Лекция 1. Предварительные сведения
Класс ![]() булевых функций от
булевых функций от ![]() переменных. Задание булевых функций с помощью таблиц. Булевы функции от 1-ой и 2-х
переменных. Булевы (логические) формулы и их
эквивалентность. Основные эквивалентности ( законы логики ).
Дизъюнктивные и конъюнктивные нормальные формы (ДНФ и КНФ).
Графы. Деревья.
переменных. Задание булевых функций с помощью таблиц. Булевы функции от 1-ой и 2-х
переменных. Булевы (логические) формулы и их
эквивалентность. Основные эквивалентности ( законы логики ).
Дизъюнктивные и конъюнктивные нормальные формы (ДНФ и КНФ).
Графы. Деревья.
Булевы функции от n переменных
Булевы функции1) названы в честь английского математика ХIХ века Дж. Буля, который впервые применил алгебраические методы для решения логических задач. Они образуют самый простой нетривиальный класс дискретных функций - их аргументы и значения могут принимать всего два значения. С другой стороны, этот класс достаточно богат и его функции имеют много интересных свойств. Булевы функции находят применение в логике, электротехнике, многих разделах информатики.
Обозначим через ![]() двухэлементное множество
двухэлементное множество ![]() .
Тогда
.
Тогда ![]() - это множество всех двоичных последовательностей (наборов, векторов) длины
- это множество всех двоичных последовательностей (наборов, векторов) длины ![]() . Булевой функцией от
. Булевой функцией от ![]() переменных (аргументов) называется любая функция
переменных (аргументов) называется любая функция ![]() .
Каждый из ее аргументов
.
Каждый из ее аргументов ![]() может принимать
одно из двух значений 0 или 1 и значением функции на любом
наборе из
может принимать
одно из двух значений 0 или 1 и значением функции на любом
наборе из ![]() также может быть 0 или 1. Обозначим через
также может быть 0 или 1. Обозначим через ![]() множество всех булевых функций от
множество всех булевых функций от ![]() переменных. Нетрудно
подсчитать их число:
переменных. Нетрудно
подсчитать их число: ![]() .
.
Имеется несколько различных способов представления и интерпретации булевых функций. В этом разделе мы рассмотрим табличное представление, а также представление с помощью логических формул. В лекциях 2 и 3 будет рассмотрено еще два способа представления булевых функций: логические схемы и упорядоченные бинарные диаграммы решений.
Табличное представление
Булевы функции от небольшого числа аргументов удобно представлять
с помощью таблиц. Таблица для функции ![]() имеет
имеет ![]() столбец.
В первых
столбец.
В первых ![]() столбцах указываются значения аргументов
столбцах указываются значения аргументов ![]() , а в
, а в ![]() -ом столбце значение функции на этих аргументах -
-ом столбце значение функции на этих аргументах - ![]() .
.
Наборы аргументов в строках обычно располагаются в лексикографическом порядке: ![]() существует такое
существует такое ![]() , что при
, что при ![]() , а
, а ![]() .
Если эти наборы рассматривать как записи чисел в двоичной системе счисления,
то 1-ая строка представляет число 0, 2-ая - 1, 3-я - 2, ... , а последняя
-
.
Если эти наборы рассматривать как записи чисел в двоичной системе счисления,
то 1-ая строка представляет число 0, 2-ая - 1, 3-я - 2, ... , а последняя
- ![]() .
.
При больших ![]() табличное представление становится громоздким,
например, для
функции от 10 переменных потребуется таблица с 1024 строками. Но для малых
табличное представление становится громоздким,
например, для
функции от 10 переменных потребуется таблица с 1024 строками. Но для малых ![]() оно достаточно наглядно.
оно достаточно наглядно.
Булевы функции от 1-ой и 2-х переменных
Перечислим вначале все булевы функции от 1-ой
переменной ![]() . Как мы знаем, их всего четыре.
. Как мы знаем, их всего четыре.
 - константа 0;
- константа 0; - константа 1;
- константа 1; - тождественная функция;
- тождественная функция; . Эта функция называется отрицанием
. Эта функция называется отрицанием  и обозначается
и обозначается  (используется также обозначение
(используется также обозначение  ,
а в языках программирования эта функция часто обозначается как
,
а в языках программирования эта функция часто обозначается как  ).
).
В следующей таблице представлены наиболее используемые 12 (из 16) функций от 2-х переменных.
0 0 0 1 1 0 1 1 | 0 0 0 0 | 1 1 1 1 | 0 0 1 1 | 1 1 0 0 | 0 1 0 1 | 1 0 1 0 | 0 0 0 1 | 0 1 1 1 | 1 1 0 1 | 0 1 1 0 | 1 0 0 1 | 1 1 1 0 |
Многие из этих функций часто считаются "элементарными" и имеют собственные обозначения.
 - константа 0;
- константа 0; - константа 1;
- константа 1; - функция, равная 1-му аргументу;
- функция, равная 1-му аргументу; - отрицание ;
- отрицание ; - функция, равная 2-му аргументу;
- функция, равная 2-му аргументу; - отрицание
- отрицание  ;
; - конъюнкция, читается
" и "
(используются также обозначения
- конъюнкция, читается
" и "
(используются также обозначения  ,
,  ,
,  и
и  AND ));
AND )); - дизъюнкция, читается
" или "
(используются также обозначения
- дизъюнкция, читается
" или "
(используются также обозначения  ,
,  и OR ));
и OR )); - импликация,
читается " влечет "
или "из следует "
(используются также обозначения
- импликация,
читается " влечет "
или "из следует "
(используются также обозначения  , и ( IF THEN ));
, и ( IF THEN )); - сложение по модулю 2,
читается " плюс "
(используется также обозначение
- сложение по модулю 2,
читается " плюс "
(используется также обозначение  );
); - эквивалентность,
читается " эквивалентно (равносильно) " (используется также обозначение
- эквивалентность,
читается " эквивалентно (равносильно) " (используется также обозначение  );
); - штрих Шеффера (антиконъюнкция),
иногда читается как "не и ".
- штрих Шеффера (антиконъюнкция),
иногда читается как "не и ".
В качестве элементарных функций будем также рассматривать 0-местные функции-константы 0 и 1.
Отметим, что функции ![]() и
и ![]() фактически не зависят от значений
обоих аргументов, функции
фактически не зависят от значений
обоих аргументов, функции ![]() и
и ![]() не зависят от значений аргумента
не зависят от значений аргумента ![]() , а функции
, а функции ![]() и
и ![]() не зависят от значений аргумента
не зависят от значений аргумента ![]() .
.
Определение 1.1. Функция
не зависит от аргумента
, если для любого набора значений
остальных аргументов
имеет место равенство
Такой аргумент
Функции
и
называются равными, если функцию
можно получить из функции
путем добавления и удаления фиктивных аргументов.
Например, равными являются одноместная функция ![]() и
двухместная функция
и
двухместная функция ![]() , так как вторая получается из первой добавлением фиктивного аргумента
, так как вторая получается из первой добавлением фиктивного аргумента ![]() . Мы не будем различать равные функции и, как правило, будем использовать для обозначения равных функций одно и то же имя функции. В частности, это позволяет считать, что во всяком конечном множестве функций все функции зависят от одного и того же множества переменных.
. Мы не будем различать равные функции и, как правило, будем использовать для обозначения равных функций одно и то же имя функции. В частности, это позволяет считать, что во всяком конечном множестве функций все функции зависят от одного и того же множества переменных.
Формулы
Как мы видели, табличное представление булевых функций подходит лишь для функций с небольшим числом аргументов. Формулы позволяют удобно представлять многие функции от большего числа аргументов и оперировать различными представлениями одной и той же функции.
Мы будем рассматривать формулы, построенные над множеством элементарных
функций ![]() .
Все эти функции, кроме констант, называются логическими связками или логическими операциями. При этом для 2-местных функций из этого списка будем использовать инфиксную запись, в которой имя логической связки помещается между 1-ым и 2-ым аргументами.
.
Все эти функции, кроме констант, называются логическими связками или логическими операциями. При этом для 2-местных функций из этого списка будем использовать инфиксную запись, в которой имя логической связки помещается между 1-ым и 2-ым аргументами.
Зафиксируем некоторое счетное множество
переменных ![]() .
Определим по индукции множество формул над
.
Определим по индукции множество формул над ![]() с
переменными из
с
переменными из ![]() . Одновременно будем определять числовую характеристику
. Одновременно будем определять числовую характеристику ![]() формулы
формулы ![]() , называемую ее глубиной, и множество ее подформул.
, называемую ее глубиной, и множество ее подформул.
Определение 1.2. а) Базис индукции. 0, 1 и каждая переменная
является формулой глубины 0, т.е.
. Множество ее подформул состоит из нее самой.
б) Шаг индукции. Пусть
и
- формулы,
. Тогда выражения
и
являются формулами. При этом
, а
. Множество подформул
включает саму формулу
все подформулы формул
Каждой формуле ![]() сопоставим булеву
функцию, которую эта формула задает, используя индукцию по глубине
формулы.
сопоставим булеву
функцию, которую эта формула задает, используя индукцию по глубине
формулы.
Базис индукции. Пусть ![]() . Тогда
. Тогда ![]() или
или ![]() В первом случае
В первом случае ![]() задает функцию
задает функцию ![]() , во втором - функцию, тождественно равную
константе
, во втором - функцию, тождественно равную
константе ![]() .
.
Шаг индукции. Пусть ![]() - произвольная формула глубины
- произвольная формула глубины ![]() .
Тогда
.
Тогда ![]() или
или ![]() для некоторой булевой связки
для некоторой булевой связки ![]() .
Так как
.
Так как ![]() , то формулам
, то формулам ![]() и
и ![]() соответствующие функции
соответствующие функции ![]() и
и ![]() уже
сопоставлены. Тогда формула
уже
сопоставлены. Тогда формула ![]() задает функцию
задает функцию ![]() ,
а формула
,
а формула ![]() задает функцию
задает функцию ![]() .
.
Для определения функции, задаваемой небольшой формулой, удобно использовать таблицу, строки которой сответствуют наборам значений переменных, а в столбце под знаком каждой логической связки стоят значения функции, задаваемой соответствующей подформулой.
Пример 1.1. Например, для формулы
0 0 0 0 0 1 0 1 0 0 1 1 1 0 0 1 0 1 1 1 0 1 1 1 | 0 0 0 1 0 0 0 0 1 0 0 1 1 0 1 0 1 1 0 1 1 1 0 1 0 1 1 0 1 0 1 1 1 0 1 1 1 1 0 1 | 1 1 0 1 1 0 0 1 | 0 0 0 0 1 0 1 1 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 1 0 1 1 1 1 0 1 0 1 1 1 0 0 0 1 0 0 1 1 1 1 0 0 1 |
Каждая строка этой таблицы задает процесс вычисления функции ![]() на соответствующих аргументах изнутри-наружу: вместо каждого вхождения переменной в формулу подставляется ее значение, затем в полученной формуле, состоящей из констант и булевых связок, последовательно вычисляются значения самых внутренних функций ( подформул ), для которых уже определены значения их аргументов, до тех пор, пока не будет получено значение всей формулы.
на соответствующих аргументах изнутри-наружу: вместо каждого вхождения переменной в формулу подставляется ее значение, затем в полученной формуле, состоящей из констант и булевых связок, последовательно вычисляются значения самых внутренних функций ( подформул ), для которых уже определены значения их аргументов, до тех пор, пока не будет получено значение всей формулы.
Эквивалентность булевых формул
Определение 1.3. Булевы формулы
называются эквивалентными, если соответствующие им функции
и
равны.
Обозначение: ![]() . Эквивалентные формулы называют
также тождественно равными, а выражения вида
. Эквивалентные формулы называют
также тождественно равными, а выражения вида ![]() логическими тождествами.
логическими тождествами.
Таким образом, эквивалентные формулы являются различными заданиями одной и той же булевой функции. Ниже мы приводим ряд пар эквивалентных формул (тождеств), отражающих существенные свойства логических операций и важные соотношения между различными операциями. Они часто позволяют находить для булевых функций по одним задающим их формулам более простые формулы. Большинство из приводимых тождеств имеют собственные имена. Часто их называют законами логики.
Пусть ![]() - это одна из функций
- это одна из функций ![]() .
Для этих трех функций выполнены следующие две эквивалентности
(законы ассоциативности и коммутативности).
.
Для этих трех функций выполнены следующие две эквивалентности
(законы ассоциативности и коммутативности).
(1) Ассоциативность:
Следующие две эквивалентности позволяют выразить импликацию и сложение по модулю 2 через дизъюнкцию, конъюкцию и отрицание.
| (7) |
| (8) |
Правильность этих эквивалентностей легко устанавливается прямым вычислением функций для их левых и правых частей.
Соглашения об упрощенной записи формул.
Законы ассоциативности показывают, что значения формул,
составленных из переменных и одних операций конъюнкции, не зависят
от расстановки скобок. Поэтому вместо формул ![]() и
и ![]() мы будем для упрощения писать
мы будем для упрощения писать ![]() . Аналогично, будем
использовать выражения
. Аналогично, будем
использовать выражения ![]() и
и ![]() для сокращения формул, состоящих из одних дизъюнкций или одних сложений по модулю 2, соответственно. Будем также опускать
внешние скобки в записи формулы, если ее внешней функцией является одна из
функций
для сокращения формул, состоящих из одних дизъюнкций или одних сложений по модулю 2, соответственно. Будем также опускать
внешние скобки в записи формулы, если ее внешней функцией является одна из
функций ![]() .
.
Таким образом, с использованием этих соглашений формула ![]() может быть записана как
может быть записана как ![]() .
.
Дизъюнктивные и конъюнктивные нормальные формы
Имеется ряд специальных подклассов формул, позволяющих задавать все булевы
функции.
В этом разделе мы определим два таких подкласса функций, использующих только
операции ![]() и
и ![]() .
.
Пусть ![]() - это множество
пропозициональных
переменных. Введем для каждого
- это множество
пропозициональных
переменных. Введем для каждого ![]() обозначения:
обозначения: ![]() и
и ![]() .
Формула
.
Формула ![]() (
( ![]() ),
в которой
),
в которой ![]() и все переменные разные, т.е.
и все переменные разные, т.е. ![]() при
при ![]() ,
называется элементарной конъюнкцией (элементарной дизъюнкцией).
,
называется элементарной конъюнкцией (элементарной дизъюнкцией).
Определение 1.4.Формула
называется дизъюнктивной нормальной формой (ДНФ), если она является дизъюнкцией элементарных конъюнкций, т.е. имеет вид
, где каждая формула
- это элементарная конъюнкция.
входят все
переменных из
. Аналогично, формула
называется конъюнктивной нормальной формой (КНФ), если она является конъюнкцией элементарных дизъюнкций, т.е.
, где каждая формула
- это элементарная дизъюнкция. Она является совершенной КНФ, если в каждую
входят все
Рассмотрим произвольную булеву функцию ![]() ,
зависящую
от переменных из
,
зависящую
от переменных из ![]() . Oбозначим через
. Oбозначим через ![]() множество наборов
значений переменных, на которых
множество наборов
значений переменных, на которых ![]() принимает значение 1, а через
принимает значение 1, а через ![]() множество наборов, на которых
множество наборов, на которых ![]() принимает значение 0,
т.е.
принимает значение 0,
т.е. ![]() и
и ![]() .
Определим по этим множествам две формулы:
.
Определим по этим множествам две формулы:


Теорема 1.1.
(1) Если функция
- это совершенная ДНФ, задающая функцию
(2) Если функция
- это совершенная КНФ, задающая функцию
Пример 1.2. Например, для функции ![]() , представленной
в таблице 1.1 совершенная ДНФ равна
, представленной
в таблице 1.1 совершенная ДНФ равна ![]()
![]() ,
а ее совершенная КНФ:
,
а ее совершенная КНФ: ![]() .
.
Отметим, что совершенные ДНФ и КНФ часто являются чересчур сложными и длинными
представлениями булевых функций. В нашем примере ![]() может быть задана
более простой ДНФ:
может быть задана
более простой ДНФ: ![]() .
.
Графы
Мы часто сталкиваемся с задачами, в условиях которых заданы некоторые объекты и между некоторыми их парами имеются определенные связи. Если объекты изобразить точками ( вершинами ), а связи - линиями ( ребрами ), соединяющими соответствующие пары точек, то получится рисунок, называемый графом. Приведем основные определения.
Граф (ориентированный) - это пара
, где
- конечное множество вершин (узлов, точек) графа, а
- некоторое множество пар вершин, т.е. подмножество множества
или бинарное отношение на
вершина
называется началом
, а вершина
- концом
В графе полустепень исхода вершины - это число исходящих из нее ребер, а полустепень захода - это число входящих в данную вершину ребер.
Заметим, что в графе может быть ребро вида ![]() , называемое петлей.
, называемое петлей.
Пример 1.3. На рис. 1.1 приведен пример графа ![]() .
Здесь
.
Здесь ![]() ,
В графе
,
В графе ![]() ребро
ребро ![]() является петлей,
полустепень исхода вершины
является петлей,
полустепень исхода вершины ![]() равна 2, а полустепень захода для нее
равна 1.
равна 2, а полустепень захода для нее
равна 1.
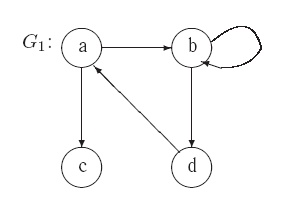
Рис. 1.1. Граф G1
Во многих приложениях с вершинами и ребрами графов связывается некоторая дополнительная информация. Обычно она представляется с помощью функций разметки вершин и ребер.
Определение 1.6.
Размеченный граф - это граф
, снабженный одной или двумя функциями разметки вида:
и
, где
и
- множества меток вершин и ребер, соответственно.
Упорядоченный граф - это размеченный граф
, упорядочены, т.е. помечены номерами
, где
- полустепень исхода
.
Упорядоченный граф с полустепенью исхода вершин
называется бинарным.
В качестве множества меток ребер ![]() часто выступают числа,
задающие "веса", "длины", "стоимости" ребер. Графы с такой разметкой
часто называют взвешенными.
часто выступают числа,
задающие "веса", "длины", "стоимости" ребер. Графы с такой разметкой
часто называют взвешенными.
Часто на одном множестве объектов определено несколько различных бинарных отношений. Для представления такой ситуации служат мультиграфы.
Определение 1.7. Мультиграф ![]() состоит из
конечного множества вершин
состоит из
конечного множества вершин ![]() и мультимножества ребер
и мультимножества ребер ![]() , состоящего из пар вершин
, состоящего из пар вершин ![]() , в которое эти пары могут входить по
нескольку раз.
, в которое эти пары могут входить по
нескольку раз.
Обычно несколько ребер, соединяющих одну и ту же пару вершин, различаются метками - именами соответствующих бинарных отношений. В лекциях 4-6 мультиграфы будут использоваться для представления диаграмм конечных автоматов.
Во многих случаях естественно не различать графы, отличающиеся лишь именами (порядком) вершин.
Определение 1.8. Изоморфизм графов. Два графа
и
называются изоморфными, если между их вершинами существует взаимно однозначное соответствие
такое, что для любой пары вершин
из
ребро
ребро
.
Для изоморфизма размеченных графов требуется также совпадение меток соответствующих вершин:
и/или ребер:
.
Многие приложения графов связаны с изучением путей между их вершинами.
Определение 1.9.
Путь в ( мульти ) графе - это последовательность ребер вида
. Этот путь ведет из начальной вершины
в конечную вершину
и имеет длину
. В этом случае будем говорить, что
, где
при
.
Путь назывется простым, если все ребра и все вершины на нем, кроме, быть может, первой и последней, различны.
Циклом в графе называется путь, в котором начальная вершина совпадает с конечной и который содержит хотя бы одно ребро. Цикл
называется простым, если в нем нет одинаковых вершин, кроме первой и последней, т.е. если все вершины
различны.
Если в графе нет циклов, то он называется ациклическим.
Следующее утверждение непосредственно следует из определений.
Лемма 1.1.Если в графе
имеется путь из вершины
Деревья
Деревья являются одним из интереснейших классов графов, используемых для представления различного рода иерахических структур.
Определение 1.10. Граф
называется деревом, если
- в нем есть одна вершина
, в которую не входят ребра ; она называется корнем дерева ;
- в каждую из остальных вершин входит ровно по одному ребру ;
- все вершины достижимы из корня.
На рисунке 2 показан пример дерева ![]()
С ориентированными деревьями связана богатая терминология, пришедшая из двух источников: ботаники и области семейных отношений.
Корень - это единственная вершина, в которую не входят ребра, листья - это вершины, из которых не выходят ребра. Путь из корня в лист называется ветвью дерева. Высота дерева - это максимальная из длин его ветвей. Глубина вершины - это длина пути из корня в эту вершину.
Для вершины ![]() , подграф дерева
, подграф дерева ![]() ,
включающий все достижимые из
,
включающий все достижимые из ![]() вершины и соединяющие их ребра
из
вершины и соединяющие их ребра
из ![]() , образует поддерево
, образует поддерево ![]() дерева
дерева ![]() с корнем
с корнем ![]() .. Высота вершины
.. Высота вершины ![]() - это высота дерева
- это высота дерева ![]() . Граф, являющийся объединением нескольких непересекающихся деревьев, называется лесом.
. Граф, являющийся объединением нескольких непересекающихся деревьев, называется лесом.
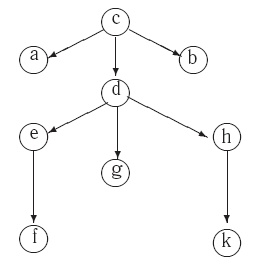
Рис. 1.2. Дерево G1
Если из вершины ![]() ведет ребро в вершину
ведет ребро в вершину ![]() ,
то
,
то ![]() называется отцом
называется отцом ![]() , а
, а ![]() - сыном
- сыном ![]() (в последнее время в ангоязычной литературе
употребляется асексульная пара терминов: родитель - ребенок). Из определения дерева
непосредственно следует,
что у каждой вершины кроме корня имеется единственный отец.
Если из вершины
(в последнее время в ангоязычной литературе
употребляется асексульная пара терминов: родитель - ребенок). Из определения дерева
непосредственно следует,
что у каждой вершины кроме корня имеется единственный отец.
Если из вершины ![]() ведет путь в вершину
ведет путь в вершину ![]() ,
то
,
то ![]() называется предком
называется предком ![]() , а
, а ![]() - потомком
- потомком ![]() . Вершины, у которых общий отец, называются братьями
или сестрами.
. Вершины, у которых общий отец, называются братьями
или сестрами.
Пример 1.4. В дереве на рис. 1.2 вершина ![]() является корнем, вершины
является корнем, вершины ![]() - листья. Путь
- листья. Путь ![]() - одна из ветвей дерева
- одна из ветвей дерева ![]() . Вершина
. Вершина ![]() является отцом (родителем) вершин
является отцом (родителем) вершин ![]() и
и ![]() , а каждая из этих вершин - ее сыном
(ребенком). Между собой вершины
, а каждая из этих вершин - ее сыном
(ребенком). Между собой вершины ![]() и
и ![]() являются
братьями (сестрами). Глубина
являются
братьями (сестрами). Глубина ![]() равна 1, а высота - 2. Высота всего дерева
равна 1, а высота - 2. Высота всего дерева ![]() равна 3.
равна 3.
Для деревьев часто удобно использовать следующее индуктивное определение.
Определение 1.11. Определим по индукции класс графов
- Граф
, с единственной вершиной
и пустым множеством ребер
является деревом (входит в
- Пусть графы
с корнями
принадлежат
- новая вершина, т.е.
. Тогда классу
, где
,
. Корнем этого дерева является вершина
- Других графов в классе
Рисунок 1.3 иллюстрирует это определение.
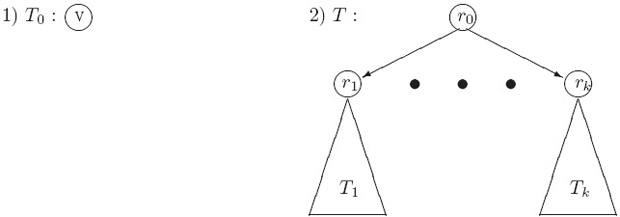
Рис. 1.3. Индуктивное определение ориентированных деревьев
Определения ориентированных деревьев 1.10 и 1.11 эквивалентны.
Выделим еще один класс графов, обобщающий деревья, ациклические графы. Два вида таких размеченных графов будут использованы далее для представления булевых функций. У этих графов может быть несколько корней - вершин, в которые не входят ребра, и в каждую вершину может входить несколько ребер, а не одно, как у деревьев.
Дерево называется бинарным или двоичным, если у каждой его внутренней вершины имеется не более двух сыновей, причем ребра, ведущие к ним помечены двумя разными метками (обычно используются метки из пар: "левый" - "правый", 0 - 1,

- и т.п.)
Бинарное дерево называется полным, если у каждой его внутренней вершины имеется два сына и все его ветви имеют одинаковую длину.
Лекция 2. Реализация булевых функций с помощью логических схем
В этой и следующей лекциях мы свяжем два основных предыдущих раздела нашего курса: булевы функции и графы. В курсе "Основы дискретной математики" мы рассматривали два основных представления булевых функций: табличное и с помощью формул общего вида или формул специального вида, в частности, дизъюнктивных или конъюнктивных нормальных форм и многочленов Жегалкина. К сожалению, эти способы не позволяют эффективно представлять функции от большого числа переменных: таблица для функции от n переменных всегда содержит 2n строк, многочлен Жегалкина может включать до 2n слагаемых (и для большинства функций по порядку столько и включает). Такие представления нельзя реализовать на практике уже для n порядка нескольких десятков. Могло показаться, что сокращенные ДНФ, которые мы научились эффективно строить с помощью метода Блейка, и минимальные ДНФ, которые можно получить, удаляя из сокращенных "лишние" конъюнкции (впрочем, хороший алгоритм для такого удаления неизвестен), дают существенно более экономные представления. булевых функций. Но в общем случае это не так. Для большинства булевых функций от n переменных минимальные ДНФ имеют экспоненциальный от n размер. В качестве примера конкретной простой функции с длинной ДНФ можно рассмотреть линейную функцию, определяющую нечетность суммы аргументов: odd(X1,X2,..., Xn)= X1 +X2 +... + Xn (см. задачу 3.1).
Те два представления булевых функций, которые мы рассматриваем в этом разделе: логические схемы ( схемы из функциональных элементов ) и упорядоченные бинарные диаграммы решений (УБДР), тоже для большинства функций имеют экспоненциальные размеры от числа переменных. Но во многих ситуациях они позволяют построить достаточно компактные представления естественно возникающих на практике булевых функций от сотен и даже тысяч агументов.
Логические схемы (схемы из функциональных элементов)
Многие элементы в современной электронике являются устройствами, преобразующими некоторые входные сигналы (данные) в выходные. Логические схемы, в отечественной литературе чаще называемые схемами из функциональных элементов, представляют собой математическую модель таких устройств, в которых временем выполнения преобразования входов в выходы можно пренебречь.
Чтобы не усложнять определение, зафиксируем конкретный базис ![]() и
определим схемы в этом базисе.
и
определим схемы в этом базисе.
Определение 2.1. Логической схемой ( схемой из функциональных элементов ) в базисе B0 называется размеченный ориентированный граф без циклов S=(V,E), в котором
- вершины, в которые не входят ребра, называются входами схемы, и каждая из них помечена некоторой переменной (разным вершинам соответствуют разные переменные);
- в каждую из остальных вершин входит одно или два ребра; вершины, в которые входит одно ребро помечены функцией
 а вершины, в которые входят по два ребра, - одной из функций
а вершины, в которые входят по два ребра, - одной из функций  или
или  Такие вершины называются функциональными элементами.
Такие вершины называются функциональными элементами.
Как и для деревьев, для ориентированных графов без циклов можно естественным образом ввести понятие глубины.
Определение 2.2. Глубина вершины ![]() в схеме S=(V,E) - это максимальная длина пути из входов S в v .
в схеме S=(V,E) - это максимальная длина пути из входов S в v .
Глубиной D(S) схемы S назовем максимальную из глубин ее вершин.
Пусть входы схемы S помечены переменными x1, ... , xn. С каждой вершиной ![]() схемы S свяжем булеву функцию fv(x1,... , xn),
реализуемую в этой вершине. Определим fv индукцией по глубине v.
схемы S свяжем булеву функцию fv(x1,... , xn),
реализуемую в этой вершине. Определим fv индукцией по глубине v.
Определение 2.3.
Базис: v имеет глубину 0. Тогда это входная вершина, которая помечена некоторой переменной xi. Положим fv(x1,... , xn) = xi.
Шаг индукции. Пусть всем вершинам w глубины <= k уже сопоставлены функции fw и пусть v - произвольная вершина глубины k+1. Тогда
если v помечена
 и в нее входит ребро (w,v) , то положим
и в нее входит ребро (w,v) , то положим
если v помечена
и в нее входят два ребра (w1,v) и (w2,v), то положим
если v помечена
 и в нее входят два ребра (w1,v) и (w2,v), то положим
и в нее входят два ребра (w1,v) и (w2,v), то положим
Нетрудно понять, что шаг индукции в этом определении корректен, так как, если в схеме S имеется ребро (w,v) и глубина вершины v равна k+1, то глубина вершины w не превосходит k и для нее fw уже определена по индукционному предположению.
Определение 2.4. Схема S реализует набор булевых функций g1, g2, ... , gm, если для каждого ![]() в схеме существует такая вершина vi, что
в схеме существует такая вершина vi, что ![]() .
.
Замечание. Определение логических схем естественным образом можно распространить и на другие базисы. При этом, однако, для вершин, помеченных несимметричными функциями ( например, импликацией), нужно явно нумеровать входящие в них ребра, указывая, каким аргументам они соответствуют.
Определение 2.5. Сложность L(S) схемы S - это число функциональных элементов в S. Сложность L(f) булевой функции f(x1, ..., xn) - это наименьшая из сложностей схем, реализующих эту функцию.
Отношения между булевыми функциями и схемами естественно приводят к двум следующим основным проблемам.
Проблема анализа: по заданной схеме из функциональных элементов и выделенному подмножеству ее выходных вершин определить булевы функции, реализуемые в этих вершинах.
Проблема синтеза: по некоторому описанию булевой функции построить схему из функциональных элементов, реализующую эту функцию. При решении проблемы синтеза для исходной функции часто стараются построить схему минимальной или почти минимальной сложности.
Пример 2.1. Рассмотрим схему S1 с тремя входными переменными x, y и z, изображенную на рис. 2.1 и решим для нее проблему анализа.
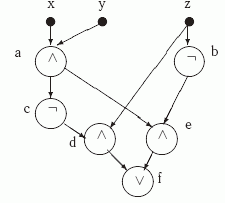
Рис. 2.1. Схема S1
В соответствии с данным выше определением вершины схемы S1 реализуют следующие функции:
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() и, наконец,
и, наконец, ![]() .
.
Глубина этой схемы D(S1)= 4, а ее сложность L(S1)=6. В то же время формула для результирующей функции ff содержит 7 функциональных знаков.
За счет чего достигнута экономия? За счет того, что функция ![]() в схеме S1 вычисляется один раз в вершине a, а в формуле приходится вычислять ее дважды.
в схеме S1 вычисляется один раз в вершине a, а в формуле приходится вычислять ее дважды.
В этом и состоит основное преимущество вычислений булевых функций схемами: каждую подформулу (подфункцию) достаточно вычислить один раз, а затем полученное значение можно использовать сколько угодно раз в качестве аргумента для других подфункций.
Схемы и линейные программы
Указанное выше свойство характерно и для программ, в которых один раз вычисленное значение выражения можно использовать неоднократно. Рассмотрим один из простейших классов программ - линейные или неветвящиеся программы. Такие программы представляют последовательности присваиваний вида:
где X, X1, ... , Xk - переменные, F - имя k -местной базисной функции.
В случае нашего базиса ![]() линейная программа состоит из присваиваний вида:
линейная программа состоит из присваиваний вида: ![]() ,
, ![]() и
и ![]() .
.
Линейная программа P с выделенными входными переменными X1, ... , Xn
порождает для каждого набора ![]() значений входных переменных естественный процесс вычисления: вначале переменным X1, ... , Xn присваиваются значения
значений входных переменных естественный процесс вычисления: вначале переменным X1, ... , Xn присваиваются значения ![]() , соответственно, а каждой из остальных
переменных присваивается значение 0. Затем последовательно выполняются присваивания
программы P, в результате чего каждая из переменных Z программы
получит заключительное значение
, соответственно, а каждой из остальных
переменных присваивается значение 0. Затем последовательно выполняются присваивания
программы P, в результате чего каждая из переменных Z программы
получит заключительное значение ![]() .
.
Определение 2.6.
Скажем, что программа P со входными переменными X1, ... , Xn
вычисляет в выходной переменной Z функцию F(X1, ..., Xn),
если для любого набора значений входов ![]() после
завершения работы
после
завершения работы ![]() .
.
Между схемами и линейными программами имеется тесная связь.
Теорема 2.1.
- По каждой логической схеме S со входами x1, ... , xn и функциональными элементами v1, ..., vm можно эффективно построить линейную программу PS со входными переменными x1, ... , xn и рабочими переменными v1, ..., vm, которая в любой переменной vi, i=1,...,m, вычисляет функцию
 .
. - По каждой линейной программе P со входными переменными X1, ... , Xn, вычисляющей в выходной переменной Z некоторую функцию F(X1, ..., Xn) можно эффективно построить логическую схему SP со входами X1, ... , Xn, в которой имеется вершина v такая, что fv((X1, ..., Xn) = F(X1, ..., Xn).
Доказательство. (1) Пусть S - схема со входами x1, ... , xn и функциональными элементами v1, ..., vm. Построим по ней линейную программу PS со входными переменными x1, ... , xn следующим образом. Упорядочим все входные и функциональные вершины S по глубине (вершины одной глубины в любом порядке): u1, ..., un+m. Программа PS будет последовательностью m присваиваний.
- Пусть вершина un+i помечена и в нее входит
- ребро из uj. Тогда в качестве i -ой команды поместим в PS присваивание
 .
. - Пусть вершина un+i помечена
 и в нее входят ребра из uj и uk. Тогда в качестве i -ой команды поместим в PS присваивание
и в нее входят ребра из uj и uk. Тогда в качестве i -ой команды поместим в PS присваивание  .
.
Упорядочение вершин по глубине гарантирует, что j <n+ i и k <n+ i. Поэтому при вычислении u_{n+i} значения аргументов уже получены и индукцией по глубине легко показать, что для каждого i=1,...,m программа PS вычисляет в переменной vi функцию ![]() .
.
Доказательство пункта (2) проведите самостоятельно (см. задачу 2.1).
Пример 2.1. Применим конструкцию теоремы к схеме S1, представленной на рис.2.1. Ее вершины можно упорядочить по глубине так: x, y, z, a, b, c, d, e, f. Порождая команды по описанным выше правилам, получим следующую линейную программу P_{S1}:

Замечание. Число команд в линейной программе PS, т.е. время ее выполнения, совпадает со сложностью L(S) схемы S. Глубина схемы D(S) также имеет смысл с точки зрения времени вычисления. Именно, D(S) - это время выполнения PS на многопроцессорной системе. Действительно, все команды, соответствующие вершинам одинаковой глубины, можно выполнять параллельно на разных процессорах, так как результаты любой из них не используются в качестве аргументов другой.
Примеры схем
Сложение по модулю 2
Рассмотрим схему S+ на рис. 2.2.

Рис. 2.2. Схема S+ для функции x+y
В соответствии с определением вершины этой схемы реализуют следующие функции:
![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Таким образом, схема S+ реализует (в вершине d ) функцию + сложения по модулю 2.
Из приведенного выше примера следует, что L(S+)=4 и L(+) <= 4.
Используя схему S+, нетрудно построить схему Sodd для реализации линейной функции-суммы n аргументов по модулю 2 odd(X1,X2,..., Xn)= X1 +X2 +... + Xn (см. рис. 2.3).
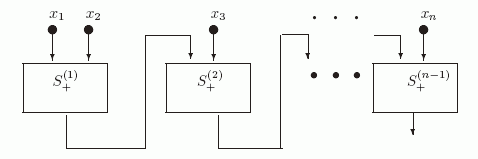
Рис. 2.3. Схема Sodd
На этой схеме прямоугольники S+(1), S+(2), ... ,S+(n) содержат копии схемы S+. При этом входами S+(1) являются переменные x1 и x2, а входами S+(i+1) являются выход схемы S+(i) и переменная xi+1. По индукции легко показать, что вершина d в S+(i) реализует функцию (x1 + x2 + ... + xi+1). Таким образом, нами установлена
Теорема 2.2. Существует схема Sodd, реализующая функцию odd(X1,X2,..., Xn)= X1 +X2 +... + Xn со сложностью L(Sodd)= 4 (n-1).
Сумматор
Сумматором порядка n называют схему, вычисляющую результат сложения
двух n -разрядных двоичных чисел ![]() и
и ![]() . Пусть
. Пусть ![]() ( здесь
( здесь ![]() - соответствующие двоичные разряды этих чисел).
- соответствующие двоичные разряды этих чисел).

Сумматор должен вычислять набор из (n+1) -ой результирующей функции:
задающих соответствующие разряды суммы c.
Обозначим через pi бит переноса из (i-1) -го разряда в i -ый. Тогда нетрудно видеть, что при i =0
c0 = a0 + b0 и ![]() ,
,
а при 1 <= i <= n-1
ci= pi + ai + bi и ![]() .
.
Старший разряд c совпадает с последним переносом: cn=pn.
Рассмотрим теперь построенную выше схему S+ как схему, вычисляющую набор из двух функций: ![]() (в вершине a ) и x+y (в вершине d ). Используя два экземпляра этой схемы S+(1) и S+(2), можно легко реализовать схему одноразрядного сумматора SUM1 (см. рис. 2.4) , которая имеет три входа ai, b_ i и pi ( 1 <= i <= n-1 ) и вычисляет ci и pi+1.
(в вершине a ) и x+y (в вершине d ). Используя два экземпляра этой схемы S+(1) и S+(2), можно легко реализовать схему одноразрядного сумматора SUM1 (см. рис. 2.4) , которая имеет три входа ai, b_ i и pi ( 1 <= i <= n-1 ) и вычисляет ci и pi+1.
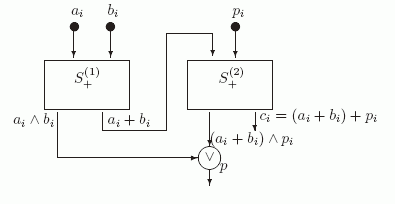
Рис. 2.4. Схема SUM1
Действительно, из построения следует, что в вершине p этой схемы вычисляется функция ![]() .
Из представленной схемы видно, что сложность одноразрядного сумматора L(SUM1)= 9.
.
Из представленной схемы видно, что сложность одноразрядного сумматора L(SUM1)= 9.
Теперь из S+ и одноразрядных сумматоров SUM1 соберем схему SUMn для n -разрядного сумматора.
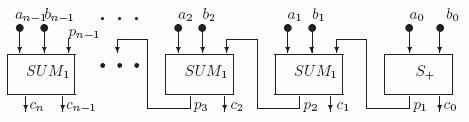
Рис. 2.5. Схема cумматора SUMn
Таким образом мы установили следующее утверждение.
Теорема 2.3.
Для каждого n >= 1 cуществует схема SUM, реализующая операцию суммирования двух n -разрядных двоичных чисел и имеющая сложность L(SUMn)= 9n -5.
Замечание Логические схемы интенсивно исследовались 50-х-70-х годах прошлого столетия. В частности, К. Шеннон и О.Б. Лупанов установили оценки сложности схем для булевых функций от n аргументов. Оказалось, что любую такую функцию можно реализовать со сложностью не большей (по порядку) 2n/n и что "почти все" они имеют не меньшую сложность. При этом до сих пор не известна ни одна последовательность "конкретных" функций fn, сложность которых по порядку превосходила бы линейную функцию.
Задачи
Задача 2.1. Докажите пункт (2) теоремы 2.1.
Задача 2.2. Докажите, что минимальная схема для сложения имеет сложность L(+) = 4.
Задача 2.3. Используя схему SUMn, постройте схему, реализующую операцию вычитания двух n -разрядных двоичных чисел: d =a - b (при условии, что a >= b ). Оцените сложность полученной схемы.
Задача 2.4. Определите глубину схем S+, Sodd, SUM1 и SUMn.
Задача 2.5. Два игрока независимо выбирают одно из четырех чисел от 0 до 3. Первый игрок выигрывает, если выбранные числа совпадают. Постройте схему, определяющую выигрыш 1-го игрока. Ее входы x1,x2 представляют число, выбранное 1-ым игроком, а y1,y2 - число, выбранное 2-ым игроком. Реализуемая функция F(x1,x2,y1,y2) равна 1 тогда и только тогда, когда x1=y1 и x2 =y2.
Задача 2.6. Постройте схему, определяющую результат голосования в комитете, состоящем из трех членов и председателя. В случае равенства голосов, голос председателя является решающим.
Задача 2.7. Пусть наборы аргументов булевой функции от трех аргументов упорядочены лексикографически, а ее значения задаются последовательностью 8 нулей и единиц. Постройте схемы, реализующие следующие функции.
- f1=(1111 1011),
- f2=(1001 1001),
- f3 =(0011 1001).
Лекция 3. Упорядоченные бинарные диаграммы решений (УБДР)
Рассматриваемый в этой лекции способ представления булевых функций с помощью специального подкласса ориентированных графов без циклов был предложен Р. Бриантом (R. Bryant) в 1986г. Его английское название - "Ordered binary decision diagram", сокращенно - OBDD. Сейчас УБДР являются одним из основных средств реализации булевых функций от большого числа переменных в задачах искусственного интеллекта, проверки правильности электронных схем, программ, протоколов и т.п.
Основные определения
Одним из предшественников УБДР являются бинарные деревья решений.
Определение 3.1. Бинарное дерево решений (БДР) - это бинарное дерево T=(V,E), все внутренние вершины которого помечены переменными, а листья - значениями 0 или 1. Из каждой внутренней вершины v выходят 2 ребра, одно помечено 0, другое - 1; вершина w0, в которую ведет ребро, помеченное 0, называется 0-сыном v, а вершина w1, в которую ведет ребро, помеченное 1, называется 1-сыном v.
Такое дерево, вершины которого помечены переменными x1, ..., xn реализует булеву
функцию f(x1, ..., xn), если для каждого набора значений переменных ![]() ветвь в дереве, соответствующая этому набору
(из вершины xi идем по ребру, помеченному
ветвь в дереве, соответствующая этому набору
(из вершины xi идем по ребру, помеченному ![]() ), завершается листом
с меткой
), завершается листом
с меткой ![]() .
.
Пример 3.1. Например, рассмотрим изображенное ниже БДР T1 (на всех рисунках предполагается, что ребра направлены сверху вниз).

Рис. 3.1.
По определению T1 реализует функцию f1(x,y,z), представленную в таблице 3.1.
| x | y | z | f(x,y,z) |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 0 |
| 1 | 1. | 1 | 0 |
Нетрудно построить ДНФ этой функции: ![]() .
.
УБДР являются модификацией БДР, в которой все листья с одной меткой представлены одной вершиной, в каждую вершину может входить несколько ребер, возможен выбор порядка появления переменных на ветвях.
Определение 3.2. Пусть зафиксирован некоторый порядок n переменных ![]() .
.
Упорядоченная бинарная диаграмма решений относительно порядка
переменных ![]() - это ориентированный граф без циклов с одним корнем, в котором
- это ориентированный граф без циклов с одним корнем, в котором
- существует лишь две вершины, из которых не выходят ребра; они помечены константами 0 и 1 и называются стоками ;
- остальные ( внутренние ) вершины помечены переменными и из каждой из них выходят два ребра, одно помечено 0, другое - 1;
- порядок, в котором переменные встречаются на любом пути из корня в сток, совместим с
 т.е. если из вершины, помеченной
т.е. если из вершины, помеченной  , есть путь в вершину, помеченную
, есть путь в вершину, помеченную  , то i < j.
, то i < j.
Как и в случае БДР, УБДР реализует булеву функцию f(x1, ..., xn), если для каждого набора значений переменных ![]() путь в диаграмме, начинающийся в корне и соответствующий этому набору
(из вершины xi идем по ребру, помеченному
путь в диаграмме, начинающийся в корне и соответствующий этому набору
(из вершины xi идем по ребру, помеченному ![]() ), завершается стоком
с меткой
), завершается стоком
с меткой ![]() .
.
Из этого определения непосредственно следует, что каждая внутренняя вершина
диаграммы v, помеченная переменной ![]() , является корнем
поддиаграммы, которая включает все вершины диаграммы,
достижимые из v, и реализует некоторую функцию
, является корнем
поддиаграммы, которая включает все вершины диаграммы,
достижимые из v, и реализует некоторую функцию ![]() от (n -k +1) переменных
от (n -k +1) переменных ![]() . При этом ее
0-сын w0 является корнем поддиаграммы, реализующей функцию
. При этом ее
0-сын w0 является корнем поддиаграммы, реализующей функцию ![]() , а
1-сын w1 - корень поддиаграммы, реализующей функцию
, а
1-сын w1 - корень поддиаграммы, реализующей функцию ![]() .
Пусть диаграмма реализует функцию
.
Пусть диаграмма реализует функцию ![]() и
и ![]() - это набор значений переменных
- это набор значений переменных ![]() , который соответствует пути из корня в вершину v (таких наборов может быть несколько).
Тогда
, который соответствует пути из корня в вершину v (таких наборов может быть несколько).
Тогда ![]() .
.
Пример 3.2. Реализуем с помощью УБДР функцию f1(x,y,z), представленную выше в примере 3.1, с помощью БДР T1 и таблицы 3.1.
Вначале зафиксируем порядок переменных: x < y < z. Объединив листья с одинаковыми метками и две z - вершины с одинаковыми потомками, получим УБДР D1, приведенную на рис.3.2.

Рис. 3.2.
Ясно, что реализация функции f1(x,y,z) с помощью УБДР D1 намного компактнее, чем с помощью БДР T1.
Под сложностью L(D) УБДР D будем понимать число внутренних вершин в D. Например, L(D1)=4. Может ли сложность диаграммы для некоторой функции зависеть от порядка переменных? Да! Рассмотрим порядок переменных y < x < z. Как показывает следующий рисунок, относительно этого порядка функцию f(x,y,z) можно реализовать УБДР D2 со сложностью L(D2)=3.

Рис. 3.3.
Сокращенные УБДР
Когда порядок переменных зафиксирован, то достаточно просто можно по произвольной УБДР для функции построить минимальную УБДР, реализующую данную функцию.
Определение 3.3. УБДР называется сокращенной, если
- из любой внутренней вершины v ее 0-сын и 1-сын не совпадают;
- нет такой пары внутренних вершин u и v, для которых поддиаграммы с корнями u и v являются изоморфными (т.е. взаимно однозначно отображаются друг на друга с сохранением всех меток).
Смысл этого определения понятен: если из некоторой вершины v оба ребра ведут в одну вершину, то такая вершина v не нужна, а если имеются две вершины с одинаковыми поддиаграммами, то их можно слить. Определим два типа эквивалентных преобразований УБДР.
Правило сокращения: если 0-сын и 1-сын вершины v совпадают и равны w, то удалить v, перенаправив все входящие в нее ребра в вершину w .
Правило слияния: если вершины v и w помечены одной переменной и имеют одинаковых 0-сыновей и 1-сыновей, то удалить вершину v, перенаправив все входящие в нее ребра в вершину w .
На следующем рисунке показаны преобразования по этим правилам.
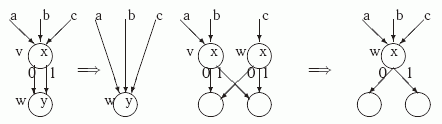
Рис. 3.4. Правило сокращения Правило слияния
Следующая простая теорема показывает, что применимость этих двух правил является критерием несокращаемости УБДР.
Теорема 3.1. УБДР D является сокращенной тогда и только тогда, когда к ней не применимо ни правило слияния, ни правило сокращения.
Доказательство. ![]() Если к D применимо правило сокращения, то не выполнено условие (1) из определения сокращенной УБДР, а если к D применимо правило слияния, то поддиаграммы с корнями v и w являются изоморфными и не выполнено условие (2).
Если к D применимо правило сокращения, то не выполнено условие (1) из определения сокращенной УБДР, а если к D применимо правило слияния, то поддиаграммы с корнями v и w являются изоморфными и не выполнено условие (2).
![]() Пусть к УБДР D нельзя применить правило сокращения. Тогда в ней нет вершин с совпадающими 0- и 1-сыновьями и выполнено условие (1). Пусть к УБДР D нельзя применить правило слияния. Тогда из следующей леммы можно заключить, что в D нет пары вершин, поддиаграммы которых являются изоморфными, и следовательно, выполнено условие (2).
Пусть к УБДР D нельзя применить правило сокращения. Тогда в ней нет вершин с совпадающими 0- и 1-сыновьями и выполнено условие (1). Пусть к УБДР D нельзя применить правило слияния. Тогда из следующей леммы можно заключить, что в D нет пары вершин, поддиаграммы которых являются изоморфными, и следовательно, выполнено условие (2).
Лемма 3.2. Если в D есть такая пара вершин u и v, для которых поддиаграммы с корнями v и w являются изоморфными, то в D имеется и пара вершин v', w' с попарно одинаковыми 0- и 1-сыновьями и, следовательно, к D применимо правило слияния.
Доказательство леммы проведем индукцией по высоте h поддиаграмм Dv и Dw с корнями v и w, соответственно (так как Dv и Dw изоморфны, то их высоты, т.е. длины максимальных путей из корней до стоков, одинаковы).
Базис: h=1. В этом случае 0- и 1-сыновьями вершин v и w являются одинаковые стоки.
Шаг индукции. Предположим, что утверждение верно для h=k. Пусть Dv и Dw -
поддиаграммы высоты h=k+1. Пусть v0 и w0 - это 0-сыновья вершин v и w,
соответственно, а v1 и w1 - их 1-сыновья. Если v0=w0 и v1=w1, то в качестве v', w' подходят сами v и w. Если же для некоторого ![]()
![]() , то
поддиаграммы
, то
поддиаграммы ![]() и
и ![]() с корнями vi и wi являются изоморфными и
имеют высоту k. Тогда по предположению индукции утверждение леммы выполнено.
с корнями vi и wi являются изоморфными и
имеют высоту k. Тогда по предположению индукции утверждение леммы выполнено.
Из теоремы 3.1 непосредственно следует, что, применяя к произвольной УБДР правила сокращения и слияния, мы, в конце концов, получим сокращенную УБДР. Чтобы эта процедура работала эффективо, нужно применять правила в порядке "снизу-вверх". Мы опишем этот алгоритм для "естественного" порядка переменных: x1, ... , xn.
Алгоритм СОКРАЩЕНИЕ-УБДР
Вход: УБДР D для функции f(x1, ... , xn).
Выход: сокращенная УБДР для ![]() .
.
1. Занумеруем множество вершин D: V = {v1, v2, ..., vm};
2. ДЛЯ i = n, n-1, ..., 1 ВЫПОЛНЯТЬ
3. {
4. V(i) = { v | v помечена переменной xi };
/* Применение правила сокращения:
5. ДЛЯ КАЖДОЙ v из V(i) ВЫПОЛНЯТЬ
6. ЕСЛИ (0-сын v) = (1-сын v) = w ТО}
7. { удалить v из V(i);
8. перенаправить все ребра, входящие в v, в вершину w;
9. удалить v из D }
10. ИНАЧЕ key(v) = (j, k), где vj - это 0-сын v, а vk - 1-сын v;
/* Применение правила слияния:
11. Отсортировать V(i) по ключу key(v):
пусть в этом порядке V(i)={ u1, ..., uki};
12. тек_ключ=(0, 0);
13. ДЛЯ j = 1, ..., ki ВЫПОЛНЯТЬ
14. ЕСЛИ тек_ключ=key(uj) ТО
15. { удалить uj из V(i);
16. перенаправить все ребра, входящие в uj, в тек_вершина;
17. удалить uj из D }
18. ИНАЧЕ} {тек_вершина= uj; тек_ключ=key(uj)}
19. }Пример 3.1. Рассмотрим пример применения алгоритма СОКРАЩЕНИЕ-УБДР, показанный на следующем рисунке.
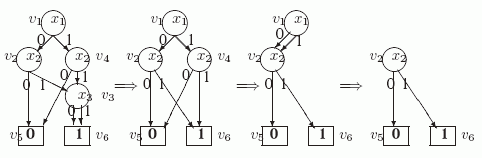
Рис. 3.5. Применение алгоритма СОКРАЩЕНИЕ-УБДР
На исходной УБДР слева все вершины уже занумерованы. Стрелки разделяют УБДР, получаемые после очередных итераций основного цикла в строках 2 - 19. При первом исполнении цикла i=3, V(3) = {v3}. Для вершины v3 условие в строке 6 выполнено ( w= v6 ), поэтому применяется правило сокращения и эта вершина удаляется, а ее входы направляются в v6. При следующем исполнении цикла i=2, V(2) = {v2, v4}. После цикла в строках 5 - 10 key(v2)= {5, 6} и key(v4)= {5, 6}. После сортировки u1=v2, u2 = v4. В цикле в строках 13-18 для u2 выполнено условие в строке 14. Поэтому применяется правило слияния и вершина v4 удаляется, а ее вход передаeтся вершине v2. При третьем исполнении цикла i=1, V(1) = {v1}. Для вершины v1 условие в строке 6 выполнено ( w= v2 ), поэтому применяется правило сокращения и эта вершина удаляется.
Оказывается, что построенная алгоритмом УБДР является единственной и минимальной для заданного порядка.
Теорема 3.2.
- Алгоритм СОКРАЩЕНИЕ-УБДР строит сокращенную УБДР, эквивалентную исходной УБДР D.
- Эта сокращенная УБДР является при данном порядке переменных единственной (с точностью до изоморфизма) и минимальной.
Доказательство первого пункта непосредственно следует из выполнения критерия теоремы 3.1, так как к результирующей диаграмме никакое правило сокращения или слияния неприменимо.
Доказательство второго пункта основано на следующем индуктивном утверждении:
Лемма 3.1.
После выполнения i -ой итерации алгоритма в полученной диаграмме для каждой подфункции ![]() при k=1,2,..., i-1 ), существенно зависящей от xi, имеется ровно одна вершина - корень поддиаграммы, реализующей эту подфункцию.
при k=1,2,..., i-1 ), существенно зависящей от xi, имеется ровно одна вершина - корень поддиаграммы, реализующей эту подфункцию.
Напомним, что функция f(x1, x2, ..., xi, ..., xn) существенно зависит от переменной xi, если существуют такие два набора значений аргументов ![]() и
и ![]() , различающиеся только значением xi, на которых f принимает разные значения:
, различающиеся только значением xi, на которых f принимает разные значения: ![]() ,
, ![]() ,
, ![]()
Доказательство этой леммы и вывод из нее утверждения 2 теоремы 3.2 оставляем в качестве задач 3.2 и 3.3.
Построение сокращенных УБДР по формулам
Алгоритм СОКРАЩЕНИЕ-УБДР позволяет построить сокращенную УБДР для функции f, по любой другой ее УБДР. Но как построить УБДР, если f задана, например, с помощью формулы? Можно, конечно, попытаться построить полное бинарное дерево решений, объединить в нем все листья с меткой 0 в один сток, а листья с меткой 1 - в другой. Затем применить к получившейся УБДР алгоритм СОКРАЩЕНИЕ-УБДР. Но этот подход годится только для функций от небольшого числа переменных, так как полное БДР для f(x1, ..., xn) будет содержать 2n листьев.
Другой подход связан с построением УБДР "сверху-вниз". Объясним его для естественного порядка переменных: x1< x2 < ... < xn.
Начнем построение с корня, помеченного x1. Рассмотрим две остаточные
функции: f0(x1, ..., xn)=f(0, x2, ..., xn) и f1(x2, ..., xn)=f(1, x2, ..., xn). Если они одинаковы, то f не
зависит от x1 и тогда изменим метку у корня на x2. Если обе
функции f0 и f1 существенно зависят от x2, то для каждой из
них добавляем вершину, помеченную x2, и далее реализуем по индукции.
Если ![]() не зависит от переменных x2,... , xj, но зависит
существенно от xj+1, то добавляем вершину, помеченную xj+1,
и проводим в нее ребро с меткой k из вершины, соответствующей f .
Пусть для некоторого i уже построены вершины для всех различных
остаточных функций вида
не зависит от переменных x2,... , xj, но зависит
существенно от xj+1, то добавляем вершину, помеченную xj+1,
и проводим в нее ребро с меткой k из вершины, соответствующей f .
Пусть для некоторого i уже построены вершины для всех различных
остаточных функций вида ![]() ,
существенно зависящих от xi. Для каждой из них получим две остаточные функции
,
существенно зависящих от xi. Для каждой из них получим две остаточные функции ![]() и
и ![]() .
Затем выберем из множества этих функций разные, для каждой из них добавим в диаграмму
вершину, помеченную xi+1, и проведем в них соответствующие ребра из вершин, помеченных x_{i}.
Продолжая построение, дойдем до функций от 1-ой переменной xn и до констант,
для которых минимальные реализации очевидны.
.
Затем выберем из множества этих функций разные, для каждой из них добавим в диаграмму
вершину, помеченную xi+1, и проведем в них соответствующие ребра из вершин, помеченных x_{i}.
Продолжая построение, дойдем до функций от 1-ой переменной xn и до констант,
для которых минимальные реализации очевидны.
Пример 3.2. Рассмотрим, например, функцию f(x1, x2, x3, x4), заданную формулой ![]()
![]() ,
и построим для нее УБДР относительно порядка x1 < x2 < x3 <x4,
используя описанную выше процедуру.
,
и построим для нее УБДР относительно порядка x1 < x2 < x3 <x4,
используя описанную выше процедуру.
Вначале создадим корень, помеченный x1, и рассмотрим остаточные функции, получающиеся при x1=0 и x1 =1. Имеем
Они разные и обе существенно зависят от x2. Поэтому добавим для каждой из них вершину, помеченную x2. Затем для каждой из них определим остаточные функции, получающиеся при x2=0 и x2 =1. Получим

Так как f00=f10, а f01 и f11 от x3 не зависят, то нам потребуется только одна
вершина, помеченая x3. Она будет представлять функцию ![]() .
При x3=0 она превращается в x4, а при x3=1 равна константе 1.
В результате получается УБДР Df, показанная на рис.3.6.
.
При x3=0 она превращается в x4, а при x3=1 равна константе 1.
В результате получается УБДР Df, показанная на рис.3.6.

Рис. 3.6.
Задачи
Задача 3.1. Докажите, что совершенная, сокращенная и минимальная ДНФ функции odd(X1,X2,..., Xn) совпадают и состоят из 2n-1 элементарных конъюнкций длины n.
Задача 3.2. Докажите лемму 3.2 возвратной индукцией по i.
Задача 3.3. Используя лемму 3.2, докажите утверждение 2 теоремы 3.2.
Задача 3.4. Постройте минимальные УБДР для двуместных функций: ![]() .
.
Задача 3.5. Постройте минимальные УБДР для функции
относительно двух упорядочений переменных:
- x1 < x2 < x3 < x4 < x5 < x6 и
- x1 < x3 < x5 < x2 < x4 < x6.
Задача 3.6. Пороговая функция Tnk от n переменных с порогом k выдает 1, если во входном наборе имеется не менее k единиц: ![]() .
.
- Постройте минимальные УБДР для пороговых функций T32, T42, T53.
- Зависит ли сложность минимальной УБДР для пороговых функций от порядка переменных?
- Оцените сложность минимальной УБДР для пороговой функции Tnk.
Задача 3.7. Выберите подходящий порядок переменных и постройте для него минимальные УБДР, реализующие функции из задач 12.5 и 12.6.
Задача 3.8. Как мы видели, логические схемы естественным образом реализуются в виде неветвящихся программ. Наоборот, для деревьев решений и УБДР естественным программным представлением являются ветвящиеся программы, включающие лишь условные операторы вида if ... then ... else ... с тестами вида "x = 0?" и "x = 1?" (они соответствуют внутренним вершинам диаграмм) и операторы присвоения значения 0 или 1 результату (они соответствуют вершинам- стокам ).
Напишите ветвящиеся программы, вычисляющие функции, представляемые УБДР D2 на рис. 3.3 и Df на рис.3.6.
Лекция 4. Конечные автоматы: преобразователи и распознаватели
Переработка информации с помощью конечных автоматов
Конечные автоматы являются математической моделью устройств, перерабатывающих дискретную входную информацию в режиме "реального времени", т.е. в темпе ее поступления.
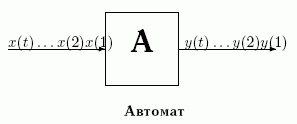
Автомат
На такие устройства в последовательные дискретные моменты времени 1,2, ..., t, t+1,... поступают входные сигналы x(1),x(2), ..., x(t),x(t+1),... и в ответ на них автомат A вырабатывает выходные сигналы y(1) y(2), ..., y(t), y(t+1),.... Конечные автоматы характеризуются двумя особенностями.
- Отсутствие предвосхищения: выходной сигнал y(t), выдаваемый автоматом в момент t, зависит лишь от полученных к этому времени входов x(1),x(2), ..., x(t), т.е. автомат не может предвосхитить будущие входы и заранее на них отреагировать. Таким образом, имеется некоторая функция выходов
 , определяющая очередной выход по предшествующему входу.
, определяющая очередной выход по предшествующему входу. - Конечная память: в каждый момент t информация в автомате о полученном к этому моменту входе x(1),x(2), ..., x(t) конечна. Это свойство удобно интерпретировать следующим образом: автомат имеет конечное множество состояний Q и в каждый момент находится в одном из этих состояний. При получении очередного входа состояние может измениться. Таким образом, состояние
 , в котором находится автомат после получения входной последовательности x(1),x(2), ..., x(t), и представляет информацию об этой последовательности, используемую в дальнейшей работе автомата при определении следующего состояния и выхода.
, в котором находится автомат после получения входной последовательности x(1),x(2), ..., x(t), и представляет информацию об этой последовательности, используемую в дальнейшей работе автомата при определении следующего состояния и выхода.
Наше обсуждение приводит к следующему определению конечного автомата с выходом.
Определение 4.1. Конечный автомат - преобразователь - это система вида
включающая следующие компоненты:
 - конечное множество - входной алфавит ;
- конечное множество - входной алфавит ; - конечное множество - выходной алфавит ;
- конечное множество - выходной алфавит ;- Q={q0, ... , qn-1} (n >= 1) - конечное множество - алфавит внутренних состояний;
 - начальное состояние автомата;
- начальное состояние автомата; - функция переходов,
- функция переходов,  - это состояние, в которое переходит автомат из состояния q, когда получает на вход символ a ;
- это состояние, в которое переходит автомат из состояния q, когда получает на вход символ a ; - функция выходов,
- функция выходов,  - это символ из
- это символ из  , который выдает на выход автомат в состоянии q, когда получает на вход символ a.
, который выдает на выход автомат в состоянии q, когда получает на вход символ a.
Иногда пару функций ![]() называют программой автомата A и задают как
список из m n команд вида
называют программой автомата A и задают как
список из m n команд вида ![]() .
.
Другой удобный способ задания функций ![]() и
и ![]() - табличный.
Каждая из них определяется таблицей
(матрицей) размера n x m, строки которой соответствуют состояниям из Q,
а столбцы - символам из входного алфавита
- табличный.
Каждая из них определяется таблицей
(матрицей) размера n x m, строки которой соответствуют состояниям из Q,
а столбцы - символам из входного алфавита ![]() . В первой из них на пересечении строки qi и столбца aj стоит состояние
. В первой из них на пересечении строки qi и столбца aj стоит состояние ![]() , а во второй - выходной символ
, а во второй - выходной символ ![]() .
.
Еще один способ представления конечного автомата основан на использовании ориентированных размеченных графов.
Определение 4.2. Диаграмма автомата ![]() - это
ориентированный (мульти) граф DA=(Q, E) с помеченными ребрами, в котором выделена вершина- начальное
состояние q0 и из каждой вершины
- это
ориентированный (мульти) граф DA=(Q, E) с помеченными ребрами, в котором выделена вершина- начальное
состояние q0 и из каждой вершины ![]() выходит
выходит ![]() ребер, помеченных парами символов
ребер, помеченных парами символов ![]() .
Таким образом, для каждой
.
Таким образом, для каждой ![]() и каждого символа
и каждого символа ![]() имеется единственное ребро
с меткой
имеется единственное ребро
с меткой ![]() из q в вершину
из q в вершину ![]() .
.
Как автомат A перерабатывает входное слово x1x2 ... xt? Он начинает работу
в состоянии q(0)=q0. Затем, получив (прочитав) входной символ x1, переходит в состояние ![]() и выдает символ
и выдает символ ![]() . Далее, получив x2 A
переходит в состояние
. Далее, получив x2 A
переходит в состояние ![]() и выдает символ
и выдает символ ![]() и т.д. Таким образом, работа автомата,
характеризуется последовательностью проходимых им состояний q(0), q(1), ... , q(t), ... и
последовательностью выходных символов y(1), ... , y(t), .... Они определяются следующими
реккурентными соотношениями:
и т.д. Таким образом, работа автомата,
характеризуется последовательностью проходимых им состояний q(0), q(1), ... , q(t), ... и
последовательностью выходных символов y(1), ... , y(t), .... Они определяются следующими
реккурентными соотношениями:

Рассмотрим несколько примеров автоматов-преобразователей.
Пример 4.1. Сумматор последовательного действия
Мы уже строили схему из функциональных элементов SUMn, реализующую для фиксированного n суммирование двух n -разрядных двоичных чисел. Построим теперь конечный автомат SUM, который сможет складывать два двоичных числа произвольной разрядности. На вход этого автомата будут последовательно подаваться пары x(i)= (x1(i),x2(i)) соответствующих i -ых (1<= i <= r) разрядов двух двоичных чисел x1=x1(r) ... x1(2) x1(1) и x2=x2(r) ... x2(2) x2(1), а признаком завершения чисел будет служить символ x(r+1)= * (если одно из слагаемых короче другого, то будем считать, что недостающие разряды - нули). Выходом автомата должна быть последовательность (r+1) двоичных разрядов суммы y = x1 + x2:

Таким образом, входной алфавит автомата: ![]() ,
а выходной алфавит:
,
а выходной алфавит: ![]() .
Что нужно знать автомату SUM о первых i разрядах x1 и x2,
чтобы получив их (i+1) -ые разряды (x1(i+1),x2(i+1)), верно определить
выход y(i+1)? Ясно, что для этого достаточно знать, был ли перенос в i -ый
разряд. Поэтому можно зафиксировать множество состояний Q = {q0, q1},
в котором q0 означает, что переноса не было, а q1 - что перенос был.
Теперь легко построить таблицы, представляющие функции переходов и выходов автомата SUM.
.
Что нужно знать автомату SUM о первых i разрядах x1 и x2,
чтобы получив их (i+1) -ые разряды (x1(i+1),x2(i+1)), верно определить
выход y(i+1)? Ясно, что для этого достаточно знать, был ли перенос в i -ый
разряд. Поэтому можно зафиксировать множество состояний Q = {q0, q1},
в котором q0 означает, что переноса не было, а q1 - что перенос был.
Теперь легко построить таблицы, представляющие функции переходов и выходов автомата SUM.
Заметим, что после получения символа * автомат SUM переходит в начальное состояние q0 и готов выполнять сложение следующей пары чисел.
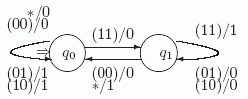
Рис. 4.1. Диаграмма автомата SUM
На диаграмме автомата у вершины q0 четыре петли, а у вершины q1 - три, объединены в одну с четырьмя и тремя метками, соответственно. Точно так же слиты два ребра из q1 в q0. Стрелкой указано начальное состояние.
Конечные автоматы - распознаватели
Детерминированные конечные автоматы (ДКА) и автоматные языки
Пусть ![]() - это алфавит, который состоит из конечного множества элементов, называемых символами (буквами).
- это алфавит, который состоит из конечного множества элементов, называемых символами (буквами).
Слово в алфавите ![]() - это конечная последовательность символов этого алфавита:
- это конечная последовательность символов этого алфавита: ![]() при i=1, ..., n .
Число букв в этой последовательности называется длиной слова
и обозначается |w|. Имеется одно специальное "пустое" слово длины 0.
Будем обозначать его через
при i=1, ..., n .
Число букв в этой последовательности называется длиной слова
и обозначается |w|. Имеется одно специальное "пустое" слово длины 0.
Будем обозначать его через ![]() На словах определена операция приписывания одного слова после другого,
называемая конкатенацией: если слово w =w1... wn, а слово v =v1... vm, то их конкатенация
На словах определена операция приписывания одного слова после другого,
называемая конкатенацией: если слово w =w1... wn, а слово v =v1... vm, то их конкатенация ![]() - это слово w1... wnv1... vm длины n+m. Обычно
знак конкатенации
- это слово w1... wnv1... vm длины n+m. Обычно
знак конкатенации ![]() будем опускать и писать просто w v
(по аналогии со знаком умножения в алгебре).
Пустое слово - это единственное слово такое, что для любого слова w
справедливо равенство
будем опускать и писать просто w v
(по аналогии со знаком умножения в алгебре).
Пустое слово - это единственное слово такое, что для любого слова w
справедливо равенство ![]() . Операция конкатенации ассоциативна:
для любых трех слов w, v и u, очевидно, имеет место
равенство: (w v)u = w(v u). Поэтому скобки при записи конкатенации нескольких слов будем опускать. Для представления нескольких конкатенаций одного и того же слова используют сокращенную
"степенную форму" записи:
. Операция конкатенации ассоциативна:
для любых трех слов w, v и u, очевидно, имеет место
равенство: (w v)u = w(v u). Поэтому скобки при записи конкатенации нескольких слов будем опускать. Для представления нескольких конкатенаций одного и того же слова используют сокращенную
"степенную форму" записи: ![]() .
Например, a3b4c2 - это сокращенная запись слова aaabbbbcc.
.
Например, a3b4c2 - это сокращенная запись слова aaabbbbcc.
Языком в алфавите ![]() называется произвольное множество слов
этого алфавита. Язык, включающий все слова в алфавите
называется произвольное множество слов
этого алфавита. Язык, включающий все слова в алфавите ![]() ( в том числе
и пустое слово
( в том числе
и пустое слово ![]() ), будем обозначать через
), будем обозначать через ![]() .
.
Конечные автоматы часто используются для определения тех или иных свойств слов,
т.е. для распознавания языков: автомат, распознающий некоторый язык L должен
по произвольному слову w ответить на вопрос " ![]() ? ". Для решения такой
задачи функция выходов может быть заменена на проверку того, в какое состояние
переходит автомат после получения входного слова w - "принимающее" или
"отвергающее".
? ". Для решения такой
задачи функция выходов может быть заменена на проверку того, в какое состояние
переходит автомат после получения входного слова w - "принимающее" или
"отвергающее".
Определение 4.3. Детерминированный конечный автомат (ДКА) - распознаватель - это система вида
включающая следующие компоненты:
 - конечное множество - входной алфавит ;
- конечное множество - входной алфавит ;- Q={q0, ... , qn-1} (n >= 1) - конечное множество - алфавит внутренних состояний;
- - начальное состояние автомата;
 - множество принимающих (допускающих, заключительных) состояний ;
- множество принимающих (допускающих, заключительных) состояний ; - функция переходов,
- функция переходов,- - это состояние, в которое переходит автомат из состояния q, когда получает на вход символ a.
Функцию ![]() называют программой автомата A и задают как список из m n команд вида
называют программой автомата A и задают как список из m n команд вида ![]() .
.
Удобно также задавать функцию ![]() с помощью описанной выше таблицы
размера n x m, строки которой соответствуют состояниям из Q,
а столбцы - символам из входного алфавита
с помощью описанной выше таблицы
размера n x m, строки которой соответствуют состояниям из Q,
а столбцы - символам из входного алфавита ![]() и в которой на пересечении строки qi и столбца aj стоит состояние
и в которой на пересечении строки qi и столбца aj стоит состояние ![]() .
.
Как и автоматы-преобразователи, автоматы-распознаватели можно представлять с помощью размеченных ориентированных графов, называемых диаграммами.
Определение 4.4. Диаграмма ДКА ![]() - это
ориентированный (мульти)граф DA=(Q, E) с помеченными ребрами,
в котором выделена вершина- начальное
состояние q0 из каждой вершины
- это
ориентированный (мульти)граф DA=(Q, E) с помеченными ребрами,
в котором выделена вершина- начальное
состояние q0 из каждой вершины ![]() выходит
выходит ![]() ребер, помеченных символами
ребер, помеченных символами ![]() так, что для каждой
так, что для каждой ![]() и каждого символа
и каждого символа ![]() имеется единственное ребро
из q в вершину
имеется единственное ребро
из q в вершину ![]() с меткой a .
с меткой a .
Скажем, что представленный последовательностью ребер путь p=e1e2 ... et в диаграмме несет слово w=w1w2 ... wt, если wi - это метка ребра ei (1 >= i >= t). Если q - начальная вершина (состояние) этого пути, а q' - его заключительная вершина, то будем говорить, что слово w переводит q в q'.
Работа конечного автомата-распознавателя состоит в чтении входного слова и изменению состояний в зависимости от его символов.
Определение 4.5. Назовем конфигурацией ДКА ![]() произвольную пару вида (q, w), в которой
произвольную пару вида (q, w), в которой ![]() и
и ![]() .
.
На множестве конфигураций введем отношение перехода за один шаг ![]() :
:
Если ![]() , то положим для каждого
, то положим для каждого ![]() :
: ![]()
![]()
![]() .
.
Через ![]() обозначим рефлексивное и транзитивное замыкание
обозначим рефлексивное и транзитивное замыкание ![]() .
.
Содержательно, ![]() означает, что автомат A, начав работу в состоянии q на слове w=w1 ... wl, через некоторое конечное число шагов 0 <= k <= l
прочтет первые k символов слова w и перейдет
в состояние q', а w' =wk+1 ... wl - это непрочтенный остаток слова w.
означает, что автомат A, начав работу в состоянии q на слове w=w1 ... wl, через некоторое конечное число шагов 0 <= k <= l
прочтет первые k символов слова w и перейдет
в состояние q', а w' =wk+1 ... wl - это непрочтенный остаток слова w.
Определение 4.6.
ДКА A распознает (допускает, принимает) слово w, если для некоторого ![]()
![]() т.е. после обработки слова w
автомат переходит в принимающее состояние.
т.е. после обработки слова w
автомат переходит в принимающее состояние.
Язык LA, распознаваемый (допускаемый, принимаемый) автоматом A, состоит из всех слов, распознаваемых этим автоматом:
Язык называется конечно автоматным, если он распознается некоторым ДКА.
Из этого определения, в частности, следует, что ![]() . Один и тот же язык может распознаваться разными автоматами.
. Один и тот же язык может распознаваться разными автоматами.
Определение 4.7. Автоматы A и B называются эквивалентными, если совпадают распознаваемые ими языки, т.е. LA = LB .
Определение распознавания слова и языка можно легко перевести на язык диаграмм.
Лемма 4.3. Автомат A распознает (допускает, принимает) слово w, если для некоторого ![]() в диаграмме DA имеется путь из q0 в q, который несет слово w, т.е. w переводит q0 в заключительное состояние q.
в диаграмме DA имеется путь из q0 в q, который несет слово w, т.е. w переводит q0 в заключительное состояние q.
Доказательство можно провести индукцией по длине слова w (см. задачу 4.3).
Tаким образом, язык LA, распознаваемый автоматом A, состоит из всех слов, которые переводят в его диаграмме DA начальное состояние q0 в заключительные состояния из F.
Наша цель теперь состоит в изучении класса конечно автоматных языков.
Во многих случаях удается доказать, что язык L конечно автоматный, непосредственно построив распознающий его автомат. Для этого нужно постараться разбить множество всех входных слов на конечное число классов "однородных", "эквивалентных" слов, т.е. слов, получение которых на входе одинаково влияет на возможность их продолжения до слов распознавемого языка. Затем для каждого такого класса создать состояние автомата и определить переходы между этими состояниями. Часто полезно бывает выделить одно состояние для представления "ошибочных" слов, для которых ни они сами, ни любые их продолжения не входят в язык.
Пример 4.4. Рассмотрим язык L, состоящий из всех слов в алфавите ![]() ,
которые начинаются на aa и содержат нечетное число символов b.
,
которые начинаются на aa и содержат нечетное число символов b.
Для выделения слов, начинающихся на aa, создадим начальное состояние q0, которое первый символ a будет переводить в состояние q1, а второй символ a будет переводить q1 в состояние q2. Ясно, что все слова, которые начинаются на ab, ba, bb, сами не входят в язык L и все их продолжения также ошибочны. Заведем для них "ошибочное" состояние q!. Остальные слова естественно разбиваются на два класса: те, в которых четное число символов b, и те, в которых число таких символов нечетно (они и принадлежат L ).
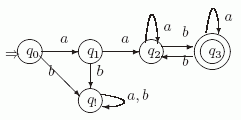
Рис. 4.2. Диаграмма автомата A
Так как после получения aa число b четно, то для представления слов первого
класса будем использовать состояние q2, а для представления слов второго - создадим состояние q3, которое и будет заключительным. В результате получаем автомат, диаграмма которого
представлена на рис. 4.2. (Мы отмечаем на рисунках диаграмм начальное состояние стрелкой ![]() а заключительные состояния - двумя окружностями).
а заключительные состояния - двумя окружностями).
Проверим работу этого автомата, например, на входном слове w=aaababa. При его чтении порождается следующая последовательность конфигураций:
Заключительное состояние этого вычисления q2 не является заключительным.
Следовательно, ![]() . Если же мы рассмотрим в качестве входа слово w1= w b= aaababab, то, продолжив на один шаг приведенное выше вычисление,
получим, что
. Если же мы рассмотрим в качестве входа слово w1= w b= aaababab, то, продолжив на один шаг приведенное выше вычисление,
получим, что ![]() . Следовательно,
. Следовательно, ![]() .
.
Мы проверили, что на двух входах автомат A работает верно. Как установить, что он построен корректно, т.е. верно работает на всех входных словах и распознает L? Типичная схема доказательства правильности конечного автомата такова:
- определить (описать) для каждого состояния язык L(q), который состоит из слов, переводящих начальное состояние q0 в q ;
- доказать, что это определение правильное, используя индукцию по длине входного слова ;
- показать, что
 .
.
Применим эту схему к доказательству правильности, построенного выше автомата A. Языки, связанные с состояниями этого автомата, фактически, уже были определены при его построении. Уточним их:

Правильность определения языков L(q0), L(q1) и L(q!) следует непосредственно из определения A. Самое короткое слово, переводящее q0 в q2 - aa, и оно принадлежит L(q2). Аналогично, самое короткое слово, переводящее q0 в q3 - aab, и оно принадлежит L(q3). Предположим теперь, что для каждого слова w длины <= n выполнено условие (*):
w переводит начальное состояние q0 в ![]() .
.
Покажем, что оно будет выполнено и для всех слов длины n +1.
Пусть |w|=n+1. Тогда ![]() , где
, где ![]() .
Так как |w'|=n, то для w' выполнено условие (*).
Поэтому, если w' переводит q0 в q2, то это слово
начинается с aa и содержит четное число b. При
.
Так как |w'|=n, то для w' выполнено условие (*).
Поэтому, если w' переводит q0 в q2, то это слово
начинается с aa и содержит четное число b. При ![]() слово w переводит q0 в q2 и также начинается с aa и содержит четное число b,
а при
слово w переводит q0 в q2 и также начинается с aa и содержит четное число b,
а при ![]() слово w переводит q0 в q3,
начинается с aa и содержит нечетное число b, т.е. принадлежит L.
слово w переводит q0 в q3,
начинается с aa и содержит нечетное число b, т.е. принадлежит L.
Аналогично, если w' переводит q0 в q3, то это слово
начинается с aa и содержит нечетное число b. При ![]() слово w также переводит q0 в q3 и также начинается с aa и содержит нечетное число b,
а при
слово w также переводит q0 в q3 и также начинается с aa и содержит нечетное число b,
а при ![]() w переводит q0 в q2, оно
начинается с aa и содержит четное число b.
Обратно, если
w переводит q0 в q2, оно
начинается с aa и содержит четное число b.
Обратно, если ![]() , то слово w переводит q0 в
, то слово w переводит q0 в ![]() w' переводит q0 в qi\ (i=2,3) и условие (*) выполнено, так как четность числа
букв b в w и в w' одинакова. Если же
w' переводит q0 в qi\ (i=2,3) и условие (*) выполнено, так как четность числа
букв b в w и в w' одинакова. Если же ![]() , то из определения автомата A
следует, что слово w переводит q0 в
, то из определения автомата A
следует, что слово w переводит q0 в ![]() w' переводит q0 в q3 и w переводит q0 в
w' переводит q0 в q3 и w переводит q0 в ![]() w' переводит q0 в q2.
Так как четность числа букв b в w и в w' разная, то и в этом случае условие (*) выполнено. Для завершения доказательства осталось заметить,
что единственным заключительным состоянием автомата A является q3 и поэтому LA = L(q3) = L.
w' переводит q0 в q2.
Так как четность числа букв b в w и в w' разная, то и в этом случае условие (*) выполнено. Для завершения доказательства осталось заметить,
что единственным заключительным состоянием автомата A является q3 и поэтому LA = L(q3) = L.
Произведение автоматов
Рассмотрим одну важную конструкцию конечного автомата по двум другим, называемую произведением автоматов, которая позволит установить замкнутость класса конечно автоматных языков относительно теоретико множественных операций.
Пусть ![]() и
и ![]() - два
конечных автомата с общим входным алфавитом
- два
конечных автомата с общим входным алфавитом ![]() распознающих языки L1 и L2,
соответственно. Определим по ним автомат M=
распознающих языки L1 и L2,
соответственно. Определим по ним автомат M= ![]() ,
называемый произведением M1 и M2 (M= M1 x M2), следующим образом.
,
называемый произведением M1 и M2 (M= M1 x M2), следующим образом. ![]() , т.е. состояния нового автомата - это пары, первый
элемент которых - состояние первого автомата, а второй - состояние второго автомата. Для каждой такой пары (q,p) и входного символа
, т.е. состояния нового автомата - это пары, первый
элемент которых - состояние первого автомата, а второй - состояние второго автомата. Для каждой такой пары (q,p) и входного символа ![]() определим функцию переходов:
определим функцию переходов: ![]() . Начальным состоянием M является
пара q0= (q01, q02),
состоящая из начальных состояний автоматов-множителей.
Что касается множества заключительных состояний, то оно определяется в зависимости от операции над языками L1 и L2, которую должен реализовать M.
. Начальным состоянием M является
пара q0= (q01, q02),
состоящая из начальных состояний автоматов-множителей.
Что касается множества заключительных состояний, то оно определяется в зависимости от операции над языками L1 и L2, которую должен реализовать M.
Теорема 4.1.
- При
 или
или  автомат
автомат  распознает язык
распознает язык  .
. - При
 и автомат
и автомат  распознает язык
распознает язык  .
. - При
 и
и  автомат M=
автомат M=  распознает язык L = L1 \ L2.
распознает язык L = L1 \ L2.
Доказательство этой теоремы непосредственно выводится из следующего утверждения.
Лемма 4.2. Для любых двух состояний (q,p) и (q', p') автомата M и любого входного слова w слово w переводит (q,p) в (q', p') в автомате M тогда и только тогда, когда оно переводит q в q' в автомате M1 и p в p' в автомате M2.
Лемма устанавливается индукцией по длине слова w.
Следствие4.1.1. Класс конечно автоматных языков замкнут относительно теоретико множественных операций объединения, пересечения и разности.
Недетерминированные конечные автоматы и их детерминизация
Недетерминированные конечные автоматы, рассматриваемые в этом параграфе, являются обобщениями детерминированных: они при чтении очередного символа на входе могут выбрать в качестве следующего одно из нескольких состояний, а кроме того, могут изменить состояние без чтения входа. Основной результат, который мы установим, утверждает, что это обощение не существенно: недетерминированные и детерминированные конечные автоматы распознают одни и те же языки.
Определение 4.8. Недетерминированный конечный автомат (НКА) - распознаватель - это система вида
включающая следующие компоненты:
- - конечное множество - входной алфавит ;
- Q={q0, ... , qn-1} (n >= 1) - конечное множество - алфавит внутренних состояний;
- - начальное состояние автомата;
- - множество принимающих (допускающих, заключительных) состояний ;
 - функция переходов.
- функция переходов.
Для ![]() значение
значение ![]() - это множество
состояний в каждое из которых может перейти автомат из состояния q, когда получает на вход символ a.
- это множество
состояний в каждое из которых может перейти автомат из состояния q, когда получает на вход символ a. ![]() - это множество
состояний в каждое из которых может перейти автомат из состояния q без чтения символа на входе.
- это множество
состояний в каждое из которых может перейти автомат из состояния q без чтения символа на входе.
Как и для детерминированных автоматов, функцию переходов можно представить с помощью
набора команд-программы: для каждой пары ![]() и
и ![]() и каждого состояния
и каждого состояния ![]() в программу помещается команда q a -> q',
и для каждого состояния
в программу помещается команда q a -> q',
и для каждого состояния ![]() в программу помещается команда q -> q'. Отличие от детерминированного случая состоит в том,
что для одной пары
в программу помещается команда q -> q'. Отличие от детерминированного случая состоит в том,
что для одной пары ![]() и
и ![]() в программе может быть несколько команд вида q a -> q' или не быть ни одной такой команды. Кроме того, могут
появиться
в программе может быть несколько команд вида q a -> q' или не быть ни одной такой команды. Кроме того, могут
появиться ![]() -команды (пустые переходы) вида q -> q', означающие возможность непосредственного перехода из q в q' без чтения символа на входе.
-команды (пустые переходы) вида q -> q', означающие возможность непосредственного перехода из q в q' без чтения символа на входе.
При табличном задании функции ![]() в таблице появляется (m+1) -ый столбец,
соответствующий пустому символу
в таблице появляется (m+1) -ый столбец,
соответствующий пустому символу ![]() и на пересечении строки q и столбца
и на пересечении строки q и столбца ![]() стоит множество состояний
стоит множество состояний ![]() .
.
Для недетерминированного автомата ![]() в диаграмме DM=(Q, E) с выделенной начальной вершиной q0 и множеством заключительных вершин F ребра взаимно-однозначно соответствуют
командам: команде вида q a -> q'
в диаграмме DM=(Q, E) с выделенной начальной вершиной q0 и множеством заключительных вершин F ребра взаимно-однозначно соответствуют
командам: команде вида q a -> q' ![]() соответствует ребро (q,q' ), с меткой a , а команде вида q -> q'
соответствует ребро (q,q' ), с меткой
соответствует ребро (q,q' ), с меткой a , а команде вида q -> q'
соответствует ребро (q,q' ), с меткой ![]() .
.
Скажем, что заданный последовательностью ребер путь p=e1e2 ... eT в диаграмме DM несет слово w=w1w2 ... wt (t <= T),
если после удаления из него "пустых" ребер (т.е. ребер с метками ![]() ) остается последовательность
из t ребер
) остается последовательность
из t ребер ![]() , метки которых образуют слово w , т.е. wi - это метка ребра
, метки которых образуют слово w , т.е. wi - это метка ребра ![]() .
Очевидно, это эквивалентно тому, что последовательность меток на ребрах пути p
имеет вид
.
Очевидно, это эквивалентно тому, что последовательность меток на ребрах пути p
имеет вид ![]() ,
где kj >= 0 (j=1,2, ... , t+1) и
,
где kj >= 0 (j=1,2, ... , t+1) и ![]() .
.
Слово w переводит q в q' в диаграмме DM, если в ней имеется путь из q в q' который несет w .
На недетерминированные автоматы естественным образом переносится определение конфигураций и отношения перехода между ними.
Определение 4.9. Назовем конфигурацией НКА ![]() произвольную пару вида (q, w), в которой
произвольную пару вида (q, w), в которой ![]() и
и ![]() .
Определим отношение
.
Определим отношение ![]() перехода из одной конфигурации в другую за один шаг:
перехода из одной конфигурации в другую за один шаг:
или
Как и для ДКА, через ![]() обозначим рефлексивное и транзитивное замыкание отношения
обозначим рефлексивное и транзитивное замыкание отношения ![]() .
.
Внешне определение распознавания слов НКА совпадает с определением для ДКА.
Определение 4.10. НКА M распознает (допускает, принимает) слово w, если для некоторого ![]() \
\ ![]()
Язык LM, распознаваемый НКА M, состоит из всех слов, распознаваемых автоматом:
Отличие состоит в том, что у НКА может быть несколько различных способов работы (путей вычисления) на одном и том же входном слове w. Считаем, что НКА распознает (допускает, принимает) это слово, если хотя бы один из этих способов приводит в заключительное состояние из F.
Из определения диаграммы DM непосредственно следует, что НКА M распознает слово w, тогда и только тогда, когда существует такое
заключительное состояние ![]() , что в диаграмме DM слово w переводит q0 в q.
Иными словами, в DM имеется путь из q0 в q, на ребрах которого написано слово w (с точностью до меток
, что в диаграмме DM слово w переводит q0 в q.
Иными словами, в DM имеется путь из q0 в q, на ребрах которого написано слово w (с точностью до меток ![]() ).
).
Пример 4.1. Рассмотрим НКА ![]() , где
, где
Его диаграмма ![]() представлена ниже на рис. 4.3.
представлена ниже на рис. 4.3.
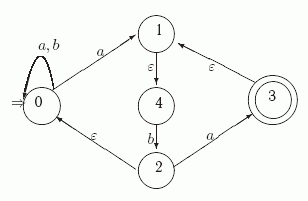
Рис. 4.3. Диаграмма автомата N1
Рассмотрим работу этого автомата на слове ababa:
Так как 3 - заключительное состояние, то ![]() . Заметим, что у автомата N1 имеются и другие способы
работы на этом слове, не ведущие к заключительному состоянию. Например,
он может после чтения каждого символа оставаться в состоянии 0. Но чтобы слово допускалось, достаточно существовать хотя бы одному "хорошему"
способу.
. Заметим, что у автомата N1 имеются и другие способы
работы на этом слове, не ведущие к заключительному состоянию. Например,
он может после чтения каждого символа оставаться в состоянии 0. Но чтобы слово допускалось, достаточно существовать хотя бы одному "хорошему"
способу.
Очевидно, что детерминированные конечные автоматы являются частными случаями недетерминированных. Естественно спросить, распознают ли недетерминированные конечные автоматы больший класс языков чем детерминированные? Следующая теорема показывает, что классы языков, распознаваемых НКА и ДКА совпадают.
Теорема 4.2. (Детерминизация НКА)
Для каждого НКА M можно эффективно построить такой ДКА A, что LA = LM.
Доказательство Пусть ![]() - НКА. Процедура построения по нему эквивалентного ДКА состоит из двух этапов: на первом по M строится эквивалентный ему
НКА M1, в программе которого отсутствуют переходы по
- НКА. Процедура построения по нему эквивалентного ДКА состоит из двух этапов: на первом по M строится эквивалентный ему
НКА M1, в программе которого отсутствуют переходы по ![]() а на втором
этапе по M1 строится эквивалентный ДКА A.
а на втором
этапе по M1 строится эквивалентный ДКА A.
Этап 1. Устранение пустых переходов.
Рассмотрим поддиаграму автомата M, в которой оставлены лишь ребра, помеченные ![]()
![]() , где
, где ![]() .
.
Пусть ![]() - это граф достижимости (транзитивного замыкания)
для
- это граф достижимости (транзитивного замыкания)
для ![]() . Тогда
. Тогда ![]() или в
или в ![]() имеется путь из q в q'}.
имеется путь из q в q'}.
Определим НКА ![]() следующим образом:
следующим образом: ![]() , т.е. кроме начального остаются лишь те состояния, в которые
входят "непустые" ребра.
, т.е. кроме начального остаются лишь те состояния, в которые
входят "непустые" ребра. ![]() ,
т.е. к заключительным состояниям M добавляются состояния, из которых можно было
попасть в заключительные по путям из
,
т.е. к заключительным состояниям M добавляются состояния, из которых можно было
попасть в заключительные по путям из ![]() -ребер.
-ребер.
Для каждой пары ![]() полагаем
полагаем ![]() , т.е. в DM1} имеется a -ребро из q в r, если в DM был (возможно пустой) путь из
, т.е. в DM1} имеется a -ребро из q в r, если в DM был (возможно пустой) путь из ![]() -ребер в некоторое состояние q', из которого a -ребро шло в r.
-ребер в некоторое состояние q', из которого a -ребро шло в r.
Из этого определения непосредственно следует, что в НКА M1 нет пустых переходов
по ![]() Установим эквивалентность M и M1.
Установим эквивалентность M и M1.
Лемма 4.1. ![]() .
.
Доказательство. Пусть w=w1w2... wt - произвольное входное слово.
Предположим, что ![]() . Это означает, что в диаграмме
. Это означает, что в диаграмме ![]() имеется путь p=e1e2 ... et (e1= (q0=r0,r1), ei=(ri-1,ri), i=2,..., t)
из q0 в некоторое состояние
имеется путь p=e1e2 ... et (e1= (q0=r0,r1), ei=(ri-1,ri), i=2,..., t)
из q0 в некоторое состояние ![]() ,
который несет слово w, т.е. ребро ei помечено символом wi.
Из определения функции
,
который несет слово w, т.е. ребро ei помечено символом wi.
Из определения функции ![]() непосредственно следует,
что для любого ребра ei(ri-1, ri) этого пути в диаграмме DM
имеется путь из ri-1 в ri, начало (возможно пустое) которого состоит
из
непосредственно следует,
что для любого ребра ei(ri-1, ri) этого пути в диаграмме DM
имеется путь из ri-1 в ri, начало (возможно пустое) которого состоит
из ![]() -ребер, а последнее ребро помечено символом wi. Объединив эти пути,
получим в диаграмме DM путь из q0 в rt , который несет слово w.
Так как
-ребер, а последнее ребро помечено символом wi. Объединив эти пути,
получим в диаграмме DM путь из q0 в rt , который несет слово w.
Так как ![]() , то либо
, то либо ![]() , либо в DM имеется путь по
, либо в DM имеется путь по ![]() -ребрам из rt в некоторое состояние
-ребрам из rt в некоторое состояние ![]() . В обоих случаях
в DM имеется путь из q0 в заключительное состояние, который несет слово w,
и следовательно,
. В обоих случаях
в DM имеется путь из q0 в заключительное состояние, который несет слово w,
и следовательно, ![]() .
.
Обратно, пусть ![]() . Тогда в DM имеется путь из q0 в
некоторое заключительное состояние r, который несет слово w. Пусть r0=q0, а ri - это состояние этого пути, в которое приводит ребро с меткой wi (i= 1,... , t).
Рассмотрим отрезок этого пути между вершинами r_{i-1} и ri. Последнее ребро этого отрезка
имеет метку wi, а все предыдущие (если они имеются) помечены
. Тогда в DM имеется путь из q0 в
некоторое заключительное состояние r, который несет слово w. Пусть r0=q0, а ri - это состояние этого пути, в которое приводит ребро с меткой wi (i= 1,... , t).
Рассмотрим отрезок этого пути между вершинами r_{i-1} и ri. Последнее ребро этого отрезка
имеет метку wi, а все предыдущие (если они имеются) помечены ![]() Тогда по определению
Тогда по определению ![]() в диаграмме
в диаграмме ![]() между r_{i-1} и ri
имеется ребро с меткой wi. Объединив эти ребра, получим в
между r_{i-1} и ri
имеется ребро с меткой wi. Объединив эти ребра, получим в ![]() путь
из q0 в rt. Так как либо
путь
из q0 в rt. Так как либо ![]() , либо в DM из rt имеется
путь из
, либо в DM из rt имеется
путь из ![]() -ребер в
-ребер в ![]() , то из определения F1 следует, что
, то из определения F1 следует, что ![]() .
Таким образом,
.
Таким образом, ![]() .
.
Этап 2. Детерминизация.
Идея детерминизации состоит в том, что состояниями ДКА объявляются подмножества состояний НКА. Тогда для каждого такого подмножества T и входного символа a однозначно определено множество состояний T', в которые НКА может попасть из состояний T при чтении a.
Определим по НКА ![]() ДКА
ДКА ![]() следующим образом.
следующим образом.

Ясно, что A - детерминированный конечный автомат. Следующая лемма устанавливает связь между его вычислениями и вычислениями исходного НКА.
Лемма 4.4. Для любой пары состояний Q', Q'' из QA и любого слова ![]() имеем
имеем
Доказательство. Применим индукцию по длине слова w.
Базис. Пусть |w|=0, тогда ![]() , Q' = Q'' и утверждение выполнено.
Пусть теперь |w|=1 и
, Q' = Q'' и утверждение выполнено.
Пусть теперь |w|=1 и ![]() . Тогда утверждение леммы следует непосредственно
из определения
. Тогда утверждение леммы следует непосредственно
из определения ![]() .
.
Шаг индукции. Предположим, что лемма справедлива для всех слов длины <= k,
и пусть |w| = k+1. Выделим в w первый символ: w=aw'.
Пусть ![]() - это такое состояние, что
- это такое состояние, что ![]() .
Тогда
.
Тогда ![]() .
Так как |w'|=k, то по индукционному предположению это эквивалентно
следующему:
.
Так как |w'|=k, то по индукционному предположению это эквивалентно
следующему: ![]() .
Но из определения
.
Но из определения ![]() следует, что
следует, что ![]()
![]() .
Объединив, эти два равенства, получаем:
.
Объединив, эти два равенства, получаем: ![]() .
.
Для завершения доказательства теоремы покажем с помощью
леммы 4.4, что ![]() .
.
Действительно, если слово w переводит состояние q0 в некоторое ![]() в автомате M1, то, положив в лемме Q' ={ q0}, получим, что
в автомате M1, то, положив в лемме Q' ={ q0}, получим, что ![]() для состояния Q'', такого, что
для состояния Q'', такого, что ![]() . Но тогда
. Но тогда ![]() и
и ![]() .
.
Обратно, если ![]() , то для некоторого
, то для некоторого ![]() имеем
имеем ![]() . Тогда в Q''
имеется некоторое состояние
. Тогда в Q''
имеется некоторое состояние ![]() и по лемме 4.4 в автомате
и по лемме 4.4 в автомате ![]() , т.е.
, т.е. ![]() .
.
Пример 4.2. Применим процедуру из теоремы о детерминизации к НКА N1 из примера 4.3.
На первом этапе получаем ![]() и
НКА M1 без пустых переходов, представленный на следующей диаграмме.
и
НКА M1 без пустых переходов, представленный на следующей диаграмме.
Рис. 4.4. Диаграмма автомата M1
Заметим, что состояние 4 исчезло, так как в автомате N1 в него можно было
попасть только по ![]() -переходу.
-переходу.
На втором этапе детерминизируем M1. ДКА A будет иметь 16 состояний: ![]() .
.
Во множество заключительных состояний войдут состояния, содержащие заключительное состояние 3 автомата M1:
F^A={{3},{0,3}, {1,3}, {0,1,3}, {0,2,3},{1,2,3}, {0,1,2, 3}}.
Функция переходов ![]() определена в следующей таблице
определена в следующей таблице
| | a | b |
|---|---|---|
| {1,2} | {0,1,3} | {0,2} |
| {1,3} | {2} | |
| {2,3} | {0,1,3} | {0,2} |
| {0,1,2} | {0,1,3} | {0,2} |
| {0,1,3} | {0,1} | {0,2} |
| {0,2,3} | {0,1,3} | {0,2} |
| {1,2,3} | {0,1,3} | {0,2} |
| {0,1,2,3} | {0,1,3} | {0,2} |
Рис. 4.5. Диаграмма автомата A
На самом деле нас интересуют лишь те состояния, в которые можно попасть из начального состояния {0}. Несложный анализ показывает, что их только три: {0,1}, {0,2 } и {0, 1, 3 }. Остальные состояния не достижимы из {0} и, следовательно, не влияют на работу автомата A. Их можно отбросить. Таким образом, в диаграмме автомата остаются 4 состояния, показанные на рис. 4.5.
Замечание. В рассмотренном примере у построенного ДКА A оказалось не больше состояний, чем у исходного НКА N1. К сожалению, это не всегда так. Существуют примеры НКА с n состояниями, для которых эквивалентные ДКА содержат не менее 2n состояний.
Задачи
Задача 4.1. Автомат по продаже кофе имеет щель для получения монет, кнопку, нажатие которой после уплаты достаточной суммы приводит к получению кофе, и накопитель, через который он выдает сдачу покупателю. Автомат принимает монеты достоинством в 1, 2 и 5 рублей. Чашка кофе стоит 8 руб. Пока полученная сумма недостаточна, горит красная лампочка. Если сумма, полученная автоматом, >= 8, то зажигается зеленая лампочка и после нажатия кнопки автомат наливает кофе и, если требуется, дает сдачу. Если автомат получает монету, когда горит зеленая лампочка, то он немедленно ее возвращает. Определите входной и выходной алфавиты конечного автомата, управляющего продажей кофе, и постройте его функции переходов и выходов.
Задача 4.2. Электронные часы имеют табло с указанием часов, минут и секунд и две управляющие кнопки. Одна кнопка переводит часы из нормального режима в режим настройки времени - вначале в настройку часов, затем - минут, затем - секунд, а затем возвращает в нормальный режим. Другая кнопка в нормальном режиме ничего не меняет, а в режиме настройки нажатие на нее увеличивает на единицу число настраеваемых часов, минут или секунд. Постройте автомат, который принимает на вход сигналы нажатия от двух кнопок, а на выходе выдает сигналы изменения режима и увеличения соответствующего числа.
Задача 4.3. Докажите лемму 4.1 индукцией по длине входного слова.
Задача 4.4. Постройте детерминированные конечные автоматы, которые
распознают следующие языки в алфавите ![]() :
:
- L = {w | длина w делится на 5} ;
- L = {w | w не содержит подслов 'aab' и 'bba'} ;
- L = {w | w содержит четное число букв а и нечетное число букв b} ;
- L = {w | число букв а делится на 3, а число букв b на 2 }.
Задача 4.5. Выше в примере 4.1 был построен автомат с выходом, выполняющий сложение двух двоичных чисел. Постройте автомат-распознаватель, который проверяет правильность сложения. На вход поступают последовательности троек нулей и единиц:
Автомат должен допустить такую последовательность, если y = y(n) ... y(2)y(1) - это первые n битов суммы двоичных чисел x1= x1(n)... x1(2)x1(1) и x2 = x2(n)... x2(2)x2(1).
Задача 4.7. Докажите лемму 4.2.
Задача 4.8. Докажите, что приведенный на рис. 4.5 автомат A распознает язык, состоящий из всех слов, заканчивающихся на 'aba'.
Задача 4.9. Используя процедуру детерминизации недетерминированных автоматов из теоремы 4.2, постройте ДКА, эквивалентный заданному НКА M.
 с программой
с программой  .
.- с программой
 .
.
Лекция 5. Регулярные языки и конечные автоматы
Регулярные выражения и языки
Регулярные выражения являются достаточно удобным средством для построения "алгебраических"
описаний языков. Они строятся из элементарных выражений ![]() с помощью операций объединения ( + ), конкатенации (
с помощью операций объединения ( + ), конкатенации ( ![]() ) и итерации ( * ).
Каждому такому выражению r соответствует представляемый им язык Lr.
Смысл операции объединения языков мы знаем. Определим операции конкатенации
и итерации (иногда ее называют замыканием Клини).
) и итерации ( * ).
Каждому такому выражению r соответствует представляемый им язык Lr.
Смысл операции объединения языков мы знаем. Определим операции конкатенации
и итерации (иногда ее называют замыканием Клини).
Пусть L1 и L2 - языки в алфавите ![]()
Тогда ![]() ,
т.е. конкатенация языков состоит из конкатенаций всех слов первого языка со всеми словами второго языка. В частности, если
,
т.е. конкатенация языков состоит из конкатенаций всех слов первого языка со всеми словами второго языка. В частности, если ![]() , то
, то ![]() , а
если
, а
если ![]() , то
, то ![]() .
.
Введем обозначения для "степеней" языка L:

Таким образом в Li входят все слова, которые можно разбить на i подряд идущих слов из L.
Итерацию (L)* языка L образуют все слова которые можно разбить на несколько подряд идущих слов из L:
Ее можно представить с помощью степеней:

Часто удобно рассматривать "усеченную" итерацию языка, которая не содержит пустое слово, если его нет
в языке: ![]() . Это не новая операция, а просто удобное сокращение
для выражения
. Это не новая операция, а просто удобное сокращение
для выражения ![]() .
.
Отметим также, что если рассматривать алфавит ![]() как
конечный язык, состоящий из однобуквенных слов, то введенное ранее обозначение
как
конечный язык, состоящий из однобуквенных слов, то введенное ранее обозначение ![]() для множества всех слов, включая и пустое, в алфавите
для множества всех слов, включая и пустое, в алфавите ![]() соответствует определению итерации
соответствует определению итерации ![]() этого языка.
этого языка.
В следующей таблице приведено формальное индуктивное определение регулярных выражений над алфавитом ![]() и представляемых ими языков.
и представляемых ими языков.
| Выражение r | Язык Lr |
|---|---|
| La={a} | |
| Пусть r1 и r2 -это | Lr1 и Lr2 -представляемые |
| регулярные выражения. | ими языки. |
| Тогда следующие выражения | |
| являются регулярными | и представляют языки: |
| r=(r1+r2) | |
| r=(r1circr2) | |
| r=(r1)* | Lr=Lr1* |
При записи регулярных выражений будем опускать знак конкатенации ![]() и будем считать, что
операция * имеет больший приоритет, чем конкатенация и +, а конкатенация - больший приоритет, чем +. Это позволит опустить многие скобки. Например,
и будем считать, что
операция * имеет больший приоритет, чем конкатенация и +, а конкатенация - больший приоритет, чем +. Это позволит опустить многие скобки. Например, ![]() можно записать как 10(1* + 0).
можно записать как 10(1* + 0).
Определение 5.1. Два регулярных выражения r и p называются эквивалентными, если совпадают представляемые ими языки, т.е. Lr=Lp. В этом случае пишем r = p.
Нетрудно проверить, например, такие свойства регулярных операций:
- r + p= p+ r (коммутативность объединения),
- (r+p) +q = r + (p+q) (ассоциативность объединения),
- (r p) q = r (p q) (ассоциативность конкатенации),
- (r*)* = r* (идемпотентность итерации ),
- (r +p) q = rq + pq (дистрибутивность).
Пример 5.1. Докажем в качестве примера не столь очевидное равенство: (r + p)* = (r*p*)*.
Пусть L1 - язык, представляемый его левой частью, а L2 - правой.
Пустое слово ![]() принадлежит обоим языкам.
Если непустое слово
принадлежит обоим языкам.
Если непустое слово ![]() , то по определению итерации оно представимо
как конкатенация подслов, принадлежащих языку
, то по определению итерации оно представимо
как конкатенация подслов, принадлежащих языку ![]() . Но этот язык является
подмножеством языка L'=Lr*Lp* (почему?). Поэтому
. Но этот язык является
подмножеством языка L'=Lr*Lp* (почему?). Поэтому ![]() .
Обратно, если слово
.
Обратно, если слово ![]() , то оно представимо
как конкатенация подслов, принадлежащих языку L'. Каждое из таких подслов v представимо
в виде v= v11... vk1 v12... vl2, где для всех i=1, ... , k подслово
, то оно представимо
как конкатенация подслов, принадлежащих языку L'. Каждое из таких подслов v представимо
в виде v= v11... vk1 v12... vl2, где для всех i=1, ... , k подслово ![]() и
для всех j=1, ... , l подслово
и
для всех j=1, ... , l подслово ![]() (возможно, что k или l равно 0).
Но это значит, что w является конкатенацией подслов, каждое из которых принадлежит
(возможно, что k или l равно 0).
Но это значит, что w является конкатенацией подслов, каждое из которых принадлежит ![]() и, следовательно,
и, следовательно, ![]() .
.
Рассмотрим несколько примеров регулярных выражений и представляемых ими языков.
Пример 5.2. Регулярное выражение (0 +1)* представляет множество всех слов в алфавите {0, 1}.
Пример 5.3. Регулярное выражение 11(0 +1)*001 представляет язык, состоящий из всех слов в алфавите {0, 1}, которые начинаются на '11', а заканчиваются на '001'.
Пример 5.4. Регулярное выражение ![]() представляет язык, состоящий из всех слов в алфавите {0, 1}, которые не содержат подслово '000' ( см. задачу 5.3).
представляет язык, состоящий из всех слов в алфавите {0, 1}, которые не содержат подслово '000' ( см. задачу 5.3).
Пример 5.5. Регулярное выражение 1*(01*01*)* представляет язык L0ч, состоящий из всех слов в алфавите {0, 1}, в которых четное число нулей.
Действительно, каждое слово из L0ч либо вообще не содержит нулей, т.е. входит в язык, представляющий 1*, либо может быть разбито на блоки вида 01i01j, i,j >= 0, которым, быть может, предшествует блок единиц. Выражение (01*01*), очевидно задает один такой блок, а его итерация - произвольную последовательность таких блоков.
Пример 5.6. Построим теперь регулярное выражение, представляющее язык L0ч1ч, который состоит из всех слов в алфавите {0, 1}, содержащих четное число нулей и четное число единиц.
Пусть w=w1w2 ... wn - произвольное слово из L0ч1ч. Тогда, разумеется, n - четно, пусть n=2k. Разобьем w на пары соседних букв pi =w2i-1w2i, i= 1,2,... ,k. Возможны 4 вида таких пар: 00, 11, 01 и 10. Пар вида 00 и 11 может быть сколько угодно, а пар вида 01 и 10 обязательно четное число. Поэтому w разбивается на блоки, каждый из которых начинается одной из пар 01 или 10 и содержит еще одну такую пару. Каждый такой блок описывается выражением (01 +10)(00 + 11)*(01+10)(00 + 11)*. При этом перед первым блоком может быть префикс, состоящий из пар 00 и 11. Множество слов состоящих из пар 00 и 11 задается выражением (00 +11)*. Отсюда получаем выражение R0ч1ч, задающее язык L0ч1ч:
Автоматы для регулярных языков
Покажем, что каждый регулярный язык можно распознать конечным автоматом.
Теорема 5.1. Для каждого регулярного выражения r можно эффективно построить такой недетерминированный конечный автомат M, который распознает язык, задаваемый r, т.е. LM= Lr.
Доказательство Построение автомата M по выражению r проведем индукцией по длине r, т.е. по общему количеству
символов алфавита ![]() символов
символов ![]() и
и ![]() знаков операций
знаков операций ![]() и скобок в записи r.
и скобок в записи r.
Базис. Автоматы для выражений длины 1: ![]()
![]() и
и ![]() показаны на следующем рисунке.
показаны на следующем рисунке.

Рис. 5.1.
Заметим, что у каждого из этих трех автоматов множество заключительных состояний состоит из одного состояния.
Индукционный шаг. Предположим теперь, что для каждого регулярного выражения длины <= k построен соответствующий
НКА, причем у него единственное заключительное состояние. Рассмотрим произвольное регулярное
выражение r длины k+1. В зависимости от последней операции
оно может иметь один из трех видов: (r1 + r2), (r1 r2) или (r1)*. Пусть ![]() и
и ![]() - это
НКА, распознающие языки Lr1 и Lr2, соответственно. Не ограничивая общности, мы будем
предполагать, что у них разные состояния:
- это
НКА, распознающие языки Lr1 и Lr2, соответственно. Не ограничивая общности, мы будем
предполагать, что у них разные состояния: ![]() .
.
Тогда НКА ![]() , диаграмма которого представлена на рис. 5.2,
распознает язык
, диаграмма которого представлена на рис. 5.2,
распознает язык ![]() .
.

Рис. 5.2.
У этого автомата множество состояний ![]() ,
где q0 - это новое начальное состояние, qf - новое (единственное !)
заключительное состояние, а программа включает программы автоматов M1 и M2 и четыре новых команды
,
где q0 - это новое начальное состояние, qf - новое (единственное !)
заключительное состояние, а программа включает программы автоматов M1 и M2 и четыре новых команды ![]() -переходов:
-переходов: ![]() .
Очевидно, что язык, распознаваемый НКА M, включает все слова из L{M1} и из L{M2}.
С другой стороны, каждое слово
.
Очевидно, что язык, распознаваемый НКА M, включает все слова из L{M1} и из L{M2}.
С другой стороны, каждое слово ![]() переводит q0 в qf, и после первого шага несущий его путь
проходит через q01 или q02. Так как состояния M1 и M2 не пересекаются, то в первом случае
этот путь может попасть в qf только по
переводит q0 в qf, и после первого шага несущий его путь
проходит через q01 или q02. Так как состояния M1 и M2 не пересекаются, то в первом случае
этот путь может попасть в qf только по ![]() -переходу из qf1 и тогда
-переходу из qf1 и тогда ![]() .
Аналогично, во втором случае
.
Аналогично, во втором случае ![]() .
.
Для выражения ![]() диаграмма НКА
диаграмма НКА ![]() , распознающего язык Lr,
представлена на следующем рисунке.
, распознающего язык Lr,
представлена на следующем рисунке.

Рис. 5.3.
У этого автомата множество состояний ![]() ,
начальное состояние q0= q01, заключительное состояние qf =qf2,
а программа включает программы автоматов M1 и M2 и одну новую команду -
,
начальное состояние q0= q01, заключительное состояние qf =qf2,
а программа включает программы автоматов M1 и M2 и одну новую команду - ![]() -переход из заключительного состояния M1
в начальное состояние M2, т.е.
-переход из заключительного состояния M1
в начальное состояние M2, т.е. ![]() .
Здесь также очевидно, что всякий путь из q0= q01 в qf =qf2 проходит
через
.
Здесь также очевидно, что всякий путь из q0= q01 в qf =qf2 проходит
через ![]() -переход из qf1 в q02. Поэтому всякое слово, допускаемое M,
представляет конкатенацию некоторого слова из LM1} с некоторым словом из LM2},
и любая конкатенация таких слов допускается. Следовательно, НКА M
распознает язык
-переход из qf1 в q02. Поэтому всякое слово, допускаемое M,
представляет конкатенацию некоторого слова из LM1} с некоторым словом из LM2},
и любая конкатенация таких слов допускается. Следовательно, НКА M
распознает язык ![]() .
.
Пусть r = r1*. Диаграмма
НКА ![]() , распознающего язык Lr=Lr1* = LM1*
представлена на рис. 5.3.
, распознающего язык Lr=Lr1* = LM1*
представлена на рис. 5.3.
Рис. 5.3. Диаграмма автомата M, распознающего язык Lr1*
У этого автомата множество состояний ![]() ,
где q0 - это новое начальное состояние, qf - новое (единственное !)
заключительное состояние, а программа включает программу автомата M1 и четыре новых команды
,
где q0 - это новое начальное состояние, qf - новое (единственное !)
заключительное состояние, а программа включает программу автомата M1 и четыре новых команды ![]() -переходов:
-переходов: ![]() .
Очевидно,
.
Очевидно, ![]() . Для непустого слова w по определению итерации
. Для непустого слова w по определению итерации ![]() для некоторого k >= 1 слово w можно разбить на k подслов: w=w1w2... wk и все
для некоторого k >= 1 слово w можно разбить на k подслов: w=w1w2... wk и все ![]() . Для
каждого i= 1,... ,k слово wi переводит q01 в qf1. Тогда для слова w
в диаграмме M имеется путь
. Для
каждого i= 1,... ,k слово wi переводит q01 в qf1. Тогда для слова w
в диаграмме M имеется путь
Следовательно, ![]() . Обратно, если некоторое слово
переводит q0 в qf, то либо оно есть
. Обратно, если некоторое слово
переводит q0 в qf, то либо оно есть ![]() либо его несет путь, который, перейдя из q0 в q01 и затем пройдя несколько раз по пути из q01 в qf1 и вернувшись из qf1 в q01 по
либо его несет путь, который, перейдя из q0 в q01 и затем пройдя несколько раз по пути из q01 в qf1 и вернувшись из qf1 в q01 по ![]() -переходу, в конце концов из qf1 по
-переходу, в конце концов из qf1 по ![]() -переходу завершается в qf.
Поэтому такое слово
-переходу завершается в qf.
Поэтому такое слово ![]() .
.
Из теорем 4.2 и 5.1 непосредственно получаем
Следствие 5.1. Для каждого регулярного выражения можно эффективно построить детерминированный конечный автомат, который распознает язык, представляемый этим выражением.
Это утверждение - один из примеров теорем синтеза: по описанию задания (языка как регулярного выражения ) эффективно строится программа (ДКА), его выполняющая. Справедливо и обратное утверждение - теорема анализа.
Теорема 5.2. По каждому детерминированному (или недетерминированному) конечному автомату можно построить регулярное выражение, которое представляет язык, распознаваемый этим автоматом.
Доказательство этой теоремы достаточно техническое и выходит за рамки нашего курса.
Таким образом, можно сделать вывод, что класс конечно автоматных языков совпадает с классом регулярных языков. Далее мы будем называть его просто классом автоматных языков.
Автомат Mr, который строится в доказательстве теоремы 5.1 по регулярному выражению r, не всегда является самым простым.
Например, для реализации
выражения-слова a1a2 ... an, где ![]() , можно просто
использовать автомат с (n+1) состоянием qi (i=0,1,2, ... , n) и командами q{i-1} ai -> qi, в котором нет пустых
, можно просто
использовать автомат с (n+1) состоянием qi (i=0,1,2, ... , n) и командами q{i-1} ai -> qi, в котором нет пустых ![]() -переходов, участвующих в общей конструкции для конкатенации.
Также при построении автомата для объединения M1 и M2 можно сливать их начальные состояния
в одно, если в них нет переходов из других состояний (тогда не потребуется новое начальное состояние).
Можно также объединить их заключительные состояния, если из них нет переходов в
другие состояния и алфавиты M1 и M2 совпадают. Если из заключительного
состояния M1 нет переходов в
другие состояния, то при конкатенации его можно объединить с начальным состоянием M2.
Вместе с тем,
утверждения задачи 5.9 показывают,
что наша общая конструкция достаточно экономна.
-переходов, участвующих в общей конструкции для конкатенации.
Также при построении автомата для объединения M1 и M2 можно сливать их начальные состояния
в одно, если в них нет переходов из других состояний (тогда не потребуется новое начальное состояние).
Можно также объединить их заключительные состояния, если из них нет переходов в
другие состояния и алфавиты M1 и M2 совпадают. Если из заключительного
состояния M1 нет переходов в
другие состояния, то при конкатенации его можно объединить с начальным состоянием M2.
Вместе с тем,
утверждения задачи 5.9 показывают,
что наша общая конструкция достаточно экономна.
Пример 5.7. Применим теорему 5.1 к регулярному выражению ![]() ,
которое, как мы заметили в примере 5.4, представляет язык, состоящий из всех
слов, которые не содержат подслово '000'.
,
которое, как мы заметили в примере 5.4, представляет язык, состоящий из всех
слов, которые не содержат подслово '000'.
На рис. 5.5 представлены диаграммы автоматов M1 и M2, построенных
по выражениям r1 = (1 +01 +001) и ![]() , соответственно, с помощью конструкций для конкатенации
и объединения. Как мы отмечали выше, автомат M1 можно было бы еще упростить, склеив
начальные состояния q2, p1 и s1, а также заключительные состояния q3, p3 и s4.
, соответственно, с помощью конструкций для конкатенации
и объединения. Как мы отмечали выше, автомат M1 можно было бы еще упростить, склеив
начальные состояния q2, p1 и s1, а также заключительные состояния q3, p3 и s4.

Рис. 5.5.
Автомат M3 для выражения r1* = (1 +01 +001)* получается из M1 добавлением нового
начального состояния q0 и заключительного состояния q5 и ![]() -переходов из q0 в q1 и q5, из q4 в q5 и из q5 в q1. Затем результирующий автомат для исходного
выражения r получается последовательным соединением M3 и M2.
Он представлен ниже на рис. 5.6.
-переходов из q0 в q1 и q5, из q4 в q5 и из q5 в q1. Затем результирующий автомат для исходного
выражения r получается последовательным соединением M3 и M2.
Он представлен ниже на рис. 5.6.

Рис. 5.6.
Задачи
Задача 5.1. Определите конкатенацию для следующих пар языков L1 и L2:
- L1= {a, ab, abb} и
 ;
;  и L2= { a, b, abb, a} ;
и L2= { a, b, abb, a} ; и
и  ;
;
Задача 5.2. Пусть L={baa, bab, bba, bbb}. Какой из следующих языков является итерацией L* этого языка?
 ;
; ;
; ;
;- { w | w=bw' и | w| >= 12 }.
Задача 5.3. Докажите правильность регулярного выражения в примере 5.4.
Задача 5.4. Докажите следующие эквивалентности для регулярных выражений.
- p*(p+q)* = (p + qp*)* = (p+q)* ;
- p(qp)* = (pq)*p ;
- (p*q*)* =(q*p*)* ;
- (pq)+(q*p* + q*) = (pq)*p q+p*.
Задача 5.5. Постройте регулярное выражение, задающее язык
язык L в алфавите ![]() .
.
- L= {w | w содержит нечетное число букв 0 и четное число букв 1}} ;
- L= {w | w содержит подслово 001 или подслово 110 } ;
- L= {w | w содержит по крайней мере мере два подряд идущих 0 } ;
- L= {w | w не содержит подслов 011 и 010}.
Задача 5.6. Определите, какой язык представляется следующими регулярными выражениями.
- (0*1*)0 ;
- (01*)0 ;
- (00 +11 +(01 + 10)(00 +11)+(01+10))*.
Задача 5.7. Упростить следующие регулярные выражения.
- (00*)0 + (00)* ;
 ;
; .
.
Задача 5.8. Выше в задаче 14.5 предлагалось построить автомат-распознаватель, который проверяет правильность сложения. Постройте регулярное выражение, задающее распознаваемый этим автоматом язык S, т.е. следующее множество слов в алфавите {0, 1}3
S= {(x1(1),x2(1),y(1)) (x1(2),x2(2),y(2)) ... (x1(n),x2(n),y(n)) | y = y(n) ... y(2)y(1) - это первые n битов суммы двоичных чисел x1= x1(n)... x1(2)x1(1) и x2 = x2(n)... x2(2)x2(1)}.
Задача 5.9. Пусть Mr - это автомат, который строится в доказательстве теоремы 5.1 по регулярному выражению r. Докажите, что
- у Mr нет переходов из единственного заключительного состояния qf ;
- в диаграмме Mr из каждой вершины выходит не более двух ребер;
- число состояний Mr не более чем вдвое превосходит длину выражения r, т.е. |Q| <= 2 |r|.
Задача 5.10. Примените процедуру детерминизации из теоремы 4.2 и постройте ДКА, эквивалентный НКА ![]() из примера 5.7.
из примера 5.7.
Лекция 6. Свойства замкнутости класса автоматных языков. Неавтоматные языки
Замкнутость относительно гомоморфизмов и их обращений
Обратимся снова к свойствам замкнутости класса автоматных языков. Как мы уже установили с помощью конструкции произведения автоматов, этот класс замкнут относительно объединения, пересечения и разности (см. следствие 4.1.1). Из теоремы 5.1 непосредственно следует, что класс автоматных языков замкнут относительно операций конкатенации и итерации. Можно легко установить, что он также замкнут относительно дополнения.
Предложение 6.1. Пусть L - автоматный язык в алфавите ![]() Тогда его дополнение - язык
Тогда его дополнение - язык ![]() также является автоматным.
также является автоматным.
Действительно, достаточно заметить, что язык ![]() , включающий все слова в алфавите
, включающий все слова в алфавите ![]() является автоматным и что
является автоматным и что ![]() .
.
Определенная ниже операция гомоморфизма формализует идею посимвольного перевода слов одного алфавита в слова другого.
Определение 6.1. Пусть ![]() и Delta - два алфавита. Отображение
и Delta - два алфавита. Отображение ![]() слов первого из них в слова второго называется гомоморфизмом, если
слов первого из них в слова второго называется гомоморфизмом, если

- для любых двух слов w1 и w2 в алфавите
 имеет место равенство
имеет место равенство  .
.
Из этого определения непосредственно следует, что гомоморфизм однозначно определяется
своими значениями на символах алфавита ![]() Если w=w1w2 ... wn,
Если w=w1w2 ... wn, ![]() ,
то
,
то ![]() .
.
Пример 6.1.Пусть ![]() , Delta ={ 0, 1}, а гомоморфизм
, Delta ={ 0, 1}, а гомоморфизм ![]() определен
на символах
определен
на символах ![]() следующим образом:
следующим образом: ![]() .
.
Тогда ![]() .
.
Определение 6.2.
Пусть ![]() - произвольный гомоморфизм и L - язык
в алфавите
- произвольный гомоморфизм и L - язык
в алфавите ![]() Образом
Образом ![]() языка L при гомоморфизме
языка L при гомоморфизме ![]() называется язык
называется язык ![]() , состоящий из образов всех слов языка L.
, состоящий из образов всех слов языка L.
Пусть L - язык в алфавите ![]() Прообразом этого языка при гомоморфизме
Прообразом этого языка при гомоморфизме ![]() называется язык
называется язык ![]() , состоящий из всех таких слов в алфавите
, состоящий из всех таких слов в алфавите ![]() чьи образы при гомоморфизме
чьи образы при гомоморфизме ![]() попадают в L.
попадают в L.
Оказывается, что класс автоматных языков замкнут относительно операций гомоморфизма и обращения гомоморфизма (взятия прообраза)
Теорема 6.1. Пусть ![]() - произвольный гомоморфизм и L - автоматный язык
в алфавите
- произвольный гомоморфизм и L - автоматный язык
в алфавите ![]() Тогда и язык
Тогда и язык ![]() вляется автоматным.
вляется автоматным.
Доказательство Пусть ![]() - ДКА, распознающий
язык L. Построим по нему НКА
- ДКА, распознающий
язык L. Построим по нему НКА ![]() ,
распознающий язык
,
распознающий язык ![]() . Идея этого построения проста: нужно каждый переход из состояния q
в q' по букве
. Идея этого построения проста: нужно каждый переход из состояния q
в q' по букве ![]() в автомате A превратить в переход из q в q' по слову
в автомате A превратить в переход из q в q' по слову ![]() в автомате M.
в автомате M.
Пусть ![]() , Q= {q0, q1, ..., qn} и
, Q= {q0, q1, ..., qn} и ![]() (если
(если ![]() ).
Для каждого ai зафиксируем простой НКА Mi, распознающий язык {d1id2i ... d{ki}i}, имеющий (ki +1) состояние p0i, p1i, ..., p{ki}i и команды p{l-1}dli -> pl (1<= l <= ki).
( Если
).
Для каждого ai зафиксируем простой НКА Mi, распознающий язык {d1id2i ... d{ki}i}, имеющий (ki +1) состояние p0i, p1i, ..., p{ki}i и команды p{l-1}dli -> pl (1<= l <= ki).
( Если ![]() , то у Mi будут два состояния, соединенные
, то у Mi будут два состояния, соединенные ![]() -переходом).
Теперь для каждой команды qj ai -> qr поместим в M между qj и qr автомат Mi (цепочку состояний p0i, p1i, ..., p{ki}i ). Чтобы состояния различных цепочек не
склеивались, придадим им верхний индекс j, т.е. у каждого qj будет своя копия каждого из автоматов Mi.
Для этого
положим
-переходом).
Теперь для каждой команды qj ai -> qr поместим в M между qj и qr автомат Mi (цепочку состояний p0i, p1i, ..., p{ki}i ). Чтобы состояния различных цепочек не
склеивались, придадим им верхний индекс j, т.е. у каждого qj будет своя копия каждого из автоматов Mi.
Для этого
положим ![]() . Таким образом, pl{ji} - это l -ое состояние на пути из qj по "старой" букве ai.
Программа
. Таким образом, pl{ji} - это l -ое состояние на пути из qj по "старой" букве ai.
Программа ![]() автомата M строится по программе A следующим образом.
Для каждой команды вида qj ai -> qr из
автомата M строится по программе A следующим образом.
Для каждой команды вида qj ai -> qr из ![]() поместим в
поместим в ![]() следующие команды:
следующие команды:

Таким образом, из qj автомат M по пустому переходу попадает в начальное состояние p0ji j -ой копии автомата Mi, затем проходит по слову ![]() и снова по пустому переходу
попадает в qr.
и снова по пустому переходу
попадает в qr.
Для завершения определения M положим q0M = q0 и FM = F.
Докажем теперь, что наше построение корректно, т.е., что ![]() .
.
 . Заметим вначале, что если
. Заметим вначале, что если  , то
, то  и по определению
и по определению  , следовательно
, следовательно  .
.Пусть
 . Тогда в диаграмме A имеется путь из q0 в некоторое
заключительное состояние
. Тогда в диаграмме A имеется путь из q0 в некоторое
заключительное состояние  , который несет слово w. Пусть это путь
, который несет слово w. Пусть это путь  . Тогда для каждого 1 <= x <= k
в имеется команда
. Тогда для каждого 1 <= x <= k
в имеется команда  . Но из определения
. Но из определения  следует,
что тогда в автомате M имеется путь из
следует,
что тогда в автомате M имеется путь из  в
в  , несущий слово
, несущий слово  .
Объединив все такие пути, получим путь из из q0 в
.
Объединив все такие пути, получим путь из из q0 в  , несущий слово
, несущий слово  .
Следовательно,
.
Следовательно,  .
. . Пусть слово
. Пусть слово  принадлежит LM. Покажем, что тогда
для некоторого
принадлежит LM. Покажем, что тогда
для некоторого 
 .
Рассмотрим для этого путь в диаграмме M из q0 в , несущий слово u .
Выделим на этом пути все состояния из Q. Пусть это будут по порядку состояния q0=q{j0}, q{j1}, ... q{jk}= q'. Тогда слово u разбивается на k подслов: u=u1u2 ... uk таких, что ux переводит в M состояние в
( 1 <= x <= k ). Покажем, что для каждого такого ux существует символ
.
Рассмотрим для этого путь в диаграмме M из q0 в , несущий слово u .
Выделим на этом пути все состояния из Q. Пусть это будут по порядку состояния q0=q{j0}, q{j1}, ... q{jk}= q'. Тогда слово u разбивается на k подслов: u=u1u2 ... uk таких, что ux переводит в M состояние в
( 1 <= x <= k ). Покажем, что для каждого такого ux существует символ  такой, что
такой, что  и в имеется команда .
Действительно, любой путь из в M начинается
и в имеется команда .
Действительно, любой путь из в M начинается  -переходом в некоторое
состояние вида
-переходом в некоторое
состояние вида  . Пусть это будет состояние на пути, который несет ux в . Далее этот путь обязательно будет проходить
по состояниям вида
. Пусть это будет состояние на пути, который несет ux в . Далее этот путь обязательно будет проходить
по состояниям вида  и
завершится -переходом из
и
завершится -переходом из  в состояние .
Тогда из определения M следует, что
в состояние .
Тогда из определения M следует, что  и в имеется команда .
Положив wx=ai,
получим, что и
и в имеется команда .
Положив wx=ai,
получим, что и  ,
для слова
,
для слова  . При этом каждый символ wx этого слова
переводит в автомате A состояние в . Поэтому в A
существует путь из q0 в , несущий слово w и, следовательно
. При этом каждый символ wx этого слова
переводит в автомате A состояние в . Поэтому в A
существует путь из q0 в , несущий слово w и, следовательно 
Пример 6.2. Пусть алфавиты ![]()
![]() и гомоморфизм
и гомоморфизм ![]() определены
как выше в примере 6.1. Рассмотрим язык L={ w | число букв а в слове w нечетно }.
определены
как выше в примере 6.1. Рассмотрим язык L={ w | число букв а в слове w нечетно }.
На следующем рисунке показана диаграмма ДКА A, распознающего язык L, и диаграммы
автоматов Ma для ![]() , Mb для
, Mb для ![]() и Mc для
и Mc для ![]() .
.

Рис. 6.1.

Рис. 6.2.
Подставив в A вместо a -переходов автомат Ma, вместо b -переходов автомат Mb и вместо c -переходов автомат Mc, получим представленный на рис. 6.2 недетерминированный
автомат M, распознающий язык ![]() .
На этом рисунке каждая из
.
На этом рисунке каждая из ![]() -петель в состояниях q0 и q1 заменяет
по три
-петель в состояниях q0 и q1 заменяет
по три ![]() -перехода, связанных с Mb.
-перехода, связанных с Mb.
Отметим, что конструкция автомата M в теореме 6.1 удобна для доказательства,
но несколько избыточна.
Без труда можно сократить в ней все ![]() -переходы, склеив
начальные и заключительные состояния автоматов Mi с соответствующими состояниями
автомата A. Например, в автомате на рис. 6.2 можно объединить начальные состояния p00 и p001 с q0, заключительные состояния p201 и p313 с q1 и т.п.
-переходы, склеив
начальные и заключительные состояния автоматов Mi с соответствующими состояниями
автомата A. Например, в автомате на рис. 6.2 можно объединить начальные состояния p00 и p001 с q0, заключительные состояния p201 и p313 с q1 и т.п.
Одним из интересных частных случаев гомоморфизма является проекция.
Определение 6.3.
Пусть ![]() . Проекцией языка L в алфавите
. Проекцией языка L в алфавите ![]() на
подалфавит
на
подалфавит ![]() называется язык
называется язык ![]() получено из некоторого слова
получено из некоторого слова ![]() вычеркиванием всех символов,
не принадлежащих алфавиту
вычеркиванием всех символов,
не принадлежащих алфавиту ![]() .
.
Определим гомоморфизм ![]() следующим образом:
следующим образом: ![]() , если
, если ![]() и
и ![]() , если
, если ![]() . Тогда для всякого языка L в алфавите
. Тогда для всякого языка L в алфавите ![]() имеет место равенство
имеет место равенство ![]() . Отсюда и из предыдущей теоремы 6.1 получаем замкнутость класса автоматных языков
относительно проекции.
. Отсюда и из предыдущей теоремы 6.1 получаем замкнутость класса автоматных языков
относительно проекции.
Предложение 6.2. Для любых алфавитов ![]() и
и ![]() таких, что
таких, что ![]() , и любого
автоматного языка L в алфавите
, и любого
автоматного языка L в алфавите ![]() проекция
проекция ![]() также является автоматным языком.
также является автоматным языком.
Отметим, что для проекции конструкция автомата M для ![]() по ДКА A для L
существенно упрощается: достаточно в A все переходы по символам из
по ДКА A для L
существенно упрощается: достаточно в A все переходы по символам из ![]() заменить на
заменить на ![]() -переходы.
-переходы.
Следующая теорема устанавливает замкнутость класса автоматных языков относительного обращения гомоморфизмов.
Теорема 6.2. Пусть ![]() - произвольный гомоморфизм и L - автоматный язык
в алфавите
- произвольный гомоморфизм и L - автоматный язык
в алфавите ![]() Тогда и язык
Тогда и язык ![]() является автоматным.
является автоматным.
Доказательство Пусть ![]() - ДКА, распознающий
язык L.
Пусть
- ДКА, распознающий
язык L.
Пусть ![]() , Q= {q0, q1, ..., qn} и
, Q= {q0, q1, ..., qn} и ![]() (если
(если ![]() ).
).
Перестроим его в ДКА ![]() с тем же множеством состояний, начальным и
заключительными состояниями, который
распознает язык
с тем же множеством состояний, начальным и
заключительными состояниями, который
распознает язык ![]() .
.
Идея этого построения состоит в том, чтобы переходить из состояния q
в q' по букве ![]() в автомате M, если в автомате A
слово
в автомате M, если в автомате A
слово ![]() переводит q в q'. Если же для
переводит q в q'. Если же для ![]() образ пуст, т.е.
образ пуст, т.е. ![]() , то в автомате M слово a переводит каждое состояние в себя, так как символы a могут встречаться в каждом слове из
, то в автомате M слово a переводит каждое состояние в себя, так как символы a могут встречаться в каждом слове из ![]() в любом месте и в любом количестве.
в любом месте и в любом количестве.
Таким образом, положим для каждой пары ![]() и
и ![]()
![]() , если
, если ![]() и в автомате A
и в автомате A ![]() . Если же
. Если же ![]() , то полагаем
, то полагаем ![]() .
.
Так как A - детерминированный автомат, то функция переходов ![]() определена однозначно и для всех пар
определена однозначно и для всех пар ![]() и
и ![]() . Следовательно, M детерминированный.
. Следовательно, M детерминированный.
Нетрудно показать, что ![]() .
.
Действительно, если слово ![]() , то в M путь
, то в M путь ![]() , несущий это слово ведет в
заключительное состояние
, несущий это слово ведет в
заключительное состояние ![]() . Из определения
. Из определения ![]() следует, что тогда в A существует
соответствующий путь из q0 в
следует, что тогда в A существует
соответствующий путь из q0 в ![]() , который несет слово
, который несет слово ![]() . Следовательно,
. Следовательно, ![]() .
.
Обратно, пусть ![]() . Тогда слово
. Тогда слово ![]() и в автомате A имеется путь,
несущий u, который переводит q0 в некоторое заключительное состояние
и в автомате A имеется путь,
несущий u, который переводит q0 в некоторое заключительное состояние ![]() .
Зафиксируем на этом пути состояния
.
Зафиксируем на этом пути состояния ![]() , в которые он попадает после
прочтения префиксов
, в которые он попадает после
прочтения префиксов ![]() слова u (j = 1, 2, ... , k).
Тогда
слова u (j = 1, 2, ... , k).
Тогда ![]() и для всех j = 1, 2, ... , k имеет место
и для всех j = 1, 2, ... , k имеет место ![]() . Отсюда и из определения
. Отсюда и из определения ![]() получаем, что в M для всех j = 1, 2, ... , k имеет место переход ха один шаг
получаем, что в M для всех j = 1, 2, ... , k имеет место переход ха один шаг ![]() . Следовательно, в M путь q0, q{i1}q{i2}... q{ik}
несет слово w и завершается в заключительном состоянии
. Следовательно, в M путь q0, q{i1}q{i2}... q{ik}
несет слово w и завершается в заключительном состоянии ![]() .
А это означает, что
.
А это означает, что ![]() .
.
Пример 6.3. Пусть алфавиты ![]()
![]() и гомоморфизм
и гомоморфизм ![]() определены
как выше в примере:
определены
как выше в примере: ![]() .
Рассмотрим язык L={ w | число букв 0 в слове w нечетно, а число букв 1 - четно}.
.
Рассмотрим язык L={ w | число букв 0 в слове w нечетно, а число букв 1 - четно}.
На следующем рисунке показана диаграмма ДКА A, распознающего язык L.
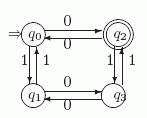
Рис. 6.3. Автомат A: L(A)=L
Применив к этому автомату конструкцию из теоремы 6.2, обнаружим, что a и b оставляют все состояния на месте, а c переводит каждое состояние в соседнее состояние "по горизонтали". В результате получаем автомат M, показанный ниже на рис. 6.4.
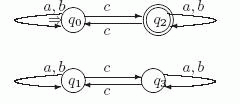
Рис. 6.4. Диаграмма автомата M, распознающего язык phi^-1(L)
Легко заметить, что в нем состояния q2 и q3 недостижимы из начального состояния q0 и что этот автомат M распознает язык
Имеется еще много операций, относительно которых замкнут класс автоматных языков. Некоторые из них приведены далее в разделе задач.
Теорема о разрастании для автоматных языков
До сих пор мы встречались лишь с автоматными языками и накопили достаточно много средств для доказательства того, что некоторый язык является автоматным. Для этого, например, достаточно построить для него регулярное выражение или получить его с помощью различных рассмотренных выше операций из заведомо автоматных языков. В этом разделе мы установим некоторое необходимое условие, которому удовлетворяют все автоматные языки. После этого, проверив, что некоторый язык этому условию не удовлетворяет, можно заключить, что он не является автоматным.
Теорема 6.3. (о разрастании для автоматных языков)
Пусть L - бесконечный автоматный язык. Тогда существует такая константа n, что любое слово ![]() длины |w| > n можно разбить на три части x, y и z так, что w = xyz и
длины |w| > n можно разбить на три части x, y и z так, что w = xyz и
- |xy| <= n ;
- |y| > 0 ;
- для любого m >= 0 слово wm = x ym z принадлежит языку L.
(Здесь ![]() ).
).
Доказательство Так как язык L автоматный, то существует ДКА ![]() , распознающий L.
Пусть |Q|= n и слово
, распознающий L.
Пусть |Q|= n и слово ![]() имеет длину k > n. Рассмотрим путь
имеет длину k > n. Рассмотрим путь ![]() в диаграмме A, который несет слово w. Очевидно, что среди первых (n+1) состояний этого
пути хотя бы одно встречается дважды. Выберем первое из таких состояний
в диаграмме A, который несет слово w. Очевидно, что среди первых (n+1) состояний этого
пути хотя бы одно встречается дважды. Выберем первое из таких состояний ![]() . Тогда для
некоторой пары чисел l < j <= n имеем
. Тогда для
некоторой пары чисел l < j <= n имеем ![]() . Пусть x=w1w2 ... wl - это префикс w, который переводит q0 в
. Пусть x=w1w2 ... wl - это префикс w, который переводит q0 в ![]() ,
, ![]() - это подслово w, которое переводит
- это подслово w, которое переводит ![]() в
в ![]() , и
, и ![]() - это суффикс w, который переводит
- это суффикс w, который переводит ![]() в
в ![]() . x и z могут быть пусты, но |y| = j-l >= 1.
Длина |xy| = j <= n. Таким образом, условия (1) и (2) теоремы выполнены.
Нетрудно убедиться и в выполнении условия (3). Действительно, выбросив из пути p
цикл
. x и z могут быть пусты, но |y| = j-l >= 1.
Длина |xy| = j <= n. Таким образом, условия (1) и (2) теоремы выполнены.
Нетрудно убедиться и в выполнении условия (3). Действительно, выбросив из пути p
цикл ![]() , получим путь p0 из q0 в
, получим путь p0 из q0 в ![]() , который несет
слово xz, а повторив этот цикл m раз, получим путь p0 из q0 в
, который несет
слово xz, а повторив этот цикл m раз, получим путь p0 из q0 в ![]() , который несет
слово xym z. Следовательно, для любого m >= 0
, который несет
слово xym z. Следовательно, для любого m >= 0 ![]() .
.
Содержательно, эта теорема утверждает, что у всякого достаточно длинного слова из автоматного языка имеется непустое подслово, которое можно вырезать или повторить сколько угодно раз, оставаясь внутри языка. Как, используя теорему ref{th-razr}, доказать, что некоторый язык L не является автоматным? Это можно сделать, используя схему доказательства "от противного":
- Предположим, что L автоматный язык. Тогда для него имеется константа n из утверждения теоремы ref{th-razr}.
- Определим по n некотрое "специальное" слово w из L длины > n и докажем, что для любого разбиения w = xyz, удовлетворяющего условиям (1) и (2) теоремы, найдется такое k >= 0, что слово wk=xyk z не принадлежит L.
- На основании полученного противоречия делаем вывод, что L - не автоматный язык.
Разумеется, в этой схеме самым сложным является выбор "специального" слова w в пункте
(2). Что касается, подбора такого k >= 0, для которого ![]() , то, как правило,
достаточно рассмотреть k = 0 или k = 2.
, то, как правило,
достаточно рассмотреть k = 0 или k = 2.
Примеры неавтоматных языков
Рассмотрим несколько примеров применения теоремы о разрастании.
Пример 6.4. Покажем, что язык L1 ={ w =0i 1i | i >= 1 } не является автоматным.
Предположим, что он автоматный. Тогда для него имеется n из утверждения теоремы 6.3.
Рассмотрим следующее ("специальное" !) слово w = 0n 1n. Очевидно, что ![]() .
Предположим, что существует разбиение w = xyz, удовлетворяющего условиям
(1) и (2) теоремы. Так как по условию (2) |xy| <= n, то y = 0i для некоторого i>0.
Но тогда слово
.
Предположим, что существует разбиение w = xyz, удовлетворяющего условиям
(1) и (2) теоремы. Так как по условию (2) |xy| <= n, то y = 0i для некоторого i>0.
Но тогда слово ![]() , что противоречит условию (3) теоремы.
Следовательно язык L1 не автоматный.
, что противоречит условию (3) теоремы.
Следовательно язык L1 не автоматный.
Пример 6.5. Покажем, что язык СКОБ правильных скобочных последовательностей в алфавите { (, ) } не является автоматным.
Схема доказательства та же. В качестве специального слова выберем слово w = (n )n, оно, очевидно, принадлежит СКОБ. Тогда для всякого разбиения w = xyz такого, что |xy| <= n слово y = (i для некоторого i>0. И, как и в предыдущем
примере, слово ![]() , что противоречит условию (3) теоремы. Следовательно, язык СКОБ не автоматный.
, что противоречит условию (3) теоремы. Следовательно, язык СКОБ не автоматный.
Пример 6.6. Покажем, что язык L2 ={ w =0i 1j | i <= 2j+1 } не является автоматным.
Здесь, предположив, что L2 автоматный язык и зафиксировав константу n из теоремы 6.3, рассмотрим слово ![]() . Для всякого разбиения w = xyz такого, что |xy| <= n слово y = 0i для некоторого i>0.
Рассмотрим слово w2 = x y2 z = 0{2n+1+i}1n. Но
. Для всякого разбиения w = xyz такого, что |xy| <= n слово y = 0i для некоторого i>0.
Рассмотрим слово w2 = x y2 z = 0{2n+1+i}1n. Но ![]() .
Следовательно,
.
Следовательно, ![]() и язык L2 не является автоматным.
и язык L2 не является автоматным.
Пример 6.7. Рассмотрим язык "квадратов" в унарном алфавите { | }:
Здесь, предположив, что L3 автоматный язык и зафиксировав константу n из
теоремы 6.3, рассмотрим слово w = |{n2}.
Для всякого разбиения w = xyz такого, что |xy| <= n слово y = |i для некоторого 0 < i <= n.
Тогда ![]() . Но n2 - i >= n2 -n > n2 -2n +1 =(n-1)2.
Следовательно, n2 - i не является полным квадратом и
. Но n2 - i >= n2 -n > n2 -2n +1 =(n-1)2.
Следовательно, n2 - i не является полным квадратом и ![]() ,
т.е. язык "квадратов" L3 не является автоматным.
,
т.е. язык "квадратов" L3 не является автоматным.
Пример 6.8. Рассмотрим язык "простых чисел" в унарном алфавите { | }:
Предположим, что Lpr - автоматный язык и зафиксируем для него константу n из
теоремы 6.3. Выберем простое число p > n и рассмотрим слово w = |p.
Пусть w = xyz - произвольное разбиение w такое, что |xy| <= n. Тогда для некоторого 0 < i <= n
слово y = |i и xz = |p -i. Положим k = p - i и рассмотрим слово wk = x yk z. Его длина p' равна |x| +k|y| + |z|= (p-i)(i+1). Так как 1 <= i < n+1 <= p,
то p' - составное число и ![]() . Следовательно, Lpr - не автоматный язык. Заметим, что в этом примере k выбирается для каждого n
по-своему.
. Следовательно, Lpr - не автоматный язык. Заметим, что в этом примере k выбирается для каждого n
по-своему.
Еще один прием доказательства неавтоматности языка L состоит в том, чтобы вместо L рассмотреть некоторый язык L' = op(L,L1,... , Lk), полученный из L и автоматных языков L1,... , Lk с помощью операций op, сохраняющих автоматность. Если доказать, что L' не является автоматным, то и исходный язык L не автоматен.
Пример 6.9. Рассмотрим язык ![]() .
.
Пусть L5= {0i1j | i >= 1, j >= 1}.
Очевидно, что язык L5 автоматный.
Нетрудно заметить, что его пересечение с дополнением L4 совпадает с языком L1
из примера 6.4, т.е. ![]() .
Так как мы установили, что L1 не автоматный, то и L4 не является автоматным.
.
Так как мы установили, что L1 не автоматный, то и L4 не является автоматным.
Являются ли условия теоремы 6.3 достаточными для того, чтобы язык оказался автоматным? Следующий пример показывает, что ответ на этот вопрос отрицателен.
Пример 6.10.Пусть L6 ={cr ai bi | r >= 1 , i>= 0 }, L7= { aibj | i >= 0, j >= 0}.
Рассмотрим язык ![]() .
.
Для этого языка можно в качестве n выбрать 1. Каждое слово w из L8 принадлежит L6 или L7. Если слово ![]() , то оно
представимо в виде xyz, где
, то оно
представимо в виде xyz, где ![]() .
Тогда w0 = z= cr-1 ai bi ( r >= 1, i >= 1 ) и при r=1 слово
.
Тогда w0 = z= cr-1 ai bi ( r >= 1, i >= 1 ) и при r=1 слово ![]() ,
а при r > 1, очевидно,
,
а при r > 1, очевидно, ![]() . При k >= 1 имеем
. При k >= 1 имеем ![]() .
Если слово
.
Если слово ![]() и i >= 1, то его можно представить как
в виде xyz, где
и i >= 1, то его можно представить как
в виде xyz, где ![]() и для каждого k>= 0
и для каждого k>= 0 ![]() . Если же i =0, то w= bj ( j >= 1 ) и его можно разбить
на части
. Если же i =0, то w= bj ( j >= 1 ) и его можно разбить
на части ![]() . И в этом случае
для каждого k >= 0
. И в этом случае
для каждого k >= 0 ![]() . Во всех случаях
. Во всех случаях ![]() и, следовательно
язык L8 удовлетворяет условиям теоремы 6.3. Но этот язык не автоматный.
Действительно, пусть
и, следовательно
язык L8 удовлетворяет условиям теоремы 6.3. Но этот язык не автоматный.
Действительно, пусть ![]() - это гомоморфизм,
заданный как
- это гомоморфизм,
заданный как ![]() .
Тогда
.
Тогда ![]() из примера 6.4. Так как язык L7 является автоматным, а L1 - нет, то и язык L8 не является автоматным.
из примера 6.4. Так как язык L7 является автоматным, а L1 - нет, то и язык L8 не является автоматным.
Задачи
Задача 6.1. Примените процедуру детерминизации из теоремы 4.2 и постройте ДКА, эквивалентный построенному выше в примере 6.2 НКА M.
Задача 6.2. Цилиндрификация - это операция, которая обратна проекции.
Для любых алфавитов ![]() и
и ![]() таких, что
таких, что ![]() , и любого
языка L в алфавите
, и любого
языка L в алфавите ![]() определим его цилиндрификацию
как язык
определим его цилиндрификацию
как язык ![]() .
.
Показать, что для автоматного языка L язык ![]() также является автоматным языком. Предложите процедуру перестройки автомата,
распознающего L , в автомат, распознающий
также является автоматным языком. Предложите процедуру перестройки автомата,
распознающего L , в автомат, распознающий ![]() .
.
Задача 6.3.
Обращением слова ![]() называется слово w{-1}= wk ... w2 w1. Показать, что для автоматного языка L его обращение - язык
называется слово w{-1}= wk ... w2 w1. Показать, что для автоматного языка L его обращение - язык ![]() также является автоматным языком.
также является автоматным языком.
Задача 6.4.
Пусть L - автоматный язык в алфавите ![]() Доказать, что автоматными
являются и следующие языки:
Доказать, что автоматными
являются и следующие языки:
 .
. .
. .
. .
.
Задача 6.5. Пусть L - автоматный язык в алфавите ![]() ,
а L1,..., Lm - это автоматные языки в алфавите
,
а L1,..., Lm - это автоматные языки в алфавите ![]() Доказать, что автоматным является
и язык ЗАМ(L), полученный из слов L заменой каждой буквы ai на некоторое слово из Li, т.е.
Доказать, что автоматным является
и язык ЗАМ(L), полученный из слов L заменой каждой буквы ai на некоторое слово из Li, т.е. ![]() и такие слова
и такие слова ![]() ,
что
,
что ![]() для всех j=1,2,... n }.
для всех j=1,2,... n }.
Задача 6.6. Пусть L - автоматный язык в алфавите ![]() k - целое положительное число и
k - целое положительное число и ![]() - отображение
- отображение ![]() в
в ![]() Доказать, что автоматным является язык
Доказать, что автоматным является язык ![]() .
.
Задача 6.7. Докажите, что теорема 6.3 о разрастании остается справедливой и при замене условия 1) |xy| <= n на условие 1') |yz| <= n, т.е. повторяющееся подслово y имеется и в суффиксе w длины <= n.
Задача 6.8. Доказать, что следующие языки в алфавите ![]() не являются автоматными.
не являются автоматными.
- Множество всех слов, в которых букв a на 3 больше, чем букв b.
- L={ ancbm | m > 3n }.
- L={ wcw-1 | w =a2bna для некоторого n > 0}.
- L={ w | |w| = 2n для некоторого целого числа n }.
 .
.
Задача 6.9. ![]() -выражение - это либо
переменная x, или символ
-выражение - это либо
переменная x, или символ ![]() за которым следует переменная,
а далее либо
за которым следует переменная,
а далее либо ![]() -выражение, либо левая скобка,
-выражение, либо левая скобка, ![]() -выражение, еще одно
-выражение, еще одно ![]() -выражение
и правая скобка.
Например,
-выражение
и правая скобка.
Например, ![]() - это правильные
- это правильные ![]() -выражения, а
-выражения, а ![]() и
и ![]() - неправильные.
Докажите, что язык
- неправильные.
Докажите, что язык ![]() -выражений в алфавите
-выражений в алфавите ![]() не является автоматным.
не является автоматным.
Задача 6.10. Выше в задаче строился автомат-распознаватель, который проверял правильность сложения двоичных чисел. Докажите, что для операции умножения двоичных чисел такого автомата не существует, т.е. что язык в алфавите троек битов U = {(x1(1),x2(1),y(1)) (x1(2),x2(2),y(2)) ... (x1(n),x2(n),y(n)) | y = y(n) ... y(2)y(1) - это первые n битов произведения двоичных чисел x1= x1(n)... x1(2)x1(1) и x2 = x2(n)... x2(2)x2(1)} не является автоматным.
Задача 6.11.
Доказать, что язык ![]() в алфавите
в алфавите ![]() не является автоматным.
не является автоматным.
Лекция 7. Алгоритмы: структурированные программы
Что такое алгоритм?
Первоначальной целью теории алгоритмов является классификация всех задач на
алгоритмически разрешимые и неразрешимые, т.е. на те, для которых
существуют решающие их алгоритмы, и те, для которых таких алгоритмов нет.
Неформально под алгоритмом ![]() можно понимать выраженный
в некотором языке набор правил (предписание, рецепт, способ),
позволяющий применить к исходным (входным) данным x из некоторого
множества допустимых данных X последовательность дискретных действий
(операций, команд), приводящую к определенному результату - выходным данным
можно понимать выраженный
в некотором языке набор правил (предписание, рецепт, способ),
позволяющий применить к исходным (входным) данным x из некоторого
множества допустимых данных X последовательность дискретных действий
(операций, команд), приводящую к определенному результату - выходным данным ![]() из некоторого множества Y.
В этом случае говорят, что алгоритм
из некоторого множества Y.
В этом случае говорят, что алгоритм ![]() вычисляет функцию
вычисляет функцию ![]() типа X -> Y.
Это нестрогое определение вполне подходит в тех
случаях, когда для некоторой функции нам предъявляется "объект",
называемый алгоритмом ее вычисления (например, алгоритм Эвклида
для вычисления наибольшего общего делителя двух целых чисел),
и можно легко проверить, позволяет ли он действительно вычислить требуемую
функцию. Однако оно совершенно не годится для доказательства того, что
для заданной функции никакого алгоритма нет.
типа X -> Y.
Это нестрогое определение вполне подходит в тех
случаях, когда для некоторой функции нам предъявляется "объект",
называемый алгоритмом ее вычисления (например, алгоритм Эвклида
для вычисления наибольшего общего делителя двух целых чисел),
и можно легко проверить, позволяет ли он действительно вычислить требуемую
функцию. Однако оно совершенно не годится для доказательства того, что
для заданной функции никакого алгоритма нет.
Начиная с тридцатых годов ХХ века, был предпринят ряд исследований для
формализации понятия алгоритма. Перечислим некоторые из предложенных
разными авторами в разное время формальных
моделей: машины Тьюринга-Поста, частично-рекурсивные функции (Гедель, Клини), ![]() -исчисление (Черч, Клини), итеративные автоматы Неймана,
нормальные алгорифмы Маркова,
счетчиковые автоматы Минского, автоматы на графах Колмогорова-Барздиня и др.
Заложенные в них идеи в значительной степени повлияли затем на архитектуру и
языки программирования реальных компьютеров (например, на базе
-исчисление (Черч, Клини), итеративные автоматы Неймана,
нормальные алгорифмы Маркова,
счетчиковые автоматы Минского, автоматы на графах Колмогорова-Барздиня и др.
Заложенные в них идеи в значительной степени повлияли затем на архитектуру и
языки программирования реальных компьютеров (например, на базе ![]() -исчисления
построен широко применяемый в задачах искусственного интеллекта язык ЛИСП,
а из нормальных алгорифмов Маркова произошел хорошо подходящий для
текстовой обработки язык РЕФАЛ). Каждый из многочисленных языков
программирования также
задает некоторую формальную модель алгоритмов. Мы вначале рассмотрим один из
простейших таких языков - простые структурированные программы.
А затем сравним их с двумя
другими моделями алгоритмов: описаниями частично рекурсивных функций и машинами Тьюринга.
-исчисления
построен широко применяемый в задачах искусственного интеллекта язык ЛИСП,
а из нормальных алгорифмов Маркова произошел хорошо подходящий для
текстовой обработки язык РЕФАЛ). Каждый из многочисленных языков
программирования также
задает некоторую формальную модель алгоритмов. Мы вначале рассмотрим один из
простейших таких языков - простые структурированные программы.
А затем сравним их с двумя
другими моделями алгоритмов: описаниями частично рекурсивных функций и машинами Тьюринга.
Хотя алгоритмы в разных прикладных областях имеют дело с дискретными объектами различных видов: целыми и рациональными числами, строками, формулами, разного рода выражениями, графами, матрицами, таблицами, точечными изображениями и др., мы в этой части курса будем рассматривать только задачи вычисления функций от натуральных аргументов, принимающих натуральные значения. Такие функции часто называют арифметическими. Дело в том, что для любого естественного множества дискретных объектов (в частности, для всех перечисленных выше) имеется простое кодирование его элементов целыми числами. Поэтому задачи вычисления функций на этих множествах превращаются в задачи вычисления арифметических функций.
Напомним, что через N обозначается
множество натуральных чисел, т.е. N={0,1,2,...}.
Для частичной n - местной арифметической функции f: Nn -> N через ![]() обозначим область ее определения. Чтобы указать, что f не определена
на некотором наборе чисел a1,..., an будем писать
обозначим область ее определения. Чтобы указать, что f не определена
на некотором наборе чисел a1,..., an будем писать ![]() ,
а если f на этом наборе определена, то будем писать
,
а если f на этом наборе определена, то будем писать ![]() .
Таким образом,
.
Таким образом, ![]() .
.
Структурированные программы
В этом разделе рассмотрим в качестве средства описания алгоритмов структурированные программы. Они вычисляют функции, используя минимальные средства: элементарные присваивания, условные операторы и циклы.
Определим вначале синтаксис структурированных программ. Зафиксируем для этого некоторое счетное множество имен переменных Var, которые будут использоваться в программах. Как обычно, будем считать, что оно включает имена x, x1,x2,..., y, y1,..., z,z1,... и т.п. В последующих определениях x, y, z - это произвольные переменные из Var.
Определение 7.1. Оператор присваивания. Присваивание - это выражение одного из следующих трех видов:
- x := x+1
- x := 0
- x := y.
Определение 7.2. Условия. Условие - это выражение одного из двух видов:
а) x = y или б) x < y.
Структурированные программы определяются индуктивно.
Определение 7.3. Структурированные программы.
- Каждое присваивание - это структурированная программа.
- Если
 и
и  - структурированные программы, то и
- структурированные программы, то и  - это структурированная программа.
- это структурированная программа. Если
и - структурированные программы, а - это условие, то
является структурированной программой.
Если
- структурированная программа, а - это условие, то
все является структурированной программой.
- Других структурированных программ нет.
Конструкция в п. (б) называется последовательным применением или композицией программ ![]() и
и ![]() , конструкция в п. (в)
называется условным оператором ; конструкция в п.
(г) - это оператор цикла,
, конструкция в п. (в)
называется условным оператором ; конструкция в п.
(г) - это оператор цикла, ![]() - условие цикла, а
- условие цикла, а ![]() - тело цикла.
- тело цикла.
С помощью структурированных программ (далее называемых просто программами)
вычисляются (частичные) функции от натуральных аргументов, принимающие натуральные
значения. С каждой программой ![]() свяжем естественным образом
множество входящих в нее переменных
свяжем естественным образом
множество входящих в нее переменных ![]() (определите это множество индукцией по построению программы).
В процессе работы программа изменяет значения этих переменных. Операционная семантика задает правила такого изменения.
(определите это множество индукцией по построению программы).
В процессе работы программа изменяет значения этих переменных. Операционная семантика задает правила такого изменения.
Определение 7.4. Состояние - это отображение ![]() из множества переменных Var во множество N.
Для
из множества переменных Var во множество N.
Для ![]() через
через ![]() обозначим значение переменной x в состоянии
обозначим значение переменной x в состоянии ![]() Через S обозначим множество всех состояний.
Через S обозначим множество всех состояний.
Разумеется, при рассмотрении конкретной программы ![]() нас будут интересовать значения переменных из
нас будут интересовать значения переменных из ![]() .
.
Определение 7.5. Операционная семантика программы ![]() - это отбражение (вообще говоря, частичное) типа S -> S, которое программа
- это отбражение (вообще говоря, частичное) типа S -> S, которое программа ![]() индуцирует на множестве всех состояний. Через
индуцирует на множестве всех состояний. Через ![]() обозначим состояние - результат применения программы
обозначим состояние - результат применения программы ![]() к состоянию
к состоянию ![]() .
Оно определяется индукцией по построению программы.
.
Оно определяется индукцией по построению программы.
 , где
, где  при
при  , и
, и  .
. , где при , и
, где при , и  .
. , где
, где  при
при  , и
, и 
- Пусть
 . Тогда
. Тогда  , при этом, если
, при этом, если  или
или  и
и  , то и
, то и  .
. Пусть
 если x = y то иначе конец. Тогда
если x = y то иначе конец. Тогда
Пусть
если x < y то иначе конец. Тогда
- Пусть пока x = y делай все. Тогда при

 , а при
, а при  - это первое такое состояние
- это первое такое состояние  в последовательности состояний
в последовательности состояний  ., что при i <= m все состояния
., что при i <= m все состояния  определены, при i <m имеет место
определены, при i <m имеет место  , и
, и  .
. - Семантику для цикла с условием x < y определите самостоятельно (см. задачу 7.1).
Пусть ![]() - программа,
- программа, ![]() - множество ее переменных. Выделим среди эти переменных некоторое подмножество входных переменных x1,..., xn и одну результирующую (выходную) переменную y (она может быть одной из входных). Переменные из
- множество ее переменных. Выделим среди эти переменных некоторое подмножество входных переменных x1,..., xn и одну результирующую (выходную) переменную y (она может быть одной из входных). Переменные из ![]() , не являющиеся входными,
будем называть вспомогательными.
, не являющиеся входными,
будем называть вспомогательными.
Определение 7.6.
Программа ![]() с входными переменными x1,..., xn и результирующей переменной y вычисляет частичную функцию F: n -> ,
если для любого набора значений аргументов
с входными переменными x1,..., xn и результирующей переменной y вычисляет частичную функцию F: n -> ,
если для любого набора значений аргументов ![]() ,
она переводит начальное состояние
,
она переводит начальное состояние ![]() в котором
в котором ![]() при 1<= i<= n и
при 1<= i<= n и ![]() при
при ![]() ,
в состояние
,
в состояние ![]() тогда и только тогда, когда
тогда и только тогда, когда ![]() и
и ![]() .
.
Функцию, вычисляемую программой ![]() с входными переменными x1,..., xn в (результирующей) переменной y, обозначим
с входными переменными x1,..., xn в (результирующей) переменной y, обозначим ![]() .
.
Арифметическая функция F(x1, ..., xn) программно вычислима, если
она вычислима некоторой программой ![]() в некоторой переменной y
при некотором разбиении переменных
в некоторой переменной y
при некотором разбиении переменных ![]() на входные: x1,..., xn
и вспомогательные.
на входные: x1,..., xn
и вспомогательные.
Заметим, что в нашем языке нет понятия процедуры (подпрограммы).
Для сокращения записи мы будем иногда использовать имя одной
ранее написанной программы внутри текста другой: ![]() . Такая запись будет означать текстовую (in-line) подстановку текста (кода) программы
. Такая запись будет означать текстовую (in-line) подстановку текста (кода) программы ![]() в соответствующее место программы
в соответствующее место программы ![]() Подчеркнем, что при этом переменные
Подчеркнем, что при этом переменные ![]() не переименовываются и программист сам должен заботиться о правильной инициализации переменных из
не переименовываются и программист сам должен заботиться о правильной инициализации переменных из ![]() .
Например, если
.
Например, если ![]() использует отдельно написанную программу
использует отдельно написанную программу ![]() из приведенного ниже примера 7.3 для сложения переменных a и b и получения результата в t, то "безопасный" и корректный способ
сделать это может выглядеть так:
из приведенного ниже примера 7.3 для сложения переменных a и b и получения результата в t, то "безопасный" и корректный способ
сделать это может выглядеть так:
т.е. вначале сохраняются текущие значения переменных x,y,z,
используемых в ![]() , затем входным переменным x и y присваиваются
нужные значения a и b и вызывается
, затем входным переменным x и y присваиваются
нужные значения a и b и вызывается ![]() , ее результат передается в t,
затем восстанавливаются значения x,y,z.
, ее результат передается в t,
затем восстанавливаются значения x,y,z.
Рассмотрим несколько примеров программ.
Пример 7.1.
![]()
Ясно, что ![]() тождественно равна 0.
тождественно равна 0.
Пример 7.2.
![]()
А здесь ![]() для любого x.
для любого x.
Пример 7.3.
![]()
Зафиксируем входные переменные x, y и выходную переменную x
( z - рабочая переменная ). Легко показать, что ![]() .
.
Действительно, при y=0 тело цикла не выполняется и выход равен x=x+0. При y >= 1 тело цикла выполняется y раз и при каждом его выполнении x увеличивается на 1.
Пример 7.4.
![]() вычисляет в x1 функцию
выбора i-го аргумента:
вычисляет в x1 функцию
выбора i-го аргумента: ![]() .
.
Пример 7.5.
Нетрудно понять, что ![]() вычисляет нигде не определенную
функцию от n переменных:
вычисляет нигде не определенную
функцию от n переменных: ![]() .
.
Задачи
Задача 7.1. Определите (по аналогии с п. (ж)) определения 7.5 семантику для программ вида
![]() пока x < y делай
пока x < y делай ![]() все.
все.
Задача 7.2.Построить структурированные программы, вычисляющие в z следующие функции, и доказать их корректность:
- f{x}(x,y)= x*y;
- ffact(x)= x!;
- f-1(x)= x
 1, где 0 1 = 0 и (x+1) 1 = x ;
1, где 0 1 = 0 и (x+1) 1 = x ; - f-(x,y)= x y, где x y = x-y, если x >= y и x y=0, если x < y ;
- fsqr(x)= [sqrt x];
- fexp(x)= 2x;
- flog(x)= [log2x];
- f/(x,y)= [x/y].
Задача 7.3.
Пусть ![]() - структурированная программа и
- структурированная программа и ![]() . Из определений
следует, что при различной фиксации входных переменных и выходной переменной
программа может вычислять различные функции.
. Из определений
следует, что при различной фиксации входных переменных и выходной переменной
программа может вычислять различные функции.
- Каково максимальное число функций от n <= m переменных, которое может вычислять
 Сколько всего разных функций может вычислить
Сколько всего разных функций может вычислить - Постройте программу
 , которая вычисляет максимальное число различных функций от n <= m переменных.
, которая вычисляет максимальное число различных функций от n <= m переменных. - Постройте программу
 с
с  , которая для каждого n <= m вычисляет максимальное число различных функций от n переменных.
, которая для каждого n <= m вычисляет максимальное число различных функций от n переменных.
Задача 7.4.Построить структурированные программы, вычисляющие в z следующие функции:
Задача 7.5.
Пусть структурированная программа ![]() вычисляет в переменной y некоторую всюду определенную взаимно однозначную функцию f(x), область значений которой
совпадает с множеством всех натуральных чисел N. Пусть
вычисляет в переменной y некоторую всюду определенную взаимно однозначную функцию f(x), область значений которой
совпадает с множеством всех натуральных чисел N. Пусть ![]() .
Постройте структурированную программу, которая вычисляет
обратную функцию f-1(x) = { z | f(z)=x}.
.
Постройте структурированную программу, которая вычисляет
обратную функцию f-1(x) = { z | f(z)=x}.
Задача 7.6. Пусть F(x) задана соотношениями F(0)=1, F(1)=1, F(x+2)= F(x)+F(x+1) (элементы последовательности F(x) называются числами Фибоначчи). Постройте структурированную программу, которая вычисляет функцию F(x).
Лекция 8. Алгоритмы: частично рекурсивные функции
В этом разделе мы изучим алгебраический подход к определению класса вычислимых функций. Каждая вычислимая функция будет получаться из некоторых простейших очевидно вычислимых базисных функций с помощью некоторых операций, вычислимость которых также не вызывает сомнения. Операция, которая дала название этому подходу - рекурсия - это способ задания функции путем определения каждого ее значения в терминах ранее определенных ее значений и других уже определенных функций.
Класс частично рекурсивных функций
Определение рекурсивных функций
Мы будем рассматривать частичные арифметические функции fn(x1, ..., xn): Nn -> N. Здесь верхний индекс n у имени функции f обозначает число ее аргументов ("арность"). Если арность ясна из контекста или несущественна, то этот индекс будем опускать. Определим вначале три оператора, позволяющих по одним функциям получать другие.
Определение 8.1. Суперпозиция. Пусть Fm и f1n,..., fmn - арифметические функции. Скажем, что функция Gn получена из Fm , f1n, ..., fmn с помощью оператора суперпозиции (обозначение: Gn=[Fm;f1n, ..., fmn] ), если для всех наборов аргументов (x1,...,xn)
При этом для каждого набора аргументов (a1, ..., an) функция ![]() (т.е. определена), если определены все значения f1n (a1, ..., an)=b1,..., fmn (a1, ..., an)=bm
и
(т.е. определена), если определены все значения f1n (a1, ..., an)=b1,..., fmn (a1, ..., an)=bm
и ![]() .
.
Определение 8.2. Примитивная рекурсия. Скажем, что функция Fn+1(x1,... ,xn,y) получена с помощью оператора рекурсии из функций gn(x1,..., xn) и hn+2(x1, ..., xn, y, z), если она может быть задана схемой примитивной рекурсии

В этом случае будем писать Fn+1 = R(gn,hn+2).
При этом ![]() и для каждого b
и для каждого b
![]() и
и ![]() .
.
В случае, когда n=0, т.е. F зависит от одного аргумента y, а аргументов x1,...,xn нет, схема примитивной рекурсии принимает вид

где ![]() .
.
Заметим, что если исходные функции в операторах суперпозиции и примитивной рекурсии всюду определены, то и результирующие функции также всюду определены. Следующий оператор позволяет задавать не всюду определенные, т.е. частичные, функции.
Определение 8.3. Минимизация.
Скажем, что функция Fn(x1,... ,xn) получена с помощью оператора минимизации( ![]() -оператора) из функции gn+1(x1,..., xn,y), если Fn(x1,...,xn)
определена и равна y тогда и только тогда, когда все
значения gn+1(x1,..., xn,0),...,gn+1(x1,..., xn,y-1)
определены и не равны 0, а gn+1(x1,..., xn,y)=0.
В этом случае будем писать
-оператора) из функции gn+1(x1,..., xn,y), если Fn(x1,...,xn)
определена и равна y тогда и только тогда, когда все
значения gn+1(x1,..., xn,0),...,gn+1(x1,..., xn,y-1)
определены и не равны 0, а gn+1(x1,..., xn,y)=0.
В этом случае будем писать
Определение 8.4. Простейшие функции. Функция называется простейшей, если она является одной из следующих функций:
- o1(x)=0 - тождественный нуль;
- s1(x)= x+1 - следующее число (плюс один);
- функции выбора аргумента Imn (x1, ... ,xn)=xm (1 <= m <= n).
Заметим, что все простейшие функции вычислимы в интуитивном смысле. Кроме того, операторы суперпозиции, примитивной рекурсии и минимизации таже вычислимы: понятны алгоритмы, по которым из программ для исходных функций можно получить программы для результирующих. Следующее определение вводит интересующий нас класс частично рекурсивных функций и его важные подклассы.
Определение 8.5. Частично рекурсивные функции. Функция f называется частично рекурсивной функцией (ч.р.ф.), если она является одной из простейших функций или может получиться из них с помощью конечного числа применений операторов суперпозиции, примитивной рекурсии и минимизации, т.е. существует последовательность функций f1,f2,..., fn=f, каждая из которых является либо простейшей, либо получена из предыдуших с помощью одного из указанных операторов. Указанная последовательность функций называется частично рекурсивным описанием функции f.
Функция f называется общерекурсивной функцией (о.р.ф.), если она частично рекурсивна и всюду определена.
Функция f называется примитивно рекурсивной функцией (п.р.ф.), если она частично рекурсивна и для нее существует частично рекурсивное описание, использующее лишь операторы суперпозиции и примитивной рекурсии. В таком случае оно называется примитивно рекурсивным описанием функции f.
Нетрудно проверить, что каждая примитивно рекурсивная функция всюду определена, т.е. является общерекурсивной (обратное, вообще говоря, неверно).
Примеры
Приведем некоторые примеры частично рекурсивных функций.
Пример 8.1. Постоянные функции.
Пусть fn(x1,...,xn)=k
для всех наборов аргументов (x1,...,xn) и числа ![]() . Тогда
. Тогда

Пример 8.2. Сложение: +2(x,y)=x+y.
Функция сложения определяется следующей примитивной рекурсией.

Следовательно, +2 =R(I11,[s1;I33]).
Пример 8.3. Умножение: x2(x,y)=x x y.
Используя сложение, умножение можно задать следующей примитивной рекурсией:

Следовательно, x2 =R(o1,[+;I33,I13]).
Пример 8.4. Минус 1: ![]() .
.
Нетрудно проверить, что ![]() .
.
Пример 8.5. Вычитание : ![]() , если x >= y
и
, если x >= y
и ![]() , если x < y.
, если x < y.
Вычитание определяется следующей примитивно рекурсивной схемой:

Следовательно, ![]() .
.
Пример 8.6. Предикаты равенства и неравенства нулю:

Примитивная рекурсивность этих функций следует из равенств ![]() и
и ![]() .
.
Пример 8.7. Модуль разности: ![]() .
.
Пример 8.8. rm(x,y)= остаток от деления y на x (при x=0 положим rm(0,y)=y ).
Заметим, что
Тогда функцию rm(x,y) можно задать примитивно рекурсивной схемой

Правую часть второго равенства легко представить как функцию g(x,y,rm(x,y)), полученную с помощью суперпозиции уже построенных примитивно рекурсивных функций.
Пример 8.9. Нигде не определенная функция ![]() .
.
Эта функция может быть задана, например, соотношением ![]() .
.
Отметим, что все функции в примерах 8.1 - 8.8 являются примитивно рекурсивными.
Программная вычислимость рекурсивных функций
В этом параграфе рассмотрим соотношение между программно вычислимыми и частично рекурсивными функциями. Справедлива следующая
Теорема 8.1. Каждая частично рекурсивная функция программно вычислима.
Доказательство индукцией по определению ч.р.ф.
Базис: программная вычислимость простейших функций была установлена в примерах 1.1, 1.2 и 1.4.
Индукционный шаг: покажем программную вычислимость операторов суперпозиции, примитивной рекурсии и минимизации.
Суперпозиция. Пусть Fm и f1n,..., fmn
- арифметические функции, вычислимые программами ![]() так, что
так, что ![]() , и
, и ![]() при i=1,...,n. Пусть переменные y1, ..., ym, z1,..., zn
не используются в программах
при i=1,...,n. Пусть переменные y1, ..., ym, z1,..., zn
не используются в программах ![]() . Кроме того, пусть все вспомогательные переменные этих программ - это w1, ... , wr. Рассмотрим следующую программу P:
. Кроме того, пусть все вспомогательные переменные этих программ - это w1, ... , wr. Рассмотрим следующую программу P:

В качестве входных переменных зафиксируем x1, ..., xn, а выходной - x1. Пусть в исходном состоянии x1=a1, ..., xn = an. Тогда в первой строке эти значения сохраняются в переменных z1, ..., zn, которые своих значений далее не меняют. Поэтому для каждого i=1,...,m-1 после выполнения фрагмента
значением переменной yi является fin(a1,..., an), x1=a1, ..., xn = an, а значения всех вспомогательных переменных равны 0. Тогда после выполнения
значением каждого xi также является fin(a1,..., an),
а после выполнения ![]() значение x1 равно
значение x1 равно ![]() .
Таким образом,
.
Таким образом, ![]() .
.
Примитивная рекурсия.
Рассмотрим для простоты случай n=1. Пусть функция F2(x1,y) получена с помощью оператора примитивной рекурсии из функций g1(x1) и h3(x1, y, z), т.е. F2 =R(g1,h3).
Предположим, что существуют программы ![]() и
и ![]() , вычисляющие функции g1 и h3 так, что
, вычисляющие функции g1 и h3 так, что ![]() и
и ![]() .
Пусть вспомогательные переменные
.
Пусть вспомогательные переменные ![]() - это z1,..., zm и они не встречаются в
- это z1,..., zm и они не встречаются в ![]() , а переменные u1, y1 и v не используются в программах
, а переменные u1, y1 и v не используются в программах ![]() и
и ![]() .
Рассмотрим программу P:
.
Рассмотрим программу P: ![]() пока v < y1 делай z:=x1; x1:=u1; y:=v;
пока v < y1 делай z:=x1; x1:=u1; y:=v; ![]() все
В качестве входных переменных P возьмем x1 и y,
а выходной - x1.
все
В качестве входных переменных P возьмем x1 и y,
а выходной - x1.
Рассмотрим работу P на исходном состоянии ![]() в котором
в котором ![]() . При b=0 цикл не выполняется и в результирующем состоянии
. При b=0 цикл не выполняется и в результирующем состоянии ![]() имеем
имеем ![]() . При b > 0 цикл будет выполняться b раз, так как в его теле v всякий
раз увеличивается на 1, а значение y1=b и не меняется. Перед первым
выполнением
. При b > 0 цикл будет выполняться b раз, так как в его теле v всякий
раз увеличивается на 1, а значение y1=b и не меняется. Перед первым
выполнением ![]() все ее рабочие переменные zi равны 0, x1=a, y=0, z=F2(a, 0), а после ее выполнения x1=h3(a,0,F(a,0))=F(a,1).
Предположим теперь по индукции, что перед (i+1) -ым выполнением
все ее рабочие переменные zi равны 0, x1=a, y=0, z=F2(a, 0), а после ее выполнения x1=h3(a,0,F(a,0))=F(a,1).
Предположим теперь по индукции, что перед (i+1) -ым выполнением ![]() все ее рабочие переменные zi равны 0, x1=a, y=i и z=F2(a, i).
После этого выполнения x1=h3(a,i,z)=h3(a,i,F(a,i))=F(a,i+1). Тогда присваивания z1:=0; ... ; zm:=0; v:= v+1 после
все ее рабочие переменные zi равны 0, x1=a, y=i и z=F2(a, i).
После этого выполнения x1=h3(a,i,z)=h3(a,i,F(a,i))=F(a,i+1). Тогда присваивания z1:=0; ... ; zm:=0; v:= v+1 после ![]() и z:=x1; x1:=u1; y:=v; перед ее следующим выполнением установят значения переменных
и z:=x1; x1:=u1; y:=v; перед ее следующим выполнением установят значения переменных ![]() так, что все ее рабочие переменные zi равны 0, x1=a, y=i+1 и z=F2(a, i+1). Следовательно, после b -го выполнения тела цикла x1=h3(a,b-1,F(a,b-1))=F(a,b).
так, что все ее рабочие переменные zi равны 0, x1=a, y=i+1 и z=F2(a, i+1). Следовательно, после b -го выполнения тела цикла x1=h3(a,b-1,F(a,b-1))=F(a,b).
Минимизация. Предположим, что функция Fn(x1,... ,xn) получена с помощью оператора минимизации ( mu -оператора) из функции gn+1(x1,..., xn,y), т.е.
Пусть программа ![]() вычисляет gn+1, так что
вычисляет gn+1, так что ![]() ,
и пусть рабочие переменные
,
и пусть рабочие переменные ![]() - это z1,..., zm. Зафиксируем переменные x1',... , xn', y';, u, z, не входяшие в
- это z1,..., zm. Зафиксируем переменные x1',... , xn', y';, u, z, не входяшие в ![]() .
Рассмотрим следующую программу
.
Рассмотрим следующую программу ![]()

Рассмотрим работу ![]() на входных значених xi = ai (i=1,...,n).
В первой строке они сохраняются в переменных x'i, которые
нигде в
на входных значених xi = ai (i=1,...,n).
В первой строке они сохраняются в переменных x'i, которые
нигде в ![]() не изменяются, z получает значение 0, которое тоже не меняется по ходу вычисления,
а u вначале получает значение 1. Поэтому условие цикла после первой строки
истинно и
он хотя бы один раз выполняется.
Докажем, что для каждого i >= 1, (i+1) -ая итерация цикла выполняется
тогда и только тогда, когда g(a1, ..., an,0)=b1 >0, ..., g(a1, ..., an, i-1)=bi-1 > 0,
не изменяются, z получает значение 0, которое тоже не меняется по ходу вычисления,
а u вначале получает значение 1. Поэтому условие цикла после первой строки
истинно и
он хотя бы один раз выполняется.
Докажем, что для каждого i >= 1, (i+1) -ая итерация цикла выполняется
тогда и только тогда, когда g(a1, ..., an,0)=b1 >0, ..., g(a1, ..., an, i-1)=bi-1 > 0, ![]() останавливается после (i+1) -ой итерации цикла с результатом x1=i
тогда и только тогда, когда g(a1, ..., an,i)=0.
При этом
перед выполнением
останавливается после (i+1) -ой итерации цикла с результатом x1=i
тогда и только тогда, когда g(a1, ..., an,i)=0.
При этом
перед выполнением ![]() входные переменные x1,...,xn,y имеют значения a1,...,an, i, соответственно, y'= i, а все рабочие переменные zj (j=1,..., m) равны 0.
входные переменные x1,...,xn,y имеют значения a1,...,an, i, соответственно, y'= i, а все рабочие переменные zj (j=1,..., m) равны 0.
Действительно, предположив это условие, получим, что после очередного выполнения фрагмента
значение u = x1 = g(a1,...,an,i), а рабочие переменные восстанавливают нулевые значения.
Если g(a1,...,an,i)=0, то u=z и в условном операторе x1 получает
значение y'=i. После этого условие цикла нарушено и ![]() завершает работу с выходным
значением x1=i =F(a1,..., an).
Если же g(a1,...,an,i)> 0, то u>z и в условном операторе y' увеличивает значение до (i+1).
Тогда условие цикла выполнено и перед (i+2) -ым выполнением
завершает работу с выходным
значением x1=i =F(a1,..., an).
Если же g(a1,...,an,i)> 0, то u>z и в условном операторе y' увеличивает значение до (i+1).
Тогда условие цикла выполнено и перед (i+2) -ым выполнением ![]() ее входные переменные x1,...,xn,y имеют значения a1,...,an, i+1, соответственно, y'= i+1, а все рабочие переменные равны 0.
ее входные переменные x1,...,xn,y имеют значения a1,...,an, i+1, соответственно, y'= i+1, а все рабочие переменные равны 0.
Из доказанного утверждения непосредственно следует, что
Имеет место и утверждение, обратное теореме 8.1, которое мы приводим здесь без доказательства.
Теорема 8.2. Каждая программно вычислимая функция является частично рекурсивной.
Леммы о рекурсивных функциях
В этом параграфе мы установим примитивную (частичную) рекурсивность некоторых важных классов функций - таблиц и нумераций, и расширим возможности определения функций с помощью суммирования, произведения, разбора случаев и взаимной рекурсии.
Лемма 8.1. Рекурсивность табличных функций. Пусть всюду определенная функция f(x) на всех аргументах, кроме конечного числа, равна некоторой константе c (такую функцию назовем табличной). Тогда она является примитивно рекурсивной.
Доказательство Пусть для функции f из условия леммы ![]() . Доказательство проведем индукцией по nf.
. Доказательство проведем индукцией по nf.
При nf=0 функция f является постоянной и поэтому примитивно рекурсивной (пример 8.1).
Предположим что все табличные функции g со значением ng <= k примитивно рекурсивны и пусть nf = k +1 и f(0)=a. Определим табличную функцию f'(x) = f(x+1). Ясно, что nf' = k, и по предположению индукции f' примитивно рекурсивна. Легко проверить, что тогда f задается следующей схемой:

и, следовательно, также примитивно рекурсивна.
Покажем замкнутость класса ч.р.ф. (п.р.ф.) относительно операций суммирования и произведения.
Лемма 8.2. Суммирование и произведение. Пусть функция f(x1,..., xn, y) является частично (примитивно) рекурсивной. Тогда и функции Fn+1 и Gn+1, заданные следующими равенствами


является частично (примитивно) рекурсивными.
Доказательство Действительно, эти функции задаются следующими примитивно рекурсивными схемами:


Приведем примеры использования леммы 8.2.
Пример 8.10. max_deg_div(x,y) = максимальная степень x, на которую нацело делится y.
Пусть exp(x,y) - экспоненциальная функция: exp(x,y) = xy. Ее примитивную рекурсивность легко установить, используя функцию умножения (см. задачу 8.1 (а) ). Тогда нетрудно проверить, что искомая функция задается соотношением

и, следовательно, является примитивно рекурсивной.
Пример 8.11. Ограниченная минимизация. Пусть примитивно рекурсивная функция g(x,y) такова, что для каждого x найдется y <= x, для которого g(x,y) =0. Положим F(x) = mu y [g(x,y) = 0].
Тогда, по определению, F(x) является частично рекурсивной функцией.
Покажем, что, на самом деле, она примитивно рекурсивна. Действительно,
определим ![]() . По лемме 8.2 эта функция
примитивно рекурсивна.
Пусть для данного x
. По лемме 8.2 эта функция
примитивно рекурсивна.
Пусть для данного x ![]() .
Тогда при i < y0 имеем h(x,i) = 1, а при i >= y0 h(x,i) =0. Поэтому искомая функция F задается равенством
.
Тогда при i < y0 имеем h(x,i) = 1, а при i >= y0 h(x,i) =0. Поэтому искомая функция F задается равенством ![]() и также является примитивно рекурсивной.
и также является примитивно рекурсивной.
Лемма 8.3. Кусочное задание или разбор случаев. Пусть h1(x1,...,xn), ..., hk(x1,...,xn) - произвольные ч.р.ф., а всюду определенные ч.р.ф. f1(x1,...,xn), ..., fk(x1,...,xn) таковы, что на любом наборе аргументов (a1, ..., an) одна и только одна из этих функций равна 0. Тогда функция g(x1,..., xn), определенная соотношениями:

является частично рекурсивной.
Доказательство Действительно, gn можно представить как сумму k произведений:
Следующий класс функций, который нас будет интересовать, - это функции для однозначной нумерации пар и n-ок целых чисел и обратные им. Определим для любой пары чисел (x,y) ее номер c2(x,y)=2x(2y+1) - 1. Например, c2(0,0)=0, c2(1,0)=1, c2(0,1)=2, c2(1,1)=5, c2(2,1)= 19. Из единственности разложения чисел на простые множители следует, что функция c2: N2 -> N взаимно однозначно нумерует пары целых чисел. Нетрудно понять, что если c2(x,y) = z, то двоичная запись числа (z+1) имеет следующий вид: (двоичная запись y ) 10x. Из такого представления можно однозначно извлечь значение x и значение y. Эти значения определяются следующими обратными функциями:
Из этих определений непосредственно следует, что для любого z выполнено равенство c2(c21(z), c22(z))=z.
Определим теперь по индукции функции cn нумерации n-ок чисел при n > 2 и обратные им координатные функции cni (1 <= i <= n):

Из этих определений также непосредственно следует, что для любого z имеет место равенство cn(cn1(z), cn2 (z),..., cnn (z))=z. (Проверьте это свойство индукцией по n.)
Лемма 8.4. Рекурсивность нумерационных функций. Для любых n >= 2 и 1 <= i <= n все определенные выше функции cn и cni являются примитивно рекурсивными.
Доказательство Примитивная рекурсивность c2(x,y) устанавливается непосредственно (см. задачу 8.1(а)). Функция c21(z) задается равенством c21(z)= max_deg_div(2,z+1) и является примитивно рекурсивной (это показано в примере 8.10). Для функции c22(z) справедливо определение c22(z) = div(2, div(2 c21(z)}, z+1) - 1) (здесь мы используем примитивную рекурсивность функции целочисленного деления div(x,y) из задачи 8.1(e)). Примитивная рекурсивность остальных нумерационных функций следует по индукции из их определений (см. задачу 8.10).
В следующей лемме обобщается оператор примитивной рекурсии.
Лемма 8.5. (совместная рекурсия) Пpедположим, что фyнкции ![]() и фyнкции
и фyнкции ![]() пpимитивно pекypсивны. Тогда фyнкции f1n+1(x1, ..., xn, y), ..., fkn+1(x1, ..., xn, y),
опpеделяемые следyющей совместной pекypсией
пpимитивно pекypсивны. Тогда фyнкции f1n+1(x1, ..., xn, y), ..., fkn+1(x1, ..., xn, y),
опpеделяемые следyющей совместной pекypсией

(1 <= i <= k) также являются пpимитивно pекypсивными.
Доказательство Обозначим чеpез ![]() набоp пеpеменных x1,...,xn. Опpеделим
следyющие пpимитивно pекypсивные фyнкции:
набоp пеpеменных x1,...,xn. Опpеделим
следyющие пpимитивно pекypсивные фyнкции: ![]() ,
, ![]() , и положим
, и положим

Фyнкция Fn+1 полyчена пpимитивной pекypсией из пpимитивно
pекypсивных фyнкций и, следовательно, сама пpимитивно pекypсивна.
Спpаведливость леммы тепеpь следyет из того, что для всякого ![]() .
.
Задачи
Задача 8.1. Показать, что следующие функции являются частично (примитивно) рекурсивными.
- exp(x,y) = xy ;
- fact(x) = x ,!;
- min(x,y)= наименьшее из x и y ;
- max(x,y)= наибольшее из x и y ;
- div(x,y)= частное от деления y на x (пусть div(0,y)=y ).
предикаты равенства и неравенства:

 .
.
Задача 8.2. Докажите, что если f(x1,...,xn) является ч.р.ф. (п.р.ф.), то и функция g(x1,...,xn)=f(x{i1},...,xin) является ч.р.ф. (п.р.ф.) для любой перестановки (i1, ..., in) чисел 1,2,...,n.
Задача 8.3. Оператор сдвига. Пусть g(x1,..., xn) - частично (примитивно) рекурсивная функция, a и b >0 - числа из N. Тогда и функция
является частично (примитивно) рекурсивной.
Задача 8.4. Показать, что следующие функции являются частично ( примитивно) рекурсивными.
 - корень n -ой степени из x (целая часть).
- корень n -ой степени из x (целая часть). (пусть при
(пусть при  или x= 0 log(i,x) =0 ).
или x= 0 log(i,x) =0 ).- p(x)=1, если x - простое число, и p(x)=0, если x составное.
- pn(k) - k -ое простое число в порядке возрастания (pn(0)=0, pn(1)=2, pn(2)=3, pn(3)=5...).
- t(x) = число pазличных делителей числа x (t(0)=0).
- d(n,m,i) - i -ый знак в m -ичном разложении числа n, т.е. если
 , где 0 <= ai <= m-1, то d(n,m,i)=ai.
, где 0 <= ai <= m-1, то d(n,m,i)=ai. - nod(x, y)= наибольший общий делитель чисел x и y (пусть nod(0,y)=nod(x,0) =0 ).
Задача 8.5. Пусть F(x) задана соотношениями F(0)=1, F(1)=1, F(x+2)= F(x)+F(x+1) ( элементы последовательности F(x) называются числами Фибоначчи). Покажите, что функция F(x) примитивно рекурсивна.
(Указание: покажите сначала, что функция g(x)= 2F(x) 3F(x+1) примитивно рекурсивна.)
Задача 8.6. Докажите, что если значения общерекурсивной функции f(x) изменить на конечном множестве, то получившаяся функция f'(x) также будет общерекурсивной.
Задача 8.7. Доказать, что из функции o(x)=0 и из функций выбора Imn(x1,...,xn)=xm с помощью суперпозиции и примитивной рекурсии нельзя получить функцию s(x)=x+1 и функцию d(x) =2*x.
Задача 8.8. Пусть g(x1,...,xn,y) - примитивно рекурсивна. Доказать, что функция
примитивно рекурсивна.
Задача 8.9. Доказать, что если функции f(x1,...,xn,y), g(x1,...,xn,y) и h(x1,..., xn,y) частично рекурсивны, то и функция
является частично рекурсивной.
Задача 8.10. Докажите, что определенные выше функция нумерации n -ок cn(x1, ... , xn) и обратные ей функции выбора i -го элемента набора cni(z) (1 <= i <= n) являются примитивно рекурсивными.
Задача 8.11. Предположим, что все пары (x,y) натуральных чисел упорядочены по возрастанию суммы (x+y), а внутри группы пар с одинаковой суммой - по возрастанию x -координаты. Этот порядок выглядит так: (0,0), (0,1), (1,0),(0,2),(1,1), (2,0),... , (0,x+y), (1, x+y-1), ... , (x,y), ... , (x+y, 0), ... . Пусть d(x,y) - это номер пары (x,y) в этом порядке (будем считать, что пара (0,0) имеет номер 0). Тогда функция d2 однозначно нумерует все пары.
- Докажите, что
 .
. - Найдите обратные функции d1(z) и d2(z) такие, что d1(d(x,y))=x, d2(d(x,y))= y и, следовательно, d(d1(z), d2(z))=z.
Лекция 9. Алгоритмы: машины Тьюринга
Основные определения
Рассматриваемая в этом разделе модель алгоритмов была предложена английским математиком Тьюрингом в 1937 г. еще до создания современных компьютеров1) Он исходил из общей идеи моделирования работы вычислителя, оперирующего в соответствии с некоторым строгим предписанием. В машине Тьюринга расчленение процесса вычисления на элементарные шаги доведено в известном смысле до предела. Элементарным действием является замена одного символа в ячейке на другой и перемещение к соседней ячейке. При таком подходе процесс вычисления значительно удлиняется, но зато логическая структура процесса сильно упрощается и приобретает удобный для теоретического исследования вид.
Машина Тьюринга (м.Т.) состоит из неограниченной в обе стороны ленты,
разбитой на ячейки, по которой передвигается головка машины.
Такая "бесконечность" ленты является математической абстракцией,
отражающей потенциальную неограниченность памяти вычислителя.
Разумеется, в каждом завершающемся вычислении используется только конечная часть
этой памяти - конечное число ячеек.
В каждой
ячейке ленты записан один символ из конечного внешнего алфавита машины ![]() . Головка машины представляет конечный автомат,
который в каждый момент
времени находится в одном из внутренних состояний Q ={q0,q1,... ,
qn }. На каждом шаге головка в зависимости от своего
внутреннего состояния и символа в ячейке, которую она наблюдает,
изменяет свое внутреннее состояние и содержимое наблюдаемой ячейки
и может сдвинуться на одну ячейку вправо или влево либо остаться
на месте.
. Головка машины представляет конечный автомат,
который в каждый момент
времени находится в одном из внутренних состояний Q ={q0,q1,... ,
qn }. На каждом шаге головка в зависимости от своего
внутреннего состояния и символа в ячейке, которую она наблюдает,
изменяет свое внутреннее состояние и содержимое наблюдаемой ячейки
и может сдвинуться на одну ячейку вправо или влево либо остаться
на месте.
Дадим более формальное определение.
Определение 9.1. Машина Тьюринга - это система вида
включающая следующие компоненты:
- Q ={q0,q1,... ,qn } - внутренний алфавит (алфавит состояний);
 - внешний алфавит (алфавит ленты );
- внешний алфавит (алфавит ленты );P - программа машины, в которой для каждой пары
 имеется (одна!) команда вида
имеется (одна!) команда вида
 задает сдвиг головки вправо, влево или на месте;
задает сдвиг головки вправо, влево или на месте;- - начальное состояние;
 - заключительное состояние.
- заключительное состояние.
Выделим в алфавите ![]() специальный пустой символ
специальный пустой символ ![]() и будем считать, что во всех ячейках ленты, кроме конечного их числа, в начальный и во все последующие моменты находится пустой символ.
и будем считать, что во всех ячейках ленты, кроме конечного их числа, в начальный и во все последующие моменты находится пустой символ.
Будем говорить, что некоторый символ стирается, если он заменяется на пустой. Два слова из ![]() будем считать равными, если они совпадают после
отбрасывания всех пустых символов слева и справа. Например,
будем считать равными, если они совпадают после
отбрасывания всех пустых символов слева и справа. Например, ![]() , но
, но ![]() .
.
Как и для конечных автоматов, программу P можно задавать с помощью таблицы
размера n x m, строки которой соответствуют состояниям из Q,
а столбцы - символам из входного алфавита ![]() в которой на пересечении строки qi и столбца aj стоит тройка qk al C - правая часть команды qi aj -> qk al C.
в которой на пересечении строки qi и столбца aj стоит тройка qk al C - правая часть команды qi aj -> qk al C.
Определение 9.2. Назовем конфигурацией м.Т. ![]() в некоторый момент времени слово K= wл qi aj wп, где
в некоторый момент времени слово K= wл qi aj wп, где ![]() - слово на ленте левее текушего положения головки, qi - внутреннее состояние в данный момент, aj - символ, обозреваемый головкой,
- слово на ленте левее текушего положения головки, qi - внутреннее состояние в данный момент, aj - символ, обозреваемый головкой, ![]() - слово на ленте правее текушего положения головки.
- слово на ленте правее текушего положения головки.
Будем считать, что слово wл aj wп содержит
все значащие символы на ленте. Поэтому, с точностью до
описанного выше равенства слов, конфигурация определена однозначно.
В частности, если ![]() , т.е. пусто, то левее положения головки все ячейки пусты, а если
, т.е. пусто, то левее положения головки все ячейки пусты, а если ![]() , то
правее положения головки все ячейки пусты.
, то
правее положения головки все ячейки пусты.
Начальная конфигурация - это конфигурация вида q0w, т.е. в начальный момент времени головка в состоянии q0 обозревает первый символ входного слова w. { it Заключительная } конфигурация - это конфигурация вида w1 qf w2, в которой машина находится в заключительном состоянии qf.
Определение 9.3. Скажем, что конфигурация K= w1 qi aj w2 м.Т. ![]() за один шаг (такт) переходит в конфигурацию
за один шаг (такт) переходит в конфигурацию ![]() , если в программе имеется команда qi aj -> qk al C и при этом,
, если в программе имеется команда qi aj -> qk al C и при этом,
- если С=Н, то w1'=w1, w2'=w2 и a{j'}=al;
- если С=Л, то w1=w1' a, a{j'}=a, w2'=al w2 (если
 то
то  и
и  );
); - если С=П, то w2=aw2', a{j'}=a, w1'=w1 al (если
 то
то  и ).
и ).
Как обычно, через ![]() обозначим рефлексивное и транзитивное
замыкание отношения
обозначим рефлексивное и транзитивное
замыкание отношения ![]() а
а ![]() будет
означать, что конфигурация K за n шагов переходит в K'.
(Если из контекста ясно, о какой машине идет речь, то
индекс
будет
означать, что конфигурация K за n шагов переходит в K'.
(Если из контекста ясно, о какой машине идет речь, то
индекс ![]() будем опускать).
будем опускать).
Пример 9.1.
Рис. 9.1. Выполнение команды q3 0 -> q5 1 П
Например, ситуации, представленной на рис.9.1 слева соответствует конфигурация ![]() . Предположим, что программа P содержит команду q30 -> q51 П. Тогда после выполнения этой команды K перейдет за один шаг в конфигурацию
. Предположим, что программа P содержит команду q30 -> q51 П. Тогда после выполнения этой команды K перейдет за один шаг в конфигурацию ![]() , показанную на этом рисунке
справа. Следовательно,
, показанную на этом рисунке
справа. Следовательно, ![]() .
.
Определение 9.4. Вычисление м.Т. ![]() на входе w - это конечная или
бесконечная последовательность конфигураций
на входе w - это конечная или
бесконечная последовательность конфигураций ![]() такая, что K0=q0w - начальная конфигурация.
Эта последовательность конечна, когда
ее последняя конфигурация Kn= v1 qf v2 - заключительная.
В этом случае вычисление назовем результативным, а слово v = v1 v2 -
его результатом на входе w (всегда будем предполагать, что v не
содержит пустых символов слева и справа).
такая, что K0=q0w - начальная конфигурация.
Эта последовательность конечна, когда
ее последняя конфигурация Kn= v1 qf v2 - заключительная.
В этом случае вычисление назовем результативным, а слово v = v1 v2 -
его результатом на входе w (всегда будем предполагать, что v не
содержит пустых символов слева и справа).
Определение 9.5. Скажем, что м.Т. ![]() вычисляет частичную словарную функцию
вычисляет частичную словарную функцию ![]() если для каждого слова w из области определения f существует результативное вычисление
если для каждого слова w из области определения f существует результативное вычисление ![]() с результатом
с результатом ![]() , а если f(w) не определена
, а если f(w) не определена ![]() , то вычисление
, то вычисление ![]() на входе w бесконечно.
на входе w бесконечно.
Скажем, что две м.Т. ![]() и
и ![]() эквивалентны, если они вычисляют одинаковые функции.
эквивалентны, если они вычисляют одинаковые функции.
Далее мы будем также рассматривать вычисления арифметических функций, т.е. функций с натуральными аргументами, принимающих натуральные значения. Для представления натуральных чисел используем унарное кодирование: число n будет представляться как слово из n палочек |n, а последовательные аргументы будем отделять *.
Определение 9.6. Скажем, что м.Т. ![]() вычисляет частичную арифметическую функцию f: Nk -> N, если для любого набора чисел (x1,x2, ... ,xk), на котором f определена, существует
результативное вычисление
вычисляет частичную арифметическую функцию f: Nk -> N, если для любого набора чисел (x1,x2, ... ,xk), на котором f определена, существует
результативное вычисление ![]() на входе
на входе ![]() с результатом
с результатом ![]() ,
а если
,
а если ![]() ,
то вычисление
,
то вычисление ![]() на соответствующем входе бесконечно.
на соответствующем входе бесконечно.
Аналогичное определение можно дать и для других спосбов кодирования чисел (двоичного, десятичного и др.). Ниже мы покажем, что класс вычислимых функций не зависит от выбора одного из таких кодирований.
Тьюрингово программирование
В этом разделе мы приведем примеры вычислений на машинах Тьюринга
и рассмотрим некоторые общие приемы, позволяющие комбинировать программы
различных м. Т. для получения более сложных вычислений. Будем считать, что
ячейки ленты м.Т. занумерованы от ![]() до
до ![]() , причем
в начальной конфигурации головка находится в 1-ой ячейке:
, причем
в начальной конфигурации головка находится в 1-ой ячейке:
Рис. 9.2. Нумерация ячеек ленты машины Тьюринга
Пример 9.2.Функция f(x)=x+1
Унарное кодирование.
Пусть м.Т.
 , где
, где  .
.- Ясно, что м.Т.
 проходит по массиву палочек слева направо и записывает в первой пустой ячейке новую |.
проходит по массиву палочек слева направо и записывает в первой пустой ячейке новую |. Бинарное кодирование.
Пусть м.Т.
 , где
, где  :
:
Нетрудно видеть, что эта машина в состоянии q0 находит младший разряд двоичного входа, затем в состоянии q1, идя справа налево, заменяет единицы на нули до тех пор, пока не находит 0 (или
) и заменяет его на 1. Следовательно, м.Т.  вычисляет функцию f(x) = x+1.
вычисляет функцию f(x) = x+1.
Пример 9.2. Копирование.
Рассмотрим функцию копирования (дублирования) слов в алфавите ![]() (мы предполагаем, что
(мы предполагаем, что ![]() ).
).
Для ее реализации используем один из типичных приемов Тьюрингова программирования - { it расширение алфавита}.Пусть ![]() и
и ![]() . М.Т.
. М.Т. ![]() , копирующая вход, работает следующим образом:
, копирующая вход, работает следующим образом:
- отмечает 1-ый символ входа, идет направо, ставит * после входа и возвращается в начало:

- в состоянии qa движется направо и записывает a в первую свободную ячейку:

- возвращается в отмеченную ячейку и передвигает метку ' на одну ячейку вправо, снова переходя в состояние q2:

- увидев символ * в состоянии q5, останавливается:

Из этого описания непосредственно следует, что ![]() для любого
для любого ![]() .
.
Стандартная заключительная конфигурация
Назовем заключительную конфигурацию стандартной, если в ней головка наблюдает первый значащий символ результата, который находится в 1-ой ячейке (т.е. в той же ячейке, где начиналось входное слово).
Лемма 9.1.Для всякой м.Т. ![]() можно построить
эквивалентную м.Т.
можно построить
эквивалентную м.Т. ![]() , у которой все заключительные конфигурации стандартны.
, у которой все заключительные конфигурации стандартны.
Доказательство. Пусть ![]() . Определим по ней м.Т.
. Определим по ней м.Т. ![]() , которая удовлетворяет требованиям
леммы. Положим
, которая удовлетворяет требованиям
леммы. Положим ![]() , где # - новый символ.
, где # - новый символ. ![]() работает
следующим образом.
работает
следующим образом.
- Отмечает символ в первой ячейке штрихом и переходит в начальное состояние
 .
. - Далее работает как
 но сохраняет штрих в первой ячейке и вместо пустого символа записывает #. Для этого для каждой команды qiaj -> qk alC из P'
но сохраняет штрих в первой ячейке и вместо пустого символа записывает #. Для этого для каждой команды qiaj -> qk alC из P' - в P' добавляется ее дубликат qiaj' -> qk al'C, в правых частях команд символ всюду заменяется на # и для каждой команды вида
 в P' добавляется команда qi # -> qk al C. После завершения этого этапа все посещенные в процессе работы головкой
в P' добавляется команда qi # -> qk al C. После завершения этого этапа все посещенные в процессе работы головкой  ячейки составляет непрерывный отрезок, не содержащий пустых символов.
ячейки составляет непрерывный отрезок, не содержащий пустых символов. - Далее
 стирает ненужные символы # слева и справа от блока ячеек, содержащего первую ячейку и все ячейки с символами результата, и переходит в одну из трех следующих конфигураций:где w - результат работы { cal M} (с заменой символов
стирает ненужные символы # слева и справа от блока ячеек, содержащего первую ячейку и все ячейки с символами результата, и переходит в одну из трех следующих конфигураций:где w - результат работы { cal M} (с заменой символов внутри w на #) и w1aw2 = w.
внутри w на #) и w1aw2 = w. - Сдвигает в нужном направлении результат, совмещая его начало с ячейкой, помеченной штрихом, заменяет все # внутри w на , снимает штрих в 1-ой ячейке и останавливается. Например, для K1 это достигается с помощью следующих команд (мы предполагаем, что ни одно из используемых ниже состояний
 не входит в Q ):
не входит в Q ):- поиск левого конца w:
 ;
;  (отметили первый символ w ),
(отметили первый символ w ),  (результат пуст);
(результат пуст); - поиск правого конца w:
 ,
,  (в состоянии p наблюдает последний символ w );
(в состоянии p наблюдает последний символ w ); - сдвиг результата на 1 ячейку влево:
 pa b' -> pb'aП; pb' # -> p1 b'П;
pa b' -> pb'aП; pb' # -> p1 b'П; - возврат к правому концу и переход к следующему сдвигу:

- при сдвиге до 1-ой ячейки замена символов # на и удаление
штриха:

удовлетворяет требованиям леммы. - поиск левого конца w:
Односторонние машины Тьюринга
Машина Тьюринга ![]() называется односторонней,
если в процессе вычисления ее головка никогда не сдвигается левее
начальной ячейки (т.е. всегда находится в ячейках с положительными
номерами).
называется односторонней,
если в процессе вычисления ее головка никогда не сдвигается левее
начальной ячейки (т.е. всегда находится в ячейках с положительными
номерами).
Лемма 9.2. Для всякой м.Т. ![]() можно построить
эквивалентную одностороннюю м.Т.
можно построить
эквивалентную одностороннюю м.Т. ![]() .
.
Доказательство. Пусть ![]() . Будем считать (используя лемму 1 ), что
. Будем считать (используя лемму 1 ), что ![]() завершает работу в стандартных конфигурациях. Требуемая м.Т.
завершает работу в стандартных конфигурациях. Требуемая м.Т. ![]() будет моделировать работу
будет моделировать работу ![]() , используя "многоэтажную" ленту. Содержимое ячеек
на 1-ом (нижнем) этаже будет на каждом такте совпадать с содержимым
тех же ячеек
, используя "многоэтажную" ленту. Содержимое ячеек
на 1-ом (нижнем) этаже будет на каждом такте совпадать с содержимым
тех же ячеек ![]() , на 2-ом этаже будет копироваться
содержимое левой полуленты: на нем в i -ой ячейке
, на 2-ом этаже будет копироваться
содержимое левой полуленты: на нем в i -ой ячейке ![]() будет тот же символ, что и в -i -ой ячейке
будет тот же символ, что и в -i -ой ячейке ![]() . Кроме того,
на 3-ем этаже в 1-ой ячейке будет стоять отмечающий ее символ #.
Таким образом,
. Кроме того,
на 3-ем этаже в 1-ой ячейке будет стоять отмечающий ее символ #.
Таким образом, ![]() . Работа
. Работа ![]() будет происходить следующим образом.
будет происходить следующим образом.
- 1) На первом этапе отмечается 1-я ячейка и содержимое входа переписывается на 1-ый этаж трехэтажной ленты:

Затем
моделирует работу  ,
используя для работы на 2-ом этаже дубликаты состояний (со штрихами)
и команды со сдвигами в обратном направлении. Для команды q ,a -> r , b ,C из P и для всех
,
используя для работы на 2-ом этаже дубликаты состояний (со штрихами)
и команды со сдвигами в обратном направлении. Для команды q ,a -> r , b ,C из P и для всех  в P'
поместим команды:
в P'
поместим команды:
Кроме того, для
 сохраним и старые команды для работы на впервые посещаемых ячейках:
сохраним и старые команды для работы на впервые посещаемых ячейках:
Сдвиги
из 1-ой ячейки налево в -1-ю и обратно моделируются переходом с одного этажа на другой в 1-ой ячейке  :
:
После завершения моделирования
результат записан
в начальных ячейках на 1-ом этаже.  переводит его
в первоначальный алфавит
переводит его
в первоначальный алфавит 

Проверка правильности работы м.Т.
предоставляется
читателю (см. задачу 9.4).
Последовательная и параллельная композиции машин Тьюринга
Используя возможность моделирования произвольной м.Т. на м.Т. со стандартными заключительными конфигурациями, легко установить справедливость следующей леммы о последовательной композиции машин Тьюринга.
Лемма 9.3.( Последовательная композиция ) Пусть м.Т. ![]() вычисляет функцию f(x),
а м.Т.
вычисляет функцию f(x),
а м.Т. ![]() - функцию g(x). Тогда существует м.Т.
- функцию g(x). Тогда существует м.Т. ![]() вычисляющая функцию h(x) = f(g(x)).
вычисляющая функцию h(x) = f(g(x)).
Доказательство Действительно, пусть ![]() а
а ![]() .
Используя лемму 9.1, будем считать, что у
.
Используя лемму 9.1, будем считать, что у ![]() заключительные конфигурации стандартны. Тогда легко проверить, что функция h
вычисляется следующей м.Т.
заключительные конфигурации стандартны. Тогда легко проверить, что функция h
вычисляется следующей м.Т. ![]() где
где ![]() .
.
Покажем, что работу двух м.Т. можно комбинировать так, чтобы в заключительной конфигурации содержались результаты работы каждой из них над независимыми входами.
Лемма 9.4. ( Параллельная композиция ) Пусть м.Т. ![]() вычисляет функцию f(x), а м.Т.
вычисляет функцию f(x), а м.Т. ![]() - функцию g(x) и символ * не входит
в алфавит м.Т.
- функцию g(x) и символ * не входит
в алфавит м.Т. ![]() . Тогда существует м.Т.
. Тогда существует м.Т. ![]() которая по любому входу вида x*y
выдает результат f(x)*g(y), т.е.
вычисляет функцию H(x*y) = f(x)*g(y).
которая по любому входу вида x*y
выдает результат f(x)*g(y), т.е.
вычисляет функцию H(x*y) = f(x)*g(y).
Доказательство. Пусть ![]() и
и ![]() - м.Т. Не ограничивая общности, будем считать, что эти машины односторонние (по Лемме 2). Определим теперь м.Т.
- м.Т. Не ограничивая общности, будем считать, что эти машины односторонние (по Лемме 2). Определим теперь м.Т. ![]() , которая работает следующим образом.
, которая работает следующим образом.
- Начав в конфигурации (p0x*y), находит 1-ый символ y
- и переходит в конфигурацию (x*q02y).
- Работая как
 вычисляет g(y) и переходит при этом в конфигурацию (x*qf2g(y)).
вычисляет g(y) и переходит при этом в конфигурацию (x*qf2g(y)). - Переписывает *x после g(y) и переходит в конфигурацию g(y)*q01x).
- Работая как
 вычисляет f(x) и переходит при этом в конфигурацию (g(y)*qf1f(x).
вычисляет f(x) и переходит при этом в конфигурацию (g(y)*qf1f(x). - Меняет
 и
и  местами и останавливается.
местами и останавливается.
Корректность этапов 2 и 4 следует из односторонности ![]() и
и ![]() а реализация этапов 1, 3 и 5 достаточно очевидна (см. задачу 9.6).
а реализация этапов 1, 3 и 5 достаточно очевидна (см. задачу 9.6).
Построенную в этой лемме м.Т. ![]() , полученную в результате параллельной композиции
, полученную в результате параллельной композиции ![]() и
и ![]() , будем обозначать
как
, будем обозначать
как ![]() . Здесь индекс * указывает
символ, которым отделяются аргументы
. Здесь индекс * указывает
символ, которым отделяются аргументы ![]() и
и ![]() на ленте
на ленте ![]() . Этот символ может быть любым символом, не входящим в алфавит
машины
. Этот символ может быть любым символом, не входящим в алфавит
машины ![]() . Например,
. Например, ![]() будет обозначать параллельную композицию
машин
будет обозначать параллельную композицию
машин ![]() и
и ![]() , в которой их аргументы отделены
символом #.
, в которой их аргументы отделены
символом #.
Конструкцию параллельной композиции можно обобщить на произвольное конечное число машин Тьюринга.
Следствие. Пусть ![]() - машины Тьюринга,
вычисляющие функции f1, ... , fm, соответственно. Пусть символ * не входит в алфавиты этих машин. Тогда существует м.Т.
- машины Тьюринга,
вычисляющие функции f1, ... , fm, соответственно. Пусть символ * не входит в алфавиты этих машин. Тогда существует м.Т. ![]() , перерабатывающая любой
вход вида x1*x2* ... *xm
, перерабатывающая любой
вход вида x1*x2* ... *xm ![]() в выход f1(x1)*f2(x2)* ... *fm(xm).
в выход f1(x1)*f2(x2)* ... *fm(xm).
Действительно, в качестве ![]() можно взять м.Т., определяемую
выражением
можно взять м.Т., определяемую
выражением ![]() .\\
Будем обозначать эту машину Тьюринга как
.\\
Будем обозначать эту машину Тьюринга как ![]() .
.
Ветвление (условный оператор)
Машину Тьюринга ![]() будем называть распознающей,
если для некоторого алфавита
будем называть распознающей,
если для некоторого алфавита ![]() и каждого входа
и каждого входа ![]() , на котором
, на котором ![]() останавливается,
ее результат
останавливается,
ее результат ![]() , т.е.
, т.е. ![]() вычисляет
некоторую двузначную функцию (возможно частичную) на словах
из
вычисляет
некоторую двузначную функцию (возможно частичную) на словах
из ![]()
Лемма 9.5. Пусть ![]() - распознающая м.Т., м.Т.
- распознающая м.Т., м.Т. ![]() вычисляет функцию f(x),
а м.Т.
вычисляет функцию f(x),
а м.Т. ![]() - функцию g(x). Тогда существует м.Т.
- функцию g(x). Тогда существует м.Т. ![]() вычисляющая функцию
вычисляющая функцию
Доказательство. Требуемая м.Т. ![]() вначале копирует вход x и получает на ленте слово x*x, затем вычисляет параллельную композицию функций
вначале копирует вход x и получает на ленте слово x*x, затем вычисляет параллельную композицию функций ![]() и тождественной функции e(x)=x и переходит в конфигурацию
и тождественной функции e(x)=x и переходит в конфигурацию ![]() . Выбор между f и g происходит
по следующим командам:
. Выбор между f и g происходит
по следующим командам:
Кроме того, обеспечим переход в новое заключительное состояние:
Таким образом, мы реализовали в терминах машин Тьюринга обычный в языках программирования оператор ветвления:
Повторение (цикл)
Используя конструкцию для ветвления легко реализовать в терминах машин Тьюринга и оператор цикла.
Лемма 9.6. Пусть ![]() - распознающая м.Т., а м.Т.
- распознающая м.Т., а м.Т. ![]() вычисляет функцию f(x).
Тогда существует м.Т.
вычисляет функцию f(x).
Тогда существует м.Т. ![]() которая вычисляет функцию, задаваемую выражением:
которая вычисляет функцию, задаваемую выражением:
Доказательство. Действительно, пусть м.Т. ![]() - вычисляет тождественную функцию g(x)=x. Построим по м.Т.
- вычисляет тождественную функцию g(x)=x. Построим по м.Т. ![]() м.Т.
м.Т. ![]() реализующую ветвление как в лемме 9.5. Тогда
искомая м.Т.
реализующую ветвление как в лемме 9.5. Тогда
искомая м.Т. ![]() получается из
получается из ![]() заменой команд
заменой команд ![]() на
соответствующие команды
на
соответствующие команды ![]() ,
обеспечивающие зацикливание.
,
обеспечивающие зацикливание.
Реализованные выше операции над машинами Тьюринга
и вычислимыми функциями позволяют получать программы новых м.Т., используя обычные конструкции языка программирования
"высокого" уровня: последовательную и параллельную композицию, ветвление и цикл. Пусть ![]() - машины Тьюринга. Последовательную композицию M1 и M2 будем обозначать M1;M2, параллельную композицию M1, M2,... , Mm
обозначаем как
- машины Тьюринга. Последовательную композицию M1 и M2 будем обозначать M1;M2, параллельную композицию M1, M2,... , Mm
обозначаем как ![]() (здесь b -
это символ, разделяющий аргументы и результаты этих машин), ветвление -
(здесь b -
это символ, разделяющий аргументы и результаты этих машин), ветвление -
цикл -
Пример 9.4. Рассмотрим в качестве примера задачу
перевода чисел из унарной системы счисления в двоичную.
Пусть fub(|n) = n(2) для всех ![]() , где n(2) - двоичная запись числа n.
, где n(2) - двоичная запись числа n.
Пусть M1 - м.Т., которая начальную конфигурацию q0 ,|n переводит в конфигурацию q1 ,0*|n; M2 - м.Т., которая прибавляет 1 к двоичному
числу-аргументу (см. пример ref{ex8-suc}); M3 - м.Т., которая вычитает 1 из унарного
числа; ![]() - м.Т., которая на аргументе вида x*|y выдает
0, если число y > 0, и выдает 1 при y=0 (т.е. на аргументе
- м.Т., которая на аргументе вида x*|y выдает
0, если число y > 0, и выдает 1 при y=0 (т.е. на аргументе ![]() ); M4 - м.Т., которая стирает * в аргументе вида x* и
останавливается. Реализация каждой из указанных м.Т. очевидна.
Теперь требуемая м.Т. Mub, вычисляющая fub, получается как
); M4 - м.Т., которая стирает * в аргументе вида x* и
останавливается. Реализация каждой из указанных м.Т. очевидна.
Теперь требуемая м.Т. Mub, вычисляющая fub, получается как
Действительно, после работы M1 получаем конфигурацию q10*|n. Предположим теперь по индукции, что после i (i <n) итераций цикла
while получается конфигурация q1 i(2)*|n-i.
Тогда на (i+1) -ой итерации цикла после параллельного
применения M2 к i(2) и M3 к |n-i
получаем конфигурацию q1(i+1)(2)*|n-i-1.
Поэтому после n итераций получится конфигурация ![]() . На ней
. На ней ![]() выдаст 1, и цикл завершится с записью
выдаст 1, и цикл завершится с записью ![]() на ленте,
из которой M4 сотрет * и оставит требуемый результат n(2).
на ленте,
из которой M4 сотрет * и оставит требуемый результат n(2).
Отметим, что из приведенного примера и из задачи \oldref{prb3-6}(a) следует, что класс вычислимых на м.Т. арифметических функций не зависит от выбора унарного или двоичного кодирования аргументов и результатов. Это же справедливо и для троичной, десятичной и других позиционных систем счисления ( почему ?).
Задачи
Задача 9.1. Постройте м.Т. для функции копирования, не
увеличивая исходный алфавит ![]()
Задача 9.2. Постройте программу м.Т., которая выполняла бы
перенос непустого слова в заданное место ленты, т.е. для любого
слова ![]() и n > 0 выполняла
преобразование конфигураций:
и n > 0 выполняла
преобразование конфигураций: ![]() .
.
Задача 9.3. Достройте программу м.Т. ![]() из леммы 9.1 на этапах 3 и 4.
из леммы 9.1 на этапах 3 и 4.
Задача 9.4. Докажите, что односторонняя м.Т. ![]() построенная в лемме 9.2, корректно моделирует исходную м.Т.
построенная в лемме 9.2, корректно моделирует исходную м.Т. ![]() .
.
Задача 9.5. Другой, по сравнению с конструкцией леммы 9.2,
подход к моделированию двухсторонней ленты на
односторонней заключается в том, чтобы содержимое правой полуленты ![]() хранить в четных ячейках
хранить в четных ячейках ![]() а содержимое
левой полуленты - в нечетных, поместив в 1-ю ячейку специальный маркер.
Постройте программу, реализующую этот подход (ее достоинство -
увеличение алфавита ленты всего на 1 символ).
а содержимое
левой полуленты - в нечетных, поместив в 1-ю ячейку специальный маркер.
Постройте программу, реализующую этот подход (ее достоинство -
увеличение алфавита ленты всего на 1 символ).
Задача 9.6. Достройте программу м.Т. ![]() из
леммы 9.4 на этапах 1, 3 и 5.
из
леммы 9.4 на этапах 1, 3 и 5.
Задача 9.7. Построить программы машин Тьюринга, вычисляющих следующие функции.
- Перевод из двоичной системы в унарную: fbu(n(2))= |n.
- Сложение и вычитание в двоичной системе: sum(n*m)=n+m и
 совпадает с - при n >= m и
совпадает с - при n >= m и  при m > n ).
при m > n ). - Умножение в двоичной системе: mul(n*m)= n x m. ( Реализуйте алгоритм умножения "в столбик".)
- Возведение в степень: exp(n*m)= nm.
- Извлечение квадратного корня:
 .
. - Логарифмирование:
 .
. - Деление:
 .
. - Остаток от деления: rest(n*m) = n mod m.
- Функция выбора аргумента:
 .
.
Задача 9.8. Используя машины Тьюринга из предыдущей задачи, построить программы машин Тьюринга, вычисляющих следующие функции.
Задача 9.9. Докажите, что всякую арифметическую функцию f(x),
вычислимую на некоторой м. Т. ![]() , можно также вычислить на м. Т. M',, алфавит ленты которой содержит лишь два символа
, можно также вычислить на м. Т. M',, алфавит ленты которой содержит лишь два символа ![]() и |. (Указание: используйте для моделирования
одного символа из
и |. (Указание: используйте для моделирования
одного символа из ![]() блок из нескольких подряд идущих ячеек,
содержащих его код в алфавите
блок из нескольких подряд идущих ячеек,
содержащих его код в алфавите ![]() ) и замените
каждую команду M группой команд, обрабатывающих соответствующий
блок ячеек).
) и замените
каждую команду M группой команд, обрабатывающих соответствующий
блок ячеек).
Задача 9.10. Построить машину Тьюринга, определяющую по слову x в алфавите {1, 2} симметрично ли оно, т. е. вычисляющую функцию:
Задача 9.11.
Построить машину Тьюринга, сравнивающую два слова x=x1x2... xn и y=y1y2... ym в алфавите {1, 2, 3} лексикографически: ![]() или для некоторого непустого слова x' выполнено y = x x'.
Эта машина Тьюринга должна вычислять функцию:
или для некоторого непустого слова x' выполнено y = x x'.
Эта машина Тьюринга должна вычислять функцию:

Лекция 10. Вычислимые функции, тезис Тьюринга-Черча и неразрешимые проблемы
В этом лекции мы установим, что классы частично рекурсивных функций, функций, вычислимых структурированными программами, и функций, вычислимых машинами Тьюринга, совпадают. Это (вместе с эквивалентностью этого класса многим другим определениям вычислимости, не рассматриваемым в этих лекциях) позволяет считать этот класс функций точно отражающим наши интуитивные представления о вычислимости.
Напомним, что в теореме 8.1 мы уже показали, что каждая ч.р.ф. вычислима некоторой структурированной программой.
Вычислимость частично рекурсивных функций по Тьюрингу
Теорема 10.1. Для всякой ч.р.ф. f существует
м.Т. ![]() , вычисляющая функцию f.
, вычисляющая функцию f.
Доказательство. Доказательство проведем индукцией по определению частично рекурсивной функции f.
Базис. Вычислимость простейших функций машинами Тьюринга очевидна.
Индукционный шаг. Покажем, что операторы суперпозиции, примитивной рекурсии и минимизации сохраняют вычислимость по Тьюрингу. Все используемые м.Т. будем предполагать односторонними со стандартными заключительными конфигурациями.
Суперпозиция. Пусть Fm и fn1,..., fnm
- ч.р.ф., вычислимые на м.Т. ![]() , соответственно. Пусть функция Gn
получена из них с помощью суперпозиции: Gn=[Fm;fn1,..., fnm]. Тогда м.Т.
, соответственно. Пусть функция Gn
получена из них с помощью суперпозиции: Gn=[Fm;fn1,..., fnm]. Тогда м.Т. ![]() ,
вычисляющая G, работает следующим образом:
,
вычисляющая G, работает следующим образом:
- m раз копирует вход
 , отделяя одну копию от другой символом # ;
, отделяя одну копию от другой символом # ; - на полученном слове вида

- запускает параллельную композицию машин
 и получает конфигурацию вида
и получает конфигурацию вида  , где
, где  .
. - заменяет все символы 0023 на * ;
- затем запускает программу м.Т.
 на получившемся после этапа 3) входе вида
на получившемся после этапа 3) входе вида  , и вычисляет требуемое значение
, и вычисляет требуемое значение  .
.
Если обозначить м.Т., выполняющую копирование на этапе (1), через Копm,
а м.Т., выполняющую замену # на * на этапе (3), через Зам*#, то требуемую для суперпозиции м.Т. ![]() можно представить как
можно представить как
Примитивная рекурсия. Пусть функция Fn+1(x1,... ,xn,y) получена с помощью оператора
примитивной рекурсии из функций gn(x1,..., xn) и fn+2(x1,... ,xn, y, z), которые вычислимы на м.Т. ![]() и
и ![]() . Определим вспомогательные м.Т.:
. Определим вспомогательные м.Т.:
 , используя
, используя  , строит по входу вида
, строит по входу вида  конфигурацию на ленте
конфигурацию на ленте 
 , используя
, используя  , строит по входу вида
, строит по входу вида  конфигурацию
конфигурацию 
 на входе вида выдает в качестве результата
на входе вида выдает в качестве результата 
- на входе вида проверяет условие
 .
.
Построение каждой из указанных м.Т. достаточно очевидно.
Из них можно получить, используя определенные в предыдущем
разделе конструкции
"языка программирования" для машин Тьюринга, требуемую м.Т. ![]() :
:
Минимизация. Пусть ![]() и м.Т.
и м.Т. ![]() вычисляет функцию gn+1.
Определим следующие вспомогательные м.Т.:
вычисляет функцию gn+1.
Определим следующие вспомогательные м.Т.:
![]() приписывает аргумент 0 ко входу, т.е. вход вида
приписывает аргумент 0 ко входу, т.е. вход вида ![]() переводит в конфигурацию на ленте
переводит в конфигурацию на ленте ![]() (напомним, что при унарном кодировании 0 соответствует пустой символ).
(напомним, что при унарном кодировании 0 соответствует пустой символ).
![]() копирует свой вход с разделителем #, т.е. по любому входу w выдает w # w.
копирует свой вход с разделителем #, т.е. по любому входу w выдает w # w.
Через E обозначим м.Т., которая ничего не делает.
Пусть ![]() , т.е. вход вида
, т.е. вход вида ![]() машина
машина ![]() перерабатывает, используя
перерабатывает, используя ![]() ,
в
,
в ![]() , где z= g(x1,... ,xn, y)
, где z= g(x1,... ,xn, y)
![]() на входе вида w # v проверяет непустоту v (т.е. условие v > 0 ).
на входе вида w # v проверяет непустоту v (т.е. условие v > 0 ).

Таким образом, при v=g(x1,...,xn,y) машина ![]() проверяет
условие
проверяет
условие ![]() .
.
![]() по входу вида
по входу вида ![]() стирает #w и прибавляет
к y единицу, т.е. выдает результат:
стирает #w и прибавляет
к y единицу, т.е. выдает результат: ![]() .
.
Наконец, ![]() по входу
по входу ![]() выдает |y, стирая ненужные блоки символов.
выдает |y, стирая ненужные блоки символов.
Ясно, что каждая из перечисленных м.Т. ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() и
и ![]() легко реализуема. Построим теперь с их помощью
следующую м.Т.
легко реализуема. Построим теперь с их помощью
следующую м.Т. ![]() :
:

Из этого определения непосредственно следует, что ![]() вычисляет функцию fn(x1,..., xn),
заданную с помощью оператора минимизации.
вычисляет функцию fn(x1,..., xn),
заданную с помощью оператора минимизации.
Моделирование структурированных программ машинами Тьюринга
На первый взгляд могло показаться, что машины Тьюринга с их примитивными элементарными действиями являются более слабыми вычислительными моделями, чем структурированные программы. Но после того, как мы научились реализовывать с их помощью операторы "высокого уровня " - условия и циклы, уже не удивительно, что они позволяют вычислить не меньше, чем структурированные программы.
Теорема 10.2. Всякая арифметическая функция, вычислимая некоторой структурированной программой, может быть вычислена также некоторой машиной Тьюринга.
Доказательство Пусть структурированная программа ![]() вычисляет арифметическую функцию f(x1, ..., xn).
Не ограничивая общности, будем считать, что
вычисляет арифметическую функцию f(x1, ..., xn).
Не ограничивая общности, будем считать, что ![]() , xn+1, ..., xm }
и что результирующей переменной является x1.
М.Т.
, xn+1, ..., xm }
и что результирующей переменной является x1.
М.Т. ![]() , моделирующая
, моделирующая ![]() будет иметь m -этажную ленту с алфавитом
будет иметь m -этажную ленту с алфавитом ![]() .
Обозначим конфигурацию ленты M\Pi, в которой на i -ом этаже, начиная с
1-ой ячейки, записано слева направо ki символов '|' (i = 1, 2, ..., m), а далее идут "пустышки "
.
Обозначим конфигурацию ленты M\Pi, в которой на i -ом этаже, начиная с
1-ой ячейки, записано слева направо ki символов '|' (i = 1, 2, ..., m), а далее идут "пустышки " ![]() как (k1, k2, ..., km).
Тогда состоянию
как (k1, k2, ..., km).
Тогда состоянию ![]() программы
программы ![]() будет соответствовать конфигурация ленты
будет соответствовать конфигурация ленты ![]() :
: ![]() .
.
![]() получается с помощью конструкций
последовательной композиции, условного оператора и цикла из простых машин Тьюринга,
реализующих элементарные присваивания и условия структурированных программ.
получается с помощью конструкций
последовательной композиции, условного оператора и цикла из простых машин Тьюринга,
реализующих элементарные присваивания и условия структурированных программ.
Команду xi := 0 (i=1,... , m) программы ![]() реализует м.Т. Mi0 , обнуляющая i -ый этаж M, т.е. переводящая любую
конфигурацию (k1,..., ki-1,ki, k i+1 ..., km) в конфигурацию (k1,..., k i-1, 0, ki+1, ... , km).
Команду xi := xi +1 (i=1,... , m) программы
реализует м.Т. Mi0 , обнуляющая i -ый этаж M, т.е. переводящая любую
конфигурацию (k1,..., ki-1,ki, k i+1 ..., km) в конфигурацию (k1,..., k i-1, 0, ki+1, ... , km).
Команду xi := xi +1 (i=1,... , m) программы ![]() реализует м.Т. Mi+1 , добавляющая один символ ' | ' справа на i -ом этаже,
т.е. переводящая любую
конфигурацию (k1,..., k i-1, ki, ki+1 ... , km) в конфигурацию (k1,..., k i-1, ki+1, ki+1, ... , km).
Команду xi := xj (i, j=1,... , m) программы
реализует м.Т. Mi+1 , добавляющая один символ ' | ' справа на i -ом этаже,
т.е. переводящая любую
конфигурацию (k1,..., k i-1, ki, ki+1 ... , km) в конфигурацию (k1,..., k i-1, ki+1, ki+1, ... , km).
Команду xi := xj (i, j=1,... , m) программы ![]() реализует м.Т. Mij, переписывающая содержимое j -го этажа на i -ый,
т.е. переводящая любую
конфигурацию (k1,..., ki, ..., kj, ... , km) в конфигурацию (k1,..., kj, ... , kj, ... , km).
реализует м.Т. Mij, переписывающая содержимое j -го этажа на i -ый,
т.е. переводящая любую
конфигурацию (k1,..., ki, ..., kj, ... , km) в конфигурацию (k1,..., kj, ... , kj, ... , km).
Условие xi = xj реализуется машиной ![]() , которая, работая на
конфигурации (k1, ..., ki, ..., kj, ... , km) выдает 0, если ki=kj,
и 1 - в противном случае.
, которая, работая на
конфигурации (k1, ..., ki, ..., kj, ... , km) выдает 0, если ki=kj,
и 1 - в противном случае.
Условие xi < xj реализуется машиной ![]() , которая, работая на
конфигурации (k1, ..., ki, ..., kj, ... , km) выдает 0, если ki < kj,
и 1 - в противном случае.
, которая, работая на
конфигурации (k1, ..., ki, ..., kj, ... , km) выдает 0, если ki < kj,
и 1 - в противном случае.
Далее по индукции: пусть ![]() и
и ![]() - структурированные программы, для которых
построены соответствующие машины Тьюринга
- структурированные программы, для которых
построены соответствующие машины Тьюринга ![]() и
и ![]() , а
, а ![]() - некоторое
условие, реализуемое м.Т.
- некоторое
условие, реализуемое м.Т. ![]() .
Тогда программа
.
Тогда программа ![]() реализуется машиной
реализуется машиной ![]() программа
программа ![]() если
если ![]() то
то ![]() иначе
иначе ![]() конец
реализуется машиной
конец
реализуется машиной ![]() ,
а программа
,
а программа ![]() пока
пока ![]() делай
делай ![]() все реализуется машиной
все реализуется машиной ![]() while
while ![]() do
do ![]() enddo.
enddo.
Используя доказанные выше свойства конструкций машин Тьюринга, нетрудно проверить по индукции следующее
Утверждение 1. Пусть м.Т. ![]() реализует в соответствии с приведенными определениями
структурированную программу
реализует в соответствии с приведенными определениями
структурированную программу ![]() Тогда для любого состояния
Тогда для любого состояния ![]() программы
программы ![]()
![]() тогда и только тогда, когда м.Т
тогда и только тогда, когда м.Т ![]() , начав работу в конфигурации
, начав работу в конфигурации ![]() завершит ее в конфигурации
завершит ее в конфигурации ![]() .
.
Теперь для завершения доказательства теоремы достаточно взять в качестве
результирующей следующую м.Т.: ![]() ,
где м.Т. Mstart переводит одноэтажную начальную конфигурацию
,
где м.Т. Mstart переводит одноэтажную начальную конфигурацию ![]() в m -этажную конфигурацию (x1, x2,..., xn, 0,..., 0),
а м.Т. Mend заключительную m -этажную конфигурацию (x1, 0,..., 0) переводит
в одноэтажную заключительную конфигурацию |x1.
в m -этажную конфигурацию (x1, x2,..., xn, 0,..., 0),
а м.Т. Mend заключительную m -этажную конфигурацию (x1, 0,..., 0) переводит
в одноэтажную заключительную конфигурацию |x1.
Частичная рекурсивность функций, вычислимых по Тьюрингу
В этом параграфе покажем, как можно промоделировать работу машины Тьюринга, используя частично рекурсивные определения.
Теорема 10.3. Всякая арифметическая функция, вычислимая на машинах Тьюринга, является частично рекурсивной функцией.
Доказательство этой теоремы - дополнительный материал, который можно при первом чтении опустить.
Доказательство Пусть м.Т. ![]() вычисляет функцию f(x1,..., xn).
Пусть также Q ={q0,q1,... ,q k-1 }, qf=q1 и
вычисляет функцию f(x1,..., xn).
Пусть также Q ={q0,q1,... ,q k-1 }, qf=q1 и ![]() . Предположим также,
не ограничивая общности, что
. Предположим также,
не ограничивая общности, что ![]() никогда не пишет пустой
символ
никогда не пишет пустой
символ ![]() (как перестроить программу произвольной м.Т.,
чтобы она удовлетворяла этому условию ?).
(как перестроить программу произвольной м.Т.,
чтобы она удовлетворяла этому условию ?).
Определим кодирование элементов конфигураций ![]() целыми числами. Пусть конфигурация
целыми числами. Пусть конфигурация ![]() имеет вид K=(w1,qi,aj,w2), где
имеет вид K=(w1,qi,aj,w2), где ![]() - слово на ленте левее головки, qi - состояние м.Т., aj - наблюдаемый в данной конфигурации символ
и w2= aj0aj1 ... ajp} - слово на ленте правее головки.
Кодом символа
- слово на ленте левее головки, qi - состояние м.Т., aj - наблюдаемый в данной конфигурации символ
и w2= aj0aj1 ... ajp} - слово на ленте правее головки.
Кодом символа ![]() будет число j,
кодом состояния qi - число i.
Слова w1 и w2 будем рассматривать как числа в R -ичной
системе счисления, читаемые в противоположных направлениях (из наших
предположений следует, что
будет число j,
кодом состояния qi - число i.
Слова w1 и w2 будем рассматривать как числа в R -ичной
системе счисления, читаемые в противоположных направлениях (из наших
предположений следует, что ![]() при m >0
и
при m >0
и ![]() при p>0 ) :
при p>0 ) :

Например, если ![]() , то для конфигурации K=(|**,q3,|,* | |) имеем code1(w1)=30 1+31 1+ 32 2= [211]3=22
и code2(w2)=30 1+ 31 2 +32 2= [221]3=25. По программе P определим следующие табличные функции, кодирующие ее команды:
, то для конфигурации K=(|**,q3,|,* | |) имеем code1(w1)=30 1+31 1+ 32 2= [211]3=22
и code2(w2)=30 1+ 31 2 +32 2= [221]3=25. По программе P определим следующие табличные функции, кодирующие ее команды:
A(i,j) - код символа, который пишет ![]() , когда она
в состоянии qi видит символ aj;
, когда она
в состоянии qi видит символ aj;
Q(i,j) - код состояния, в которое переходит ![]() , когда
она в состоянии qi видит символ aj;
, когда
она в состоянии qi видит символ aj;
C(i,j) - код направления сдвига головки ![]() , когда
она в состоянии qi видит символ aj (0 - на месте, 1 - вправо, 2 - влево).
, когда
она в состоянии qi видит символ aj (0 - на месте, 1 - вправо, 2 - влево).
Пусть при i >= k или j >= R эти функции принимают какое-нибудь фиксированное значение (например, 0). Тогда по лемме 18.1 все они примитивно рекурсивны.
Определим функции, которые по кодам компонент одной конфигурации K=(w1,qi,aj,w2) вычисляют коды компонент следующей конфигурации K’=(w1’,qm,ap,w2’).

Покажем, что все эти функции примитивно рекурсивны. Для q это следует из того, что для любых i, j q(l,i,j,m)=Q(i,j). Определения остальных трех функций зависят от сдвига. При C(i,j)=0 имеем lf(l,i,j,r)=l, rt(l,i,j,r)= r, a(l,i,j,r)=A(i,j).
Если C(i,j)=2, то lf(l,i,j,r)=div(R, l), rt(l,i,j,r)= rR+A(i,j), a(l,i,j,r)=rm(R,l). Если же C(i,j)=1, то lf(l,i,j,r)=lR+A(i,j), rt(l,i,j,r)= div(R, r), a(l,i,j,r)=rm(R,r) Объединяя эти случаи получаем, что
( здесь rm(x,y) - это функция, дающая остаток от деления y на x, а div(x,y) - функция целочисленного деления y на x ).
Аналогичные представления справедливы и для функций rt(l,i,j,r) и a(l,i,j,r). Следовательно, все эти функции примитивно рекурсивны.
Пусть из данной конфигурации K через t тактов получается конфигурация Kt. Определим коды компонент Kt как функции от компонент K и t :

Это определение задает функции A(4), Q(4), Lf(4), Rt(4) с помощью совместной рекурсии. Следовательно, по лемме 18.5 они примитивно рекурсивны.
Пусть м.Т. ![]() вычисляет функцию f(x), (т.е. n=1 ). Тогда для начальной конфигурации
вычисляет функцию f(x), (т.е. n=1 ). Тогда для начальной конфигурации ![]() code1(w1)=0, code(q0)=0, code(|)=R-1, code2( w2 ) = (R-1)Rx-2+(R-1)R x-3+ ... +(R-1)R0=R x-1-1. Положим
code1(w1)=0, code(q0)=0, code(|)=R-1, code2( w2 ) = (R-1)Rx-2+(R-1)R x-3+ ... +(R-1)R0=R x-1-1. Положим ![]() и
и ![]() . Тогда функция
. Тогда функция ![]() задает число шагов
до перехода
задает число шагов
до перехода ![]() в заключительное состояние на входе x. Эта функция, очевидно, частично рекурсивна. Тогда функция
в заключительное состояние на входе x. Эта функция, очевидно, частично рекурсивна. Тогда функция ![]() задает код правой
части заключительной конфигурации, имеющий вид Rf(x)-1-1.
Отсюда получаем, что
задает код правой
части заключительной конфигурации, имеющий вид Rf(x)-1-1.
Отсюда получаем, что
и следовательно, функция f(x) частично рекурсивна.
Тезис Тьюринга-Черча и алгоритмически неразрешимые проблемы
Мы рассмотрели три математические модели для описания алгоритмов и вычисляемых ими функций, отражающие различные аспекты и представления о работе абстрактного вычислителя. Из теорем 8.1, 10.2 и 10.3 непосредственно получаем
Следствие. Классы функций, вычислимых с помощью структурированных программ, машин Тьюринга и частично рекурсивных описаний, совпадают.
Естественно, возникает вопрос о том, насколько общим является этот результат? Верно ли, что каждый алгоритм может быть задан одним из рассмотренных способов? На эти вопросы теория алгоритмов отвечает следующей гипотезой.
Тезис Тьюринга-Черча:
Всякий алгоритм может быть задан в виде соответствующей машины Тьюринга или частично рекурсивного определения, а класс вычислимых функций совпадает с классом частично рекурсивных функций и с классом функций, вычислимых на машинах Тьюринга.
Значение этого тезиса заключается в том, что он уточняет общее неформальное определения "всякого алгоритма" и "вычислимой функции" через точные формальные понятия машины Тьюринга, частично рекурсивного определения и соответствующих им классов функций. После этого можно осмысленно ставить вопрос о существовании или несуществовании алгоритма, решающего тот или иной класс задач. Теперь этот вопрос следует понимать как вопрос о существовании или несуществовании соответствующей машины Тьюринга, или (что эквивалентно) структурированной программы, или частично рекурсивного определения соответствующей функции.
Можно ли доказать этот тезис как теорему? Нет, поскольку в его формулировке речь идет о неточных понятиях "всякого алгоритма" и "вычислимой функции", которые не могут быть объектами математических рассуждений. На чем же тогда основана уверенность в справедливости тезиса Тьюринга-Черча? В первую очередь, на опыте. Все известные алгоритмы, придуманные за многие века математиками, могут быть заданы с помощью машин Тьюринга. Для всех многочисленных моделей алгоритмов, появившихся за последние 70 лет (некоторые из них мы упоминали в начале лекции), была доказана их равносильность машинам Тьюринга. В качестве доводов в пользу тезиса Тьюринга-Черча можно также рассматривать замкнутость класса машин Тьюринга и ч.р.ф. относительно многочисленных естественных операций над алгоритмами и функциями. Отметим также, что тезис Тьюринга-Черча обращен и в будущее: он предполагает, что какие бы новые формальные определения алгоритмов ни были предложены (а таковыми, например, являются новые языки программирования), все они не выйдут из класса алгоритмов, задаваемых машинами Тьюринга.
Чтобы показать связь теории алгоритмов с "практическим" программированием, рассмотрим некоторые алгоритмичские проблемы, связанные со структурированными программами.
Зафиксируем конечный алфавит A={a0, a1,..., am-1}, включающий все символы латинского алфавита,
цифры, знак пробела (пусть это будет a0 ), знаки ' ; ', ' = ', ' < ', ' := ' , а также знаки-ключевые слова если, то, конец, пока, делай и все.
Тогда каждая структурированная программа ![]() представляет собой некоторое слово
представляет собой некоторое слово ![]() в алфавите A. Не ограничивая общности,
будем считать, что это слово начинается не с пробела, т.е. i1 >0.
Тогда слово
в алфавите A. Не ограничивая общности,
будем считать, что это слово начинается не с пробела, т.е. i1 >0.
Тогда слово ![]() однозначно определяет натуральное число
однозначно определяет натуральное число ![]() , m -ичной записью
которого оно является, т.е.
, m -ичной записью
которого оно является, т.е. ![]() . Назовем это число
номером программы
. Назовем это число
номером программы ![]() . По тексту программы
. По тексту программы ![]() ее номер
ее номер ![]() определяется однозначно.
Рассмотрим теперь обратное соответствие. Конечно, не каждое число является номером
некоторой структурированной программы. Поэтому сопоставим каждому числу
определяется однозначно.
Рассмотрим теперь обратное соответствие. Конечно, не каждое число является номером
некоторой структурированной программы. Поэтому сопоставим каждому числу ![]() структурированную программу
структурированную программу ![]() следующим образом:
если
следующим образом:
если ![]() для некоторой программы
для некоторой программы ![]() то
то ![]() , иначе, т.е. когда n не является
"естественным" номером никакой программы, сопоставим ему в качестве
, иначе, т.е. когда n не является
"естественным" номером никакой программы, сопоставим ему в качестве ![]() некоторую никогда не
останавливающуюся программу P (например, программу
некоторую никогда не
останавливающуюся программу P (например, программу ![]() : x1 := x1; пока x1=x1 делай x1:=x1 все из примера 7.5).
: x1 := x1; пока x1=x1 делай x1:=x1 все из примера 7.5).
Проблема самоприменимости заключается в проверке для каждой программы ![]() с входной переменной x и выходной переменной y того, остановится ли
с входной переменной x и выходной переменной y того, остановится ли ![]() на собственном номере
на собственном номере ![]() , т.е в вычислении
всюду определенной функции
, т.е в вычислении
всюду определенной функции

Теорема 10.4. Проблема самоприменимости алгоритмически неразрешима, т.е. не существует структурированной программы, вычисляющей функцию Fs(x).
Доказательство от противного. Предположим, что существует программа P, вычисляющая функцию Fs(x). Без ограничения общности, можно считать,
что ее выходная переменная есть y (почему?) и поэтому ![]() для всех x. Пусть переменная z не входит в P.
Рассмотрим следующую программу P’:
для всех x. Пусть переменная z не входит в P.
Рассмотрим следующую программу P’:
Легко проверить, что если P на входе x выдает результат y=1, то P’
на этом входе не останавливается, а если P выдает результат y=0, то P’
останавливается ( и тоже выдает 0). Пусть n’=nP’ - номер программы P’.
Чему тогда равно значение ![]() ?
Если оно равно 1, то на входе x=n’ программа P’ не остановится, т.е.
?
Если оно равно 1, то на входе x=n’ программа P’ не остановится, т.е. ![]() , но тогда
, но тогда ![]() .
Если же
.
Если же ![]() , то P’ на входе x=n’ останавливается с результатом 0,
т.е.
, то P’ на входе x=n’ останавливается с результатом 0,
т.е. ![]() . Но тогда
. Но тогда ![]() .
Во всех случаях получили, что
.
Во всех случаях получили, что ![]() и, следовательно,
предположение о существовании программы для вычисления функции Fs
неверно.
и, следовательно,
предположение о существовании программы для вычисления функции Fs
неверно.
Заметим, что на самом деле мы доказали отсутствие структурированной программы для вычисления функции Fs. Но тезис Тьюринга-Черча и эквивалентность структурированных программ машинам Тьюринга и ч.р.ф. позволяют сделать вывод об алгоритмической неразрешимости рассматриваемой проблемы.
Проблема самоприменимости может показаться не очень интересной с практической ("программистской") точки зрения. Но оказывается, что ее можно использовать для доказательства алгоритмической неразрешимости многих других алгоритмических проблем, более тесно связанных с практикой программирования.
Проблема останова: по произвольной структурированной программе
 определить завершится ли вычисление на входе 0, т.е вычислить всюду определенную функцию
определить завершится ли вычисление на входе 0, т.е вычислить всюду определенную функцию
В более общем виде проблема останова состоит в вычислении следующей функции:

Из этого определения следует, что программа
 останавливается
на входе a тогда и только тогда, когда Fh(n,a)=1.
останавливается
на входе a тогда и только тогда, когда Fh(n,a)=1.Проблема тотальности: по произвольной структурированной программе
определить, завершает ли она работу при всех значениях входной переменной, т.е вычислить всюду определенную функцию
- Проблема эквивалентности: по произвольным двум структурированным программам и
 определить, эквивалентны ли они, т.е вычисляют ли они одну и ту же функцию:
определить, эквивалентны ли они, т.е вычисляют ли они одну и ту же функцию:
Проблемы оптимизации текста программы. Одна из возможных оптимизаций (текста) программы состоит в удалении из нее операторов присваивания, которые никогда не работают, а другая - в замене условных операторов вида

на
в случае, когда условие  истинно на любых входных данных, и - на , если оно на любом входе
ложно. Определим соответствующие этим оптимизациям функции:
истинно на любых входных данных, и - на , если оно на любом входе
ложно. Определим соответствующие этим оптимизациям функции:
Из этого определения следует, что при Fopt1(n,m)=0 программу
можно оптимизировать, удалив из нее m -ый оператор присваивания. Назовем задачу вычисления функции Fopt1(n,m) проблемой лишнего присваивания
Ясно, что при Fopt2(n,m)=0 программу
можно оптимизировать, заменив ее m -ый условный оператор его второй альтернативой.
Назовем задачу вычисления функции Fopt2 (n,m) проблемой лишнего условияЗаметим, что проблема самоприменимости и все проблемы, перечисленные в пп. 1-4 выше, связаны с вычислением функций, принимающих два значения 0 и 1. Эти функции являются характеристическими функциями соответствующих множеств. Например, Fh0(n) является характеристической функцией множества номеров программ, останавливающихся на входе 0. Напомним, что для множества
 его характеристическая функция cAk определяется следующим образом:
его характеристическая функция cAk определяется следующим образом:
На множества переносится понятия разрешимости и неразрешимости.
Определение 10.1. Множество ![]() назовем разрешимым (или рекурсивным ), если его характеристическая функция cAk вычислима, т.е. является общерекурсивной функцией,
в противном случае, оно (и связанная с ним проблема) неразрешимо.
назовем разрешимым (или рекурсивным ), если его характеристическая функция cAk вычислима, т.е. является общерекурсивной функцией,
в противном случае, оно (и связанная с ним проблема) неразрешимо.
Используя это определение, теорему 10.4 можно переформулировать так:
Множество номеров программ, остановливающихся на собственном номере,
Обычно доказательства неразрешимости проблем используют метод сведения. Неформально его идею можно сформулировать следующим образом: "Если решение некоторой неразрешимой проблемы A можно эффективно получить, используя решение проблемы B, то тогда проблема B тоже неразрешима."
Определим отношение сводимости более формально.
Напомним, что нумерационные функции позволяют вместо
наборов (векторов, n -ок) целых чисел рассматривать их номера.
Для множества ![]() обозначим через cr(B) множество номеров входящих в B наборов:
обозначим через cr(B) множество номеров входящих в B наборов: ![]() (при r=1, разумеется, c1(B)=B ).
(при r=1, разумеется, c1(B)=B ).
Лемма 10.1.
Множество (проблема) ![]() сводится
к множеству (проблеме)
сводится
к множеству (проблеме) ![]() , если существует общерекурсивная функция f: Nk -> N
такая, что
, если существует общерекурсивная функция f: Nk -> N
такая, что ![]() .
В этом случае будем писать A <=m B посредством f.
.
В этом случае будем писать A <=m B посредством f.
Содержательно, " A сводится к B посредством f " означает, что для выяснения, входит ли x в A, можно эффективно преобразовать x в такие входные данные y=f(x)
проблемы B, что при ![]() имеем
имеем ![]() , а если
, а если ![]() , то и
, то и ![]() .
.
Разрешимые множества сводятся к любым нетривиальным множествам.
Лемма 10.2. Если A разрешимо, а B не совпадает с ![]() и N, то A <=m B.
и N, то A <=m B.
Доказательство. По условию имеются такие b и d, что ![]() , а
, а ![]() .
Положим f(x) = b , cA(x) + d ,(1 - cA(x)). Тогда при
.
Положим f(x) = b , cA(x) + d ,(1 - cA(x)). Тогда при ![]() имеем
имеем ![]() ,
а при
,
а при ![]() -
- ![]() . Таким образом, A <=m B посредством f.
. Таким образом, A <=m B посредством f.
Как мы уже отмечали, доказательство неразрешимости можно основывать на следующем утверждении.
Лемма 10.3. Если A сводится к B и проблема A неразрешима, то и проблема B неразрешима.
Доказательство. Пусть A <=m B посредством f. Тогда из определения сводимости следует, что для всех x имеет место равенство cA(x)=cB(f(x)). Поэтому, если бы B была разрешима, то ее характеристическая функция cB была бы общерекурсивна и cA также была бы общерекурсивна. Но это противоречит неразрешимости проблемы A.
Теорема 10.5. Все проблемы, перечисленные выше в пунктах 1-4, являются алгоритмически неразрешимыми.
Доказательство. Нам потребуются следующие вспомогательные
программы ![]() ( присваиваие x:=x+1
повторяется n раз). Понятно, что для любого начального состояния
( присваиваие x:=x+1
повторяется n раз). Понятно, что для любого начального состояния ![]() после выполнения
после выполнения ![]() имеем
имеем ![]() .
.
Докажем неразрешимость {проблемы останова:} по произвольной структурированной программе
определить, завершится ли вычисление на входе 0.
Пусть  . Докажем, что множество номеров
самоприменимых программ Ms сводится к Mh0. Пусть n - номер программы . преобразуем ее в программу
. Докажем, что множество номеров
самоприменимых программ Ms сводится к Mh0. Пусть n - номер программы . преобразуем ее в программу  .
Таким образом, вначале заносит в x номер n программы ,
а затем применяет к этому номеру и, если на n останавливается, выдает
результат y=0. Поэтому останавливается на любом аргументе (в том числе и на 0) тогда и только тогда,
когда
.
Таким образом, вначале заносит в x номер n программы ,
а затем применяет к этому номеру и, если на n останавливается, выдает
результат y=0. Поэтому останавливается на любом аргументе (в том числе и на 0) тогда и только тогда,
когда  . Преобразование программы в программу осуществляется эффективно. Поэтому (на основании тезиса Тьюринга-Черча)
существует такая о.р.ф. f, которая по n вычисляет номер m программы
. Преобразование программы в программу осуществляется эффективно. Поэтому (на основании тезиса Тьюринга-Черча)
существует такая о.р.ф. f, которая по n вычисляет номер m программы  .
Эта функция и будет сводить Ms к Mh0, так как
.
Эта функция и будет сводить Ms к Mh0, так как  .
Следовательно, по лемме ref{lm-red} проблемы останова Mh0 неразрешима.
.
Следовательно, по лемме ref{lm-red} проблемы останова Mh0 неразрешима.Очевидно, что и более общая форма проблемы останова
 также неразрешима, поскольку к ней
сводится Mh0:
также неразрешима, поскольку к ней
сводится Mh0:  .
.- Для сведения Ms к множеству Mt номеров программ, вычисляющих всюду
определенные функции, можно также использовать функцию f из пункта 1.
Действительно, останавливается на входе n тогда и только тогда, когда
 останавливается на всех входах, т.е.
останавливается на всех входах, т.е.  .
Следовательно, проблема тотальности Mt неразрешима.
.
Следовательно, проблема тотальности Mt неразрешима. Рассмотрим теперь проблему эквивалентности. Пусть

(x) ) Зафиксируем следующую программу P0: x:=x; y:=0. Очевидно, что она вычисляет функцию, тождественно равную нулю, т.е.
 для всякого x.
Пусть ее номер n(P0) равен k0. Для произвольного n рассмотрим
пару (f(n), k0). Из определения f следует, что останавливается на входе n тогда и только тогда, когда останавливается на всех входах и выдает результат 0:
для всякого x.
Пусть ее номер n(P0) равен k0. Для произвольного n рассмотрим
пару (f(n), k0). Из определения f следует, что останавливается на входе n тогда и только тогда, когда останавливается на всех входах и выдает результат 0:  для всех x, т.е.
для всех x, т.е.  и
и  эквивалентны. Тогда
эквивалентны. Тогда  . Положим g(n)= c2(f(n),k0) .
Тогда g является о.р.ф. и
. Положим g(n)= c2(f(n),k0) .
Тогда g является о.р.ф. и  . Следовательно, Ms
сводится к Meq посредством g и проблема Meq неразрешима.
. Следовательно, Ms
сводится к Meq посредством g и проблема Meq неразрешима.Для доказательства неразрешимости проблемы лишнего присваивания:

снова используем функцию f из пункта 1. Напомним, что
 . По n и соответствующей программе
можно легко определить номер m последнего присваивания y:=0 в
. По n и соответствующей программе
можно легко определить номер m последнего присваивания y:=0 в  :
:
Пусть g(n) - это о.р.ф., вычисляющая по n этот номер m. Тогда
 . Положим h(n)= c2(f(n),g(n)). Тогда h является о.р.ф. и
. Положим h(n)= c2(f(n),g(n)). Тогда h является о.р.ф. и  . Следовательно, Ms
сводится к Mopt1 посредством h и проблема Mopt1 неразрешима.
. Следовательно, Ms
сводится к Mopt1 посредством h и проблема Mopt1 неразрешима.Рассмотрим теперь проблему лишнего условия:

Для доказательства ее неразрешимости определим по n программу
 ( здесь - программа из п. 1).
И в этом случае программа
( здесь - программа из п. 1).
И в этом случае программа  строится по программе эффективно. Пусть ее номер вычисляется о.р.ф. f’, т.е.
строится по программе эффективно. Пусть ее номер вычисляется о.р.ф. f’, т.е.  , и пусть
о.р.ф. g’(n) определяет номер последнего условного оператора в программе
, и пусть
о.р.ф. g’(n) определяет номер последнего условного оператора в программе  .
Тогда
.
Тогда  в программе
в программе  последний условный
оператор выполняется (на любом входе) и при этом y=0, т.е. его условие
истинно, а это означает, что
последний условный
оператор выполняется (на любом входе) и при этом y=0, т.е. его условие
истинно, а это означает, что  .
Положив h’(n)= c2(f’(n),g’(n)), получим, что
.
Положив h’(n)= c2(f’(n),g’(n)), получим, что  . Следовательно, Ms
сводится к Mopt2 посредством h’ и проблема Mopt2
также неразрешима.
. Следовательно, Ms
сводится к Mopt2 посредством h’ и проблема Mopt2
также неразрешима.Теорема доказана.
Какой же вывод можно сделать из того, что некоторая алгоритмическая проблема оказалась неразрешимой? Для программистов из такого утверждения извлекаются "две новости: плохая и хорошая ". "Плохая новость" состоит в том, что невозможно построить алгоритм (программу) для автоматического решения такой проблемы. Например, из теоремы 10.5 следует, что невозможно автоматически проверить, входит ли некоторый вход в область определения вычислимой функции, нельзя определить корректность программы, т.е. то, что она вычисляет требуемую функцию, нет способа проверять эквивалентность программ (не только структурированных, но и написанных на Паскале, Си, ассемблере, Яве и других языках программирования), не существует алгоритмов для оптимизаций, связанных с удалением лишних присваиваний и условий, и т.п. Но неразрешимость проблемы не означает, что она не может быть решена для некоторых отдельных входных данных. Например, в предыдущих разделах мы построили достаточно много программ и доказали их корректность. Поэтому "хорошая новость" для программистов и математиков состоит в том, что их труд при решении неразрешимых проблем в каждом отдельном случае является творческим - никакой программой их не заменить. Появление каждой новой содержательно интересной неразрешимой проблемы только расширяет область их творчества, заставляет искать все более и более широкие алгоритмы, которые позволяют решать все более обширные подклассы относящихся к этой проблеме индивидуальных задач.
Задачи
Задача 10.1. Докажите, что машины Тьюринга ![]() и
и ![]() , определенные в доказательстве теоремы 10.1 для примитивной рекурсии и минимизации, действительно правильно реализуют указанные операторы.
, определенные в доказательстве теоремы 10.1 для примитивной рекурсии и минимизации, действительно правильно реализуют указанные операторы.
Задача 10.2. Постройте машины Тьюринга Mi0 , Mi+1, Mij, ![]() ,
, ![]() , Mstart и Mend, определенные
в доказательстве теоремы 10.2.
, Mstart и Mend, определенные
в доказательстве теоремы 10.2.
Задача 10.3.
Докажите утверждение 1, сформулированное в доказательстве теоремы 10.2, используя индукцию по построению программы ![]() и соответствующей м.Т.
и соответствующей м.Т. ![]() .
.
Задача 10.4. В доказательстве теоремы 10.3 рассмотрен случай, когда
м.Т. ![]() вычисляет функцию
от одного аргумента f(x) . Покажите, что теорема верна и в
общем случае для функций f(x1,...,xn) при любом n.
вычисляет функцию
от одного аргумента f(x) . Покажите, что теорема верна и в
общем случае для функций f(x1,...,xn) при любом n.
Задача 10.5. Докажите, что отношение алгоритмической сводимости <=m является рефлексивным и транзитивным.
Задача 10.6. Доказать алгоритмическую неразрешимость следующих проблем.
- По произвольной программе определить, является ли вычисляемая ей функция
 постоянной константой.
постоянной константой. - По произвольной программе и числам a и b проверить равенство
 .
. - По произвольной программе определить, является ли множество значений вычисляемой ею функции бесконечным.
- По произвольной паре программ и проверить, что для всех x имеет место неравенство
 .
.
Задача 10.7. Докажите, что
- пересечение двух разрешимых множеств является разрешимым множеством.
- объединение двух разрешимых множеств является разрешимым множеством.
Задача 10.8.
Докажите, что для двух разрешимых множеств A и B их "сумма" ![]() также
является разрешимым множеством.
также
является разрешимым множеством.
Задача 10.9. Пусть A - разрешимое множество, а g(x) и h(x) являются о.р.ф. Докажите, что функция
также является общерекурсивной.