Лекция 1. Основные понятия языка
Предисловие
Презентацию к данной работе Вы можете скачать ![]() здесь.
здесь.
Этот курс лекций построен на основе учебника автора 'Паскаль. Программирование на языке высокого уровня' [10], который выпускается издательством ПИТЕР с 2003 года. Учебник имеет гриф Министерства образования Российской федерации и удостоен в 2010 году премии Правительства Санкт-Петербурга 'За выдающиеся достижения в сфере высшего и профессионального образования' в составе учебно-методического комплекса по языкам программирования.
В этот комплекс входят также учебники и практикумы по языкам C/C++ и С# [11][9], построенные по единому принципу. Соответствующие учебные курсы можно найти на этом сайте. В 2010 году вышло второе издание учебника [10], объединенное с практикумом и справочной информацией. В комплекс входит более 250 индивидуальных вариантов заданий на лабораторные работы в расчете на учебную группу из 20 человек (все варианты можно найти в учебнике) и более 1000 тестовых вопросов. Преподавателям будут полезны презентации лекций. На сайте интернет-школы программирования можно проверить правильность выполнения некоторых лабораторных работ с помощью системы автоматического тестирования программ.
Доброжелательную и конструктивную критику, а также предложения по улучшению курса направляйте автору по адресу pta-ipm@yandex.ru.
Основные понятия языка
Состав языка
Для решения задачи на компьютере требуется написать программу. Программа состоит из исполняемых операторов и операторов описания. Исполняемый оператор задает законченное действие, выполняемое над данными. Примеры исполняемых операторов: вывод на экран, занесение числа в память, выход из программы.
Оператор описания, как и следует из его названия, описывает данные, над которыми в программе выполняются действия. Примером описания (конечно, не на Паскале, а на естественном языке) может служить предложение 'В памяти следует отвести место для хранения целого числа, и это место мы будем обозначать А'.
Исполняемые операторы для краткости часто называют просто операторами, а операторы описания — описаниями. Описания должны предшествовать операторам, в которых используются соответствующие данные. Операторы исполняются последовательно, один за другим, если явным образом не задан иной порядок.
Рассмотрим простейшую программу на Паскале. Все, что она делает — вычисляет и выводит на экран сумму двух целых чисел, введенных с клавиатуры.
var a, b, sum : integer; { 1 }
begin { 2 }
readln(a, b); { 3 }
sum := a + b; { 4 }
writeln('Cумма чисел ', a, ' и ', b, ' равна ', sum); { 5 }
end. { 6 }В программе шесть строк, каждая из них помечена комментарием с номером (внутри фигурных скобок можно писать все, что угодно).
В строке 1 расположен оператор описания используемых в программе величин. Для каждой из них задается имя, по которому к ней будут обращаться, и ее тип. 'Волшебным словом' var обозначается тот факт, что a, b и sum — переменные, то есть величины, которые во время работы программы могут менять свои значения. Для всех переменных задан целый тип, он обозначается integer. Тип необходим для того, чтобы переменным в памяти было отведено соответствующее место.
Исполняемые операторы программы располагаются между служебными словами begin и end, которые предназначены для объединения операторов и сами операторами не являются. Операторы отделяются друг от друга точкой с запятой.
Ввод с клавиатуры выполняется в строке 3 с помощью стандартной процедуры с именем readln. В скобках после имени указывается, каким именно переменным будут присвоены значения. Для вывода результатов работы программы в строке 5 используется стандартная процедура writeln. В скобках через запятую перечисляется все, что мы хотим вывести на экран, при этом пояснительный текст заключается в апострофы. Например, если ввести в программу числа 2 и 3, результат будет выглядеть так:
Cумма чисел 2 и 3 равна 5
В строке 4 выполняется вычисление суммы и присваивание ее значения переменной sum. Справа от знака операции присваивания, обозначаемой символами :=, находится выражение — правило вычисления значения.
Чтобы выполнить программу, требуется перевести ее на язык, понятный процессору, — в машинные коды. Этим занимается компилятор.Каждый оператор языка переводится в последовательность машинных команд. Компилятор планирует размещение данных в оперативной памяти в соответствии с операторами описания. Попутно он ищет синтаксические ошибки, то есть ошибки записи операторов. Кроме этого, в Паскале на компилятор возложена еще одна обязанность — подключение к программе стандартных подпрограмм (например, ввода данных или вычисления синуса угла).
Алфавит и лексемы
Все тексты на языке пишутся с помощью его алфавита. Алфавит Паскаля включает:
- прописные и строчные латинские буквы, знак подчеркивания _ ;
- цифры от 0 до 9 ;
- специальные символы, например +, *, { и @ ;
- пробельные символы: пробел, табуляцию и переход на новую строку.
Из символов составляются лексемы (tokens ), то есть минимальные единицы языка, имеющие самостоятельный смысл:
- константы ;
- имена ( идентификаторы );
- ключевые слова ;
- знаки операций ;
- разделители (скобки, точка, запятая, пробельные символы).
Лексемы языка программирования аналогичны словам естественного языка. Например, лексемами являются число 128, имя Vasia, ключевое слово goto и знак операции сложения +. Компилятор при синтаксическом разборе текста программы определяет границы одних лексем по другим, например разделителям или знакам операций. Из лексем строятся выражения и операторы. Рассмотрим каждый вид лексем подробнее.
Константы
Константа — величина, не изменяющая свое значение в процессе работы программы. Классификация констант Паскаля приведена в шапке таблица 1.1. Нижние строки таблицы представляют собой примеры соответствующих констант.
| Целые | Вещественные | Символьные | Строковые | ||
|---|---|---|---|---|---|
| Десятичные | Шестнадцатеричные | С плавающей точкой | С порядком | ||
| 2 | $0101 | –0.26 | 1.2e4 | 'k' | 'абырвалг' |
| 15 | $FFA4 | .005 | 0.1E–5 | #186 | 'I''m fine' |
| 21. | ^M | ||||
Десятичные целые константы представляются в естественной форме. Шестнадцатеричная константа состоит из шестнадцатеричных цифр (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F), предваряемых знаком $.
Вещественные константы записываются с точкой перед дробной частью. Либо целая, либо дробная часть могут отсутствовать. Вещественная константа с порядком представляется в виде мантиссы и порядка. Мантисса записывается слева от знака E или e, порядок — справа от знака. Значение константы равно произведению мантиссы и возведенного в указанную в порядке степень числа 10. В таблица 1.1 представлены числа 1,2 104 и 0,1 10–5 . Пробелы внутри числа не допускаются.
Символьные константы служат для представления любого символа из набора, используемого в данном компьютере. Так как под каждый символ отводится 1 байт, всего используется 256 символов. Каждому символу соответствует свой код. В операционной системе MS-DOS для кодировки символов используется стандарт ASCII, являющийся международным только в первой половине кодов (от 0 до 127), вторая половина кодов (от 128 до 255) является национальной и различна для разных стран. Первые 32 символа являются управляющими:хотя многие из них имеют графическое представление, предназначены они для передачи управляющих сигналов внешним устройствам, например монитору, принтеру или модему. Символьные константы записываются в одной из трех форм:
- Символ, заключенный в апострофы.
- Десятичный код символа, предваряемый знаком #. Применяется для представления символов, отсутствующих на клавиатуре (в таблица 1.1 в виде #186 приведено представление символа ¦ ).
- Буква, предваряемая знаком ^. Используется для представления управляющих символов. Код буквы должен быть на 64 больше, чем код представляемого таким образом символа (в таблица 1.1 в виде ^M представлен символ с кодом 13).
Строковая константа — это последовательность любых ASCII-символов, расположенная на одной строке и заключенная в апострофы. Если требуется представить сам апостроф, он дублируется. Максимальная длина строковой константы — 126 символов.
Имена, ключевые слова и знаки операций
Имена в программах служат той же цели, что и имена людей, — чтобы обращаться к программным объектам и различать их, то есть идентифицировать. Поэтому имена также называют идентификаторами.
Имена дает программист, при этом следует соблюдать следующие правила:
- имя должно начинаться с буквы (или знака подчеркивания);
- имя должно содержать только буквы, знак подчеркивания и цифры;
- прописные и строчные буквы не различаются;
- длина имени практически не ограничена.
Например, правильными именами будут Vasia, A, A13, A_and_B и _____, а неправильными — 2late, Big gig и Sюр. Имена даются элементам программы, к которым требуется обращаться: переменным, константам, процедурам, функциям, меткам и т. д.
Ключевые ( зарезервированные ) слова — это идентификаторы, имеющие специальное значение для компилятора. Их можно использовать только в том смысле, в котором они определены. Например, для оператора перехода определено ключевое слово goto, а для описания переменных — var. Имена, создаваемые программистом, не должны совпадать с ключевыми словами.
Знак операции — это один или более символов, определяющих действие над операндами. Внутри знака операции пробелы не допускаются. Например, операция сравнения 'меньше или равно' обозначается <=, а целочисленное деление записывается как div. Операции делятся на унарные (с одним операндом) и бинарные (с двумя).
Типы данных
Данные, с которыми работает программа, хранятся в оперативной памяти. Компилятору необходимо точно знать, сколько места они занимают, как именно закодированы и какие действия с ними можно выполнять. Все это задается при описании данных с помощью типа. Тип данных однозначно определяет:
- внутреннее представление данных, а следовательно и множество их возможных значений;
- допустимые действия над данными (операции и функции).
Например, целые и вещественные числа, даже если они занимают одинаковый объем памяти, имеют совершенно разные диапазоны возможных значений; целые числа можно умножать друг на друга, а, например, символы — нельзя. Каждое выражение в программе имеет определенный тип. Компилятор использует информацию о типе при проверке допустимости описанных в программе действий.
Классификация типов
Рассмотрим классификацию типов в таблица 1.2.
| Стандартные | Определяемые программистом | ||
|---|---|---|---|
| Простые | Составные | ||
| Логические | |||
| Целые | |||
| Вещественные | Перечисляемый | Массивы | Файлы |
| Символьный | Интервальный | Строки | Процедурные типы |
| Строковый | Адресные | Записи | Объекты |
| Адресный | Множества | ||
| Файловые | |||
Стандартные типы не требуют предварительного определения. Для каждого типа существует ключевое слово, которое используется при описании переменных, констант и т. д. Если же тип данных определяет сам программист, он описывает его характеристики и дает ему имя, которое затем применяется точно так же, как имена стандартных типов. Описание собственного типа данных должно задавать всю информацию, необходимую для его использования: внутреннее представление и допустимые действия.
Стандартные типы данных
Логические типы
Внутреннее представление. Основной логический тип данных Паскаля называется boolean. Величины этого типа занимают в памяти 1 байт и могут принимать всего два значения: true (истина) или false (ложь). Внутреннее представление значения false — 0 (нуль), значения true — 1.
Операции. К величинам логического типа применяются логические операции and, or, xor и not (таблица 1.3). Для наглядности вместо значения false в таблице используется 0, а вместо true — 1.
Операция and называется ' логическое И ', или логическое умножение. Ее результат имеет значение true, только если оба операнда имеют значение true.
Результат операции or ( логическое ИЛИ, логическое сложение) имеет значение true, если хотя бы один из операндов имеет значение true. Например, false or true true, true or true true.
Операция xor — так называемое исключающее ИЛИ, или операция неравнозначности. Ее результат истинен, когда значения операндов не совпадают.
Логическое отрицание not является унарной операцией, то есть имеет один операнд, который и инвертирует. Например, not true даст в результате false.
Величины логического типа можно сравнивать между собой с помощью операций отношения, перечисленных в таблица 1.4. Результат этих операций имеет логический тип.
| Операция | Знак операции | Операция | Знак операции |
|---|---|---|---|
| Больше | > | Меньше или равно | <= |
| Больше или равно | >= | Равно | = |
| Меньше | < | Не равно | <> |
Целые типы
Внутреннее представление. Целые числа представляются в компьютере в двоичной системе счисления. В Паскале определены несколько целых типов данных, отличающиеся длиной и наличием знака: старший двоичный разряд либо воспринимается как знаковый, либо является обычным разрядом числа (таблица 1.5). Внутреннее представление определяет диапазоны допустимых значений величин (от нулей до единиц во всех двоичных разрядах).
| Тип | Название | Размер | Знак | Диапазон значений |
|---|---|---|---|---|
| integer | Целое | 2 байта | Есть | –32 768 .. 32 767 (–215 .. 215–1) |
| shortint | Короткое целое | 1 байт | Есть | –128 .. 127 (–2 7 .. 27–1) |
| byte | Байт | 1 байт | Нет | 0 .. 255 (0 .. 28–1) |
| word | Слово | 2 байта | Нет | 0 .. 65 535 (0 .. 2 16–1) |
| longint | Длинное целое | 4 байта | Есть | –2 147 483 648 .. 2 147 483 647 (–2 31 .. 231–1) |
Операции.С целыми величинами можно выполнять арифметические операции (таблица 1.6). Результат их выполнения всегда целый (при делении дробная часть отбрасывается).
| Операция | Знак операции | Операция | Знак операции |
|---|---|---|---|
| Сложение | + | Деление | div |
| Вычитание | – | Остаток от деления | mod |
| Умножение | * |
К целым величинам можно также применять операции отношения, а также поразрядные операции and, or, xor и not. При выполнении этих операций каждая величина представляется как совокупность двоичных разрядов. Действие выполняется над каждой парой соответствующих разрядов операндов: первый разряд с первым, второй — со вторым, и т. д. Например, результатом операции 3 and 2 будет 2, поскольку двоичное представление числа 3 — 11, числа 2 — 10.
Для работы с целыми величинами предназначены также операции сдвига влево shl и вправо shr. Слева от знака операции указывается, с какой величиной будет выполняться операция, а справа — на какое число двоичных разрядов требуется сдвинуть величину. Например, результатом операции 12 shr 2 будет значение 3, а выполнив операцию 12 shl 1, то есть сдвинув это число влево на 1 разряд, получим 24. Освободившиеся при сдвиге влево разряды заполняются нулями, а при сдвиге вправо — знаковым разрядом.
Стандартные функции и процедуры.К целым величинам можно применять стандартные функции и процедуры, перечисленные в таблица 1.7 (в тригонометрических функциях угол задается в радианах).
| Имя | Описание | Результат | Пояснения |
|---|---|---|---|
| Функции | |||
| abs | Модуль | Целый | |x| записывается abs(x) |
| arctan | Арктангенс угла | Вещественный | arctg x записывается arctan(x) |
| cos | Косинус угла | Вещественный | cos x записывается cos(x) |
| exp | Экспонента | Вещественный | e x записывается exp(x) |
| ln | Натуральный логарифм | Вещественный | log ex записывается ln(x) |
| odd | Проверка на четность | Логический | odd(3) даст в результате true |
| pred | Предыдущее значение | Целый | pred(3) даст в результате 2 |
| sin | Синус угла | Вещественный | sin x записывается sin(x) |
| sqr | Квадрат | Целый | x 2 записывается sqr(x) |
| sqrt | Квадратный корень | Вещественный | |
| succ | Следующее значение | Целый | succ(3) даст в результате 4 |
| Процедуры | |||
| inc | Инкремент | inc(x) — увеличить х на 1 inc(x, 3) — увеличить х на 3 | |
| dec | Декремент | dec(x) — уменьшить х на 1 dec (x, 3) — уменьшить х на 3 | |
Вещественные типы
Внутреннее представление.Вещественные типы данных хранятся в памяти компьютера иначе, чем целые. Внутреннее представление вещественного числа состоит из двух частей — мантиссы и порядка, и каждая часть имеет знак. Например, число 0,087 представляется в виде 0,87 10–1, и в памяти хранится мантисса 87 и порядок –1 (для наглядности мы пренебрегли тем, что данные на самом деле представляются в двоичной системе счисления и несколько сложнее).
Существует несколько вещественных типов, различающихся точностью и диапазоном представления данных (таблица 1.8). Точность числа определяется длиной мантиссы, а диапазон — длиной порядка.
| Тип | Название | Размер | Значащих десятичных цифр | Диапазон значений |
|---|---|---|---|---|
| real | Вещественный | 6 байт | 11–12 | 2.9e–39 .. 1.7e+38 |
| single | Одинарной точности | 4 байта | 7–8 | 1.5e–45 .. 3.4e+38 |
| double | Двойной точности | 8 байт | 15–16 | 5.0e–324 .. 1.7e+308 |
| extended | Расширенный | 10 байт | 19–20 | 3.4e–4932 .. 1.1e+4923 |
| comp | Большое целое | 8 байт | 19–20 | –9.22e18 .. 9.22e18 (–2 63 .. 2 63–1) |
Величины типа comp хранятся так же, как целые, но отнести его к целым мешает то, что тип comp не относится к порядковым типам. Операции. С вещественными величинами можно выполнять арифметические операции, перечисленные в таблица 1.9. Результат их выполнения — вещественный.
| Операция | Знак операции | Операция | Знак операции |
|---|---|---|---|
| Сложение | + | Умножение | * |
| Вычитание | – | Деление | / |
В общем случае при выполнении любой операции операнды должны быть одного и того же типа, но целые и вещественные величины смешивать разрешается.
К вещественным величинам можно также применять операции отношения.
Стандартные функции.К вещественным величинам можно применять стандартные функции, приведенные в таблице 1.10 (в тригонометрических функциях угол задается в радианах).
| Имя | Описание | Результат | Пояснения |
|---|---|---|---|
| abs | Модуль | Вещественный | |x| записывается abs(x) |
| arctan | Арктангенс угла | Вещественный | arctg x записывается arctan(x) |
| cos | Косинус угла | Вещественный | cos x записывается cos(x) |
| exp | Экспонента | Вещественный | e x записывается exp(x) |
| frac | Дробная часть аргумента | Вещественный | frac(3.1) даст в результате 0,1 |
| int | Целая часть аргумента | Вещественный | int(3.1) даст в результате 3,0 |
| ln | Натуральный логарифм | Вещественный | log ex записывается ln(x) |
| pi | Значение числа | Вещественный | 3,1415926536 |
| round | Округление до целого | Целый | round(3.1) даст в результате 3 round (3.8) даст в результате 4 |
| sin | Синус угла | Вещественный | sin x записывается sin(x) |
| sqr | Квадрат | Вещественный | x 2 записывается sqr(x) |
| sqrt | Квадратный корень | Вещественный | |
| trunc | Целая часть аргумента | Целый | trunc(3.1) даст в результате 3 |
Символьный тип
Этот тип данных, обозначаемый ключевым словом char, служит для представления любого символа из набора допустимых символов. Под каждый символ отводится 1 байт. К символам можно применять операции отношения (<, <=, >, >=, =, <>), при этом сравниваются коды символов. Меньшим окажется символ, код которого меньше. Других операций с символами нет. Стандартных подпрограмм для работы с символами тоже немного (таблица 1.11).
| Имя | Описание | Результат | Пояснения |
|---|---|---|---|
| ord | Порядковый номер символа | Целый | ord('b') даст в результате 98
ord('ю') даст в результате 238 |
| chr | Преобразование в символ | Символьный | chr(98) даст в результате 'b' chr(238) даст в результате 'ю ' |
| pred | Предыдущий символ | Символьный | pred('b') даст в результате ' a ' |
| succ | Последующий символ | Символьный | succ('b') даст в результате ' c ' |
| upcase | Перевод в верхний регистр (только для символов из диапазона ' a ' … ' z ') | Символьный | upcase('b') даст в результате ' B ' |
Порядковые типы
В группу порядковых объединены целые, символьный, логический, перечисляемый и интервальный типы. Сделано это потому, что они обладают следующими общими чертами:
- все возможные значения порядкового типа представляют собой ограниченное упорядоченное множество;
- к любому порядковому типу может быть применена стандартная функция Ord, которая в качестве результата возвращает порядковый номер конкретного значения в данном типе;
- к любому порядковому типу могут быть применены стандартные функции Pred и Succ, которые возвращают предыдущее и последующее значения соответственно;
- к любому порядковому типу могут быть применены стандартные функции Low и High, которые возвращают наименьшее и наибольшее значения величин данного типа.
При изучении операторов Паскаля мы увидим, что в некоторых из них допускается использовать только величины порядковых типов.
Приведение типов
Иногда при программировании требуется явным образом преобразовывать величину одного типа в величины другого. Для этого служит операция приведения типа, которая записывается так:
имя_типа (преобразуемая_величина)
Например:
integer ('A')
byte(500)Размер преобразуемой величины должен быть равен числу байтов, отводимых под величины типа, в который она преобразуется. Исключение составляют преобразования более длинных целых типов в более короткие: в этом случае лишние биты просто отбрасываются. Приведение типа изменяет только точку зрения компилятора на содержимое ячеек памяти, никакие преобразования внутреннего представления при этом не выполняются.
Линейные программы
Линейной называется программа, все операторы которой выполняются в том порядке, в котором они записаны. Это самый простой вид программ.
Переменные
Переменная — это величина, которая во время работы программы может менять свое значение. Все переменные, используемые в программе, должны быть описаны в разделе описания переменных, начинающемся со служебного слова var. Для каждой переменной задается ее имя и тип, например:
var number : integer;
x, y : real;
option : char;Имя переменной определяет место в памяти, по которому находится значение переменной. Имя дает программист. Оно должно отражать смысл хранимой величины и быть легко распознаваемым.
Тип переменных выбирается исходя из диапазона и требуемой точности представления данных.
При объявлении можно присвоить переменной некоторое начальное значение, то есть инициализировать ее. Под инициализацией понимается задание значения, выполняемое до начала работы программы. Инициализированные переменные описываются после ключевого слова const.
const number : integer = 100;
x : real = 0.02;
option : char = 'ю';По умолчанию все переменные, описанные в главной программе, обнуляются.
Выражения
Выражение — это правило вычисления значения. В выражении участвуют операнды, объединенные знаками операций. Операндами выражения могут быть константы, переменные и вызовы функций. Операции выполняются в определенном порядке в соответствии с приоритетами, как и в математике. Для изменения порядка выполнения операций используются круглые скобки, уровень их вложенности практически не ограничен.
Результатом выражения всегда является значение определенного типа, который определяется типами операндов. Величины, участвующие в выражении, должны быть совместимых типов. Например, допускается использовать в одном выражении величины целых и вещественных типов. Результат такого выражения будет вещественным.
Ниже приведены операции Паскаля, упорядоченные по убыванию приоритетов.
- Унарная операция not, унарный минус –, взятие адреса @.
- Операции типа умножения: *, /, div, mod, and, shl, shr.
- Операции типа сложения: +, –, or, xor.
- Операции отношения: =, <, >, <>, <=, >=, in.
Функции, используемые в выражении, вычисляются в первую очередь.
Примеры выражений:
- t + sin(x)/2 * x — результат имеет вещественный тип;
- a <= b + 2 — результат имеет логический тип;
- (x > 0) and (y < 0) — результат имеет логический тип.
Порядок вычисления первого выражения такой: сначала выполняется обращение к стандартной функции sin и результат делится на 2, затем получившееся число умножается на x, и только после этого выполняется сложение с переменной t. Скобки в третьем выражении необходимы по той причине, что приоритет операций отношения ниже, чем логической операции and .
Структура программы
Программа на Паскале состоит из заголовка, разделов описаний и раздела операторов.
program имя; { заголовок – не обязателен }
разделы описаний
begin
раздел операторов
end. (* программа заканчивается точкой *)Программа может содержать комментарии, заключенные в фигурные скобки { } или в скобки вида (* *). Комментарии служат для документирования программы — компилятор их игнорирует, поэтому на их содержимое никаких ограничений не накладывается. Операторы отделяются друг от друга символом ; (точка с запятой).
В разделе операторов записываются исполняемые операторы программы. Ключевые слова begin и end не являются операторами, а служат для их объединения в так называемый составной оператор, или блок. Блок может записываться в любом месте программы, где допустим обычный оператор.
Разделы описаний бывают нескольких видов: описание модулей, констант, типов, переменных, меток, процедур и функций. Модуль — это подключаемая к программе библиотека ресурсов (подпрограмм, констант и т. п.).
Раздел описания модулей, если он присутствует, должен быть первым. Описание начинается с ключевого слова uses, за которым через запятую перечисляются все подключаемые к программе модули, как стандартные, так и собственного изготовления, например:
uses crt, graph, my_module;
Количество и порядок следования остальных разделов произвольны, ограничение только одно: любая величина должна быть описана до ее использования. Признаком конца раздела описания является начало следующего раздела. В программе может быть несколько однотипных разделов описаний.
В разделе описания переменных необходимо определить все переменные, которые будут использоваться в основной программе. Раздел описания констант служит для того, чтобы вместо значений констант можно было использовать в программе их имена. Такие константы называют именованными, например:
const MaxLen = 100; g = 9.8;
koeff = 5;Применение именованных констант при осмысленном выборе имен улучшает читабельность программы и облегчает внесение в нее изменений. А еще в разделе описания констант описываются переменные, которым требуется присвоить значение до начала работы программы:
const weight : real = 61.5;
Синтаксически такая переменная отличается от константы наличием типа. Впоследствии ею можно пользоваться так же, как и другими переменными.
Раздел описания меток начинается с ключевого слова label, за которым через запятую следует перечисление всех меток, встречающихся в программе. Метки служат для организации перехода на конкретный оператор с помощью оператора безусловного перехода goto. Метка — это либо имя, либо положительное число, не превышающее 9999. Метка ставится перед любым исполняемым оператором и отделяется от него двоеточием:
label 1, 2, error;
Оператор присваивания
Присваивание — это занесение значения в память. В общем виде оператор присваивания записывается так:
переменная := выражение
Здесь символами := обозначена операция присваивания. Механизм выполнения оператора присваивания такой: вычисляется выражение и его результат заносится в память по адресу, который определяется именем переменной, находящейся слева от знака операции:
переменная <- выражение
Примеры операторов присваивания:
a := b + c / 2; b := a; a := b; x := 1; x := x + 0.5;
Обратите внимание: b := a и a := b — это совершенно разные действия!
Правая и левая части оператора присваивания должны быть совместимы по присваиванию (о совместимости мы поговорим в конце третьей лекции). Например, выражение целого типа можно присвоить вещественной переменной.
Процедуры ввода-вывода
Любая программа при вводе исходных данных и выводе результатов взаимодействует с внешними устройствами. Совокупность стандартных устройств ввода и вывода, то есть клавиатуры и экрана дисплея, называется консолью. Обмен данными с консолью является частным случаем обмена с внешними устройствами.
Ввод с клавиатуры
Для ввода с клавиатуры определены процедуры read и readln.
read(список); readln[(список)];
В скобках указывается список имен переменных через запятую. Квадратные скобки указывают на то, что список может отсутствовать. Например:
read(a, b, c); readln(y); readln;
Вводить можно целые, вещественные, символьные и строковые величины. Вводимые значения должны разделяться любым количеством пробельных символов (пробел, табуляция, перевод строки).
Ввод значения каждой переменной выполняется так.
- Значение переменной выделяется как группа символов, расположенных между разделителями.
- Эти символы преобразуются во внутреннюю форму представления, соответствующую типу переменной.
- Значение записывается в ячейку памяти, определяемую именем переменной.
Например, при вводе вещественного числа 3.78 в переменную типа real оно преобразуется из четырех символов (3, 'точка', 7 и 8) в шестибайтовое представление в виде мантиссы и порядка.
Процедура readln после ввода всех значений выполняет переход на следующую строку исходных данных. Иными словами, если в следующей части программы есть ввод, он будет выполняться из следующей строки исходных данных. При использовании процедуры read очередные исходные данные будут взяты из той же строки. Процедура readln без параметров просто ожидает нажатия клавиши Enter.
Особенность ввода символов и строк состоит в том, что пробельные символы в них ничем не отличаются от всех остальных, поэтому разделителями являться не могут. Например, пусть определены переменные
var a : integer;
b : real;
d : char;и в программе есть процедура ввода read(a, b, c). Допустим, переменной а надо задать значение, равное 2, переменной b — 3,78, а в c записать символ #. Любой вариант расположения исходных данных приведет к неверному результату, потому что после второго числа требуется поставить пробельный символ для того, чтобы его можно было распознать, и этот же символ будет воспринят как значение переменной c.
Правильным решением является ввод чисел и символов в разных процедурах и размещение символов в отдельной строке, например:
readln(a, b); readln(c);
Ввод данных выполняется через буфер — специальную область оперативной памяти. Фактически данные сначала заносятся в буфер, а затем считываются оттуда процедурами ввода. Занесение в буфер выполняется по нажатию клавиши Enter вместе с ее кодом ( #13 #10 ). Процедура read, в отличие от readln, не очищает буфер, поэтому следующий после нее ввод будет выполняться с того места, на котором закончился предыдущий, то есть начиная с символа конца строки.
read(a); { считывается целое }
write('Продолжить? (y/n) ');
readln(c); { вместо ожидания ввода символа считывается символ #13 из предыдущего ввода }Чтобы избежать подобной ситуации, следует вместо read использовать readln.
Вывод на экран
При выводе выполняется преобразование из внутреннего представления в символы, выводимые на экран. Для этого определены стандартные процедуры write и writeln.
write(список); writeln[(список)];
Процедура write выводит указанные в списке величины на экран, а writeln вдобавок к этому переводит курсор на следующую строку. Процедура writeln без параметров просто переводит курсор на следующую строку.
Выводить можно величины логических, целых, вещественных, символьного и строкового типов. В списке могут присутствовать не только имена переменных, но и выражения, а также их частный случай — константы. Кроме того, для каждого выводимого значения можно задавать его формат, например:
writeln('Значение a = ', a:4, ' b = ', b:6:2, sin(a) + b);Рассмотрим этот оператор подробно (переменные a и b описаны выше). В списке вывода пять элементов, разделенных запятыми. В начале записана строковая константа в апострофах, которая выводится без изменений, со всеми пробелами. В непосредственной близости от нее будет выведено значение целой переменной a. После имени переменной через двоеточие указано количество отводимых под нее позиций, внутри которых значение выравнивается по правому краю.
Третьим элементом списка является строковая константа, поясняющая расположенное после нее значение переменной b. Для b указаны две форматные спецификации, означающие, что под эту переменную отводится всего шесть позиций, причем две из них — под дробную часть (еще одна позиция будет занята десятичной точкой, итого на целую часть остается три позиции).
Последний элемент списка вывода — выражение, значение которого будет выведено в форме по умолчанию (с порядком):
Значение a = 2 b = 3.78 4.6892974268E+00
Теперь, когда мы познакомились с примером, можно сформулировать общие правила записи процедур вывода.
- Список вывода разделяется запятыми.
- Список содержит выражения, а также их частные случаи — переменные и константы логических, целых, вещественных, символьного и строкового типов.
- После любого значения можно через двоеточие указать формат, то есть количество отводимых под него позиций. Если значение короче, оно 'прижимается' к правому краю отведенного поля, если длиннее, поле 'раздвигается' до необходимых размеров.
- Для вещественных чисел можно указать второй формат, указывающий, сколько позиций из общего количества отводится под дробную часть числа. Необходимо учитывать, что десятичная точка также занимает одну позицию. Если второй или оба формата не указаны, вещественное число выводится в форме с порядком.
- Если форматы не указаны, под целое число, символ и строку отводится минимально необходимое для их представления количество позиций. Под вещественное число всегда отводится 17 позиций, причем 10 из них — под его дробную часть.
- Форматы могут быть выражениями целого типа.
Теперь наконец-то мы изучили достаточно материала, чтобы с полным пониманием написать первую законченную программу.
Пример. Программа, которая переводит температуру в градусах по Фаренгейту в градусы Цельсия по формуле: С = 5/9 (F – 32), где C — температура по Цельсию, а F — температура по Фаренгейту.
program temperature;
var fahr, cels : real; { 1 }
begin
writeln('Введите температуру по Фаренгейту'); { 2 }
readln(fahr); { 3 }
cels := 5 / 9 * (fahr – 32); { 4 }
writeln('По Фаренгейту: ', fahr:6:2, ' в градусах Цельсия: ', cels:6:2); { 5 }
end.Для хранения исходных данных и результатов требуется выделить место в памяти. Это сделано в операторе 1. Для переменных fahr и cels выбран вещественный тип real. Оператор 2 представляет собой приглашение ко вводу данных.
Ввод выполняется в операторе 3 с помощью процедуры readln. В операторе 4 вычисляется выражение, записанное справа от операции присваивания, и результат присваивается переменной cels. При вычислении целые константы преобразуются компилятором в вещественную форму. В пятом операторе выводятся исходное и рассчитанное значение с соответствующими пояснениями.
Лекция 2. Управляющие операторы языка
Презентацию к данной работе Вы можете скачать ![]() здесь.
здесь.
В теории программирования доказано, что программу для решения задачи любой сложности можно составить только из трех структур, называемых следованием, ветвлением и циклом. Следованием называется конструкция, представляющая собой последовательное выполнение двух или более операторов (простых или составных). Ветвление задает выполнение либо одного, либо другого оператора в зависимости от выполнения какого-либо условия. Цикл задает многократное выполнение оператора (рис. 2.1).
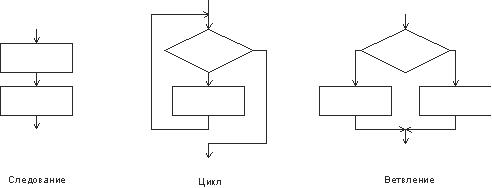
Рис. 2.1. Базовые конструкции структурного программирования
Следование, ветвление и цикл называют базовыми конструкциями структурного программирования. Их особенностью является то, что любая из них имеет только один вход и один выход, поэтому они могут вкладываться друг в друга. Например, цикл может содержать следование из нескольких ветвлений, каждое из которых включает вложенные циклы.
Целью использования базовых конструкций является получение программы простой структуры. Такую программу легко читать, отлаживать и при необходимости модифицировать. Язык Паскаль способствует созданию хорошо структурированных программ, поскольку базовые конструкции реализуются в нем непосредственно с помощью соответствующих операторов.
Операторы ветвления
Операторы ветвления if и варианта case применяются для того чтобы в зависимости от конкретных значений исходных данных обеспечить выполнение разных последовательностей операторов. Оператор if обеспечивает передачу управления на одну из двух ветвей вычислений, а оператор case — на одну из произвольного числа ветвей.
Условный оператор if
Условный оператор if используется для разветвления процесса вычислений на два направления. Структурная схема оператора приведена на рис. 2.2. Формат оператора:
if выражение then оператор_1 [else оператор_2;]
Сначала вычисляется выражение, которое должно иметь логический тип. Если оно имеет значение true, выполняется первый оператор, иначе — второй. После этого управление передается на оператор, следующий за условным.
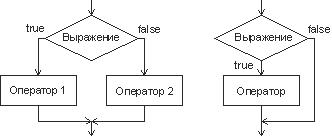
Рис. 2.2. Структурная схема условного оператора
Oператоры, входящие в состав условного оператора, могут быть простыми или составными. Составной оператор ( блок ) обрамляется ключевыми словами begin и end. Блок применяют в том случае, когда по какой-либо ветви требуется выполнить несколько операторов: ведь иначе компилятор не сможет понять, где заканчивается ветвь и начинается следующая часть программы. Одна из ветвей может отсутствовать.
Примеры условных операторов:
if a < 0 then b := 1; { 1 }
if (a < b) and ((a >d) or (a = 0)) then inc(b)
else begin
b := b * a; a := 0
end; { 2 }
if a < b then
if a < c then m := a else m := c
else
if b < c then m := b else m := c; { 3 }В примере 1 отсутствует ветвь else. Такая конструкция называется 'пропуск оператора'.
Если требуется проверить несколько условий, их объединяют знаками логических операций. Так, выражение в примере 2 будет истинно в том случае, если выполнится одновременно условие a < b и хотя бы одно из условий a > d и a = 0. Скобки, в которые заключены операции отношения, обязательны, потому что приоритет у логических операций выше, чем у операций отношения. Поскольку по ветви else требуется выполнить два оператора, они заключены в блок.
В примере 3 вычисляется наименьшее из значений трех переменных a, b и с.
Пример. Программа, которая по введенному значению аргумента вычисляет значение функции, заданной в виде графика (рис. 2.3).
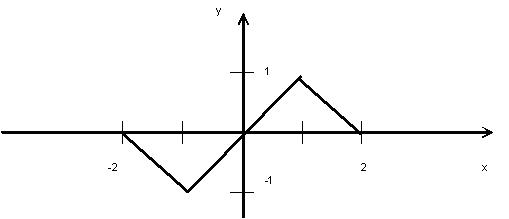
Рис. 2.3. Функция, заданная в виде графика
Составим описание алгоритма в неформальном словесном виде.
- Ввести значение аргумента х.
- Определить, какому интервалу из области определения функции оно принадлежит, и вычислить значение функции y по соответствующей формуле.
- Вывести значения х и y.
Второй пункт алгоритма следует детализировать. Сначала запишем определение функции в виде формул.

Теперь в соответствии с формулами опишем словами последовательность действий второго пункта алгоритма:
- Если x < –2, присвоить переменной y значение 0
- Если –2 <= x < –1, присвоить переменной y значение –x – 2.
- Если –1 <= x < 1, присвоить переменной y значение x.
И так далее.
Теперь шаги алгоритма представлены максимально подробно, поэтому можно приступать к написанию программы (пример 2.1).
program calc_function_1;
var x, y : real;
begin
writeln(' Введите значение аргумента'); readln(x);
if x < –2 then y := 0;
if (x >= –2) and (x < –1) then y := –x – 2;
if (x >= –1) and (x < 1) then y := x;
if (x >= 1) and (x < 2) then y := –x + 2;
if x >= 2 then y := 0;
writeln('Для x = ', x:6:2, ' значение функции y = ', y:6:2);
end.
Листинг
2.1.
Вычисление функции
(html,
txt)
Тестовые примеры для этой программы должны включать по крайней мере по одному значению аргумента из каждого интервала, а для проверки граничных условий — еще и все точки перегиба (если это кажется вам излишним, попробуйте в предпоследнем условии 'забыть' знак =, а затем ввести значение х, равное 1.
Следует избегать проверки вещественных величин на равенство, вместо этого лучше сравнивать модуль их разности с некоторым малым числом. Это связано с погрешностью представления вещественных значений в памяти. Значение величины, с которой сравнивается модуль разности, следует выбирать в зависимости от решаемой задачи и точности переменных, участвующих в выражении. Пример:
const eps = 1e-6; { Требуемая точность вычислений }
var x, y : real;
...
if (x = y) then writeln('Величины x и y равны'); { Плохо! Ненадежно! }
if (abs(x - y) < eps) then writeln('Величины x и y равны'); { Рекомендуется }Большого количества вложенных условных операторов также следует избегать, потому что они делают программу совершенно нечитабельной.
Оператор варианта case
Оператор варианта (выбора) предназначен для разветвления процесса вычислений на несколько направлений. Структурная схема оператора приведена на рис. 2.4. Формат оператора:
case выражение of
константы_1 : оператор_1;
константы_2 : оператор_2;
константы_n : оператор_n;
[ else : оператор ]
end;
Рис. 2.4. Структурная схема оператора выбора
Выполнение оператора выбора начинается с вычисления выражения. Затем управление передается на оператор, помеченный константами, значение одной из которых совпало с результатом вычисления выражения. После этого выполняется выход из оператора. Если совпадения не произошло, выполняются операторы, расположенные после слова else, а при его отсутствии управление передается оператору, следующему за case.
Выражение после ключевого слова case должно быть порядкового типа, константы — того же типа, что и выражение. Чаще всего после ключевого слова case используется имя переменной. Перед каждой ветвью оператора можно записать одну или несколько констант через запятую или операцию диапазона, обозначаемую двумя идущими подряд точками, например:
case a of
4 : writeln('4');
5, 6 : writeln('5 или 6');
7..12 : writeln('от 7 до 12');
end;Если по какой-либо ветви требуется записать не один, а несколько операторов, они заключаются в блок с помощью ключевых слов begin и end.
Операторы цикла
Операторы цикла используются для вычислений, повторяющихся многократно. В Паскале имеется три вида циклов: цикл с предусловием while, цикл с постусловием repeat и цикл с параметром for. Каждый из них состоит из определенной последовательности операторов.
Блок, ради выполнения которого и организуется цикл, называется телом цикла. Остальные операторы служат для управления процессом повторения вычислений: это начальные установки, проверка условия продолжения цикла и модификация параметра цикла (рис. 2.5). Один проход цикла называется итерацией.
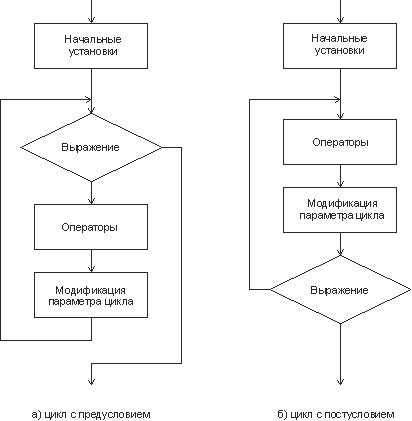
Рис. 2.5. Структурные схемы операторов цикла
Начальные установки служат для того, чтобы до входа в цикл задать значения переменных, которые в нем используются.
Проверка условия продолжения цикла выполняется на каждой итерации либо до тела цикла (тогда говорят о цикле с предусловием, см. рис. 2.5, а ), либо после тела цикла (цикл с постусловием, см. рис. 2.5, б ). Разница между ними состоит в том, что тело цикла с постусловием всегда выполняется хотя бы один раз, после чего проверяется, надо ли его выполнять еще раз. Проверка необходимости выполнения цикла с предусловием делается до тела цикла, поэтому возможно, что он не выполнится ни разу.
Параметром цикла называется переменная, которая используется при проверке условия цикла и принудительно изменяется на каждой итерации, причем, как правило, на одну и ту же величину. Если параметр цикла целочисленный, он называется счетчиком цикла. Количество повторений такого цикла можно определить заранее. Параметр есть не у всякого цикла. В так называемом итеративном цикле условие продолжения содержит переменные, значения которых изменяются в цикле по рекуррентным формулам 1)
Цикл завершается, если условие его продолжения не выполняется. Возможно принудительное завершение как текущей итерации, так и цикла в целом. Для этого служат операторы break, continue и goto. Передавать управление извне внутрь цикла не рекомендуется, потому что при этом могут не выполниться начальные установки.
Цикл с предусловием while
Формат оператора прост:
while выражение do оператор
Выражение должно быть логического типа. Например, это может быть операция отношения или просто логическая переменная. Если результат вычисления выражения равен true, выполняется расположенный после служебного слова do простой или составной оператор (напомню, что составной оператор заключается между begin и end ). Эти действия повторяются до того момента, пока результатом выражения не станет значение false. После окончания цикла управление передается на следующий за ним оператор.
Пример. Программа, печатающая таблицу значений функции

для аргумента, изменяющегося в заданных пределах с заданным шагом.
Опишем алгоритм в словесной форме.
- Ввести исходные данные.
- Взять первое значение аргумента.
- Определить, какому из интервалов оно принадлежит.
- Вычислить значение функции по соответствующей формуле.
- Вывести строку таблицы.
- Перейти к следующему значению аргумента.
- Если оно не превышает конечное значение, повторить шаги 3–6, иначе закончить.
Шаги 3–6 повторяются многократно, поэтому для их выполнения надо организовать цикл. Назовем необходимые нам переменные так: начальное значение аргумента — Xn, конечное значение аргумента — Xk, шаг изменения аргумента — dX, параметр — t. Все величины вещественные. Программа выводит таблицу, состоящую из двух столбцов — значений аргумента и соответствующих им значений функции (пример 2.2).
program tabl_fun;
var
Xn, Xk : real; { начальное и конечное значение аргумента }
dX : real; { шаг изменения аргумента }
x, y : real; { текущие значения аргумента и функции }
t : real; { параметр }
begin
writeln('Введите Xn, Xk, dX, t'); { приглашение ко вводу данных }
readln(Xn, Xk, dX, t); { ввод исходных данных – шаг 1 }
writeln(' --------------------------- '); { заголовок таблицы }
writeln('| X | Y |');
writeln(' --------------------------- ');
x := Xn; { первое значение аргумента = Xn – шаг 2 }
while x <= Xk do begin { заголовок цикла – шаг 7 }
if x < 0 then y := t; { вычисление значения функции - шаг 4 }
if (x >= 0) and (x < 10) then y := t * x; { шаг 4 }
if x >= 10 then y := 2 * t; { шаг 4 }
writeln('|', x:9:2,' |', y:9:2,' |');{ вывод строки табл. – шаг 5 }
x := x + dX; { переход к следующему значению аргумента - шаг 6 }
end;
writeln(' --------------------------- ');
end.
Листинг
2.2.
Таблица значений функции (оператор while)
(html,
txt)
Параметром этого цикла, то есть переменной, управляющей его выполнением, является х. Для правильной работы цикла необходимо присвоить параметру начальное значение до входа в цикл (шаг 2). Блок модификации параметра цикла представлен оператором, выполняющимся на шаге 6. Для перехода к следующему значению аргумента текущее значение наращивается на величину шага и заносится в ту же переменную.
Цикл с постусловием repeat
Тело цикла с постусловием заключено между служебными словами repeat и until, поэтому заключать его в блок не требуется.
repeat
тело цикла
until выражениеВ отличие от цикла while, этот цикл будет выполняться, пока логическое выражение после слова until ложно. Как только результат выражения станет истинным, произойдет выход из цикла. Вычисление выражения выполняется в конце каждой итерации цикла.
Этот вид цикла применяется в тех случаях, когда тело цикла необходимо обязательно выполнить хотя бы один раз: например, если в цикле вводятся данные и выполняется их проверка.
Пример. Программа, вычисляющая квадратный корень вещественного аргумента X с заданной точностью eps по итерационной формуле:
где y ( n –1) — предыдущее приближение к корню (в начале вычислений выбирается произвольно), y ( n ) — последующее приближение. Процесс вычислений прекращается, когда приближения станут отличаться друг от друга по абсолютной величине менее, чем на eps — величину заданной точности (пример 2.3)..
program square_root;
var X, eps, { аргумент и точность }
Yp, Y : real; { предыдущее и последующее приближение }
begin
repeat
writeln('Введите аргумент и точность (больше нуля): ');
readln(X, eps);
until (X > 0) and (eps > 0);
Y := 1;
repeat
Yp := Y;
Y := (Yp + X / Yp) / 2;
until abs(Y - Yp) < eps;
writeln('Корень из ', X:6:3, ' с точноcтью ', eps:7:5,
'равен ', Y:9:5);
end.
Листинг
2.3.
Вычисление квадратного корня
(html,
txt)
Цикл с параметром for
Этот оператор применяется, если требуется выполнить тело цикла заранее заданное количество раз. Параметр порядкового типа на каждом проходе цикла автоматически либо увеличивается, либо уменьшается на единицу.
for параметр := выражение_1 to выражение_2 do оператор for параметр := выражение_2 downto выражение_1 do оператор
Выражения должны быть совместимы по присваиванию с переменной цикла (о правилах совместимости мы поговорим в конце третьей лекции), оператор — простым или составным. Циклы с параметром обычно применяются при работе с массивами.
Пример 1. Программа выводит на экран числа от 10 до 1 и подсчитывает их сумму:
var i, sum : integer;
begin
sum := 0;
for i := 10 downto 1 do begin
writeln(i); inc(sum, i)
end;
writeln('Сумма чисел: ', sum);
end.В этом цикле переменная i автоматически уменьшается на 1.
Пример 2. Программа выводит на экран символы от 'a' до 'z' :
var ch : char;
begin
for ch := 'a' to 'z' do write(ch:2)
end.Здесь счетчик цикла ch символьного типа поочередно принимает значение каждого символа от 'a' до 'z'.
Выражения, определяющие начальное и конечное значения счетчика, вычисляются один раз до входа в цикл. Цикл for реализован в Паскале как цикл с предусловием.
После нормального завершения цикла значение счетчика не определено. Фактически оно равно первому значению, для которого выполняется условие выхода из цикла, но использовать это в программах не рекомендуется. Также не следует изменять значение счетчика внутри цикла вручную, например:
for i := 1 to 10 do begin inc(i,3); ... end; { плохо! }Это может привести к зацикливанию программы.
Рекомендации по использованию циклов
Часто встречающимися ошибками при программировании циклов являются использование в теле цикла переменных, которым не были присвоены начальные значения, а также неверная запись условия продолжения цикла. Нужно помнить и о том, что в операторе while истинным должно являться условие повторения вычислений, а в операторе repeat — условие их окончания.
Чтобы избежать ошибок, рекомендуется:
- не забывать о том, что если в теле циклов while и for требуется выполнить более одного оператора, нужно заключать их в блок;
- убедиться, что всем переменным, встречающимся в правой части операторов присваивания в теле цикла, до этого присвоены значения, а также проверить, возможно ли выполнение других операторов;
- проверить, изменяется ли в теле цикла хотя бы одна переменная, входящая в условие продолжения цикла;
- предусматривать аварийный выход из итеративного цикла по достижении некоторого предельно допустимого количества итераций (пример см. в следующем разделе).
Процедуры передачи управления
В Паскале есть несколько стандартных процедур, изменяющих последовательность выполнения операторов:
- break — завершает выполнение цикла, внутри которого записана;
- continue — выполняет переход к следующей итерации цикла;
- exit — выполняет выход из программы или подпрограммы, внутри которой записана;
- halt — немедленно завершает выполнение программы.
Кроме того, для передачи управления используется оператор перехода goto.
Рассмотрим пример применения процедуры передачи управления.
Пример. Программа вычисления значения функции sin x (синус) с помощью бесконечного ряда Тейлора с точностью ![]() по формуле:
по формуле:
y = x - x3/3! + x5/5! - x7/7! +…
Этот ряд сходится при любых значениях аргумента. Точность достигается при |Rn| < ε, где Rn —остаточный член ряда, который для данного ряда можно заменить величиной Cn очередного члена ряда, прибавляемого к сумме.
Общий алгоритм прост: задать начальное значение суммы ряда, а затем многократно вычислять очередной член ряда и добавлять его к ранее найденной сумме, пока абсолютная величина очередного члена ряда не станет меньше заданной точности.
До выполнения программы предсказать, сколько членов ряда потребуется просуммировать, невозможно. В цикле такого рода есть опасность, что он никогда не завершится. Поэтому для надежности программы необходимо предусмотреть аварийный выход из цикла с печатью предупреждающего сообщения по достижении некоторого максимально допустимого количества итераций.
Прямое вычисление члена ряда по приведенной выше общей формуле, когда х возводится в степень, вычисляется факториал, а затем числитель делится на знаменатель, имеет два недостатка, которые делают этот способ непригодным: большая погрешность вычислений и их низкая эффективность. При вычислении очередного члена ряда предыдущий уже известен, поэтому следует воспользоваться рекуррентной формулой получения последующего члена ряда через предыдущий Cn+1 = Cn *T, где T — некоторый множитель. Подставив в эту формулу Cn и Cn+1 , получим выражение для вычисления Т:
Текст программы с комментариями приведен в (пример 2.4).
program ch;
const MaxIter = 500; { максимальное количество итераций }
var x, eps : double; { аргумент и точность }
c, y : double; { член ряда и его сумма }
n : integer; { номер члена ряда }
done : boolean; { признак достижения точности }
begin
writeln('Введите аргумент и точность:');
readln(x, eps);
done := true;
c := x; y := c; { первый член ряда и нач. значение суммы }
n := 0;
while abs(c) > eps do begin
c :=- c * sqr(x) /(2 * n + 2)/(2 * n + 3); { очередной член ряда }
y := y + c; { добавление члена ряда к сумме }
inc(n);
if n > MaxIter then begin { аварийный выход из цикла }
writeln('Ряд расходится!');
done := false; break
end
end;
if done then
writeln('Для аргумента ', x, ' значение функции: ', y, #13#10,
'вычислено с точностью', eps, ' за ', n, ' итераций');
readln;
end.
Листинг
2.4.
Вычисление суммы бесконечного ряда
(html,
txt)
Оператор перехода goto
Этот оператор имеет простой синтаксис: в точке программы, из которой требуется организовать переход, после слова goto через пробел записывается имя метки, например goto 1 или goto error. При программировании на Паскале необходимость в применении оператора перехода возникает, как правило, в двух случаях:
- принудительный выход вниз по тексту программы из нескольких вложенных циклов или операторов выбора;
- переход из нескольких мест программы в одно (например, если перед выходом из программы необходимо всегда выполнять какие-либо действия).
Во всех остальных случаях следует преобразовать алгоритм так, чтобы он мог быть записан с помощью базовых конструкций.
Лекция 3. Типы данных, определяемые программистом
Презентацию к данной работе Вы можете скачать ![]() здесь.
здесь.
Информация, которую требуется обрабатывать в программе, имеет различную структуру. Для ее адекватного представления используются типы данных, которые программист определяет сам в разделе описания типов type. Типу дается произвольное имя, которое можно затем использовать для описания программных объектов точно так же, как и стандартные имена типов.
type имя_типа = описание_типа ... var имя_переменной : имя_типа
Можно задать тип и непосредственно при описании переменных:
var имя_переменной : описание_типа
Перечисляемый тип данных
При написании программ часто возникает потребность определить несколько связанных между собой именованных констант, имеющих различные значения. Для этого удобно воспользоваться перечисляемым типом данных, все возможные значения которого задаются списком констант.
type имя_типа = (список имен констант)
Константы в списке перечисляются через запятую, например:
type Menu = (READ, WRITE, EDIT, QUIT)
Переменным перечисляемого типа можно присвоить либо значение одной из перечисленных констант, либо значение другой переменной того же типа, например:
var m, n : Menu; … m := READ; n := m;
Перечисляемый тип относится к порядковым типам данных. Константы в списке нумеруются с нуля. Например, Ord(READ) даст в результате 0, Succ(EDIT) — QUIT. Попытка получения значения, следующего за последним, приведет к ошибке.
Использовать перечисляемый тип в операциях ввода-вывода нельзя. Имена констант в пределах области их описания (программы или подпрограммы) должны быть уникальными.
Интервальный тип данных
С помощью интервального типа задается диапазон значений какого-либо типа.
type имя_типа = константа_1 .. константа_2
Константы должны быть одного и того же порядкового типа. Тип, на котором строится интервал, называется базовым. Константа_1 должна быть меньше или равна константе_2. Примеры описания интервальных типов:
type Hour = 0 .. 23;
Range = –100 .. 100;
Letters = 'a' .. 'z';
Actions = READ .. EDIT;Как и для других типов, определяемых программистом, интервальный тип можно задать прямо при описании переменной, например:
var r : –100 .. 100;
С переменной интервального типа можно делать все, что допустимо для ее базового типа. Ее значение должно находиться в указанном диапазоне, в противном случае произойдет ошибка времени выполнения 'Constant out of range'.
Интервальный тип используется в программах как самостоятельно, так и внутри определения массива.
Массивы
При использовании простых переменных каждой области памяти, предназначенной для хранения какого-либо значения, соответствует свое имя. Если с группой величин одинакового типа требуется выполнять однообразные действия, им дают одно имя, а различают по порядковому номеру (индексу). Это позволяет компактно записывать множество операций с помощью циклов.
Конечная именованная последовательность однотипных величин называется массивом. Чтобы описать массив, надо определить, какого типа его элементы и каким образом они пронумерованы (какого типа его индекс).
type имя_типа = array [тип_индекса] of тип_элемента
Здесь array и of — ключевые слова, тип индекса задается в квадратных скобках. Примеры описания типа:
type mas = array [1 .. 10] of real;
Color = array [byte] of mas;
Active = array [Menu] of boolean;В первом операторе описан тип массива из вещественных элементов, которые нумеруются от 1 до 10. Во втором операторе элементами массива являются массивы типа mas, а нумеруются они в пределах, допустимых для типа byte, то есть от 0 до 255. В третьей строке в качестве индекса использовано имя типа из раздела 'Перечисляемый тип данных', а сами элементы могут принимать значения true или false.
Тип элементов массива может быть любым, кроме файлового, тип индексов — интервальным, перечисляемым или byte. Чаще всего для описания индекса используется интервальный тип данных.
Обычно при описании массива верхняя граница его индекса задается в виде именованной константы, например:
const n = 6; type intmas = array [1 .. n] of integer;
После задания типа массива переменные этого типа описываются обычным образом:
var a, b : intmas;
С массивами в целом можно выполнять только одну операцию: присваивание. При этом массивы должны быть одного типа:
b := a;
Все остальные действия выполняются с отдельными элементами массива. Для обращения к элементу массива после имени массива указывается номер элемента в квадратных скобках:
a[4] b[i]
С элементом массива можно делать все, что допустимо для переменных того же типа.
При обращении к элементу массива автоматический контроль выхода индекса за границу массива не производится. Для включения режима автоматического контроля необходимо добавить в любое место программы, предшествующее обращениям к элементу, ключ компиляции {$R+} или установить соответствующий режим в оболочке.
Инициализация массивов.Элементам массива можно присвоить значения до начала выполнения программы. Это делается так же, как и для простых переменных, — в разделе описания констант, например:
const a : intmas = (0, 5, –7, 100, 15, 1);
Количество констант должно точно соответствовать числу элементов массива. Массивы, описанные в разделе var главной программы, обнуляются автоматически.
Рассмотрим задачу поиска максимального элемента массива. Очевидно, что для отыскания самого большого элемента нужно сравнить между собой все элементы массива. Элементы выбираются попарно. При каждом сравнении из двух чисел выбирается наибольшее. Поскольку его надо где-то хранить, в программе описывается переменная того же типа, что и элементы массива. После окончания просмотра массива в ней окажется самый большой элемент. Перед началом просмотра в эту переменную заносится какой-либо элемент массива.
Сформулируем алгоритм поиска максимума.
- Принять за максимальный первый элемент массива.
- Просмотреть массив, начиная со второго элемента.
- Если очередной элемент оказывается больше максимального, принять его за максимальный.
Программа приведена в пример 3.1.
program max_elem;
const n = 20;
var a : array [1 .. n] of real;
i : integer;
max : real;
begin
writeln('Введите ', n, ' элементов массива');
for i := 1 to n do read(a[i]);
max := a[1]; { принять за максимальный первый элемент массива }
for i := 2 to n do { просмотреть массив, начиная со второго элемента }
if a[i] > max then max := a[i]; { при необходимости обновить максимум }
writeln('Максимальный элемент: ', max:6:2)
end.
Листинг
3.1.
Максимальный элемент массива из 20 вещественных элементов
(html,
txt)
Еще один простой пример работы с массивом приведен в пример 3.2 .
program sum_num;
const n = 10;
var a : array [1 .. n] of integer;
i, sum, num : integer;
begin
writeln('Введите ', n, ' элементов массива');
for i := 1 to n do read(a[i]);
sum := 0;
num := 0;
for i := 1 to n do begin
sum := sum + a[i];
if a[i] < 0 then inc(num);
end;
writeln('Сумма элементов: ', sum);
writeln('Отрицательных элементов: ', num);
end.
Листинг
3.2.
Сумма и количество отрицательных элементов целочисленного массива
(html,
txt)
Двумерные массивы
Элемент массива может быть любого типа, кроме файлового, следовательно, он может быть и массивом, например:
const n = 4; m = 3;
type mas = array [1 .. n] of integer;
mas2 = array [1 .. m] of mas;Более компактно это можно записать так:
type mas2 = array [1 .. m, 1 .. n] of integer;
Здесь описан тип массива, состоящего из m массивов, каждый из которых содержит n целых чисел. Иными словами, это матрица из m строк и n столбцов (рис. 3.1). Обе размерности массива должны быть константами или константными выражениями. Имя типа указывается при описании переменных, например:
var a, b : mas2;
В памяти двумерный массив располагается по строкам.
a11 a12 a13 a14 a21 a22 a23 a24 a31 a32 a33 a34 | – 1–я строка – | – 2–я строка – | – 3–я строка – |
Строки массива ничем не отделены одна от другой, то есть прямоугольной матрицей двумерный массив является только в нашем воображении. При просмотре массива от начала в первую очередь изменяется правый индекс (номер столбца).

Рис. 3.1. Матрица из m строк и n столбцов
К элементу двумерного массива обращаются, указывая номер строки и номер столбца, на пересечении которых он расположен, например:
a[1, 4] b[i, j] b[j, i]
При инициализации двумерных массивов каждая строка заключается в дополнительную пару круглых скобок, например:
const a : mas2 = ( ( 2, 3, 1, 0),
( 1, 9, 1, 3),
( 3, 5, 7, 0) );С массивами в целом определена только одна операция — присваивание массивов одного типа (например, b := a ) . Все остальные действия выполняются с отдельными элементами. Например, чтобы ввести с клавиатуры двумерный массив, необходимо организовать вложенные циклы:
for i := 1 to m do
for j := 1 to n do read(a[i, j]);В соответствии с приведенным здесь порядком следования циклов элементы массива должны вводиться по строкам (при этом неважно, как будут располагаться элементы массива, важен только порядок их следования).
Пример. Программа, которая для целочисленной матрицы 3x4 определяет среднее арифметическое ее элементов и количество положительных элементов в каждой строке.
Для нахождения среднего арифметического порядок перебора элементов массива (по строкам или по столбцам) роли не играет. Нахождение количества положительных элементов каждой строки требует просмотра матрицы по строкам (пример 3.3).
program sred_n;
const m = 3; n = 4;
var a : array [1 .. m, 1 .. n] of integer;
i, j, n_pos_el : integer;
sred : real;
begin
for i := 1 to m do
for j := 1 to n do read(a[i, j]);
sred := 0;
for i := 1 to m do begin
n_pos_el := 0;
for j := 1 to n do begin
sred := sred + a[i, j];
if a[i, j] > 0 then inc(n_pos_el);
end;
writeln('В ', i, '–й строке ', n_pos_el, ' положительных элементов');
end;
sred := sred / m / n;
writeln('Среднее арифметическое: ', sred:6:2);
end.
Листинг
3.3.
(html,
txt)
Строки
Строки используются для хранения последовательностей символов. В Паскале существует три типа строк:
- стандартные ( string );
- определяемые программистом на основе string ;
- строки в динамической памяти
Строка типа string может содержать до 255 символов. Под каждый символ отводится по одному байту, в котором хранится код символа. Еще один байт отводится под фактическую длину строки. Таким образом, в памяти под одну переменную типа string всегда отводится 256 байт.
Для коротких строк использовать стандартную строку неэффективно, поэтому есть возможность самостоятельно задавать максимальную длину строки, которая должна быть константой или константным выражением. Например, ниже описан собственный тип данных с именем str4:
type str4 = string [4]; { переменная такого типа занимает в памяти 5 байтов }
Примеры описания строк:
const n = 15;
var s : string; { строка стандартого типа }
s1 : str4; { строка типа str4, описанного выше }
s2 : string [n]; { описание типа задано при описании переменной }Инициализация строк, как и переменных других типов, выполняется в разделе описания констант.
const s3 : string [15] = 'shooshpanchik';
Внутреннее представление строки s3 представлено на рис. 3.2.
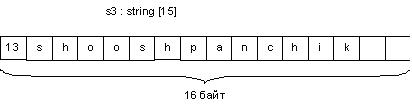
Рис. 3.2. Внутреннее представление строки s3
Операции
Строки можно присваивать друг другу. Если максимальная длина результирующей строки меньше длины исходной, лишние символы справа отбрасываются.
s2 := 'shooshpanchik';
s1 := s2; { в s1 будут помещены символы "shoo" }Строки можно склеивать (сцеплять) между собой с помощью операции конкатенации, которая обозначается знаком +, например:
s1 := 'ком';
s2 := s1 + 'пот'; { результат — "компот" }Строки можно сравнивать друг с другом с помощью операций отношения. При сравнении строки рассматриваются посимвольно слева направо, при этом сравниваются коды соответствующих пар символов. Строки равны, если они имеют одинаковую длину и посимвольно эквивалентны. В строках разной длины существующий символ всегда больше соответствующего ему отсутствующего символа.
'abc' > 'ab' 'abc' = 'abc' 'abc' < 'abc '
Имя строки может использоваться в процедурах ввода-вывода:
readln (s1, s2); write (s1);
При вводе в строку считывается из входного потока количество символов, равное длине строки или меньшее, если символ перевода строки (который вводится нажатием клавиши Enter ) встретится раньше. При выводе под строку отводится количество позиций, равное ее фактической длине.
К отдельному символу строки можно обращаться как к элементу массива символов, например s1[4] . Символ строки совместим с типом char, их можно использовать в выражениях одновременно, например:
s1[4] := 'x'; writeln (s2[3] + s2[5] + 'r');
Процедуры и функции для работы со строками
При работе со строками, как правило, возникает необходимость выполнять их копирование, вставку, удаление или поиск. Для эффективной реализации этих действий в Паскале предусмотрены стандартные процедуры и функции. Они кратко описаны ниже.
Функция Concat (s1, s2, ..., sn) возвращает строку, являющуюся слиянием строк s1, s2, ..., sn.
Функция Copy (s, start, len) возвращает подстроку длиной len, начинающуюся с позиции start строки s.
Процедура Delete (s, start, len) удаляет из строки s, начиная с позиции start, подстроку длиной len.
Процедура Insert (subs, s, start) вставляет в строку s подстроку subs, начиная с позиции start.
Функция Length (s) возвращает фактическую длину строки s, результат имеет тип byte.
Функция Pos (subs, s) ищет вхождение подстроки subs в строку s и возвращает номер первого символа subs в s или нуль, если subs не содержится в s.
Процедура Str (x, s) преобразует числовое значение x в строку s, при этом для x может быть задан формат, как в процедурах вывода write и writeln.
Процедура Val (s, x, errcode) преобразует строку s в значение числовой переменной x, при этом строка s должна содержать символьное представление числа. В случае успешного преобразования переменная errcode равна нулю. Если же обнаружена ошибка, то errcode будет содержать номер позиции первого ошибочного символа, а значение x не определено.
Пример. Программа читает текст из файла и выводит его на экран, заменяя заданную с клавиатуры последовательность символов на многоточии (пример 3.4).
program censor;
var s, str : string[10];
f : text;
i, dl : integer;
begin
assign(f, 'primer.txt'); reset(f);
writeln('Какую последовательность заменять?'); readln(s);
dl := length(s);
while not Eof(f) do begin
readln(f, str);
i := 1;
while i <> 0 do begin
i := Pos(s, str);
if i <> 0 then begin
Delete(str, i, dl); Insert('...', str, i);
end;
end;
writeln(str);
end;
close(f)
end.
Листинг
3.4.
(html,
txt)
Записи
В программах часто возникает необходимость логического объединения разнородных данных (например, база данных предприятия содержит для каждого сотрудника его фамилию, дату рождения, должность, оклад и т. д.). Для этого предназначен тип 'запись'. Он вводится с помощью ключевого слова record. Элементы записи называются полями.
type имя_типа = record
описание 1-го поля записи;
описание 2-го поля записи;
...
описание n-го поля записи;
end;Поля записи могут быть любого типа, кроме файлового. Например, для каждого товара на складе требуется хранить его наименование, цену и количество единиц:
type goods = record
name : string[20];
price : real;
number : integer;
end;Переменные типа 'запись' описываются обычным образом. Можно задавать описание типа при описании переменной, создавать массивы из записей, записи из массивов, и т. д.
var g1, g2 : goods;
stock : array [1 .. 100] of goods;
student : record
name : string [30];
group : byte;
marks : array [1 .. 4] of byte;
end;С записями целиком можно делать то же, что и с массивами: присваивать одну запись другой, если они одного типа, например:
g1 := g2; g2 := stock[3];
Все остальные действия выполняются с отдельными полями записи. Есть два способа доступа к полю записи: либо с помощью конструкции имя_записи.имя_поля, либо с использованием оператора присоединения with, например:
g1.price := 200;
with g1 do begin
price := 200; number := 10
end;Пример. Сведения о товарах на складе хранятся в текстовом файле. Для каждого товара отводится одна строка, в первых 20 позициях которой записано наименование товара, а затем через произвольное количество пробелов его цена и количество единиц. Программа по запросу выдает сведения о товаре или сообщение о том, что товар не найден (пример 3.5).
program store;
const Max_n = 100;
type str20 = string [20];
goods = record
name : str20;
price : real;
number : integer;
end;
var stock : array[1 .. Max_n] of goods;
i, j, len : integer;
name : str20;
found : boolean;
f : text;
begin
assign(f, 'stock.txt'); reset(f);
i := 1;
while not Eof(f) do begin
with stock[i] do readln(f, name, price, number);
inc(i);
if i > Max_n then begin { 1 }
writeln('Переполнение массива'); exit end;
end;
while true do begin { 2 }
writeln('Введите наименование'); Readln(name);
len := length(name);
if len = 0 then break; { 3 }
for j := len + 1 to 20 do name := name + ' '; { 4 }
found := false;
for j := 1 to i – 1 do begin { 5 }
if name <> stock[j].name then continue;
with stock[j] do writeln (name:22, price:7:2, number:5);
found := true;
break;
end;
if not found then writeln ('Товар не найден'); { 6 }
end;
end.
Листинг
3.5.
(html,
txt)
Инициализация записей выполняется в разделе констант, при этом для каждого поля задается его имя, после которого через двоеточие указывается значение.
const g : goods = (name : 'boots'; price : 200; number : 10);
Множества
Множественный тип данных в языке Паскаль соответствует математическому представлению о множествах: это ограниченная совокупность различных элементов. Множество создается на основе элементов базового типа — это может быть перечисляемый тип, интервальный или byte. В множестве не может быть более 256 элементов, а их порядковые номера должны лежать в пределах от 0 до 255.
Множество описывается с помощью служебных слов set of.
type имя_типа = set of базовый_тип;
Примеры описания множественных типов:
type Caps = set of 'A' .. 'Z';
Colors = set of (RED, GREEN, BLUE);
Numbers = set of byte;Принадлежность переменных к множественному типу может быть определена прямо в разделе описания переменных, например:
var oct : set of 0 .. 7;
Тип 'множество' задает набор всех возможных подмножеств его элементов, включая пустое. Если базовый тип, на котором строится множество, имеет k элементов, то число подмножеств, входящих в это множество, равно 2k.
Константы множественного типа записываются в виде заключенной в квадратные скобки последовательности элементов или интервалов базового типа, разделенных запятыми, например:
['A', 'D'] [1, 3, 6] [2, 3, 10 .. 13].
Порядок перечисления элементов базового типа в константах не имеет значения. Константа вида [ ] означает пустое подмножество. Переменная типа 'множество' содержит одно конкретное подмножество значений множества. Пусть имеется переменная b интервального типа:
var b : 1 .. 3; { переменная может принимать три различных значения: 1, 2 или 3 }
Переменная m типа 'множество'
var m : set of 1 .. 3;
может принимать восемь различных значений:
[ ] [1] [2] [3] [1, 2] [1, 3] [2, 3] [1, 2, 3]
Операции над множествами
Величины множественного типа не могут быть элементами списка ввода-вывода. Допустимые операции над множествами перечислены в табл. 3.1.
| Знак | Название | Математическая запись | Результат |
|---|---|---|---|
| := | Присваивание | ||
| + | Объединение | Множество | |
| * | Пересечение | Множество | |
| – | Дополнение | \ | Множество |
| = | Тождественность | = | Логический |
| <> | Нетождественность | Логический | |
| <= | Содержится в | Логический | |
| >= | Содержит | Логический | |
| in | Принадлежность | Логический |
Операции над множествами в основном соответствуют операциям, определенным в теории множеств.
В операциях могут участвовать переменные и константы совместимых множественных типов. Исключение составляет операция in: ее первый операнд должен принадлежать базовому типу элементов множества, записанного вторым операндом.
Рассмотрим примеры применения операций. Пусть задано множество, основанное на значениях прописных латинских букв.
type Caps = set of 'A' .. 'Z';
var a, b, c : Caps;
begin
a := ['A', 'U' .. 'Z'];
b := [ 'M' .. 'Z'];
c := a; { присваивание }
c := a + b; { объединение, результат ['A', 'M' .. 'Z'] }
c := a * b; { пересечение, результат ['U' .. 'Z'] }
c := b – a; { вычитание, результат ['M' .. 'T'] }
c := a – b; { вычитание, результат ['A'] }
if a = b then writeln ('тождественны'); { не выполнится }
if a <> b then writeln ('не тождественны'); { выполнится }
if c <= a then writeln ('c содержится в а'); { выполнится }
if 'N' in b then writeln ('в b есть N'); { выполнится }
end.С помощью констант-множеств часто проверяют, входит ли символ в заданный диапазон. Например, чтобы проверить, является ли введенный символ цифрой, можно написать:
var c : char; ... if c in ['0' .. '9'] then ...
Файлы
Файловые типы данных введены в язык для работы с внешними устройствами — файлами на диске, портами, принтерами и т. д. Передача данных с внешнего устройства в оперативную память называется чтением, или вводом, обратный процесс — записью, или выводом.
Файловые типы языка Паскаль бывают стандартные и определяемые программистом. Стандартными являются текстовый файл ( text ) и бестиповой файл ( file ). Они описываются в программе, например, так:
var ft : text;
fb : file;Программист может определить файл, состоящий из элементов определенного типа. Такой файл называется компонентным, или типизированным:
var fc : file of <тип_компонент>;
Компоненты могут быть любого типа, кроме файлового. Любой файл, в отличие от массива и записи, может содержать неограниченное количество элементов.
Текстовые файлы предназначены для хранения информации в виде строк символов. При выводе в текстовый файл данные преобразуются из внутренней формы представления в символьную, понятную человеку, при вводе выполняется обратное преобразование.
Бестиповые и компонентные файлы хранят данные в том же виде, в котором они представлены в оперативной памяти, то есть при обмене с файлом происходит побитовое копирование информации.
Доступ к файлам может быть последовательным, когда очередной элемент можно прочитать (записать) только после аналогичной операции с предыдущим элементом, и прямым, при котором выполняется чтение (запись) произвольного элемента по заданному адресу. Текстовые файлы позволяют выполнять только последовательный доступ, в бестиповых и компонентных можно использовать оба метода.
Прямой доступ возможен благодаря тому, что данные в этих файлах условно разделены на блоки одинакового размера, и перед операцией обмена выполняется установка текущей позиции файла на заданный блок. Прямой доступ в сочетании с отсутствием преобразований обеспечивает высокую скорость получения информации.
Чтобы не путать файлы в программе и файлы на диске, переменные файлового типа называют логическими файлами, а реальные устройства и файлы на диске — физическими файлами. Их имена задаются с помощью строк символов, например:
- 'primer.pas' — имя файла в текущем каталоге;
- 'd:\pascal\input.txt' — полное имя файла;
- 'CON' 'NUL' 'COM1' 'PRN' — имена устройств.
Для организации ввода-вывода необходимо выполнить следующие действия.
- Объявить файловую переменную.
- Связать ее с физическим файлом.
- Открыть файл для чтения и/или записи.
- Выполнить операции ввода-вывода.
- Закрыть файл.
Все стандартные процедуры и функции Паскаля, обеспечивающие ввод-вывод данных, работают только с логическими файлами. Ввод-вывод выполняется через буфер — специальную область оперативной памяти. Буфер выделяется для каждого открытого файла. При записи в файл вся информация сначала направляется в буфер и там накапливается до тех пор, пока весь буфер не заполнится. Только после этого или после специальной команды сброса происходит передача данных на внешнее устройство. При чтении из файла данные вначале считываются в буфер, причем данных считывается не столько, сколько запрашивается, а сколько поместится в буфер.
Механизм буферизации позволяет более быстро и эффективно обмениваться информацией с внешними устройствами.
В Паскале есть подпрограммы, применяемые для работы со всеми типами файлов: assign, close, erase, rename, reset, rewrite, eof и IOresult.
Текстовые файлы
Текстовый файл представляет собой последовательность строк символов переменной длины. Каждая строка заканчивается символами перевода строки и возврата каретки (их коды — 13 и 10). Эти символы вставляются в физический файл при нажатии клавиши Enter. При чтении файла эти символы не вводятся в переменные в программе, а воспринимаются как разделитель.
Текстовый файл можно открыть не только для чтения или записи с помощью процедур reset и rewrite, но и для добавления информации в конец (процедура append ). Для чтения из текстового файла применяются процедуры read (f, список) и readln (f, [список]) . Они отличаются от процедур ввода с клавиатуры только наличием первого параметра — имени логического файла.
Процедуры записи в текстовый файл — write (f, список) и writeln (f, [список]) . При записи в текстовый файл происходит преобразование из внутренней формы представления выводимых величин в символьные строки. Чтение и запись выполняются последовательно, то есть записать или считать очередной символ можно только после предыдущего.
В Паскале есть несколько стандартных подпрограмм, которые предназначены только для работы с текстовыми файлами: flush, settextbuf, seekEof и seekEoln.
Бестиповые файлы
Бестиповые файлы предназначены для хранения участков оперативной памяти на внешних носителях. После описания файловой переменной
var имя : file;
ее требуется связать с физическим файлом с помощью процедуры assign. Чтение и запись производится через буфер 'порциями', равными размеру буфера. Размер буфера, отличающийся от стандартного (128 байт), можно задать с помощью второго параметра процедур reset и rewrite при открытии файла.
reset(var f : file; bufsize : word) rewrite(var f : file; bufsize : word)
Размер буфера должен находиться в пределах от 1 байта до 64 Кбайт.
Собственно чтение и запись выполняются с помощью процедур blockread и blockwrite.
blockread(var f : file; var x; count : word; var num : word); blockwrite(var f : file; var x; count : word; var num : word);
Процедура blockread считывает в переменную x количество блоков count. Длина блока равна размеру буфера. Значение count должно быть больше или равно 1, за одно обращение нельзя ввести больше 64 Кбайт. При вводе никаких преобразований данных не выполняется. Необязательный параметр num возвращает количество прочитанных блоков.
Процедура blockwrite записывает в файл количество блоков, равное count, начиная с адреса, заданного переменной x. Длина блока равна длине буфера. Необязательный параметр num возвращает число успешно записанных блоков.
Для бестиповых файлов применяется как последовательный, так и прямой доступ.
Пример. Программа выполняет ввод вещественных чисел из текстового файла и запись их в бестиповой файл блоками по четыре числа (пример 3.6).
program create_bfile;
var buf : array[1 .. 4] of real;
f_in : text;
f_out : file;
i, k : integer;
name_in, name_out : string;
begin
{$I–}
writeln('Введите имя входного файла'); readln(name_in);
assign(f_in, name_in); reset(f_in);
if IOResult <> 0 then begin
writeln('Файл ', name_in,' не найден'); exit end;
writeln('Введите имя выходного файла'); readln(name_out);
assign(f_out, name_out); rewrite(f_out, sizeof(real) * 4);
{$I+}
i := 0;
while not eof(f_in) do begin
inc(i);
read(f_in, buf[i]);
if i = 4 then begin
blockwrite(f_out, buf, 1); i := 0; end;
end;
if i <> 0 then begin
for k := i + 1 to 4 do buf[k] := 0;
blockwrite(f_out, buf, 1);
end;
close(f_in); close(f_out);
end.
Листинг
3.6.
Запись в бестиповой файл
(html,
txt)
Компонентные файлы
Компонентные файлы применяются для хранения однотипных элементов в их внутренней форме представления. Тип компонент задается после ключевых слов file of.
var имя : file of тип_компонент;
Компоненты могут быть любого типа, кроме файлового, например вещественным числом или массивом записей. В операциях ввода-вывода могут участвовать только величины того же типа, что и компоненты файла, например:
type mas = array [1 .. 100] of real;
var a, b : mas;
f : file of mas;
begin
assign(f, 'some_file.dat'); rewrite(f);
...
write(f, a, b);
close(f)
end.Обратите внимание, что компонентой этого файла является массив целиком. За одну операцию записывается или считывается столько компонент, сколько перечислено в процедурах write или read.
Компонентные файлы, как и бестиповые, применяются не для просмотра их человеком, а для использования в программах.
Прямой доступ
Бестиповые и компонентные файлы состоят из блоков одинакового размера. В бестиповом файле размер блока равен длине буфера, а в компонентном — длине компоненты. Это позволяет применить к таким файлам прямой доступ, при котором операции выполняются с заданным блоком. Прямой доступ применяется только для физических файлов, расположенных на дисках.
С помощью стандартной процедуры seek производится установка текущей позиции в файле на начало заданного блока, и следующая операция чтения-записи выполняется, начиная с этой позиции. Первый блок файла имеет номер 0.
Ниже описаны стандартные подпрограммы для реализации прямого доступа.
filepos (var f) : longint
Функция возвращает текущую позицию в файле f. Для только что открытого файла это будет 0.
filesize (var f) : longint
Функция возвращает количество блоков в открытом файле f.
seek (var f; n: longint)
Процедура выполняет установку текущей позиции в открытом файле (позиционирование). В параметре n задается номер блока, к которому будет выполняться обращение.
truncate (var f)
Процедура устанавливает в текущей позиции признак конца файла и удаляет все последующие блоки.
Пример. Программа, которая выводит на экран заданную по номеру запись из файла, сформированного в пример 3.6.
program get_bfile;
var buf : array[1 .. 4] of real;
f : file;
i, k : integer;
filename : string;
begin
{$I–}
writeln('Введите имя входного файла'); readln(filename);
assign(f, filename);
reset(f, sizeof(real) * 4);
if IOResult <> 0 then begin
writeln('Файл ', filename, ' не найден'); exit end;
{$I+}
while true do begin
writeln('Введите номер записи или –1 для окончания');
readln(k);
if (k > filesize(f)) or (k < 0) then begin
writeln('Такой записи в файле нет',); exit end;
seek(f, k);
blockread(f, buf, 1);
for i:= 1 to 4 do write(buf[i]:6:1);
end;
close(f);
end.
Листинг
3.7.
Чтение из бестипового файла
(html,
txt)
Таким же образом можно изменять заданную запись в файле. Файл при этом может быть открыт как для чтения, так и для записи. Попытка чтения-записи несуществующего блока приводит к ошибке времени выполнения.
Совместимость типов
Операнды в выражениях должны быть совместимых типов. Совместимость типов величин, участвующих в каждой операции, достигается при выполнении по крайней мере одного из следующих условий.
- Оба типа одинаковые.
- Оба типа вещественные.
- Оба типа целочисленные.
- Один тип является поддиапазоном другого.
- Оба типа являются отрезками одного и того же основного типа.
- Оба типа являются множественными типами с совместимыми базовыми типами.
- Один тип является строковым типом, другой — строковым типом или типом pchar.
- Один тип — pointer, другой — любой тип указателя.
- Один тип — pchar, другой — символьный массив с нулевой базой вида array [0 .. X] of char (только при разрешении расширенного синтаксиса директивой {$X +}).
- Оба типа являются указателями идентичных типов (только при разрешении расширенного синтаксиса директивой {$X+}).
- Оба типа являются процедурными с идентичными типами результатов, одинаковым числом параметров и соответствием между параметрами.
Совместимость по присваиванию
Этот вид совместимости требуется при присваивании значений, например в операторе присваивания или при передаче значений в подпрограмму.
Значение типа T1 является совместимым по присваиванию с типом T2 (то есть допустим оператор T1 := T2 ), если выполняется одно из следующих условий.
- T1 и T2 — тождественные типы (кроме файловых или типов, содержащих элементы файлового типа).
- T1 и T2 — совместимые порядковые типы, при этом значения типа T2 попадают в диапазон возможных значений T1.
- T1 и T2 — вещественные типы, при этом значения типа T2 попадают в диапазон возможных значений T1.
- T1 — вещественный тип, а T2 — целочисленный.
- T1 и T2 — строковые типы.
- T1 — строковый тип, а T2 — символьный ( char ).
- T1 и T2 — совместимые множественные типы, при этом все значения типа T2 попадают в диапазон возможных значений T1.
- T1 и T2 — совместимые типы указателей.
- T1 — тип pchar, а T2 — строковая константа (только при разрешении расширенного синтаксиса директивой {$X+} ).
- T1 — тип pchar, а T2 — символьный массив с нулевой базой вида array [0 .. n] of char (только при разрешении расширенного синтаксиса директивой {$X+}).
- T1 и T2 — совместимые процедурные типы.
- T1 представляет собой процедурный тип, а T2 — процедура или функция с идентичным типом результата и соответствующими параметрами.
На этапе компиляции и выполнения выдается сообщение об ошибке, если совместимость по присваиванию необходима, а ни одно из условий предыдущего списка не выполнено.
Лекция 4. Модульное программирование
Презентацию к данной работе Вы можете скачать ![]() здесь.
здесь.
С увеличением объема программы становится невозможным удерживать в памяти все детали. Естественным способом борьбы со сложностью любой задачи является ее разбиение на части. В Паскале задача может быть разделена на более простые и понятные фрагменты — подпрограммы, после чего программу можно рассматривать в более укрупненном виде — на уровне взаимодействия подпрограмм.
Использование подпрограмм является первым шагом к повышению степени абстракции программы и ведет к упрощению ее структуры. Разделение программы на подпрограммы позволяет также избежать избыточности кода, поскольку подпрограмму записывают один раз, а вызывать ее на выполнение можно многократно из разных точек программы.
Следующим шагом в повышении уровня абстракции программы является группировка подпрограмм и связанных с ними данных в отдельные файлы ( модули ), компилируемые раздельно. Разбиение на модули уменьшает время перекомпиляции и облегчает процесс отладки, скрывая несущественные детали за интерфейсом модуля и позволяя отлаживать программу по частям (при этом, возможно, разным программистам).
Подпрограммы
Подпрограммы нужны для того, чтобы упростить структуру программы и облегчить ее отладку. В виде подпрограмм оформляются логически законченные части программы.
Подпрограмма — это фрагмент кода, к которому можно обратиться по имени. Она описывается один раз, а вызываться может столько раз, сколько необходимо. Одна и та же подпрограмма может обрабатывать различные данные, переданные ей в качестве аргументов.
В Паскале имеется два вида подпрограмм: процедуры и функции. Они определяются в соответствующих разделах описания (до начала блока исполняемых операторов) и имеют незначительные отличия в синтаксисе и правилах вызова.
Само по себе описание не приводит к выполнению подпрограммы. Чтобы подпрограмма выполнилась, ее надо вызвать. Вызов записывается в том месте программы, где требуется получить результаты работы подпрограммы .Подпрограмма вызывается по имени, за которым следует список аргументов в круглых скобках. Если аргументов нет, скобки не нужны. Список аргументов при вызове как бы накладывается на список параметров, поэтому они должны попарно соответствовать друг другу. Правила соответствия рассматриваются далее.
Процедура вызывается с помощью отдельного оператора, а функция — в правой части оператора присваивания, например:
inc(i); writeln(a, b, c); { вызовы процедур }
y := sin(x) + 1; { вызов функции }Внутри подпрограмм можно описывать другие подпрограммы. Они доступны только из той подпрограммы, в которой описаны.
Процедуры
Структура процедуры аналогична структуре основной программы:
procedure имя [(список параметров)]; { заголовок }
разделы описаний
begin
раздел операторов
end;Квадратные скобки в данном случае не являются элементом синтаксиса, а означают, что список параметров может отсутствовать. Рассмотрим простой пример.
Пример. Найти разность средних арифметических значений двух вещественных массивов из 10 элементов.
Как видно из условия, для двух массивов требуется найти одну и ту же величину — среднее арифметическое. Следовательно, логичным будет оформить его нахождение в виде подпрограммы, которая сможет работать с разными массивами (пример 4.1 ).
program dif_average;
const n = 10;
type mas = array[1 .. n] of real;
var a, b : mas;
i : integer;
dif, av_a, av_b : real;
procedure average(x : mas; var av : real); { 1 }
var i : integer;
begin
av := 0;
for i := 1 to n do av := av + x[i];
av := av / n;
end; { 2 }
begin
for i := 1 to n do read(a[i]);
for i := 1 to n do read(b[i]);
average(a, av_a); { 3 }
average(b, av_b); { 4 }
dif := av_a – av_b;
writeln('Разность значений ', dif:6:2);
end.
Листинг
4.1.
Разность средних арифметических значений массивов (процедура)
(html,
txt)
Описание процедуры average расположено в строках с {1} по {2 }. В строках {3} и {4} эта процедура вызывается сначала для обработки массива а, затем — массива b. Массивы передаются в качестве аргументов. Результат вычислений возвращается в главную программу через второй параметр процедуры.
Функции
Описание функции отличается от описания процедуры незначительно:
function имя [(список параметров)] : тип; { заголовок }
разделы описаний
begin
раздел операторов
имя := выражение;
end;Квадратные скобки в данном случае означают, что список параметров может отсутствовать. Функция вычисляет одно значение, которое передается через ее имя. Следовательно, в заголовке должен быть описан тип этого значения, а в теле функции — оператор, присваивающий вычисленное значение ее имени. Он не обязательно должен находиться в конце функции. Более того, таких операторов может быть несколько — это определяется алгоритмом. Рассмотрим пример применения функции для программы, приведенной в предыдущем разделе.
Пример. Найти разность средних арифметических значений двух вещественных массивов из 10 элементов (пример 4.2).
program dif_average1;
const n = 10;
type mas = array[1 .. n] of real;
var a, b : mas;
i : integer;
dif : real;
function average(x : mas) : real; { 1 }
var i : integer; { 2 }
av : real;
begin
av := 0;
for i := 1 to n do av := av + x[i];
average := av / n; { 3 }
end;
begin
for i := 1 to n do read(a[i]);
for i := 1 to n do read(b[i]);
dif := average(a) – average(b); { 4 }
writeln('Разность значений ', dif:6:2)
end.
Листинг
4.2.
Разность средних арифметических значений массивов (функция)
(html,
txt)
Оператор {1} представляет собой заголовок функции. Тип функции определен как вещественный, потому что к такому типу относится среднее арифметическое элементов вещественного массива. Оператор {3} присваивает имени функции вычисленное значение. В операторе {4} функция вызывается дважды: сначала для одного массива, затем для другого.
Глобальные и локальные переменные
Глобальными называются переменные, описанные в главной программе. Переменные, которые не были инициализированы явным образом, перед началом выполнения программы обнуляются. Время жизни глобальных переменных — с начала программы и до ее завершения.
Внутри подпрограмм описываются локальные переменные. Время их жизни — с начала работы подпрограммы и до ее окончания. Значения локальных переменных между двумя вызовами одной и той же подпрограммы не сохраняются, и эти переменные предварительно не обнуляются.
Глобальные переменные доступны в любом месте программы или подпрограммы, кроме тех подпрограмм, в которых описаны локальные переменные с такими же именами. Локальные переменные могут использоваться только в подпрограмме, в которой они описаны, и всех вложенных в нее.
Понятно, что никаких дополнительных усилий по передаче глобальных переменных в подпрограмму не требуется: они видны в ней естественным образом. Этот способ обмена информацией между главной программой и подпрограммой — самый простой, но он же и самый плохой.
В подавляющем большинстве случаев для обмена данными между вызывающей и вызываемой подпрограммами предпочтительнее использовать механизм параметров. Если все данные передаются подпрограммам через списки параметров, для локализации места ошибки достаточно просмотреть заголовки подпрограмм, а затем — тексты только тех из них, в которые передается интересующая нас переменная.
Виды параметров подпрограмм
Список параметров, то есть величин, передаваемых в подпрограмму и обратно, содержится в ее заголовке. Для каждого параметра обычно задаются его имя, тип и способ передачи. Либо тип, либо способ передачи могут не указываться.
В заголовке подпрограммы нельзя вводить описание нового типа — там должны использоваться либо имена стандартных типов, либо имена типов, описанных программистом ранее в разделе type.
В Паскале существует четыре вида параметров: значения, переменные, константы и нетипизированные параметры.
Кроме того, по другим критериям можно выделить особые виды параметров:
- открытые массивы и строки;
- процедурные и функциональные параметры;
- объекты.
Параметры-значения
Параметр-значение описывается в заголовке подпрограммы следующим образом:
имя : тип;
Например, передача величины целого типа в процедуру Р записывается так:
procedure P(x : integer);
Имя параметра может быть произвольным. Параметр х можно представить себе как локальную переменную, которая получает свое значение из главной программы при вызове подпрограммы. В подпрограмму передается копия значения аргумента.
Механизм передачи следующий: из ячейки памяти, в которой хранится переменная, передаваемая в подпрограмму, берется ее значение и копируется в область сегмента стека, называемую областью параметров. Подпрограмма работает с этой копией, следовательно, доступа к ячейке, где хранится сама переменная, не имеет. По завершении работы подпрограммы стек освобождается. Такой способ называется передачей по значению. Ясно, что им можно пользоваться только для величин, которые не должны измениться после выполнения подпрограммы, то есть для ее исходных данных.
При вызове подпрограммы на месте параметра, передаваемого по значению, может находиться выражение (а также, конечно, его частные случаи — переменная или константа). Тип выражения должен быть совместим по присваиванию с типом параметра.
Например, если в вызывающей программе описаны переменные
var x : integer; c : byte; y : longint;
то следующие вызовы подпрограммы Р, заголовок которой описан выше, будут синтаксически правильными:
P(x); P(c); P(y); P(200); P(x div 4 + 1);
Недостатками передачи по значению являются затраты времени на копирование параметра, затраты памяти в стеке и опасность его переполнения, когда речь идет о параметрах, занимающих много места, например массивах большого размера.
Параметры-переменные
Признаком параметра-переменной является ключевое слово var перед описанием параметра:
var имя : тип;
Например, параметр-переменная целого типа в процедуре Р записывается так:
procedure P(var x : integer);
При вызове подпрограммы в область параметров копируется не значение переменной, а ее адрес, и подпрограмма через него имеет доступ к ячейке, в которой хранится переменная. Этот способ передачи параметров называется передачей по адресу. Подпрограмма работает непосредственно с переменной из вызывающей программы и, следовательно, может ее изменить, поэтому результаты работы подпрограммы должны быть только параметрами-переменными.
При вызове подпрограммы на месте параметра-переменной может находиться только ссылка на переменную точно того же типа. Исходные данные в подпрограмму передавать по адресу не рекомендуется, чтобы исключить возможность их непреднамеренного изменения.
Проиллюстрируем передачу параметров-значений и параметров-переменных на примере (пример 4.3).
var a, b, c, d, e : word;
procedure X(a, b, c : word; var d : word);
var e : word;
begin
c := a + b; d := c; e := c;
writeln ('Значения переменных в подпрограмме:');
writeln ('c = ', c, ' d = ', d, ' e = ', e);
end;
begin
a := 3; b := 5;
x(a, b, c, d);
writeln ('Значения переменных в главной программе:');
writeln ('c = ', c, ' d = ', d, ' e = ', e);
end.
Листинг
4.3.
Параметры-значения и параметры-переменные
(html,
txt)
Результаты работы этой программы приведены ниже.
Значения переменных в подпрограмме: c = 8 d = 8 e = 8 Значения переменных в главной программе: c = 0 d = 8 e = 0
Как видите, значение переменной с в главной программе не изменилось, поскольку переменная передавалась по значению, а значение переменной е не изменилось потому, что в подпрограмме была описана локальная переменная с тем же именем.
Параметры-константы
Параметр-константу можно узнать по ключевому слову const перед описанием параметра. Оно говорит о том, что в пределах подпрограммы данный параметр изменить невозможно:
const имя : тип;
При вызове подпрограммы на месте параметра-константы, как и в случае параметра-значения, может быть записано выражение, тип которого совместим по присваиванию с типом параметра. Однако компилятор при передаче параметров-констант формирует более эффективный код, чем для параметров-значений. Фактически параметры-константы передаются по адресу, но доступ к ним обеспечивается только для чтения. Поэтому опасность переполнения стека и затраты, связанные с копированием и размещением параметров, исключаются.
Например, параметр-константа целого типа в процедуре Р записывается так:
procedure P(const x : integer);
Подведем итоги. Если данные передаются в подпрограмму по значению, их можно изменять, но эти изменения затронут только копию в области параметров и не отразятся на значении аргумента в вызывающей программе. Если данные передаются как параметры-константы, изменять их в подпрограмме нельзя. Следовательно, эти два способа передачи должны использоваться для передачи в подпрограмму исходных данных.
Параметры составных типов (массивы, записи, строки) предпочтительнее передавать как константы, потому что при этом не расходуется время на копирование и место в стеке (размер стека не может превышать 64 Кбайт, а по умолчанию устанавливается равным 16 Кбайт).
Результаты работы процедуры следует передавать через параметры-переменные, результат функции — через ее имя.
Открытые массивы и строки
Чтобы можно было передавать в подпрограмму массивы с различным количеством элементов, в списке ее параметров разрешается определять открытый массив, например:
procedure P(a : array of real);
Он может быть только одномерным и состоять из элементов любого типа, кроме файлового. На место открытого массива можно передавать одномерный массив любой размерности, состоящий из элементов такого же типа. Передавать открытый массив можно как значение, переменную или константу.
Его элементы нумеруются с нуля. Номер максимального элемента в массиве можно определить с помощью функции High.. Рассмотрите пример (пример 4.4).
function max_el(const mas : array of integer) : integer;
var i, max : integer;
begin
max := mas[0];
for i := 0 to High(mas) do
if mas[i] > max then max := mas[i];
max_el := max;
end;
Листинг
4.4.
Максимальный элемент любого целочисленного массива
(html,
txt)
Для передачи в подпрограмму по адресу строк любой длины используется либо специальный тип OpenString, называемый открытой строкой, либо тип string при включенном режиме {$P+} (по умолчанию этот режим выключен).
Напомню, что если параметр передается в подпрограмму как значение или константа, от него не требуется точного совпадения с типом аргумента — достаточно соответствия по присваиванию. Поскольку присваивать друг другу строки разной длины можно, их можно использовать и в качестве параметров, то есть на место параметра-значения или параметра-константы типа string можно передавать строку любой длины без использования открытых строк.
Пример передачи строк в подпрограмму:
type s20 = string[20];
var s1 : string[40];
s2 : string[10];
procedure P(const x : s20; y : string; var z : openstring);
...
begin
... P(s2, s1, s1); ...
end.Параметры процедурного типа
Все рассмотренные параметры подпрограмм позволяли выполнять один и тот же алгоритм с различными данными. В Паскале есть и другая возможность — параметризовать алгоритм функциями и процедурами. Это может пригодиться, если требуется выполнить одну и ту же последовательность действий, внутри которой выполняется обращение к разным функциям или процедурам.
Описание параметра подпрограммы в большинстве случаев состоит из имени и типа. Имя функции является константой процедурного ( функционального ) типа, который требуется описать в разделе type, например:
type fun = function(x : real) : real;
pr = procedure;
proc = procedure(a, b : word; var c : word);Здесь вводится описание трех типов. Первый из них соответствует любой функции с одним аргументом вещественного типа, возвращающей вещественное значение, второй — процедуре без параметров, а третий — процедуре с тремя параметрами типа word. Как видно из примеров, описание процедурного (функционального) типа соответствует заголовку подпрограммы без имени. Имя типа используется затем в списке параметров подпрограммы аналогично другим типам.
Пример. Программа, вычисляющая определенные интегралы методом прямоугольников для двух функций
![]()
на интервале [a, b] с заданным количеством его разбиений (пример 4.5).
program integrals;
type fun = function(x : real) : real; { 1 }
var a, b : real;
n : integer;
{$F+}
function Q(x : real) : real;
begin
Q := 2 * x / sqrt(1 – sin(2 * x));
end;
function R(x : real) : real;
begin
R := cos(x) – 0.2 * x;
end;
{$F–}
function integr(f : fun; a, b : real; n : integer) : real;
var sum, x, h : real;
i : integer;
begin
h := (b – a) / n; sum := 0; x := a;
for i := 1 to n do begin
sum := sum + f(x); x := x + h;
end;
integr := sum * h;
end;
begin
writeLn('Введите интервал и количество шагов');
readln(a, b, n);
writeln('Интеграл для первой функции: ', integr(Q, a, b, n):8:3);
writeln(' Интеграл для второй функции: ', integr(R, a, b, n):8:3);
end.
Листинг
4.5.
Вычисление определенного интеграла методом прямоугольников
(html,
txt)
Вычисление определенного интеграла методом прямоугольников состоит в приближенном подсчете площади, ограниченной осью абсцисс, графиком функции и границами интервала. Интервал разбивается на заданное количество промежутков, и площади получившихся фигур заменяются площадями прямоугольников.
Итак, чтобы передать имя функции или процедуры в подпрограмму, необходимо:
- Определить соответствующий процедурный тип.
- Задать для функций и процедур, предназначенных для передачи в подпрограмму, ключ компилятора {$F +}, определяющий дальнюю адресацию. При этом компилятор формирует полный адрес, состоящий из сегмента и смещения. Альтернативный способ — указать в заголовке каждой функции директиву far:
function Q(x : real) : real; far;
Рекурсивные подпрограммы
Рекурсивной называется подпрограмма, в которой содержится обращение к самой себе. Такая рекурсия называется прямой. Есть также косвенная рекурсия, когда две или более подпрограмм вызывают друг друга.
При обращении подпрограммы к самой себе происходит то же самое, что и при обращении к любой другой функции или процедуре: в стек записывается адрес возврата, резервируется место под локальные переменные, происходит передача параметров, после чего управление передается первому исполняемому оператору подпрограммы. При повторном вызове этот процесс повторяется. Для завершения вычислений каждая рекурсивная подпрограмма должна содержать хотя бы одну нерекурсивную ветвь, заканчивающуюся возвратом в вызывающую программу.
При завершении подпрограммы область ее локальных переменных освобождается, а управление передается на оператор, следующий за рекурсивным вызовом.
Простой пример рекурсивной функции — вычисление факториала (это не означает, что факториал следует вычислять именно так). Чтобы получить факториал числа n, требуется умножить на n факториал ( n – 1)!. Известно также, что 0! = 1 и 1! = 1.
function fact(n : byte) : longint;
begin
if (n = 0) or (n = 1) then fact := 1
else fact := n * fact(n – 1);
end;Рекурсивные подпрограммы чаще всего применяют для компактной записи рекурсивных алгоритмов, а также для работы со структурами данных, описанными рекурсивно, например с двоичными деревьями. Любую рекурсивную функцию можно реализовать без применения рекурсии: для этого программист должен сам обеспечить распределение памяти под необходимое количество копий параметров.
Достоинством рекурсии является компактная запись. К недостаткам относятся расход времени и памяти на повторные вызовы функции и передачу ей параметров, а главное, опасность переполнения стека.
Модули
Модуль — это подключаемая к программе библиотека ресурсов. Он может содержать описания типов, констант, переменных и подпрограмм. В модуль обычно объединяют связанные между собой ресурсы: например, в составе оболочки есть модуль Graph для работы с экраном в графическом режиме. Модули применяются как библиотеки, которые могут использоваться различными программами, и для разбиения сложной программы на составные части.
Чтобы использовать модуль, достаточно знать только его интерфейс: детали реализации модуля скрыты от его пользователя. Это позволяет успешно создавать программы большого объема, поскольку мозг человека может хранить одновременно довольно ограниченный объем информации. Кроме того, использование модулей позволяет преодолеть ограничение в один сегмент на объем кода исполняемой программы, поскольку код каждого подключаемого к программе модуля содержится в отдельном сегменте.
Модули можно разделить на стандартные, которые входят в состав системы программирования, и пользовательские, то есть создаваемые программистом. Чтобы подключить модуль к программе, его требуется предварительно скомпилировать. Результат компиляции каждого модуля хранится на диске в отдельном файле с расширением .tpu.
Описание модулей
Исходный текст каждого модуля хранится в отдельном файле с расширением .pas. Модуль состоит из секций (разделов). Общая структура модуля:
unit имя; { заголовок модуля }
interface { ------------- интерфейсная секция модуля }
{ описание глобальных элементов модуля (видимых извне) }
implementation { --------------- секция реализации модуля }
{ описание локальных (внутренних) элементов модуля }
begin { ------------------- секция инициализации }
{ может отсутствовать }
end.Модуль может использовать другие модули, для этого их надо перечислить в операторе uses, который может находиться только непосредственно после ключевых слов interface или implementation. Если модули подключаются к интерфейсной части, все константы и типы данных, описанные в интерфейсной секции этих модулей, могут использоваться в любом описании в интерфейсной части данного модуля. Если модули подключаются к части реализации, все описания из этих модулей могут использоваться только в секции реализации.
В интерфейсной секции модуля определяют константы, типы данных, переменные, а также заголовки процедур и функций. Полностью же подпрограммы описываются в секции реализации, скрытой от пользователя модуля. Это естественно, поскольку для применения подпрограммы требуется знать только информацию, которая содержится в ее заголовке.
В секции реализации описываются подпрограммы, заголовки которых приведены в интерфейсной части. Заголовок подпрограммы должен или быть идентичным указанному в секции интерфейса, или состоять только из ключевого слова procedure или function и имени подпрограммы. Для функции также указывается ее тип.
Кроме того, в этой секции можно определять константы, типы данных, переменные и внутренние подпрограммы. Они используются внешними элементами модуля и видны только в секции реализации.
Секция инициализации предназначена для присваивания начальных значений переменным, используемым в модуле или в программе, к которой он подключен. Операторы, расположенные в секции инициализации модуля, выполняются перед операторами основной программы. Если к программе подключено более одного модуля, их секции инициализации вызываются на выполнение в порядке, указанном в операторе uses.
В оболочках Borland Pascal и Turbo Pascal результат компиляции по умолчанию размещается в оперативной памяти и на диск не записывается. Поэтому для сохранения скомпилированного модуля на диске требуется установить значение пункта Compile ( Destination в значение Disk. Компилятор создаст файл с расширением .tpu, который надо переместить в специальный каталог, путь к которому указан в пункте меню Options ( Directories в поле Unit Directories.
В качестве примера оформим в виде модуля подпрограмму вычисления среднего арифметического значения элементов массива из пример 4.1 (пример 4.6).
unit Average;
interface
const n = 10;
type mas = array[1 .. n] of real;
procedure average(x : mas; var av : real);
implementation
procedure average(x : mas; var av : real);
var i : integer;
begin
av := 0;
for i := 1 to n do av := av + x[i];
av := av / n;
end;
end.
Листинг
4.6.
Пример оформления модуля
(html,
txt)
Список параметров подпрограммы в разделе реализации указывать не обязательно.
Использование модулей
Чтобы использовать в программе величины, описанные в интерфейсной части модуля, имя модуля следует указать в разделе uses. Можно записать несколько имен модулей через запятую, например:
program example; uses Average, Graph, Crt;
После этого все описания, расположенные в интерфейсных секциях модулей, становятся известными в программе, и ими можно пользоваться точно так же, как и величинами, определенными в ней непосредственно. Поиск модулей выполняется сначала в библиотеке исполняющей системы, затем в текущем каталоге, а после этого — в каталогах, заданных в диалоговом окне Options ( Directories.
Если в программе описана величина с тем же именем, что и в модуле, для обращения к величине из модуля требуется перед ее именем указать через точку имя модуля.
Пример использования модуля из пример 4.6 приведен в пример 4.7. Программа находит разность средних арифметических значений двух вещественных массивов.
program dif_average;
uses Average;
var a, b : mas;
i : integer;
dif, av_a, av_b : real;
begin
for i := 1 to n do read(a[i]);
for i := 1 to n do read(b[i]);
average(a, av_a);
average(b, av_b);
dif := av_a – av_b;
writeln('Разность значений ', dif:6:2);
end.
Листинг
4.7.
Разность средних арифметических значений массивов (модуль)
(html,
txt)
Стандартные модули Паскаля
В Паскале имеется ряд стандартных модулей, в которых описано большое количество встроенных констант, типов, переменных и подпрограмм. Каждый модуль содержит связанные между собой ресурсы. Ниже приводится краткая характеристика модулей Паскаля.
Модуль System
Модуль System содержит базовые средства языка, которые поддерживают ввод-вывод, работу со строками, операции с плавающей точкой и динамическое распределение памяти. Этот модуль автоматически используется во всех программах, его не требуется указывать в операторе uses. Он содержит все стандартные и встроенные процедуры, функции, константы и переменные Паскаля.
Модуль Crt
Модуль Crt предназначен для организации эффективной работы с экраном, клавиатурой и встроенным динамиком. При подключении модуля выводимая информация посылается в базовую систему ввода-вывода (ВIОS) или непосредственно в видеопамять. При этом ввод-вывод выполняется быстрее, кроме того, появляется возможность управлять цветом и размещением на экране.
В текстовом режиме экран представляется как совокупность строк и столбцов. Каждый символ располагается на так называемом знакоместе на пересечении строки и столбца. Символы хранятся в специальной части оперативной памяти, называемой видеопамятью. Ее содержимое отображается на экране.
Модуль Crt позволяет:
- выполнять вывод в заданное место экрана заданным цветом символа и фона;
- открывать на экране окна прямоугольной формы и выполнять вывод в пределах этих окон;
- очищать экран, окно, строку и ее часть;
- обрабатывать ввод с клавиатуры;
- управлять встроенным динамиком.
Пример. Программа "Угадай число" (пример 4.8).
program luck;
uses crt;
const max = 10;
var i, k, n : integer;
begin
clrscr; { очистить экран }
randomize;
i := random(max); { загадать число }
window(20, 5, 60, 20); { определить окно }
TextBackGround(Blue); { цвет фона – синий }
clrscr; { залить окно фоном }
TextColor(LightGray); { цвет символов – серый }
k := –1; { счетчик попыток }
GotoXY(12, 5); writeln(' Введите число : ');
repeat { цикл ввода ответа }
GotoXY(20, 9); { установить курсор }
readln(n); { ввести число }
inc(k);
until i = n;
window(20, 22, 60, 24); { определить окно результата }
TextAttr := 2 shl 4 + 14; { желтые символы за зеленом фоне }
clrscr; { залить окно фоном }
GotoXY(6, 2); { установить курсор }
writeln(' Коэффициент невезучести : ', k / max :5:1);
readkey; { ждать нажатия любой клавиши }
TextAttr := 15; { белые символы на черном фоне }
clrscr; { очистить после себя экран }
end.
Листинг
4.8.
Пример использования модуля Crt
(html,
txt)
Генератор случайных чисел формирует число, находящееся в диапазоне от нуля до max – 1. Пользователь вводит числа в одну и ту же позицию на экране до тех пор, пока не угадает это число. При угадывании с первого раза коэффициент невезучести равен нулю.
Модули Dos и WinDos
Модули Dos и WinDos содержат подпрограммы, реализующие возможности операционной системы MS-DOS, такие как переименование, поиск и удаление файлов, получение и установка системного времени, выполнение программных прерываний и т. д. Эти подпрограммы в стандартном Паскале не определены. Для поддержки подпрограмм в модулях определены константы и типы данных.
Модуль Dos использует строки Паскаля, а WinDos — строки с завершающим нулем.
Модуль Graph
Модуль обеспечивает работу с экраном в графическом режиме.
Экран в графическом режиме представляется в виде совокупности точек — пикселов (pixel, сокращение от picture element ). Цвет каждого пиксела можно задавать отдельно. Начало координат находится в левом верхнем углу экрана и имеет координаты (0, 0). Количество точек по горизонтали и вертикали ( разрешение экрана ) и количество доступных цветов зависят от графического режима. Графический режим устанавливается с помощью служебной программы — графического драйвера.
В состав оболочки входят несколько драйверов, каждый из которых может работать в нескольких режимах. Режим устанавливается при инициализации графики либо автоматически, либо программистом. Самый "мощный" режим, поддерживаемый модулем Graph, — 640 480 точек, 16 цветов. Модуль Graph обеспечивает:
- вывод линий и геометрических фигур заданным цветом и стилем;
- закрашивание областей заданным цветом и шаблоном;
- вывод текста различным шрифтом, заданного размера и направления;
- определение окон и отсечение по их границе;
- использование графических спрайтов и работу с графическими страницами.
Модуль Strings
Модуль Strings предназначен для работы со строками, заканчивающимися нуль-символом, то есть символом с кодом 0 (их часто называют ASCIIZ-строки). Этот вид строк введен в Паскаль специально для работы с длинными строками и программирования под Windows. Модуль Strings содержит функции копирования, сравнения, слияния строк, преобразования их в строки типа string, поиска подстрок и символов.
Лекция 5. Работа с динамической памятью
Презентацию к данной работе Вы можете скачать ![]() здесь.
здесь.
В PC-совместимых компьютерах память условно разделена на сегменты. Компилятор формирует сегменты кода, данных и стека, а остальная доступная программе память называется динамической (хипом, кучей ). Ее можно использовать во время выполнения программы.
В программах, приведенных ранее, для хранения данных использовались простые переменные, массивы или записи. По их описаниям в разделе var компилятор определяет, сколько места в памяти необходимо для хранения каждой величины. Такие переменные можно назвать статическими. Распределением памяти под них занимается компилятор, а обращение к этим переменным выполняется по имени. Динамические переменные создаются в хипе во время выполнения программы. Обращение к ним осуществляется через указатели.
С помощью динамических переменных можно обрабатывать данные, объем которых до начала выполнения программы не известен. Память под такие данные выделяется порциями, или блоками, которые связываются друг с другом. Такой способ хранения данных называется динамическими структурами, поскольку их размеры изменяются в процессе выполнения программы.
Указатели
Имя переменной служит для обращения к области памяти, которую занимает ее значение. Программист может определить собственные переменные для хранения адресов областей памяти. Такие переменные называются указателями. В указателе можно хранить адрес данных или программного кода (например, адрес точки входа в процедуру). Адрес занимает четыре байта и хранится в виде двух слов, одно из которых определяет сегмент, второе — смещение.
Указатели в Паскале можно разделить на два вида: стандартные и определяемые программистом. Величины стандартного типа pointer предназначены для хранения адресов данных произвольного типа, например:
var p : pointer;
Программист может определить указатель на данные или подпрограмму конкретного типа. Как и для других нестандартных типов, это делается в разделе type:
type pword = ^word; { читается как 'указатель на word' }
...
var pw : pword;Здесь определяется тип pword как указатель на величины типа word. В переменной pw можно хранить только адреса величин указанного типа. Такие указатели называются типизированными. Можно описать указатель на любой тип данных, кроме файловых.
Аналогично другим типам, тип указателя на данные можно описать и непосредственно при описании переменной, например:
var pw : ^word;
Операции с указателями
Для указателей определены только операции присваивания и проверки на равенство и неравенство. В Паскале, в отличие от других языков, запрещаются любые арифметические операции с указателями, их ввод-вывод и сравнение на больше-меньше. Рассмотрим правила присваивания указателей.
- Любому указателю можно присвоить стандартную константу nil, которая означает, что указатель не ссылается на какую-либо конкретную ячейку памяти.
- Указатели стандартного типа pointer совместимы с указателями любого типа.
- Указателю на конкретный тип данных можно присвоить только значение указателя того же или стандартного типа.
Операция @ и функция addr позволяют получить адрес переменной, например:
var x : word; { переменная }
pw : ^word; { указатель на величины типа word }
...
pw := @w; { или pw := addr(w); }Для обращения к значению переменной, адрес которой хранится в указателе, примеряется операция разадресации ( разыменования ), обозначаемая с помощью символа ^ справа от имени указателя, например:
pw^ := 2; inc(pw^); writeln(pw^);
В первом операторе в ячейку памяти, адрес которой хранится в переменной pw, заносится число 2. При выполнении оператора вывода на экране появится число 3.
С величинами, адрес которых хранится в указателе, можно выполнять любые действия, допустимые для значений этого типа. Для простоты восприятия можно считать имя указателя со следующей за ним "крышкой" просто именем переменной, на которую он указывает, хотя на самом деле это, конечно, не так.
Указатели можно сравнивать на равенство и неравенство, например:
if p1 = p2 then ... if p <> nil then ...
Динамические переменные
Динамические переменные создаются в хипе во время выполнения программы с помощью подпрограмм new или getmem. Динамические переменные не имеют собственных имен — к ним обращаются через указатели.
- Процедура new (var p : тип_указателя) выделяет в динамической памяти участок размера, достаточного для размещения переменной того типа, на который ссылается указатель p, и заносит в него адрес начала этого участка.
Функция new(тип_указателя) : pointer выделяет в динамической памяти участок размера, достаточного для размещения переменной базового типа для заданного типа указателя, и возвращает адрес начала этого участка.
Если в new использовать указатель стандартного типа pointer, память фактически не выделяется, а при попытке работать с ней выдается ошибка. Поэтому процедура и функция new обычно применяются для типизированных указателей.
- Процедура getmem (var p : pointer; size : word) выделяет в динамической памяти участок размером в size байт и присваивает адрес его начала указателю p. Эту процедуру можно применять и для указателей типа pointer, поскольку количество выделяемой памяти задается в явном виде.
Если выделить требуемый объем памяти не удалось, программа аварийно завершается.
Рассмотрим пример работы с динамическими переменными. Определим в разделе описания переменных главной программы три указателя p1, p2 и p3.
type rec = record
d : word;
s : string;
end;
pword = ^word;
var p1, p2 : pword;
p3 : ^rec;Это — обычные статические переменные, компилятор выделяет под них в сегменте данных по четыре байта и обнуляет их (рис. 5.1).
Рис. 5.1. Размещение указателей в памяти
В разделе исполняемых операторов программы запишем операторы:
new(p1); p2 := new(pword); new(p3);
В результате выполнения процедуры new(p1) в хипе выделяется объем памяти, достаточный для размещения переменной типа word, и адрес начала этого участка памяти записывается в переменную p1. Второй оператор выполняет аналогичные действия, но используется функция new. При вызове процедуры new с параметром p3 в динамической памяти будет выделено количество байтов, достаточное для размещения записи типа rec.
Доступ к выделенным областям осуществляется с помощью операции разадресации:
p1^ := 2; p2^ := 4; p3^.d := p1^; p3^.s := 'Вася';
В этих операторах в выделенную память заносятся значения (рис. 5.2).
Рис. 5.2. Выделение и заполнение динамической памяти
Динамические переменные можно использовать в операциях, допустимых для величин соответствующего типа, например:
inc(p1^); p2^ := p1^ + p3^.d; with p3^ do writeln (d, s);
Рис. 5.3. Мусор
Для освобождения динамической памяти используются процедуры Dispose и Freemem, причем если память выделялась с помощью new, следует применять Dispose, в противном случае — Freemem.
- Процедура Dispose (var p : pointer) освобождает участок памяти, выделенный для размещения динамической переменной процедурой или функцией New, и значение указателя p становится неопределенным.
- Процедура Freemem (var p : pointer; size : word) освобождает участок памяти размером size, начиная с адреса, находящегося в p. Значение указателя становится неопределенным.
При завершении программы используемая ею динамическая память освобождается автоматически, поэтому явным образом освобождать ненужную память необходимо только в том случае, если она может потребоваться при дальнейшем выполнении программы.
Динамические структуры данных
Если до начала работы с данными невозможно определить, сколько памяти потребуется для их хранения, память следует распределять во время выполнения программы по мере необходимости отдельными блоками. Блоки связываются друг с другом с помощью указателей. Такой способ организации данных называется динамической структурой данных, поскольку она размещается в динамической памяти и ее размер изменяется во время выполнения программы.
Из динамических структур в программах чаще всего используются линейные списки, стеки, очереди и бинарные деревья. Они различаются способами связи отдельных элементов и допустимыми операциями. Динамическая структура, в отличие от массива или записи, может занимать несмежные участки оперативной памяти.
Динамические структуры широко применяют и для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки, поскольку упорядочивание динамических структур не требует перестановки элементов, а сводится к изменению указателей на эти элементы. Например, если в процессе выполнения программы требуется многократно упорядочивать большой массив данных, имеет смысл организовать его в виде линейного списка. При решении задач поиска элемента в тех случаях, когда важна скорость, данные лучше всего представить в виде бинарного дерева.
Элемент динамической структуры состоит из двух частей: информационной, ради хранения которой и создается структура, и указателей, обеспечивающих связь элементов друг с другом. Элемент описывается в виде записи, например:
type
pnode = ^node;
node = record
d : word; { информационная }
s : string; { часть }
p : pnode; { указатель на следующий элемент }
end;Рассмотрим принципы работы с основными динамическими структурами.
Стеки
Стек является простейшей динамической структурой. Добавление элементов в стек и выборка из него выполняются из одного конца, называемого вершиной стека. Другие операции со стеком не определены. При выборке элемент исключается из стека.
Говорят, что стек реализует принцип обслуживания LIFO (last in — first out, последним пришел — первым обслужен). Стеки широко применяются в системном программном обеспечении, компиляторах, в различных рекурсивных алгоритмах.
Для работы со стеком используются две статические переменные: указатель на вершину стека и вспомогательный указатель.
var top, p : pnode;
Тип указателей должен соответствовать типу элементов стека.
В пример 5.1 приведена программа, которая формирует стек из пяти целых чисел и их текстового представления и выводит его на экран. Функция занесения в стек по традиции называется push, а функция выборки — pop.
program stack;
const n = 5;
type pnode = ^node;
node = record { элемент стека }
d : word;
s : string;
p : pnode;
end;
var top : pnode; { указатель на вершину стека }
i : word;
s : string;
const text : array [1 .. n] of string = ('one', 'two', 'three', 'four', 'five');
{ ------------------------------ занесение в стек --------------------------- }
function push(top : pnode; d : word; const s : string) : pnode;
var p : pnode;
begin
new(p);
p^.d := d; p^.s := s; p^.p := top;
push := p;
end;
{ ------------------------------ выборка из стека --------------------------- }
function pop(top : pnode; var d : word; var s : string) : pnode;
var p : pnode;
begin
d := top^.d; s := top^.s;
pop := top^.p;
dispose(top);
end;
{ ------------------------------- главная программа ----------------------------- }
begin
top := nil;
for i := 1 to n do top := push(top, i, text[i]); { занесение в стек: }
while top <> nil do begin { выборка из стека: }
top := pop(top, i, s); writeln(i:2, s);
end;
end.
Листинг
5.1.
Использование стека
(html,
txt)
Очереди
Очередь — это динамическая структура данных, добавление элементов в которую выполняется в один конец, а выборка — из другого конца. Другие операции с очередью не определены. При выборке элемент исключается из очереди. Говорят, что очередь реализует принцип обслуживания FIFO (first in — first out, первым пришел — первым обслужен). В программировании очереди применяются очень широко — например, при моделировании, буферизованном вводе-выводе или диспетчеризации задач в операционной системе.
Для работы с очередью используются указатели на ее начало и конец, а также вспомогательный указатель:
var beg, fin, p : pnode;
Тип указателей должен соответствовать типу элементов, из которых состоит очередь.
В пример 5.2 приведена программа, которая формирует очередь из пяти целых чисел и их текстового представления и выводит еe на экран. Для разнообразия операции с очередью оформлены в виде процедур. Процедура начального формирования называется first, помещения в конец очереди — add, а выборки — get.
program queue;
const n = 5;
type pnode = ^node;
node = record { элемент очереди }
d : word;
s : string;
p : pnode;
end;
var beg, fin : pnode; { указатели на начало и конец очереди }
i : word;
s : string;
const text : array [1 .. n] of string = ('one', 'two', 'three', 'four', 'five');
{ ------------------ начальное формирование очереди --------------------------- }
procedure first(var beg, fin : pnode; d : word; const s : string);
begin
new(beg);
beg^.d := d; beg^.s := s; beg^.p := nil;
fin := beg;
end;
{ --------------------- добавление элемента в конец --------------------------- }
procedure add(var fin : pnode; d : word; const s : string);
var p : pnode;
begin
new(p);
p^.d := d; p^.s := s; p^.p := nil;
fin^.p := p;
fin := p;
end;
{ ---------------------- выборка элемента из начала --------------------------- }
procedure get(var beg : pnode; var d : word; var s : string);
var p : pnode;
begin
d := beg^.d; s := beg^.s;
p := beg; beg := beg^.p;
dispose(p);
end;
{ ------------------------------- главная программа --------------------------- }
begin
{ занесение в очередь: }
first(beg, fin, 1, text[1]);
for i := 2 to 5 do add(fin, i, text[i]);
{ выборка из очереди: }
while beg <> nil do begin
get(beg, i, s);
writeln(i:2, s);
end;
end.
Листинг
5.2.
Использование очереди
(html,
txt)
Линейные списки
В линейном списке каждый элемент связан со следующим и, возможно, с предыдущим. В первом случае список называется односвязным, во втором — двусвязным. Также применяются термины "однонаправленный" и "двунаправленный". Если последний элемент связать указателем с первым, получится кольцевой список.
Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо строкой и является частью поля данных. В качестве ключа в процессе работы со списком могут выступать разные части поля данных. Например, если создается линейный список из записей, содержащих фамилию, год рождения, стаж работы и пол, любая часть записи может выступать в качестве ключа. При упорядочивании списка по алфавиту ключом будет фамилия, а при поиске, например, ветеранов труда — стаж. Ключи разных элементов списка могут совпадать.
Над списками можно выполнять следующие операции:
- начальное формирование списка (создание первого элемента);
- добавление элемента в конец списка;
- чтение элемента с заданным ключом;
- вставка элемента в заданное место списка (до или после элемента с заданным ключом);
- удаление элемента с заданным ключом;
- упорядочивание списка по ключу.
Стек и очередь представляют собой частные случаи линейного списка с ограниченным набором допустимых операций.
При чтении элемент списка не удаляется, в отличие от элемента, выбираемого из стека и очереди. Для работы со списком в программе требуется определить указатель на его начало. Чтобы упростить добавление новых элементов в конец списка, можно также завести указатель на конец списка.
Рассмотрим программу (пример 5.3), которая формирует односвязный список из пяти элементов, содержащих число и его текстовое представление, а затем выполняет вставку и удаление заданного элемента. В качестве ключа используется число.
program linked_list;
const n = 5;
type pnode = ^node;
node = record { элемент списка }
d : word;
s : string;
p : pnode;
end;
var beg : pnode; { указатель на начало списка }
i, key : word;
s : string;
option : word;
const text: array [1 .. n] of string = ('one', 'two', 'three', 'four', 'five');
{ -------------- добавление элемента в конец списка --------------------------- }
procedure add(var beg : pnode; d : word; const s : string);
var p : pnode; { указатель на создаваемый элемент }
t : pnode; { указатель для просмотра списка }
begin
new(p); { создание элемента }
p^.d := d; p^.s := s; { заполнение элемента }
p^.p := nil;
if beg = nil then beg := p { список был пуст }
else begin { список не пуст }
t := beg;
while t^.p <> nil do { проход по списку до конца }
t := t^.p;
t^.p := p; { привязка нового элемента к последнему }
end
end;
{ ------------------------- поиск элемента по ключу --------------------------- }
function find(beg : pnode; key : word; var p, pp : pnode) : boolean;
begin
p := beg;
while p <> nil do begin { 1 }
if p^.d = key then begin { 2 }
find := true; exit end;
pp := p; { 3 }
p := p^.p; { 4 }
end;
find := false;
end;
{ -------------------------------- вставка элемента --------------------------- }
procedure insert(beg : pnode; key, d : word; const s : string);
var p : pnode; { указатель на создаваемый элемент }
pkey : pnode; { указатель на искомый элемент }
pp : pnode; { указатель на предыдущий элемент }
begin
if not find(beg, key, pkey, pp) then begin
writeln(' вставка не выполнена'); exit; end;
new(p); { 1 }
p^.d := d; p^.s := s; { 2 }
p^.p := pkey^.p; { 3 }
pkey^.p := p; { 4 }
end;
{ ------------------------------- удаление элемента --------------------------- }
procedure del(var beg : pnode; key : word);
var p : pnode; { указатель на удаляемый элемент }
pp : pnode; { указатель на предыдущий элемент }
begin
if not find(beg, key, p, pp) then begin
writeln(' удаление не выполнено'); exit; end;
if p = beg then beg := beg^.p { удаление первого элемента }
else pp^.p := p^.p;
dispose(p);
end;
{ ------------------------------------ вывод списка --------------------------- }
procedure print(beg : pnode);
var p : pnode; { указатель для просмотра списка }
begin
p := beg;
while p <> nil do begin { цикл по списку }
writeln(p^.d:3, p^.s); { вывод элемента }
p := p^.p { переход к следующему элементу списка }
end;
end;
{ ------------------------------- главная программа --------------------------- }
begin
for i := 1 to 5 do add(beg, i, text[i]);
while true do begin
writeln('1 - вставка, 2 - удаление, 3 - вывод, 4 - выход');
readln(option);
case option of
1: begin { вставка }
writeln('Ключ для вставки?');
readln(key);
writeln('Вставляемый элемент?');
readln(i); readln(s);
insert(beg, key, i, s);
end;
2: begin { удаление }
writeln('Ключ для удаления?');
readln(key);
del(beg, key);
end;
3: begin { вывод }
writeln('Вывод списка:');
print(beg);
end;
4: exit; { выход }
end
writeln;
end
end.
Листинг
5.3.
Использование списка
(html,
txt)
Функция поиска элемента find возвращает true, если искомый элемент найден, и false в противном случае. Поскольку одного факта отыскания элемента недостаточно, функция также возвращает через список параметров два указателя: на найденный элемент p и на предшествующий ему pp. Последний требуется при удалении элемента из списка, поскольку при этом необходимо связывать предыдущий и последующий по отношению к удаляемому элементы.
Сначала указатель p устанавливается на начало списка, и организуется цикл просмотра списка (оператор 1). Если поле данных очередного элемента совпало с заданным ключом (оператор 2), формируется признак успешного поиска и функция завершается. В противном случае перед переносом указателя на следующий элемент списка (он хранится в поле p текущего элемента, оператор 4) его значение запоминается в переменной pp (оператор 3) для того, чтобы при следующем проходе цикла в ней находился указатель на предыдущий элемент.
Если элемента с заданным ключом в списке нет, цикл завершится естественным образом, поскольку последний элемент списка содержит nil в поле p указателя на следующий элемент.
Вставка элемента выполняется после элемента с заданным ключом (процедура insert ). Если с помощью функции find место вставки определить не удалось, выводится сообщение и процедура завершается (в этом случае можно было использовать и другой алгоритм — добавлять элемент к концу списка, это определяется конкретным предназначением программы). Если элемент найден, указатель на него заносится в переменную pkey.
Под новый элемент выделяется место в динамической памяти (оператор 1), и информационные поля элемента заполняются переданными в процедуру значениями (оператор 2). Новый элемент p вставляется между элементами pkey и следующим за ним (его адрес хранится в pkey^.p ). Для этого в операторах 3 и 4 устанавливаются две связи (рис. 5.4).
Рис. 5.4. Вставка элемента в список
Удаление элемента выполняет процедура del. В ней две ветви, поскольку при удалении элемента из начала списка изменяется указатель на начало, а при удалении второго и последующих элементов требуется связывать предыдущий и последующий по отношению к удаляемому элементы.
Бинарные деревья
Бинарное дерево — это динамическая структура данных, состоящая из узлов, каждый из которых содержит кроме данных не более двух ссылок на различные бинарные деревья. На каждый узел имеется ровно одна ссылка. Начальный узел называется корнем дерева.
Пример бинарного дерева приведен на рис. 5.5 (корень обычно изображается сверху). Узел, не имеющий поддеревьев, называется листом. Исходящие узлы называются предками, входящие — потомками. Высота дерева определяется количеством уровней, на которых располагаются его узлы.

Рис. 5.5. Пример бинарного дерева
Если дерево организовано таким образом, что для каждого узла все ключи его левого поддерева меньше ключа этого узла, а все ключи его правого поддерева — больше, оно называется деревом поиска. Одинаковые ключи не допускаются. В дереве поиска можно найти элемент, двигаясь от корня и переходя на левое или правое поддерево в зависимости от значения ключа в каждом узле. Такой поиск гораздо эффективнее поиска по списку, поскольку время поиска определяется высотой дерева, а она пропорциональна двоичному логарифму количества узлов.
Дерево является рекурсивной структурой данных, поскольку каждое поддерево также является деревом. Действия с такими структурами изящнее всего описываются с помощью рекурсивных алгоритмов. Например, процедуру обхода всех узлов дерева можно в общем виде описать так:
procedure print_tree( дерево );
begin
print_tree( левое_поддерево )
посещение корня
print_tree( правое_поддерево )
end;Эта процедура позволяет получить последовательность ключей, отсортированную по возрастанию. Результат обхода дерева, изображенного на рис. 5.5:
1, 6, 8, 10, 20, 21, 25, 30
Если в функции обхода первое обращение идет к правому поддереву, результат обхода будет другим:
30, 25, 21, 20, 10, 8, 6, 1
Таким образом, деревья поиска можно применять для сортировки значений. При обходе дерева узлы не удаляются.
Для бинарных деревьев определены операции:
- включения узла в дерево;
- поиска по дереву;
- обхода дерева;
- удаления узла.
Для простоты будем рассматривать дерево, каждый элемент которого содержит только целочисленный ключ и два указателя.
type pnode = ^node;
node = record
data : word; { ключ }
left : pnode; { указатель на левое поддерево }
right : pnode { указатель на правое поддерево }
end;Доступ к дереву в программе осуществляется через указатель на его корень:
var root : pnode;
Рассмотрим сначала функцию поиска по дереву, так как она используется и при включении, и при удалении элемента (пример 5.4).
function find(root : pnode; key : word; var p, parent : pnode) : boolean;
begin
p := root; { поиск начинается от корня }
while p <> nil do begin
if key = p^.data then { узел с таким ключом есть }
begin find := true; exit end;
parent := p; { запомнить указатель перед спуском }
if key < p^.data
then p := p^.left { спуститься влево }
else p := p^.right; { спуститься вправо }
end;
find := false;
end;
Листинг
5.4.
Функция поиска по бинарному дереву
(html,
txt)
Функция возвращает булевский признак успешности поиска. Ей передаются указатель на корень дерева, в котором выполняется поиск ( root ), и искомый ключ ( key ). Выходными параметрами функции являются указатели на найденный элемент ( p ) и его предка ( parent ).
Удаление элемента — более сложная задача, поскольку при этом необходимо сохранить свойства дерева поиска. Эта задача подробно описана в учебнике [10].
В пример 5.5 приведен пример программы работы с бинарным деревом.
program bintree;
uses crt;
type pnode = ^node;
node = record
data : word; { ключ }
left : pnode; { указатель на левое поддерево }
right : pnode { указатель на правое поддерево }
end;
var root : pnode;
key : word;
option : word;
{ ------------------------------------ вывод дерева --------------------------- }
procedure print_tree(p : pnode; level : integer);
var i : integer;
begin
if p = nil then exit;
with p^ do begin
print_tree(right, level + 1);
for i := 1 to level do write(' ');
writeln(data);
print_tree(left, level + 1);
end
end;
{ ------------------------------- поиск по дереву – см. рис. 5.5----------- }
function find(root : pnode; key : word; var p, parent : pnode) : boolean;
{ ---------------------------- включение в дерево ----------------------------- }
procedure insert(var root : pnode; key : word);
var p, parent : pnode;
begin
if find(root, key, p, parent) then begin
writeln(' такой элемент уже есть'); exit; end;
new(p); { создание нового элемента }
p^.data := key;
p^.left := nil;
p^.right := nil;
if root = nil then root := p { первый элемент }
else { присоединение нового элемента к дереву}
if key < parent^.data
then parent^.left := p
else parent^.right := p;
end;
{ ------------------------------ удаление из дерева - см. учебник --------- }
procedure del(var root : pnode; key : word);
{ ------------------------------- главная программа --------------------------- }
begin
root := nil;
while true do begin
writeln('1 - вставка, 2 - удаление, 3 - вывод, 4 - выход');
readln(option);
case option of
1: begin { вставка }
writeln('Введите ключ для вставки: '); readln(key);
insert(root, key);
end;
2: begin { удаление }
writeln('Введите ключ для удаления: '); readln(key);
del(root, key);
end;
3: begin { вывод }
clrscr;
if root = nil then writeln ('дерево пустое')
else print_tree(root, 0);
end;
4: exit; { выход }
end;
writeln;
end
end.
Листинг
5.5.
Использование бинарного дерева
(html,
txt)
Рассмотрим функцию обхода дерева print_tree. Вторым параметром в нее передается целая переменная, определяющая, на каком уровне находится узел. Корень находится на уровне 0. Дерево печатается по горизонтали так, что корень находится слева. Для дерева, изображенного на рис. 5.5, вывод выглядит так:
30
25
21
20
10
8
6
1Лекция 6. Введение в объектно-ориентированное программирование
Презентацию к данной работе Вы можете скачать ![]() здесь.
здесь.
Объектно-ориентированное программирование (ООП) представляет собой дальнейшее развитие идей структурного программирования, основной целью которого является создание программ простой структуры. Это достигается за счет разбиения программы на максимально обособленные части.
Структурная программа состоит из совокупности подпрограмм, связанных с помощью интерфейсов. Подпрограмма работает с данными, которые либо являются локальными, либо передаются ей в качестве параметров. Каждая подпрограмма предназначена для работы с определенными типами данных. Ошибки часто связаны с тем, что в подпрограмму передаются неверные данные. Естественный путь избежать таких ошибок — связать в одно целое данные и все подпрограммы, которые предназначены для их обработки. Эта идея лежит в основе ООП: из предметной области выделяются объекты, поведение и взаимодействие которых моделируются с помощью программы.
Принципы ООП проще всего понять на примере программ моделирования. В реальном мире каждый предмет или процесс обладает набором статических и динамических характеристик, иными словами, свойствами и поведением. Поведение объекта зависит от его состояния и внешних воздействий. Например, если в объекте "автомобиль" повернуть руль, изменится положение колес, а если в баке нет бензина, автомобиль никуда не поедет.
Понятие объекта в программе совпадает с обыденным смыслом этого слова: объект представляется как совокупность данных, характеризующих его состояние, и процедур их обработки, моделирующих его поведение. Вызов процедуры часто называют посылкой сообщения объекту.
При создании объектно-ориентированной программы предметная область представляется не в виде данных и обрабатывающих эти данные подпрограмм, как при процедурном подходе, а в виде совокупности объектов. Выполнение программы состоит в том, что объекты обмениваются сообщениями. Это позволяет использовать при программировании понятия, более адекватно отражающие предметную область.
При представлении реального объекта с помощью программного необходимо выделить в первом его существенные особенности. Их список зависит от цели моделирования. Например, объект "крыса" с точки зрения ветеринара, дачника или, скажем, повара будет иметь совершенно разные характеристики. Выделение существенных с точки зрения рассмотрения свойств называется абстрагированием. Таким образом, программный объект — это абстракция.
Важным свойством объекта является его обособленность. Чтобы пользоваться подпрограммой, достаточно знать только ее заголовок (интерфейс); объект тоже используется только через интерфейс — обычно это совокупность интерфейсов его подпрограмм. Детали реализации объекта, то есть внутренние структуры данных и алгоритмы их обработки, скрыты от пользователя и недоступны для непреднамеренных изменений.
Скрытие деталей реализации называется инкапсуляцией (от слова "капсула"). Ничего сложного в этом понятии нет: ведь и в обычной жизни мы пользуемся объектами через их интерфейсы. Сколько информации пришлось бы держать в голове, если бы для просмотра новостей надо было знать устройство телевизора!
Таким образом, объект является "черным ящиком", закрытым по отношению к внешнему миру. Это позволяет представить программу в более укрупненном виде — на уровне объектов и их взаимосвязей, а следовательно, управлять большим объемом информации и успешно отлаживать более сложные программы.
Сказанное выше можно сформулировать более кратко и строго: объект — это инкапсулированная абстракция с четко определенным интерфейсом.
Инкапсуляция позволяет изменить реализацию объекта без модификации основной части программы, если его интерфейс остался прежним (например, при необходимости изменить способ хранения данных с массива на стек). Простота модификации, как уже отмечалось, является важным критерием качества программы.
Кроме того, инкапсуляция позволяет использовать объект в другом окружении и быть уверенным, что он не испортит не принадлежащие ему области памяти, а также создавать библиотеки объектов для применения во многих программах.
Каждый год в мире пишется огромное количество новых программ, и важнейшее значение приобретает возможность повторного использования кода. Для структурных программ она сильно ограничена: любую подпрограмму либо можно использовать без изменений, либо надо переписывать. Преимущество объектно-ориентированного программирования состоит в том, что для любого объекта можно определить наследников, корректирующих или дополняющих его поведение. При этом нет необходимости иметь доступ к исходному коду родительского объекта.
Наследование позволяет создавать иерархии объектов.Иерархия представляется в виде дерева, в котором более общие объекты располагаются ближе к корню, а более специализированные — на ветвях и листьях. Наследование облегчает использование библиотек объектов, поскольку программист может взять за основу объекты из библиотеки и создать их наследников с требуемыми свойствами. В Паскале любой объект может иметь одного предка и произвольное количество потомков.
Применение ООП позволяет писать гибкие, расширяемые, хорошо читаемые программы. Во многом это обеспечивается благодаря полиморфизму, под которым понимается возможность во время выполнения программы с помощью одного и того же имени выполнять разные действия или обращаться к объектам разного типа. Чаще всего понятие полиморфизма связывают с механизмом виртуальных методов.
Подводя итог сказанному выше, сформулирую преимущества ООП:
- использование в программах понятий, более близких к предметной области;
- более простая структура программы в результате инкапсуляции, то есть объединения свойств и поведения объекта и скрытия деталей его реализации;
- возможность повторного использования кода за счет наследования;
- сравнительно простая возможность модификации программы;
- возможность создания библиотек объектов.
Эти преимущества проявляются при создании программ большого объема и классов программ. Однако создание объектно-ориентированной программы представляет собой весьма непростую задачу, поскольку в процесс добавляется этап разработки иерархии объектов, а плохо спроектированная иерархия приводит к появлению сложных и запутанных программ.
Чтобы эффективно использовать готовые объекты, необходимо освоить большой объем достаточно сложной информации. Нашу задачу облегчает то, что объектная модель Паскаля по сравнению с другими языками является упрощенной. Тем не менее на ее примере удобно изучить основные положения ООП, не увязнув в многообразии возможностей и деталей.
Описание объектов
Объект — это тип данных, поэтому он определяется в разделе описания типов. В других языках объектный тип называют классом. Объект похож на тип record, но кроме полей данных в нем можно описывать методы. Методами называются подпрограммы, предназначенные для работы с полями объекта. Внутри объекта описываются только заголовки методов.
type имя = object
[ private ]
описание полей
[ public ]
заголовки методов
end;Поля и методы называются элементами объекта. Их видимостью управляют директивы private и public. Ключевое слово private ( закрытые ) ограничивает видимость перечисленных после него элементов файлом, в котором описан объект. Действие директивы распространяется до другой директивы или до конца объекта. В объекте может быть произвольное количество разделов private и public. По умолчанию все элементы объекта считаются видимыми извне, то есть являются public ( открытыми ). Этим Паскаль отличается от других, более современных языков программирования.
Поля объекта описываются аналогично обычным переменным: для каждого поля задается его имя и тип. Тип может быть любым, кроме типа того же объекта, но может быть указателем на этот тип. Значения полей определяют состояние объекта.
При определении состава методов исходят из требуемого поведения объекта. Каждое действие, которое должен выполнять объект, оформляется в виде отдельной процедуры или функции. Рассмотрим в качестве примера объект, моделирующий персонаж компьютерной игры.
type monster = object
procedure init(x_, y_, health_, ammo_ : word);
procedure attack;
procedure draw;
procedure erase;
procedure hit;
procedure move(x_, y_ : word);
private
x, y : word;
health, ammo : word;
color : word;
end;В этом объекте пять полей данных. Поля x и y представляют собой местоположение объекта на экране, health хранит состояние здоровья, ammo — боезапас, а color — цвет. Поля описаны в разделе private, так как эта информация относится к внутренней структуре объекта.
Допустим, что нашему герою придется перемещаться по экрану, атаковать другие объекты и терять при этом здоровье и оружие. Каждому действию соответствует свой метод. Методы описаны в разделе public (по умолчанию), потому что они составляют интерфейс объекта.
Вся внешняя информация, необходимая для выполнения действий с объектом, должна передаваться методам в качестве параметров. Параметры могут иметь любой тип, в том числе и тип того же объекта. Имена параметров не должны совпадать с именами полей объекта.
Описание методов (текст подпрограмм) размещается вне объекта в разделе описания процедур и функций, при этом имени метода предшествует имя объекта, отделенное точкой, например:
procedure monster.init(x_, y_, health_, ammo_ : word);
begin
x := x_; y := y_;
health := health_;
ammo := ammo_;
color := yellow;
end;
procedure monster.draw;
begin
setcolor(color); outtextXY(x, y, '@');
end;Перед использованием объект требуется инициализировать, то есть присвоить начальные значения его полям и, возможно, выполнить другие подготовительные действия. В документации Borland Pascal процедуре инициализации объекта рекомендуется давать имя init.
Обратите внимание, что поля объекта используются внутри методов непосредственно, без указания имени объекта.
Процедура draw предназначена для вывода изображения объекта на экран. Для простоты примем, что изображение монстра представляет собой просто символ "собаки" @.
Методы представляют собой разновидность подпрограмм, поэтому внутри них можно описывать локальные переменные. Принцип здесь точно такой же, как и при написании обычных подпрограмм: если переменная используется для временного хранения данных только внутри метода, ее следует описывать в этом методе как локальную.
Как правило, поля объекта объявляют как private, а методы как public, однако это не догма. Если поле объекта представляет собой свойство, которое концептуально входит в интерфейс объекта, и пользователь должен иметь право устанавливать и получать его без каких-либо ограничений, логично поместить его в раздел public. И наоборот: если метод предназначен только для вызова из других методов, его лучше скрыть от посторонних глаз в разделе private.
Для реализации принципа инкапсуляции, то есть ограничения видимости элементов, объекты обычно описывают в модулях. Тип объекта определяется в интерфейсном разделе модуля, а тексты методов объекта — в разделе реализации.
Объекты можно описать и в разделе реализации модуля. Они подчиняются тем же ограничениям, что и любые другие типы, определенные в этом разделе. Объект, определенный в интерфейсном разделе модуля, может иметь потомков, определенных в разделе реализации. Если модуль В использует модуль А, в модуле В могут определяться потомки любых объектов, описанных в интерфейсном разделе модуля А.
Описание объекта monster в модуле приведено в пример 6.1.
unit monsters;
interface
uses Graph;
type monster = object
procedure init(x_, y_, health_, ammo_ : word);
procedure attack;
procedure draw;
procedure erase;
procedure hit;
procedure move(x_, y_ : word);
private
x, y : word;
health, ammo : word;
color : word;
end;
implementation
{ ----------------------- реализация методов объекта monster ------------------- }
procedure monster.init(x_, y_, health_, ammo_ : word);
begin
x := x_; y := y_;
health := health_;
ammo := ammo_;
color := yellow;
end;
procedure monster.attack; { ------------------------------- monster.attack ------ }
begin
if ammo = 0 then exit;
dec(ammo); setcolor(color); outtextXY(x + 15, y, 'ба-бах!');
end;
procedure monster.draw; { ------------------------------- monster.draw -------- }
begin
setcolor(color); outtextXY(x, y, '@');
end;
procedure monster.erase; { ------------------------------- monster.erase ------- }
begin
setcolor(black); outtextXY(x, y, '@');
end;
procedure monster.hit; { ------------------------------- monster.hit --------- }
begin
if health = 0 then exit;
dec(health);
if health = 0 then begin color := red; draw; exit; end;
attack;
end;
procedure monster.move(x_, y_ : word); { ------------------ monster.move -------- }
begin
if health = 0 then exit;
erase; x := x_; y := y_; draw;
end;
end.
Листинг
6.1.
Описание объекта monster
(html,
txt)
Для стирания изображения объекта с экрана от выводится поверх старого цветом фона (метод erase ). Перемещение объекта (метод move ) выполняется путем стирания на старом месте и отрисовки на новом.
Атака (метод attack ) реализована схематично: если имеется ненулевой боезапас, он уменьшается на единицу, после чего выводится диагностическое сообщение. Если объект атакован (метод hit ), он теряет единицу здоровья, но атакует в ответ, а при потере последней единицы здоровья выводится на экран красным цветом. Объект, потерявший в сражении все здоровье, двигаться и атаковать не может.
Экземпляры объектов
Переменная объектного типа называется экземпляром объекта. Часто экземпляры называют просто объектами. Время жизни и видимость объектов зависят от вида и места их описания и подчиняются общим правилам Паскаля. Экземпляры объектов, так же как и переменные других типов, можно создавать в статической или динамической памяти, например:
var Vasia : monster; { описывается статический объект }
pm : ^monster; { описывается указатель на объект }
...
new(pm); { создается динамический объект }Можно определять массивы объектов или указателей на объекты и создавать из них динамические структуры данных. Если объектный тип описан в модуле, для создания в программе переменных этого типа следует подключить модуль в разделе uses:
uses graph, monsters;
Доступ к элементам объекта осуществляется так же, как к полям записи: либо с использованием составного имени, либо с помощью оператора with.
Vasia.erase; with pm^ do begin init(100, 100, 30); draw; end;
При обращении указывается имя экземпляра объекта, а не имя типа. Если поля объекта являются открытыми или объектный тип описан в той же программной единице, где используется, к полям можно обращаться так же, как к методам:
pm^.x := 300; { если бы x было public }
Если объект описан в модуле, получить или изменить значения элементов со спецификатором private в программе можно только через обращение к соответствующим методам.
При создании каждого объекта выделяется память, достаточная для хранения всех его полей. Методы объекта хранятся в одном экземпляре. Для того чтобы методу было известно, с данными какого экземпляра объекта он работает, при вызове ему в неявном виде передается параметр self, определяющий место расположения данных этого объекта. Фактически внутри метода обращение к полю x объекта имеет вид self.x. При необходимости имя self можно использовать внутри метода явным образом, например @self представляет собой адрес начала области, в которой хранятся поля объекта.
Объекты одного типа можно присваивать друг другу, при этом выполняется поэлементное копирование всех полей. Кроме того, в Паскале определены правила расширенной совместимости типов объектов. Все остальные действия выполняются над отдельными полями объектов.
В пример 6.2 приведен пример программы, использующей модуль monsters.
program test_monster;
uses graph, crt, monsters;
var Vasia : monster; { 1 }
x, y : word;
gd, gm : integer;
begin
gd := detect; initgraph(gd, gm, '...');
if graphresult <> grOk then begin
writeln('ошибка инициализации графики'); exit end;
Vasia.init(100, 100, 10, 10); { 2 }
Vasia.draw; { 3 }
Vasia.attack; { 4 }
readln;
x := 110;
while x < 200 do begin
Vasia.move(x, x); inc(x, 7); { 5 }
Vasia.hit; { 6 }
delay(200);
end;
readln;
end.
Листинг
6.2.
Пример использования модуля monsters
(html,
txt)
Для тестирования объекта monster в программе определена переменная Vasia типа monster (оператор 1). Для нее вызываются процедуры инициализации (2), отрисовки (3) и атаки (4), а затем перемещения по экрану (5) с имитацией попадания в объект при каждом перемещении (6). Таким образом проверяется работоспособность всех методов объекта.
Пример программы, в которой используется массив объектов типа monster, приведен в пример 6.3. Все объекты инициализируются случайными значениями, а затем начинают хаотически перемещаться по экрану. Если два монстра оказываются на достаточно близком расстоянии друг от друга, они считаются атакованными (для обоих экземпляров вызывается метод hit ). Выход из этой в высшей степени медитативной программы, которую можно назвать "монстры от испуга скушали друг друга", выполняется по нажатию любой клавиши.
<$Mmonster _game>program dinner;
uses graph, crt, monsters;
const n = 30;
var stado : array [1 .. n] of monster;
x, y : array [1 .. n] of integer;
gd, gm : integer;
i, j : word;
begin
gd := detect; initgraph(gd, gm, '...');
if graphresult <> grOk then begin
writeln('ошибка инициализации графики'); exit end;
randomize;
for i := 1 to n do begin
stado[i].init(random(600), random(440), random(10), random(8));
stado[i].draw;
end;
repeat
for i := 1 to n do begin
x[i] := random(600); y[i] := random(440);
stado[i].move(x[i], y[i]);
end;
for i := 1 to n – 1 do
for j := i + 1 to n do
if (abs(x[i] – x[j]) < 15) and (abs(y[i] – y[j]) < 15)
then begin
stado[i].hit; stado[j].hit;
end;
delay(200);
until keypressed;
end.
Листинг
6.3.
Пример использования массива объектов типа monster
(html,
txt)
Лекция 7. Иерархии объектов. Работа с объектами в динамической памяти
Наследование
Презентацию к данной работе Вы можете скачать ![]() здесь.
здесь.
Управлять большим количеством разрозненных объектов достаточно сложно. С этой проблемой можно справиться путем упорядочивания и ранжирования объектов, то есть объединяя общие для нескольких объектов свойства в одном объекте и используя этот объект в качестве базового.
Эту возможность предоставляет механизм наследования. Он позволяет строить иерархии, в которых объекты-потомки получают свойства объектов-предков и могут дополнять их или изменять. Таким образом, наследование обеспечивает возможность повторного использования кода.
Объекты, расположенные ближе к началу иерархии, объединяют в себе наиболее общие черты для всех нижележащих объектов. По мере продвижения вниз по иерархии объекты приобретают все больше конкретных особенностей.
Объект в Паскале может иметь произвольное количество потомков и только одного предка. При описании объекта имя его предка записывается в круглых скобках после ключевого слова object.
Допустим, нам требуется ввести в игру еще один тип персонажей, который должен обладать свойствами объекта monster, но по-другому выглядеть и атаковать. Будет логично сделать новый объект потомком объекта monster. Проанализировав код методов этого объекта, переопределим только те, которые реализуются по-другому (пример 7.1).
type daemon = object (monster)
procedure init(x_, y_, health_, ammo_, magic_ : word);
procedure attack;
procedure draw;
procedure erase;
procedure wizardry;
private
magic : word;
end;
{ ------------------------- реализация методов объекта daemon ----------------- }
procedure daemon.init(x_, y_, health_, ammo_, magic_ : word);
begin
inherited init(x_, y_, health_, ammo_);
color := green;
magic := magic_;
end;
procedure daemon.attack; { --------------------------------- daemon.attack ---- }
begin
if ammo = 0 then exit;
dec(ammo);
if magic > 0 then begin
outtextXY(x + 15, y, 'БУ-БУХ!'); dec(magic); end
else
outtextXY(x + 15, y, 'бу-бух!');
end;
procedure daemon.draw; { ----------------------------------- daemon.draw ---- }
begin
setcolor(color); outtextXY(x, y, '%)');
end;
procedure daemon.erase; { ----------------------------------- daemon.erase ---- }
begin
setcolor(black); outtextXY(x, y, '%)');
end;
procedure daemon.wizardry; { -------------------------------- daemon.wizardry - }
begin
if magic = 0 then exit;
outtextXY(x + 15, y, 'крибле-крабле-бумс!'); dec(magic);
end;
Листинг
7.1.
Переопределение методов после добавления нового типа персонажей
(html,
txt)
Наследование полей.Унаследованные поля доступны в объекте точно так же, как и его собственные. Изменить или удалить поле при наследовании нельзя.Объект daemon содержит все поля своего предка и одно собственное поле magic, в котором хранится "магическая сила" объекта.
Наследование методов.В потомке объекта можно не только описывать новые методы, но и переопределять существующие. Метод можно переопределить либо полностью, либо дополнив метод предка.
В объекте daemon описан новый метод wizardry, с помощью которого объект применяет свою магическую силу, а метод инициализации init переопределен, потому что количество полей объекта изменилось. Однако необходимость задавать значения унаследованным полям осталась, и соответствующий метод есть в объекте monster, поэтому из нового метода инициализации сначала вызывается старый, а затем выполняются дополнительные действия (присваивание значения полю ammo ).
Вызов метода предка из метода потомка выполняется с помощью ключевого слова inherited (унаследованный). Можно вызвать метод предка и явным образом с помощью конструкции monster.init.
Методы отрисовки draw и erase также переопределены, потому что изображение демона отличается от изображения монстра и, следовательно, формируется другой последовательностью подпрограмм (для простоты представим демона в виде "смайлика").
Переопределен и метод attack: теперь атака выполняется по-разному в зависимости от наличия магической силы.
Чтобы перемещать демона, требуется выполнить те же действия, что записаны в методе move для перемещения монстра: необходимо стереть его изображение на старом месте, обновить координаты и нарисовать на новом месте. На первый взгляд, можно без проблем унаследовать этот метод, а также метод hit. Так мы и поступим.
Добавим описание объекта daemon в интерфейсную часть модуля monsters, а тексты его методов — в раздел реализации. Проверим работу новых методов с помощью программы:
program test_inheritance;
uses graph, crt, monsters;
var Vasia : daemon;
gd, gm : integer;
begin
gd := detect; initgraph(gd, gm, '...');
if graphresult <> grOk then begin
writeln('ошибка инициализации графики'); exit end;
Vasia.init(100, 100, 20, 10, 6);
Vasia.draw; Vasia.attack;
readln;
Vasia.erase;
readln;
end.И в предке, и в потомке есть одноименные методы. Вызывается всегда тот метод, который соответствует типу объекта, потому что при вызове указывается имя экземпляра заданного типа (рис. 7.1). Это можно рассматривать как простейший вид полиморфизма.
Рис. 7.1. Раннее связывание
Раннее связывание
Продолжим тестирование объекта daemon, вставив в приведенную выше программу перед первой из процедур readln вызовы методов, унаследованных из объекта monster.
Vasia.move(200, 100); Vasia.move(200, 200); Vasia.hit;
Результаты запуска программы разочаровывают: на экране появляется изображение не демона, а монстра — символ @! Значит, из метода move вызываются методы рисования и стирания объекта-предка. Да и метод атаки, вызываемый из hit, судя по диагностическому сообщению, также принадлежит объекту monster. Чтобы разобраться, отчего это происходит, рассмотрим механизм работы компилятора.
Исполняемые операторы программы в виде инструкций процессору находятся в сегменте кода. Каждая подпрограмма имеет точку входа. Вызов подпрограммы при компиляции заменяется на последовательность команд, которая передает управление в эту точку, а также выполняет передачу параметров и сохранение регистров процессора. Этот процесс называется разрешением ссылок и в других языках чаще всего выполняется не компилятором, а специальной программой — редактором связей, или компоновщиком.
Таким образом, при компиляции метода move объекта monster на место вызова методов erase и draw вставляются переходы на первые исполняемые операторы этих методов из объекта monster. Вызвав метод move из любого потомка monster, мы в любом случае попадем в методы erase и draw объекта monster, потому что они жестко связаны друг с другом еще до выполнения программы (рис. 7.1).
Аналогичная ситуация и с методом attack. Если он вызывается непосредственно для экземпляра объекта daemon, то все в порядке, но вызвать его из метода hit, описанного в объекте-предке, невозможно, потому что при компиляции метода hit в него была вставлена передача управления на метод attack объекта monster (рис. 7.1).
Этот механизм называется ранним связыванием, так как все ссылки на подпрограммы компилятор разрешает до выполнения программы. Ясно, что с помощью раннего связывания не удастся обеспечить возможность вызова из одной и той же подпрограммы метода то одного объекта, то другого. Это можно сделать только в случае если ссылки будут разрешаться на этапе выполнения программы в момент вызова метода. Такой механизм в Паскале есть: он называется поздним связыванием и реализуется с помощью так называемых виртуальных методов. Но перед тем как заняться их изучением, надо рассмотреть вопрос о совместимости типов объектов.
Совместимость типов объектов
Паскаль — язык со строгой типизацией. Операнды, участвующие в выражениях, параметры подпрограмм и их аргументы, левая и правая части оператора присваивания должны подчиняться правилам соответствия типов. Для объектов понятие совместимости расширено: производный тип совместим со своим родительским типом. Эта расширенная совместимость типов имеет три формы:
- между экземплярами объектов;
- между указателями на экземпляры объектов;
- между параметрами и аргументами подпрограмм.
Во всех трех случаях совместимость односторонняя: родительскому объекту может быть присвоен экземпляр любого из его потомков, но не наоборот. Это связано с тем, что при присваивании должны быть заполнены все поля, а потомок имеет либо такой же размер, как предок, либо больший.
Например, если определены переменные:
type pmonster = ^monster;
pdaemon = ^daemon;
var m : monster;
d : daemon;
pm : pmonster;
pd : pdaemon;то приведенные ниже операторы присваивания допустимы:
m := d; pm := pd;
Поля и методы, введенные в потомке, после таких присваиваний недоступны, потому что объекты базового класса не имеют информации о существовании элементов, определенных в производном. Например, обращение pm^.wizardry ошибочно несмотря на то, что на самом деле указатель pm ссылается на объект типа daemon.
Даже если метод переопределен в потомке, через указатель на предка вызывается метод, описанный в предке. Так, в результате выполнения оператора pm^.draw на экране появится изображение объекта-предка — символ @, потому что тип вызываемого метода соответствует типу указателя, а не типу того объекта, на который он ссылается.
Если известно, что указатель на предка на самом деле хранит ссылку на потомка, можно обратиться к элементам, определенным в потомке, с помощью явного преобразования типа, например pdaemon(pm)^.wizardry.
Если объект является параметром подпрограммы, ему может соответствовать аргумент того же типа или типа любого из его потомков, но есть разница между передачей объектов по значению и по адресу.
Параметр, передаваемый по значению, представляет собой копию объекта-аргумента, содержащую только те поля данных и методы, которые имеются в объекте-параметре. Это значит, что при передаче по значению тип аргумента приводится к типу параметра.
При передаче объекта по адресу подпрограмме передается указатель на фактический объект, то есть приведение типов не выполняется. В подпрограмме тип объекта, передаваемого по адресу, может изменяться в зависимости от аргумента.
Если параметр подпрограммы является указателем на объект, передаваемым по значению, то аргумент может быть указателем как на этот же объект, так и на любого из его потомков. Например, если заголовок процедуры имеет вид
procedure checkp(p1 : pmonster; var p2 : pmonster);
первым параметром в нее можно передавать указатели как на объекты типа monster, так и на любые производные объекты. На месте второго параметра может быть только указатель типа pmonster.
Объекты, фактический тип которых может изменяться во время выполнения программы, называются полиморфными. Полиморфным может быть объект, определенный через указатель или переданный в подпрограмму по адресу.
Полиморфные объекты широко применяются в программах, потому что они обеспечивают гибкость: например, список, содержащий указатели на объект базового класса, может на самом деле хранить ссылки на любые объекты иерархии. Подпрограммы, параметрами которых являются полиморфные объекты, могут без изменений и даже без перекомпиляции использоваться для объектов, о существовании которых при написании подпрограммы еще ничего не было известно.
Полиморфные объекты обычно применяются вместе с виртуальными методами, которые мы рассмотрим в следующем разделе.
Позднее связывание. Виртуальные методы
При раннем связывании программа, готовая для выполнения, представляет собой структуру, логика выполнения которой жестко определена. Если же требуется, чтобы решение о том, какой из одноименных методов разных объектов иерархии использовать, принималось в зависимости от конкретного объекта, для которого выполняется вызов, то ясно, что заранее связывать жестко эти методы с остальной частью кода нельзя. Следовательно, надо каким-то образом дать знать компилятору, что эти методы будут обрабатываться по-другому. Для этого в Паскале существует директива virtual. Она записывается в заголовке метода, например:
procedure attack; virtual;
Слово virtual в переводе с английского значит "фактический". Объявление метода виртуальным означает, что все ссылки на этот метод будут разрешаться по факту его вызова, то есть не на стадии компиляции, а во время выполнения программы. Этот механизм называется поздним связыванием. Для его реализации необходимо, чтобы адреса виртуальных методов хранились там, где ими можно будет в любой момент воспользоваться, поэтому компилятор формирует для этих методов таблицу виртуальных методов (VMT — virtual method table). В первое поле этой таблицы записывается размер объекта, а затем идут адреса виртуальных методов (в том числе и унаследованных) в порядке описания в объекте. Для каждого объектного типа создается одна VMT.
Каждый объект во время выполнения программы должен иметь доступ к VMT. Обеспечение этой связи нельзя поручить компилятору, так как она должна устанавливаться позже — при создании объекта во время выполнения программы. Поэтому связь экземпляра объекта с VMT устанавливается с помощью специального метода, называемого конструктором.
Класс, имеющий хотя бы один виртуальный метод, должен содержать конструктор:
type monster = object
constructor init(x_, y_, health_, ammo_ : word);
procedure attack; virtual;
procedure draw; virtual;
procedure erase; virtual;
procedure hit;
procedure move(x_, y_ : word);
private
x, y : word;
health, ammo : word;
color : word;
end;
daemon = object (monster)
constructor init(x_, y_, health_, ammo_, magic_ : word);
procedure attack; virtual;
procedure draw; virtual;
procedure erase; virtual;
procedure wizardry;
private
magic: word;
end;По ключевому слову constructor компилятор вставляет в начало метода фрагмент, который записывает ссылку на VMT в специальное поле объекта (память под это поле выделяется компилятором). Следовательно, прежде чем использовать виртуальные методы, необходимо вызвать конструктор объекта.
Конструктор обычно используется для инициализации объекта. В нем выполняется выделение памяти под динамические переменные или структуры, если они есть в объекте, и присваиваются начальные значения. Если в объекте есть поля, которые также являются объектами, в конструкторе вызываются конструкторы этих объектов.
Объект может содержать несколько конструкторов. Повторный вызов конструктора вреда программе не наносит, а вот если конструктор вообще не вызвать и попытаться использовать виртуальный метод, поведение программы не определено. Конструктор должен быть вызван для каждого создаваемого объекта. Присваивание одного объекта другому возможно только после конструирования обоих.
Вызов виртуального метода выполняется так: из объекта берется адрес его VMT, из VMT выбирается адрес метода, а затем управление передается этому методу (рис. 7.2). Таким образом, при использовании виртуальных методов из всех одноименных методов иерархии всегда выбирается тот, который соответствует фактическому типу вызвавшего его объекта.
Рис. 7.2. Позднее связывание
Поскольку связь с VMT устанавливается в самом начале конструктора, в его теле также можно пользоваться виртуальными методами.
Правила описания виртуальных методов:
- Если в объекте метод определен как виртуальный, во всех потомках он также должен быть виртуальным. Отсутствие ключевого слова virtual в заголовке метода потомка приведет к ошибке.
- Заголовки всех одноименных виртуальных методов должны совпадать (параметры должны иметь одинаковый тип, количество и порядок следования, функции должны возвращать значение одного и того же типа).
- Переопределять виртуальный метод в каждом из потомков не обязательно: если он выполняет устраивающие потомка действия, он будет унаследован.
- Объект, имеющий хотя бы один виртуальный метод, должен содержать конструктор.
Для иллюстрации работы виртуальных методов используем программу из предыдущей лекции, сменив в ней тип элементов массива с monster на daemon ( пример 7.2). Предварительно в модуле monsters методы attack, draw и erase объявим как виртуальные, а в процедурах init заменим ключевое слово procedure на слово constructor.
program game_2;
uses graph, crt, monsters;
const n = 30;
var stado : array [1 .. n] of daemon;
x, y : array [1 .. n] of integer;
gd, gm : integer;
i, j : word;
begin
gd := detect; initgraph(gd, gm, '...');
if graphresult <> grOk then begin
writeln('ошибка инициализации графики'); exit end;
randomize;
for i := 1 to n do begin
stado[i].init(random(600), random(440), random(10), random(8), random(6));
stado[i].draw;
end;
repeat
for i := 1 to n do begin
x[i] := random(600); y[i] := random(440);
stado[i].move(x[i], y[i]);
end;
for i := 1 to n – 1 do
for j := i + 1 to n do
if (abs(x[i] – x[j]) < 15) and (abs(y[i] – y[j]) < 15)
then begin
stado[i].hit; stado[j].hit;
end;
delay(200);
until keypressed;
end.
Листинг
7.2.
Пример использования виртуальных методов
(html,
txt)
Единственное изменение, которое пришлось сделать в части исполняемых операторов программы, — добавление еще одного параметра в метод инициализации init. Запустив программу, можно наблюдать процесс самоуничтожения демонов, что свидетельствует о том, что теперь из методов move и hit, унаследованных из базового класса, вызываются методы attack, draw и erase, определенные в производном классе.
Виртуальные методы незаменимы и при передаче объектов в подпрограммы. В заголовке подпрограммы описывается либо объект базового типа, передаваемый по адресу, либо указатель на этот объект, а при вызове в нее передается объект или указатель производного класса. В этом случае виртуальные методы, вызываемые для объекта из подпрограммы, будут соответствовать типу аргумента, а не параметра.
При описании классов рекомендуется определять как виртуальные те методы, которые в производных классах будут реализовываться по-другому. Если во всех классах иерархии метод будет выполняться одинаково или если в потомках он не потребуется, его лучше определить как статический (обычный). Применение виртуальных методов обеспечивает гибкость и возможность расширения функциональности модуля, но несколько замедляет выполнение программы, поскольку эти методы вызываются через обращение к VMT, а не непосредственно.
Объекты в динамической памяти
Для хранения объектов в программах чаще всего используется динамическая память, поскольку это обеспечивает гибкость программы и эффективное использование памяти. Благодаря расширенной совместимости типов можно описать указатель на базовый класс и хранить в нем ссылку на любой его объект-потомок, что в сочетании с виртуальными методами позволяет единообразно работать с различными классами иерархии. Из объектов или указателей на объекты создают различные динамические структуры.
Для выделения памяти под объекты используются процедура и функция new. Например, если определены указатели:
type pmonster = ^monster;
pdaemon = ^daemon;
var pm : pmonster;
pd : pdaemon;можно создать объекты с помощью вызовов:
new(pm); { или pm := new(pmonster); }
new(pd); { или pd := new(pdaemon); }При использовании new в форме процедуры параметром является указатель, а в функцию передается его тип. Так как после выделения памяти объект обычно инициализируют, для удобства определены расширенные формы new с двумя параметрами. На месте второго параметра задается вызов конструктора объекта.
new(pm, init(1, 1, 1, 1); { или pm := new(pmonster, init(1, 1, 1, 1)); }
new(pd, init(1, 1, 1, 1, 1); { или pd := new(pdaemon, init(1, 1, 1, 1, 1)); }Обращение к методам динамического объекта выполняется по обычным правилам Паскаля, например:
pm^.draw; pm^.attack;
С объектами в динамической памяти часто работают через указатели на базовый класс, то есть описывают указатель базового класса, а инициализируют его, создав объект производного класса, например:
pm := new(pdaemon, init(1, 1, 1, 1, 1));
Как уже говорилось, такие объекты называют полиморфными. Они используются для того, чтобы можно было единообразно работать в программе с объектами разных классов. Например, оператор pm^.draw будет автоматически вызывать разные методы в зависимости от того, на объект какого типа в данный момент ссылается указатель pm (это справедливо только для виртуальных методов).
Для освобождения памяти, занятой объектом, применяется процедура Dispose:
Dispose(pm);
При выполнении этой процедуры освобождается количество байтов, равное размеру объекта, соответствующего типу указателя. Следовательно, если на самом деле в указателе хранится ссылка на объект производного класса, который, как известно, может быть больше своего предка, часть памяти не будет помечена как свободная, но доступ к ней будет невозможен, то есть появится мусор (рис. 7.3). Второй случай появления мусора возникает при применении процедуры Dispose к объекту, поля которого являются указателями (рис. 7.4). Объект, содержащий динамические поля, мы рассмотрим в конце этой лекции.
Рис. 7.3. Неверное удаление полиморфного объекта
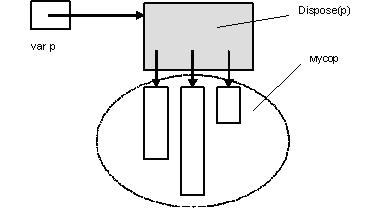
Рис. 7.4. Неверное удаление объекта с динамическими полями
Для корректного освобождения памяти из-под полиморфных объектов следует использовать вместе с процедурой Dispose специальный метод — деструктор. В документации по Borland Pascal ему рекомендуется давать имя done, например:
destructor monster.done; begin end;
Для правильного освобождения памяти деструктор записывается вторым параметром процедуры Dispose.
Dispose(pm, done);
Для простых объектов деструктор может быть пустым, а для объектов, содержащих динамические поля, в нем записываются операторы освобождения памяти для этих полей. В деструкторе можно описывать любые действия, необходимые для конкретного объекта, например закрытие файлов. Исполняемый код деструктора никогда не бывает пустым, потому что компилятор по служебному слову destructor вставляет в конец тела метода операторы получения размера объекта из VMT. Деструктор передает этот размер процедуре Dispose, и она освобождает количество памяти, соответствующее фактическому типу объекта.
Деструкторы рекомендуется делать виртуальными, для того чтобы при вызове всегда выполнялся деструктор, соответствующий типу объекта. Деструкторы обязательно использовать только для динамических полиморфных объектов, однако можно их применять и для статических объектов. В объекте можно определить несколько деструкторов (естественно, в этом случае они должны иметь разные имена).
Вариант кода модуля monsters, содержащий конструкторы и деструкторы (он используется в следующем разделе), приведен в пример 7.3.
unit monsters;
interface
uses Graph;
type pmonster = ^monster;
monster = object
constructor init(x_, y_, health_, ammo_ : word);
procedure attack; virtual;
procedure draw; virtual;
procedure erase; virtual;
procedure hit;
procedure move(x_, y_ : word);
destructor done;
private
x, y : word;
health, ammo : word;
color : word;
end;
pdaemon = ^daemon;
daemon = object (monster)
constructor init(x_, y_, health_, ammo_, magic_ : word);
procedure attack; virtual;
procedure draw; virtual;
procedure erase; virtual;
procedure wizardry;
private
magic : word;
end;
implementation
{ ------------------- реализация методов объекта monster ---------------------- }
constructor monster.init(x_, y_, health_, ammo_ : word);
begin
x := x_; y := y_;
health := health_;
ammo := ammo_;
color := yellow;
end;
procedure monster.attack; { -------------------------------- monster.attack --- }
begin
if ammo = 0 then exit;
dec(ammo); setcolor(color); outtextXY(x + 15, y, 'ба-бах!');
end;
procedure monster.draw; { -------------------------------- monster.draw ----- }
begin
setcolor(color); outtextXY(x, y, '@');
end;
procedure monster.erase; { ---------------------------------- monster.erase --- }
begin
setcolor(black); outtextXY(x, y, '@');
end;
procedure monster.hit; { ---------------------------------- monster.hit ----- }
begin
if health = 0 then exit;
dec(health);
if health = 0 then begin color := red; draw; exit; end;
attack;
end;
procedure monster.move(x_, y_ : word); { --------------------- monster.move --- }
begin
if health = 0 then exit;
erase;
x := x_; y := y_;
draw;
end;
destructor monster.done; { ----------------------------------- monster.done --- }
begin
end;
{ ----------------------- реализация методов объекта daemon ------------------- }
constructor daemon.init(x_, y_, health_, ammo_, magic_ : word);
begin
inherited init(x_, y_, health_, ammo_);
color := green;
magic := magic_;
end;
procedure daemon.draw; { ----------------------------------- daemon.draw ---- }
begin
setcolor(color); outtextXY(x, y, '%)');
end;
procedure daemon.erase; { ----------------------------------- daemon.erase --- }
begin
setcolor(black); outtextXY(x, y, '%)');
end;
procedure daemon.attack; { ---------------------------------- daemon.attack --- }
begin
if ammo = 0 then exit;
dec(ammo);
if magic > 0 then begin
outtextXY(x + 15, y, 'БУ-БУХ!'); dec(magic); end
else outtextXY(x + 15, y, 'бу-бух!');
end;
procedure daemon.wizardry; { -------------------------------- daemon.wizardry - }
begin
if magic = 0 then exit;
outtextXY(x + 15, y, 'крибле-крабле-бумс!'); dec(magic);
end;
end.
Листинг
7.3.
Модуль monsters, использующий конструкторы и деструкторы
(html,
txt)
Для использования этого модуля не обязательно иметь в распоряжении его полный исходный код — достаточно интерфейсного раздела (и, конечно, файла .tpu ). В программе, использующей этот модуль, можно описывать производные классы, в которых добавлены новые поля и методы и переопределены имеющиеся. При этом новые объекты будут перемещаться с помощью метода, который был написан до их появления!
Контейнер для полиморфных объектов
Если объект предназначается для хранения других объектов, он называется контейнером. Объекты в контейнере могут храниться в виде массива, списка, стека или другой динамической структуры. Методы контейнера обычно включают его создание, дополнение, просмотр, а также поиск и удаление элементов.
В качестве примера контейнера рассмотрим объект list, предназначенный для работы со связным списком объектов класса monster и его потомков:
type list = object
constructor init;
procedure add(pm : pmonster);
procedure draw;
destructor done;
private
beg : pnode;
end;В объекте одно поле beg — указатель на начало списка элементов типа node:
type pnode = ^node;
node = record
pm : pmonster; { указатель на объект pmonster }
next : pnode; { указатель на следующий элемент списка }
end;Структура объекта list поясняется на рис. 7.5.
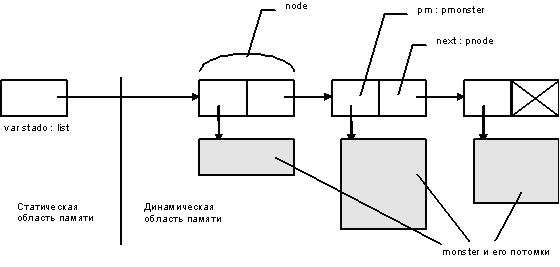
Рис. 7.5. Список полиморфных объектов
В программе (пример 7.4) создается список из n объектов. Вследствие расширенной совместимости типов методу add может быль передан указатель на любой тип, производный от monster. Объекты выводятся на экран, при этом в одном и том же цикле вызываются разные виртуальные методы draw в соответствии с фактическим типом объекта. Затем динамическая память освобождается с помощью одного вызова деструктора.
program demo_list;
uses graph, crt, monsters;
const n = 30;
type pnode = ^node;
node = record
pm : pmonster;
next : pnode;
end;
list = object
constructor init;
procedure add(pm : pmonster);
procedure draw;
destructor done;
private
beg : pnode;
end;
constructor list.init; { --------------------------------------- list.init ---- }
begin beg := nil end;
procedure list.add(pm : pmonster); { --------------------------- list.add ----- }
var p : pnode;
begin
new(p);
p^.pm := pm;
p^.next := beg;
beg := p;
end;
procedure list.draw; { --------------------------------------- list.draw ---- }
var p : pnode;
begin
p := beg;
while p <> nil do begin
p^.pm^.draw;
p := p^.next;
end;
end;
destructor list.done; { --------------------------------------- list.done ---- }
var p : pnode;
begin
while beg <> nil do begin
p := beg;
dispose(p^.pm, done); { 1 }
beg := p^.next; { 2 }
dispose(p); { 3 }
end
end;
procedure report(message: string); { --------------------------- report ------- }
var s : string;
begin
str(MemAvail, s);
outtext(message + s);
moveto(0, GetY + 12);
end;
var stado : list;
x, y : integer;
gd, gm : integer;
p : pmonster;
i : word;
{ ---------------------------------- главная программа ------------------------ }
begin
gd := detect; initgraph(gd, gm, '...');
if graphresult <> grOk then begin
writeln('ошибка инициализации графики'); exit end;
randomize;
report(' доступно в начале программы: ');
stado.init;
for i := 1 to n do begin
case random(2) of
0 : p := new(pmonster, init(random(600), random(440), 10, 8));
1 : p := new(pdaemon, init(random(600), random(440), 10, 8, 6));
end;
stado.add(p); { добавление объекта в список }
end;
report(' доступно после выделения памяти: ');
stado.draw; { отрисовка объектов }
stado.done; { уничтожение объектов }
report(' доступно после освобождения памяти: ');
readln;
end.
Листинг
7.4.
Программа, работающая со списком полиморфных объектов
(html,
txt)
Подробные пояснения к этой программе приведены в учебнике [10].