Лекция 1. Комбинаторные вычисления
Введение
Комбинаторная математика является старой дисциплиной. Она получила свое наименование в 1666 г. от Лейбница в его "Dissertation de Arte Combinatori". Комбинаторные алгоритмы с их акцентом на разработку, анализ и реализацию практических алгоритмов являются продуктом века вычислительных машин.
Предмет теории комбинаторных алгоритмов - вычисления на дискретных математических структурах. Это новое направление исследований. Лишь в последние несколько лет из наборов искусных приемов и разрозненных алгоритмов сформировалась система знаний о разработке, реализации и анализе алгоритмов.
Комбинаторные вычисления находятся в таком же отношении к комбинаторной математике (дискретной, конечной математике), как численные методы анализа - к анализу. Комбинаторные вычисления развиваются в следующем направлении:
- интенсивно изобретаются новые алгоритмы;
- происходит быстрый прогресс (главным образом в математическом плане) в понимании алгоритмов, их разработки и анализа;
- происходит переход от изучения отдельных алгоритмов к исследованию свойств, присущих классам алгоритмов.
В отличие от некоторых других разделов математики, комбинаторные вычисления не имеют "ядра", то есть некоторого количества "фундаментальных теорем", составляющих суть предмета, из которых выводится большинство результатов. Сначала может показаться, что в целом эта область состоит из наборов специальных методов и хитрых приемов. Однако после того, как было исследовано достаточно много комбинаторных алгоритмов, стали вырисовываться некоторые общие принципы. Именно эти принципы делают комбинаторные вычисления связной областью знаний и позволяют изложить ее в систематизированном виде.
Проблема представления: коды, сохраняющие разности
Чрезвычайно важной проблемой в комбинаторных вычислениях является задача эффективного представления объектов, подлежащих обработке. Она возникает потому, что обычно имеется много возможных способов представления сложных объектов более простыми структурами, которые можно заложить в языки программирования, но не все такие представления в одинаковой степени эффективны с точки зрения времени и памяти. Более того, идеальное представление зависит от вида производимых операций.
Приведем примеры, в которых задаются весьма специфические операции над целыми. Целые определяются как данные простейшего типа почти во всех вычислительных устройствах и языках программирования. Таким образом, проблема представления, как правило, не возникает. Имеющееся представление почти всегда наилучшее. Однако существуют некоторые заслуживающие внимания исключения, когда выгодно или даже необходимо использовать представление целых в вычислительном устройстве иным способом. Эти исключения появляются в следующих случаях:
- Необходимы целые, больше имеющихся непосредственно в аппаратном оборудовании.
- Необходимы только небольшие целые, и требуется сэкономить память, упаковывая их по несколько в одну ячейку.
- Действия с целыми производятся не общепринятыми арифметическими операциями.
- Целые используются для представления других типов объектов, и необходимо иметь возможность легко обращать целое в соответствующий ему объект и обратно.
Проблемы кодов, сохраняющих разности, касаются случаев 2 и 3.
В задачах распознавания образов и классификации для решения вопроса, будут ли
два объекта ![]() эквивалентными,стандартной является следующая процедура.
эквивалентными,стандартной является следующая процедура. ![]() представляются векторами признаков
представляются векторами признаков ![]() соответственно, где каждая компонента означает признак объекта, выраженный целым значением. Считается, что
соответственно, где каждая компонента означает признак объекта, выраженный целым значением. Считается, что ![]() эквиваленты тогда и только тогда, если
эквиваленты тогда и только тогда, если

Классы алгоритмов
Одной из причин быстрого прогресса комбинаторных вычислений является усиление внимания к исследованию классов алгоритмов в противоположность изучению отдельных из них. Для того чтобы утверждать, например, что "все алгоритмы, предназначенные для выполнения того-то и того-то, должны обладать такими-то и такими-то свойствами" или "не существует алгоритма, удовлетворяющего тому-то и тому-то", необходимо иметь дело с четко определенным классом алгоритмов. Именно при таком определении становится возможным говорить, что данный алгоритм является оптимальным по отношению к некоторому свойству, если он работает по крайней мере так же хорошо (относительно этого свойства), как любой другой алгоритм из рассматриваемого класса.
Как можно строго определить, возможно, бесконечный, класс алгоритмов? Исследуем этот вопрос на примере задачи о фальшивой монете. Рассматриваемый в этом примере класс алгоритмов порождает более обширный и более важный класс алгоритмов - так называемые деревья решений.
Задача. Имеется ![]() монет, о которых известно, что
монет, о которых известно, что ![]() из них являются настоящими и не более чем одна монета, фальшивая (легче или тяжелее остальных монет). Дополнительно к группе из
из них являются настоящими и не более чем одна монета, фальшивая (легче или тяжелее остальных монет). Дополнительно к группе из ![]() сомнительных монет дается еще одна монета, причем заведомо известно, что она настоящая. Имеются также весы, с помощью которых можно сравнить общий вес любых
сомнительных монет дается еще одна монета, причем заведомо известно, что она настоящая. Имеются также весы, с помощью которых можно сравнить общий вес любых ![]() монет с общим
весом любых других
монет с общим
весом любых других ![]() монет и тем самым установить, имеют ли две группы
по
монет и тем самым установить, имеют ли две группы
по ![]() монет одинаковый вес либо одна из групп легче другой. Задача состоит в том, чтобы найти фальшивую монету, если она есть, за наименьшее число взвешиваний, или
сравнений.
монет одинаковый вес либо одна из групп легче другой. Задача состоит в том, чтобы найти фальшивую монету, если она есть, за наименьшее число взвешиваний, или
сравнений.
Решение Пусть сомнительные монеты занумерованы числами ![]() . Монете, о которой известно, что она настоящая, поставим в соответствие номер 0.
Пусть
. Монете, о которой известно, что она настоящая, поставим в соответствие номер 0.
Пусть ![]() - множество монет. Если
- множество монет. Если ![]() — непересекающиеся непустые подмножества множества
— непересекающиеся непустые подмножества множества ![]() , то через
, то через ![]() обозначим операцию сравнения весов множества
обозначим операцию сравнения весов множества ![]() . При сравнении возможны три исхода, которые обозначим следующим образом:
. При сравнении возможны три исхода, которые обозначим следующим образом: ![]() в зависимости от того, является ли вес
в зависимости от того, является ли вес ![]() меньшим, равным или большим веса
меньшим, равным или большим веса ![]() .
.
Рассматриваемые алгоритмы можно представить в форме дерева решений.
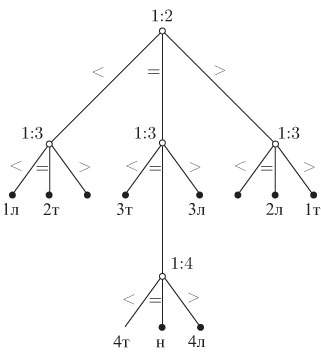
Рис. 1.1. Дерево решений для задачи о фальшивой монете с четырьмя монетами
Корень дерева на рисунке изображен полой окружностью и помечен
отношением ![]() . Это означает, что алгоритм начинает работу
сравнением весов монет с номерами 1 и 2. Три исходящие из корня ветви ведут к поддеревьям,
определяющим продолжение работы алгоритма после каждого из трех возможных
исходов первого сравнения. Окружности, залитые черной краской, называются
листьями дерева и означают, что работа алгоритма заканчивается. Метки
соответствуют исходам: "1л" - монета 1 легкая, "1т"
- монета 1 тяжелая, "н" - все монеты настоящие. Непомеченная вершина дерева
означает, что при наших предположениях этот случай возникнуть не может.
. Это означает, что алгоритм начинает работу
сравнением весов монет с номерами 1 и 2. Три исходящие из корня ветви ведут к поддеревьям,
определяющим продолжение работы алгоритма после каждого из трех возможных
исходов первого сравнения. Окружности, залитые черной краской, называются
листьями дерева и означают, что работа алгоритма заканчивается. Метки
соответствуют исходам: "1л" - монета 1 легкая, "1т"
- монета 1 тяжелая, "н" - все монеты настоящие. Непомеченная вершина дерева
означает, что при наших предположениях этот случай возникнуть не может.
Алгоритм, приведенный на рис. 1.1, требует двух сравнений в одних случаях и трех - в других. Скажем, что он требует "трех сравнений в худшем случае". Обычно важно знать, сколько работы требует алгоритм в среднем, однако для этого требуется задать вероятности различных исходов. Если предположим, что все девять исходов 1л, 1т, 2л, 2т, 3л, 3т, 4л, 4т, - равновероятны, то тогда этот алгоритм требует в среднем 7/3 сравнений.
На одну чашку весов можем положить больше одной монеты. Например, можно начать сравнения, положив на одну чашку весов монеты 1 и 2, а на другую - монеты 3 и 4 (рис. 1.2).
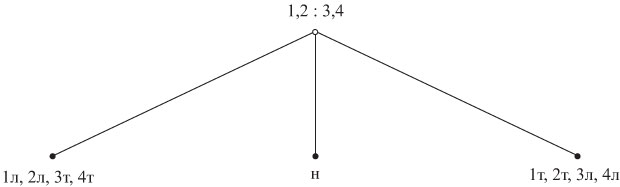
Рис. 1.2. Корень другого дерева решений для задачи о четырех монетах
Если посчастливится, задачу можно решить за одно сравнение - это может
произойти, когда все монеты настоящие. Независимо от того, как дополняется это дерево
решений, в худшем случае задача все равно потребует тех же трех сравнений, поскольку
единственное тернарное решение не может идентифицировать один из четырех
исходов, которые возможны на ветви, помеченной символом " ![]() ", так же как и один из четырех исходов на ветви, помеченной символом "
", так же как и один из четырех исходов на ветви, помеченной символом " ![]() ". К тому же, независимо от того, как дополняется это дерево решений, оно потребует в
среднем по крайней мере 7/3 сравнений, и в этом случае оно не лучше, чем дерево на
рис.1.1.
". К тому же, независимо от того, как дополняется это дерево решений, оно потребует в
среднем по крайней мере 7/3 сравнений, и в этом случае оно не лучше, чем дерево на
рис.1.1.
Используя монету 0, о которой известно, что она настоящая, можно получить приведенное на рис. 1.3 дерево решений (полное двухъярусное тернарное дерево), которое и в худшем, и в среднем случае требует двух сравнений.
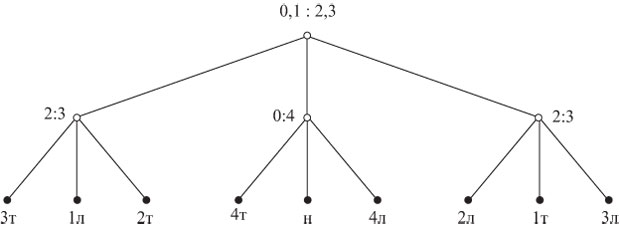
Рис. 1.3. Оптимальное дерево решений для задачи о четырех монетах
Рассматриваемый класс алгоритмов решения задачи о фальшивой монете есть множество тернарных деревьев решений (примеры на рис.1.1, рис.1.2, рис.1.3), обладающих следующими свойствами:
- каждый узел помечен сравнением
 , где
, где  и
и  - непересекающиеся непустые подмножества множества
- непересекающиеся непустые подмножества множества  всех монет;
всех монет; - каждый лист либо не помечен, что соответствует невозможному исходу в предположении существования не более чем одной фальшивой монеты, либо помечен одним из исходов iл, iT, н, означающим соответственно, что все монеты настоящие. Четко определив подлежащий дальнейшему рассмотрению класс алгоритмов, можно исследовать свойства, которыми должно обладать каждое дерево из этого класса, и определить, как найти алгоритмы, являющиеся в некотором смысле оптимальными. Решим эту проблему в начале для четырех монет, а затем перейдем к общему случаю.
Поскольку в задаче о четырех монетах требуется различить девять возможных
исходов, любое дерево решений для этой задачи должно иметь, по крайней мере,
девять листьев и, следовательно, не менее двух ярусов. Поэтому дерево на
рис.1.3 является оптимальным и для худшего случая, и для среднего. Существуют ли
другие оптимальные деревья? Для ответа на этот вопрос нужно рассмотреть множество
всех деревьев решений для задачи о четырех монетах. Попытаемся исключить из
дальнейшего рассмотрения какую-либо часть этого множества. Прежде всего видно,
что путем любой перестановки множества ![]() сомнительных монет из одного дерева, приведенного на рис.1.3, можно получить другие оптимальные деревья.
Все они будут изоморфны дереву на рис.1.3. Исходя из этого, уточним постановку
задачи и будем интересоваться попарно неизоморфными деревьями.
сомнительных монет из одного дерева, приведенного на рис.1.3, можно получить другие оптимальные деревья.
Все они будут изоморфны дереву на рис.1.3. Исходя из этого, уточним постановку
задачи и будем интересоваться попарно неизоморфными деревьями.
Рассмотрим затем, существует ли оптимальное дерево среди тех, у которых в
корне не используется монета с номером n. При таком ограничении в корне дерева
можно сделать только два различных сравнения, а именно ![]() и
и ![]() .
Рассмотрим разбиение исходов по трем ветвям, выходящим из корня, как показано
на рис.1.2. Для получения такого, как на рис.1.3, полного двухъярусного тернарного дерева, девять возможных исходов должны были бы быть разбиты в отношении (3, 3, 3). Они же вместо этого разбиваются, соответственно, в отношении (2, 5, 2)
и (4,1,4). Таким образом, заключаем, что задачу для четырех монет нельзя решить за два
сравнения, не используя дополнительную настоящую монету.
.
Рассмотрим разбиение исходов по трем ветвям, выходящим из корня, как показано
на рис.1.2. Для получения такого, как на рис.1.3, полного двухъярусного тернарного дерева, девять возможных исходов должны были бы быть разбиты в отношении (3, 3, 3). Они же вместо этого разбиваются, соответственно, в отношении (2, 5, 2)
и (4,1,4). Таким образом, заключаем, что задачу для четырех монет нельзя решить за два
сравнения, не используя дополнительную настоящую монету.
Наконец, рассмотрим те деревья решений, которые используют монету 0 в
корне. В этом случае видно, что в корне фактически возможны только два
сравнения: ![]() и
и ![]() . Для первого сравнения набор исходов
будет (1, 7, 1), в связи с чем все алгоритмы, начинающиеся таким способом, для нас непригодны. Набор исходов (3, 3, 3) приводит к оптимальному дереву, показанному на рис.1.3. Аналогичным образом устанавливается, что для оптимального дерева сравнения в первом от корня ярусе определяются единственным образом. Отсюда заключаем, что для задачи о четырех
монетах фактически существует только одно оптимальное дерево.
. Для первого сравнения набор исходов
будет (1, 7, 1), в связи с чем все алгоритмы, начинающиеся таким способом, для нас непригодны. Набор исходов (3, 3, 3) приводит к оптимальному дереву, показанному на рис.1.3. Аналогичным образом устанавливается, что для оптимального дерева сравнения в первом от корня ярусе определяются единственным образом. Отсюда заключаем, что для задачи о четырех
монетах фактически существует только одно оптимальное дерево.
Когда используемые идеи анализа задачи о четырех монетах переносятся на
произвольный случай, в некоторой степени все идеи обобщаются на случай любого
числа монет. Однако некоторые из них не имеют практического значения, когда ![]() значительно больше четырех. В принципе, оптимальные деревья решений всегда
можно найти путем систематического поиска в множестве деревьев, поскольку для
любого заданного
значительно больше четырех. В принципе, оптимальные деревья решений всегда
можно найти путем систематического поиска в множестве деревьев, поскольку для
любого заданного ![]() в качестве кандидатов требуется рассмотреть
лишь конечное число деревьев решений. В лекции обсуждается техника исчерпывающего поиска в
таких конечных множествах. Однако, если даже поиск организован разумно и
рассматриваются лишь существенно различные (не изоморфные) деревья, эта
процедура не может служить практическим способом отыскания оптимальных
деревьев решений. С ростом
в качестве кандидатов требуется рассмотреть
лишь конечное число деревьев решений. В лекции обсуждается техника исчерпывающего поиска в
таких конечных множествах. Однако, если даже поиск организован разумно и
рассматриваются лишь существенно различные (не изоморфные) деревья, эта
процедура не может служить практическим способом отыскания оптимальных
деревьев решений. С ростом ![]() число деревьев растет
экспоненциально, и поэтому техника исчерпывающего поиска имеет практическое значение только для малых значений
число деревьев растет
экспоненциально, и поэтому техника исчерпывающего поиска имеет практическое значение только для малых значений ![]() .
.
Поскольку число листьев в дереве решений должно быть по крайней мере
таким же, как и число возможных исходов задачи ( ![]() для задачи
о монетах), сразу же можно получить нижнюю оценку необходимого числа сравнений (или, что
эквивалентно, верхнюю оценку числа монет для данного сравнения).
для задачи
о монетах), сразу же можно получить нижнюю оценку необходимого числа сравнений (или, что
эквивалентно, верхнюю оценку числа монет для данного сравнения).
Анализ алгоритмов
В процессе разработки и реализации алгоритма естественным образом раскрываются некоторые его свойства. По мере того как алгоритмы становятся все более и более сложными, все менее и менее вероятно, что их важные свойства проявятся на стадиях разработки и реализации. Как правило, некоторые важные аспекты поведения алгоритма, такие как его корректность, необходимое число операций или объем памяти, определить трудно. Поэтому обычно глубокое понимание нового алгоритма предваряется очень длинной стадией его анализа.
Из-за трудностей анализа им зачастую просто пренебрегают. Вместо этого программа выполняется для того, чтобы увидеть, что получается (например, измеряется время работы). Такой подход можно признать удовлетворительным, если есть основание полагать, что тестовые задачи достаточно хорошо характеризуют работу алгоритма в общем случае; если же это не так, то описанный подход даст мало ценной информации. Даже если тест прекрасно характеризует работу алгоритма, он никогда не даст ответ на придирчивый вопрос, могут ли существовать лучшие алгоритмы для решения той же самой задачи. Проблему оптимальности алгоритма можно решить только путем его анализа.
В анализе алгоритмов существуют две фундаментальные проблемы:
- Какими свойствами обладает данный алгоритм?
- Какие свойства должен иметь любой алгоритм, решающий данную проблему?
Фундаментальная разница между этими двумя вопросами состоит в подходе к ответу на них. В первом случае алгоритм задан и заключения выводятся путем изучения свойств, присущих ему. Во втором случае задается проблема и точно определяется структура алгоритма. Заключения выводятся на основе изучения существа проблемы по отношению к данному классу алгоритмов.
Программа
Программа 1.Поиск фальшивой монеты
//Монета ищется простым перебором.
//Алгоритм реализован на языке программирования Turbo-C++.
#include <stdlib.h>
#include <conio.h>
#include <stdio.h>
int main() {
clrscr();
int k, n, flag = -1;
int *mas;
printf("Введите число монет: ");
scanf("%i", &n);
mas = (int*)malloc(sizeof(n));
randomize();
k = random (10) + 1;
for (int i = 0; i < n; i++) {
mas[i] = k;
}
for (i = k; i == k; i = random (20));
mas[random (n)] = i;
printf("Масса монет: ");
for (i = 0; i < n; i++) {
printf("%5i", mas[i]);
if (mas[i] != k) {
flag = i;
}
}
printf("\nФальшивая монета под номером %i ее вес %i", flag+1,
mas[flag]);
getch();
free(mas);
return 0;
}Лекция 2. Целые и последовательности (последовательное распределение)
Введение
Большинство вычислительных устройств в качестве основных объектов допускает только двоичные наборы, целые и символы, поэтому, прежде чем работать с более сложными объектами, их необходимо представить двоичными наборами, целыми или символами. Например, числа с плавающей запятой кодируются целыми - мантиссой и порядком этого числа, но такое кодирование обычно незаметно для пользователя. В противоположность этому, рассмотренные во второй и третьей лекции способы кодирования объектов (множества, последовательности, деревья) всегда адресованы пользователю.
Любой заданный класс объектов может иметь несколько возможных представлений, и выбор наилучшего из них решающим образом зависит от того, каким образом объект будет использован, а также от типа производимых над ним операций. Поэтому рассмотрим не только свойства самих представлений, но также и некоторые приложения.
Целые
Целые являются основными объектами в вычислительной комбинаторике. В различных вычислительных теоретико-числовых исследованиях изучаются сами целые числа, но мы будем использовать их главным образом при подсчете и индексировании. В последнее время установлено, что полезны различные представления. В этой лекции обсудим общий класс позиционных представлений.
Мы будем рассматривать только неотрицательные целые. Кроме того, к любому представлению неотрицательных целых легко присоединить одиночный знаковый двоичный разряд.
Позиционные системы для представления целых чисел очень широко известны,
поскольку они встречаются во многих разделах математики, начиная с "новой
математики" и кончая углубленным курсом теории чисел. В системе счисления
с основанием ![]() каждое положительное целое число имеет
единственное представление в виде конечной последовательности
каждое положительное целое число имеет
единственное представление в виде конечной последовательности
| (2.1) |
Единственность этого представления можно доказать методом от противного.
Числа ![]() и
и ![]() очевидно, имеют единственное
представление. Предположим, что представление не единственно, и пусть
очевидно, имеют единственное
представление. Предположим, что представление не единственно, и пусть ![]() будет наименьшим целым числом, имеющим два различных представления:
будет наименьшим целым числом, имеющим два различных представления:

| (2.2) |
Для доказательства того, что каждое положительное целое имеет представление
по основанию ![]() достаточно задать алгоритм, конструирующий (с
необходимостью единственное) представление данного числа
достаточно задать алгоритм, конструирующий (с
необходимостью единственное) представление данного числа ![]()
Алгоритм 1. Преобразование числа ![]() в его представление
в его представление ![]() в системе счисления с основанием
в системе счисления с основанием ![]() .
.
Он строит последовательность ![]() путем
повторения деления на
путем
повторения деления на ![]() и записи остатков. Пусть на первом шаге при
делении
и записи остатков. Пусть на первом шаге при
делении ![]() на
на ![]() остаток будет
остаток будет ![]() Частное,
полученное в результате первого шага, делим на
Частное,
полученное в результате первого шага, делим на ![]() вновь полученное частное делим на
вновь полученное частное делим на ![]() и так далее. Полученная в
результате такого процесса последовательность остатков и будет требуемым
представлением
и так далее. Полученная в
результате такого процесса последовательность остатков и будет требуемым
представлением ![]() по основанию
по основанию ![]()
Важным обобщением систем счисления с основанием ![]() являются смешанные системы счисления, в которых задается не единственное основание
являются смешанные системы счисления, в которых задается не единственное основание ![]() а последовательность оснований
а последовательность оснований ![]() , и последовательность
(2.2) соответствует целому
, и последовательность
(2.2) соответствует целому

Смешанные системы счисления могут вначале показаться странными, но в действительности в повседневной жизни они встречаются почти так же часто, как и десятичные.
Пример. Рассмотрим нашу систему измерения времени: секунды, минуты, часы,
дни недели и годы. Это - в точности смешанная система с ![]()
Представление целого ![]() в смешанной системе
счисления
в смешанной системе
счисления ![]() осуществляется с помощью алгоритма 2, который является простым обобщением алгоритма 1. Вместо того, чтобы для получения
осуществляется с помощью алгоритма 2, который является простым обобщением алгоритма 1. Вместо того, чтобы для получения ![]() в качестве делителя всегда использовалась
в качестве делителя всегда использовалась ![]() в алгоритме 2 используется
в алгоритме 2 используется ![]()
Алгоритм 2. Преобразование числа ![]() в его
представление
в его
представление ![]() в смешанной системе счисления
в смешанной системе счисления ![]() .
.
Последовательности
Бесконечная последовательность
| (2.3) |
В комбинаторных алгоритмах часто приходится встречаться с представлениями конечных последовательностей (или начальных сегментов бесконечных последовательностей ) и операциями над ними.
Различные способы представлений конечных последовательностей (или начальных сегментов бесконечных последовательностей) и операции над ними
Последовательное распределение. С вычислительной точки зрения простейшим представлением конечной последовательности является список ее членов, расположенных по порядку в последовательных ячейках памяти.

Рис. 2.1.
Так, ![]() хранится, начиная с ячейки
хранится, начиная с ячейки ![]()
![]() хранится, начиная с ячейки
хранится, начиная с ячейки ![]()
![]() хранится, начиная с ячейки
хранится, начиная с ячейки ![]() и так далее, где
и так далее, где ![]() - число ячеек, требуемых для хранения одного элемента последовательности.
- число ячеек, требуемых для хранения одного элемента последовательности.
Описанное выше представление последовательности имеет ряд преимуществ.
Во-первых, оно легко осуществимо и требует небольших расходов в смысле памяти.
Кроме того, оно полезно и потому, что существует простое соотношение
между ![]() и адресом ячейки, в которой хранится
и адресом ячейки, в которой хранится ![]()
Например, чтобы представить массив размером ![]()
 | (2.4) |
Последовательное распределение, наряду с преимуществами, имеет
значительные недостатки. Например, такое представление становится неудобным,
если
требуется изменить последовательность путем включения новых и исключения
имеющихся там элементов. Включение между ![]() и
и ![]() нового элемента
требует сдвига
нового элемента
требует сдвига ![]() вправо на одну
позицию; аналогично,
исключение
вправо на одну
позицию; аналогично,
исключение ![]() требует сдвига тех же элементов на одну позицию
влево. С точки
зрения времени обработки, такое передвижение элементов может оказаться
дорогостоящим, и в случае динамических последовательностей лучше использовать
технику связного распределения, рассматриваемую в следующей лекции.
требует сдвига тех же элементов на одну позицию
влево. С точки
зрения времени обработки, такое передвижение элементов может оказаться
дорогостоящим, и в случае динамических последовательностей лучше использовать
технику связного распределения, рассматриваемую в следующей лекции.
Характеристические
векторы. Важной разновидностью последовательного
распределения является случай, когда такому представлению подвергается
последовательность некоторой основной последовательности ![]() В этом случае можно представить последовательность более удобно,
используя характеристический
вектор - последовательность из нулей и единиц,
где
В этом случае можно представить последовательность более удобно,
используя характеристический
вектор - последовательность из нулей и единиц,
где ![]() -й разряд равен единице, если
-й разряд равен единице, если ![]() принадлежит
рассматриваемой последовательности, и нулю в противном случае.
принадлежит
рассматриваемой последовательности, и нулю в противном случае.
Например, характеристический вектор начального сегмента последовательности (2.3)
Характеристические векторы полезны в ряде случаев. Их полезность вытекает
из их компактности, существования простого фиксированного соотношения
между ![]() и адресом
и адресом ![]() -го разряда и возможности при таком
представлении очень легко исключать элементы.
-го разряда и возможности при таком
представлении очень легко исключать элементы.
Главное неудобство характеристических векторов состоит в том, что они не
экономичны. Исключение составляют "плотные" последовательности
последовательностей ![]() Кроме того, их трудно
использовать, если не существует простого соотношения между
Кроме того, их трудно
использовать, если не существует простого соотношения между ![]() и
и ![]() Если такое соотношение сложное, то использование характеристических векторов может быть очень не экономичным в смысле времени обработки. Если последовательности недостаточно
плотные, то значительным может оказаться объем памяти. В случае простых чисел
между
Если такое соотношение сложное, то использование характеристических векторов может быть очень не экономичным в смысле времени обработки. Если последовательности недостаточно
плотные, то значительным может оказаться объем памяти. В случае простых чисел
между ![]() и
и ![]() имеется простое соотношение:
имеется простое соотношение: ![]() (или
(или ![]() если использовать только нечетные числа). Теорема о простых числах утверждает, что число простых чисел, меньших
если использовать только нечетные числа). Теорема о простых числах утверждает, что число простых чисел, меньших ![]() приблизительно равно
приблизительно равно ![]() ; таким образом, простые числа относительно плотно распределены в множестве целых чисел.
; таким образом, простые числа относительно плотно распределены в множестве целых чисел.
Лекция 3. Последовательности (связанное распределение, стеки и очереди)
Связанное распределение
В лекции 11 даны примеры и программные реализации списков, стеков и
очередей. Неудобство включения и исключения элементов при последовательном
распределении происходит из-за того, что порядок следования элементов задается
неявно требованием, чтобы смежные элементы последовательности находились в
смежных ячейках памяти. В результате многие элементы последовательности во
время включения или исключения должны передвигаться. Если это требование опущено, то
можно выполнить операции включения и исключения без того, чтобы передвигать
элементы последовательности. При связанном распределении
последовательности (связанном списке) каждому ![]() поставлен в соответствии указатель (ссылка)
поставлен в соответствии указатель (ссылка) ![]() , отмечающий ячейку, в
которой записаны
, отмечающий ячейку, в
которой записаны ![]() и
и ![]() . Существует также указатель
. Существует также указатель ![]() , который
указывает начальную ячейку
последовательности, то есть ячейку с символами
, который
указывает начальную ячейку
последовательности, то есть ячейку с символами ![]() и
и ![]() . Все сказанное выше
проиллюстрировано на рис. 3.1.
. Все сказанное выше
проиллюстрировано на рис. 3.1.

Рис. 3.1.
Здесь каждый узел состоит
из двух полей. Под узлом понимается одно или
несколько последовательных слов в памяти машины, которые выступают как единое
целое и разделены на части, именуемые полями. В поле ![]() размещен сам
элемент последовательности, а в поле
размещен сам
элемент последовательности, а в поле ![]() - указатель на
следующий за ним элемент.
- указатель на
следующий за ним элемент.
Linked list - список с использованием указателей: список, в котором
каждый элемент
содержит указатель на следующий элемент или два указателя - на следующий и
предыдущий. Поскольку для ![]() следующего элемента
не существует, будем использовать обозначение
следующего элемента
не существует, будем использовать обозначение ![]() , где
, где ![]() - пустой
, или нулевой указатель
. Так как точные значения
- пустой
, или нулевой указатель
. Так как точные значения ![]() для
программиста не существенны, то в более общем виде связанное представление,
показанное на рис. 3.1, можно изобразить так, как показано на рис.3.2.
для
программиста не существенны, то в более общем виде связанное представление,
показанное на рис. 3.1, можно изобразить так, как показано на рис.3.2.

Рис. 3.2. Другой, более употребительный, способ представления списка
Связанное представление последовательностей облегчает операции включения
элемента после некоторого ![]() и исключения элемента
и исключения элемента ![]() , если ячейка для
, если ячейка для ![]() известна. Для этого необходимо лишь изменить значения
некоторых указателей.
Например, чтобы исключить элемент
известна. Для этого необходимо лишь изменить значения
некоторых указателей.
Например, чтобы исключить элемент ![]() из последовательности,
изображенной на
рис. 3.2, необходимо только положить
из последовательности,
изображенной на
рис. 3.2, необходимо только положить ![]() после такой
операции элемента
после такой
операции элемента ![]() в последовательности больше не будет
(рис.3.3). Чтобы в
последовательность, изображенную на рис. 3.2, включить новый элемент
в последовательности больше не будет
(рис.3.3). Чтобы в
последовательность, изображенную на рис. 3.2, включить новый элемент ![]() ,
необходимо только воспроизвести новый элемент в некоторой ячейке
,
необходимо только воспроизвести новый элемент в некоторой ячейке ![]() с
с ![]() и
и ![]() и
присвоить
и
присвоить ![]() .Это изображено на
рис.3.4.
.Это изображено на
рис.3.4.
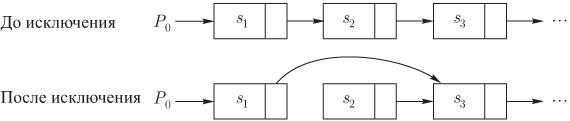
Рис. 3.3. Исключение элемента из связанного списка
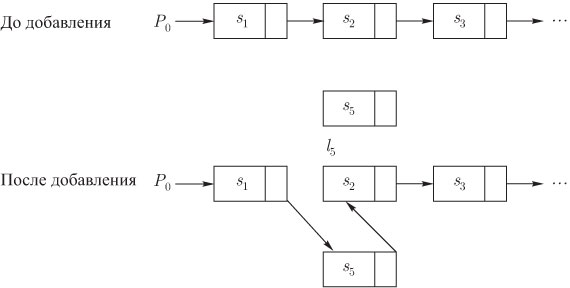
Рис. 3.4. Включение элемента в связанный список
Использование связанного представления предполагает существование некоторого механизма, который по мере надобности поставляет новые ячейки и собирает старые ячейки, когда они освобождаются, но эта проблема выходит за рамки нашего курса.
Будем предполагать, с целью использования в различных алгоритмах,
существование операции порождения ячейки get_cell ;
если эта операция
присутствует в правой части оператора присваивания, то она дает адрес (место)
новой неиспользованной ячейки памяти. Таким образом, чтобы добавить элемент ![]() , как показано на рис. 3.4 нужно фактически использовать
оператор get_cell для того чтобы найти значение
, как показано на рис. 3.4 нужно фактически использовать
оператор get_cell для того чтобы найти значение ![]() .
Проблему сбора ненужных ячеек памяти будем
полностью игнорировать, предполагая лишь, что их каким-то образом собирают для
последующего использования; такой процесс носит название сбора мусора.
.
Проблему сбора ненужных ячеек памяти будем
полностью игнорировать, предполагая лишь, что их каким-то образом собирают для
последующего использования; такой процесс носит название сбора мусора.
Недостаток при связанном распределении - приходится тратить память на
указатели ![]() . В приложениях при выборе
последовательного или связанного представления нужно сначала проанализировать
типы операций, которые будут выполняться над последовательностью.
Если операции производятся преимущественно над случайными элементами, осуществляют
поиск специфических элементов или производят упорядочение элементов, то обычно
лучше применять последовательное распределение. Связанное распределение
предпочтительнее, если в
значительной степени используются операции включения и(или) исключения
элементов, а также сцепления и (или) разбиения последовательностей.
. В приложениях при выборе
последовательного или связанного представления нужно сначала проанализировать
типы операций, которые будут выполняться над последовательностью.
Если операции производятся преимущественно над случайными элементами, осуществляют
поиск специфических элементов или производят упорядочение элементов, то обычно
лучше применять последовательное распределение. Связанное распределение
предпочтительнее, если в
значительной степени используются операции включения и(или) исключения
элементов, а также сцепления и (или) разбиения последовательностей.
Разновидности связанных списков
Тривиальной модификацией связанного списка, изображенного на рис 3.2, будет
следующее несколько более гибкое представление последовательности: если ![]() указывает на
указывает на ![]() , как показано на рис.3.5, то мы
имеем так называемый циклический
список. Такая форма списка дает возможность достигнуть
любой
элемент из любого другого элемента последовательности. Включение и исключение
элементов здесь осуществляется так же, как и в нециклических списках, в то
время как сцепление и разбиение реализуются несколько более сложно.
, как показано на рис.3.5, то мы
имеем так называемый циклический
список. Такая форма списка дает возможность достигнуть
любой
элемент из любого другого элемента последовательности. Включение и исключение
элементов здесь осуществляется так же, как и в нециклических списках, в то
время как сцепление и разбиение реализуются несколько более сложно.
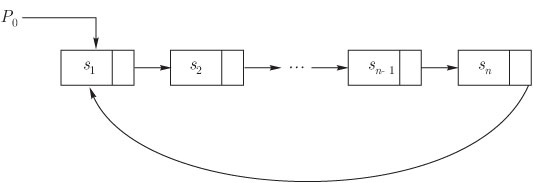
Рис. 3.5. Циклический список
Еще большая гибкость достигается, если использовать дважды связанный
список, когда каждый элемент ![]() последовательности
вместо одного имеет два
связанных с ним указателя. Как показано на рис. 3.6, они указывают на элементы
последовательности
вместо одного имеет два
связанных с ним указателя. Как показано на рис. 3.6, они указывают на элементы ![]() и
и ![]() . В таком списке для любого элемента
имеется мгновенный прямой
доступ к предыдущему и последующему элементам, в связи с чем облегчаются такие
операции, как включение нового элемента перед
. В таком списке для любого элемента
имеется мгновенный прямой
доступ к предыдущему и последующему элементам, в связи с чем облегчаются такие
операции, как включение нового элемента перед ![]() и исключение
элемента
и исключение
элемента ![]() без предварительного знания его предшественника. Если есть необходимость,
дважды
связанный список очевидным образом можно сделать циклическим.
без предварительного знания его предшественника. Если есть необходимость,
дважды
связанный список очевидным образом можно сделать циклическим.

Рис. 3.6. Дважды связанный список
Стеки и очередь
В комбинаторных алгоритмах особую важность представляют две структуры данных, основанные на динамических последовательностях, т.е. последовательностях, которые изменяются вследствие включения новых и исключения имеющихся элементов. В обоих случаях операции включения и исключения, которым подвергается последовательность, имеют ограниченный вид: они производятся только в концах последовательности. Стек есть последовательность, у которой все включения и исключения происходят только в ее правом конце, называемом вершиной стека (соответственно, левый конец последовательности называется основанием ). Таким образом, элементы включаются в стек и исключаются из него в соответствии с правилом "Первым пришел - последним ушел ". Очередь - это последовательность, в которой все включения производятся на правом конце списка ( в конце очереди ), в то время как все исключения производятся на левом конце ( в начале очереди ). В противоположность стеку очередь оперирует в режиме " Первым пришел - первым ушел ".
Стеки и очереди имеют важное значение. Для выполнения какой-либо определенной задачи может потребоваться выполнение ряда подзадач. Каждая подзадача может также привести к другим требующим выполнения подзадачам. И стеки, и очереди являются механизмом, посредством которого запоминаются подзадачи, подлежащие выполнению, а также порядок, в котором они должны быть выполнены. В некоторых случаях порядок таков: " Первым пришел - последним ушел "; тогда удобно использовать стеки. Если порядок подчиняется правилу " Первым пришел - первым ушел ", то подходящим инструментом являются очереди.
Задачи
Задача 1. Создать список, элементами которого являются числа: 1 2 3 4 5 6 7 8 9. Вывести список на экран терминала. Включить в связанный список элемент 2005 после каждого элемента, который делится на 3. Модифицированный список вывести на экран терминала.
Задача 2. Очередью с приоритетом называется линейный список, который оперирует в режиме "первым включается - с высшим приоритетом исключается"; иными словами, каждому элементу очереди сопоставлено некоторое число - приоритет. Включения производятся в конец очереди, а исключения - в любом месте очереди, поскольку исключаемый элемент - это всегда элемент с высшим приоритетом. Нужно описать алгоритм (и его реализацию) включения и исключения для очередей с приоритетом.
Программы
Программа 1. Создание списка.
// Алгоритм реализован на языке программирования Turbo-C++.
#include <stdio.h>
#include <conio.h>
#include <dos.h>
struct List{int i;
List*next;
};
List*head=NULL;
void Hed(int i)
{if(head==NULL){head=new List;
head->i=1;
head->next=NULL;
}else
{
struct List*p,*p1;
p=head;
while(p->next!=NULL)
p=p->next;
p1=new List;
p1->i=i;
p1->next=NULL;
p->next=p1;
}
}
int s=0;
void Print(List*p)
{cprintf(" %d",p->i);
if(p->next!=NULL)Print(p->next);
}
void delist()
{List*p;
while(head!=NULL)
{p=head;
head=head->next;
delete(p);
}
}
void Vstavka(int i1,int c)
{List*p=head,*p1;
while(p->i!=i1)
p=p->next;
p1=new List;
p1->i=c;
p1->next=p->next;
p->next=p1;
}
void main()
{
clrscr();
for(int i=1;i<=10;i++)
Hed(i);
textcolor(12);
Print(head);
textcolor(1);
Vstavka(10,11);
printf("\n");
Print(head);
textcolor(11);
Vstavka(3,12);
printf("\n");
Print(head);
textcolor(14);
Vstavka(5,13);
printf("\n");
Print(head);
delist();
getch();
}Программа 2. Создание стека и работа со стеком.
//Работа со стеком
// Алгоритм реализован на языке программирования Turbo-C++.
#include <stdio.h>
#include <dos.h>
#include <iostream.h>
#include <PROCESS.H>
#include <STDLIB.H>
#include <conio.H>
#define max_size 200
// char s[max_size]; //компоненты стека
int s[max_size];
int next=0; // позиция стека
int Empty()
{
return next==0;
}
int Full()
{
return next==max_size;
}
void Push()
{ if (next==max_size)
{
cout <<"Ошибка: стек полон"<<endl;}
else { next++;cout <<"Добавлен"<<endl;
cout <<"Что поместить в стек?"<<endl;
cin <<s[next-1];
}
}
void OUTst()
{int i=0;
if (next==0)
{
cout <<"Cтек пуст"<<endl;}
else { for(i=0;i <next;i++)
cout <<s[i] <<"" <<endl;
}
}
void Clear()
{
next=0;
}
Poz()
{
return next;
}
void Del()
{
int a;
if (next==0) cout <<"Ошибка: стек пуст" <<endl; else
{next--;cout <<"Удален" <<endl;}
}
void menu(){
cout <<"0: распечатать стек" <<endl;
cout <<"1: добавить в стек" <<endl;
cout <<"2: удалить из стека" <<endl;
cout <<"3: узнать номер позиции в стеке" <<endl;
cout <<"4: узнать, пуст ли стек" <<endl;
cout <<"5: узнать, полон ли стек" <<endl;
cout <<"6: очистить стек" <<endl;
cout <<"7: выход" <<endl;
}
main()
{
char c;
clrscr();
textcolor(11);
do {
menu();
cin"c;
clrscr();
switch (c) {
case "0":OUTst();getch();break;
case "1":Push();break;
case "2":Del();getch();break;
case "3":cout <<"Hомер" <<Poz() <<endl;getch();break;
case "4":if (Empty()==1) cout <<"Пуст" <<endl; else cout <<"Hе
пуст" <<endl;getch();break;
case '5':if (Full()==1)cout <<"Полон" <<endl; else cout <<"Hе
полон" <<endl;getch();break;
case '6':Clear();cout <<"Стек очищен" <<endl;getch();break;
case '7':exit(1);
}
delay(200);
}
while (c!=7);
return 0;
}Лекция 4. Последовательности (деревья)
Деревья
Конечное
корневое дерево ![]() формально определяется как непустое
множество упорядоченных узлов, таких, что существует один выделенный узел,
называемый корнем
дерева, а оставшиеся узлы разбиты на
формально определяется как непустое
множество упорядоченных узлов, таких, что существует один выделенный узел,
называемый корнем
дерева, а оставшиеся узлы разбиты на ![]() поддеревьев
поддеревьев ![]() . Будем рассматривать только
корневые деревья. Узлы, не имеющие поддеревьев, называются листьями ; остальные узлы
называются внутренними
узлами.
. Будем рассматривать только
корневые деревья. Узлы, не имеющие поддеревьев, называются листьями ; остальные узлы
называются внутренними
узлами.

Рис. 4.1.
В первой лекции уже было использовано дерево - при изучении необходимого
числа взвешиваний в задаче о фальшивой монете с ![]() монетами. Так
"рано" деревья появились в тексте не случайно, поскольку понятие дерева используется в
различных важных аспектах данного курса. Посредством деревьев изображаются
иерархические организации, поэтому они являются наиболее важными нелинейными
структурами в комбинаторных алгоритмах.
монетами. Так
"рано" деревья появились в тексте не случайно, поскольку понятие дерева используется в
различных важных аспектах данного курса. Посредством деревьев изображаются
иерархические организации, поэтому они являются наиболее важными нелинейными
структурами в комбинаторных алгоритмах.
В описании соотношений между узлами дерева используем терминологию,
принятую в генеалогических деревьях. Так, говорят, что в дереве или поддереве
все узлы являются потомками
его корня, и наоборот, корень есть предок всех
своих потомков. Корень именуют отцом
корней его поддеревьев, которые в свою очередь будут сыновьями корня.
Например, на рис. 4.1 узел ![]() является
отцом узлов
является
отцом узлов ![]() и
и ![]() ;
; ![]() - сыновья
- сыновья ![]() , а
, а ![]() - братья.
- братья.
Все рассматриваемые нами деревья будут упорядочены, то есть для них будет важен относительный порядок поддеревьев каждого узла. Таким образом, деревья считаются различными.
Рис. 4.2. Различные деревья
Определим лес как
упорядоченное множество деревьев; в связи с этим
можно перефразировать определение дерева: дерево есть непустое
множество узлов, такое, что существует один выделенный узел, называемый корнем
дерева, а оставшиеся узлы образуют лес с ![]() поддеревьями корня.
Важной разновидностью корневых деревьев является класс бинарных деревьев. Бинарное дерево
поддеревьями корня.
Важной разновидностью корневых деревьев является класс бинарных деревьев. Бинарное дерево ![]() либо пустое,
либо состоит из выделенного узла,
называемого корнем, и двух бинарных поддеревьев: левого
либо пустое,
либо состоит из выделенного узла,
называемого корнем, и двух бинарных поддеревьев: левого ![]() и
правого
и
правого ![]() .
Бинарные деревья не являются подмножеством множества деревьев, они полностью
отличаются по своей структуре, поскольку два следующих рисунка не изображают
одно и то же бинарное дерево.
.
Бинарные деревья не являются подмножеством множества деревьев, они полностью
отличаются по своей структуре, поскольку два следующих рисунка не изображают
одно и то же бинарное дерево.

Рис. 4.3. Различные бинарные деревья
Как деревья, однако, они не отличаются от дерева, изображенного на рис. 4.4.
Рис. 4.4. Не бинарное дерево
Различие между деревом и бинарным деревом состоит в том, что дерево не может быть пустым, а каждый узел дерева может иметь произвольное число поддеревьев; в то же время, бинарное дерево может быть пустым. Каждая из вершин бинарного дерева может иметь 0, 1 или 2 поддерева, и существует различие между левым и правым поддеревьями.
Представления
Почти все машинные представления деревьев основаны на связанных
распределениях. Каждый узел состоит из поля ![]() и нескольких
полей для
указателей. Например, представление, которое будет удобным для изложения
множества и мультимножества, для каждого узла имеет единственное поле для
указателя
и нескольких
полей для
указателей. Например, представление, которое будет удобным для изложения
множества и мультимножества, для каждого узла имеет единственное поле для
указателя ![]() , указывающего на отца данного узла. При этом
приведенное на рис. 4.1 дерево будет выглядеть так,
как показано на рис. 4.5.
Такое представление полезно, если необходимо подниматься по дереву от
потомков к предкам. Такая операция встречается довольно редко. Чаще требуется
опуститься по дереву от предков к потомкам.
, указывающего на отца данного узла. При этом
приведенное на рис. 4.1 дерево будет выглядеть так,
как показано на рис. 4.5.
Такое представление полезно, если необходимо подниматься по дереву от
потомков к предкам. Такая операция встречается довольно редко. Чаще требуется
опуститься по дереву от предков к потомкам.
Представление дерева (или леса) с использованием указателей, ведущих от предков к потомкам, довольно сложно, поскольку узел, имея не более чем одного отца, может в то же время иметь произвольно много сыновей. Другими словами, при таком представлении узлы должны различаться по размеру, что является определенным неудобством. Один из путей обхода этой трудности состоит в том, чтобы определить соответствие между деревьями и бинарными деревьями, поскольку бинарные деревья легко представить узлами фиксированного размера.

Рис. 4.5.
Каждый узел в этом случае имеет три поля: ![]() , указатель
местоположения корня левого поддерева,
, указатель
местоположения корня левого поддерева, ![]() , содержимое узла,
и
, содержимое узла,
и ![]() , указатель местоположения
корня правого поддерева. Все сказанное выше проиллюстрировано на рис. 4.6.
, указатель местоположения
корня правого поддерева. Все сказанное выше проиллюстрировано на рис. 4.6.

Рис. 4.6.
Можно представлять деревья как бинарные, используя узлы фиксированного
размера, представляя каждый узел леса в виде узла, состоящего из полей ![]() ,
, ![]() ,
, ![]() . При этом
. При этом ![]() предназначается для указания самого левого
сына данного узла, а поле
предназначается для указания самого левого
сына данного узла, а поле ![]() - для указания следующего брата
данного дочернего/сыновнего узла.
- для указания следующего брата
данного дочернего/сыновнего узла.
Прохождения
Во многих приложениях необходимо пройти лес, заходя в узлы, то есть обрабатывая их некоторым систематическим образом. Посещение каждого узла может быть связано с простой операцией, такой как печать содержимого, или со сложной, такой как вычисление функции. Будем предполагать, что при посещении узла структура леса не меняется. Рассмотрим четыре основных способа прохождения леса: в глубину, снизу вверх, в горизонтальном порядке и для бинарных деревьев - в симметричном порядке.
При прохождении в глубину, известном также как прохождение в прямом порядке, узлы леса проходятся в соответствии со следующей рекурсивной процедурой:
- Посетить корень первого дерева.
- пройти в глубину поддерева первого дерева (если оно есть).
- Пройти в глубину оставшиеся деревья, если они есть.
Например, для леса, показанного на рис. 4.7, узлы будут проходиться в
следующем
порядке: ![]() .
.
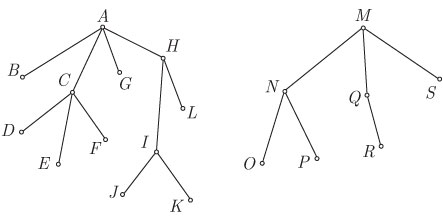
Рис. 4.7. Лес
Название "в глубину" отражает тот факт, что после посещения некоторого узла мы продолжаем прохождение в глубь дерева всякий раз, когда это возможно. Такой порядок особенно полезен в процедурах поиска.
Для бинарных деревьев эта процедура упрощается и выглядит следующим образом.
- Посетить корень.
- Пройти в глубину левое поддерево
- Пройти в глубину правое поддерево.
Прохождение снизу вверх, известное также как обратный порядок или концевой порядок, осуществляется согласно следующей рекурсивной процедуре:
- Пройти снизу вверх поддеревья первого дерева, если они есть.
- Посетить корень первого дерева.
- Пройти снизу вверх оставшиеся деревья, если они есть.
Название "снизу вверх" связано с тем, что в момент посещения
произвольного узла
его потомки оказываются уже пройденными. Такой порядок прохождения полезен, в
частности, потому, что он позволяет вычислять рекурсивно определенные функции
на
лесах. При этом порядке прохождения узлы леса, показанного на
рис. 4.7,
проходятся в такой последовательности: ![]() .
Рекурсивная
процедура прохождения снизу вверх применительно к бинарным деревьям имеет
следующий вид:
.
Рекурсивная
процедура прохождения снизу вверх применительно к бинарным деревьям имеет
следующий вид:
- Пройти снизу вверх левое дерево.
- Пройти снизу вверх правое дерево.
- Посетить корень.
Симметричный порядок для бинарных деревьев определяется рекурсивно следующим образом:
- Пройти в симметричном порядке левое поддерево.
- Посетить корень.
- Пройти в симметричном порядке правое поддерево.
Такой способ прохождения известен также как лексикографический порядок или внутренний порядок. Заметим, что прохождение леса снизу вверх эквивалентно прохождению в симметричном порядке бинарного дерева, соответствующего этому лесу (при естественном соответствии).
Сравнивая рекурсивные процедуры прохождения бинарных деревьев в глубину, снизу вверх и в симметричном порядке, можно обнаружить их значительное сходство:
| прохождение в глубину | симметричный порядок | прохождение снизу вверх |
|---|---|---|
| посетить корень | левое поддерево | левое поддерево |
| левое поддерево | посетить корень | правое поддерево |
| правое поддерево | правое поддерево | посетить корень |
Это сходство позволяет построить общий нерекурсивный алгоритм, который может быть применен к каждому из этих порядков прохождения бинарных деревьев.
Горизонтальный
порядок прохождения. При таком способе узлы леса
проходятся слева направо, уровень за уровнем от корня вниз. Таким образом, в
соответствии с этой процедурой узлы леса, показанного на рис.4.7, будут
проходиться в следующем порядке: ![]() .
Такое прохождение дерева полезно в определенных алгоритмах на графах.
.
Такое прохождение дерева полезно в определенных алгоритмах на графах.
Длина путей
Деревья можно использовать не только как способ представления структуры данных, но также как средство для анализа поведения определенных алгоритмов. В связи с этим возникает потребность в количественных измерениях различных характеристик деревьев и, в частности, бинарных деревьев.
Наиболее важные количественные характеристики деревьев связаны с уровнями узлов. Уровень ![]() определяется рекурсивно и считается равным нулю,
если
определяется рекурсивно и считается равным нулю,
если ![]() корень
корень ![]() ; в противном случае уровень
; в противном случае уровень ![]() определяется как
определяется как ![]() . Понятие уровня дает возможность
определить высоту
. Понятие уровня дает возможность
определить высоту ![]() дерева
дерева ![]() :
:
Задача
Задача 1. Построить алгоритм обхода бинарного дерева (см. рис. 4.6,(а)) в глубину.
Программa
Программа 1. Обход бинарного дерева в глубину
//Обход ориентированных графов - поиск в глубину -
//обобщение обхода дерева в прямом порядке
#include <stdio.h>
#include <string.h>
#include <conio.h>
#include <stdlib.h>
int matr_sm[50][50];
int mark[50];
int n;
void vvod ()
{int v1,v2;
printf("Введите кол-во вершин в графе: ");
do
{
scanf("%d",&n);
if (n>51) printf("Ошибка!! Введите кол-во вершин в графе: ");
}
while (n>51);
for (int i=0;i <50;i++) for (int j=0;j <50;j++) matr_sm[i][j]=0;
printf("\nВведите связанные вершины : \n");
do
{ scanf("%d ",&v1);
if (v1>n) //исходящая вершина
{ printf("ОШИБКА ВВОДА !!!!!!!!!");
abort();
}
if (v1==0){break;} // конец ввода
scanf(" %d ",&v2);
if (v2>n) // входящая вершина
{ printf("ОШИБКА ВВОДА !!!!!!!!!");
abort();
}
if (v2==0){break;} //конец ввода
matr_sm[v2-1][v1-1]=1;
} while(1);
}
void vivod()
{
for (int j=0;j <n;j++)
{
for (int i=0;i<n;i++) printf("%d ",matr_sm[j][i]);
printf("\n");
}
}
void dfs(int v)
{
int w;
mark[v]=1; //посетили
printf("%i ",v+1); //и выдали на экран
for (w=0;w<n;w++)
if (matr_sm[v][w]==1);
else if (mark[w]==0) dfs(w);
}
void main()
{ clrscr();
vvod();
// printf("\n"); printf("МАТРИЦА СМЕЖНОСТИ\n");
// vivod();
printf("\n РЕЗУЛЬТАТ ПОИСКА В ГЛУБИНУ \n");
for (int v=0;v<50;v++) mark[v]=0;
for (v=0;v<n;v++) //если вершина не посещалась, то посетить
if (mark[v]==0) dfs(v);
getch();
}Лекция 5. Комбинаторика разбиений
Введение
В задачах, которые мы сейчас рассмотрим, элементы делятся на группы, и надо найти все способы такого раздела. При этом могут встретиться различные случаи. Иногда существенную роль играет порядок элементов в группах: например, когда сигнальщик вывешивает сигнальные флаги на нескольких мачтах, то для него важно не только то, на какой мачте окажется тот или иной флаг, но и то, в каком порядке эти флаги развешиваются. В других же случаях порядок элементов в группах никакой роли не играет. Когда игрок в домино выбирает кости из кучи, ему безразлично, в каком порядке они придут, а важен лишь окончательный результат.
Отличаются задачи и по тому, играет ли роль порядок самих групп. При игре в домино игроки сидят в определенном порядке, и важно не только то, как разделились кости, но и то, кому какие кости достались. Если раскладывать фотографии по одинаковым конвертам, чтобы разослать их, то существенно, как распределяются фотографии по конвертам, но порядок самих конвертов совершенно несущественен.
Играет роль и то, различаем ли мы между собой сами элементы или нет, а также различаем ли между собой группы, на которые делятся элементы. Наконец, в одних задачах некоторые группы могут оказаться пустыми, то есть не содержащими ни одного элемента, а в других такие группы недопустимы. В соответствии со всем сказанным возникает целый ряд различных комбинаторных задач на разбиение.
Задачи
Общая постановка этих задач:
Задача 1. Раскладка по ящикам
Даны ![]() различных предметов и
различных предметов и ![]() ящиков. Надо положить
в первый ящик
ящиков. Надо положить
в первый ящик ![]() предметов, во второй
-
предметов, во второй
- ![]() предметов,..., в
предметов,..., в ![]() -й
-
-й
- ![]() предметов, где
предметов, где ![]() Сколькими способами можно сделать такое распределение?
Сколькими способами можно сделать такое распределение?
Число различных раскладок по ящикам равно
Задача 2. Перестановки с повторением.
Имеются предметы ![]() различных типов. Сколько различных
перестановок можно сделать из
различных типов. Сколько различных
перестановок можно сделать из ![]() предметов первого
типа,
предметов первого
типа, ![]() предметов второго типа, ...,
предметов второго типа, ..., ![]() предметов
предметов ![]() -го типа? Число элементов в каждой
перестановке равно
-го типа? Число элементов в каждой
перестановке равно ![]() .
Поэтому если бы все элементы были различны, то число перестановок равнялось бы
.
Поэтому если бы все элементы были различны, то число перестановок равнялось бы ![]() ! .
Но из-за того, что некоторые элементы совпадают, получится меньшее число
перестановок. В самом деле, возьмем, например, перестановку
! .
Но из-за того, что некоторые элементы совпадают, получится меньшее число
перестановок. В самом деле, возьмем, например, перестановку
| (5.1) |
Перестановки элементов первого типа, второго типа и так далее можно делать
независимо друг от друга. Поэтому элементы перестановки 5.1. можно
переставлять друг с другом ![]() ! способами так, что она
остается неизменной. То же самое верно и для любого другого
расположения элементов. Поэтому множество всех
! способами так, что она
остается неизменной. То же самое верно и для любого другого
расположения элементов. Поэтому множество всех ![]() ! перестановок
распадается на части, состоящие из
! перестановок
распадается на части, состоящие из ![]() ! одинаковых перестановок каждая. Значит, число различных перестановок с
повторениями, которые можно сделать из данных элементов, равно
! одинаковых перестановок каждая. Значит, число различных перестановок с
повторениями, которые можно сделать из данных элементов, равно
| (5.2) |
Пользуясь формулой 5.2, можно ответить на вопрос: сколько перестановок можно сделать из букв слова "Миссисипи"? Здесь у нас одна буква "м", четыре буквы "и", три буквы "с" и одна буква "п", а всего 9 букв. Значит, по формуле 5.2 число перестановок равно
В рассмотренных задачах мы не учитывали порядок, в котором расположены элементы каждой части. В некоторых задачах этот порядок надо учитывать.
Задача 3. Флаги на мачтах.
Имеется ![]() различных сигнальных флагов и
различных сигнальных флагов и ![]() мачт, на
которые их вывешивают. Значение сигнала зависит от того, в каком
порядке развешены флаги. Сколькими способами можно развесить флаги, если все
флаги должны быть использованы, но некоторые из мачт могут оказаться
пустыми?
мачт, на
которые их вывешивают. Значение сигнала зависит от того, в каком
порядке развешены флаги. Сколькими способами можно развесить флаги, если все
флаги должны быть использованы, но некоторые из мачт могут оказаться
пустыми?
Каждый способ развешивания флагов можно осуществить в два этапа. На
первом этапе мы переставляем всеми возможными способами
данные ![]() флагов. Это можно сделать
флагов. Это можно сделать ![]() ! способами. Затем
берем один из способов распределения
! способами. Затем
берем один из способов распределения ![]() одинаковых флагов
по
одинаковых флагов
по ![]() мачтам (число этих способов
мачтам (число этих способов ![]() ).
Пусть этот способ заключается в
том, что на первую мачту надо повесить
).
Пусть этот способ заключается в
том, что на первую мачту надо повесить ![]() флагов, на вторую
-
флагов, на вторую
- ![]() флагов, ..., на
флагов, ..., на ![]() -ю
-ю ![]() флагов,
где
флагов,
где ![]() Тогда берем
первые
Тогда берем
первые ![]() флагов данной последовательности и развешиваем в
полученном порядке на первой
мачте; следующие
флагов данной последовательности и развешиваем в
полученном порядке на первой
мачте; следующие ![]() флагов развешиваем на второй мачте и т.д.
Ясно, что используя все перестановки
флагов развешиваем на второй мачте и т.д.
Ясно, что используя все перестановки ![]() флагов и все способы
распределения
флагов и все способы
распределения ![]() одинаковых флагов по
одинаковых флагов по ![]() мачтам, получим
все способы решения поставленной задачи. По правилу произведения
получаем, что число способов развешивания флагов равно
мачтам, получим
все способы решения поставленной задачи. По правилу произведения
получаем, что число способов развешивания флагов равно
| (5.3) |
Разные статистики
Задачи о раскладке предметов по ящикам весьма важны для статистической
физики. Эта наука изучает, как распределяются по своим свойствам физические
частицы; например, какая часть молекул данного газа имеет при данной
температуре ту или иную скорость. При этом множество всех возможных состояний распределяют на
большое число ![]() маленьких ячеек (фазовых состояний), так что каждая
из
маленьких ячеек (фазовых состояний), так что каждая
из ![]() частиц попадет в одну из ячеек.
частиц попадет в одну из ячеек.
Вопрос о том, какой статистике подчиняются те или иные частицы, зависит от
вида этих частиц. В классической статистической физике, созданной Максвеллом и
Больцманом, частицы считаются различимыми друг от друга. Такой статистике
подчиняются, например, молекулы газа. Известно, что ![]() различных
частиц можно распределить по
различных
частиц можно распределить по ![]() ячейкам
ячейкам ![]() способами.
Если все эти
способами.
Если все эти ![]() способов при заданной энергии имеют равную
вероятность, то говорят о статистике Максвелла-Больцмана.
способов при заданной энергии имеют равную
вероятность, то говорят о статистике Максвелла-Больцмана.
Оказалось, что этой статистике подчиняются не все физические объекты. Фотоны, атомные ядра и атомы, содержащие четное число элементарных частиц, подчиняются иной статистике, разработанной Эйнштейном и индийским ученым Бозе. В статистике Бозе-Эйнштейна частицы считаются неразличимыми друг от друга. Поэтому имеет значение лишь то, сколько частиц попало в ту или иную ячейку, а не то, какие именно частицы туда попали.
Однако для многих частиц, например таких как электроны, протоны и
нейтроны, не годится и статистика Бозе-Эйнштейна. Для них в каждой ячейке может
находится не более одной частицы, причем различные распределения,
удовлетворяющие указанному условию, имеют равную вероятность. В этом случае
может быть ![]() различных распределений. Эта статистика называется статистикой Дирака-Ферми.
различных распределений. Эта статистика называется статистикой Дирака-Ферми.
Деревья и перестановки из n элементов
С помощью леса можно представить перестановки из ![]() элементов
множества
элементов
множества ![]() (множество мы определяем так: множество
- это неупорядоченная совокупность различных объектов или структура данных,
используемая для представления множества). Подсчитаем, сколько можно
получить перестановок. Для
(множество мы определяем так: множество
- это неупорядоченная совокупность различных объектов или структура данных,
используемая для представления множества). Подсчитаем, сколько можно
получить перестановок. Для ![]() такой лес изображен на
рис. 5.1.
такой лес изображен на
рис. 5.1.
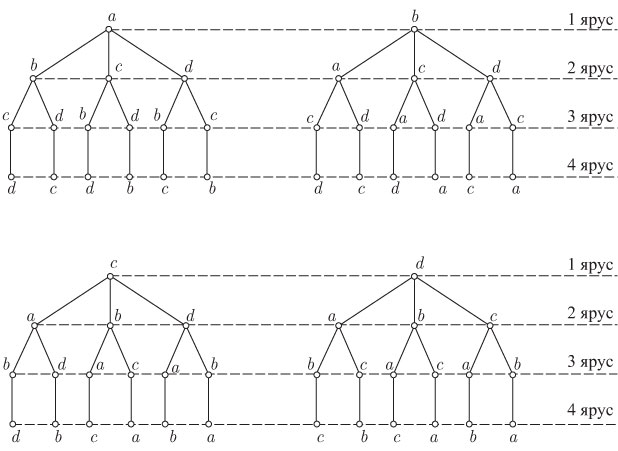
Рис. 5.1. Всевозможные перестановки прочитываются по этой схеме от корневой до висячей вершины соответствующего дерева. Ярус показывает номер места, на котором расположен элемент. Число висячих вершин леса равно числу перестановок
Число сочетаний
Рассмотрим подмножества множества, состоящего из пяти элементов, и
подсчитаем их число. При этом записывать подмножества будем не с помощью букв,
как обычно, а в виде последовательностей длиной пять, составленных из нулей и
единиц. Каждая из единиц указывает на наличие в подмножестве соответствующего
элемента. Например, подмножества, содержащие один элемент, будут изображаться
следующими последовательностями: 10000, 01000, 00100, 00010, 00001. Пустое
подмножество ![]() будет соответствовать последовательности
00000. Подмножества, содержащие по два элемента из пяти, запишутся с помощью
следующих последовательностей: 11000, 10100, 10010, 10001, 01100. 01010, 01001,
00110, 00101, 00011. Всего их
будет соответствовать последовательности
00000. Подмножества, содержащие по два элемента из пяти, запишутся с помощью
следующих последовательностей: 11000, 10100, 10010, 10001, 01100. 01010, 01001,
00110, 00101, 00011. Всего их ![]()
Вообще, число сочетаний из ![]() элементов по
элементов по ![]() равно
числу всевозможных последовательностей из
равно
числу всевозможных последовательностей из ![]() единиц и
единиц и ![]() нулей.
нулей.
Задачи на разбиение чисел
Теперь мы переходим к задачам, в которых все разделяемые предметы совершенно одинаковы. В этом случае можно говорить не о разделении предметов, а о разбиении натуральных чисел на слагаемые (которые, конечно, тоже должны быть натуральными числами).
Здесь возникает много различных задач. В одних задачах учитывается порядок слагаемых, в других - нет.
Задача 4. Отправка бандероли.
За пересылку бандероли надо уплатить 18 рублей. Сколькими способами можно оплатить ее марками стоимостью 4, 6, и 10 рублей, если два способа, отличающиеся порядком марок, считаются различными (запас марок различного достоинства считаем неограниченным)?
Обозначим через ![]() число способов, которыми можно наклеить
марки в 4, 6 и 10 рублей так, чтобы общая стоимость этих марок равнялась
число способов, которыми можно наклеить
марки в 4, 6 и 10 рублей так, чтобы общая стоимость этих марок равнялась ![]() Тогда
для
Тогда
для ![]() справедливо следующее соотношение:
справедливо следующее соотношение:
| (5.4) |
Точно так же доказывается, что число комбинаций, оканчивающихся на
шестирублевую марку, равно ![]() а на десятирублевую марку
оканчиваются
а на десятирублевую марку
оканчиваются ![]() комбинацией. Поскольку любая комбинация
оканчивается на марку одного из указанных типов, то по правилу суммы получаем соотношение 5.4.
комбинацией. Поскольку любая комбинация
оканчивается на марку одного из указанных типов, то по правилу суммы получаем соотношение 5.4.
Соотношение 5.4 позволяет свести задачу о наклеивании марок на
сумму ![]() рублей к задачам о наклеивании марок на меньшие суммы. Но
при малых значениях
рублей к задачам о наклеивании марок на меньшие суммы. Но
при малых значениях ![]() задачу легко решить непосредственно. Простой
подсчет показывает, что
задачу легко решить непосредственно. Простой
подсчет показывает, что
Точно так же получаем значение ![]() а для
а для ![]() имеем
имеем ![]()
Задача 5.Общая задача о наклейке марок.
Разобранная задача является частным случаем следующей общей задачи: Имеются марки достоинством в ![]() Сколькими
способами можно оплатить с их помощью сумму в
Сколькими
способами можно оплатить с их помощью сумму в ![]() рублей, если два
способа, отличающиеся порядком, считаются различными? Все числа
рублей, если два
способа, отличающиеся порядком, считаются различными? Все числа ![]() различны, а запас марок неограничен. Здесь на первом месте
мы будем указывать число слагаемых, на втором – разбиваемое число и на
последнем - ограничения на величину слагаемых.
различны, а запас марок неограничен. Здесь на первом месте
мы будем указывать число слагаемых, на втором – разбиваемое число и на
последнем - ограничения на величину слагаемых.
В этом случае число ![]() способов удовлетворяет соотношению
способов удовлетворяет соотношению
| (5.5) |
Рассмотрим частный случай этой задачи, когда ![]()
![]() Мы получаем всевозможные разбиения
числа
Мы получаем всевозможные разбиения
числа ![]() на слагаемые
на слагаемые ![]() причем разбиения,
отличающиеся порядком слагаемых, считаются различными. Обозначим число
этих разбиений через
причем разбиения,
отличающиеся порядком слагаемых, считаются различными. Обозначим число
этих разбиений через ![]() ( На первом месте мы будем указывать число слагаемых, на втором -
разбиваемое число и на последнем – ограничения на величину слагаемых.) Из
соотношения 5.5 следует, что
( На первом месте мы будем указывать число слагаемых, на втором -
разбиваемое число и на последнем – ограничения на величину слагаемых.) Из
соотношения 5.5 следует, что
| (5.6) |
| (5.7) |
| 5 = 5 | 5 = 3 + 1 + 1 | 5 = 1 + 2 + 2 |
| 5 = 4 + 1 | 5 = 1 + 3+ 1 | 5 = 2 + 1 + 1 + 1 |
| 5 = 1 + 4 | 5 = 1 + 1 + 3 | 5 = 1 + 2 + 1 + 1 |
| 5 = 2 + 3 | 5 = 2 + 2 + 1 | 5 = 1 + 1 + 2 + 1 |
| 5 = 3 + 2 | 5 = 2 + 1 + 2 | 5 = 1 + 1 + 1 + 2 |
| 5 = 1 + 1 + 1 + 1 + 1 |
Комбинаторные задачи теории информации
Информация - сведения, неизвестные до их получения, или данные, или значения, приписанные данным.
Теория информации - математическая дисциплина, изучающая количественные свойства информации.
Задачу, похожую на только что решенную, приходится решать в теории
информации. Предположим, что сообщение передается с помощью сигналов
нескольких типов. Длительность передачи сигнала первого типа
равна ![]() второго типа -
второго типа - ![]() -го типа
-
-го типа
- ![]() единиц времени.
единиц времени.
Задача 6. Сколько различных сообщений можно передать с помощью этих сигналов
за ![]() единиц времени? При этом учитываются лишь "максимальные" сообщения,
то есть сообщения, к которым нельзя присоединить ни одного сигнала, не выйдя за рамки
отведенного для передачи времени.
единиц времени? При этом учитываются лишь "максимальные" сообщения,
то есть сообщения, к которым нельзя присоединить ни одного сигнала, не выйдя за рамки
отведенного для передачи времени.
Обозначим число сообщений, которые можно передать за время ![]() через
через ![]() Рассуждая точно так же, как и в задаче о марках, получаем,
что
Рассуждая точно так же, как и в задаче о марках, получаем,
что ![]() удовлетворяет соотношению
удовлетворяет соотношению
| (5.8) |
Лекция 6. Последовательности (множества и мультимножества)
Множества и мультимножества
Не существует формального определения множества ; считается что это понятие первичное и не определяется. Так, можно говорить, что множество есть объединение различных элементов, но при этом мы оставляем неопределяемыми понятия "объединение" и "элементы". Дадим следующее определение множеству: множество - это неупорядоченная совокупность различных объектов или структура данных, используемая для представления множества. Мультимножество есть объединение не обязательно различных элементов; его можно считать множеством, в котором каждому элементу поставлено в соответствие положительное целое число, называемое кратностью.
Конечное множество ![]() будем записывать в следующем виде:
будем записывать в следующем виде:

Как и для последовательностей, наилучший метод представления множеств или
мультимножеств существенно зависит от операций, которые выполняются над ними.
Предположим, например, что имеем дело с непересекающимися подмножествами
множества ![]() и что над ними необходимо
выполнить две следующие операции: объединение двух
множеств и отыскание подмножества, содержащего данное
и что над ними необходимо
выполнить две следующие операции: объединение двух
множеств и отыскание подмножества, содержащего данное ![]() . Таким
образом, в любой момент времени имеем разбиение
. Таким
образом, в любой момент времени имеем разбиение ![]() на непустые
непересекающиеся подмножества. Рассмотрим эти операции в конце
данной лекции.
на непустые
непересекающиеся подмножества. Рассмотрим эти операции в конце
данной лекции.
С целью идентификации считаем, что каждое из непересекающихся
подмножеств множества ![]() имеет имя. Имя - это просто один из элементов подмножества,
или, иначе, - представитель подмножества. Когда мы будем ссылаться на имя подмножества, то
будем под этим подразумевать его представителя. Рассмотрим, например,
множество
имеет имя. Имя - это просто один из элементов подмножества,
или, иначе, - представитель подмножества. Когда мы будем ссылаться на имя подмножества, то
будем под этим подразумевать его представителя. Рассмотрим, например,
множество
| (6.1) |
Именем множества ![]()
![]()
![]() может быть или 2, или 10.Предполагаем,
что вначале имеется разбиение множества
может быть или 2, или 10.Предполагаем,
что вначале имеется разбиение множества ![]() на
на ![]() подмножеств, каждое из которых состоит из одного элемента
подмножеств, каждое из которых состоит из одного элемента
| (6.2) |
Для реализации операций и объединения, и отыскания опишем процедуры
(операции) ![]() и
и ![]() . Процедура
(операция)
. Процедура
(операция) ![]() по именам двух различных подмножеств
по именам двух различных подмножеств ![]() и
и ![]() образует новое подмножество, содержащее все элементы множеств
образует новое подмножество, содержащее все элементы множеств ![]() и
и ![]() . Процедура (операция)
. Процедура (операция) ![]() выдает имя множества, содержащего
выдает имя множества, содержащего ![]() . Например, если нужно
множество,содержащее
. Например, если нужно
множество,содержащее ![]() , объединить с множеством, содержащим
, объединить с множеством, содержащим ![]() ,
необходимо выполнить следующую последовательность операторов:
,
необходимо выполнить следующую последовательность операторов:

Предположим, что мы имеем ![]() операций объединения, перемешанных
с
операций объединения, перемешанных
с ![]() операциями отыскания, и что начинаем алгоритм с множества
операциями отыскания, и что начинаем алгоритм с множества ![]() , которое разбито на подмножества, состоящие из одного
элемента (см. 6.2.). Найдем такую структуру данных для представления
непересекающихся подмножеств множества
, которое разбито на подмножества, состоящие из одного
элемента (см. 6.2.). Найдем такую структуру данных для представления
непересекающихся подмножеств множества ![]() , чтобы последовательность
операций можно было производить эффектно. Такой структурой данных
является представление в виде леса с указателями отца, как показано на
рис. 4.5 лекции 4. Каждый элемент
, чтобы последовательность
операций можно было производить эффектно. Такой структурой данных
является представление в виде леса с указателями отца, как показано на
рис. 4.5 лекции 4. Каждый элемент ![]() множества будет узлом
леса, а отцом его будет элемент из того же подмножества, что и
множества будет узлом
леса, а отцом его будет элемент из того же подмножества, что и ![]() . Если
элемент не имеет отца, то есть является корнем, то он будет именем своего
подмножества. В соответствии с этим разбиение 6.1 может быть представлено
так:
. Если
элемент не имеет отца, то есть является корнем, то он будет именем своего
подмножества. В соответствии с этим разбиение 6.1 может быть представлено
так:
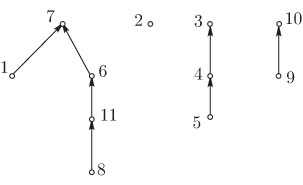
Рис. 6.1. Представление разбиения
При таком представлении процедура (операция) ![]() состоит в
переходах по указателям отцов от
состоит в
переходах по указателям отцов от ![]() до корня, то есть имени, его
подмножества. Процедура (операция)
до корня, то есть имени, его
подмножества. Процедура (операция) ![]() состоит в
связывании вместе некоторым образом деревьев, имеющих корни
состоит в
связывании вместе некоторым образом деревьев, имеющих корни ![]() и
и ![]() . Например, такую связь можно осуществить, сделав
. Например, такую связь можно осуществить, сделав ![]() отцом
отцом ![]() .
.
После ![]() операций объединения наибольшее из возможных
подмножеств, получающихся в результате разбиения
операций объединения наибольшее из возможных
подмножеств, получающихся в результате разбиения ![]() , будет содержать
, будет содержать ![]() элементов. Поскольку каждое объединение уменьшает число подмножеств на
единицу, последовательность операций может содержать не более
элементов. Поскольку каждое объединение уменьшает число подмножеств на
единицу, последовательность операций может содержать не более ![]() объединений, откуда
объединений, откуда ![]() . Так как каждая операция
объединения изменяет имя подмножества, содержащего
некоторые элементы, можно считать, что каждому объединению предшествует по
крайней мере одно отыскание, в связи с чем естественно предположить, что
. Так как каждая операция
объединения изменяет имя подмножества, содержащего
некоторые элементы, можно считать, что каждому объединению предшествует по
крайней мере одно отыскание, в связи с чем естественно предположить, что ![]() . Выясним, насколько эффективно можно выполнить
последовательность из
. Выясним, насколько эффективно можно выполнить
последовательность из ![]() операций объединения,
перемешанных с
операций объединения,
перемешанных с ![]() операциями отыскания. Время,
требуемое на операции объединения, очевидно, пропорционально
операциями отыскания. Время,
требуемое на операции объединения, очевидно, пропорционально ![]() , потому
что необходимая для каждой операции объединения переделка некоторых
указателей требует фиксированного количества работы. Поэтому сосредоточим свое
внимание на времени, требуемом для
, потому
что необходимая для каждой операции объединения переделка некоторых
указателей требует фиксированного количества работы. Поэтому сосредоточим свое
внимание на времени, требуемом для ![]() операций отыскания.
операций отыскания.
Если операция ![]() выполняется путем назначения
выполняется путем назначения ![]() отцом
отцом ![]() , то после
, то после ![]() операций
объединения может получиться лес, показанный ниже.
операций
объединения может получиться лес, показанный ниже.

В этом случае, если ![]() операций отыскания
выполняются после всех операций объединения и каждый поиск начинается
внизу цепи из
операций отыскания
выполняются после всех операций объединения и каждый поиск начинается
внизу цепи из ![]() элементов множества, то ясно, что время,
требуемое на операции отыскания, будет пропорционально
элементов множества, то ясно, что время,
требуемое на операции отыскания, будет пропорционально ![]() .
Очевидно, оно не может быть больше, чем константа, умноженная на
.
Очевидно, оно не может быть больше, чем константа, умноженная на ![]() . Можно существенно уменьшить эту оценку.
. Можно существенно уменьшить эту оценку.
Формула включений и исключений
Пусть имеется ![]() предметов, некоторые из которых обладают
свойствами
предметов, некоторые из которых обладают
свойствами ![]() . При этом каждый предмет
может либо не обладать ни одним из этих свойств, либо обладать одним или несколькими
свойствами. Обозначим через
. При этом каждый предмет
может либо не обладать ни одним из этих свойств, либо обладать одним или несколькими
свойствами. Обозначим через ![]() количество предметов, обладающих свойствами
количество предметов, обладающих свойствами ![]() (и быть может, еще некоторыми из других свойств).
Если нужно взять предметы, не обладающие некоторым свойством, то эти свойства
пишем со штрихом. Например, через
(и быть может, еще некоторыми из других свойств).
Если нужно взять предметы, не обладающие некоторым свойством, то эти свойства
пишем со штрихом. Например, через ![]() ) обозначено количество предметов, обладающих свойствами
) обозначено количество предметов, обладающих свойствами ![]() , но не обладающих свойством
, но не обладающих свойством ![]() (вопрос об
остальных свойствах останется открытым). Число предметов, не обладающих ни одним из указанных свойств,
обозначается по этому правилу через
(вопрос об
остальных свойствах останется открытым). Число предметов, не обладающих ни одним из указанных свойств,
обозначается по этому правилу через ![]() . Общий закон состоит в том, что
. Общий закон состоит в том, что
 | (6.3) |
Решето Эратосфена
Одной из самых больших загадок математики является расположение
простых чисел в ряду всех натуральных чисел. Иногда два простых числа идут
через одно, (например, 17 и 19, 29 и 31), а иногда подряд идет миллион
составных чисел. Сейчас ученые знают уже довольно много о том, сколько
простых чисел содержится среди ![]() первых натуральных чисел. В этих
подсчетах весьма полезным оказался метод, восходящий еще к
древнегреческому ученому Эратосфену. Он жил в третьем веке до новой эры в
Александрии.
первых натуральных чисел. В этих
подсчетах весьма полезным оказался метод, восходящий еще к
древнегреческому ученому Эратосфену. Он жил в третьем веке до новой эры в
Александрии.
Эратосфен занимался самыми различными вопросами - ему принадлежат интересные исследования в области математики, астрономии и других наук. Впрочем, такая разносторонность привела его к некоторой поверхностности. Современники несколько иронически называли Эратосфена "во всем второй": второй математик после Евклида, второй астроном после Гиппарха и т.д.
В математике Эратосфена интересовал как раз вопрос о том, как найти все
простые числа среди натуральных чисел от 1 до ![]() . (Эратосфен
считал 1 простым числом. Сейчас математики считают 1 числом особого
вида, которое не относится ни к простым, ни к составным числам.) Он придумал
для этого следующий способ. Сначала вычеркивают все числа, делящиеся на 2 (исключая
само число 2). Потом берут первое из оставшихся чисел (а именно 3). Ясно, что
это число - простое. Вычеркивают все идущие после него числа, делящиеся на 3.
Первым оставшимся числом будет 5. Вычеркивают все идущие после него числа, делящиеся
на 5, и т.д. Числа, которые уцелеют после всех вычеркиваний, и являются простыми.
Так как во времена Эратосфена писали на восковых табличках и не вычеркивали, а
"выкалывали" цифры, то табличка после описанного процесса напоминала решето.
Поэтому метод Эратосфена для нахождения простых чисел получил название
"решето Эратосфена".
. (Эратосфен
считал 1 простым числом. Сейчас математики считают 1 числом особого
вида, которое не относится ни к простым, ни к составным числам.) Он придумал
для этого следующий способ. Сначала вычеркивают все числа, делящиеся на 2 (исключая
само число 2). Потом берут первое из оставшихся чисел (а именно 3). Ясно, что
это число - простое. Вычеркивают все идущие после него числа, делящиеся на 3.
Первым оставшимся числом будет 5. Вычеркивают все идущие после него числа, делящиеся
на 5, и т.д. Числа, которые уцелеют после всех вычеркиваний, и являются простыми.
Так как во времена Эратосфена писали на восковых табличках и не вычеркивали, а
"выкалывали" цифры, то табличка после описанного процесса напоминала решето.
Поэтому метод Эратосфена для нахождения простых чисел получил название
"решето Эратосфена".
Подсчитаем, сколько останется чисел в первой сотне, если мы вычеркнем по методу Эратосфена числа, делящиеся на 2, 3 и 5. Иными словами, поставим такой вопрос: сколько чисел в первой сотне не делится ни на одно из чисел 2, 3, 5? Эта задача решается по формуле включения и исключения.
Обозначим через ![]() свойство числа делиться на 2, через
свойство числа делиться на 2, через ![]() - свойство делимости на 3 и через
- свойство делимости на 3 и через ![]() - свойство делимости на 5. Тогда
- свойство делимости на 5. Тогда ![]() означает, что число делится на 6,
означает, что число делится на 6, ![]() означает,
что оно делится на 10, и
означает,
что оно делится на 10, и ![]() - оно делится на
15. Наконец,
- оно делится на
15. Наконец, ![]() означает, что число
делится на 30. Надо найти, сколько чисел от 1 до 100 не делится
ни на 2, ни на 3, ни на 5, то есть не обладает ни одним из свойств
означает, что число
делится на 30. Надо найти, сколько чисел от 1 до 100 не делится
ни на 2, ни на 3, ни на 5, то есть не обладает ни одним из свойств ![]() ,
, ![]() ,
, ![]() . По
формуле 6.3 имеем
. По
формуле 6.3 имеем
А из первой тысячи после первых трех шагов процесса Эратосфена останется 335 чисел. Это следует из того, что в этом случае
Примеры программы
Программа 1. Решето Эратосфена.
{В примере, иллюстрирующем работу с множествами, реализуется алгоритм
выделения из первой сотни натуральных чисел всех простых чисел. В основе
алгоритма лежит прием "решета Эратосфена".
Алгоритм написан на языке программирования Turbo-Pascal.}
Uses crt;
Const
N=100; {количество элементов исходного множества}
Type
SetN=set of 1..N;
var
n1, next, I : word; {вспомогательные переменные }
BeginSet, {исходное множество }
PrimerSet: SetN; {множество простых чисел }
Begin
Clrscr; {почистить экран}
BeginSet:=[2..N]; {создать исходное множество}
PrimerSet:=[1]; {первое простое число}
next:=2; {следующее простое число}
while BeginSet <> [ ] do {начало основного цикла}
begin
n1:=next; {n1-число, кратное очередному простому (next)}
while n1<=N do
{цикл удаления из исходного множества непростых чисел}
begin
BeginSet:=BeginSet-[n1];
n1:=n1+next {следующее кратное}
end; {конец цикла удаления}
repeat {получить следующее простое число, которое есть первое
не вычеркнутое из исходного множества}
inc(next)
until(next in BeginSet) or (next > N)
end; {конец основного цикла}
{вывод результата}
textcolor(15); {задание цвета}
for I:=1 to N do
if i in PrimerSet then write(I:8);
readln;
end.Программа 2. Простые числа в порядке убывания от 200.
{Находит и пишет все простые числа в порядке убывания от 2 до 200.
Алгоритм написан на языке программирования Turbo-Pascal.}
Uses crt;
const
n=197;
var
i,q,w,e,r,t:integer;
prost:array[1..n] of integer;
begin
clrscr;
e:=1;
r:=0;
for q:=1 to n do begin
r:=0;
for w:=2 to n-1 do
if (q<>w) and (q mod w = 0) then r:=1;
{prost[e]:=q; e:=e+1;}
if r=0 then begin{begin write(q,' ');}
prost[e]:=q;
e:=e+1;
end;
end;
for i:=e downto 2 do begin
write (prost[i],' ');
if wherex>70 then writeln;
end;
readln;
end.Программа 3. Поиск литер в строке.
{Поиск числа вхождений в данную сроку литер a, c, e, h.
Алгоритм написан на языке программирования Turbo-Pascal.}
Uses crt;
type
liter_set = set of char;
var
c:integer;
let: liter_set;
a:char;
begin
clrscr;
let:=['a','c','e','h'];
repeat
a:=readkey;
write(a);
if a in let then c:=c+1;
until a = '.';
writeln;
writeln('Общее число вхожений литер a,c,e,h в вашу запись:',c);
readln;
end.Лекция 7. Рекуррентные соотношения
Размещения без повторений
Имеется ![]() различных предметов. Сколько из них можно составить
различных предметов. Сколько из них можно составить ![]() -расстановок? При этом две расстановки считаются различными,
если они либо отличаются друг от друга хотя бы одним элементом, либо состоят из
одних и тех же элементов, но расположенных в разном порядке. Такие
расстановки называют размещениями без повторений, а их число
обозначают
-расстановок? При этом две расстановки считаются различными,
если они либо отличаются друг от друга хотя бы одним элементом, либо состоят из
одних и тех же элементов, но расположенных в разном порядке. Такие
расстановки называют размещениями без повторений, а их число
обозначают ![]() . При составлении
. При составлении ![]() -размещений без
повторений из
-размещений без
повторений из ![]() предметов нам надо сделать
предметов нам надо сделать ![]() выборов. На первом шагу можно
выбрать любой из имеющихся
выборов. На первом шагу можно
выбрать любой из имеющихся ![]() предметов. Если этот выбор уже сделан, то на
втором шагу приходится выбирать из оставшихся
предметов. Если этот выбор уже сделан, то на
втором шагу приходится выбирать из оставшихся ![]() предметов. На
предметов. На ![]() - м шагу
- м шагу ![]() предметов. Поэтому по правилу произведения получаем, что число
предметов. Поэтому по правилу произведения получаем, что число ![]() -размещений без повторения из
-размещений без повторения из ![]() предметов
выражается следующим образом:
предметов
выражается следующим образом:
Перестановки
При составлении размещений без повторений из ![]() элементов по
элементов по ![]() мы получили расстановки, отличающиеся друг от друга и составом,
и порядком элементов. Но если брать расстановки, в которые входят все
мы получили расстановки, отличающиеся друг от друга и составом,
и порядком элементов. Но если брать расстановки, в которые входят все ![]() элементов, то они могут отличаться друг от друга лишь порядком входящих в них
элементов. Такие расстановки называют перестановками из n
элементов, или, короче,
элементов, то они могут отличаться друг от друга лишь порядком входящих в них
элементов. Такие расстановки называют перестановками из n
элементов, или, короче, ![]() - перестановками.
- перестановками.
Сочетания
В тех случаях, когда нас не интересует порядок элементов в комбинации, а
интересует лишь ее состав, говорят о сочетаниях. Итак, ![]() - сочетаниями из
- сочетаниями из ![]() элементов называют всевозможные
элементов называют всевозможные ![]() - расстановки, составленные из
этих элементов и отличающиеся друг от друга составом, но не порядком элементов.
Число
- расстановки, составленные из
этих элементов и отличающиеся друг от друга составом, но не порядком элементов.
Число ![]() -сочетаний, которое можно составить из
-сочетаний, которое можно составить из ![]() элементов,
обозначают через
элементов,
обозначают через ![]() .
.
Формула для числа сочетаний получается из формулы для числа размещений. В
самом деле, составим сначала все ![]() -сочетания из
-сочетания из ![]() элементов, а потом переставим входящие в каждое сочетание элементы всеми
возможными способами. При этом получается, что все
элементов, а потом переставим входящие в каждое сочетание элементы всеми
возможными способами. При этом получается, что все ![]() -размещения
из
-размещения
из ![]() элементов, причем каждое только по одному разу. Но из
каждого
элементов, причем каждое только по одному разу. Но из
каждого ![]() - сочетания можно сделать
- сочетания можно сделать ![]() ! перестановок,
а число этих сочетаний равно
! перестановок,
а число этих сочетаний равно ![]() . Значит справедлива формула
. Значит справедлива формула
Рекуррентные соотношения
При решении многих комбинаторных задач пользуются методом сведения данной задачи к задаче, касающейся меньшего числа предметов. Метод сведения к аналогичной задаче для меньшего числа предметов называется методом рекуррентных соотношений (от латинского "recurrere" - "возвращаться").
Понятие рекуррентных соотношений проиллюстрируем классической проблемой, которая была поставлена около 1202 года Леонардо из Пизы, известным как Фибоначчи. Важность чисел Фибоначчи для анализа комбинаторных алгоритмов делает этот пример весьма подходящим.
Фибоначчи поставил задачу в форме рассказа о скорости роста популяции кроликов при следующих предположениях. Все начинается с одной пары кроликов. Каждая пара становится фертильной через месяц, после чего каждая пара рождает новую пару кроликов каждый месяц. Кролики никогда не умирают, и их воспроизводство никогда не прекращается.
Пусть ![]() - число пар кроликов в популяции по прошествии
- число пар кроликов в популяции по прошествии ![]() месяцев, и пусть эта популяция состоит из
месяцев, и пусть эта популяция состоит из ![]() пар
приплода и
пар
приплода и ![]() "старых" пар, то есть
"старых" пар, то есть ![]() . Таким образом, в очередном месяце произойдут следующие события:
. Таким образом, в очередном месяце произойдут следующие события: ![]() . Старая популяция в
. Старая популяция в ![]() -й момент увеличится на число родившихся в момент времени
-й момент увеличится на число родившихся в момент времени ![]() .
. ![]() . Каждая старая пара в момент времени
. Каждая старая пара в момент времени ![]() производит пару приплода в момент времени
производит пару приплода в момент времени ![]() .
В последующий месяц эта картина повторяется:
.
В последующий месяц эта картина повторяется:
Объединяя эти равенства, получим следующее рекуррентное соотношение:
| (7.1) |
Выбор начальных условий для последовательности чисел Фибоначчи не важен;
существенное свойство этой последовательности определяется рекуррентным
соотношением. Будем предполагать ![]() (иногда
(иногда ![]() ).
).
Рассмотрим эту задачу немного иначе.
Пара кроликов приносит раз в месяц приплод из двух крольчат (самки и самца), причем новорожденные крольчата через два месяца после рождения уже приносят приплод. Сколько кроликов появится через год, если в начале года была одна пара кроликов?
Из условия задачи следует, что через месяц будет две пары кроликов. Через
два месяца приплод даст только первая пара кроликов, и получится 3 пары. А еще
через месяц приплод дадут и исходная пара кроликов, и пара кроликов, появившаяся два
месяца тому назад. Поэтому всего будет 5 пар кроликов. Обозначим через ![]() количество пар кроликов по истечении
количество пар кроликов по истечении ![]() месяцев с начала года. Ясно, что через
месяцев с начала года. Ясно, что через ![]() месяцев будут эти
месяцев будут эти ![]() пар и еще столько новорожденных пар
кроликов, сколько было в конце месяца
пар и еще столько новорожденных пар
кроликов, сколько было в конце месяца ![]() , то есть еще
, то есть еще ![]() пар кроликов. Иными словами, имеет место рекуррентное
соотношение
пар кроликов. Иными словами, имеет место рекуррентное
соотношение
| (7.2) |
В частности, ![]() .
.
Числа ![]() называются числами Фибоначчи. Они обладают целым рядом
замечательных свойств. Теперь выведем выражение этих чисел через
называются числами Фибоначчи. Они обладают целым рядом
замечательных свойств. Теперь выведем выражение этих чисел через ![]() . Для
этого установим связь между числами Фибоначчи и следующей комбинаторной задачей.
. Для
этого установим связь между числами Фибоначчи и следующей комбинаторной задачей.
Найти число ![]() последовательностей,состоящих из нулей и единиц,
в которых никакие две единицы не идут подряд.
последовательностей,состоящих из нулей и единиц,
в которых никакие две единицы не идут подряд.
Чтобы установить эту связь, возьмем любую такую последовательность и сопоставим ей пару кроликов по следующему правилу: единицам соответствуют месяцы появления на свет одной из пар "предков" данной пары (включая и исходную), а нулями - все остальные месяцы. Например, последовательность 010010100010 устанавливает такую "генеалогию": сама пара появилась в конце 11-го месяца, ее родители - в конце 7-го месяца, "дед" - в конце 5-го месяца и "прадед" - в конце второго месяца. Исходная пара кроликов тогда зашифровывается последовательностью 000000000000.
Ясно, что при этом ни в одной последовательности не могут стоять две единицы подряд - только что появившаяся пара не может, по условию, принести приплод через месяц. Кроме того, при указанном правиле различным последовательностям отвечают различные пары кроликов, и обратно, две различные пары кроликов всегда имеют разную "генеалогию", так как, по условию, крольчиха дает приплод, состоящий только из одной пары кроликов.
Установленная связь показывает, что число ![]() -последовательностей,
обладающих указанным свойством, равно
-последовательностей,
обладающих указанным свойством, равно ![]() .
.
Докажем теперь, что
| (7.3) |
В самом деле, ![]() - это число всех
- это число всех ![]() -
последовательностей из 0 и 1, в которых никакие две единицы не стоят рядом.
Число же таких последовательностей, в которые входит ровно
-
последовательностей из 0 и 1, в которых никакие две единицы не стоят рядом.
Число же таких последовательностей, в которые входит ровно ![]() единиц и
единиц и ![]() нулей, равно
нулей, равно ![]() . Так как при этом
должно выполняться неравенство
. Так как при этом
должно выполняться неравенство ![]() , то
, то ![]() изменяется от 0 до
изменяется от 0 до ![]() .
Применяя правило суммы, приходим к соотношению (7.3).
.
Применяя правило суммы, приходим к соотношению (7.3).
Равенство (7.3) можно доказать и иначе. Положим ![]() где
где ![]() . Из равенства
. Из равенства ![]() легко следует, что
легко следует, что
| (7.4) |
Другой метод доказательства
В предыдущем разделе непосредственно установлена связь между задачей
Фибоначчи и комбинаторной задачей. Эту связь можно установить и иначе,
непосредственно доказав, что число ![]() решений комбинаторной
задачи удовлетворяет тому же рекуррентному соотношению
решений комбинаторной
задачи удовлетворяет тому же рекуррентному соотношению
| (7.5) |
Пусть теперь последовательность оканчивается на 1. Так как двух единиц
подряд быть не может, то перед этой единицей стоит нуль. Иными словами,
последовательность оканчивается на 01. Остающаяся же после отбрасывания 0 и 1 ![]() -последовательность может быть любой, лишь бы в ней не шли
подряд две единицы. Поэтому число последовательностей, оканчивающихся единицей, равно
-последовательность может быть любой, лишь бы в ней не шли
подряд две единицы. Поэтому число последовательностей, оканчивающихся единицей, равно ![]() . Но каждая последовательность оканчивается или на 0, или на 1. В
силу правила суммы получаем, что
. Но каждая последовательность оканчивается или на 0, или на 1. В
силу правила суммы получаем, что ![]() .
.
Таким образом, получено то же самое рекуррентное соотношение. Отсюда еще
не вытекает, что числа ![]() и
и ![]() совпадают.
совпадают.
Процесс последовательных разбиений
Для решения комбинаторных задач часто применяют метод, использованный в предыдущем пункте: устанавливают для данной задачи рекуррентное соотношение и показывают, что оно совпадает с рекуррентным соотношением для другой задачи, решение которой нам уже известно. Если при этом совпадают и начальные члены последовательностей в достаточном числе, то обе задачи имеют одинаковые решения.
Применим описанный прием для решения следующей задачи.
Пусть дано некоторое множество из ![]() предметов, стоящих в
определенном порядке. Разобьем это множество на две
непустые части так, чтобы одна из этих частей лежала левее второй (то есть,
скажем, одна часть состоит из элементов от первого до
предметов, стоящих в
определенном порядке. Разобьем это множество на две
непустые части так, чтобы одна из этих частей лежала левее второй (то есть,
скажем, одна часть состоит из элементов от первого до ![]() - го, а
вторая - из элементов от
- го, а
вторая - из элементов от ![]() -го до
-го до ![]() -го).
После этого каждую из частей таким же образом разобьем на две непустые
части (если одна из частей состоит уже из одного предмета, она не подвергается
дальнейшим разбиениям). Этот процесс продолжается до тех пор, пока не получим
части, состоящие из одного предмета каждая. Сколько существует таких процессов
разбиения (два процесса считаются различными, если хотя бы на одном шагу они
приводят к разным результатам)?
-го).
После этого каждую из частей таким же образом разобьем на две непустые
части (если одна из частей состоит уже из одного предмета, она не подвергается
дальнейшим разбиениям). Этот процесс продолжается до тех пор, пока не получим
части, состоящие из одного предмета каждая. Сколько существует таких процессов
разбиения (два процесса считаются различными, если хотя бы на одном шагу они
приводят к разным результатам)?
Обозначим число способов разбиения для множества из ![]() предметов через
предметов через ![]() . На первом шагу это множество может быть
разбито
. На первом шагу это множество может быть
разбито ![]() способами (первая часть может содержать один предмет,
два предмета,…,
способами (первая часть может содержать один предмет,
два предмета,…, ![]() предметов). В соответствии с этим множество всех
процессов разбиений распадается
на
предметов). В соответствии с этим множество всех
процессов разбиений распадается
на ![]() классов - в
классов - в ![]() - класс входят процессы, при
которых первая часть состоит из
- класс входят процессы, при
которых первая часть состоит из ![]() предметов.
предметов.
Подсчитаем число процессов в ![]() -м классе. В первой части
содержится
-м классе. В первой части
содержится ![]() элементов. Поэтому ее можно разбивать далее
элементов. Поэтому ее можно разбивать далее ![]() различными процессами. Вторая же часть содержит
различными процессами. Вторая же часть содержит ![]() элементов, и ее можно разбивать далее
элементов, и ее можно разбивать далее ![]() процессами. По правилу произведения получаем, что
процессами. По правилу произведения получаем, что ![]() - класс
состоит из
- класс
состоит из ![]() различных процессов. По правилу
суммы отсюда вытекает, что
различных процессов. По правилу
суммы отсюда вытекает, что
| (7.6) |
Задача: "Затруднение мажордома"
Бывают комбинаторные задачи, в которых приходится составлять не одно
рекуррентное соотношение, а систему соотношений, связывающую несколько
последовательностей. Эти соотношения выражают ![]() -у члены
последовательностей через предыдущие члены не только данной, но и
остальных последовательностей.
-у члены
последовательностей через предыдущие члены не только данной, но и
остальных последовательностей.
Задача: "Затруднение мажордома". Однажды мажордом короля Артура обнаружил, что к обеду за круглым столом приглашено 6 пар враждующих рыцарей. Сколькими способами можно рассадить их так, чтобы никакие два врага не сидели рядом?
Если мы найдем какой-то способ рассадки рыцарей, то, пересаживая их по кругу, получим еще 11 способов. Мы не будем сейчас считать различными способы, получающиеся друг из друга такой циклической пересадкой.
Введем следующие обозначения. Пусть число рыцарей равно ![]() .
Через
.
Через ![]() обозначим число способов рассадки, при которых
никакие два врага не сидят рядом.
Через
обозначим число способов рассадки, при которых
никакие два врага не сидят рядом.
Через ![]() обозначим число способов, при которых рядом сидит ровно
одна пара врагов, и через
обозначим число способов, при которых рядом сидит ровно
одна пара врагов, и через ![]() - число способов, при которых есть ровно две пары
враждующих соседей.
- число способов, при которых есть ровно две пары
враждующих соседей.
Выведем сначала формулу, выражающую ![]() через
через ![]() . Пусть
. Пусть ![]() пар рыцарей посажены так,
что никакие два врага не сидят рядом. Мы будем считать,
что все враждующие пары рыцарей занумерованы. Попросим встать из-за стола пару
рыцарей с номером
пар рыцарей посажены так,
что никакие два врага не сидят рядом. Мы будем считать,
что все враждующие пары рыцарей занумерованы. Попросим встать из-за стола пару
рыцарей с номером ![]() . Тогда возможны три случая: среди
оставшихся за столом нет одной пары соседей-
врагов, есть одна такая пара и есть две такие пары (ушедшие рыцари могли
разделять эти пары). Мы считаем, что
. Тогда возможны три случая: среди
оставшихся за столом нет одной пары соседей-
врагов, есть одна такая пара и есть две такие пары (ушедшие рыцари могли
разделять эти пары). Мы считаем, что ![]() . При
. При ![]() последующие рассуждения теряют силу.
последующие рассуждения теряют силу.
Выясним теперь, сколькими способами можно снова посадить ушедших рыцарей за стол так, чтобы после этого не было одной пары соседей-врагов.
Проще всего посадить их, если за столом рядом сидят две пары врагов. В этом
случае один из вновь пришедших садится между рыцарями первой пары, а другой –
между рыцарями второй пары. Это можно сделать двумя способами. Но так как число
способов рассадки ![]() рыцарей, при которых две пары соседей
оказались врагами, равно
рыцарей, при которых две пары соседей
оказались врагами, равно ![]() , то всего получилось
, то всего получилось ![]() способов.
способов.
Пусть теперь рядом сидит только одна пара врагов. Один из вернувшихся
должен сесть между ними. Тогда за столом окажутся ![]() рыцарей,
между которыми есть
рыцарей,
между которыми есть ![]() мест. Из них два места - рядом с
только что севшим гостем – запретны для второго
рыцаря, и ему остается
мест. Из них два места - рядом с
только что севшим гостем – запретны для второго
рыцаря, и ему остается ![]() мест. Так как первым может войти
любой из двух вышедших рыцарей, то получается
мест. Так как первым может войти
любой из двух вышедших рыцарей, то получается ![]() способов рассадки. Но число случаев, когда
способов рассадки. Но число случаев, когда ![]() рыцарей сели так, чтобы ровно одна пара врагов оказалась
соседями, ровно
рыцарей сели так, чтобы ровно одна пара врагов оказалась
соседями, ровно ![]() . Поэтому мы получаем
. Поэтому мы получаем ![]() способов посадить гостей требуемым образом.
способов посадить гостей требуемым образом.
Наконец, пусть никакие два врага не сидели рядом. В этом случае первый
рыцарь садится между любыми двумя гостями - это он может сделать ![]() способами. После этого для его врага останется
способами. После этого для его врага останется ![]() мест - он может занять любое место, кроме двух мест, соседних с
только что севшим рыцарем. Таким образом, если
мест - он может занять любое место, кроме двух мест, соседних с
только что севшим рыцарем. Таким образом, если ![]() рыцарей уже сидели нужным
образом, то вернувшихся гостей можно посадить
рыцарей уже сидели нужным
образом, то вернувшихся гостей можно посадить ![]() способами. Как уже отмечалось, разработанными случаями исчерпываются все
возможности. Поэтому имеет место рекуррентное соотношение
способами. Как уже отмечалось, разработанными случаями исчерпываются все
возможности. Поэтому имеет место рекуррентное соотношение
| (7.7) |
Этого соотношения пока недостаточно, чтобы найти ![]() для всех значений
для всех значений ![]() . Надо еще узнать, как выражаются
. Надо еще узнать, как выражаются ![]() через
через ![]() .
.
Предположим, что среди ![]() рыцарей оказалась ровно
одна пара врагов-соседей. Мы знаем, что это может
произойти в
рыцарей оказалась ровно
одна пара врагов-соседей. Мы знаем, что это может
произойти в ![]() случаях. Во избежание ссоры попросим их
удалиться из-за стола. Тогда останется
случаях. Во избежание ссоры попросим их
удалиться из-за стола. Тогда останется ![]() рыцарей, причем
возможно одно из двух: либо среди оставшихся нет врагов-соседей,
либо есть ровно одна пара таких врагов - до ухода покинувших зал они сидели
по обе стороны от них и теперь оказались рядом. Во втором случае ушедших можно
посадить обратно только на старое место - иначе появится вторая пара враждующих
соседей. Но так как
рыцарей, причем
возможно одно из двух: либо среди оставшихся нет врагов-соседей,
либо есть ровно одна пара таких врагов - до ухода покинувших зал они сидели
по обе стороны от них и теперь оказались рядом. Во втором случае ушедших можно
посадить обратно только на старое место - иначе появится вторая пара враждующих
соседей. Но так как ![]() рыцарей можно посадить
рыцарей можно посадить ![]() способами
так, чтобы была только одна пара враждующих соседей, то мы получаем
способами
так, чтобы была только одна пара враждующих соседей, то мы получаем ![]() вариантов (возвратившихся рыцарей можно поменять местами). В
первом же случае можно посадить ушедших между любыми двумя рыцарями, то есть
вариантов (возвратившихся рыцарей можно поменять местами). В
первом же случае можно посадить ушедших между любыми двумя рыцарями, то есть ![]() способами, а так как их еще можно поменять местами, то получится
способами, а так как их еще можно поменять местами, то получится ![]() способов. Комбинируя их со всеми способами посадки
способов. Комбинируя их со всеми способами посадки ![]() пар рыцарей, при которых нет соседей врагов, получаем
пар рыцарей, при которых нет соседей врагов, получаем ![]() способов. Наконец, номер ушедшей и вернувшейся пары рыцарей
мог быть любым от 1 до
способов. Наконец, номер ушедшей и вернувшейся пары рыцарей
мог быть любым от 1 до ![]() . Отсюда вытекает, что рекуррентное соотношение для
. Отсюда вытекает, что рекуррентное соотношение для ![]() имеет вид
имеет вид
| (7.8) |
Наконец, разберем случай, когда среди ![]() рыцарей было две
пары врагов-соседей. Номера этих пар можно выбрать
рыцарей было две
пары врагов-соседей. Номера этих пар можно выбрать ![]() способами. Заменим каждую пару одним новым рыцарем, причем будем
считать новых двух рыцарей врагами. Тогда за столом будут сидеть
способами. Заменим каждую пару одним новым рыцарем, причем будем
считать новых двух рыцарей врагами. Тогда за столом будут сидеть ![]() рыцарей, причем среди них либо не будет ни одной пары врагов-соседей (если
новые рыцари не сидят рядом), либо только одна такая пара.
рыцарей, причем среди них либо не будет ни одной пары врагов-соседей (если
новые рыцари не сидят рядом), либо только одна такая пара.
Первый вариант может быть в ![]() случаях. Вернуться к исходной
компании мы можем 4 способами благодаря возможности изменить порядок рыцарей в каждой
паре. Поэтому первый вариант приводит к
случаях. Вернуться к исходной
компании мы можем 4 способами благодаря возможности изменить порядок рыцарей в каждой
паре. Поэтому первый вариант приводит к ![]() способами.
способами.
Второй же вариант может быть в ![]() случаях. Имеется
случаях. Имеется ![]() случаев, когда какая-нибудь пара врагов сидит рядом. Если указать, какая именно пара
должна сидеть рядом, получим в
случаев, когда какая-нибудь пара врагов сидит рядом. Если указать, какая именно пара
должна сидеть рядом, получим в ![]() раз меньше случаев.
раз меньше случаев.
Здесь тоже можно вернуться к исходной компании 4 способами, и мы получаем
всего ![]() способов. Отсюда вытекает, что при
способов. Отсюда вытекает, что при ![]()
| (7.9) |
| (7.10) |
| (7.11) |
| (7.12) |
Лекция 8. Алгоритмы рекуррентных соотношений
Решение рекуррентных соотношений
Будем говорить, что рекуррентное соотношение имеет порядок ![]() ,
если оно позволяет выразить
,
если оно позволяет выразить ![]() через
через ![]() . Например,
. Например,
Пользуясь рекуррентным соотношением и начальными членами, можно один за
другим выписывать члены последовательности, причем рано или поздно получим
любой ее член. Однако при этом придется выписать и все предыдущие члены -
ведь не узнав их, мы не узнаем и последующих членов. Но во многих случаях нужно
узнать только один определенный член последовательности, а остальные не нужны. В этих
случаях удобнее иметь явную формулу для ![]() -го члена
последовательности. Некоторая последовательность является решением данного рекуррентного соотношения,
если при подстановке этой последовательности соотношение тождественно выполняется. Например,
последовательность
-го члена
последовательности. Некоторая последовательность является решением данного рекуррентного соотношения,
если при подстановке этой последовательности соотношение тождественно выполняется. Например,
последовательность
Решение рекуррентного соотношения ![]() -го порядка называется общим, если оно зависит от
-го порядка называется общим, если оно зависит от ![]() произвольных постоянных
произвольных постоянных ![]() и путем подбора этих постоянных
можно получить любое решение данного соотношения. Например, для соотношения
и путем подбора этих постоянных
можно получить любое решение данного соотношения. Например, для соотношения
| (8.1) |
| (8.2) |
Линейные рекуррентные соотношения с постоянными коэффициентами
Для решения рекуррентных соотношений общих правил, вообще говоря, нет. Однако существует весьма часто встречающийся класс соотношений, решаемый единообразным методом. Это - рекуррентные соотношения вида
| (8.3) |
Сначала рассмотрим, как решаются такие соотношения при ![]() ,
то есть изучим соотношение вида
,
то есть изучим соотношение вида
| (8.4) |
- Если
 и
и  являются решениями
рекуррентного соотношения (8.4), то при любых числах
являются решениями
рекуррентного соотношения (8.4), то при любых числах  и
и  последовательность
последовательность  также является решением этого соотношения.
также является решением этого соотношения.В самом деле, по условию, имеем


Умножим эти равенства на
и соответственно и
сложим полученные тождества. Получим, чтоА это означает, что
 является решением
соотношения(8.4).
является решением
соотношения(8.4).
- Если
 является корнем квадратного уравнениято последовательность
является корнем квадратного уравнениято последовательность является решением рекуррентного соотношения
является решением рекуррентного соотношения В самом деле, если
В самом деле, если
 , то
, то  и
и  .
Подставляя эти значения в соотношение (8.4), получаем равенствоОно справедливо, так как по условию имеем
.
Подставляя эти значения в соотношение (8.4), получаем равенствоОно справедливо, так как по условию имеем
 .
Заметим, что наряду с последовательностью
.
Заметим, что наряду с последовательностью  любая последовательность видатакже является решением соотношения (8.4). Для доказательства достаточно использовать утверждение (8.4), положив в нем
любая последовательность видатакже является решением соотношения (8.4). Для доказательства достаточно использовать утверждение (8.4), положив в нем
 .
.
Из утверждений 1 и 2 вытекает следующее правило решения линейных рекуррентных соотношений второго порядка с постоянными коэффициентами.
Пусть дано рекуррентное соотношение
| (8.5) |
| (8.6) |
Чтобы доказать это правило, заметим сначала, что по утверждению 2 ![]() являются решениями нашего
соотношения. А тогда по утверждению 1 и
являются решениями нашего
соотношения. А тогда по утверждению 1 и ![]() является его решением. Надо только показать,
что любое решение соотношения (8.5) можно записать в этом виде. Но любое решение
соотношения второго порядка определяется значениями
является его решением. Надо только показать,
что любое решение соотношения (8.5) можно записать в этом виде. Но любое решение
соотношения второго порядка определяется значениями ![]() .
Поэтому достаточно показать, что система уравнений
.
Поэтому достаточно показать, что система уравнений
Пример на доказанное правило.
При изучении чисел Фибоначчи мы пришли к рекуррентному соотношению
| (8.7) |
| (8.8) |
| (8.9) |
Случай равных корней характеристического уравнения
Рассмотрим случай, когда оба корня характеристического уравнения совпадают: ![]() . В этом случае выражение
. В этом случае выражение ![]() уже не будет общим решением. Ведь из-за того, что
уже не будет общим решением. Ведь из-за того, что ![]() , это решение можно записать в виде
, это решение можно записать в виде
| (8.10) |
Значит, ![]() - решение рассматриваемого соотношения.
- решение рассматриваемого соотношения.
Итак, имеются два решения ![]() и
и ![]() заданного соотношения. Его общее решение запишется
так:
заданного соотношения. Его общее решение запишется
так:
Линейные рекуррентные соотношения с постоянными коэффициентами, порядок которых больше двух, решаются таким же способом. Пусть соотношение имеет вид
| (8.11) |
Составляя такое выражение для всех корней и складывая их, получаем общее решение соотношения (8.3).
Например, решим рекуррентное соотношение
Производящие функции
В комбинаторных задачах на подсчет числа объектов при наличии
некоторых ограничений искомым решением часто является последовательность ![]() , где
, где ![]() - число искомых
объектов "размерности"
- число искомых
объектов "размерности" ![]() . Например, если мы ищем число
разбиений числа, то можем принять
. Например, если мы ищем число
разбиений числа, то можем принять ![]() , если ищем число подмножеств
, если ищем число подмножеств ![]() -элементного множества, то
-элементного множества, то ![]() и т.д. В этом случае удобно
последовательности
и т.д. В этом случае удобно
последовательности ![]() , поставить в соответствие
формальный ряд
, поставить в соответствие
формальный ряд
 | (8.12) |

 | (8.13) |
 | (8.14) |
 | (8.15) |
 | (8.16) |
| (8.17) |


Лекция 9. Комбинаторика и ряды
Введение
Метод рекуррентных соотношений позволяет решать многие комбинаторные задачи. Но в целом ряде случаев рекуррентные соотношения довольно трудно составить, а еще труднее решить. Зачастую эти трудности удается обойти, использовав производящие функции. Поскольку понятие производящей функции связано с бесконечными степенными рядами, познакомимся с этими рядами.
Деление многочленов
Если заданы два многочлена ![]() и
и ![]() , то
всегда существуют многочлены
, то
всегда существуют многочлены ![]() ( частное )
и
( частное )
и ![]() ( остаток ),
такие, что
( остаток ),
такие, что ![]() , причем степень
, причем степень ![]() меньше степени
меньше степени ![]() или
или ![]() . При этом
. При этом ![]() называется делимым,
а
называется делимым,
а ![]() - делителем. Если же мы хотим, чтобы деление выполнялось без остатка,
то придется допустить в качестве частного не только многочлены, но и бесконечные
степенные ряды. Для получения
частного надо расположить многочлены по возрастающим степеням
- делителем. Если же мы хотим, чтобы деление выполнялось без остатка,
то придется допустить в качестве частного не только многочлены, но и бесконечные
степенные ряды. Для получения
частного надо расположить многочлены по возрастающим степеням ![]() и
делить "углом", начиная с младших членов. Рассмотрим, например, деление
и
делить "углом", начиная с младших членов. Рассмотрим, например, деление ![]() на
на ![]()

| (9.1) |
Лишь в случае, когда ![]() делится без остатка на
делится без остатка на ![]() , ряд (9.1) обрывается и мы получаем многочлен.
, ряд (9.1) обрывается и мы получаем многочлен.
Алгебраические дроби и степенные ряды
При делении многочлена ![]() на многочлен
на многочлен ![]() мы получаем бесконечный степенной ряд. Возникает вопрос: как связан
этот ряд с алгебраической дробью
мы получаем бесконечный степенной ряд. Возникает вопрос: как связан
этот ряд с алгебраической дробью ![]() , то есть какой смысл можно придать записи
, то есть какой смысл можно придать записи
| (9.2) |
| (9.3) |
То же самое получится, если вместо ![]() подставить в обе части
(9.3) число
подставить в обе части
(9.3) число ![]() . Левая часть равенства примет значение 2, а правая превратится в
бесконечный числовой ряд
. Левая часть равенства примет значение 2, а правая превратится в
бесконечный числовой ряд ![]() Беря последовательно одно, два, три, четыре,
слагаемых, мы получим числа 1;
Беря последовательно одно, два, три, четыре,
слагаемых, мы получим числа 1; ![]() ;
; ![]() ;
; ![]() ,…,
,…, ![]() . Ясно, что с возрастанием
. Ясно, что с возрастанием ![]() эти числа стремятся к
числу 2.
эти числа стремятся к
числу 2.
Однако, если взять ![]() , то левая часть (9.3) примет значение
, то левая часть (9.3) примет значение ![]() , а в правой получим ряд
, а в правой получим ряд ![]() Если последовательно складывать члены этого ряда, то получаются суммы 1; 5;
21; 85; … Эти суммы неограниченно увеличиваются и не приближаются к числу
Если последовательно складывать члены этого ряда, то получаются суммы 1; 5;
21; 85; … Эти суммы неограниченно увеличиваются и не приближаются к числу ![]() .
.
Мы встретились, таким образом, с двумя случаями. Чтобы их различать, введем общее понятие о сходимости и расходимости числового ряда. Пусть задан бесконечный числовой ряд
| (9.4) |
Проведенное выше исследование показывает, что
| (9.5) |
Отметим, что равенство (9.5) - это известная из школьного курса математики формула для суммы бесконечно убывающей геометрической прогрессии.
Мы выяснили, таким образом, смысл записи
Пусть при делении многочлена ![]() на многочлен
на многочлен ![]() получился степенной ряд
получился степенной ряд
| (9.6) |
Иными словами, всегда есть область ![]() , в
которой выполняется равенство
, в
которой выполняется равенство
| (9.7) |
Действия над степенными рядами
Перейдем теперь к действиям над степенными рядами. Пусть функции ![]() и
и ![]() разложены в степенные ряды
разложены в степенные ряды
| (9.12) |
| (9.13) |
| (9.14) |
Посмотрим теперь, как разлагается в степенной ряд произведение функций ![]() и
и ![]() . Мы имеем
. Мы имеем
| (9.15) |
| (9.16) |
В частности, возводя ряд (9.12) в квадрат, получаем
| (9.17) |
Посмотрим теперь, как делят друг на друга степенные ряды. Пусть свободный член ряда (9.13) отличен от нуля. Покажем, что в этом случае существует такой степенной ряд
| (9.18) |
| (9.19) |
Для того чтобы этот ряд совпадал с рядом (9.12), необходимо и достаточно, чтобы выполнялись равенства
Лекция 10. Производящие функции и рекуррентные соотношения
Применение степенных рядов для доказательства тождеств
С помощью степенных рядов можно доказывать многие тождества. Для этого
берут некоторую функцию и двумя способами разлагают ее в степенной ряд.
Поскольку функция может быть представлена лишь единственным образом в виде
степенного ряда, то коэффициенты при одинаковых степенях ![]() в
обоих рядах должны совпадать. Это и приводит к доказываемому тождеству.
в
обоих рядах должны совпадать. Это и приводит к доказываемому тождеству.
Рассмотрим, например, известное нам разложение
Возведя обе части этого разложения в квадрат, получаем
| (10.1) |
| (10.2) |
 | (10.3) |
Очевидно, что коэффициенты при нечетных степенях ![]() обращаются
в нуль, каждое слагаемое дважды входит в эти коэффициенты с противоположными знаками.
Коэффициент же
обращаются
в нуль, каждое слагаемое дважды входит в эти коэффициенты с противоположными знаками.
Коэффициент же ![]() равен
равен
| (10.4) |
Производящие функции
Пусть дана некоторая последовательность чисел ![]() .
Образуем степенной ряд
.
Образуем степенной ряд
Нас будут интересовать производящие функции для последовательностей ![]() , так или иначе связанных с комбинаторными
задачами. С помощью таких функций удается получить самые разные свойства
этих последовательностей. Кроме того, мы рассмотрим, как связаны
производящие функции с решением рекуррентных соотношений.
, так или иначе связанных с комбинаторными
задачами. С помощью таких функций удается получить самые разные свойства
этих последовательностей. Кроме того, мы рассмотрим, как связаны
производящие функции с решением рекуррентных соотношений.
Бином Ньютона
Получим производящую функцию для конечной последовательности чисел ![]() . Известно, что
. Известно, что
| (10.4) |
| (10.5) |
| (10.6) |
| (10.7) |
| (10.8) |
Ряд Ньютона
Мы назвали, как это обычно делают, формулу ![]() биномом
Ньютона. Это наименование с точки зрения истории математики неверно.
Формулу для
биномом
Ньютона. Это наименование с точки зрения истории математики неверно.
Формулу для ![]() хорошо знали среднеазиатские математики
Омар Хайям, Гиясэдди и другие. В
Западной Европе задолго до Ньютона она была известна Блэзу Паскалю. Заслуга же
Ньютона была в ином - ему удалось обобщить формулу
хорошо знали среднеазиатские математики
Омар Хайям, Гиясэдди и другие. В
Западной Европе задолго до Ньютона она была известна Блэзу Паскалю. Заслуга же
Ньютона была в ином - ему удалось обобщить формулу ![]() на
случай нецелых показателей. Именно, он доказал, что если
на
случай нецелых показателей. Именно, он доказал, что если ![]() -
положительное число и
-
положительное число и ![]() , то для любого
действительного значения
, то для любого
действительного значения ![]() имеет место равенство
имеет место равенство
 | (10.9) |
Производящие функции и рекуррентные соотношения
Теория производящих функций тесно связана с рекуррентными соотношениями.
Вернемся снова к делению многочленов. Пусть функции ![]() и
и ![]() разложены в степенные ряды,
разложены в степенные ряды,
| (10.10) |
 | (10.11) |
| (10.12) |
Обратно, если дано рекуррентное соотношение (10.12) и заданы члены ![]() , то мы сначала по формулам (10.11) вычислим
значения
, то мы сначала по формулам (10.11) вычислим
значения ![]() . А тогда производящей функцией для
последовательности чисел
. А тогда производящей функцией для
последовательности чисел ![]() является
алгебраическая дробь
является
алгебраическая дробь
| (10.13) |
Об едином нелинейном рекуррентном соотношении
При решении задачи о разбиении последовательности мы пришли к рекуррентному соотношению
| (10.14) |
| (10.15) |
| (10.16) |
Но по рекуррентному соотношению (10.14),
Лекция 11. Алгоритмы на абстрактных структурах данных
Введение
Н. Вирт определил программирование как алгоритм + структуры данных. При этом структура данных может не зависеть от конкретных языковых конструкций (абстрактная структура данных).
Рассмотрим некоторые основные структуры данных.
Стеки
Стеком называется одномерная структура данных, загрузка или увеличение элементов для которой осуществляется с помощью указателя стека в соответствии с правилом LIFO ("last-in, first-out" "последним введен,первым выведен").
Указатель стека sp (stack pointer) содержит в любой момент времени индекс (адрес) текущего элемента, который является единственным элементом стека, доступным в данный момент времени для обработки.
Существуют следующие основные базисные операции для работы со стеком (для случая, когда указатель стека всегда задает ячейку, находящуюся непосредственно над его верхним элементом).
- Начальная установка:
Sp:=1;
- Загрузка элемента x в стек:
Stack[sp]:=x; Sp:=sp+1;
- Извлечение элемента из стека:
Sp:=sp-1; X:=stack[sp];
- Проверка на переполнение и загрузка элемента в стек:
If sp<=sd then
Begin stack[sp]:=x; sp:=sp+1 end
Else
\{ переполнение \};
Здесь sd - размерность стека.- Проверка наличия элементов и извлечение элемента стека:
If sp>1 then
Begin sp:=sp-1; x:=stack[sp] end
Else
\{ антипереполнение \}- Чтение данных из указателя стека без извлечения элемента:
x:=stack[sp-1].
Программа 1. Работа со стеком.
{Реализованы основные базисные операции для работы со стеком.
Программа написана на языке программирования Turbo-Pascal }
uses crt,graph;
type PEl=^El;
El=record
n:byte;
next:PEl;
end;
var ster:array[1..3] of PEl;
number: byte;
p:PEl;
th,l: integer;
i:integer;
nhod:word;
s:string;
procedure hod(n,f,t:integer);
begin
if n>1 then begin
hod(n-1,f,6-(f+t));
hod(1,f,t);
hod(n-1,6-(f+t),t);
end else begin
p:=ster[f];
ster[f]:=ster[f]^.next;
p^.next:=ster[t];
ster[t]:=p;
inc(nhod);
str(nhod,s);
{**********************************************************}
setfillstyle(1,0);bar(0,0,50,10);
setcolor(2);outtextxy(0,0,s);
setfillstyle(1,0);setcolor(0);p:=ster[f];i:=1;
while p<>nil do begin p:=p^.next;inc(i);end;
fillellipse(160*f,460-(i-1)*th,(number-ster[t]^.n+1)*l,10);
setfillstyle(1,4);setcolor(4);p:=ster[t];i:=1;
while p<>nil do begin fillellipse(160*t,460-(i-1)*th,(number-
ster[t]^.n+1)*l,10);inc(i);p:=p^.next;end;
{**********************************************************}
{ readkey;}{delay(50);}
end;
end;
procedure start;
var i:integer;grD,grM: Integer;
begin
clrscr;write('Enter the number of rings, please.');readln(number);
for i:=1 to 3 do ster[i]:=nil;
for i:=1 to number do begin new(p);p^.n:=i;p^.next:=ster[1];ster[1]:=p;end;
nhod:=0;
grD:=Detect;{InitGraph(grD,grM,'');}InitGraph(grD,grM,'c:\borland\tp\bgi');
th:=20;l:=round(50/number);
setfillstyle(1,4);setcolor(4);
for i:=1 to number do begin fillellipse(160,460-(i-1)*th,(number-
i+1)*l,10);end;
end;
begin
start;
{readkey;}
hod(number,1,3);
{closegraph;}
end.Программа 2. Ханойская башня.
На стержне ![]() в исходном порядке находится
в исходном порядке находится ![]() дисков, уменьшающихся по размеру снизу вверх. Диски должны быть переставлены
на стержень в исходном порядке при использовании в случае необходимости
промежуточного стержня
дисков, уменьшающихся по размеру снизу вверх. Диски должны быть переставлены
на стержень в исходном порядке при использовании в случае необходимости
промежуточного стержня ![]() для временного хранения дисков. В
процессе перестановки дисков обязательно
должны соблюдаться правила: одновременно может быть переставлен только один
самый верхний диск ( с одного из стержней на другой); ни в какой момент времени
диск не может находиться на другом диске меньшего размера.
для временного хранения дисков. В
процессе перестановки дисков обязательно
должны соблюдаться правила: одновременно может быть переставлен только один
самый верхний диск ( с одного из стержней на другой); ни в какой момент времени
диск не может находиться на другом диске меньшего размера.
Программа реализована с помощью абстрактного типа данных – стек для произвольного числа дисков.
{Программа написана на языке программирования Turbo-Pascal}
uses crt,graph;
type PEl=^El;
El=record
n:byte;
next:PEl;
end;
var ster:array[1..3] of PEl;
number: byte;
p:PEl;
th,l: integer;
i:integer;
nhod:word;
s:string;
procedure hod(n,f,t:integer);
begin
if n>1 then begin
hod(n-1,f,6-(f+t));
hod(1,f,t);
hod(n-1,6-(f+t),t);
end else begin
p:=ster[f];
ster[f]:=ster[f]^.next;
p^.next:=ster[t];
ster[t]:=p;
inc(nhod);
str(nhod,s);
{**********************************************************}
setfillstyle(1,0);bar(0,0,50,10);
setcolor(2);outtextxy(0,0,s);
setfillstyle(1,0);setcolor(0);p:=ster[f];i:=1;
while p<>nil do begin p:=p^.next;inc(i);end;
fillellipse(160*f,460-(i-1)*th,(number-ster[t]^.n+1)*l,10);
setfillstyle(1,4);setcolor(4);p:=ster[t];i:=1;
while p<>nil do begin fillellipse(160*t,460-(i-1)*th,(number-
ster[t]^.n+1)*l,10);inc(i);p:=p^.next;end;
{**********************************************************}
{ readkey;}{delay(50);}
end;
end;
procedure start;
var i:integer;grD,grM: Integer;
begin
clrscr;write('Enter the number of rings, please.');readln(number);
for i:=1 to 3 do ster[i]:=nil;
for i:=1 to number do begin new(p);p^.n:=i;p^.next:=ster[1];ster[1]:=p;end;
nhod:=0;
grD:=Detect;{InitGraph(grD,grM,'');}InitGraph(grD,grM,'c:\borland\tp\bgi');
th:=20;l:=round(50/number);
setfillstyle(1,4);setcolor(4);
for i:=1 to number do begin fillellipse(160,460-(i-1)*th,(number-
i+1)*l,10);end;
end;
begin
start;
{readkey;}
hod(number,1,3);
{closegraph;}
end.Очереди
Очередь - одномерная структура данных, для которой загрузка или извлечение элементов осуществляется с помощью указателей начала извлечения (head) и конца (tail) очереди в соответствии с правилом FIFO ("first-in, first-out" - "первым введен, первым выведен").
- Начальная установка:
Head:=1; tail:=1;
- Добавление элемента x:
Queue[tail]:=x; tail:=tail+1; If tail>qd then tail:=1; Здесь qd - размерность очереди.
- Исключение элемента x:
x:=queue[head]; head:=head+1; if head>qd then head:=1;
- Проверка переполнения очереди и включение в нее элемента:
Temp:=tail+1;
If temp>qd then temp:=1;
If temp=head then \{переполнение\}
Else btgin queue[tail]:=x; tail:=temp end;- Проверка элементов и исключение элемента:
If head:=tail then
\{очередь пуста\}
else begin
x:=queue[head]; head:=head+1;
if yead>qd then head:=1;
end;Отметим, что при извлечении элемента из очереди все элементы могут также перемещаться на один шаг к ее началу.
Связанные списки
Связанный список представляет собой структуру данных, которая состоит из узлов (как правило, записей), содержащих указатели на следующий узел. Указатель, который ни на что не указывает, снабжается значением nil. Таким образом, в каждый элемент связанного списка добавляется указатель (звено связи).
Приведем основные базисные операции для работы с однонаправленным связанным списком.
- Включение элемента после элемента:
Link[q]:=link[p]; Link[p]:=q;
Здесь q – индекс элемента, который должен быть вставлен в список после элемента с индексом p.
- Исключение преемника элемента x:
If link[x]<>null then
Link[x]:=[link[x]]
else
\{Элемент x не имеет преемника\};Отметим, что элемент, следующий в списке за элементом x, называется преемником элемента x, а элемент, pасположенный перед элементом x, называется предшественником элемента x. Если элемент x не имеет преемника, то содержащемуся в нем указателю присваивается значение nil.
- Включение элемента y перед элементом x:
Prev:=0;
While(link[prev]<>nil)and(link[prev]<>x)do
Prev:=link[prev];
If link[prev]=x then
Btgin link[prev]:=y; link[y]:=x end
Else
\{Элемент x не найден\};
Здесь link[0]является началом списка.Отметим, что исключение последнего элемента из однонаправленного списка связано с просмотром всего списка.
В двунаправленном связанным списке каждый элемент имеет два указателя (succlink - описывает связь элемента с преемником, predlink - с предшественником).
Приведем основные базисные операции для работы с двунаправленным связанным списком.
Ответ 1 Включение y перед элементом x:
Succlink[y]:=x; Predlink[y]:=predlink[x]; Succlink[predlink[x]]:=y; Predlink[x]:=y;
Ответ 2 Включение элемента y после элемента x:
Succlink[y]:=succlink[x]; Predlink[y]:=x; Predlink[succlink[x]]:=y; Succlink[x]:=y;
Ответ 3 Исключение элемента x.
Predlink[succlink[x]]:=predlink[x]; Succlink[predlink[x]]:=succlink[x];
Программа 3.Список целых чисел.
{Создается список целых чисел. Числа выбираются случайным образом
из интервала 0..9999, затем он упорядочивается,
сначала - по возрастанию, затем - по убыванию.
Программа написана на языке программирования Turbo-Pascal}
uses crt;
type TLink=^Link;
Link=record
v : integer;
p, n : TLink
end;
var i : integer;
p, q, w : TLink;
s1,s2,rs : TLink;
procedure Sort( sp : TLink; t : integer );
var temp : integer;
begin
q:=sp;
while q^.n<>nil do begin
q:=q^.n;
p:=sp;
while p^.n<>nil do begin
if (p^.v-p^.n^.v)*t>0 then begin
temp:=p^.v;
p^.v:=p^.n^.v;
p^.n^.v:=temp;
end;
p:=p^.n;
end;
end;
end;
function CreatRndSpis(deep : integer):TLink;
begin
new(q);
for i:=1 to deep do begin
if i=1 then begin
p:=q;q^.p:=nil;
end;
q^.v:=random(9999);
new(q^.n);
q^.n^.p:=q;
q:=q^.n;
end;
q^.p^.n:=nil;
dispose(q);
CreatRndSpis:=p;
end;
function CreatSortDawnSpis(deep : integer):TLink;
begin
if deep<9999 then begin
new(q);
for i:=1 to deep do begin
if i=1 then begin
q^.p:=nil;p:=q;
end;
q^.v:=random(round(9999/deep))+round(9999*(1-i/deep));
new(q^.n);
q^.n^.p:=q;
q:=q^.n;
end;
q^.p^.n:=nil;
dispose(q);
end else p:=nil;
CreatSortDawnSpis:=p;
end;
procedure Show( s : TLink; sp: integer );
var i : integer;
begin
p:=s;
i:=1;
while p<>nil do begin
gotoxy(sp,i);write(' ' : 5); gotoxy(sp,i);writeln(p^.v);
p:=p^.n;
inc(i);
end;
end;
function min( c1, c2 : integer) : integer;
begin
case c1<c2 of
true : min:=c1;
false: min:=c2;
end;
end;
function CreatConcSortUpSpis( sp1, sp2 : TLink ) : TLink;
begin
q:=sp1;while q^.n<>nil do q:=q^.n;
w:=sp2;while w^.n<>nil do w:=w^.n;
new(p);
CreatConcSortUpSpis:=p;
p^.p:=nil;
while(w<>nil)and(q<>nil)do begin
if(w<>nil)and(q<>nil)then begin
p^.v:=min(q^.v,w^.v);
case p^.v=q^.v of
true : q:=q^.p;
false: w:=w^.p;
end;
new(p^.n);
p^.n^.p:=p;
p^.n^.n:=nil;
p:=p^.n;
end;
if(w=nil)and(q<>nil)then begin
while q<>nil do begin
p^.v:=q^.v;q:=q^.p;
new(p^.n);
p^.n^.p:=p;
p^.n^.n:=nil;
p:=p^.n;
end;
end;
if(w<>nil)and(q=nil)then begin
while w<>nil do begin
p^.v:=w^.v;w:=w^.p;
new(p^.n);
p^.n^.p:=p;
p^.n^.n:=nil;
p:=p^.n;
end;
end;
end;
p^.p^.n:=nil;
dispose(p);
end;
begin
clrscr;
randomize;
s1:=CreatRndSpis(15);Sort(s1,-1);
s2:=CreatRndSpis( 5);Sort(s2,-1);
rs:=CreatConcSortUpSpis(s1,s2);
Show(s1,10);
Show(s2,20);
Show(rs,30);
Sort(rs,-1);
Show(rs,40);
readln;
end.Двоичные деревья
Основные определения и понятия о графах даются в лекции 12. В лекции 16 и 17 рассматриваются комбинаторные алгоритмы на графах. В данной лекции приведены несколько понятий, необходимых для описания абстрактной структуры данных, - двоичное дерево.
При решении многих задач математики используется понятие графа. Граф - набор точек на плоскости (эти точки называются вершинами графа ), некоторые из которых соединены отрезками (эти отрезки называются ребрами графа ). Вершины могут располагаться на плоскости произвольным образом. Причем неважно, является ли ребро, соединяющее две вершины, отрезком прямой или кривой линией. Важен лишь факт соединения двух данных вершин графа ребром. Примером графа может служить схема линий железных дорог. Если требуется различать вершины графа, их нумеруют или обозначают разными буквами. В изображении графа на плоскости могут появляться точки пересечения ребер, не являющиеся вершинами.
Говорят, что две вершины графа соединены путем, если из одной вершины можно пройти по ребрам в другую вершину. Путей между двумя данными вершинами может быть несколько. Поэтому обычно путь обозначают перечислением вершин, которые посещают при движении по ребрам. Граф называется связным, если любые две его вершины соединены некоторым путем.
Состоящий из различных ребер замкнутый путь называется циклом. Связный граф, в котором нет циклов, называется деревом. Одним из основных отличительных свойств дерева является то, что в нем любые две вершины соединены единственным путем. Дерево называется ориентированным, если на каждом его ребре указано направление. Следовательно, о каждой вершине можно сказать, какие ребра в нее входят, а какие - выходят. Точно так же о каждом ребре можно сказать, из какой вершины оно выходит, и в какую - входит. Двоичное дерево - это такое ориентированное дерево, в котором:
- Имеется ровно одна вершина, в которую не входит ни одного ребра. Эта вершина называется корнем двоичного дерева.
- В каждую вершину, кроме корня, входит одно ребро.
- Из каждой вершины (включая корень) исходит не более двух ребер.
Граф задается аналогично спискам через записи и указатели.
Программа 4. Создание и работа с деревом.
//Алгоритм реализован на языке Turbo-C++.
//Вершины дерева задаются структурой: поле целых,
//поле для размещения адреса левого "сына" и поле для размещения
//адреса правого "сына"
//Значение целого выбирается случайным образом из интервала 0..99.
//Число уровней дерева равно N. В примере N = 5.
#include <stdio.h>
#include <conio.h>
#include <stdlib.h>
#include <time.h>
#define N 5
struct tree{int a;
tree* left;
tree* right;};
void postr(tree* root,int h)
{
root->a=random(100);
if (h!=0){
if (random(3)){
root->left=new(tree);
postr(root->left,h-1);}
else root->left=NULL;
if (random(3))
{root->right=new(tree);postr(root->right,h-1);}
else root->right=NULL;}
else {root->right=NULL;root->left=NULL;}
}
void DFS(tree* root)
{printf("%d ",root->a);
if (root->left!=NULL) DFS(root->left);
if (root->right!=NULL) DFS(root->right);}
void main()
{clrscr();
randomize();
tree* root1;
root1=new(tree);
postr(root1,N);
DFS(root1);
getch();
}Лекция 12. Что такое граф? Определения и примеры
Введение
Множество самых разнообразных задач естественно формулируется в терминах графов. Так, например, могут быть сформулированы задачи составления расписаний в исследовании операций, анализа сетей в электротехнике, установления структуры молекул в органической химии, сегментации программ в программировании, анализа цепей Маркова в теории вероятностей. В задачах, возникающих в реальной жизни, соответствующие графы часто оказываются так велики, что их анализ неосуществим без ЭВМ. Таким образом, решение прикладных задач с использованием теории графов возможно в той мере, в какой возможна обработка больших графов на ЭВМ, и поэтому эффективные алгоритмы решения задач теории графов имеют большое практическое значение. В 16 и 17 лекциях мы излагаем несколько эффективных алгоритмов на графах и используем их для демонстрации некоторой общей техники решения задач на графах с помощью ЭВМ.
Конечный граф ![]() состоит из конечного множества вершин
состоит из конечного множества вершин ![]() и конечного множества ребер
и конечного множества ребер ![]() . Каждому ребру соответствует пара вершин: если ребро
. Каждому ребру соответствует пара вершин: если ребро ![]() соответствует ребру
соответствует ребру ![]() , то говорят, что
, то говорят, что ![]() инцидентно вершинам
инцидентно вершинам ![]() и
и ![]() . Граф
. Граф ![]() изображается следующим образом: каждая вершина
представляется точкой и каждое ребро представляется отрезком линии, соединяющим его
концевые вершины. Граф
называется ориентированным, если
пара вершин
изображается следующим образом: каждая вершина
представляется точкой и каждое ребро представляется отрезком линии, соединяющим его
концевые вершины. Граф
называется ориентированным, если
пара вершин ![]() , соответствующая каждому ребру, упорядочена. В
таком случае говорят, что ребро
, соответствующая каждому ребру, упорядочена. В
таком случае говорят, что ребро ![]() ориентированно
из вершины
ориентированно
из вершины ![]() в вершину
в вершину ![]() , а направление обозначается стрелкой
на ребре. Мы будем называть ориентированные графы орграфами. В неориентированном графе концевые вершины каждого ребра не упорядочены, и ребра не имеют направления. Ребро называется петлей, если оно начинается и кончается в одной и той же вершине.
Говорят, что два ребра
параллельны, если они имеют одну и ту же пару концевых вершин (и
если они имеют одинаковую ориентацию в случая ориентированного графа). Граф называется простым, если он не имеет ни петель,
ни параллельных ребер. Если не указывается противное, будем считать, что
рассматриваемые графы являются простыми. Всюду в 16 и
17 лекции будем
использовать символы
, а направление обозначается стрелкой
на ребре. Мы будем называть ориентированные графы орграфами. В неориентированном графе концевые вершины каждого ребра не упорядочены, и ребра не имеют направления. Ребро называется петлей, если оно начинается и кончается в одной и той же вершине.
Говорят, что два ребра
параллельны, если они имеют одну и ту же пару концевых вершин (и
если они имеют одинаковую ориентацию в случая ориентированного графа). Граф называется простым, если он не имеет ни петель,
ни параллельных ребер. Если не указывается противное, будем считать, что
рассматриваемые графы являются простыми. Всюду в 16 и
17 лекции будем
использовать символы ![]() и
и ![]() для обозначения соответственно числа вершин и числа ребер в графе
для обозначения соответственно числа вершин и числа ребер в графе ![]() .
.
Представления
Наиболее известный способ представления графа на бумаге состоит в геометрическом изображении точек и линий. В ЭВМ граф должен быть представлен дискретным способом, причем возможно много различных представлений. Простота использования, так же как и эффективность алгоритмов на графе, зависит от подходящего выбора представления графа. Рассмотрим различные структуры данных для представления графов.
Матрица
смежностей. Одним из наиболее распространенных
машинных представлений простого графа является матрица смежностей или соединений. Матрица смежностей графа ![]() есть
есть ![]() -матрица
-матрица ![]() , в
которой
, в
которой ![]() , если в
, если в ![]() существует ребро, идущее из
существует ребро, идущее из ![]() -й вершины в
-й вершины в ![]() -ю, и
-ю, и ![]() в противном случае. Орграф и его
матрица смежностей представлены на рис. 12.1.
в противном случае. Орграф и его
матрица смежностей представлены на рис. 12.1.
Рис. 12.1. Ориентированный граф и его матрица смежностей

Заметим, что в матрице смежностей петля может быть представлена соответствующим единичным диагональным элементом. Кратные ребра можно представить, позволив элементу матрицы быть больше 1, но это не принято, так как обычно удобно представлять каждый элемент матрицы одним двоичным разрядом.
Для задания матрицы смежностей требуется ![]() двоичных разрядов. У неориентированного графа матрица смежностей симметрична, и
для ее представления достаточно хранить только верхний треугольник. В
результате экономится почти 50% памяти, но время вычислений может при этом немного
увеличиться, потому что каждое обращение к
двоичных разрядов. У неориентированного графа матрица смежностей симметрична, и
для ее представления достаточно хранить только верхний треугольник. В
результате экономится почти 50% памяти, но время вычислений может при этом немного
увеличиться, потому что каждое обращение к ![]() должно быть
заменено следующим: if
должно быть
заменено следующим: if ![]() then
then ![]() else
else ![]() .
В случае представления графа его матрицей смежностей для большинства алгоритмов
требуется время вычисления, по крайней мере пропорциональное
.
В случае представления графа его матрицей смежностей для большинства алгоритмов
требуется время вычисления, по крайней мере пропорциональное ![]() .
.
Матрица весов. Граф,
в котором ребру ![]() сопоставлено число
сопоставлено число ![]() ,
называется взвешенным
графом, а число
,
называется взвешенным
графом, а число ![]() называется весом ребра
называется весом ребра ![]() . В сетях связи
или транспортных сетях эти веса представляют некоторые физические
величины, такие как стоимость, расстояние, эффективность, емкость или
надежность соответствующего ребра. Простой взвешенный граф может быть представлен своей
матрицей весов
. В сетях связи
или транспортных сетях эти веса представляют некоторые физические
величины, такие как стоимость, расстояние, эффективность, емкость или
надежность соответствующего ребра. Простой взвешенный граф может быть представлен своей
матрицей весов ![]() ,
где
,
где ![]() есть вес ребра, соединяющего вершины
есть вес ребра, соединяющего вершины ![]() и
и ![]() .
Веса несуществующих ребер обычно полагают равными
.
Веса несуществующих ребер обычно полагают равными ![]() или 0 в зависимости от приложений. Когда
вес несуществующего ребра равен 0, матрица весов является простым обобщением матрицы смежностей.
или 0 в зависимости от приложений. Когда
вес несуществующего ребра равен 0, матрица весов является простым обобщением матрицы смежностей.
Список ребер. Если
граф является разреженным, то возможно, что более
эффектно представлять ребра графа парами вершин. Это представление можно
реализовать двумя массивами ![]() и
и ![]() . Каждый
элемент в массиве есть метка вершины, а
. Каждый
элемент в массиве есть метка вершины, а ![]() -е ребро графа выходит из
вершины
-е ребро графа выходит из
вершины ![]() и входит в вершину
и входит в вершину ![]() . Например, орграф,
изображенный на рис. 12.1, будет представляться следующим
образом:
. Например, орграф,
изображенный на рис. 12.1, будет представляться следующим
образом:
Структура смежности.
В ориентированном графе вершина ![]() называется последователем другой
вершины
называется последователем другой
вершины ![]() , если существует ребро, направленное
из
, если существует ребро, направленное
из ![]() в
в ![]() . Вершина
. Вершина ![]() называется тогда предшественником
называется тогда предшественником ![]() . В случае неориентированного графа две вершины называются соседями,
если между ними есть ребро. Граф может быть описан его структурой смежности, то
есть списком всех последователей (соседей) каждой вершины; для каждой
вершины
. В случае неориентированного графа две вершины называются соседями,
если между ними есть ребро. Граф может быть описан его структурой смежности, то
есть списком всех последователей (соседей) каждой вершины; для каждой
вершины ![]() задается
задается ![]() - список всех последователей
(соседей) вершины
- список всех последователей
(соседей) вершины ![]() . В большинстве алгоритмов на графах
относительный порядок вершин, смежных с вершиной
. В большинстве алгоритмов на графах
относительный порядок вершин, смежных с вершиной ![]() в
в ![]() ,
не важен, и в таком случае удобно считать
,
не важен, и в таком случае удобно считать ![]() мультимножеством (или множеством,
если граф является простым) вершин, смежных
с
мультимножеством (или множеством,
если граф является простым) вершин, смежных
с ![]() . Структура смежности орграфа, представленного на рис. 12.1,
такова:
. Структура смежности орграфа, представленного на рис. 12.1,
такова:
Adj(v) 1: 6 2: 1, 3, 4, 6 3: 4, 5 4: 5 5: 3, 6, 7 6: 7: 1, 6
Если для хранения метки вершины используется одно машинное слово, то
структура смежности ориентированного графа требует ![]() слов. Если граф неориентированный, нужно
слов. Если граф неориентированный, нужно ![]() слов, так как каждое ребро встречается дважды.
слов, так как каждое ребро встречается дважды.
Структуры смежности могут быть удобно реализованы массивом из ![]() линейно связанных списков, где каждый список содержит
последователей некоторой вершины. Поле данных содержит метку одного из последователей, и поле указателей
указывает следующего последователя. Хранение списков смежности в виде
связанного списка желательно для алгоритмов, в которых в графе добавляются или удаляются вершины.
линейно связанных списков, где каждый список содержит
последователей некоторой вершины. Поле данных содержит метку одного из последователей, и поле указателей
указывает следующего последователя. Хранение списков смежности в виде
связанного списка желательно для алгоритмов, в которых в графе добавляются или удаляются вершины.
Матрица инцидентности - ![]() задает граф :
задает граф : ![]() ,
если ребро
,
если ребро ![]() выходит из вершины
выходит из вершины ![]() ,
, ![]() ,
если ребро
,
если ребро ![]() входит в вершину
входит в вершину ![]() , и
, и ![]() в остальных случаях.
в остальных случаях.
Связность и расстояние
Говорят, что вершины ![]() и
и ![]() в графе смежны,
если существует ребро, соединяющее их.
Говорят, что два ребра смежны, если они
имеют общую вершину. Простой
путь, или для краткости, просто путь,
записываемый иногда как
в графе смежны,
если существует ребро, соединяющее их.
Говорят, что два ребра смежны, если они
имеют общую вершину. Простой
путь, или для краткости, просто путь,
записываемый иногда как ![]() , - это
последовательность смежных ребер
, - это
последовательность смежных ребер ![]() , в которой все
вершины
, в которой все
вершины ![]() различны, исключая, возможно,
случай
различны, исключая, возможно,
случай ![]() . В орграфе этот путь называется ориентированным
из
. В орграфе этот путь называется ориентированным
из ![]() в
в ![]() , в неориентированном графе он называется
путем между
, в неориентированном графе он называется
путем между ![]() и
и ![]() . Число ребер в пути называется длиной пути. Путь наименьшей длины
называется кратчайшим
путем. Замкнутый путь называется циклом.
Граф, который не содержит циклов, называется ациклическим.
. Число ребер в пути называется длиной пути. Путь наименьшей длины
называется кратчайшим
путем. Замкнутый путь называется циклом.
Граф, который не содержит циклов, называется ациклическим.
Подграф графа ![]() есть граф, вершины и ребра которого
лежат в
есть граф, вершины и ребра которого
лежат в ![]() . Подграф
. Подграф ![]() , индуцированный
подмножеством
, индуцированный
подмножеством ![]() множества
множества ![]() вершин
графа
вершин
графа ![]() , - это подграф, который получается в результате удаления
всех вершин из
, - это подграф, который получается в результате удаления
всех вершин из ![]() и всех ребер, инцидентных им.
и всех ребер, инцидентных им.
Неориентированный
граф ![]() связен,
если существует хотя бы один путь в
связен,
если существует хотя бы один путь в ![]() между
каждой парой вершин
между
каждой парой вершин ![]() и
и ![]() . Ориентированный граф
. Ориентированный граф ![]() связен,
если неориентированный граф, получающийся
из
связен,
если неориентированный граф, получающийся
из ![]() путем удаления ориентации ребер, является связным. Граф, состоящий из
единственной изолированной вершины, является (тривиально) связным.
Максимальный связный подграф графа
путем удаления ориентации ребер, является связным. Граф, состоящий из
единственной изолированной вершины, является (тривиально) связным.
Максимальный связный подграф графа ![]() называется связной компонентой или просто компонентой
называется связной компонентой или просто компонентой ![]() . Несвязный граф состоит из двух или более компонент.
Максимальный сильно связный подграф называется сильно связной компонентой.
. Несвязный граф состоит из двух или более компонент.
Максимальный сильно связный подграф называется сильно связной компонентой.
Иногда недостаточно знать, что граф связен; нас может интересовать, насколько "сильно связен" связный граф. Например, связный граф может содержать вершину, удаление которой вместе с инцидентными ей ребрами разъединяет оставшиеся вершины. Такая вершина называется точкой сочленения или разделяющей вершиной. Граф, содержащий точку сочленения, называется разделимым. Граф без точек сочленения называется двусвязным или неразделимым. Максимальный двусвязный подграф графа называется двусвязной компонентой или блоком.
Большинство основных вопросов о графах касается связности, путей и расстояний. Нас может интересовать вопрос, является ли граф связным; если он связен, то может оказаться нужным найти кратчайшее расстояние между выделенной парой вершин или определить кратчайший путь между ними. Если граф несвязен, то может потребоваться найти все его компоненты. В нашем курсе строятся алгоритмы для решения этих и других подобных вопросов.
Остовные деревья
Связный неориентированный ациклический граф называется деревом,
множество деревьев называется лесом.
В связном неориентированном графе ![]() существует по
крайней мере один путь между каждой парой вершин; отсутствие
циклов в
существует по
крайней мере один путь между каждой парой вершин; отсутствие
циклов в ![]() означает, что существует самое большее один такой путь
между любой парой вершин
в
означает, что существует самое большее один такой путь
между любой парой вершин
в ![]() . Поэтому, если
. Поэтому, если ![]() - дерево, то между каждой парой
вершин в
- дерево, то между каждой парой
вершин в ![]() существует в точности один путь. Рассуждение легко
обратимо, и поэтому
неориентированный граф
существует в точности один путь. Рассуждение легко
обратимо, и поэтому
неориентированный граф ![]() будет деревом тогда и только тогда, если
между каждой парой вершин в
будет деревом тогда и только тогда, если
между каждой парой вершин в ![]() существует в точности один путь. Так
как наименьшее число ребер, которыми можно
соединить
существует в точности один путь. Так
как наименьшее число ребер, которыми можно
соединить ![]() вершин, равно
вершин, равно ![]() и дерево
с
и дерево
с ![]() вершинами содержит в точности
вершинами содержит в точности ![]() ребер, то
деревья можно считать минимально связными графами. Удаление из дерева
любого ребра превращает его в несвязный граф, разрушая единственный путь между
по крайней мере одной парой вершин.
ребер, то
деревья можно считать минимально связными графами. Удаление из дерева
любого ребра превращает его в несвязный граф, разрушая единственный путь между
по крайней мере одной парой вершин.
Особый интерес представляют остовные деревья графа ![]() , то есть деревья,
являющиеся подграфами графа
, то есть деревья,
являющиеся подграфами графа ![]() и содержащие все его вершины. Если
граф
и содержащие все его вершины. Если
граф ![]() несвязен, то множество, состоящее из остовных деревьев
каждой компоненты
называется остовном
лесом графа. Для построения остовного дерева (леса)
данного неориентированного графа
несвязен, то множество, состоящее из остовных деревьев
каждой компоненты
называется остовном
лесом графа. Для построения остовного дерева (леса)
данного неориентированного графа ![]() , мы последовательно
просматриваем ребра
, мы последовательно
просматриваем ребра ![]() , оставляя те, которые не образуют циклов с
уже выбранными.
, оставляя те, которые не образуют циклов с
уже выбранными.
Во взвешенном графе ![]() часто интересно определить
остовное дерево (лес) с минимальным общим весом
ребер, то есть дерево (лес), у которого сумма весов всех его ребер
минимальна. Такое
дерево называется
минимумом оставных деревьев или минимальное
остовное дерево. Другими словами, на каждом шаге мы выбираем новое
ребро с наименьшим весом (наименьшее ребро), не образующее циклов с уже выбранными
ребрами; этот процесс продолжаем до тех пор, пока не будет
выбрано
часто интересно определить
остовное дерево (лес) с минимальным общим весом
ребер, то есть дерево (лес), у которого сумма весов всех его ребер
минимальна. Такое
дерево называется
минимумом оставных деревьев или минимальное
остовное дерево. Другими словами, на каждом шаге мы выбираем новое
ребро с наименьшим весом (наименьшее ребро), не образующее циклов с уже выбранными
ребрами; этот процесс продолжаем до тех пор, пока не будет
выбрано ![]() ребер, образующих остовное
дерево
ребер, образующих остовное
дерево ![]() . Этот процесс известен как жадный алгоритм.
. Этот процесс известен как жадный алгоритм.
Жадный алгоритм может быть выполнен в два этапа. Сначала ребра сортируются по весу и затем строится остовное дерево путем выбора наименьших из имеющихся в распоряжении ребер.
Существует другой метод получения минимума остовных деревьев, который не
требует ни сортировки ребер, ни проверки на цикличность на каждом шаге, - так
называемый алгоритм
ближайшего соседа. Мы начинаем с некоторой
произвольной вершины ![]() в заданном графе. Пусть
в заданном графе. Пусть ![]() -
ребро с наименьшим весом, инцидентное
-
ребро с наименьшим весом, инцидентное ![]() ;
ребро
;
ребро ![]() включается в дерево. Затем среди всех ребер,
инцидентных либо
включается в дерево. Затем среди всех ребер,
инцидентных либо ![]() , либо
, либо ![]() , выбираем ребро с
наименьшим весом и включаем его в частично построенное дерево.
В результате этого в дерево добавляется новая вершина,
например,
, выбираем ребро с
наименьшим весом и включаем его в частично построенное дерево.
В результате этого в дерево добавляется новая вершина,
например, ![]() . Повторяя процесс, ищем наименьшее ребро,
соединяющее
. Повторяя процесс, ищем наименьшее ребро,
соединяющее ![]() ,
, ![]() или
или ![]() с некоторой другой
вершиной графа. Процесс продолжается до тех пор, пока
все вершины из
с некоторой другой
вершиной графа. Процесс продолжается до тех пор, пока
все вершины из ![]() не будут включены в дерево, то есть пока дерево не
станет остовным.
не будут включены в дерево, то есть пока дерево не
станет остовным.
Наихудшим для этого алгоритма будет случай, когда ![]() - полный граф (то есть когда
каждая пара вершин в графе соединена ребром);
в этом случае для того, чтобы найти ближайшего соседа, на каждом шаге нужно
сделать максимальное число сравнений. Чтобы выбрать первое ребро, мы сравниваем
веса всех
- полный граф (то есть когда
каждая пара вершин в графе соединена ребром);
в этом случае для того, чтобы найти ближайшего соседа, на каждом шаге нужно
сделать максимальное число сравнений. Чтобы выбрать первое ребро, мы сравниваем
веса всех ![]() ребер, инцидентных
вершине
ребер, инцидентных
вершине ![]() , и выбираем наименьшее; этот шаг требует
, и выбираем наименьшее; этот шаг требует ![]() сравнений. Для выбора второго ребра мы ищем наименьшее среди
возможных
сравнений. Для выбора второго ребра мы ищем наименьшее среди
возможных ![]() ребер
(инцидентных
ребер
(инцидентных ![]() или
или ![]() ) и делаем для этого
) и делаем для этого ![]() сравнений. Таким образом, ясно, что для
выбора
сравнений. Таким образом, ясно, что для
выбора ![]() -го ребра требуется
-го ребра требуется ![]() сравнений, и поэтому в сумме потребуется
сравнений, и поэтому в сумме потребуется

Клики
Максимальный полный подграф графа ![]() называется кликой графа
называется кликой графа ![]() ;
другими словами, клика графа
;
другими словами, клика графа ![]() есть подмножество его вершин,
такое, что между каждой парой вершин этого подмножества существует ребро
и, кроме того, это подмножество не принадлежит никакому большому
подмножеству с тем же свойством. Например, на рис. 12.3 показан граф и
его клики.
есть подмножество его вершин,
такое, что между каждой парой вершин этого подмножества существует ребро
и, кроме того, это подмножество не принадлежит никакому большому
подмножеству с тем же свойством. Например, на рис. 12.3 показан граф и
его клики.
Рис. 12.2. Граф G и все его клики
Клики графа представляют "естественные" группировки вершин, и определение клик графа полезно в кластерном анализе в таких областях, как информационный поиск и социология.
Изоморфизм
Два графа ![]() называются изоморфными, если
существует взаимно однозначное соответствие
называются изоморфными, если
существует взаимно однозначное соответствие ![]() , такое,
что
, такое,
что ![]() тогда и только тогда, если
тогда и только тогда, если ![]() , то есть существует соответствие между вершинами
графа
, то есть существует соответствие между вершинами
графа ![]() и вершинами графа
и вершинами графа ![]() , сохраняющее отношение
смежности. Например, на рис. 12.3 показаны два
изоморфных орграфа: вершины
, сохраняющее отношение
смежности. Например, на рис. 12.3 показаны два
изоморфных орграфа: вершины ![]() в
орграфе
в
орграфе ![]() соответствуют вершинам 2, 3, 6, 1, 4, 5 в указанном
порядке в орграфе
соответствуют вершинам 2, 3, 6, 1, 4, 5 в указанном
порядке в орграфе ![]() . Вообще говоря,
между
. Вообще говоря,
между ![]() и
и ![]() может быть более чем одно соответствие,
и на рис. 12.3 графы имеют на самом деле
второй изоморфизм:
может быть более чем одно соответствие,
и на рис. 12.3 графы имеют на самом деле
второй изоморфизм: ![]() соответствуют в указанном порядке
вершинам 2, 3, 6, 1, 5, 4. Изоморфные графы
отличаются только метками вершин, в связи с чем задача определения изоморфизма
возникает в ряде практических ситуаций, таких, как информационный поиск и
определение химических соединений.
соответствуют в указанном порядке
вершинам 2, 3, 6, 1, 5, 4. Изоморфные графы
отличаются только метками вершин, в связи с чем задача определения изоморфизма
возникает в ряде практических ситуаций, таких, как информационный поиск и
определение химических соединений.
Заметим, что можно ограничится орграфами. Любой неориентированный граф превращается в орграф заменой каждого ребра двумя противоположно направленными ребрами. Два полученные таким образом орграфа, очевидно, изоморфны тогда и только тогда, если изоморфны исходные графы.
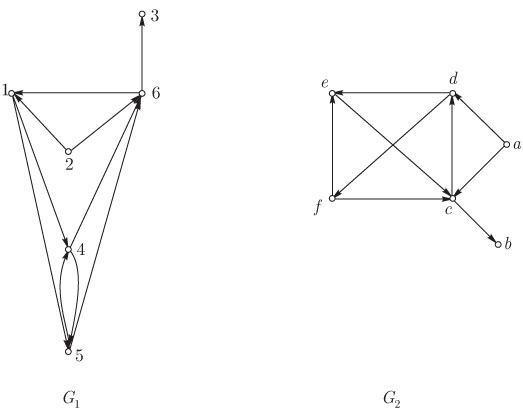
Рис. 12.3. Изоморфные орграфы
Планарность
Граф называют планарным, если существует такое изображение на плоскости его вершин и ребер, что:
- каждая вершина
 изображается отдельной
точкой
изображается отдельной
точкой  на плоскости;
на плоскости; - каждое ребро
 изображается простой кривой, имеющей
концевые точки
изображается простой кривой, имеющей
концевые точки  ;
; - эти кривые пересекаются только в общих концевых точках. Задача определения того, можно ли изобразить граф на плоскости без пересечения ребер, имеет большой практический интерес (например, при конструировании интегральных схем или печатных плат необходимо выяснить, можно ли окончательную схему вложить в плоскость).
Определение планарности графа отличается от других рассмотренных нами задач, поскольку при изображении точек и линий на плоскости приходится больше иметь дело с непрерывными, а не с дискретными величинами. Взаимосвязь между дискретными и непрерывными аспектами планарности заинтересовала математиков и привела к различным характеристикам планарных графов. С точки зрения математики эти характеристики изящны, но эффективных алгоритмов определения планарности они не дают. Наиболее успешный подход к определению планарности состоит просто в том, что граф разбивается на подграфы и затем делается попытка разместить его на плоскости, добавляя подграфы один за другим и сохраняя при размещении планарность.
Вначале сделаем несколько простых, но полезных наблюдений. Поскольку орграф планарен тогда и только тогда, если планарен соответствующий неориентированный граф, полученный игнорированием направления ребер, то достаточно рассматривать только неориентированные графы, поскольку неориентированный граф планарен тогда и только тогда, если все его двусвязные компоненты планарны. Поэтому если неориентированный граф является разделимым, мы можем разложить его на двусвязные компоненты и рассматривать их отдельно. Наконец, поскольку параллельные ребра и петли всегда можно добавить к графу или удалить из него без нарушения свойства планарности, нам достаточно рассматривать только простые графы. Поэтому при определении планарности будем предполагать, что граф неориентированный, простой и двусвязный.
Наша основная стратегия состоит прежде всего в том, чтобы в
графе ![]() найти цикл
найти цикл ![]() , разместить
, разместить ![]() на
плоскости в виде простой замкнутой кривой, разложить оставшуюся часть
на
плоскости в виде простой замкнутой кривой, разложить оставшуюся часть ![]() на непересекающиеся по ребрам пути и затем попытаться разместить
каждый из этих
путей либо целиком внутри
на непересекающиеся по ребрам пути и затем попытаться разместить
каждый из этих
путей либо целиком внутри ![]() , либо целиком вне
, либо целиком вне ![]() . Если
нам удалось разместить так весь граф
. Если
нам удалось разместить так весь граф ![]() , то он планарен, в
противном случае он непланарен. Трудность этого способа
заключается в том, что при размещении путей можно выбирать либо внутренность,
либо внешность
, то он планарен, в
противном случае он непланарен. Трудность этого способа
заключается в том, что при размещении путей можно выбирать либо внутренность,
либо внешность ![]() , и мы должны проконтролировать, чтобы неправильный
выбор области размещения на
ранней стадии не устранял возможности размещения последующих путей, - это
могло бы привести нас к неверному заключению, что планарный граф непланарен.
, и мы должны проконтролировать, чтобы неправильный
выбор области размещения на
ранней стадии не устранял возможности размещения последующих путей, - это
могло бы привести нас к неверному заключению, что планарный граф непланарен.
Лекция 13. Поиск
Введение
Задача поиска является фундаментальной в комбинаторных алгоритмах, так как
она формулируется в такой общности, что включает в себя множество задач,
представляющих практический интерес. При самой общей постановке
"Исследовать множество ![]() с тем чтобы найти элемент, удовлетворяющий некоторому
условию
с тем чтобы найти элемент, удовлетворяющий некоторому
условию ![]() ", о задаче поиска едва ли можно сказать что-либо
стоящее. Удивительно, однако, что
достаточно незначительных ограничений на структуру множества
", о задаче поиска едва ли можно сказать что-либо
стоящее. Удивительно, однако, что
достаточно незначительных ограничений на структуру множества ![]() ,
чтобы задача стала интересной: возникает множество разнообразных стратегий
поиска различной степени эффективности. Мы сделаем некоторые предположения о
структуре множества
,
чтобы задача стала интересной: возникает множество разнообразных стратегий
поиска различной степени эффективности. Мы сделаем некоторые предположения о
структуре множества ![]() , позволяющие исследовать
, позволяющие исследовать ![]()
![]() или
или ![]() . Большинство
алгоритмов поиска попадает в одну из трех категорий, характеризуемых
временем поиска
. Большинство
алгоритмов поиска попадает в одну из трех категорий, характеризуемых
временем поиска ![]() .
.
Поиск и другие операции над таблицами
Любой способ поиска оперирует с элементами, которые будем называть именами, взятыми из множества имен ![]() - оно называется пространством
имен. Это пространство имен может быть
конечным или бесконечным. Самыми распространенными пространствами имен
являются множества целых чисел с их числовым порядком (нумерацией), и множества
последовательностей символов над некоторым конечным алфавитом с их
лексикографическим (то есть словарным) порядком. Каждый из алгоритмов поиска,
обсуждаемых в этой лекции, основан на одном из трех следующих предположений о
пространстве
- оно называется пространством
имен. Это пространство имен может быть
конечным или бесконечным. Самыми распространенными пространствами имен
являются множества целых чисел с их числовым порядком (нумерацией), и множества
последовательностей символов над некоторым конечным алфавитом с их
лексикографическим (то есть словарным) порядком. Каждый из алгоритмов поиска,
обсуждаемых в этой лекции, основан на одном из трех следующих предположений о
пространстве ![]() .
.
Предположение 1. На ![]() определен линейный порядок, называемый естественным порядком и
обозначаемый знаком <. Такой порядок имеет следующие свойства.
определен линейный порядок, называемый естественным порядком и
обозначаемый знаком <. Такой порядок имеет следующие свойства.
- Любые два элемента
 сравнимы, то есть должно
выполняться в точности одно из трех условий:
сравнимы, то есть должно
выполняться в точности одно из трех условий:  ,
,  ,
,  .
. - Порядок обладает транзитивностью, то есть если и
 ,
то
,
то  для любых элементов
для любых элементов  . Мы
используем обозначения
. Мы
используем обозначения  ,
,  ,
,  в очевидном смысле. При
анализе эффективности алгоритма поиска полагаем, что исход (
в очевидном смысле. При
анализе эффективности алгоритма поиска полагаем, что исход (  ,
,  или ) зависит от
сравнения.
или ) зависит от
сравнения.
Предположение 2. Каждое
имя в ![]() есть последовательность символов или цифр над конечным
линейно упорядоченным алфавитом
есть последовательность символов или цифр над конечным
линейно упорядоченным алфавитом ![]() . Естественным порядком на
. Естественным порядком на ![]() является лексикографический порядок, индуцированный линейным
порядком на
является лексикографический порядок, индуцированный линейным
порядком на ![]() . Мы полагаем, что исход (
. Мы полагаем, что исход ( ![]() ,
, ![]() или
или ![]() ) сравнения
двух символов (не имен) получается
за время, не зависящее от
) сравнения
двух символов (не имен) получается
за время, не зависящее от ![]() или
или ![]() .
.
Предположение 3. Имеется
функция ![]() ,
которая равномерно отображает пространство имен
,
которая равномерно отображает пространство имен ![]() в
множество
в
множество ![]() , то есть все целые
, то есть все целые ![]() , приблизительно с одинаковой частотой являются образами имен из
, приблизительно с одинаковой частотой являются образами имен из ![]() при отображении
при отображении ![]() . Мы полагаем, что функция
. Мы полагаем, что функция ![]() не
зависела от
не
зависела от ![]() , это с теоретической точки зрения выглядит шатко, но с
практической - довольно реально.
, это с теоретической точки зрения выглядит шатко, но с
практической - довольно реально.
Как уже было отмечено, поиск производится не в самом пространстве ![]() имен, а в конечном подмножестве
имен, а в конечном подмножестве ![]() множества
множества ![]() , называемом таблицей. На большинстве таблиц, которые мы
рассматриваем,
определен линейный порядок, называемый табличным порядком: ему
соответствует нижний индекс имени (то есть
, называемом таблицей. На большинстве таблиц, которые мы
рассматриваем,
определен линейный порядок, называемый табличным порядком: ему
соответствует нижний индекс имени (то есть ![]() есть первое имя в
таблице,
есть первое имя в
таблице, ![]() - второе и тому подобное). Табличный порядок
часто совпадает с естественным порядком, определенным на пространстве имен, однако такое совпадение не
обязательно.
- второе и тому подобное). Табличный порядок
часто совпадает с естественным порядком, определенным на пространстве имен, однако такое совпадение не
обязательно.
Мощность таблицы ![]() обычно намного меньше, чем мощность
пространства имен
обычно намного меньше, чем мощность
пространства имен ![]() , даже если
, даже если ![]() конечно.
конечно.
Представление о таблице как об упорядоченном множестве имен существенно для многих целей. Но иногда бывает необходимо рассматривать таблицу как множество ячеек, каждая из которых может содержать одно имя. Например, если процесс включения нового имени рассматривать более подробно, то обнаружится, что сначала нужно расширить таблицу добавлением ячейки, для того чтобы заготовить место для новой записи: только потом туда заносится новое имя.
Мы будем предполагать, что имена появляются в таблице не больше одного
раза (исключение составляет переходный период, в течение которого заносится
новое имя; в таблице допускается два вхождения одного имени). В большинстве случаев
вследствие такого предположения таблица с ![]() именами имеет ровно
именами имеет ровно ![]() ячеек. Однако важный класс алгоритмов, основанных на вычислении
адреса, опирается на предположение о том, что таблица содержит больше ячеек, чем имен. Эти
алгоритмы должны четко принимать во внимание наличие пустых ячеек.
ячеек. Однако важный класс алгоритмов, основанных на вычислении
адреса, опирается на предположение о том, что таблица содержит больше ячеек, чем имен. Эти
алгоритмы должны четко принимать во внимание наличие пустых ячеек.
Существует ряд синонимов для объектов, именуемых здесь таблицей и именем. В обработке данных существуют файлы, элементами которых являются записи ; каждая запись есть последовательность полей, одно из которых (участвующее в поиске) называется ключом. Если сам файл проходится во время поиска, "файл" и "ключ" представляют собой то, что мы называем "таблицей" и "именем" соответственно. (Эта терминология несколько двусмысленна, поскольку понятие "ключ" можно отнести либо к самой ячейке, либо к содержимому ячейки.) Однако при поиске в большом файле часто не подразумевается просмотр самого файла; вместо этого поиск осуществляется на справочнике или указателе файла. При успешном поиске найденная в указателе отдельная запись указывает на соответствующую запись в файле. В таком типе организации файлов нашему понятию таблицы соответствует указатель или справочник.
Мы рассматриваем только четыре табличные операции: поиск, включение,
исключение и распечатка. Подробное определение того, что должны делать эти
операции над таблицей ![]() , зависит от
структуры данных, использованной для реализации таблицы.
, зависит от
структуры данных, использованной для реализации таблицы.
поиск ![]() : если
: если ![]() , то отметить его
указателем, то есть переменной
, то отметить его
указателем, то есть переменной ![]() присвоить такое значение, что
присвоить такое значение, что ![]() ; в противном случае указать, что
; в противном случае указать, что ![]() ;
;
включение ![]() : если
: если ![]() , то поместить его
на соответствующее место.
, то поместить его
на соответствующее место.
Включение в общем случае предполагает прежде всего поиск соответствующего
места, поэтому иногда удобно разделить операцию на две фазы. Сначала используем
процедуру поиска для отыскания места, куда должно быть помещено ![]() , и затем помещаем z на это место.
, и затем помещаем z на это место.
включить ![]() на
на ![]() -е место: включить
-е место: включить ![]() сразу после имени
сразу после имени ![]() . До включения
. До включения ![]() .
.
исключить ![]() : если
: если ![]() , то исключить его.
, то исключить его.
Как и включение, исключение иногда реализуется процедурой поиска для
получения
места ![]() и последующей процедурой:
и последующей процедурой:
исключить с ![]() -го места: исключить
-го места: исключить ![]() из
из ![]() .До исключения
.До исключения ![]() \\ & После исключения
\\ & После исключения ![]()
Таблица, в которой осуществляются включения или исключения, называется динамической ; в противном случае она носит название статической.
Последней операцией, которую мы будем рассматривать для каждой табличной структуры, является
распечатка: & напечатать все имена из ![]() в их естественном
порядке
в их естественном
порядке
Среди всех операций, которые можно производить над таблицами, четыре, рассматриваемые в этой лекции (поиск, включение, исключение и распечатка), и сортировка (лекции 14, 15) - наиболее важные.
Последовательный поиск
Под последовательным поиском мы подразумеваем исследование имен в том
порядке, в котором они встречаются в таблице. При таком поиске в таблице в
худшем случае получается просмотр всей таблицы; даже в среднем последовательный поиск
имеет тенденцию к использованию числа операций, пропорционального ![]() . Для больших таблиц его не следует относить к методам быстрого
поиска, поскольку последовательный поиск асимптотически гораздо медленнее других алгоритмов,
описанных в этой лекции. Несмотря на его низкие асимптотические возможности,
имеется ряд причин, по которым этот метод следует обсудить вначале. Во-первых,
хотя идея его проста, он позволяет нам ввести важные понятия и методы, применимые к
поиску вообще. Во-вторых, последовательный поиск является единственным методом
поиска, применимым к отдельным устройствам памяти и к тем таблицам, которые
строятся на пространстве имен без линейного порядка. Наконец, последовательный
поиск является быстрым для достаточно малых таблиц и для больших таблиц,
организованных иерархическим способом: более быстрый метод используется для
исследования окрестности верхушки иерархии, а последовательный поиск – для
подтаблицы на нижнем уровне иерархии.
. Для больших таблиц его не следует относить к методам быстрого
поиска, поскольку последовательный поиск асимптотически гораздо медленнее других алгоритмов,
описанных в этой лекции. Несмотря на его низкие асимптотические возможности,
имеется ряд причин, по которым этот метод следует обсудить вначале. Во-первых,
хотя идея его проста, он позволяет нам ввести важные понятия и методы, применимые к
поиску вообще. Во-вторых, последовательный поиск является единственным методом
поиска, применимым к отдельным устройствам памяти и к тем таблицам, которые
строятся на пространстве имен без линейного порядка. Наконец, последовательный
поиск является быстрым для достаточно малых таблиц и для больших таблиц,
организованных иерархическим способом: более быстрый метод используется для
исследования окрестности верхушки иерархии, а последовательный поиск – для
подтаблицы на нижнем уровне иерархии.
Для последовательного поиска по таблице ![]() мы предполагаем, что имеется указатель
мы предполагаем, что имеется указатель ![]() , значение
которого принадлежит отрезку
, значение
которого принадлежит отрезку ![]() или, возможно,
или, возможно, ![]() . Над этим указателем разрешается производить
только следующие операции; первоначальное присваивание ему значения 1 или
. Над этим указателем разрешается производить
только следующие операции; первоначальное присваивание ему значения 1 или ![]() (или, если удобнее, 0 или
(или, если удобнее, 0 или ![]() , увеличение и /или
уменьшение его на единицу и сравнение его с 0, 1,
, увеличение и /или
уменьшение его на единицу и сравнение его с 0, 1, ![]() или
или ![]() . При
таких соглашениях наиболее очевидный алгоритм поиска в таблице
. При
таких соглашениях наиболее очевидный алгоритм поиска в таблице ![]() первого вхождения
данного имени
первого вхождения
данного имени ![]() имеет вид алгоритма 13.1. Здесь, как и во всех других
алгоритмах поиска, изложенных в настоящей лекции, мы полагаем, что алгоритм
останавливается немедленно по отыскании
имеет вид алгоритма 13.1. Здесь, как и во всех других
алгоритмах поиска, изложенных в настоящей лекции, мы полагаем, что алгоритм
останавливается немедленно по отыскании ![]() или установлении, что
или установлении, что ![]() в таблице нет.
в таблице нет.
Алгоритм 13.1. Последовательный поиск
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() найдено:
найдено: ![]() указывает на
указывает на ![]()
![]() не найдено:
не найдено: ![]() не входит в
не входит в ![]()
Рассмотрим некоторые аспекты эффективности последовательного поиска, начиная со стандартных методов программирования. В программе, построенной в виде одного цикла, как алгоритм 13.1, любое значительное ускорение должно быть следствием улучшения кода в цикле. Для того чтобы увидеть, какие операции выполняются внутри цикла, необходимо переписать алгоритм 13.1 в форме, близкой к языку машины:
i<-1
цикл: if z = xi then найдено
if i = n then не найдено
i<-i + 1
goto циклЗа каждую итерацию выполняется до четырех команд: два сравнения, одна операция увеличения и одна передача управления.
Для ускорения внутреннего цикла общим приемом является добавление в
таблицу специальных строк, которые делают необязательной явную проверку
того, достиг ли указатель границ таблицы. Это можно сделать в алгоритме
13.1. Если перед поиском мы добавим искомое имя ![]() в конце
таблицы, то цикл всегда будет завершаться отысканием вхождения
в конце
таблицы, то цикл всегда будет завершаться отысканием вхождения ![]() ; таким
образом, нам не нужно в цикле каждый раз делать проверку
; таким
образом, нам не нужно в цикле каждый раз делать проверку ![]() . В конце цикла
проверка условия
. В конце цикла
проверка условия ![]() , выполняемая лишь однажды, говорит о
том, является ли найденное вхождение
, выполняемая лишь однажды, говорит о
том, является ли найденное вхождение ![]() истинным или специальным
элементом таблицы. Это демонстрируется в алгоритме 13.2.
истинным или специальным
элементом таблицы. Это демонстрируется в алгоритме 13.2.
i<-1
while z !=xi do i <-i+1
if i<=n then{найдено: i указывает на z}
else{не найдено}Алгоритм 13.2. Улучшенный последовательный поиск
Улучшение алгоритма 13.1 будет наиболее очевидным, если мы перепишем алгоритм 13.2 в тех же близких к языку машины обозначениях, которые использовались раньше:
i<-1
цикл: if z = xi then goto возможно
i<-i+1
goto цикл
возможно: if i<=n then {найдено:i указывает на z}
else{не найдено}При каждой итерации выполняются лишь три действия вместо четырех, как это было в алгоритме 13.1. Таким образом, в большинстве вычислительных устройств цикл в алгоритме 13.2 будет выполняться гораздо быстрее, чем в алгоритме 13.1, и поскольку скорость цикла определяет скорость всей программы, такое же сравнение имеет место для двух программ.
Печально то, что фокус с добавлением ![]() в конец таблицы
перед поиском удается, только если мы имеем прямой
непосредственный доступ к концу таблицы. Это возможно, если таблица хранится в
памяти с произвольным доступом, но невозможно в общем случае, когда
используется
связанное размещение или память с последовательным доступом.
в конец таблицы
перед поиском удается, только если мы имеем прямой
непосредственный доступ к концу таблицы. Это возможно, если таблица хранится в
памяти с произвольным доступом, но невозможно в общем случае, когда
используется
связанное размещение или память с последовательным доступом.
Единственным недостатком алгоритма 13.2 является то, что при безуспешном
поиске (поиске имен, которых нет в таблице) всегда просматривается вся
таблица. Если
такой поиск возникает часто, то имена надо хранить в естественном порядке; это
позволяет завершать поиск, как только при просмотре попалось первое имя,
большее
или равное аргументу поиска. В этом случае в конец таблицы следует добавить
фиктивное имя ![]() для того, чтобы гарантировать выполнение
условия завершения (
для того, чтобы гарантировать выполнение
условия завершения ( ![]() - это новое имя, которое по
предположению больше любого имени из пространства
имен
- это новое имя, которое по
предположению больше любого имени из пространства
имен ![]() ). Таким образом получаем алгоритм 13.3.
). Таким образом получаем алгоритм 13.3.
i<-1
while z > xi do i <- i+1
if z=xi then{найдено:i указывает на z}
else{не найдено}Алгоритм 13.3.Последовательный поиск по таблице, хранимой в естественном порядке
Логарифмический поиск в статических таблицах
Мы говорим о логарифмическом времени поиска, как только возникает
возможность за время ![]() , не зависящее от
, не зависящее от ![]() ,
последовательно свести задачу поиска в таблице, содержащей
,
последовательно свести задачу поиска в таблице, содержащей ![]() имен, к задаче поиска в таблице, содержащей не более
имен, к задаче поиска в таблице, содержащей не более ![]() имен, где
имен, где ![]() - константа. В этом случае время
- константа. В этом случае время ![]() , требующееся для поиска в таблице с
, требующееся для поиска в таблице с ![]() именами,
удовлетворяет рекуррентному соотношению
именами,
удовлетворяет рекуррентному соотношению
Самыми распространенными предположениями, которые дают возможность
уменьшить размер таблицы от ![]() до
до ![]() за время, не зависящее от
за время, не зависящее от ![]() , являются предположения о том, что
пространство имен
, являются предположения о том, что
пространство имен ![]() линейно упорядочено и что сравнение двух имен
линейно упорядочено и что сравнение двух имен ![]() из
из ![]() (для определения
(для определения ![]() есть элементарная операция, требующая постоянного количества
времени, не
зависящего от
есть элементарная операция, требующая постоянного количества
времени, не
зависящего от ![]() . В результате время, необходимое для большинства
логарифмических алгоритмов
поиска,естественно измеряется числом сравнений (с тремя исходами) пар имен. Для
некоторых алгоритмов, однако, более естественны сравнения с большим, но
фиксированным числом исходов.
. В результате время, необходимое для большинства
логарифмических алгоритмов
поиска,естественно измеряется числом сравнений (с тремя исходами) пар имен. Для
некоторых алгоритмов, однако, более естественны сравнения с большим, но
фиксированным числом исходов.
В этом разделе мы рассматриваем только статические таблицы, то есть таблицы, в которых включение и исключение либо не встречаются, либо так редки, что когда они появляются, строится новая таблица. Динамические структуры таблиц, допускающие логарифмическое время поиска, так же как и эффективные алгоритмы включения и исключения, обсуждаются в конце этой лекции. Для статических таблиц нужно обсудить лишь алгоритмы поиска и построения таблицы. Алгоритмы поиска достаточно просты, но некоторые из алгоритмов построения таблицы сложны. Такая ситуация возникает потому, что в случае статической таблицы разумно считать частоты обращения известными, и, может быть, стоит затратить существенные усилия на построение оптимальной таблицы – таблицы с минимальным средним временем поиска (относительно данных частот обращения). Алгоритмы построения таблиц и их анализ являются наиболее важными темами этого раздела.
Бинарный поиск
Когда ячейки таблицы последовательно распределены в памяти с произвольным
доступом и имена хранятся в таблице в их естественном порядке, возможен бинарный поиск - один
из наиболее широко используемых методов поиска. Идея
этого метода состоит в том, чтобы искать имя ![]() в интервале,
крайними точками которого являются два заданных указателя
в интервале,
крайними точками которого являются два заданных указателя ![]() (для
"низа") и
(для
"низа") и ![]() (для "верха"). Новый указатель
(для "верха"). Новый указатель ![]() (для "средней точки") устанавливается где-то около
середины интервала, и либо
(для "средней точки") устанавливается где-то около
середины интервала, и либо ![]() с именем в этой ячейке сводит
интервал поиска к одному из интервалов
с именем в этой ячейке сводит
интервал поиска к одному из интервалов ![]() или
или ![]() . Если интервал становится пустым, поиск завершается безуспешно.
. Если интервал становится пустым, поиск завершается безуспешно.
Для получения логарифмического времени поиска существенно устанавливать
указатель ![]() за время, не зависящее от длины интервала; это
требование делает непригодным
бинарный поиск на большинстве вспомогательных запоминающих устройств.
Требование, чтобы
за время, не зависящее от длины интервала; это
требование делает непригодным
бинарный поиск на большинстве вспомогательных запоминающих устройств.
Требование, чтобы ![]() помещалось точно в середине интервала,
несущественно, хотя выбор средней точки в
качестве
помещалось точно в середине интервала,
несущественно, хотя выбор средней точки в
качестве ![]() обычно дает самый эффективный алгоритм. В некоторых
частных случаях полезно
разбить интервал на подинтервалы длины
обычно дает самый эффективный алгоритм. В некоторых
частных случаях полезно
разбить интервал на подинтервалы длины ![]() и
и ![]() для фиксированного значения
для фиксированного значения ![]() , отличного от
, отличного от ![]() . Когда таблица размещена не последовательно, а хранится в виде
списка древовидной
структуры, доля
. Когда таблица размещена не последовательно, а хранится в виде
списка древовидной
структуры, доля ![]() должна, вероятно, меняться от интервала к
интервалу.
должна, вероятно, меняться от интервала к
интервалу.
Бинарный поиск по идее прост, но с деталями условия завершения поиска
нужно обращаться осторожно. Частные случаи ![]() и
и ![]() требуют пристального внимания в любой программе бинарного поиска.
В алгоритме 13.4 эти случаи обрабатываются тем же кодом, что и в общем случае, и
поучительно посмотреть, как это делается, проследив за выполнением алгоритма для
требуют пристального внимания в любой программе бинарного поиска.
В алгоритме 13.4 эти случаи обрабатываются тем же кодом, что и в общем случае, и
поучительно посмотреть, как это делается, проследив за выполнением алгоритма для ![]() и
и ![]() .
.

Корректность алгоритма 13.4 следует из утверждения, данного в
комментарии в начале тела цикла. Он устанавливает, что если ![]() находится где-либо в таблице, то оно должно находиться в интервале
находится где-либо в таблице, то оно должно находиться в интервале ![]() ;
иначе говоря, при нашем предположении, что имя появляется в таблице не больше
одного раза, утверждается, что
;
иначе говоря, при нашем предположении, что имя появляется в таблице не больше
одного раза, утверждается, что ![]() не встречается ни в интервале
не встречается ни в интервале ![]() , ни в интервале
, ни в интервале ![]() . Это утверждение очевидно
первый раз, когда мы входим в цикл при
. Это утверждение очевидно
первый раз, когда мы входим в цикл при ![]() и
и ![]() , и
непосредственно по индукции проверяется, что оно выполняется при каждом проходе через цикл.
Когда мы выходим из цикла, то должно быть
, и
непосредственно по индукции проверяется, что оно выполняется при каждом проходе через цикл.
Когда мы выходим из цикла, то должно быть ![]() , и поэтому
утверждение принимает вид
, и поэтому
утверждение принимает вид ![]() и
и ![]() , откуда следует, что
, откуда следует, что ![]() .
.
Оптимальные деревья бинарного поиска
Бинарный поиск в последовательно распределенной таблице ( алгоритм 13.4.)
обеспечивает очень быстрое нахождение имен, которые являются средними точками
на раннем этапе процесса деления пополам, именно имен, близких к вершине дерева ![]() . Таким образом, любое имя в таблице можно выбрать примерно
за
. Таким образом, любое имя в таблице можно выбрать примерно
за ![]() сравнений.
сравнений.
Рис. 13.1. Четыре дерева бинарного поиска над множеством имен {A,B,C,D}
На практике в большинстве таблиц встречаются имена, к которым обращаются гораздо чаще, чем к другим, и "привилегированные" места в таблице разумно постараться использовать для наиболее часто вызываемых имен, а не для имен, выбранных для этих мест в результате бинарного поиска. Это невозможно осуществить для последовательно распределенных таблиц, поскольку место имени определяется его положением относительно естественного порядка имен в таблице. Введем структуру данных, легко приспосабливаемую как к месту бинарного поиска, так и к возможности выделять точки, в которых таблица делится на две части.
Деревом
бинарного поиска над именами ![]() называется расширенное бинарное дерево, все внутренние узлы которого помечены
различными именами из списка
называется расширенное бинарное дерево, все внутренние узлы которого помечены
различными именами из списка ![]() таким образом,
что симметричный порядок узлов совпадает с естественным порядком.
Каждый из
таким образом,
что симметричный порядок узлов совпадает с естественным порядком.
Каждый из ![]() внешних узлов соответствует промежутку в
таблице. На рис. 13.1 показаны четыре
различных дерева бинарного поиска на множестве имен
внешних узлов соответствует промежутку в
таблице. На рис. 13.1 показаны четыре
различных дерева бинарного поиска на множестве имен ![]() .
Деревья (а) и (b) - вырожденные, поскольку они по существу являются линейными
списками, которые должны просматриваться последовательно.
.
Деревья (а) и (b) - вырожденные, поскольку они по существу являются линейными
списками, которые должны просматриваться последовательно.
Поиск имени ![]() в дереве бинарного поиска осуществляется путем
сравнения
в дереве бинарного поиска осуществляется путем
сравнения ![]() с именем, стоящим в корне. Тогда
с именем, стоящим в корне. Тогда
- Если корня нет (дерево пусто), то
 в таблице отсутствует и
поиск завершается безуспешно.
в таблице отсутствует и
поиск завершается безуспешно. - Если совпадает с именем в корне, поиск завершается
успешно.
- Если предшествует имени в корне, поиск продолжается ниже в
левом поддереве корня.
- Если следует за именем в корне, поиск продолжается ниже в
правом поддереве корня.
Пусть бинарное дерево имеет вид, в котором каждый узел представляет собой
тройку (LEFT, NAME, RIGHT), где LEFT и RIGHTсодержат указатели левого и правого
сыновей соответственно, и NAME содержит имя, хранящееся в узле. Указатели могут
иметь значение ![]() , означающее, что поддерево, на которое они
указывают пусто. Если указатель корня
дерева есть
, означающее, что поддерево, на которое они
указывают пусто. Если указатель корня
дерева есть ![]() , то само дерево пусто. Как и следовало
ожидать, успешный поиск завершается во
внутреннем узле дерева бинарного поиска и безуспешный поиск завершается во
внешнем узле.
, то само дерево пусто. Как и следовало
ожидать, успешный поиск завершается во
внутреннем узле дерева бинарного поиска и безуспешный поиск завершается во
внешнем узле.
Эта процедура нахождения имени ![]() в таблице, организованная в
виде дерева бинарного поиска
в таблице, организованная в
виде дерева бинарного поиска ![]() , показана в алгоритме 13.5.
Отметим его сходство с алгоритмом 13.4 (бинарный поиск).
, показана в алгоритме 13.5.
Отметим его сходство с алгоритмом 13.4 (бинарный поиск).
Алгоритм 13.5. Поиск в дереве бинарного поиска
Логарифмический поиск в динамических таблицах
Здесь мы рассмотрим организацию в виде деревьев для таблиц, в которых часто
встречаются включения и исключения. Что происходит с временем поиска в дереве,
которое модифицировалось путем включения и исключения? Если включенные и
исключенные имена выбраны случайно, то оказывается, что в среднем время поиска
мало изменяется; но в худшем случае поведение плохое - деревья могут
вырождаться
в линейные списки, поиск в которых нужно осуществлять последовательно.
Проблема
вырождения дерева в линейный список, приводящая к времени поиска ![]() вместо
вместо ![]() в практических применениях
выражена более резко, чем это указывается
теоретическим анализом. Такой анализ обычно предполагает, что включения и
исключения появляются случайным образом, но на практике часто это не так.
в практических применениях
выражена более резко, чем это указывается
теоретическим анализом. Такой анализ обычно предполагает, что включения и
исключения появляются случайным образом, но на практике часто это не так.
Случайные деревья бинарного поиска. Как ведут себя деревья бинарного поиска без ограничений в качестве динамических деревьев? Другими словами, предположим, что дерево бинарного поиска меняется при случайных включениях и исключениях.
Для включения ![]() мы используем незначительную модификацию
алгоритма 13.5. Если
мы используем незначительную модификацию
алгоритма 13.5. Если ![]() не было найдено, мы получаем
для
не было найдено, мы получаем
для ![]() новую ячейку и связываем ее с последним узлом, пройденным во
время безуспешного поиска
новую ячейку и связываем ее с последним узлом, пройденным во
время безуспешного поиска ![]() . Соответствующее предложение нельзя однако просто
добавить в конце алгоритма 13.5, поскольку при нормальном окончании
цикла
. Соответствующее предложение нельзя однако просто
добавить в конце алгоритма 13.5, поскольку при нормальном окончании
цикла ![]() указатель
указатель ![]() не указывает больше на последний
пройденный узел, а вместо этого имеет значение
не указывает больше на последний
пройденный узел, а вместо этого имеет значение ![]() . В связи с
этим мы должны производить включение до того, как выполняется
предположение
. В связи с
этим мы должны производить включение до того, как выполняется
предположение ![]() или
или ![]() ; мы можем осуществить это, сделав процедуру включения
рекурсивной. Процедура
; мы можем осуществить это, сделав процедуру включения
рекурсивной. Процедура ![]() выдает в качестве значения
указатель на дерево, в которое добавлено
выдает в качестве значения
указатель на дерево, в которое добавлено ![]() . Таким образом,
. Таким образом, ![]() используется для
включения
используется для
включения ![]() в
в ![]() .
.

Алгоритм 13.6. Включение в дерево бинарного поиска
Исключение гораздо сложнее включения, и мы изложим здесь только основную
идею. Если подлежащее удалению имя ![]() имеет самое большее одного сына,
то при исключении
имеет самое большее одного сына,
то при исключении ![]() его сын (если он вообще есть) объявляется
сыном отца
его сын (если он вообще есть) объявляется
сыном отца ![]() . Если
. Если ![]() имеет двух сыновей, его прямо
удалить нельзя. Вместо этого мы находим в таблице
либо имя
имеет двух сыновей, его прямо
удалить нельзя. Вместо этого мы находим в таблице
либо имя ![]() , которое непосредственно предшествует
, которое непосредственно предшествует ![]() , либо имя
, либо имя ![]() , которое непосредственно следует за
, которое непосредственно следует за ![]() в естественном порядке. Оба имени принадлежат узлам, которые
имеют не больше
одного сына, и, таким образом,
в естественном порядке. Оба имени принадлежат узлам, которые
имеют не больше
одного сына, и, таким образом, ![]() можно исключить заменой его либо
именем
можно исключить заменой его либо
именем ![]() , либо
, либо ![]() , и затем исключением узла,
который содержал
, и затем исключением узла,
который содержал ![]() или
или ![]() , соответственно.
, соответственно.
Сбалансированные сильно ветвящиеся деревья
Деревья бинарного поиска естественным образом обобщаются до ![]() -арных
деревьев поиска, в которых каждый узел имеет
-арных
деревьев поиска, в которых каждый узел имеет ![]() сыновей и
содержит
сыновей и
содержит ![]() имен. Имена в узле делят множество
имен на
имен. Имена в узле делят множество
имен на ![]() подмножеств, каждое подмножество соответствует одному из
подмножеств, каждое подмножество соответствует одному из ![]() поддеревьев узла. На рис. 13.2 показано полностью заполненное 5-арное
дерево с двумя уровнями. Заметим, что мы не можем требовать, чтобы каждый
узел
поддеревьев узла. На рис. 13.2 показано полностью заполненное 5-арное
дерево с двумя уровнями. Заметим, что мы не можем требовать, чтобы каждый
узел ![]() -арного дерева имел ровно
-арного дерева имел ровно ![]() сыновей и включал
равно
сыновей и включал
равно ![]() имен; если мы захотим включить
имен; если мы захотим включить ![]() в дерево на рисунке
13.2, то должны
будем создать узлы с меньше чем
в дерево на рисунке
13.2, то должны
будем создать узлы с меньше чем ![]() сыновьями и меньше чем
сыновьями и меньше чем ![]() именами. Таким образом, определение
именами. Таким образом, определение ![]() -арного дерева
утверждает
только, что каждый узел имеет не более
-арного дерева
утверждает
только, что каждый узел имеет не более ![]() сыновей и содержит не
более
сыновей и содержит не
более ![]() имен. Ясно, что на
имен. Ясно, что на ![]() -арных деревьях можно осуществлять
поиск так же,
как и на бинарных деревьях.
-арных деревьях можно осуществлять
поиск так же,
как и на бинарных деревьях.
Как и в деревьях бинарного поиска, полезно различать внутренние узлы и
листья. Внутренний узел содержит ![]() имен, записанных в
естественном порядке, и имеет
имен, записанных в
естественном порядке, и имеет ![]() сыновей, каждый из которых
может быть либо внутренним узлом, либо листом. Лист
не содержит имен (разве что временно в процессе включения), и, как раньше, в
листьях
- завершаются безуспешные поиски. Обычно за очевидностью мы на рисунке их
опускаем.
сыновей, каждый из которых
может быть либо внутренним узлом, либо листом. Лист
не содержит имен (разве что временно в процессе включения), и, как раньше, в
листьях
- завершаются безуспешные поиски. Обычно за очевидностью мы на рисунке их
опускаем.
Рис. 13.2. Абсолютно сбалансированное, полностью заполненное 5-арное дерево поиска
Сбалансированное сильно ветвящееся дерево порядка ![]() есть
есть ![]() -арное дерево в котором:
-арное дерево в котором:
- Все листья расположены на одном уровне.
- Корень имеет
 сыновей,
сыновей,  .
. - Другие внутренние узлы имеют
 сыновей,
сыновей,  .
.
Лекция 14. Сортировка (часть 1)
Введение
Рассматриваемые здесь задачи можно отнести к наиболее часто встречающимся классам комбинаторных задач. Почти во всех машинных приложениях множество объектов должно быть переразмещено в соответствии с некоторым заранее определенным порядком. Например, при обработке коммерческих данных часто бывает необходимо расположить их по алфавиту или по возрастанию номеров. В числовых расчетах иногда требуется знать наибольший корень многочлена, и т.д.
Будем считать заданной таблицу с ![]() именами, обозначаемыми
именами, обозначаемыми ![]() ,
, ![]() . Каждое имя
. Каждое имя ![]() принимает
значение из пространства имен, на котором определен линейный порядок.
Будем считать, что никакие два имени не имеют одинаковых значений; то есть
любые
принимает
значение из пространства имен, на котором определен линейный порядок.
Будем считать, что никакие два имени не имеют одинаковых значений; то есть
любые ![]() обладают тем свойством, что если
обладают тем свойством, что если ![]() ,
то либо
,
то либо ![]() , либо
, либо ![]() .
Ограничение
.
Ограничение ![]() при
при ![]() упрощает
анализ без потери общности, ибо и при наличии равных имен корректность
идей и алгоритмов не нарушается. Наша цель состоит в том, чтобы выяснить что-
нибудь относительно перестановки
упрощает
анализ без потери общности, ибо и при наличии равных имен корректность
идей и алгоритмов не нарушается. Наша цель состоит в том, чтобы выяснить что-
нибудь относительно перестановки ![]() для которой
для которой ![]() . В задаче полной
сортировки требуется полностью определить
. В задаче полной
сортировки требуется полностью определить ![]() , хотя
обычно это делается неявно путем переразмещения имени в порядке возрастания. В
задачах частичной
сортировки требуется либо извлечь частичную
информацию о
, хотя
обычно это делается неявно путем переразмещения имени в порядке возрастания. В
задачах частичной
сортировки требуется либо извлечь частичную
информацию о ![]() (например,
(например, ![]() для нескольких
значений
для нескольких
значений ![]() ), либо полностью определить
), либо полностью определить ![]() по
некоторой заданной частичной информации о
ней (так обстоит дело при слиянии двух упорядоченных таблиц).
по
некоторой заданной частичной информации о
ней (так обстоит дело при слиянии двух упорядоченных таблиц).
При внутренней
сортировке решается задача полной сортировки для
случая достаточно малой таблицы, умещающейся непосредственно в адресной памяти. Внешняя
сортировка представляет собой задачу полной сортировки для случая
такой большой таблицы, что доступ к ней организован по частям, расположенным на
внешних запоминающих устройствах. Частичная сортировка - задачи выбора ![]() -
наибольшего имени и слияния двух упорядоченных таблиц.
-
наибольшего имени и слияния двух упорядоченных таблиц.
Внутренняя сортировка
Существует по крайней мере пять широких классов алгоритмов внутренней сортировки.
- Вставка. На
 -м этапе -е имя помещается на
надлежащее место между
-м этапе -е имя помещается на
надлежащее место между  уже отсортированным именами:
уже отсортированным именами:

- Обмен. Два имени, расположение которых не соответствует порядку, меняются местами (обмен). Эти процедуры повторяются до тех пор, пока остаются такие пары.

- Выбор. На -м этапе из неотсортированных имен выбирается -е наибольшее (наименьшее) имя и помещается на соответствующее
место.

- Распределение. Имена распределяются по группам, и содержимое групп затем объединяется таким образом, чтобы частично отсортировать таблицу; процесс повторяется до тех пор, пока таблица не будет отсортирована полностью.
- Слияние. Таблица делится на подтаблицы, которые сортируются по отдельности и затем сливаются в одну.

Эти классы нельзя назвать ни взаимоисключающими, ни исчерпывающими: одни алгоритмы сортировки можно с полным основанием отнести более чем к одному классу (пузырьковую сортировку можно рассматривать и как выбор, и как обмен), а другие не укладываются ни в один из классов. Тем не менее, перечисленные пять классов достаточно удобны для классификации обсуждаемых алгоритмов сортировки.
Сосредоточим внимание на первых четырех классах алгоритмов сортировки. Алгоритмы, основанные на слиянии, приемлемы для внутренней сортировки, но более естественно рассматривать их как методы внешней сортировки.
В описываемых алгоритмах сортировки имена образуют последовательность,
которую будем обозначать ![]() независимо от
возможных пересылок данных; таким образом, значением
независимо от
возможных пересылок данных; таким образом, значением ![]() является
любое текущее имя в
является
любое текущее имя в ![]() -й позиции последовательности. Многие
алгоритмы сортировки наиболее применимы к
массивам; в этом случае
-й позиции последовательности. Многие
алгоритмы сортировки наиболее применимы к
массивам; в этом случае ![]() обозначает
обозначает ![]() -й элемент
массива. Другие алгоритмы более приспособлены для работы со
связанными списками: здесь
-й элемент
массива. Другие алгоритмы более приспособлены для работы со
связанными списками: здесь ![]() обозначает
обозначает ![]() -й
элемент списка. Следующие обозначения используются для пересылок данных:
-й
элемент списка. Следующие обозначения используются для пересылок данных:
![]() значения
значения ![]() и
и ![]() меняются местами.
меняются местами. ![]() значение
значение ![]() присваивается имени
присваивается имени ![]() .
. ![]() значение имени
значение имени ![]() присваивается
присваивается ![]() .
.
Таким образом, операция ![]() , которая
встречается в различных алгоритмах сортировки, временно нарушает
предположение о том, что никакие два имени не имеют одинаковых значений. Однако
это условие всегда обязательно восстанавливается.
, которая
встречается в различных алгоритмах сортировки, временно нарушает
предположение о том, что никакие два имени не имеют одинаковых значений. Однако
это условие всегда обязательно восстанавливается.
В каждом из рассматриваемых алгоритмов будем считать, что имена нужно
сортировать на месте. Другими словами, переразмещение имен должно происходить
внутри последовательности ![]() ; при этом существуют
одна или две дополнительные ячейки, в которых временно
размещается значение имени. Ограничение "на месте" основано на
предположении,
будто число имен настолько велико, что во время сортировки не допускается
перенос
их в другую область памяти. Если в распоряжении имеется память, достаточная для
такого переноса, то некоторые из обсуждаемых алгоритмов можно значительно
ускорить. Эти рассмотрения заставляют нас в алгоритмах распределяющей
сортировки
и сортировки слиянием реализовать последовательность
; при этом существуют
одна или две дополнительные ячейки, в которых временно
размещается значение имени. Ограничение "на месте" основано на
предположении,
будто число имен настолько велико, что во время сортировки не допускается
перенос
их в другую область памяти. Если в распоряжении имеется память, достаточная для
такого переноса, то некоторые из обсуждаемых алгоритмов можно значительно
ускорить. Эти рассмотрения заставляют нас в алгоритмах распределяющей
сортировки
и сортировки слиянием реализовать последовательность ![]() как связанный список.
как связанный список.
Вставка
Вставка - простейшая
сортировка вставками проходит через этапы ![]() : на этапе
: на этапе ![]() имя
имя ![]() вставляется на свое правильное
место среди
вставляется на свое правильное
место среди ![]() .
.
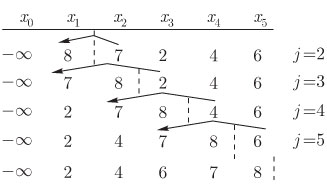
Рис. 14.1. Простая сортировка вставками, используемая на таблице из n = 5 имен. Пунктирные вертикальные линии разделяют уже отсортированную часть таблицы и еще не отсортированную
При вставке имя ![]() временно размещается в
временно размещается в ![]() , и
просматриваются имена
, и
просматриваются имена ![]() ; они
сравниваются с
; они
сравниваются с ![]() и сдвигаются вправо, если обнаруживается, что
они больше
и сдвигаются вправо, если обнаруживается, что
они больше ![]() . Имеется фиктивное имя
. Имеется фиктивное имя ![]() , значение
которого
, значение
которого ![]() служит для остановки просмотра слева. На рис.
14.1 работа этого алгоритма
проиллюстрирована на примере таблицы из пяти имен.
служит для остановки просмотра слева. На рис.
14.1 работа этого алгоритма
проиллюстрирована на примере таблицы из пяти имен.
Алгоритм 14.1. Простая сортировка вставками
Эффективность этого алгоритма, как и большинства алгоритмов сортировки,
зависит
от числа сравнений имен и числа пересылок данных, осуществляемых в трех
случаях :
худшем, среднем (в предположении, что все ![]() ! перестановок
равновероятны) и лучшем.
! перестановок
равновероятны) и лучшем.
Обменная сортировка
Обменная сортировка некоторым систематическим образом меняет местами
пары имен, не отвечающие порядку, до тех пор, пока такие пары существуют.
Фактически алгоритм 14.1 можно рассматривать как обменную сортировку, в которой
имя ![]() меняется местами со своим соседом слева, пока не
оказывается на правильном месте. В
этом разделе мы обсуждаем два типа обменных сортировок: хорошо известную, но
относительно неэффективную пузырьковую сортировку и быструю сортировку —
один
из лучших со всех точек зрения алгоритмов внутренней сортировки.
меняется местами со своим соседом слева, пока не
оказывается на правильном месте. В
этом разделе мы обсуждаем два типа обменных сортировок: хорошо известную, но
относительно неэффективную пузырьковую сортировку и быструю сортировку —
один
из лучших со всех точек зрения алгоритмов внутренней сортировки.
Пузырьковая сортировка. Наиболее очевидный метод систематического обмена местами имен с неправильным порядком состоит в просмотре пар смежных имен последовательно слева направо и перемене мест тех имен, которые не отвечают порядку.
Рис. 14.2. Пузырьковая сортировка, примененная к таблице. Показан вектор инверсии таблицы после каждого прохода
Эта техника получила название пузырьковой сортировки, так как большие
имена "пузырьками всплывают" вверх (то есть на правый конец)
таблицы. В
алгоритме 14.2 эта простая идея реализуется с одним небольшим
усовершенствованием: ясно, что не имеет смысла продолжать просмотр для
больших имен (в правом конце таблицы), про которые известно, что они
находятся на своих окончательных позициях. В алгоритме 14.2 используется
переменная ![]() , значение которой в начале цикла
, значение которой в начале цикла ![]() равно наибольшему индексу
равно наибольшему индексу ![]() , такому, что про имя
, такому, что про имя ![]() еще не известно,
стоит ли оно в
окончательной позиции. На рис. 14.2 показана работа алгоритма на примере
таблицы с
еще не известно,
стоит ли оно в
окончательной позиции. На рис. 14.2 показана работа алгоритма на примере
таблицы с ![]() именами.
именами.
Алгоритм 14.2. Пузырьковая сортировка
Анализ пузырьковой сортировки зависит от трех факторов: числа проходов (то
есть числа выполнений тела цикла ![]() ), числа сравнений
), числа сравнений ![]() и числа обменов
и числа обменов ![]() . Число
обменов равно,
как в алгоритме 14.1, числу инверсий: 0 в лучшем случае,
. Число
обменов равно,
как в алгоритме 14.1, числу инверсий: 0 в лучшем случае, ![]() в худшем случае и
в худшем случае и ![]() - в среднем.
Рисунок 14.2
дает возможность предположить, что каждый проход пузырьковой сортировки,
исключая последний, уменьшает на единицу каждый ненулевой элемент вектора
инверсий и циклически сдвигает вектор на одну позицию влево; легко
доказать, что это верно в общем случае, и поэтому число проходов равно
единице плюс наибольший элемент вектора инверсий. В лучшем случае имеется
всего один проход, в худшем случае -
- в среднем.
Рисунок 14.2
дает возможность предположить, что каждый проход пузырьковой сортировки,
исключая последний, уменьшает на единицу каждый ненулевой элемент вектора
инверсий и циклически сдвигает вектор на одну позицию влево; легко
доказать, что это верно в общем случае, и поэтому число проходов равно
единице плюс наибольший элемент вектора инверсий. В лучшем случае имеется
всего один проход, в худшем случае - ![]() проходов и в среднем -
проходов и в среднем - ![]() проходов, где
проходов, где ![]() - вероятность того, что
наибольшим
элементом вектора инверсии является
- вероятность того, что
наибольшим
элементом вектора инверсии является ![]() . Общее число сравнений
имен
трудно определить, но можно показать, что оно равно
. Общее число сравнений
имен
трудно определить, но можно показать, что оно равно ![]() в лучшем
случае,
в лучшем
случае, ![]() в худшем случае и
в худшем случае и ![]()
![]() - в среднем.
- в среднем.
Пузырьковую сортировку можно несколько улучшить, но при этом она все еще не сможет конкурировать с более эффективными алгоритмами сортировки. Ее единственным преимуществом является простота.
Как в простой сортировке вставками, так и в пузырьковой сортировке (алгоритм
14.2) основной причиной неэффективности является тот факт, что обмены дают
слишком малый эффект, так как в каждый момент времени имена сдвигаются только
на одну позицию. Такие алгоритмы непременно требуют порядка ![]() операций, как в среднем, так и в худшем случаях.
операций, как в среднем, так и в худшем случаях.
Быстрая сортировка. Идея метода быстрой сортировки состоит в том, чтобы выбрать одно из имен в таблице и использовать его для разделения таблицы на две подтаблицы, составленные соответственно из имен меньших и больших выбранного, которые затем рекурсивно сортируются с использованием быстрой сортировки. Разделение можно реализовать, одновременно просматривая таблицу и слева направо, и справа налево, меняя местами имена в неправильных частях таблицы. Имя, используемое для расщепления таблицы, затем помещается между двумя подтаблицами, и две подтаблицы сортируются рекурсивно.
В алгоритме 14.3 показаны детали быстрой сортировки для сортировки
таблицы ![]() , где
, где ![]() используется для
разбиения таблицы на подтаблицы. На рис. 14.3 показано, как алгоритм 14.3
использует два указателя
используется для
разбиения таблицы на подтаблицы. На рис. 14.3 показано, как алгоритм 14.3
использует два указателя ![]() и
и ![]() для просмотра таблицы
во время
разбиения. В начале цикла "
для просмотра таблицы
во время
разбиения. В начале цикла " ![]()
![]() "
" ![]() и
и ![]() указывают
соответственно на первое и последнее имена, о которых известно, что они
находятся не в тех частях файла, в которых требуется. Когда
указывают
соответственно на первое и последнее имена, о которых известно, что они
находятся не в тех частях файла, в которых требуется. Когда ![]() встречаются, то есть когда
встречаются, то есть когда ![]() , все имена находятся в
соответствующих частях таблицы и
, все имена находятся в
соответствующих частях таблицы и ![]() помещается между двумя
частями,
меняясь при этом местами с
помещается между двумя
частями,
меняясь при этом местами с ![]() , алгоритм предполагает, что имя
, алгоритм предполагает, что имя ![]() определено и больше, чем
определено и больше, чем ![]() .
.


Рис. 14.3.
Алгоритм 14.3 изящен, но непрактичен. Проблема состоит в том, что рекурсия
используется для записи подтаблиц, которые рассматриваются на более поздних
этапах, и в худших случаях (когда таблица уже отсортирована) глубина рекурсии
может равняться ![]() . Следовательно, для стека, реализующего
рекурсию, необходима память,
пропорциональная
. Следовательно, для стека, реализующего
рекурсию, необходима память,
пропорциональная ![]() ; для больших
; для больших ![]() такое
требование становится неприемлемым. Кроме того, второе рекурсивное
обращение к быстрой сортировке в алгоритме 14.3 может быть легко исключено. По
этим причинам мы предлагаем алгоритм 14.4, итерационный вариант быстрой
сортировки, в которой стек ведется явно. Элементом стека является пара
такое
требование становится неприемлемым. Кроме того, второе рекурсивное
обращение к быстрой сортировке в алгоритме 14.3 может быть легко исключено. По
этим причинам мы предлагаем алгоритм 14.4, итерационный вариант быстрой
сортировки, в которой стек ведется явно. Элементом стека является пара ![]() : когда пара находится в стеке, это значит, что нужно
сортировать соответствующие
: когда пара находится в стеке, это значит, что нужно
сортировать соответствующие ![]() . Алгоритм 14.4
помещает в стеке большую из двух подтаблиц и немедленно
применяет алгоритм к меньшей подтаблице. Это уменьшает глубину стека в худшем
случае примерно до
. Алгоритм 14.4
помещает в стеке большую из двух подтаблиц и немедленно
применяет алгоритм к меньшей подтаблице. Это уменьшает глубину стека в худшем
случае примерно до ![]() . Заметим, что подтаблицы длины 1
игнорируются и что расщепление подтаблицы
делается с использованием случайно выбранного имени в этой подтаблице.
. Заметим, что подтаблицы длины 1
игнорируются и что расщепление подтаблицы
делается с использованием случайно выбранного имени в этой подтаблице.

увеличить изображение
Алгоритм 14.4.Итерационный вариант быстрой сортировки
Лекция 15. Сортировка (часть 2)
Выбор
В сортировке посредством выбора основная идея состоит в том, чтобы
идти по шагам ![]() , находя
, находя ![]() -е
наибольшее (наименьшее)
имя и помещая его на его место на
-е
наибольшее (наименьшее)
имя и помещая его на его место на ![]() -ом шаге. Простейшая форма
сортировки выбором представлена алгоритмом 15.1:
-ом шаге. Простейшая форма
сортировки выбором представлена алгоритмом 15.1: ![]() -е наибольшее
имя
находится очевидным способом просмотром оставшихся
-е наибольшее
имя
находится очевидным способом просмотром оставшихся ![]() имен. Число
сравнений имен на
имен. Число
сравнений имен на ![]() -ом шаге равно
-ом шаге равно ![]() , что
приводит к общему числу
сравнений имен
, что
приводит к общему числу
сравнений имен ![]() независимо от входа, поэтому ясно, что это не очень хороший способ
сортировки.
независимо от входа, поэтому ясно, что это не очень хороший способ
сортировки.
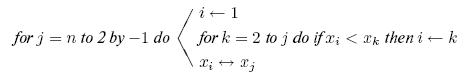
Алгоритм 15.1. Простая сортировка выбором
Несмотря на неэффективность алгоритма 15.1, идея выбора может привести
и к эффективному алгоритму сортировки. Весь вопрос в том, чтобы найти
более эффективный метод определения ![]() -го наибольшего имени, чего
можно добиться, используя механизм турнира с выбыванием. Суть его
такова: сравниваются
-го наибольшего имени, чего
можно добиться, используя механизм турнира с выбыванием. Суть его
такова: сравниваются ![]() , затем сравниваются "победители" (то есть большие
имена) этих
сравнений и т.д.; эта процедура для
, затем сравниваются "победители" (то есть большие
имена) этих
сравнений и т.д.; эта процедура для ![]() показана на рис. 15.1.
Заметим, что для определения наибольшего имени этот процесс требует
показана на рис. 15.1.
Заметим, что для определения наибольшего имени этот процесс требует ![]() сравнений имен; но, определив наибольшее имя, мы обладаем большим
объемом информации о втором по величине (в порядке убывания) имени: оно
должно быть одним из тех, которые "потерпели поражение" от
наибольшего имени. Таким образом, второе по величине имя теперь можно определить,
заменяя наибольшее имя на
сравнений имен; но, определив наибольшее имя, мы обладаем большим
объемом информации о втором по величине (в порядке убывания) имени: оно
должно быть одним из тех, которые "потерпели поражение" от
наибольшего имени. Таким образом, второе по величине имя теперь можно определить,
заменяя наибольшее имя на ![]() и вновь осуществляя сравнение
вдоль пути от наибольшего имени к корню. На рис. 15.2 эта процедура показана для
дерева из рис. 15.1.
и вновь осуществляя сравнение
вдоль пути от наибольшего имени к корню. На рис. 15.2 эта процедура показана для
дерева из рис. 15.1.
Идея турнира с выбыванием прослеживается при сортировке весьма отчетливо,
если имена образуют пирамиду. Пирамида
- это полностью сбалансированное бинарное дерево высоты ![]() , в котором все листья находятся на
расстоянии
, в котором все листья находятся на
расстоянии ![]() или
или ![]() от корня и все потомки узла
меньше его самого; кроме того, в нем все листья уровня
максимально смещены влево. На рис. 15.3 показано множество имен, организованных
в виде пирамиды. Чтобы получить удобное линейное представление дерева, пирамиду
можно хранить по уровням в одномерном массиве: сыновья имени из
от корня и все потомки узла
меньше его самого; кроме того, в нем все листья уровня
максимально смещены влево. На рис. 15.3 показано множество имен, организованных
в виде пирамиды. Чтобы получить удобное линейное представление дерева, пирамиду
можно хранить по уровням в одномерном массиве: сыновья имени из ![]() -ой позиции есть имена в позициях
-ой позиции есть имена в позициях ![]() и
и ![]() . Таким образом, пирамида, представленная на рисунке 15.3, принимает
вид
. Таким образом, пирамида, представленная на рисунке 15.3, принимает
вид
Заметим, что в пирамиде наибольшее имя должно находиться в корне и, таким
образом, всегда в первой позиции массива, представляющего пирамиду. Обмен
местами первого имени с ![]() -м помещает наибольшее имя в его
правильную позицию, но нарушает свойство
пирамидальности в первых
-м помещает наибольшее имя в его
правильную позицию, но нарушает свойство
пирамидальности в первых ![]() именах. Если мы можем сначала
построить пирамиду, а затем эффективно
восстановить ее, то все в порядке, так как тогда можно производить сортировку
следующим образом:
построить пирамиду из
именах. Если мы можем сначала
построить пирамиду, а затем эффективно
восстановить ее, то все в порядке, так как тогда можно производить сортировку
следующим образом:
построить пирамиду из ![]() ,
,

Это общее описание пирамидальной сортировки.
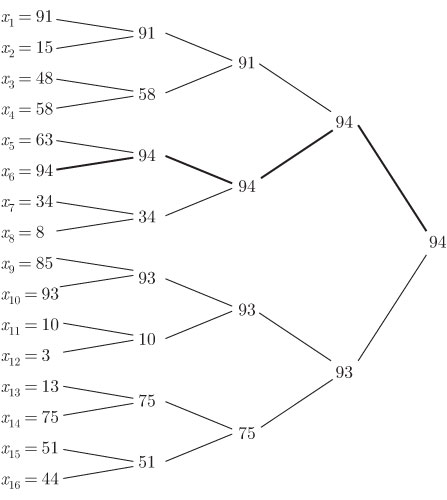
Рис. 15.1. Использование турнира с выбыванием для отыскания наибольшего имени.Путь наибольшего имени показан жирной линией

Рис. 15.2.
Процедура RESTORE ![]() восстановления пирамиды из
последовательности
восстановления пирамиды из
последовательности ![]() в предположении, что
все поддеревья суть пирамиды, такова:
в предположении, что
все поддеревья суть пирамиды, такова:

Переписывая это итеративным способом и дополняя деталями, мы получим алгоритм 15.2.
Алгоритм 15.2.Восстановление пирамиды из дерева, поддеревья которого суть пирамиды
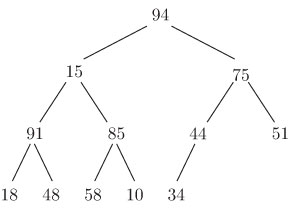
Рис. 15.3. Пирамида, содержащая 12 имен
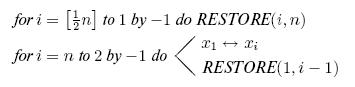
Алгоритм 15.3.Пирамидальная сортировка
Распределяющая сортировка
Обсуждаемый здесь алгоритм сортировки отличается от рассматривавшихся до
сих пор тем, что он основан не на сравнениях между именами, а на представлении
имен. Мы полагаем, что каждое из имен ![]() имеет
вид
имеет
вид
Цифровая распределяющая сортировка
Цифровая распределяющая сортировка основана на наблюдении, что если имена
уже отсортированы по младшим разрядами ![]() , то их
можно полностью отсортировать, сортируя только по старшим разрядам
, то их
можно полностью отсортировать, сортируя только по старшим разрядам ![]() при условии, что сортировка осуществляется таким
образом, чтобы не нарушить
относительный порядок имен с одинаковыми цифрами в старших разрядах. Заметим,
что к самой таблице обращаются по правилу "первым включается – первым
исключается", и поэтому лучшим способом представления являются очереди. В
частности, предположим, что с каждым ключом
при условии, что сортировка осуществляется таким
образом, чтобы не нарушить
относительный порядок имен с одинаковыми цифрами в старших разрядах. Заметим,
что к самой таблице обращаются по правилу "первым включается – первым
исключается", и поэтому лучшим способом представления являются очереди. В
частности, предположим, что с каждым ключом ![]() ассоциируется
поле связи
ассоциируется
поле связи ![]() ; тогда эти поля связи можно использовать для
сцепления всех имен в таблице вместе
во входную очередь
; тогда эти поля связи можно использовать для
сцепления всех имен в таблице вместе
во входную очередь ![]() . При помощи полей связи можно также сцеплять
имена в очереди
. При помощи полей связи можно также сцеплять
имена в очереди ![]() , используемые для
представления стопок. После того как имена распределены по
стопкам, очереди, представляющие эти стопки, связываются вместе для получения
вновь таблицы
, используемые для
представления стопок. После того как имена распределены по
стопкам, очереди, представляющие эти стопки, связываются вместе для получения
вновь таблицы ![]() . Алгоритм 15.4. представляет эту процедуру в
общих чертах (очереди описаны в лекции 11).
В результате применения алгоритма очередь
. Алгоритм 15.4. представляет эту процедуру в
общих чертах (очереди описаны в лекции 11).
В результате применения алгоритма очередь ![]() будет
содержать имена в порядке возрастания; то есть имена будут связаны в порядке
возрастания полями связи, начиная с головы очереди
будет
содержать имена в порядке возрастания; то есть имена будут связаны в порядке
возрастания полями связи, начиная с головы очереди ![]() .
.
Использовать поля связи ![]() для формирования
для формирования ![]() во входную очередь
во входную очередь ![]()

Алгоритм 15.4.Цифровая распределяющая сортировка
Внешняя сортировка
В методах сортировки, обсуждавшихся в предыдущем разделе, мы полагали, что таблица умещается в быстродействующей внутренней памяти. Хотя для большинства реальных задач обработки данных это предположение слишком сильно, оно, как правило, выполняется для комбинаторных алгоритмов. Сортировка обычно используется только для некоторого сокращения времени работы алгоритмов, в которых сортировка применяется только для некоторого сокращения времени работы алгоритмов, когда оно недопустимо велико даже для задач "умеренных" размеров. Например, часто бывает необходимо сортировать отдельные предметы во времени исчерпывающего поиска (лекция 13), но поскольку такой поиск обычно требует экспоненциального времени, маловероятно, что подлежащая сортировке таблица будет настолько большой, чтобы потребовалось использование запоминающих устройств. Однако задача сортировки таблицы, которая слишком велика для основной памяти, служит хорошей иллюстрацией работы с данными большого объема, и поэтому в этом разделе мы обсудим важные идеи внешней сортировки. Более того, будем рассматривать только сортировку таблицы путем использования вспомогательной памяти с последовательным доступом. Условимся называть эту память лентой.
Общей стратегией в такой внешней сортировке является использование
внутренней памяти для сортировки имен из ленты по частям так, чтобы производить исходные отрезки
(известные также как цепочки ) имен в возрастающем
порядке. По мере порождения эти отрезки распределяются по ![]() рабочим лентам, и затем производится их слияние по
рабочим лентам, и затем производится их слияние по ![]() отрезков
обратно на исходную
отрезков
обратно на исходную ![]() -ю ленту так, что она будет содержать
меньшее число более длинных отрезков. Затем
отрезки снова распределяются по остальным
-ю ленту так, что она будет содержать
меньшее число более длинных отрезков. Затем
отрезки снова распределяются по остальным ![]() лентам, и снова
производится их слияние по
лентам, и снова
производится их слияние по ![]() штук обратно на
штук обратно на ![]() -ю ленту. Процесс продолжается до тех пор, пока не получится один
отрезок, то есть
пока таблица не будет полностью отсортирована. Имеются, таким образом, две
отдельные проблемы: как порождать исходные отрезки и как осуществлять
слияние.
-ю ленту. Процесс продолжается до тех пор, пока не получится один
отрезок, то есть
пока таблица не будет полностью отсортирована. Имеются, таким образом, две
отдельные проблемы: как порождать исходные отрезки и как осуществлять
слияние.
Самый очевидный метод для получения исходных отрезков состоит в том, что
можно просто считывать ![]() -ю ленту
-ю ленту ![]() имен,
рассортировывать их во внутренней памяти и записывать их на ленту в виде
отрезка, продолжая процесс до тех пор, пока не будут исчерпаны все имена. Все
полученные таким образом исходные отрезки содержат
имен,
рассортировывать их во внутренней памяти и записывать их на ленту в виде
отрезка, продолжая процесс до тех пор, пока не будут исчерпаны все имена. Все
полученные таким образом исходные отрезки содержат ![]() имен
(исключая, возможно, последний отрезок). Поскольку число исходных отрезков
в конце концов определяет время слияния, мы хотели бы найти некоторый метод
образования более длинных исходных отрезков и, следовательно, меньшего их
количества. Это можно сделать, используя для сортировки идею турнира
(пирамидальную сортировку). При этом подходе
имен
(исключая, возможно, последний отрезок). Поскольку число исходных отрезков
в конце концов определяет время слияния, мы хотели бы найти некоторый метод
образования более длинных исходных отрезков и, следовательно, меньшего их
количества. Это можно сделать, используя для сортировки идею турнира
(пирамидальную сортировку). При этом подходе ![]() имен, которые
умещаются в памяти, хранятся в виде такой пирамиды, что сыновья
узла больше узла (вместо того, чтобы быть меньше его). Этот метод отвечает
определению "победителя" при сравнении имен в сортировках типа
турнира как
меньшего из двух имен, и это позволяет нам следить за наименьшим
именем.
имен, которые
умещаются в памяти, хранятся в виде такой пирамиды, что сыновья
узла больше узла (вместо того, чтобы быть меньше его). Этот метод отвечает
определению "победителя" при сравнении имен в сортировках типа
турнира как
меньшего из двух имен, и это позволяет нам следить за наименьшим
именем.
Порождение исходных отрезков продолжается следующим образом. Из входной
ленты считываются первые ![]() имен, и затем из них формируется
пирамида, как описано выше. Наименьшее
имя выводится как первое в первом отрезке и заменяется в пирамиде следующим
именем из входной ленты в соответствии с алгоритмом 15.2. модифицированным
так,
чтобы для восстановления пирамиды следить за наименьшим, а не за наибольшим
именем. Процесс, известный как выбор с замещением, продолжается таким
образом, что к текущему отрезку всегда добавляется наименьшее в пирамиде имя,
большее или равное имени, которое последним добавлено к отрезку; при этом
добавленное имя заменяется на следующее из входной ленты и восстанавливается
пирамида. Когда в пирамиде нет имен, больших, чем последнее имя в текущем
отрезке, отрезок обрывается и начинается новый. Этот процесс продолжается до тех пор,
пока все имена не сформируются в отрезки.
имен, и затем из них формируется
пирамида, как описано выше. Наименьшее
имя выводится как первое в первом отрезке и заменяется в пирамиде следующим
именем из входной ленты в соответствии с алгоритмом 15.2. модифицированным
так,
чтобы для восстановления пирамиды следить за наименьшим, а не за наибольшим
именем. Процесс, известный как выбор с замещением, продолжается таким
образом, что к текущему отрезку всегда добавляется наименьшее в пирамиде имя,
большее или равное имени, которое последним добавлено к отрезку; при этом
добавленное имя заменяется на следующее из входной ленты и восстанавливается
пирамида. Когда в пирамиде нет имен, больших, чем последнее имя в текущем
отрезке, отрезок обрывается и начинается новый. Этот процесс продолжается до тех пор,
пока все имена не сформируются в отрезки.
Разумный путь реализации этой процедуры состоит в том, чтобы рассматривать
каждое имя ![]() как пару
как пару ![]() , где
, где ![]() есть
номер отрезка, в котором находится
есть
номер отрезка, в котором находится ![]() . Иначе говоря, считается,
что пирамида состоит из пар
. Иначе говоря, считается,
что пирамида состоит из пар ![]() ; сравнения между парами осуществляются лексикографически. Когда
считывается имя, меньшее последнего имени в текущем отрезке, оно должно быть в
следующем отрезке, и благодаря наличию номера отрезка это имя будет ниже всех
имен пирамиды, которые входят в текущий отрезок.
; сравнения между парами осуществляются лексикографически. Когда
считывается имя, меньшее последнего имени в текущем отрезке, оно должно быть в
следующем отрезке, и благодаря наличию номера отрезка это имя будет ниже всех
имен пирамиды, которые входят в текущий отрезок.
Порождает ли этот выбор с замещением длинные отрезки? Ясно, что он делает
это, по крайней мере, не хуже, чем очевидный метод, так как все отрезки (кроме,
возможно, последнего) содержат не меньше ![]() имен. На самом деле
можно показать, что средняя длина отрезков,
порождаемых выбором с замещением, равна
имен. На самом деле
можно показать, что средняя длина отрезков,
порождаемых выбором с замещением, равна ![]() , и это вполне можно
считать улучшением по сравнению с очевидным методом,
в котором средняя длина отрезков равна
, и это вполне можно
считать улучшением по сравнению с очевидным методом,
в котором средняя длина отрезков равна ![]() . Конечно, в лучшем
случае все заканчивается только одним исходным
отрезком, то есть отсортированной таблицей.
. Конечно, в лучшем
случае все заканчивается только одним исходным
отрезком, то есть отсортированной таблицей.
После того, как порождены исходные отрезки, возникает задача повторного
распределения их по рабочим лентам и слияния их вместе до тех пор, пока в конце
концов мы не получим окончательную отсортированную таблицу. Простейший метод
состоит в том, чтобы распределить отрезки по лентам ![]() равномерно и произвести их слияние на ленту
равномерно и произвести их слияние на ленту ![]() . Получаемые в
результате отрезки снова равномерно распределить по лентам
. Получаемые в
результате отрезки снова равномерно распределить по лентам ![]() и снова произвести слияние, образуя более длинные
отрезки на ленте
и снова произвести слияние, образуя более длинные
отрезки на ленте ![]() . Процесс продолжается до тех пор, пока на
ленте
. Процесс продолжается до тех пор, пока на
ленте ![]() не останется только один отрезок (отсортированная
таблица).
не останется только один отрезок (отсортированная
таблица).
Частичная сортировка
Ранее мы изучали проблему полного упорядочения множества имен, не имея a priori информации об
абстрактном порядке имен. Имеется два очевидных
уточнения этой проблемы. Вместо полного упорядочения требуется только
определить ![]() -е наибольшее имя (то есть
-е наибольшее имя (то есть ![]() -е имя в порядке
убывания) (выбор) или, вместо того чтобы начинать процесс,
не располагая информацией о порядке, начинать с двух отсортированных подтаблиц
(слияние). Мы рассматриваем обе проблемы частичной сортировки.
-е имя в порядке
убывания) (выбор) или, вместо того чтобы начинать процесс,
не располагая информацией о порядке, начинать с двух отсортированных подтаблиц
(слияние). Мы рассматриваем обе проблемы частичной сортировки.
Частичная сортировка (выбор)
Как при данных именах ![]() можно найти
можно найти ![]() -е из наибольших в порядке убывания? Задача, очевидно,
симметрична: отыскание
-е из наибольших в порядке убывания? Задача, очевидно,
симметрична: отыскание ![]() -го наибольшего
(
-го наибольшего
( ![]() -го наименьшего) имени можно осуществить, используя алгоритм
отыскания
-го наименьшего) имени можно осуществить, используя алгоритм
отыскания ![]() -го наибольшего, но меняя местами действия,
предпринимаемые при результатах < и
>сравнения имен. Таким образом, отыскание наибольшего имени
-го наибольшего, но меняя местами действия,
предпринимаемые при результатах < и
>сравнения имен. Таким образом, отыскание наибольшего имени ![]() эквивалентно отысканию наименьшего имени
эквивалентно отысканию наименьшего имени ![]() ;
отыскание второго наибольшего имени
;
отыскание второго наибольшего имени ![]() эквивалентно
отысканию второго наименьшего
эквивалентно
отысканию второго наименьшего ![]() и т.д.
и т.д.
Конечно, все перечисленные варианты задачи выбора можно решить, используя
любой из методов полной сортировки имен и затем тривиально обращаясь к ![]() -му наибольшему. Такой подход потребует порядка
-му наибольшему. Такой подход потребует порядка ![]() сравнений имен независимо от значений
сравнений имен независимо от значений ![]() .
.
При использовании алгоритма сортировки для выбора наиболее подходящим
будет один из алгоритмов, основанных на выборе: либо простая сортировка выбором
(алгоритм 15.1) либо пирамидальная сортировка (алгоритм 15.3). В каждом случае
мы можем остановиться после того, как выполнены первые ![]() шагов. Для
простой сортировки выбором это означает использование
шагов. Для
простой сортировки выбором это означает использование
Частичная сортировка (слияние)
Вторым направлением исследования частичной сортировки является задача
слияния двух отсортированных таблиц ![]() и
и ![]() в одну отсортированную таблицу
в одну отсортированную таблицу ![]() . Существует очевидный способ это сделать: таблицы,
подлежащие слиянию,
просматривать параллельно, выбирая на каждом шаге меньшее из двух имен и
помещая его в окончательную таблицу. Этот процесс немного упрощается
добавлением имен-сторожей
. Существует очевидный способ это сделать: таблицы,
подлежащие слиянию,
просматривать параллельно, выбирая на каждом шаге меньшее из двух имен и
помещая его в окончательную таблицу. Этот процесс немного упрощается
добавлением имен-сторожей ![]() , как в
алгоритме 15.5. В этом алгоритме
, как в
алгоритме 15.5. В этом алгоритме ![]() и
и ![]() указывают,
соответственно, на последние имена в двух входных таблицах,
которые еще не были помещены в окончательную таблицу.
указывают,
соответственно, на последние имена в двух входных таблицах,
которые еще не были помещены в окончательную таблицу.
Алгоритм 15.5. Прямое слияние
Лекция 16. Алгоритмы на графах
Поиск в глубину
При решении многих задач, касающихся ориентированных графов, необходим
эффективный метод систематического обхода вершин и дуг орграфов. Таким методом
является метод поиск в
глубину. Метод поиска в глубину является основой
многих эффективных алгоритмов работы с графами. Предположим, что есть
ориентированный граф ![]() , в котором первоначально все вершины
помечены меткой "
, в котором первоначально все вершины
помечены меткой " ![]() ". Поиск в глубину
начинается с выбора начальной вершины
". Поиск в глубину
начинается с выбора начальной вершины ![]() орграфа
орграфа ![]() ,
для этой вершины метка "
,
для этой вершины метка " ![]() " меняется на метку
"
" меняется на метку
" ![]() ". Затем для каждой вершины, смежной с
вершиной
". Затем для каждой вершины, смежной с
вершиной ![]() и не посещаемой раньше, рекурсивно применяется поиск в
глубину. Когда все
вершины, которых можно достичь из вершины
и не посещаемой раньше, рекурсивно применяется поиск в
глубину. Когда все
вершины, которых можно достичь из вершины ![]() , будут рассмотрены,
поиск заканчивается. Если некоторые вершины остались не
посещенными, то выбирается одна из них и алгоритм повторяется. Этот процесс
продолжается до тех пор, пока не будут обойдены все вершины орграфа
, будут рассмотрены,
поиск заканчивается. Если некоторые вершины остались не
посещенными, то выбирается одна из них и алгоритм повторяется. Этот процесс
продолжается до тех пор, пока не будут обойдены все вершины орграфа ![]() .
.
Метод получил свое название - поиск в глубину, поскольку поиск не
посещенных вершин идет в направлении вглубь до тех пор, пока это возможно.
Например, пусть ![]() является последней посещенной нами вершиной.
Выбираем очередную дугу
является последней посещенной нами вершиной.
Выбираем очередную дугу ![]() (ребро), выходящую из вершины
(ребро), выходящую из вершины ![]() . Возможна следующая альтернатива: вершина
. Возможна следующая альтернатива: вершина ![]() помечена меткой "
помечена меткой " ![]() "; вершина
"; вершина ![]() помечена меткой "
помечена меткой " ![]() ". Если вершина
". Если вершина ![]() уже посещалась, то отыскивается другая вершина, смежная с
вершиной
уже посещалась, то отыскивается другая вершина, смежная с
вершиной ![]() ; иначе вершина
; иначе вершина ![]() метится меткой
"
метится меткой
" ![]() " и поиск начинается заново от вершины
" и поиск начинается заново от вершины ![]() . Пройдя все пути, которые начинаются в вершине
. Пройдя все пути, которые начинаются в вершине ![]() ,
возвращаемся в вершину
,
возвращаемся в вершину ![]() , то есть в ту вершину, из которой
впервые была достигнута вершина
, то есть в ту вершину, из которой
впервые была достигнута вершина ![]() . Затем процесс повторяется, то
есть продолжается выбор нерассмотренных дуг,
исходящих из вершины
. Затем процесс повторяется, то
есть продолжается выбор нерассмотренных дуг,
исходящих из вершины ![]() , и так до тех пор, пока не будут исчерпаны
все эти дуги.
, и так до тех пор, пока не будут исчерпаны
все эти дуги.
Алгоритм Дейкстры нахождения кратчайшего пути
Рассмотрим алгоритм нахождения путей в ориентированном графе. Пусть есть
ориентированный граф ![]() , у которого все дуги имеют
неотрицательные метки (веса дуг), а одна вершина
определена как источник.
Задача состоит в нахождении весов кратчайших
путей от источника ко всем другим вершинам граф
, у которого все дуги имеют
неотрицательные метки (веса дуг), а одна вершина
определена как источник.
Задача состоит в нахождении весов кратчайших
путей от источника ко всем другим вершинам граф ![]() . Здесь
длина пути определяется как сумма весов дуг, составляющих путь. Эта задача
часто называется задачей нахождения кратчайшего пути с одним источником.
Отметим, что мы будем говорить о длине пути даже тогда, когда она измеряется в
других, не линейных, единицах измерения, например, во временных единицах или в
денежном эквиваленте.
. Здесь
длина пути определяется как сумма весов дуг, составляющих путь. Эта задача
часто называется задачей нахождения кратчайшего пути с одним источником.
Отметим, что мы будем говорить о длине пути даже тогда, когда она измеряется в
других, не линейных, единицах измерения, например, во временных единицах или в
денежном эквиваленте.
Можно представить орграф ![]() в виде карты маршрутов
рейсовых полетов из одного города в другой. Каждая вершина соответствует городу, а
ребро (дуга)
в виде карты маршрутов
рейсовых полетов из одного города в другой. Каждая вершина соответствует городу, а
ребро (дуга) ![]() - рейсовому маршруту из города
- рейсовому маршруту из города ![]() в город
в город ![]() . Вес
дуги
. Вес
дуги ![]() - это время полета из города
- это время полета из города ![]() в город
в город ![]() . В этом случае
решение задачи нахождения кратчайшего пути с одним источником для
ориентированного графа трактуется как минимальное время перелета между
различными городами.
. В этом случае
решение задачи нахождения кратчайшего пути с одним источником для
ориентированного графа трактуется как минимальное время перелета между
различными городами.
Для решения поставленной задачи будем использовать "жадный"
алгоритм, который называют алгоритмом Дейкстры (Dijkstra). Алгоритм строит множество ![]() вершин, для которых кратчайшие пути от источника уже известны.
На каждом шаге к множеству
вершин, для которых кратчайшие пути от источника уже известны.
На каждом шаге к множеству ![]() добавляется та из оставшихся вершин, расстояние до
которой от источника меньше,
чем для других оставшихся вершин. Если веса всех дуг неотрицательны, то можно
быть уверенным, что кратчайший путь от источника к конкретной вершине проходит
только через вершины множество
добавляется та из оставшихся вершин, расстояние до
которой от источника меньше,
чем для других оставшихся вершин. Если веса всех дуг неотрицательны, то можно
быть уверенным, что кратчайший путь от источника к конкретной вершине проходит
только через вершины множество ![]() . Назовем такой путь особым. На каждом шаге
алгоритма используется также
массив
. Назовем такой путь особым. На каждом шаге
алгоритма используется также
массив ![]() , в который записываются длины кратчайших особых путей
для каждой вершины.
Когда множество
, в который записываются длины кратчайших особых путей
для каждой вершины.
Когда множество ![]() будет содержать все вершины орграфа, то есть
для всех вершин будут найдены особые
пути, тогда массив
будет содержать все вершины орграфа, то есть
для всех вершин будут найдены особые
пути, тогда массив ![]() будет содержать длины кратчайших путей от
источника к каждой вершине.
будет содержать длины кратчайших путей от
источника к каждой вершине.
Алгоритм Флойда нахождения кратчайших путей между парами вершин
Предположим, что мы имеем помеченный орграф, который содержит время полета по маршрутам, связывающим определенные города, и~мы хотим построить таблицу, где приводилось бы минимальное время перелета из одного (произвольного) города в любой другой. В этом случае мы сталкиваемся с общей задачей нахождения кратчайших путей, то есть нахождения кратчайших путей между всеми парами вершин орграфа.
Формулировка задачи.Есть ориентированный граф ![]() , каждой дуге
(ребру)
, каждой дуге
(ребру) ![]() этого графа сопоставлен неотрицательный вес
этого графа сопоставлен неотрицательный вес ![]() . Общая задача нахождения кратчайших путей заключается в нахождении для
каждой упорядоченной пары вершин
. Общая задача нахождения кратчайших путей заключается в нахождении для
каждой упорядоченной пары вершин ![]() любого пути от вершины
любого пути от вершины ![]() в вершину
в вершину ![]() , длина которого минимальна среди всех возможных путей
от
, длина которого минимальна среди всех возможных путей
от ![]() к
к ![]() .
.
Можно решать эту задачу, последовательно применяя алгоритм Дейкстры для
каждой вершины, объявляемой в качестве источника. Но мы для решения
поставленной задачи воспользуемся алгоритмом, предложенным Флойдом (R.W.
Floyd). Пусть все вершины орграфа последовательно пронумерованы от 1 до ![]() .
Алгоритм Флойда использует матрицу
.
Алгоритм Флойда использует матрицу ![]() ,
в которой находятся длины кратчайших путей:
,
в которой находятся длины кратчайших путей:
![]() , если
, если ![]() ;
;
![]() , если
, если ![]() ;
;
![]() если отсутствует путь из вершины
если отсутствует путь из вершины ![]() в вершину
в вершину ![]() .
.
Над матрицей ![]() выполняется
выполняется ![]() итераций. После
итераций. После ![]() -й итерации
-й итерации ![]() содержит значение наименьшей
длины пути из вершины
содержит значение наименьшей
длины пути из вершины ![]() в вершину
в вершину ![]() , причем путь не
проходит через вершины с номерами большими
, причем путь не
проходит через вершины с номерами большими ![]() .
.
Вычисление на ![]() -ой итерации выполняется по формуле:
-ой итерации выполняется по формуле: ![]() Верхний индекс
Верхний индекс ![]() обозначает значение матрицы
обозначает значение матрицы ![]() после
после ![]() -ой итерации.
-ой итерации.
Для вычисления ![]() проводится сравнение величины
проводится сравнение величины ![]() (то есть стоимость пути от вершины
(то есть стоимость пути от вершины ![]() к вершине
к вершине ![]() без участия
вершины
без участия
вершины ![]() или другой вершины с более высоким номером) с величиной
или другой вершины с более высоким номером) с величиной ![]() (стоимость пути от вершины
(стоимость пути от вершины ![]() к вершине
к вершине ![]() плюс стоимость пути от вершины
плюс стоимость пути от вершины ![]() до вершины
до вершины ![]() ). Если путь через
вершину
). Если путь через
вершину ![]() дешевле, чем
дешевле, чем ![]() , то
величина
, то
величина ![]() изменяется. Рассмотрим орграф:
изменяется. Рассмотрим орграф:

Рис. 16.1. Помеченный орграф
Матрица A(3 * 3) на нулевой итерации (k = 0)

Матрица A(3 * 3) после первой итерации (k = 1)

Матрица A(3 * 3) после второй итерации (k = 2)

Матрица A(3 * 3) после третьей итерации (k = 3)

Программы
Программа 1. Построение матрицы инциндентности.
//Построение матрицы инциндентности
//Программа реализована на языке программирования Turbo-C++
\begin{verbatim}
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <conio.h>
#include <iostream.h>
struct elem
{
int num; /* Номер вершины */
int suns; /* Количество сыновей */
char str[20]; /* Строка с номерами сыновей */
elem *next; /* Указатель на следующую вершину */
} *head, *w1, *w2;
int Connected(int i, int j)
{
int k;
char *str1;
w2 = head;
if(i == j) return 0;
for(k=1; k<i; k++)
w2 = w2->next;
if( strchr(w2->str, j) ) return 1;
return 0;
}
void main()
{
int tops;
int i,j,k,l;
char *str1;
clrscr();
printf("Введите количество вершин \n");
scanf("%d", &tops);
head = (elem *)malloc(sizeof(elem));
head->num = 1;
head->suns = 0;
head->str[0] = '\0';
head->next = NULL;
w1 = head;
for(i=2;i<=tops;i++)
{
w2 = (elem *)malloc(sizeof(elem));
w2->num = i;
w2->suns = 0;
w2->str[0] = '\0';
w2->next = NULL;
w1->next = w2;
w1 = w2;
}
w1 = head;
for(i=1; i<=tops; i++)
{
// clrscr();
printf("Введите количество путей из вершины %d\n", i);
scanf("%d", &k);
for(j=1; j<=k; j++)
{
printf("Введите связь %d\n", j);
scanf("%d", &l);
if((l<=0) || (l > tops))
{
printf("Такой вершины нет, повторите попытку\n");
l = 0;
j--;
continue;
}
w1->str[w1->suns++] = l;
w1->str[w1->suns] = '\0';
if(w1->suns == 49)
{
printf("Слишком много связей !");
exit(1);
}
}
w1 = w1->next;
}
clrscr();
printf("\n\n Матрица инциндентности :\n");
for(i=1; i<=tops; i++)
{
printf("\n %d) ", i);
for(j=1; j<=tops; j++)
{
printf("%d ", Connected(i, j));
}
}
printf("\n\n Нажмите любую клавишу\ldots ");
getch();
}Программа 2.Поиск вершин, недостижимых из заданной вершины графа.
//Поиск вершин, недостижимых из заданной вершины графа.
//Программа реализована на языке программирования Turbo-C++
\begin{verbatim}
#include <iostream.h>
#include <fstream.h>
//- - - - - - - - - - - - - - - - - - - - - -
int n,s;
int c[20][20];
int r[20];
//- - - - - - - - - - - - - - - - - - - - - -
int load();
int save();
int solve();
//- - - - - - - - - - - - - - - - - - - - - -
int main(){
load();
solve();
save();
return 0;
}
//- - - - - - - - - - - - - - - - - - - - - -
int load(){
int i,j;
ifstream in("input.txt");
in"n"s;
s--;
for (i=0; i<n; i++)
for (j=0; j<n; j++)
in"c[i][j];
in.close();
return 0;
}
int save(){
int i;
ofstream out("output.txt");
for (i=0; i<n; i++)
if (r[i]==0)
out"i+1"" ";
out.close();
return 0;
}
//- - - - - - - - - - - - - - - - - - - - - -
int solve(){
int i,h,t;
int q[400];
for (i=0; i<n+1; i++) q[i]=0;
r[s]=1;
h=0;
t=1;
q[0]=s;
while (h<t){
for (i=0;i<n;i++)
if ((c[q[h]][i]>0)&(r[i]==0)){
q[t]=i;
t++;
r[i]=1;
}
h++;
}
return 0;
}Программа 3. Поиск циклов в графе.
{>
Реализация на Turbo-Pascal.
Поиск циклов в графе
<}
{$R-,I-,S-,Q-}
const MAXN = 40;
QUERYSIZE = 600;
type vert = record x: integer; s: array [1..MAXN] of integer; end;
var c : array [1..MAXN,1..MAXN] of integer;
n : integer;
wr : vert;
res : array [1..MAXN] of string;
resv: integer;
ss : string;
procedure load;
var i,j: integer;
begin
assign(input,'input.txt');
reset(input);
read(n);
for i:=1 to n do
for j:=1 to n do
read(c[i][j]);
close(input);
end;
function saveway(i:integer):string;
var e:string;
begin
str(i,e);
if (wr.s[i]=-1) then
saveway:=e+' '
else
saveway:=saveway(wr.s[i])+e+' ';
end;
p>function findss(s: string): boolean;
var i : integer;
l1,l2,rs : string;
i1,i2,i22 : integer;
begin
findss:=false;
l2:=copy(s,1,pos(' ',s)-1);
i2:=length(l2);
i22:=length(s);
for i:=1 to resv do begin
l1:=copy(res[i],1,pos(' ',res[i])-1);
i1:=length(l1);
rs:=copy(res[i],1,length(res[i])-i1)+res[i];
if (length(res[i])+i2=i22+i1)and(pos(s,rs)>0)
then begin
findss:=true;
exit;
end;
end;
end;
procedure solve;
var h,t,i,j: integer;
q : array [1..QUERYSIZE] of vert;
e : string;
begin
resv:=0;
fillchar(res,sizeof(res),0);
for i:=1 to n do begin
fillchar(q[i],sizeof(q[i]),0);
q[i].x:=i;
q[i].s[i]:=-1;
end;
t:=n+1;
h:=1;
while h<t do begin
for i:=1 to n do
if (c[q[h].x,i]>0) then begin
if (q[h].s[i]=-1) then begin
wr:=q[h];
str(i,e);
ss:=saveway(q[h].x)+e;
if (not findss(ss)) then begin
inc(resv);
res[resv]:=ss;
end;
end;
if (q[h].s[i]=0) then begin
q[t]:=q[h];
q[t].x:=i;
q[t].s[i]:=q[h].x;
inc(t);
end;
end;
inc(h);
end;
close(output);
end;
procedure save;
var i: integer;
begin
assign(output,'output.txt');
rewrite(output);
for i:=1 to resv do
writeln(res[i]);
close(output);
end;
begin
load;
solve;
save;
end.Лекция 17. Калейдоскоп из комбинаторных алгоритмов
Автоматическое построение лабиринтов
Тезей должен был найти выход из Критского лабиринта или погибнуть, убитый Минотавром. Но что поразительно: найти вход в лабиринт - задача не менее трудная.
Здесь не представляется возможным описать все мыслимые лабиринты, да это и
не требуется. Мы займемся простыми лабиринтами, построенными на
прямоугольнике ![]() ,
где
,
где ![]() — положительные целые числа. Внутри и на границах
прямоугольника
поставлены стенки по ребрам покрывающей его единичной квадратной сетки. Чтобы
построить из прямоугольника лабиринт, выбьем одну единичную стенку на одной из
сторон прямоугольника (получится вход в лабиринт); выбьем одну единичную стенку
на противоположной стороне (получится выход) и еще удалим какое-то число строго
внутренних стенок. Говорят, что лабиринт имеет решение, если между входом и
выходом внутри лабиринта есть путь в виде ломаной, не имеющей общих точек со
стенками. Решение единственно, если любые два таких пути проходят через одни и
те же внутренние ячейки сетки. На рис. 17.1 приведен пример
лабиринта
— положительные целые числа. Внутри и на границах
прямоугольника
поставлены стенки по ребрам покрывающей его единичной квадратной сетки. Чтобы
построить из прямоугольника лабиринт, выбьем одну единичную стенку на одной из
сторон прямоугольника (получится вход в лабиринт); выбьем одну единичную стенку
на противоположной стороне (получится выход) и еще удалим какое-то число строго
внутренних стенок. Говорят, что лабиринт имеет решение, если между входом и
выходом внутри лабиринта есть путь в виде ломаной, не имеющей общих точек со
стенками. Решение единственно, если любые два таких пути проходят через одни и
те же внутренние ячейки сетки. На рис. 17.1 приведен пример
лабиринта ![]() .
.

Рис. 17.1. Пример лабиринта
Один из возможных подходов к решению таков. Выбираем вход; затем, начав от него, добавляем по одной ячейке к главному пути-решению, пока он не достигнет выходной стороны. После этого удаляем некоторые внутренние стенки так, чтобы все клетки оказались соединенными с главным путем. Чтобы главный путь не получился прямым коридором, следует при его построении предусмотреть случайные повороты. Программа должна также следить за тем, чтобы при построении главного пути или при открытии боковых ячеек не нарушалась единственность решения. Наблюдательный читатель заметит, что определение единственности решения не годится в случае, когда путь заходит в боковой тупик и затем возвращается.
Программу можно написать почти на любом из процедурных языков.
Программа 1. Лабиринт.
{Программно задаются вход и выход. Нажимая на клавишу "Enter",
перебираем всевозможные пути от входа до выхода в лабиринте.
Выход из программы по клавише "Esc".
Алгоритм реализован на языке программирования Turbo-Pascal}
program Maze;
uses
Graph, Crt;
var
m,n: Integer;
Matrix: array [1..100,1..100] of Boolean;
Start,Finish: Integer;
procedure PrepareGraph;
var
Driver,Mode: Integer;
begin
Driver:=VGA;
Mode:=VGAHi;
InitGraph(Driver,Mode,'c:\borland\tp\bgi');
end;
procedure DisplayMaze(x1,y1,x2,y2: Integer);
var
i,j: Integer;
dx,dy: Real;
begin
SetFillStyle(1,8);
SetColor(15);
dx:=(x2-x1)/m;
dy:=(y2-y1)/n;
for i:=1 to n do
for j:=1 to m do
if not Matrix[i,j] then
Rectangle(Round(x1+(i-1)*dx),Round(y1+(j-1)*dy),
Round(x1+i*dx),Round(y1+j*dy));
end;
function CreatesPath(i,j: Integer): Boolean;
var
Result: Boolean;
Count: Integer;
ii,jj: Integer;
begin
Count:=0;
if (i>1) and Matrix[i-1,j] then Inc(Count);
if (i<m) and Matrix[i+1,j] then Inc(Count);
if (j>1) and Matrix[i,j-1] then Inc(Count);
if (j<m) and Matrix[i,j+1] then Inc(Count);
if Count>1 then Result:=true else Result:=false;
CreatesPath:=Result;
end;
function DeadEnd(i,j: Integer): Boolean;
var
Result: Boolean;
Count: Integer;
begin
Count:=0;
if (i=2) or CreatesPath(i-1,j) then Inc(Count);
if (i=m-1) or CreatesPath(i+1,j) then Inc(Count);
if (j=2) or CreatesPath(i,j-1) then Inc(Count);
if (j=n-1) or CreatesPath(i,j+1) then Inc(Count);
if Count=4 then Result:=true else Result:=false;
DeadEnd:=Result;
end;
function CreateMaze: Boolean;
var
i,j: Integer;
di,dj: Integer;
Result: Boolean;
begin
Randomize;
for i:=1 to n do
for j:=1 to m do Matrix[i,j]:=false;
Start:=Random(m-2)+2;
i:=Start;
j:=2;
Matrix[Start,1]:=true;
repeat
Matrix[i,j]:=true;
di:=0;
dj:=0;
while (di=0) and (dj=0) do begin
di:=1-Random(3);
if (i+di=1) or (i+di=m) then di:=0;
if di=0 then dj:=1-Random(3);
if j+dj=1 then dj:=0;
if CreatesPath(i+di,j+dj) then begin
di:=0;
dj:=0;
end;
end;
i:=i+di;
j:=j+dj;
until DeadEnd(i,j) or (j=n);
Finish:=i;
Matrix[Finish,n]:=true;
if j<n then Result:=false else Result:=true;
CreateMaze:=Result;
end;
begin
m:=6;
n:=6;
PrepareGraph;
repeat
ClearDevice;
repeat until CreateMaze;
DisplayMaze(120,40,520,440);
repeat until KeyPressed;
until ReadKey=#27;
CloseGraph;
end.Программа 2. Лабиринт.
{Лабиринт реализуется автоматически, без участия пользователя.
Алгоритм реализован на языке программирования Turbo-Pascal }
uses graph,crt;
var
mpos,npos,m,n,delx,x,y,t,gd,gm,i,k:integer;
begin
randomize;
writeln('Input labyrint size (x and y)');
readln(m,n);
writeln('Input entrance&exit coordinates (mpos<m and npos<m)');
readln(mpos,npos);
initgraph(gd,gm,'c:\borland\tp\bgi');
for i:=1 to m do
begin
for k:=1 to n do
begin
rectangle(90+10*i,90+10*k,90+10*i+10,90+10*k+10);
end;
end;
setfillstyle(1,0);
setcolor(0);
line(100+(mpos-1)*10+1,100,100+(mpos-1)*10+9,100);
line(100+(npos-1)*10+1,100+n*10,100+(npos-1)*10+9,100+n*10);
y:=n;
x:=npos;
readln;
while y>1 do
begin
delx:=random(m)-x+1;
if y=2 then delx:=mpos-x;
i:=91+x*10;
if i<90+(x+delx)*10 then
begin
while i<>90+(x+delx)*10 do
begin
i:=i+1;
line(i,91+y*10,i,99+y*10);
end;
end;
if i>91+(x+delx)*10 then
begin
while i<>91+(x+delx)*10 do
begin
i:=i-1;
line(i,91+y*10,i,99+y*10);
end;
end;
x:=x+delx;
line(91+10*x,90+y*10,99+10*x,90+y*10);
y:=y-1;
end;
readln;
end.Бинарное дерево
Строится бинарное дерево. В узлы дерева засылаются целые положительные числа, выбранные случайным образом. После задания значений вершин на каждом уровне эти значения выводятся на экран, начиная с корневой. Пользователю предлагается сделать выбор номера уровня, в нем определяется максимальное значение и выводится на экран.
Программа 3. Поиск максимального элемента.
{ Алгоритм реализован на языке программирования Turbo-Pascal}
uses crt;
type sp=^tree;
tree=record
val:integer;
l:sp;
r:sp;
end;
var
t:sp;
nh, max,h,i:integer;
procedure find(t:sp; h,nh:integer);
begin
if t=nil then exit;
if h=nh then
begin
if t^.val> max then max:=t^.val;
end
else
begin
find(t^.l,h+1,nh);
find(t^.r,h+1,nh);
end;
end;
procedure zadtree(var t:sp; h,nh:integer);
begin
if h=5 then
begin
new(t);
t^.l:=nil;
t^.r:=nil;
t^.val:=random(100);
end
else
begin
new(t);
zadtree(t^.l, h+1,nh);
zadtree(t^.r, h+1,nh);
t^.val:=random(100);
end;
end;
procedure writetree(t:sp; h,nh:integer);
begin
if t=nil then exit;
if h=nh then
begin
write(t^.val,' ');
end
else
begin
writetree(t^.l,h+1,nh);
writetree(t^.r,h+1,nh);
end;
end;
begin
clrscr;
randomize;
t:=nil;
zadtree(t,1,nh);
for i:=1 to 5 do
begin
writetree(t,1,i);
writeln;
end;
max:=0;
write('vvedite uroven ');
readln(nh);
find(t,1,nh);
write('max= ',max);
readln;
end.Задача о восьми ферзях
Условие задачи. Найти все такие расстановки восьми ферзей на шахматной доске, при которых ферзи не бьют друг друга.
Анализ задачи. Пусть ![]() - множество искомых расстановок (конфигураций).
Рассмотрим следующий подход к решению задачи. Будем искать множество
конфигураций
- множество искомых расстановок (конфигураций).
Рассмотрим следующий подход к решению задачи. Будем искать множество
конфигураций ![]() со следующими свойствами:
со следующими свойствами:
 .
.- Имеется условие, позволяющее по элементу из определить,
принадлежит ли он .
- Имеется процедура, генерирующая все элементы из .
С помощью процедуры из пункта 3 будем генерировать по очереди все
элементы из ![]() ; для элементов из
; для элементов из ![]() проверяем (см.
пункт 2) принадлежит
ли он
проверяем (см.
пункт 2) принадлежит
ли он ![]() : в результате в силу 1 свойства будут порождены все
элементы
: в результате в силу 1 свойства будут порождены все
элементы ![]() .
.
Заметим теперь, что ферзи, которые не бьют друг друга, должны располагаться
на разных горизонталях. Поэтому можно упорядочить ферзи и всегда ставить ![]() -го ферзя на
-го ферзя на ![]() -ю горизонталь. Тогда в качестве
-ю горизонталь. Тогда в качестве ![]() можно
взять множество конфигураций, в которых на каждой из первых
можно
взять множество конфигураций, в которых на каждой из первых ![]() горизонталей стоит
ровно по одному ферзю, причем никакие два ферзя не бьют друг друга.
горизонталей стоит
ровно по одному ферзю, причем никакие два ферзя не бьют друг друга.
Программа 4. Расстановка восьми ферзей на шахматной доске.
{ Программа выдает все комбинации ферзей, которые не бьют друг друга.
Алгоритм реализован на языке программирования Turbo-Pascal }
program ferz;
uses crt;
const desksize=8;
type sizeint=1..desksize;
unuses=set of sizeint;
combinates=array[shortint] of sizeint;
var num:byte;
combinate:combinates;
unuse:unuses;
function attack(combinate:combinates):boolean;
var i,j:byte;
rightdiag,leftdiag:combinates;
begin
attack:=false;
for i:=1 to desksize do
begin
leftdiag[i]:=i+combinate[i];
rightdiag[i]:=i-combinate[i];
end;
for j:=1 to desksize do
for i:=1 to desksize do
begin
if (i<>j) and ((leftdiag[i]=leftdiag[j])or(rightdiag[i]=rightdiag[j]))
then
begin
attack:=true;
exit;
end;
end;
end;
procedure output(combinate:combinates);
var i,j:byte;
begin
for i:=1 to desksize do
for j:=1 to desksize do
begin
gotoxy(i,j);
if(combinate[i]=j) then write(#2) else write(' ');
end;
readln;
end;
procedure create(num:byte; unuse:unuses; combinate:combinates);
var i:byte;
begin
if num<=desksize then
for i:=1 to desksize do
begin
if i in unuse then
begin
combinate[num]:=i;
create(num+1,unuse-[i],combinate);
end;
end
else if not attack(combinate) then output(combinate);
end;
begin
textmode(c40);
clrscr;
unuse:=[1..desksize];
create(1,unuse,combinate);
end.Сортировки
В лекциях 14 и 15 мы рассматривали более подробно различные способы сортировки. Здесь мы напоминаем некоторые из них и приводим пример программ.
Сортировка упорядочивает совокупность объектов в соответствии с заданным отношением порядка. Ключ сортировки - поле или группа полей элемента сортировки, которые используются при сравнении во время сортировки. Сортирующая последовательность - схема упорядочивания. Например, можно взять последовательность символов алфавита, задающую способ упорядочения строк этого алфавита.
Способ сортировки: сортировка по возрастанию, сортировки по убыванию. Методы сортировки:
- метод прямого выбора;
- метод пузырька;
- метод по ключу;
- сортировки слиянием;
- сортировки Батчера.
Сортировка по возрастанию - это сортировка, при которой записи упорядочиваются по возрастанию значений ключевых полей.
Сортировка по убыванию - это сортировка, при которой записи упорядочиваются по убыванию значений ключевых полей.
Сортировка методом пузырька (пузырьковая сортировка) - способ сортировки, заключающийся в последовательной перестановке соседних элементов сортируемого массива.
Сортировка по ключу - это сортировка записей с упорядочением по значению указанного поля или группы полей.
Сортировка слиянием - это внешняя сортировка, при которой на первом этапе группы записей сортируются в оперативной памяти и записываются на несколько внешних носителей; на втором этапе упорядоченные группы сливаются с нескольких внешних носителей на один носитель данных. Носитель данных - материальный объект, предназначенный для хранения данных, или среда передачи данных.
Сортировка Батчера - это сортировка, внутренний алгоритм которой работает
за время ![]() .
.
Программа 5. Сортировка массива по возрастанию методом пузырька.
//Данные, которые нужно отсортировать, берутся из файла "massiv.txt",
//результат записывается в массив int mas['K'] и выводится на экран
// Алгоритм реализован на Turbo C++.
#include <conio.h>
#include <stdio.h>
#define K 1000; //Размер массива
int mas['K'];
int n;
void puzirek()//функция сортирует массив по возрастанию методом пузырька
{
int i,j,t;
for(i=0;i<n;i++)
for(j=1;j<n-i;j++)
if(mas[j]<mas[j-1])
{
t=mas[j];
mas[j]=mas[j-1];
mas[j-1]=t;
}
}
int main()
{
clrscr();
FILE *filePointer=fopen("massiv.txt","r");
int i=0;
while (!feof(filePointer))
{
fscanf(filePointer,"%d",&mas[i]);
i++;
}
n=i;
puzirek();
for(i=0;i<n;i++)
printf("%d ",mas[i]);
//scanf("%d",&n);
getch();
return 0;
}Программа 6. Пузырьковая сортировка и сортировка методом прямого выбора.
{Сортировка. Алгоритм реализован на языке программирования Turbo-Pascal}
uses crt;
var
M, N : array[0..10] of integer;
i:integer;
procedure Input;
begin
for i := 0 to 10 do
begin
writeln('Число');
readln(M[i]); {Ввод массива}
end;
end;
Procedure Sort1; {Пузырьковый метод сортировки}
var
q,i,x:integer;
begin
for i:=10 downto 0 do
begin
for q:=0 to 10 do
if M[q]<M[q+1] then
begin
x:=M[q];
M[q]:=M[q+1];
M[q+1]:=x
end;
end;
end;
procedure Sort2; {Метод прямого выбора}
var
i,j,k,x:integer;
begin
for i:=0 to 9 do
begin
k:=i;
x:=M[i];
for j:=i+1 to 10 do
if M[j] >x then begin k:=j; x:=M[k];
end;
M[k]:= M[i];
M[i]:=x;
end;
end;
{---------------------------------------------}
begin
clrscr;
input; {Ввод исходного массива}
writeln('Исходный массив');
for i:=0 to 10 do write(M[i],' '); {Вывод исходного массива}
writeln;
Sort1;{Сортировка массива методом пузырька}
writeln ('Сортированный массив');
for i:=0 to 10 do write(M[i],' '); {Вывод отсортированного массива}
input; {Ввод исходного массива}
writeln('Исходный массив');
for i:=0 to 10 do write(M[i],' '); {Вывод исходного массива}
writeln;
sort2;
writeln ('Сортированный массив методом прямого выбора');
for i:=0 to 10 do write(M[i],' '); {Вывод отсортированного массива}
readln;
end.Программа 7. Сестры.
//Две строки матрицы назовем сестрами, если совпадают
//множества чисел, встречающихся в этих строках. Программа
//определяет всех сестер матрицы, если они есть,
//и выводит номера строк. Алгоритм реализован на Turbo C++.
//#include <graphics.h>
#include <stdlib.h>
//#include <string.h>
#include <stdio.h>
#include <conio.h>
//#include <math.h>
#include <dos.h>
#include <values.h>
#include <iostream.h>
const n=4,//кол-во строк
m=4; //столбцов
int m1[n][m];
//исходный массив
struct mas{int i,i1;};
//i-индекс сравниваемой строки с i1 строкой
mas a[n*2];
//массив типа mas, где будут лежать сестры, пример) a[1].i и a[1].i1 -
сестры
void main()
{clrscr();
int i,j;
randomize();
for( i=0;i<n;i++)
for( j=0;j<m;j++)
m1[i][j]=random(2);
//случайным образом в массив заносим цифры
for(i=0;i<n;i++)
{printf("\n %d) ",i);
for(int j=0;j<m;j++)
printf(" %d",m1[i][j]);
//распечатываем этот массив
}
int min,
p;
//индекс минимального элемента после s-го элемента i-ой строки
//сортировка строк массива по возрастанию
for(i=0;i<n;i++)//i-сортировка i-ой строки
{
for(int s=0;s<m-1;s++)
{min=m1[i][s+1];
for(int j=s;j<m;j++)
if(m1[i][j]<=min){min=m1[i][j];p=j;}
//запоминаем минимальный элемент в ряде после s-го элемента
if(m1[i][s]>=min)
{m1[i][p]=m1[i][s];m1[i][s]=min;}
//меняем местами s-й и p-й элемент,если s-й>p-го(минимального)
}
}
printf("\n");
for(i=0;i<n;i++)
{printf("\n %d) ",i);
for(int j=0;j<m;j++)
printf(" %d",m1[i][j]);
//выводим отсортированный массив
}
int s=0 //сколько элементов в i-й строке совпадают с
эл-ми i1 строки, k=0;
//сколько строк совпали
int i1;
for(i=0;i<n-1;i++) //верхняя строка i
for( i1=i+1;i1<n;i1++) //нижняя строка i1
{s=0;
for(int j=0;j<m;j++)
//сравнение идет по j-му столбцу
// ! !
if(m1[i][j]==m1[i1][j])s++; //если соответствующие элементы в
//i-й и i1-й строки совпадают, то кол-во совпавших увеличивается на 1
if(s==m){a[k].i=i;a[k].i1=i1;k++;}
//если все элементы i-й и i1-й строки совпали, то они сестры
}
printf("\nСестры :");
for(i=0;i<k;i++)
printf("\n %d и %d",a[i].i,a[i].i1);
//распечатываем a[i].i-ю и a[i].i1-ю сестру
getch();
}Программа 8. Поиск узоров из простых чисел.
//Построить матрицу А(15 Х 15)таким образом: А(8,8)=1, затем
//по спирали против часовой стрелки,
//увеличивая значение очередного элемента на единицу
//и выделяя все простые числа красным цветом, заполнить матрицу
//Алгоритм реализован на Turbo C++.
#include <stdio.h>
#include <conio.h>
void main(void)
{
clrscr();
int mas[15][15];
int n=1,x=6,y=6,k=1;
int i,j;
while(1){
mas[x][y]=k++;
switch(n){
case 1: x++;break;
case 2: y--;break;
case 3: x--;break;
case 4: y++;break;
}
if(x==15) break;
if(x==y && x<6) n=4;
else if(x+y==12 && x<6) n=1;
else if(x+y==12 && x>6) n=3;
else if(x==y+1 && x>6) n=2;
}
for(i=0;i<15;i++)
{
for(j=0;j<15;j++)
{
textcolor(12);
if(mas[j][i]>2)
for(k=2;k<mas[j][i];k++)
if(mas[j][i]%k==0) textcolor(15);
cprintf("%3d ",mas[j][i]);
}
printf("\n");
}
getch();
}Программа 9. Сортировка строк матрицы.
//Cортировка строк матрицы. В каждой строке подсчитывается сумма
//простых чисел. Полученный вектор упорядочивается по возрастанию.
//Строки матрицы переставляются по новому вектору.
//Алгоритм реализован на Turbo C++.
#include<stdio.h>
#include<conio.h>
#define n 5
struct summa
{
int value;
int idx;
} sum,massum[n],a;
void main(void){
clrscr();
int mas1[n][n],mas[n][n]={{1,1,1,1,1},
{3,16,11,6,4},
{8,10,15,23,1},
{3,8,10,15,3},
{7,3,20,15,10}};
int i,j,k,flag;
for(i=0;i<n;i++){
sum.value=0;
for(j=0;j<n;j++){
flag=0;
if(mas[i][j]>2)
for(k=2;k<mas[i][j];k++)
if(mas[i][j]%k==0) flag=1;
if(flag==0) sum.value=sum.value+mas[i][j];
}
sum.idx=i;
massum[i]=sum;
}
for(i=0;i<n-1;i++)
for(j=0;j<n-1-i;j++){
if (massum[j].value>massum[j+1].value){
a=massum[j];
massum[j]=massum[j+1];
massum[j+1]=a;
}
}
for(i=0;i<n;i++)
for(j=0;j<n;j++)
mas1[i][j]=mas[massum[i].idx][j];
for(i=0;i<n;i++){
for(j=0;j<n;j++)
printf("%3d ",mas[i][j]);
printf("\n");
}
printf("\n\n\n");
for(i=0;i<n;i++){
for(j=0;j<n;j++)
printf("%3d ",mas1[i][j]);
printf("\n");
}
getch();
}Задача о назначениях (задачи выбора)
Эта задача состоит в следующем. Пусть имеется ![]() работ и
работ и ![]() кандидатов для
выполнения этих работ. Назначение кандидата
кандидатов для
выполнения этих работ. Назначение кандидата ![]() на работу
на работу ![]() связано с затратами
связано с затратами ![]()
![]() . Требуется найти
назначение кандидатов на все работы, дающее
минимальные суммарные затраты; при этом каждого кандидата можно назначить
только на одну работу и каждая работа может быть занята только одним
кандидатом.
. Требуется найти
назначение кандидатов на все работы, дающее
минимальные суммарные затраты; при этом каждого кандидата можно назначить
только на одну работу и каждая работа может быть занята только одним
кандидатом.
Иначе говоря, решение этой задачи представляет собой перестановку
( ![]() ) чисел
) чисел ![]() ; каждое
из производимых
назначений описывается соответствием
; каждое
из производимых
назначений описывается соответствием ![]() (
( ![]() ).
Указанные условия единственности при этом автоматически выполняются, и
нашей целью является минимизация суммы
).
Указанные условия единственности при этом автоматически выполняются, и
нашей целью является минимизация суммы
 | (17.1) |
Перед нами типичная экстремальная комбинаторная задача. Ее решение путем
прямого перебора, то есть вычисления значений функции 17.1 на всех
перестановках и сравнения, практически невозможно при сколько-нибудь
больших ![]() , поскольку число перестановок равно
, поскольку число перестановок равно ![]() . Попытаемся свести дело к линейному программированию.
. Попытаемся свести дело к линейному программированию.
Конечное множество, на котором задана целевая функция 17.1, представляет
собой множество всех перестановок чисел ![]() . Как
известно, каждая такая перестановка может быть описана точкой в
. Как
известно, каждая такая перестановка может быть описана точкой в ![]() -мерном евклидовом
пространстве; эту точку удобнее всего представить в виде
-мерном евклидовом
пространстве; эту точку удобнее всего представить в виде ![]() -матрицы
-матрицы ![]() . Элементы
. Элементы ![]() интерпретировать следующим образом:
интерпретировать следующим образом:
![]() , если i-й кандидат назначается на j-ю работу,
, если i-й кандидат назначается на j-ю работу,
![]() , в противном случае.
, в противном случае.
Элементы матрицы должны быть подчинены двум условиям:
 | (17.3) |
 | (17.4) |
Теперь задача заключается в нахождении чисел ![]() ,
удовлетворяющих условиям
17.2, 17.3, 17.4 и минимизирующих суммарные затраты 17.1, которые теперь можно
переписать в виде
,
удовлетворяющих условиям
17.2, 17.3, 17.4 и минимизирующих суммарные затраты 17.1, которые теперь можно
переписать в виде
 | (17.5) |
| (17.6) |
Программа 10.Назначение на работу.
program one;{Назначение на работу.
Рассматривается случай: 10 работ и 10 желающих.
реализовано на Turbo-Pascal}
uses crt;
const n=10;
var C : array [1..n,1..n] of integer;
T : array [1..n] of integer;
M : array [1..n,1..4] of integer;
Sum,tmj,z,min,i,j,tmp:integer;
begin
clrscr;
randomize;
write('work - ');
for i:=1 to n do write(i:2,' ');
for i:=1 to n do begin
writeln;
write(i:2,' man ');
for j:=1 to n do begin
C[i,j]:=random(100);
{if M[i,j]>max then max:=M[i,j];}
{if C[i,j]<min then begin M[1]:=C[i,j]; M[2]:=i; M[3]:=j; end; }
write(C[i,j]:2,' ');
end;
end;
writeln;
for j:=1 to n do T[j]:=0;
Sum:=0;
for i:=1 to n do begin
writeln;
write(i:2,' man ');
min:=100;
for j:=1 to n do begin
if (C[i,j]<min) and (T[j]=0) then begin min:=C[i,j]; M[i,1]:=i;
M[i,2]:=j; M[i,3]:=C[i,j]; tmj:=j;
end;
write(C[i,j]:2,' ');
end;
T[tmj]:=1;
{M[i,3]:=min;}
Sum:=Sum+M[i,3];
write('=',M[i,3]:2,' man=',M[i,1],' job=',M[i,2]);
end;
writeln;
{for i:=1 to n do begin
for j:=1 to n do begin
if (i<>j) and (M[i,2]=M[j,2]) then begin
M[j,3]:=C[j,1];
for z:=1 to n do begin
if (M[j,3]>C[j,z]) and (z<>M[j,2]) then begin M[j,3]:=C[j,z];
M[j,2]:=z; end;
end;
end;
end;
writeln('=',M[i,3]:2,' man=',M[i,1],' job=',M[i,2]);
end;
}
write('sum=',Sum);
readln;
end.Программа 11.Назначение на работу.
/*
Назначение на работу.
Рассматривается случай: 6 работ и 6 желающих.
*/
//Назначение на работу. Реализовано на Turbo C++.
#include <stdio.h>
#include <iostream.h>
#include <stdlib.h>
#include <conio.h>
#define k 6
int Sum,tmj,i,j,zj,min,tmp,min2,tmj2,p,q,ki;
int M[k][4], C[k][k], T[k][2], Temper[k][2];
char a;
/*struct myst
{int cel;
float rac;
};
myst ctpyk[k];*/
main()
{
Sum=0;
min=100;
for(i=1;i<k;i++)
{ T[i][1]=0;
printf("\n");
for(j=1;j<k;j++)
{C[i][j]=rand()/1000 +1;
// printf(" %d ", C[i][j]);
}
}
for(i=1;i<k;i++)
{
min=100;
printf("\n");
for(j=1;j<k;j++)
{
if(C[i][j]<min/* && T[j][1]==0*/)
{
if(T[j][1]==0)
{
min=C[i][j]; //m[i][1] - 4el, m[i][2] -job, m[i][3]
- stoimost.
M[i][1]=i;
M[i][2]=j;
M[i][3]=C[i][j];
tmj=j;
}
/* else
{
if(C[i][j]<C[T[j][2]][j])
{
ki=T[j][2];
T[j][2]=0;
// T[j][1]=0;
min=C[i][j];
M[i][1]=i;
M[i][2]=j;
M[i][3]=C[i][j];
tmj=j;
for(zj=1;zj<k;zj++)
{
min2=100;
if(C[ki][zj]<min2 && zj!=tmj &&
T[zj][1]==0)
{
min2=C[ki][zj];
tmj2=zj;
M[ki][1]=ki;
M[ki][2]=zj;
M[ki][3]=C[ki][zj];
}
}
T[tmj2][2]=ki;
T[tmj2][1]=min2;
}
*/
}
printf(" %d ", C[i][j]);
}
T[tmj][2]=i;
T[tmj][1]=min;
//na4alo mega funkcii
/* if(C[i][j]<min && T[j][1]!=0)
{
for(p=1;pk;p++)
{
if(C[T[tmj][2]][p]
}
}
*/
//konec.
Sum=Sum+M[i][3];
printf(" $= %d, man= %d, job= %d ",M[i][3],M[i][1],M[i][2]);
}
/* for(i=0;i<k;i++)
{ctpyk[i].cel=rand();
ctpyk[i].rac=rand()/1000;
printf("%d %f \n", ctpyk[i].cel, ctpyk[i].rac);}
*/
scanf("%d",a);
return 0;
}Ханойская башня
В лекции 11 дана реализация алгоритма "Ханойская башня". Здесь используется другой подход. В программе реализован пользовательский интерфейс с развитым эргономическим компонентом. Пользователю предоставляется возможность самому решить поставленную задачу. В программе использована работа с видеостраницами.
Постановка задачи.
На стержне в исходном порядке находится дисков, уменьшающихся по размеру снизу вверх. Диски должны быть переставлены на стержень в исходном порядке при использовании в случае необходимости промежуточного стержня для временного хранения дисков. В процессе перестановки дисков обязательно должны соблюдаться правила: одновременно может быть переставлен только один самый верхний диск (с одного из стержней на другой); ни в какой момент времени диск не может находиться на другом диске меньшего размера.
Программа 12. Ханойская башня.
{Программа реализована с помощью абстрактного типа данных –
стек для произвольного числа дисков. Число колец задается
константой maxc. Программа написана на языке
программирования Turbo-Pascal}
program Tower;
uses Crt, Graph;
const maxc = 4;{Максимальное число колец на одной башне}
type TTower = record
num: byte;
sizes: array[1..maxc] of byte;
up: byte;
end;
var Towers: array[1..3] of TTower;
VisVP, ActVP: byte; {видимая и активная видеостраницы}
ActTower: byte;
Message: String;
Win: boolean;
font1: integer;
function CheckEnd: boolean;
var res: boolean;
i: byte;
begin
res:=False;
if (Towers[2].num=maxc) or (Towers[3].num=maxc) then res:=true;
CheckEnd:=res;
end;
procedure BeginDraw;
begin
SetActivePage(ActVP);
end;
procedure EndDraw;
begin
VisVP:=ActVP;
SetVisualPage(VisVP);
if VisVP=1 then ActVP:=0 else ActVP:=1;
end;
procedure Init;
var grDr, grM: integer;
ErrCode: integer;
i: integer;
begin
grDr:=VGA;
grM:=VGAMed;
InitGraph(grDr, grM, 'c:\borland\tp\bgi');
ErrCode:=GraphResult;
if ErrCode <> grOk then
begin
Writeln('Graphics error:', GraphErrorMsg(ErrCode));
Halt;
end;
Towers[1].num:=maxc;
Towers[1].up:=0;
for i:=0 to maxc-1 do
Towers[1].sizes[i+1]:=maxc-i;
Towers[2].num:=0;
Towers[2].up:=0;
for i:=0 to maxc-1 do
Towers[2].sizes[i+1]:=0;
p>Towers[3].num:=0;
Towers[3].up:=0;
for i:=0 to maxc-1 do
Towers[2].sizes[i+1]:=0;
ActTower:=1;
VisVP:=0; ActVP:=1;
SetVisualPage(VisVP);
SetActivePage(ActVP);
Message:='';
Win:=False;
end;
procedure Close;
begin
closegraph;
end;
procedure DrawTower(x, y: integer; n: integer);
var i: integer;
begin
if n=ActTower then
SetColor(yellow);
Line(x, y, x, y+15+maxc*15);
for i:=1 to Towers[n].num do
begin
Rectangle(x-10*Towers[n].sizes[i], y+15+15*(maxc-i+1),
x+10*Towers[n].sizes[i], y+15+15*(maxc-i))
end;
if Towers[n].up<>0 then
begin
Rectangle(x-10*Towers[n].up, y-15, x+10*Towers[n].up, y-30);
end;
SetColor(White);
end;
procedure DrawInfo;
begin
OutTextXY(50, 20, 'Ханойская башня.);
OutTextXY(80, 40, 'Работа с программой: стрелки влево-вправо - выбор
башни');
OutTextXY(130, 60, 'текущая башня выделяется желтым цветом');
OutTextXY(60, 80, 'стрелка вверх - поднять кольцо, стрелка вниз -
положить кольцо');
OutTextXY(80, 100, '(две последние операции выполняются для активной
башни)');
end;
procedure Draw;
begin
BeginDraw;
ClearDevice;
OutTextXY(180, 140, Message); Message:='';
DrawTower(150, 200, 1);
DrawTower(300, 200, 2);
DrawTower(450, 200, 3);
if win then
begin
SetTextStyle(GothicFont, HorizDir, 8);
SetColor(Red);
Outtextxy(70, 0, 'Congratulations');
Outtextxy(160, 70, 'You win');
SetTextStyle(DefaultFont, HorizDir, 1);
SetColor(White);
OutTextXY(250, 330, 'Press any key');
end
else
DrawInfo;
EndDraw;
end;
procedure MainCycle;
var ch: char;
ex: boolean;
up: byte;
begin
ex:=False;
repeat
if KeyPressed then
begin
ch:=ReadKey;
case ch of
#27: begin
Ex:=True;
end;
#77: begin
up:=Towers[ActTower].up;
Towers[ActTower].up:=0;
inc(ActTower);
if ActTower>3 then ActTower:=1;
Towers[ActTower].up:=up;
end;
#75: begin
up:=Towers[ActTower].up;
Towers[ActTower].up:=0;
dec(ActTower);
if ActTower<1 then ActTower:=3;
Towers[ActTower].up:=up;
end;
#80: begin {вниз}
if Towers[ActTower].up<>0 then
begin
if Towers[ActTower].num=0 then
begin
Towers[ActTower].num:=Towers[ActTower].num+1;
Towers[ActTower].sizes[Towers[ActTower].num]:=Towers[ActTower].up;
Towers[ActTower].up:=0;
end
else
begin
if
Towers[ActTower].sizes[Towers[ActTower].num]>Towers[ActTower].up then
begin
Towers[ActTower].num:=Towers[ActTower].num+1;
Towers[ActTower].sizes[Towers[ActTower].num]:=Towers[ActTower].up;
Towers[ActTower].up:=0;
end
else
Message:='Это кольцо сюда опускать нельзя';
end;
end;
end;
#72: begin {вверх}
if Towers[ActTower].num<>0 then
begin
Towers[ActTower].num:=Towers[ActTower].num-1;
Towers[ActTower].up:=Towers[ActTower].sizes[Towers[ActTower].num+1];
Towers[ActTower].sizes[Towers[ActTower].num+1]:=0;
end;
end;
end;
if CheckEnd then
begin
Win:=True;
ex:=True;
end;
Draw;
end;
until ex;
end;
begin
Init;
Draw;
MainCycle;
if win then repeat until keypressed;
Close;
end.