Лекция 1. Введение в MySQL
Компьютерные системы хранения
В наши дни люди часто говорят о базах данных. Компьютеры составляют неотъемлемую часть современного общества, поэтому нередко можно услышать фразы вроде "Я поищу твою запись в базе данных". И речь идет не о больших ящиках, где хранятся груды папок, а о компьютерных системах, предназначенных для ускоренного поиска информации.
Компьютеры так прочно вошли в нашу жизнь, потому что их можно запрограммировать на выполнение утомительных, повторяющихся операций и решение задач, которые нам самим было бы не под силу решить без их вычислительной скорости и емкости информационных носителей. Помещение информации на бумагу и разработка схемы хранения бумаг в папках и картотеках — достаточно четко отработанный процесс, но многие вздохнули с облегчением, когда задача свелась к перемещению электронных документов в папки на жестком диске.
Одной из функций баз данных является упорядочение и индексация информации. Как и в библиотечной картотеке, не нужно просматривать половину архива, чтобы найти нужную запись. Все выполняется гораздо быстрее.
Не все базы данных создаются на основе одних и тех же принципов, но традиционно в них применяется идея организации данных в виде записей. Каждая запись имеет фиксированный набор полей. Записи помещаются в таблицы, а совокупность таблиц формирует базу данных.
Для работы с базой данных необходима СУБД (система управления базами данных), т.е. программа, которая берет на себя все заботы, связанные с доступом к данным. Она содержит команды, позволяющие создавать таблицы, вставлять в них записи, искать и даже удалять таблицы..
MySQL - это быстрая, надежная, открыто распространяемая СУБД. MySQL, как и многие другие СУБД, функционирует по модели "клиент/сервер". Под этим подразумевается сетевая архитектура, в которой компьютеры играют роли клиентов либо серверов. На рис. 1.1 изображена схема передачи информации между компьютером клиента и жестким диском сервера.

Рис. 1.1. Схема передачи данных в архитектуре "клиент/сервер"
СУБД управляет одной или несколькими базами данных. База данных представляет собой совокупность информации, организованной в виде множеств. Каждое множество содержит записи унифицированного вида. Сами записи состоят из полей. Обычно множества называют таблицами, а записи — строками таблиц.
Такова логическая модель данных. На жестком диске вся база данных может находиться в одном файле. В MySQL для каждой базы данных создается отдельный каталог, а каждой таблице соответствуют три файла. В других СУБД могут использоваться иные принципы физического хранения данных.
Строки таблиц могут быть связаны друг с другом одним из трех способов. Простейшее отношение — "один к одному". В этом случае строка первой таблицы соответствует одной единственной строке второй таблицы. На диаграммах такое отношение выражается записью 1:1.
Отношение "один ко многим" означает ситуацию, когда строка одной таблицы соответствует нескольким строкам другой таблицы. Это наиболее распространенный тип отношений. На диаграммах он выражается записью 1:N.
Наконец, при отношении "многие ко многим" строки первой таблицы могут быть связаны с произвольным числом строк во второй таблице. Такое отношение записывается как N:M.
СУБД
Программист, работающий с базой данных, не заботится о том, как эти данные хранятся, и приложения, взаимодействующие с СУБД, не знают о способе записи данных на диск. "Снаружи" виден лишь логический образ данных, и это позволяет менять код СУБД, не затрагивая код самих приложений.
Подобная обработка данных осуществляется посредством языка четвертого поколения (4GL), который поддерживает запросы, записываемые и исполняемые немедленно. Данные быстро утрачивают свою актуальность, поэтому скорость доступа к ним важна. Кроме того, программист должен иметь возможность формулировать новые запросы. Они называются нерегламентированными (ad hoc), поскольку не хранятся в самой базе данных и служат узкоспециализированным целям.
Язык четвертого поколения позволяет создавать схемы — точные определения данных и отношений между ними. Схема хранится как часть базы данных и может быть изменена без ущерба для данных.
Схема предназначена для контроля целостности данных. Если, к примеру, объявлено, что поле содержит целочисленные значения, то СУБД откажется записывать в него числа с плавающей запятой или строки. Отношения между записями тоже четко контролируются, и несогласованные данные не допускаются. Операции можно группировать в транзакции, выполняемые по принципу "все или ничего".
СУБД обеспечивает безопасность данных. Пользователям предоставляются определенные права доступа к информации. Некоторым пользователям разрешено лишь просматривать данные, тогда как другие пользователи могут менять содержимое таблиц.
СУБД поддерживает параллельный доступ к базе данных. Приложения могут обращаться к базе данных одновременно, что повышает общую производительность системы. Кроме того, отдельные операции могут "распараллеливаться" для еще большего улучшения производительности.
Наконец, СУБД помогает восстанавливать информацию в случае непредвиденного сбоя, незаметно для пользователей создавая резервные копии данных. Все изменения, вносимые в базу данных, регистрируются, поэтому многие операции можно отменять и выполнять повторно.
Концепции баз данных
Системы управления файлами
Простейшая база данных организована в виде набора обычных файлов. Эта модель напоминает картотечную организацию документов, при которой папки хранятся в ящиках, а в каждой папке подшито некоторое число страниц.
Системы управления файлами нельзя классифицировать как СУБД, так как обычно они являются частью операционной системы и ничего не знают о внутреннем содержимом файлов. Это знание заложено в прикладных программах, работающих с файлами. В качестве примера можно привести таблицу пользователей UNIX, хранящуюся в файле /etc/passwd. Программы, обращающиеся к этому файлу, знают, что в его первом поле находится имя пользователя, оканчивающееся двоеточием. Если приложению нужно отредактировать эту информацию, оно должно непосредственно открыть файл и позаботиться о правильном форматировании полей.
Такая модель базы данных очень неудобна, поскольку она требует использовать язык третьего поколения (3GL). В результате время программирования запросов увеличивается, а программист должен обладать более высокой квалификацией, так как ему нужно продумать не только логическую, но и физическую структуру хранения данных. Это приводит к тому, что между приложением и файлом образуется тесная связь. Вся информация о полях таблиц закодирована в приложении. Другое приложение, обращающееся к тому же файлу, вынуждено дублировать существующий код.
По мере увеличения числа приложений растет сложность управления базой данных. Изменения схемы данных приводят к необходимости изменения каждого программного компонента, для которого это актуально. Формирование новых запросов занимает столько времени, что зачастую теряет всякий смысл.
Системы управления файлами не могут помешать дублированию информации. Хуже того, не существует механизмов, предотвращающих несогласованность данных. Представьте себе файл, содержащий сведения обо всех служащих компании. В каждой строке есть поле, где записано имя начальника. Под руководством одного начальника работает много служащих, поэтому его имя будет неизбежно повторяться. Если где-то это имя будет записано неправильно, формально получится, что у служащего другой начальник. При замене начальника его имя придется "вылавливать" по всей базе данных.
Безопасность обычных файлов контролируется операционной системой. Отдельный файл может быть заблокирован для просмотра или модификации со стороны того или иного пользователя, но это выполняется только на уровне операционной системы. В конкретный момент времени лишь одно приложение может осуществлять запись в файл, что снижает общую производительность.
Иерархические базы данных
Иерархические базы данных поддерживают древовидную организацию информации. Связи между записями выражаются в виде отношений предок/потомок, а у каждой записи есть ровно одна родительская запись. Это помогает поддерживать ссылочную целостность. Когда запись удаляется из дерева, все ее потомки также должны быть удалены.
На рис. 1.2 изображена простая иерархическая база данных, в которой фиксируется деятельность независимого подрядчика. Корень дерева представляет собой запись о клиенте. Ее потомками являются две записи о счет-фактурах и три записи об оплатах счетов. Структура счета номер 17 уточняется в трех дочерних записях, у счета номер 23 одна такая запись.
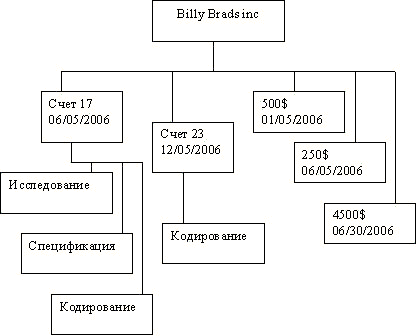
Рис. 1.2. Иерархическая база данных
Иерархические базы данных имеют централизованную структуру, т.е. безопасность данных легко контролировать. К сожалению, определенные знания о физическом порядке хранения записей все же необходимы, так как отношения предок/потомок реализуются в виде физических указателей из одной записи на другую.
Это означает, что поиск записи осуществляется методом прямого обхода дерева. Записи, расположенные в одной половине дерева, ищутся быстрее, чем в другой. Отсюда следует необходимость правильно упорядочивать записи, чтобы время их поиска было минимальным. Это трудно, так как не все отношения, существующие в реальном мире, можно выразить в иерархической базе данных. Отношения "один ко многим" являются естественными, но практически невозможно описать отношения "многие ко многим" или ситуации, когда запись имеет несколько предков. До тех пор пока в приложениях будут кодироваться сведения о физической структуре данных, любые изменения этой структуры будут грозить перекомпиляцией.
Сетевые базы данных
Сетевая модель расширяет иерархическую модель, позволяя группировать связи между записями в множества. С логической точки зрения связь — это не сама запись. Связи лишь выражают отношения между записями. Как и в иерархической модели, связи ведут от родительской записи к дочерней, но на этот раз поддерживается множественное наследование.
Следуя спецификации CODASYL, сетевая модель поддерживает DDL (Data Definition Language — язык определения данных) и DML (Data Manipulation Language — язык обработки данных). Это специальные языки, предназначенные для определения структуры базы данных и составления запросов. Несмотря на их наличие, программист по-прежнему должен знать структуру базы данных.
В сетевой модели допускаются отношения "многие ко многим", а записи не зависят друг от друга. При удалении записи удаляются и все ее связи, но не сами связанные записи.
В сетевой модели требуется, чтобы связи устанавливались между существующими записями во избежание дублирования и искажения целостности. Данные можно изолировать в соответствующих таблицах и связать с записями в других таблицах.
Программисту не нужно заботиться о том, как организуется физическое хранение данных на диске. Это ослабляет зависимость приложений и данных. Но в сетевой модели требуется, чтобы программист помнил структуру данных при формировании запросов.
Оптимальную структуру базы данных сложно сформировать, а готовую структуру трудно менять. Если вид таблицы претерпевает изменения, все отношения с другими таблицами должны быть установлены заново, чтобы не нарушилась целостность данных. Сложность подобной задачи приводит к тому, что программисты зачастую отменяют некоторые ограничения целостности ради упрощения приложений.
Реляционные базы данных
В сравнении с рассмотренными выше моделями реляционная модель требует от СУБД гораздо более высокого уровня сложности. В ней делается попытка избавить программиста от выполнения рутинных операций по управлению данными, столь характерных для иерархической и сетевой моделей.
В реляционной модели база данных представляет собой централизованное хранилище таблиц, обеспечивающее безопасный одновременный доступ к информации со стороны многих пользователей. В строках таблиц часть полей содержит данные, относящиеся непосредственно к записи, а часть — ссылки на записи других таблиц. Таким образом, связи между записями являются неотъемлемым свойством реляционной модели.
Каждая запись таблицы имеет одинаковую структуру. Например, в таблице, содержащей описания автомобилей, у всех записей будет один и тот же набор полей: производитель, модель, год выпуска, пробег и т.д. Такие таблицы легко изображать в графическом виде.
В реляционной модели достигается информационная и структурная независимость. Записи не связаны между собой настолько, чтобы изменение одной из них затронуло остальные, а изменение структуры базы данных не обязательно приводит к перекомпиляции работающих с ней приложений.
В реляционных СУБД применяется язык SQL, позволяющий формулировать произвольные, нерегламентированные запросы. Это язык четвертого поколения, поэтому любой пользователь может быстро научиться составлять запросы. К тому же, существует множество приложений, позволяющих строить логические схемы запросов в графическом виде. Все это происходит за счет ужесточения требований к производительности компьютеров. К счастью, современные вычислительные мощности более чем адекватны.
Реляционные базы данных страдают от различий в реализации языка SQL, хотя это и не проблема реляционной модели. Каждая реляционная СУБД реализует какое-то подмножество стандарта SQL плюс набор уникальных команд, что усложняет задачу программистам, пытающимся перейти от одной СУБД к другой. Приходится делать нелегкий выбор между максимальной переносимостью и максимальной производительностью. В первом случае нужно придерживаться минимального общего набора команд, поддерживаемых в каждой СУБД. Во втором случае программист просто сосредоточивается на работе в данной конкретной СУБД, используя преимущества ее уникальных команд и функций.
MySQL — это реляционная СУБД, и настоящий учебный курс посвящен изучению именно реляционной модели. Но теория баз данных не стоит на месте. Появляются новые технологии, которые расширяют реляционную модель.
Объектно-ориентированные базы данных
Объектно-ориентированная база данных (ООБД) позволяет программистам, которые работают с языками третьего поколения, интерпретировать все свои информационные сущности как объекты, хранящиеся в оперативной памяти. Дополнительный интерфейсный уровень абстракции обеспечивает перехват запросов, обращающихся к тем частям базы данных, которые находятся в постоянном хранилище на диске. Изменения, вносимые в объекты, оптимальным образом переносятся из памяти на диск.
Преимуществом ООБД является упрощенный код. Приложения получают возможность интерпретировать данные в контексте того языка программирования, на котором они написаны. Реляционная база данных возвращает значения всех полей в текстовом виде, а затем они приводятся к локальным типам данных. В ООБД этот этап ликвидирован. Методы манипулирования данными всегда остаются одинаковыми независимо от того, находятся данные на диске или в памяти.
Данные в ООБД способны принять вид любой структуры, которую можно выразить на используемом языке программирования. Отношения между сущностями также могут быть произвольно сложными. ООБД управляет кэш-буфером объектов, перемещая объекты между буфером и дисковым хранилищем по мере необходимости.
С помощью ООБД решаются две проблемы. Во-первых, сложные информационные структуры выражаются в них лучше, чем в реляционных базах данных, а во-вторых, устраняется необходимость транслировать данные из того формата, который поддерживается в СУБД. Например, в реляционной СУБД размерность целых чисел может составлять 11 цифр, а в используемом языке программирования — 16. Программисту придется учитывать эту ситуацию.
Объектно-ориентированные СУБД выполняют много дополнительных функций. Это окупается сполна, если отношения между данными очень сложны. В таком случае производительность ООБД оказывается выше, чем у реляционных СУБД. Если же данные менее сложны, дополнительные функции оказываются избыточными. В объектной модели данных поддерживаются нерегламентированные запросы, но языком их составления не обязательно является SQL. Логическое представление данных может не соответствовать реляционной модели, поэтому применение языка SQL станет бессмысленным. Зачастую удобнее обрабатывать объекты в памяти, выполняя соответствующие виды поиска.
Большим недостатком объектно-ориентированных баз данных является их тесная связь с применяемым языком программирования. К данным, хранящимся в реляционной СУБД, могут обращаться любые приложения, тогда как, к примеру, Java-объект, помещенный в ООБД, будет представлять интерес лишь для приложений, написанных на Java.
Объектно-реляционные базы данных
Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении.
Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Представим себе музыкальную базу данных. Песню, закодированную в виде аудиофайла, можно поместить в текстовое поле большого размера, но как в таком случае будет осуществляться текстовый поиск?
Перестройка СУБД с целью включения в нее поддержки нового типа данных — не лучший выход из положения. Вместо этого объектно-реляционная СУБД позволяет загружать код, предназначенный для обработки "нетипичных" данных. Таким образом, база данных сохраняет свою табличную структуру, но способ обработки некоторых полей таблиц определяется извне, т.е. программистом.
Основные характеристики MySQL
Клиентская программа MySQL представляет собой утилиту командной строки. Эта программа подключается к серверу по сети. Команды, выполняемые сервером, обычно связаны с чтением и записью данных на жестком диске.
Клиентские программы могут работать не только в режиме командной строки. Есть и графические клиенты, например MySQL GUI, PhpMyAdmin и др. Но они – тема отдельного курса.
MySQL взаимодействует с базой данных на языке, называемом SQL (Structured Query Language — язык структурированных запросов).
SQL предназначен для манипуляции данными, которые хранятся в Системах управления реляционными базами данных (RDBMS). SQL имеет команды, с помощью которых данные можно извлекать, сортировать, обновлять, удалять и добавлять. Стандарты языка SQL определяет ANSI (American National Standards Institute). В настоящее время действует стандарт, принятый в 2003 году (SQL-3).
SQL можно использовать с такими RDBMS как MySQL, mSQL, PostgreSQL, Oracle, Microsoft SQL Server, Access, Sybase, Ingres. Эти системы RDBMS поддерживают все важные и общепринятые операторы SQL, однако каждая из них имеет множество своих собственных патентованных операторов и расширений.
SQL является общим языком запросов для нескольких баз данных различных типов. Данный курс рассматривает систему MySQL, которая является RDBMS c открытым исходным кодом, доступной для загрузки на сайте MySQL.com.
Вот как характеризуют MySQL её разработчики.
- MySQL - это система управления базами данных.
База данных представляет собой структурированную совокупность данных. Эти данные могут быть любыми - от простого списка предстоящих покупок до перечня экспонатов картинной галереи или огромного количества информации в корпоративной сети. Для записи, выборки и обработки данных, хранящихся в компьютерной базе данных, необходима система управления базой данных, каковой и является ПО MySQL. Поскольку компьютеры замечательно справляются с обработкой больших объемов данных, управление базами данных играет центральную роль в вычислениях. Реализовано такое управление может быть по-разному - как в виде отдельных утилит, так и в виде кода, входящего в состав других приложений.
- MySQL - это система управления реляционными базами данных.
В реляционной базе данные хранятся в отдельных таблицах, благодаря чему достигается выигрыш в скорости и гибкости. Таблицы связываются между собой при помощи отношений, благодаря чему обеспечивается возможность объединять при выполнении запроса данные из нескольких таблиц. SQL как часть системы MySQL можно охарактеризовать как язык структурированных запросов плюс наиболее распространенный стандартный язык, используемый для доступа к базам данных.
- Программное обеспечение MySQL - это ПО с открытым кодом.
ПО с открытым кодом означает, что применять и модифицировать его может любой желающий. Такое ПО можно получать по Internet и использовать бесплатно. При этом каждый пользователь может изучить исходный код и изменить его в соответствии со своими потребностями.
- Технические возможности СУБД MySQL
ПО MySQL является системой клиент-сервер, которая содержит многопоточный SQL-сервер, обеспечивающий поддержку различных вычислительных машин баз данных, а также несколько различных клиентских программ и библиотек, средства администрирования и широкий спектр программных интерфейсов (API).
- Безопасность
Система безопасности основана на привилегиях и паролях с возможностью верификации с удаленного компьютера, за счет чего обеспечивается гибкость и безопасность. Пароли при передаче по сети при соединении с сервером шифруются. Клиенты могут соединяться с MySQL, используя сокеты TCP/IP, сокеты Unix или именованные каналы (named pipes, под NT)
- Вместимость данных
Начиная с MySQL версии 3.23, где используется новый тип таблиц, максимальный размер таблицы доведен до 8 миллионов терабайт (263 bytes). Однако следует заметить, что операционные системы имеют свои собственные ограничения по размерам файлов. Ниже приведено несколько примеров:
- 32-разрядная Linux-Intel – размер таблицы 4 Гб.
- Solaris 2.7 Intel - 4 Гб
- Solaris 2.7 UltraSPARC - 512 Гб
- WindowsXP - 4 Гб
Как можно видеть, размер таблицы в базе данных MySQL обычно лимитируется операционной системой. По умолчанию MySQL-таблицы имеют максимальный размер около 4 Гб. Для любой таблицы можно проверить/определить ее максимальный размер с помощью команд SHOW TABLE STATUS или myisamchk -dv table_name. Если большая таблица предназначена только для чтения, можно воспользоваться myisampack, чтобы слить несколько таблиц в одну и сжать ее. Обычно myisampack ужимает таблицу по крайней мере на 50%, поэтому в результате можно получить очень большие таблицы.
Лекция 2. Подготовка к работе с MySQL
Пользователю базы данных необязательно знать, как инсталлировать MySQL. В крупных организациях есть системные администраторы, которые этим занимаются. Что касается разработчиков, то им нужно понимать особенности данного процесса. Именно здесь у них появляется доступ к различным конфигурационным установкам, с помощью которых можно настроить производительность программы. Естественно, необходимо обладать правами администратора на том компьютере, где MySQL устанавливается в виде сервиса, запускаемого автоматически. Программу можно запускать также из персональных учетных записей.
Загрузка MySQL
MySQL можно инсталлировать двумя способами: скомпилировав исходные коды программы или воспользовавшись предварительно скомпилированными двоичными файлами. Первый вариант допускает больше возможностей в плане конфигурации, но более продолжителен. Второй вариант удобнее, так как есть готовые дистрибутивы для многих операционных систем. На текущий момент существуют версии MySQL для FreeBSD, HP-UX, IBM AIX, Linux, Mac OS X, SCO, SGI Irix, Solaris и многих вариантов Microsoft Windows.
Информацию обо всех дистрибутивах можно получить на Web-узле http://www.mysql.com. Там же публикуются последние новости о программе.
Проверка исходных требований
Если инсталлируются двоичные файлы, следует убедиться в том, что система соответствует исходным требованиям программы. Важным моментом является поддержка потоков. При инсталляции в старых версиях некоторых операционных систем MySQL требует наличия отдельной библиотеки потоковых функций POSIX. POSIX — это международный стандарт, определяющий работу системных сервисов, а потоки — это механизм, позволяющий программам выполнять несколько задач одновременно. Современные операционные системы поддерживают стандарт POSIX. Если вы все же не уверены, проверьте в интерактивной документации, будет ли программа MySQL работать в данной версии операционной системы.
Выбор версии
Команда разработчиков MySQL публикует тестовые и стабильные версии дистрибутивов отдельно. Информацию о статусе той или иной версии программы можно найти на Web-узле. Эти же сведения закодированы в названии дистрибутива.
В целом лучше выбирать самую новую версию. Исключение составляют лишь альфа-версии, в которых впервые вводятся новые функциональные возможности. Программа MySQL отвечает самым высоким критериям качества и надежности, поэтому ее бета-версии зачастую вполне сопоставимы с финальными версиями других программ.
Инсталляция с помощью менеджера пакетов RedHat Linux
Если программа MySQL инсталлируется в Linux, то лучше всего воспользоваться модулем RPM (RedHat Packet Manager— менеджер пакетов RedHat). MySQL работает в Linux версий 2.0 и выше. Тестирование программы выполнялось в RedHat 6.2. В программе используется библиотека glibc, подключаемая статически. Если в системе установлена более старая версия библиотеки, программу придется скомпилировать заново.
В таблице 2.1 приведено описание доступных модулей RPM (для последней версии пакета MySQL 4.01.10, на момент создания этого материала)
| MySQL-4.01.10-1.i386.rpm | Содержит все файлы, необходимые для запуска сервера MySQL, включая клиентские программы. |
| MySQL-4.01.10-l.src.rpm | Содержит все исходные коды MySQL |
| MySQL-bench-4.01.10-1.i386.rpm | Содержит программы, предназначенные для тестирования производительности MySQL. Для запуска тестов необходим основной дистрибутив, а также интерпретатор Perl. |
| MySQL-client-4.01.10-1.i386.rpm | Содержит лишь клиентские программы |
| MySQL-devel-4.01.10-1.i386.rpm | Содержит библиотеки и файлы заголовков, необходимые для компиляции клиентских программ |
| MySQL-shared-4.01.10-1.i386.rpm | Содержит совместно используемые библиотеки для клиентских программ |
Опытные пользователи Linux знают, что флаг -i служит программе rpm указанием инсталлировать пакет. Таким образом, основной модуль MySQL инсталлируется следующей командой:
rpm -i MySQL-4.01.10-1.i386.rpm
В результате инсталляции в каталог /etc/rc.d добавляется файл сценария, содержащий команду запуска сервера MySQL после перезагрузки компьютера. Однако сам серверный домен запускается немедленно.
По окончании инсталляции потребуется изменить стандартные привилегии доступа к базам данных, о чем пойдет речь в конце лекции.
Можно также инсталлировать модуль RPM с исходными кодами программы. В этом случае воспользуйтесь опцией --rebuild, чтобы подготовить бинарный модуль.
Обычно пользователи инсталлируют лишь модули MySQL-4.01.10-1.i386.rpm и MySQL-client-4.01.10-l.i386.rpm. Для тех, кто собирается писать собственные клиентские программы, потребуется также модуль MySQL-devel-4.01.10-1.i386.rpm.
Инсталляция в Windows
Программа MySQL распространяется и в виде ZIP-архива, содержащего набор инсталляционных файлов. Перед извлечением файлов из архива создайте отдельный каталог, например с:\windows\mysql, так как в архиве нет информации о путевых именах файлов.
Чтобы приступить к инсталляции, выполните двойной щелчок на файле setup.ехе, после чего начнут появляться различные диалоговые окна. Первый вопрос, на который предстоит ответить, касается папки, куда должна быть помещена программа. По умолчанию предлагается папка с:\mysql. Можно выбрать любую другую папку, но в таком случае придется отредактировать конфигурационный файл.
Следующий вопрос касается инсталлируемых компонентов. Если выбрать "типичную" инсталляцию, будут инсталлированы серверный модуль, справочные файлы, а также набор файлов, содержащих описание стандартных привилегий доступа. В случае инсталляции "на выбор" можно будет дополнительно установить утилиты тестирования и библиотеки функций разработки.
Далее начнется собственно установка программы. Если инсталляционный каталог называется не с:\mysql, то по окончании инсталляции нужно будет дополнительно установить файл my.ini. Для этого перейдите в каталог программы и найдите файл my-example.cnf. Скопируйте его в системный каталог (с:\windows) и переименуйте в my.ini. Можно поступить и по-другому: скопировать файл в корневой раздел диска С: и назвать его my.cnf.
Теперь нужно отредактировать этот файл, чтобы переменная basedir указывала на инсталляционный каталог. Если соответствующая строка присутствует в виде комментария, удалите символы комментария. В противном случае добавьте эту строку самостоятельно, например:
basedir = d:\mysql
Если программа MySQL инсталлируется в Windows 2000 (XP), то, возможно, ее нужно запустить в виде сервиса. Для этого требуется перейти в режим командной строки и ввести следующую команду:
c:\mysql\bin\mysqld-nt --install
Название сервиса появится в окне сервисов панели управления, где можно будет настроить программу на автоматический запуск. Утилита winmysqladmin, входящая в Windows-дистрибутив, позволяет автоматизировать множество задач, включая конфигурацию.
Если Вы хотите запустить MySQL вручную, то Вам потребуется выполнить следующую последовательность действий:
- запустите сеанс MS-DOS и перейдите в каталог c:\mysql\bin
- введите в строке приглашения:
mysqld-shareware --standalone
или (в зависимости от версии)
mysqld
тем самым будет запущен сервер MySQL.
- введите "mysql" (без кавычек) в приглашении DOS.
- приглашение изменится на приглашение "mysql".
- чтобы протестировать сервер MySQL, введите в строке приглашения "show databases;"
- на экране должно появиться окно, изображенное на рис 2.1
Рис. 2.1. Запуск MySQL
Если появится подобный результат, то можно считать, что установка системы MySQL успешно завершена.
- введите "quit" в приглашении mysql.
- снова появится приглашение MS-DOS.
- так как в данный момент работа закончена, необходимо остановить сервер MySQL. выполните в приглашении следующую команду.
mysqladmin -u root shutdown
Инсталляция вручную
Если программа MySQL инсталлируется не в Linux или Windows либо если услуги менеджера пакетов не нужны, можно инсталлировать двоичные файлы вручную. Соответствующий дистрибутив распространяется в виде tar-архива, сжатого с помощью программы gzip.
Первый этап заключается в добавлении нового пользователя, от имени которого будет работать демон MySQL. Естественно, это не должен быть пользователь root.
Программе MySQL нельзя предоставлять права суперпользователя, и никакие компромиссы здесь недопустимы. Можно, например, создать группу mysql и одноименного пользователя с помощью команд addgroup и adduser либо groupadd и useradd, в зависимости от версии UNIX. Ниже показан пример для RedHat Linux:
groupadd mysql useradd -g mysql mysql
Обычно начальным каталогом MySQL выбирают /usr/local/mysql. После распаковки архива будет создан каталог, имя которого совпадает с именем дистрибутива, поэтому удобнее всего просто создать символическую ссылку mysql. Вот как это делается:
cd /usr/local tar xvfz mysql-4.01.10-pc-linux-gnu-i686.tar.gz ln -s mysql-4.01.10-pc-linux-gnu-i686 mysql cd mysql
Далее необходимо запустить сценарий mysql_install_db, находящийся в каталоге scripts. Он создаст базу данных с описанием существующих привилегий и тестовую базу данных.
Как правило, программа MySQL инсталлируется от имени пользователя root, поэтому следующий шаг заключается в изменении владельца всех файлов программы:
chown -R mysql /usr/local/mysql chgrp -R mysql /usr/local/mysql
Теперь можно запустить демон MySQL с помощью сценария safe_mysqld. Следующая команда запускает демон от имени пользователя mysql:
/usr/local/mysql/bin/safe_mysqld --user=mysql &
Если нужно, чтобы сервер MySQL запускался всякий раз после перезагрузки компьютера, добавьте соответствующую строку в файл /etc/rc.d/rc.local или же скопируйте сценарий mysql.server в каталог /etc/init.d и создайте правильные символические ссылки на него. В комментариях к файлу support-files/mysql.server рекомендуются такие ссылки:
/etc/rc3.d/S99mysql
и
/etc/rcO.d/SOlmysql.
Чтобы запустить программу клиента mysql вручную, введем в строке приглашения команду:
mysql -u root -p
Система попросит ввести пароль. Введите пароль для root (mysqldata).
Если приглашение ввести пароль не появилось, то это может означать, что сервер MySQL не работает. Чтобы запустить сервер, перейдите в каталог /etc/rc.d/init.d/ и выполните команду ./mysql start (или mysql start, в зависимости от значения переменной PATH). Затем вызовите программу клиента mysql.
Если клиент MySQL работает, то появится приглашение mysql>. Введите в строке приглашения следующее:
show databases;
На экране должен появиться вывод, как на рис. 2.1.
Теперь можно считать, что система MySQL успешно установлена в Linux.
Компиляция программы
Если в вашем распоряжении имеются исходные коды программы, создайте из них двоичные файлы и следуйте приведенным выше инструкциям. Поскольку исходные тексты были подготовлены с помощью утилиты autoconf, для компиляции программы нужно будет ввести последовательность команд configure, make и make install.
По возможности следует избегать перекомпиляции программы. Разработчики MySQL досконально знают все тонкости процесса компиляции, поэтому они умеют создавать максимально оптимизированные исполняемые файлы.
При компиляции исходных кодов появляется возможность подключить компоненты, не встроенные в стандартные инсталляционные пакеты. Для некоторых из них требуются библиотеки функций разработки. Инсталлируйте их до начала компиляции программы.
Предоставление привилегий
Сценарий mysql_install_db предоставляет любому пользователю локального компьютера привилегии, позволяющие регистрироваться на сервере баз данных. Сетевые соединения не допускаются. По умолчанию любой пользователь имеет доступ к базе test, а пользователь root имеет полный доступ ко всем базам данных. Если в какой-то из баз хранится важная информация, нужно назначить суперпользователю пароль.
Программа MySQL не работает со списком пользователей, который есть у операционной системы. У нее своя таблица пользователей. Тем не менее, если при работе с имеющимися клиентскими программами не ввести имя пользователя в процессе регистрации на сервере, будет подставлено системное имя пользователя.
Чтобы поменять пароль пользователя root, нужно запустить интерпретатор команд MySQL от имени суперпользователя. Данный интерпретатор представляет собой программу mysql, путь к которой должен быть указан в переменной среды PATH.
Пользователям Windows придется вводить путевое имя целиком, например c:\mysql\bin\mysql. С помощью опции --user задается имя для регистрации. В нашем случае интерпретатор запускается с помощью такой команды:
mysql --user=root mysql
Вызвав интерпретатор, необходимо обновить две строки в таблице user, касающиеся пользователя root. Это делает следующая инструкция:
UPDATE user SET Password = PASSWORD('secret')
WHERE User = 'root';В ответ на эту инструкцию интерпретатор отобразит две модифицируемые записи. Естественно, вместо строки 'secret' следует выбрать более надежный пароль. Этот пароль должен применяться лишь в административных целях.
Далее нужно сообщить серверу об изменении привилегий. Для этого предназначена такая инструкция:
FLUSH PRIVILEGES;
Любой пользователь может захотеть создать персональную базу данных для собственных экспериментов, но делать это разрешено только пользователю root. Он же может создавать учетные записи новых пользователей и предоставлять им необходимые привилегии. Рассмотрим пример:
CREATE DATABASE mybase;
GRANT ALL
ON freak.*
TO freak @'%' IDENTIFIED BY PASSWORD('secret');Первая инструкция создает базу данных mybase. Вторая инструкция создает учетную запись пользователя freak и предоставляет ему доступ к одноименной базе данных. Пароль для доступа — 'secret'. Пользователь freak может подключаться к базе данных с любого компьютера, даже если он расположен в сети Internet.
В следующей лекции мы перейдем к рассмотрению основ собственно системы MySQL.
Лекция 3. Создание базы данных, основы работы с таблицами
В этой лекции мы научимся создавать базы данных.
Команды для создания базы данных в Windows и Linux одинаковы. Однако предварительные команды в Linux немного сложнее. Так как этот материал рассчитан на широкий круг читателей, в том числе и слабо знакомых с ОС Linux, то системы Windows и Linux будут рассмотрены по отдельности.
Создадим базу данных с именем employees, которая содержит данные о сотрудниках некой компании BigFoot. Предполагается хранить имя, зарплату, возраст, адрес, e-mail, дату рождения, увлечения, номера телефонов, и т.д. сотрудников.
Создание базы данных в Windows
1. Запустите сервер MySQL, выполняя команду mysqld-shareware -standalone в строке приглашения в каталоге c:\mysql\bin. Более подробно об этом сказано выше, в лекции об установке MySQL в Windows.
2. Затем вызовите программу клиента mysql, вводя в строке приглашения mysql.
3. Приглашение изменится на mysql>. Введите команду:
create database employees;
(Примечание: Команда заканчивается символом точки с запятой).
4. Сервер MySQL должен ответить примерно как на рис. 3.1
Рис. 3.1. Результат работы команды создания таблицы
[Запрос обработан, изменилась 1 строка (0.00 сек)]
5. Это означает, что была успешно создана база данных. Теперь давайте посмотрим, сколько баз данных имеется в системе. Выполните следующую команду.
show databases;
Сервер ответит списком баз данных, как показано на рис. 3.2.
Рис. 3.2. Просмотр баз данных
Здесь показаны три базы данных, две были созданы MySQL во время установки и вновь созданная база данных employees.
6. Чтобы вернуться снова к приглашению DOS, введите команду quit в приглашении mysql.
Создание базы данных в Linux
1. Пусть пользователь работает под своей учетной записью, а не как суперпользователь root. Необходимо запустить терминальный сеанс и стать суперпользователем (Для этого выполните команду su и введите пароль суперпользователя root ).
2. Запустим сервер MySQL. Вводим:
mysql -u root -p
Система предлагает ввести пароль пользователя root MySQL, который был задан при установке MySQL в Linux. (Примечание: Это пароль пользователя root системы MySQL, а не пользователя root системы Linux). Введите пароль, который не изображается на экране по соображениям безопасности.
После успешной регистрации, система выводит приветствие и приглашение mysql, как показано на рис.3.3
Рис. 3.3. Приветствие системы
(Вас приветствует монитор MySQL. Команды заканчиваются символами ; или \g. id соединения с MySQL равен 1 для сервера версии: 5.01.01. Введите 'help', чтобы получить справку).
3. Теперь можно создавать базу данных employees. Выполните команду:
create database employees;
(Примечание: команда заканчивается точкой с запятой)
4. Важно отметить, что эта база данных создается пользователем root и поэтому будет доступна только тем пользователям, которым это разрешит root. Чтобы использовать эту базу данных с другой учетной записью, например, freak, необходимо задать соответствующие полномочия, выполняя следующую команду:
GRANT ALL ON employees.* TO freak@localhost IDENTIFIED BY "pass"
Эта команда предоставляет учетной записи freak@localhost все полномочия на базу данных employees и задает пароль pass. Для любого другого пользователя freak можно заменить на любое другое имя пользователя и выбрать подходящий пароль.
5. Закройте сеанс mysql, вводя в приглашении команду quit. Выйдите из режима суперпользователя и перейдите в свою учетную запись. (Введите exit ).
6. Чтобы соединиться с MySQL с помощью обычной учетной записи, введите:
mysql -u имя_пользователя -p
Затем введите после приглашения пароль. (Этот пароль был задан выше командой GRANT ALL...). После успешной регистрации в MySQL система выведет приветственное сообщение. Сеанс пользователя должен выглядеть как показано на рис. 3.4.
Рис. 3.4. Приветствие системы MySQL
7. Ввод команды SHOW DATABASES; выведет список всех доступных в системе баз данных.
mysql> SHOW DATABASES;
На экране должно появиться окно, аналогичное рис. 3.2.
Введите quit в строке приглашения mysql>, чтобы выйти из программы клиента mysql.
Команда CREATE DATABASE
Синтаксис команды CREATE DATABASE имеет вид:
CREATE DATABASE [IF NOT EXISTS] имя_базы_данных [спецификация_create[,спецификация_create]...]
Команда CREATE DATABASE создает базу данных с указанным именем. Для использования команды необходимо иметь привилегию CREATE для базы данных. Если база данных с таким именем существует, генерируется ошибка.
спецификация_create:
[DEFAULT] CHARACTER SET имя_набора_символов
[DEFAULT] COLLATE имя_порядка_сопоставленияОпция спецификация_сrеаtе может указываться для определения характеристик базы данных. Характеристики базы данных сохраняются в файле db.opt, расположенном в каталоге данных. Конструкция CHARACTER SET определяет набор символов для базы данных по умолчанию. Конструкция COLLATION задает порядок сопоставления по умолчанию.
Базы данных в MySQL реализованы в виде каталогов, которые содержат файлы, соответствующие таблицам базы данных. Поскольку изначально в базе нет никаких таблиц, оператор CREATE DATABASE только создает подкаталог в каталоге данных MySQL.
Работа с таблицами
Теперь рассмотрим команды MySQL для создания таблиц базы данных и выбора базы данных.
Базы данных хранят данные в таблицах. Чем же являются эти таблицы?
Проще всего таблицы можно представлять себе, как состоящие из строк и столбцов. Каждый столбец определяет данные определенного типа. Строки содержат отдельные записи.
Рассмотрим таблицу 3.1, в которой приведены персональные данные некоторых людей:
| Имя | Возраст | Страна | |
|---|---|---|---|
| Михаил Петров | 28 | Россия | misha@yandex.ru |
| Джон Доусон | 32 | Австралия | j.dow@australia.com |
| Морис Дрюон | 48 | Франция | md@france.fr |
| Снежана | 19 | Болгария | sneg@bulgaria.com |
Приведенная выше таблица содержит четыре столбца, в которых хранятся имя, возраст, страна, и адрес e-mail. Каждая строка содержит данные одного человека. Эта строка называется записью. Чтобы найти страну и адрес e-mail Снежаны, сначала надо выбрать имя в первом столбце, а затем посмотреть содержимое третьего и четвертого столбцов этой же строки.
База данных может содержать множество таблиц, именно таблицы содержат реальные данные.
Следовательно, можно выделить связанные (или несвязанные) данные в различные таблицы. Для базы данных employees определена одна таблица, которая содержит данные компании о сотрудниках, а другая таблица будет содержать персональные данные. Давайте создадим первую таблицу.
Команда SQL для создания такой таблицы выглядит следующим образом:
CREATE TABLE employee_data ( emp_id int unsigned not null auto_increment primary key, f_name varchar(20), l_name varchar(20), title varchar(30), age int, yos int, salary int, perks int, email varchar(60) );
Примечание: в MySQL команды и имена столбцов не различают регистр символов, однако имена таблиц и баз данных могут зависеть от регистра в связи с используемой платформой (как в Linux). Поэтому можно вместо CREATE TABLE использовать create table.
За ключевыми словами CREATE TABLE следует имя создаваемой таблицы employee_data. Каждая строка внутри скобок представляет один столбец. Эти столбцы хранят для каждого сотрудника идентификационный номер ( emp_id ), фамилию ( l_name ), имя ( f_name ), должность ( title ), возраст ( age ), стаж работы в компании ( yos ), зарплату ( salary ), надбавки ( perks ), и адрес e-mail ( email ).
За именем каждого столбца следует тип столбца. Типы столбцов определяют тип данных, которые будет содержать столбец. В данном примере столбцы f_name, l_name, title и email будут содержать текстовые строки, поэтому тип столбца задан как varchar, что означает переменное количество символов. Максимальное число символов для столбцов varchar определяется числом, заключенным в скобки, которое следует сразу за именем столбца. Столбцы age, yos, salary и perks будут содержать числа (целые), поэтому тип столбца задается как int. Первый столбец ( emp_id ) содержит идентификационный номер ( id ) сотрудника. Его тип столбца выглядит несколько перегруженным, поэтому рассмотрим его по частям:
- int: определяет тип столбца как целое число.
- unsigned: определяет, что число будет без знака (положительное целое).
- not null: определяет, что значение не может быть null (пустым); то есть каждая строка в этом столбце должна иметь значение.
- auto_increment: когда MySQL встречается со столбцом с атрибутом auto_increment, то генерируется новое значение, которое на единицу больше, чем наибольшее значение в столбце. Поэтому мы не должны задавать для этого столбца значения, MySQL генерирует их самостоятельно. Из этого также следует, что каждое значение в этом столбце будет уникальным.
- primary key: помогает при индексировании столбца, что ускоряет поиск значений. Каждое значение должно быть уникально. Ключевой столбец необходим для того, чтобы исключить возможность совпадения данных. Например, два сотрудника могут иметь одно и то же имя, и тогда встанет проблема – как различать этих сотрудников, если не задать им уникальные идентификационные номера. Если имеется столбец с уникальными значениями, то можно легко различить две записи. Лучше всего поручить присваивание уникальных значений самой системе MySQL.
Использование базы данных
База данных employees уже создана. Для работы с ней, необходимо её "активировать" или "выбрать". В приглашении mysql выполните команду:
SELECT DATABASE();
На экране увидим ответ системы, как показано на рис. 3.5

Рис. 3.5. Выбор базы данных
Это говорит о том, что ни одна база данных не была выбрана. На самом деле всякий раз при работе с клиентом mysql необходимо определять, какая база данных будет использоваться.
Определить текущую базу данных можно несколькими способами:
- определение имени базы данных при запуске
Введите в приглашении системы следующее:
mysql employees (в Windows) mysql employees -u manish -p (в Linux)
- определение базы данных с помощью оператора USE в приглашении mysql
mysql>USE employees;
- Определение базы данных с помощью \u в приглашении mysql
mysql>\u employees;
При работе необходимо определять базу данных, которая будет использоваться, иначе MySQL будет порождать ошибку.
Создание таблицы
После выбора базы данных employees, выполните в приглашении mysql команду CREATE TABLE.
CREATE TABLE employee_data ( emp_id int unsigned not null auto_increment primary key, f_name varchar(20), l_name varchar(20), title varchar(30), age int, yos int, salary int, perks int, email varchar(60) );
Примечание: нажатие клавиши Enter после ввода первой строки изменяет приглашение mysql на ->. Это означает, что mysql понимает, что команда не завершена и приглашает ввести дополнительные операторы. Помните, что каждая команда mysql заканчивается точкой с запятой, а каждое объявление столбца отделяется запятой. Можно также при желании ввести всю команду на одной строке.
Вывод на экране должен соответствовать рис. 3.6.
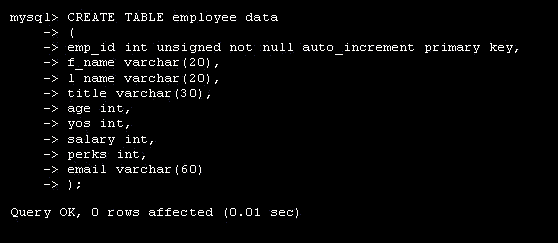
Рис. 3.6. Создание таблицы
Синтаксис команды CREATE TABLE
Общий формат инструкции CREATE TABLE таков:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] имя [(спецификация, ...)] [опция, ...] [ [IGNORE | REPLACE] запрос]
Флаг TEMPORARY задает создание временной таблицы, существующей в течение текущего сеанса. По завершении сеанса таблица удаляется. Временным таблицам можно присваивать имена других таблиц, делая последние временно недоступными. Спецификатор IF NOT EXIST подавляет вывод сообщений об ошибках в случае, если таблица с указанным именем уже существует. Имени таблицы может предшествовать имя базы данных, отделенное точкой. Если это не сделано, таблица будет создана в базе данных, которая установлена по умолчанию.
Чтобы задать имя таблицы с пробелами, необходимо заключить его в обратные кавычки, например 'courses list'. То же самое нужно будет делать во всех ссылках на таблицу, поскольку пробелы используются для разделения идентификаторов.
Разрешается создавать таблицы без столбцов, однако в большинстве случаев спецификация хотя бы одного столбца все же присутствует. Спецификации столбцов и индексов приводятся в круглых скобках и разделяются запятыми. Формат спецификации следующий:
имя тип [NOT NULL | NULL] [DEFAULT значение] [AUTO_INCREMENT] [KEY] [ссылка]
Типы столбцов более подробно будут рассмотрены в лекции 4.
Спецификация типа включает название типа и его размерность. По умолчанию столбцы принимают значения NULL. Спецификатор NOT NULL запрещает подобное поведение.
У любого столбца есть значение по умолчанию. Если оно не указано, программа MySQL выберет его самостоятельно. Для столбцов, принимающих значения NULL, значением по умолчанию будет NULL, для строковых столбцов — пустая строка, для численных столбцов — нуль. Изменить эту установку позволяет предложение DEFAULT.
Поля-счетчики, создаваемые с помощью флага AUTO_INCREMENT, игнорируют значения по умолчанию, так как в них записываются порядковые номера. Тип счетчика должен быть беззнаковым целым. В таблице может присутствовать лишь одно поле-счетчик. Им не обязательно является первичный ключ.
Удаление таблиц
Для того, чтобы удалить таблицу, убедимся сперва, что она существует. Это можно проверить с помощью команды SHOW TABLES, как показано на рис. 3.7.

Рис. 3.7. Просмотр таблиц в базе
Для удаления таблицы используется команда DROP TABLE, как показано на рис. 3.8.

Рис. 3.8. Удаление таблицы
Теперь команда SHOW TABLES ; этой таблицы больше не покажет.
Синтаксис команды DROP TABLE
Инструкция DROP TABLE имеет следующий синтаксис:
DROP TABLE [IF EXISTS] таблица [RESTRICT | CASCADE]
Спецификация IF EXISTS подавляет вывод сообщения об ошибке, выдаваемого в случае, если заданная таблица не существует. Можно указывать несколько имен таблиц, разделяя их запятыми.
Флаги RESTRICT и CASCADE предназначены для выполнения сценариев, созданных в других СУБД.
Лекция 4. Типы данных столбцов
MySQL поддерживает несколько типов столбцов, которые можно разделить на три категории: числовые типы данных, типы данных для хранения даты и времени и символьные (строковые) типы данных. В данной лекции мы вначале рассмотрим все возможные типы и приведём требования по хранению для каждого типа столбца, затем опишем свойства типов более подробно по каждой категории.
Ниже перечислены типы столбцов, поддерживаемые MySQL. В описаниях используются обозначения, которые использовали разработчики MySQL в официальной документации:
- M - указывает максимальный размер вывода. Максимально допустимый размер вывода составляет 255 символов.
- D - употребляется для типов данных с плавающей точкой и указывает количество разрядов, следующих за десятичной точкой. Максимально возможная величина составляет 30 разрядов, но не может быть больше, чем M-2.
Квадратные скобки ('[' и ']') указывают для типа данных группы необязательных признаков.
В таблице 4.1 представлены типы полей MySQL.
| TINYINT[(M)] [UNSIGNED] [ZEROFILL] | Очень малое целое число. Диапазон со знаком от -128 до 127. Диапазон без знака от 0 до 255 |
| BIT, BOOL | Синонимы TINYINT(1) |
| SMALLINT[(M)] [UNSIGNED] [ZEROFILL] | Малое целое число. Диапазон со знаком от -32768 до 32767. Диапазон без знака от 0 до 65535. |
| MEDIUMINT[(M)] [UNSIGNED] [ZEROFILL] | Целое число среднего размера. Диапазон со знаком от -8388608 до 8388607. Диапазон без знака от 0 до 16777215 |
| INT[(M)] [UNSIGNED] [ZEROFILL] | Целое число нормального размера. Диапазон со знаком от -2147483648 до 2147483647. Диапазон без знака от 0 до 4294967295. |
| INTEGER[(M)] [UNSIGNED] [ZEROFILL] | Синоним для INT |
| BIGINT[(M)] [UNSIGNED] [ZEROFILL] | Большое целое число. Диапазон со знаком от -9223372036854775808 до 9223372036854775807. Диапазон без знака от 0 до 18446744073709551615 |
| FLOAT(точность) [UNSIGNED] [ZEROFILL] | Число с плавающей точкой. Атрибут точности может иметь значение <=24 для числа с плавающей точкой обычной (одинарной) точности и между 25 и 53 - для числа с плавающей точкой удвоенной точности. Эти типы данных сходны с типами FLOAT и DOUBLE, описанными ниже. FLOAT(X) относится к тому же интервалу, что и соответствующие типы FLOAT и DOUBLE, но диапазон значений и количество десятичных знаков не определены. |
| FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] | Малое число с плавающей точкой обычной точности. Допустимые значения: от -3,402823466E+38 до -1,175494351E-38, 0, и от 1,175494351E-38 до 3,402823466E+38. Если указан атрибут UNSIGNED, отрицательные значения недопустимы. Атрибут M указывает количество выводимых пользователю знаков, а атрибут D - количество разрядов, следующих за десятичной точкой. Обозначение FLOAT без указания аргументов или запись вида FLOAT(X), где X <=24, справедливы для числа с плавающей точкой обычной точности. |
| DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] | Число с плавающей точкой удвоенной точности нормального размера. Допустимые значения: от -1,7976931348623157E+308 до -2,2250738585072014E-308, 0, и от 2,2250738585072014E-308 до 1,7976931348623157E+308. Если указан атрибут UNSIGNED, отрицательные значения недопустимы. Атрибут M указывает количество выводимых пользователю знаков, а атрибут D - количество разрядов, следующих за десятичной точкой. Обозначение DOUBLE без указания аргументов или запись вида FLOAT(X), где 25 <= X <= 53, справедливы для числа с плавающей точкой двойной точности. |
| DECIMAL[(M[,D])][UNSIGNED] [ZEROFILL] или DEC[(M[,D])] [UNSIGNED] [ZEROFILL] или NUMERIC[(M[,D])][UNSIGNED] [ZEROFILL] | "Неупакованное" число с плавающей точкой. Ведет себя подобно столбцу CHAR, содержащему цифровое значение. Термин "неупакованное" означает, что число хранится в виде строки и при этом для каждого десятичного знака используется один символ. Разделительный знак десятичных разрядов, а также знак '-' для отрицательных чисел не учитываются в M (но место для них зарезервировано). Если атрибут D равен 0, величины будут представлены без десятичного знака, т.е. без дробной части. Максимальный интервал значений типа DECIMAL тот же, что и для типа DOUBLE, но действительный интервал для конкретного столбца DECIMAL может быть ограничен выбором значений атрибутов M и D. Если указан атрибут UNSIGNED, отрицательные значения недопустимы. Если атрибут D не указан, его значение по умолчанию равно 0. Если не указан M, его значение по умолчанию равно 10. |
| DATE | Дата. Поддерживается интервал от '1000-01-01' до '9999-12-31'. MySQL выводит значения DATE в формате 'YYYY-MM-DD', но можно установить значения в столбец DATE, используя как строки, так и числа. |
| DATETIME | Комбинация даты и времени. Поддерживается интервал от '1000-01-01 00:00:00' до '9999-12-31 23:59:59'. MySQL выводит значения DATETIME в формате 'YYYY-MM-DD HH:MM:SS', но можно устанавливать значения в столбце DATETIME, используя как строки, так и числа. |
| TIMESTAMP[(M)] | Временная метка. Интервал от '1970-01-01 00:00:00' до некоторого значения времени в 2037 году. MySQL выводит значения TIMESTAMP в форматах YYYYMMDDHHMMSS, YYMMDDHHMMSS, YYYYMMDD или YYMMDD в зависимости от значений M: 14 (или отсутствующее), 12, 8, или 6; но можно также устанавливать значения в столбце TIMESTAMP, используя как строки, так и числа. Столбец TIMESTAMP полезен для записи даты и времени при выполнении операций INSERT или UPDATE, так как при этом автоматически вносятся значения даты и времени самой последней операции, если эти величины не введены программой. Можно также устанавливать текущее значение даты и времени, задавая значение NULL. |
| TIME | Время. Интервал от '-838:59:59' до '838:59:59'. MySQL выводит значения TIME в формате 'HH:MM:SS', но можно устанавливать значения в столбце TIME, используя как строки, так и числа. |
| YEAR[(2|4)] | Год в двухзначном или четырехзначном форматах (по умолчанию формат четырехзначный). Допустимы следующие значения: с 1901 по 2155, 0000 для четырехзначного формата года и 1970-2069 при использовании двухзначного формата (70-69). MySQL выводит значения YEAR в формате YYYY, но можно задавать значения в столбце YEAR, используя как строки, так и числа. |
| [NATIONAL] CHAR(M) [BINARY] | Строка фиксированной длины, при хранении всегда дополняется пробелами в конце строки до заданного размера. Диапазон аргумента M составляет от 0 до 255 символов. Концевые пробелы удаляются при выводе значения. Если не задан атрибут чувствительности к регистру BINARY, то величины CHAR сортируются и сравниваются как независимые от регистра в соответствии с установленным по умолчанию алфавитом. Атрибут NATIONAL CHAR (или его эквивалентная краткая форма NCHAR ) представляет собой принятый в ANSI SQL способ указания, что в столбце CHAR должен использоваться установленный по умолчанию набор символов ( CHARACTER ). |
| CHAR | Это синоним для CHAR(1). |
| [NATIONAL] VARCHAR(M) [BINARY] | Строка переменной длины. Примечание: концевые пробелы удаляются при сохранении значения (в этом заключается отличие от спецификации ANSI SQL). Диапазон аргумента M составляет от 0 до 255 символов. Если не задан атрибут чувствительности к регистру BINARY, то величины VARCHAR сортируются и сравниваются как независимые от регистра. |
| TINYBLOB, TINYTEXT | Столбец типа BLOB или TEXT с максимальной длиной 255 символов. |
| BLOB, TEXT | Столбец типа BLOB или TEXT с максимальной длиной 65535 символов. |
| MEDIUMBLOB, MEDIUMTEXT | Столбец типа BLOB или TEXT с максимальной длиной 16777215 символов. |
| LONGBLOB, LONGTEXT | Столбец типа BLOB или TEXT с максимальной длиной 4294967295 символов. |
| ENUM('значение1','значение2',...) | Перечисляемый тип данных. Объект строки может иметь только одно значение, выбранное из заданного списка величин 'значение1', 'значение2', ..., NULL или специальная величина ошибки "". Список ENUM может содержать максимум 65535 различных величин |
| SET('значение1','значение2',...) | Набор. Объект строки может иметь ноль или более значений, каждое из которых должно быть выбрано из заданного списка величин 'значение1', 'значение2', ... Список SET может содержать максимум 64 элемента. |
Числовые типы данных
MySQL поддерживает все числовые типы данных языка SQL92 по стандартам ANSI/ISO. Они включают в себя типы точных числовых данных ( NUMERIC, DECIMAL, INTEGER и SMALLINT ) и типы приближенных числовых данных ( FLOAT, REAL и DOUBLE PRECISION ). Ключевое слово INT является синонимом для INTEGER, а ключевое слово DEC - синонимом для DECIMAL.
Типы данных NUMERIC и DECIMAL реализованы в MySQL как один и тот же. Они используются для величин, для которых важно сохранить повышенную точность, например для денежных данных. Требуемая точность данных и масштаб могут задаваться (и обычно задаются) при объявлении столбца данных одного из этих типов, например:
salary DECIMAL(5,2)
В этом примере - 5 (точность) представляет собой общее количество значащих десятичных знаков, с которыми будет храниться данная величина, а цифра 2 (масштаб) задает количество десятичных знаков после запятой. Следовательно, в этом случае интервал величин, которые могут храниться в столбце salary, составляет от -99,99 до 99,99 (в действительности для данного столбца MySQL обеспечивает возможность хранения чисел вплоть до 999,99, поскольку можно не хранить знак для положительных чисел).
Величины типов DECIMAL и NUMERIC хранятся как строки, а не как двоичные числа с плавающей точкой, чтобы сохранить точность представления этих величин в десятичном виде. При этом используется по одному символу строки для каждого разряда хранимой величины, для десятичного знака (если масштаб > 0) и для знака '-' (для отрицательных чисел). Если параметр масштаба равен 0, то величины DECIMAL и NUMERIC не содержат десятичного знака или дробной части.
Максимальный интервал величин DECIMAL и NUMERIC тот же, что и для типа DOUBLE, но реальный интервал может быть ограничен выбором значений параметров точности или масштаба для данного столбца с типом данных DECIMAL или NUMERIC. Если конкретному столбцу присваивается значение, имеющее большее количество разрядов после десятичного знака, что разрешено параметром масштаба, то данное значение округляется до количества разрядов, разрешенного масштаба. Если столбцу с типом DECIMAL или NUMERIC присваивается значение, выходящее за границы интервала, заданного значениями точности и масштаба (или принятого по умолчанию), то MySQL сохранит данную величину со значением соответствующей граничной точки данного интервала.
Все типы целочисленных данных могут иметь необязательный и не оговоренный в стандарте атрибут UNSIGNED. Беззнаковые величины можно использовать для разрешения записи в столбец только положительных чисел, если необходимо немного увеличить числовой интервал в столбце.
Тип FLOAT обычно используется для представления приблизительных числовых типов данных. Если ключевое слово FLOAT в обозначении типа столбца используется без указания точности, MySQL выделяет 4 байта для хранения величин в этом столбце. Возможно также иное обозначение, с двумя числами в круглых скобках за ключевым словом FLOAT. В этом варианте первое число по-прежнему определяет требования к хранению величины в байтах, а второе число указывает количество разрядов после десятичной запятой, которые будут храниться и показываться. Если в столбец подобного типа попытаться записать число, содержащее больше десятичных знаков после запятой, чем указано для данного столбца, то значение величины при ее хранении в MySQL округляется для устранения излишних разрядов.
Для типов REAL и DOUBLE PRECISION не предусмотрены установки точности. В MySQL оба типа реализуются как 8-байтовые числа с плавающей точкой удвоенной точности. Чтобы обеспечить максимальную совместимость, в коде, требующем хранения приблизительных числовых величин, должны использоваться типы FLOAT или DOUBLE PRECISION без указаний точности или количества десятичных знаков.
Если в числовой столбец попытаться записать величину, выходящую за границы допустимого интервала для столбца данного типа, то MySQL ограничит величину до соответствующей граничной точки данного интервала и сохранит результат вместо исходной величины.
Например, интервал столбца INT составляет от -2147483648 до 2147483647. Если попытаться записать в столбец INT число -9999999999, то оно будет усечено до нижней конечной точки интервала и вместо записываемого значения в столбце будет храниться величина -2147483648. Аналогично, если попытаться записать число 9999999999, то взамен запишется число 2147483647.
Если для столбца INT указан параметр UNSIGNED, то величина допустимого интервала для столбца останется той же, но его граничные точки сдвинутся к 0 и 4294967295. Если попытаться записать числа -9999999999 и 9999999999, то в столбце окажутся величины 0 и 4294967296.
Для команд ALTER TABLE, LOAD DATA INFILE, UPDATE и многострочной INSERT выводится предупреждение, если могут возникнуть преобразования данных вследствие вышеописанных усечений. В таблице 4.2 представлены наиболее часто используемые числовые типы полей MySQL.
| Тип | Байт | От | До |
|---|---|---|---|
| TINYINT | 1 | -128 | 127 |
| SMALLINT | 2 | -32768 | 32767 |
| MEDIUMINT | 3 | -8388608 | 8388607 |
| INT | 4 | -2147483648 | 2147483647 |
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
Типы данных даты и времени
Существуют следующие типы данных даты и времени: DATETIME, DATE, TIMESTAMP, TIME и YEAR. Каждый из них имеет интервал допустимых значений, а также значение "ноль", которое используется, когда пользователь вводит действительно недопустимое значение. Отметим, что MySQL позволяет хранить некоторые не вполне достоверные значения даты, например 1999-11-31. Причина в том, что управление проверкой даты входит в обязанности конкретного приложения, а не SQL-серверов. Для ускорения проверки правильности даты MySQL только проверяет, находится ли месяц в интервале 0-12 и день в интервале 0-31. Данные интервалы начинаются с 0, это сделано для того, чтобы обеспечить для MySQL возможность хранить в столбцах DATE или DATETIME даты, в которых день или месяц равен нулю. Эта возможность особенно полезна для приложений, которые предполагают хранение даты рождения - здесь не всегда известен день или месяц рождения. В таких случаях дата хранится просто в виде 1999-00-00 или 1999-01-00 (при этом не следует рассчитывать на то, что для подобных дат функции DATE_SUB() или DATE_ADD дадут правильные значения).
Ниже приведены некоторые общие рекомендации, полезные при работе с типами данных даты и времени:
MySQL извлекает значения для данного типа даты или времени только в стандартном формате, но в то же время пытается интерпретировать разнообразные форматы, которые могут поступать от пользователей (например, когда задается величина, которой следует присвоить тип даты или времени или сравнить со значением, имеющим один из этих типов). Тем не менее, поддерживаются только форматы, описанные в следующих разделах. Предполагается, что пользователь будет вводить допустимые значения величин, так как использование величин в других форматах может дать непредсказуемые результаты.
- Хотя MySQL пытается интерпретировать значения в нескольких форматах, во всех случаях ожидается, что крайним слева будет раздел значения даты, содержащий год. Даты должны задаваться в порядке год-месяц-день (например, '98-09-04'), а не в порядке месяц-день-год или день-месяц-год, т.е. не так, как мы их обычно записываем (например '09-04-98', '04-09-98').
- MySQL автоматически преобразует значение, имеющее тип даты или времени, в число, если данная величина используется в числовом контексте, и наоборот.
- Значение, имеющее тип даты или времени, которое выходит за границы установленного интервала или является недопустимым для этого типа данных (см. начало раздела), преобразуется в значение "ноль" для данного типа. (Исключение составляют выходящие за границы установленного интервала величины типа TIME, которые усекаются до соответствующей граничной точки заданного интервала TIME ). В таблице 4.3. представлены форматы значения "ноль" для каждого из типов столбцов:
| Тип столбца | Значение "Ноль" |
|---|---|
| DATETIME | '0000-00-00 00:00:00' |
| DATE | '0000-00-00' |
| TIMESTAMP | 00000000000000 (длина зависит от количества выводимых символов) |
| TIME | '00:00:00' |
| YEAR | 0000 |
- Значения 'ноль' - особые. Для их хранения или ссылок на них можно явно применять представленные в таблице значения, а можно использовать '0', что легче в написании.
Типы данных DATETIME, DATE и TIMESTAMP
Далее рассмотрим типы DATETIME, DATE и TIMESTAMP, которые являются родственными типами данных. Опишем их свойства, общие черты и различия.
Тип данных DATETIME используется для величин, содержащих информацию как о дате, так и о времени. MySQL извлекает и выводит величины DATETIME в формате 'YYYY-MM-DD HH:MM:SS'. Поддерживается диапазон величин от '1000-01-01 00:00:00' до '9999-12-31 23:59:59'. ("поддерживается" означает, что хотя величины с более ранними временными значениями, возможно, тоже будут работать, но нет гарантии того, что они будут правильно храниться и отображаться).
Тип DATE используется для величин с информацией только о дате, без части, содержащей время. MySQL извлекает и выводит величины DATE в формате 'YYYY-MM-DD'. Поддерживается диапазон величин от '1000-01-01' до '9999-12-31'.
Тип столбца TIMESTAMP обеспечивает тип представления данных, который можно использовать для автоматической записи текущих даты и времени при выполнении операций INSERT или UPDATE. При наличии нескольких столбцов типа TIMESTAMP только первый из них обновляется автоматически.
Для остальных (кроме первого) столбцов типа TIMESTAMP также можно задать установку в значение текущих даты и времени. Для этого необходимо просто установить столбец в NULL или в NOW().
Любой столбец типа TIMESTAMP (даже первый столбец данного типа) можно установить в значение, отличное от текущих даты и времени. Это делается путем явной установки его в желаемое значение. Данное свойство можно использовать, например, если необходимо установить столбец TIMESTAMP в значение текущих даты и времени при создании строки, а при последующем обновлении этой строки значение столбца не должно изменяться.
Величины типа TIMESTAMP могут принимать значения от начала 1970 года до некоторого значения в 2037 году с разрешением в одну секунду. Эти величины выводятся в виде числовых значений.
Формат данных, в котором MySQL извлекает и показывает величины TIMESTAMP, зависит от количества показываемых символов. Это проиллюстрировано в таблице 4.4. Полный формат TIMESTAMP составляет 14 десятичных разрядов, но можно создавать столбцы типа TIMESTAMP и с более короткой строкой вывода:
| Тип столбца | Формат вывода |
|---|---|
| TIMESTAMP(14) | YYYYMMDDHHMMSS |
| TIMESTAMP(12) | YYMMDDHHMMSS |
| TIMESTAMP(10) | YYMMDDHHMM |
| TIMESTAMP(8) | YYYYMMDD |
| TIMESTAMP(6) | YYMMDD |
| TIMESTAMP(4) | YYMM |
| TIMESTAMP(2) | YY |
Величины DATETIME, DATE и TIMESTAMP могут быть заданы любым стандартным набором форматов:
- Как строка в формате 'YYYY-MM-DD HH:MM:SS' или в формате 'YY-MM-DD HH:MM:SS'. Допускается "облегченный" синтаксис - можно использовать любой знак пунктуации в качестве разделительного между частями разделов даты или времени. Например, величины '98-12-31 11:30:45', '98.12.31 11+30+45', '98/12/31 11*30*45' и '98@12@31 11^30^45' являются эквивалентными.
- Как строка в формате 'YYYY-MM-DD' или в формате 'YY-MM-DD'. Здесь также допустим "облегченный" синтаксис. Например, величины '98-12-31', '98.12.31', '98/12/31' и '98@12@31' являются эквивалентными.
- Как строка без разделительных знаков в формате 'YYYYMMDDHHMMSS' или в формате 'YYMMDDHHMMSS', при условии, что строка понимается как дата. Например, величины '19970523091528' и '970523091528' можно интерпретировать как '1997-05-23 09:15:28', но величина '971122129015' является недопустимой (значение раздела минут является абсурдным) и преобразуется в '0000-00-00 00:00:00'.
- Как строка без разделительных знаков в формате 'YYYYMMDD' или в формате 'YYMMDD', при условии, что строка интерпретируется как дата. Например, величины '19970523' и '970523' можно интерпретировать как '1997-05-23', но величина '971332' является недопустимой (значения разделов месяца и дня не имеют смысла) и преобразуется в '0000-00-00'.
- Как число в формате YYYYMMDDHHMMSS или в формате YYMMDDHHMMSS, при условии, что число интерпретируется как дата. Например, величины 19830905132800 и 830905132800 интерпретируются как '1983-09-05 13:28:00'.
- Как число в формате YYYYMMDD или в формате YYMMDD, при условии, что число интерпретируется как дата. Например, величины 19830905 и 830905 интерпретируются как '1983-09-05'.
- Как результат выполнения функции, возвращающей величину, приемлемую в контекстах типов данных DATETIME, DATE или TIMESTAMP (например, функции NOW() или CURRENT_DATE() ).
Тип данных TIME
MySQL извлекает и выводит величины типа TIME в формате 'HH:MM:SS' (или в формате 'HHH:MM:SS' для больших значений часов). Величины TIME могут изменяться в пределах от '-838:59:59' до '838:59:59'. Причина того, что "часовая" часть величины может быть настолько большой, заключается в том, что тип TIME может использоваться не только для представления времени дня (которое должно быть меньше 24 часов), но также для представления общего истекшего времени или временного интервала между двумя событиями (который может быть значительно больше 24 часов или даже отрицательным).
Величины TIME могут быть заданы в различных форматах:
Как строка в формате 'D HH:MM:SS.дробная часть' (следует учитывать, что MySQL пока не обеспечивает хранения дробной части величины в столбце рассматриваемого типа). Можно также использовать одно из следующих "облегченных" представлений: HH:MM:SS.дробная часть, HH:MM:SS, HH:MM, D HH:MM:SS, D HH:MM, D HH или SS. Здесь D - это дни из интервала значений 0-33.
- Как строка без разделителей в формате 'HHMMSS', при условии, что строка интерпретируется как дата. Например, величина '101112' понимается как '10:11:12', но величина '109712' будет недопустимой (значение раздела минут является абсурдным) и преобразуется в '00:00:00'.
- Как число в формате HHMMSS, при условии, что строка интерпретируется как дата. Например, величина 101112 понимается как '10:11:12'. MySQL понимает и следующие альтернативные форматы: SS, MMSS, HHMMSS, HHMMSS.дробная часть. При этом следует учитывать, что хранения дробной части MySQL пока не обеспечивает.
- Как результат выполнения функции, возвращающей величину, приемлемую в контексте типа данных типа TIME (например, такой функции, как CURRENT_TIME ).
Тип данных YEAR
Тип YEAR - это однобайтный тип данных для представления значений года.
MySQL извлекает и выводит величины YEAR в формате YYYY. Диапазон возможных значений - от 1901 до 2155.
Величины типа YEAR могут быть заданы в различных форматах:
- Как четырехзначная строка в интервале значений от '1901' до '2155'.
- Как четырехзначное число в интервале значений от 1901 до 2155.
- Как двухзначная строка в интервале значений от '00' до '99'. Величины в интервалах от '00' до '69' и от '70' до '99' при этом преобразуются в величины YEAR в интервалах от 2000 до 2069 и от 1970 до 1999 соответственно.
- Как двухзначное число в интервале значений от 1 до 99. Величины в интервалах от 1 до 69 и от 70 до 99 при этом преобразуются в величины YEAR в интервалах от 2001 до 2069 и от 1970 до 1999 соответственно. Необходимо принять во внимание, что интервалы для двухзначных чисел и двухзначных строк несколько различаются, так как нельзя указать "ноль" непосредственно как число и интерпретировать его как 2000. Необходимо задать его как строку '0' или '00', или же оно будет интерпретировано как 0000.
- Как результат выполнения функции, возвращающей величину, приемлемую в контексте типа данных YEAR (такой как NOW() ).
Недопустимые величины YEAR преобразуются в 0000.
Символьные типы данных
Существуют следующие символьные типы данных: CHAR, VARCHAR, BLOB, TEXT, ENUM и SET. Рассмотрим описание их работы, требований к их хранению и использования их в запросах. В таблице 4.5 приведены символьные типы данных и их размерность.
| Тип | Макс.размер | Байт |
|---|---|---|
| TINYTEXT или TINYBLOB | 2^8-1 | 255 |
| TEXT или BLOB | 2^16-1 (64K-1) | 65535 |
| MEDIUMTEXT или MEDIUMBLOB | 2^24-1 (16M-1) | 16777215 |
| LONGBLOB | 2^32-1 (4G-1) | 4294967295 |
Типы данных CHAR и VARCHAR
Типы данных CHAR и VARCHAR очень схожи между собой, но различаются по способам их хранения и извлечения.
В столбце типа CHAR длина поля постоянна и задается при создании таблицы. Эта длина может принимать любое значение между 1 и 255. Величины типа CHAR при хранении дополняются справа пробелами до заданной длины. Эти концевые пробелы удаляются при извлечении хранимых величин.
Величины в столбцах VARCHAR представляют собой строки переменной длины. Так же как и для столбцов CHAR, можно задать столбец VARCHAR любой длины между 1 и 255. Однако, в противоположность CHAR, при хранении величин типа VARCHAR используется только то количество символов, которое необходимо, плюс один байт для записи длины. Хранимые величины пробелами не дополняются, наоборот, концевые пробелы при хранении удаляются.
Если задаваемая в столбце CHAR или VARCHAR величина превосходит максимально допустимую длину столбца, то эта величина соответствующим образом усекается.
Различие между этими двумя типами столбцов в представлении результата хранения величин с разной длиной строки в столбцах CHAR(4) и VARCHAR(4) проиллюстрировано следующей таблицей 4.6.
| Величина | CHAR(4) | Требуемая память | VARCHAR(4) | Требуемая память |
|---|---|---|---|---|
| '' | ' ' | 4 байта | '' | 1 байт |
| 'ab' | 'ab ' | 4 байта | 'ab' | 3 байта |
| 'abcd' | 'abcd' | 4 байта | 'abcd' | 5 байтов |
| 'abcdefgh' | 'abcd' | 4 байта | 'abcd' | 5 байтов |
Извлеченные из столбцов CHAR(4) и VARCHAR(4) величины в каждом случае будут одними и теми же, поскольку при извлечении концевые пробелы из столбца CHAR удаляются.
Если при создании таблицы не был задан атрибут BINARY для столбцов, то величины в столбцах типа CHAR и VARCHAR сортируются и сравниваются без учета регистра. При задании атрибута BINARY величины в столбце сортируются и сравниваются с учетом регистра в соответствии с порядком таблицы ASCII на том компьютере, где работает сервер MySQL.
Типы данных BLOB и TEXT
Тип данных BLOB представляет собой двоичный объект большого размера, который может содержать переменное количество данных. Существуют 4 модификации этого типа - TINYBLOB, BLOB, MEDIUMBLOB и LONGBLOB, отличающиеся только максимальной длиной хранимых величин.
Тип данных TEXT также имеет 4 модификации - TINYTEXT, TEXT, MEDIUMTEXT и LONGTEXT, соответствующие упомянутым четырем типам BLOB и имеющие те же максимальную длину и требования к объему памяти. Единственное различие между типами BLOB и TEXT состоит в том, что сортировка и сравнение данных выполняются с учетом регистра для величин BLOB и без учета регистра для величин TEXT. Другими словами, TEXT - это независимый от регистра BLOB.
Если размер задаваемого в столбце BLOB или TEXT значения превосходит максимально допустимую длину столбца, то это значение соответствующим образом усекается.
Тип перечисления ENUM
ENUM (перечисление) - это столбец, который может принимать значение из списка допустимых значений, явно перечисленных в спецификации столбца в момент создания таблицы.
Перечисление может иметь максимум 65535 элементов.
Регистр не играет роли, когда вы делаете вставку в столбец ENUM. Однако регистр значений, получаемых из этого столбца, совпадает с регистром в написании соответствующего значения, заданного во время создания таблицы.
Если вам нужно получить список возможных значений для столбца ENUM, вы должны вызвать SHOW COLUMNS FROM имя_таблицы LIKE имя_столбца_enum и проанализировать определение ENUM во втором столбце.
Тип множества SET
SET - это строковый тип, который может принимать ноль или более значений, каждое из которых должно быть выбрано из списка допустимых значений, определенных при создании таблицы. Элементы множества SET разделяются запятыми. Как следствие, сами элементы множества не могут содержать запятых.
Например, столбец, определенный как SET("один", "два") NOT NULL может принимать такие значения:
"" "один" "два" "один,два"
Множество SET может иметь максимум 64 различных элемента.
Оконечные пробелы удаляются из значений множества SET в момент создания таблицы.
Если вы вставляете в столбец SET некорректную величину, это значение будет проигнорировано.
Если вам нужно получить все возможные значения для столбца SET, вам следует вызвать SHOW COLUMNS FROM имя_таблицы LIKE имя_столбца_set и проанализировать SET-определение во втором столбце.
Выбор правильного типа данных в столбце
Для того чтобы память использовалась наиболее эффективно, всегда следует стараться применять тип данных, обеспечивающий максимальную точность. Например, для величин в диапазоне между 1 и 99999 в целочисленном столбце наилучшим типом будет MEDIUMINT UNSIGNED.
Часто приходится сталкиваться с такой проблемой, как точное представление денежных величин. В MySQL для представления таких величин необходимо использовать тип данных DECIMAL. Поскольку данные этого типа хранятся в виде строки, потерь в точности не происходит. А в случаях, когда точность не имеет слишком большого значения, вполне подойдет и тип данных DOUBLE.
Если же требуется высокая точность, всегда можно выполнить конвертирование в тип данных с фиксированной точкой. Такие данные хранятся в виде BIGINT. Это позволяет выполнять все вычисления с ними как с целыми числами, а впоследствии при необходимости результаты можно преобразовать обратно в величины с плавающей точкой.
Требования к памяти для различных типов столбцов
Требования к объему памяти для столбцов каждого типа, поддерживаемого MySQL, перечислены ниже по категориям.
Требования к памяти для числовых типов приведены в таблице 4.7
| Тип столбца | Требуемая память |
|---|---|
| TINYINT | 1 байт |
| SMALLINT | 2 байта |
| MEDIUMINT | 3 байта |
| INT | 4 байта |
| INTEGER | 4 байта |
| BIGINT | 8 байтов |
| FLOAT(X) | 4, если X <= 24 или 8, если 25 <= X <= 53 |
| FLOAT | 4 байта |
| DOUBLE | 8 байтов |
| DOUBLE PRECISION | 8 байтов |
| REAL | 8 байтов |
| DECIMAL(M,D) | M+2 байт, если D > 0, M+1 байт, если D = 0 (D+2, если M < D) |
| NUMERIC(M,D) | M+2 байт, если D > 0, M+1 байт, если D = 0 (D+2, если M < D) |
Требования к памяти для типов даты и времени приведены в таблице 4.8.
| Тип столбца | Требуемая память |
|---|---|
| DATE | 3 байта |
| DATETIME | 8 байтов |
| TIMESTAMP | 4 байта |
| TIME | 3 байта |
| YEAR | 1 байт |
Требования к памяти для символьных типов приведены в таблице 4.9.
| Тип столбца | Требуемая память |
|---|---|
| CHAR(M) | M байт, 1 <= M <= 255 |
| VARCHAR(M) | L+1 байт, где L <= M и 1 <= M <= 255 |
| TINYBLOB, TINYTEXT | L+1 байт, где L < 2^8 |
| BLOB, TEXT | L+2 байт, где L < 2^16 |
| MEDIUMBLOB, MEDIUMTEXT | L+3 байт, где L < 2^24 |
| LONGBLOB, LONGTEXT | L+4 байт, где L < 2^32 |
| ENUM('value1','value2',...) | 1 или 2 байт, в зависимости от количества перечисляемых величин (максимум 65535) |
| SET('value1','value2',...) | 1, 2, 3, 4 или 8 байт, в зависимости от количества элементов множества (максимум 64) |
Лекция 5. Работа с таблицами. Внесение, извлечение, поиск и удаление данных
Запись данных в таблицы
Оператор INSERT заполняет таблицу данными. Вот общая форма INSERT.
INSERT into table_name (column1, column2, ...) values (value1, value2...);
где table_name является именем таблицы, в которую надо внести данные; column1, column2 и т.д. являются именами столбцов, а value1, value2 и т.д. являются значениями для соответствующих столбцов.
Следующий оператор вносит первую запись в таблицу employee_data, которую мы рассматривали в лекции 3.
INSERT INTO employee_data
(f_name, l_name, title, age, yos, salary, perks, email)
values
("Михаил", "Петров", "директор", 28, 4, 200000,
50000, "misha@yandex.ru");Как и другие операторы MySQL, эту команду можно вводить на одной строке или разместить ее на нескольких строках.
Несколько важных моментов:
- Значениями для столбцов f_name, l_name, title и email являются текстовые строки, и они записываются в кавычках.
- Значениями для age, yos, salary и perks являются числа (целые), и они не имеют кавычек.
- Можно видеть, что данные заданы для всех столбцов кроме emp_id. Значение для этого столбца задает система MySQL, которая находит в столбце наибольшее значение, увеличивает его на единицу, и вставляет новое значение.
Если приведенная выше команда правильно введена в приглашении клиента mysql, то программа выведет сообщение об успешном выполнении, как показано на рис. 5.1.

Рис. 5.1. Ввод данных в таблицу.
Создание дополнительных записей требует использования отдельных операторов INSERT. Чтобы облегчить эту работу можно поместить все операторы INSERT в файл ![]() здесь. Это должен быть обычный текстовый файл с оператором INSERT в каждой строке.
здесь. Это должен быть обычный текстовый файл с оператором INSERT в каждой строке.
Заполнение таблицы employee_data данными с помощью файла employee.dat
В системе Windows
1) Поместите файл в каталог c:\mysql\bin.
2) Проверьте, что MySQL работает.
3) Выполните команду
mysql employees <employee.dat
В системе Linux
1) Перейдите в каталог с файлом данных.
2) Выполните команду
mysql employees <employee.dat -u username -p
3) Введите свой пароль.
Пусть таблица содержит теперь 21 запись (20 из файла employee.dat и одну, вставленную оператором INSERT в начале лекции).
Запрос данных из таблицы MySQL
Таблица employee_data содержит теперь достаточно данных, чтобы можно было начать с ней работать. Запрос данных выполняется с помощью команды MySQL SELECT. Оператор SELECT имеет следующий формат:
SELECT имена_столбцов from имя_таблицы [WHERE ...условия];
Часть оператора с условиями является необязательной (мы рассмотрим ее позже). По сути, требуется знать имена столбцов и имя таблицы, из которой извлекаются данные.
Например, чтобы извлечь имена и фамилии всех сотрудников, выполните следующую команду.
SELECT f_name, l_name from employee_data;
Оператор приказывает MySQL вывести все данные из столбцов f_name и l_name. Результат работы оператора представлен на рис. 5.2.
Рис. 5.2. Вывод данных из таблицы
При ближайшем рассмотрении можно заметить, что данные представлены в том порядке, в котором они были введены. Более того, последняя строка указывает число строк в таблице - 21.
Чтобы вывести всю таблицу, можно либо ввести имена всех столбцов, либо воспользоваться упрощенной формой оператора SELECT.
SELECT * from employee_data;
Символ * в этом выражении означает 'ВСЕ столбцы'. Поэтому этот оператор выводит все строки всех столбцов.
Рассмотрим ещё один пример.
SELECT f_name, l_name, age from employee_data;
Выборка столбцов f_name, l_name и age представлена на рис. 5.3.
Рис. 5.3. Выборка столбцов f_name, l_name и age
Задания
1. Напишите оператор SQL для создания новой базы данных с именем addressbook
2. Какой оператор используется для получения информации о таблице? Как используется этот оператор?
3. Как получить список всех баз данных, доступных в системе?
4. Напишите оператор для записи следующих данных в таблицу employee_data
Имя: Рудольф Фамилия: Курочкин Должность: Программист Возраст: 34 Стаж работы в компании: 2 Зарплата: 95000 Надбавки: 17000 email: rudolf@yandex.ru
5. Приведите две формы оператора SELECT, которые будут выводить все данные из таблицы employee_data.
6. Как извлечь данные столбцов f_name, email из таблицы employee_data?
7. Напишите оператор для вывода данных из столбцов salary, perks и yos таблицы employee_data.
8. Как узнать число строк в таблице с помощью оператора SELECT?
9. Как извлечь данные столбцов salary, l_name из таблицы employee_data?
Возможные решения
1. create database addressbook;
или
CREATE DATABASE addressbook;
Примечание: Операторы SQL не различают регистр символов, однако имена таблиц и имена баз данных могут различать регистр символов, в зависимости от используемой операционной системы.
2. Оператор DESCRIBE, например:
DESCRIBE employee_data;
3. SHOW DATABASES; (в приглашении mysql)
4.
INSERT INTO employee_data
(f_name, l_name, title, age, yos, salary, perks, email)
values
("Рудольф", "Курочкин", "программист", 34, 2, 95000, 17000, "rudolf@yandex.ru");Примечание: Текстовые строки заключаются в кавычки.
5. SELECT emp_id, f_name, l_name, title, age, yos, salary, perks, email from employee_data;
или
SELECT * from employee_data;
Вторая форма лучше. Ее легче использовать и труднее ошибиться.
6. Чтобы вывести данные столбцов f_name и email, используем следующий оператор.
select f_name, email from employee_data;
7. SELECT salary, perks, yos from employee_data;
8. Последняя строка вывода любого оператора SELECT содержит число полученных строк. Поэтому при выводе всех данных в любом столбце (или всех столбцах), последняя строка будет указывать число строк в таблице.
9. select salary, l_name from employee_data;
Выборка данных с помощью условий
Теперь более подробно рассмотрим формат оператора SELECT. Его полный формат имеет вид:
SELECT имена_столбцов from имя_таблицы [WHERE ...условия];
В операторе SELECT условия являются необязательными.
Оператор SELECT без условий выводит все данные из указанных столбцов. Одним из достоинств RDBMS является возможность извлекать данные на основе определенных условий.
Теперь перейдём к рассмотрению операторов сравнения.
Операторы сравнения = и !=
SELECT f_name, l_name from employee_data where f_name = 'Иван';
Результат запроса приведен на рис. 5.4.

Рис. 5.4. Выборка столбцов с условием для поля "имя".
Этот оператор выводит имена и фамилии всех сотрудников, которые имеют имя Иван. Отметим, что слово Иван в условии заключено в одиночные кавычки. Можно использовать также двойные кавычки. Кавычки являются обязательными, так как MySQL будет порождать ошибку при их отсутствии. Кроме того сравнения MySQL не различают регистр символов, что означает, что с равным успехом можно использовать "Иван", "иван" и даже "ИвАн".
SELECT f_name,l_name from employee_data where title="программист";
Результат запроса приведен на рис. 5.5.
Рис. 5.5. Выборка столбцов с условием для поля "должность"
Выбирает имена и фамилии всех сотрудников, которые являются программистами.
SELECT f_name, l_name from employee_data where age = 32;
Результат запроса приведен на рис. 5.6.
Рис. 5.6. Выборка столбцов с условием для поля "возраст"
Это список имен и фамилий всех сотрудников с возрастом 32 года. Вспомните, что тип столбца age был задан как int, поэтому кавычки вокруг 32 не требуются. Это - незначительное различие между текстовым и целочисленным типами столбцов.
Оператор != означает 'не равно' и является противоположным оператору равенства.
Операторы больше и меньше
Давайте получим имена и фамилии всех сотрудников, которые старше 32 лет.
SELECT f_name, l_name from employee_data where age > 32;
Результат запроса приведен на рис. 5.7.
Рис. 5.7. Выборка столбцов с условием "больше" для поля "возраст"
Попробуем найти сотрудников, которые получают зарплату больше 120000.
SELECT f_name, l_name from employee_data where salary > 120000;
Результат запроса приведен на рис. 5.8.

Рис. 5.8. Выборка столбцов с условием "больше" для поля "зарплата"
Теперь перечислим всех сотрудников, которые имеют стаж работы в компании менее 3 лет.
SELECT f_name, l_name from employee_data where yos < 3;
Результат запроса приведен на рис. 5.9.

Рис. 5.9. Выборка столбцов с условием "меньше" для поля "стаж"
Операторы <= и >=
Используемые в основном с целочисленными данными операторы меньше или равно ( <= ) и больше или равно ( >= ) обеспечивают дополнительные возможности.
select f_name, l_name, age, salary from employee_data where age >= 32;
Результат запроса приведен на рис. 5.10.
Рис. 5.10. Выборка столбцов с условием "больше или равно" для поля "возраст"
Выборка содержит имена, возраст и зарплаты сотрудников, которым больше 32 лет.
select f_name, l_name from employee_data where yos <= 2;
Результат запроса приведен на рис. 5.11.
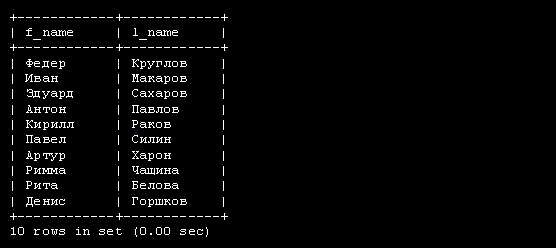
Рис. 5.11. Выборка столбцов с условием "меньше или равно" для поля "стаж"
Запрос выводит имена сотрудников, которые работают в компании не более 2 лет.
Задания
1. Напишите оператор SELECT для извлечения идентификационного номера сотрудников, которые старше 30 лет.
2. Напишите оператор SELECT для извлечения имен и фамилий всех Web-разработчиков.
3. Что выведет следующий оператор SELECT:
SELECT * from employee_data where salary <=100000;
4. Как вывести зарплаты и надбавки сотрудников, которые получают в качестве надбавок более 16000?
5. Перечислите имена всех сотрудников (фамилия, а затем имя), которые занимают должность бухгалтера.
Возможные решения
1. select emp_id from employee_data where age > 30;
2. select f_name, l_name from employee_data where title='Web-разработчик';
3. Следующий оператор выводит всю информацию о сотрудниках, которые получают зарплату не больше 100000.
SELECT * from employee_data where salary <=100000;
4. select salary, perks from employee_data where perks > 16000;
5. select l_name, f_name from employee_data where title = 'бухгалтер';
Поиск текстовых данных по шаблону
В данной части мы рассмотрим поиск текстовых данных по шаблону с помощью предложения where и оператора LIKE.
Оператор сравнения на равенство ( = ) помогает выбрать одинаковые строки. Таким образом, чтобы перечислить имена сотрудников, которых зовут Иван, можно воспользоваться следующим оператором SELECT.
select f_name, l_name from employee_data where f_name = "Иван";
Результат запроса приведен на рис. 5.12.
Рис. 5.12. Результат поиска сотрудников, которых зовут Иван
Как быть, если надо вывести данные о сотрудниках, имя которых начинается с буквы В? Язык SQL позволяет выполнить поиск строковых данных по шаблону. Для этого в предложении where используется оператор LIKE следующим образом.
select f_name, l_name from employee_data where f_name LIKE "В%";
Результат запроса приведен на рис. 5.13.
Рис. 5.13. Результат поиска сотрудников, имя которых начинается с буквы В
Можно видеть, что здесь в условии вместо знака равенства используется LIKE и знак процента в шаблоне.
Знак % действует как символ-заместитель (аналогично использованию * в системах DOS и Linux). Он заменяет собой любую последовательность символов. Таким образом "В%" обозначает все строки, которые начинаются с буквы В. Аналогично "%В" выбирает строки, которые заканчиваются символом В, а "%В%" строки, которые содержат букву В.
Давайте выведем, например, всех сотрудников, которые имеют в названии должности строку "про".
select f_name, l_name, title from employee_data where title like '%про%';
Результат запроса приведен на рис. 5.14.

Рис. 5.14. Результат поиска сотрудников, в названии должности которых содержится строка "про"
Перечислим всех сотрудников, имена которых заканчиваются буквой 'а'. Это очень просто сделать.
mysql> select f_name, l_name from employee_data where f_name like '%a';
Результат запроса приведен на рис. 5.15.
Рис. 5.15. Результат поиска сотрудников, имена которых заканчиваются буквой 'а'
Задания
1. Перечислить всех сотрудников, фамилии которых начинаются с буквы P.
2. Вывести имена всех сотрудников в отделе продаж.
3. Что выведет следующий оператор
SELECT f_name, l_name, salary from employee_data where f_name like '%к%';
4. Перечислить фамилии и должности всех программистов
Возможные решения
1. select l_name, f_name from employee_data where l_name like 'P%';
2. select f_name, l_name from employee_data where title like '%продавец%';
3. Этот оператор выводит имена, фамилии и заплаты всех сотрудников, у которых имя содержит букву 'к'.
SELECT f_name, l_name, salary from employee_data where f_name like '%к%';
4. SELECT l_name, title from employee_data where title like '%программист%';
Предложение HAVING
Чтобы вывести среднюю зарплату сотрудников в различных подразделениях (должностях), используется предложение GROUP BY, например:
select title, AVG(salary) from employee_data GROUP BY title;
Результат запроса приведен на рис. 5.16.
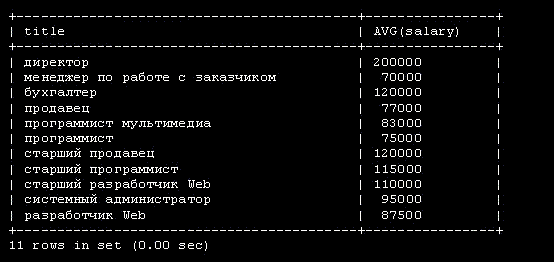
Рис. 5.16. Вывод средней зарплаты сотрудников по подразделениям
Предположим теперь, что требуется вывести только те подразделения, где средняя зарплата более 100000. Это можно сделать с помощью предложения HAVING.
select title, AVG(salary) from employee_data GROUP BY title HAVING AVG(salary) > 100000;
Результат запроса приведен на рис. 5.17.

Рис. 5.17. Вывод средней зарплаты определённого диапазона по подразделениям
Задание
Вывести подразделения и средний возраст, где средний возраст больше 30.
Возможное решение
mysql> select title, AVG(age)
-> from employee_data
-> GROUP BY title
-> HAVING AVG(age) > 30;Результат запроса приведен на рис. 5.18.
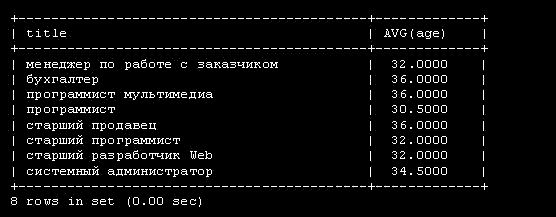
Рис. 5.18. Вывод подразделения и среднего возраста, где средний возраст больше 30 лет
Удаление записей из таблицы
Для удаления записей из таблицы можно использовать оператор DELETE.
Оператор удаления DELETE требует задания имени таблицы и необязательных условий.
DELETE from имя_таблицы [WHERE условия];
Примечание: Если никакие условия не будут заданы, то удаляются все данные в таблице.
Предположим, один из специалистов по мультимедиа 'Василий Пупкин' уволился из компании. Надо удалить его запись.
DELETE from employee_data WHERE l_name = 'Пупкин';
Результат запроса приведен на рис. 5.19.
Рис. 5.19. Результат удаления записи из таблицы
Лекция 6. Логические операторы
В этой лекции мы рассмотрим, как выбрать данные на основе условий SQL, представленных с помощью булевых (логических) операторов.
- AND
- OR
- NOT
Использовать их очень просто. Ниже показан оператор SELECT, который выводит имена сотрудников, которые получают более 70000, но меньше 90000.
SELECT f_name, l_name from employee_data where salary > 70000 AND salary < 90000;
На рис. 6.1. приведен результат запроса.

Рис. 6.1. Имена сотрудников, которые получают более 70000, но меньше 90000
Давайте выведем список сотрудников, фамилии которых начинаются с буквы К или Л.
SELECT l_name from employee_data where l_name like 'К%' OR l_name like 'Л%';
На рис. 6.2. приведен результат запроса.
Рис. 6.2. Сотрудники, фамилии которых начинаются с буквы К или Л
Вот более сложный пример: список имен и возраста сотрудников, фамилии которых не начинаются с К или Л, и которые младше 30 лет.
SELECT f_name, l_name , age from employee_data where (l_name not like 'К%' OR l_name not like 'Л%') AND age < 30;
На рис. 6.3. приведен результат запроса.
Рис. 6.3. Список имен и возраста сотрудников, фамилии которых не начинаются с К или Л, и которые младше 30 лет
Обратите внимание на использование скобок в представленном выше операторе. Скобки предназначены для выделения различных логических условий и удаления двусмысленностей.
Оператор NOT поможет при поиске всех сотрудников, которые не являются программистами. (Программисты включают старших программистов, программистов мультимедиа и программистов).
SELECT f_name, l_name, title from employee_data where title NOT LIKE "%программист%";
На рис. 6.4. приведен результат запроса.

Рис. 6.4. Поиск всех сотрудников, которые не являются программистами
И последний пример перед упражнениями.
Показать всех сотрудников со стажем работы в компании более 3 лет, которые старше 30 лет.
select f_name, l_name from employee_data where yos > 3 AND age > 30;
На рис. 6.5. приведен результат запроса.

Рис. 6.5. Все сотрудники, которые старше 30 лет, и имеют стаж работы более 3 лет
Задания
1. Вывести имена и фамилии всех сотрудников, которые получают зарплату не более 90000 и не являются программистами, старшими программистами или программистами мультимедиа.
2. Что делает следующий оператор?
SELECT l_name, f_name from employee_data where title NOT LIKE '%продавец%' AND age < 30;
3. Вывести все идентификационные номера и имена сотрудников в возрасте между 32 и 40 годами.
4. Выберите имена всех сотрудников в возрасте 32 лет, которые не являются программистами.
Возможные решения
mysql> select f_name, l_name from employee_data -> where salary <= 90000 -> AND title NOT LIKE '%программист%';
- Команда выводит имена (фамилию, за которой следует имя) сотрудников, которые не работают в отделе продаж и моложе 30 лет.
mysql> SELECT l_name, f_name from employee_data -> where title NOT LIKE '%продавец%' -> AND age < 30; mysql> select emp_id, f_name, l_name from -> employee_data where age > 32 -> and age < 40;
mysql> select f_name, l_name from employee_data -> where age = 32 AND -> title NOT LIKE '%программист%';
Операторы IN и BETWEEN
Чтобы найти сотрудников, которые являются разработчиками Web или системными администраторами, можно использовать оператор SELECT следующего вида:
SELECT f_name, l_name, title from
-> employee_data where
-> title = 'разработчик Web' OR
-> title = 'системный адм.';На рис. 6.6. приведен результат запроса.
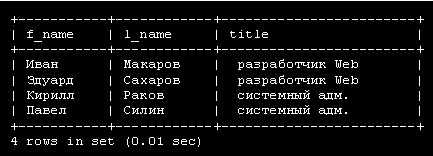
Рис. 6.6. Поиск сотрудников, которые являются разработчиками Web или системными администраторами
В SQL имеется более простой способ сделать это с помощью оператора IN (в множестве). Его использование не представляет никаких трудностей.
SELECT f_name, l_name, title from
-> employee_data where title
-> IN ('разработчик Web', 'системный адм.');Результат будет аналогичен рис. 6.6.
Использование NOT перед IN позволяет вывести данные, которые не входят в множество, определяемое условием IN. Следующий оператор выводит список сотрудников, которые не занимают должность программиста или системного администратора.
SELECT f_name, l_name, title from
-> employee_data where title NOT IN
-> ('программист', 'системный адм.');Оператор BETWEEN используется для определения целочисленных границ. Поэтому вместо age >= 32 AND age <= 40 можно использовать age BETWEEN 32 AND 40.
select f_name, l_name, age from
-> employee_data where age BETWEEN
-> 32 AND 40;На рис. 6.7. приведен результат запроса.
Рис. 6.7. Поиск сотрудников, возраст которых лежит в промежутке от 32-х до 40 лет
NOT также можно использовать вместе с BETWEEN, как в следующем операторе, который выводит сотрудников, зарплата которых меньше 90000 или больше 150000.
select f_name, l_name, salary
-> from employee_data where salary
-> NOT BETWEEN
-> 90000 AND 150000;Задания
1. Найдите всех сотрудников, которые занимают должность "старший программист" и "программист мультимедиа".
2. Выведите список имен сотрудников, зарплата которых составляет от 70000 до 90000.
3. Что делает следующий оператор?
SELECT f_name, l_name, title from
employee_data where title NOT IN
('программист', 'старший программист',
'программист мультимедиа');4. Вот более сложный оператор, который объединяет BETWEEN и IN. Что он делает?
SELECT f_name, l_name, title, age
from employee_data where
title NOT IN
('программист', 'старший программист',
'программист мультимедиа') AND age
NOT BETWEEN 28 and 32;Возможные решения
mysql> select l_name, f_name, title -> from employee_data where -> title IN -> ('старший программист', -> 'программист мультимедиа');2. mysql> select f_name, l_name, salary from -> employee_data where salary BETWEEN -> 70000 AND 90000;- Выводятся имена и должности всех, кто не является программистом.
mysql> SELECT f_name, l_name, title from -> employee_data where title NOT IN -> ('программист', 'старший программист', -> 'программист мультимедиа'); - Этот оператор выводит список тех, кто не является программистом, и которые младше 28 или старше 32 лет.
mysql> SELECT f_name, l_name, title, age from -> employee_data where title NOT IN -> ('программист', 'старший программист', -> 'программист мультимедиа') AND -> age NOT BETWEEN 28 AND 32;
Упорядочивание данных
Рассмотрим вопрос о том, как можно изменить порядок вывода данных, извлеченных из таблиц MySQL, используя предложение ORDER BY оператора SELECT.
Извлекаемые до сих пор данные всегда выводились в том порядке, в котором они были сохранены в таблице. В действительности SQL позволяет сортировать извлеченные данные с помощью предложения ORDER BY. Это предложение требует имя столбца, на основе которого будут сортироваться данные. Давайте посмотрим, как можно вывести имена сотрудников с упорядоченными по алфавиту фамилиями сотрудников (в возрастающем порядке).
SELECT l_name, f_name from employee_data ORDER BY l_name;
А вот так сотрудников можно отсортировать по возрасту.
SELECT f_name, l_name, age from employee_data ORDER BY age;
Предложение ORDER BY может сортировать в возрастающем порядке ( ASCENDING или ASC ) или в убывающем порядке ( DESCENDING или DESC ) в зависимости от указанного аргумента.
Чтобы вывести список сотрудников в убывающем порядке, можно использовать следующий оператор.
SELECT f_name from employee_data ORDER by f_name DESC;
Примечание: Возрастающий порядок ( ASC ) используется по умолчанию.
Задания
1. Вывести список сотрудников в порядке, определяемом зарплатой, которую они получают.
2. Выведите список сотрудников в убывающем порядке их стажа работы в компании.
3. Что делает следующий оператор?
SELECT emp_id, l_name, title, age from employee_data ORDER BY title DESC, age ASC;
4. Вывести список сотрудников (фамилию и имя), которые занимают должность "программист" или "разработчик Web" и отсортировать их фамилии по алфавиту.
Возможные решения
mysql> SELECT f_name, l_name, salary -> from employee_data -> ORDER BY salary;mysql> SELECT f_name, l_name, yos -> from employee_data -> ORDER by yos DESC;- Оператор выводит список сотрудников с идентификационным номером, должностью, и возрастом, отсортированный по должности в убывающем порядке и по возрасту в возрастающем порядке.
mysql> SELECT emp_id, l_name, title, age -> from employee_data ORDER BY -> title DESC, age ASC;Примечание: Сначала сортируются должности в убывающем порядке. Затем для каждой должности сортируется возраст сотрудников в возрастающем порядке.
mysql> SELECT l_name, f_name from employee_data -> where title IN ('программист', -> 'разработчик Web') ORDER BY l_name;
Ограничение количества извлекаемых данных
Далее рассмотрим, как ограничить число записей, выводимых оператором SELECT.
По мере увеличения таблиц возникает необходимость вывода только подмножества данных. Этого можно добиться с помощью предложения LIMIT.
Например, чтобы вывести из таблицы имена только первых пяти сотрудников, используется оператор LIMIT с аргументом равным 5.
SELECT f_name, l_name from employee_data LIMIT 5;
На рис. 6.8. приведен результат запроса.
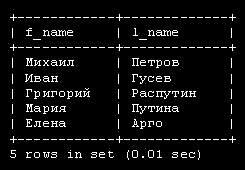
Рис. 6.8. Имена первых пяти сотрудников
Это первые пять записей таблицы.
Можно соединить оператор LIMIT с оператором ORDER BY. Таким образом, следующий оператор выведет четверых самых молодых сотрудников компании.
SELECT f_name, l_name, age FROM employee_data ORDER BY age LIMIT 4;
На рис. 6.9. приведен результат запроса.
Рис. 6.9. Четверо самых старых сотрудников компании
Аналогично можно вывести двух самых молодых сотрудников.
SELECT f_name, l_name, age from employee_data ORDER BY age DESC LIMIT 2;
На рис. 6.10. приведен результат запроса.
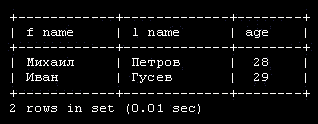
Рис. 6.10. Двое самых молодых сотрудников
Извлечение подмножеств
LIMIT можно использовать также для извлечения подмножества данных, используя дополнительные аргументы.
Общая форма оператора LIMIT имеет следующий вид:
SELECT (что-нибудь) from таблица LIMIT начальная строка, извлекаемое число записей; SELECT f_name, l_name from employee_data LIMIT 6,3;
На рис. 6.11. приведен результат запроса.

Рис. 6.11. Извлечение трёх строк начиная с 7-й
Будут извлечены три строки, начиная с седьмой.
Задания
- Найдите имена 5 самых молодых сотрудников компании.
- Извлеките 5 записей, начиная с 10 строки.
- Выведите имя, фамилию и зарплату сотрудника, который получает самую большую зарплату.
- Что делает следующий оператор?
SELECT emp_id, age, perks from employee_data ORDER BY perks DESC LIMIT 10;
Возможные решения
mysql> SELECT f_name, l_name, age from -> employee_data ORDER BY age -> LIMIT 5;mysql> SELECT * from employee_data -> LIMIT 10, 5;mysql> select f_name, l_name, salary -> from employee_data -> ORDER BY salary DESC -> LIMIT 1;- Этот оператор выводит идентификационный номер, возраст и надбавки 10 сотрудников, которые получают наибольшие надбавки.
mysql> SELECT emp_id, age, perks -> from employee_data ORDER BY -> perks DESC LIMIT 10;
Ключевое слово DISTINCT
Рассмотрим теперь, как выбрать и вывести записи таблиц MySQL с помощью ключевого слова DISTINCT (РАЗЛИЧНЫЙ), использование которого исключает появление повторяющихся данных.
Чтобы вывести все должности базы данных компании, можно выполнить следующий оператор:
select title from employee_data;
На рис. 6.12. приведен результат запроса.
Рис. 6.12. Все должности базы данных компании
Можно видеть, что список содержит повторяющиеся данные. Предложение SQL DISTINCT выводит только уникальные данные. Вот как оно используется.
select DISTINCT title from employee_data;
На рис. 6.13. приведен результат запроса.

Рис. 6.13. Все должности базы данных компании без повторов
Из этого можно видеть, что в компании имеется 11 уникальных должностей.
Уникальные записи можно также отсортировать с помощью ORDER BY.
select DISTINCT age from employee_data ORDER BY age;
На рис. 6.14. приведен результат запроса.
Рис. 6.14. Значения возраста сотрудников компании без повторов
DISTINCT часто используется вместе с функцией COUNT, которая будет рассмотрена далее.
Задания
- Сколько уникальных вариантов зарплаты имеется в компании? Представьте их в убывающем порядке.
- Сколько различных имен имеется в базе данных?
Возможные решения
select distinct salary from employee_data order by salary DESC;
mysql> select distinct f_name from employee_data;
Изменение записей
Команда UPDATE выполняет изменение данных в таблицах. Она имеет очень простой формат.
UPDATE имя_таблицы SET имя_столбца_1 = значение_1, имя_столбца_2 = значение_2, имя_столбца_3 = значение_3, ... [WHERE условия];
Как и все другие команды SQL можно вводить ее на одной строке или на нескольких строках.
Рассмотрим несколько примеров.
Предположим, директор увеличил свою зарплату на 20000 и надбавки на 5000. Его предыдущая зарплата была 200000, а надбавки были 50000.
UPDATE employee_data SET salary=220000, perks=55000 WHERE title='директор';
На рис. 6.15. приведен результат запроса.

Рис. 6.15. Данные обновлены
Можно проверить эту операцию, выводя данные из таблицы.
select salary, perks from employee_data WHERE title = 'директор';
На рис. 6.16. приведен результат запроса.

Рис. 6.16. Данные обновлены
В действительности предыдущую зарплату знать не требуется. Можно воспользоваться арифметическими операторами. Следующий оператор сделает то же самое, при этом исходные данные знать заранее не требуется.
UPDATE employee_data SET salary = salary + 20000, perks = perks + 5000 WHERE title='директор';
Результат запроса аналогичен рис. 6.15.
В качестве другого примера можно попробовать изменить название должности "разработчик Web" на "программист Web".
mysql> update employee_data SET
-> title = 'программист Web'
-> WHERE title = 'разработчик Web';На рис. 6.17. приведен результат запроса.

Рис. 6.17. Данные обновлены
Важно также перед выполнением изменений внимательно изучить часть оператора с условием, так как легко можно изменить не те данные. Оператор UPDATE без условий изменит все данные столбца во всех строках. Надо быть очень осторожным при внесении изменений.
Задания
- Измените фамилию Чащина на Петрова. Внесите соответствующие изменения в базу данных.
- Название должности "программист мультимедиа" необходимо изменить на "специалист по мультимедиа".
- Увеличьте зарплату всем сотрудниками (кроме директора) на 10000.
Возможные решения
mysql> update employee_data SET -> l_name = 'Петрова' -> WHERE l_name = 'Чащина';Примечание: Если бы были еще сотрудники с фамилией Чащина, то эти записи также были бы изменены. В таком случае может помочь столбец emp_id, так как он содержит уникальные значения. Лучше использовать значение emp_id вместо l_name, как в следующем примере:
mysql> update employee_data SET -> l_name = 'Петрова' -> WHERE emp_id = 4;mysql> update employee_data set -> title = 'специалист по мультимедиа' -> where title = 'программист мультимедиа';mysql> update employee_data set -> salary = salary + 10000 -> where title != 'директор';
Лекция 7. Команды обработки данных
Поиск минимального и максимального значений
В MySQL имеются встроенные функции для вычисления минимального и максимального значений.
SQL имеет 5 агрегатных функций.
- MIN(): минимальное значение
- MAX(): максимальное значение
- SUM(): сумма значений
- AVG(): среднее значений
- COUNT(): подсчитывает число записей
В этом параграфе мы рассмотрим поиск минимального и максимального значений столбца.
Минимальное значение
select MIN(salary) from employee_data;
На рис. 7.1. приведен результат запроса.
Рис. 7.1. Поиск минимальной зарплаты
Максимальное значение
select MAX(salary) from employee_data;
На рис. 7.2. приведен результат запроса.
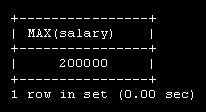
Рис. 7.2. Поиск максимальной зарплаты
Задания
- Найдите минимальные надбавки.
- Найдите максимальную зарплату среди всех "программистов".
- Найдите возраст самого старого "продавца".
- Найдите имя и фамилию самого старого сотрудника.
Возможные решения
1. mysql> select MIN(perks) from employee_data;
На рис. 7.3. приведен результат запроса.

Рис. 7.3. Минимальные надбавки
2.
mysql> select MAX(salary) from employee_data
-> where title = 'программист';На рис. 7.4. приведен результат запроса.
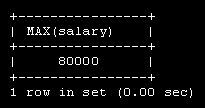
Рис. 7.4. Максимальная зарплата среди программистов
3. mysql> select MAX(age) from employee_data
-> where title = 'продавец';На рис. 7.5. приведен результат запроса.
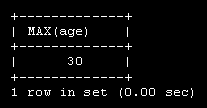
Рис. 7.5. Возраст самого старого продавца
4. Вот один из способов сделать без использования агрегатных функций.
mysql> select f_name, l_name, age
-> from employee_data
-> order by age DESC limit 1;На рис. 7.6. приведен результат запроса.
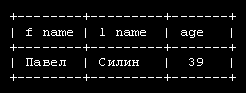
Рис. 7.6. Имя и фамилия самого старого сотрудника
Поиск среднего значения и суммы
Суммирование значений столбца с помощью функции SUM
Агрегатная функция SUM() вычисляет общую сумму значений в столбце. Для этого необходимо задать имя столбца, которое должно быть помещено внутри скобок.
Давайте посмотрим, сколько компания BigFoot тратит на зарплату своих сотрудников.
select SUM(salary) from employee_data;
На рис. 7.7. приведен результат запроса.
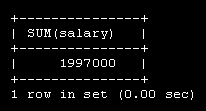
Рис. 7.7. Сумма всех зарплат
Аналогично можно вывести общую сумму надбавок, выдаваемых сотрудникам.
select SUM(perks) from employee_data;
На рис. 7.8. приведен результат запроса.
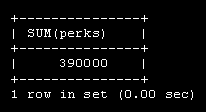
Рис. 7.8. Сумма всех надбавок
Можно найти также общую сумму зарплаты и надбавок.
select sum(salary) + sum(perks) from employee_data;
На рис. 7.9. приведен результат запроса.
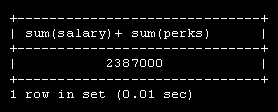
Рис. 7.9. Общая сумма зарплаты и надбавок
Здесь показаны также дополнительные возможности команды SELECT. Значения можно складывать, вычитать, умножать или делить. В действительности можно записывать полноценные арифметические выражения.
Вычисление среднего значения
Агрегатная функция AVG() используется для вычисления среднего значения данных в столбце.
select avg(age) from employee_data;
На рис. 7.10. приведен результат запроса.
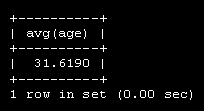
Рис. 7.10. Средний возраст сотрудников
Пример выше вычисляет средний возраст сотрудников компании BigFoot, а следующий выводит среднюю зарплату.
select avg(salary) from employee_data;
На рис. 7.11. приведен результат запроса.
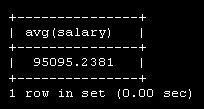
Рис. 7.11. Средняя зарплата сотрудников
Задания
- Вывести сумму всех возрастов сотрудников, работающих в компании BigFoot.
- Как вычислить общее количество лет стажа работы сотрудников в компании BigFoot?
- Вычислите сумму зарплат и средний возраст сотрудников, которые занимают должность "программист".
- Что делает следующий оператор?
select (SUM(perks)/SUM(salary) * 100) from employee_data;
Возможные решения
1. mysql> select SUM(age) from employee_data;
На рис. 7.12. приведен результат запроса.
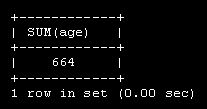
Рис. 7.12. Сумма всех возрастов сотрудников
2. mysql> select SUM(yos) from employee_data;
На рис. 7.13. приведен результат запроса.
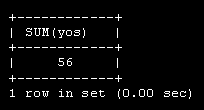
Рис. 7.13. Общее количество лет стажа работы сотрудников
3. mysql> select SUM(salary), AVG(age)
-> from employee_data where
-> title = 'программист';На рис. 7.14. приведен результат запроса.
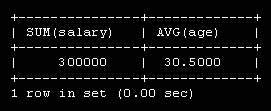
Рис. 7.14. Сумма зарплат и средний возраст программистов
4. Этот оператор выводит процент зарплаты, который сотрудники BigFoot получают в качестве надбавок.
mysql> select (SUM(perks)/SUM(salary) * 100)
-> from employee_data;На рис. 7.15. приведен результат запроса.
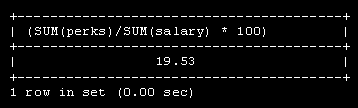
Рис. 7.15. Процент зарплаты, который сотрудники получают в качестве надбавок
Именование столбцов
MySQL позволяет задавать имена для выводимых столбцов. Поэтому вместо f_name или l_name и т.д. можно использовать более понятные и наглядные термины. Это делается с помощью оператора AS.
select avg(salary) AS 'Средняя зарплата' from employee_data;
На рис. 7.16. приведен результат запроса.

Рис. 7.16. Вывод средней зарплаты с использованием псевдо-имен столбцов.
Такие псевдо-имена могут сделать вывод более понятным для пользователей. Важно только помнить, что при задании псевдо-имен с пробелами необходимо заключать такие имена в кавычки. Вот еще один пример:
select (SUM(perks)/SUM(salary) * 100) AS 'Процент надбавок' from employee_data;
На рис. 7.17. приведен результат запроса.
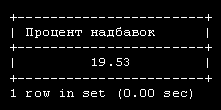
Рис. 7.17. Вывод процента зарплаты, которую сотрудники получают в качестве надбавок с использованием псевдо-имен
Подсчет числа записей
Агрегатная функция COUNT() подсчитывает и выводит общее число записей. Например, чтобы подсчитать общее число записей в таблице, выполните следующую команду.
select COUNT(*) from employee_data;
На рис. 7.18. приведен результат запроса.
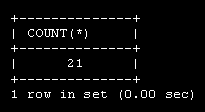
Рис. 7.18. Общее количество записей
Как мы уже знаем, знак * означает "все данные".
Теперь давайте подсчитаем общее число сотрудников, которые занимают должность "программист".
select COUNT(*) from employee_data where title = 'программист';
На рис. 7.19. приведен результат запроса.
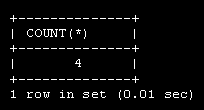
Рис. 7.19. Общее количество сотрудников-программистов
Группировка данных
Предложение GROUP BY позволяет группировать аналогичные данные. Поэтому, чтобы вывести все уникальные должности в таблице, можно выполнить команду
select title from employee_data GROUP BY title;
На рис. 7.20. приведен результат запроса.
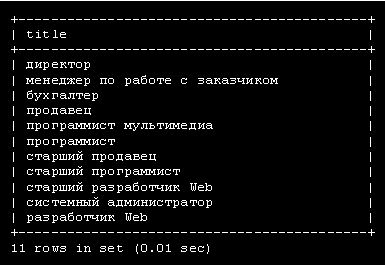
Рис. 7.20. Все уникальные должности сотрудников
Можно видеть, что это аналогично использованию DISTINCT в предыдущей лекции.
Вот как можно подсчитать число сотрудников имеющих определенную должность.
select title, count(*) from employee_data GROUP BY title;
На рис. 7.21. приведен результат запроса.
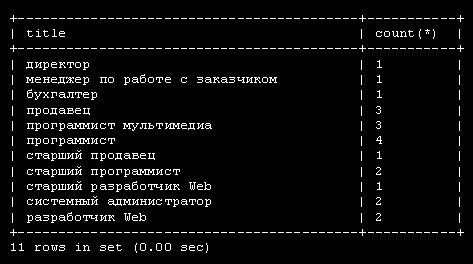
Рис. 7.21. Количество сотрудников по должностям
В предыдущей команде MySQL сначала создает группы различных должностей, а затем выполняет подсчет в каждой группе.
Сортировка данных
Теперь давайте найдем и выведем число сотрудников, имеющих различные должности, и отсортируем их с помощью ORDER BY.
select title, count(*) AS Number from employee_data GROUP BY title ORDER BY Number;
На рис. 7.22. приведен результат запроса.
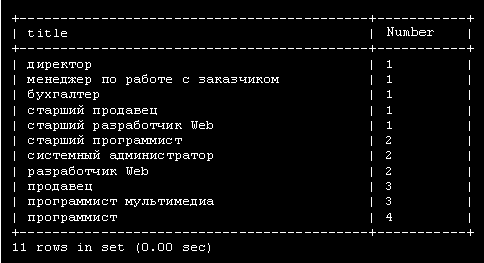
Рис. 7.22. Количество сотрудников по должностям с сортировкой
Задания
- Подсчитайте число сотрудников, которые проработали в BigFoot более трех лет.
- Подсчитайте количество сотрудников в группах одного возраста.
- Измените предыдущее задание так, чтобы возраст выводился в убывающем порядке.
- Найдите средний возраст сотрудников в различных подразделениях (должностях).
- Измените предыдущий оператор так, чтобы данные выводились в убывающем порядке среднего возраста.
Возможные решения
1. mysql> select count(*) from employee_data
-> where yos > 3;На рис. 7.23. приведен результат запроса.
Рис. 7.23. Число сотрудников, которые проработали более трех лет
2. mysql> select age, count(*)
-> from employee_data
-> GROUP BY age;На рис. 7.24. приведен результат запроса.
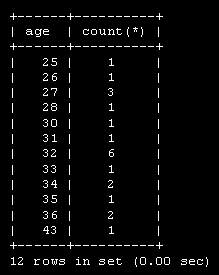
Рис. 7.24. Количество сотрудников в группах одного возраста
3. mysql> select age, count(*)
-> from employee_data
-> GROUP BY age
-> ORDER by age DESC;На рис. 7.25. приведен результат запроса.
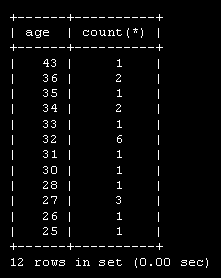
Рис. 7.25. Количество сотрудников в группах одного возраста с обратной сортировкой
4. mysql> select title, AVG(age)
-> from employee_data
-> GROUP BY title;На рис. 7.26. приведен результат запроса.

Рис. 7.26. Средний возраст сотрудников по должностям
5. mysql> select title, AVG(age)
-> AS 'средний возраст'
-> from employee_data
-> GROUP BY title
-> ORDER BY 'средний возраст' DESC;На рис. 7.27. приведен результат запроса.
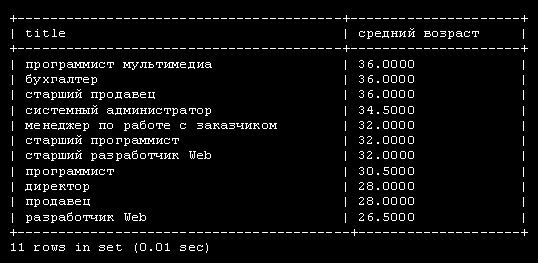
Рис. 7.27. Средний возраст сотрудников по должностям с использованием псевдо-имени столбца
Примечание: Нам нужно задать псевдо-имя для столбца, содержащего среднее значение возраста, чтобы его можно было сортировать.
Лекция 8. Математические функции
Математические функции MySQL
Описанные ниже функции выполняют различные математические операции. В качестве аргументов большинство из них принимает числа с плавающей запятой и возвращает результат аналогичного типа.
ABS(число)
Эта функция возвращает модуль числа
На рис. 8.1(а) и 8.1(б) приведены примеры работы с функцией ABS.
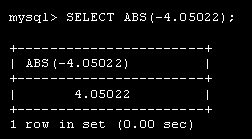
Рис. 8.1(а). Модуль числа
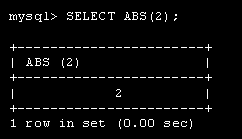
Рис. 8.1(б). Модуль числа
ASIN(число)
Эта функция возвращает арксинус числа. Диапазон допустимых значений – от -1 до 1. Вне этого диапазона значение арксинуса не определено.
На рис. 8.2(а), 8.2(б) и 8.2(в) приведены примеры работы с функцией ASIN.
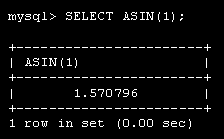
Рис. 8.2(а). Арксинус числа
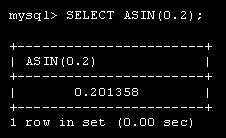
Рис. 8.2(б). Арксинус числа
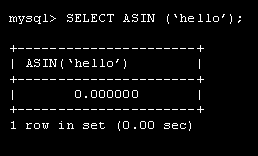
Рис. 8.2(в). Арксинус числа
ACOS(число)
Эта функция возвращает арккосинус числа. Диапазон допустимых значений – от -1 до 1. Вне этого диапазона значение арккосинуса не определено.
На рис. 8.3(а), 8.3(б) и 8.3(в) приведены примеры работы с функцией ACOS.
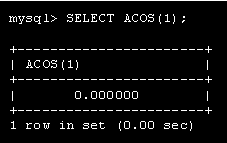
Рис. 8.3(а). Арккосинус числа
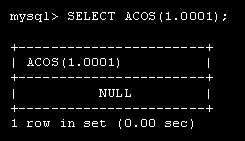
Рис. 8.3(б). Арккосинус числа
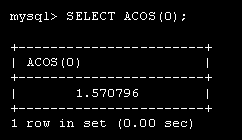
Рис. 8.3(в). Арккосинус числа
ATAN(число)
Эта функция возвращает арктангенс числа.
На рис. 8.4(а), 8.4(б) и 8.4(в) приведены примеры работы с функцией ATAN.

Рис. 8.4(а). Арктангенс числа
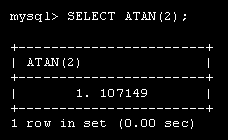
Рис. 8.4(б). Арктангенс числа
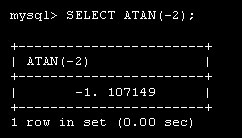
Рис. 8.4(в). Арктангенс числа
ATAN2(число1, число2)
Эта функция возвращает угол в радианах точки с заданными координатами.
На рис. 8.5(а), 8.5(б) и 8.5(в) приведены примеры работы с функцией ATAN2.
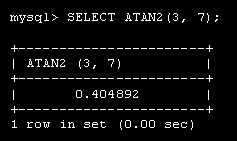
Рис. 8.5(а). Угол по координатам точки
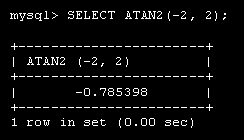
Рис. 8.5(б). Угол по координатам точки
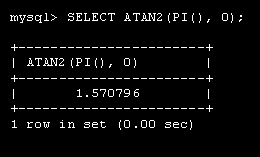
Рис. 8.5(в). Угол по координатам точки
CEILING(число)
CEIL(число)
Эта функция округляет число до ближайшего большего целого числа.
На рис. 8.6(а), 8.6(б) и 8.6(в) приведены примеры работы с функцией CEIL.
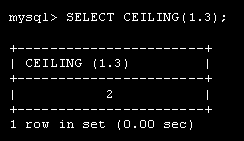
Рис. 8.6(а). Функция CEIL
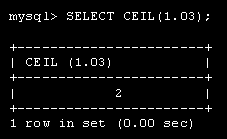
Рис. 8.6(б). Функция CEIL
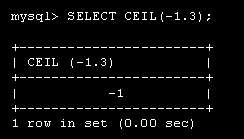
Рис. 8.6(в). Функция CEIL
COS(число)
Возвращает косинус числа
На рис. 8.7 приведен пример работы с функцией COS.
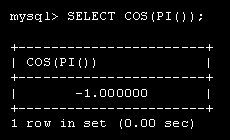
Рис. 8.7. Косинус числа
COT(число)
Возвращает котангенс числа.
На рис. 8.8(а) и 8.8(б) приведены примеры работы с функцией COT.
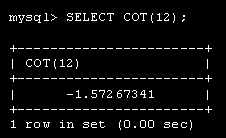
Рис. 8.8(а). Котангенс числа
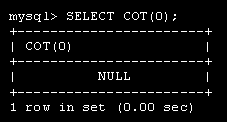
Рис. 8.8(б). Котангенс числа
CRC32(выражение)
Вычисляет проверочное значение в циклическом избыточном коде и возвращает 32-разрядное целое. Результат равен NULL, если передается аргумент NULL. Ожидается, что аргумент будет строкой, и будет рассматриваться в качестве таковой в противном случае.
На рис. 8.9 приведен пример работы с функцией CRC32.
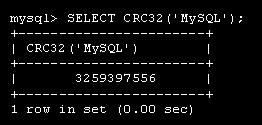
Рис. 8.9. Циклический избыточный код
DEGREES(число)
Возвращает аргумент, преобразованный из радианов в градусы.
На рис. 8.10 приведен пример работы с функцией DEGREES.
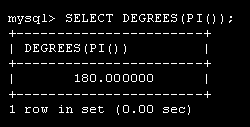
Рис. 8.10. Преобразование из радианов в градусы
ЕХР(число)
Эта функция возводит число e (основание натурального логарифма) в заданную степень.
На рис. 8.11(а) и 8.11(б) приведены примеры работы с функцией EXP.
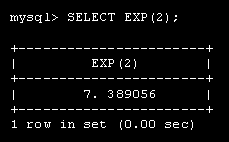
Рис. 8.11(а). Экспонента
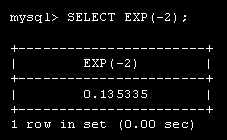
Рис. 8.11(б). Экспонента
FLOOR(число)
Эта функция округляет число до ближайшего меньшего целого числа.
На рис. 8.12(а), 8.12(б) и 8.12(в) приведены примеры работы с функцией FLOOR.
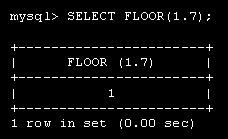
Рис. 8.12(а). Функция FLOOR
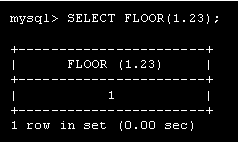
Рис. 8.12(б). Функция FLOOR
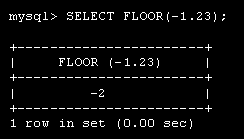
Рис. 8.12(в). Функция FLOOR
GREATEST(...)
Эта функция возвращает наибольшее значение из списка. Она может работать как с числами, так и со строками.
На рис. 8.13 приведен пример работы с функцией GREATEST.
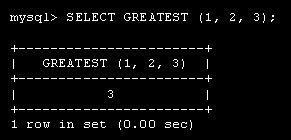
Рис. 8.13. Наибольшее значение из списка
LEAST(...)
Функция возвращает наименьшее значение из списка.
На рис. 8.14 приведен пример работы с функцией LEAST.
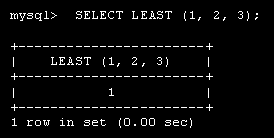
Рис. 8.14. Наименьшее значение из списка
LN(число)
LOG(число)
Эта функция возвращает натуральный логарифм числа.
На рис. 8.15(а) и 8.15(б) приведены примеры работы с функцией LN.
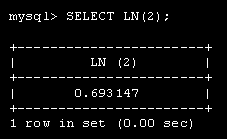
Рис. 8.15(а). Натуральный логарифм числа
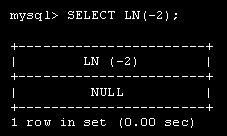
Рис. 8.15(б). Натуральный логарифм числа
LOG(число1, число2)
При вызове с одним параметром функция LOG возвращает натуральный логарифм числа, а при вызове с двумя параметрами - возвращает логарифм числа2 по основанию число1.
На рис. 8.16(а) и 8.16(б) приведены примеры работы с функцией LOG2.

Рис. 8.16(а). Логарифм числа по основанию
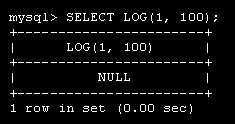
Рис. 8.16(б). Логарифм числа по основанию
LOG(число1, число2) эквивалентна LOG(число2) / LOG(число1).
LOG2(число)
Возвращает логарифм числа по основанию 2.
На рис. 8.17(а) и 8.17(б) приведены примеры работы с функцией LOG.

Рис. 8.17(а). Логарифм числа по основанию 2
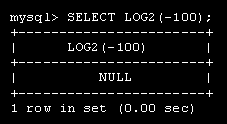
Рис. 8.17(б). Логарифм числа по основанию 2
Функция LOG2() удобна для того, чтобы определить, сколько бит потребуется для сохранения числа. Вместо нее можно использовать LOG(число) /LOG(2).
LOG10(число)
Возвращает логарифм числа по основанию 10.
На рис. 8.18(а), 8.18(б) и 8.18(в) приведены примеры работы с функцией LOG10.

Рис. 8.18(а). Десятичный логарифм
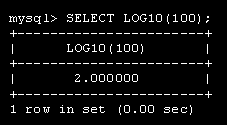
Рис. 8.18(б). Десятичный логарифм
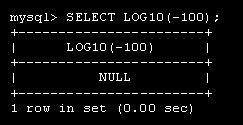
Рис. 8.18(в). Десятичный логарифм
MOD(число1, число2)
число1 % число2
число1 MOD число2
Эта функция возвращает остаток от деления первого числа на второе подобно оператору %.
На рис. 8.19(а), 8.19(б), 8.19(в) и 8.19(г) приведены примеры работы с функцией MOD.
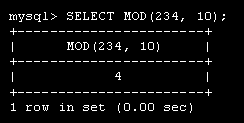
Рис. 8.19(а). Остаток от деления
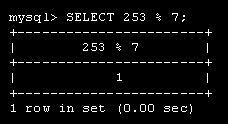
Рис. 8.19(б). Остаток от деления
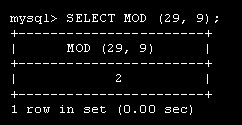
Рис. 8.19(в). Остаток от деления
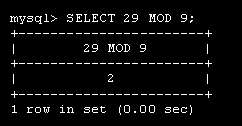
Рис. 8.19(г). Остаток от деления
PI()
Возвращает значение числа ![]() . По умолчанию отображается пять знаков после десятичной запятой, но внутренне MySQL использует полное представление действительного числа двойной точности.
. По умолчанию отображается пять знаков после десятичной запятой, но внутренне MySQL использует полное представление действительного числа двойной точности.
На рис. 8.20(а) и 8.20(б) приведены примеры работы с функцией PI.

Рис. 8.20(а). Число Пи
Рис. 8.20(б). Число Пи
POW(число1, число2)
POWER(число1, число2)
Возвращает значение число1, возведенное в степень число2.
На рис. 8.21(а), 8.21(б) и 8.21(в) приведены примеры работы с функцией POW.
Рис. 8.21(а). Возведение числа в степень
Рис. 8.21(б). Возведение числа в степень
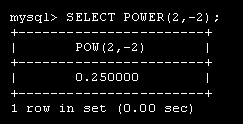
Рис. 8.21(в). Возведение числа в степень
RADIANS(число)
Возвращает аргумент, преобразованный из градусов в радианы.
На рис. 8.22(а) и 8.22(б) приведены примеры работы с функцией RADIANS.
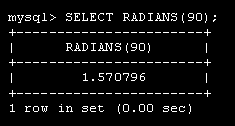
Рис. 8.22(а). Преобразование из градусов в радианы
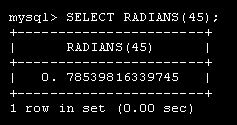
Рис. 8.22(б). Преобразование из градусов в радианы
RAND([число])
Возвращает случайное число двойной точности в диапазоне от 0 до 1. Если указан целочисленный аргумент, он служит начальным числом для генератора случайных чисел (генерируя повторяющуюся последовательность). Если аргумент отсутствует, используется значение системных часов.
На рис. 8.23(а) и 8.23(б) приведены примеры работы с функцией RAND.
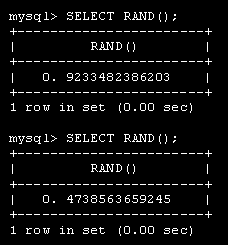
Рис. 8.23(а). Создание случайных чисел
Рис. 8.23(б). Создание случайных чисел
Функцию можно использовать для извлечения строк в случайном порядке.
mysql> SELECT * FROM имя_таблицы ORDER BY RAND();
ORDER BY RAND() в комбинации с LIMIT удобно для выбора случайного примера из набора строк:
mysql> SELECT * FROM tablel, table2 WHERE a=b AND c<d -> ORDER BY RAND() LIMIT 1000;
Следует отметить, что RAND() в конструкции WHERE вычисляется заново при каждом выполнении WHERE.
ROUND(число [, точность])
Эта функция округляет число с плавающей запятой до целого числа или, если указан второй аргумент, до заданного количества цифр после запятой. Если точность отрицательная, обнуляется целая часть числа.
На рис. 8.24(а), 8.24(б), 8.24(в), 8.24(г), 8.24(д) и 8.24(е) приведены примеры работы с функцией ROUND.
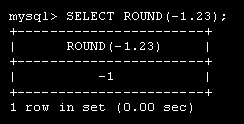
Рис. 8.24(а). Округление числа

Рис. 8.24(б). Округление числа

Рис. 8.24(в). Округление числа

Рис. 8.24(г). Округление числа

Рис. 8.24(д). Округление числа
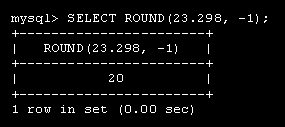
Рис. 8.24(е). Округление числа
Следует отметить, что поведение ROUND(), когда аргумент точно на середине отрезка между двумя целыми, зависит от реализации библиотеки С. Различные реализации округляют до ближайшего четного, либо всегда в большую сторону, либо всегда в меньшую сторону, либо в сторону ближайшего нуля. Если вам нужно иметь предсказуемое поведение в этом случае, применяйте вместо этой функции TRUNCATE() ИЛИ FLOOR().
SIGN(число)
Возвращает знак аргумента как -1, 0 или 1, в зависимости от того, число отрицательное, нуль или положительное.
На рис. 8.25(а), 8.25(б) и 8.25(в) приведены примеры работы с функцией SIGN.
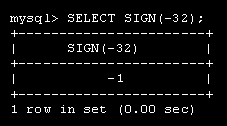
Рис. 8.25(а). Знак числа

Рис. 8.25(б). Знак числа

Рис. 8.25(в). Знак числа
SIN(число)
Эта функция возвращает синус числа в радианах.
На рис. 8.26(а) и 8.26(б) приведены примеры работы с функцией SIN.
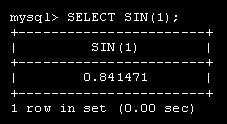
Рис. 8.26(а). Синус числа

Рис. 8.26(б). Синус числа
SQRT(число)
Эта функция возвращает квадратный корень числа.
На рис. 8.27(а), 8.27(б) и 8.27(в) приведены примеры работы с функцией SQRT.
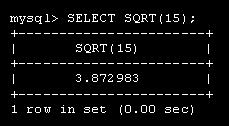
Рис. 8.27(а). Квадратный корень
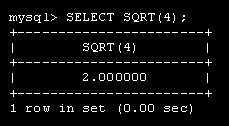
Рис. 8.27(б). Квадратный корень

Рис. 8.27(в). Квадратный корень
TAN(число)
Возвращает тангенс числа.
На рис. 8.28 приведен пример работы с функцией TAN.
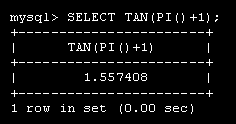
Рис. 8.28. Тангенс числа
TRUNCATE(число1, число2)
Возвращает число1 с дробной частью, усеченной до число2 десятичных разрядов. Если число2 равно 0, результат не имеет точки и дробной части. Если число2 отрицательное, целая часть числа длиной число2 обнуляется.
На рис. 8.29(а), 8.29(б), 8.29(в), 8.29(г) и 8.29(д) приведены примеры работы с функцией TRUNCATE.
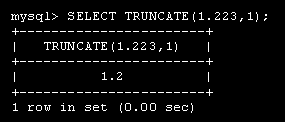
Рис. 8.29(а). Усечение числа

Рис. 8.29(б). Усечение числа
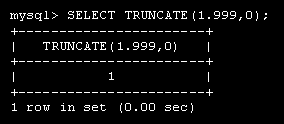
Рис. 8.29(в). Усечение числа
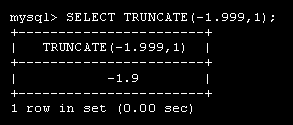
Рис. 8.29(г). Усечение числа
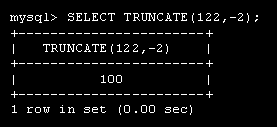
Рис. 8.29(д). Усечение числа
Все числа округляются в сторону нуля. Следует отметить, что десятичные числа обычно не хранятся в компьютерах именно в виде чисел, а в виде двоичных значений двойной точности, поэтому иногда результат может вызвать удивление (рис. 8.29(е))
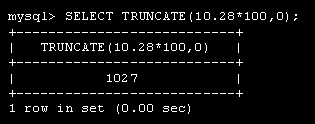
Рис. 8.29(е). Усечение числа
Это происходит потому, что 10.28 на самом деле сохраняется как 10.27999999999999...
Лекция 9. Работа с датой и временем
Работа с датой
До сих пор мы имели дело с текстом ( varchar ) и числами ( int ). Чтобы понять тип данных date (дата) создадим еще одну таблицу, аналогично тому, как была создана первая таблица.
Создадим в текстовом редакторе файл employee_per.dat, который содержит оператор создания таблицы CREATE следующего вида:
CREATE TABLE employee_per (
e_id int unsigned not null primary key, -- идентификационный номер
address varchar(60), -- адрес
phone int, -- номер телефона
p_email varchar(60), -- адрес e-mail
birth_date DATE, -- дата рождения
sex ENUM('M', 'F'), -- пол
m_status ENUM('Y','N'), -- статус
s_name varchar(40), -- имя
children int); -- количество детейи последовательность операторов INSERT, например, такого вида. Количество записей может быть произвольно.
INSERT INTO employee_per (e_id, address, phone, p_email, birth_date, sex, m_status, s_name, children) values (1, 'Арбат, 12', 7176167, 'anna@yandex.ru', '1972-03-16', 'F', 'Y', 'Анна Петрова', 2);
Затем загрузим этот файл, как мы делали раньше, в базу данных.
В системе Windows
1). Поместите файл в каталог c:\mysql\bin.
2). Выполните в приглашении DOS команду.
dosprompt> mysql employees <employee_per.dat
3). Запустите программу клиента mysql и проверьте, что таблица была создана, с помощью команды SHOW TABLES;.
В системе Linux
1). Перейдите в каталог, в котором находится файл.
2). В приглашении введите следующую команду:
$prompt> mysql employees <employee_per.dat -u your_username -p
3). Проверьте, что таблица была создана с помощью команды SHOW TABLES; в программе клиента mysql.
Данные таблицы можно вывести с помощью команды DESCRIBE.
mysql> DESCRIBE employee_per;
Результат запроса представлен на рис. 9.1.

Рис. 9.1. Просмотр данных таблицы
Обратите внимание, что столбец birth_date имеет тип столбца date (дата). Здесь также присутствует еще один новый тип столбца ENUM, который был рассмотрен в лекции 4.
e_id: идентификатор сотрудника, такой же как в таблице employee_data
address: адрес сотрудника
phone: номер телефона
p_email: личный адрес e-mail
birth_date: дата рождения
sex: Пол сотрудника, мужской (M) или женский (F)
m_status: семейное положение, в браке (Y) или холост (N).
s_name: Имя супруга ( NULL, если сотрудник холост)
children: Число детей ( NULL, если детей нет)
Особенности типа данных Date
Даты в MySQL всегда представлены с годом, за которым следует месяц и затем день месяца. Даты часто записывают в виде YYYY-MM-DD, где YYYY -- 4 цифры года, MM -- 2 цифры месяца и DD -- 2 цифры дня месяца.
Операции с датами
Тип столбца даты позволяет выполнять несколько операций, таких как сортировка, проверка условий с помощью операторов сравнения и т.д.
Использование операторов = и !=
select p_email, phone from employee_per where birth_date = '1969-12-31';
Результат запроса представлен на рис. 9.2.
Рис. 9.2. Поиск по дате рождения
Примечание: MySQL требует, чтобы даты были заключены в кавычки.
Использование операторов >= и <=
select e_id, birth_date from employee_per where birth_date >= '1970-01-01';
Результат запроса представлен на рис. 9.3.

Рис. 9.3. Поиск по дате рождения с использованием оператора >=
Определение диапазонов
select e_id, birth_date from employee_per where birth_date BETWEEN '1969-01-01' AND '1974-01-01';
Результат запроса представлен на рис. 9.4.
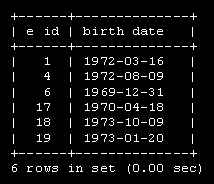
Рис. 9.4. Поиск по дате рождения в определенном диапазоне
Тот же запрос можно представить без конструкции BETWEEN:
select e_id, birth_date from employee_per where birth_date >= '1969-01-01' AND birth_date <= '1974-01-01';
Результат запроса будет аналогичен рис. 9.4.
Задания
- Вывести идентификаторы и даты рождения всех сотрудников, которые родились до 1965 г.
- Вывести идентификаторы и даты рождения сотрудников, родившихся между 1970 и 1973 гг.
Возможные решения
mysql> select e_id, birth_date -> from employee_per -> where birth_date <= '1964-12-31';mysql> select e_id, birth_date -> from employee_per -> where birth_date >= '1970-01-01' -> and birth_date <= '1972-12-31';
Результат запроса представлен на рис. 9.5.
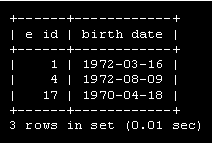
Рис. 9.5. Поиск по дате рождения в определенном диапазоне
Использование Date для сортировки данных
select e_id, birth_date from employee_per ORDER BY birth_date;
Результат запроса представлен на рис. 9.6.
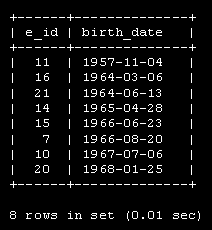
Рис. 9.6. Поиск по дате рождения в определенном диапазоне
Выбор данных с помощью Date
Вот как можно выбрать сотрудников, которые родились в марте.
select e_id, birth_date from employee_per where MONTH(birth_date) = 3;
Результат запроса представлен на рис. 9.7.
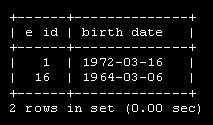
Рис. 9.7. Поиск по месяцу
Можно также использовать вместо чисел названия месяцев.
select e_id, birth_date from employee_per where MONTHNAME(birth_date) = 'January';
Результат запроса представлен на рис. 9.8.
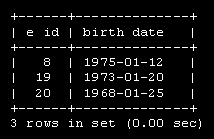
Рис. 9.8. Использование названия месяца в поиске
Будьте внимательны при использовании названий месяцев, так как они различают регистр символов. Поэтому January будет работать, а JANUARY не будет!
Аналогично можно выбрать сотрудников, родившихся в определенный год или в определенный день.
select e_id, birth_date from employee_per where year(birth_date) = 1972;
Результат запроса представлен на рис. 9.9.

Рис. 9.9. Поиск по году рождения
select e_id, birth_date from employee_per where DAYOFMONTH(birth_date) = 20;
Результат запроса представлен на рис. 9.10.

Рис. 9.10. Поиск по дате рождения
Текущие даты
Ранее мы видели, что текущую дату, месяц и год можно вывести с помощью аргумента CURRENT_DATE предложений DAYOFMONTH(), MONTH() и YEAR(), соответственно. То же самое можно использовать для выборки данных из таблиц.
select e_id, birth_date from employee_per where MONTH(birth_date) = MONTH(CURRENT_DATE);
Результат запроса представлен на рис. 9.11.

Рис. 9.11. Поиск по текущему месяцу
Задания
- Вывести идентификаторы, даты рождения и адреса e-mail сотрудников, родившихся в апреле.
- Вывести идентификаторы, даты рождения и имена супругов сотрудников, родившихся в 1968 г., и отсортируйте записи на основе имен их супругов.
- Выведите идентификаторы сотрудников, родившихся в текущем месяце.
- Сколько в базе данных имеется уникальных годов рождения?
- Вывести список уникальных годов рождения и число сотрудников, родившихся в каждом таком году.
- Сколько сотрудников родились в каждом месяце? Выдача должна содержать названия месяцев (не номера), и записи должны быть упорядочены по убыванию по месяцам, начиная от наибольшего номера.
Возможные решения
mysql> select e_id, birth_date, p_email -> from employee_per -> where month(birth_date) = 4;Результат запроса представлен на рис. 9.12.

Рис. 9.12. Сотрудники, родившиеся в апрелеили
mysql> select e_id, birth_date, p_email -> from employee_per -> where MONTHNAME(birth_date) = 'April';Результат аналогичен рис. 9.12.
mysql> select e_id, birth_date, s_name -> from employee_per where -> YEAR(birth_date) = 1968 -> ORDER BY s_name;Результат запроса представлен на рис. 9.13.
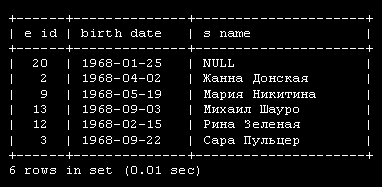
Рис. 9.13. Сотрудники 1968 года рождения, с сортировкой по именамПримечание: Значение NULL показано в самом верху. Более подробно значение NULL будет рассмотрено ниже.
mysql> select e_id from employee_per -> where month(birth_date) = month(current_date);Результат запроса представлен на рис. 9.14.
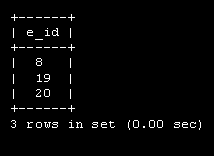
Рис. 9.14. Сотрудники родившиеся в этом месяцеmysql> select distinct year(birth_date) from employee_per;
Результат запроса представлен на рис. 9.15.
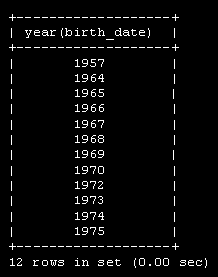
Рис. 9.15. Уникальные годы рожденияmysql> select year(birth_date) as Year, -> count(*) from employee_per -> GROUP BY Year;Результат запроса представлен на рис. 9.16.
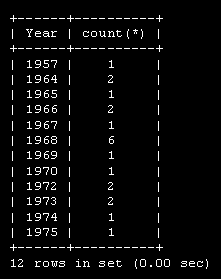
Рис. 9.16. Количество сотрудников, родившихся в каждом годуmysql> select MONTHNAME(birth_date) AS Month, -> count(*) AS Number -> from employee_per -> GROUP BY Month -> ORDER BY Number DESC;Результат запроса представлен на рис. 9.17.
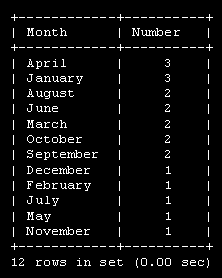
Рис. 9.17. Количество сотрудников, родившихся в каждом месяце
Тип столбца Null
В этой лекции мы уже встречались с типом NULL. Теперь рассмотрим его подробнее.
Тип столбца NULL является специальным значением. Чтобы вставить значение NULL, удалите просто имя столбца из оператора INSERT. Столбцы содержат NULL по умолчанию, если только не определены как NOT NULL. Значение null может использоваться для целочисленных, а также текстовых или двоичных данных.
NULL нельзя сравнивать с помощью арифметических операторов. Сравнение для NULL можно делать с помощью IS NULL или IS NOT NULL.
select e_id, children from employee_per where children IS NOT NULL;
Результат запроса представлен на рис. 9.18.
Рис. 9.18. Сотрудники, имеющие детей
Приведенная выше команда выводит идентификаторы и количество детей сотрудников, у которых есть дети.
Задания
- Найти и вывести идентификаторы и имена супругов всех сотрудников, которые состоят в браке.
- Изменить предыдущее задание так, чтобы вывод был отсортирован по именам супругов.
- Сколько имеется сотрудников каждого пола (мужчин и женщин)?
- Сколько сотрудников состоят в браке, и сколько холостых?
- Найдите общее число детей.
- Сделайте уникальные группы по количеству детей и определите число детей каждой группы. Отсортируйте вывод групп по убыванию по количеству детей.
Возможные решения
mysql> select e_id, s_name -> from employee_per -> where m_status = 'Y';или
mysql> select e_id, s_name -> from employee_per -> where s_name IS NOT NULL;mysql> select e_id, s_name -> from employee_per -> where m_status = 'Y' -> ORDER BY s_name; mysql> select e_id, s_name -> from employee_per -> where s_name IS NOT NULL -> ORDER BY s_name;mysql> select sex, count(*) -> from employee_per -> GROUP BY sex;mysql> select m_status, count(*) -> from employee_per -> GROUP BY m_status;mysql> select sum(children) from employee_per;
mysql> select children, count(*) AS -> number from employee_per -> GROUP BY children -> ORDER BY number DESC;
Лекция 10. Работа со строками
Строковые функции
В этой лекции рассмотрим команды MySql, предназначенные для обработки строковых данных.
ASCII(строка)
ORD(строка)
Возвращает числовое значение первого символа строки строка. Возвращает 0, если строка является пустой. Возвращает NULL, если строка равна NULL. ASCII() работает с символами в диапазоне кодов от 0 до 255.
mysql> SELECT ASCII('2');
-> 50
mysql> SELECT ASCII(2);
-> 50
mysql> SELECT ASCII('dx');
-> 100BIN(N)
Возвращает строковое представление двоичного значения N, где N - длинное целое ( BIGINT ). Это эквивалентно CONV(N, 10,2). Возвращает NULL, если N равно NULL.
mysql> SELECT BIN(12); -> '1100'
ВIT_LENGTH(строка)
Возвращает длину строки строка в битах.
mysql> SELECT BIT_LENGTH('text');
-> 32CHAR(iV,...)
Интерпретирует аргументы как целые и возвращает строку, состоящую из символов с кодами, заданными этими целыми. Значение NULL пропускаются.
mysql> SELECT CHAR(77,121,83,81,'76'); -> 'MySQL' mysql > SELECT CHAR(77,77.3,'77.3'); -> 'МММ'
CHAR_LENGTH(строка)
CHARACTER_LENGTH(строка)
Возвращает длину строки строка, измеренную в символах. Многобайтные символы считаются как один. Это значит, что для строки, состоящей из пяти двухбайтных символов, LENGTH() вернет 10, в то время как CHAR_LENGTH('') вернет 5.
COMPRESS(строка_для_сжатия)
Сжимает строку. Эта функция требует, чтобы MySQL был скомпилирован с библиотекой поддержки сжатия, такой как zlib. В противном случае возвращаемым значением всегда будет NULL.
Содержимое сжатой строки сохраняется следующим образом:
- Пустая строка сохраняется как пустая строка.
- Непустая строка сохраняется как четырехбайтовая длина несжатой строки (младший байт идет первым), за которой следует сжатая строка. Если строка завершается пробелом, добавляется дополнительный символ ' . ' во избежание усечения завершающих пробелов, которое имеет место при сохранении в столбцах CHAR или VARCHAR. (Использовать для сохранения сжатых строк столбцы CHAR или VARCHAR не рекомендуется. Взамен лучше применять столбцы BLOB ).
CONCAT(строка1, строка2, ...)
Возвращает строку, которая состоит из сцепленных аргументов. Возвращает NULL, если любой из аргументов равен NULL. Принимает один или более аргументов. Числовой аргумент преобразуется в эквивалентную строковую форму.
mysql> SELECT CONCAT('My', 'S', 'QL');
-> 'MySQL'
mysql> SELECT CONCAT('My', NULL, 'QL');
-> NULL
mysql> SELECT CONCAT(14.3);
-> '14.3'CONCAT_WS(разделитель, строка1, строка2, ...)
CONCAT_WS означает "Concat With Separator" ("CONCAT с разделителем") и представляет собой особую форму CONCAT(). Первый аргумент - это разделитель для остальных аргументов. Разделитель добавляется между соединяемыми строками. Разделитель может быть строкой, как и остальные аргументы. Если разделитель равен NULL, результат тоже равен NULL. Функция пропускает любые аргументы NULL после разделителя.
mysql> SELECT CONCAT_WS( ',', 'First name', 'Second name' , 'Last Name'); -> 'First name,Second name,Last Name'
CONV(N, основание_начальное, основание_конечное)
Конвертирует числа между разными системами счисления. Возвращает строковое представление числа N, преобразованное из системы счисления с основанием основание_начальное в систему счисления с основанием основание_конечное. Возвращает NULL, если любой из аргументов равен NULL. Аргумент N интерпретируется как целое, но может указываться и как целое, и как строка. Минимальное основание системы счисления - 2, максимальное - 36. Если значение основание_конечное отрицательное, N рассматривается как целое со знаком. В противном случае N считается беззнаковым целым. CONV() работает с 64-разрядной точностью.
mysql> SELECT CONV('а',16,2);
-> '1010'
mysql> SELECT CONV('6E',18,8);
-> '172'
mysql> SELECT CONV(-17,10,-18);
-> '-H'
mysql> SELECT CONV(10+'10'+'10'+0xa,10,10);
-> '40'ELT(N, строка1, строка2, строкаЗ, ...)
Возвращает строка1, если N = 1, строка2, если N = 2, и так далее. Возвращает NULL, если N меньше 1 или больше количества аргументов. ELT() - это дополнение FIELD().
mysql> SELECT ELT(1, 'ej', 'Heja', 'hej', 'foo'); -> 'ej' mysql> SELECT ELT(3, 'ej', 'Heja', 'hej', 'foo'); -> 'hej'
FIELD(строка, строка1, строка2, строка3, ...)
Возвращает позицию вхождения аргумента строка в список строка1, строка2, строка3, ... Возвращает 0, если вхождение не найдено.
FIELD() - это дополнение ELT().
mysql> SELECT FIELD('еj', 'Hej', 'ej', 'Heja', 'hej1', 'foo');
- > 2FIND_IN_SET(строка, список_строк)
Возвращает значение от 1 до N, если строка находится в списке строк список_строк, состоящего из N подстрок. Список строк - это строка, состоящая из подстрок, разделенных символом ',' . Возвращает 0, если строка не входит в список строк, или если список_строк — пустая строка.
mysql> SELECT FIND_IN_SET('b','a,b,c,d');
-> 2HEX(Ч_или_С)
Если Ч_или_С - число, возвращает строковое представление шестнадцатеричного значения N, где N - длинное целое ( BIGINT ). Это эквивалентно CONV(N,10,16).
Если Ч_или_С - строка, то возвращается шестнадцатеричная строка Ч_или_С, в которой каждый символ преобразован в два шестнадцатеричных разряда.
mysql> SELECT HEX(255);
-> 'FF'
mysql> SELECT HEX('abc');
-> '616263'INSERT(строка, позиция, длина, новая_строка)
Возвращает строку строка, в которой подстрока длиной длина, начинающаяся с позиции позиция, заменяется строкой новая_строка.
mysql> SELECT INSERT('Quadratic', 3, 4, 'What');
-> 'QuWhattic'INSTR(строка, подстрока)
Возвращает позицию первого вхождения подстроки подстрока в строку строка. Это то же самое, что двухаргументная форма LOCATE(), только аргументы переставлены местами.
mysql> SELECT INSTR('foobarbar', 'bar');
-> 4
mysql> SELECT INSTR('xbar', 'foobar');
-> 0LEFT(строка, длина)
Возвращает первые длина символов строки строка.
mysql> SELECT LEFT('foobarbar', 5);
-> 'fooba'LENGTH(строка)
Возвращает длину строки строка в байтах.
mysql> SELECT LENGTH('text');
-> 4LOAD_FILE(имя_файла)
Читает файл и возвращает его содержимое в виде строки. Файл должен находиться на сервере и к нему должен указываться полный путь. Кроме того, необходимо иметь привилегию FILE. Файл должен быть доступен по чтению всем, и иметь размер менее max_allowed_packet байт.
Если файл не существует или не может быть прочитан, функция возвращает NULL.
LOCATE(подстрока, строка)
LOCATE(подстрока, строка, позиция)
POSITION(подстрока IN строка)
Первый синтаксис возвращает позицию первого вхождения подстроки подстрока в строку строка. Второй синтаксис возвращает позицию первого вхождения подстроки подстрока в строку строка, начиная с позиции позиция. Если подстрока не входит в строку, возвращается 0.
mysql> SELECT LOCATE('bar', 'foobarbar');
-> 4
mysql> SELECT LOCATE('xbar', 'foobar');
-> 0
mysql> SELECT LOCATE('bar', 'foobarbar',5);
-> 7LOWER(строка)
LCASE(строка)
Возвращает строку строка, в которой все символы приведены к нижнему регистру в соответствии с текущим набором символов.
mysql> SELECT LOWER('QUADRATICALLY');
-> 'quadratically'LPAD(строка, длина, строка-заполнитель).
Возвращает строку строка, добавив слева строкой строка-заполнитель до длины длина. Если строка длиннее, чем указано в аргументе длина, возвращается значение, усеченное до длина символов.
mysql> SELECT LPAD('hi',4,'*');
-> '**hi'
mysql> SELECT LPAD('hi',1,'*');
-> 'h'LTRIM(строка)
Возвращает строку строка с удаленными ведущими пробелами.
mysql> SELECT LTRIM(' barbar');
-> 'barbar'OCT(N)
Возвращает строковое представление восьмеричного значения N, где N - длинное целое.
Это эквивалент CONV(N,10,8).
Возвращает NULL, если N равно NULL.
mysql> SELECT ОСТ(12); -> '14'
QUOTE(строка)
Заключает строку в кавычки, чтобы результат можно было использовать как допустимое значение в SQL-операторах. Строка окружается одинарными кавычками, а все вхождения в нее одинарной кавычки - обратной косой чертой ("\").
mysql> SELECT QUOTE("Don't");
-> 'Don\'t'REPEAT(строка, количество)
Возвращает строку, состоящую из аргумента строка, повторенного количество раз.
mysql> SELECT REPEAT('MySQL', 3);
-> 'MySQLMySQLMySQL'REPLACE(строка, строка_2, строка_3)
Возвращает строку строка, в которой все вхождения строка_2 заменены на строка_3.
mysql> SELECT REPLACE('www.mysql.com', 'w', 'Ww');
-> 'WwWwWw.mysql.com'REVERSE(строка)
Возвращает строку строка с обратным порядком символов.
mysql> SELECT REVERSE('abc');
-> 'cba'RIGHT(строка, длина)
Возвращает длина правых символов строки строка.
mysql> SELECT RIGHT('foobarbar', 4);
-> 'rbar'RPAD(строка, длина, строка-заполнитель)
Возвращает строку строка, дополненную справа строкой строка-заполнитель до длины длина. Если строка длиннее, чем длина, возвращается значение, усеченное до длина символов.
mysql> SELECT RPAD('hi',5,'?');
-> 'hi???'
mysql> SELECT RPAD('hi',1,'?');
-> 'h'RTRIM(строка)
Возвращает строку строка с удаленными завершающими пробелами.
mysql> SELECT RTRIM('barbar ');
-> 'barbar'SOUNDEX(строка)
Возвращает строку, описывающую звучание ( soundex ) строки строка. Две строки, которые произносятся почти одинаково, должны иметь идентичные строки звучания.
mysql> SELECT SOUNDEX('Hello');
-> 'H400'
mysql> SELECT SOUNDEX('Quadratically' );
-> 'Q36324'SPACE(N)
Возвращает строку, состоящую из N пробелов.
mysql> SELECT SPACE(6); -> ' '
SUBSTRING(строка, позиция)
SUBSTRING(строка FROM позиция)
SUBSTRING(строка, позиция, длина)
SUBSTRING(строка FROM позиция FOR длина)
Формы без аргумента длина возвращают подстроку строки строка, начиная с позиции позиция. Формы с аргументом длина возвращают подстроку строки строка длиной длина символов, начиная с позиции позиция. Формы, использующие FROM, представляют стандартный синтаксис SQL.
mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'SUBSTRING_INDEX(строка, разделитель, количество)
Возвращает подстроку строки строка до вхождения номер количество разделителя разделитель. Если значение количество положительное, возвращается все, что лежит слева от финального разделителя (считая слева направо). Если значение количество отрицательное, возвращается все, что лежит справа от финального разделителя (считая справа налево).
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);
-> 'www.mysql'
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);
-> 'mysql.com'TRIM([[BOTH | LEADING | TRAILING] [удаляемая_строка] FROM] строка)
Возвращает строку строка с удаленными префиксами и/или суффиксами удаляемая_строка. Если не указано ни BOTH, ни LEADING, ни TRAILING, подразумевается BOTH. Если не указано удаляемая_строка, удаляются пробелы.
mysql> SELECT TRIM(' bar ');
-> 'bar'
mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx'
mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar'
mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx'UNCOMPRESS(строка_для_распаковки)
Распаковывает строку, сжатую функцией COMPRESS(). Если аргумент не является упакованной строкой, возвращается NULL.
mysql> SELECT UNCOMPRESS(COMPRESS('any string'));
-> 'any string'
mysql> SELECT UNCOMPRESS('any string');
-> NULLUNHEX(строка)
Выполняет действие, противоположное функции HEX(строка). То есть, интерпретирует каждую пару шестнадцатеричных цифр аргумента как число и преобразует в символ, представленный этим числом. Символы результата возвращаются в виде бинарной строки.
mysql> SELECT UNHEX('4D7953514C');
-> 'MySQL'
mysql> SELECT 0x4D7953514C;
-> 'MySQL'
mysql> SELECT UNHEX(HEX('string'));
-> 'string'
mysql> SELECT HEX(UNHEX('1267' ) );
-> ' 1267 'UPPER(строка)
UCASE(строка)
Возвращает строку строка, у которой все символы приведены к верхнему регистру в соответствии с текущим набором символов.
mysql> SELECT UPPER('Неj');
-> 'HEJ'Функции сравнения строк
Обычно если любое выражение в сравнении строк чувствительно к регистру, то сравнение также чувствительно к регистру.
выражение LIKE шаблон [ESCAPE 'символ-отмены']
Проверка на соответствие шаблону, заданному простыми регулярными выражениями SQL. Возвращает 1 ( TRUE ) или 0 ( FALSE ). Если выражение или шаблон равны NULL, возвращает NULL.
В шаблонах LIKE можно использовать следующие два символа:
"%" – соответствие любому числу символов, включая нуль символов.
"_" – соответствие любому одному символу.
mysql> SELECT 'David!' LIKE 'David_';
-> 1
mysql> SELECT 'David!' LIKE '%D%v%';
-> 1Если требуется исследовать строку на вхождения в неё шаблонных символов (% или _), то шаблонный символ следует предварить экранирующим символом (ESCAPE). Если экранирующий символ не указан явно, то по умолчанию им считается символ '\':
"\%" – соответствует одному символу '%'
"\_" – соответствует одному символу '_'
mysql> SELECT 'David!' LIKE 'David\_';
-> 0
mysql> SELECT 'David_' LIKE 'David\_';
-> 1Для указания конкретного экранирующего символа используется выражение ESCAPE:
mysql> SELECT 'David_' LIKE 'David|_' ESCAPE '|';
-> 1В следующих двух примерах показано, что сравнение строк производится без учета регистра, если ни один из операндов не является строкой с двоичными данными:
mysql> SELECT 'abc' LIKE 'ABC';
-> 1
mysql> SELECT 'abc' LIKE BINARY 'ABC';
-> 0В функции LIKE допускаются числовые выражения.
mysql> SELECT 10 LIKE '1%';
-> 1expr REGEXP pat
expr RLIKE pat
Выполняет сравнение строкового выражения expr с шаблоном pat. Шаблон может представлять собой расширенное регулярное выражение. Возвращает 1, если expr соответствует pat, в противном случае - 0.
mysql> SELECT 'Monty!' REGEXP 'm%y%%';
-> 0
mysql> SELECT 'Monty!' REGEXP '.*';
-> 1
mysql> SELECT 'new*\n*line' REGEXP 'new\\*.\\*line';
-> 1
mysql> SELECT "a" REGEXP "A", "a" REGEXP BINARY "A";
-> 1 0
mysql> SELECT "a" REGEXP "^[a-d]";
-> 1STRCMP(expr1,expr2)
Функция STRCMP() возвращает: 0, если строки идентичны, -1 - если первый аргумент меньше второго (в соответствии с имеющимся порядком сортировки), и 1 - в остальных случаях:
mysql> SELECT STRCMP('text', 'text2');
-> -1
mysql> SELECT STRCMP('text2', 'text');
-> 1
mysql> SELECT STRCMP('text', 'text');
-> 0Лекция 11. Дополнительные функции MySQL
Битовые функции
MySQL использует для двоичных операций 64-битовые величины BIGINT, следовательно, для двоичных операторов максимальный диапазон составляет 64 бита.
Побитовое ИЛИ ( | )
mysql> SELECT 29 | 15;
-> 31Побитовое И ( & )
mysql> SELECT 29 & 15;
-> 13Побитовый XOR (побитовое сложение по модулю 2) ( ^ )
mysql> SELECT 1 ^ 1;
-> 0
mysql> SELECT 1 ^ 0;
-> 1
mysql> SELECT 11 ^ 3;
-> 8Сдвиг числа влево ( << )
mysql> SELECT 1 << 2;
-> 4Сдвиг числа вправо ( >> )
mysql> SELECT 4 >> 2;
-> 1Инвертировать биты ( ~ )
mysql> SELECT 5 & ~1;
-> 4BIT_COUNT(N)
Возвращает количество битов аргумента N, которые установлены в единицу
mysql> SELECT BIT_COUNT(29);
-> 4Функции шифрования
Функции, описанные в данном разделе, шифруют и дешифруют значения данных. Если вы хотите сохранять результаты функции шифрования, которые могут иметь произвольные байтовые значения, применяйте столбцы типа BLOB вместо CHAR или VARCHAR, чтобы избежать потенциальных проблем с удалением завершающих пробелов, которые изменяют значения данных.
AES_ENCRYPT(строка, строка_ключа)
AES_DECRYPT(зашифрованная_строка, строка_ключа)
Эти функции позволяют выполнять шифрование и дешифрацию данных с использованием официального алгоритма AES (Advanced Encryption Standard), ранее известного как "Rijndael". Применяется кодирование с 128-разрядным ключом, но можно расширить его до 256 разрядов, должным образом изменив исходные тексты. Длина ключа 128 бит выбрана, поскольку он работает намного быстрее и при этом обеспечивает приемлемый уровень безопасности.
Входные аргументы могут иметь любую длину. Если любой из них равен NULL, результатом функции также будет NULL.
Поскольку AES - алгоритм блочного типа, дополнение применяется для строк с нечетным количеством символов, и поэтому длина результирующей строки может быть рассчитана как 16* (trunc (длина_строки/16) +1).
Если функция AES_DECRYPT() обнаруживает неверные данные или неправильное дополнение, она возвращает NULL. Однако существует вероятность, что AES_DECRYPT() вернет значение, не равное NULL (возможно, "мусор"), если входные данные или ключ неверны.
Вы можете использовать AES-функции для сохранения данных в зашифрованной форме, модифицировав существующие запросы:
INSERT INTO t VALUES (1, AES_ENCRYPT('text', 'password'));Можно обеспечить даже более высокий уровень безопасности, если не передавать значение ключа для каждого запроса, а сохранять его в переменной сервера во время подключения, например:
SELECT @password:='my password';
INSERT INTO t VALUES (1, AES_ENCRYPT('text', 'password'));Функции AES_ENCRYPT() и AES_DECRYPT() были добавлены в MySQL 4.0.2 и могут рассматриваться как наиболее криптографически безопасные функции, доступные в MySQL на текущий момент.
DECODE(зашифрованная_строка, строка_пароля)
Расшифровывает строку зашифрованная_строка, используя значение строка_пароля в качестве пароля. Аргумент зашифрованная_строка должен быть строкой, ранее возвращенной функцией ENCODE().
ENCODE(строка, строка_пароля)
Шифрует строку строка, используя значение строка_пароля в качестве пароля. Для расшифровки результата применяется функция DECODE(). Результатом является бинарная строка той же длины, что и строка. Если нужно сохранить ее в столбце, применяйте тип BLOB.
DES_DECRYPT(зашифрованная_строка [, строка_ключа])
Расшифровывает строку зашифрованная_строка, зашифрованную с помощью DES_ENCRYPT(). В случае ошибки возвращает NULL. Следует отметить, что эта функция работает, только если MySQL настроен на поддержку SSL. Если не указан аргумент строка_ключа, DES_DECRYPT() проверяет первый байт зашифрованной строки для определения номера DES-ключа, использованного при шифровании исходной строки, а затем читает ключ из файла DES-ключей для расшифровки сообщения. Чтобы это работало, пользователь должен иметь привилегию SUPER. Файл ключей может быть указан с помощью опции сервера --des-key-file.
Если вы передаете этой функции аргумент строка_ключа, он используется в качестве ключа при расшифровке сообщения.
Если аргумент зашифрованная_строка не выглядит как зашифрованная строка, MySQL вернет строку зашифрованная_строка без изменений.
DES_ENCRYPT(строка[, (номер_ключа | строка_ключа)])
Шифрует строку с помощью заданного ключа, используя тройной DES-алгоритм. В случае ошибки возвращает NULL.
Следует отметить, что эта функция работает, только если MySQL настроен на поддержку SSL. Ключ шифрования выбирается на базе второго аргумента DES_ENCRYPT(). Если таковой не указан, то берётся первый ключ из используемого файла DES-ключей. Если задан номер_ключа, то он берётся из используемого файла DES-ключей. Если задана строка_ключа, то она используется в качестве ключа для шифрования.
Имя файла ключей указывается в опции сервера --des-key-file.
Длина строки результата рассчитывается как новая_длина = оригинальная_длина + (8 – (оригинальная_длина % 8)) + 1. Каждая строка в файле DES-ключей имеет следующий формат: номер_ключа строка_ключа_des.
Каждый номер_ключа должен быть числом в диапазоне от 0 до 9. Строки в файле могут следовать в любом порядке. строка_ключа_des - это строка, которая будет использоваться для шифрования сообщения. Между номером и ключом должен быть, по меньшей мере, один пробел. Первый ключ является ключом по умолчанию, который применяется в случае, если не указан аргумент строка_ключа в функции DES_ENCRYPT().
Можно указать MySQL на необходимость чтения новых значений ключа из файла ключей с помощью оператора FLUSH DES_KEY_FILE. Это требует наличия привилегии RELOAD.
Одна выгода от наличия набора ключей по умолчанию состоит в том, что это дает возможность приложениям проверить наличие зашифрованных значений столбцов, без необходимости предоставления конечному пользователю прав непосредственного доступа к ключам.
mysql> SELECT customer_address FROM customer_table WHERE
-> crypted_credit_card = DES_ENCRYPT('credit_card_number');ENCRYPT(строка [, нач])
Шифрует строку строка, используя системный вызов Unix crypt(). Необязательный аргумент нач должен быть строкой из не менее двух символов. Если аргумент нач отсутствует, то будет использовано случайное значение Unix crypt().
mysql> SELECT ENCRYPT('hello');
-> 'VxuFAJXVARROc'ENCRYPT() игнорирует все, кроме первых восьми символов аргумента строка. Это поведение определяется реализацией лежащего в основе системного вызова crypt().
Если функция crypt() не доступна в вашей системе, ENCRYPT() всегда возвращает NULL. По этой причине следует всегда применять вместо этой функции MD5(), поскольку эта функция представлена на всех платформах.
MD5(строка)
Вычисляет 128-разрядную контрольную сумму MD5 для аргумента строка. Значение возвращается в виде 32-разрядной шестнадцатеричной строки или же NULL, если аргумент равен NULL. Возвращаемое значение может быть использовано, например, в качестве хэш-ключа.
mysql> SELECT MD5('testing');
-> 'ae2blfca515949e5d54fb22b8ed95575'PASSWORD(строка)
Вычисляет и возвращает строку пароля по значению пароля строка, заданному простым текстом. Эта функция применяется для шифрования паролей, сохраняемых в столбце Password таблицы привилегий user.
mysql> SELECT PASSWORD('badpwd');
-> '7f84554057dd964b'Шифрование функцией PASSWORD() является однонаправленным (то есть необратимым).
Примечание: функция PASSWORD() используется системой аутентификации сервера MySQL, которая не должна быть задействованной в ваших собственных приложениях. Для этой цели вместо нее применяйте функции MD5() и SHA1().
Информационные функции
BENCHMARK(количество, выражение)
Функция BENCHMARK() выполняет выражение в точности количество раз. Она может использоваться для определения того, насколько быстро MySQL выполняет выражение. Возвращаемый результат всегда равен 0. Предполагаемое применение - в среде клиента mysql, который сообщает время выполнения запроса:
mysql> SELECT BENCHMARK(1000000,ENCODE("hello","goodbye"));
+----------------------------------------------+
| BENCHMARK(1000000,ENCODE("hello","goodbye")) |
+----------------------------------------------+
| 0 |
+----------------------------------------------+
1 row in set (4.74 sec)Время, которое сообщает mysql - это время обслуживания клиента, а не потраченное центральным процессором время на стороне сервера. Рекомендуется выполнить BENCHMARK() несколько раз, и интерпретировать результат в зависимости от степени загруженности сервера.
CHARSET(строка)
Возвращает набор символов аргумента строка.
mysql> SELECT CHARSET('abc');
-> 'latinl'
mysql> SELECT CHARSET(CONVERT('abc' USING utf8));
-> 'utf8'
mysql> SELECT CHARSET(USER());
-> 'utf8'COERCIBILITY(строка)
Возвращает значение принуждения сопоставления для аргумента строка.
mysql> SELECT COERCIBILITY('abc' COLLATE latinl_swedish_сi);
-> 0
mysql> SELECT COERCIBILITY('abc') ;
-> 3
mysql> SELECT COERCIBILITY(USER());
-> 2Возвращаемые значения имеют следующий смысл:
0 - явное сравнение
1 - нет сравнения
2 - неявное сравнение
3 - принуждаемое
Меньшие значения обладают большим приоритетом.
COLLATION(строка)
Возвращает наименование порядка сопоставления символьного набора для заданного аргумента строка.
mysql> SELECT COLLATION('abc');
-> 'latinl_swedish_ci'CONNECTION_ID()
Возвращает идентификатор соединения (идентификатор потока) текущего сеанса. Каждое клиентское соединение получает свой собственный уникальный идентификатор.
mysql> SELECT CONNECTION_ID();
-> 23786CURRENT_USER()
Возвращает комбинацию имени пользователя и имени хоста после аутентификации в текущем сеансе. Это значение соответствует пользовательской учетной записи MySQL, которая определяет ваши права доступа. Оно может отличаться от значения, возвращаемого функцией USER().
mysql> SELECT USER();
-> 'davida@localhost'
mysql> SELECT * FROM mysql.user;
ERROR 1044: Access denied for user: '@localhost' to database 'mysql'
mysql> SELECT CURRENT_USER();
-> '@localhost'Приведенный выше пример иллюстрирует, что, несмотря на то, что клиент имеет имя davida (как показывает функция USER ), сервер аутентифицировал клиента, использующего анонимный доступ (что видно по пустой части имени пользователя в значении CURRENT_USER() ). Единственной причиной, почему такое может случиться, является отсутствие учетной записи для davida в таблице привилегий.
DATABASE()
Возвращает имя базы данных по умолчанию (текущей базы данных).
mysql> SELECT DATABASE();
-> 'test1'Если текущей базы данных нет, DATABASE() возвращает NULL.
FOUND_ROWS()
Оператор SELECT может включать конструкцию LIMIT для ограничения количества строк, которые сервер возвращает клиенту. В некоторых случаях желательно знать, сколько строк сервер вернул бы без конструкции LIMIT, но без повторного выполнения запроса. Чтобы получить значение счетчика строк, включите опцию SQL_CALC_FOUND_ROWS в состав оператора SELECT, после чего вызовите FOUND_ROWS():
mysql> SELECT SQL_CALC_FOUND_ROWS * FROM tbl_name
-> WHERE id > 100 LIMIT 10;
mysql> SELECT FOUND_ROWS();Второй оператор SELECT вернет число, показывающее, сколько строк первый оператор SELECT вернул бы, будь он без конструкции LIMIT.
Следует отметить, что когда используется SELECT SQL_CALC_FOUND_ROWS, то MySQL приходится посчитать, сколько строк будет в полном результирующем наборе. Однако это делается быстрее, чем если запустить запрос снова без конструкции LIMIT, поскольку результирующий набор не приходится отсылать клиенту.
SQL_CALC_FOUND_ROWS и FOUND_ROWS() могут оказаться удобными в ситуациях, когда нужно ограничить число строк, возвращаемых запросом, но при этом определить количество строк в полном результирующем наборе, не запуская запрос снова. Примером может служить Web-сценарий, который представляет постраничный список ссылок на страницы, содержащие другие разделы результата поиска.
Функция FOUND_ROWS() позволяет определить, сколько других страниц необходимо для отображения оставшейся части результата.
Применение SQL_CALC_FOUND_ROWS и FOUND_ROWS() более сложно для запросов с UNION, чем для простых операторов SELECT, потому что LIMIT может встретиться в UNION во многих местах. Они могут касаться отдельных операторов SELECT в составе UNION либо общего результата UNION в целом.
Цель SQL_CALC_FOUND_ROWS для UNION состоит в том, что он должен вернуть количество строк, которые будут возвращены без глобального LIMIT. Условия применения SQL_CALC_FOUND_ROWS с UNION перечислены ниже:
- Ключевое слово SQL_CALC_FOUND_ROWS должно указываться в первом операторе SELECT.
- Значение FOUND_ROWS() будет точным только при условии применения UNION ALL. Если указано UNION без ALL, происходит исключение дубликатов, и значение FOUND_ROWS() будет лишь приблизительным.
- Если в UNION не присутствует LIMIT, то SQL_CALC_FOUND_ROWS игнорируется и возвращается количество строк во временной таблице, которая создается для выполнения UNION.
LAST_INSERT_ID()
LAST_INSERT_ID(выражение)
Возвращает последнее автоматически сгенерированное значение, которое было вставлено в столбец AUTO_INCREMENT.
mysql> SELECT LAST_INSERT_ID();
-> 195Последний идентификатор, который был сгенерирован, поддерживается на сервере на основе соединений. Это означает, что значение, возвращаемое клиенту, соответствует последнему сгенерированному значению AUTO_INCREMENT в сеансе данного клиента. Оно никак не может быть затронуто другими клиентами, равно как не требует блокировок или транзакций.
Значение, возвращаемое LAST_INSERT_ID() не изменяется, если вы обновляете столбец AUTO_INCREMENT в строке не с помощью "магических" значений (то есть, не NULL и не 0 ).
Если вы вставляете много строк одним оператором, LAST_INSERT_ID() возвращает значение для первой вставленной строки. Цель этого состоит в том, чтобы облегчить воспроизведение того же оператора INSERT на другом сервере.
Если указан аргумент выражение, значение аргумента возвращается функцией и запоминается как следующее значение, которое LAST_INSERT_ID() вернет при следующем вызове. Это можно использовать для эмуляции последовательностей:
- Создать таблицу для хранения счетчика последовательности и инициализировать его:
mysql> CREATE TABLE sequence (id INT NOT NULL); mysql> INSERT INTO sequence VALUES(0);
- Использовать таблицу для генерации последовательности чисел:
mysql> UPDATE sequence SET id=LAST_INSERT_ID(id+l); mysql> SELECT LAST_INSERT_ID();
Оператор UPDATE увеличивает счетчик последовательности и заставляет следующий вызов LAST_INSERT_ID() возвращать измененное значение.
Вы можете генерировать последовательности без вызова LAST_INSERT_ID(), но польза от ее применения заключается в том, что значение идентификатора поддерживается сервером как последнее автоматически сгенерированное значение.
Это обеспечивает безопасное использование в многопользовательской среде, поскольку множество клиентов могут отправлять операторы UPDATE и получать свои собственные значения последовательности через оператор SELECT (или mysql_insert_id() ), никак не влияя и не подвергаясь влиянию других клиентов, для которых генерируются их собственные значения последовательности.
USER()
SESSION_USER()
SYSTEM_USER()
Возвращает имя текущего пользователя MySQL и имя хоста, с которого он подключился.
mysql> SELECT USER();
-> 'davida@localhost'Значение представляет имя пользователя, которое было указано во время подключения к серверу, и имя компьютера-хоста, с которого произошло подключение. Возвращаемое значение может отличаться от того, которое выдает CURRENT_USER().
Вы можете извлечь имя пользователя, независимо от того, включает ли значение имя хоста или нет, следующим образом:
mysql> SELECT SUBSTRING_INDEX(USER(),'@',1);
-> 'davida'VERSION()
Возвращает строку, содержащую информацию о версии сервера MySQL:
mysql > SELECT VERSION();
-> '4.1.2-alpha-log'Следует отметить, что если строка версии заканчивается на '-log', это означает, что регистрация в журнале включена.
Прочие функции
FORMAT(X,D)
Форматирует число X в формате, подобном ' #,###,###.## ', округленное до D разрядов, и возвращает результат в виде строки. Если D равно 0, результат не имеет десятичной точки или дробной части.
mysql> SELECT FORMAT(12332.123456, 4) ;
-> '12,332.1235'
mysql> SELECT FORMAT(12332.1,4) ;
-> '12,332.1000'
mysql> SELECT FORMAT(12332.2,0) ;
-> '12,332'GET_LOCK(строка, таймаут)
Пытается получить блокировку по имени, заданном строкой строка, с таймаутом длительностью таймаут секунд. Возвращает 1, если блокировка получена успешно, 0, если время ожидания превысило таймаут (например, из-за того, что другой клиент уже заблокировал это имя), либо NULL, если произошла ошибка (такая как переполнение памяти или уничтожение потока командой mysqladmin kill ). Если у вас есть блокировка, полученная через GET_LOCK(), она снимается после выполнения RELEASE_LOCK(), нового вызова GET_LOCK() либо разрыва соединения (как нормального, так и ненормального).
Эта функция может использоваться для реализации блокировок приложений или для эмуляции блокировок записей. Имена блокируются в глобальном контексте сервера. Если имя блокировано одним клиентом, GET_LOCK() блокирует любой запрос другого клиента на получение блокировки с тем же именем. Это позволяет клиентам согласовывать попытки доступа к общим ресурсам.
mysql> SELECT GET_LOCK('lock1',10) ;
-> 1
mysql> SELECT IS_FREE_LOCK('lock2');
-> 1
mysql> SELECT GET_LOCK('lock2',10);
-> 1
mysql> SELECT RELEASE_LOCK('lock2');
-> 1
mysql> SELECT RELEASE_LOCK('lock1');
-> NULLСледует отметить, что второй вызов RELEASE_LOCK() возвращает NULL, поскольку блокировка ' lock1 ' была автоматически снята вторым вызовом GET_LOCK().
INET_ATON(выражение)
Принимает сетевой адрес, представленный четырьмя числами с разделителем-точкой, и возвращает целое, представляющее числовое значение адреса. Адрес может быть 4- или 8-байтным.
mysql> SELECT INET_ATON('209.207.224.40');
-> 3520061480Сгенерированное число всегда содержит байты в порядке, заданном в сетевом адресе. Для только что приведенного примера оно вычисляется как 209 * 2563 + 207 * 2562 + 224 * 256 + 40.
INET_ATON() также понимает IP-адреса в сокращенной форме:
mysql> SELECT INET_ATON('127.0.0.1'), INET_ATON('127.1');
-> 2130706433, 2130706433INET_NTOA(выражение)
Принимает сетевой адрес в виде числа (4- или 8- байтного), возвращает адрес, представленный строкой, состоящей из четырех чисел, разделенных точкой.
mysql> SELECT INET_NTOA(3520061480); -> '209.207.224.40'
IS_FREE_LOCK(строка)
Проверяет, свободна ли блокировка с именем строка. Возвращает 1, если блокировка свободна (никем не используется), 0, если занята, и NULL в случае ошибки.
IS_USED_LOCK(строка). Проверяет, используется ли блокировка с именем строка (то есть, установлена ли она). Если это так, возвращает идентификатор соединения клиента, который удерживает блокировку. В противном случае возвращает NULL.
MASTER_POS_WAIT(имя_журнала, позиция_в_журнале [, таймаут])
Эта функция удобна для управления синхронизацией главный/подчиненный. Блокирует главный сервер до тех пор, пока подчиненный сервер не прочитает и не проведет все изменения вплоть до указанной позиции в бинарном журнале главного сервера. Возвращаемое значение представляет количество событий в журнале, обработку которых нужно выполнить системе синхронизации, чтобы дойти до указанной позиции. Функция возвращает NULL, если поток SQL подчиненного сервера не запущен, либо информация о главном сервере не инициализирована на подчиненном, либо указаны неправильные аргументы. Возвращает -1, если истекло время таймаута. Если подчиненный сервер уже достиг указанной позиции, функция возвращает управление немедленно.
Если задано значение таймаут, MASTER_POS_WAIT() прекращает ожидание, когда истекают таймаут секунд. Значение таймаут может быть больше 0, а если его значение равно 0 или является отрицательным, то ожидания нет.
RELEASE_LOCK(строка)
Снимает блокировку с именем строка, которая была получена с помощью функции GET_LOCK(). Возвращает 1, если блокировка снята, 0, если блокировка была установлена другим потоком (а значит, не может быть снята), и NULL, если блокировка с таким именем не существует. Блокировка не существует, если не была установлена вызовом GET_LOCK(), либо она уже снята.
UUID()
Возвращает Универсальный Уникальный Идентификатор (Universal Unique Identifier - UUID). Идентификатор UUID спроектирован как число, которое является глобально уникальным во времени и пространстве. Ожидается, что два вызова UUID сгенерируют два разных значения, даже если эти два вызова произойдут на двух разных компьютерах, которые не подключены друг к другу.
UUID - это 128-разрядное число, представленное в виде строки, состоящей из пяти шестнадцатеричных чисел в формате aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee:
- Первые три числа генерируются на основе временной метки.
- Четвертое число предохраняет темпоральную уникальность в случае, если значение временной метки теряет монотонность (например, из-за перехода на летнее время и обратно).
- Пятое число - это номер узла IЕЕ 802, который представляет пространственную уникальность. Случайное число подставляется в случае, если последнее недоступно (например, если компьютер-хост не имеет сетевой платы Ethernet, или нет возможности извлечь аппаратный адрес интерфейса вашего компьютера). В этом случае пространственная уникальность не может быть гарантирована. Однако, несмотря на это, коллизии крайне маловероятны. В настоящее время МАС-адрес интерфейса принимается во внимание только в средах FreeBSD и Linux. В других операционных системах MySQL использует случайно сгенерированное 48-разрядное число.
mysql> SELECT UUID(); -> '6ccd780c-baba-1026-9564-0040f4311e29'
Дополнения
Дополнение. PHP и MySQL
Для понимания этой лекции от вас требуются знания принципов работы баз данных. Для начала создаем базу данных и таблицу. Входим в командную строку MySQL, и выполняем команды:
mysql> CREATE DATABASE mydb; mysql> CREATE TABLE employees (id tinyint(4) DEFAULT '0' NOT NULL AUTO_INCREMENT, first varchar(20), last varchar(20), address varchar(255), position varchar(50), PRIMARY KEY (id), UNIQUE id (id)); INSERT INTO employees VALUES (1,'Bob','Smith','128 Here St, Cityname','Marketing Manager'); INSERT INTO employees VALUES (2,'John','Roberts','45 There St ,Townville','Telephonist'); INSERT INTO employees VALUES (3,'Brad','Johnson','1/34 Nowhere Blvd, Snowston','Doorman');
В результате будет создана база данных mydb. В ней будет создана таблица employees (работники). И в эту таблицу будут вставлены три записи с данными о работниках. Для экспериментов с PHP и MySQL этого вполне достаточно.
Давайте выведем эти данные из базы данных в HTML-страницу. Для общения с MySQL из PHP понадобятся следующие функции.
- int mysql_connect(string hostname, string username, string password); - создать соединение с MySQL.
Параметры:
Hostname – имя хоста, на котором находится база данных.
Username – имя пользователя.
Password – пароль пользователя.
Функция возвращает параметр типа int, который больше 0, если соединение прошло успешно, и равен 0 в противном случае.
- int mysql_select_db(string database_name, int link_identifier); - выбрать базу данных для работы.
Параметры:
Database_name – имя базы данных.
link_identifier – ID соединения, которое получено в функции mysql_connect. (параметр необязательный, если он не указывается, то используется ID от последнего вызова mysql_connect )
Функция возвращает значение true или false
- int mysql_query(string query, int link_identifier); - функция выполняет запрос к базе данных.
Параметры:
query – строка, содержащая запрос
link_identifier – см. предыдущую функцию.
Функция возвращает ID результата или 0, если произошла ошибка.
- int mysql_result(int result, int i, column); - функция возвращает значение поля в столбце column и в строке i.
- int mysql_close(int link_identifier); - функция закрывает соединение с MySQL.
Параметры:
link_identifier – см. выше.
Функция возвращает значение true или false
Создайте файл с расширением .php и наберите в нем следующий текст:
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
$result = mysql_query("SELECT * FROM employees",$db);
printf("First Name: %s<br>\n", mysql_result($result,0,"first"));
printf("Last Name: %s<br>\n", mysql_result($result,0,"last"));
printf("Address: %s<br>\n", mysql_result($result,0,"address"));
printf("Position: %s<br>\n", mysql_result($result,0,"position"));
mysql_close($db);
?>
</body>
</html>Теперь рассмотрим построчно, что происходит в этой программе. Функция mysql_connect() открывает связь с сервером баз данных MySQL. В качестве параметров мы указываем ей имя узла ( localhost ), на котором находится база данных, имя пользователя ( root ), под которым мы будем с ней работать, и пароль (в данном случае он пустой и потому не указывается).
Имя узла localhost означает, что сервер MySQL находится на той же машине, что и сам Web-сервер с PHP - движком. В принципе ничто не мешает вам (имея права) обратиться к серверу MySQL, который находится на соседней машине или вообще на другом конце земного шара.
В результате выполнения этой функции получаем некое значение, которое присваиваем переменной $db. Эта переменная называется идентификатором соединения (см. выше описание синтаксиса).
Соединившись с сервером выбираем базу данных, с которой будем работать (ведь на одном и том же сервере могут "крутиться" несколько баз данных). Это делается с помощью функции mysql_select_db(). В качестве параметров мы передаем название нужной нам базы данных и идентификатор соединения, полученный нами при выполнении предыдущей команды.
В результате выполнения функции mysql_select_db() мы получаем значение true или false. Если соединение с базой данных произошло успешно – true, если нет – false. Для того, чтобы наша программа-страница работала более интеллектуально, мы можем при желании проанализировать возвращаемое значение и если оно будет false, вывести хорошее информативное сообщение об ошибке.
И наконец мы обращаемся к базе данных с запросом, написанным на языке SQL. Для этого служит функция mysql_query(). В качестве первого параметра мы передаем текст запроса, а в качестве второго – передаём идентификатор, полученный от выполнения функции mysql_connect().
Результаты выполнения функции mysql_query() – записи, удовлетворяющие нашему запросу - помещаем в переменную $result.
И наконец, с помощью функции mysql_result() извлекаем из результатов выполнения нашего запроса (т.е. переменной $result ), первый ряд-запись (который имеет порядковый номер 0), и значение определенного поля (по его имени). Перебирая друг за другом записи от 0 до 2, мы выберем все записи, что хранятся в нашей маленькой базе данных.
В данном коде в полной мере используется функция printf(). Если говорить коротко, то в каждой приведенной выше строке комбинация символов " %s " обозначает, что вместо нее должна быть поставлена переменная, идущая во второй части выражения printf. Причем эта переменная должна быть переведена в тип "строковая переменная". Более подробное описание синтаксиса функции printf() читайте в руководстве по языку.
Далее мы познакомимся с более интеллектуальными, чем mysql_result(), функциями выборки данных из БД mysql_fetch_row() и mysql_fetch_array(), В дальнейшем мы рекомендуем пользоваться именно ими, как более быстрыми и удобными, чем mysql_result().
Вывод данных из базы данных
Давайте теперь попробуем вывести все записи, хранящиеся в нашей базе данных. Обратимся к базе данных со следующим кодом:
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
$result = mysql_query("SELECT * FROM employees",$db);
echo "<table border=1>\n";
echo "<tr><td>Name</td><td>Position</td></tr>\n";
while ($myrow = mysql_fetch_row($result))
{
printf("<tr><td>%s %s</td><td>%s</td></tr>\n", $myrow[1],
$myrow[2], $myrow[3]);
}
echo "</table>\n";
?>
</body>
</html>Вы вероятно заметили, что в данном коде вы ввели несколько новых функций и конструкций. Наиболее очевидной из них является цикл while(). Цикл говорит, что до тех пор, пока в переменной $result остается запись для выборки, ее необходимо извлечь с помощью функции mysql_fetch_row и присвоить переменной $myrow. А после этого выполнить код, что расположен внутри фигурных скобок "{}". Приглядитесь к коду внимательнее и разберитесь в этой конструкции.
Для понимания этого кода разберем понятие "массив". Выполнение функции mysql_query дает в результате массив, который хранится в переменной $result. Если представить этот массив схематически, то он будет выглядеть как показано в табл 12.1:
| 0 id | 1 first | 2 last | 3 address | 4 position | Порядковый номер элемента массива |
|---|---|---|---|---|---|
| 1 | Bob | Smith | 128 Here St, Cityname | Marketing Manager | 0 |
| 2 | John | Roberts | 45 There St ,Townville | Telephonist | 1 |
| 3 | Brad | Johnson | 1/34 Nowhere Blvd, Snowston | Doorman | 2 |
Переменная $result является массивом. Причем не простым массивом, а двумерным. В нем содержатся три строки с номерами от 0 до 2. каждая из которых содержит 5 столбцов от 0 до 4. Для того, чтобы вывести на странице все записи, нам надо пройти от 0-й строчки массива до 2-й. Лучше всего это делать в цикле с помощью функции mysql_fetch_row (которая в переводе буквально означает – "выбрать ряд").
Функции mysql_fetch_row в качестве параметра подается массив $result. Функция выбирает из него строку, которую мы можем записать в переменную $myrow и автоматически переходит на следующую строку. Вызвав снова mysql_fetch_row, выберем следующую строку из массива, и так далее до тех пор, пока не достигнем конца массива. В этом случае mysql_fetch_row вернет значение false, которое послужит сигналом, что все записи выбраны и можно завершить цикл.
Теперь стоит задача как-то вывести в теле цикла полученную запись. Выбранный ряд хранится в переменной $myrow. Она также, как и $result, является массивом, только одномерным. Схематически это выглядит как в табл. 12.2:
| 0 id | 1 first | 2 last | 3 address | 4 position | Порядковый номер элемента массива |
|---|---|---|---|---|---|
| 1 | Bob | Smith | 128 Here St, Cityname | Marketing Manager | 0 |
А вот как будет выглядеть содержимое переменной $myrow при втором прохождении цикла (табл. 12.3):
| 0 id | 1 first | 2 last | 3 address | 4 position | Порядковый номер элемента массива |
|---|---|---|---|---|---|
| 2 | John | Roberts | 45 There St ,Townville | Telephonist | 1 |
При третьем прохождении – как в табл. 12.4
| 0 id | 1 first | 2 last | 3 address | 4 position | Порядковый номер элемента массива |
|---|---|---|---|---|---|
| 3 | Brad | Johnson | 1/34 Nowhere Blvd, Snowston | Doorman | 2 |
К каждому столбцу в массиве $myrow мы можем обратиться по его порядковому номеру, который заключается в квадратные скобки. Например, в первом цикле, $myrow[1] равно "Bob", во втором $myrow[4] равно "Telephonist".
На первый взгляд процедура извлечения данных весьма сложна, но она вполне логически понятна и объяснима. Главное не забывайте, что элементы массивов нумеруются от 0, а не от 1.
Далее, вывод переменных в HTML с помощью функции printf() – дело техники, уже знакомой нам по предыдущему примеру.
Наш код содержит недостаток: если в базе данных не будут найдены записи, удовлетворяющие нашему запросу, мы не получим никакого сообщения об этом. Неплохо было бы, чтобы программа выдавала какое-нибудь сообщение. Сделаем ее более дружественной.
Взгляните на следующий код:
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
$result = mysql_query("SELECT * FROM employees",$db);
if ($myrow = mysql_fetch_array($result))
{
echo "<table border=1>\n";
echo "<tr><td>Name</td><td>Position</td></tr>\n";
do{
printf("<tr><td>%s %s</td><td>%s</tr>\n", $myrow["first"], $myrow["last"],
$myrow["address"]);
} while ($myrow = mysql_fetch_array($result));
echo "</table>\n";
} else
{
echo "Sorry, no records were found!";
}
?>
</body>
</html>В данном коде мы опять ввели некоторые новые понятия, но они достаточно просты. Во-первых, вместо функции mysql_fetch_row() мы использовали функцию mysql_fetch_array(). Она работает точно так же, как и mysql_fetch_row() за одним замечательным исключением: с помощью этой функции мы можем обращаться к каждому полю массива не по номеру, а по имени.
Например, если раньше для получения имени нам приходилось писать $myrow[1] (1 – второй столбец массива), то теперь мы можем писать $myrow["first"] ("first" – название столбца в базе данных и в массиве). Второй вариант естественно гораздо информативнее и удобнее.
Кроме этого, в коде использован цикл do/while и условная конструкция if-else. Выражение if-else говорит, что если мы можем присвоить значение $myrow, то надо начать выборку, в противном случае мы понимаем, что записей нет, переходим к блоку else и выводим соответствующее сообщение.
Чтобы проверить, как работает эта часть кода, замените SQL-выражение на " SELECT * FROM employees WHERE id=6 " или на какое-нибудь другое, которое не даст результата.
Цикл do/while – это всего лишь вариант цикла while(), который мы использовали в предыдущем примере. Мы обратились за помощью к циклу do/while по одной простой причине. В конструкции if мы уже сделали выборку первого ряда и присвоили его переменной $myrow.
Если бы мы сейчас воспользовались прежней конструкцией (т.е. while ($myrow = mysql_fetch_row($result) ), мы бы затерли значения первой выбранной записи, заменив ее значениями второй записи. В случае же с циклом do/while мы проверяем условие после того, как код цикла выполнится по крайней мере один раз. Таким образом, ни одна запись не ускользнет из наших рук.
А сейчас давайте сделаем код в цикле и if-else конструкцию еще более красивым.
Создаем ссылки на лету
Сейчас поработаем с параметрами запроса. Как вы уже наверняка знаете, существует три способа передачи параметров запроса. Первый, использовать метод GET в форме. Второй – набрать параметры прямо в адресной строке броузера. И третий, это вставить параметры в обычную ссылку на странице. То есть сделать ссылку примерно такого вида
<a href="http://my_machine/mypage.php3?id=1">
Научимся создавать такие ссылки на лету.
Для начала, давайте обратимся к базе данных и выведем список персонала. Взгляните на следующий код. Многое в нем вам будет знакомо.
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
$result = mysql_query("SELECT * FROM employees",$db);
if ($myrow = mysql_fetch_array($result))
{
do{
printf("<a href=\"%s?id=%s\">%s %s</a><br>\n",
$PHP_SELF, $myrow["id"],$myrow["first"],
$myrow["last"]);
}while ($myrow = mysql_fetch_array($result));
}else
{
echo "Sorry, no records were found!";
}
?>
</body>
</html>Все вам должно быть знакомо, кроме функции printf(). Поэтому, давайте рассмотрим ее поближе. Во-первых, обратите внимание на обратные косые черты. Они говорят PHP-движку, что необходимо вывести символ, следующий за чертой, а не рассматривать его, как служебный символ или как часть кода. В данном случае это касается кавычки, которая нам нужна в тексте ссылки, но для PHP является символом окончания текстовой строки.
Далее, в коде используется интересная переменная $PHP_SELF. В этой переменной всегда хранится имя и URL текущей страницы. В данном случае эта переменная важна для нас потому, что мы хотим через ссылку вызвать страницу из нее самой. То есть вместо того, чтобы делать две страницы, содержащие разные коды для разных действий, мы все действия запихнули в одну страницу. С помощью условий if-else мы будем переводить стрелки с одного кода на другой, гоняя одну и ту же страницу по кругу. Это конечно увеличит размер страницы и время, необходимое на ее обработку, но в некоторых случая, такой трюк очень удобен.
Переменная $PHP_SELF гарантирует нам, что наша страница будет работать даже в том случае, если мы перенесем ее в другой каталог или даже на другую машину.
Ссылки, сгенерированные в цикле ссылаются на ту же самую страницу, только к имени самой страницы на лету добавлена некоторая информация: переменные и их значения.
Переменные, которые передаются в строке-ссылке, автоматически создаются PHP-движком, и к ним можно обращаться так, как если бы вы их создавали в коде сами. При втором проходе страницы наша программа отреагирует на эти пары name=value и направит ход исполнения на другие рельсы. В данном случае мы проверим, есть ли переменная $id, и в зависимости от результата выполним тот или иной код. Вот как это будет выглядеть:
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db); // display individual record
if ($id)
{
$result = mysql_query("SELECT * FROM employees WHERE id=$id",$db);
$myrow = mysql_fetch_array($result);
printf("First name: %s\n<br>", $myrow["first"]);
printf("Last name: %s\n<br>", $myrow["last"]);
printf("Address: %s\n<br>", $myrow["address"]);
printf("Position: %s\n<br>", $myrow["position"]);
}else
{
// show employee list
$result = mysql_query("SELECT * FROM employees",$db);
if ($myrow = mysql_fetch_array($result))
{
// display list if there are records to display
do{
printf("<a href=\"%s?id=%s\">%s %s</a><br>\n", $PHP_SELF, $myrow["id"],
$myrow["first"], $myrow["last"]);
}while ($myrow = mysql_fetch_array($result));
}else
{
// no records to display
echo "Sorry, no records were found!";
}
}
?>
</body>
</html>
Листинг
12.1.
(html,
txt)
Код усложнился, поэтому мы добавили в него некоторые комментарии, чтобы он стал яснее. Для однострочных комментариев можно использовать символы //. Если комментарий нужно уместить на нескольких строчках, используйте скобки /* ... */.
Итак, вы наконец создали действительно полезную PHP-страницу, работающую с MySQL.
Сохранение данных в базе данных
Мы научились извлекать данные из базы и выводить их на странице. Теперь давай попробуем осуществить обратное действие. С PHP это не составит большого труда.
Создадим простую форму:
<html>
<body>
<form method="post" action="<?php echo $PHP_SELF?>">
First name:<input type="Text" name="first"><br>
Last name:<input type="Text" name="last"><br>
Address:<input type="Text" name="address"><br>
Position:<input type="Text" name="position"><br>
<input type="Submit" name="submit" value="Enter information">
</form>
</body>
</html>Обратите внимание, мы опять используем переменную $PHP_SELF. Как мы уже сказали, PHP-код можно как угодно перемешивать с обычным HTML. Также обратите внимание, что название каждого элемента формы совпадает с названием поля в базе данных.
Вообще-то, это не обязательно, но весьма удобно, чтобы в дальнейшем не запутаться в том, какая переменная какому полю в базе данных соответствует.
Помимо этого мы присвоили имя кнопке Submit. Это сделано для того, чтобы в коде затем проверить, есть ли переменная $submit. Таким образом, когда страница будет вызываться, мы будем узнавать, вызывается ли она в первый или во второй раз.
Следует еще раз отметить, что вовсе не обязательно писать код так, чтобы страница снова и снова вызывала саму себя. Программу можно разделить на две, три и более страниц, если угодно. Но при таком подходе, вся программа находится в одном файле, а это бывает весьма удобно.
Итак, давайте добавим код, который будет проверять, введены ли в форму данные. Пока это будет лишь простая проверка, при которой все переменные, передаваемые странице, будут выводиться на экран с помощью переменной $HTTP_POST_VARS. Эта переменная удобна в случае отладки. Если вы хотите вывести на экран вообще все переменные, используемые в странице, вызовите переменную $GLOBALS.
<html>
<body>
<?php
if ($submit)
{
// process form
while (list($name, $value) = each($HTTP_POST_VARS)) {
echo "$name = $value<br>\n";
}
} else
{
// display form
?>
<form method="post" action="<?php echo $PHP_SELF?>">
First name:<input type="Text" name="first"><br>
Last name:<input type="Text" name="last"><br>
Address:<input type="Text" name="address"><br>
Position:<input type="Text" name="position"><br>
<input type="Submit" name="submit" value="Enter
information">
</form>
<?php
} // end if
?>
</body>
</html>Теперь давайте возьмем переданную через форму информацию и внесем ее в базу данных.
<html>
<body>
<?php
if ($submit)
{
// process form
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
$sql = "INSERT INTO employees (first,last,address,position)
VALUES ('$first','$last','$address','$position')";
$result = mysql_query($sql);
echo "Thank you! Information entered.\n";
} else{
// display form
?>
<form method="post" action="<?php echo $PHP_SELF?>">
First name:<input type="Text" name="first"><br>
Last name:<input type="Text" name="last"><br>
Address:<input type="Text" name="address"><br>
Position:<input type="Text" name="position"><br>
<input type="Submit" name="submit" value="Enter information">
</form>
<?php
}
// end if
?>
</body>
</html>
Листинг
12.2.
(html,
txt)
Мы внесли данные в базу. Тем не менее наш код далек от идеального. Что случится, если при заполнении формы кто-то оставит пустые поля или введет текст в поле, в которое надо ввести число? Что произойдет, если в поданных данных будет ошибка?
Ранее мы записывали SQL-выражение в переменную ( $sql ), прежде чем передать запрос в базу данных через функцию mysql_query(). Это делается на случай отладки. Если что-то пойдет не так, мы всегда сможем вывести интересующее нас SQL-выражение на экран и проверить, нет ли в нем ошибок.
Мы уже знаем, как вставлять данные в базу. Теперь давайте научимся менять записи, которые уже находятся в таблице.
Редактирование данных сочетает в себе два кода. Которые мы уже проходили: извлечение данных из базы с выводом их на экран, и внесение данных через форму обратно в базу. Тем не менее программа правки данных немного отличается тем, что мы в форме должны вывести некую конкретную запись. Для начала давайте воспользуемся кодом для вывода списка служащих на экран. Однако теперь информацию о служащих мы будет отображать в форме. Код страницы будет выглядеть так:
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
if ($id) {
// query the DB
$sql = "SELECT * FROM employees WHERE id=$id";
$result = mysql_query($sql);
$myrow = mysql_fetch_array($result);
?>
<form method="post" action="<?php echo $PHP_SELF?>">
<input type=hidden name="id" value="<?php echo
$myrow["id"] ?>">
First name:<input type="Text" name="first" value="<?php
echo $myrow["first"] ?>"><br>
Last name:<input type="Text" name="last" value="<?php
echo $myrow["last"] ?>"><br>
Address:<input type="Text" name="address" value="<?php
echo $myrow["address"] ?>"><br>
Position:<input type="Text" name="position" value="<?php
echo $myrow["position"] ?>"><br>
<input type="Submit" name="submit" value="Enter
information">
</form>
<?php
} else {
// display list of employees
$result = mysql_query("SELECT * FROM employees",$db);
while ($myrow = mysql_fetch_array($result)) {
printf("<a href=\"%s?id=%s\">%s %s</a><br>\n", $PHP_SELF,
$myrow["id"], $myrow["first"],
$myrow["last"]);
}
}
?>
</body>
</html>
Листинг
12.3.
(html,
txt)
В этой странице мы просто вывели в каждое поле формы соответствующее значение из базы данных. Теперь усложним программу. Добавим к ней возможность внесения отредактированных данных назад в базу. Опять таки мы прибегаем к помощи кнопки Submit, которой присваиваем имя, чтобы при втором проходе страницы проверить, какую часть кода нам надо выполнять.
Также мы здесь используем слегка измененное SQL-выражение.
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
if ($id) {
if ($submit) {
$sql = "UPDATE employees SET first='$first',last='$last',
address='$address',position='$position' WHERE id=$id";
$result = mysql_query($sql);
echo "Thank you! Information updated.\n";
} else {
// query the DB
$sql = "SELECT * FROM employees WHERE id=$id";
$result = mysql_query($sql);
$myrow = mysql_fetch_array($result);
?>
<form method="post" action="<?php echo $PHP_SELF?>">
<input type=hidden name="id" value="<?php echo
$myrow["id"] ?>">
First name:<input type="Text" name="first" value="<?php
echo $myrow["first"] ?>"><br>
Last name:<input type="Text" name="last" value="<?php
echo $myrow["last"] ?>"><br>
Address:<input type="Text" name="address" value="<?php
echo $myrow["address"] ?>"><br>
Position:<input type="Text" name="position" value="<?php
echo $myrow["position"] ?>"><br>
<input type="Submit" name="submit" value="Enter
information">
</form>
<?php
}
} else {
// display list of employees
$result = mysql_query("SELECT * FROM employees",$db);
while ($myrow = mysql_fetch_array($result)) {
printf("<a href=\"%s?id=%s\">%s %s</a><br>\n",
$PHP_SELF, $myrow["id"], $myrow["first"],
$myrow["last"]);
}
}
?>
</body>
</html>
Листинг
12.4.
(html,
txt)
Вот так. Нам удалось вместить все, что мы знаем и умеем в один код. Здесь вы можете увидеть, как мы используем выражение if() внутри другого выражения if() для последовательно проверки нескольких условий.
Теперь пришло время свести все вместе.
<html>
<body>
<?php
$db = mysql_connect("localhost", "root");
mysql_select_db("mydb",$db);
if ($submit) {
// here if no ID then adding else we're editing
if ($id) {
$sql = "UPDATE employees SET first='$first',last='$last',
address='$address',position='$position'
WHERE id=$id";
} else {
$sql = "INSERT INTO employees (first,last,address,position)
VALUES
('$first','$last','$address','$position')";
}
// run SQL against the DB
$result = mysql_query($sql);
echo "Record updated/edited!<p>";
} else if ($delete) {
// delete a record
$sql = "DELETE FROM employees WHERE id=$id";
$result = mysql_query($sql);
echo "$sql Record deleted!<p>";
} else {
// this part happens if we don't press submit
if (!$id) {
// print the list if there is not editing
$result = mysql_query("SELECT * FROM employees",$db);
while ($myrow = mysql_fetch_array($result)) {
printf("<a href=\"%s?id=%s\">%s %s</a> \n", $PHP_SELF,
$myrow["id"], $myrow["first"],
$myrow["last"]);
printf("<a href=\"%s?id=%s&delete=yes\">(DELETE)</a><br>",
$PHP_SELF, $myrow["id"]);
}
}
?>
<P>
<a href="<?php echo $PHP_SELF?>">ADD A RECORD</a>
<P>
<form method="post" action="<?php echo $PHP_SELF?>">
<?php
if ($id)
{
// editing so select a record
$sql = "SELECT * FROM employees WHERE id=$id";
$result = mysql_query($sql);
$myrow = mysql_fetch_array($result);
$id = $myrow["id"];
$first = $myrow["first"];
$last = $myrow["last"];
$address = $myrow["address"];
$position = $myrow["position"];
// print the id for editing
?>
<input type=hidden name="id" value="<?php echo $id ?>">
<?php
}
?>
First name:<input type="Text" name="first" value="<?php echo
$first ?>"><br>
Last name:<input type="Text" name="last" value="<?php echo
$last ?>"><br>
Address:<input type="Text" name="address" value="<?php echo
$address ?>"><br>
Position:<input type="Text" name="position" value="<?php echo
$position ?>"><br>
<input type="Submit" name="submit" value="Enter information">
</form>
<?php
}
?>
</body>
</html>
Листинг
12.5.
(html,
txt)
На первый взгляд код выглядит сложным, однако это не так. Программа делится на три части. Первое if() выражение проверяет, была ли нажата кнопка Submit, и если была, проводится проверка, есть ли в поданных данных переменная $id. Если ее нет, значит происходит добавление новой записи. В противном случае мы редактируем уже существующую запись.
Далее мы проверяем, определена ли переменная $delete. Если да, мы удаляем запись. Обратите внимание, что в первом выражении if() мы проверяем переменную, которая была подана с помощью метода POST, а в данном if() выражении мы проверяем переменную, которая является частью данных отправленных с помощью метода GET.
Наконец, мы переходим к действию, которое будет выполняться по умолчанию: то есть выводим просто список служащих и форму. Здесь мы опять проверяем существование переменной $id. Если она существует, мы просим базу данных выдать сведения о выбранном служащем. В противном случае выводим пустую форму.
Все, что мы рассмотрели, мы поместили в один большой код. Мы использовали циклы while() и выражения if(), а также целую гамму основных команд языка SQL - SELECT, INSERT, UPDATE, и DELETE.
Наконец, мы рассмотрели, как можно передавать информацию от одной страницы к другой через URL с помощью ссылок и через формы.
Дополнение. Perl и MySQL
Язык программирования Perl превратился из инструмента, используемого преимущественно администраторами Unix-систем, в наиболее распространенную платформу разработки для World Wide Web. Perl не предназначался изначально для Web, но простота его использования и мощные функции для работы с текстом сделали естественным его применение для CGI-программирования. Сходным образом, когда mSQL впервые появилась на сцене, исключительные компактность и скорость выполнения сделали ее очень привлекательной для разработчиков Web, которым требовалось обслуживать ежедневно тысячи операций. MySQL со своей высокой скоростью и расширенными возможностями стала еще более привлекательным средством для веб-разработчиков. Естественно поэтому, что был разработан интерфейс Perl к обеим базам - MySQL и mSQL, - объединив таким образом их достоинства.
В то время, когда писался этот материал, существовали два интерфейса между Perl и MySQL с mSQL. Более ранний состоит из специализированных интерфейсов Myaql.pm и Msql.pm, которые работают только с MySQL и mSQL соответственно. Другой, более новый интерфейс является подключаемым модулем в комплекте DBI (DataBase Independent) - независимых от базы данных модулей. DBI является попыткой обеспечить общий Perl API для доступа к любым базам данных и предоставления более высокой переносимости. Интерфейс DBI стал наиболее надежным и стандартным, и разработчики MySQL рекомендуют пользоваться только DBI, поскольку дальнейшая разработка модулей Mysql.pm и Msql.pm прекращена. Именно о DBI мы и расскажем здесь.
DBI
Рекомендуемым методом доступа к базам данных MySQL и mSQL из Perl является интерфейс DBD/DBI. DBD/DBI означает DataBase Dependent/DataBase Independent (Зависимый от базы данных/Независимый от базы данных). Название связано с двухъярусной реализацией интерфейса. В нижнем ярусе находится зависимый от базы данных уровень. На нем существуют свои модули для каждого типа базы данных, доступного из Perl. Поверх этого уровня находится независимый от базы данных уровень. Это тот интерфейс, которым вы пользуетесь при доступе к базе данных. Выгода такой схемы в том, что программисту нужно знать только один API уровня независимости от базы данных. Когда появляется новая база данных, кому-нибудь нужно лишь написать для нее модуль DBD (зависимый), и она станет доступна всем программистам, использующим DBD/DBI.
Как и в любом модуле Perl, для получения доступа нужно указать DBI в директиве use:
#!/usr/bin/perl -w use strict; use CGI qw(:standard); use DBI;
При запуске программ Perl для MySQL/mSQL следует всегда задавать аргумент командной строки -w. Благодаря этому DBI будет перенаправлять все специфические для MySQL и mSQL сообщения об ошибках на STDERR, и вы сможете увидеть ошибки, вызванные работой с базой данных, не прибегая к явной проверке их в программе.
Всякое взаимодействие между Perl, с одной стороны, и MySQL и mSQL - с другой, производится с помощью объекта, известного как описатель базы данных ( handle ). Описатель базы данных ( database handle ) - это объект, представленный в Perl как скалярная ссылка и реализующий все методы, используемые для связи с базой данных. Одновременно можно открыть любое число описателей базы данных, ограничение накладывают только ресурсы системы. Метод connect() использует для создания описателя формат соединения DBI:servertype:database:hostname:port (имя узла и порта необязательны), дополнительными аргументами служат имя пользователя и пароль:
my $dbh = DBI->connect( 'DBI:mysql:mydata ', undef, undef); my $dbh = DBI->connect( 'DBI:mSQL:mydata:myserver', undef, undef); my $dbh = DBI->connect( 'DBI:mysql:mydata', 'me', 'mypass')',
Атрибут servertype является именем специфического для базы данных DBD-модуля, в нашем случае "mysql" или "mSQL" (обратите внимание на точное использование регистра). В первом варианте создается соединение с сервером MySQL на локальной машине через сокет Unix. Это наиболее эффективный способ связи с базой данных, который должен использоваться при соединении на локальном сервере. Если указано имя узла, оно используется для соединения с сервером на этом узле через стандартный порт, если только не задан и номер порта. Если при соединении с сервером MySQL вы не указываете имя пользователя и пароль, то пользователь, выполняющий программу, должен обладать достаточными привилегиями в базе данных MySQL. Для баз данных mSQL имя пользователя и пароль не должны указываться.
В Perl 5 используются два соглашения по вызову модулей. В объектно-ориентированном синтаксисе для ссылки на метод определенного класса используется символ стрелки "->" (как в DBI->connect ). Другой метод - использование непрямого синтаксиса, в котором за именем метода следует имя класса, а затем - аргументы. В последнем примере метод connect следовало бы записать как connect DBI 'DBI:mysql:mydata', 'me', ' mypass. В ранних версиях Msql.pm использовался исключительно непрямой синтаксис, и требовалось придерживаться метода использования заглавных букв, обусловленного mSQL С API. Поэтому значительная часть старого кода MsqlPerl содержит строки типа SelectDB $dbh 'test' там, где можно было бы написать проще: $dbh->selectdb('test'). Если вы еще не догадались, то сообщаем, что мы неравнодушны к объектно-ориентированному синтаксису, хотя бы потому, что использование стрелки делает ясной связь между классом и методом.
Как только вы соединились с сервером MySQL или mSQL, описатель базы данных - во всех примерах этого раздела $dbh - становится шлюзом к базе данных. Например, так готовится запрос SQL:
$dbh->prepare($query);
При работе с mSQL для одного описателя базы данных можно одновременно выбрать только одну базу данных, это ограничение накладывается сервером mSQL. Однако в любой момент можно сменить текущую базу данных, повторно вызвав connect . При работе с MySQL можно включать в запрос другие базы данных, явно указывая их имена. Кроме того, и в MySQL, и в mSQL при необходимости одновременного доступа к нескольким базам данных можно создать несколько описателей базы данных и использовать их совместно.
Для иллюстрации использования DBI рассмотрим следующие простые программы. В примере 1 datashow.cgi принимает в качестве параметра имя узла; при отсутствии параметра принимается имя " local-host ". Затем программа выводит список всех баз данных, имеющихся на этом узле.
Пример 1. Программа CGI datashow.cgi показывает все базы данных, имеющиеся на сервере MySQL или mSQL
#!/usr/bin/perl -w
use strict;
use CGI qw( standard);
use CGI::Carp;
# Использовать модуль DBI use DBI; CGI::use_named_parameters(1);
my ($server, $sock, $host);
my $output = new CGI;
$server = param('server') or Sserver = '';
# Подготовить DBD-драйвер для MySQL
my $driver = DBI->install_driver('mysql');
my @databases = $driver->func($server, '_ListDBs');
# Если параметр @databases неопределен, предполагаем,
# что на этом узле не запущен
# сервер MySQL. Однако это может быть вызвано
# другими причинами. Полный текст сообщения об ошибке
# можно получить, проверив $DBI::errmsg.
if (not @databases) {
print header, start_html('title'=>"Данные no Sserver", 'BGCOLOR'=>'white');
print<<END_OF_HTML; <H1>$server</h1>
Ha Sserver , по-видимому, не запущен сервер mSQL. </body></html> END_OF_HTML
exit(0); }
print header, start_html('title'=>" Данные по $host",
'BGCOLOR'=>'white'); print <<END_OF_HTML; <H1>$host</h1>
<P>
Соединение с $host на сокете $sock.
<p>
Базы данных:<br>
<UL>
END_OF_HTML
foreach(@databases) {
print "<LI>$_\n"; }
print <<END_OF_HTML;
</ul>
</body></html>
HTML
exit(0)
Листинг
13.1.
(html,
txt)
В примере 2 tableshow.cgi принимает в качестве параметров имя сервера базы данных (по умолчанию " localhost ") и имя базы данных на этом сервере. Затем программа показывает все таблицы, имеющиеся в этой базе данных.
Пример 2. Программа CGI tableshow.cgi выводит список всех таблиц в базе данных
#!/usr/bin/perl -w
use strict;
use CGI qw(:standard);
use CGI::Carp;
# Использовать модуль Msql.pm use DBI;
CGI::use_named_parameters(1);
my ($db);
my $output = new CGI;
$db = param('db')'or die("He указана база данных!");
# Connect to the requested server.
my $dbh = DBI->connect("DBI:mysql:$db;$server", undef, undef);
# Если не существует $dbh, значит, попытка соединения с сервером
# базы данных не удалась. Возможно, сервер не запущен,
# или не существует указанной базы данных, if (not $dbh) {
print header, start_html('title'=>"Данные по $host => $db",
'BGCOLOR'=>'white');
print <<END_OF_HTML; <H1>$host</h1> <H2>$db</h2>
Попытка соединения не удалась по следующей причине:<BR>
$DBI::errstr
</body></html>
END_OF_HTML
exit(0); }
print header, start_html('title'=>"Данные по $host => $db",
'BGCOLOR'=>'white'); print <<END_OF_HTML; <H1>$host</h1>
<H2>$db</h2>
<р>
Таблицы:<br>
<UL>
END_OF_HTML
# $dbh->listtable возвращает массив таблиц,
# имеющихся в текущей базе данных.
my ©tables = $dbh->func( '_ListTables' );
foreach (@tables) {
print "<LI>$_\n"; }
print <<END_OF_HTML; </ul>
</body></html> END_OF_HTML
exit(0);
Листинг
13.2.
(html,
txt)
И наконец, пример 3 показывает, как вывести все сведения о некоторой таблице.
Пример 3. Программа CGI tabledump.cgi выводит сведения об указанной таблице
#!/usr/bin/perl -w
use strict;
use CGI qw(:standard);
use CGI::Carp;
# Использовать модуль DBI use DBI; CGI::use_named_parameters(1);
my ($db,Stable);
my Soutput = new CGI;
$server = param('server') or $server = ";
$db = param('db') or die("He указана база данных !");
# Соединиться с указанным сервером.
my $dbh = DBI->connect("DBI:mysql:$db:$server", undef, undef);
# Готовим запрос к серверу, требующий все данные
# таблицы.
my $table_data = $dbh->prepare("select * from Stable");
# Посылаем запрос серверу.
$table_data->execute;
# Если возвращаемое значение не определено, таблица не существует
# или пуста; мы не проверяем, что из двух верно.
if (not $table_data) {
print header, startjtml( 'title'=>
"Данные по $host => $db => Stable", 'BGCOLOR'=>'white');
print<<END_OF_HTML;
<H1>$host</h1>
<H2>$db</h2>
Таблицы'Stable' нет в $db на $host.
</body></html>
END_OF_HTML
exit(0); }
# Теперь мы знаем, что есть данные для выдачи. Сначала выведем
# структуру таблицы.
print header, start_html( title'=>"Данные по $host => $db => $table",
'BGCOLOR'=>'white');
print <<END_OF_HTML; <H1>$host</h1> <H2>$db</h2> <H3>$table</h3>
<P>
<TABLE BOROER> <CAPTION>Пoля</caption> <TR>
<ТН>Поле<ТН>Тип<ТН>Размер<ТН>МОТ NULL </tr> <UL> END_OF_HTML
If $table_data->name возвращает ссылку
# на массив полей таблицы.
my ©fields = @{$table_data->NAME};
# $table_data->type возвращает ссылку на массив типов полей.
# Возвращаемые типы имеют стандартные обозначения SQL,
# а не специфические для MySQL.
my @types = @{$table_data->TYPE};
# $table_data->is_not_null возвращает ссылку на массив типа Boolean,
# указывающий, в каких полях установлен флат 'NOT NULL'.
my @>not_null = @{$table_data->is_not_null};
# $table_data->length возвращает ссылку на массив длин полей.
Они фиксированные
# для типов INT и REAL, но переменые (заданные при создании
# таблицы) для CHAR.
my @length = @{$table_data->length};
# Все перечисленные выше массивы возвращаются в одном и том же
порядке,
# поэтому $fields[0], $types[0], $ndt_null[0] and $length[0]
относятся к одному полю.
foreach $field (0..$#fields) {
print "<TR>\n";
print "<TD>$fields[$field]<TD>$types[$field]<TD>";
print $length[$field]
if $types[$field] eq 'SQL_CHAR';
print "<TD>";
print 'Y' if ($not_null[$field]);
print "</tr>\n"; }
print <<END_OF_HTML; </table>
<P>
<B>Data</b><br>
<OL>
END_OF_HTML
# Теперь мы будем построчно перемещаться по данным с помощью
DBI::fetchrow_array().
# Мы сохраним данные в массиве в таком же порядке, как и в
информационных
# массивах (§fields, @types, etc,), которые мы создали раньше.
while(my(@data)=$table_data->fetchrow_array) {
print "<LI>\n<UL>";
for (0..$#data) {
print "<LI>$fields[$_] => $data[$_]</li>\n"; }
print "</ulx/li>"; }
print "END_OF_HTML;
</ol>
</body></html>
END_OF_HTML
Листинг
13.3.
(html,
txt)
Пример приложения, использующего DBI
DBI допускает любые SQL-запросы, поддерживаемые MySQL и mSQL. Например, рассмотрим базу данных, используемую в школе для ведения учета учащихся, состава классов, результатов экзаменов и т. д. База данных должна содержать несколько таблиц: одну для данных о предметах, другую для данных об учащихся, таблицу для списка экзаменов и по одной таблице для каждого экзамена. Возможность MySQL и mSQL выбирать данные из нескольких таблиц, используя объединение таблиц, позволяет совместно использовать таблицы как согласованное целое для создания приложения, облегчающего работу учителя.
Для начала мы хотим учесть данные об экзаменах по разным предметам. Для этого нам нужна таблица, содержащая названия и числовые идентификаторы для экзаменов. Нам потребуется также отдельная таблица для каждого экзамена. В этой таблице будут содержаться результаты испытаний для всех учащихся, а также высший балл для проведения сравнения. Таблица test имеет следующую структуру:
CREATE TABLE test ( id INT NOT NULL AUTO_INCREMENT, name CHAR(100), subject INT, num INT)
Для каждого отдельного экзамена структура таблицы такая:
CREATE TABLE t7 ( id INT NOT NULL, q1 INT, q2 INT, q3 INT, q4 INT, total INT )
К имени таблицы t присоединен идентификатор экзамена из таблицы test. При создании таблицы пользователь определяет количество вопросов. Поле total содержит сумму баллов по всем вопросам.
Программа, обрабатывающая данные экзаменов, называется test.cgi. Эта программа, текст которой следует ниже, позволяет только добавлять новые экзамены. Просмотр экзаменов и их изменение не реализованы и оставлены в качестве упражнения. Дополнить этот сценарий будет несложной задачей, если воспользоваться в качестве справочного материала другими сценариями, приведенными в данной лекции. Этот сценарий хорошо показывает возможности DBI:
#!/usr/bin/perl -w
use strict; require my_end;
use CGI qw(:standard);
my Soutput = new CGI;
use_named_parameters(1);
# Использовать модуль DBI. use DBI;
# DBI::connect() использует формат 'DBI:driver:database', в нашем
случае
# используется драйвер MySQL и открывается база данных 'teach',
my $dbh = DBI->connect('DBI:mysql:teach');
# Операция добавления распределена между тремя отдельными функциями.
Первая функция, add,
# выводит пользователю форму шаблона для создания нового экзамена,
sub add {
$subject = param('subject')
if (param('subjects'));
$subject = ""
if $subject eq 'all';
print header, start_html('title'=>'Create a New Test',
'BGCOLOR'=>'white'); print <<END_OF_HTML;
<Н1>Создание нового экзамена</п1> <FORM ACTION="test.cgi"
METHOD=POST>
<INPUT TYPE=HIDDEN NAME="action" VALUE="add2"> Предмет: END_OF_HTML
my @ids = (); my %subjects = ();
my $out2 = $dbh->prepare("select id,name from subject order by
name" $out2->execute;
# DBI: :fetchrow_array() совершенно аналогична Msql: :fetchrow()
while(my($id,$subject)=$out2->fetchrow_array) {
push(@ids,Sid); $subjects{"$id"} = Ssubject; }
print popup_menu('name'=>'subjects', 'values'=>[@ids],
'default'=>$subject, 'labels'=>\%subjects);
print <<END_OF_HTML; <br>
Число вопросов: <INPUT NAME="num" SIZE=5><br> Название или
идентификатор (например, дата) экзамена:
<INPUT NAME="name" SIZE=20>
<Р>
<INPUT TYPE=SUBMIT VALUE=" Следующая страница ">
<INPUT TYPE=RESET> </form></body></html>
END_OF_HTML }
Листинг
13.4.
(html,
txt)
Эта функция выводит форму, позволяющую пользователю выбрать предмет для экзамена, а также количество вопросов и название. Для вывода списка имеющихся предметов выполняется запрос к таблице предметов. При выполнении в DBI запроса SELECT он должен быть сначала подготовлен, а затем выполнен. Функция DBI::prepare полезна при работе с некоторыми серверами баз данных, позволяющими осуществить операции над подготовленными запросами, прежде чем выполнить их. Для MySQL и mSQL это означает лишь запоминание запроса до вызова функции DBI:: execute.
Результаты работы этой функции посылаются функции add2, как показано ниже:
sub add2 {
my Ssubject = param('subjects');
[
my $num = param('num');
$name = param('name') if param('name');
my $out = $dbl"prepare("select name from subject where id=$subject");
$out->execute;
my (Ssubname) = $out->fetchrow_a.rray;
print header, start_html('title'=>"Создание экзамена по предмету
$subname", ' BGCOLOR'=>'white');
print <<END_OF_HTML;
<H1> Создание экзамена по предмету $subname</h1> <h2>$name</h2>
<P>
<FORM ACTION="test.cgi" METHOD=POST>
<INPUT TYPE=HIDDEN NAME="action" VALUE="add3">
<INPUT TYPE=HIDDEN NAME="subjects" VALUE="$subject">
<INPUT TYPE=HIDOEN NAME="num" VALUE="$num">
<INPUT TYPE=HIDDEN NAME="name" VALUE="$name">
Введите количество баллов за каждый правильный ответ.
Сумма баллов не обязательно должна равняться 100.
<Р> END_OF_HTML
for (1..$num) {
print qq%$_: <INPUT NAME="q$_" SIZE=3> %; if (not.$_ % 5)
{ print "<br>\n"; } } print <<END_OF_HTML;
<P>
Введите текст экзамена:<br>
<TEXTAREA NAME="test" ROWS=20 COLS=60> </textarea> <p>
<INPUT TYPE=SUBMIT VALUE="Ввести экзамен ">
<INPUT TYPE=RESET> </form></body></html>
END_OF_HTML }Эта функция динамически генерирует форму для экзамена, основываясь на параметрах, введенных в предыдущей форме. Пользователь может ввести количество баллов для каждого вопроса экзамена и полный текст самого экзамена. Выходные данные этой функции посылаются завершающей функции add3, как показано ниже:
sub add3 {
my $subject = para'm( 'subjects');
my $num = param('num');
$name = param('name') if param('name');
my $qname;
($qname = $name) =" s/'/\\'/g;
my $q1 = "insert into test (id, name, subject, num) values ( '.'-,
'$qname', $subject, $num)";
my Sin = $dbh->prepare($q1); $in->execute;
# Извлечем значение ID , которое MySQL создал для нас
my $id = $in->insertid;
my $query = "create table t$id ( id INT NOT NULL,
my $def = "insert into t$id values ( 0, ";
my $total = 0;
my @qs = grep(/^q\d+$/,param);
foreach (@qs) {
$query .= $_ . " INT,\n";
my $value = 0;
$value = param($_) if param($_);
$def .= "lvalue, ";
$total += $value; }
$query .= "total INT\n)"; $def .=-"$total)";
my $in2 = $dbh->prepare($query);
$in2->execute;
my $in3 = $dbh->prepare($def);
$in3->execute;
# Обратите внимание, что мы запоминаем экзамены в отдельных файлах.
# Это полезно при работе с mSQL, поскольку он не поддерживает BLOB.
# (Тип TEXT, поддерживаемый в mSQL 2, можно использовать,
# но это неэффективно.)
# Поскольку мы используем MySQL, можно с таким же успехом
# поместить весь экзамен в BLOB.
open(TEST,">teach/tests/$id") or die("A: $id $!");
print TEST param('test'), "\n";
close TEST;
print header, start_html('title'=>'Экзамен создан',
'BGCOLOR'=>'white');
print <<END_OF_HTML;
<Н1>Экзамен создан</h1> <P>
Экзамен создан.
<р>
<А HREF=".">Перейти</а> на домашнюю страницу 'В помощь учителю'.<br>
<А HREF="test.cgi">nepeimi</a> на главную страницу экзаменов.<br>
<А HREF="test.cgi?actio,n=add">Добавить</a> следующий экзамен.
</body></html>
END_OF_HTML
}
Листинг
13.5.
(html,
txt)
Теперь осталось ввести информацию об экзамене в базу данных. Позднее, после сдачи экзамена учащимися, для каждого учащегося будет создана запись в таблице экзамена. Но эти действия ложатся на плечи читателя, поскольку целью данного материала было лишь введение в мир Perl и MySQL.