Лекция 1. Элементы оптимизации прикладных программ для Intel Xeon Phi: Intel MKL, Intel VTune Amplifier XE
Использование библиотеки Intel MKL при программировании на сопроцессоре Intel Xeon Phi
Презентацию к лекции Вы можете скачать здесь.
В данном разделе рассматриваются модели использования библиотеки Intel Math Kernel Library при программировании на Intel Xeon Phi. Дается обзор способов вызова функций библиотеки, а также рекомендации по повышению производительности приложений.
Intel Math Kernel Library (Intel MKL) [1.7] является одной из самых производительных библиотек математических функции для работы на аппаратном обеспечении компании Intel. Библиотека включает в себя основные функции, используемые при разработке сложных высокопроизводительных программных комплексов.
Библиотека содержит функционал из следующих областей:
- Линейная алгебра (BLAS, LAPACK, работа с разреженными данными);
- Быстрое преобразование Фурье;
- Векторные функции (тригонометрические, гиперболические, экспоненциальные и логарифмические, возведение в степень и взятие корня, округление);
- Векторные генераторы случайных чисел и функции математической статистики;
- Интерполяция данных.
На текущий момент Intel MKL поддерживает параллельное выполнение как на системах с общей памятью (в частности, на сопроцессорах Intel MIC), так и на кластерах (рис. 1.1). Поддержка сопроцессора Intel Xeon Phi появилась в библиотеке с версии 11.0.
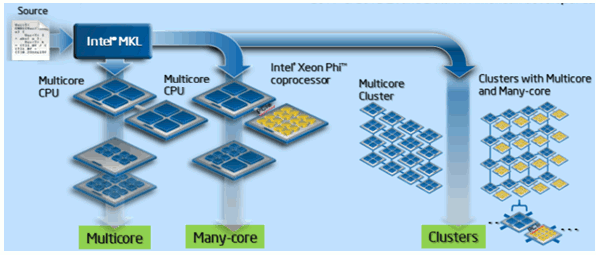
Рис. 1.1. Типы вычислителей, поддерживаемые библиотекой Intel MKL
Поддержка сопроцессора включает в себя возможность исполнения кода библиотеки Intel MKL одновременно на центральном процессоре и сопроцессоре, позволяя получать все преимущества от использования гетерогенного режима вычислений. Код библиотеки был оптимизирован для работы с 512-битными SIMD инструкциями.
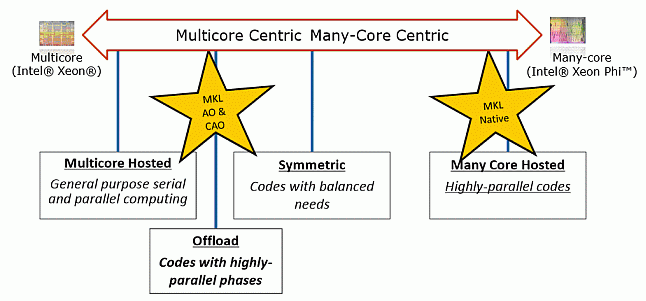
Для работы с библиотекой программисту доступны три модели (рис. 1.2):
- Автоматический offload (Automatic Offload, AO) – прозрачная модель гетерогенных вычислений;
- Offload с помощью компилятора (Compiler Assisted Offload, CAO) – предоставляет возможности контроля offload’а.
- Выполнение только на сопроцессоре (Native Execution) – использование сопроцессоров в качестве независимых узлов.
увеличить изображение
Рис. 1.2. Модели исполнения Intel MKL
Automatic Offload (AO)
Модель автоматического offload’а является наиболее простым способом, позволяющим эффективно использовать возможности библиотеки Intel MKL на системах с одним или несколькими сопроцессорами.
Данная модель практически не требует изменения существующего кода, написанного для центрального процессора. Использование сопроцессора библиотекой Intel MKL происходит автоматически при вызове функций библиотеки. Это означает, что все обмены данными и передача управления ускорителю происходят внутри вызова функции без участия программиста.
По умолчанию, MKL заботится и о балансировке нагрузки на систему. Библиотека сама решает, нужно ли в данном случае использовать сопроцессор, и как распределить нагрузку между процессором и сопроцессором. Основной критерий использования ускорителя для выполнения той или иной функции – эффективность. Т.е. если данная функция при данных входных параметрах будет работать лучше на CPU, то ускоритель использоваться не будет. В случае если в момент вызова функции сопроцессор занят другой задачей, для вычисления этой функции будет использован центральный процессор.
Распределение нагрузки также может быть выполнено автоматически. При этом используются все доступные в системе сопроцессоры и CPU, количество ускорителей и процент нагрузки на них выбирается библиотекой исходя из достижения лучшей производительности в каждом конкретном случае. Это позволяет автоматически эффективно использовать все доступные вычислительные ресурсы системы. Следует отметить, что программист может задавать желаемое распределение нагрузки самостоятельно.
Для того чтобы начать работать с AO, достаточно включить этот режим. Из программы это делается вызовом функции:
mkl_mic_enable();
Возможно также использование переменной окружения:
MKL_MIC_ENABLE=1
Отметим, что если в системе не установлено ни одного сопроцессора, функции Intel MKL будут работать на CPU без дополнительных накладных расходов.
Еще раз заметим, что исполняться на сопроцессоре будут только те функции, для которых существует эффективная реализация. В версии Intel MKL 11.0 на сопроцессоре будут выполняться только функции BLAS 3-го уровня *GEMM, *TRSM и *TRMM. В следующих версиях библиотеки планируется расширить поддержку сопроцессора.
Для указанных выше функций выполнение на сопроцессоре зависит и от входных размеров матрицы:
- Функции *GEMM выполняются на ускорителе, если M, N > 2048;
- Функции *TRSM/*TRMM выполняются на ускорителе, если M, N > 3072.
Для квадратных матриц вычисления на сопроцессоре происходят быстрее.
Для того чтобы задать желаемое распределение нагрузки между процессором и сопроцессорами можно воспользоваться функцией:
mkl_mic_set_Workdivision(MKL_TARGET_MIC, 0, 0.5);
В данном примере указывается, что на нулевой сопроцессор должно приходиться 50% общей нагрузки.
Такого же эффекта можно добиться с помощью переменной окружения:
MKL_MIC_0_WORKDIVISION=0.5
Обратим внимание, что данные команды являются лишь советами среде выполнения Intel MKL и реально могут не исполняться либо исполняться не точно.
Для того чтобы отключить режим AO после того, как он был задействован, необходимо либо вызвать функцию:
mkl_mic_disable();
либо перенести всю вычислительную нагрузку на центральный процессор вызовом функции:
mkl_mic_set_workdivision(MIC_TARGET_HOST, 0, 1.0);
либо воспользоваться переменной окружения:
MKL_HOST_WORKDIVISION=100
Для более эффективной работы режима автоматического offload’а рекомендуется избегать использования ядра операционной системы ускорителя для вычислений, т.к. это ядро обычно используется для выполнения передач данных и очистки памяти.
Приведем пример настройки соответствующей переменной окружения для случая сопроцессора с 60 ядрами и 4 потоками на ядро:
MIC_KMP_AFFINITY=explicit,granularity=fine,proclist=[1-236:1]
В данном примере для вычислений резервируются первые 59 ядер, т.е. первые 236 потоков.
Дополнительно следует явно привязать потоки хоста к ядрам, чтобы избежать миграции потоков:
KMP_AFFINITY=granularity=fine,compact,1,0
Обратите внимание на различие имен переменных окружения для хоста и сопроцессора. В случае Intel MIC, к имени переменной добавляется приставка MIC_ (OMP_NUM_THREADS/MIC_OMP_NUM_THREADS и т.п.).
Подробнее об этих переменных окружения для Intel компилятора и описанных выше параметрах можно почитать здесь [1.9].
Compiler Assisted Offload (CAO)
В данной модели процесс offload’а явно контролируется программистом с помощью директив компилятора. По сути, данная модель является обычной offload моделью программирования ускорителя, а значит, позволяет пользоваться всеми возможностями компилятора для переноса части вычислений на сопроцессор. Подробности о программировании в режиме offload можно найти в лекции №5 курса "Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi)".
Рассмотрим пример вызова функции для умножения матриц:
#pragma offload target(mic) \
in(transa, transb, N, alpha, beta) \
in(A:length(matrix_elements)) \
in(B:length(matrix_elements)) \
in(C:length(matrix_elements)) \
out(C:length(matrix_elements) alloc_if(0))
{
sgemm(&transa, &transb, &N, &N, &N, &alpha, A, &N, B,
&N, &beta, C, &N);
}
В данном случае явно указан код (функция умножения матриц), который переносится на сопроцессор, а также описаны все действия по управлению передачей данных.
В отличие от режима AO, где на Intel Xeon Phi может работать только некоторое подмножество функций Intel MKL, текущая модель позволяет запускать на сопроцессоре абсолютно все функции библиотеки. Однако это не означает, что во всех случаях удастся получить лучшую производительность, чем при работе только на CPU.
Модель CAO позволяет использовать все offload возможности компилятора для достижения лучшей производительности, в частности оптимизировать работу с данными на сопроцессоре, явно указывая моменты выделения/удаления памяти. Это позволяет, например, организовать переиспользование данных на сопроцессоре и тем самым обеспечить снижение объема передаваемой на хост (или с хоста) информации:
__declspec(target(mic)) static float *A, *B, *C, *C1;
// Transfer matrices A, B, and C to coprocessor and do not
// de-allocate matrices A and B
#pragma offload target(mic) \
in(transa, transb, M, N, K, alpha, beta, LDA, LDB, LDC) \
in(A:length(NCOLA * LDA) free_if(0))\
in(B:length(NCOLB * LDB) free_if(0)) \
inout(C:length(N * LDC))
{
sgemm(&transa, &transb, &M, &N, &K, &alpha, A, &LDA,
B, &LDB, &beta, C, &LDC);
}
// Transfer matrix C1 to coprocessor and reuse
// matrices A and B
#pragma offload target(mic) \
in(transa1, transb1, M, N, K, alpha1, \
beta1, LDA, LDB, LDC1) \
nocopy(A:length(NCOLA * LDA) alloc_if(0) free_if(0)) \
nocopy(B:length(NCOLB * LDB) alloc_if(0) free_if(0)) \
inout(C1:length(N * LDC1))
{
sgemm(&transa1, &transb1, &M, &N, &K, &alpha1,
A, &LDA, B, &LDB, &beta1, C1, &LDC1);
}
// Deallocate A and B on the coprocessor
#pragma offload target(mic) \
nocopy(A:length(NCOLA * LDA) free_if(1)) \
nocopy(B:length(NCOLB * LDB) free_if(1)) \
{ }
Явное управление запуском кода на ускорителе позволяет также делать перекрытие вычислений с обменом данными, либо обеспечивать одновременную работу CPU и ускорителя. Однако возможности автоматической балансировки нагрузки теряются.
При использовании модели CAO прежде всего следует избегать ненужных обменов данными между хостом и сопроцессором (по аналогии с приведенным выше примером). Также как и для AO, следует освободить ядро операционной системы ускорителя от вычислений. И наконец, имеет смысл работать с увеличенным до 2 МБ размером страницы памяти. Для этого следует использовать переменную окружения, инициализированную как:
MIC_USE_2MB_BUFFERS=64K
При этом будут использоваться страницы размером в 2 МБ (64 КБ для данной переменной является пороговым значением, начиная с которого размер страниц памяти будет увеличен до 2 МБ).
Заметим также, что в рамках одной программы возможно использование обеих этих моделей. Одни вызовы можно делать в режиме AO, другие в режиме CAO. Единственное ограничение здесь состоит в необходимости явно указывать распределение нагрузки для AO вызовов, иначе все они будут использовать только CPU.
Выполнение только на сопроцессоре
Режим исполнения только на сопроцессоре предполагает использование только сопроцессоров без CPU. Каждый сопроцессор представляет собой отдельный вычислительный узел, который может обмениваться данными с другими узлами посредством MPI сообщений.
Данная модель предполагает написание программы так, как это делается для обычного центрального процессора, а затем ее компиляцию с ключом "–mmic". Запуск полученного бинарного файла должен осуществляться непосредственно на сопроцессоре.
Иными словами, это обычная модель программирования с выполнением кода только на Intel Xeon Phi.
При использовании этой модели рекомендуется задействовать все доступные потоки ускорителя, например, для Intel Xeon Phi с 60 ядрами и 4 потоками на ядро:
MIC_OMP_NUM_THREADS=240
Переменную KMP_AFFINITY рекомендуется устанавливать как [1.9]:
KMP_AFFINITY=explicit,proclist=[1-240:1,0,241,242,243],granularity=fine
Также рекомендуется использовать большие 2 МБ страницы памяти.
Рекомендации по выбору модели программирования
При выборе модели программирования для вашего приложения следует обратить внимание на следующие факторы:
- Если код имеет высокую степень параллелизма либо необходимо использовать ускорители как отдельные вычислительные узлы, то имеет смысл использовать модель выполнения только на сопроцессоре;
- Если в вашем случае доля вычислений на единицу памяти велика и вам нужны функции *GEMM, *TRMM, *TRSM либо функции LU и QR факторизации (появятся в ближайших релизах), тогда лучше выбрать модель AO;
- Если в программе есть участки вычислений, подходящие для перекрытия передач данных либо возможно переиспользование участков памяти на сопроцессоре, тогда можно использовать модель CAO.
Отметим также, что в случае недостаточной производительности в режимах offload, вы всегда можете легко перейти на использование CPU.
Оптимизация приложений с помощью Intel VTune Amplifier XE
В данном разделе описаны подходы к оптимизации программ для Intel Xeon Phi с использованием инструмента профилировки приложений Intel VTune Amplifier XE. Дается краткий обзор Intel VTune Amplifier, приводятся способы запуска профилировщика на сопроцессоре как в режиме GUI, так и с помощью командной строки. Описываются основные метрики эффективности, получаемые с помощью профилировки, на которые следует обратить внимание при оптимизации приложений.
Основная рекомендация при оптимизации программ для Intel Xeon Phi состоит в том, что первым шагом должна стать оптимизация приложения для центрального процессора.
Для того чтобы выделить те участки программы, которые нуждаются в оптимизации прежде всего, имеет смысл воспользоваться инструментом Intel VTune Amplifier XE. Применение hotspot анализа покажет те функции и участки программы, на которые тратится больше всего времени. Часто этого бывает достаточно. А если требуется более детальная оптимизация, тогда можно обратиться к другим типам анализа с целью получения низкоуровневой информации о ходе выполнения приложения.
Отметим, что найти кандидатов для оптимизации можно и с помощью отчетов компилятора Intel. В частности, можно получить информацию о функциях и циклах, занимающих больше всего времени, а также о среднем, минимальном и максимальном числе итераций этих циклов. Для этого следует собирать приложение с ключами:
-profile-functions -profile-loops=all -profile-loops-report=2
Результаты профилировки, которые будут записаны в файлы в текущей директории по окончании работы приложения, можно будет посмотреть либо в виде таблицы (dump файл), либо с помощью специального инструмента с GUI – Loop Profile Viewer (xml файл).
В процессе оптимизации приложения необходимо поддерживать его корректность, что особенно актуально при распараллеливании. Для выявления ошибок многопоточности можно использовать инструмент Intel Inspector XE. Также для эффективного распараллеливания приложения полезно иметь возможность анализа его выполнения с точки зрения работы потоков в нем. Такая возможность присутствует в Intel VTune Amplifier XE.
Однако Intel Inspector XE и анализ многопоточного исполнения в Intel Amplifier XE поддерживаются только для CPU. Поэтому:
- Рекомендуется использовать Intel Inspector XE для вашего кода с отключенной функцией offload’а для выявления в нем таких ошибок, как зависимость по данным, тупики и т.п. После исправления всех выявленных ошибок можно включать offload режим и продолжать отладку на сопроцессоре;
- Рекомендуется использовать инструменты анализа эффективности параллельных приложений в Intel VTune Amplifier XE для вашего кода с отключенной функцией offload’а для выявления проблем эффективности распараллеливания. И только после того, как удастся устранить все, что возможно, переходить на работу с сопроцессором и проводить на нем дальнейшую оптимизацию. При этом следует обратить внимание на эффективность синхронизации, т.к. число потоков на ускорителе значительно превосходит это число на обычном CPU. А также следует позаботиться о балансировке нагрузки опять же в силу значительно большего числа потоков.
Краткий обзор инструмента Intel VTune Amplifier XE
Инструмент Intel VTune Amplifier XE является профилировщиком производительности и масштабируемости приложений на многоядерных системах. Входит в состав набора для разработки ПО Intel Parallel Studio XE.
Инструмент, в частности, позволяет:
- Находить функции и участки кода, на выполнение которых расходуется больше всего времени. Анализирует стеки вызовов и исходный код;
- Определять количество внутренних событий процессора, которые влияют на производительность. Например, промахи кэша разных уровней, неверно предсказанные ветвления и др.;
- Определять время ожидания в блокировках потоков, а также уровень загрузки CPU.
Intel VTune Amplifier XE позволяет настроить желаемые параметры анализа работы приложения, а также включает в себя определенное количество предварительно настроенных типов анализа, наиболее используемые из которых:
- Hotspots. Предназначен для выявления "узких мест" в программе. Определяет, какие функции или участки программы работают дольше всего. В основном используется на первом этапе оптимизации для выявления областей кода, требующих ускорения.
- Concurrency. Этот тип анализа показывает эффективность использования ядер процессора во время выполнения программы. Демонстрирует качество распараллеливания кода и участки, которые следует распараллелить.
- Locks and Waits. Показывает точки блокировки и время ожидания потоков. Предназначен для оценки эффективности используемой схемы синхронизации.
Кроме описанных выше типов анализа в инструменте присутствует возможность сбора информации о событиях микроархитектурного уровня, таких как доступ к кэшам различного уровня и промахи кэша, доступ к памяти, неверно предсказанные ветвления и др. Присутствуют и различные готовые типа анализа, направленные на выявление определенных проблем с производительностью (например, проблем доступа в кэши или память).
Инструмент доступен для операционных систем семейства Windows и Linux.
Профилировка приложений на Intel Xeon Phi
Intel VTune Amplifier XE позволяет выполнять профилировку приложений непосредственно на сопроцессоре. На текущий момент пользователю доступны следующие готовые типы анализа:
- Lightweight Hotspots. Позволяет определить функции и участки кода, на выполнение которых тратится больше всего времени. Аналогичен hotspots, но статистика собирается с использованием специальных регистров процессора для мониторинга производительности [1.10].
- General Exploration. Позволяет выявить микроархитектурные особенности, отрицательно влияющие на производительность. Это могут быть, например, частые промахи L1 или L2 кэша, промахи TLB кэша или степень векторизации кода.
- Bandwidth. Предназначен для анализа пропускной способности памяти.
На текущий момент поддерживается только одна технология сбора данных о работе приложения – Event-Based Sampling. Эта технология опирается на использование специальных аппаратных регистров (Performance Monitoring Units), предназначенных для учета различных низкоуровневых событий, происходящих во время работы программы. В текущих сопроцессорах Intel Xeon Phi на ядро приходится 2 регистра, накапливающих информацию о событиях, специфичных для потока или ядра. Присутствуют также 4 регистра за пределами ядра, не обладающих информацией о потоках и ядрах.
Соответственно за один запуск можно получить информацию максимум о 2 событиях ядра и 4 внешних событиях. Если нужно больше информации, то Intel VTune Amplifier XE будет выполнять ваше приложение несколько раз.
В дополнение к существующим типам анализа пользователь может создавать свои типы для получения информации о других интересующих его событиях. Проще всего новый тип анализа создавать на основе существующего. Для этого необходимо скопировать наиболее подходящий тип анализа и добавить в него интересующие вас счетчики событий.
Подробнее о событиях сопроцессора Intel Xeon Phi можно почитать в документации PMU [1.10].
Далее рассмотрим процесс запуска профилировки приложения на Intel Xeon Phi. Предполагается, что все действия выполняются на машине с подключенным к ней сопроцессором.
Запуск процесса профилировки из GUI.
Рассмотрим процесс запуска приложения с помощью GUI компонента Intel VTune Amplifier XE. Во-первых, создаем новый проект, в рамках которого будем исследовать нужное нам приложение. В случае offload программы заполняем поля свойств проекта следующим образом (вкладка Target):
- Application: полный путь к исполняемому файлу;
- Application parameters: параметры приложения (если необходимо);
- Working directory: путь к рабочей директории, где будут храниться результаты профилировки (обычно не имеет значения).
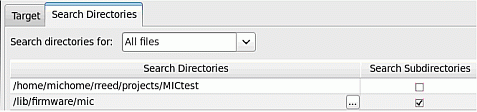
увеличить изображение
Рис. 1.3. Настройка путей к исходным файлам приложения в Intel VTune Amplifier
На вкладке Search Directories нужно указать путь к исходным файлам приложения для возможности навигации по коду программы при просмотре результатов (рис. 1.3).
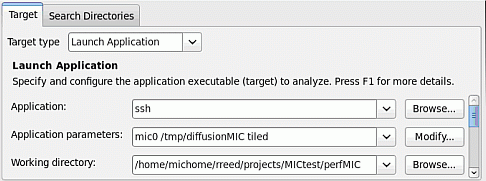
увеличить изображение
Рис. 1.4. Настройка параметров проекта в Intel VTune Amplifier X
Если выполняется запуск программы в режиме работы только на сопроцессоре, то в качестве приложения для запуска указывается ssh, а само приложение указывается в качестве параметра в поле Application Parameters (рис. 1.4).
Следующий шаг – выполнение профилировки приложения. Для этого необходимо выбрать пункт меню "New Analysis…", выбрать нужный тип анализа в дереве типов из папки "Knights Corner Platform Analysis" и начать профилировку (рис. 1.5).

увеличить изображение
Рис. 1.5. Выбор типа анализа в Intel VTune Amplifier XE

увеличить изображение
Рис. 1.6. Результаты профилировки в Intel VTune Amplifier XE
Для создания собственного типа анализа на основе существующего достаточно нажать на кнопку "Copy" и в открывшемся окне добавить нужные счетчики. Также обратите внимание, что нажав на кнопку "Command Line…" вы получите командную строку для текущего типа анализа, с помощью которой можно запустить профилировку из консоли.
По завершении профилировки результаты будут отражены на экране (рис. 1.6).
Запуск процесса профилировки из командной строки.
Для работы с Intel VTune Amplifier XE из командной строки прежде всего необходимо создать все нужные переменные окружения. Это можно сделать вызовом специального скрипта из папки с установленным инструментом:
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh
После этого можно запускать процесс профилировки.
Для offload приложения это делается командой:
amplxe-cl –collect knc-lightweight-hotspots –knob target-cards=0,1 –result-dir ./offload_cmd -- ./offload.out
Рассмотрим подробнее ключи запуска профилировщика.
Ключ "–collect knc-lightweight-hotspots" говорит о том, что будет проводиться один из предварительно настроенных типов анализа. В данном примере используется Lightweight Hotspots. Остальные типы имеют имена "knc-general-exploration" и "knc-bandwidth" соответственно.
Следующий ключ "–knob target-cards=0,1" говорит о том, на каких сопроцессорах запускать анализ приложения. Имеет смысл только для offload приложений.
Ключ "–result-dir ./offload_cmd" указывает на директорию, куда будут записаны результаты анализа.
И, наконец, параметр "-- ./offload.out" говорит о том, какое приложение (в нашем случае это "./offload.out" ) и с какими аргументами должно быть запущено.
Для приложений в режиме исполнения только на сопроцессоре командная строка будет такой:
amplxe-cl –collect knc-lightweight-hotspots –reslut-dir ./native-cmd -- ssh mic0 "export LD_LIBRARY_PATH=~/; export OMP_NUM_THREADS=244; export KMP_AFFINITY=balanced; ./native.out"
Обратите внимание, что в качестве приложения для запуска используется команда ssh, после которой следует имя узла сопроцессора, и далее команды для выполнения на этом сопроцессоре.
Приведем пример того, как из командной строки запустить свой собственный тип анализа:
amplxe-cl –collect-with runsa-knc –knob event-config=CPU_CLK_UNHALTED,L2_DATA_READ_MISS_MEM_FILL:sa=1000, L2_DATA_WRITE_MISS_MEM_FILL,L2_VICTIM_REQ_WITH_DATA,SNP_HINT_L2,HWP_L2MISS –knob target-cards=0,1 –result-dir ./custom-cmd -- ./offload.out
Для указания того, что будет использоваться пользовательский тип анализа на ускорителе, используется ключ "–collect-with runsa-knc". Конкретные события, результаты по которым вы хотите получить, описаны в качестве параметров ключа "–knob event-config=…". Используемые здесь имена событий описаны по ссылке [1.10].
Напомним, что нужный вам тип анализа можно настроить через GUI приложение, после чего там же получить командную строку для его запуска. Описание дополнительных аргументов приложения ample-cl можно узнать из его справки:
amplxe-cl –help
Просмотр результатов анализа, полученных после запуска профилировщика из командной строки, может быть осуществлен двумя методами.
Первый метод предполагает использование GUI приложения. Вам нужно скопировать результаты анализа с удаленной на локальную машину с GUI, после чего открыть файл *.amplxe с помощью GUI приложения Intel VTune Amplifier XE. Отметим, что это предпочтительный метод работы с результатами, так как он является наиболее удобным и наглядным.
Второй метод использует исключительно возможности командной строки.
Для просмотра общей статистики по конкретному запуску необходимо выполнить команду:
amplxe-cl –report summary –r ./offload_cmd/
Здесь "./offload_cmd/" это директория с результатами анализа. Ключ "-report" указывает на тип выводимой информации. Например, если мы хотим получить список наиболее медленных функций, тогда нужно запросить вывод данных о "горячих точках":
amplxe-cl –report hotspots –r ./offload_cmd/
Еще один вариант – получение информации об аппаратных событиях, произошедших за время работы приложения:
amplxe-cl –report hw-events –r ./offload_cmd/
Результаты выдачи можно фильтровать по имени процесса или модуля:
amplxe-cl –report hotspots –filter process=offload_main –filter module=offload.out –r ./offload_cmd/
Можно записывать выдачу в файл:
amplxe-cl –report hotspots –report-output ./vtune-output.txt –r ./offload_cmd/
Метрики для оценки эффективности приложений на Intel Xeon Phi
В данном разделе приведено описание основных метрик для оценки эффективности приложений на Intel Xeon Phi c помощью Intel VTune Amplifier XE. Приведенные здесь метрики и рекомендации по оптимизации кода актуальны и для CPU, однако конкретные значения этих метрик приводятся только для сопроцессоров Intel Xeon Phi.
Количество тактов на инструкцию (cycles per instruction, CPI).
Эта метрика показывает среднее число тактов процессора, которое требуется для выполнения одной инструкции. Иными словами это индикатор того, как сильно латентность доступа к памяти влияет на производительность приложения.
Данная метрика может вычисляться относительно аппаратного потока либо относительно ядра процессора. Чем меньше этот показатель, тем лучше работает приложение. Для сопроцессоров Intel Xeon Phi минимальные значения этого показателя приведены в таблице 6.1.
| Число аппаратных потоков на ядро | Минимальный (лучший) показатель CPI на ядро | Минимальный (лучший) показатель CPI на поток |
|---|---|---|
| 1 | 1.0 | 1.0 |
| 2 | 0.5 | 1.0 |
| 3 | 0.5 | 1.5 |
| 4 | 0.5 | 2.0 |
Для вычисления описанных выше характеристик Intel VTune Amplifier XE использует события CPU_CLK_UNHALTED и INSTRUCTIONS_EXECUTED. В частности:
- CPI Per Thread = CPU_CLK_UNHALTED / INSTRUCTIONS_EXECUTED
- CPI Per Core = (CPI Per Thread) / (Число используемых аппаратных потоков)
Во время применения определенных шагов по оптимизации приложения рекомендуется следить за этими характеристиками. Приемлемым можно считать следующие значения этих метрик:
- CPI Per Thread <= 4.0;
- CPI Per Core <= 1.0.
Если одна из характеристик больше соответствующего значения – это повод задуматься о дополнительной оптимизации. Причем большие значения CPI следует расценивать как повод к уменьшению латентности доступа к памяти.
Таким образом, задача оптимизации состоит в том, чтобы уменьшать значение CPI. И приведенные ниже метрики и рекомендации по их улучшению помогают этой цели добиться. Однако следует отметить, что, например, при использовании векторизации CPI может увеличиваться. И это нормально. Связано это с тем, что мы переходим от скалярных инструкций к векторным. И при этом на выполнение одной векторной инструкции может потребоваться больше тактов. Но не стоит забывать, что за одну векторную инструкцию мы выполним больше операций.
Объем вычислений на единицу данных (compute to data access ratio).
Данная метрика позволяет оценить средний объем вычислений, который приходится на единицу данных в вашем приложении. Очевидно, что чем больше этот показатель, тем эффективнее будет работать программа.
Выделяют два типа этой метрики:
- L1 Compute to Data Access Ratio – используется для оценки того, насколько ваше приложение подходит для переноса на Intel Xeon Phi. Для того чтобы программа могла эффективно выполняться на сопроцессоре, она должна быть векторизованной, и в идеале выполнять несколько операций с одними и теми же данными (или линейками кэша). Данная метрика вычисляет среднее число векторных операций, приходящихся на один доступ к L1 кэшу.
- L2 Compute to Data Access Ratio – показывает среднее число векторных операций, приходящихся на один доступ к L2 кэшу.
Для вычисления этих метрик используются следующие события:
- VPU_ELEMENTS_ACTIVE – число векторных операций на поток;
- DATA_READ_OR_WRITE – число операций чтения и записи в L1 кэш данных на поток;
- DATA_READ_MISS_OR_WRITE_MISS – число L1 кэш промахов при чтении и записи на поток.
Описанные выше метрики вычисляются по формулам:
- L1 Compute to Data Access Ratio = VPU_ELEMENTS_ACTIVE / DATA_READ_OR_WRITE;
- L2 Compute to Data Access Ratio = VPU_ELEMENTS_ACTIVE / DATA_READ_MISS_OR_WRITE_MISS.
Приведем некоторые рекомендации для оценки эффективности приложения с помощью этих метрик. Приложения, приемлемо работающие на сопроцессоре, должны обладать следующими значениями метрик:
- L1 Compute to Data Access Ratio < показателя интенсивности векторизации (см. Векторизация);
- L2 Compute to Data Access Ratio < 100 * (L1 Compute to Data Access Ratio) .
Для улучшения этих показателей следует увеличить плотность вычислений посредством векторизации, а также сократить число обращений к памяти. Обратите внимание эффективную работу с кэш памятью, пользуйтесь выравниванием данных.
Латентность доступа к памяти.
Высокая латентность доступа к данным существенно снижает эффективность приложения. Для оценки влияния этого фактора рекомендуется использовать следующую метрику:
Оценка влияния латентности (Estimated Latency Impact) = (CPU_CLK_UNHALTED – EXEC_STAGE_CYCLES – DATA_READ_OR_WRITE) / DATA_READ_OR_WRITE_MISS.
Здесь EXEC_STAGE_CYCLES – число тактов процессора, на которых поток выполнял вычислительные операции. Остальные события описаны выше.
Применять оптимизацию здесь следует тогда, когда значение этого показателя больше 145. Для оптимизации следует повышать локальность данных, используя программную предвыборку данных, блочный доступ к данным в кэш памяти, потоковые операции работы с данными и выравнивание.
Использование TLB кэша.
Неэффективное использование TLB кэша приводит к увеличению латентности доступа к памяти и, как следствие, снижению производительности приложений.
Для оценки эффективности доступа в TLB кэш используются следующие показатели:
- L1 TLB miss ratio = DATA_PAGE_WALK / DATA_READ_OR_WRITE
- L2 TLB miss ratio = LONG_DATA_PAGE_WALK / DATA_READ_OR_WRITE
- L1 TLB misses per L2 TLB miss = DATA_PAGE_WALK / LONG_DATA_PAGE_WALK
Здесь DATA_PAGE_WALK – число промахов L1 TLB кэша, а LONG_DATA_PAGE_WALK – число промахов L2 TLB кэша.
Необходимость в оптимизации здесь появляется, если:
- L1 TLB miss ratio > 1%;
- L2 TLB miss ratio > 0.1%;
- L1 TLB misses per L2 TLB miss > 1.
Для улучшения ситуации следует обратить внимание на эффективность использования кэша и уменьшать латентность доступа к памяти.
Если отношение (L1 TLB miss / L2 TLB miss) достаточно велико, можно попробовать использовать страницы TLB кэша большего размера.
Если в коде есть циклы, в теле которых на каждой итерации выполняются действия с разными участками данных, лучше разбить такой цикл на несколько более маленьких.
Векторизация.
Рассмотрим такую метрику, как интенсивность векторизации. Она показывает, насколько эффективно векторизован ваш код:
Интенсивность векторизации (vectorization intensity) = VPU_ELEMENTS_ACTIVE / VPU_INSTRUCTIONS_EXECUTED.
Здесь VPU_INSTRUCTIONS_EXECUTED – число векторных инструкций, выполняемых потоком, VPU_ELEMENTS_ACTIVE – число активных векторных элементов на векторную инструкцию, или, другими словами, число векторных операций (за одну векторную инструкцию может выполняться несколько операций).
Оптимизировать нужно, если этот параметр меньше 8 при использовании чисел двойной точности и меньше 16 при использовании чисел одинарной точности.
Компилятор Intel может выполнять автоматическую векторизацию вашего кода. Для получения информации о том, какие циклы были векторизованы, а какие – нет, используйте соответствующие отчеты компилятора.
Для подсказки компилятору используйте директивы #pragma ivdep, #pragma simd и др. Для ручной векторизации используйте возможности технологии Intel Cilk Plus.
Следите за выравниванием данных при векторизации.
Пропуская способность памяти.
Величина показателя пропускной способности памяти вычисляется следующим образом:
- Read bandwidth = (L2_DATA_READ_MISS_MEM_FILL + L2_DATA_WRITE_MISS_MEM_FILL + HWP_L2MISS) * 64 / CPU_CLK_UNHALTED
- Write bandwidth = L2_VICTIM_REQ_WITH_DATA + SNP_HITM_L2) * 64 / CPU_CLK_UNHALTED
- Memory Bandwidth = (Read bandwidth + Write bandwidth) * (Частота процессора в ГГц).
Здесь:
- L2_DATA_READ_MISS_MEM_FILL – число операций чтения, приводящих к обращению к оперативной памяти, включая операции предвыборки;
- L2_DATA_WRITE_MISS_MEM_FILL – число операций записи, приводящих к обращению к оперативной памяти на чтение, включая операции предвыборки;
- L2_VICTIM_REQ_WITH_DATA – число замещений данных, приводящих к обращению к оперативной памяти на запись;
- HWP_L2MISS – число аппаратных предвыборок, которые привели к L2 кэш промаху;
- SNP_HITM_L2 – число событий возникающих в случае, когда данные, измененные в кэше одного ядра, нужны другому ядру;
- CPU_CLK_UNHALTED – число тактов процессора.
Если эта величина < 80 GB/сек (практический максимум для 8 контроллеров памяти равен 140 GB/сек), тогда имеет смысл выполнять соответствующую оптимизацию.
Для этого следует улучшить локальность данных в кэшах, использовать операции потоковой работы с данными, задействовать программную предвыборку.
Подробнее об этих метриках и приемах оптимизации приложений для Intel Xeon Phi можно узнать здесь [1.4,1.5].
Лекция 2. Принципы переноса прикладных программных пакетов на Intel Xeon Phi
Введение
Презентацию к лекции Вы можете скачать здесь.
В 2012 году корпорация Intel представила на рынке новый сопроцессор – Intel Xeon Phi, построенный в рамках парадигмы manycore и содержащий 61 вычислительное ядро близкой к x86 архитектуры. В отличие от других активно применяющихся представителей manycore-архитектур, в частности, GPU, Intel сделала акцент не только на пиковой производительности устройства, но и на существенном упрощении процесса создания новых и портирования существующих программных пакетов путем использования стандартных языков и технологий для параллельного программирования.
Так, в ряде случаев можно обойтись без какой-либо переработки существующего кода, добавив ключ компилятора и получив программу, способную выполняться на Xeon Phi. Производительность результата подобного портирования на Xeon Phi зависит от многих факторов и может варьироваться от многократного замедления до многократного ускорения по сравнению с исходной версией на CPU.
Существенное замедление может наблюдаться для приложений, значительная часть (по вкладу в общее время) которых выполняется последовательно, либо задач, не имеющих достаточный ресурс параллелизма для использования большого количества ядер Xeon Phi. Напротив, приложения с большой долей и степенью параллелизма, написанные с учетом векторизации, могут достигать высокой производительности на Xeon Phi без дополнительных усилий. На практике же обычно имеет место некий средний случай – в результате начального портирования приложение на Xeon Phi демонстрирует производительность, сравнимую с версией на CPU, но далекую от пиковой производительности Xeon Phi; таким образом, огромные вычислительные ресурсы Xeon Phi используются далеко не полностью.
В этом случае возникает вопрос, какие усилия требуются для того, чтобы превратить программу, работающую на CPU, в программу, эффективно работающую на Xeon Phi? Этот и другие подобные вопросы, определенно, представляют интерес для научного сообщества. В литературе появляются первые работы, рассказывающие об опыте портирования на Xeon Phi приложений из разных областей.
Анализ позволяет сделать следующий вывод: портирование программ на Xeon Phi может быть выполнено в весьма сжатые сроки (несколько дней) даже при весьма значительных объемах кода. При этом код будет работать достаточно эффективно только в тех случаях, когда приложение уже было оптимизировано для CPU и содержало большой запас внутреннего параллелизма как с точки зрения многопоточности, так и с точки зрения использования инструкций SIMD. Данное условие является необходимым, но не достаточным. Так, многие алгоритмы успешно распараллеливаются на 8 16, но не на 120 240 потоков, допускают эффективное использование SIMD для небольшой длины регистра, упираются в ограниченный на Xeon Phi объем встроенной памяти, требуют вдумчивой реализации с целью активного использования команд Fused Multiply-Add (FMA) и т.д. Все это означает, что получение максимальной производительности требует от программиста определенных усилий.
В данной лекции рассматриваются подходы к портированию и оптимизации на Xeon Phi двух прикладных программных пакетов, осуществляющих решение задач вычислительной физики: моделирование динамики электромагнитного поля методом FDTD (раздел 2) и моделирование переноса излучения методом Монте-Карло (раздел 3). Используются типичные приемы оптимизации, способные привести к выигрышу производительности в рамках multicore- и manycore-архитектур.
Подходы к оптимизации программного пакета для моделирования динамики электромагнитного поля методом FDTD
Одним из широко используемых методов вычислительной электродинамики является метод FDTD (Finite-Difference Time-Domain) [2.1]. Это явный конечно-разностный метод численного решения уравнений Максвелла. Особенностью метода является использование специальной сетки для компонент электромагнитного поля. Точки пространства, соответствующие разным компонентам поля, сдвинуты относительно друг друга на половинные шаги по пространству и времени, благодаря чему все конечно-разностные аппроксимации первых производных являются центральными, и достигается второй порядок точности по времени и пространственным компонентам.
В данном разделе рассматривается портирование на Xeon Phi и оптимизация реализации метода FDTD, созданной на основе программного пакета для моделирования плазмы PICADOR [2.2]. Для простоты рассматривается базовая версия FDTD. На практике вместе с FDTD часто используется приграничный поглощающий слой PML, оптимизация с его учетом рассматривается в [2.3].
Общее описание метода FDTD
Рассматривается трехмерная область в виде прямоугольного параллелепипеда
![]() ,
которую в дальнейшем будем называть расчетной областью. В каждый момент времени
,
которую в дальнейшем будем называть расчетной областью. В каждый момент времени ![]() в каждой точке расчетной области
в каждой точке расчетной области ![]() определены 3-компонентное электрическое поле, которое будем обозначать
определены 3-компонентное электрическое поле, которое будем обозначать ![]() , и 3-компонентное магнитное поле
, и 3-компонентное магнитное поле ![]() . Пара векторных полей
. Пара векторных полей ![]() называется электромагнитным полем.
называется электромагнитным полем.
Рассматривается задача моделирования динамики электромагнитного поля от начального момента времени ![]() до заданного конечного момента времени
до заданного конечного момента времени ![]() . Динамика электромагнитного поля подчиняется системе уравнений Максвелла (приведена запись двух уравнений для случая вакуума в системе единиц СГС,
. Динамика электромагнитного поля подчиняется системе уравнений Максвелла (приведена запись двух уравнений для случая вакуума в системе единиц СГС, ![]() – скорость света в вакууме):
– скорость света в вакууме):

Для численного решения задачи расчетная область покрывается равномерной пространственной сеткой, содержащей ![]() узлов (
узлов (![]() ячеек) по соответствующим размерностям. Шаги сетки равны
ячеек) по соответствующим размерностям. Шаги сетки равны ![]() . Моделирование по времени происходит с заданным шагом
. Моделирование по времени происходит с заданным шагом ![]() , т.е. в дискретные моменты 0,
, т.е. в дискретные моменты 0, ![]() , последовательность завершается при превышении
, последовательность завершается при превышении ![]() . Для индексирования узлов сетки используются естественные трехмерные индексы
. Для индексирования узлов сетки используются естественные трехмерные индексы ![]() .
.
FDTD использует специальную сетку (сетку Yee [2.1]) следующего вида. Сеточное значение ![]() соответствует точке физического пространства
соответствует точке физического пространства
![]() соответствует точке
соответствует точке ![]() и
и ![]() – точке
– точке ![]() . Сеточные значения компонент магнитного поля
. Сеточные значения компонент магнитного поля ![]() сооветствуют точкам
сооветствуют точкам ![]() ,
, ![]() ,
, ![]() . Таким образом, разные компоненты поля сдвинуты относительно центра соответствующей ячейки на полшага по одной или двум осям. Кроме того, компоненты магнитного поля сдвинуты относительно компонент электрического поля на полшага вперед по времени.
. Таким образом, разные компоненты поля сдвинуты относительно центра соответствующей ячейки на полшага по одной или двум осям. Кроме того, компоненты магнитного поля сдвинуты относительно компонент электрического поля на полшага вперед по времени.
Моделирование производится итерационно по времени, на каждом шаге хранится текущий набор сеточных значений поля. Начальные значения поля определяются из заданных начальных условий. Итерация метода состоит из двух этапов: использование текущих значений ![]() и
и ![]() для вычисления новых значений
для вычисления новых значений ![]() (обновление
(обновление ![]() ), использование текущих значений
), использование текущих значений ![]() и новых значений
и новых значений ![]() для вычисления новых значений
для вычисления новых значений ![]() (обновление
(обновление ![]() ). В приводимых далее формулах подразумевается, что вычисления производятся для всех узлов сетки
). В приводимых далее формулах подразумевается, что вычисления производятся для всех узлов сетки ![]() , для которых все члены правой части определены. Обновление
, для которых все члены правой части определены. Обновление ![]() выполняется по следующей схеме:
выполняется по следующей схеме:
Обновление ![]() выполняется по следующей схеме:
выполняется по следующей схеме:
Очевидно, данные формулы не могут быть использованы для обновления значений ![]() на "правой" границе сетки (
на "правой" границе сетки (![]() или
или ![]() ), и для обновления значений
), и для обновления значений ![]() на "левой" границе (
на "левой" границе (![]() или
или ![]() ). Способ вычисления данных сеточных значений зависит от используемых граничных условий. В данном разделе используются периодические граничные условия по всем осям:
). Способ вычисления данных сеточных значений зависит от используемых граничных условий. В данном разделе используются периодические граничные условия по всем осям: ![]() ,
,![]() , аналогично для других границ и компонент поля.
, аналогично для других границ и компонент поля.
Программная реализация
Рассмотрим базовую программную реализацию метода FDTD. Сеточные значения электрического и магнитного поля будем хранить как динамические 3-мерные массивы из 3-компонентных векторов. Ядро реализации составляют функции обновления сеточных значений ![]() и
и ![]() , являющиеся прямой записью разностной схемы метода FDTD. Приведем код данных функций:
, являющиеся прямой записью разностной схемы метода FDTD. Приведем код данных функций:
struct Double3 {
double x, y, z;
};
struct Parameters {
int nx, ny, nz;
double dx, dy, dz, dt;
};
const double C = 29979245800.0;
void updateE(const Parameters & parameters, Double3 *** b, Double3 *** e)
{
const double cx = C * parameters.dt / parameters.dx;
const double cy = C * parameters.dt / parameters.dy;
const double cz = C * parameters.dt / parameters.dz;
#pragma omp parallel for
for (int i = 0; i < parameters.nx; i++)
for (int j = 0; j < parameters.ny; j++)
for (int k = 0; k < parameters.nz; k++)
{
e[i][j][k].x += cy * (b[i][j + 1][k].z - b[i][j][k].z) - cz * (b[i][j][k + 1].y - b[i][j][k].y);
e[i][j][k].y += cz * (b[i][j][k + 1].x - b[i][j][k].x) - cx * (b[i + 1][j][k].z - b[i][j][k].z);
e[i][j][k].z += cx * (b[i + 1][j][k].y - b[i][j][k].y) - cy * (b[i][j + 1][k].x - b[i][j][k].x);
}
}
void updateB(const Parameters & parameters, Double3 *** e, Double3 *** b)
{
const double cx = C * parameters.dt / parameters.dx;
const double cy = C * parameters.dt / parameters.dy;
const double cz = C * parameters.dt / parameters.dz;
#pragma omp parallel for
for (int i = 1; i <= parameters.nx; i++)
for (int j = 1; j <= parameters.ny; j++)
for (int k = 1; k <= parameters.nz; k++)
{
b[i][j][k].x += cz * (e[i][j][k].y - e[i][j][k - 1].y) - cy * (e[i][j][k].z - e[i][j - 1][k].z);
b[i][j][k].y += cx * (e[i][j][k].z - e[i - 1][j][k].z) - cz * (e[i][j][k].x - e[i][j][k - 1].x);
b[i][j][k].z += cy * (e[i][j][k].x - e[i][j - 1][k].x) - cx * (e[i][j][k].y - e[i - 1][j][k].y);
}
}
В функциях updateE, updateB из циклов вынесены инварианты ![]() ,
, ![]() ,
, ![]() . Произведено прямолинейное распараллеливание циклов с независимыми итерациями с помощью OpenMP. Данные функции выполняют обновление сеточных значений области во "внутренней области" – без учета граничных условий. Учет граничных условий делается в отдельных функциях для исключения условных операций в основных циклах и упрощения использования других типов граничных условий. Таким образом, основной вычислительный цикл имеет вид:
. Произведено прямолинейное распараллеливание циклов с независимыми итерациями с помощью OpenMP. Данные функции выполняют обновление сеточных значений области во "внутренней области" – без учета граничных условий. Учет граничных условий делается в отдельных функциях для исключения условных операций в основных циклах и упрощения использования других типов граничных условий. Таким образом, основной вычислительный цикл имеет вид:
for (int t = 0; t < numSteps; t++)
{
updateE(parameters, b, e);
updateBoundaryE(parameters, e);
updateB(parameters, b, e);
updateBoundaryB(parameters, b);
}
В силу сходства функций updateE, updateB в дальнейшем будем демонстрировать техники оптимизации лишь для updateE, подразумевая выполнение аналогичных преобразований и для updateB. Для анализа производительности будем использовать следующий бенчмарк: моделирование распространения плоской волны на сетке 256x256x256 со 100 итерациями по времени.
Эксперименты проводились на следующей инфраструктуре:
| Процессор | 2x Intel Xeon Xeon E5-2690 (2.9 GHz, 8 ядер) |
| Сопроцессор | Intel Xeon Phi 7110X |
| Память | 64 GB |
| Операционная система | Linux CentOS 6.2 |
| Компилятор, профилировщик, отладчик | Intel C/C++ Compiler 13 |
Результаты производительности базовой версии на CPU и Xeon Phi в режиме только сопроцессора приведены на рис. 1. CPU-версия неидеально масштабируется с 1 до 4 ядер и демонстрирует замедление при переходе от 4 до 8 ядер. Версия на Xeon Phi немного обгоняет CPU-версию. Во всех запусках на Xeon Phi используется 1 поток на ядро. Данный выбор нетипичен для большинства приложений рекомендуется использование от 2 до 4 потоков на ядро. Однако для рассматриваемого приложения опытным путем было определено, что оптимальной конфигурацией запуска является 1 поток на ядро. Возможное обоснование состоит в том, что производительность ограничена в первую очередь пропусккой способностью памяти, а не скоростью выполнения вычислительных операций.
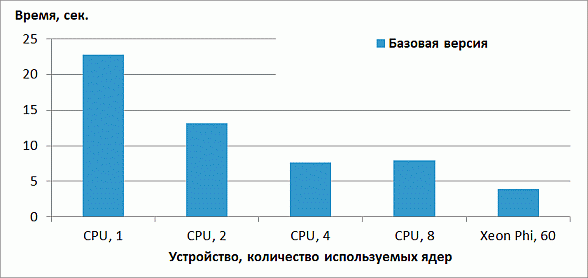
увеличить изображение
Рис. 2.1. Время работы базовой версии на CPU и Xeon Phi
Оптимизация 1: векторизация и изменение структуры данных
Для исследования возможности векторизации кода воспользуемся отчетом о векторизации с помощью опции компилятора –vec-report3. Как видно из отчета, основные циклы (внутренние циклы в updateE, updateB) не векторизуются из-за неподдерживаемой структуры цикла:
naive.cpp(24): (col. 5) remark: loop was not vectorized: unsupported loop structure
Причина в том, что в условии цикла используется поле структуры Parameters. Для преодоления данной проблемы скопируем parameters.nz в локальную переменную и будем использовать ее в условии цикла.
После этого структура цикла становится пригодной для векторизации, однако векторизация не происходит из-за потенциальных зависимостей между итерациями (список потенциальных зависимостей зависимостей очень длинный, приведено его начало):
naive.cpp(25): (col. 5) remark: loop was not vectorized: existence of vector dependence naive.cpp(27): (col. 9) remark: vector dependence: assumed ANTI dependence between b line 27 and e line 29 naive.cpp(29): (col. 9) remark: vector dependence: assumed FLOW dependence between e line 29 and b line 27 naive.cpp(27): (col. 9) remark: vector dependence: assumed ANTI dependence between b line 27 and e line 31 naive.cpp(31): (col. 9) remark: vector dependence: assumed FLOW dependence between e line 31 and b line 27 naive.cpp(27): (col. 9) remark: vector dependence: assumed ANTI dependence between b line 27 and e line 27
Действительно, в случае перекрытия массивов в памяти векторизация цикла может быть некорректной, поэтому компилятор не вправе ее осуществить.
Разработчик кода обладает информацией о том, что массивы не пересекаются в памяти и может повлиять на векторизацию цикла с использованием нескольких средств: #pragma ivdep , #pragma simd , ключевое слово restrict , ключ -ansi-alias . Воспользуемся #pragma simd для векторизации внутреннего цикла и соберем программу с ключом -ansi-alias . Кроме того, для повышения производительности сделаем выделение памяти выровненным по 64, используя при выделении массивов сеточных значений функцию _mm_malloc . Функция updateE принимает вид:
void updateE(const Parameters & parameters, Double3 *** b, Double3 *** e)
{
const double cx = C * parameters.dt / parameters.dx;
const double cy = C * parameters.dt / parameters.dy;
const double cz = C * parameters.dt / parameters.dz;
const int nz = parameters.nz;
#pragma omp parallel for
for (int i = 0; i < parameters.nx; i++)
for (int j = 0; j < parameters.ny; j++)
#pragma simd
for (int k = 0; k < nz; k++)
{
e[i][j][k].x += cy * (b[i][j + 1][k].z - b[i][j][k].z) - cz * (b[i][j][k + 1].y - b[i][j][k].y);
e[i][j][k].y += cz * (b[i][j][k + 1].x - b[i][j][k].x) - cx * (b[i + 1][j][k].z - b[i][j][k].z);
e[i][j][k].z += cx * (b[i + 1][j][k].y - b[i][j][k].y) - cy * (b[i][j + 1][k].x - b[i][j][k].x);
}
}
Результаты производительности данной версии приведены на рис. 2.2.
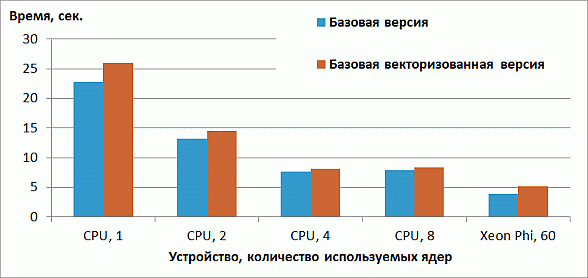
увеличить изображение
Рис. 2.2. Время работы базовой векторизованной версии на CPU и Xeon Phi
Как видно из рис. 2.2, векторизация не только привела к повышению производительности, но даже немного замедлила код. Наиболее вероятная причина данного эффекта состоит в том, что загрузка данных из памяти производится неэффективно и векторизация лишь усиливает расходы на загрузку данных.
Для повышения эффективности загрузки данных из памяти воспользуемся стандартной техникой преобразования массива структур в структуру массивов. Для каждого из полей вместо хранения массива Double3 будем использовать отдельный массив из double для каждой компоненты. Кроме того, перепишем внутренний цикл в терминах работы с одномерными массивами. Код приобретает следующий вид:
void updateE(const Parameters & parameters, double *** bx, double *** by, double *** bz,
double *** ex, double *** ey, double *** ez)
{
const double cx = C * parameters.dt / parameters.dx;
const double cy = C * parameters.dt / parameters.dy;
const double cz = C * parameters.dt / parameters.dz;
const int nz = parameters.nz;
#pragma omp parallel for
for (int i = 0; i < parameters.nx; i++)
for (int j = 0; j < parameters.ny; j++)
{
double * ex_ij = ex[i][j];
double * ey_ij = ey[i][j];
double * ez_ij = ez[i][j];
const double * bx_ij = bx[i][j];
const double * bx_ij1 = bx[i][j + 1];
const double * by_ij = by[i][j];
const double * by_i1j = by[i + 1][j];
const double * bz_ij = bz[i][j];
const double * bz_i1j = bz[i + 1][j];
const double * bz_ij1 = bz[i][j + 1];
#pragma simd
for (int k = 0; k < nz; k++)
{
ex_ij[k] += cy * (bz_ij1[k] - bz_ij[k]) -
cz * (by_ij[k + 1] - by_ij[k]);
ey_ij[k] += cz * (bx_ij[k + 1] - bx_ij[k]) -
cx * (bz_i1j[k] - bz_ij[k]);
ez_ij[k] += cx * (by_i1j[k] - by_ij[k]) -
cy * (bx_ij1[k] - bx_ij[k]);
}
}
}
Результаты версии с учетом данных изменений приведены на рис. 2.3. Векторизация дает почти двукратное ускорение на Xeon Phi и небольшое ускорение на CPU. Данные ускорения весьма далеки от теоретически максимально возможных: на Xeon Phi векторные операции могут осуществляться с 8 значениями типа double, а на используемом CPU – с 4. Это объясняется тем, что задача в первую очередь ограничена доступом к памяти. С другой стороны, именно большая пропускная способность памяти главным образом обеспечивает превосходство Xeon Phi над CPU.
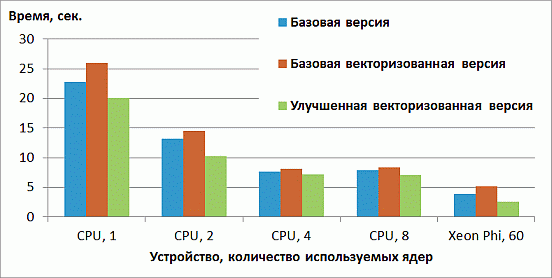
увеличить изображение
Рис. 2.3. Время работы улучшенной векторизованной версии на CPU и Xeon Phi
Оптимизация 2: улучшение масштабируемости
Помимо векторизации, производительность на Xeon Phi существенно зависит от эффективности масштабируемости приложения. В предыдущих версиях с помощью технологии OpenMP распараллеливался внешний цикл. Количество его итераций слишком мало для эффективного использования Xeon Phi: на рассматриваемом бенчмарке имеется 257 итераций, в зависимости от конфигурации запуска количество потоков составляет от 60 до 240. Таким образом, при некоторых конфигурациях запуска большинство потоков делает лишь одну итерацию внешнего цикла, и малое количество потоков делает две итерации, в то время как остальные простаивают. Параллелизм в данной задаче чрезмерно крупнозернистый (coarse grained) для Xeon Phi. Данная проблема также рассмотрена в [2.3].
Используем стандартную технику уменьшения зернистости параллелизма объединим два внешних цикла в один и будем распараллеливать его. Тогда на рассматриваемом бенчмарке число итераций будет уже достаточно велико. В приводимом ниже коде объединение циклов произведено вручную, его также можно делать автоматически с помощью #pragma omp collapse (2).
void updateE(const Parameters & parameters, double *** bx, double *** by, double *** bz,
double *** ex, double *** ey, double *** ez)
{
const double cx = C * parameters.dt / parameters.dx;
const double cy = C * parameters.dt / parameters.dy;
const double cz = C * parameters.dt / parameters.dz;
const int nz = parameters.nz;
const int numIterations = parameters.nx * parameters.ny;
#pragma omp parallel for
for (int iteration = 0; iteration < numIterations; iteration++)
{
int i = iteration / parameters.ny;
int j = iteration % parameters.ny;
double * ex_ij = ex[i][j];
double * ey_ij = ey[i][j];
double * ez_ij = ez[i][j];
const double * bx_ij = bx[i][j];
const double * bx_ij1 = bx[i][j + 1];
const double * by_ij = by[i][j];
const double * by_i1j = by[i + 1][j];
const double * bz_ij = bz[i][j];
const double * bz_i1j = bz[i + 1][j];
const double * bz_ij1 = bz[i][j + 1];
#pragma simd
for (int k = 0; k < nz; k++)
{
ex_ij[k] += cy * (bz_ij1[k] - bz_ij[k]) -
cz * (by_ij[k + 1] - by_ij[k]);
ey_ij[k] += cz * (bx_ij[k + 1] - bx_ij[k]) -
cx * (bz_i1j[k] - bz_ij[k]);
ez_ij[k] += cx * (by_i1j[k] - by_ij[k]) -
cy * (bx_ij1[k] - bx_ij[k]);
}
}
}
Этот подход позволяет немного увеличить производительность на 8 ядрах CPU и Xeon Phi, данные приведены на рис. 2.4.
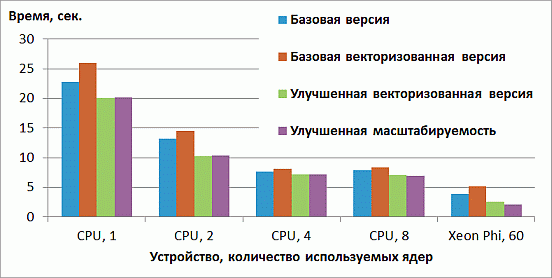
увеличить изображение
Рис. 2.4. Время работы версии с улучшенной масштабируемостью на CPU и Xeon Phi
Общие результаты оптимизации
В результате проделанных оптимизаций удалось повысить производительность программы для Intel Xeon Phi вдвое, при этом производительность на CPU также увеличилась на 10 30% (в зависимости от количества используемых ядер). При этом лучшая версия на Xeon Phi обгоняет лучшую версию на CPU примерно в 3.3 раза.
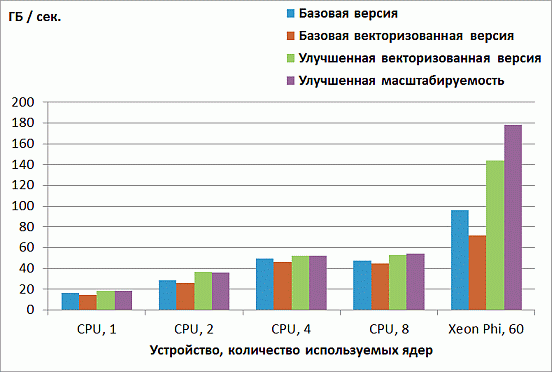
Как уже отмечалось, производительность реализации метода FDTD ограничена в первую очередь пропускной способностью памяти. Оценим пропускную способность памяти, достигаемую рассмотренными реализациями. В рассматриваемом бенчмарке используется сетка 256x256x256 и 100 итераций по времени. На каждой итерации выполняется две эквивалентных с точки зрения доступа к памяти операции. Для каждой из операций происходит 15 обращений к памяти (выполнение += приводит к чтению и записи и, поэтому, считается за 2 операции). Таким образом, всего обрабатывается ![]() элементов типа double, что составляет 375 ГБ данных. Разделив объем обрабатываемой информации на время выполнения бенчмарка, получаем оценку достигаемой пропускной способности памяти, данные представлены на рис. 2.5.
элементов типа double, что составляет 375 ГБ данных. Разделив объем обрабатываемой информации на время выполнения бенчмарка, получаем оценку достигаемой пропускной способности памяти, данные представлены на рис. 2.5.
увеличить изображение
Рис. 2.5. Достигнутая пропускная способность памяти на CPU и Xeon Phi
При этом пиковая пропускная способность памяти используемой модели Xeon Phi составляет 352 ГБ / сек., а на каждом из используемых CPU – 53 ГБ / сек. Таким образом, на обоих устройствах достигается примерно половина от пиковой пропускной способности памяти (в запусках на CPU половина потоков работает на одном CPU, а половина – на втором). Большое преимущество Xeon Phi в пропускной способности памяти является основной причиной значительного превосходства Xeon Phi над CPU в данной задаче. Достигнутый результат в 178 ГБ / сек. на Xeon Phi очень близок к результату на бенчмарке для измерения пропускной способности памяти STREAM, представленному в статье http://software.intel.com/en-us/articles/optimizing-memory-bandwidth-on-stream-triad, данная статья также использует конфигурацию запуска 1 поток на ядро.
Авторы выражают благодарность студенту ВМК ННГУ А. Ларину за помощь в проверке некоторых идей по оптимизации.
Подходы к оптимизации программного пакета для Монте-Карло моделирования переноса излучения
В настоящее время в медицинских исследованиях, в том числе предклинических, существует потребность в развитии новых неинвазивных и доступных методов диагностики, поскольку используемые традиционные методы (магнитно-резонансная томография, компьютерная томография, позитронно-эмиссионная томография) имеют ряд ограничений связанных с их небезопасностью, высокими требованиями к инфраструктуре и стоимостью оборудования. Классом наиболее перспективных методов диагностики, которые могут применяться как в сочетании с существующими методами, так и в некоторых случаях вместо них, являются оптические методы. Их основными преимуществами являются безопасность для пациента, сравнительно невысокая стоимость приборов и широкие функциональные возможности, обусловленные возможной вариативностью параметров зондирующего излучения (длина волны, модуляция, длина импульса и т.д.).
Для диагностики биотканей на больших глубинах необходимо применять методы, для которых информативным является многократно рассеянное излучение. Одним из таких методов является оптическая диффузионная спектроскопия (ОДС), предоставляющая широкие возможности для неинвазивной диагностики. Метод основан на регистрации многократно рассеянного объектом зондирующего излучения на нескольких длинах волн, определяемых спектрами поглощения исследуемых компонент организма.
Применение метода оптической диффузионной спектроскопии позволяет решать такие задачи, как диагностика и лечение раковых опухолей, в частности, рака груди; мониторинг активности зон коры головного мозга; планирование фотодинамической терапии; мониторинг состояния пациента при хирургическом вмешательстве; определение состояния кожных покровов; и др.
Для успешного применения метода ОДС на практике необходимо выполнять подбор параметров этого метода (таких как взаимное расположение источника и детекторов, длина волны зондирования и др.) путем проведения предварительного моделирования распространения зондирующего излучения в исследуемых биологических тканях. Алгоритм решения этой задачи обсуждается в рамках данного раздела.
Общее описание алгоритма Монте-Карло моделирования переноса излучения
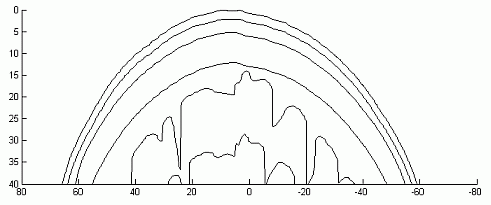
Рассматривается объект в трехмерном пространстве, состоящий из набора слоев. Каждый слой описывает определенный тип биологической ткани, обладающей набором оптических характеристик. Оптические характеристики постоянны в рамках слоя. Например, если моделировать перенос излучения в голове человека, то в ней можно выделить такие слои, как кожа головы, жировая ткань, череп, цереброспинальная жидкость, серое и белое вещество головного мозга (рис. 2.6).
увеличить изображение
Рис. 2.6. Двумерное сечение слоев головы человека
Каждый слой помимо оптических параметров характеризуется набором границ. Границы слоя описываются в виде одной или нескольких поверхностей в трехмерном пространстве. Каждая из поверхностей состоит из набора треугольников.
Источник излучения представляет собой бесконечно тонкий луч фотонов и описывается направлением и положением в трехмерном пространстве.
Для решения задач ОДС было введено в рассмотрение понятие детектора как некоторой замкнутой области на поверхности исследуемого объекта, которая способна улавливать проходящие через нее фотоны [2.4].
Идея метода Монте-Карло в данной задаче состоит в случайной трассировке набора фотонов в биоткани. Фотоны объединяются в пакеты, каждый пакет обладает весом. Далее понятия "фотон" и "пакет фотонов" будут отождествляться. Начинает движение пакет фотонов от источника излучения. Далее на каждом шаге трассировки случайным образом определяется его направление и величина смещения, определяется поглощенный вес. Моделирование пакета завершается либо при его поглощении средой (когда вес пакета становится меньше минимального), либо если он вылетает за границы исследуемого объекта (рис. 2.7).
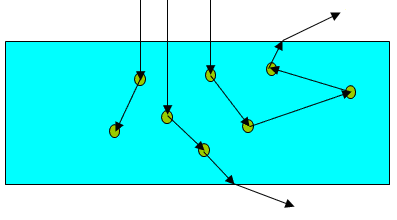
Рис. 2.7. Трассировка фотонов в биоткани
Так как рассматриваются обычно многослойные биоткани, на каждом шаге трассировки фотона необходимо дополнительно проверять, не пересекает ли траектория его движения границу текущего слоя. Для этого может использоваться, например, алгоритм, основанный на переборе всех треугольников, из которых строится поверхность границы, и поиске пересечения с каждым из этих треугольников. Однако более эффективным подходом здесь будет поиск пересечений с помощью BVH деревьев [2.5].
Особенностью данного алгоритма является полная независимость процесса трассировки различных фотонов друг от друга. Соответственно, каждый параллельный поток может выполнять трассировку своего набора фотонов, и теоритически алгоритм является идеально распараллеливаемым.
Результатами моделирования являются:
- интенсивность рассеянного назад излучения на детекторах (сигнал на детекторах);
- фотонные карты траекторий для каждого детектора (для фотонов, попавших из источника на детектор);
- общая карта траекторий (для всех фотонов).
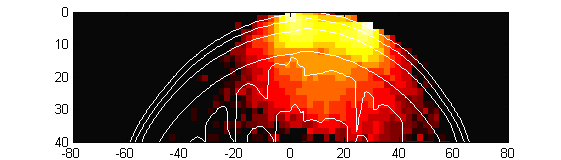
Рис. 2.8. Двумерное сечение фотонной карты траекторий для детектора, расположенного на расстоянии 30 мм от источника излучения (источник находится в начале координат, детектор – справа от него)
На рис. 2.8 показано двумерное сечение фотонной карты траекторий. Рассматриваются траектории фотонов, попавших из источника излучения на детектор. Источник находится в начале координат, детектор – справа от него на расстоянии 30 мм. Цветовая шкала используется для отображения частоты попадания фотонов в определенную подобласть. Чем светлее цвет – тем больше фотонов попало в данную подобласть. Цветовая шкала (белый – желтый – красный – черный) является логарифмической.
Для хранения фотонных карт используется равномерная трехмерная сетка, в ячейках которой содержится число посещений фотоном данной подобласти пространства (рис. 2.9).
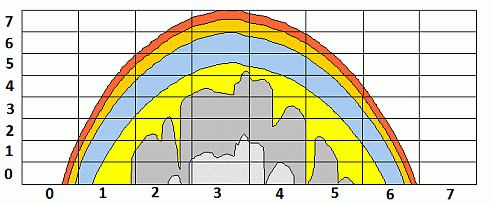
увеличить изображение
Рис. 2.9. Сетка для хранения информации о фотонных картах траекторий
Прямой перенос программного пакета на сопроцессор
Кратко опишем особенности исходной версии программного пакета.
Распараллеливание ведется по фотонам, каждый поток обсчитывает свой набор траекторий. Фотоны делятся поровну между потоками:
void LaunchOMP(InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, int numThreads)
{
omp_set_num_threads(numThreads);
…
#pragma omp parallel
{
int threadId = omp_get_thread_num();
for (uint64 i = threadId;
i < input->numberOfPhotons; i += numThreads)
{
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]), trajectory);
}
}
…
}
Работа ведется с числами двойной точности.
Результатами трассировки являются:
- Величина сигнала на детекторе – массив, количество элементов которого равно числу детекторов, размер для 10 детекторов – 80 Б.
- Общая фотонная карта траекторий – массив, количество элементов которого равно числу ячеек сетки. Для хранения результатов используется трехмерная сетка, сохраняются данные о количестве посещений фотонами каждой из ее ячеек (рис. 2.10). Если рассматривать сетку размером 100*100*50 элементов, размер ее будет равен 4 МБ.
- Фотонные карты траекторий для каждого детектора. Фотонная карта для каждого детектора хранится в массиве, аналогичном массиву с общей фотонной картой. Размер результатов для 10 детекторов – 40 МБ.
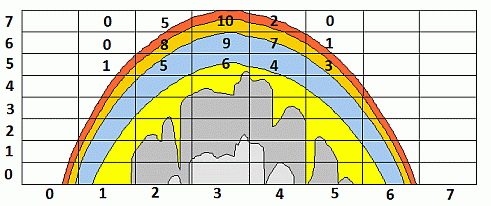
увеличить изображение
Рис. 2.10. Хранение числа посещений фотоном ячеек сетки в самой сетке
Каждому фотону требуется доступ к массивам результатов для их обновления, а значит необходимо либо использовать синхронный доступ к данным на запись, либо воспользоваться техникой дублирования данных.
В исходной версии программы применяется второй подход: создаются копии результирующих массивов для каждого потока исполнения, а после окончания расчетов данные этих копий суммируются. Применение данной техники позволяет, с одной стороны, избежать затрат на синхронизацию, но, с другой, приводит к дополнительным затратам памяти.
И если для исполнения на центральном процессоре объем дополнительной памяти будет равен 350 МБ при использовании 8 потоков, то для работы на сопроцессоре Intel Xeon Phi с 240 потоками понадобится хранить уже более 10 ГБ данных.
Еще одна особенность алгоритма состоит в необходимости хранения траектории каждого отдельного фотона в процессе его трассировки. Это связано с тем, что до окончания трассировки фотона узнать, попал ли он в детектор, нельзя. Соответственно, если фотон попал в детектор, траектория его движения суммируется с общей картой траекторий для данного детектора, а если нет – игнорируется.
В исходной версии выделяется массив для хранения траектории для каждого потока. С точки зрения структур данных используется все та же трехмерная сетка, соответственно размер массива равен 4 МБ. Перед началом трассировки каждого отдельного фотона этот массив обнуляется.
Отметим, что для переноса используется режим работы только на сопроцессоре. Выбор этого режима обусловлен отсутствием необходимости модифицировать код для его запуска на Intel MIC. А значит мы можем выполнять оптимизацию и отладку одного и того же кода параллельно на CPU и на сопроцессоре.
Тестовые запуски проводились на следующем оборудовании: CPU Intel Xeon E5-2690 2.9 ГГц (8 ядер), Intel Xeon Phi 7110X, 64 ГБ RAM, использовался компилятор Intel C/C++ Compiler 14.0, операционная система – CentOS 6.2.
Во всех экспериментах расчеты выполнялись с двойной точностью.
Результаты прямого переноса приведены на рис. 2.11.
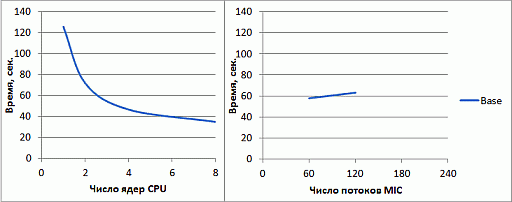
увеличить изображение
Рис. 2.11. Время работы исходной версии программы на CPU и Intel Xeon Phi
Прямой перенос базовой версии программы позволяет получить производительность на сопроцессоре, вдвое меньшую, чем производительность одного 8-ми ядерного CPU. Запуск программы в 240 потоков невозможен в силу недостатка памяти на сопроцессоре.
Оптимизация 1: обновление структуры данных для хранения траектории фотона в процессе трассировки
Перед началом оптимизации имеет смысл выявить наиболее медленные участки программы. Для этого воспользуемся профилировщиком Intel VTune Amplifier XE. Результаты профилировки приведены на рис. 2.12.
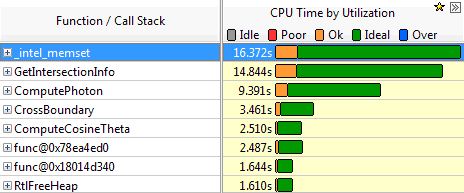
Рис. 2.12. Результаты профилировки базовой версии программы
Как видно из графиков, наибольшее время занимает функция memset(), которая используется в момент начала процесса трассировки фотона для обнуления памяти, предназначенной для хранения траектории его движения. Напомним, что текущая траектория движения фотона хранится в виде трехмерной сетки (рис. 2.10).
увеличить изображение
Рис. 2.13. Хранение числа посещений фотоном ячеек сетки в виде списка координат этих ячеек
Кроме необходимости обнуления памяти на каждой итерации, данный подход обладает еще несколькими недостатками. А именно, размер массива слишком велик по сравнению с размером L2 кэш памяти, и доступ к элементам массива осуществляется в случайном порядке (в силу случайности траектории фотона).
Для устранения описанных выше недостатков предлагается использовать другую структуру данных для хранения траектории фотона: следует хранить не число посещений данной ячейки для всей сетки, а список координат посещенных ячеек (рис. 2.13).
Экспериментальные данные показывают, что максимальная длина траектории фотона в данном примере не превосходит 2048 шагов (эта величина существенно зависит от параметров биотканей и размера сетки). Размер структуры данных в этом случае составляет всего 6 КБ.
Результаты применения этой оптимизации приведены на рис. 2.14.
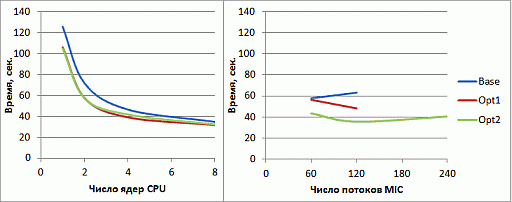
увеличить изображение
Рис. 2.14. Время работы программы после оптимизации структуры данных для хранения траектории движения фотона на CPU и Intel Xeon Phi
Изменение используемой структуры данных позволило сократить время вычислений на CPU в 1 поток на 18%, а в 8 – на 9%. Время работы программы на MIC в 120 потоков сократилось на 31%.
Оптимизация 2: отказ от использования дублирующих массивов
Основной недостаток текущей версии программы состоит в том, что мы не можем использовать все возможности сопроцессора – число потоков, на которых мы можем запустить программу, ограничено объемом памяти сопроцессора. И если при работе на CPU использование дублирующих массивов – вполне нормальная и часто применяемая практика, то при переходе на Intel Xeon Phi эта техника не всегда себя оправдывает.
В нашем случае дублирование выполнено для двух типов результатов: общей фотонной карты траекторий и фотонных карт для каждого из детекторов. Объем операций доступа к этим массивам существенно различен. Общая фотонная карта траекторий обновляется каждым фотоном, в то время как фотонные карты детекторов обновляются реже, так как далеко не каждый фотон попадает в тот или иной детектор. С другой стороны, суммарный размер фотонных карт для всех детекторов на порядок превосходит размер общей фотонной карты (в примере это 40 и 4 МБ соответственно).
Отказ от дублирования общей фотонной карты с одной стороны приводит к существенным затратам на синхронизацию, а с другой – выигрыш по памяти в этом случае не так велик.
Таким образом, наиболее эффективным выглядит отказ от дублирующих массивов только для фотонных карт детекторов. В этом случае существенно уменьшается размер дополнительно используемой памяти, а затраты на синхронизацию будут не так велики. Вероятность, что в одно и то же время фотоны из разных потоков попадут в детекторы, невелика.
Результаты применения этой оптимизации приведены на рис. 2.15.
увеличить изображение
Рис. 2.15. Время работы программы после отказа от использования дублирующих массивов на CPU и Intel Xeon Phi
Время работы программы на центральном процессоре после применения оптимизации практически не изменилось, а на сопроцессоре в 120 потоков сократилось еще на 35%. Отметим, что использование 240 потоков не дает ожидаемого повышения производительности.
Оптимизация 3: балансировка нагрузки
Профилировка программы с использованием Intel VTune Amplifier XE выявила еще одну особенность используемого алгоритма – разное время выполнения отдельных потоков (рис. 2.16).

Рис. 2.16. Диаграмма исполнения потоков на CPU (до балансировки нагрузки)
В текущей версии программы используется статическая схема балансировки нагрузки, при которой каждый поток проводит трассировку примерно одинакового количества фотонов.
Более эффективным будет использование динамической схемы балансировки нагрузки. Динамическая балансировка осуществляется средствами библиотеки OpenMP:
void LaunchOMP(InputInfo* input, OutputInfo* output, MCG59* randomGenerator, int numThreads)
{
…
#pragma omp parallel for schedule(dynamic)
for (uint64 i = 0; i < input->numberOfPhotons; ++i)
{
int threadId = omp_get_thread_num();
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]),
&(trajectory[threadId]));
}
…
}
Диаграмма выполнения потоков после оптимизации приведена на рис. 2.17.

увеличить изображение
Рис. 2.17. Диаграмма исполнения потоков на CPU (после балансировки нагрузки)
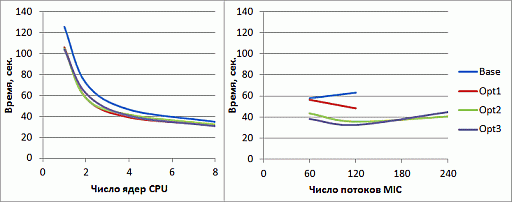
увеличить изображение
Рис. 2.18. Время работы программы после выполнения динамической балансировки нагрузки на CPU и Intel Xeon Phi
Общие результаты оптимизации
В результате проделанных оптимизаций удалось повысить производительность программы для Intel Xeon Phi вдвое. Причем минимальное время работы достигается за счет использования 120 потоков сопроцессора. Такой результат, а так же невысокая эффективность распараллеливания программы, объясняется достаточно большим количеством операций чтения/записи данных в алгоритме, а также наличием синхронизации в оптимизированных версиях.
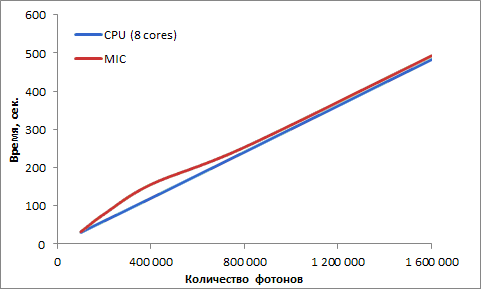
Рис. 2.19. Сравнение времени работы программы для моделирования переноса излучения на CPU и Intel MIC
Сравнение времени работы лучших версий программы для процессора и сопроцессора при различном числе трассируемых фотонов продемонстрировано на рис. 2.19.
Приведенные результаты показывают линейную сложность алгоритма в зависимости от количества трассируемых фотонов, время работы программы на сопроцессоре Intel Xeon Phi примерно соответствует времени ее работы на CPU.
Отметим, что продемонстрированные в работе техники оптимизации не являются исчерпывающими для данной задачи, в частности, не описана векторизация кода, применение которой является одним из важнейших способов повысить эффективность программы на Intel Xeon Phi.
Еще одна особенность программы – применение алгоритма поиска пересечения фотона с границами слоя на каждом шаге моделирования. Как показывают результаты профилировки, это один из самых трудоемких этапов алгоритма моделирования, а значит, необходим анализ существующих алгоритмов поиска пересечений с целью выбора наиболее подходящего для работы на сопроцессоре, и его дальнейшая оптимизация.
Отдельного обсуждения заслуживает и выбор модели программирования на сопроцессоре, которую следует использовать для переноса. Режим "исполнения только на сопроцессоре" оптимален на начальном этапе, когда оптимизация проводится одновременно на CPU и на Intel Xeon Phi. Однако для более эффективного использования сопроцессора имеет смысл использовать один из гетерогенных (CPU + MIC) режимов: offload или симметричный.
И, наконец, не стоит пренебрегать такими стандартными подходами к оптимизации кода на Intel Xeon Phi, как работа с выровненными данными, использование команд программной предвыборки данных и др.
Заключение
В данной лекции были рассмотрены принципы переноса прикладных программных пакетов на Intel Xeon Phi на примере двух приложений из области вычислительной физики: моделирования динамики электромагнитного поля методом FDTD и моделирования переноса излучения методом Монте-Карло. Для обоих приложений были рассмотрены некоторые типичные проблемы, связанные с недостаточно эффективным использованием Xeon Phi, и стандартные подходы к их решению.
В задаче моделирования динамики электромагнитного поля методом FDTD была произведена векторизация кода и перепаковка данных для обеспечения более эффективного паттерна обращения к памяти. Также была продемонстрирована стандартная техника снижения гранулярности параллелизма путем объединения циклов. В результате проделанных оптимизаций удалось повысить производительность программы для Intel Xeon Phi вдвое по сравнению с исходной версией, при этом производительность на CPU также увеличилась в среднем на 20%. При этом лучшая версия на Xeon Phi обгоняет лучшую версию на CPU примерно в 3.3 раза. Реализации на CPU и Xeon Phi достигаются примерно половину пиковой пропускной способности памяти – 54 ГБ / сек. и 178 ГБ / сек. соответственно.
В задаче моделирования переноса излучения методом Монте-Карло было произведено изменение структуры данных для хранения траектории фотона, отказ от использования дублирующих массивов и балансировка нагрузки. В результате проделанных оптимизаций удалось повысить производительность программы для Intel Xeon Phi вдвое по сравнению с начальной версией.
Лекция 3. Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Метод Монте-Карло
Введение
Презентацию к лабораторной работе Вы можете скачать здесь.
В настоящее время в медицинских исследованиях, в том числе предклинических, существует потребность в развитии новых неинвазивных и доступных методов диагностики, поскольку используемые традиционные методы (магнитно-резонансная томография, компьютерная томография, позитронно-эмиссионная томография) имеют ряд ограничений связанных с их небезопасностью, высокими требованиями к инфраструктуре и стоимостью оборудования. Классом наиболее перспективных методов диагностики, которые могут применяться как в сочетании с существующими методами, так и в некоторых случаях вместо них, являются оптические методы. Их основными преимуществами являются безопасность для пациента, сравнительно невысокая стоимость приборов и широкие функциональные возможности, обусловленные возможной вариативностью параметров зондирующего излучения (длина волны, модуляция, длина импульса и т.д.).
Для диагностики биотканей на больших глубинах необходимо применять методы, для которых информативным является многократно рассеянное излучение. Одним из таких методов является оптическая диффузионная спектроскопия (ОДС), предоставляющая широкие возможности для неинвазивной диагностики. Метод основан на регистрации многократно рассеянного объектом зондирующего излучения на нескольких длинах волн, определяемых спектрами поглощения исследуемых компонент организма.
Применение метода оптической диффузионной спектроскопии позволяет решать такие задачи, как диагностика и лечение раковых опухолей, в частности, рака груди; мониторинг активности зон коры головного мозга; планирование фотодинамической терапии; мониторинг состояния пациента при хирургическом вмешательстве; определение состояния кожных покровов; и др.
Для успешного применения метода ОДС на практике необходимо выполнять подбор параметров этого метода (таких как взаимное расположение источника и детекторов, длина волны зондирования и др.) путем проведения предварительного моделирования распространения зондирующего излучения в исследуемых биологических тканях. Алгоритм решения этой задачи обсуждается в рамках данной лабораторной работы.
Методические указания
Цели и задачи работы
Цель данной работы – обозначить основные направления и описать техники оптимизации алгоритма моделирования распространения излучения в сложных биологических тканях методом Монте-Карло для эффективного использования сопроцессоров Intel Xeon Phi.
Данная цель предполагает решение следующих основных задач:
- Изучение базовых принципов и особенностей алгоритма моделирования переноса излучения.
- Прямой перенос алгоритма на сопроцессор Intel Xeon Phi.
- Выявление "узких мест" в алгоритме с использованием соответствующих инструментов профилировки.
- Выполнение оптимизации алгоритма с последующей проверкой результатов его производительности.
Структура работы
Работа построена следующим образом: дан краткий обзор алгоритма моделирования распространения излучения в сложных биологических тканях, описана базовая программная реализация этого алгоритма. Описаны особенности распараллеливания и структуры данных, используемые в базовой версии программы. Проведен анализ эффективности базовой версии с помощью профилировщика Intel VTune Amplifier, выявлены направления ее оптимизации. Описаны техники оптимизации, даны результаты их применения.
Тестовая инфраструктура
Вычислительные эксперименты проводились с использованием следующей инфраструктуры (таблица 3.1).
| Процессор | Intel Xeon E5-2690 (2.9 GHz, 8 ядер) |
| Сопроцессор | Intel Xeon Phi 7110X |
| Память | 64 GB |
| Операционная система | Linux CentOS 6.2 |
| Компилятор, профилировщик, отладчик | Intel C/C++ Compiler 14 |
Рекомендации по проведению занятий
Для выполнения лабораторной работы рекомендуется следующая последовательность действий:
- Дать студентам краткое описание алгоритма моделирования распространения излучения в сложных биологических тканях.
- Рассмотреть прилагаемый к лабораторной работе программный код базовой реализации алгоритма, описать метод проверки корректности результатов. Описать способ распараллеливания и структуры данных базовой версии алгоритма.
- Провести анализ эффективности предложенной реализации, выделить направления для оптимизации.
- Последовательно описать каждую из трех техник оптимизации в данной задаче с демонстрацией полученных результатов.
- Сформулировать выводы, дать задания для самостоятельной работы.
Алгоритм Монте-Карло моделирования переноса излучения
Общее описание задачи
Рассматривается объект в трехмерном пространстве, состоящий из набора слоев. Каждый слой описывает определенный тип биологической ткани, обладающей набором оптических характеристик. Оптические характеристики постоянны в рамках слоя. Например, если моделировать перенос излучения в голове человека, то в ней можно выделить такие слои, как кожа головы, жировая ткань, череп, цереброспинальная жидкость, серое и белое вещество головного мозга (рис. 3.1).
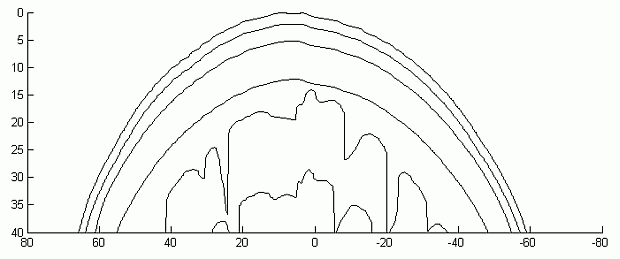
увеличить изображение
Рис. 3.1. Двумерное сечение слоев головы человека
Каждый слой помимо оптических параметров характеризуется набором границ. Границы слоя описываются в виде одной или нескольких поверхностей в трехмерном пространстве. Каждая из поверхностей состоит из набора треугольников.
Источник излучения представляет собой бесконечно тонкий луч фотонов и описывается направлением и положением в трехмерном пространстве.
Для решения задач ОДС было введено в рассмотрение понятие детектора как некоторой замкнутой области на поверхности исследуемого объекта, которая способна улавливать проходящие через нее фотоны. В данной лабораторной работе используются прямоугольные детекторы.
Идея метода Монте-Карло в данной задаче состоит в случайной трассировке набора фотонов в биоткани. Фотоны объединяются в пакеты, каждый пакет обладает весом. Далее понятия "фотон" и "пакет фотонов" будут отождествляться. Начинает движение пакет фотонов от источника излучения. Далее на каждом шаге трассировки случайным образом определяется его направление и величина смещения, определяется поглощенный вес. Моделирование пакета завершается либо при его поглощении средой (когда вес пакета становится меньше минимального), либо если он вылетает за границы исследуемого объекта (рис. 3.2).
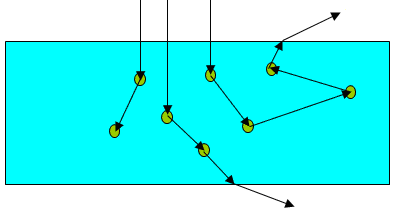
Рис. 3.2. Трассировка фотонов в биоткани
Так как рассматриваются обычно многослойные биоткани, на каждом шаге трассировки фотона необходимо дополнительно проверять, не пересекает ли траектория его движения границу текущего слоя. В данной лабораторной работе для этого используется алгоритм, основанный на переборе всех треугольников, из которых строится поверхность границы, и поиске пересечения с каждым из этих треугольников. Более эффективным подходом здесь будет поиск пересечений с помощью BVH деревьев.
Особенностью данного алгоритма является полная независимость процесса трассировки различных фотонов друг от друга. Соответственно, каждый параллельный поток может выполнять трассировку своего набора фотонов, и теоритически алгоритм является идеально распараллеливаемым.
Результатами моделирования являются:
- интенсивность рассеянного назад излучения на детекторах (сигнал на детекторах);
- фотонные карты траекторий для каждого детектора (для фотонов, попавших из источника на детектор);
- общая карта траекторий (для всех фотонов).

Рис. 3.3. Двумерное сечение фотонной карты траекторий для детектора, расположенного на расстоянии 30 мм от источника излучения (источник находится в начале координат, детектор – справа от него)
На рис. 3.3 показано двумерное сечение фотонной карты траекторий. Рассматриваются траектории фотонов, попавших из источника излучения на детектор. Источник находится в начале координат, детектор – справа от него на расстоянии 30 мм. Цветовая шкала используется для отображения частоты попадания фотонов в определенную подобласть. Чем светлее цвет – тем больше фотонов попало в данную подобласть. Цветовая шкала (белый – желтый – красный – черный) является логарифмической.
Для хранения фотонных карт используется равномерная трехмерная сетка, в ячейках которых содержится число посещений фотоном данной подобласти пространства (рис. 3.4).
увеличить изображение
Рис. 3.4. Сетка для хранения информации о фотонных картах траекторий
Общее описание базовой версии программы
Базовая версия алгоритма, используемая в данной лабораторной работе, состоит из трех компонентов:
- Библиотеки для чтения XML файлов TinyXML [http://www.grinninglizard.com/tinyxml/];
- Библиотеки, содержащей набор функций для трассировки фотона в среде (xmcml);
- Исполняемого модуля, в задачи которого входит чтение параметров задачи, параллельный запуск процесса моделирования и запись результатов работы программы в файл (xmcmlLauncher).
Для компиляции программы в операционных системах семейства Windows следует воспользоваться проектом Visual Studio 2010. При работе на ОС Linux компиляция осуществляется скриптами cpu_make.sh (компиляция для CPU) и mic_make.sh (компиляция для Intel Xeon Phi в режиме работы только на сопроцессоре).
Входными файлами программы являются:
- XML файл с описанием входных параметров задачи. В качестве примера к программе прилагается файл brain_915.xml, описывающий биоткани головы человека при длине волны источника излучения в 915 нм.
- SURFACE файл с описанием геометрии границ биотканей. В качестве примера к программе прилагается файл planes.surface. В данном случае реальная геометрия тканей головы человека аппроксимируется набором параллельных плоскостей. Файл имеет бинарный формат.
Для исследования производительности и проведения оптимизации программы имеет смысл варьировать только следующие параметры задачи (содержатся в XML файле):
- NumberOfPhotons – количество трассируемых фотонов. От этого параметра напрямую зависит время работы программы. Зависимость линейна.
- Area.PartitionNumber – содержит количество разбиений сетки по осям X, Y и Z. Сетка используется для хранения фотонных карт траекторий. Чем больше ее размер, тем больше памяти необходимо программе для работы.
При запуске программы используются следующие параметры командной строки (запуск программы без параметров приводит к выводу соответствующей справки):
xmcmlLauncher.exe –i <ИмяXMLФайла>.xml -s <ИмяSURFACEФайла>.surface -o <ИмяФайлаСРезультатамиМоделирования>.mcml.out –nthreads <КоличествоПараллельныхПотоков>
Пример запуска программы приведен на рис. 3.5.
увеличить изображение
Рис. 3.5. Запуск программы xmcmlLauncher для ОС Windows
Результатом работы программы является бинарный файл *.mcml.out, который содержит как фотонные карты траекторий, так и данные о сигналах на детекторе.
Для просмотра результатов моделирования следует использовать программу mcmlVisualizer. Программа использует .NET Framework 4.0 и предназначена для работы на ОС Windows.
Помимо визуализации результатов, данная программа позволяет проводить сравнение двух *.mcml.out файлов на предмет их совпадения. Найденные ошибки с указанием места выводятся на экран. Отметим, что для проверки корректности полученных после оптимизации результатов следует выполнять сравнение *.mcml.out файлов. Обычное побитовое сравнение не всегда является показательным, поэтому для этих целей лучше использовать предложенную программу.
Отметим также, что полное совпадение результатов в рамках одной версии программы гарантируется только при запуске с неизменным числом потоков. В силу специфики алгоритма, результаты запусков с разным числом потоков будут различны.
Перенос алгоритма на Intel Xeon Phi
Прямой перенос базовой версии
Перед тем, как начать выполнение переноса программы на сопроцессор, необходимо обсудить некоторые ее особенности.
Распараллеливание ведется по фотонам, каждый поток обсчитывает свой набор траекторий (./Base/xmcmlLauncher/launcher_omp.cpp):
void LaunchOMP(InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, int numThreads)
{
omp_set_num_threads(numThreads);
…
#pragma omp parallel
{
int threadId = omp_get_thread_num();
InitOutput(input, &(threadOutputs[threadId]));
threadOutputs[threadId].specularReflectance =
specularReflectance;
uint64* trajectory =
new uint64[threadOutputs[threadId].gridSize];
for (uint64 i = threadId;
i < input->numberOfPhotons; i += numThreads)
{
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]), trajectory);
}
delete[] trajectory;
}
…
}
Результаты трассировки сохраняются в структуре OutputInfo (./Base/xmcml/mcml_kernel_types.h):
typedef struct __OutputInfo
{
uint64 numberOfPhotons;
double specularReflectance;
uint64* commonTrajectory;
int gridSize;
double* weightInDetector;
DetectorTrajectory* detectorTrajectory;
int numberOfDetectors;
} OutputInfo;
Сохраняются три типа результатов:
- Величина сигнала на детекторе – массив weightInDetector, количество элементов равно числу детекторов (в примере – 10), размер – 80 Б.
- Общая фотонная карта траекторий – массив commonTrajectory, количество элементов равно числу ячеек сетки (рис. 3.6) (в примере – 100*100*50=500 000 элементов), размер – 4 МБ.
- Фотонные карты траекторий для каждого детектора – массив detectorTrajectory. Для каждого из детекторов хранится массив, аналогичный commonTrajectory, того же размера. Общий размер данных для 10 детекторов – 40 МБ.

увеличить изображение
Рис. 3.6. Хранение числа посещений фотоном ячеек сетки в самой сетке
Каждому фотону требуется доступ к массивам результатов для их обновления, а значит необходимо либо использовать синхронный доступ к данным на запись, либо воспользоваться техникой дублирования данных.
В базовой версии программы применяется второй подход: создаются копии результирующих массивов для каждого потока исполнения, а после окончания расчетов данные этих копий суммируются. Применение данной техники позволяет, с одной стороны, избежать затрат на синхронизацию, но, с другой, приводит к дополнительным затратам памяти.
И если для исполнения на центральном процессоре объем дополнительной памяти будет равен 350 МБ при использовании 8 потоков, то для работы на сопроцессоре Intel Xeon Phi с 240 потоками понадобится хранить уже более 10 GB данных.
Еще одна особенность алгоритма состоит в необходимости хранения траектории каждого отдельного фотона в процессе его трассировки. Это связано с тем, что до окончания трассировки фотона узнать, попал ли он в детектор, нельзя. Соответственно, если фотон попал в детектор, траектория его движения суммируется с общей картой траекторий для данного детектора, а если нет – игнорируется.
В базовой версии выделяется массив для хранения траектории для каждого потока. С точки зрения структур данных используется все та же трехмерная сетка, соответственно размер массива равен 4 МБ. Перед началом трассировки каждого отдельного фотона этот массив обнуляется.
Процесс оптимизации программы начнем с выполнения ее прямого переноса на сопроцессор. Для этого скомпилируем программу под Intel Xeon Phi с помощью скрипта mic_make.sh.
Отметим, что для переноса используется режим работы только на сопроцессоре. Выбор этого режима обусловлен отсутствием необходимости модифицировать код для его запуска на Intel MIC. А значит мы можем выполнять оптимизацию и отладку одного и того же кода параллельно на CPU и на сопроцессоре.
Выполнение программы на 8 потоках CPU для моделирования 100 000 фотонов занимает 35 секунды. При запуске в 1 поток это время равно 125 секундам.
Используемый в тестах сопроцессор обладает 8 GB встроенной памяти, поэтому запустить программу в текущей версии в 240 потоков не представляется возможным. Использование же 120 потоков дает время выполнения в 63 секунды. А на 60 потоках Intel Xeon Phi программа работает еще быстрее – 57 секунд.
Таким образом, прямой перенос базовой версии программы позволяет получить производительность на сопроцессоре, вдвое меньшую, чем производительность одного 8-ми ядерного CPU.
Оптимизация 1: обновление структуры данных для хранения траектории фотона в процессе трассировки
Перед началом оптимизации имеет смысл выявить наиболее медленные участки программы. Для этого воспользуемся профилировщиком Intel VTune Amplifier XE. Запустим программу в 4 потока с количеством трассируемых фотонов 20 000. Результаты времени работы функций программы приведены на рис. 3.7.
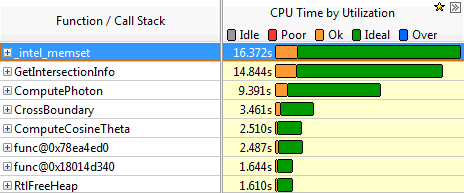
Рис. 3.7. Результаты профилировки базовой версии программы
Как видно из графиков, наибольшее время занимает функция memset(). Единственным местом в программе, где она используется, является функция трассировки фотона ComputePhoton() (./Base/xmcml/mcml_kernel.cpp):
void ComputePhoton(double specularReflectance,
InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, uint64* trajectory)
{
PhotonState photon;
int trajectorySize = input->area->partitionNumber.x*
input->area->partitionNumber.y*
input->area->partitionNumber.z;
memset(trajectory, 0, trajectorySize * sizeof(uint64));
…
}
Функция memset() предназначена для того, чтобы обнулять память для хранения текущей траектории фотона перед его трассировкой. Эта память выделяется один раз для каждого потока в начале работы программы. Напомним, что элемент массива trajectory соответствует ячейке трехмерной сетки и хранит количество посещений фотоном данной ячейки. Размер массива для нашего примера равен 100*100*50 элементов или 4 МБ.
Следует отметить, что кроме необходимости обнуления памяти на каждой итерации, данный подход обладает еще несколькими недостатками. А именно, размер массива слишком велик по сравнению с размером L2 кэш памяти, и доступ к элементам массива осуществляется в случайном порядке (в силу случайности траектории фотона).
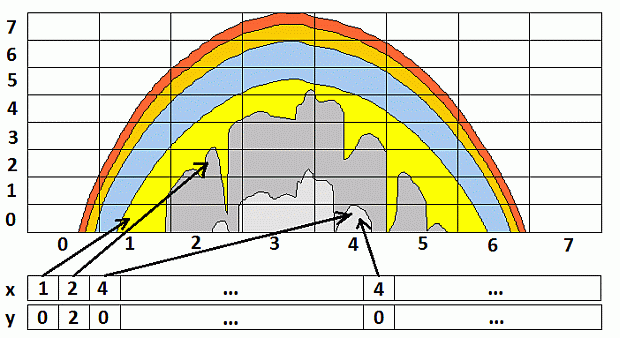
увеличить изображение
Рис. 3.8. Хранение числа посещений фотоном ячеек сетки в виде списка координат этих ячеек
Для устранения описанных выше недостатков предлагается использовать другую структуру данных для хранения траектории фотона: следует хранить не число посещений данной ячейки для всей сетки, а список координат посещенных ячеек (рис. 3.8) (./Opt1/xmcml/mcml_kernel_types.h):
#define MAX_TRAJECTORY_SIZE 2048
typedef struct __PhotonTrajectory
{
byte x[MAX_TRAJECTORY_SIZE];
byte y[MAX_TRAJECTORY_SIZE];
byte z[MAX_TRAJECTORY_SIZE];
uint size;
} PhotonTrjectory;
Массивы x, y и z хранят координаты ячеек сетки в трехмерном пространстве, size – текущая длина траектории.
Экспериментальные данные показывают, что максимальная длина траектории фотона в данном примере не превосходит 2048 шагов (эта величина существенно зависит от параметров биотканей и размера сетки). Размер структуры данных в этом случае составляет всего 6 КБ.
Для того чтобы использовать эту новую структуру данных, в программу необходимо внести некоторые изменения.
Во-первых, в функции LaunchOMP() меняем часть, связанную с выделением памяти под траекторию (./Opt1/xmcmlLauncher/launcher_omp.cpp):
void LaunchOMP(InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, int numThreads)
{
…
#pragma omp parallel
{
int threadId = omp_get_thread_num();
InitOutput(input, &(threadOutputs[threadId]));
threadOutputs[threadId].specularReflectance =
specularReflectance;
PhotonTrjectory trajectory;
for (uint64 i = threadId;
i < input->numberOfPhotons; i += numThreads)
{
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]), &trajectory);
}
}
…
}
Во-вторых, в функции ComputePhoton() избавляемся от обнуления памяти (./Opt1/xmcml/mcml_kernel.cpp):
void ComputePhoton(double specularReflectance, InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, PhotonTrjectory* trajectory)
{
PhotonState photon;
trajectory->size = 0;
…
}
И в-третьих, необходимо исправить функции работы с траекторией. Исправляем код функции UpdatePhotonTrajectory() (./Opt1/xmcml/mcml_kernel.cpp):
void UpdatePhotonTrajectory(PhotonState* photon, InputInfo* input, OutputInfo* output,
PhotonTrjectory* trajectory, double3 previousPhotonPosition)
{
…
while ((plane <= finishPosition.z) && (plane <
input->area->corner.z + input->area->length.z))
{
double3 intersectionPoint =
GetPlaneSegmentIntersectionPoint(startPosition,
finishPosition, plane);
byte3 areaIndexVector =
GetAreaIndexVector(intersectionPoint,
input->area);
if (areaIndexVector.x == 255 &&
areaIndexVector.y == 255 &&
areaIndexVector.z == 255)
break;
assert(trajectory->size < MAX_TRAJECTORY_SIZE);
trajectory->x[trajectory->size] =
areaIndexVector.x;
trajectory->y[trajectory->size] =
areaIndexVector.y;
trajectory->z[trajectory->size] =
areaIndexVector.z;
++(trajectory->size);
int index = areaIndexVector.x*
input->area->partitionNumber.y*
input->area->partitionNumber.z +
areaIndexVector.y*
input->area->partitionNumber.z +
areaIndexVector.z;
++(output->commonTrajectory[index]);
plane += step;
}
}
Функция assert() используется для генерации ошибки в случае, если реальная длина траектории фотона будет больше, чем размер массива, выделенного под ее хранение. Для использования этой функции следует подключить заголовочный файл "assert.h".
Здесь byte3 – новый тип данных (./Opt1/xmcml/mcml_types.h):
typedef union __byte3
{
struct { int x, y, z; };
struct { int cell[3]; };
} byte3;
Функцию GetAreaIndexVector() также следует добавить (./Opt1/xmcml/mcml_kernel.cpp):
byte3 GetAreaIndexVector(double3 photonPosition,
Area* area)
{
byte3 result;
result.x = 255;
result.y = 255;
result.z = 255;
double indexX = area->partitionNumber.x*
(photonPosition.x - area->corner.x)/area->length.x;
double indexY = area->partitionNumber.y*
(photonPosition.y - area->corner.y)/area->length.y;
double indexZ = area->partitionNumber.z*
(photonPosition.z - area->corner.z)/area->length.z;
bool isPhotonInArea = !((indexX < 0.0 ||
indexX >= area->partitionNumber.x) ||
(indexY < 0.0 || indexY >= area->partitionNumber.y)
|| (indexZ < 0.0 ||
indexZ >= area->partitionNumber.z));
if (isPhotonInArea)
{
result.x = (byte)indexX;
result.y = (byte)indexY;
result.z = (byte)indexZ;
}
return result;
}
И наконец, необходимо полностью обновить функцию UpdateDetectorTrajectory() (./Opt1/xmcml/mcml_kernel.cpp):
void UpdateDetectorTrajectory(OutputInfo* output,
Area* area, PhotonTrjectory* trajectory,
int detectorId)
{
int index;
int ny = area->partitionNumber.y;
int nz = area->partitionNumber.z;
uint64* detectorTrajectory =
output->detectorTrajectory[detectorId].trajectory;
for (int i = 0; i < trajectory->size; ++i)
{
index = trajectory->x[i]*ny*nz +
trajectory->y[i]*nz + trajectory->z[i];
++(detectorTrajectory[index]);
}
++(output->detectorTrajectory[detectorId].
numberOfPhotons);
}Изменение используемой структуры данных позволило сократить время вычислений на CPU в 1 поток до 106 секунд (на 18%). При этом моделирование с использованием 8 потоков CPU стало занимать 32 секунды (ускорение на 9%). Время работы программы на MIC в 60 потоков сократилось до 56, а на 120 – до 48 секунд. Таким образом, описанная выше оптимизация позволила уменьшить время вычислений с использованием сопроцессора на 31%.
Оптимизация 2: отказ от использования дублирующих массивов
Основной недостаток текущей версии программы состоит в том, что мы не можем использовать все возможности сопроцессора – число потоков, на которых мы можем запустить программу, ограничено объемом памяти сопроцессора. И если при работе на CPU использование дублирующих массивов – вполне нормальная и часто применяемая практика, то при переходе на Intel Xeon Phi эта техника не всегда себя оправдывает.
В нашем случае дублирование выполнено для двух типов результатов: общей фотонной карты траекторий и фотонных карт для каждого из детекторов. Объем операций доступа к этим массивам существенно различен. Общая фотонная карта траекторий обновляется каждым фотоном, в то время как фотонные карты детекторов обновляются реже, так как далеко не каждый фотон попадает в тот или иной детектор. С другой стороны, суммарный размер фотонных карт для всех детекторов на порядок превосходит размер общей фотонной карты (в примере это 40 и 4 МБ соответственно).
Отказ от дублирования общей фотонной карты с одной стороны приводит к существенным затратам на синхронизацию, а с другой – выигрыш по памяти в этом случае не так велик.
Таким образом, наиболее эффективным выглядит отказ от дублирующих массивов только для фотонных карт детекторов. В этом случае существенно уменьшается размер дополнительно используемой памяти, а затраты на синхронизацию будут не так велики. Вероятность, что в одно и то же время фотоны из разных потоков попадут в детекторы, невелика.
Заметим, что в данной версии мы отказываемся от дублирования еще одного массива – массива сигналов на детекторах (output->weightInDetector). Целесообразность такого решения предлагается оценить слушателю в рамках дополнительных заданий.
Для реализации предложенной идеи прежде всего следует избавиться от дублирования данных. Основные изменения коснутся функции параллельного запуска процесса моделирования LaunchOMP() (./Opt2/xmcmlLauncher/launcher_omp.cpp):
void LaunchOMP(InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, int numThreads)
{
…
#pragma omp parallel
{
int threadId = omp_get_thread_num();
InitThreadOutput(&(threadOutputs[threadId]),
output);
PhotonTrjectory trajectory;
for (uint64 i = threadId;
i < input->numberOfPhotons; i += numThreads)
{
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]), &trajectory);
}
}
output->specularReflectance = specularReflectance;
for (int i = 0; i < numThreads; ++i)
{
for (int j = 0; j < output->gridSize; ++j)
{
output->commonTrajectory[j] +=
threadOutputs[i].commonTrajectory[j];
}
}
for (int i = 0; i < numThreads; ++i)
{
FreeThreadOutput(threadOutputs + i);
}
delete[] threadOutputs;
}
Финальное суммирование осталось только для общей фотонной карты, вместо функций InitOutput() и FreeOutput() используются (./Opt2/xmcmlLauncher/launcher_omp.cpp):
void InitThreadOutput(OutputInfo* dst, OutputInfo* src)
{
dst->gridSize = src->gridSize;
dst->detectorTrajectory = src->detectorTrajectory;
dst->numberOfDetectors = src->numberOfDetectors;
dst->numberOfPhotons = src->numberOfPhotons;
dst->specularReflectance = src->specularReflectance;
dst->weightInDetector = src->weightInDetector;
dst->commonTrajectory = new uint64[dst->gridSize];
memset(dst->commonTrajectory, 0, dst->gridSize*sizeof(uint64));
}
void FreeThreadOutput(OutputInfo* output)
{
if (output->commonTrajectory != NULL)
{
delete[] output->commonTrajectory;
}
}
Избавившись от дублирования, необходимо позаботиться о синхронизации. Для этого прежде нужно изменить функцию UpdateDetectorTrajectory() (./Opt2/xmcml/mcml_kernel.cpp):
void UpdateDetectorTrajectory(OutputInfo* output, Area* area, PhotonTrjectory* trajectory, int detectorId)
{
int index;
int ny = area->partitionNumber.y;
int nz = area->partitionNumber.z;
uint64* detectorTrajectory =
output->detectorTrajectory[detectorId].trajectory;
for (int i = 0; i < trajectory->size; ++i)
{
index = trajectory->x[i]*ny*nz +
trajectory->y[i]*nz + trajectory->z[i];
#pragma omp atomic
++(detectorTrajectory[index]);
}
#pragma omp atomic
++(output->detectorTrajectory[detectorId].
numberOfPhotons);
}
Также изменению подвергнется функция UpdateWeightInDetector() (./Opt2/xmcml/mcml_kernel.cpp):
void UpdateWeightInDetector(OutputInfo* output,
double photonWeight, int detectorId)
{
#pragma omp atomic
output->weightInDetector[detectorId] += photonWeight;
}
Время работы программы на центральном процессоре после применения оптимизации практически не изменилось. Время работы программы на сопроцессоре в 120 потоков уменьшилось до 36 секунд. Более того, появилась возможность запуска программы в 240 потоков. Однако время моделирования в этом случае составило 40 секунд. Итого, данная оптимизация позволила сократить время вычислений на сопроцессоре еще на 35%.
Оптимизация 3: балансировка нагрузки
Профилировка программы с использованием Intel VTune Amplifier XE выявила еще одну особенность используемого алгоритма – разное время выполнения отдельных потоков (рис. 3.9).

увеличить изображение
Рис. 3.9. Диаграмма исполнения потоков на CPU (до балансировки нагрузки)
В текущей версии программы используется статическая схема балансировки нагрузки, при которой каждый поток проводит трассировку примерно одинакового количества фотонов.
Более эффективным будет использование динамической схемы балансировки нагрузки. Динамическая балансировка осуществляется средствами библиотеки OpenMP (./Opt3/xmcmlLauncher/launcher_omp.cpp):
void LaunchOMP(InputInfo* input, OutputInfo* output, MCG59* randomGenerator, int numThreads)
{
…
OutputInfo* threadOutputs = new OutputInfo[numThreads];
for (int i = 0; i < numThreads; ++i)
{
InitThreadOutput(&(threadOutputs[i]), output);
}
PhotonTrjectory* trajectory =
new PhotonTrjectory[numThreads];
#pragma omp parallel for schedule(dynamic)
for (uint64 i = 0; i < input->numberOfPhotons; ++i)
{
int threadId = omp_get_thread_num();
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]),
&(trajectory[threadId]));
}
…
delete[] trajectory;
}
Время работы программы на CPU после проведенной оптимизации незначительно уменьшилось, а на сопроцессоре уменьшилось еще на 9% до 32 секунд.

увеличить изображение
Рис. 3.10. Диаграмма исполнения потоков на CPU (после балансировки нагрузки)
Сводные результаты
Результаты тестовых запусков алгоритма для моделирования переноса излучения на центральном процессоре и сопроцессоре приведены ниже (таблица 3.1 и таким образом, в результате проделанных оптимизаций удалось повысить производительность программы для intel xeon phi вдвое. причем минимальное время работы достигается за счет использования 120 потоков сопроцессора. такой результат, а так же невысокая эффективность распараллеливания программы, объясняется достаточно большим количеством операций чтения/записи данных в алгоритме, а также наличием синхронизации в оптимизированных версиях. Таблица 13.2 соответственно).
| Число ядер CPU | ||||
|---|---|---|---|---|
| 1 | 2 | 4 | 8 | |
| Базовая версия | 125,41 | 71,57 | 46,41 | 34,65 |
| Оптимизация 1 | 105,85 | 57,49 | 38,98 | 31,7 |
| Оптимизация 2 | 104,74 | 57,19 | 41,56 | 32,17 |
| Оптимизация 3 | 103,79 | 61,85 | 40,41 | 30,54 |
Таким образом, в результате проделанных оптимизаций удалось повысить производительность программы для Intel Xeon Phi вдвое. Причем минимальное время работы достигается за счет использования 120 потоков сопроцессора. Такой результат, а так же невысокая эффективность распараллеливания программы, объясняется достаточно большим количеством операций чтения/записи данных в алгоритме, а также наличием синхронизации в оптимизированных версиях.
| Число ядер CPU | |||
|---|---|---|---|
| 60 | 120 | 240 | |
| Базовая версия | 57,74 | 63,05 | - |
| Оптимизация 1 | 56,28 | 48,15 | - |
| Оптимизация 2 | 43,36 | 35,5 | 40,41 |
| Оптимизация 3 | 38,1 | 32,45 | 44,64 |
Сравнение времени работы лучших версий программы для процессора и сопроцессора при различном числе трассируемых фотонов продемонстрировано на рис. 3.11.
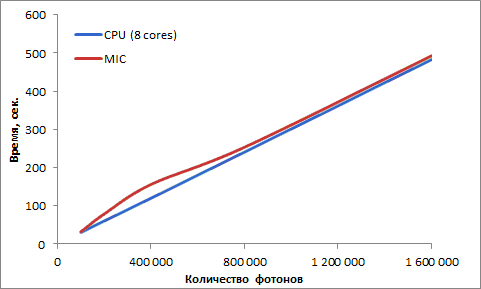
Рис. 3.11. Сравнение времени работы программы для моделирования переноса излучения на CPU и Intel MIC
Приведенные результаты показывают линейную сложность алгоритма в зависимости от количества трассируемых фотонов, время работы программы на сопроцессоре Intel Xeon Phi примерно соответствует времени ее работы на CPU.
Отметим, что продемонстрированные в работе техники оптимизации не являются исчерпывающими для данной задачи, в частности, не описана векторизация кода, применение которой является одним из важнейших способов повысить эффективность программы на Intel Xeon Phi.
Еще одна особенность программы – применение алгоритма поиска пересечения фотона с границами слоя на каждом шаге моделирования. Как показывают результаты профилировки (рис. 3.7), это один из самых трудоемких этапов алгоритма моделирования, а значит, необходим анализ существующих алгоритмов поиска пересечений с целью выбора наиболее подходящего для работы на сопроцессоре, и его дальнейшая оптимизация.
Отдельного обсуждения заслуживает и выбор модели программирования на сопроцессоре, которую следует использовать для переноса. Режим "исполнения только на сопроцессоре" оптимален на начальном этапе, когда оптимизация проводится одновременно на CPU и на Intel Xeon Phi. Однако для более эффективного использования сопроцессора имеет смысл использовать один из гетерогенных (CPU + MIC) режимов: offload или симметричный.
И, наконец, не стоит пренебрегать такими стандартными подходами к оптимизации кода на Intel Xeon Phi, как работа с выровненными данными, использование команд программной предвыборки данных и др.
Дополнительные задания
- Реализовать версию алгоритма с дублированием массива сигналов на детекторах – output->weightInDetector (избавиться от синхронизации записи результатов в этот массив). Оценить целесообразность такой оптимизации.
- Реализовать версию алгоритма, работающего в режиме offload. Выносить на сопроцессор имеет смысл только распараллеленную часть кода, все остальное должно делаться на процессоре.
- Применить технику двойной буферизации в режиме offload для обеспечения эффективной передачи результатов моделирования с сопроцессора на CPU. На каждой итерации, начиная со второй, в момент обсчета новой порции фотонов можно организовать передачу результатов трассировки предыдущей порции на CPU.
Лекция 4. Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Линейные сортировки
Введение
Хаос – это порядок, который нам непонятен.
Презентацию к лабораторной работе Вы можете скачать здесь.
Сортировка (упорядочивание) данных имеет очевидное практическое применение во многих областях (решение систем линейных уравнений, упорядочивание графов [[22]], базы данных и др.). На протяжении многих лет изучение алгоритмов сортировки является неотъемлемой частью курсов "Алгоритмы и структуры данных", читаемых как в российских, так и в зарубежных университетах. По данной теме по-прежнему публикуются статьи, предлагающие миру новые идеи и подходы к их реализации. Кажущаяся элементарность постановки задачи не должна удивлять математиков: не все, что просто формулируется, просто решается; чего только стоит известная проблема о доказательстве теоремы Ферма, решение которой потребовало столько времени и усилий. Казалось бы, причем тут сортировка? С проникновением информатики в школьную программу чуть ли не любой ученик выпускного класса может описать алгоритм для упорядочивания массива. Проблема, однако, в том, что таким, скорее всего весьма простым алгоритмом, не удастся воспользоваться при решении прикладных задач большой размерности, где объемы упорядочиваемых данных исчисляются десятками миллионов элементов. В современном мире число таких задач и их важность неуклонно растут. Решение их на одном компьютере становится невозможным, в дело вступают мощные вычислительные системы – кластеры и суперкомпьютеры, содержащие тысячи и десятки тысяч многопроцессорных многоядерных вычислительных устройств. Эффективное использование таких систем для упорядочивания данных является актуальной задачей.
Алгоритмы сортировки рассматриваются в огромном числе источников. Прежде всего, необходимо отметить фундаментальную работу [[23]], освещающую многие классические алгоритмы и раскрывающую методику их анализа. Полезно ознакомиться и с другими источниками, среди которых один из лучших в мире учебников по алгоритмам и структурам данных, подготовленный в MIT, первые два издания которого переведены на русский язык [[21]], а недавно вышедшее третье издание [[20]] содержит важные рекомендации по распараллеливанию сортировки слиянием. Также необходимо отметить работу М.В. Якобовского [[22]], рассмотревшего распараллеливание алгоритмов сортировки для кластерных систем. Есть и другие источники, безусловно заслуживающие внимания, среди которых как печатные издания [[24]-[26] и др.], так и публикации в интернет [[27]-[29]].
Алгоритмы сортировки можно классифицировать по-разному. Для одних алгоритмов время работы существенно зависит от входных данных, для других – нет. Одни алгоритмы быстро сортируют уже упорядоченные или почти упорядоченные массивы, другие не обладают таким свойством. Некоторые сортировки упорядочивают данные без использования дополнительной памяти (in-place), другие требуют создания дополнительных массивов. Обратим основное внимание на время работы. С этой точки зрения можно разделить множество алгоритмов сортировки на те, которые основаны на использовании операции сравнения (время работы ![]() , и, те, которые, как это не странно звучит, обходятся без нее (время работы
, и, те, которые, как это не странно звучит, обходятся без нее (время работы ![]() . Имеющаяся литература наиболее подробно описывает первый класс алгоритмов, выделяя в нем медленные "пузырьковые" сортировки, работающие за время
. Имеющаяся литература наиболее подробно описывает первый класс алгоритмов, выделяя в нем медленные "пузырьковые" сортировки, работающие за время ![]() (метод выбора, метод вставки, метод пузырька и др.), и так называемые "быстрые" сортировки (сортировка слиянием, метод Хоара, сортировка кучей и др.), в среднем работающие за время
(метод выбора, метод вставки, метод пузырька и др.), и так называемые "быстрые" сортировки (сортировка слиянием, метод Хоара, сортировка кучей и др.), в среднем работающие за время ![]() . Теоретически доказано, что этот результат является наилучшим в данном классе. По нашим наблюдениям и публикациям в открытой печати наибольшей популярностью на практике пользуется сортировка Хоара, не требующая дополнительной памяти, имеющая малую константу при
. Теоретически доказано, что этот результат является наилучшим в данном классе. По нашим наблюдениям и публикациям в открытой печати наибольшей популярностью на практике пользуется сортировка Хоара, не требующая дополнительной памяти, имеющая малую константу при ![]() nlogn и простая в реализации. Главный недостаток алгоритма, состоит в том, что время его работы в худшем случае все-таки достигает
nlogn и простая в реализации. Главный недостаток алгоритма, состоит в том, что время его работы в худшем случае все-таки достигает ![]() , однако при случайном выборе ведущего элемента (pivot) этого почти никогда не происходит. Алгоритм может быть реализован как рекурсивно, так и итеративно. Итеративная реализация с использованием собственного стека более безопасна с точки зрения отсутствия проблемы переполнения системного стека, а также ориентировочно на 20% быстрее рекурсивной (в книге [[26]] приведены рекомендации по подготовке итеративной версии). Еще одно важное достоинство метода Хоара состоит в достаточно эффективном использовании кэш-памяти.
, однако при случайном выборе ведущего элемента (pivot) этого почти никогда не происходит. Алгоритм может быть реализован как рекурсивно, так и итеративно. Итеративная реализация с использованием собственного стека более безопасна с точки зрения отсутствия проблемы переполнения системного стека, а также ориентировочно на 20% быстрее рекурсивной (в книге [[26]] приведены рекомендации по подготовке итеративной версии). Еще одно важное достоинство метода Хоара состоит в достаточно эффективном использовании кэш-памяти.
В данной лабораторной работе рассматривается алгоритм из другого класса, работающий за время ![]() .
. ![]() , – линейная поразрядная сортировка (Radix Sort). Практика показывает, что указанный алгоритм не слишком сложен в программной реализации и хорошо себя показывает при упорядочивании огромных объемов данных. Одна из главных проблем – распараллеливание. Зачастую получается, что лучший последовательный алгоритм имеет сугубо последовательную природу, в связи с чем приходится либо брать менее эффективный, но распараллеливаемый алгоритм, либо делить массив на блоки с целью их сортировки и последующего слияния. Демонстрации подобных проблем и некоторых подходов к их решению в существенно многоядерных системах с общей памятью посвящена данная лабораторная работа.
, – линейная поразрядная сортировка (Radix Sort). Практика показывает, что указанный алгоритм не слишком сложен в программной реализации и хорошо себя показывает при упорядочивании огромных объемов данных. Одна из главных проблем – распараллеливание. Зачастую получается, что лучший последовательный алгоритм имеет сугубо последовательную природу, в связи с чем приходится либо брать менее эффективный, но распараллеливаемый алгоритм, либо делить массив на блоки с целью их сортировки и последующего слияния. Демонстрации подобных проблем и некоторых подходов к их решению в существенно многоядерных системах с общей памятью посвящена данная лабораторная работа.
Ускорители являются специализированными вычислителями и не предназначены для эффективного решения всех существующих задач. Они часто используются при решении задач, в которых допускается эффективная векторная обработка данных и имеется большой запас внутреннего параллелизма. В данной работе специально рассматривается "тяжелая" задача для реализации на сопроцессоре, в которой огромное число операций доступа к памяти и практически нет вычислений. В работе демонстрируются некоторые подходы к оптимизации и распараллеливанию подобных приложений.
Методические указания
Цели и задачи работы
Цель данной работы – изучение подходов к распараллеливанию алгоритмов упорядочивания данных, работающих за линейное время, в существенно многоядерных системах.
Данная цель предполагает решение следующих основных задач:
- Подготовка тестовой инфраструктуры для проведения экспериментов с последовательными и параллельными реализациями алгоритмов сортировки больших вещественных массивов данных.
- Рассмотрение разных способов распараллеливания алгоритма LSD для традиционных систем с общей памятью, а также существенно многоядерных систем на базе Intel Xeon Phi, анализ результатов, выявление существующих проблем и обсуждение возможных подходов к их решению.
- Демонстрация подходов к оптимизации и распараллеливанию программ, решающих задачи, изначально достаточно "тяжелые" для эффективной параллельной реализации.
Структура работы
Работа построена следующим образом. Ставится задача упорядочивания данных. Описываются подходы к распараллеливанию одного из самых эффективных алгоритмов линейной сортировки (LSD). Проводится сравнение с параллельной сортировкой, включенной в библиотеку Intel TBB. Изучаются проблемы при распараллеливании алгоритма LSD и возможные подходы к их решению. Результаты подтверждаются вычислительными экспериментами, как на процессорах общего назначения, так и на сопроцессоре Intel Xeon Phi. Студентам предлагаются задачи для самостоятельной проработки.
Тестовая инфраструктура
Вычислительные эксперименты проводились с использованием инфраструктуры представленной в таблице ниже (табл.4.1).
| Процессор | 2 восьмиядерных процессора Intel Xeon E5-2690 (2.9 GHz) |
| Память | 64 GB |
| Операционная система | Linux CentOS 6.2 |
| Сопроцессор | 2 сопроцессора Intel Xeon Phi 7110X (61 ядро) |
| Компилятор, профилировщик, отладчик, математическая библиотека | Intel Parallel Studio XE 2013:
|
Рекомендации по проведению занятий
Для выполнения лабораторной работы рекомендуется следующая последовательность действий.
- Дать введение в проблематику упорядочивания больших объемов данных, обзор наиболее показательных алгоритмов.
- Описать программную инфраструктуру для проведения экспериментов.
- Провести вычислительные эксперименты с последовательной реализацией алгоритма LSD. Убедиться в корректности, обратить внимание на производительность.
- Реализовать параллельные алгоритмы для систем с общей памятью с применением разных подходов. Рассмотреть подходы к разработке параллельных программ под Intel Xeon Phi и обсудить результаты экспериментов. Выполнить анализ полученных результатов.
- Сформулировать основные выводы, дать задания для самостоятельной проработки
Разработка проекта
Возьмём за основу последовательную версию сортировки LSD из лабораторной работы "Сортировки" из курса "Параллельные численные методы". Заметим, что в указанной работе разработка выполнялась под ОС Windows, в то время как в текущей – будет выполняться под ОС Linux (CentOS 6.2). Это отличие является существенным и мы его будем учитывать при разработке.
В процессе разработки будут использовать следующие инструменты:
- PuTTY – доступ к консоли Linux [[35]];
- WinSCP – манипуляция с файлами [[36]];
- mcedit, vi – текстовые редакторы [[37]];
- icc – компилятор Intel C++ Compiler;
- taskset – выбор ядер, на которых будет запускаться приложение.
Портировние под Linux
Разработанный программный код LSD не получится сразу скомпилировать под Linux:
- В Linux нет заговочного файла windows.h. Строку #include "windows.h" необходимо удалить из программного кода.
- Измерение времени с помощью функций QueryPerformanceCounter не поддерживается в Linux.
Внесём изменения в программный код. Время будем измерять с помощью функций TBB. Добавим требуемый заголовочный файл:
#include "tbb/tick_count.h"
Внесём изменения в программный код измерения времени функции main:
tick_count start, finish;
…
start = tick_count::now();
LSDSortDouble(mas, size, nThreads);
finish = tick_count::now();
…
printf("Execution time: %lf\n",
(finish - start).seconds());
Сборка программы под Linux
Скопируйте исходные коды портированной версии поразрядной сортировки LSD (main.cpp) на машину под управлением Linux с помощью WinSCP. Зайдите на машину с установленным Intel C++ Compiler с помощью PuTTY и выполните сборку программы:
-sh-4.1$ icc -tbb -mkl -lrt main.cpp -o sort.out
В результате будет собран исполняемый модуль sort.out1) .
Сборка под Intel Xeon Phi
Для сборки программы под Intel Xeon Phi нужно добавить ключ –mmic:
-sh-4.1$ icc –mmic -tbb -mkl -lrt main.cpp -o sort_mic.out
Полученная после компиляция программа sort_mic.out должна запускаться непосредственно на сопроцессоре Intel Xeon Phi.
Проведение экспериментов
Для проведения экспериментов удобно использовать скрипты. Ниже приведён пример скрипта на Shell для проведения серийных экспериментов. Для удобства дальнейшей обработки, формат вывода программы sort.out был изменён:
#!/bin/sh
var0_end=245
var1=5000000
var1_end=105000000
step=5000000
while test "$var1" != "$var1_end"
do
var0=1
while test "$var0" != "$var0_end"
do
./sort.out -r $var1 $var0 666 >> log_$var1
./sort.out -r $var1 $var0 666 >> log_$var1
./sort.out -r $var1 $var0 666 >> log_$var1
echo "" >> log_$var1
echo "$var1 $var0 "
var0=`expr $var0 + 1`
done
var1=`expr $var1 + $step`
done
С помощью подобных скриптов проводились эксперименты как на хостовой машине с процессором общего назначения, так и на сопроцессоре Intel Xeon Phi.
Обратим особое внимание на архитектуру процессоров, на которых будут проводиться эксперименты (табл. 1). На хостовой машине установлено два процессора Intel Xeon E5-2690 с базовой частотой 2.9 GHz. Каждый процессор содержит 8 ядер по 2 потока на каждом (Hyper Threading). Таким образом, на хостовой машине доступно 32 логических процессора. Нумерация ядер в системе следующая2):
- логические процессоры с номером от 0 до 7 – ядра первого процессора (первые потоки),
- от 8 до 15 – ядра первого процессора (вторые потоки),
- от 16 до 23 – ядра второго процессора (первые потоки),
- от 24 до 31 – ядра второго процессора (вторые потоки).
Итак, каждая пара логических процессоров с номерами (0, 8), (1, 9), (2, 10) и т.д. принадлежат отдельному ядру. Таким образом, параллельную программу в 2 потока можно запустить тремя различными способами, которые будут отличаться использованием аппаратных возможностей системы:
- На одном ядре (например, на логических ядрах 0 и 8).
- На двух ядрах одного процессора (например, на логических ядрах 0 и 1).
- На двух ядрах разных процессоров (например, на логических ядрах 0 и 16).
С помощью утилиты taskset можно задать ядра, на которых будет запускаться приложение. Таким образом, планировщик потоков ОС будет распределять потоки программы только между этими ядрами. Обратим внимание, что привязки потоков к ядрам происходить не будет – потоки могут перемещаться между ядрами. Для запуска приложения не более чем по одному потоку на ядро можно использовать утилиту taskset следующим образом:
-sh-4.1$ taskset -c 0-7,16-23 ./sort.out –r 1000000 16 666
Сопроцессор Intel Xeon Phi 7110X имеет 61 ядро по 4 потока на каждом (244 логических процессора). Базовая частота ядер 1.2 Ghz. Нумерация ядер отличается от хостовой. Логические процессоры в группах с номерами (1, 2, 3, 4), (5, 6, 7, 8) и т.д. принадлежат отдельному ядру. Стоить обратить внимание на логический процессор с номером ноль. Он принадлежит одному ядру вместе с логическими процессорами 241, 242, 243.
Параллельная реализация
Простое слияние
Можно выделить два подхода к реализации параллельного алгоритма сортировки: внутренняя реализация параллельного алгоритма или внешнее распараллеливание за счёт слияния отсортированных частей.
Алгоритм побайтовой восходящей сортировки заключается в последовательном применении сортировки подсчётом к каждому байту чисел, поэтому параллельно может выполняться только сортировка подсчётом для каждого байта. При этом параллельная версия сортировки подсчётом должна сохраняться свойство устойчивости сортировки (а это тяжелая задача). Этот алгоритм будет рассмотрен позднее.
Идея параллельной реализации с использованием слияния заключается в выполнении следующих шагов:
- Сортировка частей массива.
- Слияние отсортированных частей массива.
Сортировка частей массива может выполняться без каких-либо синхронизаций, поэтому теоретическое ускорение этого этапа является линейным. Этап слияние в зависимости от алгоритма может иметь различную эффективность.
Идея простого слияния заключается в том, что один поток может выполнять слияние двух отсортированных массивов по классическому алгоритму. В этом случае слияние n массивов могут выполнять n/2 параллельных потоков. На следующем шаге слияние n/2 полученных массивов будут выполнять n/4 потоков и т.д. (рис. 4.1). Таким образом, последнее слияние будет выполнять один поток, а учитывая, что сортировка частей массива имеет линейную трудоемкость, то слияние вносит существенный вклад во время работы алгоритма.
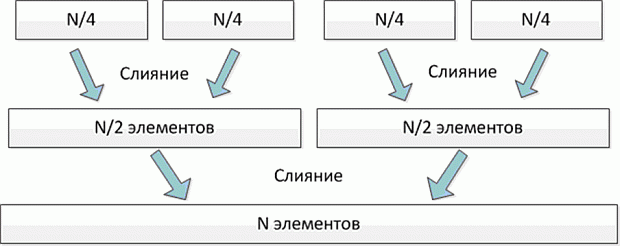
увеличить изображение
Рис. 4.1. Простое слияние
Создайте пустой файл main.cpp и скопируйте в него код из файла main_lsd1.cpp.
Параллельную реализацию слияния построим на основе рекурсивного алгоритма с использованием tbb::task. Каждый экземпляр класса LSDParallelSorter будет выполнять сортировку части массива либо за счёт вызова последовательного алгоритма (если размер сортируемой части массива достаточно мал), либо за счёт слияния уже отсортированных массивов с помощью метода Split().
class LSDParallelSorter:public task
{
private:
double *mas;
double *tmp;
int size;
int portion;
void Split(int size1, int size2)
{
for(int i=0; i<size1; i++)
tmp[i] = mas[i];
double *mas2 = mas + size1;
int a = 0;
int b = 0;
int i = 0;
while( (a != size1) && (b != size2))
{
if(tmp[a] <= mas2[b])
{
mas[i] = tmp[a];
a++;
}
else
{
mas[i] = mas2[b];
b++;
}
i++;
}
if (a == size1)
for(int j=b; j<size2; j++)
mas[size1+j] = mas2[j];
else
for(int j=a; j<size1; j++)
mas[size2+j] = tmp[j];
}
public:
LSDParallelSorter(double *_mas, double *_tmp, int _size,
int _portion): mas(_mas), tmp(_tmp),
size(_size), portion(_portion)
{}
task* execute()
{
if(size <= portion)
{
LSDSortDouble(mas, tmp, size);
}
else
{
LSDParallelSorter &sorter1 = *new (allocate_child())
LSDParallelSorter(mas, tmp, size/2, portion);
LSDParallelSorter &sorter2 = *new (allocate_child())
LSDParallelSorter(mas + size/2, tmp + size/2,
size - size/2, portion);
set_ref_count(3);
spawn(sorter1);
spawn_and_wait_for_all(sorter2);
Split(size/2, size - size/2);
}
return NULL;
}
};
Функция LSDParallelSortDouble() создаёт корневой task, начиная с которого будет разворачиваться рекурсия. В этой функции также создаётся вспомогательный массив размера size и выполняется вычисление размера порции, которая определяет, будет вызываться последовательный алгоритм поразрядной сортировки или, начиная с этого размера, будет выполняться слияние.
void LSDParallelSortDouble(double *inp, int size,
int nThreads)
{
double *out=new double[size];
int portion = size/nThreads;
if(size%nThreads != 0)
portion++;
LSDParallelSorter& sorter = *new (task::allocate_root())
LSDParallelSorter(inp ,out, size, portion);
task::spawn_root_and_wait(sorter);
delete[] out;
}
Далее осталось лишь заменить вызов функции сортировки.
... start = tick_count::now(); LSDParallelSortDouble(mas, size, nThreads); finish = tick_count::now(); ...
Соберите получившуюся реализацию для Intel Xeon Phi и проведите тест для 10 миллионов элементов при разном числе потоков на сопроцессоре. Результаты, полученные авторами на тестовой инфраструктуре, представлены на рис. 4.2.
Рис. 4.2. Результаты работы параллельной побайтовой восходящей сортировки при использовании простого слияния на Intel Xeon Phi
Здесь мы запускали только вариант со случайным заполнением, но с разным числом потоков. Можно заметить, что время работы программы в 40 и 80 потоков практически не отличается. Это свидетельствует о том, что трудоёмкость побайтовой сортировки соизмерима со временем слияния массивов. При увеличении количества потоков количество слияний также увеличивается, а для небольшого массива элементов это приводит к тому, что слияние начинает занимать больше времени, чем сортировка. Из-за этого время работы программы в 120 и 244 потока ощутимо больше, чем в 40. Для наглядности приведём график времени сортировки 10 миллионов элементов с помощью параллельного алгоритма LSD с использованием простого слияния на сопроцессоре (рис. 4.3).
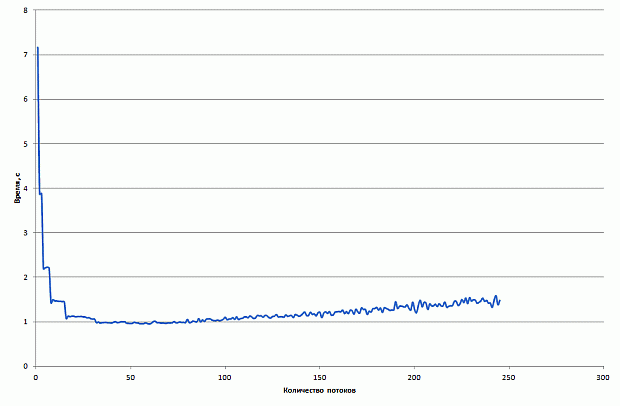
увеличить изображение
Рис. 4.3. Время сортировки 10 миллионов элементов с помощью параллельного алгоритма LSD с использованием простого слияния на Intel Xeon Phi
Ступенчатость графика вызвана особенностью параллельного алгоритма, который использует для вычислений только количество потоков равное степени 2. Остальные потоки просто не используются. Т.е. при запуске в ![]() , потоков будет использоваться только из них. Приведём аналогичный график для 100 миллионов элементов.
, потоков будет использоваться только из них. Приведём аналогичный график для 100 миллионов элементов.
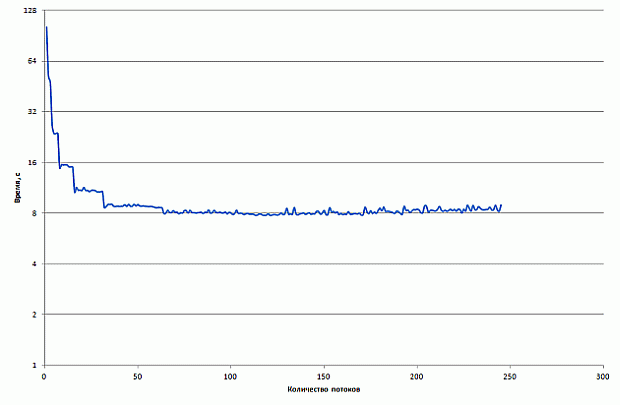
увеличить изображение
Рис. 4.4. Время сортировки 100 миллионов элементов с помощью параллельного алгоритма LSD с использованием простого слияния на Intel Xeon Phi
Максимальное ускорение, равное 13, достигается при использовании 128 потоков.
Чётно-нечетное слияние Бэтчера
Чётно-нечётное слияние Бэтчера заключается в том, что два упорядоченных массива, которые необходимо слить, разделяются на чётные и нечётные элементы [[22]]. Такое слияние может быть выполнено параллельно. Чтобы массив стал окончательно отсортированным, достаточно сравнить пары элементов, стоящие на нечётной и чётной позициях. Первый и последний элементы массива проверять не надо, т.к. они являются минимальным и максимальным элементов массивов.
Чётно-нечётное слияние Бэтчера позволяет задействовать 2 потока при слиянии двух упорядоченных массивов. В этом случае слияние n массивов могут выполнять n параллельных потоков. На следующем шаге слияние n/2 полученных массивов будут выполнять n/2 потоков и т.д. На последнем шаге два массива будут сливать 2 потока.
увеличить изображение
Рис. 4.5. Чётно-нечётное слияние Бэтчера
Создайте пустой файл main.cpp и скопируйте в него код из файла main_lsd2.cpp.
Классы EvenSplitter и OddSplitter выполняют слияние чётных и нечётных элементов массивов соответственно.
class EvenSplitter:public task
{
private:
double *mas;
double *tmp;
int size1;
int size2;
public:
EvenSplitter(double *_mas, double *_tmp, int _size1,
int _size2): mas(_mas), tmp(_tmp),
size1(_size1), size2(_size2)
{}
task* execute()
{
for(int i=0; i<size1; i+=2)
tmp[i] = mas[i];
double *mas2 = mas + size1;
int a = 0;
int b = 0;
int i = 0;
while( (a < size1) && (b < size2))
{
if(tmp[a] <= mas2[b])
{
mas[i] = tmp[a];
a+=2;
}
else
{
mas[i] = mas2[b];
b+=2;
}
i+=2;
}
if (a == size1)
for(int j=b; j<size2; j+=2,i+=2)
mas[i] = mas2[j];
else
for(int j=a; j<size1; j+=2,i+=2)
mas[i] = tmp[j];
return NULL;
}
};
class OddSplitter:public task
{
private:
double *mas;
double *tmp;
int size1;
int size2;
public:
OddSplitter(double *_mas, double *_tmp, int _size1,
int _size2): mas(_mas), tmp(_tmp),
size1(_size1), size2(_size2)
{}
task* execute()
{
for(int i=1; i<size1; i+=2)
tmp[i] = mas[i];
double *mas2 = mas + size1;
int a = 1;
int b = 1;
int i = 1;
while( (a < size1) && (b < size2))
{
if(tmp[a] <= mas2[b])
{
mas[i] = tmp[a];
a+=2;
}
else
{
mas[i] = mas2[b];
b+=2;
}
i+=2;
}
if (a == size1)
for(int j=b; j<size2; j+=2,i+=2)
mas[i] = mas2[j];
else
for(int j=a; j<size1; j+=2,i+=2)
mas[i] = tmp[j];
return NULL;
}
};
Класс SimpleComparator выполняется сравнение чётных и нечётных пар элементов массива, проходя по массиву один раз.
class SimpleComparator
{
private:
double *mas;
int size;
public:
SimpleComparator(double *_mas, int _size): mas(_mas), size(_size)
{}
void operator()(const blocked_range<int>& r) const
{
int begin = r.begin(), end = r.end();
for(int i=begin; i<end; i++)
if(mas[2*i] < mas[2*i-1])
{
double _tmp = mas[2*i-1];
mas[2*i-1] = mas[2*i];
mas[2*i] = _tmp;
}
}
};Класс LSDParallelSorter как и ранее реализует рекурсивный алгоритм слияния, выполняя последовательную сортировку, в том случае, если размер сортируемой порции массива меньшее, чем значение поля portion (значение этого поля задаётся при создании объекта в функции LSDParallelSortDouble()).
class LSDParallelSorter:public task
{
private:
double *mas;
double *tmp;
int size;
int portion;
public:
LSDParallelSorter(double *_mas, double *_tmp, int _size,
int _portion): mas(_mas), tmp(_tmp),
size(_size), portion(_portion)
{}
task* execute()
{
if(size <= portion)
{
LSDSortDouble(mas, tmp, size);
}
else
{
int s = size/2 + (size/2)%2;
LSDParallelSorter &sorter1 = *new (allocate_child())
LSDParallelSorter(mas, tmp, s, portion);
LSDParallelSorter &sorter2 = *new (allocate_child())
LSDParallelSorter(mas + s, tmp + s, size - s,
portion);
set_ref_count(3);
spawn(sorter1);
spawn_and_wait_for_all(sorter2);
EvenSplitter &splitter1 = *new (allocate_child())
EvenSplitter(mas, tmp, s, size - s);
OddSplitter &splitter2 = *new (allocate_child())
OddSplitter(mas, tmp, s, size - s);
set_ref_count(3);
spawn(splitter1);
spawn_and_wait_for_all(splitter2);
parallel_for(blocked_range<int>(1, (size+1)/2),
SimpleComparator(mas, size));
}
return NULL;
}
};
Соберите получившуюся реализацию для Intel Xeon Phi и проведите тест для 10 миллионов элементов при разном числе потоков на сопроцессоре. Результаты, полученные авторами на Intel Xeon Phi, представлены на рис. 4.6.
Рис. 4.6. Результаты параллельной побайтовой восходящей сортировки при использовании чётно-нечётного слияния Бэтчера на Intel Xeon Phi
Здесь мы запускали только вариант со случайным заполнением, но с разным числом потоков. Результаты очень похожи на предыдущие. Для наглядности приведём графики времени сортировки 10 миллионов (рис. 4.7) и 100 миллионов (рис. 4.8) элементов с помощью параллельного алгоритма LSD с использованием чётно-нечётного слияния Бэтчера на сопроцессоре.
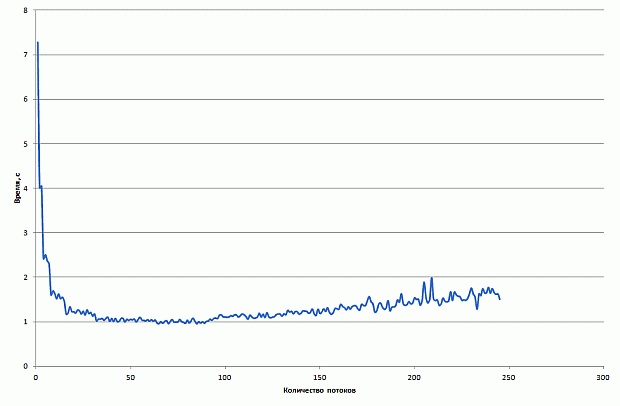
увеличить изображение
Рис. 4.7. Время сортировки 10 миллионов элементов с помощью параллельного алгоритма LSD с использованием чётно-нечётного слияния Бэтчера на Intel Xeon Phi
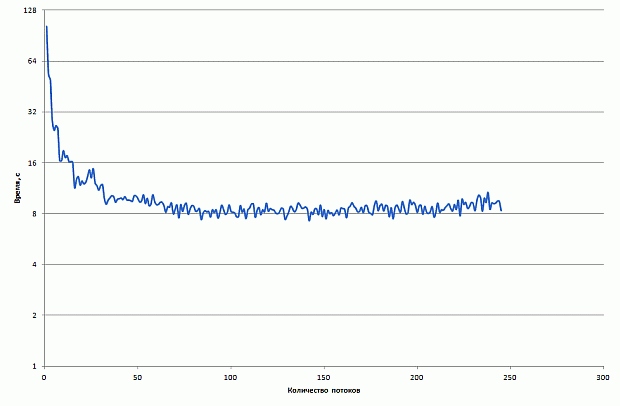
увеличить изображение
Рис. 4.8. Время сортировки 100 миллионов элементов с помощью параллельного алгоритма LSD с использованием чётно-нечётного слияния Бэтчера на Intel Xeon Phi
Максимальное ускорение, равное 14.1, достигается при использовании 142 потоков.
Слияние "Разделяй и властвуй"
Идея слияния по алгоритму "Разделяй и властвуй" заключается в разбиении массивов на участки, которые можно слить независимо [[27]]. В первом массиве выбирается центральный элемент x (он разбивает массив на две равные половины), а во втором массиве с помощью бинарного поиска находится позиция наибольшего элемента меньшего x (позиция этого элемента разбивает второй массив на две части). После такого разбиения первые и вторые половины массивов могут сливать независимо, т.к. в первых половинах находятся элементы меньшие элемента x, а во второй – большие (рис. 4.9). Для слияния двух массивов несколькими потоками можно в первом массиве выбрать несколько ведущих элементов, разделив его на равные порции, а во втором массиве найти соответствующие подмассивы. Каждый поток получит свои порции на обработку.
Эффективность такого слияние во многом зависит от того, насколько равномерно произошло "разделение" второго массива.
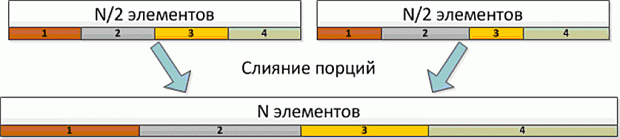
увеличить изображение
Рис. 4.9. Слияние "Разделяй и властвуй"
Создайте пустой файл main.cpp и скопируйте в него код из файла main_lsd3.cpp.
Класс Splitter выполняет слияние двух отсортированных массивов.
class Splitter:public task
{
private:
double *mas1;
double *mas2;
double *tmp;
int size1;
int size2;
public:
Splitter(double *_mas1, double *_mas2, double *_tmp,
int _size1, int _size2): mas1(_mas1),
mas2(_mas2), tmp(_tmp), size1(_size1),
size2(_size2)
{}
task* execute()
{
int a = 0;
int b = 0;
int i = 0;
while( (a != size1) && (b != size2))
{
if(mas1[a] <= mas2[b])
{
tmp[i] = mas1[a];
a++;
}
else
{
tmp[i] = mas2[b];
b++;
}
i++;
}
if (a == size1)
{
int j = b;
for(; j<size2; j++, i++)
tmp[i] = mas2[j];
}
else
{
int j=a;
for(; j<size1; j++, i++)
tmp[i] = mas1[j];
}
return NULL;
}
};
Класс LSDParallelSorter реализует рекурсивный алгоритм слияния, выполняя последовательную сортировку, в том случае, если размер сортируемой порции массива меньше, чем значение поля portion (значение этого поля задаётся при создании объекта в функции LSDParallelSortDouble). Слияние двух отсортированных массивов начинается с разбиения массивов на порции (для этого используется метод BinSearch(), реализующий бинарный поиск). Далее создаются задачи для слияния каждой пары полученных подмассивов и выполняется их параллельный запуск на выполнение.
class LSDParallelSorter:public task
{
private:
double *mas;
double *tmp;
int size;
int portion;
int threads;
private:
int BinSearch(double *mas, int l, int r, double x)
{
if(l==r)
return l;
if(l+1==r)
if(x<mas[l])
return l;
else
return r;
int m = (l+r)/2;
if(x<mas[m])
r = m;
else
if(x>mas[m])
l=m;
else
return m;
return BinSearch(mas, l, r, x);
}
public:
LSDParallelSorter(double *_mas, double *_tmp, int _size,
int _portion, int _threads): mas(_mas),
tmp(_tmp), size(_size),
portion(_portion), threads(_threads)
{}
task* execute()
{
if(size <= portion)
{
LSDSortDouble(mas, tmp, size);
}
else
{
LSDParallelSorter &sorter1 = *new (allocate_child())
LSDParallelSorter(mas, tmp, size/2, portion,
threads/2);
LSDParallelSorter &sorter2 = *new (allocate_child())
LSDParallelSorter(mas + size/2, tmp + size/2,
size - size/2, portion,
threads/2);
set_ref_count(3);
spawn(sorter1);
spawn_and_wait_for_all(sorter2);
Splitter **sp = new Splitter*[threads-1];
int s = size/2;
s /= threads;
int l = 0, r = s;
int l2 = 0, r2;
for(int i=0; i<threads-1; i++)
{
double x = mas[r];
r2 = BinSearch(mas + size/2, 0, size - size/2, x);
sp[i] = new (allocate_child())
Splitter(mas+l, mas + size/2 + l2,
tmp+l+l2, r-l, r2-l2);
l += s;
r += s;
l2 = r2;
}
Splitter &spl = *new (allocate_child())
Splitter(mas+l, mas + size/2 + l2,
tmp+l+l2, size/2-l,
size - size/2 - l2);
set_ref_count(threads+1);
for(int i=0; i<threads-1; i++)
spawn(*(sp[i]));
spawn_and_wait_for_all(spl);
for(int i=0; i<size; i++)
mas[i] = tmp[i];
delete[] sp;
}
return NULL;
}
};
В функцию LSDParallelSortDouble() необходимо внести небольшие изменения, т.к. теперь в конструктор класса LSDParallelSorter передаётся количество потоков.
void LSDParallelSortDouble(double *inp, int size,
int nThreads)
{
double *out=new double[size];
int portion = size/nThreads;
if(size%nThreads != 0)
portion++;
LSDParallelSorter& sorter = *new (task::allocate_root())
LSDParallelSorter(inp ,out, size, portion, nThreads);
task::spawn_root_and_wait(sorter);
delete[] out;
}
Соберите получившуюся реализацию и проведите тест для 10 миллионов элементов при разном числе потоков. Результаты, полученные авторами на тестовой инфраструктуре, представлены на рис. 4.10.
Рис. 4.10. Результаты параллельной побайтовой восходящей сортировки при использовании слияния "Разделяй и властвуй" на Intel Xeon Phi
Здесь мы запускали только вариант со случайным заполнением, но с разным числом потоков. Результаты очень похожи на предыдущие. Для наглядности приведём графики времени сортировки 10 миллионов (рис. 4.11) и 100 миллионов (рис. 4.12) элементов с помощью параллельного алгоритма LSD с использованием слияния "Разделяй и властвуй" на сопроцессоре.

увеличить изображение
Рис. 4.11. Время сортировки 10 миллионов элементов с помощью параллельного алгоритма LSD с использованием слияния "Разделяй и властвуй" на Intel Xeon Phi
увеличить изображение
Рис. 4.12. Время сортировки 100 миллионов элементов с помощью параллельного алгоритма LSD с использованием слияния "Разделяй и властвуй" на Intel Xeon Phi
Максимальное ускорение, равное 19.7, достигается при использовании 129 потоков.
Параллельная поразрядная сортировка
Наиболее эффективными параллельными алгоритмами являются те, которые имеют внутренний параллелизм.
Алгоритм побайтовой сортировки заключается в последовательном применении сортировки подсчётом к каждому байту чисел, поэтому параллельно может выполняться только сортировка подсчётом для каждого байта. Сортировка подсчётом состоит из двух этапов: подсчёт количества элементов и их размещение. Первый этап может быть выполнен параллельно над частями массива и в последующем редуцирован. Второй этап может быть выполнен параллельно только в том случае, если при его выполнении будет сохраняться свойство устойчивости сортировки. Для этого достаточно пересчитать смещения для каждой порции массива.
Параллельный алгоритм сортировки подсчётом будет состоять из следующих шагов:
- Для каждого потока создаётся массив подсчётов и заполняется нулями.
- Каждый поток получает на обработку часть массива и выполняет подсчёт элементов в свой массив подсчётов.
- С помощью массивов подсчётов со всех потоков выполняется вычисление смещений, по которым будут располагаться элементы при втором проходе по массиву.
- Каждый поток получает на обработку ту же часть массива, что и ранее, и выполняет копирование элемента во вспомогательный массив по соответствующему индексу в массиве смещений.
Ниже представлен программный код указанного алгоритма с использованием TBB. Класс Counter выполняет подсчёт по указанному байту количества элементов.
class Counter:public task
{
double *mas;
int size;
int byteNum;
int *counter;
public:
Counter(double *_mas, int _size, int _byteNum,
int *_counter) : mas(_mas), size(_size),
byteNum(_byteNum), counter(_counter)
{}
task* execute()
{
unsigned char *masUC=(unsigned char *)mas;
memset(counter, 0, sizeof(int)*256);
for(int i=0; i<size; i++)
counter[masUC[8*i+byteNum]]++;
return NULL;
}
};
Класс Placer выполняет размещение элементов по указанным смещениям.
class Placer:public task
{
double *inp, *out;
int size;
int byteNum;
int *counter;
public:
Placer(double *_inp, double *_out, int _size,
int _byteNum, int *_counter) : inp(_inp),
out(_out), size(_size), byteNum(_byteNum),
counter(_counter)
{}
task* execute()
{
unsigned char *inpUC=(unsigned char *)inp;
for(int i=0; i<size; i++)
{
out[counter[inpUC[8*i+byteNum]]]=inp[i];
counter[inpUC[8*i+byteNum]]++;
}
return NULL;
}
};
Класс ParallelCounterSort реализует параллельную сортировку подсчётом.
class ParallelCounterSort:public task
{
private:
double *mas;
double *tmp;
int size;
int nThreads;
int *counters;
int byteNum;
public:
ParallelCounterSort(double *_mas, double *_tmp,
int _size, int _nThreads,
int *_counters, int _byteNum):
mas(_mas), tmp(_tmp), size(_size),
nThreads(_nThreads),
counters(_counters),
byteNum(_byteNum)
{}
task* execute()
{
Counter **ctr = new Counter*[nThreads-1];
Placer **pl = new Placer*[nThreads-1];
int s = size / nThreads;
for(int i=0; i<nThreads-1; i++)
ctr[i] = new (allocate_child()) Counter(mas + i*s, s,
byteNum, counters + 256 * i);
Counter &ctrLast = *new (allocate_child())
Counter(mas + s * (nThreads-1),
size - s * (nThreads-1) ,
byteNum,
counters + 256 * (nThreads-1));
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(ctr[i]));
spawn_and_wait_for_all(ctrLast);
int sm = 0;
for(int j=0; j<256; j++)
{
for(int i=0; i<nThreads; i++)
{
int b=counters[j + i * 256];
counters[j + i * 256]=sm;
sm+=b;
}
}
for(int i=0; i<nThreads-1; i++)
pl[i] = new (allocate_child()) Placer(mas + i*s, tmp,
s, byteNum,
counters + 256 * i);
Placer &plLast = *new (allocate_child())
Placer(mas + s * (nThreads-1), tmp,
size - s * (nThreads-1) , byteNum,
counters + 256 * (nThreads-1));
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(pl[i]));
spawn_and_wait_for_all(plLast);
delete[] pl;
delete[] ctr;
return NULL;
}
};
Класс ParallelCounterSort реализует побайтовую восходящую сортировку для типа double. Для этого в методе execute() 8 раз вызывается параллельная поразрядная сортировка.
class LSDParallelSorter:public task
{
private:
double *mas;
double *tmp;
int size;
int nThreads;
public:
LSDParallelSorter(double *_mas, double *_tmp, int _size,
int _nThreads): mas(_mas), tmp(_tmp),
size(_size), nThreads(_nThreads)
{}
task* execute()
{
int *counters = new int[256 * nThreads];
ParallelCounterSort *pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 0);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 1);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 2);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 3);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 4);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 5);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 6);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 7);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
delete[] counters;
return NULL;
}
};
Создайте пустой файл main.cpp и скопируйте в него код из файла main_lsd4.cpp. Добавьте рассмотренный выше программный код в файл main.cpp с заменой реализации класса LSDParallelSorter на новую.
Соберите получившуюся реализацию и проведите тест для 10 миллионов элементов при разном числе потоков. Результаты, полученные авторами на тестовой инфраструктуре, представлены на рис. 4.13.
Рис. 4.13. Результаты параллельной побайтовой восходящей сортировки
Здесь мы запускали только вариант со случайным заполнением, но с разным числом потоков. Для наглядности приведём графики времени сортировки 100 миллионов (рис. 4.14) элементов с помощью параллельного алгоритма LSD на сопроцессоре.
увеличить изображение
Рис. 4.14. Время сортировки 100 миллионов элементов с помощью параллельного алгоритма LSD на Intel Xeon Phi
Максимальное ускорение, равное 56,2, достигает при использовании 115 потоков. Таким образом, алгоритм внутреннего распараллеливания обладает наилучшей масштабируемостью из рассмотренных. Далее разберём этот алгоритм подробнее.
Заключение
Мы рассмотрели 3 алгоритма внешнего распараллеливания сортировки за счёт слияния отсортированных частей. Трудоёмкость слияния является линейной и, при использование сортировок со сложностью ![]() , подобные алгоритмы дают существенный выигрыш. Определяющим тут является асимптотическая трудоёмкость сортировки и алгоритма слияния. При использовании линейных сортировок асимптотический выигрыш пропадает и использование алгоритмов слияния становится неэффективным. При сортировке 100 миллионов элементов удалось достигнуть ускорения всего в 19 раз (всего доступно 61 ядро).
, подобные алгоритмы дают существенный выигрыш. Определяющим тут является асимптотическая трудоёмкость сортировки и алгоритма слияния. При использовании линейных сортировок асимптотический выигрыш пропадает и использование алгоритмов слияния становится неэффективным. При сортировке 100 миллионов элементов удалось достигнуть ускорения всего в 19 раз (всего доступно 61 ядро).
Внутренняя реализация параллельного алгоритма LSD показала себя с лучшей стороны. Максимальное ускорение составило 56 раз по сравнению с последовательной версией.
Анализ параллельной реализации
Для начала, приведём результаты экспериментов на хостовой машине в двух режимах запуска (рис. 4.15):
- Запуск на всех доступных логических процессорах (максимум 32 потока);
- Запуск не более чем одного потока на каждое ядро (максимум 16 потоков).
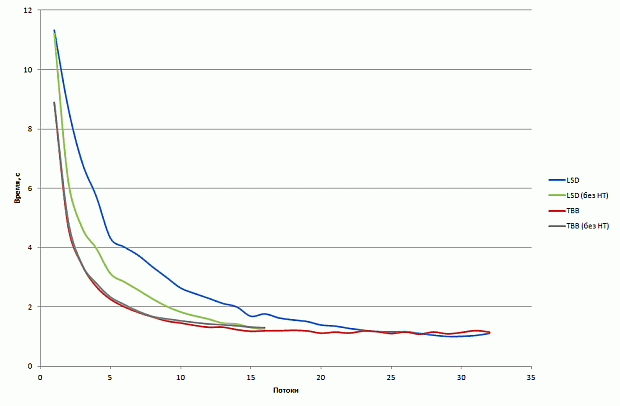
увеличить изображение
Рис. 4.15. Время сортировки 100 миллионов элементов на хосте с привязкой и без привязки к ядрам. Реализации: TBB и LSD (внутренне распараллеливание)
Приведём аналогичные результата при запуске только на одном процессоре (рис. 4.16). Будет снова два режима запуска:
- Запуск на всех доступных логических процессорах (максимум 16 потоков);
- Запуск не более чем одного потока на каждое ядро (максимум 8 потоков).
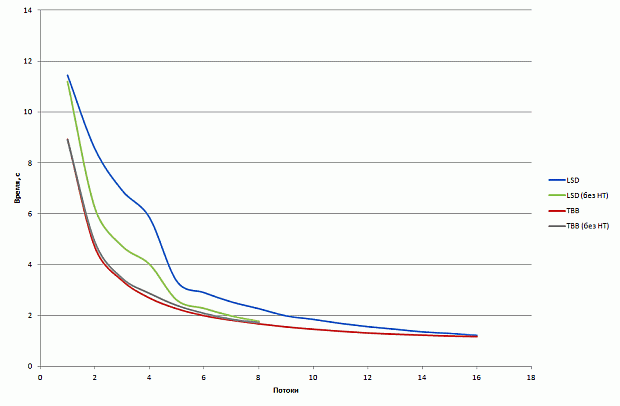
увеличить изображение
Рис. 4.16. Время сортировки 100 миллионов элементов на 1 процессоре на хосте с привязкой и без привязки к ядрам. Реализации: TBB и LSD (внутренне распараллеливание)
Время работы параллельной LSD реализации на одном процессоре (16 потоков) составило 1.22 с, на двух процессорах (32 потока) – 1 с. Далее все эксперименты на хосте будут проводиться на всех доступных логических процессорах.
Реализация сортировки в MKL не является параллельной, поэтому она не приведена на графике выше. На 100 миллионах элементов время сортировки с использованием библиотеки MKL составляет 9.4 с.
Из рис. 4.16 видно, что при запуске приложения в 16 потоков в режиме одного потока на ядро время работы LSD реализации ощутимо меньше, чем при запуске на всех доступных логических ядрах. Планировщик потоков ОС выбирает для приложения наиболее свободные логические процессоры из доступных. Таким образом, когда приложение выполняется на всех логических ядрах, может сложиться ситуация, когда 2 потока будут выполняться на одном ядре, поэтому результат получается достаточно предсказуемым, т.к. два аппаратных потока, работающих на одном ядре, будут конкурировать за ресурсы этого ядра (кэш-память, вычислительные блоки), что снизит общую производительность приложения.
Ниже представлены графики зависимости времени работы параллельных реализаций TBB и LSD в зависимости от количества сортируемых элементов (рис. 4.17). На графике также приведены результаты работы функции сортировки из библиотеки MKL.
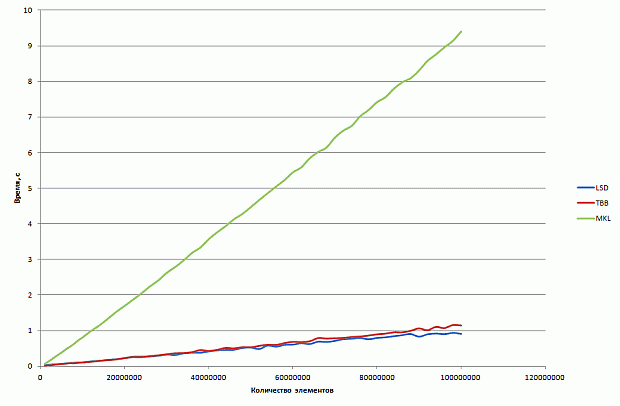
увеличить изображение
Рис. 4.17. Время сортировки при запуске в 32 потока. Реализации: MKL, TBB и LSD (внутренне распараллеливание)
Далее рассмотрим результаты запусков на сопроцессоре. Intel Xeon Phi имеет по 4 аппаратных потока на каждое ядро, поэтому на графике представлены три кривые (рис. 4.18):
- LSD – приложение выполнялось на всех логических процессорах – по 4 потока на ядро;
- LSD:2 – приложение выполнялось только на логических процессорах с нечётными номерами (1, 3, 5, 7 и т.д.)1) – по 2 потока на ядро;
- LSD:4 - приложение выполнялось только на логических процессорах с номерами 1, 5, 9 и т.д. – по 1 потоку на ядро.
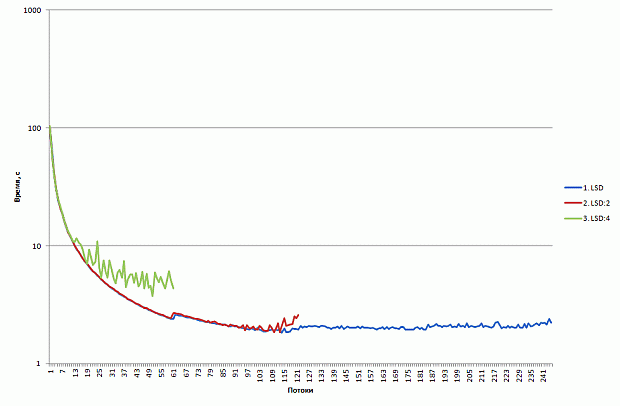
увеличить изображение
Рис. 4.18. Время сортировки 100 миллионов элементов на сопроцессоре с различной привязкой к ядрам
Обратим внимание, что сначала все три графика совпадают. При увеличении количества потоков версия 3 начинает работать медленнее, чем остальные. Дело в том, что в версии LSD:4 количество доступных потоков для приложения ограничено величиной 61 и ОС вынуждена планировать потоки приложения только среди них, при этом в ОС есть и другие потоки, которым требуется процессорное время. Это приводит к конкуренции сторонних потоков за выбранные логические процессоры. Это утверждение будет справедливо и для версии 2 (LSD:2). Для лучшей визуализации данного эффекта имеет смысл для каждого количества потоков выполнить несколько запусков и выбрать среди них минимальное время работы. Тогда кривая LSD:4 будет наиболее близка к LSD:2, а LSD:2 – к LSD. Читателю рекомендуется проделать это самостоятельно.
Для наглядности представим диаграмму времени работы параллельной LSD реализации при сортировке 100 миллионов элементов с привязкой к ядрам.
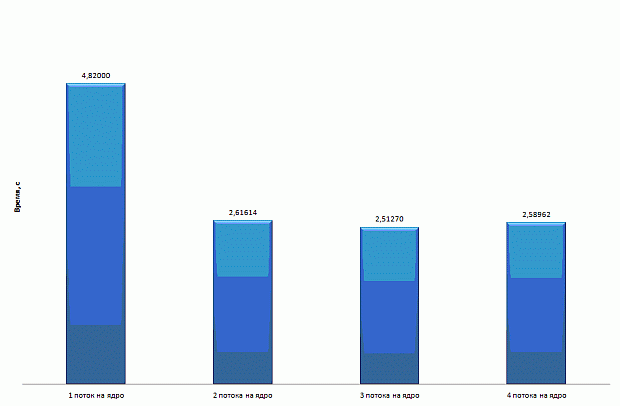
увеличить изображение
Рис. 4.19. Времени работы параллельной LSD реализации при сортировке 100 миллионов элементов с привязкой к ядрам
Приведём график ускорения параллельной LSD реализации на Intel Xeon Phi при сортировке 100 миллиона элементов (рис. 4.20). Отметим, что на границе в 61-62 потока наблюдается резкий скачок времени. На сопроцессоре доступно 61 ядро, а при использовании 62 потоков, как минимум два из всех потоков будут выполняться на одном ядре. Это приводит к конкуренции потоков за ресурсы кэш-памяти ядер.
Максимальное ускорение, а следовательно и минимальное время работы, достигается на 115 потоках и составляет 56,2. Минимальное время работы LSD на сопроцессоре составляет 1,83 с. Таким образом, максимальная эффективность достигается при использовании двух потоков на ядро. Увеличение количества потоков негативно сказывается на времени работы программы из-за возрастающей конкуренции за ресурсы ядер.
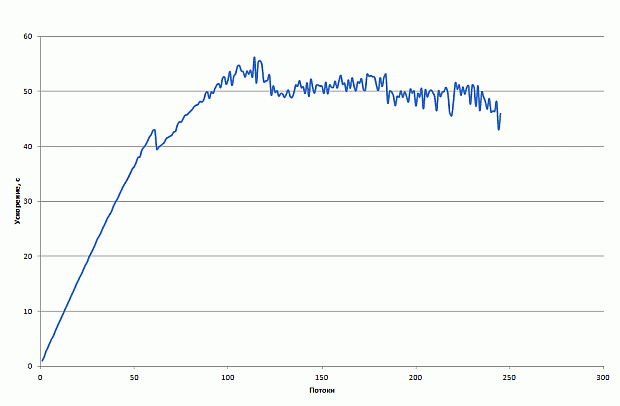
увеличить изображение
Рис. 4.20. Масштабируемость параллельной версии LSD на Intel Xeon Phi
Время работы поразрядной сортировки (LSD) на одном ядре на хосте составило 11,47 с, на сопроцессоре – 102,95 с. Значительное отставание по времени работы на сопроцессоре обусловлено существенной разницей в производительности ядер. Кроме того, как уже отмечалось, однопоточное приложение на Intel Xeon Phi простаивает каждый второй такт процессора. Для наглядности приведём диаграмму времени работы параллельной LSD реализации при запуске на одном ядре (рис. 4.21).
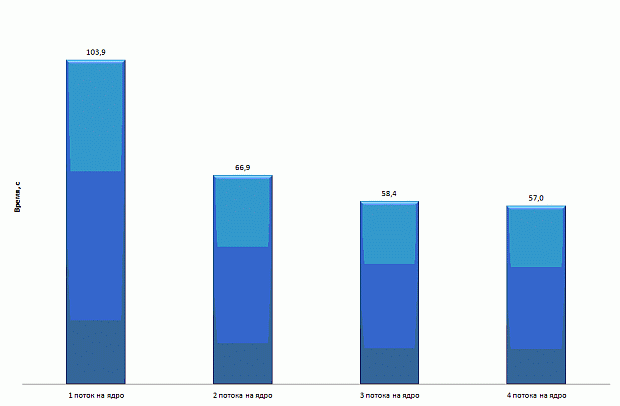
увеличить изображение
Рис. 4.21. Время сортировки 100 миллионов элементов на сопроцессоре на одном ядре
Из рис. 4.21 видно, что при использовании двух потоков на ядро получается существенное ускорение. Использование 4-х потоков на ядро не даёт существенного выигрыша по сравнению с 3-мя.
Ниже представлены графики зависимости времени работы параллельных реализаций TBB и LSD в зависимости от количества сортируемых элементов (рис. 4.22) на хосте и сопроцессоре (MIC). Все реализации запускались на максимально доступном количестве аппаратных потоков: 32 на хосте и 244 на сопроцессоре. Заметим, что лучшее время работы параллельной реализации LSD на сопроцессоре достигается при использовании 115 потоков, но на общем виде графиков это не отразится. Читателю рекомендуется самостоятельно провести эксперименты с выбором оптимального количества потоков для каждого количества сортируемых элементов (для каждой размерности необходимо выполнить запуск на всём диапазоне допустимого количества потоков и выбрать из них минимум).

увеличить изображение
Рис. 4.22. Время сортировки на хосте и сопроцессоре на всех ядрах
Из графиков выше можно сделать вывод, что сортировка не лучшим образом реализуется на сопроцессоре Intel Xeon Phi. Заметим, что минимальное время работы сортировки 100 миллиона элементов на хосте составило 1 с при использование двух процессоров и 1.22 с при использовании одного процессора, на Intel Xeon Phi – 1,83 с. Времена получились сопоставимы. Разберём подробнее полученные результаты.
Анализ параллельной реализации LSD на Intel Xeon Phi
Параллельный алгоритм LSD состоит из следующих шагов:
- 1. Выделение памяти.
- 2. Цикл по количеству байт в сортируемом типе данных1):
- Создание логических задач.
- Подсчёт элементов (Counter).
- Пересчёт массива counters.
- Размещение элементов (Placer).
- Освобождение памяти.
Представим графики времени работы каждого этапа параллельного алгоритма LSD на хосте и сопроцессоре при сортировке 100 миллиона элементов (рис. 4.23, рис. 4.24). Предварительно внесём изменения в программный код и сделаем следующие замечания:
- Количество потоков в программе будем всегда устанавливать в автоматическом режиме.
task_scheduler_init init();
- Параметр nThreads будем так же передавать в функцию сортировки. Таким образом, если nThreads меньше количества потоков, то программа будет использовать только nThreads потоков. Если nThreads больше количества доступных потоков, то часть потоков получат несколько порций массива на обработку. Таким образом, это будет способствовать лучшей балансировке нагрузки между потоками, а параметр nThreads по сути будет задавать размер порции планирования.
- В код программы будут добавлены измерения времени каждого из этапов алгоритма.

увеличить изображение
Рис. 4.23. Профиль параллельной сортировки LSD на хосте
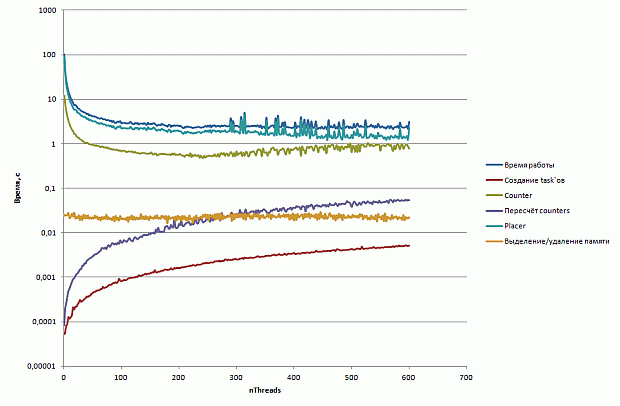
увеличить изображение
Рис. 4.24. Профиль параллельной сортировки LSD на сопроцессоре
Глядя на профили можно сделать следующие выводы:
- Время, которое отводится на выделение/освобождение памяти, создание логических задач и пересчёт элементов массива counters, очень мало по сравнению со временем работы программы и им можно пренебречь. Стоит также отметить, что время выделения/освобождения памяти не зависит от параметра nThreads, в то время как остальные две величины растут при увеличении этого параметра.
- Основной вклад в работу алгоритма вносят подсчёт и размещение элементов.
- На сопроцессоре время подсчёта сначала уменьшается при увеличении nThreads, а потом начинает возрастать из-за возрастающей конкуренции за ресурсы кэш-памяти между потоками.
Задача сортировки не является вычислительной, поэтому её производительность во многом определяется эффективностью использования подсистемы памяти вычислительной системы (в частности кэш-памяти).
Модификация сортировки LSD
Внесём изменения в метод exectute класса Placer1) :
- Избавимся от повторного вычисления значений inpUC[i<<3] .
- Выполним разворачивание цикла на две итерации – это уменьшит ко-личество операций сравнения и снизит зависимость между итерациями.
- Выполним упреждающую загрузку данных в кэш-память с помощью функции _mm_prefetch. Значение _MM_HINT_T0 означает, что данные надо загрузить в ближайший кэш к ядру L1 (а т.к. архитектура кэша инклюзивная, то и в L2).
task* execute()
{
unsigned char *inpUC=(unsigned char *)inp + byteNum;
int end = size - size%2;
int end_prefetch = end-8;
_mm_prefetch((const char*)&(out[counter[inpUC[(0)<<3]]]), _MM_HINT_T0);
_mm_prefetch((const char*)&(out[counter[inpUC[(1)<<3]]]), _MM_HINT_T0);
for(int i=0; i<end_prefetch; i+=2)
{
int next = i+1;
_mm_prefetch(
(const char*)&(out[counter[inpUC[(i+8)<<3]]]),
_MM_HINT_T0);
_mm_prefetch(
(const char*)&(out[counter[inpUC[(i+9)<<3]]]),
_MM_HINT_T0);
int &c1=counter[inpUC[i<<3]];
int &c2=counter[inpUC[next<<3]];
out[c1++]=inp[i];
out[c2++]=inp[next];
}
for(int i=end_prefetch; i<end; i+=2)
{
int &c1=counter[inpUC[i<<3]];
int &c2=counter[inpUC[(i+1)<<3]];
out[c1++]=inp[i];
out[c2++]=inp[i+1];
}
for(int i=end; i<size; i++)
{
int &c=counter[inpUC[i<<3]];
out[c++]=inp[i];
}
return NULL;
}
Внесём изменения в функцию exectute класса LSDParallelSorter, чтобы выделять память под масси-вы объектов один раз.
task* execute()
{
int *counters = new int[256 * nThreads];
int byteNum = 0;
Counter **ctr1 = new Counter*[nThreads-1];
Placer **pl1 = new Placer*[nThreads-1];
Counter **ctr2 = new Counter*[nThreads-1];
Placer **pl2 = new Placer*[nThreads-1];
int s = size / nThreads;
for(;byteNum<8;byteNum+=2)
{
for(int i=0; i<nThreads-1; i++)
{
ctr1[i] = new (allocate_child())
Counter(mas + i*s, s, byteNum, counters + 256 * i);
ctr2[i] = new (allocate_child())
Counter(tmp + i*s, s, byteNum+1, counters + 256 * i);
pl1[i] = new (allocate_child())
Placer(mas + i*s, tmp, s, byteNum, counters + 256 * i);
pl2[i] = new (allocate_child())
Placer(tmp + i*s, mas, s, byteNum+1, counters + 256 * i);
}
Counter &ctrLast1 = *new (allocate_child())
Counter(mas + s * (nThreads-1), size - s * (nThreads-1) ,
byteNum, counters + 256 * (nThreads-1));
Counter &ctrLast2 = *new (allocate_child())
Counter(tmp + s * (nThreads-1), size - s * (nThreads-1) ,
byteNum+1, counters + 256 * (nThreads-1));
Placer &plLast1 = *new (allocate_child())
Placer(mas + s * (nThreads-1),tmp, size - s * (nThreads-1),
byteNum, counters + 256 * (nThreads-1));
Placer &plLast2 = *new (allocate_child())
Placer(tmp + s * (nThreads-1),mas, size - s * (nThreads-1),
byteNum+1, counters + 256 * (nThreads-1));
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(ctr1[i]));
spawn_and_wait_for_all(ctrLast1);
int sm = 0;
for(int j=0; j<256; j++)
{
for(int i=0; i<nThreads; i++)
{
int b=counters[j + i * 256];
counters[j + i * 256]=sm;
sm+=b;
}
}
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(pl1[i]));
spawn_and_wait_for_all(plLast1);
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(ctr2[i]));
spawn_and_wait_for_all(ctrLast2);
sm = 0;
for(int j=0; j<256; j++)
{
for(int i=0; i<nThreads; i++)
{
int b=counters[j + i * 256];
counters[j + i * 256]=sm;
sm+=b;
}
}
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(pl2[i]));
spawn_and_wait_for_all(plLast2);
}
delete[] pl1;
delete[] pl2;
delete[] ctr1;
delete[] ctr2;
delete[] counters;
return NULL;
}
Сравним время работы модифицированной версии и базовой на хосте (рис. 4.25) и сопроцессоре (рис. 4.26, рис. 4.27) при сортировке 100 миллионов эле-ментов.
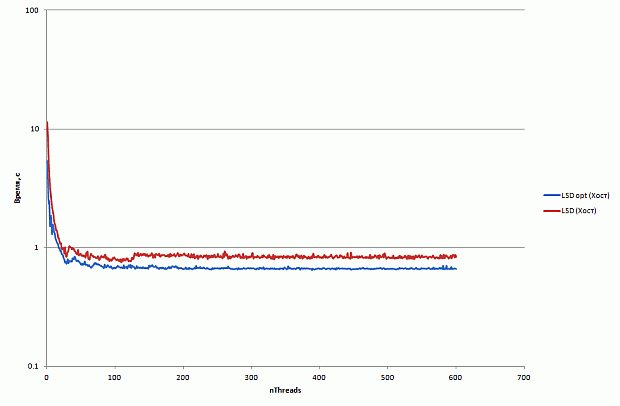
увеличить изображение
Рис. 4.25. Сравнение параллельных реализаций LSD на хосте при сор-тировки 100 миллионов элементов
Модификация позволила ускорить однопоточную версию на хосте с 11. 3 с до 5.3 с, т.е. почти в 2 раза. Параллельная версия стала работать 0.66 с, против 1 с в исходной версии, а при запуске на одном процессоре – 0.72 с, против 1.22 с. Запуск экспериментов на одном процессоре читателю пред-лагается выполнить самостоятельно.
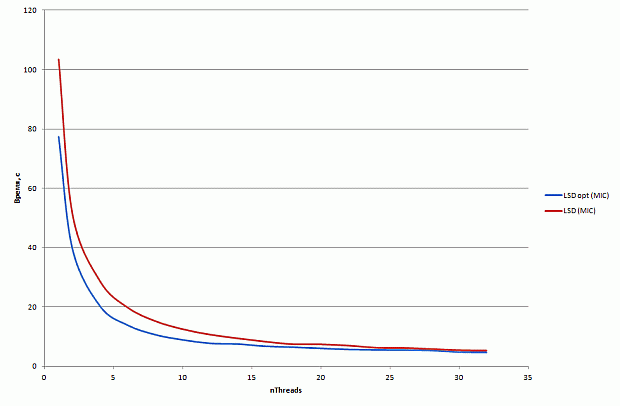
увеличить изображение
Рис. 4.26. Сравнение параллельных реализаций LSD на Intel Xeon Phi при сортировки 100 миллионов элементов (малое значение nThreads)
Однопоточная версия LSD на Intel Xeon Phi после модификация стала ра-ботать 77 с. Исходная версия работала 103 с.
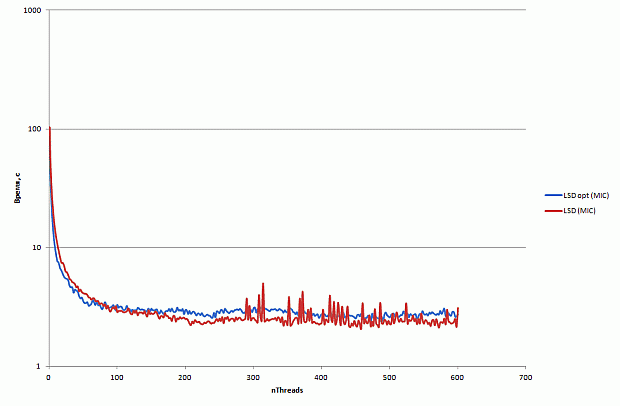
увеличить изображение
Рис. 4.27. Сравнение параллельных реализаций LSD на Intel Xeon Phi при сортировки 100 миллионов элементов
При работе модифицированной версии LSD на большом количестве пото-ков наблюдается проигрыш исходной версии в связи с тем, что возрастает конкуренция потоков за кэш-память процессора, а реализованная упреж-дающая загрузка способствует ещё большей конкуренции за кэш-память.
Для полноты картины приведём профиль модифицированной версии LSD на сортировке 100 миллионов элементов на хосте (рис. 4.28) и сопроцессоре (рис. 4.29).
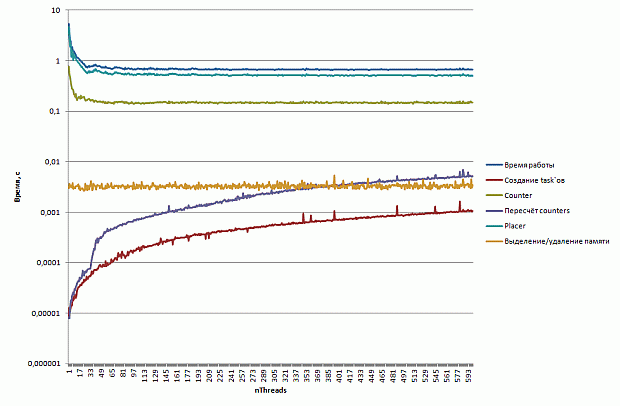
увеличить изображение
Рис. 4.28. Профиль модифицированной параллельной сортировки LSD на хосте при сортировки 100 миллионов элементов
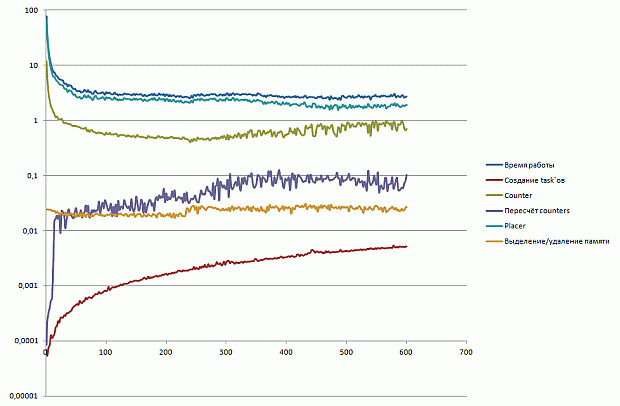
увеличить изображение
Рис. 4.29. Профиль модифицированной параллельной сортировки LSD на сопроцессоре при сортировки 100 миллионов элементов
Заключение
Пиковая теоретическая производительность сопроцессора Intel Xeon Phi 7110X составляет 1.21) терафлопс. Пиковая теоретическая производитель-ность двух процессоров Intel Xeon E5-2690 составляет 3712) гигафлопс.
Разница в пиковой теоретической производительности между сопроцессо-ром и хостом составляет больше 3 раз, но параллельная реализация LSD работает в 3 раза быстрее на хосте, чем на сопроцессоре. Этому есть не-сколько причин:
- Задача сортировки не является вычислительно сложной, поэтому пока-затель количества операций с плавающей запятой в секунду не столь важен. Основная нагрузка ложиться на подсистему памяти и опреде-ляющим является эффективность работы с ней. Intel Xeon Phi имеет большое количество ядер и сложную организацию подсистемы памяти с кэшами на кольцевой шине. Для решения задачи когерентности дан-ных в сопроцессоре используется распределённый словарь. Всё это не-гативно сказывается на скорости работы параллельных программ, об-ладающих низкой степенью локальности данных.
- Подходы к оптимизации, которые работали в параллельных системах с процессорами общего назначения, могут не работать на нестандартной архитектуре Intel Xeon Phi.
Всё вышесказанное справедливо и для сортировки из библиотеки TBB.
Обратим внимание на масштабируемость полученной параллельной реализации. На хосте время работы на одном процессоре (8 ядер) составило 1.22 с, а на двух (16 ядер) – 1 с. Увеличение количества процессоров в два раза даёт крайне малый выигрыш во времени работы. А общее ускорение от использования 16 ядер составило 11 (68.75% от линейного ускорения). На сопроцессоре (61 ядро) удалось достигнуть ощутимо лучшего результата – ускорение более 56 раз, 91.8% от линейного ускорения (стоит, конечно, отметить, что ядра на сопроцессоре проще и однопоточная версия простаивает каждый второй такт). Несмотря на большую разницу в полученном ускорении, времена работы на хосте и сопроцессоре получились сопоставимы (1.22 с на хосте против 1.83 с Xeon Phi). В первую очередь это связано с медленной работой однопоточной версии на сопроцессоре. Таким образом, если оптимизировать программный код под архитектурные особенности Xeon Phi, то на сопроцессоре могут быть получены ощутимо лучшие результаты.
Итак, даже в достаточно сложных для решения на Intel Xeon Phi задачах (а сортировка – именно такая задача в связи с малым запасом внутреннего параллелизма, неудачным соотношением количества вычислительных операций и операций с памятью, сомнительным потенциалом использования векторных вычислений) путем умелой организации вычислений можно добиться приемлемой производительности, что и продемонстрировано в данной работе.
Дополнительные задания
Дополнительные задания имеют разный уровень сложности. Некоторые из них являются достаточно трудоемкими и требуют изучения дополнитель-ной литературы.
Все задания предполагают выполнение реализаций для систем с общей памятью.
- Реализуйте более эффективную генерацию массивов для сортировки (эффективность повысится, если функция viRngUniformBits( будет генерировать большие последовательности бит). Оценить эффективность реализации.
- Реализуйте побайтовую восходящую сортировку для типа double в общем случае (числа могут быть как положительные, так и отрицательные). Оценить эффективность реализации для разных типов сгенерированных последовательностей чисел.
- Реализуйте побайтовую восходящую сортировку для типов int, unsigned int, float. Оценить эффективность реализации.
- Реализуйте побитовую восходящую сортировку для типов int, unsigned int, float, double. Оценить эффективность реализации.
- Реализуйте побайтовую восходящую сортировку для типа double в общем случае (числа могут быть как положительные, так и отрицательные) на Intel Xeon Phi. Оценить эффективность реализации для разных типов сгенерированных последовательностей чисел.
- Реализуйте побайтовую восходящую сортировку для типов int, unsigned int, float на Intel Xeon Phi. Оценить эффективность реализации.
- Реализуйте побитовую восходящую сортировку для типов int, unsigned int, float, double на Intel Xeon Phi. Оценить эффективность реализации.
Дополнения
Дополнение. Инструмент проверки корректности использования памяти и потоков Intel-Inspector-XE-2013-PB--082213
Орингинал текста Вы можете скачать здесь.
Основные возможности
- Проверяет код на языках C, C++, C# и Fortran
- Не требует специальной перекомпиляции. Пользуйтесь обычными параметрами компиляции и сборки
- Проверяет весь исполненный код даже при отсутствии исходников
- Показывает все фрагменты кода c ошибками и соответствующие стеки вызовов
- Новое: поддержка интеграции с отладчиками, упрощающая диагностику трудных ошибок
- Новое: анализ роста динамической памяти помогает найти причины некорректного роста памяти в проблемных участках программы
"Мы целую неделю пытались понять причину аварийного завершения программы. Было установлено, что происходила порча памяти, но источник найти никак не удавалось. Потом мы запустили Intel Inspector XE, и сразу же выяснилось, что еще задолго до самого сбоя происходил выход за пределы массива. Если бы мы сделали это раньше, то сэкономили бы неделю!"
Intel Inspector XE входит в состав следующих пакетов:
- Intel® Parallel Studio XE
- Intel® C++ Studio XE
- Intel® Fortran Studio XE
- Intel® Cluster Studio XE
Поддержка операционных систем:
- Windows*
- Linux*
Создавайте более надежные приложения
Intel Inspector XE 2013 - это удобный инструмент поиска ошибок работы с памятью и потоками для Windows и Linux. Он повышает продуктивность поиска трудновоспроизводимых дефектов, сокращает затраты и ускоряет выпуск программных продуктов на рынок.
Находите ошибки использования памяти и потоков на ранних стадиях цикла разработки. Чем раньше обнаружена ошибка, тем меньше затраты на её исправление. Регулярное использование Intel Inspector XE в разработке и оценка качества программ упрощает поиск и диагностику ошибок на ранних этапах разработки приложения.
Находите ошибки, пропущенные при обычном регрессионном тестировании и статическом анализе. Intel Inspector XE находит скрытые дефекты в исполняемом коде, а также нестабильно проявляющиеся проблемы, причем даже в тех случаях, когда последовательность исполнения потоков, приводящая к ошибке, не реализовалась, а только была возможна.
| Ошибки работы с памятью | Ошибки использования потоков |
|---|---|
|
|
Поддержка C, C++, C#, Fortran или любого сочетания этих языков. Например, если пользовательский интерфейс написан на C#, код высокого быстродействия - на C++, если в программе используется старый код на Fortran или библиотеки без исходников, то Intel Inspector XE поможет во всех этих случаях. Динамический анализ позволяет Intel Inspector XE проверять любой код, в том числе сторонние библиотеки, для которых исходный код недоступен.
Intel Inspector XE легко встраивается в процесс разработки. Для него не нужны специальные настройки компиляции и сборки, достаточно обычных настроек для сборки отладочной версии или релиза. Инспектируйте именно тот код, который вы отлаживаете или готовите к выпуску. Пользуйтесь графическим интерфейсом или автоматизируйте регрессионное тестирование с помощью командной строки. Графический интерфейс можно использовать отдельно в Windows и Linux, а можно интегрировать его в Microsoft Visual Studio.
Бонус: при покупке пакетов инструментов доступны дополнительные возможности проверки кода – статический анализатор и Pointer Checker (проверка корректности работы с указателями). Для работы с Intel Inspector XE обязательно использовать компилятор Intel. Но при покупке пакета инструментов компилятор Intel предоставляет дополнительные функции проверки кода. Статический анализ кода обеспечивает проверку безопасности программы, а Pointer Checker диагностирует некорректный доступ за пределами выделенных блоков памяти.
увеличить изображение
Intel Inspector XE показывает ошибки использования памяти и потоков в исходном коде. Стеки вызовов поясняют, какая последовательность функций привела к проблеме.
Основные возможности Intel Inspector XE
 | Выбор между быстрым и более подробным анализом Первый уровень анализа характеризуется очень низкими накладными расходами, поэтому им удобно пользоваться постоянно во время разработки. Второй уровень (на скриншоте) требует больше времени, но находит больше проблем. Он подходит для использования перед сдачей новой функциональности. Третий уровень оптимален для регрессионного тестирования. |
 | Остановка в отладчике упрощает диагностику ошибок При использовании анализа с отладчиком, Intel Inspector XE прервёт исполнение программы в точке останова непосредственно перед возникновением ошибки. В этот момент остановки в отладчике вы можете проверить значения переменных, стеки вызовов и состояния всех параллельных потоков, приводящие к проблеме. Поддерживаются отладчики Microsoft Visual Studio, GDB и IDB. Для отладки конкретной проблемы выделите её в списке и выберите пункт Debug This Problem в выпадающем меню. |
 | Анализируйте рост памяти и получайте "мгновенные" отчеты об утечках Если вы не можете понять, чем вызван рост динамической памяти в процессе выполнения приложения, провести диагностику поможет функция анализа роста памяти Heap Growth Analysis. Она позволяет получить отчет обо всей памяти, которая была выделена со времени последней контрольной точки и не была овобождена на момент вызова функции Show Leaks/Growth Now. Теперь Intel Inspector XE тажке позволяет получить мгновенный отчет об утечках памяти, происшедших с момента последней контрольной точки. Начало работы программы считается контрольной точкой по умолчанию, а функция Reset Leak/Growth Detection позволяет установить данный момент времени как новую контрольную точку для проверки памяти. |
 | Функция паузы и возобновления ускоряет анализ Ограничивайте анализируемую область приложения, вставляя вызовы API паузы и возобновления анализа в исходном коде. Включайте анализ только для тех участков кода, где предполагаются проблемы. Это снизит задержки анализа на длинных участках кода, которые вас не интересуют. При продуманном применении эта возможность полезна в тех случаях, когда от начала выполнения программы до появления ошибки проходит много времени. |
 | Отключите вывод ложных ошибок и делитесь исключениями с командой Добавляйте ложные ошибки в список исключений, чтобы в следующий раз на них не останавливаться. Можно составить несколько списков исключений и делиться ими с другими участниками проекта. Кроме того, вы можете составлять персональные списки исключений для блокировки вывода ошибок из чужого кода. Исключение отображения ошибок для целого модуля позволит ускорить анализ программы. |
 | Командное взаимодействие Каждая отмеченная ошибка сопровождается информацией о ее состоянии: "новая", "подтвержденная", "исправленная", "не исправленная", "регрессия", "не является проблемой", "отложенная". Это помогает сортировать ошибки и определять их приоритеты. Информацию о состоянии ошибок от нескольких разработчиков можно объединять и делиться ей со всей командой. |
 | Управляйте списком ошибок с помощью фильтров Если вы хотите видеть ошибки только из вашего файла исходного кода, это можно сделать буквально за один клик мыши. Аналогично фильтруются все новые ошибки или только самые критические. Доступны фильтры по целому ряду категорий: уровень критичности, тип ошибки, состояние, модуль и т.д. Фильтры позволяют отсечь "шум" и сфокусироваться на том, что важно. |
 | Находите труднодиагностируемые ошибки выхода за пределы выделенной памяти Pointer Checker (проверка корректности работы с указателями) – механизм диагностики, основанный на возможностях компилятора. Он отлавливает обращения к памяти за пределами зарезервированной области и удобен для поиска висячих указатели, переполнений буфера и т. п. Диагностика проблемы ускоряется благодаря вызову отладчика при возникновении исключения. |
**Bonus feature available when purchased as a part of one of the Intel® Parallel Studio XE family of tool suites.
Подробности
Меньше ложно-положительных срабатываний, более информативные сообщения об ошибках
Intel Inspector XE распознает семантику моделей параллельного программирования Intel® Threading Building Blocks (Intel® TBB), Intel® OpenMP и Intel® Cilk™ Plus, помогая экономить время анализа найденных ошибок.
- Инструмент характеризуется меньшим числом ложно-положительных срабатываний, чем конкурентные продукты.
- Ошибки описываются в понятных терминах исходного кода, нет сложных внутренних обозначений.
Динамический анализ: просто, надежно и точно
В отличие от других инструментов анализа ошибок памяти и многопоточности, Intel Inspector XE не нуждается в специальных процедурах перекомпиляции для анализа - пользуйтесь вашими обычными настройками сборки отладочной версии или релиза. Рекомендуется включать в сборку релизной конфигурации отладочные символы, чтобы Intel Inspector XE мог привязать ошибки к исходному коду программы. Динамический анализ не только ускоряет внедрение Intel Inspector XE в рабочий процесс, не требуя особой перекомпиляции, но также повышает надежность и точность поиска ошибок. Конкурентные продукты, в которых используются методики инструментирования, основанные на статической компиляции, не справляются с динамически генерируемым или линкуемым кодом. Intel Inspector XE анализирует весь код, включая сторонние библиотеки, для которых недоступны исходники.
Одинаковый пользовательский интерфейс в Windows и Linux
Разрабатываете для Windows и Linux? Удобно, когда в разных операционных системах есть одни и те же инструменты анализа. Пользовательский интерфейс Intel Inspector XE одинаков для Windows и Linux. В Windows инструментарий можно использовать отдельно или интегрировать его в Microsoft Visual Studio.
Анализ ошибок использования памяти и многопоточности в приложениях MPI
С появлением многоядерных процессоров и технологии Hyperthreading в некоторых приложениях MPI появилась многопоточность. Intel Inspector XE позволяет искать ошибки использования памяти и потоков в таких приложениях. Многие ошибки обнаруживаются при первичном анализе на системе с общей памятью. Затем стоит провести дополнительный анализ программы на кластере, где полученные результаты сортируются по рангу.
Что нового
| Особенность | Преимущество |
|---|---|
| Точки останова для отладчика | Точки останова упрощают диагностику трудных ошибок, вызывая отладчик непосредственно перед возникновением ошибки. Для диагностики проблемы можно изучать значения переменных и состояния всех потоков программы. Поддерживаются отладчики Visual Studio, GDB и IDB. |
| Анализ роста динамической памяти | Если вы не можете понять, почему при работе приложения растет объем зарезервированной памяти, функция анализа роста памяти в куче поможет выяснить причину. Она выдает перечень выделений памяти, которые не были освобождены на интервале работы программы. Интересующий интервал выбирается с помощью кнопок графического пользовательского интерфейса или включением в код программы специального API. |
Отчет об утечках памяти – в любое время по требованию  | Мгновенно получайте отчеты об утечках памяти в любой точке выполнения программы. Указывайте контрольную точку и просматривайте утечки памяти только с момента ее выполнения. Это позволит сосредоточиться только на утечках за определенный промежуток времени или в определенной секции кода. Отчеты доступны через графический пользовательский интерфейс и вызовы API. |
| Ускоряйте анализ за счет ограничения анализируемых областей программы | С помощью API можно активизировать анализ только в процессе выполнения предположительно проблемного участка кода. При продуманном использовании данная возможность очень помогает в ситуациях, когда от начала работы программы до появления ошибки проходит много времени. |
| Ограничивайте диапазон анализа | Устраняйте ложные ошибки и ускоряйте анализ, используя API для маркировки участков памяти, которые не нужно анализировать (например, содержащие синхронизационные структуры данных). |
| Точный контроль исключений | Создавайте точные правила исключения ложных ошибок, выбирая один или несколько вызовов в стеке ошибки. Делитесь исключениями с коллегами. |
| Поддержка исключений, настроенных для других инструментов | Импортируйте списки исключений из других популярных отладчиков ошибок памяти, например Purify и Valgrind. Переходите на Intel Inspector XE без затрат времени на повторное создание списков исключений. Теперь списки доступны в свободно редактируемом текстовом формате. |
| Улучшенные средства командного взаимодействия | Информацию о состоянии ошибок ("подтверждена", "не является проблемой", "исправлена", "не исправлена" и т. д.), изменяемую несколькими участниками команды, можно объединять и делиться ею. |
| Анализируйте программы для сопроцессора Intel Xeon Phi | С помощью Intel Inspector XE можно анализировать приложения для сопроцессора Intel Xeon Phi. При этом сам инструмент анализа работает на центральном процессоре. Во время анализа приложения, исполняемого на многоядерном процессоре, Intel Inspector XE выявляет ошибки использования памяти и потоков, которые произойдут при выполнении на сопроцессоре Intel Xeon Phi. |
| Анализ приложений MPI | Находите ошибки использования памяти в приложениях MPI. Обнаруживайте ошибки использования памяти и потоков в гибридных приложениях на основе MPI и OpenMP. Intel Inspector XE легко устанавливается на кластере и обеспечивает просмотр результатов анализа с сортировкой по рангу. |
| OpenMP 4.0 | Intel Inspector XE поддерживает семантику OpenMP и благодаря этому может выдавать сообщения об ошибках в терминах из исходного кода, а не с использованием непонятных внутренних обозначений этой библиотеки параллельного программирования. Кроме того, инструментарий выдает меньше ложных сообщений об ошибках. |
 – Новое со времени выхода gold-релиза. В обновлениях продукта новая функциональность появляется регулярно. При наличии действующего договора на оказание услуг поддержки обновления предоставляются без дополнительной оплаты.
– Новое со времени выхода gold-релиза. В обновлениях продукта новая функциональность появляется регулярно. При наличии действующего договора на оказание услуг поддержки обновления предоставляются без дополнительной оплаты.
Варианты приобретения: пакеты для одного языка
Several suites are available combining the tools to build, verify and tune your application. The product covered in this product brief is highlighted in blue. Named-user or multi-user licenses along with volume, academic, and student discounts are available.

увеличить изображение
Технические характеристики
| Коротко о характеристиках | |
|---|---|
| Поддержка процессоров | При анализе приложений, компилируемых в инструкции Intel, поддерживаются процессоры Intel и совместимые. |
| Операционные системы | Windows и Linux |
| Инструменты и среды разработки | Intel Inspector XE совместим с компиляторами от разработчиков, придерживающихся платформенных стандартов (в том числе Microsoft, GCC и Intel). Возможна интеграция с Microsoft Visual Studio 2008, 2010 и 2012. Самая свежая информация доступна по ссылке http://www.intel.com/software/products/systemrequirements for the latest details. |
| Языки программирования | C, C++, Fortran, C# (только анализ потоков) |
| Системные требования | Подробные системные требования доступны по ссылке http://www.intel.com/software/products/systemrequirements for details. |
| Поддержка | Пользователи получают обновления продуктов и доступ к онлайн-форумам технической поддержки Intel. Кроме того, в стоимость включен доступ к службе Intel Premier Support сроком на год, предоставляющий возможность получения веб-консультаций от инженеров Intel. |
| Сообщество | Присоединяйтесь к онлайн-форумам технической поддержки Intel для просмотра, обучения и обмена идеями. http://software.intel.com/en-us/forums |
 | Чтобы узнать больше о Intel Parallel Studio XE,
|  | Скачайте бесплатную 30-дневную пробную версию
|
| ведомление об оптимизации | Notice revision #20110804 |
| Оптимизации, не рассчитанные исключительно на микропроцессоры Intel, на процессорах других производителей могут быть менее эффективными. В частности, это касается оптимизаций наборов команд SSE2, SSE3, SSSE3, а также других. Intel не гарантирует доступность, функциональность и эффективность любой оптимизации на микропроцессорах, выпущенных другими производителями. Оптимизации перечисленных в документе продуктов, зависящие от микропроцессоров, предназначены для микропроцессоров Intel. Некоторые оптимизации, не характерные для микроархитектуры Intel, резервируются только для микропроцессоров Intel. Дополнительную информацию о конкретных наборах инструкций, к которым относится данное уведомление, можно получить из соответствующих руководств пользователя и справочников. | |
Дополнение. Высокопроизводительные компиляторы Intel C++ и Fortran Intel Composer XE 2013
Орингинал текста Вы можете скачать здесь.
Основные особенности
- Лидирующее быстродействие приложений
- Мощные модели параллелизма упрощают реализацию поддержки многоядерных процессоров
- Оптимизированные библиотеки многопоточности, математики, а также обработки мультимедиа и данных
- Совместимость с ведущими средами разработки
"В Intel разработали отличные компиляторы C++ и Fortran, а также математические библиотеки"
Рональд Янг, президент Multipath Corporation
Доступны варианты с поддержкой одиночных языков:
- Intel® C++ Composer XE
- Intel® Fortran Composer XE
Интероперабельные продукты:
- Intel® VTune. Amplifier XE Performance Analyzer
- Intel® Inspector XE Error Checker
- Intel Advisor XE Threading Assistant
Пакет входит в состав следующих продуктов
- Intel® Parallel Studio XE
- Intel® C++ Studio XE
- Intel® Fortran Studio XE
- Intel® Cluster Studio XE
Поддержка операционных систем
- Windows*
- Linux*
- OS X(Доступна в редакциях Intel C++ Composer XE for OS X и Intel Fortran Composer XE for OS X)
Fortran, C++ и библиотеки в одном удобным комплекте
Intel Composer XE 2013 SP1 предназначен для программистов на Fortran, которым нужен компилятор C++ с равными возможностями. В состав комплекта включены все компиляторы и инструменты из пакетов Intel C++ Composer XE и Intel Fortran Composer XE, помогающие обеспечивать превосходное быстродействие приложений на системах с процессорами Intel Core, Xeon и совместимыми с ними, а также с сопроцессорами Intel Xeon Phi. Воспользуйтесь возможностью сильно сэкономить по сравнению с покупкой компонентов по отдельности.
Инструментарий предлагается в версиях для Windows и Linux. В Windows обязательно наличие Microsoft Visual Studio 2008, 2010 или 2012.
Новации в области параллельного программирования и векторизации, реализованные в компиляторах Intel Composer XE, упрощают разработку прикладного программного обеспечения высокого быстродействия. В числе новшеств - Intel® Cilk™ Plus, OpenMP* 4.0 и система контролируемого автоматического распараллеливания. Intel Composer XE совместим с лидирующими компиляторами C++ и средами разработки для Windows и Linux.
В состав пакета также входят библиотеки: Intel Math Kernel Library (Intel MKL) для сложных математических вычислений и Intel Integrated Performance Primitives (Intel IPP) для обработки мультимедиа, сигналов и данных. Библиотеки предоставляют высокооптимизированные многопоточные функции, ускоряющие разработку и повышающие быстродействие приложений. Дополнение для разработчиков на C++: библиотека Intel Threading Building Blocks (Intel TBB), упрощающая распараллеливание и использование возможностей многоядерных процессоров Intel.
Быстродействие, совместимость и инновационные, простые в использовании средства распараллеливания делают Intel Composer XE мощным инструментом повышения продуктивности. Загрузите пробную версию уже сегодня!

увеличить изображение
Основные возможности
 | Директивы #pragma SIMD, реализованные в модуле Intel Clik Plus, - мощный инструмент векторизации, дополняющий последовательную семантику C/C++ поддержкой параллелизма на уровне данных с использованием соответствующих SIMD-инструкций. Данная директива указывает компилятору генерировать векторизованный код с определенными параметрами. К примеру, параметр vectorlength задает длину вектора. Поддерживаются также параметры reduction, private, linear, assert, firstprivate, lastprivate и vectorlengthfor. Данная возможность Intel C++ облегчает корректное использование векторизации и позволяет увеличивать быстродействие приложений. |
 | Intel Fortran - превосходная поддержка стандартов В Intel Fortran улучшена поддержка стандартов Fortran 2003 и 2008, а также обеспечена полная совместимость на уровне исходного кода с Compaq Visual Fortran. В Windows и Linux поддерживается Fortran Co-Array для одиночных многопроцессорных узлов с разделяемой памятью. В Intel Cluster Studio XE реализована поддержка кластеров. Преимущество - высокое быстродействие приложений на Fortran, работающих на индивидуальных компьютерах или на кластерах. |
 | Библиотеки Intel® MKL, Intel® IPP и Intel® TBB - быстродействие и продуктивность без лишних сложностей Один из самых простых способов воспользоваться возможностями систем с широким вектором и многими ядрами - воспользоваться оптимизированными функциями из библиотек Intel Performance Libraries. Intel® MKL и Intel® IPP предлагают широкий выбор подпрограмм, позволяющих улучшить быстродействие и ускорить разработку. Эти функции автоматически масштабируются при использовании процессоров нынешних и будущих архитектур. Просто перелинкуйте код с самой новой версией библиотеки, и он автоматически сможет пользоваться возможностями самых современных процессоров. Intel TBB предлагает основанный на заданиях принцип выражения параллелизма в программе на C++. Это библиотека, позволяющая воспользоваться возможностями многоядерного процессора даже тем, кто не является экспертом в области многопоточности. Доступна также библиотека The Rogue Wave* IMSL* Numerical Library для Intel Visual Fortran (только в Windows). Данная ведущая библиотека предлагает широчайший выбор коммерчески доступных математических и статистических функций для научных, технических и бизнес-сред. |
 | Поддержка разгрузки и сопроцессоров в Linux и Windows Компиляторы Intel поддерживают системы под Linux, оснащенные сопроцессорами Intel Xeon Phi. А в SP1 также реализована поддержка Windows-систем с процессорами Xeon и сопроцессорами Xeon Phi. При разработке для сопроцессоров Intel Xeon Phi, процессоров Intel Xeon или Intel Core пользуйтесь компонентом Intel Cilk Plus компилятора Intel C++, чтобы указать, для каких фрагментов приложения выполнять разгрузку. Как при создании новых приложений, так и при доработке имеющихся модель программирования Intel C++ и Intel Cilk Plus позволит обеспечить превосходное быстродействие. |
Intel Composer XE совместим с вашим кодом и вашими методами работы
Intel Composer XE интегрируется в Microsoft Visual Studio 2008, 2010 и 2012, и поддерживает инструменты GNU для Linux. В Linux-версии предусмотрено расширение Intel Debugger Extension для GDB, позволяющее отлаживать приложения для сопроцессоров Intel Xeon Phi. А компилятор C++ генерирует код, совместимый на уровне двоичного кода с Visual C++ в Windows и с GCC в Linux. Кроме того, Windows-версия Intel Fortran, как и раньше, полностью совместима на уровне исходного кода с Compaq Visual Fortran. Благодаря этому инвестиции в ваш код и средства разработки эффективно сохраняются. Composer XE поддерживает все архитектуры IA-32 и Intel 64, в том числе сопроцессор Intel Xeon Phi, и сопровождается годом услуг технической поддержки. Кроме того, существует официальный форум, на котором разработчики активно делятся своим опытом.
Intel Composer XE предлагает простые в использовании средства повышения быстродействия
Компилятор Intel C++ и Intel Composer XE ориентированы на высокое быстродействие приложений и поддерживают несколько моделей параллельного программирования. Intel Cilk Plus, компонент Intel C++, упрощает разработку векторизованного кода, поддерживая директиву #pragma SIMD, разметку массивов и распараллеливание с помощью легко запоминаемых ключевых слов. Аналогичный основанный на директивах подход к векторизации применяется и в Intel Fortran. В обоих компиляторах усовершенствованы ранее отлично зарекомендовавшие себя возможности, в том числе High-Performance Parallel Optimizer, мощный механизм, выполняющий векторизацию, распараллеливание и преобразование циклов за один проход - быстрее, эффективнее и надежнее, чем когда эти действия выполняются по отдельности. Поддерживается также векторизация кода на системах с обычными процессорами Intel Xeon, Core и совместимыми, имеются инструменты векторизации для приложений, рассчитанных на архитектуру Intel MIC. Межпроцедурная оптимизация и оптимизация по профилю дают дополнительные возможности повышения производительности за счет подстановки и реструктуризации кода в зависимости от рабочей задачи. Быстродействию в Intel всегда уделяют первоочередное внимание.
Библиотеки Intel повышают вашу продуктивность и быстродействие приложений
Intel Composer XE это не только компиляторы C++ и Fortran. В пакет входит Intel Threading Building Blocks, широко применяемая, отмеченная наградами библиотека шаблонов C++, упрощающая создание надежных, переносимых, требующих мало обслуживания масштабируемых параллельных приложений. Кроме того, в комплект включена Intel Math Kernel Library - библиотека высокооптимизированных многопоточных математических подпрограмм, в том числе BLAS, LAPACK, ScaLAPACK, а также модули операций с разреженными данными, быстрых преобразований Фурье, векторной математики и многие другие. Еще один компонент пакета - Intel Integrated Performance Primitives: набор высокооптимизированных многопоточных функций обработки мультимедиа, компрессии данных, связи и не только. Для удобства и ускорения освоения в Intel Composer XE есть множество примеров кода и учебных пособий.
Попробуйте Intel Composer XE, чтобы лично увидеть, как пакет повышает быстродействие приложений
На сайте Intel доступны для загрузки 30-дневные пробные версии Intel Composer XE (http://intel.ly/sw-tools-eval). В Windows понадобится Visual Studio 2008, 2010 или 2012, в Linux - инструменты GNU. Подробности можно узнать по ссылке выше. В состав загрузки включены учебные материалы и множество примеров кода, но вы также сможете сразу начать работать и с собственным кодом. Чтобы присоединиться к онлайн-сообществу разработчиков, пользующихся Intel Composer XE, посетите форум Intel Software Network Forums (http://software.intel.com/en-us/forums/) или зайдите на сайт Composer XE (http://software.inteo.com/en-us/articles/intel-composer-xe/) и перейдите по ссылке Support.
Что нового
| Особенность | Преимущество |
|---|---|
| Лидирующая производительность | Пользователи вашего программного обеспечения смогут получить уровень быстродействия, не обеспечиваемый другими компиляторами и библиотеками |
| Инструменты и методы параллелизма | Новое в SP1: улучшенная поддержка OpenMP 4.0 и стандартов C++11, C++ 03, Fortran 2003 и Fortran 2008. Усовершенствованные средства отладки приложений Linux для сопроцессоров Intel Xeon Phi. |
| Совместимость | Сохраняйте инвестиции в ваш код, пользуйтесь имеющимся знанием сред и инструментов разработки и выпускайте ПО с превосходным быстродействием для систем с процессорами Intel и совместимыми. |
Варианты приобретения: пакеты для одного языка
Several suites are available combining the tools to build, verify and tune your application. The product covered in this product brief is highlighted in blue. Named-user or multi-user licenses along with volume, academic, and student discounts are available.

увеличить изображение
Технические характеристики
| Коротко о характеристиках | |
|---|---|
| Поддержка процессоров | Поддерживаются процессоры производства корпорации Intel и совместимые |
| Операционные системы | Windows*, Linux*, OS X* |
| Языки программирования | C, C++, Fortran |
| Совместимость | Рассчитано на использование со средствами разработки от Microsoft и компиляторами GNU C/C++ с расширенной поддержкой многоядерных 32- и 64-разрядных процессоров, в том числе расширения набора инструкций Intel AVX. Компилятор Intel C++ поддерживает самые новые стандарты C и C++, в том числе основные возможности C++11 и C99. В компиляторе Intel Fortran расширена поддержка стандартов Fortran 90, 77 и IV, почти полностью поддерживается Fortran 2003, а также важнейшие элементы Fortran 2008. |
| Системные требования | Intel Composer XE доступен для платформ архитектуры IA-32 и Intel 64 и совместимых. Подробные требования к аппаратному и программному обеспечению доступны по ссылке: www.intel.com/software/products/systemrequirements/ |
| Документация и заметки к релизу | C++: http://software.intel.com/en-us/articles/intel-c-composer-xe-documentation/ |
| Fortran: http://software.intel.com/en-us/articles/intel-fortran-composer-xe-documentation/ | |
| Поддержка | Пользователи получают обновления продуктов и доступ к онлайн-форумам технической поддержки Intel. Кроме того, в стоимость включен доступ к службе Intel Premier Support сроком на год, предоставляющий возможность защищенного получения веб-консультаций от инженеров Intel. |
 | Узнайте больше о Intel Composer XE
|  | Загрузите 30-дневную пробную версию
|
| Optimization Notice | Notice revision #20110804 |
| Оптимизации, не рассчитанные исключительно на микропроцессоры Intel, на процессорах других производителей могут быть менее эффективными. В частности, это касается оптимизаций наборов команд SSE2, SSE3, SSSE3, а также других. Intel не гарантирует доступность, функциональность и эффективность любой оптимизации на микропроцессорах, выпущенных другими производителями. Оптимизации перечисленных в документе продуктов, зависящие от микропроцессоров, предназначены для микропроцессоров Intel. Некоторые оптимизации, не характерные для микроархитектуры Intel, резервируются только для микропроцессоров Intel. Дополнительную информацию о конкретных наборах инструкций, к которым относится данное уведомление, можно получить из соответствующих руководств пользователя и справочников. | |
Дополнение. Высокопроизводительная библиотека MPI для организации обмена сообщениями в кластерах Intel MPI Library 4.1
Орингинал текста Вы можете скачать здесь.
Главные особенности
- Масштабируется до 120 тыс. процессов
- Показатели задержки - самые низкие в отрасли
- Независимость от типа межсоединений, гибкий выбор в период исполнения
- Утилита оптимизации приложений MPI по быстродействию
Доступность в других конфигурациях:
- Intel® Cluster Studio XE
- Intel® Cluster Studio
Интероперабельность с другими продуктами
- Intel® Composer XE
- Intel® VTune. Amplifier XE
- Intel® Inspector XE
- Intel® Math Kernel Library
- Intel® Trace Analyzer and Collector
Поддержка операционных систем:
- Windows*
- Linux*
"В компании S & I Engineering Solutions Pvt, Ltd. занимаются разработкой быстрых и точных методов решения задач вычислительной гидродинамики. Важнейшими факторами при выборе библиотек MPI для нас являются масштабируемость и эффективность. Библиотека Intel MPI Library позволяет нашим алгоритмам масштабироваться более чем до 10 тыс. ядер, обеспечивая при этом высокие эффективность и быстродействие."
Гибкий, эффективный, масштабируемый обмен сообщениями в кластерах
Библиотека Intel MPI Library позволяет повышать быстродействие приложений, работающих на кластерах архитектуры Intel. Она реализует высокопроизводительный протокол Message Passing Interface Version 2.2, поддерживая различные типы межсоединений. Библиотека позволяет быстро обеспечивать максимальное быстродействие, в том числе при замене или модернизации межсоединений; при этом не нужно вносить изменения в программное обеспечение и операционную среду.
Данную высокопроизводительную библиотеку MPI можно применять для создания приложений, работающих поверх кластерных межсоединений разных типов, выбирать которые может пользователь в период исполнения. Для продуктов, разработанных с помощью Intel MPI Library, предоставляется не требующий лицензионных отчислений комплект среды выполнения. Библиотека позволяет обеспечить превосходное быстродействие высокопроизводительным вычислительным приложениям для предприятий, подразделений, отделов, рабочих групп, а также персональным.
увеличить изображение
Intel MPI Library (Intel MPI) уменьшает задержку MPI, способствуя тем самым повышению пропускной способности.
Главные особенности
 | Масштабируемость
|
 увеличить изображение | Быстродействие
|
 | Независимость от типа межсоединений и гибкость выбора протокола в период выполнения
|
Подробности
Масштабируемость
Intel MPI Library 4.1 для Windows и Linux реализует отличающуюся высокой производительностью версию 2.2 спецификации MPI-2 для различных типов межсоединений. Назначение библиотеки - повышать быстродействие приложений на кластерах архитектуры IA. Intel MPI Library позволяет быстро обеспечить максимальный уровень быстродействия приложениям конечных пользователей, в том числе при замене или модернизации межсоединений; при этом не понадобится вносить серьезные изменения в ПО или операционную среду. Intel также предоставляет бесплатный комплект среды выполнения для программных продуктов, разработанных с использованием Intel MPI Library
Быстродействие
Оптимизированный интерфейс разделяемой памяти обеспечивает увеличенную пропускную способность и снижает задержку. Дополнительно ее уменьшению способствует нативный интерфейс InfiniBand (OFED Verbs). Благодаря многоканальной передаче данных обеспечивается повышение пропускной способности и ускорение межпроцессной связи, а поддержка Tag Matching Interface (TMI) увеличивает производительность при использовании межсоединений Qlogic* PSM и Myricom* MX.
Intel MPI Library поддерживает многие сетевые технологии
Intel MPI Library поддерживает TCP-сокеты, разделяемую память и различные межсоединения на основе удаленного прямого доступа к памяти (RDMA). Библиотека реализует универсальный слой поддержки межсоединений разного типа посредством методологий Direct Access Programming Library (DAPL*) и Open Fabrics Association (OFA*). Разрабатывая код для MPI, можно быть уверенным, что он будет эффективно работать независимо от того, какой тип межсоединений пользователь выбрал в период выполнения.
Кроме того, Intel MPI Library обеспечивает высокие быстродействие и гибкость для приложений за счет улучшенной поддержки интерфейсов межсоединений Myrinet* MX и QLogic* PSM, более быстрого обмена сообщениями на узлах и механизма оптимизации, адаптирующегося в зависимости от архитектуры кластера и структуры приложения.
Intel MPI Library динамически устанавливает соединение, но только по мере необходимости, за счет чего уменьшается расход памяти. Кроме того, библиотека автоматически выбирает самый быстрый из доступных транспортных протоколов. Потребности в памяти снижаются с применением нескольких методов, в том числе с помощью механизма двухэтапного увеличения коммуникационного буфера, резервирующего в точности требуемый объем памяти.
Что нового
| Особенность | Преимущество |
|---|---|
| Повышение быстродействия MPI | Новый диспетчер соединений и механизмы автовыбора улучшают масштабируемость при использовании межсоединений на основе RDMA. Улучшенная поддержка приложений NUMA и новые развитые средства управления привязкой процессов позволяют разрабатывать и развертывать приложения с расчетом на дальнейший рост мощности высокопроизводительных вычислительных систем. |
| Улучшенная масштабируемость в Windows | Высокомасштабируемый диспетчер процессов Hydra теперь доступен в экспериментальной реализации для кластеров под Windows. |
| Поддержка самых новых процессоров - Haswell, Ivy Bridge и сопроцессоров Intel® Xeon Phi™ | В Intel неизменно первыми выпускают инструменты, пользующиеся усовершенствованиями самых новых продуктов корпорации, сохраняя при этом совместимость с предыдущими процессорами Intel и аналогами. Библиотека MPI поддерживает характеристики шин перечисленных процессоров и реализует новые алгоритмы копирования и доступа к памяти. |
Варианты приобретения: пакеты для одного языка
Several suites are available combining the tools to build, verify and tune your application. The products covered in this product brief are highlighted in blue. Named-user or multi-user licenses along with volume, academic, and student discounts are available.

увеличить изображение
Технические характеристики
| Коротко о характеристиках | |
|---|---|
| Поддержка процессоров | Библиотека аттестована на совместимость с несколькими поколениями процессоров Intel и аналогов, в том числе с Intel Core 2 второго поколения, Intel Core 2, Intel Core, Intel Xeon, Intel Core и сопроцессором Intel Xeon Phi. |
| Операционные системы | Windows* и Linux* |
| Языки прогаммирования | Нативная поддержка C и Fortran |
| Системные требования | Подробные требования к аппаратному и программному обеспечению доступны по ссылке www.intel.com/software/products/systemrequirements/ for details on hardware and software requirements. |
| Поддержка | Для приложений, разработанных с помощью Intel MPI Library, доступен бесплатный комплект периода исполнения. Обновления продукта, услуги Intel Premier Support и доступ к форумам поддержки Intel предоставляются в течение одного года. Служба Intel Premier Support позволяет получать защищенные веб-консультации от инженеров Intel. |
 | Чтобы узнать больше о Intel MPI Library,
|  | Скачайте бесплатную 30-дневную пробную версию
|
| Optimization Notice | Notice revision #20110804 |
| Оптимизации, не рассчитанные исключительно на микропроцессоры Intel, на процессорах других производителей могут быть менее эффективными. В частности, это касается оптимизаций наборов команд SSE2, SSE3, SSSE3, а также других. Intel не гарантирует доступность, функциональность и эффективность любой оптимизации на микропроцессорах, выпущенных другими производителями. Оптимизации перечисленных в документе продуктов, зависящие от микропроцессоров, предназначены для микропроцессоров Intel. Некоторые оптимизации, не характерные для микроархитектуры Intel, резервируются только для микропроцессоров Intel. Дополнительную информацию о конкретных наборах инструкций, к которым относится данное уведомление, можно получить из соответствующих руководств пользователя и справочников. | |
Дополнение. Продуктивное создание быстрых, масштабируемых, надежных приложений Intel-Parallel-Studio-XE-2013SP1-PB--082213
Орингинал текста Вы можете скачать здесь.
Главные возможности
- Самое высокое в отрасли быстродействие приложений, растущее с увеличением числа ядер и ширины вектора
- Эффективное масштабирование на оборудовании завтрашнего дня с сохранением существующего кода
- Совместимость с лидирующими средами разработки
"Если вам нужно высокое быстродействие приложений на С++ и Fortran, вы просто обязаны попробовать средства разработки ПО от Intel".
"В обновленном VTune Amplifier XE возможности этого незаменимого инструмента стали еще шире. Перейти на новую версию стоит хотя бы ради возможности анализа горячих точек кода методом сэмплирования со стеками."
Также доступны версии для одиночных языков:
- Intel® C++ Studio XE
- Intel® Fortran Studio XE
Поддерживаемые операционные системы:
- Windows*
- Linux*
Передовые средства разработки кода высокого быстродействия
Создавайте приложения высочайшего быстродействия, затрачивая минимум времени и усилий на разработку, оптимизацию и тестирование. Intel Parallel Studio XE предоставляет разработчикам на C/С++ и Fotran компиляторы, оптимизированные библиотеки, модели параллельного программирования, а также вспомогательные инструменты анализа. Инструментарий Intel без труда встраивается в Microsoft Visual Studio* и GNU, позволяя работать с высокой продуктивностью, сохраняя инвестиции в имеющиеся средства разработки. Повышайте быстродействие ваших приложений для работы на сегодняшних и завтрашних процессорах и сопроцессорах архитектуры Intel, в том числе на чипах Intel® Xeon® и сопроцессорах Intel® Xeon Phi™..
Intel Parallel Studio XE представляет собой новое поколение средств разработки программного обеспечения:
- лидирующие в отрасли компиляторы C, С++ и Fortran;
- высоко-оптимизированные библиотеки Intel® Math Kernel Library (Intel® MKL) и Intel® Integrated Performance Primitives (Intel® IPP);
- модели параллельного программирования Intel® Threading Building Blocks (Intel® TBB) и Intel® Cilk™ Plus;
- инструмент прототипирования многопоточного кода Intel® Advisor XE;
- мощный профилировщик потоков и анализатор производительности Intel® VTune™ Amplifier XE;
- отладчик ошибок памяти и потоков Intel® Inspector XE
Получите больше производительности, тратя меньше усилий. Оптимизируйте производительность, пользуясь самыми новыми версиями инструментов Intel для разработки ПО. Просто соберите имеющийся проект заново с помощью компиляторов Intel, перелинковав библиотеки. Тогда приложения, нуждающиеся в быстродействии смогут воспользоваться возможностями самых новых процессоров, совместимых с архитектурой IA. Разработчикам програмных продуктов, интструменты Intel позволят добиться максимального быстродействия приложений, инструменты Intel позволят добиться ещё более высокого быстродействия приложений.
Самое высокое в отрасли быстродействие - с помощью компиляторов Intel C/С++ и Fortran (чем больше, тем лучше)

увеличить изображение
Другие результаты тестирования см. по ссылке http://intel.ly/composer-xe
Главные особенности
| Компоненты Intel Composer Лидирующие в отрасли компиляторы C, C++ и Fortran, библиотеки и модели программирования  увеличить изображение |
Отлично зарекомендовавшие себя компиляторы и библиотеки С++ и Fortan Intel® Composer XE ориентированный на быстродействие инструмент разработчика, включающий в себя компиляторы Intel C++ и Fortran, а также библиотеки, позволяющие ускорять многопоточные приложения, математические функции, мультимедиа и обработку сигналов.
Дополнительная информация: http://intel.ly/composer-xe |
 увеличить изображение | Инновационный инструмент прототипирования многопоточного кода Intel® Advisor XE - инструмент прототипирования многопоточного кода на C, С++, С# и Fortran. Он позволяет выявлять участки кода, распараллеливание которых даст максимальное преимущество в быстродействии, и выявить критические проблемы синхронизации.
Дополнительная информация: http://intel.ly/intel-advisor-xe |
 Быстро находите код, отнимающий много процессорного времени | Оптимизируйте быстродействие последовательного и параллельного кода Intel® VTune™ Amplifier XE - мощный профилировщик быстродействия и многопоточного кода, позволяющий оптимизировать производительность вашего приложения.
Дополнительная информация: http://intel.ly/vtune-amplifier-xe |
 Просматривайте результаты прямо в коде | |
 Динамический анализ Intel Inspector XE выявляет местонахождение ошибок потоков и работы с памятью в исходном коде и отображает стек вызовов для удобства навигации | Повышайте надежность приложений Intel® Inspector XE - это простой в использовании детектор ошибок памяти и потоков для Windows* и Linux*.
Дополнительная информация: http://intel.ly/inspector-xe |
Совместимость
Инструменты Intel для разработки ПО позволяют сохранить ваши инвестиции в разработку и кодовые базы, предоставляя возможность получить максимум быстродействия приложений. Пакет Intel® Parallel Studio XE полностью совместим с лидирующими компиляторами. Инструменты Intel также поддерживают разработку и сопровождение ПО, рассчитанного на исполнение на системах с процессорами, совместимыми с архитектурой IA.
Продукты Intel для разработки ПО совместимы с ведущими средами разработки. В частности, Windows-версии совместимы с Microsoft Visual Studio* 2008, 2010 и 2012, а в Linux с помощью расширения Intel® Debugger Extension to GDB можно отлаживать приложения для сопроцессоров Intel Xeon Phi.
Поддержка различных операционных систем и языков программирования
Intel Parallel Studio XE предлагается в версиях для Windows и Linux. Кроме того, доступны компиляторы C/С++ и Fortran, а также библиотеки параллелизма и производительности для OS X, предоставляющие развитые средства оптимизации приложений для этой платформы.
Инструментарий Intel Parallel Studio XE адресуется разработчикам, которым нужны равные по возможностям компиляторы C++ и Fortran. Программистам, пишущим только на одном языке, предлагается Intel C++ Studio XE и Intel Fortran Studio XE. Доступны лицензионные соглашения для архитектур IA-32, Intel 64 и Intel Many Integrated Core (MIC), предусматривающие год технической поддержки и получения обновлений.
Попробуйте инструменты Intel
Применение единого пакета средств разработки упрощает процесс поставки средств разработки и позволяет максимально использовать возможности сегодняшнего и будущего оборудования.
Покупая инструменты Intel, вы получаете дополнительное преимущество в виде возможности присоединиться к пользовательскому сообществу и обмениваться кодом и идеями на онлайн-форумах корпорации. Кроме того, вы получаете квалифицированную техническую помощь от службы Intel Premium Support.
На сайте Intel можно загрузить бесплатные пробные копии инструментов со сроком действия 30 дней: http://intel.ly/sw-tools-eval. В состав загружаемого пакета входят обучающие материалы и образцы кода. Вы также сможете сразу начать работу с ранее написанным собственным кодом.
Что нового
| Особенность | Преимущество |
|---|---|
| Поддержка самых новых процессоров | В Intel неизменно первыми выпускают инструменты, поддерживающие возможности самых новых продуктов корпорации и совместимые с предыдущими моделями процессоров самой Intel и аналогов |
| Поддержка сопроцессоров Intel Xeon Phi на нескольких операционных системах | Теперь сопроцессор Intel Xeon Phi поддерживается на хостах как с Windows, так и с Linux |
| Поддержка OpenMP 4.0 | Компилятор и средства анализа теперь поддерживают основные возможности OpenMP 4.0, в том числе разгрузку и расширения SIMD |
| Условная численная воспроизводимость результатов | Расширенные средства обеспечения численной воспроизводимости результатов в Intel Math Kernel Library (Intel MKL) следят за тем, чтобы результаты вычислений были одинаковыми на похожих платформах - как существующих архитектур, так и будущих |
| Поддержка стандартов Fortran и С++ | Intel Fortran Compiler полностью поддерживает стандарт F2004 и многие элементы стандарта 2008 года, в том числе Co-array Fortran. Кроме того, в данном релизе расширена совместимость со стандартом C++11, который в Intel планируют поддерживать и дальше |
| Поддержка дополнительных отладчиков | Для отладки приложений, пользующихся сопроцессором Intel Xeon Phi, в Linux программисты могут пользоваться средством GNU Project Dubugger (GDB) и расширением Intel Debugger Extension для GDB. |
| Улучшенный инструмент прототипирования многопоточного кода Intel Advisor XE | Осваивать Intel Advisor XE стало проще благодаря новым обучающим средствам и усовершенствованному окну помощи. Функция паузы/возобновления экономит время за счет фокусировки на важнейших участках кода. |
| Поддержка нескольких ОС и самых новых сред разработки | Инструменты Intel поддерживают самые новые дистрибутивы Linux и версии Windows и являются совместимыми с другими инструментами разработки. Подробнее о каждом инструменте - в разделе "Системные требования". |
Варианты приобретения: пакеты для одного языка
В состав Intel Parallel Studio XE входят инструменты для разработки, сборки и оптимизации приложений, пользующихся возможностями многоядерных процессоров. Пакет доступен, в том числе, и в редакциях для какого-либо одного языка программирования. Если вам нужны инструменты разработки для кластеров, организованных с использованием MPI, воспользуйтесь Intel Cluster Studio XE. Доступны индивидуальные именные лицензии, а также многопользовательские со скидками за объем, академические и студенческие.

увеличить изображение
1. Операционные системы: W=Windows, L=Linux, O=OS X
2. Доступно в Intel Visual Fortran Composer XE for Windows with IMSL
3. Отдельно для OS X недоступно: входит в состав пакетов Intel С++ и Fortran Composer XE for OS X
Технические характеристики
| Коротко о характеристиках | |
|---|---|
| Поддержка процессоров | Инструменты аттестованы на совместимость с несколькими поколениями процессоров Intel и аналогов, в том числе с Intel Xeon, Intel Core и Intel Xeon Phi. |
| Операционные системы | Windows* и Linux*. |
| Инструменты и среды разработки | Инструментарий совместим с компиляторами от разработчиков, соблюдающих платформенные стандарты (таких как Microsoft, GCC, Intel). Может быть интегрирован с инструментами GNU и с Microsoft Visual Studio 2008, 2010 и 2012 |
| Языки программирования | Встроенная поддержка разработки на C, C++ и Fortran. |
| Системные требования | Подробные требования к аппаратному и программному обеспечению доступны по ссылке www.intel.com/software/products/systemrequirements/. |
| Поддержка | Пользователи получают обновления продуктов и доступ к онлайн-форумам технической поддержки Intel. Кроме того, в стоимость включен доступ к службе Intel Premier Support сроком на год, предоставляющий возможность защищенного получения веб-консультаций от инженеров Intel. |
| Сообщество | Присоединяйтесь к онлайн-форумам технической поддержки Intel, чтобы учиться и обмениваться идеями. http://software.intel.com/en-us/forums |
 | Чтобы узнать больше о Intel Parallel Studio XE,
|  | Скачайте бесплатную 30-дневную пробную версию
|
| Уведомление об оптимизации | Редакция #20110804 |
| Оптимизации, не рассчитанные исключительно на микропроцессоры Intel, на процессорах других производителей могут быть менее эффективными. В частности, это касается оптимизаций наборов команд SSE2, SSE3, SSSE3, а также других. Intel не гарантирует доступность, функциональность и эффективность любой оптимизации на микропроцессорах, выпущенных другими производителями. Оптимизации перечисленных в документе продуктов, зависящие от микропроцессоров, предназначены для микропроцессоров Intel. Некоторые оптимизации, не характерные для микроархитектуры Intel, резервируются только для микропроцессоров Intel. Дополнительную информацию о конкретных наборах инструкций, к которым относится данное уведомление, можно получить из соответствующих руководств пользователя и справочников. | |
Дополнение. Intel-VTune-Amplifier-XE-2013-PB-Russian
Орингинал текста Вы можете скачать здесь.
Основные особенности
- Профилирует C, C++, C#, Fortran, Assembly и Java.
- Собирайте полные данные для настройки производительности центрального и графического процессоров, многоядерного масштабирования, пропускной способности и многого другого.
- Средства мощного анализа позволяет вам сортировать, фильтровать и визуализировать результаты по оси времени для вашего исходного кода.
- Командная строка для автоматизации регрессионного тестирования и упрощения удаленного сбора данных.
"Новый VTune™ Amplifier XE еще больше расширяет функциональность уже существующего инструмента, без которого невозможно обойтись. Анализ горячих точек стека вызовов на базе выборки - замечательная функция, и только ради нее стоит приобрести данное обновление. Мы также были поражены возможностями анализа параллельности, блокировок и ожиданий, который в состоянии предоставлять полезные данные по таким сложным приложениям как Premiere Pro"
Также доступно в:
- Intel® Parallel Studio XE
- Intel® C++ Studio XE
- Intel® Fortran Studio XE
- Intel® Cluster Studio XE
Взаимодействующие продукты
- Intel® Graphics Performance Analyzer
Поддержка ОС:
- Windows*
- Linux*
Оптимизация производительности последовательных и параллельных портов
Intel® VTune™ Amplifier XE 2013 представляет собой основной профилировщик C, C++, C#, Fortran, Assembly и Java*.
Простота
Анализ производительности может оказаться трудоемким, но инструмент должен быть простым.
- Отсутствие специальных конструкций – Используйте рабочую конструкцию с символами Вашего обычного компилятора.
- Предварительно заданные профили производительности – Предварительно заданные профили производительности обеспечивают простое задание параметров.
- Низкие издержки – Точные результаты, на которые вы можете положиться.
- Командная строка – автоматический регрессионный анализ. Простой удаленный сбор данных.
Универсальность – Широкий выбор профилей производительности
Независимо от того, осуществляете ли вы первую настройку или расширенную оптимизацию, VTune Amplifier XE предоставляет данные, необходимые для обеспечения соответствия разнообразным требованиям настройки.
- Анализ горячих точек – Быстрое нахождение кода, которое обычно занимает много времени. См. вызывающие последовательности.
- Расширенный анализ горячих точек – низкие издержки, высокое разрешение с использованием встроенного оборудования.
- Блокировки и ожидания – Многопоточная настройка. Поиск объектов синхронизации, препятствующих масштабированию производительности.
- Анализ в масштабе системы – настройка драйверов, модулей ядра и мультипроцессовых приложений.
- Анализ числа вызов – поиск кода, использующего преимущества встраивания.
- Анализ пропускной способности, памяти, сегмента и т. д. – расширенный анализ для комплексного подхода.
- Приложения MPI – анализ гибридных приложений с использованием MPI и OpenMP. Установка в кластер.
- GPU Compute – настройка OpenCL*. Собирайте и изучайте показатели производительности ГП (новые модели процессоров, только для Windows*).
Производительность – Сортировка, фильтрация и визуализация
Наличия качественных данных недостаточно. Вам необходимы инструменты для интеллектуального анализа данных и облегчения их понимания.
- Просмотр кода – Просматривайте данные профиля в своем коде и узлах. (C, C++, C#, Fortran, и Java).
- Временная линия – Визуализация взаимодействия потоков, балансировка рабочих нагрузок, фильтрация данных.
- Результаты фильтрации – устранение шума из данных. Выбор нужного представления.
- Комментарии к задаче – добавление комментариев к источнику и добавление смысловых меток к задаче на временной линии.
- Анализ фреймов – обнаружение фреймов DirectX* и фильтрация результатов для отображения медленного кода в медленных фреймах.
- Intel® TBB, OpenMP* 4.0 – встроенная поддержка моделей параллельного программирования.
- Выделение ключевых объектов – выделение потенциальных возможностей для настройки. При наведении курсора выводятся соответствующие предложения по отладке.
 увеличить изображение | Функции, использующие большую часть времени, которую процессор затрачивает на операции с плавающей точкой, находятся вверху списка. Дважды щелкните на функции, чтобы увидеть источник с подробной информацией по профилю. |
Основные особенности
 | Быстрое нахождение кода, потребляющего большое количество времени центрального (или графического) процессора В результате анализа горячих точек вы получаете отсортированный список функций, использующих большое количество времени процессора. Именно здесь настройка дает наибольшее преимущество. Нажмите [+] для просмотра стека вызовов. Дважды щелкните для просмотра исходного кода. Новая функция! На последних моделях процессоров появилась возможность собирать данные графического процессора для настройки OpenCL-приложений. |
 | Посмотрите результаты для Вашего исходного кода При двойном нажатии на список функций открывается самая горячая точка функции. |
 | Многопоточная настройка с анализом блокировок и ожиданий Быстрое выявление общей причины низкой производительности при параллельном программировании: длительное время ожидания при блокировке, когда ядра недостаточно эффективно используются во время ожидания. Профили для горячей точки, а также блокировок и ожиданий используют программный сборщик, который работает на Intel® и совместимых процессорах. Новая функция! Поддержка OpenMP 4.0 и упрощение представления данных OpenMP. |
 | Интеллектуальный анализ данных с фильтрацией временной линии Выберите временной диапазон во временной линии и отфильтруйте данные (например, запуск приложения) для получения необходимой информации. При выполнении выбора и фильтрации во временной линии сетка, содержащая перечень функций, использующих большое количество времени процессора, обновляется для отображения списка, отфильтрованного для выбранного времени. |
 | Визуализация поведения потока Следите за выполнением потоков или их нахождением в режиме ожидания, а также за переходами. Балансировка рабочих нагрузок. |
 увеличить изображение | Профилировка удаленных систем - Профилировка работающих приложений Профилировка удаленных систем. Используйте локальный графический интерфейс для настройки командной строки, выполняйте сбор удаленно, а затем анализируйте результаты при помощи графического интерфейса или командной строки. Профилировка без перезапуска приложения. Профилировка запущенного процесса или всей системы с выборкой аппаратных событий с последующей фильтрацией необходимых объектов. |
 | Низкие издержки / Профилирование оборудования с высоким разрешением Вдобавок к анализу горячих точек, который работает на Intel® и совместимых процессорах, Intel® VTune™ Amplifier XE оборудован расширенной функцией анализа горячих точек, которая использует блок мониторинга производительности (PMU) на процессорах Intel для сбора данных с очень малыми издержками. Увеличенное разрешение (1 мс против 10 мс) помогает обнаруживать горячие точки в небольших быстро выполняющихся функциях. Теперь есть возможность опционального сбора данных из стека для определения вызывающей последовательности. |
 | Предварительно заданные профили событий оборудования Получайте удовольствие от простоты профилирования для новых процессоров. Больше не требуется запоминать сложные имена событий. Усовершенствованные профили, например, анализ пропускной способности памяти, доступ к памяти и возможности настройки поиска ошибочности прогнозирования ветвления. Теперь с опциональным сбором данных из стека для определения вызывающей последовательности. Профили различаются по микроархитектуре. |
 | Подсветка функциональных возможностей Ячейка выделяется розовым цветом при наличии возможности настройки. При наведении курсора выводятся соответствующие предложения по отладке. |
Подробная информация
Настройка параллельных (и последовательных) приложений
Профайлеры старого стиля предоставляют данные только для настройки последовательных приложений. Хотя это и важно, они являются недостаточными при необходимости в оптимизации современных последовательных приложений. Возможности VTune Amplifier XE анализа параллельности, блокировок и ожиданий в сочетании с потоковой временной линией предоставляют вам инструменты, необходимые для масштабируемости и параллельной производительности.
Мощный анализ данных
В отличие от большинства конкурирующих продуктов Intel VTune Amplifier XE выполняет не только отображение данных, но и позволяет их анализировать.
Выберите временной диапазон, используя временную линию, и отфильтруйте данные, чтобы исключить все ненужное за пределами данного временного диапазона. Это приведет к обновлению списка функций, потребляющих большую часть времени процессора для показа потребителей времени процессора на протяжении выбранного промежутка времени. Это позволит вам отфильтровать шум, например, при инициализации, или выделить падение производительности, которое имеет место только в определенный момент времени.
По умолчанию данные группируются по функциям, затем происходит вызов стека для получения списка функций, использующих большую часть времени процессора. Однако перегруппировка данных может выполняться различными способами. Например, перегруппировка по функции, а затем по потоку, чтобы оценить сбалансированность стандартного разделения на потоки.
Сочетание выбора и группирования может быть особенно эффективным. Настраиваете графическое приложение? Используйте перегруппировку по фрейму для поиска медленных фреймов. Выберите самые медленные фреймы и выполните фильтрацию. Затем выполните перегруппировку по функции. Теперь у вас имеется список функций, использующих большую часть времени в медленных фреймах. Это в точности то, что вам необходимо знать при настройке ускорения медленных фреймов.
Что нового?
| Свойство | Преимущество |
|---|---|
| Настройка встраивания вместе со счетом вызовов | При частом вызове функции, возможно, имеет смысл "встроить" код, чтобы избежать издержек при вызове функции. Новая функция: статистические данные для счета вызовов помогут вам принять наилучшее решение по встраиванию. |
| Выборка из аппаратного стека | Intel® VTune™ Amplifier XE теперь поддерживает выборку из стека из аппаратных и программных сборщиков. Расширенные аппаратные события, например ошибки кэш-памяти, могут также иметь стеки, что облегчает поиск возможностей для настройки. |
| Улучшенный анализ пропускной способности памяти | VTune Amplifier XE выполняет более точный анализ пропускной способности памяти для операций чтения и записи в кэш и память. Также добавляется анализ для дополнительных типов процессора. |
| Профилирование Java | Анализ Java-кода или смешанного Java- и собственного кода. Результаты отображаются в оригинальном исходном коде Java. |
Профилировка запущенного приложения Java | Прикрепление к запущенному процессу теперь работает и для приложений Java, что устраняет необходимость перезапускать эти приложения для профилировки. |
| Анализ пользовательских задач | API для добавления комментариев к задаче используется для добавления комментариев к исходному коду, чтобы VTune Amplifier XE отображал информацию о выполняемых задачах. Например, если вы отмечаете сегменты вашего конвейера, то они будут маркироваться во временной линии, а также будет приводиться подробная информация. Это облегчает понимание данных профилирования. |
| Автоматическое обнаружение фреймов Microsoft DirectX* | Наблюдается недостаточная производительность игрового окружения? Вам следует узнать, где вы тратите большое количество времени при малой частоте обновления кадров. Intel VTune Amplifier XE может автоматически обнаруживать фреймы Microsoft DirectX и осуществлять фильтрацию результатов, чтобы показать вам, что происходит в случае медленных фреймов. Не используется DirectX? Просто задайте критическую область, используя API, и анализ фреймов станет мощным инструментом для анализа задержки. Теперь поддерживается несколько регионов. |
| Настройка на сопроцессоры Intel® Xeon Phi™ | Профилирование оборудования поддерживается для сопроцессоров Intel Xeon Phi. Может осуществляться сбор расширенных данных о горячих точках и событиях. Временные маркеры позволяют сопоставлять данные по нескольким картам. Предлагается для Windows* и Linux*. |
| Анализ MPI-приложений | Анализ гибридных приложений с использованием MPI и OpenMP (или других потоков). Простая установка в кластер. Результаты сортируются в определенном порядке. |
| Данные профилирования ГП | Сбор и анализ данных о производительности ГП для настройки OpenCL*. Сопоставляйте показатели производительности ГП/ЦП (новые модели процессоров, только для Windows*). |
| OpenMP 4.0 | Упрощенное представление данных OpenMP благодаря управлению сходством потоков, задачами и анализу масштабируемости. |
| Окно вызывающего/вызываемого | Упрощенный анализ первичных и вторичных функций для конкретной приоритетной функции. |
| Улучшенный вид сетки | Возможность поиска, метрические показатели издержек и времени прокрутки и отображение иерархии циклов упрощают интерпретацию данных. |
| Анализ циклов | Найдите горячие циклы, отнимающие большую часть времени. Их векторизация может значительно увеличить быстродействие. |
| Усовершенствование временных линий | Сортировка временных линий, метрические показатели издержек и времени прокрутки, настраиваемая шкала времени упрощают анализ данных. |
| Поддержка новых процессоров | VTune Amplifier XE постоянно добавляет поддержку новейших процессоров. Обновления появляются сразу после анонса новых процессоров. |
 – функция добавлена после первоначального выпуска. Новые функции постоянно добавляются в обновлениях и предлагаются бесплатно при наличии подписки.
– функция добавлена после первоначального выпуска. Новые функции постоянно добавляются в обновлениях и предлагаются бесплатно при наличии подписки.
Варианты приобретения: Пакеты программ, ориентированные на конкретный язык
Имеется несколько пакетов, объединяющих в себе программные средства для построения, верификации и настройки Вашего приложения. Программные продукты, включенные в настоящий обзор, выделены голубым цветом. Имеются однопользовательские и многопользовательские лицензии, а также предоставляются скидки при продаже большого количества товара, академические и студенческие скидки.
Покупка включает в себя годовую подписку на обновления продукта.

увеличить изображение
Технические характеристики
| Краткое описание характеристик | |
|---|---|
| Поддержка процессора | Процессоры Intel® и совместимые процессоры при анализе приложений, содержащих инструкции Intel®. Многие функции профилирования работают как на оригинальных процессорах Intel®, так и на совместимых процессорах. Функции, использующие встроенный блок мониторинга производительности, требуют наличия оригинального процессора Intel® для сбора данных, однако анализ результатов может выполняться на совместимых процессорах. |
| Операционные системы | Windows* и Linux* |
| Средства и среды разработки | Библиотека совместима с компиляторами поставщиков продукции на стандартных платформах (например, Microsoft*, GCC, Intel). Может интегрироваться с Microsoft Visual Studio* 2008, 2010 и 2012. Подробную информацию можно получить по адресу: http://www.intel.com/software/products/systemrequirements |
| Языки программирования | C, C++, C#, Fortran, ассемблер. |
| Системные требования | http://www.intel.com/software/products/systemrequirements |
| Поддержка | Цена включает в себя обновления продукта, услуги Intel® Developer Zone Support и форумы по технической поддержке (Support Forums) в течение одного года. Услуги Intel Developer Zone Support включают в себя конфиденциальную веб-поддержку соответствующими специалистами. |
| Сообщество | Присоединяйтесь к сообществу Intel Developer Zone Support, где вы сможете учиться, делиться своим опытом или просто просматривать новости. http://software.intel.com/en-us/forums |
 | Узнайте больше о Intel VTune Amplifier XE
|  | Скачайте бесплатную пробную версию со сроком тестирования 30 дней
|
| Уведомление об оптимизации | Редакция уведомления № 20110804 |
| Компиляторы Intel могут не обеспечивать для процессоров других производителей такой же уровень оптимизации для оптимизаций, которые не являются присущими только микропроцессорам Intel. В число этих оптимизаций входят оптимизации для наборов команд SSE2, SSE3 и SSSE3, а также другие оптимизации. Корпорация Intel не гарантирует наличие, функциональность или эффективность оптимизаций микропроцессоров других производителей. Содержащиеся в данной продукции оптимизации, зависящие от микропроцессора, предназначены для использования с микропроцессорами Intel. Некоторые оптимизации, не относящиеся к микроархитектуре Intel, зарезервированы для микропроцессоров Intel. Более подробную информацию о конкретных наборах команд, предусмотренных настоящим уведомлением, можно найти в руководствах пользователя и справочных руководствах на соответствующую продукцию. | |
Дополнение. Intel-Cluster-Studio-XE-2013SP1-PB-RU-082713
Орингинал текста Вы можете скачать здесь.
Основные характеристики
- Интегрированный набор инструментов для разработки кластерных приложений.
- Высокопроизводительная библиотека MPI.
- Высокопроизводительные компиляторы C++ и Fortran и мощные модели параллельности для многоядерных процессоров.
- Анализ корректности и инструменты профилирования для приложений общего доступа и для распределенных и гибридных приложений.
"Уникальное преимущество Flow-3D состоит в возможности моделирования сложных потоков жидкости. Собственно говоря, требование параллельного выполнения, выдвигаемое нашими клиентами, является трудновыполнимым. Чтобы удовлетворить эту потребность, мы активно используем все функции Intel Cluster Studio XE, предназначенные для сокращения и поиска ранее сложно обнаруживаемых ошибок памяти и общего доступа, для повышения общей производительности и масштабирования нашего программного обеспечения на различных системах с многоядерной архитектурой, используемых нашими клиентами. В дополнение к преимуществам, связанным с разработкой, инструменты Cluster Studio XE позволяют разрешить невоспроизводимые проблемы, возникающие у заказчика."
Взаимодействующие продукты:
- Intel® OpenCL*
Входит в состав других конфигураций:
Поддержка ОС:
- Windows*
- Linux*
Масштабируй с перспективой на будущее, масштабируй быстрее
Эволюция архитектуры высокопроизводительных кластеров с большим количеством ядер и более широкими векторами на нескольких узлах ставит перед разработчиками задачи создания приложений, использующих эти продвинутые архитектуры, соблюдая, в то же время, установленные сроки. Пакет Intel ® Cluster Studio XE содержит полный набор параллельных стандартов программирования на языке C / C++ и средств разработки Fortran, а также модели программирования, которые позволяют разработчикам эффективно разрабатывать, анализировать и оптимизировать HPC-приложения для масштабирования, ускорения и повышения производительности IA-совместимых процессоров, включая сопроцессоры Intel® Xeon Phi™.
Intel Cluster Studio XE включает в себя инструменты для разработки программ нового поколения:
- Intel® MPI Library – Коммутационно-независимая MPI-библиотека с высоким уровнем масштабируемости и малым временем задержки.
- Intel® Trace Analyzer and Collector – Профилировщик производительности MPI-коммуникаций.
- Компиляторы Intel® C, C++ и Fortran – самые лучшие в отрасли компиляторы.
- Intel® Math Kernel Library (Intel® MKL) и Intel® Integrated Performance Primitives (Intel® IPP) – библиотеки повышения производительности для математических примитивов и мультимедиа.
- Intel® Threading Building Blocks (Intel® TBB) и Intel® Cilk™ Plus – модели параллельного программирования на основе потоков.
- Intel® Advisor XE – инструмент моделирования потоков для разработчиков на языках C/C++, C# и Fortran. Включите в проектирование масштабируемость. Исключите из проектирования проблемы совместного использования данных.
- Intel® VTune™ Amplifier XE – профилировщик производительности и потоков, настраивает гибридные приложения MPI/OpenMP*.
- Intel® Inspector XE – средство отладки памяти и потоков находит ошибки, пропускаемые при статическом анализе.
- Static Analysis – средство для поиска труднообнаруживаемых дефектов
- Intel® MPI Benchmarks – Набор открытых программных кодов MPI и ядер тестовых программ кластера
увеличить изображение
В приложении Flow-3D компании Flow Science был использован набор Intel® Cluster Studio XE с целью повышения производительности. На рисунке представлены результаты моделирования опорожнения бака окислителя ракеты-носителя.
Основные характеристики
 увеличить изображение | Интегрированный набор инструментов для разработки кластерных приложений Великолепная производительность совместно используемых, распределенных или гибридных приложений обеспечивается ведущими в отрасли компиляторами, параллельными моделями и библиотеками компании Intel, обладающими передовыми оптимизациями производительности для систем высокопроизводительных кластеров с мультиядерными (на сегодняшний день) и многоядерными (в будущем) процессорами. |
 увеличить изображение | Ведущая в отрасли библиотека MPI Библиотека Intel® MPI Library обеспечивает новые уровни производительности, масштабируемости и гибкости приложениям, исполняемым на кластерах платформ Intel®.
|
 | Intel® Trace Analyzer and Collector Intel Trace Analyzer and Collector представляет собой мощный инструмент для определения корректности и режима работы MPI-приложения.
|
 увеличить изображение | Высокопроизводительные компиляторы и библиотеки языков C, C++ и Fortran Компиляторы Intel® C, C++ и Fortran имеют встроенные технологии оптимизации и поддержку многопоточности, что помогает создавать код, максимально эффективно работающий на новейших мультиядерных процессорах Intel® и многоядерных архитектурах.
|
Особенности
Комплект Intel Cluster Studio XE помогает разработчикам, работающим с высокопроизводительными кластерами, решать стоящие перед ними задачи, предлагая первый в своем роде всеобъемлющий пакет программных средств, дающий возможность разработчикам увеличить производительность и надежность кластерных приложений. Он сочетает в себе проверенные практикой наборы инструментов Intel для кластерных приложений и передовые средства компании Intel для анализа корректности организации потоков/памяти и профилирования производительности, что дает пользователю возможность разработки масштабируемых приложений для современных и будущих высокопроизводительных кластерных систем.
Масштабируемая производительность
Великолепная производительность совместно используемых, распределенных или гибридных приложений обеспечивается ведущими в отрасли компиляторами, параллельными моделями и библиотеками компании Intel, обладающими передовыми оптимизациями производительности для систем высокопроизводительных кластеров с мультиядерными (на сегодняшний день) и многоядерными (в будущем) процессорами.
- Время задержки MPI – скорость работы библиотеки Intel MPI Library почти в 6,5 раз превышает скорость работы альтернативных библиотек MPI.
- Производительность компилятора – ведущие в отрасли компиляторы Intel на языках C, C++ и Fortran.
- Универсальное профилирование производительности — Intel VTune Amplifier XE собирает полный набор данных о производительности для оптимизации последовательной и параллельной производительности.
- Инструмент моделирования потоков — Intel Advisor XE позволяет разработчикам программного обеспечения быстро прогнозировать масштабирование производительности различных способов организации потоков в системах с большим числом ядер. Теперь вы можете включить в проектирование масштабируемость и исключить из него проблемы совместного использования данных.
Масштабирование с перспективой на будущее
Комплект Intel Cluster Studio XE представляет собой средства, модели программирования и высокопроизводительные библиотеки, дающие разработчикам возможность создавать код, который масштабируется на процессорах Intel® Xeon® сегодня и который может быть легко расширен до архитектуры Intel® Many Integrated Core (Intel® MIC).
- Производительность MPI – библиотека MPI компании Intel масштабируется на более чем 120 тысяч процессов.
- Модели параллельного программирования — поддерживаемые в промышленном масштабе версии открытого кода Intel Threading Building Blocks (Intel TBB) и Intel Cilk Plus для параллелизма потоков.
Эффективность масштабирования
Давление со стороны бюджета и графика выполнения работ ясно показывают необходимость применения надлежащих средств и моделей программирования для быстрой разработки и установки надежных высокопроизводительных кластерных приложений. Комплект Intel Cluster Studio XE представляет собой мощные средства организации потоков и проверки корректности кода для разработки гибридных приложений и простые в использовании модели параллельного программирования.
- Инструменты анализа для удобной работы в кластерах — продукты Intel VTune Amplifier XE и Intel Inspector XE устанавливаются в кластер и способны анализировать гибридные приложения, использующие MPI и OpenMP.
- Отладка памяти и потоков — Intel Inspector XE находит ошибки памяти и потоков, пропускаемые при традиционном регрессивном тестировании и статическом анализе. Интеграция отладчика ускоряет диагностику.
- Корректность MPI – увеличение производительности процесса поиска ошибок MPI.
- Модели параллельного программирования – создание параллельного кода с помощью трех ключевых слов, используя Intel Cilk Plus.
- Инновационный помощник в организации многопоточности Intel Advisor XE анализирует код и определяет регионы по признаку наличия потенциала параллелизации для повышения производительности кода, использующего общую память.
Что нового
| Свойство | Преимущество |
|---|---|
| Повышенная масштабируемость и производительность MPI | Новый диспетчер соединений и методы автовыбора повышают масштабируемость по сравнению с соединениями на базе RDMA. Улучшенная поддержка приложений NUMA и добавление расширенных средств управления закреплением процессов допускают дальнейший рост производительности систем HPC при разработке и развертывании. Высокомасштабируемый диспетчер процессов Hydra* Process Manager теперь доступен для кластеров на базе Windows*, обеспечивая более высокую производительность по сравнению с устройствами RDMA с малым временем задержки. |
| Обновленный пользовательский интерфейс и расширенная поддержка профилирования | Intel® Trace Analyzer and Collector теперь отличается обновленным и улучшенным пользовательским интерфейсом, в который добавлены новые панели инструментов, значки и диалоги для более оптимального протекания анализа. Расширенная поддержка инструментальных средств обеспечивает более высокую взаимную совместимость для стандартных интерфейсов профилирования. |
| Поддержка новейших процессоров: Haswell, Ivy Bridge, сопроцессоры Intel® Xeon Phi™ | Intel постоянно предлагает первый набор инструментов, позволяющих воспользоваться передовыми средствами повышения производительности новейших продуктов Intel®, сохраняя совместимость со старыми процессорами Intel® и совместимыми процессорами. Теперь поддержка включает в себя AVX2, TSX, FMA3 и AVX-512. |
| Добавлена поддержка OpenMP* 4.0 | Компилятор и инструменты анализа теперь поддерживают главные функции OpenMP* 4.0, включая выгрузку в сопроцессор и расширения SIMD. |
| Получение воспроизводимых результатов | Расширенная поддержка условной числовой воспроизводимости (conditional numerical reproducibility) в библиотеке Intel® Math Kernel Library (Intel® MKL), обеспечивающая воспроизводимые результаты на сходных платформах, к которым относятся современные и будущие архитектуры. |
| Поддержка стандартов C++ и Fortran | Компилятор Intel® Fortran Compiler полностью поддерживает стандарт F2003 и частично стандарт 2008, включая распределенные массивы. В данной версии Intel демонстрирует свое стремление к дальнейшей поддержке стандарта C++11. |
| Поддержка дополнительных отладчиков | Разработчики могут использовать GNU Project Debugger* (GDB*) на операционной системе Linux* и Intel® Debugger Extension для GDB, чтобы отлаживать приложения для сопроцессоров Intel® Xeon Phi™. |
| Усовершенствованный инструмент моделирования потоков, Intel® Advisor XE | Благодаря новому учебному курсу и усовершенствованному окну помощи Intel® Advisor XE стал проще в освоении. Возможность приостановки/возобновления экономит время, устраняя анализ кода с низким риском. |
| Поддержка различных операционных систем, новейшие интегрированные среды разработки | Инструменты Intel® поддерживают последние дистрибутивы Linux* и операционные системы Windows* и совместимы с другими средствами разработки программного обеспечения. В Требованиях к системе приведена подробная информация для каждого инструмента. |
Варианты приобретения
Intel Cluster Studio XE объединяет все средства разработки компании Intel в один комплект. Он выделен голубым цветом. Имеются однопользовательские и многопользовательские лицензии, а также предоставляются скидки при продаже большого количества товара, академические и студенческие скидки.

увеличить изображение
- Операционная система: W=Windows*, L= Linux*, O= OS* X.
- Входит в состав Intel® Visual Fortran Composer XE для Windows* с IMSL*
- Не поставляется отдельно для OS* X, входит в состав наборов Intel® C++ и Fortran Composer XE для OS* X
Технические спецификации
| Краткий обзор спецификаций | |
|---|---|
| Поддержка процессора | Библиотека протестирована на использование с различными поколениями процессоров Intel и совместимыми с ними процессорами, включая помимо прочего: процессор 2-го поколения Intel® Core™2, процессор Intel® Core™ 2, процессор Intel® Core™, процессор Intel® Xeon™ и сопроцессор Intel® Xeon Phi™ . . |
| Операционные системы | Windows* и Linux* |
| Языки программирования | Разработка с поддержкой родного формата C, C++ и Fortran |
| Системные требования | Подробную информацию о требованиях к аппаратному и программному обеспечению можно получить по адресу www.intel.com/software/products/systemrequirements/. |
| Поддержка | Цена включает в себя обновления продукта, услуги по Премьер-поддержке (Intel® Premier Support) и форумы по технической поддержке (Intel® Support Forums) в течение одного года. Услуги Intel Premier Support включают в себя конфиденциальную веб-поддержку соответствующими специалистами. |
 В настоящее время поддерживается только для Linux
В настоящее время поддерживается только для Linux
 | Узнайте больше о Intel Cluster Studio XE
|  | Скачайте 30-дневную оценочную версию бесплатно
|
| Уведомление об оптимизации | Редакция Уведомления №20110804 |
| Компиляторы Intel могут не обеспечивать для процессоров других производителей такой же уровень оптимизации для оптимизаций, которые не являются присущими только процессорам Intel. В число этих оптимизаций входят оптимизации для наборов команд SSE2, SSE3 и SSSE3, а также другие оптимизации. Корпорация Intel не гарантирует наличие, функциональность или эффективность оптимизаций микропроцессоров других производителей. Содержащиеся в данной продукции оптимизации, зависящие от микропроцессора, предназначены для использования с микропроцессорами Intel. Некоторые оптимизации, не относящиеся к микроархитектуре Intel, зарезервированы для микропроцессоров Intel. Более подробную информацию о конкретных наборах команд, предусмотренных настоящим уведомлением, можно найти в руководствах пользователя и справочных руководствах на соответствующую продукцию. | |
Дополнение. Программные инструменты Intel для разработчиков
Орингинал текста Вы можете скачать здесь.
Intel® Parallel Studio XE 2013. Пакет инструментов для разработки высокопроизводительных приложений
http://software.intel.com/ru-ru/intel-parallel-studio-xe
Обеспечьте максимальную производительность приложений при минимальных затратах времени и усилий на разработку, тестирование и оптимизацию. Intel® Parallel Studio XE 2013 предоставляет разработчикам на языках C, C++ и Fortran самые современные инструменты для создания приложений. Решение интегрируется в Visual Studio* и совместимо с пакетами программ GNU, обеспечивая производительность при умеренных инвестициях в среду разработки приложений от компании Intel. Увеличьте производительность своих приложений, работающих на базе процессоров и сопроцессоров Intel текущего и будущих поколений, в том числе на процессорах Intel® Xeon® и сопроцессорах Intel® Xeon Phi™.
Преимущества
- Высокая производительность приложений, которые масштабируются по мере увеличения числа ядер и длины регистра процессора
- Эффективное масштабирование на платформах будущих поколений при сохранении инвестиций в существующий программный код
- Совместимость с лучшими средами для разработки приложений
Основные характеристики
- Общепризнанные компиляторы С/C++ и Fortran, а также библиотеки к ним
- Современный помощник в разработке многопоточных программ для Linux* и Windows* – Intel® Advisor XE 2013
- Простое в использовании средство поиска ошибок памяти и потоков Intel® Inspector XE 2013 обеспечивает создание более надежных приложений как с последовательным, так и с параллельным кодом
Intel® Inspector XE 2013
http://software.intel.com/en-us/intel-inspector-xe
Преимущества
- Инструмент позволяет производить проверку корректности программ на языках C, C++, C# и Fortran
- Не требует специальных настроек сборки приложения. Можно использовать обычную сборку
Intel® Advisor XE 2013
http://software.intel.com/en-us/intel-advisor-xe
Инструмент представляет собой программу-помощник в организации многопоточности для разработчиков на C, C++, C# и Fortran, выявляет области с наибольшим потенциалом производительности за счет параллельности и определяет критические проблемы синхронизации.
- Оценка всех альтернатив перед инвестированием в реализацию
- Оценка прироста производительности
- Выявление проблем, связанных с возможным некорректным исполнением многопоточного кода
- Подбор оптимального варианта для реализации
"Средства анализа, входящие в состав Intel® Parallel Studio XE, значительно расширили наши возможности по скорейшему выявлению узких мест, определению/устранению проблем с памятью и отслеживанию сложных для выявления ошибок многопоточности до того, как наша продукция выходит на рынок"
"Intel Parallel Studio XE стал основным инновационным продуктом в нашей компании Golaem, который помог нам добиться более высокой частоты кадров при воспроизведении и более высокой скорости передачи. Все это дало возможность анимационным студиям и студиям, занимающимся спецэффектами, экономить время и деньги, добиваясь при этом впечатляющих результатов"
Intel® Composer XE 2013. Fortran, C++ и библиотеки в одном удобном пакете
http://software.intel.com/ru-ru/intel-composer-xe
Продукт Intel® Composer XE 2013 предназначен для разработчиков, которым требуются компиляторы C++ и Fortran. Данный набор инструментов сочетает все возможности пакетов Intel® C++ Composer XE и Intel® Fortran Composer XE, помогая повысить производительность создаваемых приложений, запускаемых на системах с процессорами Intel® Core™ или Xeon®, сопроцессорами Intel® Xeon Phi™, а также совместимыми с ними.
Пакет инструментов является весьма выгодным предложением, учитывая тот факт, что покупка отдельных компонентов обойдется значительно дороже. Поддерживаемые ОС — Windows* и Linux*. При использовании под ОС Windows необходимо установить Microsoft Visual Studio* 2008, 2010 или 2012.
В состав пакета Intel® Composer XE 2013 входят компиляторы Intel® C++ и Fortran с новыми возможностями для векторизации и разработки высокопроизводительных параллельных приложений. Поддерживаются технологии Intel® Cilk™ Plus, OpenMP*, автоматическое распараллеливание и множество других возможностей. Пакет совместим с популярными компиляторами C++ и средами для разработки приложений для Windows и Linux.
Основные возможности
- Средства работы с массивами Intel® Cilk™ Plus для эффективной векторизации
- Поддержка новых стандартов языка в компиляторе Intel® Fortran
- Библиотеки Intel® MKL, Intel® IPP и Intel® TBB: готовые решения для повышения производительности в руках разработчиков
- Рекомендации по повышению производительности от Performance Guide


Intel® VTune Amplifier XE 2013
http://software.intel.com/ru-ru/intel-vtune-amplifier-xe
Профилировщики предыдущего поколения собирают данные только для последовательных приложений. Хотя это и важно, но недостаточно для оптимизации современных параллельных программ. Возможности анализа параллельности, блокировок и времени ожидания VTune Amplifier XE в сочетании с временной шкалой потоков предоставляют вам инструменты, необходимые для масштабируемости и параллельной производительности ваших приложений.
Основные возможности
- Быстрый поиск участков кода, исполняемых длительное время
- Просмотр результатов в исходном коде
- Профилировка потоков с анализом блокировок и времени ожидания
- Интеллектуальный анализ данных с фильтрацией на временной шкале
- Визуализация поведения потоков
- Профилировка уже запущенных приложений
- Низкие издержки; профилирование оборудования с высоким разрешением
- Предустановленные профили аппаратных событий
- Подсветка потенциальных проблем и возможностей

увеличить изображение
Intel® Cluster Studio XE 2013. Набор для разработки высокопроизводительных MPI- и гибридных приложений
http://software.intel.com/en-us/intel-cluster-studio-xe
Эволюция архитектуры высокопроизводительных кластеров, наряду с большим количеством ядер и новыми векторными инструкциями на узлах, ставит перед разработчиками задачи создания приложений, использующих эти возможности, соблюдая, в то же время, установленные сроки для завершения разработки. Пакет Intel® Cluster Studio XE содержит полный набор средств разработки на языках C/C++ и Fortran. Он поддерживает модели программирования, которые позволяют эффективно создавать, анализировать и оптимизировать HPC-приложения (высокопроизводительные приложения) для процессоров на базе архитектуры Intel, включая сопроцессоры Intel® Xeon Phi™.

увеличить изображение
"Уникальное преимущество Flow-3D состоит в возможности моделирования сложных потоков жидкости. Собственно говоря, требование параллельного выполнения, выдвигаемое нашими клиентами, является трудновыполнимым. Чтобы удовлетворить эту потребность, мы активно используем все функции Intel Cluster Studio XE, предназначенные для сокращения и поиска ранее сложно обнаруживаемых ошибок памяти и общего доступа, для повышения общей производительности и масштабирования нашего программного обеспечения на различных системах с многоядерной архитектурой, используемых нашими клиентами. В дополнение к преимуществам, связанным с разработкой, инструменты Cluster Studio XE позволяют разрешить трудновоспроизводимые проблемы, возникающие у заказчика"
Основные характеристики
- Интегрированный набор инструментов для разработки распределенных приложений
- Высокопроизводительная и масшабируемая библиотека MPI
- Оптимизирующие компиляторы С++ и Fortran и мощные параллельные библиотеки для многоядерных процессоров
- Анализ корректности и инструменты профилирования для приложений, ориентированных на компьютеры с общей памятью, гибридных и распределенных приложений
Комплект Intel Cluster Studio XE помогает разработчикам, работающим с высокопроизводительными кластерами, решать стоящие перед ними задачи увеличения производительности и надежности приложений. Он сочетает в себе проверенные практикой наборы инструментов Intel, включая передовые средства для анализа корректности работы с потоками/памятью и профилирования производительности, что дает пользователю возможность создания масштабируемых приложений для современных и будущих высокопроизводительных кластерных систем.

увеличить изображение
Intel® Math Kernel Library 11.0 (Intel® MKL). Библиотека для высокопроизводительных математических вычислений
http://software.intel.com/en-us/intel-mkl
Библиотека Intel® Math Kernel Library v11.0 (Intel® MKL) содержит функции и процедуры, ускоряющие разработку программ и повышающие скорость их работы на современных процессорах, отличающихся увеличенным числом ядер, разнообразием архитектур и векторными вычислениями. Чтобы использовать всю мощь вычислительных ресурсов процессора, примените оптимизированную библиотеку, разработанную для использования этого потенциала. Написанный с помощью Intel® MKL код будет работать оптимальным образом на существующих и будущих процессорах Intel.
Библиотека Intel® MKL включает подпрограммы для вычислительной линейной алгебры с высокой степенью векторизации и распараллеливания, алгоритмы вычисления быстрого преобразования Фурье (БПФ), векторные и статистические функции. Достаточно одного вызова этих функций с помощью интерфейса C или Fortran, чтобы автоматически применить их к существующим и будущим архитектурам процессоров с выбором оптимальной ветви кода в каждом случае.
"Библиотека Intel MKL незаменима для всех высокопроизводительных вычислений на платформах x86"
Основные возможности
- Математические вычисления для всевозможных приложений
- Стандартные интерфейсы для получения быстрого результата
- Производительность и масштабируемость на существующих и будущих процессорах
- Адаптация под требования разработчиков
- Условная численная воспроизводимость результата
- Оптимизация для процессоров с архитектурами Haswell, Ivy Bridge и сопроцессоров Intel® Xeon Phi™
- Автоматическая передача вычислений и балансировка нагрузки между процессорами Intel® Xeon® и сопроцессорами Intel® Xeon Phi™
- Интерполяция данных

увеличить изображение
Преимущества
- Векторные параллельные вычисления для достижения высокой производительности на процессорах Intel и совместимых с ними
- Совместимость с целым рядом компиляторов C, C++ и Fortran
- Лицензия, адаптированная для сокращения затрат при разработке ваших продуктов
Лицензирование программных инструментов Intel и обучение для разработчиков
http://software.intel.com/ru-ru/buy-or-renew
http://www.intuit.ru/catalog/se/intel/
Лицензирование программных инструментов Intel осуществляется по количеству разработчиков, т. е. в зависимости от количества сотрудников, использующих определенный продукт, можно составить комплект из однопользовательских (одновременно к лицензии обращается только один разработчик) и "плавающих" (до 25 разработчиков) лицензий.
Лицензии на программные продукты Intel бессрочные, но, приобретая лицензию, разработчик получает 1 или 3 года поддержки (обновление до последней выпущенной версии, управление лицензией, техническая поддержка в случае каких-либо сложностей).
- Коммерческие лицензии на программные пакеты или отдельные инструменты Intel предусматривают использование продукта для получения кода коммерческого назначения (http://software.intel.com/ru-ru/buy-or-renew)
- Академические лицензии предоставляют доступ к полноформатным версиям программных продуктов и отдельных инструментов, входящих в состав этих продуктов, но при этом реализуются по специальной цене для использования только для решения задач в научных, исследовательских и учебных заведениях (http://software.intel.com/ru-ru/buy-or-renew)
- Студенческие лицензии предоставляют доступ к полноформатным версиям программных продуктов для учебных классов (до 25 разработчиков), а также доступ к бесплатным инструментам для С++ (http://software.intel.com/ru-ru/intel-education-offerings)
- Со всеми программными инструментами Intel можно ознакомиться бесплатно (30-дневные ознакомительные лицензии: http://software.intel.com/ru-ru/intelsoftware-evaluation-center)
В рамках развития инициативы в области разработки и применения современных инструментов программирования, специалисты Intel в сотрудничестве с университетами России разработали сертификационную программу подготовки профессиональных программистов – специалистов в области параллельного программирования и программирования для мобильных устройств с использованием инструментов Intel.
На образовательном портале Национального Открытого Университета "ИНТУИТ" создана "Академия Intel" (http://intel.intuit.ru/), где публикуются курсы по программному обеспечению Intel. Часть курсов также размещена на портале Центра компетенции по образовательным программам Нижегородского государственного университета (http://nncc.unn.ru) и на портале Intel Software Network (http://software.intel.com/).
Классические варианты курсов имеют два уровня сложности:
- Вводный курс, который предлагает слушателю основной теоретический материал (например, по технологиям параллельного программирования), а также начальное знакомство с программным обеспечением Intel. После успешного прохождения тестовой сертификации слушатели получают сертификат уровня Introduction.
- Основной курс, который предполагает практическую работу с программным обеспечением Intel в объеме не менее 50% от объема курса. После успешного прохождения тестовой сертификации слушатели получают сертификат уровня Basic.
Для опытных групп пользователей может быть подготовлен и проведен "Курс решения практических проблем". Учебная программа для этого курса составляется индивидуально и с учетом реальных исследовательских задач слушателей. После успешного прохождения тестовой сертификации слушатели получают сертификат уровня Expert.
Возможны следующие модели обучения с "Академией Intel":
- Самостоятельное изучение материала
- Авторские вебинары с консультациями и домашними заданиями
- Для преподавателей: использование курсов и их фрагментов для поддержки учебных программ вузов
- Для студентов: получение информации о молодежных школах с краткосрочными курсами
Приведем интеллект-карту с краткими названиями основных курсов в области параллельного программирования. Курсы 7 и 8 находятся в процессе подготовки.

увеличить изображение