='abc'; {s: string}Константе автоматически присваивается "минимальный" тип данных, достаточный для ее представления: char или string[k]. Поэтому попытка написать
c:='zzz'; {c: char}вызовет ошибку уже на этапе компиляции.
Кроме того, не забывайте, что если константа длиннее той переменной- строки, куда ваша программа пытается ее записать, то в момент присваивания произойдет усечение ее до нужной длины.
Пустая строка задается двумя последовательными апострофами:
st:= '';
Если же необходимо сделать так, чтобы среди символов строки содержался и сам апостроф, его нужно удвоить:
s:='Don''t worry about the apostrophe!';
Если теперь вывести на экран эту строку, то получится следующее:
Don't worry about the apostrophe!
Нетипизированные константы
Все правила задания символов и строк как неименованных констант остаются в силе и при задании именованных нетипизированных констант в специальном разделе const. Например:
const c3 = ''''; {это один символ - апостроф!}
s3 = 'This is a string';Типизированные константы
Типизированная константа, которая будет иметь тип char или string, задается в разделе const следующим образом:
const c4: char = ''''; {это один символ - апостроф!}
s4: string[20] = 'This is a string';Действия с символами
Операции
Результатом унарной операции
#<положительная_неименованная_константа_целого_типа>
является символ, номер которого в таблице ASCII соответствует заданному числу. Например,
#100 = 'd'
#39 = '''' {апостроф}
#232 = 'ш'
#1000 = 'ш' {потому что (1000 mod 256)= 232}Кроме того, к символьным переменным, как и к значениям всех порядковых типов данных, применимы операции сравнения <, <>, >, =, результат которых также опирается на номера символов из таблицы ASCII.
Стандартные функции
Функция chr(k:byte):char "превращает"; номер символа в символ. Действие этой функции аналогично действию операции #. Например:
c:= chr(48); {c: char}
{c = '0'}Обратной к функции chr() является уже изученная нами функция ord(). Таким образом, для любого числа k и для любого символа с
ord(chr(k)) = k и chr(ord(c)) = c
Надеемся, читатель помнит, что стандартные процедуры и функции pred(), succ(), inc() и dec(), определенные для значений любого порядкового типа1), применимы также и к символам (значениям порядкового типа данных char ). Например:
pred('[') = 'Z'
succ('z') = '{'
inc('a') = 'b'
inc('c',2) = 'e'
dec('z') = 'y'
dec(#0,4) = '№' {#252}Стандартная функция upcase(c: char):char превращает строчную букву в прописную. Символы, не являющиеся строчными латинскими буквами, остаются без изменения (к сожалению, в их число попадают и все русские буквы).
Стандартные функции и процедуры обработки строк
Для обработки символьных массивов, которыми являются строки, в языке Pascal существуют специальные подпрограммы:
Функция concat(s1,_,sN:string):string осуществляет слияние ( конкатенацию ) всех перечисленных строк или символов в указанном порядке. Если длина итоговой строки больше 255-ти символов, то произойдет отсечение "хвоста". Кроме того, даже если результат конкатенации не был усечен, но программа пытается сохранить его в переменную заведомо меньшей длины, то усечение все равно состоится:
concat('abc','3de',' ','X','yz') = 'abc3de Xyz'Функция copy(s:string;i,k:byte):string вычленяет из строки s подстроку длиной k символов, начиная с i -го. Если i больше длины строки, то результатом будет пустая строка. Если же k больше, чем длина оставшейся части строки, то результатом будет только ее "хвост":
copy('abc3de Xyz',2,4) = 'bc3d' copy('abc3de Xyz',12,4) = '' copy('abc3de Xyz',8,14) = 'Xyz'Процедура delete(s:string;i,k:byte) удаляет из строки s подстроку длиной k символов, начиная с i -го. Если i больше длины строки, то ничего удалено не будет. Если же k больше, чем длина оставшейся части строки, то удален будет только ее "хвост":
{s = 'abc3de Xyz'} {s = 'abc3de Xyz'} delete(s,2,3); delete(s,8,13); {s = 'ade Xyz'} {s = 'abc3de '}Процедура insert(ss,s:string;i:byte) вставляет подстроку ss в строку s, начиная с i -го символа. Если i выходит за конец строки, то подстрока ss припишется в конец строки s (если результат длиннее, чем допускается для строки s, произойдет его усечение):
{s = 'abc3de Xyz'} {s = 'abc3de'} insert('xyz',s,2); insert('xyz',s,12); {s = 'axyzbc3de Xyz'} {s = 'abc3dexyz'}Функция length(s:string):byte возвращает длину строки s:
length('abc3de Xyz') = 10Функция pos(ss,s:string):byte определяет позицию, с которой начинается первое (считая слева направо) вхождение подстроки ss в строку s. Если ss не встречается в s ни разу, функция вернет 0:
pos('X', 'abc3de Xyz') = 8Процедура str(x[:w[:d]],s:string) превращает десятичное число x (можно указать, что в этом числе w цифр, из них d дробных) в строку s. Если число короче указанных величин, то спереди и/или сзади оно будет дополнено пробелами:
str(156.4:7:2,s); {s = ' 156.4 '}Процедура val(s:string;i:<арифметический_тип>;err:byte) превращает строку s в десятичное число i (в случае ошибки в переменную err будет записан номер первого недопустимого символа ):
{s = '15.47'} val(s,x,err); {x = 15.47}
Операции со строками
Сравнения
Строки - это единственный структурированный тип данных, для элементов которого определен порядок и, следовательно, возможны операции сравнения ( =, >, < ).
На строках определен так называемый лексикографический порядок: из двух строк меньшей считается та, у которой первый различный символ меньше. Считается, что пустая строка меньше любой другой строки.
Таким образом, если начальные символы двух сравниваемых строк совпадают, то эта совпадающая часть никак не повлияет на отношение порядка между строками, поэтому ее можно откинуть и сравнивать только первые символы оставшихся подстрок. Если одна из строк полностью совпадает с началом другой, то после удаления совпадающих частей она превратится в пустую строку. Это с очевидностью будет свидетельствовать о том, что начало слова всегда меньше, чем все слово.
Итак,
'abc' < 'xyz' 'a' < 'abc' '1200' < '45' 'Anny' < 'anny'
Обращение к компонентам строки
Доступ к k -му символу строки осуществляется так же, как к k -й компоненте массива (жирные скобки являются обязательным элементом синтаксиса):
<имя_строки>[<индекс>]
Например:
{s = '15.47'}
c:= s[3];
{c = '.'}Однако, в отличие от массива, нельзя напрямую заменять символы в строке, то есть действие
s[i]:= 'a';
не вызовет ошибки при компиляции, но, скорее всего, не станет работать во время выполнения программы. Для того чтобы изменить символ в строке, нужно воспользоваться стандартными функциями length(), concat() и copy(). В этом случае простое, казалось бы, действие приходится представлять как последовательность четырех операций:
В качестве первой под строки взять из строки s символы с 1 -го по ( k-1 )-й:
s1:= copy(s,1,k-1);
В качестве второй под строки взять новое значение заменяемого символа:
s2:= new_char;
В качестве третьей подстроки взять оставшуюся часть строки s:
s3:= copy(s,k+1,length(s)-k);
Слить эти строки воедино, а результат записать вместо исходной строки s:
s:= concat(s1,s2,s3);
Или можно объединить все четыре действия в одном операторе:
s:= concat(copy(s,1,k-1), new_char, copy(s,k+1,length(s)-k));
Конкатенация
Единственная операция, которую разрешается производить с переменными строкового типа, - это слияние строк или символов ( конкатенация ). Она полностью эквивалентна функции concat() и записывается при помощи знака " + ". Таким образом, предыдущий оператор можно сделать более простым:
s:= copy(s,1,k-1) + new_char + copy(s,k+1,length(s)-k);
Множества
Еще один структурированный тип данных - это множество ( set ). В нем может содержаться не более 256 элементов.
Важное отличие множества от остальных структурированных типов состоит в том, что его элементы не являются упорядоченными.
Описание множеств
В разделе var множества описываются следующим образом:
var <имя_множества>: set of <тип_элементов_множества>;
Элементы могут принадлежать к любому порядковому типу, размер которого не превышает 1 байт (256 элементов). Например:
var s1: set of char; {множество из 256-ти элементов}
s2: set of 'a'..'z','A'..'Z'; {множество из 52-х элементов}
s3: set of 0..10; {множество из 11-ти элементов}
s4: set of boolean; {множество из 2-х элементов}Множество-константа
Неименованная константа
Множество можно задать неименованной константой прямо в тексте программы. Для этого необходимо заключить список элементов создаваемого множества в квадратные скобки:
[<список_элементов>]
Список элементов может быть задан перечислением элементов нового множества через запятую, интервалом или объединением этих двух способов. Элементы и границы интервалов могут быть переменными, константами и выражениями. Если левая граница интервала окажется больше правой, результатом будет пустое множество.
Примеры конструирования и использования различных множеств:
if c in ['a','e','i','o','u']
then writeln('Гласная буква');
if set1 < [k*2+1..n,13] then set1:=[];Нетипизированная константа
Множество - это структурированный тип данных, поэтому его невозможно задать нетипизированной константой.
Типизированная константа
Задать множество как типизированную константу можно в разделе const:
<имя_константы> : set of <тип_элементов> =[<список_элементов>];
Например:
type cipher = set of '0'..'9'; const odds: cipher = ['1','3','5','7','9']; vowels: set of 'a'..'z' = ['a','o','e','u','i'];
Операции с множествами
Все теоретико-множественные операции реализованы и в языке Pascal:
| 1) Пересечение двух множеств s1 и s2: | s:=s1*s2; |
| 2) Объединение двух множеств s1 и s2: | s:=s1+s2; |
| 3) Разность двух множеств s1 и s2 (все элементы, которые принадлежат множеству s1 и одновременно не принадлежат множеству s2 )1): | s:=s1-s2; |
| 4) Проверка принадлежности элемента el множеству s (результат этой операции имеет тип boolean ): | el in s |
| 5) Обозначение для пустого множества: | [] |
| 6) Создание множества из списка элементов: | s:=[e1,_,eN]; |
| 7) Проверка двух множеств на равенство или строгое включение (результат этих операций имеет тип boolean ): | s1 = s2 s1 > s2 s1 < s2 |
Не существует никакой процедуры, позволяющей распечатать содержимое множества. Это приходится делать следующим образом:
{s: set of type1; k: type1}
for k:= min_type1 to max_type1
do if k in s then write(k);Представление множеств массивами
Одно из основных неудобств при работе с множествами - это ограничение размера всего лишь 256-ю элементами. Мы приведем здесь два очень похожих способа представления больших множеств массивами. Единственным условием является наличие некоторого внутреннего порядка среди представляемых элементов: без этого невозможно будет их перенумеровать.
Представление множеств линейными массивами
Задав линейный массив достаточной длины, можно "вручную" сымитировать множество для более широкого, чем 256 элементов, диапазона значений. Например, чтобы работать с множеством, содержащим 10 000 элементов, достаточно такого массива:
set_arr: array[1..10000] of boolean;
При таком способе представления возможно задать множество до 65 000 элементов.
Для простоты изложения мы ограничимся только числовыми множествами, однако все сказанное ниже можно применять и к множествам, элементы которых имеют другую природу. Итак, признаком того, что элемент k является элементом нашего множества, будет значение true в k -й ячейке этого массива.
Посмотрим теперь, какими способами мы вынуждены будем имитировать операции над "массивными" множествами.
Проверка множества на пустоту может быть осуществлена довольно просто:
pusto:= true; for i:= 1 to N do if set_arr[i] then begin pusto:= false; break end;Проверка элемента на принадлежность множеству также не вызовет никаких затруднений, поскольку соответствующая компонента массива содержит ответ на этот вопрос:
is_in:= set_arr[element];
Добавление элемента в множество нужно записывать так:
set_arr[element]:= true;
Удаление элемента из множества записывается аналогичным образом:
set_arr[element]:= false;
- Построение пересечения множеств реализуется как проверка вхождения каждого элемента в оба множества и последующее добавление удовлетворивших этому условию элементов в результирующее множество.
- Построение объединения множеств аналогичным образом базируется на проверке вхождения элемента хотя бы в одно из объединяемых множеств и дальнейшем добавлении элементов в результирующее множество.
- Построение разности двух множеств также опирается на проверку вхождения элемента в оба множества, причем добавление элемента в создаваемое множество происходит только в том случае, если элемент присутствует в множестве-уменьшаемом и одновременно отсутствует в множестве-вычитаемом.
Проверка двух множеств на равенство не требует особых пояснений:
equal:= true; for i:=1 to N do if set1[i]<> set2[i] then begin equal:= false; break end;
Проверка двух множеств на включение ( set1<set2 ) тоже не потребует больших усилий:
subset:= true; for i:= 1 to N do if set1[i]and not set2[i] then begin subset:= false; break end;
Представление множеств битовыми массивами
В случае, если 65 000 элементов недостаточно для задания всех необходимых множеств (например, 10 множеств по 10 000 элементов в каждом), это число можно увеличить в 8 раз, перейдя от байтов к битам. Тогда 1 байт будет хранить информацию не об одном, а сразу о восьми элементах: единичный бит будет означать наличие элемента в множестве, а нулевой бит - отсутствие.
Задавая битовый массив, начнем нумерацию его компонент с 0:
set_bit: array[0..N-1] of byte;
Тогда результатом операции <номер_элемента> div 8 будет номер той компоненты массива, в которой содержится информация об этом элементе. А вот номер бита, в котором содержится информация об этом элементе, придется вычислять более сложным образом:
bit:= <номер_элемента> mod 8; if bit=0 then bit:= 8;
Эти вычисления потребуются нам еще не раз, поэтому запишем их снова, более строго, а затем будем использовать по умолчанию ( element - это "номер" обрабатываемого элемента в нашем множестве):
kmp:= element div 8; {номер компоненты массива}
bit:= element mod 8; {номер бита}
if bit=0 then bit:= 8;Перечислим теперь действия, которые потребуются для реализации операций над множествами, заданными битовыми массивами.
Проверка множества на пустоту почти не будет отличаться от аналогичной проверки в случае представления множества не битовым, а обычным массивом:
pusto:= true; for i:= 0 to N-1 do if set_arr[i]<>0 then begin pusto:= false; break end;Проверка элемента на принадлежность множеству потребует несколько большей изворотливости ведь нам теперь нужно вычленить соответствующий бит:
if set_arr[kmp]and(1 shl(bit-1))=0 then is_in:= false else is_in:= true;
Поясним, что здесь используется операция "побитовое и" (см. лекцию 2), которая работает непосредственно с битами нужной нам компоненты массива и числа, состоящего из семи нулей и единицы на месте с номером bit.
Добавление элемента в множество теперь будет записано так:
set_arr[kmp]:= set_arr[kmp]or(1 shl(bit-1));
Здесь нельзя использовать обычную операцию сложения ( + ), так как если добавляемый компонент уже содержится в множестве (то есть соответствующий бит уже имеет значение 1 ), то в результате сложения 1+1 получится 10: единица автоматически перенесется в старший бит, а на нужном месте окажется 0.
Удаление элемента из множества придется записать более сложным образом:
set_arr[kmp]:= set_arr[kmp]and not(1 shl(bit-1));
Операция not превратит все 0 в 1 и наоборот, следовательно, теперь в качестве второго операнда для побитового and будет фигурировать число, состоящее из семи единиц и нуля на месте с номером bit. Единицы сохранят любые значения тех битов, которые должны остаться без изменения, и лишь 0 "уничтожит" значение единственного нужного бита.
Пересечение множеств реализуется теперь при помощи операции "побитовое и":
for i:= 0 to N-1 do set_res[i]:= set1[i] and set2[i];
Объединение множеств реализуется при помощи операции "побитовое или":
for i:= 0 to N-1 do set_res[i]:= set1[i] or set2[i];
Разность двух множеств может быть построена так:
for i:= 0 to N-1 do set_res[i]:= (set1[i] or set2[i]) and not set2[i];
Поясним, что здесь мы вначале прибавляем содержимое второго множества к первому, чтобы затем быть полностью уверенными в правомерности операции вычитания.
Проверка двух множеств на равенство по-прежнему не требует особых пояснений:
equal:= true; for i:=0 to N-1 do if set1[i]<> set2[i] then begin equal:= false; break end;Проверка двух множеств на включение ( set1<set2 ) будет производиться по схеме: "Если (A\B)∪B=A, то B⊂A ", доказательство которой настолько очевидно, что мы не станем на нем задерживаться:
subset:= true; for i:= 0 to N-1 do if((set1[i] or set2[i])and not set2[i]) or set2[i] <> set1[i] then begin subset:= false; break end;
Замечание. Если предстоит многократно выполнять действия с элементами битовых массивов, то используемые для этого значения "единиц" удобнее всего сразу задать в специальном массиве:
{ed: array[1..8] of byte;}
ed[1]:=1;
for k:= 2 to 8 do
ed[k]:= ed[k-1] shl 1;И далее вместо громоздкой конструкции 1 shl(bit-1) можно использовать просто ed[bit].
Примеры использования символов, строк и множеств
Задача 1. Оставить в строке только первое вхождение каждого символа, взаимный порядок оставленных символов сохранить.
program z1; var s: set of char; inp, res: string; i: byte; begin s:=[]; res:= ''; for i:= 1 to length(inp) do if not(inp[i] in s) then begin res:= res+inp[i]; s:= s+[inp[i]]; end; end.
Задача 2 1) Оставить в строке только последнее вхождение каждого символа, взаимный порядок оставленных символов сохранить.
program z2; var inp, res: string; i, k: byte; begin res:= ''; for i:= 1 to length(inp) do begin k:= pos(inp[i],res); if k<>0 then delete(res,k,1); res:= res+inp[i]; end; end.
Задача 3. Выдать первые 100 000 натуральных чисел в случайном порядке без повторений.
program z3;
var bset: array[0..12499] of byte; {множество, битовый
массив}
ed: array[1..8] of byte;
el,k: longint;
kmp,bin: integer;
begin
ed[1]:= 1; {генерация массива
битовых единиц}
for k:= 2 to 8 do ed[k]:= ed[k-1] shl 1;
{-------------------------------------------------------}
k:=0;
randomize; {процедура активизации генератора случайных
чисел}
while k<100000 do
begin
el:= 1+random(99999); {случайное число из диапазона 0..99999}
kmp:= el div 8;
bin:= el mod 8;
if bin=0 then bin:= 8;
if bset[kmp]and ed[bin]=0 {проверка повторов}
then begin inc(k);
writeln(el);
bset[kmp]:= bset[kmp]or ed[bin]
end;
end
end.Лекция 6. Ввод и вывод информации: текстовые файлы
Ввод и вывод: файлы
В первой лекции мы уже рассматривали ввод информации с клавиатуры и вывод ее на экран1). Однако процесс ввода с консоли весьма трудоемок, а результат вывода на консоль - недолговечен. К счастью, существует более удобный способ записывать, хранить, пересылать и по необходимости считывать информацию из постоянной памяти компьютера. Для этого применяются файлы.
Что такое файл
В последнее время студенты все реже задают этот вопрос, однако на него все-таки стоит дать короткий ответ.
Файл - это самостоятельная последовательность символов, записанная в постоянную память компьютера.
В английском языке слово " file " имеет вполне понятный смысл: "вереница", что очень хорошо отражает внутреннюю структуру любого файла. Файл - это именно вереница символов, причем связанных в определенной последовательности: символы файла не могут по своему желанию перепрыгивать с одного места на другое.
"Самостоятельность" файлов заключается в том, что они не зависят от работы какой-либо программы. И даже если выключить компьютер, файлы будут продолжать свое существование на винчестере или на дискете.
Файлы могут хранить в себе все, что поддается кодированию:
- исходные тексты программ или входные данные (тесты);
- машинные коды выполняемых программ (игры, вирусы, обучающие и сервисные программы, др.);
- информацию о текущем состоянии какого-либо процесса;
- различные документы, в том числе и Интернет-страницы;
- картинки (рисунки, фотографии, видео);
- музыку;
- и т.д. и т.п.
Когда нужно использовать файлы
Выбор между консолью и файлами вам придется делать каждый раз, когда вы станете писать очередную программу.
Между тем ответ на вопрос, вынесенный в заголовок этого пункта, прост.
- Файлы полезны, если объем входных данных превосходит посильный при ручном вводе. (Крайним является случай, когда входные или выходные данные заведомо не могут поместиться в оперативной памяти.)
- Файлы нужны, если приходится многократно вводить одну и ту же информацию, с минимальными изменениями или вовсе без изменений (например, при отладке программы).
- Файлы необходимы, если нужно сохранять информацию о результатах работы программы, полученных при вводе различных входных данных (то есть: при поиске ошибок в программе).
Например, если вашей программе необходимо получить два или три числа (пять - уже многовато) или строку длиной символов десять, вы вполне можете задавать такие данные с клавиатуры вручную. Если же вам (а еще вероятнее - не вам, а некоему усредненному и потому посредственному оператору) придется вводить, скажем, массив чисел 10х10, то вероятность ошибки при ручном вводе возрастает многократно. Значит, возможность этой ошибки нужно исключить: записать данные в файл, который легко отредактировать в случае необходимости. Кроме того, однажды созданный файл можно использовать многократно (может быть, с незначительными изменениями).
Разновидности файлов
В языке Pascal имеется возможность работы с тремя видами файлов:
- текстовыми ;
- типизированными;
- нетипизированными.
Последние два типа объединяются под названием бинарные: информация в них записывается по байтам и потому недоступна для просмотра или редактирования в удобных для человека текстовых редакторах, зато такие файлы более компактны, чем текстовые.
В отличие от бинарных, текстовые файлы возможно создавать, просматривать и редактировать "вручную" - в любом доступном текстовом редакторе. Кроме того, при считывании данных из текстового файла нет необходимости заботиться об их преобразовании: в языке Pascal имеются средства автоматического перевода содержимого текстовых файлов в нужный тип и формат, и это позволяет сэкономить немало времени и сил.
Описание файлов
В разделе var переменные, используемые для работы с файлами ( файловые переменные ), описываются следующим образом:
var f1,f2: text; {текстовые файлы}
g: file of <тип_элементов_файла>; {типизированные файлы}
in, out: file; {нетипизированные файлы}Файловая переменная не может быть задана константой.
Текстовые файлы
В этой лекции мы ограничимся рассмотрением только текстовых файлов, а о типизированных расскажем позже (см. лекцию 7).
Оперирование файлами
С этого момента и до конца лекции под словом "файл" мы будем подразумевать " текстовый файл " (разумеется, если специально не оговорено обратное). Однако многие описываемые ниже команды пригодны не только для текстовых, но и для бинарных файлов.
Назначение файла
Процедура assign(f,'<имя_файла>'); служит для установления связи между файловой переменной f и именем того файла, за действия с которым эта переменная будет отвечать.
На разных этапах работы программы одной и той же файловой переменной можно присваивать разные значения. Например, если в начале программы мы напишем
assign(f,'input.txt');
то переменной f будет соответствовать файл, из которого производится считывание входных данных, вплоть до того момента, когда в программе встретится, скажем, команда
assign(f,'output.txt');
после которой переменной f будет уже соответствовать тот файл, куда выводятся результаты.
Строка '<имя_файла>' может содержать полный путь к файлу. Если путь не указан, файл считается расположенным в той же директории, что и исполняемый модуль программы. Именно этот вариант обычно считается наиболее удобным.
Открытие файла
В зависимости от того, какие действия ваша программа собирается производить с открываемым файлом, возможно троякое его открытие:
reset(f); | - открытие файла для считывания из него информации; если такого файла не существует, попытка открыть его вызовет ошибку и аварийную остановку работы программы. Эта же команда служит для возвращения указателя на начало файла; |
rewrite(f); | - открытие файла для записи в него информации; если такого файла не существует, он будет создан; если файл с таким именем уже есть, вся содержавшаяся в нем ранее информация исчезнет; |
append(f); | - открытие файла для записи в него информации (указатель помещается в конец этого файла). Если такого файла не существует, он будет создан; а если файл с таким именем уже есть, вся содержащаяся в нем ранее информация будет сохранена, потому что запись будет производиться в его конец. |
Закрытие файла
После того как ваша программа закончит работу с файлом, очень желательно закрыть его:
close(f);
В противном случае информация, содержащаяся в этом файле, может быть потеряна.
Считывание из файла
Чтение данных из файла, открытого для считывания, производится с помощью команд read() и readln(). В скобках сначала указывается имя файловой переменной, а затем - список ввода1). Например:
read(f,a,b,c); | - читать из файла f три переменные a, b и c. После выполнения этой процедуры указатель в файле передвинется за переменную с ; |
readln(f,a,b,c); | - читать из файла f три переменные a, b и c, а затем перевести указатель ("курсор") на начало следующей строки; если кроме уже считанных переменных в строке содержалось еще что-то, то этот "хвост" будет проигнорирован. |
Если вспомнить, что в памяти компьютера любой файл записывается линейной последовательностью символов и никакой разбивки на строки там реально нет, то действия процедуры readln() можно пояснить так: читать все указанные переменные, а затем игнорировать все символы вплоть до ближайшего символа "конец строки" или "конец файла". Указатель при этом перемещается на позицию непосредственно за первым найденным символом "конец строки".
Если же символ конца строки встретится где-нибудь между переменными, указанными в списке ввода, то обе процедуры его просто проигнорируют.
Считывать из текстового файла можно только переменные простых типов: целых, вещественных, символьных, - а также строковых. Численные переменные, считываемые из файла, должны разделяться хотя бы одним пробельным символом. Типы вводимых данных и типы тех переменных, куда эти данные считываются, обязаны быть совместимыми2). Здесь действуют все те же правила, что и при считывании с клавиатуры.
Считываемые переменные могут иметь различные типы. Например, если в файле3) f записана строка
1 2.5 с
то командой read(f,a,b,c); можно прочитать одновременно значения для трех переменных, причем все - разных типов:
a: byte; b: real; c: char;
Замечание: Обратите внимание, что символьную переменную c пришлось считывать дважды, так как после числа " 2.5 " сначала идет символ пробела и только затем буква " c ".
Из файла невозможно считать переменную составного типа (например, если а - массив, то нельзя написать read(f,a), можно ввести его только поэлементно, в цикле), файлового, а также логического.
Особенно внимательно нужно считывать строки ( string[length] и string ): эти переменные "забирают" из файла столько символов, сколько позволяет им длина (либо вплоть до ближайшего конца строки). Если строковая переменная неопределенной длины (тип данных string ) является последней в текущей строке файла, то никаких проблем с ее считыванием не возникнет. Но в случае, когда необходимо считывать переменную типа string из начала или из середины строки файла, это придется делать с помощью цикла - посимвольно. Аналогичным образом - посимвольно, от пробела до пробела - считываются из текстового файла слова.
Есть еще один, гораздо более трудоемкий способ: считать из файла всю строку целиком, а затем "распотрошить" ее - разобрать на части специальной процедурой выделения подстрок copy(). После чего (где необходимо) применить процедуру превращения символьной записи числа в само число, применяя стандартную процедуру val(). Кроме того, совсем не очевидно, что длина вводимой строки не будет превышать 256 символов, поэтому такой способ приходится признать неудовлетворительным.
Запись в файл
Сохранять переменные в файл, открытый для записи командами rewrite(f) или append(f), можно при помощи команд write() и writeln(). Так же как в случае считывания, первой указывается файловая переменная, а за ней - список вывода:
| write(f,a,b,c); | - записать в файл f переменные a, b и c ; |
| writeln(f,a,b,c); | - записать в файл f переменные a, b и c, а затем записать туда же символ " конец строки ". |
Выводить в текстовый файл можно переменные любых базовых типов (вместо значений логического типа выведется их строковый аналог TRUE или FALSE ) или строки.
Структурированные типы данных можно записывать только поэлементно.
Пробельные символы
К пробельным символам (присутствующим в файле, но невидимым на экране) относятся:
- символ горизонтальной табуляции ( #9 );
- символ перевода строки ( #10 ) (смещение курсора на следующую строку, в той же позиции);
- символ вертикальной табуляции ( #11 );
- символ возврата каретки ( #13 ) (смещение курсора на начальную позицию текущей строки; в кодировке UNIX один этот символ служит признаком конца строки);
- символ конца файла ( #26 );
- символ пробела ( #32 ).
Замечание: Пара символов #13 и #10 является признаком конца строки текстового файла (в кодировках DOS и Windows).
В (текстовом) файле границами чисел служат пробельные символы, и при считывании чисел эти пробельные символы игнорируются, сколько бы их ни было. Таким образом, если ввод многих чисел производится с помощью команды read(), то нет никакой разницы, как именно записаны эти числа: в одну строку, в несколько строк или вовсе в один столбик. В любом случае считывание пройдет корректно и завершится только по достижении конца файла.
Если же считывание тестового файла производится посимвольно, то нужно аккуратно отслеживать пробельные (особенно концевые) символы.
Поиск специальных пробельных символов (нас интересуют в основном #10, #13 и #26 ) можно осуществлять при помощи стандартных функций:
eof(f) - возвращает значение TRUE, если уже достигнут конец файла f (указатель находится сразу за последним элементом файла), и FALSE в противном случае;
seekeof(f) - возвращает значение TRUE, если "почти" достигнут конец файла f (между указателем и концом файла нет никаких символов, кроме пробельных ), и FALSE в противном случае;
eoln(f) - возвращает значение TRUE, если достигнут конец строки в файле f (указатель находится сразу за последним элементом строки), и FALSE в противном случае;
seekeoln(f) - возвращает значение TRUE, если "почти" достигнут конец строки в файле f (между указателем и концом строки нет никаких символов, кроме пробельных ), и FALSE в противном случае.
Ясно, что в большинстве случаев предпочтительнее использовать функции seekeof(f) и seekeoln(f): они предназначены специально для текстовых файлов, игнорируют концы строк (и вообще все пробельные символы ) и потому позволяют автоматически обработать сразу несколько частных случаев.
Например, если по условию задачи файл входных данных может содержать только одну строку, то правильнее всего будет написать программу, обрабатывающую все возможные варианты:
- одна строка, заканчивающаяся символом конца файла;
- одна строка, заканчивающаяся несколькими концевыми пробелами, а затем - символом конца файла;
- одна строка, заканчивающаяся символом конца строки, а затем - символом конца файла (на самом деле получается, что в файле содержится не одна, а две строки, но вторая - пустая);
- одна строка, заканчивающаяся несколькими концевыми пробелами, затем - символом конца строки, а затем - символом конца файла.
Поскольку функции seekeof() и seekeoln() при каждой проверке пытаются проигнорировать все пробельные символы, то и результаты их работы отличаются от результатов работы функций eof() и eoln(). Эти различия нужно учитывать.
Например, для входного файла f, состоящего из двух строк 1_2_ _3_#13#10 (всего 9 символов, вторая строка пустая, подчеркивания здесь обозначают пробелы), следующие куски программ будут выдавать такие результаты:
Cодержимое результирующего файла g | Длина файла g | |
while not eof(f) do
begin read(f,c); {c: char}
write(g,c)
end; | 1_2_ _3_#13#10 | 9 байт |
while not seekeof(f) do
begin read(f,c); {c: char}
write(g,c)
end; | 123 | 3 байта |
while not eof(f) do
while not seekeoln(f) do
begin read(f,c); {c: char}
write(g,c)
end; | Зацикливание | |
while not seekeof(f) do
while not eoln(f) do
begin read(f,c); {c: char}
write(g,c)
end; | 1_2_ _3_ | 7 байт |
while not seekeof(f) do
while not eoln(f) do
begin read(f,k); {k: byte}
write(g,k)
end; | 1230 | 4 байта |
Пример использования файлов
Задача. В текстовом файле f.txt записаны (вперемешку) целые числа: поровну отрицательных и положительных. Используя только один вспомогательный файл, переписать в текстовый файл h.txt все эти числа так, чтобы:
- порядок отрицательных чисел был сохранен;
- порядок положительных чисел был сохранен;
- любые два числа, стоящие рядом, имели разные знаки.
Решение
Если бы нам разрешили использовать два вспомогательных файла, мы бы просто переписали все положительные числа в один из них, а все отрицательные - в другой. А затем объединили бы два этих файла. В нашем же случае придется переписать во вспомогательный файл только положительные числа. Затем при "сборке" мы будем считывать из вспомогательного файла "все подряд", а из исходного - только отрицательные числа.
Реализация
program z1;
var f,g,h: text;
k: integer;
begin
assign(f,'f.txt');
assign(g,'g.txt');
assign(h,'h.txt');
{Переписываем положительные числа в доп.файл}
reset(f);
rewrite(g);
while not eof(f) do
begin read(f,k);
if k>0 then write(g,k,' ');
end;
{Собираем числа в новый файл h.txt}
reset(f); {Возвращаем указатель на начало файла f}
reset(g);
rewrite(h);
while not eof(g) do
begin read(g,k);
write(h,k,' ');
repeat
read(f,k)
until k<0;
write(h,k,' ');
end;
close(f);
close(g);
close(h);
end.Изменение реакции на ошибку
По умолчанию любая ошибка ввода или вывода вызывает аварийную остановку работы программы. Однако существует возможность отключить такое строгое реагирование; в этом случае программа сможет либо игнорировать эти ошибки (что, правда, далеко не лучшим образом отразится на результатах ее работы), либо обрабатывать их при помощи системной функции IOResult: integer.
Директива компилятора1) {$I-} отключает режим проверки, соответственно директива {$I+} - включает.
Если при отключенной проверке правильности ввода-вывода ( {$I-} ) происходит ошибка, то все последующие операции ввода-вывода игнорируются - вплоть до первого обращения к функции IOResult. Ее вызов "очищает" внутренний показатель ("флаг") ошибки, после чего можно продолжать ввод или вывод.
Если функция IOResult возвращает 0, значит, операция ввода-вывода была завершена успешно. В противном случае функция вернет номер произошедшей ошибки.
Пример использования директив {$I}
flag:= false;
write('Введите имя файла: ');
repeat
readln(s); {s:string}
{$I-}
assign(f,s);
reset(f);
case IOResult of
0: flag:= true;
3: write('Путь к файлу указан неверно. Измените путь: ');
5: write('Доступа к файлу нет. Измените имя файла: ');
152: write('Такого диска нет. Измените имя диска: ');
else write('Такого файла нет. Измените имя файла: ');
end;
until flag;
{$I+}| Номер ошибки | Описание ошибки | Генерирующие процедуры 2) | |
2 | File not found | Файл не найден | append, erase, rename, reset, rewrite |
3 | Path not found | Директория не найдена | append, chdir, erase, mkdir, rename, reset, rewrite, rmdir |
4 | Too many open files | Открыто более 15 файлов одновременно | append, reset, rewrite |
5 | File access denied | Отказ в доступе к файлу | append, blockread, blockwrite, erase, mkdir, read, readln, rename, reset, rewrite, rmdir, write, writeln |
12 | Invalid file access code | Попытка использовать текстовый файл как типизированный или наоборот | append, reset |
16 | Cannot remove current directory | Невозможно удалить заданную директорию | rmdir |
100 | Disk read error | Попытка чтения после конца файла | read, readln |
101 | Disk write error | Ошибка записи на диск (диск полон) | close, write, writeln |
102 | File not assigned | Файл не назначен | append, erase, rename, reset, rewrite |
103 | File not open | Файл не открыт{бинарные файлы} | blockread, blockwrite, close, eof, filepos, filesize, read, seek, write |
104 | File not open for input | Файл не открыт для ввода { текстовые файлы } | eof, eoln, read, readln, seekeof, seekeoln |
105 | File not open for output | Файл не открыт для вывода { текстовые файлы } | write, writeln |
106 | Invalid numeric format | Неправильный числовой формат { текстовые файлы } | read, readln |
152 | Drive not ready | Задано неверное имя диска | append, erase, rename, reset, rewrite |
Лекция 7. Записи. Бинарные файлы
Записи
Продолжая изучение структурированных типов данных, переходим к записям.
Как и массивы, записи являются структурами прямого доступа, однако, в отличие от массивов, могут хранить элементы, относящиеся к разным типам данных.
Таким образом, запись - это вектор, компоненты которого ( поля ) могут относиться к разным типам данных.
Описание записей
В разделе var переменную типа запись описывают так:
var <имя_записи>: record <имя_поля1>: <тип_поля1>;
[<имя_поля2>: <тип_поля2>;]
[...]
end;Имена полей должны подчиняться общим правилам построения идентификаторов. Повторение имен полей внутри одной записи не допускается.
Замечание: Имена полей могут совпадать с именами других переменных, поскольку на самом деле являются составными:
<имя_записи>.<имя_поля>.
Поэтому можно записать:
var x: real;
r: record x: real;
y: real
end;Поля могут относиться к любым стандартным (базовым или сконструированным) или определенным ранее типам, даже к файловому или процедурному (см. лекцию 8).
Если несколько подряд идущих полей принадлежат к одному типу данных, их описания можно объединить:
var <имя_записи>: record <имя_поля1>,_,<имя_поляN>: <тип_полей>;
<имя_поляS>: <тип_поляS>;
...
end;Например:
var zap1: record x,y: real;
i,j,k: integer;
flag: boolean;
s: set of 'a'..'z';
a: array[1..100] of byte;
data: record day:1..31;
month: 1..12;
year: 1900..2100;
end;
end;Эта запись содержит 9 полей, три из которых сами являются составными.
Наиболее распространенный способ использования записей - двумерная таблица, каждый столбец которой имеет свой тип. Такую структуру описывают, например, следующим образом:
var tabl: array[1..100] of zap1;
Задание записей константой
Как и массивы, записи не могут быть заданы неименованной или нетипизированной константой.
Для того чтобы задать запись типизированной константой, следует вначале описать соответствующий тип в разделе type, а затем воспользоваться им в разделе const:
type <имя_типа> = record <имя_поля1>: <тип_поля1>;
[<имя_поля2>: <тип_поля2>;]
[...]
end;
const <имя_константы>: <имя_типа> = <начальное_значение>;Начальное значение для переменной типа запись задается перечислением в круглых скобках начальных значений для всех полей (соответствующих типов!) с обязательным указанием имени задаваемого поля. Имя поля от его начального значения отделяется двоеточием, значения соседних полей разделяются точкой с запятой:
(<имя_поля1>: <значение_поля1>; _; <имя_поляN>: <значение_поляN>);
Например:
type data = record day: 1..31;
month: 1..12;
year: 1900..2100;
end;
const my_birthday: data = (day:17; month:3; year:2004);Можно, конечно, не описывать тип константы отдельно, а объединить оба определения:
const my_birthday: record day: 1..31; month: 1..12; year: 1900..2100; end; = (day:17; month:3; year:2004);
Если описана двумерная таблица, то ее начальные значения задаются как вектор, каждый компонент которого является записью. Таким образом, правила задания типизированной константы-таблицы сочетают в себе правила задания массива и записи:
type family = (mother, father, child); const birthdays : array[family] of data = ((day: 8; month: 3; year: 1975), (day: 23; month: 2; year: 1970), (day: 1; month: 9; year: 2000));
Доступ к полям
Обратиться к полю записи можно следующим способом:
<имя_записи>.<имя_поля>
Например:
month:= my_birthday.month +1;
Как уже было упомянуто, коллизий между переменной с именем month и полем записи my_birthday.month не возникает.
Доступ к полю двумерной таблицы осуществляется аналогичным образом (жирные скобки являются обязательным элементом синтаксиса):
<имя_таблицы>[<индекс>].<имя_поля>
Эту запись можно трактовать так:
(<имя_таблицы>[<индекс>]).<имя_поля>
Например:
birthdays[mother].day := 9;
Оперирование несколькими полями
Если программе предстоит несколько раз подряд обращаться к полям одной и той же записи, может оказаться неудобным записывать это обращение полностью:
my_birthday.day:= 17; my_birthday.month:= 3; my_birthday.year:= 2004;
Для сокращения таких участков служит оператор with, позволяющий обращаться к полям, не указывая каждый раз имя всей записи:
with <имя_записи> do
begin <операторы>
{имена полей здесь используются как <имя_поля>,
а не как <имя_записи>.<имя_поля>}
end;Например:
with my_birthday do begin day:= 17; month:= 3; year:= 2004; end;
Замечание. Для того чтобы внутри оператора with можно было обратиться не к полю записи, а к глобальной переменной с таким же именем, перед этой переменной нужно указать (через точку) имя программы: <имя_программы>.<имя_переменной>.
Например:
with my_birthday do
begin day:= 17;
month:= 3; {поле записи birthday.month}
year:= 2004;
programma.month:= 5; {глобальная переменная month}
end;Вложенные операторы with
Если возникает необходимость расположить один оператор with внутри другого, то любую переменную (если перед ней явно не указано имя записи ), находящуюся под внутренним оператором with, компилятор пытается интерпретировать в такой последовательности:
- если во внутренней записи есть поле с искомым именем, то поиск заканчивается;
- если во внутренней записи поля с таким именем нет, то поиск производится среди полей внешней записи (если вложенных операторов with больше, чем два, то поиск ведется последовательно во всех задействованных записях в направлении "изнутри наружу");
- если среди полей всех вложенных записей нет искомого идентификатора, компилятор считает его глобальной переменной.
Например:
type date = record day: 1..31;
month: 1..12;
year: 1900..2005;
end;
student = record name: string[100];
year: 1950..2005; {год поступления}
gruppa: string[5];
birth: date;
end;
var ivanov: student;
begin
...
with ivanov do
begin
...
with birth do
begin
...
year:= 2001; {birth.year}
gruppa:= 'IT01'; {ivanov.gruppa}
...
end;
...
end;
end;Запись с вариантной частью
Если заранее известно, что в массиве записей (таблице) некоторые поля могут оставаться пустыми (наборы пустых полей могут быть разными для разных записей ), то вполне понятно желание как-то сократить неиспользуемый, но занимаемый объем памяти.
Специально для таких случаев существуют записи с вариантной частью.
Описание записи с вариантной частью
В разделе var запись с вариантной частью описывают так:
var <имя_записи>: record <поле1>: <тип1>;
[<поле2>: <тип2>;]
[...]
case <поле_переключатель>: <тип> of
<варианты1>: (<поле3>: <тип3>;
<поле4>: <тип4>;
...);
<варианты2>: (<поле5>: <тип5>;
<поле6>: <тип6>;
...);
[...]
end;Невариантная часть записи (до ключевого слова case ) подчиняется тем же правилам, что и обычная запись. Вообще говоря, невариантная часть может и вовсе отсутствовать.
Вариантная часть начинается зарезервированным словом case, после которого указывается то поле записи, которое в дальнейшем будет служить переключателем. Как и в случае обычного оператора case, переключатель обязан принадлежать к одному из перечислимых типов данных (см. лекцию 3). Список вариантов может быть константой, диапазоном или объединением нескольких констант или диапазонов. Набор полей, которые должны быть включены в структуру записи, если выполнился соответствующий вариант, заключается в круглые скобки.
Пример. Для того чтобы описать содержимое библиотеки, необходима следующая информация:
| Для книг | Для газет | Для журналов |
|---|---|---|
Автор Название Год издания Издательство | Название Дата выхода (день, месяц, год) Издательство . | Название Год и месяц издания Номер Издательство |
Графы "Название" и "Издательство" являются общими для всех трех вариантов, а остальные поля зависят от типа печатного издания. Для реализации этой структуры воспользуемся записью с вариантной частью:
type biblio = record name,publisher: string[20]; case item: char of 'b': (author: string[20]; year: 0..2004); 'n': (data: date); 'm': (year: 1700..2004; month: 1..12; number: integer); end;
В зависимости от значения поля item, в записи будет содержаться либо 4, либо 5, либо 6 полей.
Механизм использования записи с вариантной частью
Количество байтов, выделяемых компилятором под запись с вариантной частью, определяется самым "длинным" ее вариантом. Более "короткие" наборы полей из других вариантов занимают лишь некоторую часть выделяемой памяти.
В приведенном выше примере самым "длинным" является вариант ' b ': для него требуется 23 байта (21 байт для строки и 2 байта для целого числа). Для вариантов ' n ' и ' m ' требуется 4 и 5 байт соответственно (см. таблицу).
Бинарные файлы
Бинарные файлы хранят информацию в том виде, в каком она представлена в памяти компьютера, и потому неудобны для человека. Заглянув в такой файл, невозможно понять, что в нем записано; его нельзя создавать или исправлять вручную - в каком-нибудь текстовом редакторе - и т.п. Однако все эти неудобства компенсируются скоростью работы с данными.
Кроме того, текстовые файлы относятся к структурам последовательного доступа, а бинарные - прямого. Это означает, что в любой момент времени можно обратиться к любому, а не только к текущему элементу бинарного файла.
Типизированные файлы
Переменные структурированных типов данных (кроме строкового) невозможно считать из текстового файла. Например, если нужно ввести из текстового файла данные для наполнения записи toy информацией об имеющихся в продаже игрушках (название товара, цена товара и возрастной диапазон, для которого игрушка предназначена):
type toy = record name: string[20];
price: real;
age: set of 0..18; {в файле задано границами}
end;то придется написать следующий код:
var f: text; c: char; i,j,min,max: integer; a: array[1..100] of toy; begin assign(f,input); reset(f); for i:=1 to 100 do if not eof(f) then with a[i] do begin readln(f,name,price,min,max); age:=[]; for j:= min to max do age:=age+[j]; end; close(f); ... end.
Как видим, такое поэлементное считывание весьма неудобно и трудоемко.
Выход из этой ситуации предлагают типизированные файлы - их элементы могут относиться к любому базовому или структурированному типу данных. Единственное ограничение: все элементы должны быть одного и того же типа. Это кажущееся неудобство является непременным условием для организации прямого доступа к элементам бинарного файла: как и в случае массивов, если точно известна длина каждого компонента структуры, то адрес любого компонента может быть вычислен по очень простой формуле:
<начало_структуры> + <номер_компонента>*<длина_компонента>
Описание типизированных файлов
В разделе var файловые переменные, предназначенные для работы с типизированными файлами, описываются следующим образом:
var <файловая_перем>: file of <тип_элементов_файла>;
Никакая файловая переменная не может быть задана константой.
Назначение типизированного файла
С этого момента и до конца раздела под словом "файл" мы будем подразумевать " бинарный типизированный файл " (разумеется, если специально не оговорено иное).
Команда assign(f,'<имя_файла>'); служит для установления связи между файловой переменной f и именем того файла, за работу с которым эта переменная будет отвечать.
Строка ' <имя_файла> ' может содержать полный путь к файлу. Если путь не указан, файл считается расположенным в той же директории, что и исполняемый модуль программы.
Открытие и закрытие типизированного файла
В зависимости от того, какие действия ваша программа собирается производить с открываемым файлом, возможно двоякое его открытие:
reset(f); - открытие файла для считывания из него информации и одновременно для записи в него (если такого файла не существует, попытка открытия вызовет ошибку). Эта же команда служит для возвращения указателя на начало файла;
rewrite(f); - открытие файла для записи в него информации; если такого файла не существует, он будет создан; если файл с таким именем уже есть, вся содержавшаяся в нем ранее информация исчезнет.
Закрываются типизированные файлы процедурой close(f), общей для всех типов файлов.
Считывание из типизированного файла
Чтение из файла, открытого для считывания, производится с помощью команды read(). В скобках сначала указывается имя файловой переменной, а затем - список ввода1):
read(f,a,b,c); - читать из файла f три однотипные переменные a, b и c.
Вводить из файла можно только переменные соответствующего объявлению типа, но этот тип данных может быть и структурированным. Cкажем, если вернуться к примеру, приведенному в начале п. " Типизированные файлы ", то станет очевидным, что использование типизированного файла вместо текстового позволит значительно сократить текст программы:
type toy = record name: string[20];
price: real;
age: set of 0..18; {задано границами}
end;
var f: file of toy;
a: array[1..100] of toy;
begin
assign(f,input);
reset(f);
for i:=1 to 100 do
if not eof(f) then read(f,a[i]);
close(f);
...
end.Поиск в типизированном файле
Уже знакомая нам функция eof(f:file):boolean сообщает о достигнутом конце файла. Все остальные функции "поиска конца" ( eoln(), seekeof() и seekeoln() ), свойственные текстовым файлам, нельзя применять к файлам типизированным.
Зато существуют специальные подпрограммы, которые позволяют работать с типизированными файлами как со структурами прямого доступа:
- Функция filepos(f:file):longint сообщит текущее положение указателя в файле f. Если он указывает на самый конец файла, содержащего N элементов, то эта функция выдаст результат N. Это легко объяснимо: элементы файла нумеруются начиная с нуля, поэтому последний элемент имеет номер N-1. А номер N принадлежит, таким образом, "несуществующему" элементу - признаку конца файла.
- Функция filesize(f:file):longint вычислит длину файла f.
- Процедура seek(f:file,n:longint) передвинет указатель в файле f на начало записи с номером N. Если окажется, что n больше фактической длины файла, то указатель будет передвинут и за реальный конец файла.
- Процедура truncate(f:file) обрежет "хвост" файла f: все элементы начиная с текущего и до конца файла будут из него удалены. На самом же деле произойдет лишь переписывание признака "конец файла" в то место, куда указывал указатель, а физически "отрезанные" значения останутся на прежних местах - просто они станут "бесхозными".
Запись в типизированный файл
Сохранять переменные в файл, открытый для записи, можно при помощи команды write(). Так же как и в случае считывания, первой указывается файловая переменная, а за ней - список вывода:
write(f,a,b,c); - записать в файл f (предварительно открытый для записи командами rewrite(f) или reset(f) ) переменные a, b, c.
Выводить в типизированный файл можно только переменные соответствующего описанию типа данных. Неименованные и нетипизированные константы нельзя выводить в типизированный файл.
Типизированные файлы рассматриваются как структуры одновременно и прямого, и последовательного доступа. Это означает, что запись возможна не только в самый конец файла, но и в любой другой его элемент. Записываемое значение заместит предыдущее значение в этом элементе (старое значение будет "затерто").
Например, если нужно заместить пятый элемент файла значением, хранящимся в переменной а, то следует написать следующий отрывок программы:
seek(f,5); {указатель будет установлен на начало 5-го элемента}
write(f,a); {указатель будет установлен на начало 6-го элемента}
Замечание: Поскольку и чтение из файла, и запись в файл сдвигают указатель на следующую позицию, то в случае, когда необходимо сначала прочитать значение, хранящееся в каком-то элементе, а затем вписать на это место новые данные, необходимо производить поиск дважды:
seek(f,5); {указатель - на начало 5-го элемента}
read(f,a); {указатель - на начало 6-го элемента}
seek(f,5); {указатель - на начало 5-го элемента}
write(f,b); {указатель - на начало 6-го элемента}
А что произойдет, если в файле содержится всего N элементов, а запись производится в ( N+k )-й? Тогда начало файла останется прежним, затем в файл будет включен весь тот "мусор", что оказался между его концом и записываемой переменной, и, наконец, последним элементом нового файла станет записанное значение.
Нетипизированные файлы
Главное преимущество нетипизированных файлов - это высокая скорость их обработки. Открыть как нетипизированный можно и файл любой другой природы: текстовый или бинарный типизированный. В основном это применяется в тех случаях, когда нужно перекопировать довольно большой кусок одного файла в другой без изменений.
Описание нетипизированных файлов
В разделе var файловые переменные, предназначенные для работы с нетипизированными файлами, описываются следующим образом:
var g: file;
Никакая файловая переменная не может быть задана константой.
Назначение нетипизированного файла
Содержимое этого раздела дословно повторяет все сказанное в разделе " Назначение типизированного файла ".
Открытие и закрытие нетипизированного файла
В зависимости от того, какие действия ваша программа собирается производить с открываемым файлом, возможно двоякое его открытие:
reset(f[,size]); - открытие файла для считывания из него информации и одновременно для записи в него (если такого файла не существует, попытка открытия вызовет ошибку). Эта же команда служит для возвращения указателя на начало файла;
rewrite(f[,size]); - открытие файла для записи в него информации; если такого файла не существует, он будет создан; если файл с таким именем уже есть, вся содержавшаяся в нем ранее информация исчезнет.
Необязательная переменная size может задать количество байтов, единовременно считываемых из нетипизированного файла или записываемых в него. По умолчанию размер таких "кусков" принимается равным 128 байт.
Закрываются нетипизированные файлы процедурой close(f), общей для всех типов файлов.
Поиск в нетипизированном файле
Все подпрограммы, описанные в разделе " Поиск в типизированном файле ", будут работать и для нетипизированного файла. Но, поскольку тип элементов нетипизированного файла не определен, то размер одного "элемента" принимается равным 128 байт (по умолчанию) или указанному в переменной size во время открытия файла.
Запись и чтение
Для осуществления записи в нетипизированный файл и считывания из него применяются две специальные процедуры blockread() и blockwrite().
Процедура blockread(f:file; buf,count:word [;result:word]) предназначена для считывания из файла f нескольких элементов разом (их количество указывается в переменной count, а длина устанавливается во время открытия файла) при помощи буфера обмена данными buf. Необязательная переменная result может хранить количество элементов, фактически считанных из файла.
Процедура blockwrite(f:file; buf,count:word [;result:word]) производит запись данных в нетипизированный файл при помощи буфера buf.
Подпрограммы обработки директорий
Приведем здесь также несколько стандартных процедур, осуществляющих работу с директориями, а также с файлами, но внешним относительно самих файлов образом (без их открытия).
Процедура erase(f: file) удалит файл, связанный с файловой переменной f. Если такого файла нет, произойдет ошибка, реакцию на которую можно отрегулировать при помощи директивы компилятора {$I} (см. лекцию 6).
Процедура rename(f: file; s: string) даст файлу, связанному с файловой переменной f, новое имя, указанное в строке s. Если такого файла нет, произойдет ошибка.
Процедура chdir(s: string) сделает текущей директорию, указанную в строке s. Если такой директории нет, произойдет ошибка.
Процедура getdir(disk: byte; s:string) запишет в строку s имя текущей директории на указанном диске ( 0 - текущий диск, 1 - диск А , 2 - диск В и т.д.).
Процедура mkdir(s: string) создаст в текущей директории новую поддиректорию с указанным в строке s именем. Если в текущей директории уже существуют файл или директория с указанным именем, произойдет ошибка.
Процедура rmdir(s: string) удалит пустую директорию с заданным в строке s именем. Если такой директории нет, произойдет ошибка.
Применимость подпрограмм обработки файлов
Сведем информацию о применимости процедур и функций работы с файлами в единую таблицу.
| Текстовые | Типизированные | Нетипизированные | |
|---|---|---|---|
| append | + | ||
| assign | + | + | + |
| blockread | + | ||
| blockwrite | + | ||
| close | + | + | + |
| eof | + | + | + |
| eoln | + | ||
| filepos | + | + | |
| filesize | + | + | |
| read | + | + | |
| readln | + | ||
| reset | + | + | + |
| rewrite | + | + | + |
| seek | + | + | |
| seekeof | + | ||
| seekeoln | + | ||
| truncate | + | + | |
| write | + | + | |
| writeln | + |
Замечание: Реакция на ошибку, возникающую при выполнении любой из перечисленных здесь подпрограмм, зависит от состояния директивы компилятора {$I} (см. лекцию 6).
Лекция 8. Процедуры и функции
Подпрограммы
Весьма поэтичное объяснение понятия подпрограмма дал В.Ф. Очков: " Подпрограмма - это припев песни, который поют несколько раз, а в текстах песен печатают только один раз"1).
В самом деле, если есть необходимость многократно совершать одни и те же действия, то вполне логично описать их единожды, а потом лишь ставить на них ссылку. Именно такой смысл имеет использование подпрограмм.
С математической же точки зрения любая подструктура - это замкнутая часть целого, которую можно рассматривать как самостоятельную структуру: подмножество является множеством, подгруппа - группой, подалгебра - алгеброй, подпространство - пространством и т.д.
Таким образом, подпрограмма - это в первую очередь программа. Со всеми полагающимися полноценной программе атрибутами: именем, разделами описания меток ( label ), констант ( const ), типов ( type ), переменных ( var ) и даже со своими (вложенными) функциями и процедурами.
В языке Pascal имеется два вида подпрограмм: процедуры и функции. Описывая их общие черты, мы будем употреблять обобщенный термин " подпрограмма ". Если же в тексте встретятся слова " процедура " или " функция ", то это будет означать, что излагаемая информация свойственна только одному конкретному виду подпрограмм: либо только процедурам, либо только функциям.
Объявление и описание
Подпрограммы объявляются и описываются в начале Pascal-программы, до ключевого слова begin, означающего начало тела программы.
Различия между процедурами и функциями начинаются уже с момента их объявления.
Объявление функции
Функции объявляются следующим образом:
function <имя_функции> [(<список_параметров>)]:<тип_результата>;
В отличие от констант и переменных, объявление подпрограммы может быть оторвано от ее описания. В этом случае после объявления нужно указать ключевое слово forward:
function <имя_функции> [(<параметры>)]:<тип_результата>; forward;
Объявление процедуры
Процедуры следует объявлять так:
procedure <имя_процедуры> [(<список_параметров>)];
Если объявление процедуры оторвано от ее описания, нужно поставить после него ключевое слово forward:
procedure <имя_процедуры> [(<список_параметров>)]; forward;
Описание подпрограммы
Описание подпрограммы должно идти после ее объявления. Оно осуществляется по следующей схеме (единой для процедур и функций ):
[ uses <имена_подключаемых_модулей>;]
[ label <список_меток>;]
[ const <имя_константы> = <значение_константы>;]
[ type <имя_типа> = <определение_типа>;]
[ var <имя_переменной> : <тип_переменной>;]
[ procedure <имя_процедуры> <описание_процедуры>]
[ function <имя_функции> <описание_функции>;]
begin {начало тела подпрограммы}
<операторы>
end; (* конец тела подпрограммы *)Если объявление подпрограммы было оторвано от ее описания, то описание начинается дополнительной строкой с указанием только имени подпрограммы:
function <имя_подпрограммы>;
или
procedure <имя_подпрограммы>;
Описания двух различных подпрограмм не могут пересекаться: каждый блок должен быть логически законченным. Однако внутри любой подпрограммы (она ведь тоже является программой, помните?) могут быть описаны другие процедуры или функции - вложенные. На них распространяются все те же правила объявления и описания подпрограмм.
Пример подпрограммы-процедуры:
procedure err(c:byte; s:string);
var zz: byte;
begin if c = 0
then writeln(s)
else writeln('Ошибка!')
end;Список параметров
В заголовке подпрограммы (в ее объявлении) указывается список формальных параметров переменных, которые принимают значения, передаваемые в подпрограмму извне во время ее вызова. Для краткости мы далее будем опускать слово "формальный".
Поскольку внутри подпрограммы параметры рассматриваются как переменные с начальным значением, то имена локальных переменных, описываемые в разделе var (внутреннем для подпрограммы ), не могут совпадать с именами параметров этой же подпрограммы. Подробнее о локальных и глобальных переменных мы расскажем в пункте "Разграничение контекстов ".
Список параметров может и вовсе отсутствовать:
procedure proc1; function func1: boolean;
В этом случае подпрограмма не получает никаких переменных "извне". Упомянутый в начале лекции песенный припев как раз и является примером подпрограммы, в которую не передается никаких данных при вызове.
Однако отсутствие параметров и, как следствие, передаваемых извне значений вовсе не означает, что при каждом вызове подпрограмма будет выполнять абсолютно одинаковые действия. Поскольку глобальные переменные видны изнутри любой подпрограммы, их значения могут неявно изменять внутреннее состояние подпрограмм. Этому очень нежелательному эффекту будет посвящен пункт " Побочный эффект ".
Если же параметры имеются, то каждый из них описывается по следующему шаблону:
[<способ_подстановки>]<имя_параметра>:<тип>;
О возможных способах подстановки значений в параметры ( <пустой>, var, const ) мы расскажем в разделе "Способы подстановки аргументов ".
Если способ подстановки и тип нескольких параметров совпадают, описание этих параметров можно объединить:
[<способ_подстановки>]<имя1>,...,<имяN>: <тип>;
Пример описания всех трех способов подстановки:
function func2(a,b:byte; var x,y,z:real; const c:char) : integer;
В заголовке подпрограммы можно указывать только простые (не составные) типы данных. Следовательно, попытка записать
procedure proc2(a: array[1..100]of char);
вызовет ошибку уже на этапе компиляции. Для того чтобы обойти это ограничение, составной тип данных нужно описать в разделе type, а при объявлении подпрограммы воспользоваться именем этого типа:
type arr = array[1..100] of char; procedure proc2(a: arr); function func2(var x: string): arr;
Возвращаемые значения
Основное различие между функциями и процедурами состоит в количестве возвращаемых ими значений.
Любая функция, завершив свою работу, должна вернуть основной программе (или другой вызвавшей ее подпрограмме ) ровно одно значение, причем его тип нужно явным образом указать уже при объявлении функции.
Для возвращения результата применяется специальная "переменная", имеющая имя, совпадающее с именем самой функции. Оператор присваивания значения этой "переменной" обязательно должен встречаться в теле функции хотя бы один раз.
Например:
function min(a,b: integer): integer; begin if a>b then min:= b else min:= a end;
В отличие от функций, процедуры вообще не возвращают (явным образом) никаких значений. О том, как все-таки получить результаты работы процедуры, вы узнаете из пункта " Параметр-переменная ".
Вызов подпрограмм
Любая подпрограмма может быть вызвана не только из основного тела программы, но и из любой другой подпрограммы, объявленной позже нее.
При вызове в подпрограмму передаются фактические параметры или аргументы (в круглых скобках после имени подпрограммы, разделенные запятыми):
<имя_подпрограммы>(<список_аргументов>)
Аргументами могут быть переменные, константы и выражения, включающие в себя вызовы функций.
Количество и типы передаваемых в подпрограмму аргументов должны соответствовать количеству и типам ее параметров. Кроме того, тип каждого аргумента должен обязательно учитывать способ подстановки, указанный для соответствующего параметра (подробнее об этом будет рассказано в разделе "Способы подстановки аргументов "). Если у подпрограммы вообще нет объявленных параметров, то при вызове список передаваемых аргументов будет отсутствовать вместе с обрамляющими его скобками.
Вызов функции не может быть самостоятельным оператором, потому что возвращаемое значение нужно куда-то записывать. Зато оно может стать равноправным участником арифметического выражения. Например:
c:= min(a,a*2); if min(z, min(x,y))= 0 then...;
Процедура же ничего не возвращает явным образом, поэтому ее вызов является отдельным оператором в программе. Например:
err(res,'Привет!');
Замечание: После того как вызванная подпрограмма завершит свою работу, управление передается оператору, следующему за оператором, вызвавшим эту подпрограмму.
Способы подстановки аргументов
Как уже упоминалось выше, при вызове подпрограммы подстановка значений аргументов в параметры производится в соответствии с правилами, указанными в атрибуте <способ_подстановки>. Мы рассмотрим три различных значения этого атрибута:
- <пустой> ;
- var ;
- const 1).
Параметр-значение
Описание
В списке параметров подпрограммы перед параметром-значением служебное слово отсутствует1). Например, функция func3 имеет три параметра-значения:
function func3(x:real; k:integer; flag:boolean):real;
При вызове подпрограммы параметру-значению может соответствовать аргумент, являющийся выражением, переменной или константой, например:
dlina:= func3(shirina/2, min(a shl 1,ord('y')), true)+0.5;Для типов данных здесь не обязательно строгое совпадение (эквивалентность), достаточно и совместимости по присваиванию (см. лекцию 2).
Механизм передачи значения
В области памяти, выделяемой для работы вызываемой подпрограммы, создается переменная с именем <имя_подпрограммы>.<имя_параметра>, и в эту переменную записывается значение переданного в соответствующий параметр аргумента. Дальнейшие действия, производимые подпрограммой, выполняются именно над этой новой переменной. Значение же входного аргумента не затрагивается. Следовательно, после окончания работы подпрограммы, когда весь ее временный контекст будет уничтожен, значение аргумента останется точно таким же, каким оно было на момент вызова подпрограммы.
В качестве примера рассмотрим последовательность действий, выполняемых при передаче аргументов 1+а/2, а и true в описанную выше функцию func3. Пусть а - переменная, имеющая тип byte, тогда значение выражения 1+a/2 будет иметь тип real, а true и вовсе является константой (неименованной).
Итак, при вызове func3(1+a/2,a,true) будут выполнены следующие действия:
- создать временные переменные func3.x, func3.k, func3.flag ;
- вычислить значение выражения 1+а/2 и записать его в переменную func3.x ;
- записать в переменную func3.k значение переменной а ;
- записать в переменную func3.flag значение константы true ;
- произвести действия, описанные в теле функции ;
- уничтожить все временные переменные, в том числе func3.x, func3.k, func3.flag.
Уже видно, что значения аргументов не изменятся.
Замечание: При использовании параметров-значений в контексте подпрограммы создаются хотя и временные, но вполне полноценные копии входных аргументов. Поэтому нежелательно передавать в параметры-значения "большие" аргументы (например, массивы): они будут занимать много лишней памяти.
Параметр-переменная
Описание
В списке параметров подпрограммы перед параметром-переменной ставится служебное слово var. Например, процедура proc3 имеет три параметра-переменные и один параметр-значение:
procedure proc3(var x,y:real; var k:integer; flag:boolean);
При вызове подпрограммы параметру-переменной может соответствовать только аргумент-переменная; константы и выражения запрещены. Кроме того, тип аргумента и тип параметра-переменной должны быть эквивалентными (см. лекцию 2).
Механизм передачи значения
В отличие от параметра-значения, для параметра-переменной не создается копии при вызове подпрограммы. Вместо этого в работе подпрограммы участвует та самая переменная, которая послужила аргументом. Понятно, что если ее значение изменится в процессе работы подпрограммы, то это изменение сохранится и после того, как будет уничтожен контекст подпрограммы. Понятно опять же и ограничение на аргументы, которые должны соответствовать параметрам-переменным: ни константа, ни выражение не смогут сохранить изменения, внесенные в процессе работы подпрограммы.
Итак, параметры-переменные и служат теми посредниками, которые позволяют получать результаты работы процедур, а также увеличивать количество результатов, возвращаемых функциями.
Замечание: Для экономии памяти в параметр-переменную можно передавать и такую переменную, изменять значение которой не требуется. Скажем, если нужно передать в качестве аргумента массив, то лучше не создавать его копию, как это будет сделано при использовании параметра-значения, а использовать параметр-переменную.
Параметр-константа
Описание
В списке параметров подпрограммы перед параметром-константой ставится служебное слово const. Например, процедура proc4 имеет один параметр-переменную и один параметр-константу:
procedure proc4(var k:integer; const flag:boolean);
При вызове подпрограммы параметру-константе может соответствовать аргумент, являющийся выражением, переменной или константой. Во время выполнения подпрограммы соответствующая переменная считается обычной константой. Ограничением является то, что при вызове другой подпрограммы из тела текущего параметра-константе не может быть подставлен в качестве аргумента в параметр-переменную.
Для типов данных здесь не обязательно строгое совпадение (эквивалентность), достаточно и совместимости по присваиванию (см. лекцию 2).
Механизм передачи значения
В некоторых источниках2) можно встретить утверждение о том, что для параметра-константы, как и для параметра-переменной, не создается копии в момент вызова подпрограммы. Однако выполнение простейшей проверки
var a: byte;
procedure prob(const c:byte);
begin
writeln(longint(addr(c))); {физ.адрес параметра с}
end;
begin
a:=0;
writeln(longint(addr(a))); {физ.адрес переменной а}
prob(a);
end.доказывает обратное: физические адреса3) переменной а и параметра с различаются. Следовательно, в памяти эти переменные занимают разные позиции, а не одну, как было бы в случае параметра-переменной. Вы можете убедиться в этом самостоятельно, запустив данную программу в трех разных вариантах (для параметра-значения, параметра-переменной и параметра-константы ), а затем сравнив результаты.
Области действия имен
Разграничение контекстов
Глобальные объекты - это типы данных, константы и переменные, объявленные в начале программы до объявления любых подпрограмм. Эти объекты будут видны во всей программе, в том числе и во всех ее подпрограммах. Глобальные объекты существуют на протяжении всего времени работы программы.
Локальные объекты объявляются внутри какой-нибудь подпрограммы и "видны" только этой подпрограмме и тем подпрограммам, которые были объявлены как внутренние для нее. Локальные объекты не существуют, пока не вызвана подпрограмма, в которой они объявлены, а также после завершения ее работы.
program prog; var a:byte; | ||
procedure pr1 (p:byte); var b:byte; (первый уровень вложенности) | ||
function f (pp:byte); var c:byte; (второй уровень вложенности) begin (здесь "видны" переменные a, b, c, p, pp) end; | ||
begin (здесь "видны" переменные a, b, p) end; | ||
var g:byte | ||
procedure pr2; var d:byte; (первый уровень вложенности) begin (здесь видны переменные a, d, g) end; | ||
begin (тело программы; здесь "видны" переменные a, g) end; | ||
Побочный эффект
Поскольку глобальные переменные видны в контекстах всех блоков, то их значение может быть изменено изнутри любой подпрограммы. Этот эффект называется побочным, а его использование очень нежелательно, потому что может стать источником непонятных ошибок в программе.
Чтобы избежать побочного эффекта, необходимо строго следить за тем, чтобы подпрограммы изменяли только свои локальные переменные (в том числе и параметры-переменные ).
Совпадение имен
Вообще говоря, совпадения глобальных и локальных имен допустимы, поскольку к каждому локальному имени неявно приписано имя той подпрограммы, в которой оно объявлено. Таким образом, в приведенном выше примере (см. пример 8.1) фигурируют переменные a, g, pr1.p, pr1.b, pr1.f.pp, pr1.f.c, pr2.d.
Если имеются глобальная и локальная переменные с одинаковым именем, то изнутри подпрограммы к глобальной переменной можно обратиться, приписав к ней спереди имя программы:
<имя_программы>.<имя_глобальной переменной>
Например ( локальной переменной здесь присваивается значение глобальной ):
a:= prog.a;
Замечание: Несмотря на то что совпадения имен локальных и глобальных переменных не вызывают никаких коллизий на уровне компилятора, стоит все-таки воздерживаться от них, потому что они также могут стать причиной непредвиденного побочного эффекта, аналогичного описанному в предыдущем пункте.
Нетипизированные параметры
В объявлении подпрограммы можно не указывать тип параметра-переменной:
procedure proc5(var x);
Такой параметр будет называться нетипизированным. В этот параметр можно передать аргумент, относящийся к любому типу данных.
Для того чтобы внутри самой подпрограммы корректно обрабатывать значения, поступившие через нетипизированный параметр, существует два различных способа.
Явное преобразование типа
При помощи операции явного преобразования типа данных (см. лекцию 2) можно преобразовать нетипизированное значение, относящееся к нужному типу данных. Например, в процедуре proc5 значение одного и того же параметра х интерпретируется тремя разными способами: как целое число, как вещественное число и как массив:
procedure proc5(var x); type arr = array[1..10] of byte; var y: integer; z: real; m: arr; begin ... y:= integer(x); z:= real(x); m:= arr(x); ... end;
Совмещение в памяти
Второй способ: описать внутри подпрограммы локальную переменную, которая будет физически совпадать с переменной, передаваемой через нетипизированный параметр:
<локальная_переменная>: <тип> absolute <нетипизир_параметр>;
В этом случае будут совмещены значения, физически записанные в этих переменных, в точности так же, как это происходит при подстановке аргумента в параметр-переменную, однако без контроля за совпадением типов данных. Поэтому вполне возможна, например, ситуация, когда первые четыре байта строки ( аргумента, переданного в нетипизированный параметр ) будут восприниматься как longint -число:
function func5(var x):real;
var xxx: longint absolute x;
begin
{здесь с началом любой переменной,
поступившей в параметр х,
... можно обращаться как с longint-числом:
при помощи локальной переменной ххх}
end;Открытые параметры
Открытые параметры - это массивы и строки неопределенной длины. Открытым параметром может стать только параметр-переменная. Возможность работать с открытыми параметрами в подпрограммах появилась в версии Turbo Pascal 7.0.
Открытые массивы
В параметр, который является открытым массивом, можно передавать как аргумент массив любой длины и размерности. Единственное ограничение: типы компонент у этих двух массивов должны совпадать.
В заголовке подпрограммы открытый параметр-массив описывается по следующему шаблону:
var <имя_параметра>: array of <тип_компонентов_массива>
Например, если описано
procedure proc6 (var a: array of byte);
то аргументом могут стать такие массивы:
a1: array[1..100] of byte; a2: array[-10..10] of byte; a3: array[1..2,1..3] of byte;
Компоненты открытого параметра-массива нумеруются начиная с нуля - этим достигается единообразие обращения к массивам переменной длины.
Если в качестве аргумента поступил многомерный массив, его компоненты "вытягиваются" в одну строку: сначала все компоненты первой строки массива, затем - второй строки и т.д. Например, если массив а3 имеет значения
1 2 3 4 5 6
то внутри процедуры proc6 параметр а будет иметь уже следующий вид:
1 2 3 4 5 6
причем компоненты двух массивов будут соотноситься так:
Открытые строки
Поскольку строки - это массивы символов, то они тоже могут стать открытыми параметрами. Описывается это следующим образом:
var <имя_параметра>: string
Например:
function func6 (var s: string): byte;
Длина такого параметра будет автоматически скорректирована в соответствии с длиной строки-аргумента.
Процедурный тип данных
Имена подпрограмм могут выступать в роли аргументов для других подпрограмм.
Описание
В разделе type процедурный тип данных задается одним из следующих способов:
<имя_типа> = function[(<список_параметров>)]:<тип_результата>;
или
<имя_типа> = procedure[(<список_параметров>)];
Например:
type func = function(a,b:integer):integer;
Аргументы
Аргументами, которые можно передать в параметр процедурного типа, могут быть только подпрограммы первого уровня вложенности, чье объявление полностью соответствует этому типу. Кроме того, объявления подпрограмм, которые могут стать аргументами, необходимо снабдить ключевым словом far, означающим, что программа будет использовать не только основной сегмент данных.
Например, для параметра, имеющего описанный выше тип func, аргументами могут послужить такие функции:
function min(a,b: integer): integer; far; begin if a>b then min:= b else min:= a end;
и
function max(a,b: integer): integer; far; begin if a<b then max:= b else max:= a end;
Вызов
Приведем пример подпрограммы, имеющей параметр процедурного типа:
procedure count(i,j:integer; f:func); var c: integer; begin ... c:= f(i,j); ... end;
Теперь, если будет осуществлен вызов count(x,y,min), то в локальную переменную с запишется минимум из x и y. Если же вызвана будет count(x,y,max), то в локальную переменную с запишется максимум из x и y.
Лекция 9. Рекурсивные подпрограммы
Динамические структуры данных
Динамические структуры данных служат полезным дополнением к стандартным структурам, уже определенным в языке Pascal. Динамическими они называются потому, что их элементы создаются и уничтожаются "на ходу" - в процессе работы программы.
Стек
Стеком называется динамическая структура данных, у которой в каждый момент времени доступен только верхний (последний) элемент. Лучше всего понятие стека можно проиллюстрировать примером стопки книг: в стопку можно добавить еще одну книжку, положив ее сверху; из стопки можно взять, не разрушив ее, только верхнюю книгу. А для того, чтобы достать книжку из середины стопки, необходимо сначала убрать по одной все лежащие выше нее.
Последовательность обработки элементов стека хорошо отражают аббревиатуры LIFO ( L ast I n F irst O ut - "последним вошел, первым вышел") и FILO ( F irst I n L ast O ut - "первым вошел, последним вышел").
Реализовать стек можно любым удобным для программиста способом: например, массивом. Тогда началом стека (его "верхним" элементом) будет последний компонент массива, а освобождение стека будет происходить в направлении от конца массива к его началу. При такой реализации нет необходимости в постоянном перемещении компонент массива.
Впрочем, наиболее эффективной все равно будет реализация при помощи односвязного линейного списка, о котором пойдет речь в следующей лекции.
Операции
Для стека должны быть определены следующие операции:
| empty(<нач_стека>):boolean | - проверка стека на пустоту; |
| add(<нач_стека>,<новый_элемент>):<нач_стека> | - добавление элемента в стек ; |
| take(<нач_стека>):<тип_элементов_стека> | - считывание значения верхнего элемента; |
| del(<нач_стека>):<нач_стека>. | - удаление верхнего элемента из стека. |
Очередь
Очередью называется динамическая структура, у которой в каждый момент времени доступны два элемента: первый и последний. Из начала очереди элементы можно удалять, а к концу - добавлять. Примером очереди программистcкой вполне может служить очередь обывательская: скажем, в продуктовом магазине.
Последовательность обработки элементов очереди хорошо отражают аббревиатуры LILO ( L ast I n L ast O ut - "последним вошел, последним вышел") и FIFO ( F irst I n F irst O ut - "первым вошел, первым вышел").
Реализовать очередь также можно при помощи массива, хотя здесь уже не удастся полностью избежать перемещения его компонент. Пусть k -я компонента массива хранит начало очереди, а ( k+s )-я - ее конец. Тогда можно приписать новый элемент очереди в ( k+s+1 )-ю компоненту массива, а при удалении элемента из начала очереди ее голова сдвинется в ( k+1 )-ю компоненту. В процессе работы может оказаться, что вся очередь "сдвинулась" к концу массива, и ее снова нужно вернуть к началу. В этом случае и потребуется s перемещений компонент массива ( s - это текущая длина очереди ).
Однако наиболее эффективной снова будет реализация при помощи односвязного линейного списка (см. лекцию 10).
Операции
Для очереди должны быть определены следующие операции:
| empty(<нач_очереди>):boolean | - проверка очереди на пустоту; |
| add(<кон_очереди>,<нов_эл-т>):<кон_очереди> | - добавление элемента в конец очереди ; |
| take_beg(<нач_очереди>):<тип_эл-тов_очереди> | - считывание значения первого элемента; |
| take_end(<кон_очереди>):<тип_эл-тов_очереди> | - считывание значения последнего элемента; |
| del(<нач_очереди>):<нач_очереди> | - удаление элемента из начала очереди. |
Дек
Дональд Кнут1) ввел понятие усложненной очереди, которая называется дек (deque - D ouble- E nded QUE ue - двухконцевая очередь ). В каждый момент времени у дека доступны как первый, так и последний элемент, причем добавлять и удалять элементы можно и в начале, и в конце дека. Таким образом, дек - это симметричная двусторонняя очередь.
Реализация дека при помощи массива ничем не отличается от реализации обычной очереди, а вот в терминах списков дек удобнее представлять двусвязным (разнонаправленным) линейным списком (см. лекцию 10).
Набор операций для дека аналогичен набору операций для очереди, с той лишь разницей, что добавление и удаление элементов можно производить и в конце, и в начале структуры.
Рекурсия
В математике, да и не только в ней одной, часто встречаются объекты, определяемые при помощи самих себя. Они называются рекурсивными.
Например, рекурсивно определяется функция факториал:
0! =1 n! = n*(n-1)!, для любого натурального n.
Другим примером рекурсивного определения может послужить определение арифметического выражения, приведенное в лекции 2.
Рекурсивные подпрограммы
В программировании рекурсивной называется подпрограмма, исполнение которой приводит к ее же повторному вызову.
Если подпрограмма просто вызывает сама себя, то такая рекурсия называется прямой. Например:
procedure rec1(k: byte); function rec2(k: byte): byte;
begin begin
... ...
rec1(k+1); x:= rec2(k+1);
... ...
end; end;Если же несколько подпрограмм вызывают друг друга, но эти вызовы "замкнуты в кольцо", то такая рекурсия называется косвенной.
В случае косвенной рекурсии возникает проблема с описанием подпрограмм: по правилу языка Pascal, нельзя использовать никакой объект раньше, чем он был описан. Следовательно, невозможно написать в программе:
procedure rec_А(k: byte); begin ... reс_В(k+1); ... end; procedure rec_В(k: byte); begin ... rec_А(k+1); ... end;
И здесь полезной оказывается возможность отрывать объявление подпрограммы от ее описания (см. лекцию 8). Например, для косвенной рекурсии в случае двух процедур, вызывающих друг друга ( rec_A -> rec_B -> rec_A ), нужно такое описание:
procedure rec_А(k: byte); forward; procedure rec_В(k: byte); begin ... reс_А(k+1); ... end; procedure rec_A; begin ... rec_В(k+1); ... end;
Пример рекурсивного алгоритма
Задача. Двумерный массив целых чисел представляет цвета клеток рисунка. Найдите самую большую связную область одного цвета. (Связи по диагонали не учитываются.)
Алгоритм решения
Будем считать, что цвета задаются целыми положительными числами. В процессе работы программы будем изменять значения пройденных клеток на 0. Кроме того, обрамим исходный массив каймой из нулей, чтобы предотвратить выход за его границы без дополнительных проверок на каждом шагу рекурсии. Теперь массив будет задан не как
array[1..N,1..M] of byte;
а как
array[0..N+1,0..M+1] of byte;
Теперь опишем рекурсивную процедуру, делающую по массиву один "шаг вперед":
Пока в массиве еще остаются не посещенные клетки (их пометка отлична от нуля), мы будем "шагать" на любую из них и проверять оказавшийся "под ногами" цвет.
- Если цвет новой клетки не совпадает с цветом предыдущей "посчитанной" клетки, то нам она не нужна. Сделаем шаг назад. Если этот шаг выводит нас из массива наружу, то это означает, что мы просмотрели все клетки одной связной области: пора сравнивать их количество с ранее найденным максимумом.
- Если клетка помечена тем же номером, что и предыдущая, увеличим счетчик найденных клеток, изменим пометку этой клетки на 0, а затем шагнем снова: поочередно вверх, вниз, влево и вправо (последовательность не принципиальна). Здесь важно понимать, что шагнем мы только в одну сторону, а остальные просто запомним. И лишь после того, как мы вновь возвратимся в эту же клетку, мы "вспомним", что из нее мы еще не пытались уйти туда-то и туда-то, и продолжим этот процесс.
После того как мы посетим все клетки, найденный максимум можно будет объявить итоговым.
Замечание. Рекурсивный алгоритм обхода можно представить в двух вариантах: "посмотрел-шагнул" и "шагнул-посмотрел". Другими словами, в первом случае мы сначала выбираем подходящее место для шага вперед и только потом делаем этот шаг (что очень хорошо сообразуется с правилами передвижения, скажем, по болоту). Во втором же случае мы сначала делаем шаг вперед и только потом проверяем, что же именно оказалось у нас под ногами. Все-таки "ходим" мы не по болоту и в любой момент можем "спастись" из неправильно выбранной клетки.
Стековая организация рекурсии
В момент вызова подпрограммы в памяти создается ее контекст: выделяется место под все ее параметры, локальные переменные и константы. Уничтожается этот контекст только после того, как будет достигнут оператор end, закрывающий подпрограмму, либо в ее тексте встретится оператор exit, насильственно прерывающий ее выполнение.
Если некоторая подпрограмма в процессе выполнения вызывает другую подпрограмму, то для вызванной процедуры или функции создается новый отдельный контекст ( контекст вызвавшей подпрограммы при этом сохраняется) и т.д. Активным в каждый момент времени является последний контекст. После ликвидации текущего активного контекста активным становится последний "отложенный" контекст - тот, из которого только что закрытый и был вызван.
Таким образом, на внутреннем уровне организован стек контекстов подпрограмм.
Проследим состояние стека контекстов на примере рекурсивной процедуры, решающей задачу разложения натурального числа на сомножители всеми возможными способами (без повторений):
procedure razlozh(k,t:integer; s:string); var i: integer; sss: string; begin for i:= t to trunc(sqrt(k)) do if k mod i = 0 then begin str(i,sss); razlozh(k div i, i,s+sss+'*'); end; str(k,sss); s:=s+sss; writeln(s); end; begin readln(n); razlozh(n,2,''); end.
Для n = 24 стек контекстов этой программы пройдет последовательно такие стадии (значения параметров указаны на моменты вызова процедуры, состояния стека приведены только на моменты времени, предшествующие закрытию очередного контекста ):
| 4 | k | 3 | ||||||||||||||||||||||||
| t | 2 | |||||||||||||||||||||||||
| s | 2*2*2 | |||||||||||||||||||||||||
| 3 | k | 6 | 3 | k | 6 | 3 | k | 4 | ||||||||||||||||||
| t | 2 | t | 2 | t | 3 | |||||||||||||||||||||
| s | 2*2 | s | 2*2 | s | 2*3* | |||||||||||||||||||||
| 2 | k | 12 | 2 | k | 12 | 2 | k | 12 | 2 | k | 12 | 2 | k | 8 | 2 | k | 6 | |||||||||
| t | 2 | t | 2 | t | 2 | t | 2 | t | 3 | t | 4 | |||||||||||||||
| s | 2* | s | 2* | s | 2* | s | 2* | s | 3* | s | 4* | |||||||||||||||
| 1 | k | 24 | 1 | k | 24 | 1 | k | 24 | 1 | k | 24 | 1 | k | 24 | 1 | k | 24 | 1 | k | 24 | ||||||
| t | 2 | t | 2 | t | 2 | t | 2 | t | 2 | t | 2 | t | 2 | |||||||||||||
| s | s | s | s | s | s | s | ||||||||||||||||||||
Непосредственно перед закрытием самого верхнего контекста происходит печать на консоль. Таким образом, на экране появляются результаты:
2*2*2*3 2*2*6 2*3*4 2*12 3*8 4*6 24
Ограничение глубины рекурсии
Теоретически, рекурсия может быть бесконечной. Однако такой вариант вряд ли кого-нибудь устроит: рекурсивный алгоритм, как и любой нерекурсивный его собрат, обязан выдавать результат своей работы за некое обозримое время. Кроме того, память у компьютера не резиновая, в ней может поместиться лишь конечное число контекстов одновременно открытых экземпляров рекурсивной подпрограммы.
Следовательно, каждая рекурсивная подпрограмма должна содержать в себе признак окончания - своеобразный "забор", определяющий максимальную глубину вложенности для этой рекурсии. Признак конца рекурсии может быть как явным (например, в случае реализации факториала), так и неявным (в частности, описанная выше процедура razlozh рано или поздно обязательно закончится, поскольку на каждом шаге происходит уменьшение разлагаемого натурального числа).
Замена рекурсивных алгоритмов итеративными
Поскольку новый контекст создается каждый раз, когда очередной экземпляр рекурсивной подпрограммы (сам еще оставаясь незавершенным) заново вызывает себя же, то память компьютера расходуется очень быстро. Поэтому рекурсию при всей ее наглядности нельзя отнести к экономичным способам программирования. Существует даже специальная наука - динамическое программирование, изучающая способы замены рекурсивных алгоритмов адекватными итеративными алгоритмами. Мы не станем сейчас углубляться в изложение принципов динамического программирования, а ограничимся лишь примерами превращения рекурсивных программ в нерекурсивные.
Если исполнение подпрограммы приводит только к одному вызову этой же самой подпрограммы, то такая рекурсия называется линейной. Линейную рекурсию довольно легко заменить итеративным алгоритмом. Например, можно реализовать функцию факториала, определенную в начале пункта " Рекурсия ", двояко.
| Рекурсивная реализация | Итеративная реализация |
|---|---|
function fact(k:byte): longint;
var x: longint;
begin
if k = 0
then fact:= 1
else begin x:= fact(k-1)*k;
fact:=x;
end;
end; | fact:= 1 for i:= 2 to k do fact:= fact * i; |
Если же каждый экземпляр подпрограммы может вызвать себя несколько раз, то рекурсия называется нелинейной или " ветвящейся ". Для того чтобы превратить такую рекурсию в итеративный алгоритм, придется приложить много усилий и, возможно, даже внести некоторые изменения в обрабатываемую структуру данных. Примером " ветвящейся" рекурсии может служить рассмотренная выше процедура разложения числа на сомножители.
Пример сравнения рекурсивного и нерекурсивного алгоритма
Задача. Двое друзей решили пойти в поход, собрали и взвесили все необходимые вещи. Как им разделить набор предметов на две части наиболее честным образом?
(Имеется набор натуральных чисел, быть может, с повторениями. Необходимо разделить его на два поднабора так, чтобы разность сумм весов была минимальной.)
Рекурсивный алгоритм
Нужно перебрать все возможные подмножества заданного набора весов. Для решения этой задачи существует несколько классических алгоритмов, мы воспользуемся простейшим, который носит название "полный перебор". В полном соответствии со своим названием, этот алгоритм перебирает все возможные варианты наборов.
Реализация рекурсивного алгоритма
program pohod_rec;
var f: text;
a: array[1..100] of integer;
n: integer;
min,obsh_ves: longint;
procedure step(t:byte; ves:longint);
var j: longint;
begin
j:= abs(obsh_ves - 2*ves);
if j<min then min:= j;
for j:= t+1 to n do step(j,ves+a[t]);
end;
begin
assign(f,'in');
reset(f);
n:=0; {кол-во всех предметов}
obsh_ves:= 0;
while not eof(f) do
begin inc(n);
read(f,a[n]);
inc(obsh_ves,a[n]);
end;
close(f);
min:= MaxLongInt;
step(1,0);
writeln('difference ',min)
end.Полный перебор с отсечением
Приведенная выше программа делает много лишней работы. Скажем, незачем продолжать генерирование очередного набора после того, как текущая разность уже превысила ранее найденный минимум. Кроме того, если в некоторый момент времени минимум вдруг окажется равным 1 или 0 (в зависимости от четности входных данных), то дальнейшие усилия также становятся ненужными, поскольку все равно ничего меньшего быть не может.
С учетом этих замечаний можно усовершенствовать текст программы. Мы оставляем эту несложную работу желающим.
Нерекурсивный алгоритм
Здесь нам потребуется несколько дополнительных рассуждений и линейных массивов.
Основная часть приводимой ниже программы является итеративной реализацией алгоритма полного перебора всех возможных вариантов, удовлетворяющих входным ограничениям. Ее основное отличие от рекурсии - использование малого объема памяти для хранения текущих данных. Вся информация хранится в массивах ves, take и dif. Для вычислений на каждом шаге используется только эта информация. Такой подход позволяет избежать непрерывных перевычислений, которые и являются причиной "тяжеловесности" рекурсивного алгоритма.
Итак, первая часть программы должна заниматься подсчетом и упорядочением вводимых предметов по убыванию их весов. Для экономии места мы не станем приводить подробную реализацию этого блока: здесь годится любой метод сортировки (см. лекцию 4). Важно лишь, что в результате этой сортировки все входные данные будут записаны в два линейных массива длины k (количество разных весов).
Считаем теперь, что массив ves хранит различные веса предметов, упорядоченные по убыванию, а массив kol - количество предметов каждого веса.
Кроме того, в процессе ввода данных производится суммирование весов всех предметов, этот общий вес записывается в переменную sum. Правда, затем эта же переменная будет хранить не весь общий вес, а только его половину (с учетом четности исходной суммы) - для удобства дальнейших сравнений.
Мы не приводим в тексте программы и реализацию функции min() - как не представляющую особенного интереса.
Реализация нерекурсивного алгоритма
program pohod;
const nnn = 100; {максимально возможное количество различных весов}
var f: text;
d,razn,k,i,j,n: integer;
sum: longint;
ves,kol: array[1..nnn] of word;
take, dif: array[0..nnn] of word;
procedure vyvod(a: integer);
begin
writeln(a);
halt; {принудительное завершение работы программы}
end;
begin
{---- Ввод данных и их сортировка ---}
...
{---- Основная часть программы -----}
d:= sum mod 2; {показатель четности общего веса}
sum:=(sum div 2)+ d; {"большая половина" общего веса}
dif[0]:= sum;
razn:= sum;
for i:= 1 to k do
begin
take[i]:= min(dif[i-1] div ves[i],kol[i]);
dif[i]:= dif[i-1]- take[i]*ves[i];
if dif[i]< razn then razn:= dif[i];
if razn <= d then vyvod(d);
{проверка того, что уже на первом шаге найдено решение}
end;
{---- Заполнение массива --------}
i:= k;
while i>0 do
begin
if take[i]= 0
then i:= i-1 {переход к следующей компоненте}
else begin
dec(take[i]); уменьшение текущей компоненты на 1}
inc(dif[i],ves[i]); {увеличение остатка на соотв. величину}
for j:= i+1 to k do {перезаполнение хвоста}
begin
take[j]:= min(dif[j-1] div ves[j],kol[j]);
dif[j]:= dif[j-1]- take[j]*ves[j];
if dif[j]< razn then razn:= dif[j];
if razn <= d then vyvod(d); {проверка результата}
end;
i:= k;
end;
end;
vyvod(2*razn-d);
end.Иллюстрация
Наиболее понятным образом принцип работы нашей программы можно продемонстрировать на примере.
Пусть имеется семь предметов ( n = 7 ) с весами 9, 5, 25, 11, 9, 5, и 11 единиц (килограмм, фунтов, бушелей...). Тогда всего есть четыре разных вида предметов ( k = 4 ).
Общая сумма весов равна 75 ; следовательно, "большая половина" sum = 38. Теперь нужно найти такой набор предметов, чей суммарный вес будет наиболее близким к этой "золотой середине". Кроме того, не стоит забывать и о сделанном ранее замечании: как только найдется набор, вес которого отличается от "золотого" лишь на единицу, поиск можно закончить.
Начнем теперь заполнять массивы take и dif (массив dif хранит остатки, в пределах которых можно проводить дальнейшие вычисления).
На начальном ("нулевом") шаге мы заполним массив take так, чтобы в создаваемый набор попали по возможности самые тяжелые предметы (см. раздел реализации "Основная часть программы"). Таким образом, получим следующие состояния массивов:
После этого шага переменная razn, которая хранит отклонение текущего набора весов от оптимального, будет содержать значение 2. Попытаемся уменьшить это значение (переход к разделу реализации "Заполнение массива").
Двигаясь от конца массива take к его началу, будем уменьшать поочередно каждую его ненулевую компоненту. Разумеется, при этом будут возникать изменения в хвосте этого массива; эти изменения мы будем вносить туда в обычной последовательности "от начала к концу".
Таким образом, наши массивы последовательно примут следующие значения (некоторые непринципиальные шаги опущены):
1
2
3
4
5
6
7
10
12
17
22
24
Итак, мы убедились в том, что найденное в самом начале значение переменной razn и было минимальным (найденные группы весов соответственно 25 + 11 = 36 и 11 + 9 + 9 + 5 + 5 = 39 ). Необходимо отметить, что из приведенных выше таблиц видно (см. шаг 5), что существует еще один способ разделить приведенный набор весов таким же оптимальным образом: ( 11 + 11 + 9 + 5 = 36 и 25 + 9 + 5 = 39 ). Найденная разница 39 - 36 = 3 и будет окончательным результатом, который программа сообщит пользователю.
Эффективность
В отличие от рекурсивного алгоритма, верхним пределом для которого можно смело считать наборы длиной в 50 предметов, итеративный алгоритм способен обработать до 5 000 различных весов (общее количество предметов может быть гораздо больше).
Другие примеры сравнения рекурсивных и нерекурсивных алгоритмов, решающих одну и ту же задачу, будут приведены в лекции 12.
Быстрая сортировка
Возвратимся теперь к методам сортировки массивов, которым была посвящена лекция 4. Наиболее эффективный способ сортировки остался тогда не рассмотренным по причине того, что самая удобная его реализация подразумевает рекурсию.
Алгоритм Быстр
- Возьмем в сортируемом массиве срединный элемент: x:=a[(1+N)div 2] ;
- Будем производить следующие действия:
- начав с левого конца массива, будем перебирать его компоненты до тех пор, пока не встретим элемент a[i], больший х ;
- начав с правого конца массива, будем перебирать его компоненты до тех пор, пока не встретим элемент a[j], меньший х ;
- поменяем местами элементы a[i] и a[j] ;
до тех пор, пока не произойдет "рандеву". В результате массив будет разделен на две части. В левой части окажутся все компоненты, меньшие х, а в правой - большие х.
Теперь применим эти же действия к левой и к правой части массива - рекурсивно.
Реализация алгоритма Быстр
type index = 1..N;
var a: array[index] of integer;
procedure quicksort(l,r:index);
var i,j: index;
x,z: integer;
begin
i:= l;
j:= r;
x:= a[(l+r)div 2];
repeat
while a[i]< x do inc(i);
while a[j]> x do dec(j);
if i <= j
then begin
z:= a[i];
a[i]:= a[j];
a[j]:= z;
inc(i);
dec(j);
end;
until i>j;
if l<j then quicksort(l,j);
if i<r then quicksort(i,r);
end;
begin {тело программы}
...
quicksort(1,n);
...
end.Эффективность алгоритма Быстр
Алгоритм Быстрой сортировки имеет в среднем1) сложность N*log N и, следовательно, относится к улучшенным методам сортировки массивов (см. лекцию 4). Кроме того, даже среди улучшенных методов упорядочения Быстрая сортировка дает наилучшие результаты по времени (для относительно больших входных последовательностей - начиная с N = 100 ).
Конечно же, существует и итеративный вариант алгоритма Быстрой сортировки, который еще более эффективен. Мы предлагаем читателям построить его самостоятельно.
Лекция 10. Адреса и указатели. Списочные структуры данных
Статически выделяемая память
Для того, чтобы лучше понять специфику динамически выделяемой памяти, рассмотрим сначала ее "антипод" - память, распределяемую статически.
Такое выделение памяти используется всякий раз при объявлении "обычных" переменных в разделе var. Каждая переменная обладает двумя атрибутами: именем и описанием.
var a: integer;
Описание переменной нужно для того, чтобы компилятор знал, сколько ячеек памяти необходимо выделить для ее хранения. Память под статическую переменную выделяется один раз (до начала работы программы), и затем до конца работы выделенная область памяти считается "занятой" - никакая другая информация не может быть записана в эту ячейку.
Имя переменной позволяет обращаться в процессе работы программы к той ячейке памяти, которая была выделена под эту переменную на этапе компиляции.
Адреса
Имя переменной является ее своеобразным (буквенным) адресом. Однако у любой переменной есть также и обычный (цифровой или физический ) адрес: номер ячейки, выделенной под эту переменную.
При страничной организации памяти адреса являются составными и состоят из номера сегмента памяти и смещения ячейки относительно начала этого сегмента.
Лучшая иллюстрация страничной организации памяти компьютера - это страничная организация любой печатной книги. Для того чтобы найти нужную строчку, нет необходимости задавать ее номер, считая от начала текста. Вместо этого можно задать сначала номер страницы ( = сегмент ) и только затем номер строки, считая от начала этой страницы ( = смещение ).
Для обращения к статически заданной переменной можно использовать как ее имя, объявленное в разделе var, так и ее физический адрес.
Например, " адрес " одной и той же географической точки можно записать по-разному: "49°47' северной широты и 86°36' восточной долготы" или просто "вершина пика Белуха Восточная1) ".
Указатели
Для того чтобы хранить (цифровые) адреса, нужны особые переменные. Их называют указателями и относят к специальному типу данных.
Описание указателей
При описании типизированного указателя необходимо сообщить компилятору, адреса переменных какого типа он может хранить:
var <имя_указателя>: ^<тип_адресуемой_переменной>;
Например:
var p: ^integer; q: ^real; s: ^array[1..10] of byte;
Кроме того, существуют универсальные нетипизированные указатели, которые могут хранить адрес переменной любого типа:
var <имя_указателя>: pointer;
Операции с указателями
Определение адреса
Физический адрес любой переменной можно узнать при помощи стандартной функции addr(<имя_переменной>):<указатель> или унарной операции @<имя_переменной>.
В зависимости от значения директивы компилятора {$T}, результатом операции @ будет либо типизированный указатель (если установлено {$T+} ), тип которого будет определен в соответствии с типом использованной переменной, либо нетипизированный указатель pointer (если установлено {$T-} ).
Результат функции addr() совместим с указателями любых типов:
p:= addr(x); {x: real; p: ^byte)Разыменование
Для того чтобы воспользоваться значением, хранящимся по некоторому адресу, необходимо его оттуда "извлечь". Унарная операция ^ называется разыменованием и записывается по следующему шаблону:
<имя_указателя>^
Результатом операции ^ является значение, хранящееся по указанному адресу. Тип этого значения будет определяться типом ( типизированного ) указателя. К нетипизированным указателям операцию разыменования применять нельзя.
Из-за вольностей, допускаемых процедурой addr(), при разыменовании порой могут возникнуть забавные ситуации. Например, в результате выполнения такой вот программы:
const a: array[1..3] of char ='ААА'; {код(А)=128 или 01000000}
var p: ^word;
begin p:= addr(a);
writeln(p^)
endна экран будет выведено 32896, что в двоичной системе счисления выглядит как 01000000.01000000 (точкой помечена граница двух байтов). Иными словами, коды двух первых букв оказались слитыми в значение типа word.
Замечание: Операции @ и ^ являются взаимно обратными, то есть для любой переменной a и для любого типизированного указателя p верны следующие равенства:
@(p^)= p и (@a)^ = a
Присваивания
Для указателей действуют гораздо более жесткие правила совместимости типов, чем для обычных переменных. В операции присваивания могут фигурировать только указатели, адресующие переменные одинаковых типов данных. Нельзя, скажем, записать
p:= q; {p: ^integer; q: ^byte}Обойти эти ограничения позволяет универсальность нетипизированного указателя pointer, совместимого с указателями любых типов:
{p: ^integer; q: ^byte; t: pointer}
t:= q;
p:= t;У указателей также существует свой "ноль", который означает, что указатель не указывает никуда:
p:= nil;
Замечание: Если указатель не хранит конкретного адреса (его значение не определено ), то это вовсе не означает, что он никуда не указывает. Скорее всего, он все-таки указывает, но только в какую-нибудь неожиданную (хорошо, если не системную) область памяти.
Сравнения
Для указателей определены две операции сравнения: = и <>.
Две переменные, описанные как указатели на один и тот же тип данных, считаются совпадающими, если они указывают на одну и ту же область памяти.
Для разнотипных указателей сравнения невозможны: попытка записать
if p = q then writeln('yes'); {p: ^byte; q: ^integer}вызовет ошибку уже на этапе компиляции.
Однако сравнивать типизированный и нетипизированный указатели можно.
Динамически распределяемая память
Поскольку к любой переменной можно обратиться двояко - по имени и по адресу, - есть возможность сократить эту избыточность и оставить только один способ. Как мы уже видели, наличие имени означает и наличие адреса. Иными словами, если вы дали переменной имя в разделе var, то в процессе компиляции у нее появится и адрес.
Задумаемся теперь: а если у переменной есть адрес, но нет имени, можно ли оперировать ею с прежней легкостью? Ответ на этот вопрос: "Да, можно!"
Итак, пусть у некоторой переменной нет имени. Тем не менее можно расположить ее в памяти, выделив под нее необходимое количество байтов, и т.д. У переменной будет адрес, будет значение, но не будет имени. Следовательно, обратиться к такой переменной можно будет только с помощью указателя.
"Безымянные" переменные отличаются от "нормальных" переменных:
- Нет имени - нечего описывать в разделе var.
- Ничего не описано, значит, на этапе компиляции память под переменную не выделена. Следовательно, необходима возможность выделять память (и отменять это выделение) прямо в процессе работы программы. Именно из-за этой гибкости такие переменные и называют динамическими.
- Если "потерять" указатель на переменную, то "никто не узнает, где могилка" ее: переменная останется недоступным "мусором", занимая место в памяти, вплоть до конца работы программы.
Динамическое выделение памяти
Типизированные указатели
Для выделения памяти служит стандартная процедура new():
new(<имя_указателя>);
Эта процедура ищет в незанятой памяти подходящий по размеру кусок и, "застолбив" это место для безымянной динамической переменной, записывает в типизированный указатель адрес выделенного участка. Поэтому часто говорят, что процедура new() создает динамическую переменную. Размер выделяемого "куска памяти" напрямую зависит от типа указателя.
Например, если переменная p была описана как указатель на integer -переменную, то процедура new(p) выделит два байта; под real -переменную необходимо выделить четыре байта и т.д.
Нетипизированные указатели
Для того чтобы выделить память, на которую будет указывать нетипизированный указатель pointer, нужно воспользоваться стандартной процедурой getmem(p: pointer; size: word), которая выделит столько байт свободной памяти, сколько указано в переменной size.
Динамическое освобождение памяти
Типизированные указатели
Для уничтожения динамической переменной, то есть для освобождения занимаемой ею памяти, предназначена стандартная процедура
dispose(<имя_типизир_указателя>).
Процедура dispose() снимает пометку "занято" с определенного количества байтов, начиная с указанного адреса. Эта область памяти в дальнейшем считается свободной (хотя старое значение бывшей переменной в ней может некоторое время еще оставаться). Количество освобождаемых байтов определяется типом указателя p.
В результате освобождения памяти при помощи процедуры dispose() значение указателя, хранившего адрес освобожденной области, становится неопределенным. Во избежание проблем его лучше сразу же "обнулить":
dispose(p); p:= nil;
Нетипизированные указатели
Для того чтобы освободить память, на которую указывает нетипизированный указатель, нужно воспользоваться стандартной процедурой freemem(p: pointer; size: word), которая освободит в памяти столько байтов (начиная с указанного в переменной p адреса ), сколько задано в переменной size.
Списочные структуры
Если для каждой динамической переменной описывать и хранить ее "личный" указатель, то никакой выгоды на этапе выполнения программы получить не удастся: часть памяти, как и прежде, будет выделяться статически, а ее общий объем даже увеличится - ведь каждый указатель требует для себя четыре байта.
Следовательно, нужно сделать так, чтобы место под хранение адресов будущих переменных также выделялось динамически. Решением этой проблемы и служат списки - специальные динамические структуры.
Списки применяются, например, в таких ситуациях:
- программист заранее ничего не знает о том, какой именно объем памяти может потребоваться его программе;
- некоторые (особенно "тяжелые") переменные нужны поочередно, и после того как первые "отработали свое", их можно смело стирать из памяти, не дожидаясь конца работы программы, - освобождать место для других "тяжелых" переменных;
- в процессе обработки данных нужно провести большую работу по перестройке всей структуры "на ходу"; и т.д.
Структура списков
Итак, каждый элемент создаваемого списка должен содержать:
- полезную информацию, которая может иметь любой формат: integer, real, array, record и т.п.;
- специально выделенное поле (и, может быть, не одно), которое хранит адрес другого элемента этой же структуры.
Приведем примеры различных списочных структур:
- a) Односвязный (линейный) список: структура, каждый элемент которой "знает" адрес только следующего за ним элемента (см. рис. 10.1 (a)). Очень удобно представлять таким списком стек и очередь (см. лекцию 9).
- b) Двусвязный линейный список: структура, каждый элемент которой "помнит" адрес не только следующего, но и предыдущего элемента списка (см. рис. 10.1 (b)). Этот список удобен для работы с деками (см. лекцию 9)
- c) Бинарное дерево (см. лекцию 11) может быть представлено двусвязным нелинейным списком: каждая вершина помнит обоих своих возможных потомков (см. рис. 10.1 (c)). Если каждой вершине необходимо помнить не только потомков, но и предка, то список становится трехсвязным.
- d) Для представления ориентированного графа (см. лекцию 11) можно использовать иерархические списки - комбинацию из двух различных линейных списков (см. рис. 10.1 (d): вершины задаются структурой, содержащей три поля, а дуги - два; справа показан орграф, представленный приведенной списочной структурой ).
Описание списков
Сначала мы рассмотрим только самый простой случай: односвязный список (см. рис. 10.1 (а)). Напомним, что каждый элемент этого списка должен хранить адрес другого элемента из этого же списка.
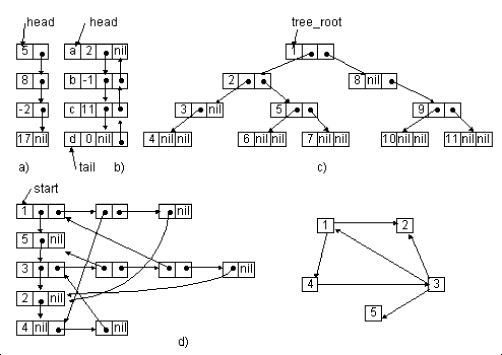
Рис. 10.1. Примеры списочных структур
Логичнее всего было бы дать этой структуре такое описание:
type element_spiska = record znachenie : integer; next_element : ^element_spiska; end;
Однако этот вариант невозможен по правилам языка Pascal: рекурсивные описания недопустимы, следовательно, структура не может ссылаться сама на себя. Поэтому приходится использовать более сложный, хотя и совершенно эквивалентный, вариант:
type ukazatel = ^element_spiska; element_spiska = record znachenie : integer; next_element : ukazatel; end;
Обратите внимание: это единственный случай, когда компилятор согласится принять использование структуры ( element_spiska ) до ее описания.
Замечание: Кажется, что гораздо более естественным было бы отнести поле next_element к типу pointer: тогда не пришлось бы вводить дополнительный тип данных ukazatel. Однако неудобства, которые непременно возникнут из-за нетипизированности указателей в процессе написания программы, будут гораздо серьезнее, чем одна лишняя строчка при описании типов.
В качестве примера приведем описания всех четырех структур, представленных на рис. 10.1 (см. табл. 10.1):
| a) | Односвязный список | type ukazatel = ^elem_spiska;
elem_spiska = record
znach : integer;
sled : ukazatel;
end; |
| b) | Двусвязный линейный список | type point = ^element_spiska; list = record znachenie : integer; sled : point pred : point; end; |
| с) | Бинарное дерево (иерархический список) | type point = ^tree;
tree = record
data : integer;
left_sibling : point;
right_sibling: point;
end; |
| d) | Ориентированный граф (двусвязный нелинейный список) | type uk_versh = ^versh; uk_duga = ^duga; vershina = record nomer : integer; sled_versh : uk_versh; spisok_dug : uk_duga; end; duga = record konec_dugi : uk_versh; sled_duga : uk_duga; end; |
Оперирование элементами списка
Хранение списка
Для того чтобы сохранить информацию обо всем списке, достаточно только одной переменной - указателя на первый элемент этого списка. Обычно его называют головой списка. Указатель на голову должен быть выделенным: с ним нельзя производить никаких действий, которые могут стать причиной утери всего списка. Для работы со списком обычно заводят вспомогательный указатель.
Например:
var head,p,q: uk_spisok;
Но, вообще говоря, нет никаких специальных правил, которые обязали бы программиста давать выделенным указателям особые имена. Например, на рис. 10.1 выделенные указатели имеют имена head, tail, tree_root и start.
Обращение к элементам списка
Если есть указатель, указывающий на некоторый элемент списка, то содержимое полей этого элемента и даже следующих за ним можно получить так (см. рис. 10.2):
| p | - адрес текущего элемента списка; |
| p^ | - запись из нескольких полей, хранящаяся по адресу p ; |
| p^.znachenie | - значение первого поля этой записи; |
| p^.next_element | - значение второго поля этой записи, являющееся адресом следующего элемента списка; |
| p^.next_element^.znachenie | - значение, хранящееся в первом поле элемента списка, следующего за тем, на который указывает р. |
Рис. 10.2. Правила обращения к элементам списка
Создание списков
Предположим, что есть некоторый набор значений (например, в файле), которые необходимо записать в создаваемый односвязный список. Тогда у нас есть две возможности создавать этот список: от хвоста к голове или от головы к хвосту.
Мы приведем здесь обе программы, позволив себе для краткости опустить описания типов, воспользовавшись описанием, показанным в табл. 1 (a):
var head,p: ukazatel; f: text;
begin
...
head:= nil;
while not eof(f) do
begin
new(p);
read(f,p^.znach);
p^.next:= head;
head:= p;
end;
end. |  Рис. 10.3. Очередной шаг процесса генерации списка "от хвоста к голове" |
var head,p,q: ukazatel; f: text;
begin
...
if eof(f)
then head:= nil
else begin
new(head); {головной элемент создается отдельно}
read(f,head^.znach);
head^.next:= nil;
q:= head;
while not eof(f) do
begin
new(p);
read(f,p^.znach);
p^.next:= nil;
q^.next:= p;
q:= q^.next;
end;
end;
end. |  Рис. 10.4. Очередной шаг процесса генерации списка "от головы к хвосту" |
Просмотр элементов списка
Для того чтобы распечатать значения, хранящиеся в элементах линейного односвязного списка, заданного указателем на голову, годится такая программа:
p:= head; {начать просмотр с головы списка}
while p<>nil do
begin
writeln(p^.znach);
p:= p^.next; {переход к следующему элементу списка}
end;Замечание: Для того чтобы во время работы со списком не произошло выхода за его пределы, любой список обязательно должен оканчиваться "нулевым" указателем nil.
Удаление элементов списка
Для того чтобы при удалении элемента из середины списка не терялась целостность всей структуры, необходимо при поиске удаляемого элемента "остановиться" за один шаг до него: в тот момент, когда следующий за текущим элемент должен быть удален (см. рис. 10.5):
p:= head; {начать с головы списка}
while p^.next^.zhach<>х do p:= p^.next; {поиск}
q:= p^.next; {удаляемый элемент}
p^.next:= q^.next; {связка "через один"}
dispose(q); {освобождение памяти}Перестройка списков
Разницу между структурой статической (массив) и структурой динамической (список) очень доступно проиллюстрировал Никлаус Вирт в своей книге "Алгоритмы и структуры данных". Мы позволим себе позаимствовать оттуда, хотя и не дословно, красивый пример.
Представим обычную очередь у прилавка в магазине. Первый покупатель - это тот, кто в данную минуту стоит непосредственно возле прилавка; следующий за ним - второй, за вторым - третий и т.д. Покупатели занумерованы строго в порядке следования, и вновь пришедшие встают в хвост. В принципе, взглянув на очередь, всегда можно сказать, кто за кем стоит. А что происходит, если один из покупателей желает покинуть очередь? Хвост тут же сдвигается: каждый человек делает шаг вперед, чтобы очередь не утратила целостности. Если же, наоборот, некто желает встроиться в середину очереди (невзирая на крики "А вас тут не стояло!"), то задним приходится пятиться, чтобы освободить ему место. Точно так же ведут себя элементы линейного массива.
Теперь возьмем другую очередь: в приемной у зубного врача. Во-первых, посетители уже не привязаны так жестко к линии прилавка: они сидят в креслах, расположенных там и сям, где только нашлось удобное место. Во-вторых, каждому вновь пришедшему нет необходимости знать, кто в этой очереди первый, а кто второй: достаточно лишь выяснить, кто последний. И вовсе не обязательно садиться рядом с последним пациентом: вновь пришедший может занять любое свободное кресло в приемной. А если у кого-то вдруг перестали болеть зубы и он радостно уходит из очереди, то "стоявшему" за ним достаточно спросить: - "А вы за кем занимали?" При этом физического перемещения пациентов в пространстве не происходит. Аналогично, если вдруг появляется пациент с талончиком на более раннее время, "задние" пропускают его вперед, не сдвигаясь со своих кресел. Именно так ведут себя и элементы динамических списков1).
Примеры перестройки линейных списков
На рис. 10.5 приведены четыре примера перестройки односвязных списков. Пунктирами изображены указатели, получающие новые значения в процессе работы программ.
- Удаление всех нулей из списка.
- Вставка в список, хранящий все нечетные числа от 1 до 11, трех новых элементов - 0, 8 и 12 - с сохранением его упорядоченности.
- Обмен второго и третьего элементов списка.
- Обращение порядка всех четных элементов списка.
Реализация
Приведем фрагменты программ, решающих первую и третью задачи:
{- голову списка обрабатываем отдельно -} while (head<>nil)and(head^.znach =0)do begin p:= head; head:= head^.next; dispose(p); end; {- середина и конец списка обрабатываются вместе -} p:= head; while p^.next <> nil do if p^.next^.znach = 0 then begin q:= p^.next; p^.next:= p^.next^.next; dispose(q); end else p:= p^.next;
p:= head^.next; head^.next:= p^.next; p^.next:= p^.next^.next; head^.next^.next:= p;
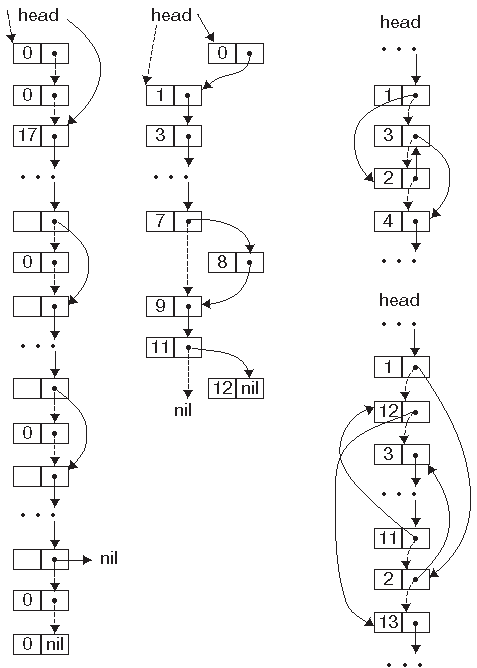
Рис. 10.5. Примеры перестройки односвязных списков
Лекция 11. Графы и деревья
Чуть-чуть истории
Теория графов - довольно молодая наука (по сравнению, скажем, с геометрией). В 1736 году Санкт-Петербургская академия наук опубликовала труд Леонарда Эйлера, где рассматривалась задача о кенигсбергских1) мостах ("Можно ли, пройдя все городские мосты ровно по одному разу, вернуться в исходную точку?"). Это была первая работа по будущей теории графов.
Особенно приятно то, что в данном случае Россия - родина пусть и не новой породы слонов, но зато нового научного направления!
Графы: определения и примеры
Итак, перейдем к изложению некоторых понятий современной теории графов.
Неориентированные графы
Граф - это двойка <V, E>, где V - непустое множество вершин, а Е - множество ребер, соединяющих эти вершины попарно2). Две вершины, связанные между собой ребром, равноправны, и именно поэтому такие графы называются неориентированными: нет никакой разницы между "началом" и "концом" ребра.
| Граф | Вершины | Ребра |
|---|---|---|
| Семья | Люди | Родственные связи |
| Город | Перекрестки | Улицы |
| Сеть | Компьютеры | Кабели |
| Домино | Костяшки | Возможность |
| Дом | Квартиры | Соседство |
| Лабиринт | Развилки и тупики | Переходы |
| Метро | Станции | Пересадки |
| Листок в клеточку | Клеточки | Наличие общей границы |
Говоря простым языком, граф - это множество точек (для удобства изображения - на плоскости) и попарно соединяющих их линий (не обязательно прямых). В графе важен только факт наличия связи между двумя вершинами. От способа изображения этой связи структура графа не зависит.
Например, три графа на рис. 11.1 совпадают, а два графа на рис. 11.2 - различны.
Рис. 11.1. Три способа изображения одного графа
Из приведенного выше определения вытекает, что в графах не бывает петель - ребер, соединяющих некоторую вершину саму с собой (см. рис. 11.3). Кроме того, в классическом графе не бывает двух различных ребер, соединяющих одну и ту же пару вершин.
Ребро е и вершина v называются инцидентными друг другу, если вершина v является одним из концов ребра е.
Рис. 11.2. Пример двух разных графов
Рис. 11.3. Псевдограф
Любому ребру инцидентно ровно две вершины, а вот вершине может быть инцидентно произвольное количество ребер, это количество и определяет степень вершины. Изолированная вершина вообще не имеет инцидентных ей ребер (ее степень равна 0 ).
Две вершины называются смежными, если они являются разными концами одного ребра (иными словами, эти вершины инцидентны одному ребру ). Аналогично, два ребра называются смежными, если они инцидентны одной вершине.
Путь в графе - это последовательность вершин (без повторений), в которой любые две соседние вершины смежны. Например, в графе, изображенном на рис. 11.1, есть два различных пути из вершины a в вершину с: adbc и abc.
Вершина v достижима из вершины u, если существует путь, начинающийся в u и заканчивающийся в v.
Граф называется связным, если все его вершины взаимно достижимы.
Компонента связности - это максимальный связный подграф. В общем случае граф может состоять из произвольного количества компонент связности. Заметим, что любая изолированная вершина является отдельной компонентой связности. На рис. 11.4 изображен граф, состоящий из четырех компонент связности: [abhk], [gd], [c] и [f].
Длина пути - количество ребер, из которых этот путь состоит. Например, длина уже упомянутых путей adbc и abc (см. рис. 11.1) - 3 и 2 соответственно.
Рис. 11.4. Несвязный граф
Говорят, что вершина v принадлежит k -му уровню относительно вершины u, если существует путь из u в v длиной ровно k ребер. Одна и та же вершина может относиться к разным уровням. Например, в графе, изображенном на рис. 11.1, относительно вершины a существует 4 уровня:
- 0) a ;
- 1) b, d ;
- 2) b, d, c ( пути adb, abd, abc );
- 3) c ( путь adbc ).
Расстояние между вершинами u и v - это длина кратчайшего пути от u до v. Из этого определения видно, что расстояние между вершинами a и c в графе на рис. 11.1 равно 2.
Цикл - это замкнутый путь. Все вершины в цикле, кроме первой и последней, должны быть различны. Например, циклом является путь abda в графе на рис. 11.1.
Эйлеров граф - это граф, в котором существует путь или цикл, содержащий все ребра графа ( вершины могут повторяться). Именно такие графы положительно решают упомянутую в начале лекции задачу о кенигсбергских мостах. Например, граф на рис. 11.5 является Эйлеровым: искомым путем в нем будет dbacfbcdf.
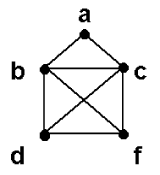
Рис. 11.5. Граф Эйлера
Гамильтонов граф - это граф, в котором существует путь или цикл (без повторений), содержащий все вершины графа (см. рис. 11.5; искомый цикл: abdfca ).
Ориентированные графы
Орграф - это граф, все ребра которого имеют направление. Такие направленные ребра называются дугами. На рисунках дуги изображаются стрелочками (см. рис. 11.6).
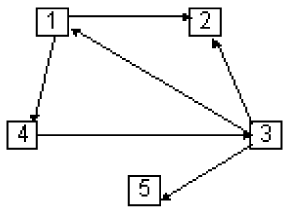
Рис. 11.6. Орграф
В отличие от ребер, дуги соединяют две неравноправные вершины: одна из них называется началом дуги ( дуга из нее исходит ), вторая - концом дуги ( дуга в нее входит ). Можно сказать, что любое ребро - это пара дуг, направленных навстречу друг другу.
Если в графе присутствуют и ребра, и дуги, то его называют смешанным.
Все основные понятия, определенные для неориентированных графов ( инцидентность, смежность, достижимость, длина пути и т.п.), остаются в силе и для орграфов - нужно лишь заменить слово " ребро " словом " дуга ". А немногие исключения связаны с различиями между ребрами и дугами.
Степень вершины в орграфе - это не одно число, а пара чисел: первое характеризует количество исходящих из вершины дуг, а второе - количество входящих дуг.
Путь в орграфе - это последовательность вершин (без повторений), в которой любые две соседние вершины смежны, причем каждая вершина является одновременно концом одной дуги и началом следующей дуги. Например, в орграфе на рис. 11.6 нет пути, ведущего из вершины 2 в вершину 5. "Двигаться" по орграфу можно только в направлениях, заданных стрелками.
| Орграф | Вершины | Дуги |
|---|---|---|
| Чайнворд | Слова | Совпадение последней и первой букв (возможность связать два слова в цепочку) |
| Стройка | Работы | Необходимое предшествование (например, стены нужно построить раньше, чем крышу, т. п.) |
| Обучение | Курсы | Необходимое предшествование (например, курс по языку Pascal полезно изучить прежде, чем курс по Delphi, и т.п.) |
| Одевание ребенка | Предметы гардероба | Необходимое предшествование (например, носки должны быть надеты раньше, чем ботинки, и т.п.) |
| Европейский город | Перекрестки | Узкие улицы с односторонним движением |
| Организация | Сотрудники | Иерархия (начальник - подчиненный) |
Взвешенные графы
Взвешенный (другое название: размеченный ) граф (или орграф ) - это граф ( орграф ), некоторым элементам которого ( вершинам, ребрам или дугам ) сопоставлены числа. Наиболее часто встречаются графы с помеченными ребрами. Числа-пометки носят различные названия: вес, длина, стоимость.
Замечание: Обычный (не взвешенный) граф можно интерпретировать как взвешенный, все ребра которого имеют одинаковый вес 1.
Длина пути во взвешенном (связном) графе - это сумма длин (весов) тех ребер, из которых состоит путь. Расстояние между вершинами - это, как и прежде, длина кратчайшего пути. Например, расстояние от вершины a до вершины d во взвешенном графе, изображенном на рис. 11.7, равно 6.
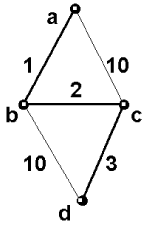
Рис. 11.7. Взвешенный граф
N - периферия вершины v - это множество вершин, расстояние до каждой из которых (от вершины v ) не меньше, чем N.
| Граф | Вершины | Вес вершины | Ребра (дуги) | Вес ребра (дуги) |
|---|---|---|---|---|
| Таможни | Государства | Площадь территории | Наличие наземной границы | Стоимость получения визы |
| Переезды | Города | Стоимость ночевки в гостинице | Дороги | Длина дороги |
| Супер-чайнворд | Слова | - | Совпадение конца и начала слов(возможность "сцепить" слова) | Длина пересекающихся частей |
| Карта | Государства | Цвет на карте | Наличие общей границы | - |
| Сеть | Компьютеры | - | Сетевой кабель | Стоимость кабеля |
Способы представления графов
Существует довольно большое число разнообразных способов представления графов. Однако мы изложим здесь только самые полезные с точки зрения программирования.
Матрица смежности
Матрица смежности Sm - это квадратная матрица размером NxN ( N - количество вершин в графе ), заполненная единицами и нулями по следующему правилу:
Если в графе имеется ребро e, соединяющее вершины u и v, то Sm[u,v] = 1, в противном случае Sm[u,v] = 0.
Заметим, что данное определение подходит как ориентированным, так и неориентированным графам: матрица смежности для неориентированного графа будет симметричной относительно своей главной диагонали, а для орграфа - несимметричной.
Задать взвешенный граф при помощи матрицы смежности тоже возможно. Необходимо лишь внести небольшое изменение в определение:
Если в графе имеется ребро e, соединяющее вершины u и v, то Sm[u,v] = ves(e), в противном случае Sm[u,v] = 0.
Это хорошо согласуется с замечанием, сделанным в предыдущем пункте: невзвешенный граф можно интерпретировать как взвешенный, все ребра которого имеют одинаковый вес 1.
Небольшое затруднение возникнет в том случае, если в графе разрешаются ребра с весом 0. Тогда придется хранить два массива: один с нулями и единицами, которые служат показателем наличия ребер, а второй - с весами этих ребер.
В качестве примера приведем матрицы смежности для трех графов, изображенных на рис. 11.5, рис. 11.6 и рис. 11.7 (см. рис. 11.8).
| a | b | c | d | f | 1 | 2 | 3 | 4 | 5 | a | b | c | d | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | a | 0 | 1 | 10 | 0 |
| b | 1 | 0 | 1 | 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | b | 1 | 0 | 2 | 10 |
| c | 1 | 1 | 0 | 1 | 1 | 3 | 1 | 1 | 0 | 0 | 1 | c | 10 | 2 | 0 | 3 |
| d | 0 | 1 | 1 | 0 | 1 | 4 | 0 | 0 | 1 | 0 | 0 | d | 0 | 10 | 3 | 0 |
| f | 0 | 1 | 1 | 1 | 0 | 5 | 0 | 0 | 0 | 0 | 0 |
Удобство матрицы смежности состоит в наглядности и прозрачности алгоритмов, основанных на ее использовании. А неудобство - в несколько завышенном требовании к памяти: если граф далек от полного, то в массиве, хранящем матрицу смежности, оказывается много "пустых мест" (нулей). Кроме того, для "общения" с пользователем этот способ представления графов не слишком удобен: его лучше применять только для внутреннего представления данных.
Список ребер
Этот способ задания графов наиболее удобен для внешнего представления входных данных. Пусть каждая строка входного файла содержит информацию об одном ребре ( дуге ):
<номер_начальной_вершины> <номер_конечной_вершины> [<вес_ребра>]
В качестве примера приведем списки ребер ( дуг ), задающие те же три графа с рис. 11.5, рис. 11.6 и рис. 11.7 (см. рис. 11.9).
a b a c b c b d c d c f f d b f | 1 2 1 4 3 1 3 2 3 5 4 3 | a b 1 a c 10 b c 2 b d 10 c d 3 |
Если задается ориентированный граф, то номера вершин понимаются как упорядоченная пара, а если граф неориентированный - как неупорядоченная.
Списки смежности
Этот способ задания графов подразумевает, что для каждой вершины будет указан список всех смежных с нею вершин (для орграфа - список вершин, являющихся концами исходящих дуг ). Конкретный формат входного файла, содержащего списки смежности, необходимо обговорить отдельно. Например, в нашем случае начальная вершина отделена от списка смежности двоеточием:
<номер_начальной_вершины>: <номера_смежных_вершин>
Наиболее естественно применять этот способ для задания орграфов, однако и для остальных вариантов он тоже подходит.
В качестве примера приведем списки смежности, задающие все те же три графа, изображенные на рис. 11.5, рис. 11.6 и рис. 11.7 (см. рис. 11.10).
a: b c b: c d f c: d f d: f | 1: 2 4 3: 1 2 5 4: 3 | b: a 1 c 2 d 10 c: a 10 d 3 |
Иерархический список
Собственно, этот способ представления графов является всего лишь внутренней реализацией списка смежности: в одном линейном списке содержатся номера "начальных вершин ", а в остальных - номера смежных вершин или указатели на эти вершины. В качестве примера (см. рис. 11.11) приведем иерархический список, задающий орграф, изображенный на рис. 11.6.
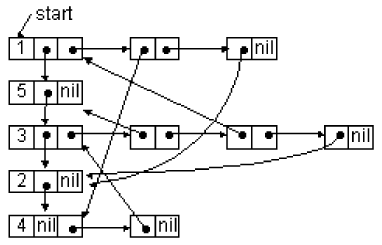
Рис. 11.11. Пример иерархического списка
type uk_versh = ^vershina; uk_duga = ^duga vershina = record number : integer; sled_vershina : uk_versh; spisok_dug : uk_duga end; duga = record konec_dugi : uk_versh; sled_duga : uk_duga; end;
Очевидное преимущество такого способа представления графов заключается в экономичном использовании памяти. И даже небольшая избыточность данных, к которой приходится прибегать в случае неориентированного графа, задавая каждое ребро как две дуги, искупается гибкостью всей структуры, что особенно удобно при необходимости частых перестроений в процессе работы программы.
Если в приведенные описания типов данных добавить поля, которые могли бы хранить веса вершин и дуг, то таким же способом можно задавать и взвешенные графы ( орграфы ).
Деревья
Дерево - это частный случай графа, наиболее широко применяемый в программировании.
Основные определения
Существует довольно много равносильных определений деревьев, вот лишь некоторые из них.
- Дерево - это связный граф без циклов.
- Дерево - это связный граф, в котором при N вершинах всегда ровно N-1 ребро.
- Дерево - это граф, между любыми двумя вершинами которого существует ровно один путь.
Аналогичным образом определяется и ориентированное дерево - как орграф, в котором между любыми двумя вершинами существует не более одного пути.
| Дерево | Вершины | Ребра (дуги) |
|---|---|---|
| Армия | Солдаты и офицеры | Иерархия (командир - подчиненный) |
| Династия (родословная по мужской линии) | Монархи | Отношение "отец - сын" |
Рис. 11.12. Корневое дерево высоты 3
Мы будем изучать и использовать только один частный случай ориентированных деревьев - корневые деревья (см. рис. 11.12).
Корневое дерево - это ориентированное дерево, в котором можно выделить вершины трех видов: корень, листья (другое их название: терминальные вершины ) и остальные вершины ( нетерминальные ); причем должны выполняться два обязательных условия:
- из листьев не выходит ни одна дуга ; из других вершин может выходить сколько угодно дуг ;
- в корень не заходит ни одна дуга ; во все остальные вершины заходит ровно по одной дуге.
Традиционно в математике и в родственных ей науках (в том числе и в теоретическом программировании) деревья "растут" вниз головой: это делается просто для удобства наращивания листьев в случае необходимости. Таким образом, на рисунках корень дерева оказывается самой верхней вершиной, а листья - самыми нижними.
Предок вершины v - это вершина, из которой исходит дуга, заходящая в вершину v. Потомок вершины v - это вершина, в которую заходит дуга, исходящая из вершины v. В этих терминах можно дать другие определения понятиям корень и лист: у корня нет предков, у листа нет потомков.
Бинарное дерево - это корневое дерево, каждая вершина которого имеет не более двух потомков. В таком случае иногда говорят о левом потомке и правом потомке для текущей вершины.
Высота корневого дерева - это максимальное количество дуг, отделяющих листья от корня. Если дерево не взвешенное, то его высота - это просто расстояние от корня до самого удаленного листа.
И в заключение мы приведем определение, связывающее произвольные графы с деревьями более плотно.
Каркас графа - это дерево, полученное после выбрасывания из графа некоторых ребер (см. рис. 11.13).
Рис. 11.13. Каркас графа
Примером каркаса является ( корневое ) дерево кратчайших путей от некоторой выделенной вершины (она будет корнем каркаса ) до всех остальных вершин графа.
Способы представления деревьев
Поскольку любое дерево является графом, то его можно задавать любым из способов, перечисленных в п. "Способы представления графов ". Однако существуют и специальные способы представления, предназначенные только для деревьев. Мы рассмотрим только два наиболее распространенных частных случая.
Представление корневого дерева
Этот способ подходит только для тех корневых деревьев, у которых точно известно максимальное количество потомков для любой вершины.
type ukazatel = ^tree; tree = record znachenie : integer; siblings : array[1..S] of ukazatel; end;
Разумеется, в общем случае значение переменной S (количество потомков ) может достигать N-1 ( N - количество всех вершин в дереве ). Однако ясно, что в такой ситуации особого смысла в динамической древесной структуре нет: экономии памяти не получается. Гораздо лучше, если у всех вершин примерно одинаковое и заранее известное количество потомков.
Представление бинарного дерева
Разновидностью описанного выше частного случая является бинарное корневое дерево: каждая его вершина имеет не более двух потомков:
type ukazatel = ^tree; tree = record znachenie : integer; left_sibling : ukazatel; right_sibling: ukazatel; end;
Примеры использования деревьев
Здесь мы ограничимся только примерами использования бинарных корневых деревьев: именно такой вид графа чаще всего применяется в программировании.
Дерево двоичного поиска
Дерево двоичного поиска для множества чисел S - это размеченное бинарное дерево, каждой вершине которого сопоставлено число из множества S, причем все пометки удовлетворяют следующим условиям:
- существует ровно одна вершина, помеченная любым числом из множества S ;
- все пометки левого поддерева строго меньше, чем пометка текущей вершины ;
- все пометки правого поддерева строго больше, чем пометка текущей вершины.
Если выражаться простым языком, то структура дерева двоичного поиска подчиняется простому правилу: "если больше - направо, если меньше - налево".
Например, для набора чисел 7, 3, 5, 2, 8, 1, 6, 10, 9, 4, 11 получится такое дерево (см. рис. 11.14).
Для того чтобы правильно учесть повторения чисел, можно ввести дополнительное поле, которое будет хранить количество вхождений для каждого числа.
Более подробно процессы построения и анализа дерева бинарного поиска будут изложены в следующей лекции, посвященной алгоритмам, использующим деревья и графы.
Рис. 11.14. Дерево двоичного поиска
Дерево частотного словаря
Дерево частотного словаря - это результат построения дерева двоичного поиска не для чисел, а для слов некоторого текста. Генерирование дерева частотного словаря полезно при подсчете количества вхождений каждого слова в некоторый текст.
Приведем описание структуры этого дерева:
type ukazatel = ^tree; derevo = record slovo : string[20]; kolichestvo : integer; levyj : ukazatel; pravyj: ukazatel; end;
Дерево синтаксического анализа
Дерево синтаксического анализа арифметического выражения - это бинарное дерево, листьями которого служат операнды, а остальными вершинами - операции, причем уровень вершины соответствует приоритету выполнения операции: чем ближе к листьям, тем приоритет выше.
Например, на рис. 11.15 изображено дерево синтаксического анализа для выражения ((a / (b + c)) + (x * (y - z))).
Деревья синтаксического разбора строятся компиляторами во время синтаксического анализа программ. Помимо арифметических выражений, которые являются простейшим случаем, аналогичные, но более сложные деревья строятся для всех грамматических конструкций компилируемой программы.
Рис. 11.15. Дерево синтаксического анализа
Лекция 12. Алгоритмы на графах и деревьях
В этой лекции мы рассмотрим некоторые классические алгоритмы, использующие графы и деревья, приведем и сравним рекурсивные и итеративные их варианты.
Используемая здесь терминология полностью совпадает с терминологией, введенной в предыдущей лекции.
Генерация дерева синтаксического анализа
Одно и то же арифметическое выражение может быть записано тремя способами:
Инфиксный способ записи (знак операции находится между операндами):
((a / (b + c)) + (x * (y - z)))
Все арифметические операции, привычные нам со школьных лет, записываются именно таким образом.
Префиксный способ записи (знак операции находится перед операндами):
+( /(a, +(b,c)), *(x, -(y,z)))
Из знакомых всем нам функций префиксный способ записи используется, например, для sin(x), tg(x), f(x,y,z) и т.п.
Постфиксный способ записи (знак операции находится после операндов):
((a,(b,c)+ )/ ,(x,(y,z)- )* )+
Этот способ записи менее распространен, однако и с ним многим из нас приходилось сталкиваться уже в школе: примером будет n! (факториал).
Разумеется, вид дерева синтаксического анализа (ДСА)1) арифметического выражения не зависит от способа записи этого выражения (см. рис. 12.1), поскольку определяет его не форма записи, а порядок выполнения операций. Но процесс построения дерева, конечно же, зависит от способа записи выражения. Далее мы разберем все три варианта алгоритма построения ДСА.
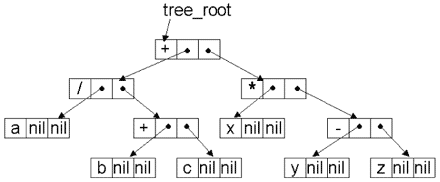
Рис. 12.1. Дерево синтаксического анализа и способ описания его элементов
type ukaz = ^tree;
tree = record
symbol: char;
left: ukaz;
right: ukaz;
end;Построение из инфиксной записи
Для простоты мы будем считать, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Приоритет операций определяется расставленными скобками: ими должна быть снабжена каждая операция.
Алгоритм Infix
Если не достигнут конец строки ввода, прочитать очередной символ.
Если этот символ - открывающая скобка, то:
- создать новую вершину дерева;
- вызвать алгоритм Infix для ее левого поддерева;
- прочитать символ операции и занести его в текущую вершину;
- вызвать алгоритм Infix для правого поддерева;
- прочитать символ закрывающей скобки (и ничего с ним не делать).
Иначе:
- создать новую вершину дерева;
- занести в нее этот символ.
Реализация
Мы воспользуемся здесь описанием типа данных ukaz, приведенным на рис. 12.1:
procedure infix(var p: ukaz);
var c: char;
begin
read(c);
if c = '('
then begin
new(p);
infix(p^.left);
read(p^.symbol); {'+', '-', '*', '/'}
infix(p^.right);
read(c); {')'}
end
else begin {'a'..'z','A'..'Z'}
new(p);
p^.symbol:= c;
p^.right:= nil;
p^.left:= nil
end;
end;
begin
...
infix(root);
...
end.Построение из префиксной записи
Для простоты предположим, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Кроме того, будем считать, что из записи удалены все скобки: это вполне допустимо, так как операция всегда предшествует своим операндам, следовательно, путаница в порядке выполнения невозможна.
Алгоритм Prefix
- Если не достигнут конец строки ввода, прочитать очередной символ.
- Создать новую вершину дерева, записать в нее этот символ.
- Если символ - операция, то:
- вызвать алгоритм Prefix для левого поддерева;
- вызвать алгоритм Prefix для правого поддерева.
Реализация
Вновь воспользуемся описанием типа данных ukaz, приведенным на рис. 12.1:
procedure prefix(var p: ukaz); begin new(p); read(p^.symbol); if p^.symbol in ['+','-','*','/'] then begin prefix(p^.left); prefix(p^.right); end else begin p^.left:= nil; p^.right:= nil; end end; begin ... prefix(root); ... end.
Построение из постфиксной записи
Для простоты предположим, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Кроме того, снова будем считать, что из записи удалены все скобки.
Алгоритм Postfix
- Если не достигнут конец строки ввода, прочитать очередной символ,если этот символ - операнд, то занести его в стек1),иначе (символ - операция):
- создать новый элемент, записать в него эту операцию;
- достать из стека два верхних (последних) элемента, присоединить их в качестве левого и правого операндов в новый элемент;
- занести полученный "треугольник" в стек.
По окончании работы этого алгоритма в стеке будет содержаться ровно один элемент - указатель на корень построенного дерева.
Реализация
Для того чтобы упростить работу, добавим в структуру элемента дерева (см. рис. 1.12) дополнительное поле next:ukaz, которое будет служить для связки стека:
stek:= nil;
while not eof(f) do
begin
new(p);
read(f,p^.symbol);
if p^.symbol in ['+','-','*','/']
then begin
p^.right:= stek;
p^.left:= stek^.next;
p^.next:= stek^.next^.next;
stek:= p
end
else begin
p^.left:= nil;
p^.right:= nil;
p^.next:= stek;
stek:= p
end;
end;Обходы деревьев и графов
Прежде чем приступить к изложению алгоритмов обхода, дадим пару необходимых определений.
Обход дерева - это некоторая последовательность посещения всех его вершин.
Обход графа - это обход некоторого его каркаса.
В этом разделе будут представлены только алгоритмы обхода бинарных деревьев. Большинство из них может быть с легкостью изменено для случая произвольного корневого дерева, каковым является и каркас произвольного графа.
Напомним, что структуру бинарного дерева мы описываем следующим образом:
type ukazatel = ^tree;
tree = record mark: integer;
left: ukazatel;
right: ukazatel;
end;Итак, приступим теперь к изучению различных вариантов обхода деревьев и графов.
Прямой обход
Другие названия
Префиксный обход: результатом прямого обхода2) дерева синтаксического анализа арифметического выражения будет префиксный вариант записи этого выражения.
Обход в глубину "сверху вниз": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Алгоритм PreOrder
- Начать с корня дерева.
- Пометить3) текущую вершину.
- Совершить прямой обход левого поддерева.
- Совершить прямой обход правого поддерева.
Замечание: Этот алгоритм может быть естественным образом распространен и на случай произвольного корневого дерева.
Реализация
procedure preorder(p:ukaz; k:integer);
begin p^.mark:= k;
if p^.left<>nil then preorder(p^.left,k+1);
if p^.right<>nil then preorder(p^.right,k+1);
end;
begin
...
preorder(root,1); {Вызов из тела программы}
...
end.
Рис. 12.2. Последовательность нумерации вершин при прямом обходе дерева
Прямой обход произвольного связного графа
Для простоты изложения будем считать, что граф задан матрицей смежности, которая хранится в квадратном массиве sm. Дополнительный линейный массив mark хранит информацию о последовательности посещения вершин:
procedure preorder_graph(v: byte);
var i: byte;
begin
k:= k+1;
mark[v]:= k; {текущей вершине v присвоен порядковый номер}
for i:= 1 to n do
if (mark[i]=0)and(sm[v,i]=1) {есть ребро из текущей вершины v
в еще не помеченную вершину i}
then preorder_graph(i);
end;
begin
...
k:= 0;
preorder_graph(start); {Вызов из тела программы}
...
end.Обратный обход
Другие названия
Постфиксный обход: результатом обратного обхода ДСА арифметического выражения будет постфиксный вариант записи этого выражения.
Обход в глубину "снизу вверх": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Алгоритм PostOrder
- Начать с корня дерева.
- Совершить обратный обход левого поддерева.
- Совершить обратный обход правого поддерева.
- Пометить текущую вершину.
Замечание: Этот алгоритм также может быть распространен на случай произвольного корневого дерева.
Рис. 12.3. Последовательность нумерации вершин при обратном обходе дерева
Реализация
procedure postorder(p:ukaz; k:integer);
begin if p^.left<>nil then postorder(p^.left,k+1);
if p^.right<>nil then postorder(p^.right,k+1)
p^.mark:=k;
end;
begin
...
postorder(root,1); {Вызов из тела программы}
...
end.Обратный обход произвольного связного графа
Для простоты изложения будем считать, что граф задан матрицей смежности, которая хранится в квадратном массиве sm. Дополнительный линейный массив mark хранит информацию о последовательности обхода вершин, а массив posesh - о фактах их посещения:
procedure postorder_graph(v:byte);
var i: integer;
begin
posesh[v]:=1; {текущая вершина v стала посещенной}
for i:=1 to n do
if (posesh[i]=0)and(sm[v,i]=1) {есть ребро из текущей вершины v
в еще не помеченную вершину i}
then postorder_graph(i);
inc(k);
mark[v]:=k; {текущей вершине v
присвоен порядковый номер}
end;
begin
...
k:=0;
postorder_graph(start); {вызов из тела программы}
...
end.Синтаксический обход
Другие названия
Инфиксный обход: результатом синтаксического обхода ДСА арифметического выражения будет инфиксный вариант записи этого выражения.
Обход "слева направо": название имеет смысл лишь в случае стандартного расположения дерева корнем кверху.
Алгоритм SyntOrder
- Начать с корня дерева.
- Совершить прямой обход левого поддерева.
- Пометить текущую вершину.
- Совершить прямой обход правого поддерева.
Замечание: Этот обход специфичен только для бинарных деревьев, поэтому невозможно применить его к произвольному графу, каркасом которого совершенно не обязательно будет именно бинарное дерево.
Реализация
procedure syntorder(p:ukaz; k:integer);
begin if p^.left<>nil then syntorder(p^.left,k+1);
p^.mark:=k;
if p^.right<>nil then syntorder(p^.right,k+1);
end;
begin
...
syntorder(root,1); {Вызов из тела программы}
...
end.Обход в ширину
Последовательность обхода
- Пометить вершину 0-го уровня (корень дерева).
- Пометить все вершины 1-го уровня.
- Пометить все вершины 2-го уровня.
- ...
Рис. 12.4. Последовательность нумерации вершин при синтаксическом обходе дерева
Замечание: Этот алгоритм может быть естественным образом распространен и на случай произвольного корневого дерева.
Алгоритм WideOrder
- Занести в очередь1) корень дерева.
- Пока очередь не станет пустой, повторять следующие действия:
- удалить первый элемент из головы очереди;
- добавить в хвост очереди всех потомков удаленной вершины.
Реализация
Для простоты реализации вновь пополним структуру дерева полем next:ukaz, которое будет служить для связки очереди:
head:= root;
tail:= root;
k:= 0;
repeat
tail^.next:= head^.left;
if head^.left<>nil then tail:= tail^.next;
tail^.next:= head^.right;
if head^.right<>nil then tail:= tail^.next;
inc(k);
head^.znachenie:= k; {можно write(head^.znachenie);}
head:= head^.next
until head = nil;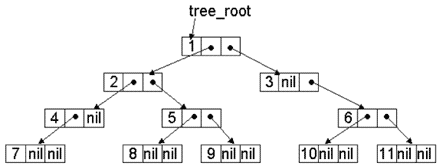
Рис. 12.5. Последовательность нумерации вершин при обходе дерева в ширину
Древесная сортировка
Задача. Упорядочить заданный набор (возможно, с повторениями) некоторых элементов (чисел, слов, т.п.).
Алгоритм TreeSort
- Для сортируемого множества элементов построить дерево двоичного поиска:
- первый элемент занести в корень дерева;
- для всех остальных элементов: начать проверку с корня; двигаться влево или вправо (в зависимости от результата сравнения с текущей вершиной дерева) до тех пор, пока не встретится такой же элемент, либо пока не встретится nil. Во втором случае нужно создать новый лист в дереве, куда и будет записано значение нового элемента.
- Совершить синтаксический обход построенного дерева, печатая каждую встреченную вершину столько раз, сколько было ее вхождений в сортируемый набор.
Реализация
Мы приведем реализацию первого шага алгоритма, сортирующего числа (для элементов другой природы потребуется изменить только процесс считывания):
new(root);
read(f,root^.chislo);
root^.kol:= 1;
root^.left:= nil;
root^.right:= nil;
while not eof(f) do
begin
read(f,x);
p:= root;
while true do
begin
if x = p^.chislo
then begin inc(p^.kol);
break
end;
if x > p^.chislo
then if p^.right <> nil
then p:= p^.right
else begin new(p^.right);
p:= p^.right;
p^.chislo:= x;
p^.kol:= 1;
p^.left:= nil;
p^.right:= nil;
break
end
(* x < p^.chislo *)
else if p^.left <> nil
then p:= p^.left
else begin new(p^.left);
p:= p^.left;
p^.chislo:= x;
p^.kol:= 1;
p^.left:= nil;
p^.right:= nil;
break
end
end;
end;Подсчет количества компонент связности
Задача. Определить количество компонент связности в заданном графе.
Рекурсивный алгоритм
Считаем, что граф задан матрицей смежности sm.
Каждый элемент специального линейного массива mark будет хранить номер компоненты связности, к которой принадлежит соответствующая вершина графа.
Алгоритм КомпСвяз-Рек
- Совершить обход в глубину всех компонент связности графа, помечая вершины каждой из них отдельным номером.
Рекурсивная процедура обхода в глубину ( прямого или обратного обхода ) переберет все вершины, достижимые из начальной. Начальной вершиной для очередной компоненты связности может стать любая вершина, еще не отнесенная ни к какой другой компоненте связности (то есть еще не помеченная в массиве mark ).
По окончании работы программы переменная kol будет содержать количество найденных компонент связности.
Реализация
procedure step (v: integer);
var j: integer;
begin
mark[v]:= k;
for j:=1 to N do
if (mark[j]=0)and(sm[v,j]<>0) then step(j);
end;
begin
...
for i:= 1 to N do mark[i]:=0;
k:= 0; {номер текущей компоненты связности}
for i:= 1 to N do
if mark[i]=0 then
begin inc(k);
step(i);
end;
...
end.Итеративный алгоритм
Для этого алгоритма удобно, чтобы граф был представлен списком ребер.
Массив mark, как и прежде, будет хранить номера компонент связностей, к которым принадлежат помеченные вершины графа.
Алгоритм КомпСвяз-Итер
Прочитать начало и конец очередного ребра. Далее возможны 4 различные ситуации:
- Оба конца ребра еще не относятся ни к одной из ранее встретившихся компонент связности ( mark[u]=0 и mark[v]=0 ). В этом случае количество компонент связности kol увеличивается на единицу, а новая компонента связности получает очередной номер ks+1.
- Один конец ребра уже относится к какой-то компоненте связности, а второй - еще нет ( mark[u]=0, а mark[v]<>0 ). В этом случае общее количество компонент связности kol остается прежним, а непомеченный конец ребра получает ту же пометку, что и второй его конец.
- Оба конца нового ребра относятся к одной и той же компоненте связности ( mark[u]= mark[v]<>0 ). В этом случае не нужно производить никаких действий.
- Концы нового ребра относятся к разным компонентам связности (
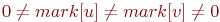 ). В этом случае нужно объединить две ранее созданные компоненты связности в одну. Общее количество компонент связности kol уменьшается на 1, а все вершины, принадлежавшие к более новой компоненте связности (больший номер), получают новую пометку. Заметим, что переменная ks, обозначающая очередной свободный номер для следующей компоненты связности, в данном случае изменяться не должна, поскольку нет никакой гарантии, что изменен будет номер именно самой последней компоненты связности.
). В этом случае нужно объединить две ранее созданные компоненты связности в одну. Общее количество компонент связности kol уменьшается на 1, а все вершины, принадлежавшие к более новой компоненте связности (больший номер), получают новую пометку. Заметим, что переменная ks, обозначающая очередной свободный номер для следующей компоненты связности, в данном случае изменяться не должна, поскольку нет никакой гарантии, что изменен будет номер именно самой последней компоненты связности.
По окончании работы этого алгоритма в массиве mark будет записано S различных целых чисел, каждое из которых будет означать отдельную компоненту связности. Кроме того, в массиве могут остаться нулевые компоненты: каждая из них будет соответствовать изолированной вершине, которая тоже является отдельной компонентой связности. Следовательно, количество нулей должно быть прибавлено к количеству компонент, найденному в процессе работы основного алгоритма.
Реализация
kol:=0;
ks:=0;
while not eof(f) do
begin
readln(f,u,v);
if mark[u]=0
then if mark[v]=0
then begin {случай 1}
inc(kol);
inc(ks);
mark[u]:= ks;
mark[v]:= ks;
end
else mark[u]:= mark[v] {случай 2}
else if mark[v]=0
then mark[v]:= mark[u]
{случай 2 - симметричный}
else if mark[u]<>mark[v] {случай 4}
then begin
max:= v;
min:= u;
if u>v then begin
max:= u;
min:= v end;
for i:= 1 to n do
if mark[i]= max
then mark[i]:= min;
dec(kol);
end
end;
for i:=1 to N do
if mark[i]=0 then inc(kol);Сравнение алгоритмов КомпСвяз-Рек и КомпСвяз-Итер
В худшем случае (при полном графе) рекурсивный алгоритм, перебирая все возможные ребра, будет вынужден вызвать основную процедуру (N-1)! раз. Велика вероятность, что при достаточно большом N произойдет переполнение оперативной памяти, которое вызовет аварийную остановку программы. Кроме того, размеры квадратной матрицы смежности дают сильное ограничение на возможное количество вершин графа: не более 250 (см. лекцию 3).
Итеративный же алгоритм переберет все ребра графа, которых может быть не более чем N*(N+1)/2. В половине этих случаев возможна ситуация объединения двух компонент связности в одну, для чего потребуется еще N операций. Следовательно, общая сложность алгоритма может быть приблизительно оценена значением N3/8. Возможное количество вершин графа ограничено только максимальным размером линейного массива ( 32 000 ).
Нахождение минимального каркаса
Задача. В заданном взвешенном связном графе определить множество ребер, составляющих некоторый его оптимальный каркас (например, минимальный по сумме весов входящих в него ребер).
Рекурсивный алгоритм
Алгоритм Каркас-Рек
Этот алгоритм базируется на прямом обходе графа, который учитывает два условия: во-первых, чтобы суммарный вес текущего каркаса был меньше текущего минимума и, во-вторых, чтобы в каркасе было ровно N-1 ребро1) ( N - количество вершин графа).
Реализация
procedure step(v,k: byte; r: longint);
var j: byte;
begin
if r < min then
if k = N-1
then min:= r
else for j:= 1 to N do
if (sm[v,j]<>0)and(mark[j]=0)
then begin
mark[j]:= 1;
step(j,k+1,r+sm[v,j]);
mark[j]:= 0
end;
end;
begin
...
for i:= 1 to N do mark[i]:= 0;
min:= MaxLongInt;
for i:= 1 to N do
begin mark[i]:=1;
step(i,1,0);
mark[i]:=0;
end;
writeln(min);
...
end.Для того чтобы помимо суммарного веса каркаса алгоритм также запоминал включенные в каркас ребра, необходимо добавить дополнительный квадратный массив, в котором будут храниться пометки включения ребер в каркас.
Итеративный алгоритм
Алгоритм Краскала
- Упорядочить все ребра графа по возрастанию их весов.
- Применить алгоритм КомпСвяз-Итер (см. пункт "Подсчет количества компонент связности").
Замечание: Выполнение алгоритма Краскала можно завершить сразу же, как только в каркас будет добавлено ( N-1 )-е ребро (поскольку в дереве с N вершинами должно быть ровно N-1 ребро).
Реализация
Реализация основной части алгоритма (шаг 2) совпадает с реализацией алгоритма КомпСвяз-Итер, за исключением того, что в случаях 1, 2 и 4 необходимо ввести подсчет добавленных в каркас ребер, а внешний цикл завершить не в момент достижения конца файла, а в момент, когда счетчик добавленных ребер станет равным N-1.
Нахождение кратчайших путей
Задача. В заданном взвешенном связном графе найти расстояние (длину кратчайшего пути) от выделенной вершины s до вершины t. Веса всех ребер строго положительны.
Рекурсивный алгоритм
Алгоритм Расст-Рек
Совершить обход графа в глубину, при каждом "шаге вперед" прибавляя длину ребра к длине текущего пути, при каждом возврате - отнимая длину этого ребра от длины текущего пути. При движении "вперед" пометки посещенности вершин ставятся, при "откате" - снимаются. По достижении выделенной вершины t производится сравнение длины текущего пути с ранее найденным минимумом.
Реализация
Пусть граф задан матрицей смежности sm, а массив mark хранит информацию о посещениях вершин. Напомним, что уменьшение длины пути "на возврате" совершается рекурсией автоматически, поскольку в ее заголовке использован параметр-значение, а вот аналогичное обнуление соответствующих позиций массива mark приходится делать вручную, поскольку задавать массив параметром-значением чересчур накладно:
procedure rasst(v: byte; r: longint);
var i: byte;
begin
if v = t
then if r< min then min:= r
else
else for i:= 1 to N do
if (mark[i]=0)and(sm[v,i]<>0)
then begin mark[i]:=1;
rasst(i,r+sm[v,i]);
mark[i]:=0
end
end;
begin
...
for i:= 1 to N do mark[i]:= 0;
min:= MaxLongInt;
mark[s]:= 1;
rasst(s,0);
mark[s]:= 0;
...
end.Итеративный алгоритм
Алгоритм, предложенный Дейкстрой2), настолько мощнее рекурсивного алгоритма Расст-Рек, что, при тех же начальных условиях и не прикладывая дополнительных усилий, он может найти расстояние от выделенной вершины s не только до одной вершины t, но и до всех остальных вершин графа.
Итак, пусть граф задан матрицей смежности.
Линейный массив dist будет хранить длины текущих путей от вершины s до всех остальных вершин. В начале этот массив будет инициирован числами MaxLongInt, символизирующими "бесконечность". По окончании работы алгоритма в этом массиве останутся только минимальные значения длин путей, которые и являются расстояниями.
Еще один линейный массив done потребуется нам для того, чтобы хранить информацию о том, найден ли уже минимальный путь (он же расстояние) до соответствующей вершины и можно ли исключить эту вершину из дальнейшего рассмотрения.
Переменная last будет хранить номер последней помеченной вершины.
Отметим особо, что на каждом шаге Алгоритм Дейкстры находит длину кратчайшего пути до очередной вершины графа. Именно поэтому достаточно сделать ровно N-1 итераций.
Алгоритм Дейкстры
Расстояние от s до s, конечно же, равно 0. Кроме того, это расстояние уже никогда не сможет стать меньше - ведь веса всех ребер графа у нас положительны. Таким образом:
dist[s]:= 0; done[s]:= true; last:= s;
Повторить N-1 раз следующие действия:
для всех непомеченных вершин х, связанных ребром с вершиной last, необходимо пересчитать расстояние:
dist[x]:= min(dist[x], dist[last]+ sm[last,x]);
- среди всех непомеченных вершин найти минимум в массиве dist: это будет новая вершина last ;
- пометить эту новую вершину в массиве done.
Реализация
Мы надеемся, что функцию поиска меньшего из двух целых чисел min, использованную в тексте программы, читатели смогут написать самостоятельно.
dist[s]:= 0; done[s]:= true; last:= s; for i:= 1 to N-1 do begin for x:= 1 to N do if (sm[last,x]<>0)and(not done[x]) then dist[x]:= min(dist[x],dist[last]+ sm[last,x]); min_dist:= MaxLongInt; for x:= 1 to N do if (not done[x])and(min_dist>dist[x]) then begin min_dist:= dist[x]; last:= x; end; done[last]:= true; end.
Сравнение алгоритмов Расст-Рек и Дейкстры
Сложность рекурсивного алгоритма пропорциональна N!, а алгоритм Дейкстры имеет сложность ~N2. Комментарии, как говорится, излишни.
Лекция 13. Модульная структура программы
Модульность программ
Модуль - это кусок программы, компилируемый отдельно от остальных ее частей. Именно возможность раздельной компиляции и является основным преимуществом модулей.
Простейшая модульность программы может достигаться за счет применения процедур и функций, однако этого не всегда достаточно. Если все подпрограммы содержатся в одном файле, то исправление единственной ошибки в какой-либо подпрограмме приведет к неизбежной перекомпиляции всего кода. А при современных размерах программ компиляция может длиться даже не минуты, а часы.
Кроме того, если коллектив программистов пишет одну большую программу (а именно в таких условиях работают сегодня все производители программного обеспечения), то каждому из них нужно обеспечить более или менее независимый "фронт работ". Даже два человека не могут одновременно исправлять один и тот же файл, иначе конфликт обновлений будет гарантирован. Что уж тут говорить о проектах, над которыми работают десятки и даже сотни человек! В такой ситуации модули, которые хранятся каждый в отдельном файле и могут быть отредактированы, откомпилированы и протестированы независимо от остальных частей программы, являются наилучшим решением этой проблемы.
Несколько модулей, являющихся составными частями одной программы, объединяются в библиотеку. Например, вместе с компилятором языка Pascal поставляются стандартные библиотеки, содержащие важнейшие подпрограммы обработки данных.
Стандартные модули языка Pascal
Перечислим самые распространенные модули, входящие в состав стандартных библиотек языка Pascal. Подробное описание этих библиотек можно найти в любом справочном издании1).
System
Модуль System является основным: в нем содержатся все изученные нами стандартные процедуры и функции обработки арифметических выражений, множеств, строк и т.п. Специального подключения этот модуль не требует: его содержимым можно пользоваться по умолчанию.
Напомним, что этот модуль содержит следующие типы подпрограмм:
- подпрограммы для обработки величин порядковых типов данных ( dec, inc, odd, pred, succ );
- арифметические функции ;
- функции преобразования типов данных ( chr, ord, round, trunc );
- процедуры управления процессом выполнения программы ( break, continue, exit, halt );
- подпрограммы обработки строк ( concat, copy, delete, insert, length, pos, str, val );
- подпрограммы файлового ввода и вывода ;
- подпрограммы динамического распределения памяти ( dispose, freemem, getmem, new );
- функции для работы с указателями и адресами ( addr );
- а также некоторые другие подпрограммы (например, exclude, include, random, randomize, upcase ).
Crt
Модуль Crt служит для организации "хорошего" вывода на экран. Подробнее о содержимом этого модуля мы расскажем в следующей лекции.
Wincrt
Модуль WinCrt предназначен для создания программ, поддерживающих простейший оконный интерфейс.
Printer
Модуль Printer позволяет производить вывод информации не на консоль, а на принтер (под операционной системой DOS).
Winprn
Модуль WinPrn является аналогом модуля Printer для операционной системы Windows.
Dos
Модуль Dos позволяет обмениваться информацией с операционной системой. Системное время, прерывания, состояния параметров окружения, процедуры обработки процессов, работа с дисковым пространством - всем этим занимается модуль Dos.
Windos
Модуль WinDos является аналогом модуля Dos для операционной системы Windows.
Strings
Модуль Strings позволяет перейти от стандартных строк языка Pascal к строкам, ограниченным нулем. В отличие от обычных строк, чья длина не может превышать 255 символов, эти строки могут состоять из 65 535 символов, причем конец каждой такой строки помечен символом #0.
Graph
Модуль Graph содержит разнообразнейшие подпрограммы, которые позволяют создавать на экране различные рисунки из многоцветных геометрических фигур. Модуль управляет также палитрами, фактурами фона и шрифтами.
Overlay
Модуль Overlay предоставляет возможность делать большие программы оверлейными (многократно использующими одну и ту же область памяти).
Winapi
Модуль WinApi отвечает за создание динамических библиотек. Этот модуль свойственен лишь поздним версиям языка Pascal (например, Turbo Pascal 7.0).
Подключение модулей
Для того чтобы подключить к программе какой-либо модуль, необходимо сразу после заголовка программы поместить следующую строку:
uses <имя_модуля>;
Если подключаемых модулей несколько, эта строка примет вид:
uses <имя_модуля_1>,...,<имя_модуля_N>;
Впрочем, совершенно не обязательно указывать имена всех модулей, так или иначе фигурирующих в программе. Достаточно указать имена лишь тех, к которым она будет обращаться непосредственно. А к каждому модулю, подключенному к головной программе, в случае необходимости можно подключить другие модули - и т. д.
Все константы, типы данных, переменные, процедуры и функции, описанные в каком-либо модуле, после его подключения к основной программе (или к другому модулю ) становятся доступными этой программе (или модулю ) без дополнительных объявлений.
Например, вы можете пользоваться функцией abs(), не объявляя и не описывая ее, поскольку эта функция включена в состав стандартного модуля System, автоматически подключаемого к любой программе на языке Pascal. Если же вы захотите очистить экран монитора перед выдачей результатов, вам придется подключить к вашей программе модуль crt и воспользоваться содержащейся в нем процедурой clrscr (см. лекцию 14).
Создание модульной программы
Перейдем теперь к детальному изучению структуры модулей и правил их создания и использования.
Структура модуля
В состав модуля входят четыре секции (любая из них может быть пустой, но ее заголовок все равно обязан присутствовать):
unit <имя_модуля>;
interface {секция внешних связей}
implementation {секция реализаций}
begin {секция инициализации}
end.Разберем каждую из этих секций отдельно.
Название
В отличие от заголовка программы ( program <имя_программы>; ), который может и отсутствовать, заголовок модуля ( unit <имя_модуля>; ) обязан присутствовать всегда.
Кроме того, очень полезно давать модулям и содержащим их файлам одинаковые имена. Иначе говоря, модуль с именем modul_1 желательно разместить в файле с именем modul_1.pas, и т.п.
Секция внешних связей
Эта секция содержит объявления тех типов данных, констант, переменных, подпрограмм и т.п., которые должны быть видны вне модуля.
Если для объявления какого-либо объекта нужны сведения об объекте, объявленном в другом модуле, то имя этого модуля необходимо указать в этой же секции:
interface [uses <список_вспомогательных_модулей>;] [const <список_внешних_констант>;] [type <список_внешних_типов_данных>;] [var <список_внешних_переменных>;] [procedure <объявление_внешней_процедуры>;] [function <объявление_внешней_функции>;]
Например, пусть у нас есть два модуля: mod_const, содержащий описания базовых констант и типов данных, и mod1, использующий эти описания (мы приводим только секции внешних связей ):
unit mod_const; interface const sto = 100; type one_to_sto = 1..sto; ... unit mod1; interface uses mod_const; const dvesti = 2*sto; type massiv = array[1..dvesti] of byte; var a: massiv; b: one_to_sto; function min(x,y:one_to_sto):one_to_sto; ...
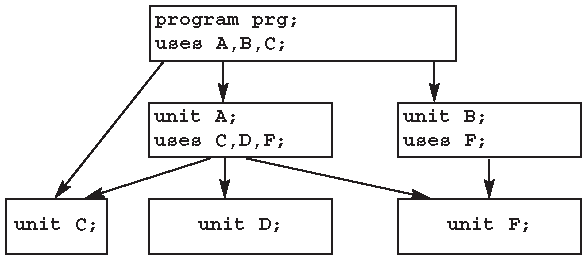
Рис. 13.1. Пример структуры модульной программы
Теперь, если в каком-либо третьем модуле встретится строка
uses mod1;
то внутри этого третьего модуля можно будет использовать (без дополнительных объявлений) тип massiv, переменные a и b, а также функцию min. Необходимо отметить, что использовать константу sto третий модуль не сможет, поскольку в нем не было указано
uses mod_const;
Если в секциях связей нескольких модулей были определены константы или переменные с одинаковыми именами, но с разными значениями, то путаницы позволит избежать уже знакомый нам прием: указание имени модуля перед идентификатором:
<имя_модуля>.<идентификатор>
Если имя модуля не указано, то идентификатор считается принадлежащим текущему модулю. И только если в текущем модуле этот идентификатор не был объявлен, то начинается поиск в подключенных модулях.
Например, если модульная программа имеет структуру, изображенную на рис. 13.1, то таблица доступности переменных будет выглядеть так:
| Связи | Способ обращения к одноименным переменным | |||||||
| program prg; | uses A,B,C; | p | a.p | b.p | c.p | не видна | не видна | |
| unit A; | uses C,D,F; | не видна | p | не видна | c.p | d.p | f.p | |
| unit B; | uses F; | не видна | не видна | p | не видна | не видна | f.p | |
| unit C; | - | не видна | не видна | не видна | p | не видна | не видна | |
| unit D; | - | не видна | не видна | не видна | не видна | p | не видна | |
| unit F; | - | не видна | не видна | не видна | не видна | не видна | p | |
Замечание: В секциях связей не допускается рекурсивное использование модулями друг друга. Иными словами, нельзя одновременно написать
unit mod_1; interface uses mod_2; ... unit mod_2; interface uses mod_1; ...
Секция реализации
Этот раздел модуля содержит реализации всех подпрограмм, которые были объявлены в секции внешних связей. Как и в случае косвенной рекурсии (см. лекцию 9), здесь объявление подпрограммы оторвано от ее описания. Однако ключевое слово forward здесь является излишним.
Кроме того, в этой же секции объявляются и описываются внутренние (невидимые вне модуля ) метки, константы, типы данных, переменные и подпрограммы.
implementation [uses <список_вспомогательных_модулей>;] [const <список_внутренних_констант>;] [type <список_внутренних_типов_данных>;] [var <список_внутренних_переменных>;] [procedure <описание_внешней_процедуры>;] [function <описание_внешней_функции>;] [procedure <объявление_и_описание_внутренней_процедуры>;] [function <объявление_и_описание_внутренней_функции>;]
В отличие от секции внешних связей, секции реализации из различных модулей могут использовать друг друга рекурсивно. Иными словами, совершенно законной будет запись, например, такого вида:
unit mod_1; interface ... implementation uses mod_2; ... unit mod_2; interface ... implementation uses mod_1; ...
Хороший пример реальной рекурсии при обращениях к модулям (позаимствованный, правда, из оригинальной документации) дается в книге М.В. Сергиевского и А.В. Шалашова "Турбо Паскаль 7.0. Язык. Среда программирования". Позволим себе привести (с небольшими изменениями) этот пример.
Смысл рекурсии здесь состоит в том, что вывод некоторого сообщения на заданную позицию экрана при помощи процедуры message, содержащейся в модуле mod_1, может сгенерировать ошибку, сообщение о которой (процедура _error из модуля mod_2 ) снова задействует процедуру message - но уже с другими параметрами.
unit mod_1;
interface
procedure message(x,y: byte; msg: string);
implementation
uses mod_2, crt;
procedure message;
begin if(x in [1..80-length(msg)]and(y in [1..25])
then begin gotoxy(x,y); {позиционирование курсора}
write(msg)
end
else _error('Сообщение не входит в экран')
{вызов процедуры из модуля mod_2}
end;
end.
unit mod_2;
interface
procedure _error(msg:string);
implementation
uses mod_1;
procedure _error;
begin message(1,25,msg); {вызов процедуры из модуля mod_1}
end;
end.Секция инициализации
Секции инициализации всех подключенных к программе модулей исполняются один раз, перед началом работы основной программы:
begin <произвольные_операторы> end.
Если сразу несколько модулей содержат секции инициализации, то порядок выполнения этих секций будет следующим:
- Если модуль А подключает модуль В (не важно, в какой именно секции), то секция инициализации модуля В будет выполнена раньше, чем секция инициализации, содержащаяся в модуле А.
- Если два модуля В и С подключаются на одном уровне (считаются равноправными), то их секции инициализации будут выполнены в том порядке, в каком имена этих модулей указаны в разделе uses.
Замечание: Последовательность подключения модулей соответствует обратному обходу орграфа связей (см. лекцию 12).
Если каждый модуль из тех, что составляют программу на рис. 13.1, имеет непустую секцию инициализации, то эти секции будут выполнены в следующей последовательности: C, D, F, A, B. Если же к головной программе модули будут подключены в другом порядке, например:
uses B,A,C;
то секции инициализации будут выполняться в другой последовательности: F, B, C, D, A.
Замечание: Если секция инициализации в модуле отсутствует (а так чаще всего и бывает), то ключевое слово begin указывать не обязательно. Однако end. обязан закрывать текст модуля в любом случае.
Взаимодействие модулей
Если необходимо сделать так, чтобы несколько равноправных модулей имели доступ к одним и тем же переменным, константам и т.п., то наиболее практичным способом является введение дополнительного модуля, в котором будут объявлены все глобальные переменные, константы и типы данных. Секция реализации у этого нового модуля будет пустой.
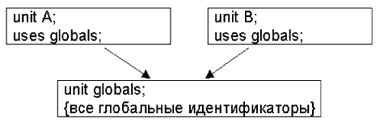
Рис. 13.2. Использование модуля определений
Компиляция модулей
Исходные тексты модулей хранятся в файлах с расширением .pas, а результаты их компиляции - в файлах с расширением .tpu.
Существует три варианта превращения модульной программы в исполняемый код.
- Все подключаемые модули должны быть откомпилированы заранее; после этого можно компилировать головную программу, используя команду Compile | Compile главного меню или нажатие клавиш ALT+F9. Если вы случайно забыли откомпилировать какой-либо модуль (соответствующий файл с расширением .tpu отсутствует), то компилятор выдаст сообщение о недостающем файле. Если в текст какого-либо модуля были внесены изменения, но перекомпиляция не производилась (изменился файл .pas, но файл .tpu остался прежним), то в исполняемый код программы будет включена старая версия этого модуля.
- Компилирование при помощи команды Compile | Make (ей эквивалентно нажатие клавиши F9 ) обновит все подключаемые к программе модули, которые либо еще не были откомпилированы, либо изменились с момента последней компиляции. Кроме того, перекомпилированы будут также модули, которые обращаются к тем модулям, чьи секции связи изменились (изменения в секциях реализации такого эффекта не вызовут).
- Компиляция, активизированная при помощи команды Compile | Build, затронет все модули, вне зависимости от наличия в них изменений.
Пример модуля
В качестве примера мы приведем модуль, содержащий арифметические функции min и max для целых чисел, а также функцию возведения в степень. Все эти функции отсутствуют в стандартном модуле System.
unit my_arifm; interface function min(a,b: longint): longint; function max(a,b: longint): longint; function deg(a,b: double): double; implementation function min; begin if a>b then min:= b else min:= a; end; function max; begin if a<b then max:= b else max:= a; end; function deg; begin deg:= exp(b*ln(a)) end; end.
Теперь, подключив этот модуль к любой своей программе, вы сможете пользоваться этими тремя функциями. Остальные необходимые в работе подпрограммы (например, тригонометрические функции tg, ctg, sec, arcsin, arсcos, arctg, arcctg, arcsec ) желающие могут добавить в этот модуль самостоятельно.
Аналогичным образом, полезно единожды написать и отладить подпрограммы, обрабатывающие динамические структуры данных (списки, деревья, стеки и т.п.), сохранить их в специальном модуле, а затем пользоваться ранее проделанной работой вновь и вновь, не тратя времени на повторное программирование. Такой подход очень распространен в программировании вообще и носит несколько неуклюжее название " Повторное использование ранее созданных компонентов " 1).
Передача аргументов из командной строки
В лекции 8 мы уже говорили о том, что любая процедура или функция, по сути, является полноценной программой. Но если подпрограммы способны получать аргументы извне, то почему этого не могут делать сами программы?
Однако в языке Pascal нет нарушений единообразия: любая программа тоже способна получать аргументы во время начала работы. Для этого нужно лишь вызывать ее из командной строки следующим образом:
<имя_программы> <список_аргументов>
Список аргументов - это последовательность передаваемых в программу значений, разделенных пробелами или символами табуляции.
В стандартном модуле System, автоматически подключаемом к любой программе на языке Pascal, имеются две функции, позволяющие программе принимать аргументы, переданные из командной строки.
Функция paramcount: word возвращает количество аргументов, переданных в программу из командной строки при вызове.
Функция paramstr(k: word): string возвращает k -й аргумент, переданный в программу из командной строки.
Если программа модульная, то обработку поступающих из командной строки аргументов удобнее всего занести в секцию инициализации одного из модулей. Впрочем, это не обязательно.
Например:
program arguments;
var i,k,n: word;
begin
n:= paramcount;
writeln('Из командной строки поступило ',n,'
аргументов:');
for i:= 1 to n do
writeln(i,'-й аргумент = ',paramstr(i));
end.Если теперь вызвать эту программу из командной строки, скажем, с такими аргументами:
arguments abcd -36 +25.062 -t /&
то на экране получится следующий результат:
Из командной строки поступило 5 аргументов: 1-й аргумент = abcd 2-й аргумент = -36 3-й аргумент = +25.062 4-й аргумент = -t 5-й аргумент = /&
Хорошим стилем считается включать в программу так называемый внешний help: если в нее можно передавать какие-либо аргументы из командной строки, необходимо сообщить потенциальному пользователю их возможные значения и смысл.
Чаще всего для отображения на экране внешней подсказки используются аргументы ? или /?.
Примером может служить краткая экранная подсказка хорошо известного архиватора arj.exe, которая появляется на экране в случае некорректного обращения к этой программе. Подсказка сообщает пользователю: а) имя программы; б) суть того, что именно появилось на экране; в) правила корректного вызова программы; г) примеры корректного вызова; д) краткий список возможных аргументов (команд и ключей).
ARJ 2.50a SHAREWARE Copyright (c) 1990-95 ARJ Software. Dec 12 1995 List of frequently used commands and switches. Type ARJ -? for more help. Usage: ARJ <command> [-<sw> [-<sw>...]] <archive_name> [<file_names>...] Examples: ARJ a -e archive, ARJ e archive, ARJ l archive *.doc <Commands> a: Add files to archive m: Move files to archive d: Delete files from archive t: Test integrity of archive e: Extract files from archive u: Update files to archive f: Freshen files in archive v: Verbosely list contents of archive l: List contents of archive x: eXtract files with full pathname <Switches> c: skip time-stamp Check r: Recurse subdirectories e: Exclude paths from names s: set archive time-Stamp to newest f: Freshen existing files u: Update files (new and newer) g: Garble with password v: enable multiple Volumes i: with no progress Indicator w: assign Work directory m: with Method 0, 1, 2, 3, 4 x: eXclude selected files n: only New files (not exist) y: assume Yes on all queries
Более подробно о правилах организации хорошего интерфейса мы расскажем в следующей лекции.
Лекция 14. Методы создания пользовательского интерфейса
Любая программа, написанная на языке Pascal, может работать с экраном в двух режимах: в текстовом или в графическом. По умолчанию всегда используется текстовый режим.
Текстовый режим
В текстовом режиме единицей вывода информации служит символ. На экране каждый символ занимает одно знакоместо - прямоугольный участок размером 8х8 пикселей (зерен экрана). Во весь экран помещается 80х25 знакомест.
Курсор (мигающий прямоугольник) помечает то место на экране, куда по умолчанию будет осуществлен вывод очередного символа, - текущую позицию. Для определения текущей позиции курсора предназначена сетка координат, мысленно накладываемая на экран. Левое верхнее знакоместо имеет координаты (1,1), правое верхнее - (1,80), левое нижнее - (25,1) и правое нижнее - соответственно (25,80).
Рассмотренные в лекции 6 процедуры write() и writeln() работают именно с текстовым экраном: они выводят информацию посимвольно, начиная с текущей позиции курсора.
Если при выводе информации в текстовый файл любой символ записывается туда в виде своего изображения, то при выводе на экран существуют четыре исключения из этого правила:
- Вместо изображения символа #7 компьютер издаст звуковой сигнал.
- Вместо изображения символа #8 курсор на экране будет передвинут на одну позицию влево.
- Вместо изображения символа #10 курсор на экране будет передвинут на одну строку вниз.
- Вместо изображения символа #13 курсор на экране будет передвинут на начало текущей строки.
Остальные символы выводятся на экран в "правильном" виде.
Процедуры модуля Crt
В предыдущей лекции мы уже упоминали, что модуль Crt, входящий в состав стандартных библиотек языка Pascal, содержит средства для работы с экраном в текстовом режиме.
Для того чтобы сделать работоспособными все описанные ниже процедуры и функции, ваша программа должна подключить стандартный модуль Crt:
uses crt;
Активная область ввода / вывода
Процедура Window(x1,y1,x2,y2: byte) создаст на экране окно с координатами левого верхнего угла в точке (x1,y1) и координатами правого нижнего угла в точке (x2,y2). Теперь активная область экрана будет ограничена этим окном. Текущие координаты курсора будут отсчитываться не от левого верхнего угла экрана, а от левого верхнего угла этого окна.
Очистка
Процедура ClrScr очистит весь экран (или активное окно); курсор будет помещен в верхний левый его угол.
Процедура ClrEol очистит текущую строку, начиная с текущей позиции курсора и до правого края экрана (окна).
Процедура DelLine удалит строку, в которой находится курсор.
Процедура InsLine очистит текущую строку целиком. Курсор останется на прежней позиции.
Цвета
Процедура TextBackground(color: byte) установит цвет фона.
Процедура TextColor(color: byte) установит цвет выводимого текста.
Замечание: Вместо номера цвета возможно использовать соответствующую константу (см. табл. 14.1).
| Стандартная константа | Номер | Цвет | Стандартная константа | Номер | Цвет |
|---|---|---|---|---|---|
| black | 0 | Черный | darkgray | 8 | Темно-серый |
| blue | 1 | Синий | lightblue | 9 | Ярко-синий |
| green | 2 | Зеленый | lightgreen | 10 | Ярко-зеленый |
| cyan | 3 | Голубой | lightcyan | 11 | Ярко-голубой |
| red | 4 | Красный | lightred | 12 | Розовый |
| magenta | 5 | Фиолетовый | lightmagenta | 13 | Ярко-фиолетовый |
| brown | 6 | Коричневый | yellow | 14 | Желтый |
| lightgray | 7 | Светло-серый | white | 15 | Белый |
Помимо этого, можно использовать константу blink = 128 (мерцание).
Звук
Процедура Sound(hz: word) включит звуковой сигнал с частотой hz герц.
Процедура NoSound выключит звуковой сигнал.
Позиционирование
Процедура GotoXY(x,y: byte) переместит курсор в заданную позицию в пределах текущего окна (экрана).
Функция WhereX: byte вычислит положение курсора в текущем окне (или на экране): его горизонтальную составляющую. Напомним, что координата X отсчитывается от левого края экрана (окна).
Функция WhereY: byte вычислит положение курсора в текущем окне (или на экране): его вертикальную составляющую. Напомним, что координата Y отсчитывается от верхнего края экрана (окна).
Ожидание
Процедура Delay(ms: word) приостановит исполнение программы на ms миллисекунд.
Функция KeyPressed: boolean отслеживает нажатия клавиш (на клавиатуре).
Функция ReadKey: char возвращает код символа, чья клавиша (или комбинация клавиш) была нажата.
Пример использования текстовой графики
Задача 1. Написать простейший скрин-сейвер (screen-saver) - программу, предохраняющую монитор от пережигания. Его основными чертами должны стать:
- преобладание черного фона;
- регулярная смена позиций цветовых пятен;
- прекращение работы при нажатии произвольной клавиши на клавиатуре.
Решение
program scrsav;
uses crt;
var n,i,x,y,c,t,z: word;
err: integer;
begin
n:=10;
if paramcount>0
then if paramstr(1)='?'
then begin
writeln('scrsav [density: byte] (=10 by default)');
halt
end
else begin
val(paramstr(1),n,err);
if (err<>0)or(n<=0) then n:=10;
end;
randomize; {активизация генератора случайных чисел}
while not keypressed do
begin
y:= random(24)+1; {генерация случайного числа от 1 до 25}
x:= random(79)+1; {генерация случайного числа от 1 до 80}
z:= random(220)+33; {генерация случайного символа}
c:= random(14)+1; {генерация случайного цвета от 1 до 15}
gotoxy(x,y);
textcolor(c);
delay(n);
write(chr(z));
for i:= 1 to 10 do
begin
y:= random(24)+1; {генерация случайного числа от 1 до 25}
x:= random(79)+1; {генерация случайного числа от 1 до 80}
gotoxy(x,y);
textcolor(black);
delay(n);
write(' ');
end;
end;
end.Замечание: Параметр, регулирующий густоту и скорость изменения символов на экране, можно задавать как аргумент из командной строки во время вызова программы (см. лекцию 13).
Создание дружественного интерфейса
Напомним, что пользовательский интерфейс - это обеспечение взаимодействия программы и человека1).
Хорошим считается дружественный (или дружелюбный ) интерфейс - тот, который удобен не программисту, а пользователю. Несколько раз на протяжении нашего курса лекций мы подчеркивали это. Теперь, когда у нас уже есть все инструменты, позволяющие создавать хорошие интерфейсы к программам, пришло время поговорить о них подробнее.
Заставка
Первым делом - сразу после запуска - ваша программа должна сообщить пользователю, какую именно задачу она собирается решать. Причем информация о решаемой задаче должна быть исчерпывающей. Это особенно важно, если в постановке задачи имеются серьезные ограничения, о которых пользователя нужно уведомить сразу же.
Информационная часть интерфейса, появляющаяся на экране сразу после запуска программы, называется заставкой. Заставка может содержать:
- название программы;
- пояснение (краткую или подробную информацию о решаемой задаче);
- информацию об авторе(-ах) программы;
- номер версии программы;
- и т.п.
Заставка может состоять как из отдельного экрана, который исчезает после нажатия произвольной клавиши (его сменяет рабочая область программы), так и лишь из одной строки, которая остается на экране до конца работы программы (или пока ее не вытеснит объемный вывод). Например:
Сортировка линейного массива (до 10 000 элементов) методом пирамиды. Нахождение кратчайшего пути в связном графе. Зодиак. Определение знака гороскопа по дате рождения. Поиграем в крестики-нолики на доске 5х5!
Ввод информации
Язык Pascal относится к процедурно-ориентированным языкам, поэтому последовательность ввода информации жестко задается самой программой2). Эта жесткость накладывает на программиста дополнительные обязательства при оформлении интерфейса.
Пользователь может вводить информацию двумя способами: свободным вводом или выбором из предоставленных возможностей.
Свободный ввод информации может потребоваться, например, при запросе имени файла, хранящего какие-либо объемные данные. Можно также просить пользователя ввести свое имя или несколько небольших чисел. Напомним, что ввод больших объемов информации (например, таблиц или матриц) желательно организовывать через файлы. В противном случае многократно возрастает вероятность ошибки и, как следствие, необходимость программировать дополнительные блоки, позволяющие эти ошибки исправлять.
Приглашения
Каждый раз, когда программа ждет свободного ввода от пользователя, она должна сообщать об этом, выводя на экран приглашение к вводу.
Приглашение вида " Введите х:" невозможно считать удовлетворительным, поскольку оно не содержит никакой информации об ожидаемых данных. Хорошее приглашение должно сообщать пользователю, что именно от него хотят получить в данный момент: тип, формат и размер вводимых данных.
Например:
Введите координаты центра окружности (два целых числа -10000<=x,y<=10000):
Защита
При свободном вводе пользователь, вообще говоря, может вводить что угодно (а то и вовсе что попало) и совсем не обязательно информацию в ожидаемом программой формате. А в языке Pascal, как мы уже знаем, недопустимы несоответствия типов данных. Например, если не отключен контроль ввода/вывода (см. лекцию 6), то попытка ввести букву "О", когда ожидается цифра "0", приведет к аварийной остановке программы. Еще сложнее бывает разобраться с форматами дат, вещественных чисел (часто вместо десятичной точки пользователи ставят привычную русскому человеку запятую) и т.п.
Таким образом, для надежности работы программы необходимо предусмотреть проверки любой введенной пользователем информации. Такой контроль получил в среде программистов не слишком вежливое название " защита от дурака ". При правильной организации этой защиты ваша программа "не сломается" даже в том случае, если вместо ввода данных пользователь просто сядет на клавиатуру.
Если по каким-либо причинам ввод все-таки получился ошибочным, сообщение об этом должно появиться немедленно, вместе с предложением ввести информацию заново. Кроме того, даже в случае правильного ввода полезно сразу же напечатать значение, которое получила переменная. Так можно уменьшить вероятность возникновения ошибки из-за ввода нескольких переменных там, где ожидается лишь одна: увидев, что результатом стало только первое число из введенной строки, пользователь тут же скорректирует свои действия.
Меню
Меню предоставляет пользователю возможность выбора из нескольких предложенных программой вариантов. Самое простое меню в программе на языке Pascal - это пронумерованный список возможных действий с запросом у пользователя номера выбранного варианта. При обработке этого номера также необходим контроль правильности ввода.
Способы создания более сложных и красивых форм меню мы здесь рассматривать не будем, поскольку современные интерфейсно-ориентированные языки (например, Delphi) предоставляют для этого гораздо более мощные средства. Курсы по этим языкам мы и порекомендуем всем желающим.
Вывод информации
Не следует думать, что вывод информации происходит только в конце работы программы. Напротив, операторами вывода прошита вся ее ткань.
Каждый раз, когда пользователь должен что-то ввести, этому предшествует вывод приглашения. Каждый раз, когда программа приступает к выполнению объемного блока работ, она должна сообщать об этом пользователю - чтобы исключить вероятность прерывания "по окончании терпения", а еще лучше, если на экране будет находиться какой-нибудь индикатор процесса, отображающий текущее "состояние дел".
Какими же должны быть сообщения программы, выводимые на экран? В любом случае они обязаны быть доброжелательными и вежливыми. И, кроме того:
Адекватными выполняемой задаче
Это означает, что терминология сообщений должна соответствовать той области, к которой относится задача.
Учитывающими контингент пользователей, на которых рассчитана программа
Например, если вы пишете обучающую программу для младших школьников, то в пояснениях не должно быть сложных предложений и "заумных" слов. А если вы создаете игру для своих сверстников, то в ее сообщениях возможен и молодежный сленг (однако мы настоятельно советуем избегать табуированной лексики, даже иноязычной).
Логично сгруппированными
Все запросы данных, относящихся к одному и тому же логическому блоку, стоит объединять и на экране. Например, если необходимо ввести информацию по нескольким налогоплательщикам, то не стоит сначала запрашивать все фамилии, а затем только номера банковских счетов.
Информативными
Программа, как вы помните, должна сообщать результаты своей работы. Однако "голый" вывод неприемлем: результаты обязательно должны сопровождаться исчерпывающими пояснениями. Кроме того, помимо окончательного результата, нужно выводить и промежуточные результаты - по окончании обработки каждого логически самостоятельного крупного блока. Если же работа программы оказывается прерванной из-за какой-либо ошибки, сообщение о ее причинах должно появиться на экране.
Эргономичными
Понятие эргономичность включает в себя минимизацию умственных и физических усилий пользователя: например, если есть возможность заменить ввод выбором, это нужно делать. Следует стремиться к кратким сообщениям - но, разумеется, не за счет потери части их смысла! Цветовое оформление также не должно становиться причиной дискомфорта или ошибок пользователя: например, не стоит выводить сообщение о неправильном вводе зеленым цветом, а сообщение об успешно пройденном тесте - красным.
Пример пользовательского интерфейса
В качестве примера мы приведем программу, реализующую широко известную игру "Быки и коровы". Эта программа отслеживает все варианты некорректного ввода (первая цифра вводимого числа - не ноль; все цифры различны; вводится именно цифра, а не любой другой символ), а также нажатие клавиш ESCAPE и BACK SPACE.
Автор программы попытался застраховать ее и от пытающегося жульничать игрока, и от случая, когда игрок не понял правил игры или понял их неправильно; постарался учесть возможность "сдваивания" нажатой на клавиатуре клавиши, "промаха" мимо цифровой клавиши или случайного нажатия произвольной клавиши; организовал правильную реакцию на желание пользователя прервать игру.
Мы приводим программу в полном, работающем виде, поскольку лишь 10% ее текста не относятся к обеспечению интерфейса:
program bull_and_cow;
uses crt;
const cifr: set of '0'..'9' = ['0'..'9'];
yes: set of char = ['Y','y','Д','д','L','l'];
cifr10: set of 0..9 = [0..9];
type cifr_char = '0'..'9';
vector = array[1..10] of 0..9;
var zagadano,popytka: vector;
i,j,jj,n: 1..10;
flag: boolean;
c: cifr_char;
c1: char;
set_of_popyt,set_of_zagad: set of 0..9;
num_of_popyt,cow,bull,err: integer;
procedure error_(st: string; x,y: integer);
begin
textcolor(lightred);
write(' Ошибка: ',st);
gotoxy(wherex+x,wherey+y);
textcolor(white);
flag:= false;
end;
function check(cc: char):integer;
begin
case cc of
chr(27) : begin {Escape}
check:= 1;
textcolor(lightgreen);
clreol;
write('До свидания? Y/N');
if readkey in yes
then begin clrscr; halt end
else begin
gotoxy(wherex-16,wherey);
clreol;
end;
textcolor(white);
end;
chr(8) : begin {BackSpace}
check:= 2;
if j>1 then dec(j);
if popytka[j]= zagadano[j]
then dec(bull)
else if popytka[j] in set_of_zagad
then dec(cow);
set_of_popyt:= set_of_popyt-[popytka[j]];
gotoxy(wherex-1,wherey);
clreol;
end;
chr(13) : if (j<>n) {Enter}
then begin
writeln('Недостаточно цифр! Введите число заново.');
gotoxy(1,wherey-1);
check:= 3;
end;
'0'..'9' : begin
write(cc);
check:= 0;
end;
else begin
write(cc);
check:= 4;
end;
end; {end-of-case}
end;
begin
clrscr;
textcolor(lightmagenta);
writeln(' Поиграем в "Быков и коров"?');
textcolor(yellow);
writeln(' (бык - это цифра, стоящая на своем месте; а корова - просто верная)');
textcolor(green);
writeln(' Итак... Я загадываю число из разных цифр. Вам отгадывать! ');
writeln(' (Выход из программы - <ESC> )');
textcolor(cyan);
write('Введите количество цифр в угадываемом числе: ');
{$I-};
flag:= false;
repeat
textcolor(white);
c1:= readkey;
clreol;
err:= check(c1);
if err= 4
then error_('введена не цифра!',-27,0);
if err = 0
then case c1 of
'0' : begin
writeln;
error_('в числе должна быть хотя бы одна цифра!',-3,-1)
end;
'1' : begin
c1:= readkey;
flag:= true;
case c1 of
'0' : begin n:=10; writeln(c1) end;
#13 : n:= 1;
else
begin
writeln(c1);
error_('в числе может быть не более 10 разных цифр!',-7,-1);
end;
end;{case}
end;
else begin val(c1,n,err); flag:= true; end;
end;
if n>10
then
until flag;
writeln;
{-- Zagadyvanie chisla --------------------}
randomize;
zagadano[1]:= random(9)+1;
set_of_zagad:=[zagadano[1]];
for i:=2 to n do
repeat
zagadano[i]:= random(10);
if not (zagadano[i] in set_of_zagad)
then begin
set_of_zagad:= set_of_zagad+[zagadano[i]];
flag:= true;
end
else flag:=false;
until flag;
{--- Game --------------------------}
textcolor(lightmagenta);
write('Начинаем! ');
textcolor(cyan);
clreol;
writeln('Вводите Ваши числа:');
textcolor(white);
num_of_popyt:= 0;
flag:= true;
repeat {Ввод очередного числа}
cow:= 0;
bull:= 0;
set_of_popyt:= [];
j:=1;
while j<=n do {Ввод по цифрам}
repeat
c:= readkey;
err:= check(c);
clreol;
if err = 4
then error_('Введена не цифра! Измените последний символ.',-54,0);
if err = 0
then if (c='0')and(j=1)
then error_('Первой цифрой не может быть ноль! Повторите ввод.',-59,0)
else
begin
val(c,popytka[j],err);
if popytka[j] in set_of_popyt
then error_('Одинаковых цифр быть не должно! Измените последнюю цифру.',-67,0)
else begin
set_of_popyt:= set_of_popyt+[popytka[j]];
flag:= true;
if popytka[j]=zagadano[j]
then inc(bull)
else if popytka[j] in set_of_zagad
then inc(cow);
inc(j)
end;
end;
until flag;
clreol;
readln;
textcolor(yellow);
gotoxy(n+1,wherey-1);
writeln(' Быков - ',bull,'; коров - ',cow);
inc(num_of_popyt);
textcolor(white);
until bull = n;
textcolor(green);
if bull= n
then writeln('Поздравляю! Вы выиграли за ',num_of_popyt,' шагов!');
readln;
clrscr
end.Графический режим
Единицей изображения в графическом режиме служит один пиксель, поэтому линии на рисунках получаются почти гладкими. Графический режим используется довольно редко - например, для построения графиков и диаграмм или при создании обучающих программ, игр, скрин-сейверов и т.п.
Для изучения богатых графических возможностей языка Pascal совершенно недостаточно даже целой лекции: здесь нужен как минимум полугодичный курс. Поэтому мы не станем и пытаться "объять необъятное". В качестве оправдания заметим лишь, что для того, чтобы писать примитивные графические программки и создавать "хороший" интерфейс, вполне достаточно уже рассмотренных возможностей текстового режима.
Лекция 15. Технология программирования и отладки
Существуют классические способы написания правильных и надежных программ, облегчающие отладку и тестирование. О них и пойдет речь в последней лекции нашего курса.
Советы по технологии написания быстро отлаживаемых программ
Вы приступаете к решению какой-либо задачи_ Первым делом вы выбираете алгоритм, а затем - подчас уже в процессе кодирования - детализируете его. Не секрет, что многие шаги алгоритма могут проясниться только тогда, когда большая часть программы уже написана, так что придется вносить в ее текст изменения, уточнения и поправки. В крайнем случае вы будете вынуждены полностью отказаться от исходного алгоритма и перейти к реализации другого, более подходящего. И вся уже проделанная работа по написанию текста программы окажется напрасной...
Для того чтобы не приходилось "менять коней на переправе", необходимо уже в самом начале:
- правильно оценить эффективность выбранного алгоритма (например, если в процессе работы будет производиться постоянная перестройка структуры, хранящей данные, то лучше остановить выбор на списочном алгоритме);
- убедиться в том, что он корректно обрабатывает весь спектр входных данных (например, алгоритм Дейкстры нельзя применять, если в графе есть ребра с отрицательным весом);
- оценить вероятные трудозатраты на его создание (например, гораздо легче написать простую, а не улучшенную сортировку, и если объем входных данных позволяет, именно так и следует поступить) и т.п.
Если же на этапе выбора алгоритма все-таки была допущена ошибка, то программу придется писать заново. При этом некоторые блоки старого варианта (например, ввод/вывод1) ) могут не зависеть от выбора алгоритма, тогда переписывать их не нужно. Но основной алгоритм все-таки необходимо исправить.
При коренной переделке программы особенно важно аккуратно отслеживать все вносимые в текст программы изменения.
Далее мы перечислим общеизвестные правила, которые помогут вам минимизировать затраты времени и сил при написании программы.
Несмотря на то что некоторые из этих правил могут показаться вам ненужными и занудными, следование им в процессе создания сложной программы очень облегчает и, главное, ускоряет ее отладку. В общем, если перефразировать известное выражение, "овчинка стоит выделки".
Имена, имена, имена...
Советы, которые касаются различных идентификаторов, используемых в программе, можно кратко изложить так.
Совет 1. Создание любой программы (по выбранному алгоритму решения) начинайте с описания переменных. Разумеется, невозможно сразу же предусмотреть все переменные, которые могут потребоваться в ходе написания программы, однако самые важные - те, ради которых вся работа и затевается, - должны быть описаны с самого начала.
Описывая переменные, размещайте их по одной на каждой строке (впрочем, однотипные переменные можно размещать и группами) и в обязательном порядке снабжайте комментариями, разъясняющими смысл этих переменных. В противном случае вы обречены будете в процессе работы раз за разом сверяться с форматом ввода или, еще хуже, рыскать по уже написанному тексту, вспоминая, что же именно должна была хранить в себе каждая переменная. Потери времени и нервов при этом могут оказаться значительными.
Совет 2. Старайтесь давать основным переменным говорящие имена. Ясно, что безликие rez1 и rez2 несут в себе гораздо меньше информации, чем, скажем, dlina и shirina. Однако не стоит заводить очень длинные - более 6-7 символов - имена, поскольку это, во-первых, затормозит написание программы, а во-вторых, повысит вероятность возникновения "очепяток". Стоит использовать сокращения, короткие синонимы, русские слова (русские по смыслу и прочтению, однако латинские по написанию).
Следите за тем, чтобы имена переменных заметно отличались друг от друга. Имена, которые различаются только одним символом, следует считать крайне неудачными. Однако во всем нужно знать меру и, разумеется, шесть вспомогательных переменных, отражающие шесть последовательных состояний одного и того же процесса, стоит назвать а1, а2, ... а6. Тем самым вы подчеркнете их единую сущность.
При выборе имен переменных стоит также пользоваться интуитивно знакомыми вам условностями. Например, i и j обычно служат вспомогательными счетчиками, m и n чаще всего хранят размерность, а x и y - координаты. Лучше не отступать от привычных вам сокращений и обозначений, даже если они и не являются общепринятыми.
Совет 3. Имена функциям и процедурам также нужно давать говорящие, причем здесь ограничения на длину гораздо мягче: до 10-15 символов. Вряд ли ваша программа будет обращаться к процедурам и функциям столь же часто, как к переменным, поэтому здесь на первый план выходит наполнение имен подпрограмм объяснением выполняемых ею операций. Лучше не полениться и набрать два-три раза, например schet_min_zatrat, чем путаться во время отладки между schet_z и schet_p. Удобнее всего, если имена подпрограмм соответствуют выполняемым ими шагам алгоритма той или иной степени детализации: в этом случае легче выявить ошибки процесса кодирования и разработки (неправильный порядок операций, преждевременная остановка и т.п.).
Совет 4. Не вводите лишних переменных. Раздел описания должен содержать в себе только те переменные, которые затем будут встречаться в тексте программы. Это требование вызвано соображениями экономии, причем не столько места в памяти, сколько ваших усилий по вылавливанию непонятных ошибок.
Если в процессе написания программы вы решите отказаться от некоторой переменной, поймете, что она лишняя - обязательно удалите ее не только из текста программы, но и из раздела описаний. Этим вы застрахуетесь от непреднамеренного ее использования где-нибудь, откуда из-за невнимательности вы забыли ее выкинуть. Если вы уже выбросили "убиваемую" переменную из раздела описаний, но случайно оставили ее в паре мест в тексте программы - не беда: первая же компиляция исправленной программы найдет эти неописанные переменные.
Особенно внимательно нужно выполнять это правило, когда переменные не уничтожаются, а превращаются из глобальных в локальные. В этом случае забытое описание может стать причиной серьезных и при этом трудно локализуемых ошибок.
Совет 5. Всегда проверяйте, верно ли вы указали способ подстановки аргументов в параметры подпрограммы (см. лекцию 8). Особенно важно не забывать об этом правиле, если вы создаете рекурсивную подпрограмму, где одна переменная (параметр-переменная) должна возвращать самой себе какое-то значение, а другая переменная (параметр-значение), наоборот, при возвращении выполнения в данный экземпляр подпрограммы должна восстанавливать то значение, какое она имела до рекурсивного вызова.
Совет 6. Всегда отслеживайте области действия локальных переменных. Лучше всего, если в разных подпрограммах, пользующихся одними и теми же данными, параметры будут называться по-разному. Это избавит вас от такой трудно вылавливаемой ошибки, как изменение значения переменной там, где предполагается, что оно останется неизменным (так называемый "побочный эффект"). Особенно много подводных камней таится в бесконтрольном использовании одинаковых счетчиков в телах вызывающих друг друга процедур или функций. Синтаксис подобное использование разрешает, поэтому компилятор не распознает ошибку и не просигнализирует о ней. Стоит безобидной переменной-счетчику оказаться глобальной, и вам будет очень сложно понять, отчего же это она ведет себя самым загадочным образом, меняя свое значение совсем не так, как предписывает ей заголовок цикла.
Кусочки, куски и кусищи...
Во время написания текста программы всегда следуйте правилам структурного программирования. Их придумали умные люди как раз для того, чтобы облегчить процесс конструирования правильных, надежных и удобочитаемых программ.
Совет 7. Не нуждается в особой пропаганде главное правило: на каждой строке должен находиться только один оператор. А сложные операторы лучше и вовсе размещать на нескольких последовательных строках. Тогда при пошаговой прогонке легче будет локализовать искомую ошибку.
Совет 8. Не нужно полагать, что если вы являетесь автором программы, то никаких трудностей ее чтение во время отладки у вас не вызовет. Невозможно выучить непрерывно изменяемую программу настолько, чтобы ориентироваться в ней "с закрытыми глазами", поэтому не скупитесь на краткие, но дельные комментарии. Следите, чтобы они верно отражали происходящее: если, прочитав комментарий, вы будете думать, что поясняемый им блок программы "делает шаг на север", в то время как на самом деле производится "шаг на юг", то понять причину ошибки вы вряд ли сможете.
Совет 9. Пишите программы "лесенкой", позволяющей легко видеть, где кончается один блок и начинается другой. Разные блоки должны иметь различные отступы, а все операторы одного блока - одинаковые; причем чем глубже уровень вложенности блока, тем дальше отстоит он от левого края экрана. Совсем без отступа можно записывать только разделы описаний головной программы, слова begin...end., ограничивающие основное тело программы, а также заголовки процедур и функций. Все остальные операторы, даже строки-комментарии, должны иметь отступ.
Исключение из этого правила составляют лишь операторы отладочной печати, которые затем будут удалены из окончательного варианта программы. Их лучше всего начинать с первой позиции строки, невзирая на отступы текущего блока. Так они будут сильнее выделяться.
Совет 10. Большие блоки, отвечающие за крупные шаги алгоритма, отделяйте друг от друга строками-комментариями, облегчающими ориентирование по тексту программы в процессе ее отладки.
Совет 11. Операторные скобки begin...end всегда расставляйте парами, причем каждый end должен начинаться с той же позиции строки, что и открывший его begin, а заключенный между ними операторный блок должен быть сдвинут еще как минимум на одну позицию вправо, чтобы скобки не сливались с остальным текстом программы.
Порядок написания любого блока должен быть следующим:
- begin
- <...> {вложенный блок}
- end;
В этом случае вы надежно застрахуетесь от долгих поисков того места, в которое, судя по алгоритму, нужно поставить забытый end.
Если в вашей программе несколько (хуже - много) вложенных или просто очень длинных блоков (для одного или двух коротких это еще не так актуально), то возле каждого оператора end ставьте комментарий-пометку, какой именно begin он закрывает. Не забывайте, что простое совпадение количества begin -ов и end -ов не может служить гарантией того, что все они расставлены в нужных местах. А если среди нескольких идущих подряд end -ов, закрывающих обычные begin -ы, встречается и end, замыкающий оператор case, то возле него обязательно нужно поставить указание {end_case}, иначе вы можете потратить немало времени на поиски якобы недостающего оператора begin. Дело в том, что когда мозг человека настраивается на поиск какого-либо конкретного слова, то не похожие на него слова он имеет обыкновение пропускать, не обращая на них никакого внимания, а поскольку слово case даже отдаленно не напоминает begin , то при таком поиске-просмотре оно, скорее всего, будет отброшено.
Совет 12. Желательно, чтобы каждый оператор if имел не только then-, но и else -ветвь, даже если она останется пустой. Это позволит вам избежать двусмысленных структур вроде
if ... then if ... then ... else ...
которая на самом деле воспринимается компилятором совершенно иначе:
if ... then if ... then ... else ...
Такие ошибки наиболее опасны при удалении из текста уже правильно работающей программы отладочных операторов. Например, если полностью удалить из конструкции
if ... then if ... then ... else <один отладочный оператор> else ...
якобы ненужную четвертую строку, то сохранить работоспособность программа не сможет. Хорошо еще, если вам повезет и результат либо вообще не будет выдан, либо окажется настолько неправдоподобным, что не заметить этой странности будет нельзя. В противном случае получится якобы правильная программа, которая на самом деле правильной не является.
Спасением от такой напасти могут послужить и добавочные операторные скобки - нужно только следить, чтобы они не слишком засоряли текст блока:
if ...
then begin if ...
then ...
else <один отладочный оператор>
end
else ...Если теперь мы удалим ту же строку, никакого вреда программе это не нанесет. Поэтому:
Совет 13. Ненужные с точки зрения алгоритма, однако не нарушающие структуры программы операторные скобки еще никому не мешали. Как говорится, "кашу маслом не испортишь"!
Совет 14. Никогда не пользуйтесь оператором goto! Язык Pascal предоставляет достаточное количество операторов, позволяющих легко структурировать любую программу. Единственным исключением из этого правила является ситуация нескольких вложенных циклов, описанная в лекции 3. И в любом случае оператор goto не должен передавать управление назад по тексту программы.
Спасение утопающих - дело рук самих утопающих
Дадим еще один важный
Совет 15. Не полагайтесь на надежность техники, производите время от времени сохранение написанного. Простое нажатие клавиши F2 может спасти от многих неприятностей в случае "зависания" задачи, не говоря уж о внезапном отключении электроэнергии (конечно, большинство серьезных организаций сейчас имеют источники бесперебойного питания, позволяющие в экстренных случаях спасти содержимое оперативной памяти, однако особенно рассчитывать на это не стоит). По крайней мере, если вдруг когда-нибудь вы попадете в такую неприятную ситуацию, не говорите, что вас не предупреждали.
Отладка и тестирование
Если вы уже пробовали программировать, то вам, без сомнения, знакома ситуация, когда программа, которая вроде бы должна работать правильно, почему-то упорно не желает этого делать. Но даже если вы еще только начинаете приобщаться к таинствам этого нелегкого искусства - программирования, то рано или поздно вы обязательно столкнетесь с такой проблемой.
Программа написана, но не работает так, как надо...
Кажется, исправлены уже все возможные ошибки и неточности, много раз проверен и перепроверен алгоритм, и тем не менее результат выдается совсем не тот, каким он должен быть... Вот тут-то и начинается собственно процесс отладки, то есть поиска логических ошибок в программе.
Если предположить, что алгоритм для решения задачи вы избрали верно, то остается согласиться с тем, что ошибки были сделаны на этапе кодирования. Значит, некоторые части вашей программы выполняют совсем не то, чего вы от них хотите. Поэтому необходимо:
- во-первых, найти этих делинквентов;
- во-вторых, призвать их к порядку.
Поиск и исправление ошибок
При поиске ошибок большим подспорьем является возможность пошагового выполнения ( трассировки ) программы с параллельным отслеживанием того, как меняются в ходе нее значения переменных. В среде Turbo Pascal для этого имеются следующие инструменты:
- Нажатие клавиши F4 выполнит программу до той строки, на которой установлен курсор, затем приостановит выполнение.
- Нажатие клавиши F7 или F8 позволяет выполнять программу пошагово: по одному оператору (различие между этими функциями состоит в том, производится или нет трассировка текстов подпрограмм).
- Использование окна отладочной выдачи Debug | Watch позволяет в процессе выполнения программы следить за тем, как изменяются значения переменных (нажатие клавиши Insert добавляет в это окно новую переменную).
Более подробно эти возможности описаны в руководствах по языку и среде Turbo Pascal.
Можно дать несколько полезных советов, касающихся локализации ошибок в программе.
Совет 16. Пользуйтесь всеми доступными инструментами отладки.
Совет 17. На всех ключевых участках, а также на границах логически самостоятельных блоков вставляйте в программу отладочные операторы печати, которые позволят вам проследить изменение состояния основных переменных. Эта процедура не всегда может быть заменена просмотром изменений, который можно осуществить с помощью окна Watch. Зачастую бывает необходимо иметь перед собой для сравнения результаты нескольких последовательных итераций, либо нужно видеть одновременно первые и последние результаты, либо в процессе прогонки возвращаться по списку выдачи назад, к предыдущим результатам. Ничего этого параллельный просмотр в Watch сделать не позволяет.
Если отладочная выдача настолько объемна, что не помещается целиком на экран, ее приходится производить в файл.
Совет 18. Следите за тем, чтобы отладочная печать выдавала именно то, что нужно. Совершенно невозможно отловить ошибку в программе, если под именем проверяемой переменной вам выдается значение другой переменной!
Самый легкий случай, - когда из-за опечатки полностью меняется вид вывода. Например, правильный оператор writeln(a+1) должен выдать число, если же вместо числа на экране вдруг появляется слово FALSE, то это явный признак того, что произошла опечатка и выдается результат сравнения переменной а с единицей: writeln(a=1).
Однако не всегда удается так легко отделаться, поэтому обязательно удостоверьтесь в том, что правильной является и конечная печать результата: выдается значение нужной переменной, значение выводится в правильном формате и т.п. Такие ошибки возникают только из-за невнимательности и бывают подчас трудноуловимыми.
Совет 19. Если вы уже локализовали небольшой участок программы, в котором находится ошибка, удалите операторы отладочной печати из остальных частей программы, а в отлаживаемом участке, наоборот, увеличьте их количество.
Совет 20. Пишите " заглушки " для еще не отлаженных процедур и функций. Это значит, что вместо того, чтобы мучиться одновременно с несколькими подпрограммами, вы вынуждаете большую их часть возвращать не тот результат, какой они реально вырабатывают, а тот, который они должны были бы возвращать при правильной работе.
Совет 21. За один раз исправляйте ровно одну ошибку. Нет ничего хуже, чем гадать, которое из внесенных исправлений оказало решающее влияние на поведение программы.
Правила составления тестов
Для того чтобы отладить программу, нужно проверить ее работоспособность на каких-то входных данных. Следовательно, эти входные данные нужно каким-то образом подобрать. Затем, после выполнения программы на этих входных данных, нужно сравнить полученный результат с тем, который должен получиться, если программа работает правильно. Этот процесс и называется тестированием.
Заметим, что если полученный результат отличается от эталонного, то тест считается удачным (!), потому что он помог обнаружить ошибку. А если полученный ответ совпал с правильным - радоваться рано. Один тест не может полностью проверить всю программу, ошибка вполне могла затаиться в той части, которая осталась на сей раз невыполненной. Для того чтобы протестировать всю программу, проверить все возможные частные случаи, составляют не один тест, а набор тестов.
И здесь существуют следующие правила.
Правило 1. Любой тест должен состоять не только из входных, но и из соответствующих им выходных данных. Ведь для того чтобы понять, верный или неверный результат выдала вам программа, необходимо самому знать правильный ответ.
Проверяйте вручную результаты тестов, с помощью которых вы отлаживаете программу. Немногого можно добиться, если выдаваемый программой правильный ответ вы считаете неверным и продолжаете поиск несуществующей ошибки. Хуже того - если вы все-таки добьетесь, чтобы программа выдавала ожидаемый вами неверный результат, объяснить ее неправильное поведение на других тестах вам будет еще сложнее.
Из двух предыдущих абзацев вытекает очень важный вывод: нельзя строить тесты при помощи генератора случайных чисел. Конечно, вы можете случайным образом составить входные данные, но как быть с правильным ответом? Откуда его взять, если вы сами понятия не имеете, что там подается на вход?
Правило 2. После того как программа начала правильно работать на одном или нескольких простых тестах, усложните задания, введите тест на граничные условия или тест, содержащий значения, выходящие за рамки формата входных данных. Иногда ошибка может скрываться в тех частях программы, которые кажутся самыми прозрачными. Например, в проверке нескольких переменных на равенство между собой. Если до сих пор все переменные в тестах были разными, попробуйте прогнать программу через тесты, в которых сравниваемые значения будут совпадать - все сразу или только некоторые из них в разных комбинациях.
Правило 3. Не ограничивайтесь только похожими тестами.
Все тесты можно разделить на три группы: регулярные, граничные и критические. Например, при заданных ограничениях на параметр 0 <= x <= 100 регулярными будут все тесты, где 1 <= x <= 99; граничными, где х = 0 и х = 100 ; остальные - критическими. Если ваша программа правильно работает для пяти-шести тестов из какой-либо группы, можно предположить, что она выдаст правильный результат и для всех остальных тестов из этой группы.
В тестовом наборе, составленном для проверки программ, обязательно должны присутствовать тесты первых двух групп, а для проверки работоспособности "защиты от дурака" (см. лекцию 14) - и третьей тоже. Если входных параметров несколько - комбинируйте! Пусть в одном и том же тесте первый параметр будет граничным, второй - регулярным, а третий - критическим. Всегда интересно посмотреть, достаточно ли надежна ваша программа, справится ли она с таким заданием.
В хорошей, надежной программе всегда нужно писать проверку того, что файл ввода существует, не пуст и содержит данные в правильном формате, что считываемые из входного файла данные попадают в определенные условием задачи диапазоны.
Правило 4. Исправления, вносимые в программу, могут повлиять на результаты нескольких тестов.
После того, как вы нашли и исправили ошибку, вновь выполните программу на всех тех тестах, которые раньше не были успешными (то есть выдавали правильные ответы) - а вдруг найдется новая ошибка?
Вообще же, составление исчерпывающих тестовых наборов для тестирования любой программы - задача очень нетривиальная, зачастую требующая математического доказательства полноты.
Оптимизация программ
Процесс оптимизации уже написанной программы начинается только после того, как вы убедились, что ваша программа работает правильно. Стараться оптимизировать неправильную программу бессмысленно, правильнее она от этого не станет, поскольку оптимизация - это замена некоторых программных кусков эквивалентными им с точки зрения результата, но более экономичными с точки зрения выполнения.
Основная часть процесса оптимизации программы приходится на этап выбора наилучшего алгоритма. Однако даже при правильном выборе алгоритма неграмотное кодирование может привести к неэффективно работающему результату. Чтобы такого не происходило, внимательнее относитесь к тому, что и как вы пишете, реализуя выбранный вами алгоритм. Не всегда те действия, которые кажутся оптимальными с точки зрения логики алгоритма, стоит пытаться запрограммировать "в лоб".
Если же алгоритм выбран и запрограммирован "почти" правильно, можно попытаться улучшить его, внося изменения, сокращающие его работу.
В первую очередь стоит оптимизировать часто повторяющиеся куски программы, то есть циклы. Старайтесь не допускать ситуаций, когда в теле цикла раз за разом производятся одни и те же вычисления, никак не изменяющие состояние переменных. И вообще, избегайте вносить в повторяющиеся участки "тяжелые" операции.
Например, ясно, что из двух эквивалентных кусков
k:= 0; for i:= 1 to b*100 do k:= k+i+1000*b+100*(b div 2);
и
a:= 1000*b+100*(b div 2); k:= 0; for i:= 1 to b*100 do k:= k+i+a;
второй является и более быстрым (особенно если b = 10000 ), и более компактным, чем первый.
Лишние вычисления, лишние действия с файлами или структурами, лишние пересылки элементов из одной ячейки памяти в другую (и список этот далеко не полон!) - все это снижает эффективность программы. Старайтесь помнить о том, что лаконичность приветствуется всегда и везде, а особенно в программировании.
Успехов вам в написании красивых и полезных программ!