Лекция 0. Введение
Имитационное моделирование как необходимая часть инженерного образования сложилось в середине прошлого, двадцатого века. Воспринятое поначалу как своеобразный численный метод решения сложных задач, как "младший брат" аналитического моделирования, оно постепенно стало основным, подчас единственным методом при анализе и синтезе сложных систем и процессов.
Общеизвестно, что правильно поставленный натурный эксперимент, то есть исследование свойств объекта на самом объекте, максимально информативен. Оказывается, что эксперимент с компьютерной имитационной моделью вполне конкурентоспособен с натурным. Не говоря о том, что натурный эксперимент в ряде случаев вообще невозможен или нецелесообразен, эксперимент с имитационной моделью может быть приемлемо информативен и выполнен значительно быстрее и дешевле натурного. Это и предопределило стремительное и повсеместное внедрение имитационного моделирования в научный и инженерный обиход.
В популяризации имитационного моделирования заметную роль сыграли работы Р. Шеннона [45] и Т. Д. Шрайбера [46]. В свое время эти работы были широко известны в среде научных работников и инженеров. Большую положительную роль в распространении компьютерного имитационного моделирования у нас в стране сыграли работы по моделированию сложных систем на ЭВМ члена-корреспондента АН СССР Н. П. Бусленко и выдающегося математика академика АН СССР А. А. Самарского. Их работы в области математического моделирования и вычислительного эксперимента широко используются на практике.
Огромный мировой опыт применения имитационного моделирования вызвал необходимость теоретического осмысления этого метода познания. Образовались центры в Москве, Санкт-Петербурге, Казани и др., объединяющие инженеров, научных сотрудников и преподавателей высшей школы, применяющих и пропагандирующих как само имитационное моделирование, так те или иные инструментальные средства. Регулярно проводятся общероссийские научно-практические конференции [27, 28]. Все чаще стали появляться публикации, посвященные общей теории имитационного моделирования. В частности, к таким можно отнести работы Окольнишникова В. В. [40] и Н. Б. Кобелева [31].
Курс имитационного моделирования под разными названиями: "Компьютерное моделирование", "Моделирование систем", "Моделирование" и т. п. является обязательным в учебных планах технических ВУЗов, в том числе и военных. Соответствующие знания включены в квалификационные характеристики выпускников.
Настоящий курс представляет собой учебное пособие для изучения материала по этим дисциплинам. Содержание курса определено типовыми программами соответствующих специальностей и изложено в восьми лекциях.
Первая лекция носит вводный характер. Разъясняются понятия моделирования и основных терминов. Классификация моделей и моделирования дается в самом общем виде. Подробная классификация не актуальна для настоящего пособия, главной целью которого является обучение практическим приемам имитационного моделирования и проведению компьютерных экспериментов с моделью. Заметим, что и общепринятой универсальной классификации нет, да и вряд ли она целесообразна. Этапы моделирования также рассматриваются в виде общего представления. Углубленное раскрытие содержания этапов демонстрируется в ходе курсового проектирования, предусмотренного тематическими планами вышеназванных дисциплин.
Во второй лекции рассматриваются подходы к аналитическому моделированию дискретных процессов, обладающих свойством марковости. Как показывает практика, такие процессы присущи многим аспектам функционального и надежностного поведения систем - объектов профессионального предназначения выпускников учебных заведений соответствующих специальностей. Демонстрируемые в лекции аналитические модели противоборства, массового обслуживания и некоторые другие утилитарного значения не имеют; на этих примерах демонстрируются возможные подходы к построению аналитических моделей процессов в объектах разного назначения. Заметим, что для сравнительно несложных процессов, например, для ряда структур систем массового обслуживания, аналитические модели можно обнаружить в соответствующих справочниках.
В основной части курса (лекции 3…8) излагаются обоснования и приемы имитационного моделирования дискретных процессов - моделирования поведения вероятностных систем, т. е. таких, на которые воздействуют различного рода случайности. Такие модели называются статистическими, поскольку искомые результаты получают посредством статистической обработки данных.
В качестве основного инструментального средства в курсе рассматривается система моделирования GPSS World. Эта система распространена в нашей стране и не только; ей посвящены представительные научно-практические конференции и издания. Авторы имеют опыт применения и преподавания всех вариаций семейства GPSS, начиная с самой первой. И если версии GPSS-360, GPSS/PC, GPSS/H можно упрекнуть в некоторой ограниченности средств по сравнению, например, с Simpas, то последнюю на сегодняшний день версию GPSS World можно, по мнению инженерной общественности и авторов, считать вполне удовлетворяющей современным требованиям практиков. В учебном пособии нельзя, да и нецелесообразно отобразить все возможности GPSS World. Для дальнейшего профессионального совершенствования следует обратиться к [5].
При работе над курсом авторы опирались на свой опыт моделирования и преподавания, а также на многие издания по теме. В наибольшей степени были учтены работы, указанные в списке литературы.
Авторы признательны Д. В. Боеву, помощь которого в подготовке и оформлении рукописи была существенна.
Лекция 1. Понятие модели и моделирования
Сам по себе процесс моделирования в полной мере не формализован, большая роль в этом принадлежит опыту инженера. Но, тем не менее, рассматриваемый в теме процесс создания модели в виде шести этапов может стать основой для начинающих и с накоплением опыта может быть индивидуализирован.
Математическая модель, являясь абстрактным образом моделируемого объекта или процесса, не может быть его полным аналогом. Достаточно сходства в тех элементах, которые определяют цель исследования. Для качественной оценки сходства вводится понятие адекватности модели объекту и, в связи с этим, раскрываются понятия изоморфизма и изофункционализма. Формальных приемов, позволяющих автоматически, "бездумно", создавать адекватные математические модели, нет. Окончательное суждение об адекватности модели дает практика, то есть сопоставление модели с действующим объектом. И, тем не менее, усвоение всех последующих тем пособия позволит инженеру справляться с проблемой обеспечения адекватности моделей.
Завершается тема изложением требований к моделям, которые были сформулированы Р. Шенноном на заре компьютерного моделирования тридцать лет назад в книге "Имитационное моделирование систем - искусство и наука". Актуальность этих требований сохраняется и в настоящее время.
1.1. Общее определение модели
Практика свидетельствует: самое лучшее средство для определения свойств объекта - натурный эксперимент, т. е. исследование свойств и поведения самого объекта в нужных условиях. Дело в том, что при проектировании невозможно учесть многие факторы, расчет ведется по усредненным справочным данным, используются новые, недостаточно проверенные элементы (прогресс нетерпелив!), меняются условия внешней среды и многое другое. Поэтому натурный эксперимент - необходимое звено исследования. Неточность расчетов компенсируется увеличением объема натурных экспериментов, созданием ряда опытных образцов и "доводкой" изделия до нужного состояния. Так поступали и поступают при создании, например, телевизора или радиостанции нового образца.
Однако во многих случаях натурный эксперимент невозможен.
Например, наиболее полную оценку новому виду вооружения и способам его применения может дать война. Но не будет ли это слишком поздно?
Натурный эксперимент с новой конструкцией самолета может вызвать гибель экипажа.
Натурное исследование нового лекарства опасно для жизни человека.
Натурный эксперимент с элементами космических станций также может вызвать гибель людей.
Время подготовки натурного эксперимента и проведение мероприятий по обеспечению безопасности часто значительно превосходят время самого эксперимента. Многие испытания, близкие к граничным условиям, могут протекать настолько бурно, что возможны аварии и разрушения части или всего объекта.
Из сказанного следует, что натурный эксперимент необходим, но в то же время невозможен либо нецелесообразен.
Выход из этого противоречия есть и называется он "моделирование".
Моделирование - это замещение одного объекта другим с целью получения информации о важнейших свойствах объекта-оригинала.
Отсюда следует.
Моделирование - это, во-первых, процесс создания или отыскания в природе объекта, который в некотором смысле может заменить исследуемый объект. Этот промежуточный объект называется моделью. Модель может быть материальным объектом той же или иной природы по отношению к изучаемому объекту (оригиналу). Модель может быть мысленным объектом, воспроизводящим оригинал логическими построениями или математическими формулами и компьютерными программами.
Моделирование, во-вторых, это испытание, исследование модели. То есть, моделирование связано с экспериментом, отличающимся от натурного тем, что в процесс познания включается "промежуточное звено" - модель. Следовательно, модель является одновременно средством эксперимента и объектом эксперимента, заменяющим изучаемый объект.
Моделирование, в-третьих, это перенос полученных на модели сведений на оригинал или, иначе, приписывание свойств модели оригиналу. Чтобы такой перенос был оправдан, между моделью и оригиналом должно быть сходство, подобие.
Подобие может быть физическим, геометрическим, структурным, функциональным и т. д. Степень подобия может быть разной - от тождества во всех аспектах до сходства только в главном. Очевидно, модели не должны воспроизводить полностью все стороны изучаемых объектов. Достижение абсолютной одинаковости сводит моделирование к натурному эксперименту, о возможности или целесообразности которого было уже сказано.
Остановимся на основных целях моделирования.
Прогноз - оценка поведения системы при некотором сочетании ее управляемых и неуправляемых параметров. Прогноз - главная цель моделирования.
Объяснение и лучшее понимание объектов. Здесь чаще других встречаются задачи оптимизации и анализа чувствительности. Оптимизация - это точное определение такого сочетания факторов и их величин, при котором обеспечиваются наилучший показатель качества системы, наилучшее по какому-либо критерию достижение цели моделируемой системой. Анализ чувствительности - выявление из большого числа факторов тех, которые в наибольшей степени влияют на функционирование моделируемой системы. Исходными данными при этом являются результаты экспериментов с моделью.
Часто модель создается для применения в качестве средства обучения: модели-тренажеры, стенды, учения, деловые игры и т. п.
Моделирование как метод познания применялось человечеством - осознанно или интуитивно - всегда. На стенах древних храмов предков южно-американских индейцев обнаружены графические модели мироздания. Учение о моделировании возникло в средние века. Выдающаяся роль в этом принадлежит Леонардо да Винчи (1452-1519).
Гениальный полководец А. В. Суворов перед атакой крепости Измаил тренировал солдат на модели измаильской крепостной стены, построенной специально в тылу.
Наш знаменитый механик-самоучка И. П. Кулибин (1735-1818) создал модель одноарочного деревянного моста через р. Неву, а также ряд металлических моделей мостов. Они были полностью технически обоснованы и получили высокую оценку российскими академиками Л. Эйлером и Д. Бернулли. К сожалению, ни один из этих мостов не был построен.
Огромный вклад в укрепление обороноспособности нашей страны внесли работы по моделированию взрыва - генерал-инженер Н. Л. Кирпичев, моделированию в авиастроении - М. В. Келдыш, С. В. Ильюшин, А. Н. Туполев и др., моделированию ядерного взрыва - И. В. Курчатов, А.Д. Сахаров, Ю. Б. Харитон и др.
Широко известны работы Н. Н. Моисеева по моделированию систем управления. В частности, для проверки одного нового метода математического моделирования была создана математическая модель Синопского сражения - последнего сражения эпохи парусного флота. В 1833 году адмирал П. С. Нахимов разгромил главные силы турецкого флота. Моделирование на вычислительной машине показало, что Нахимов действовал практически безошибочно. Он настолько верно расставил свои корабли и нанес первый удар, что единственное спасение турок было отступление. Иного выхода у них не было. Они не отступили и были разгромлены.
Сложность и громоздкость технических объектов, которые могут изучаться методами моделирования, практически неограниченны. В последние годы все крупные сооружения исследовались на моделях - плотины, каналы, Братская и Красноярская ГЭС, системы дальних электропередач, образцы военных систем и др. объекты.
Поучительный пример недооценки моделирования - гибель английского броненосца "Кэптен" в 1870 году. В стремлении еще больше увеличить свое тогдашнее морское могущество и подкрепить империалистические устремления в Англии был разработан суперброненосец "Кэптен". В него было вложено все, что нужно для "верховной власти" на море: тяжелая артиллерия во вращающихся башнях, мощная бортовая броня, усиленное парусное оснащение и очень низкими бортами - для меньшей уязвимости от снарядов противника. Консультант инженер Рид построил математическую модель устойчивости "Кэптена" и показал, что даже при незначительном ветре и волнении ему грозит опрокидывание. Но лорды Адмиралтейства настояли на строительстве корабля. На первом же учении после спуска на воду налетевший шквал перевернул броненосец. Погибли 523 моряка. В Лондоне на стене одного из соборов прикреплена бронзовая плита, напоминающая об этом событии и, добавим мы, о тупоумии самоуверенных лордов Британского Адмиралтейства, пренебрегших результатами моделирования.
1.2. Классификация моделей и моделирования
Каждая модель создается для конкретной цели и, следовательно, уникальна. Однако наличие общих черт позволяет сгруппировать все их многообразие в отдельные классы, что облегчает их разработку и изучение. В теории рассматривается много признаков классификации, и их количество не установилось. Тем не менее, наиболее актуальны следующие признаки классификации:
- характер моделируемой стороны объекта;
- характер процессов, протекающих в объекте;
- способ реализации модели.
1.2.1. Классификация моделей и моделирования по признаку "характер моделируемой стороны объекта"
В соответствии с этим признаком модели могут быть:
- функциональными (кибернетическими);
- структурными;
- информационными.
Функциональные модели отображают только поведение, функцию моделируемого объекта. В этом случае моделируемый объект рассматривается как "черный ящик", имеющий входы и выходы. Физическая сущность объекта, природа протекающих в нем процессов, структура объекта остаются вне внимания исследователя, хотя бы потому, что неизвестны. При функциональном моделировании эксперимент состоит в наблюдении за выходом моделируемого объекта при искусственном или естественном изменении входных воздействий. По этим данным и строится модель поведения в виде некоторой математической функции.
Компьютерная шахматная программа - функциональная модель работы человеческого мозга при игре в шахматы.
Структурное моделирование - это создание и исследование модели, структура которой (элементы и связи) подобна структуре моделируемого объекта. Как мы выяснили ранее, подобие устанавливается не вообще, а относительно цели исследования. Поэтому она может быть описана на разных уровнях рассмотрения. Наиболее общее описание структуры - это топологическое описание с помощью теории графов.
Учение войск - структурная модель вида боевых действий.
1.2.2. Классификация моделей и моделирования по признаку "характер процессов, протекающих в объекте"
По этому признаку модели могут быть детерминированными или стохастическими, статическими или динамическими, дискретными или непрерывными или дискретно-непрерывными.
Детерминированные модели отображают процессы, в которых отсутствуют случайные воздействия.
Стохастические модели отображают вероятностные процессы и события.
Статические модели служат для описания состояния объекта в какой-либо момент времени.
Динамические модели отображают поведение объекта во времени.
Дискретные модели отображают поведение систем с дискретными состояниями.
Непрерывные модели представляют системы с непрерывными процессами.
Дискретно-непрерывные модели строятся тогда, когда исследователя интересуют оба эти типа процессов.
Очевидно, конкретная модель может быть стохастической, статической, дискретной или какой-либо другой, в соответствии со связями, показанными на рис. 1.1.
1.2.3. Классификация моделей и моделирования по признаку "способ реализации модели"
Согласно этому признаку модели делятся на два обширных класса:
- абстрактные (мысленные) модели;
- материальные модели.
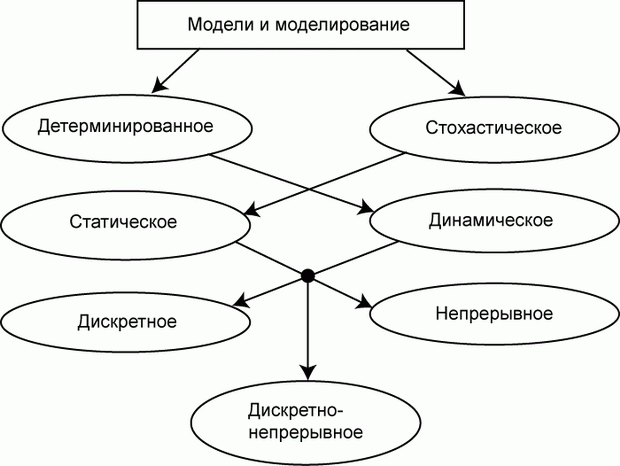
Рис. 1.1. Классификация моделей и моделирования
Нередко в практике моделирования присутствуют смешанные, абстрактно-материальные модели.
Абстрактные модели представляют собой определенные конструкции из общепринятых знаков на бумаге или другом материальном носителе или в виде компьютерной программы.
Абстрактные модели, не вдаваясь в излишнюю детализацию, можно разделить на:
- символические;
- математические.
Символическая модель - это логический объект, замещающий реальный процесс и выражающий основные свойства его отношений с помощью определенной системы знаков или символов. Это либо слова естественного языка, либо слова соответствующего тезауруса, графики, диаграммы и т. п.
Символическая модель может иметь самостоятельное значение, но, как правило, ее построение является начальным этапом любого другого моделирования.
Математическое моделирование - это процесс установления соответствия моделируемому объекту некоторой математической конструкции, называемой математической моделью, и исследование этой модели, позволяющее получить характеристики моделируемого объекта.
Математическое моделирование - главная цель и основное содержание изучаемой дисциплины.
Математические модели могут быть:
- аналитическими;
- имитационными;
- смешанными (аналитико-имитационными).
Аналитические модели - это функциональные соотношения: системы алгебраических, дифференциальных, интегро-дифференциальных уравнений, логических условий. Уравнения Максвелла - аналитическая модель электромагнитного поля. Закон Ома - модель электрической цепи.
Преобразование математических моделей по известным законам и правилам можно рассматривать как эксперименты. Решение на основе аналитических моделей может быть получено в результате однократного просчета безотносительно к конкретным значениям характеристик ("в общем виде"). Это наглядно и удобно для выявления закономерностей. Однако для сложных систем построить аналитическую модель, достаточно полно отражающую реальный процесс, удается не всегда. Тем не менее, есть процессы, например, марковские, актуальность моделирования которых аналитическими моделями доказана практикой.
Имитационное моделирование. Создание вычислительных машин обусловило развитие нового подкласса математических моделей - имитационных.
Имитационное моделирование предполагает представление модели в виде некоторого алгоритма - компьютерной программы, - выполнение которого имитирует последовательность смены состояний в системе и таким образом представляет собой поведение моделируемой системы.
Процесс создания и испытания таких моделей называется имитационным моделированием, а сам алгоритм - имитационной моделью.
В чем заключается отличие имитационных и аналитических моделей?
В случае аналитического моделирования ЭВМ является мощным калькулятором, арифмометром. Аналитическая модель решается на ЭВМ.
В случае же имитационного моделирования имитационная модель - программа - реализуется на ЭВМ.
Имитационные модели достаточно просто учитывают влияние случайных факторов. Для аналитических моделей это серьезная проблема. При наличии случайных факторов необходимые характеристики моделируемых процессов получаются многократными прогонами (реализациями) имитационной модели и дальнейшей статистической обработкой накопленной информации. Поэтому часто имитационное моделирование процессов со случайными факторами называют статистическим моделированием.
Если исследование объекта затруднено использованием только аналитического или имитационного моделирования, то применяют смешанное (комбинированное), аналитико-имитационное моделирование. При построении таких моделей процессы функционирования объекта декомпозируются на составляющие подпроцессы, и для которых, возможно, используют аналитические модели, а для остальных подпроцессов строят имитационные модели.
Материальное моделирование основано на применении моделей, представляющих собой реальные технические конструкции. Это может быть сам объект или его элементы (натурное моделирование). Это может быть специальное устройство - модель, имеющая либо физическое, либо геометрическое подобие оригиналу. Это может быть устройство иной физической природы, чем оригинал, но процессы в котором описываются аналогичными математическими соотношениями. Это так называемое аналоговое моделирование. Такая аналогия наблюдается, например, между колебаниями антенны спутниковой связи под ветровой нагрузкой и колебанием электрического тока в специально подобранной электрической цепи.
Нередко создаются материально-абстрактные модели. Та часть операции, которая не поддается математическому описанию, моделируется материально, остальная - абстрактно. Таковы, например, командно-штабные учения, когда работа штабов представляет собой натурный эксперимент, а действия войск отображаются в документах.
Классификация по рассмотренному признаку - способу реализации модели - показана на рис. 1.2.
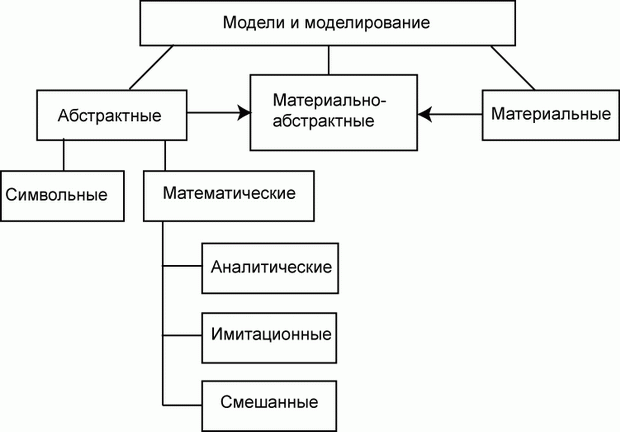
Рис. 1.2. Классификация по способу реализации модели
1.3. Этапы моделирования
Математическое моделирование как, впрочем, и любое другое, считается искусством и наукой. Известный специалист в области имитационного моделирования Роберт Шеннон так назвал свою широко известную в научном и инженерном мире книгу: "Имитационное моделирование - искусство и наука". Поэтому в инженерной практике нет формализованной инструкции, как создавать модели. И, тем не менее, анализ приемов, которые используют разработчики моделей, позволяет усмотреть достаточно прозрачную этапность моделирования.
Первый этап: уяснение целей моделирования. Вообще-то это главный этап любой деятельности. Цель существенным образом определяет содержание остальных этапов моделирования. Заметим, что различие между простой системой и сложной порождается не столько их сущностью, но и целями, которые ставит исследователь.
Обычно целями моделирования являются:
- прогноз поведения объекта при новых режимах, сочетаниях факторов и т. п.;
- подбор сочетания и значений факторов, обеспечивающих оптимальное значение показателей эффективности процесса;
- анализ чувствительности системы на изменение тех или иных факторов;
- проверка различного рода гипотез о характеристиках случайных параметров исследуемого процесса;
- определение функциональных связей между поведением ("реакцией") системы и влияющими факторами, что может способствовать прогнозу поведения или анализу чувствительности;
- уяснение сущности, лучшее понимание объекта исследования, а также формирование первых навыков для эксплуатации моделируемой или действующей системы.
Второй этап: построение концептуальной модели. Концептуальная модель (от лат. conception) - модель на уровне определяющего замысла, который формируется при изучении моделируемого объекта. На этом этапе исследуется объект, устанавливаются необходимые упрощения и аппроксимации. Выявляются существенные аспекты, исключаются второстепенные. Устанавливаются единицы измерения и диапазоны изменения переменных модели. Если возможно, то концептуальная модель представляется в виде известных и хорошо разработанных систем: массового обслуживания, управления, авторегулирования, разного рода автоматов и т. д. Концептуальная модель полностью подводит итог изучению проектной документации или экспериментальному обследованию моделируемого объекта.
Результатом второго этапа является обобщенная схема модели, полностью подготовленная для математического описания - построения математической модели.
Третий этап: выбор языка программирования или моделирования, разработка алгоритма и программы модели. Модель может быть аналитической или имитационной, или их сочетанием. В случае аналитической модели исследователь должен владеть методами решения.
В истории математики (а это, впрочем, и есть история математического моделирования) есть много примеров тому, когда необходимость моделирования разного рода процессов приводила к новым открытиям. Например, необходимость моделирования движения привела к открытию и разработке дифференциального исчисления (Лейбниц и Ньютон) и соответствующих методов решения. Проблемы аналитического моделирования остойчивости кораблей привели академика Крылова А. Н. к созданию теории приближенных вычислений и аналоговой вычислительной машины.
Результатом третьего этапа моделирования является программа, составленная на наиболее удобном для моделирования и исследования языке - универсальном или специальном.
Четвертый этап: планирование эксперимента. Математическая модель является объектом эксперимента. Эксперимент должен быть в максимально возможной степени информативным, удовлетворять ограничениям, обеспечивать получение данных с необходимой точностью и достоверностью. Существует теория планирования эксперимента, нужные нам элементы этой теории мы изучим в соответствующем месте дисциплины.
Результат четвертого этапа - план эксперимента.
Пятый этап: выполнение эксперимента с моделью. Если модель аналитическая, то эксперимент сводится к выполнению расчетов при варьируемых исходных данных. При имитационном моделировании модель реализуется на ЭВМ с фиксацией и последующей обработкой получаемых данных. Эксперименты проводятся в соответствии с планом, который может быть включен в алгоритм модели. В современных системах моделирования такая возможность есть.
Шестой этап: обработка, анализ и интерпретация данных эксперимента. В соответствии с целью моделирования применяются разнообразные методы обработки: определение разного рода характеристик случайных величин и процессов, выполнение анализов - дисперсионного, регрессионного, факторного и др. Многие из этих методов входят в системы моделирования (GPSS World, AnyLogic и др.) и могут применяться автоматически. Не исключено, что в ходе анализа полученных результатов модель может быть уточнена, дополнена или даже полностью пересмотрена.
После анализа результатов моделирования осуществляется их интерпретация, то есть перевод результатов в термины предметной области. Это необходимо, так как обычно специалист предметной области (тот, кому нужны результаты исследований) не обладает терминологией математики и моделирования и может выполнять свои задачи, оперируя лишь хорошо знакомыми ему понятиями.
На этом рассмотрение последовательности моделирования закончим, сделав весьма важный вывод о необходимости документирования результатов каждого этапа. Это необходимо в силу следующих причин.
Во-первых, моделирование процесс итеративный, то есть с каждого этапа может осуществляться возврат на любой из предыдущих этапов для уточнения информации, необходимой на этом этапе, а документация может сохранить результаты, полученные на предыдущей итерации.
Во-вторых, в случае исследования сложной системы в нем участвуют большие коллективы разработчиков, причем различные этапы выполняются различными коллективами. Поэтому результаты, полученные на каждом этапе, должны быть переносимы на последующие этапы, то есть иметь унифицированную форму представления и понятное другим заинтересованным специалистам содержание.
В-третьих, результат каждого из этапов должен являться самоценным продуктом. Например, концептуальная модель может и не использоваться для дальнейшего преобразования в математическую модель, а являться описанием, хранящим информацию о системе, которое может использоваться как архив, в качестве средства обучения и т. д.
1.4. Адекватность модели
Итак, мы установили: модель предназначена для замены оригинала при исследованиях, которым подвергать оригинал нельзя или нецелесообразно. Но замена оригинала моделью возможна, если они в достаточной степени похожи или адекватны.
Адекватность означает, достаточно ли хорошо с точки зрения целей исследования результаты, полученные в ходе моделирования, отражают истинное положение дел. Термин происходит от латинского adaequatus - приравненный.
Говорят, что модель адекватна оригиналу, если при ее интерпретации возникает "портрет", в высокой степени сходный с оригиналом.
До тех пор, пока не решен вопрос, правильно ли отображает модель исследуемую систему (то есть адекватна ли она), ценность модели нулевая!
Термин "адекватность" как видно носит весьма расплывчатый смысл. Понятно, что результативность моделирования значительно возрастет, если при построении модели и переносе результатов с модели на систему-оригинал может воспользоваться некоторой теорией, уточняющей идею подобия, связанную с используемой процедурой моделирования.
К сожалению теории, позволяющей оценить адекватность математической модели и моделируемой системы нет, в отличие от хорошо разработанной теории подобия явлений одной и той же физической природы.
Проверку адекватности проводят на всех этапах построения модели, начиная с самого первого этапа - концептуального анализа. Если описание системы будет составлено не адекватно реальной системе, то и модель, как бы точно она не отображала описание системы, не будет адекватной оригиналу. Здесь сказано "как бы точно", так как имеется в виду, что вообще не существуют математические модели, абсолютно точно отображающие процессы, существующие в реальности.
Если изучение системы проведено качественно и концептуальная модель достаточно точно отражает реальное положение дел, то далее перед разработчиками стоит лишь проблема эквивалентного преобразования одного описания в другое.
Итак, можно говорить об адекватности модели в любой ее форме и оригинала, если:
- описание поведения, созданное на каком-либо этапе, достаточно точно совпадает с поведением моделируемой системы в одинаковых ситуациях;
- описание убедительно представительно относительно свойств системы, которые должны прогнозироваться с помощью модели.
Предварительно исходный вариант математической модели подвергается следующим проверкам:
- все ли существенные параметры включены в модель;
- нет ли в модели несущественных параметров;
- правильно ли отражены функциональные связи между параметрами;
- правильно ли определены ограничения на значения параметров;
- не дает ли модель абсурдные ответы, если ее параметры принимают предельные значения.
Такая предварительная оценка адекватности модели позволяет выявить в ней наиболее грубые ошибки.
Но все эти рекомендации носят неформальный, рекомендательный характер. Формальных методов оценки адекватности не существует! Поэтому, в основном, качество модели (и в первую очередь степень ее адекватности системе) зависит от опыта, интуиции, эрудиции разработчика модели и других субъективных факторов.
Окончательное суждение об адекватности модели может дать лишь практика, то есть сравнение модели с оригиналом на основе экспериментов с объектом и моделью. Модель и объект подвергаются одинаковым воздействиям и сравниваются их реакции. Если реакции одинаковы (в пределах допустимой точности), то делается вывод, что модель адекватна оригиналу. Однако надо иметь в виду следующее:
- воздействия на объект носят ограниченный характер из-за возможного разрушения объекта, недоступности к элементам системы и т. д.;
- воздействия на объект имеют физическую природу (изменение питающих токов и напряжений, температуры, скорости вращения валов и т. д.), а на математическую модель - это числовые аналоги физических воздействий.
Для оценки степени подобия структур объектов (физических или математических) существует понятие изоморфизма (изо - одинаковый, равный, морфе - форма, греч.).
Две системы изоморфны, если существует взаимно однозначное соответствие между элементами и отношениями (связями) этих систем.
Изоморфны, например, множество действительных положительных чисел и множество их логарифмов. Каждому элементу одного множества - числу соответствует значение его логарифма в другом, умножению двух чисел в первом множестве - сложение их логарифмов в другом. C точки зрения пассажира план метрополитена, находящийся в каждом вагоне поезда метро, изоморфен реальному географическому расположению рельсовых путей и станций, хотя для рабочего, ремонтирующего рельсовые пути, этот план естественно не является изоморфным. Фотография является изоморфным отображением реального лица для милиционера, но не является таковым для художника.
При моделировании сложных систем достигнуть такого полного соответствия трудно, да и нецелесообразно. При моделировании абсолютное подобие не имеет места. Стремятся лишь к тому, чтобы модель достаточно хорошо отражала исследуемую сторону функционирования объекта. Модель по сложности может стать аналогичной исследуемой системе и никакого упрощения исследования не будет.
Для оценки подобия в поведении (функционировании) систем существует понятие изофункционализма.
Две системы произвольной, а подчас неизвестной структуры изофункциональны, если при одинаковых воздействиях они проявляют одинаковые реакции. Такое моделирование называется функциональным или кибернетическим и в последние годы получает все большее распространение, например, при моделировании человеческого интеллекта (игра в шахматы, доказательство теорем, распознавание образов и т. д.). Функциональные модели не копируют структуры. Но, копируя поведение, исследователи последовательно "подбираются" к познанию структур объектов (человеческого мозга, Солнца, и др.).
1.5. Требования, предъявляемые к моделям
Итак, общие требования к моделям.
- Модель должна быть актуальной. Это значит, что модель должна быть нацелена на важные для лиц, принимающих решения, проблемы.
- Модель должна быть результативной. Это значит, что полученные результаты моделирования могут найти успешное применение. Данное требование может быть реализовано только в случае правильной формулировки требуемого результата.
- Модель должна быть достоверной. Это значит, что результаты моделирования не вызовут сомнения. Данное требование тесно связано с понятием адекватности, то есть, если модель неадекватна, то она не может давать достоверных результатов.
- Модель должна быть экономичной. Это значит, что эффект от использования результатов моделирования превышает расходы ресурсов на ее создание и исследование.
Эти требования (обычно их называют внешними) выполнимы при условии обладания моделью внутренними свойствами.
Модель должна быть:
- Существенной, т. е. позволяющей вскрыть сущность поведения системы, вскрыть неочевидные, нетривиальные детали.
- Мощной, т. е. позволяющей получить широкий набор существенных сведений.
- Простой в изучении и использовании, легко просчитываемой на компьютере.
- Открытой, т. е. позволяющей ее модификацию.
В заключение темы сделаем несколько замечаний. Трудно ограничить область применения математического моделирования. При изучении и создании промышленных и военных систем практически всегда можно определить цели, ограничения и предусмотреть, чтобы конструкция или процесс подчинялись естественным, техническим и (или) экономическим законам.
Круг аналогий, которые можно использовать в качестве моделей, также практически неограничен. Следовательно, надо постоянно расширять свое образование в конкретной области, но, в первую очередь, в математике.
В последние десятилетия появились проблемы с неясными и противоречивыми целями, диктуемыми политическими и социальными факторами. Математическое моделирование в этой области пока еще проблематично. Что это за проблемы? Защита от загрязнения окружающей среды; предсказаний извержений вулканов, землетрясений, цунами; рост городов; руководство боевыми действиями и ряд других. Но, тем не менее, "процесс пошел", прогресс не остановим, и проблемы моделирования таких сверхсложных систем постоянно находят свое разрешение. Здесь следует отметить лидирующую роль отечественных ученых и, в первую очередь, академика Н. Н. Моисеева, его учеников и последователей.
Вопросы для самоконтроля
- Что такое модель? Раскройте смысл фразы: "модель есть объект и средство эксперимента".
- Обоснуйте необходимость моделирования.
- На основе какой теории основано моделирование?
- Назовите общие классификационные признаки моделей.
- Нужно ли стремиться к абсолютному подобию модели и оригинала?
- Назовите и поясните три аспекта процесса моделирования.
- Что значит структурная модель?
- Что такое функциональная модель?
- Классификация моделей по характеру процессов, протекающих в моделируемых объектах.
- Сущность математического моделирования и его основных классов: аналитического и имитационного.
- Назовите этапы моделирования и дайте им краткую характеристику.
- Что такое адекватность модели? Дайте понятия изоморфизма и изофункционализма.
- Общие требования (внешние) к моделям.
- Внутренние свойства модели.
- Приведите примеры объектов и возможных их моделей в своей предметной области.
Лекция 2. Типовые математические модели
Во многих случаях модель может быть представлена в виде конструкций из математических символов. В первой теме такие модели мы назвали аналитическими, чтобы отделить от других математических моделей - имитационных. С развитием последних область применения аналитических моделей сократилась. Однако актуальность такого моделирования сохраняется для систем, особенно тех, в которых протекают так называемые процессы без последействия. Процессы без последействия находят место при функционировании многих технических систем. Впервые один из типов такого процесса ввел в научный обиход и исследовал отечественный математик А. А. Марков, поэтому процессы без последействия и системы, в которых они протекают, названы марковскими, а один из типов такого процесса назван цепью Маркова. В настоящее время теория марковских процессов разработана широко и детально, в основном, благодаря отечественным ученым А. Я. Хинчину, Б. В. Гнеденко, А. Н. Колмогорову и другим. Популярность этой теории состоит еще и в том, что она может быть применена и к системам с последействием, которые с помощью некоторых ухищрений можно трактовать как марковские.
В этой теме рассматриваются элементы теории марковских процессов и ряд аналитических моделей, в основе которых лежит допущение о марковости протекающих в моделируемых объектах процессов. К таковым, в первую очередь, относится широкий класс самых разнообразных объектов, имеющих общее название систем массового обслуживания (СМО). Для ряда стандартных структур СМО аналитические модели, связывающие показатели эффективности СМО с характеристиками элементов СМО, приведены в соответствующих справочниках. Здесь же приводятся классификация СМО и приемы построения графов состояний СМО, позволяющих строить или применять готовые аналитические модели.
Заметим, что для ряда современных сложных СМО аналитическое моделирование неприемлемо в силу недостаточности адекватных математических средств. В этих случаях следует применять имитационное моделирование, которое детально рассматривается в следующих темах.
В многоэлементных системах с большим числом состояний аналитическое моделирование на основе теории марковских процессов становится весьма громоздким. В этом случае используется так называемый метод динамики средних, который в основе имеет также марковость процесса. Этот метод существенно упрощает аналитическое моделирование для случаев определения средних характеристик состояний моделируемой системы. В этой теме дано обоснование метода и приводятся примеры его применения.
2.1. Дискретные марковские процессы
Наиболее полное исследование процесса функционирования систем получается, если известны явные математические зависимости, связывающие искомые показатели с начальными условиями, параметрами и переменными исследуемой системы. Для многих современных систем, являющихся объектами моделирования, такие математические зависимости отсутствуют или малопригодны, и следует применять другое моделирование, как правило, имитационное.
Однако есть ряд конкретных математических схем, проверенных практикой и доказавших эффективность моделированием. Целью изучения настоящей темы является освоение таких математических моделей.
В инженерной практике часто возникает задача моделирования процессов случайной смены состояний в исследуемом объекте. В рамках нашей профессии нас интересуют дискретные состояния. Например, техническое состояние объекта может характеризоваться дискретными состояниями: исправен - неисправен, загружен - находится в простое и т. п. Численности боевых средств противоборствующих сторон изменяются дискретно, очереди объектов, ожидающих обслуживания, и многое другое.
Вид очередного состояния может определяться случайным образом, смена состояний может происходить в случайные или не случайные моменты времени.
Большой класс случайных процессов составляют процессы без последействия, которые в математике называют марковскими процессами в честь Андрея Андреевича Маркова - старшего (1856-1922), выдающегося русского математика, разработавшего основы теории таких процессов.
Сущность процесса без последействия понятна из определения.
Случайный процесс называется марковским, если вероятность перехода системы в новое состояние зависит только от состояния системы в настоящий момент и не зависит от того, когда и каким образом система перешла в это состояние.
Практически любой случайный процесс является марковским или может быть сведен к марковскому. В последнем случае достаточно в понятие состояния включить всю предысторию смен состояний системы.
А. А. Марков имеет дополнение к фамилии "старший" потому, что его сын - тоже Андрей Андреевич Марков - выдающийся математик, специалист в области теории алгоритмов и др.
А. А. Марков - старший известен также как давший вероятностное обоснование метода наименьших квадратов, приведший одно из доказательств предельной теоремы теории вероятностей и многое другое.
Дальнейшее развитие теория марковских процессов получила в работах выдающегося отечественного математика Андрея Николаевича Колмогорова.
Марковские процессы делятся на два класса:
- дискретные марковские процессы (марковские цепи);
- непрерывные марковские процессы.
Дискретной марковской цепью называется случайный процесс, при котором смена дискретных состояний происходит в определенные моменты времени.
Непрерывным марковским процессом называется случайный процесс, при котором смена дискретных состояний происходит в случайные моменты времени.
Итак, моделирование на основе дискретных марковских процессов.
Рассмотрим ситуацию, когда моделируемый процесс обладает следующими особенностями.
Система ![]() имеет
имеет ![]() возможных состояний:
возможных состояний: ![]() ,
, ![]() , ...,
, ..., ![]() . Вообще говоря, число состояний может быть бесконечным. Однако модель, как правило, строится для конечного числа состояний.
. Вообще говоря, число состояний может быть бесконечным. Однако модель, как правило, строится для конечного числа состояний.
Смена состояний происходит, будем считать, мгновенно и в строго определенные моменты времени ![]() В дальнейшем будем называть временные точки
В дальнейшем будем называть временные точки ![]() шагами.
шагами.
Известны вероятности перехода ![]() системы за один шаг из состояния
системы за один шаг из состояния ![]() в состояние
в состояние ![]() .
.
Цель моделирования: определить вероятности состояний системы после ![]() -го шага.
-го шага.
Обозначим эти вероятности ![]() (не путать с вероятностями
(не путать с вероятностями ![]() ).
).
Если в системе отсутствует последействие, то есть вероятности ![]() не зависят от предыстории нахождения системы в состоянии
не зависят от предыстории нахождения системы в состоянии ![]() , а определяются только этим состоянием, то описанная ситуация соответствует модели дискретной марковской цепи.
, а определяются только этим состоянием, то описанная ситуация соответствует модели дискретной марковской цепи.
Марковская цепь называется однородной, если переходные вероятности ![]() от времени не зависят, то есть от шага к шагу не меняются. В противном случае, то есть если переходные вероятности
от времени не зависят, то есть от шага к шагу не меняются. В противном случае, то есть если переходные вероятности ![]() зависят от времени, марковская цепь называется неоднородной.
зависят от времени, марковская цепь называется неоднородной.
Значения ![]() обычно сводятся в матрицу переходных вероятностей:
обычно сводятся в матрицу переходных вероятностей:
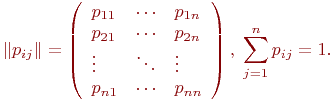
Значения ![]() могут также указываться на графе состояний системы. На рис. 2.1 показан размеченный граф для четырех состояний системы. Обычно вероятности переходов "в себя" -
могут также указываться на графе состояний системы. На рис. 2.1 показан размеченный граф для четырех состояний системы. Обычно вероятности переходов "в себя" - ![]() ,
, ![]() и т. д. на графе состояний можно не проставлять, так как их значения дополняют до 1 сумму переходных вероятностей, указанных на ребрах (стрелках), выходящих из данного состояния.
и т. д. на графе состояний можно не проставлять, так как их значения дополняют до 1 сумму переходных вероятностей, указанных на ребрах (стрелках), выходящих из данного состояния.
Не указываются также нулевые вероятности переходов. Например, на рис. 2.1 это вероятности ![]() ,
, ![]() и др.
и др.
Математической моделью нахождения вероятностей состояний однородной марковской цепи является рекуррентная зависимость
где ![]() - вероятность
- вероятность ![]() -го состояния системы после
-го состояния системы после ![]() -го шага,
-го шага, ![]() ;
;
![]() - вероятность
- вероятность ![]() -го состояния системы после
-го состояния системы после ![]() -го шага,
-го шага, ![]() ;
;
![]() - число состояний системы;
- число состояний системы;
![]() - переходные вероятности.
- переходные вероятности.
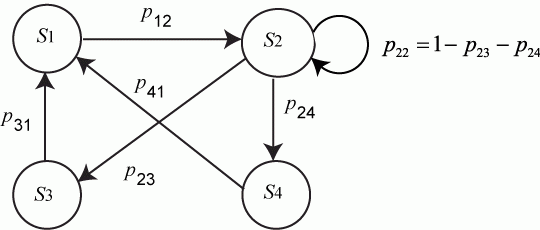
Рис. 2.1. Размеченный граф состояний системы
Для неоднородной марковской цепи вероятности состояний системы находятся по формуле:
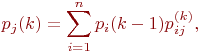
где ![]() - значения переходных вероятностей для
- значения переходных вероятностей для ![]() -го шага.
-го шага.
Пример 2.1. По группе из четырех объектов производится три последовательных выстрела. Найти вероятности состояний группы объектов после третьего выстрела.
Матрица переходных вероятностей имеет вид:

Размеченный граф состояний приведен на рис. 2.2.
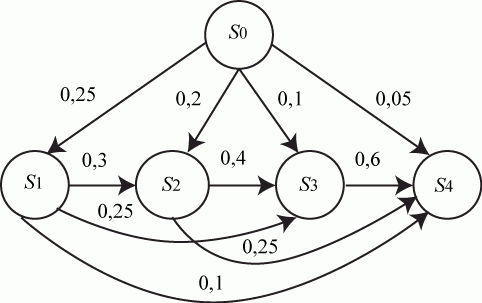
Рис. 2.2. Размеченный граф состояний четырех объектов
Прежде чем приступить к вычислениям, необходимо ответить на следующие вопросы.
- Является ли рассматриваемый процесс поражения целей марковским? Да, так как степень поражения объекта (смена его состояния) не зависит от того - когда и каким образом объект был приведен в настоящее состояние, а зависит только от его текущего состояния.
- Подходит ли рассматриваемая задача под схему марковской цепи? Да, так как время представляет собой дискретные отрезки - время между выстрелами (шаги).
- Процесс однородный или неоднородный? Есть основания полагать, что процесс однородный, так как переходные вероятности не зависят от времени. Кроме этого, мы полагаем, что объекты - неподвижные и во времени обстрела менять свое положение не могут (что привело бы к изменениям
 после каждого выстрела).
после каждого выстрела). - И, наконец, надо правильно определить начальное состояние системы, так как от этого могут существенно зависеть результаты моделирования. В нашем случае вполне естественно считать начальным состояние
 - все объекты целы.
- все объекты целы.
Следовательно, есть все основания для применения ранее введенного рекуррентного выражения (2.1).
Решение. Так как до первого выстрела все объекты целы, то ![]() .
.
После первого выстрела все значения вероятностей ![]() соответствуют первой строке матрицы переходных вероятностей. Рассчитаем вероятности остальных состояний.
соответствуют первой строке матрицы переходных вероятностей. Рассчитаем вероятности остальных состояний.
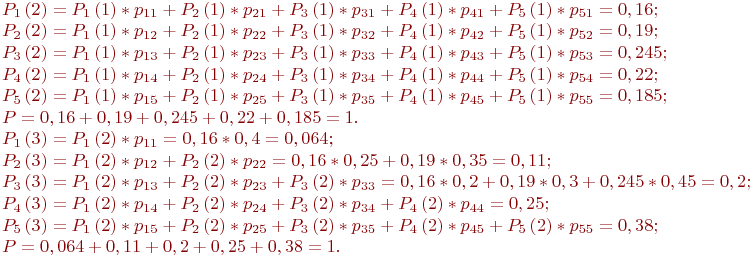
Сформулируем методику моделирования по схеме дискретных марковских процессов (марковских цепей).
- Зафиксировать исследуемое свойство системы.
Определение свойства зависит от цели исследования. Например, если исследуется объект с целью получения характеристик надежности, то в качестве свойства следует выбрать исправность. Если исследуется загрузка системы, то - занятость. Если, как в примере 2.1, состояния объектов, то - поражен или непоражен.
- Определить конечное число возможных состояний системы и убедиться в правомерности моделирования по схеме дискретных марковских процессов.
- Составить и разметить граф состояний.
- Определить начальное состояние.
- По рекуррентной зависимости (2.1) определить искомые вероятности.
В рамках изложенной методики моделирования исчерпывающей характеристикой поведения системы является совокупность вероятностей ![]() .
.
При неоднородном марковском процессе переходная вероятность ![]() представляет собой условную вероятность перехода
представляет собой условную вероятность перехода
![]() , зависящую от
, зависящую от ![]() - очередного временного шага. В этом случае должны быть указаны более одной матрицы значений
- очередного временного шага. В этом случае должны быть указаны более одной матрицы значений ![]() (для некоторых шагов матрицы могут быть одинаковыми).
(для некоторых шагов матрицы могут быть одинаковыми).
Например, при нанесении ударов по объектам, которые могут перемещаться (танковая группировка, корабли и т. п.), последние будут принимать меры по рассредоточению средств или другому защитному маневру, вплоть до активного противодействия атакующей стороне. Очевидно, все эти меры приведут к уменьшению поражающих возможностей стороны, наносящей удары, т. е. к соответствующему изменению переходных вероятностей. Процесс становится неоднородным.
2.2. Моделирование по схеме непрерывных марковских процессов
Существует широкий класс систем, которые меняют свои состояния в случайные моменты времени ![]() . Как и в предыдущем случае, в этих системах рассматривается процесс с дискретными состояниями
. Как и в предыдущем случае, в этих системах рассматривается процесс с дискретными состояниями ![]() . Например, переход объекта от исправного состояния к неисправному, соотношение сил сторон в ходе боя и т. п. Оценка эффективности таких систем определяется с помощью вероятностей каждого состояния
. Например, переход объекта от исправного состояния к неисправному, соотношение сил сторон в ходе боя и т. п. Оценка эффективности таких систем определяется с помощью вероятностей каждого состояния ![]() на любой момент времени
на любой момент времени ![]() ,
, ![]() .
.
Чтобы определить вероятности состояния системы ![]() для любого момента времени
для любого момента времени ![]() необходимо воспользоваться математическими моделями марковских процессов с непрерывным временем (непрерывных марковских процессов).
необходимо воспользоваться математическими моделями марковских процессов с непрерывным временем (непрерывных марковских процессов).
При моделировании состояния систем с непрерывными марковскими процессами мы уже не можем воспользоваться переходными вероятностями ![]() , так как вероятность "перескока" системы из одного состояния в другое точно в момент времени
, так как вероятность "перескока" системы из одного состояния в другое точно в момент времени ![]() равна нулю (как вероятность любого отдельного значения непрерывной случайной величины).
равна нулю (как вероятность любого отдельного значения непрерывной случайной величины).
Поэтому вместо переходных вероятностей вводятся в рассмотрение плотности вероятностей переходов ![]() :
:
где ![]() - вероятность того, что система, находившаяся в момент времени
- вероятность того, что система, находившаяся в момент времени ![]() в состоянии
в состоянии ![]() за время
за время ![]() перейдет в состояние
перейдет в состояние ![]() .
.
С точностью до бесконечно малых второго порядка из приведенной формулы можно представить:
Непрерывный марковский процесс называется однородным,если плотности вероятностей переходов ![]() не зависят от времени
не зависят от времени ![]() (от момента начала промежутка
(от момента начала промежутка ![]() ). В противном случае непрерывный марковский процесс называется неоднородным.
). В противном случае непрерывный марковский процесс называется неоднородным.
Целью моделирования, как и в случае дискретных процессов, является определение вероятностей состояний системы ![]() . Эти вероятности находятся интегрированием системы дифференциальных уравнений Колмогорова.
. Эти вероятности находятся интегрированием системы дифференциальных уравнений Колмогорова.
Сформулируем методику моделирования по схеме непрерывных марковских процессов.
- Определить состояния системы и плотности вероятностей переходов
 .
. - Составить и разметить граф состояний.
- Составить систему дифференциальных уравнений Колмогорова. Число уравнений в системе равно числу состояний. Каждое уравнение формируется следующим образом.
- B левой части уравнения записывается производная вероятности
 -го состоянии
-го состоянии  .
. - В правой части записывается алгебраическая сумма произведений
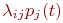 и
и 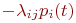 . Число произведений столько, сколько стрелок связано с данным состоянием. Если стрелка графа направлена в данное состояние, то соответствующее произведение имеет знак плюс, если из данного состояния - минус.
. Число произведений столько, сколько стрелок связано с данным состоянием. Если стрелка графа направлена в данное состояние, то соответствующее произведение имеет знак плюс, если из данного состояния - минус. - Определить начальные условия и решить систему дифференциальных уравнений.
Пример 2.2. Составить систему дифференциальных уравнений Колмогорова для нахождения вероятностей состояний системы, размеченный граф состояний которой представлен на рис. 2.3.
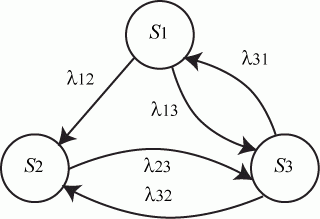
Рис. 2.3. Размеченный граф состояний
Решение
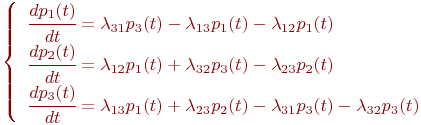
Очевидно, ![]() .
.
Поэтому любое из первых трех уравнений можно исключить, как линейно зависимое.
Для решения уравнений Колмогорова необходимо задать начальные условия. Для рассмотренного примера 2.2, можно задать такие начальные условия: ![]() ,
, ![]() .
.
Однородный марковский процесс с непрерывным временем можно трактовать как процесс смены состояний под влиянием некоторого потока событий. То есть плотность вероятности перехода можно трактовать как интенсивность потока событий, переводящих систему из ![]() -го состояния в
-го состояния в ![]() -е. Такими потоками событий являются отказы техники, вызовы на телефонной станции, рождение и т. п.
-е. Такими потоками событий являются отказы техники, вызовы на телефонной станции, рождение и т. п.
При исследовании сложных объектов всегда интересует: возможен ли в исследуемой системе установившейся (стационарный) режим? То есть, как ведет себя система при ![]() ? Существуют ли предельные значения
? Существуют ли предельные значения ![]() ? Как правило, именно эти предельные значения интересуют исследователя.
? Как правило, именно эти предельные значения интересуют исследователя.
Ответ на данный вопрос дает теорема Маркова.
Если для однородного дискретного марковского процесса с конечным или счетным числом состояний все ![]() , то предельные значения
, то предельные значения ![]() существуют и их значения не зависят от выбранного начального состояния системы.
существуют и их значения не зависят от выбранного начального состояния системы.
Применительно к непрерывным марковским процессам теорема Маркова трактуется так: если процесс однородный и из каждого состояния возможен переход за конечное время в любое другое состояние и число состояний счетно или конечно, то предельные значения ![]() существуют и их значения не зависят от выбранного начального состояния.
существуют и их значения не зависят от выбранного начального состояния.
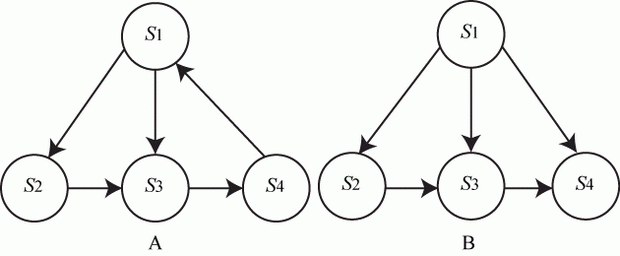
Например (рис. 2.4), в системе А стационарный режим есть, а в системе В стационарного режима нет: если система окажется в состоянии ![]() она не сможет перейти ни в какое другое состояние.
она не сможет перейти ни в какое другое состояние.
увеличить изображение
Рис. 2.4. Примеры графов состояний систем с различными режимами
2.3. Схема гибели и размножения
Часто в системах самого различного назначения протекают процессы, которые можно представить в виде модели "гибели и размножения".
Граф состояний такого процесса показан на рис. 2.5.

увеличить изображение
Рис. 2.5. Схема "гибели и размножения"
Особенностью модели является наличие прямой и обратной связей с каждым соседним состоянием для всех средних состояний; первое и последнее (крайние) состояния связаны только с одним "соседом" (с последующим и предыдущим состояниями соответственно).
Название модели - "гибель и размножение" - связано с представлением, что стрелки вправо означают переход к состояниям, связанным с ростом номера состояния ("рождение"), а стрелки влево - с убыванием номера состояний ("гибель").
Очевидно, стационарное состояние в этом процессе существует. Составлять уравнения Колмогорова нет необходимости, так как структура регулярна, необходимые формулы приводятся в справочниках, а также в рекомендованной литературе.
Для приведенных на рис. 2.5 обозначений формулы имеют вид:
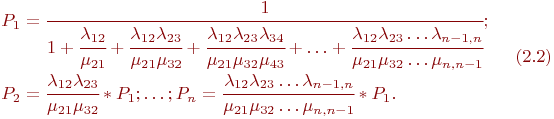
Пример 2.3. Имеется система из двух одинаковых и работающих параллельно компьютеров.
Требуется определить надежностные характеристики этой системы.
Решение
В этой системе возможны три состояния:
![]() - оба компьютера исправны;
- оба компьютера исправны;
![]() - один компьютер исправен, другой ремонтируется;
- один компьютер исправен, другой ремонтируется;
![]() - оба компьютера неисправны и ремонтируются. Будем полагать, что процессы отказов и восстановлений - однородные марковские, одновременный выход из строя обоих компьютеров, как и одновременное восстановление двух отказавших компьютеров практически невозможно.
- оба компьютера неисправны и ремонтируются. Будем полагать, что процессы отказов и восстановлений - однородные марковские, одновременный выход из строя обоих компьютеров, как и одновременное восстановление двух отказавших компьютеров практически невозможно.
Поскольку компьютеры одинаковые, то с точки зрения надежности, неважно, какой именно компьютер неисправен в состоянии ![]() , важно, что один.
, важно, что один.
С учетом сказанного, ситуация моделируется схемой "гибели и размножения" (рис. 2.6).
Рис. 2.6.
На рис. 2.6:
![]() ,
, ![]() - интенсивности потоков отказов;
- интенсивности потоков отказов;
![]() ,
, ![]() - интенсивности потоков восстановлений.
- интенсивности потоков восстановлений.
Пусть среднее время безотказной работы каждого компьютера ![]() , а среднее время восстановления одного компьютера
, а среднее время восстановления одного компьютера ![]() .
.
Тогда интенсивность отказов одного компьютера будет равна ![]() , а интенсивность восстановления одного компьютера -
, а интенсивность восстановления одного компьютера - ![]() .
.
В состоянии ![]() работают оба компьютера, следовательно:
работают оба компьютера, следовательно:
В состоянии ![]() работает один компьютер, значит:
работает один компьютер, значит:
В состоянии ![]() восстанавливается один компьютер, тогда:
восстанавливается один компьютер, тогда:
В состоянии ![]() восстанавливаются оба компьютера:
восстанавливаются оба компьютера:
Используем зависимости (2.2). Вероятность состояния, когда обе машины исправны:
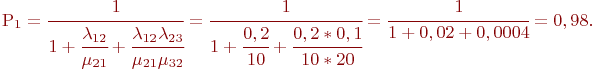
Вероятность второго состояния ![]() (работает один компьютер):
(работает один компьютер):
Аналогично вычисляется и ![]() . Хотя найти
. Хотя найти ![]() можно и так:
можно и так:
Пример 2.4. В полосе объединения работают передатчики противника. Подразделение операторов-связистов армейской контрразведки ведет поиск передатчиков по их радиоизлучениям. Каждый оператор, обнаружив передатчик противника, следит за его частотой, при этом новым поиском не занимается. В процессе слежения частота может быть потеряна, после чего оператор снова осуществляет поиск.
Разработать математическую модель для определения эффективности службы подразделения операторов. Под эффективностью понимается среднее число обнаруженных передатчиков за установленный промежуток времени.
Решение
Будем считать, что наши операторы и радисты противника обладают высокой квалификацией, хорошо натренированы. Следовательно, можно принять, что интенсивности обнаружения частот передатчиков противника и потерь слежения - постоянны. Обнаружение частоты и ее потеря зависят только от того, сколько запеленговано передатчиков в настоящий момент и не зависят от того, когда произошло это пеленгование. Следовательно, процесс обнаружения и потерь слежения за частотами можно считать непрерывным однородным марковским процессом.
Исследуемое свойство этой системы пеленгации: загруженность операторов, что, очевидно, совпадает с числом обнаруженных частот.
Введем обозначения:
![]() - количество операторов;
- количество операторов;
![]() - количество передатчиков противника, полагаем
- количество передатчиков противника, полагаем ![]() ;
;
![]() - среднее число операторов, ведущих слежение;
- среднее число операторов, ведущих слежение;
![]() - среднее число запеленгованных передатчиков;
- среднее число запеленгованных передатчиков;
![]() - интенсивность пеленгации передатчика противника одним оператором;
- интенсивность пеленгации передатчика противника одним оператором;
![]() - интенсивность потока потерь слежения оператором;
- интенсивность потока потерь слежения оператором;
![]() - текущая численность запеленгованных передатчиков
- текущая численность запеленгованных передатчиков ![]() .
.
В системе пеленгации возможны следующие состояния:
![]() - запеленгованных передатчиков нет, поиск ведут
- запеленгованных передатчиков нет, поиск ведут ![]() операторов, вероятность состояния
операторов, вероятность состояния ![]() ;
;
![]() - запеленгован 1 передатчик, поиск ведут
- запеленгован 1 передатчик, поиск ведут ![]() операторов, вероятность состояния
операторов, вероятность состояния ![]() ;
;
![]() - запеленгованы 2 передатчика, поиск ведут
- запеленгованы 2 передатчика, поиск ведут ![]() операторов, вероятность состояния
операторов, вероятность состояния ![]() ;
;
…
![]() - запеленгованы
- запеленгованы ![]() передатчиков, вероятность
передатчиков, вероятность ![]() ;
;
…
![]() - запеленгованы
- запеленгованы ![]() передатчиков, вероятность
передатчиков, вероятность ![]() .
.
Цель моделирования - ![]() - достигается вычислением:
- достигается вычислением:
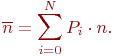
Как и в примере 2.3 полагаем, что одновременное обнаружение или потеря двух и более частот практически невозможно. Граф состояний системы показан на рис. 2.7.

увеличить изображение
Рис. 2.7. Граф состояний системы пеленгации
Граф соответствует процессу "гибели и размножения", полносвязный, число состояний системы конечно, значит, установившийся режим, и предельные значения вероятностей в системе пеленгации существуют.
Пусть, к примеру, количество операторов ![]() , а количество передатчиков противника
, а количество передатчиков противника ![]() . В этом случае граф состояний имеет вид (рис. 2.8):
. В этом случае граф состояний имеет вид (рис. 2.8):
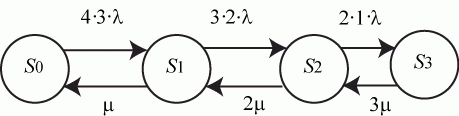
Рис. 2.8. Вариант графа состояний системы пеленгации
Для упрощения вычислений примем ![]() . Тогда для этой схемы "гибели и размножения" по зависимостям (2.2) имеем:
. Тогда для этой схемы "гибели и размножения" по зависимостям (2.2) имеем:
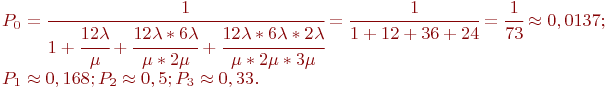
Окончательно:
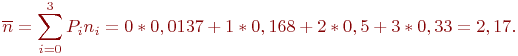
Таким образом, в условиях данного примера в среднем будут пеленговаться не менее двух передатчиков противника.
Непрерывный марковский процесс полностью определяется значениями плотностей вероятностей переходов ![]() ,
, ![]() . Ранее был установлен их физический смысл как интенсивности потоков событий, переводящих систему из одного состояния в другое. Поток событий в однородных непрерывных марковских процессах характеризуется экспоненциальным законом распределения случайных интервалов времени между событиями. Такой поток называют простейшим или стационарным пуассоновским.
. Ранее был установлен их физический смысл как интенсивности потоков событий, переводящих систему из одного состояния в другое. Поток событий в однородных непрерывных марковских процессах характеризуется экспоненциальным законом распределения случайных интервалов времени между событиями. Такой поток называют простейшим или стационарным пуассоновским.
Простейший поток обладает свойствами:
- стационарности, что означает независимость характеристик потока от времени;
- ординарности, что означает практическую невозможность появления двух и более событий одновременно;
- отсутствия последействия, об этом говорилось в начале темы.
2.4. Элементы СМО, краткая характеристика
При решении задач управления, в том числе и управления войсками, часто возникает ряд однотипных задач:
- оценка пропускной способности направления связи, железнодорожного узла, госпиталя и т. п.;
- оценка эффективности ремонтной базы;
- определение количества частот для радиосети и др.
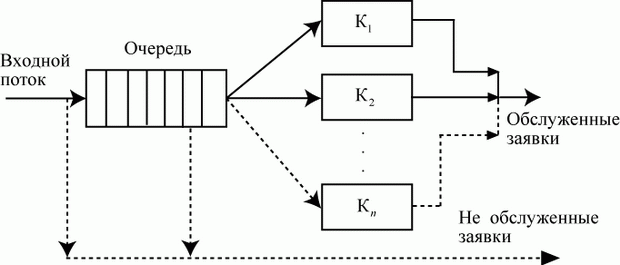
Все эти задачи однотипны в том смысле, что в них присутствует массовый спрос на обслуживание. В удовлетворении этого спроса участвует определенная совокупность элементов, образующая систему массового обслуживания (СМО) (рис. 2.9).
увеличить изображение
Рис. 2.9. Система массового обслуживания
Элементами СМО являются:
- входной (входящий) поток требований (заявок) на обслуживание;
- приборы (каналы) обслуживания;
- очередь заявок, ожидающих обслуживания;
- выходной (выходящий) поток обслуженных заявок;
- поток не обслуженных заявок;
- очередь свободных каналов (для многоканальных СМО).
Входящий поток - это совокупность заявок на обслуживание. Часто заявка отождествляется с ее носителем. Например, поток неисправной радиоаппаратуры, поступающий в мастерскую объединения, представляет собой поток заявок - требований на обслуживание в данной СМО.
Как правило, на практике имеют дело с так называемыми рекуррентными потоками, - потоками, обладающими свойствами:
- стационарности;
- ординарности;
- ограниченного последействия.
Первые два свойства мы определили ранее. Что касается ограниченного последействия, то оно заключается в том, что интервалы между поступающими заявками являются независимыми случайными величинами.
Рекуррентных потоков много. Каждый закон распределения интервалов порождает свой рекуррентный поток. Рекуррентные потоки иначе называют потоками Пальма.
Поток с полным отсутствием последействия, как уже отмечалось, называется стационарным пуассоновским. У него случайные интервалы между заявками имеют экспоненциальное распределение:
здесь ![]() - интенсивность потока.
- интенсивность потока.
Название потока - пуассоновский - происходит от того, что для этого потока вероятность ![]() появления
появления ![]() заявок за интервал
заявок за интервал ![]() определяется законом Пуассона:
определяется законом Пуассона:
Поток такого типа, как отмечалось ранее, называют также простейшим. Именно такой поток предполагают проектировщики при разработке СМО. Вызвано это тремя причинами.
Во-первых,поток этого типа в теории массового обслуживания аналогичен нормальному закону распределения в теории вероятностей в том смысле, что к простейшему потоку приводит предельный переход для потока, являющегося суммой потоков с произвольными характеристиками при бесконечном увеличении слагаемых и уменьшении их интенсивности. То есть сумма произвольных независимых (без преобладания) потоков с интенсивностями ![]() является простейшим потоком с интенсивностью
является простейшим потоком с интенсивностью
Во-вторых, если обслуживающие каналы (приборы) рассчитаны на простейший поток заявок, то обслуживание других типов потоков (с той же интенсивностью) будет обеспечено с не меньшей эффективностью.
В-третьих, именно такой поток определяет марковский процесс в системе и, следовательно, простоту аналитического анализа системы. При других потоках анализ функционирования СМО сложен.
Часто встречаются системы, у которых поток входных заявок зависит от количества заявок, находящихся в обслуживании. Такие СМО называют замкнутыми (иначе - разомкнутыми). Например, работа мастерской связи объединения может быть представлена моделью замкнутой СМО. Пусть эта мастерская предназначена для обслуживания радиостанций, которых в объединении ![]() . Каждая из них имеет интенсивность отказов
. Каждая из них имеет интенсивность отказов ![]() . Входной поток отказавшей аппаратуры будет иметь интенсивность
. Входной поток отказавшей аппаратуры будет иметь интенсивность ![]() :
:
где ![]() - количество радиостанций, уже находящихся в мастерской на ремонте.
- количество радиостанций, уже находящихся в мастерской на ремонте.
Заявки могут иметь разные права на начало обслуживания. В этом случае говорят, что заявки неоднородные. Преимущества одних потоков заявок перед другими задаются шкалой приоритетов.
Важной характеристикой входного потока является коэффициент вариации:
где ![]() - математическое ожидание длины интервала;
- математическое ожидание длины интервала;
![]() - среднеквадратическое отклонение случайной величины (длины интервала)
- среднеквадратическое отклонение случайной величины (длины интервала) ![]() .
.
Для простейшего потока 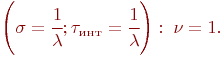
Для большинства реальных потоков ![]() .
.
При ![]() поток регулярный, детерминированный.
поток регулярный, детерминированный.
Коэффициент вариации - характеристика, отражающая степень неравномерности поступления заявок.
Каналы (приборы) обслуживания. В СМО могут быть один или несколько обслуживающих приборов (каналов). Согласно с этим СМО называют одноканальными или многоканальными.
Многоканальные СМО могут состоять из однотипных или разнотипных приборов. Обслуживающими приборами могут быть:
- линии связи;
- мастера ремонтных органов;
- взлетно-посадочные полосы;
- транспортные средства;
- причалы;
- парикмахеры, продавцы и др.
Основная характеристика канала - время обслуживания. Как правило, время обслуживания - величина случайная.
Обычно практики полагают, что время обслуживания имеет экспоненциальный закон распределения:
где ![]() - интенсивность обслуживания,
- интенсивность обслуживания, ![]() ;
;
![]() - математическое ожидание времени обслуживания.
- математическое ожидание времени обслуживания.
То есть процесс обслуживания - марковский, а это, как теперь нам известно, дает существенные удобства в аналитическом математическом моделировании.
Кроме экспоненциального встречаются ![]() -распределение Эрланга, гиперэкспоненциальное, треугольное и некоторые другие. Это нас не должно смущать, так как показано, что значение критериев эффективности СМО мало зависят от вида закона распределения вероятностей времени обслуживания.
-распределение Эрланга, гиперэкспоненциальное, треугольное и некоторые другие. Это нас не должно смущать, так как показано, что значение критериев эффективности СМО мало зависят от вида закона распределения вероятностей времени обслуживания.
При исследовании СМО выпадает из рассмотрения сущность обслуживания, качество обслуживания.
Каналы могут быть абсолютно надежными, то есть не выходить из строя. Вернее, так может быть принято при исследовании. Каналы могут обладать конечной надежностью. В этом случае модель СМО значительно сложнее.
Очередь заявок. В силу случайного характера потоков заявок и обслуживания пришедшая заявка может застать канал (каналы) занятым обслуживанием предыдущей заявки. В этом случае она либо покинет СМО не обслуженной, либо останется в системе, ожидая начало своего обслуживания. В соответствии с этим различают:
- СМО с отказами;
- СМО с ожиданием.
СМО с ожиданием характеризуются наличием очередей. Очередь может иметь ограниченную или неограниченную емкость: ![]() .
.
Исследователя обычно интересуют такие статистические характеристики, связанные с пребыванием заявок в очереди:
- среднее количество заявок в очереди за интервал исследования;
- среднее время пребывания (ожидания) заявки в очереди. СМО с ограниченной емкостью очереди относят к СМО смешанного типа.
Нередко встречаются СМО, в которых заявки имеют ограниченное время пребывания в очереди независимо от ее емкости. Такие СМО также относят к СМО смешанного типа.
Выходящий поток - это поток обслуженных заявок, покидающих СМО.
Встречаются случаи, когда заявки проходят через несколько СМО: транзитная связь, производственный конвейер и т. п. В этом случае выходящий поток является входящим для следующей СМО. Совокупность последовательно связанных между собой СМО называют многофазными СМО или сетями СМО.
Входящий поток первой СМО, пройдя через последующие СМО, искажается и это затрудняет моделирование. Однако следует иметь в виду, что при простейшем входном потоке и экспоненциальном обслуживании (то есть в марковских системах) выходной поток тоже простейший. Если время обслуживания имеет не экспоненциальное распределение, то выходящий поток не только не простейший, но и не рекуррентный.
Заметим, что интервалы между заявками выходящего потока, это не то же самое, что интервалы обслуживания. Ведь может оказаться, что после окончания очередного обслуживания СМО какое-то время простаивает из-за отсутствия заявок. В этом случае интервал выходящего потока состоит из времени незанятости СМО и интервала обслуживания первой, пришедшей после простоя, заявки.
В системах с отказами есть поток необслуженных заявок. Если в СМО с отказами поступает рекуррентный поток, а обслуживание - экспоненциальное, то и поток необслуженных заявок - рекуррентный.
Очереди свободных каналов. В многоканальных СМО могут образовываться очереди свободных каналов. Количество свободных каналов - величина случайная. Исследователя могут интересовать различные характеристики этой случайной величины. Обычно это среднее число каналов, занятых обслуживанием за интервал исследования.
Таким образом, по признакам, влияющим на функционирование, СМО может принадлежать к одному из типов в соответствии с приводимой классификацией (рис. 2.10).

Рис. 2.10. Классификация СМО
Для обозначения простых (однофазных) СМО используется символика, предложенная Кендаллом:
![]() - входящий поток заявок:
- входящий поток заявок: ![]() - рекуррентный поток;
- рекуррентный поток; ![]() - простейший поток с показательным законом распределения вероятностей;
- простейший поток с показательным законом распределения вероятностей; ![]() - регулярный или детерминированный поток (с постоянными интервалами между моментами поступления заявок).
- регулярный или детерминированный поток (с постоянными интервалами между моментами поступления заявок).
![]() - случайная длительность обслуживания:
- случайная длительность обслуживания: ![]() или
или ![]() - рекуррентное обслуживание с одной и той же функцией распределения
- рекуррентное обслуживание с одной и той же функцией распределения ![]() для разных каналов;
для разных каналов; ![]() - показательное обслуживание;
- показательное обслуживание; ![]() - регулярное обслуживание.
- регулярное обслуживание.
![]() - количество обслуживающих каналов. Если
- количество обслуживающих каналов. Если ![]() , то система называется многоканальной.
, то система называется многоканальной.
![]() - количество мест для ожидания заявок в очереди. Если
- количество мест для ожидания заявок в очереди. Если ![]() , то СМО с потерями (без ожидания);
, то СМО с потерями (без ожидания); ![]() - система с неограниченным ожиданием;
- система с неограниченным ожиданием; ![]() - система с ограниченным числом мест для ожидания.
- система с ограниченным числом мест для ожидания.
2.5. Моделирование СМО в классе непрерывных марковских процессов
Под операцией в СМО понимают комплекс мероприятий по обслуживанию входящего потока заявок на интервале времени ![]() .
.
В зависимости от типа системы показателями исхода операции или эффективности системы массового обслуживания являются следующие.
Для СМО с отказами:
- абсолютная пропускная способность (
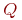 ) - среднее число заявок, обслуживаемое системой за время
) - среднее число заявок, обслуживаемое системой за время 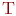 ;
; - относительная пропускная способность (
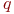 ) - средняя доля поступивших заявок, обслуживаемая системой (отношение среднего числа обслуженных заявок к среднему числу поступивших за время );
) - средняя доля поступивших заявок, обслуживаемая системой (отношение среднего числа обслуженных заявок к среднему числу поступивших за время ); - среднее число занятых каналов (
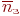 );
); - коэффициент занятости (использования) каналов (
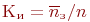 , где
, где 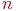 - число каналов в системе);
- число каналов в системе); - коэффициент простоя каналов,
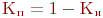 .
.
Для СМО с неограниченным ожиданием как абсолютная, так и относительная пропускная способности теряют смысл, так как каждая поступившая заявка рано или поздно будет обслужена. Для такой СМО важными показателями являются:
- среднее число заявок в очереди (
 );
); - среднее число заявок в системе (в очереди и на обслуживании,
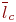 );
); - среднее время ожидания заявки в очереди (
 );
); - среднее время пребывания заявки в системе (в очереди и на обслуживании,
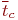 );
); - коэффициенты использования и простоя каналов (
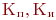 );
); - среднее число свободных и занятых каналов (
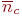 , ).
, ).
Для СМО смешанного типа используются обе группы показателей: как относительная и абсолютная пропускная способности, так и характеристики ожидания.
В зависимости от цели операции массового обслуживания любой из приведенных показателей (или совокупность показателей) может быть выбран в качестве критерия эффективности.
Аналитической моделью СМО является совокупность уравнений или формул, позволяющих определять вероятности состояний системы в процессе ее функционирования и рассчитывать показатели эффективности по известным характеристикам входящего потока и каналов обслуживания.
Всеобщей аналитической модели для произвольной СМО не существует. Аналитические модели разработаны для ограниченного числа частных случаев СМО. Аналитические модели, более или менее точно отображающие реальные системы, как правило, сложны и труднообозримы.
Аналитическое моделирование СМО существенно облегчается, если процессы, протекающие в СМО, марковские (потоки заявок простейшие, времена обслуживания распределены экспоненциально). В этом случае все процессы в СМО можно описать обыкновенными дифференциальными уравнениями, а в предельном случае, для стационарных состояний - линейными алгебраическими уравнениями и, решив их, определить выбранные показатели эффективности.
Рассмотрим примеры некоторых СМО.
2.5.1. Многоканальная СМО с отказами
Пример 2.5. Три автоинспектора проверяют путевые листы у водителей грузовых автомобилей. Если хотя бы один инспектор свободен, проезжающий грузовик останавливают. Если все инспекторы заняты, грузовик, не задерживаясь, проезжает мимо. Поток грузовиков простейший, время проверки случайное с экспоненциальным распределением.
Такую ситуацию можно моделировать трехканальной СМО с отказами (без очереди). Система разомкнутая, с однородными заявками, однофазная, с абсолютно надежными каналами.
Описание состояний:
![]() - все инспекторы свободны;
- все инспекторы свободны;
![]() - занят один инспектор;
- занят один инспектор;
![]() - заняты два инспектора;
- заняты два инспектора;
![]() - заняты три инспектора.
- заняты три инспектора.
Граф состояний системы приведен на рис. 2.11.
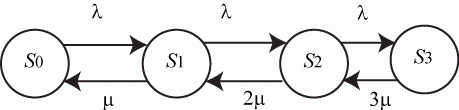
Рис. 2.11. Граф состояний трехканальной СМО с отказами
На графе: ![]() - интенсивность потока грузовых автомобилей;
- интенсивность потока грузовых автомобилей; ![]() - интенсивность проверок документов одним автоинспектором.
- интенсивность проверок документов одним автоинспектором.
Моделирование проводится с целью определения части автомобилей, которые не будут проверены.
Решение
Искомая часть вероятности ![]() - вероятности занятости всех трех инспекторов. Поскольку граф состояний представляет типовую схему "гибели и размножения", то найдем
- вероятности занятости всех трех инспекторов. Поскольку граф состояний представляет типовую схему "гибели и размножения", то найдем ![]() , используя зависимости (2.2).
, используя зависимости (2.2).
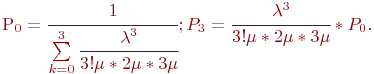
Пропускную способность этого поста автоинспекторов можно характеризовать относительной пропускной способностью:
Пример 2.6. Для приема и обработки донесений от разведгруппы в разведотделе объединения назначена группа в составе трех офицеров. Ожидаемая интенсивность потока донесений - 15 донесений в час. Среднее время обработки одного донесения одним офицером - ![]() . Каждый офицер может принимать донесения от любой разведгруппы. Освободившийся офицер обрабатывает последнее из поступивших донесений. Поступающие донесения должны обрабатываться с вероятностью не менее 95 %.
. Каждый офицер может принимать донесения от любой разведгруппы. Освободившийся офицер обрабатывает последнее из поступивших донесений. Поступающие донесения должны обрабатываться с вероятностью не менее 95 %.
Определить, достаточно ли назначенной группы из трех офицеров для выполнения поставленной задачи.
Решение
Группа офицеров работает как СМО с отказами, состоящая из трех каналов.
Поток донесений с интенсивностью ![]() можно считать простейшим, так как он суммарный от нескольких разведгрупп. Интенсивность обслуживания
можно считать простейшим, так как он суммарный от нескольких разведгрупп. Интенсивность обслуживания ![]() . Закон распределения неизвестен, но это несущественно, так как показано, что для систем с отказами он может быть произвольным.
. Закон распределения неизвестен, но это несущественно, так как показано, что для систем с отказами он может быть произвольным.
Описание состояний и граф состояний СМО будут аналогичны приведенным в примере 2.5.
Поскольку граф состояний - это схема "гибели и размножения", то для нее имеются готовые выражения для предельных вероятностей состояния:
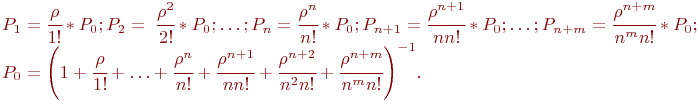
Отношение ![]() называют приведенной интенсивностью потока заявок. Физический смысл ее следующий: величина
называют приведенной интенсивностью потока заявок. Физический смысл ее следующий: величина ![]() представляет собой среднее число заявок, приходящих в СМО за среднее время обслуживания одной заявки.
представляет собой среднее число заявок, приходящих в СМО за среднее время обслуживания одной заявки.
В примере ![]() .
.
В рассматриваемой СМО отказ наступает при занятости всех трех каналов, то есть ![]() . Тогда:
. Тогда:
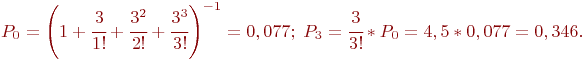
Так как вероятность отказа в обработке донесений составляет более 34 % ( ![]() ), то необходимо увеличить личный состав группы. Увеличим состав группы в два раза, то есть СМО будет иметь теперь шесть каналов, и рассчитаем
), то необходимо увеличить личный состав группы. Увеличим состав группы в два раза, то есть СМО будет иметь теперь шесть каналов, и рассчитаем ![]() :
:
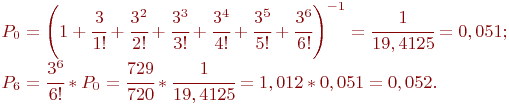
Теперь ![]() .
.
Таким образом, только группа из шести офицеров сможет обрабатывать поступающие донесения с вероятностью 95 %.
2.5.2. Многоканальная СМО с ожиданием
Пример 2.7. На участке форсирования реки имеются 15 однотипных переправочных средств. Поток поступления техники на переправу в среднем составляет 1 ед./мин, среднее время переправы одной единицы техники - 10 мин (с учетом возвращения назад переправочного средства).
Оценить основные характеристики переправы, в том числе вероятность в немедленной переправе сразу по прибытии единицы техники.
Решение
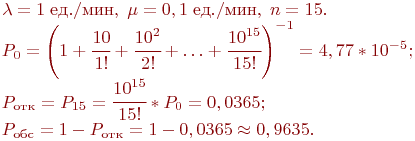
Абсолютная пропускная способность ![]() , т. е. все, что подходит к переправе, тут же практически переправляется.
, т. е. все, что подходит к переправе, тут же практически переправляется.
Среднее число работающих переправочных средств:
Коэффициенты использования и простоя переправы:
Для решения примера была также разработана программа. Интервалы времени поступления техники на переправу, время переправы приняты распределенными по экспоненциальному закону.
Коэффициенты использования переправы после 50 прогонов практически совпадают: ![]() .
.
Максимальная длина очереди 15 ед., среднее время пребывания в очереди около 10 мин.
Если взять число переправочных средств 10, то коэффициент использования близок к 1 ( ![]() ), максимальная длина очереди - 43 единицы техники.
), максимальная длина очереди - 43 единицы техники.
2.5.3. Одноканальная СМО с ограниченной очередью
Если в очереди ![]() мест для ожидания, то система может находиться в одном из следующих
мест для ожидания, то система может находиться в одном из следующих ![]() состояний:
состояний:
![]() - в системе нет заявок (ни в очереди, ни на обслуживании);
- в системе нет заявок (ни в очереди, ни на обслуживании);
![]() - в системе обслуживается одна заявка, очередь пуста;
- в системе обслуживается одна заявка, очередь пуста;
![]() - в системе обслуживается одна заявка, и одна заявка находится в очереди, ожидает обслуживания;
- в системе обслуживается одна заявка, и одна заявка находится в очереди, ожидает обслуживания;
…
![]() - в системе обслуживается одна заявка и
- в системе обслуживается одна заявка и ![]() заявок находятся в очереди, ожидают обслуживания.
заявок находятся в очереди, ожидают обслуживания.
Граф состояний такой системы представляет схему "гибели и размножения" (рис. 2.12).

Рис. 2.12. Граф состояний одноканальной СМО с ограниченной очередью
2.5.4. Одноканальная замкнутая СМО
Опишем состояния одноканальной замкнутой СМО.
![]() - заявок на обслуживание нет.
- заявок на обслуживание нет.
![]() - на обслуживании находится
- на обслуживании находится ![]() заявок;
заявок;
![]() - общее число заявок, циркулирующих в системе;
- общее число заявок, циркулирующих в системе;
![]() - интенсивность требований на обслуживание от одной заявки.
- интенсивность требований на обслуживание от одной заявки.
Граф состояний одноканальной замкнутой СМО приведен на рис. 2.13. Модель данной СМО также представляет "схему гибели и размножения".

увеличить изображение
Рис. 2.13. Граф состояний одноканальной замкнутой СМО
Однако не менее часто модель СМО не сводится к схеме "гибели и размножения". Например, в СМО с конечной надежностью каналов обслуживания.
2.5.5. Одноканальная СМО с конечной надежностью
Построить граф состояний одноканальной СМО с очередью на три заявки и с конечной надежностью каналов обслуживания. При отказе канала обслуживания заявка, находившаяся на обслуживании, теряется. Процессы в системе - марковские.
Описание состояний СМО:
![]() - состояния исправной СМО;
- состояния исправной СМО;
![]() - состояния неисправной СМО.
- состояния неисправной СМО.
Обозначения:
![]() - интенсивность поступления заявок;
- интенсивность поступления заявок;
![]() - интенсивность обработки заявки каналом;
- интенсивность обработки заявки каналом;
![]() - интенсивность поломок канала;
- интенсивность поломок канала;
![]() - интенсивность ремонта неисправного канала.
- интенсивность ремонта неисправного канала.
Граф состояний СМО с конечной надежностью каналов обслуживания приведен на рис. 2.14.
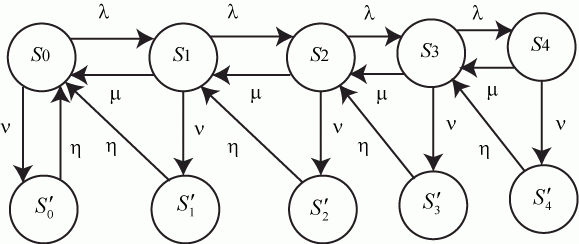
Рис. 2.14. Граф состояний СМО с конечной надежностью
Если в состоянии ![]() (канал свободен, в очереди заявок нет) система выйти из строя не может, то состояния
(канал свободен, в очереди заявок нет) система выйти из строя не может, то состояния ![]() нет. Так как при отказе заявка, находившаяся на обслуживании, теряется, то после восстановления переход осуществляется к предыдущему состоянию, например, из состояния
нет. Так как при отказе заявка, находившаяся на обслуживании, теряется, то после восстановления переход осуществляется к предыдущему состоянию, например, из состояния ![]() в состояние
в состояние ![]() .
.
Эта модель не является моделью "гибели и размножения". Поэтому соответствующие вероятности находятся решением системы линейных алгебраических уравнений, полученных из уравнений Колмогорова для стационарного режима.
2.6. Метод динамики средних. Сущность и содержание метода
В многоэлементных системах часто целью моделирования является определение средних количеств элементов, находящихся в одинаковых состояниях.
Например, в задаче о пеленгации передатчиков противника командира интересует число запеленгованных передатчиков, а не вероятности пеленгации одного передатчика, двух, трех и т. д. Но чтобы определить среднее число их, надо знать вероятности всех возможных состояний ![]() , так как
, так как
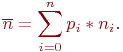
Но число состояний и, следовательно, число уравнений Колмогорова может оказаться настолько большим, что вызовет непреодолимые трудности при моделировании по схеме марковских процессов.
Например, в соединении имеется 100 радиостанций. Каждая из них может находиться в боевых условиях в пяти состояниях:
![]() - исправна, работает, не обнаружена;
- исправна, работает, не обнаружена;
![]() - исправна, работает, обнаружена;
- исправна, работает, обнаружена;
![]() - работоспособна, но подавлена помехами;
- работоспособна, но подавлена помехами;
![]() - обнаружена, поражена;
- обнаружена, поражена;
![]() - находится в ремонте.
- находится в ремонте.
Для определения средних численностей каждого из этих состояний пришлось бы составить ![]() уравнений Колмогорова. Очевидно, такое моделирование не годится.
уравнений Колмогорова. Очевидно, такое моделирование не годится.
В исследовании операций есть метод, позволяющий успешно решать такие и аналогичные задачи. Этот метод называется метод динамики средних.
Метод динамики средних позволяет непосредственно определять математическое ожидание числа элементов сложной системы, находящихся в одинаковых состояниях.
Метод дает приближенные результаты. Но обладает замечательным свойством: чем больше система имеет элементов и состояний, тем точнее результат математического моделирования.
Для получения расчетных формул метода предположим, что имеем дело с системой, обладающей следующими признаками:
- в системе протекает случайный марковский процесс;
- элементы системы однородны в том смысле, что состояния, их число и их вероятности - одинаковые;
- элементы меняют состояния независимо друг от друга.
Цель моделирования: определить средние количества элементов (математические ожидания) ![]() , находящихся в одинаковых состояниях
, находящихся в одинаковых состояниях ![]() , и дисперсию
, и дисперсию ![]() .
.
Схематично такая система может быть представлена так, как показано на рис. 2.15.
Система имеет ![]() элементов, а каждый элемент имеет
элементов, а каждый элемент имеет ![]() состояний. Численность
состояний. Численность ![]() -го состояния на любой момент времени - величина случайная. Обозначим ее
-го состояния на любой момент времени - величина случайная. Обозначим ее ![]() . Матожидание и дисперсия этой случайной величины:
. Матожидание и дисперсия этой случайной величины:
В дальнейшем для лучшей обозримости формул аргумент ![]() писать не будем:
писать не будем:
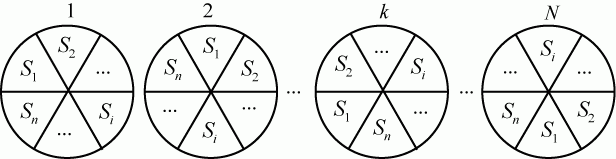
Рис. 2.15. Схематичное представление системы
Введем переменную ![]() так что:
так что:
Отсюда следует, что случайная величина ![]() равна:
равна:
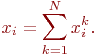
В силу однородности элементов и независимости состояний случайная величина ![]() имеет биномиальное распределение (распределение Бернулли) с матожиданием и дисперсией соответственно:
имеет биномиальное распределение (распределение Бернулли) с матожиданием и дисперсией соответственно:
или окончательно
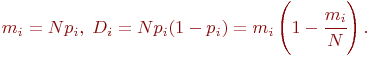
Равенство ![]() связывает вероятность
связывает вероятность ![]() -го состояния элемента в произвольный момент времени с матожиданием численности этих состояний по всем элементам.
-го состояния элемента в произвольный момент времени с матожиданием численности этих состояний по всем элементам.
Определять значения ![]() для одного элемента мы умеем. Для этого достаточно составить систему уравнений Колмогорова и решить ее.
для одного элемента мы умеем. Для этого достаточно составить систему уравнений Колмогорова и решить ее.
Вспомним, что система уравнений Колмогорова для одного элемента содержит ![]() уравнений, для всех
уравнений, для всех ![]() элементов -
элементов - ![]() , а метод динамики средних в
, а метод динамики средних в ![]() раз меньше. В этом и состоит выигрыш, который дает применение метода динамики средних.
раз меньше. В этом и состоит выигрыш, который дает применение метода динамики средних.
Порядок моделирования с использованием метода динамики средних заключается в следующем.
- Описать состояния одного элемента системы.
- Составить размеченный граф состояний для одного элемента, указав рядом с каждым состоянием
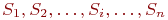 средние численности состояний
средние численности состояний 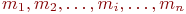 , полученные умножением
, полученные умножением 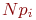 .
. - Составить дифференциальные уравнения (ДУ) по следующим правилам:
- производная средней численности состояния равна сумме стольких членов, сколько стрелок связано с данным состоянием;
- если стрелка направлена из состояния, член имеет знак минус, если в состояние - знак плюс;
- каждый член равен произведению интенсивности потока событий, переводящего элемент по данной стрелке, на среднюю численность того состояния, из которого исходит стрелка.
- Решить систему дифференциальных уравнений относительно
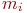 .
. - Вычислить значения дисперсий
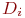 и средних квадратических отклонений
и средних квадратических отклонений 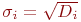 .
.
Поскольку процессы в элементах - марковские, то справедливы все рассуждения об установившихся значениях ![]() , об условиях существования установившихся значений
, об условиях существования установившихся значений ![]() .
.
Полученные уравнения для ![]() называют уже не уравнениями Колмогорова, а уравнениями динамики средних. Поскольку они получаются из уравнений Колмогорова путем умножения всех членов на постоянное число
называют уже не уравнениями Колмогорова, а уравнениями динамики средних. Поскольку они получаются из уравнений Колмогорова путем умножения всех членов на постоянное число ![]() , то их можно писать сразу для средних численностей состояний
, то их можно писать сразу для средних численностей состояний ![]() по образцу уравнений для вероятностей
по образцу уравнений для вероятностей ![]() .
.
Рассмотрим на примере методику моделирования с использованием метода динамики средних.
Пример 2.8. В части имеются 100 средств связи (СС). СС выходят из строя с интенсивностью ![]() . При нахождении СС в неисправном состоянии проводится его диагностика, в результате чего оно может быть отправлено в ремонтное подразделение части (интенсивность отправки
. При нахождении СС в неисправном состоянии проводится его диагностика, в результате чего оно может быть отправлено в ремонтное подразделение части (интенсивность отправки ![]() ), либо во внешнее ремонтное подразделение (интенсивность отправки
), либо во внешнее ремонтное подразделение (интенсивность отправки ![]() ), либо списано (интенсивность списания
), либо списано (интенсивность списания ![]() ).
В ремонтном подразделении части СС ремонтируются с интенсивностью
).
В ремонтном подразделении части СС ремонтируются с интенсивностью ![]() , а во внешнем ремонтном подразделении - с интенсивностью
, а во внешнем ремонтном подразделении - с интенсивностью ![]() . СС части пополняются с интенсивностью
. СС части пополняются с интенсивностью ![]() , в среднем равной интенсивности списания.
, в среднем равной интенсивности списания.
Требуется провести моделирование с целью определения средних численностей каждого состояния СС.
Решение
- Описание состояний одного средства связи
Система может иметь следующие четыре состояния:
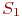 - СС исправно;
- СС исправно;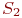 - СС неисправно, производится диагностика;
- СС неисправно, производится диагностика; - СС находится на ремонте в ремонтном подразделении части;
- СС находится на ремонте в ремонтном подразделении части; - СС находится на ремонте во внешнем ремонтном подразделении.
- СС находится на ремонте во внешнем ремонтном подразделении. - Построение размеченного графа состояний
Размеченный граф состояний представлен на рис. 2.16.
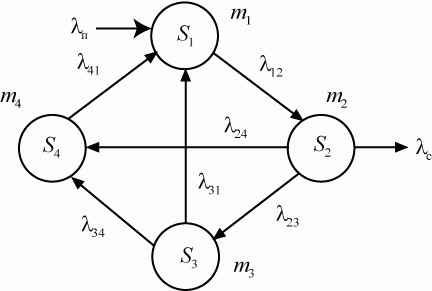
Рис. 2.16. Размеченный граф состояний системы ремонта - Составление системы дифференциальных уравнений
Каждое уравнение системы составляется по тому же правилу, что и система дифференциальных уравнений Колмогорова.
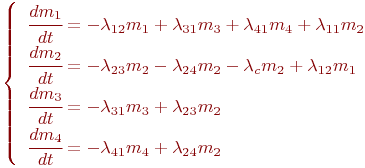
Численности состояний являются функциями времени, т. е.
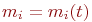 . В системе дифференциальных уравнений запись упрощена. Выражение для пополняющего члена написано из условия равенства в среднем пополнения и убыли
. В системе дифференциальных уравнений запись упрощена. Выражение для пополняющего члена написано из условия равенства в среднем пополнения и убыли 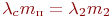 . Также мы не можем воспользоваться нормировочным условием
. Также мы не можем воспользоваться нормировочным условием 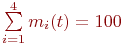 , так как в силу случайного характера списания и пополнения в некоторые моменты времени оно может не выполняться. Общее число СС в части при этом меняется со временем:
, так как в силу случайного характера списания и пополнения в некоторые моменты времени оно может не выполняться. Общее число СС в части при этом меняется со временем: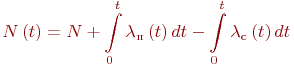
- Решение системы дифференциальных уравнений относительно m_{i}
Решить систему ДУ можно методом численного интегрирования, например, Рунге-Кутта, задав начальные значения численностей состояний для момента
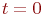 :
: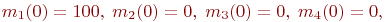
считая интенсивности
 известными.
известными. - Вычисление дисперсий и среднеквадратических отклонений
Дисперсия вычисляется по формуле:
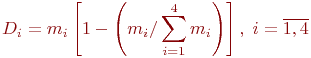
По дисперсии определяется среднеквадратическое отклонение численности состояний
и находится диапазон возможных значений численности 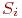 состояния
состояния  .
.
Метод динамики средних справедлив и для предельных значений численностей состояний. В данной задаче уравнения динамики средних - система линейных алгебраических уравнений:
Однако прежде чем переходить к этим уравнениям, нужно сначала убедиться, что стационарные значения ![]() существуют. Здесь численности состояний
существуют. Здесь численности состояний ![]() не являются функциями времени. Поэтому можно воспользоваться нормировочным условием.
не являются функциями времени. Поэтому можно воспользоваться нормировочным условием.
2.7. Принцип квазирегулярности
Как показывает практика, метод динамики средних вполне приемлем и для немарковских процессов, то есть для произвольных распределений времен нахождения элементов в состояниях ![]() .
.
Хотя в этих случаях мы формально не имеем права написать уравнения динамики средних, однако массовость явления делает вид распределения не очень существенным. Следовательно, при моделировании не следует тратить время на проверку марковости процесса. Чем больше элементов в системе, чем она сложнее, тем точнее она моделируется методом динамики средних.
При большом числе элементов также становится не очень существенным требование однородности элементов.
Теперь попробуем разобраться с требованием, которое мы также ввели ранее - требование независимости элементов.
Применяя метод динамики средних, мы можем встретиться с очень серьезной трудностью. Дело в том, что интенсивности потоков событий, переводящих элементы из одного состояния в другое, могут зависеть от численности состояний. Например, в примере 2.6 интенсивность ![]() зависит от того, сколько в данный момент времени находится СС в состоянии
зависит от того, сколько в данный момент времени находится СС в состоянии ![]() : СС может либо сразу ремонтироваться, либо ожидать очереди ввиду занятости рабочих мест. Численности состояний случайны, следовательно, интенсивности потоков событий тоже случайны и неизвестны. Точное решение в таких ситуациях невозможно, однако вполне приемлемое для практики решение находится с помощью допущения, которое называют "принцип квазирегулярности".
: СС может либо сразу ремонтироваться, либо ожидать очереди ввиду занятости рабочих мест. Численности состояний случайны, следовательно, интенсивности потоков событий тоже случайны и неизвестны. Точное решение в таких ситуациях невозможно, однако вполне приемлемое для практики решение находится с помощью допущения, которое называют "принцип квазирегулярности".
Принцип квазирегулярности состоит в следующем: интенсивности ![]() зависят не от мгновенных значений численности состояний
зависят не от мгновенных значений численности состояний ![]() , а от их средних значений (математических ожиданий)
, а от их средних значений (математических ожиданий) ![]() .
.
Погрешность от этого допущения при моделировании тем меньше, чем ближе к линейной зависимости ![]() и чем больше общее количество элементов
и чем больше общее количество элементов ![]() .
.
На практике проверено, что при ![]() точность моделирования приемлема для инженерных "прикидок", если же функции
точность моделирования приемлема для инженерных "прикидок", если же функции ![]() близки к линейным, то приемлемые результаты получаются и при
близки к линейным, то приемлемые результаты получаются и при ![]() .
.
Пример 2.9. Каждый автомат, находящийся на вооружении в воинской части, может находиться в исправном состоянии или ремонтироваться в мастерской части. Если бы каждый неисправный автомат сразу попадал к свободному мастеру, то никаких очередей из автоматов, ожидающих ремонта, не было, и граф состояний автомата имел бы вид, приведенный на рис. 2.17.
Здесь:
![]() - автомат исправен;
- автомат исправен;
![]() - автомат неисправен, ремонтируется;
- автомат неисправен, ремонтируется;
![]() - интенсивность выхода автомата из строя;
- интенсивность выхода автомата из строя;
![]() - интенсивность ремонта автомата одним мастером.
- интенсивность ремонта автомата одним мастером.
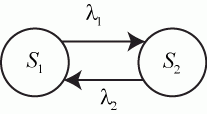
Рис. 2.17. Граф состояний автомата
В этом случае ![]() и
и ![]() были бы постоянными величинами и, естественно, не зависели от численности состояний. Уравнения динамики средних имели бы вид:
были бы постоянными величинами и, естественно, не зависели от численности состояний. Уравнения динамики средних имели бы вид:
так как мы полагаем, что процессы наработки на отказ и ремонта - марковские и стационарный режим существует. ![]() - общее число автоматов в части.
- общее число автоматов в части.
Уравнение для состояния ![]() не пишем, так как оно линейно зависит от первого.
не пишем, так как оно линейно зависит от первого.
А теперь предположим, что в мастерской части два мастера и неисправные автоматы могут ожидать ремонта. В этом случае интенсивность переходов из неисправного состояние в исправное зависит от числа автоматов, находящихся в мастерской. Обозначим эту интенсивность ![]() . Граф состояний имеет вид (рис. 2.18).
. Граф состояний имеет вид (рис. 2.18).
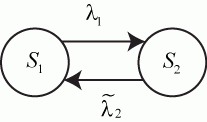
Рис. 2.18. Граф состояний автомата
Общую интенсивность ремонта мастерской обозначим ![]() . График ее показан на рис. 2.19а.
. График ее показан на рис. 2.19а.
Рис. 2.19. Графики \phi(x2) и \lambda 2
При ![]() интенсивность
интенсивность ![]() максимальна, так как работают оба мастера. При дальнейшем увеличении
максимальна, так как работают оба мастера. При дальнейшем увеличении ![]() интенсивность
интенсивность ![]() возрастать не может.
возрастать не может.
Очевидно, интенсивность ремонта, приходящаяся на один автомат, находящийся в мастерской:
График зависимости ![]() от
от ![]() показан на рис. 2.19б.
показан на рис. 2.19б.
Применим принцип квазирегулярности, то есть будем считать, что ![]() зависит не от случайных численностей
зависит не от случайных численностей ![]() , а от среднего значения (матожидания)
, а от среднего значения (матожидания) ![]() . Тогда:
. Тогда:
и уравнения динамики средних примут вид:
Зависимость ![]() задана рис. 2.19б.
задана рис. 2.19б.
Пример 2.10. Вернемся к задаче о пеленгации передатчиков противника. Поскольку целью ее решения являлось определение среднего числа запеленгованных передатчиков, то возможно применение метода динамики средних. Обозначим:
![]() - состояние "передатчик запеленгован";
- состояние "передатчик запеленгован";
![]() - случайная численность состояния
- случайная численность состояния ![]() ;
;
![]() - состояние "передатчик потерян";
- состояние "передатчик потерян";
![]() - интенсивность обнаружения частоты передатчика противника одним оператором;
- интенсивность обнаружения частоты передатчика противника одним оператором;
![]() - интенсивность потерь слежения запеленгованного передатчика противника;
- интенсивность потерь слежения запеленгованного передатчика противника;
![]() - текущее число операторов, ведущих поиск;
- текущее число операторов, ведущих поиск;
![]() - интенсивность обнаружения всеми операторами одного передатчика;
- интенсивность обнаружения всеми операторами одного передатчика;
![]() - число не захваченных частот передатчиков, находящихся в состоянии
- число не захваченных частот передатчиков, находящихся в состоянии ![]() .
.
Граф состояний одного передатчика приведен на рис. 2.20. Заменим, в соответствии с принципом квазирегулярности, случайную численность обнаруженных передатчиков ![]() на среднее значение
на среднее значение ![]() и, учитывая наличие стационарности, запишем уравнение динамики средних:
и, учитывая наличие стационарности, запишем уравнение динамики средних:
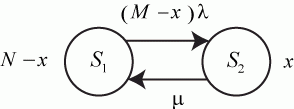
Рис. 2.20. Граф состояний передатчика
Уравнения динамики средних могут быть нелинейными и, следовательно, решение будет не единственным. В таких случаях берется то решение, которое не противоречит смыслу задачи.
Для упрощения расчетов положим ![]() . В этом случае уравнение принимает вид:
. В этом случае уравнение принимает вид:
Его решение ![]() передатчика (знак плюс перед корнем отбрасываем, так как в этом случае корень будет равен 13,7, что бессмысленно). Решение этого примера с помощью уравнений Колмогорова дает ответ
передатчика (знак плюс перед корнем отбрасываем, так как в этом случае корень будет равен 13,7, что бессмысленно). Решение этого примера с помощью уравнений Колмогорова дает ответ ![]() . Расхождение в 2,5 % объясняется малочисленностью группировок
. Расхождение в 2,5 % объясняется малочисленностью группировок ![]() и
и ![]() . Впрочем, полученный результат может быть вполне приемлемым.
. Впрочем, полученный результат может быть вполне приемлемым.
2.8. Элементарные модели боя
Приемлемая по точности математическая модель такой сложной системы как бой невозможна из-за наличия неопределенных и неформализуемых факторов и уникальных ситуаций. Однако, приблизительные частные модели возможны и целесообразны для количественного обоснования некоторых решений, оценки обстановки, прогнозирования результатов решений и др.
Рассмотрим некоторые элементарные модели боя.
2.8.1. Модель высокоорганизованного боя
Постановка задачи
Две группировки А и Б ведут бой. В составе группировок А и Б ![]() и
и ![]() боевых единиц со скорострельностями
боевых единиц со скорострельностями ![]() и
и ![]() и вероятностями поражения цели при одном выстреле
и вероятностями поражения цели при одном выстреле ![]() и
и ![]() соответственно. Каждая группировка однородна, но не обязательно группировки однородны между собой. Например, бой танков с танками, танков с противотанковыми средствами, истребителей с бомбардировщиками и т. п.
соответственно. Каждая группировка однородна, но не обязательно группировки однородны между собой. Например, бой танков с танками, танков с противотанковыми средствами, истребителей с бомбардировщиками и т. п.
Высокоорганизованным боем называют бой с полной информацией, а именно:
- любая боевая единица одной стороны, пока она не поражена, может вести огонь по любой непораженной боевой единице другой стороны;
- разведка, связь и управление идеальны, то есть перенос огня каждого средства на новую цель происходит мгновенно после поражения предыдущей цели;
- пораженная боевая единица в дальнейших действиях не участвует, то есть за время боя не восстанавливается, пополнения сторон нет;
- временем полета носителя заряда пренебрегаем;
- перенос огня не влияет на скорострельность и вероятность поражения;
- количество боеприпасов неограниченно;
- противоборствующие группировки достаточно многочисленны (это необходимое допущение будет обосновано при моделировании).
При этих допущениях процесс динамики боя двух группировок может рассматриваться как случайный марковский процесс с дискретными состояниями и непрерывным временем, для которого могут быть получены уравнения динамики средних, позволяющие определить для любого момента времени средние численности сторон.
Цель моделирования. Прогнозирование средних количеств пораженных и непораженных боевых единиц каждой группировки на любой момент времени.
Моделирование
Описание состояний одной боевой единицы
Каждое средство противоборствующих сторон А и Б может находиться в одном из двух состояний соответственно:
![]() - не поражено;
- не поражено;
![]() - поражено.
- поражено.
Построение размеченных графов состояний
Графы состояний для каждой группировки элементарны (рис. 2.21).

Рис. 2.21. Граф состояний противоборствующих сторон
Интенсивность ![]() - интенсивность потока поражающих выстрелов стороны Б, приходящихся на одну боевую единицу стороны А, то есть переводящих ее из состояния
- интенсивность потока поражающих выстрелов стороны Б, приходящихся на одну боевую единицу стороны А, то есть переводящих ее из состояния ![]() в состояние
в состояние ![]() .
.
Аналогичные рассуждения объясняют ![]() . Очевидно, для начального состояния (
. Очевидно, для начального состояния ( ![]() ):
):
Составление уравнений динамики средних
В ходе боя численности боеспособных единиц сторон будут случайным образом изменяться (уменьшаться, так как пополнение средств поражения сторон мы пока не рассматриваем). Обозначим эти случайные численности каждой стороны ![]() и
и ![]() соответственно. Тогда:
соответственно. Тогда:
Зависимость ![]() и
и ![]() от случайных значений
от случайных значений ![]() и
и ![]() делает аналитическое решение задачи практически невозможным. Поэтому, используя принцип квазирегулярности, заменим
делает аналитическое решение задачи практически невозможным. Поэтому, используя принцип квазирегулярности, заменим ![]() и
и ![]() их матожиданиями
их матожиданиями ![]() и
и ![]() .
.
Заметим, что ![]() и
и ![]() являются целью моделирования.
являются целью моделирования.
После замены выражения для ![]() и
и ![]() принимают вид:
принимают вид:
Запишем уравнения динамики средних для состояний ![]() и
и ![]() :
:
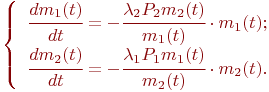
Для состояний ![]() и
и ![]() уравнения не нужны, так как средние численности этих состояний
уравнения не нужны, так как средние численности этих состояний ![]() и
и ![]() однозначно связаны с
однозначно связаны с ![]() и
и ![]() :
:
После очевидного упрощения уравнения динамики средних принимают вид:
Здесь и далее для лучшей обозримости аргумент ![]() в
в ![]() и
и ![]() опустим.
опустим.
Систему уравнений (2.3) обычно называют уравнениями динамики боя, иногда - уравнениями Ланчестера. Ланчестер - полковник английской армии времен первой мировой войны. Именно он предложил излагаемые подходы формализации боевых действий.
Решение уравнений динамики средних
Искомые численности сторон ![]() и
и ![]() находятся интегрированием системы (2.3) при начальных условиях:
находятся интегрированием системы (2.3) при начальных условиях:
Решение имеет вид:
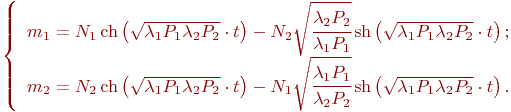
Для лучшей обозримости введем обозначения:
![]() - эффективная скорострельность стороны А;
- эффективная скорострельность стороны А;
![]() - эффективная скорострельность стороны Б.
- эффективная скорострельность стороны Б.
Эффективные скорострельности характеризуют плотности потоков успешных выстрелов соответствующей стороны.
![]() - доля боеспособных единиц стороны А;
- доля боеспособных единиц стороны А;
![]() - доля боеспособных единиц стороны Б;
- доля боеспособных единиц стороны Б;
![]() - коэффициент преимущества стороны А над стороной Б;
- коэффициент преимущества стороны А над стороной Б;
![]() - приведенное время.
- приведенное время.
С учетом этих обозначений решение модели высокоорганизованного боя выглядит так:
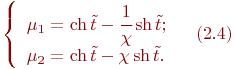
Графически варианты решений модели в зависимости от коэффициента превосходства представлены на рис. 2.22.
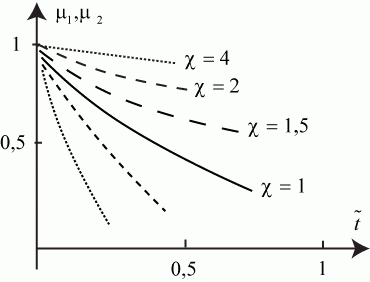
Рис. 2.22. Графики решений уравнений динамики средних
Из формул видно, что убывание численности группировок в большей мере зависит от соотношения сил ![]() , чем от соотношения эффективных скорострельностей
, чем от соотношения эффективных скорострельностей ![]() : первое отношение входит в формулы непосредственно, а второе - под знаком корня. Увеличение начальной численности
: первое отношение входит в формулы непосредственно, а второе - под знаком корня. Увеличение начальной численности ![]() в два раза удваивает параметр
в два раза удваивает параметр ![]() , тогда как удвоение
, тогда как удвоение ![]() увеличивает
увеличивает ![]() только в
только в ![]() раза. Поэтому повышение скорострельности менее выгодно.
раза. Поэтому повышение скорострельности менее выгодно.
В рамках данной модели при ![]() выигрывает бой сторона А, при
выигрывает бой сторона А, при ![]() - сторона Б.
- сторона Б.
Кривые ![]() на рис. 2.22 оборваны до достижения нуля, так как при малочисленных группировках метод динамики средних дает большие ошибки.
на рис. 2.22 оборваны до достижения нуля, так как при малочисленных группировках метод динамики средних дает большие ошибки.
Если силы сторон равны ( ![]() ), то динамика сохранения сил сторон одинакова;
), то динамика сохранения сил сторон одинакова; ![]() в любой момент боя. Бой будет продолжаться до определенного уровня истощения сил, после чего неизбежны попытки политического решения конфликта.
в любой момент боя. Бой будет продолжаться до определенного уровня истощения сил, после чего неизбежны попытки политического решения конфликта.
В рамках этой модели бой заканчивается разгромом слабой стороны тем быстрее, чем больше превосходство другой. Победа в этой модели достигается числом, не уменьем. Не учитывается опыт, способности командиров, обученность личного состава. Впрочем, параметр ![]() косвенно учитывает обученность экипажей средств поражения.
косвенно учитывает обученность экипажей средств поражения.
Пример 2.11. Группировка, в составе которой 270 противотанковых средств (ПТС), находится в обороне. Скорострельность каждого ПТС 6 выстр./мин, вероятность поражения одним ПТС одного танка равна 0,3. Скорострельность танка 4 выстр./мин, вероятность поражения одним танком одного ПТС 0,25 при коэффициенте превосходства 1,2.
Спрогнозировать, сколько нужно танков, чтобы прорвать оборону при полном уничтожении ПТС группировки.
Решение
Известно, что
откуда
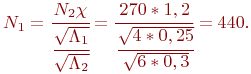
Заметим, коэффициент преимущества ![]() не имеет иного смысла, кроме упрощения формул для вычисления
не имеет иного смысла, кроме упрощения формул для вычисления ![]() и
и ![]() . Поэтому результаты расчетов не имеют оперативно-тактического обоснования.
. Поэтому результаты расчетов не имеют оперативно-тактического обоснования.
Задача 2.12. Сторона А имеет 30 огневых средств со скорострельностью каждого 5 выстр./мин и вероятностью поражения 0,2. Сторона Б имеет 40 огневых средств со скорострельностью каждого 4 выстр./мин и вероятностью поражения 0,3.
Провести расчеты для прогноза исхода боя, времени его окончания и количества сохранившихся огневых средств у победившей стороны.
Решение
Исходные данные
Прогнозирование исхода боя
Составим соотношения превосходства сторон:
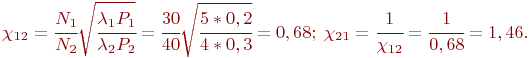
Так как ![]() , то преимущество будет у стороны Б, то есть победить должна сторона Б.
, то преимущество будет у стороны Б, то есть победить должна сторона Б.
Прогнозирование времени окончания боя
Бой продолжается до полной победы, то есть ![]() или из (2.4)
или из (2.4)
Учтем, что ![]() , откуда
, откуда
С другой стороны, из (2.5) ![]() .
.
Из выражений (2.5) и (2.6) имеем:
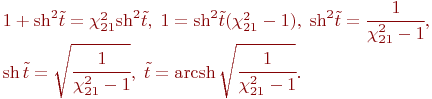
Так как ![]() , то
, то 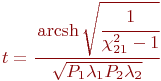 .
.
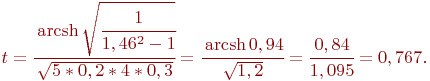
Определение количества огневых средств, сохранившихся у стороны Б
Так как из выражения (2.5) ![]() , то
, то
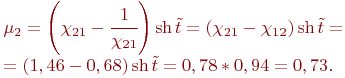
Теперь ![]() .
.
К концу боя у стороны Б останется от 29 до 30 огневых средств, тогда как огневые средства стороны А будут полностью уничтожены.
Приведенные результаты прогноза исхода боя двух группировок являются приблизительными, оценочными, так как при малых количествах огневых средств ( ![]() ) метод динамики средних, лежащий в основе уравнений динамики боя, может давать существенные ошибки.
) метод динамики средних, лежащий в основе уравнений динамики боя, может давать существенные ошибки.
2.8.2. Высокоорганизованный бой с пополнением группировок
В ходе боя противоборствующие стороны могут вводить резервы. Пусть сторона А вводит резерв ![]() в момент времени
в момент времени ![]() , сторона Б - резерв
, сторона Б - резерв ![]() в момент времени
в момент времени ![]() . Такую ситуацию можно наглядно представить диаграммой (рис. 2.23).
. Такую ситуацию можно наглядно представить диаграммой (рис. 2.23).
Весь интервал исследования содержит три подинтервала, так в сумме резервы обеими сторонами вводятся три раза.
 . Значения
. Значения  и
и 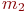 находятся интегрированием уравнения динамики боя (2.3) при начальных условиях
находятся интегрированием уравнения динамики боя (2.3) при начальных условиях 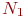 и
и 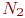 .
.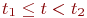 . Значения и на этом временном участке находятся интегрированием тех же уравнений динамики боя (2.3), но при начальных условиях
. Значения и на этом временном участке находятся интегрированием тех же уравнений динамики боя (2.3), но при начальных условиях 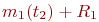 и
и 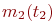 .
.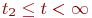 . Значения и на этом временном участке находятся интегрированием тех же уравнений динамики боя (2.3), но при начальных условиях
. Значения и на этом временном участке находятся интегрированием тех же уравнений динамики боя (2.3), но при начальных условиях 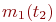 и
и 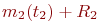 .
.
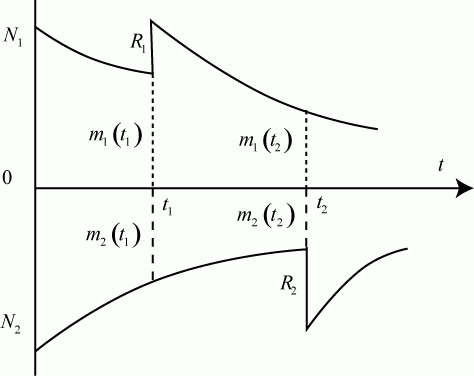
Рис. 2.23. Иллюстрация к пополнению группировок
2.8.3. Высокоорганизованный бой с упреждением ударов
Предположим, что одна из сторон, например, сторона А, ведет огонь в то время, когда сторона Б еще не в состоянии ответить. Представим эту ситуацию диаграммой (рис. 2.24).
Цель моделирования также состоит в определении ![]() и
и ![]() на любой момент противоборства сторон. Как и в предыдущем случае, решение находится по частям для каждого характерного временного промежутка. Здесь их два.
на любой момент противоборства сторон. Как и в предыдущем случае, решение находится по частям для каждого характерного временного промежутка. Здесь их два.
 . На этом временном промежутке огонь ведет только сторона А (
. На этом временном промежутке огонь ведет только сторона А (  - время упреждения). Уравнения динамики боя здесь выглядят так:
- время упреждения). Уравнения динамики боя здесь выглядят так:
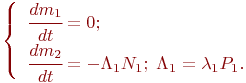
Значения
находят интегрированием при начальном условии 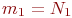 .
.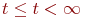 . Значения и на этом участке также находятся интегрированием уравнений динамики средних, но при начальных условиях и
. Значения и на этом участке также находятся интегрированием уравнений динамики средних, но при начальных условиях и 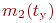 . Величина известна, а величину
. Величина известна, а величину 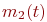 найдем из уравнения
найдем из уравнения 
Рис. 2.24. Иллюстрация к упреждению удара
2.8.4. Модель боя с неполной информацией
Боевые единицы двух противоборствующих сторон распределены случайно (для противоположной стороны) на площадях ![]() и
и ![]() . Каждая боевая единица занимает некоторую площадь - позицию, величина которой
. Каждая боевая единица занимает некоторую площадь - позицию, величина которой ![]() и
и ![]() у сторон А и Б соответственно. Цель уничтожается при попадании заряда в площадь цели.
у сторон А и Б соответственно. Цель уничтожается при попадании заряда в площадь цели.
Схематично такое противоборство показано на рис. 2.25.
Как и в предыдущих случаях, ![]() и
и ![]() - первоначальные численности боевых единиц, скорострельности боевых единиц
- первоначальные численности боевых единиц, скорострельности боевых единиц ![]() и
и ![]() , вероятности поражения одним выстрелом -
, вероятности поражения одним выстрелом - ![]() и
и ![]() сторон А и Б соответственно.
сторон А и Б соответственно.
Огонь по площадям ![]() и
и ![]() ведется неприцельно.
ведется неприцельно.
Рис. 2.25. Иллюстрация к модели боя с неполной информацией
Цель моделирования - определение среднего числа непораженных целей ![]() и
и ![]() на каждый момент времени ведения огня.
на каждый момент времени ведения огня.
Уравнения динамики боя соответствуют уравнениям динамики средних (2.3). Однако, в отличие от высокоорганизованного боя, вероятности ![]() и
и ![]() зависят от числа непораженных целей
зависят от числа непораженных целей ![]() и
и ![]() :
:
Следовательно, уравнения имеют вид:
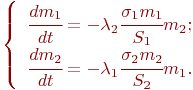
Начальные условия для интегрирования: ![]() и
и ![]() .
.
Если площади целей различны ( ![]() ), то в уравнениях очевидны замены:
), то в уравнениях очевидны замены:
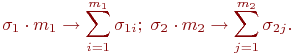
2.8.5. Учет запаздывания в переносе и открытии огня
Такая ситуация возможна при плохой разведке, связи, управлении огнем.
Пусть ![]() - время запаздывания открытия огня стороной А,
- время запаздывания открытия огня стороной А, ![]() - стороной Б. Тогда интенсивности потоков поражающих выстрелов сторон, приходящихся на одну цель, равны:
- стороной Б. Тогда интенсивности потоков поражающих выстрелов сторон, приходящихся на одну цель, равны:
Уравнения динамики боя принимают вид:
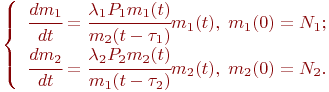
На рис. 2.26 в момент времени ![]() действительные значения боеспособных средств сторон равны
действительные значения боеспособных средств сторон равны ![]() и
и ![]() . Но в это время сторона А ведет огонь по целям, разведанным ранее, в момент времени
. Но в это время сторона А ведет огонь по целям, разведанным ранее, в момент времени ![]() ; сторона Б - по целям, разведанным в момент времени
; сторона Б - по целям, разведанным в момент времени ![]() .
.
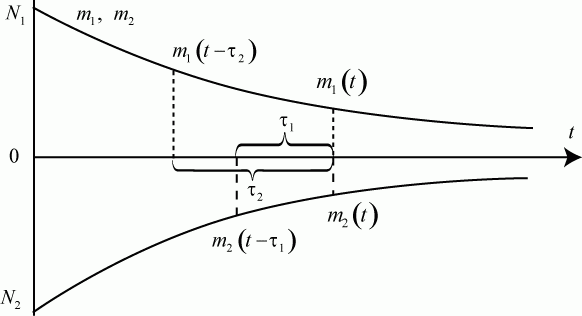
Рис. 2.26. Иллюстрация к учету запаздывания в переносе и открытии огня
Ценность рассмотренных моделей противоборства сторон в функциональном плане всегда ограничена - об этом было сказано в начале п. 2.8. Но они, бесспорно, расширяют наши представления о приемах и подходах к аналитическому моделированию сложных процессов.
Вопросы для самоконтроля
- Что такое аналитическая модель? Ее отличия от других моделей.
- Определение марковского случайного процесса. Причина "популярности" моделирования по схеме марковских процессов.
- Что такое однородный и неоднородный марковские процессы?
- Правило составления уравнений Колмогорова.
- Эргодическая теорема Маркова.
- Схема "гибели и размножения".
- Характеристика элементов СМО.
- Показатели СМО с отказами.
- Показатели СМО с ожиданием.
- Одноканальная СМО с очередью на 4 заявки и конечной надежностью канала. В момент отказа заявка, которая обслуживалась в канале, возвращается в очередь, если там есть место, иначе теряется. Во время ремонта заявки в СМО не поступают. Интенсивности поступления и обслуживания заявок
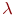 и
и 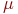 , соответственно. Интенсивности выхода из строя и ремонта канала
, соответственно. Интенсивности выхода из строя и ремонта канала  и
и 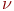 соответственно. Описать состояния системы, составить размеченный граф состояний, уравнения Колмогорова и систему алгебраических уравнений для вычисления предельных вероятностей состояний системы. Привести пример количественного решения полученных уравнений в математической программе.
соответственно. Описать состояния системы, составить размеченный граф состояний, уравнения Колмогорова и систему алгебраических уравнений для вычисления предельных вероятностей состояний системы. Привести пример количественного решения полученных уравнений в математической программе. - Двухканальная СМО с очередью на 4 заявки и конечной надежностью канала. В момент отказа заявки, которые обслуживались в канале, возвращаются в очередь, если там есть место, иначе теряются. Во время ремонта заявки в СМО не поступают. Интенсивности поступления и обслуживания заявок и , соответственно. Интенсивности выхода из строя и ремонта канала и соответственно. Описать состояния системы, составить размеченный граф состояний, уравнения Колмогорова и систему алгебраических уравнений для вычисления предельных вероятностей состояний системы. Привести пример количественного решения полученных уравнений в математической программе.
- Зачем нужно знать метод динамики средних?
- Допущения при выводе моделей динамики средних.
- В организации 2000 однотипных приборов, каждый из которых может быть в одном из трех состояний: исправен, находиться в ремонте в мастерской организации (МО), на ремонтном предприятии. Интенсивность выхода из строя . В МО прибор может быть отремонтирован и возвращен в организацию, либо отправлен на ремонтное предприятие. Средняя длительность ремонта в МО
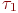 , а интенсивность отправки на предприятие . Средняя длительность ремонта на предприятии
, а интенсивность отправки на предприятие . Средняя длительность ремонта на предприятии 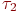 . После ремонта на предприятии прибор возвращается в организацию. Составить аналитическую модель с целью определения средних численностей приборов в каждом состоянии. Привести пример количественного решения полученных уравнений в математической программе.
. После ремонта на предприятии прибор возвращается в организацию. Составить аналитическую модель с целью определения средних численностей приборов в каждом состоянии. Привести пример количественного решения полученных уравнений в математической программе. - Сформулируйте принцип квазирегулярности. Когда возникает необходимость его применения?
- Применение метода динамики средних при выводе модели противоборства двух сторон.
- Как учесть в модели противоборства ввод резервов?
- Как учесть в модели противоборства упреждающие удары одной из сторон?
- Как учесть в модели противоборства отсутствие разведки в ходе обмена ударами?
- Как учесть в модели противоборства запаздывание в переносе огня?
Лекция 3. Статистическое моделирование
Имитационная модель представляет собой программу, реализованную на компьютере, описывающую (моделирующую) функционирование элементов моделируемой системы, их связь между собой и внешней средой. Поэтому имитационную модель следует называть компьютерной моделью и имитационное моделирование - компьютерным моделированием, тем более, что название "имитационное моделирование" несет в себе тавтологию: имитация и моделирование - очень сходные понятия. Тем не менее, термин "имитационное моделирование" прижился и широко используется в отечественной технической и научной литературе.
Имитационная модель является функциональной, так как она создается для получения характеристик моделируемого процесса, а не структуры. Однако, моделирующий алгоритм, как правило, имеет модульную структуру, аналогичную размещению и связям элементов в моделируемом объекте.
Имитационная модель дает численное решение задачи, что не позволяет непосредственно усматривать функциональные связи между параметрами процесса, как это демонстрируют аналитические модели. Однако, выполнив серию экспериментов с моделью, направленно изменяя значения исследуемого фактора, и, выполнив обработку результатов, можно построить искомую связь между показателем эффективности системы и исследуемым фактором.
Имитационную модель, в отличие от аналитической модели, можно разработать с любой детализацией процесса или явления.
Как правило, имитационные модели создают для исследования процессов, на течение которых влияют различного рода случайности: отказы и сбои технических устройств, неточности измерений, рассеивание попаданий относительно точек прицеливания, и многое другое. Следовательно, результат такого процесса случаен. В имитационной модели случайные факторы моделируются при помощи специально подобранных генераторов случайных величин, которые входят в современные системы имитационного моделирования. Для получения характеристик таких вероятностных операций имитационная модель многократно реализуется на компьютере. Полученный при этом ряд значений исследуемого параметра подвергается статистической обработке, в результате которой и определяются характеристики случайных показателей процесса - матожидание, дисперсия, закон распределения и т. п. Такие имитационные модели называют статистическими имитационными или статистическими.
3.1. Сущность имитационного моделирования
Сущность имитационного моделирования рассмотрим на примере.
Пример 3.1. По объекту наносится одиночный ракетный удар. Радиус поражения ![]() .
.
Попадание ракеты в цель характеризуется рассеиванием, распределенным по нормальному закону со среднеквадратическими отклонениями:
- по дальности
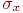 ;
; - по направлению
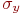 .
.
Цель будет уничтожена, если расстояние ![]() от нее (то есть от точки прицеливания) до центра взрыва ракеты будет меньше или равно
от нее (то есть от точки прицеливания) до центра взрыва ракеты будет меньше или равно ![]() , то есть
, то есть ![]() .Так как
.Так как ![]() размеров объекта, то цель можно считать точечной.
размеров объекта, то цель можно считать точечной.
Наличие рассеивания исключает однозначный ответ: "цель поражена - цель не поражена". Задача носит вероятностный характер, поэтому в результате моделирования может быть получен ответ: цель будет поражена с вероятностью ![]() .
.
Цель моделирования: определить вероятность ![]() поражения объекта одиночным ракетным ударом.
поражения объекта одиночным ракетным ударом.
Решение
Построим декартову систему координат так, чтобы точечный объект находился в начале координат, а направление пуска ракеты совпадало с осью ![]() (рис. 3.1).
(рис. 3.1).
Возьмем две последовательности нормально распределенных случайных чисел:
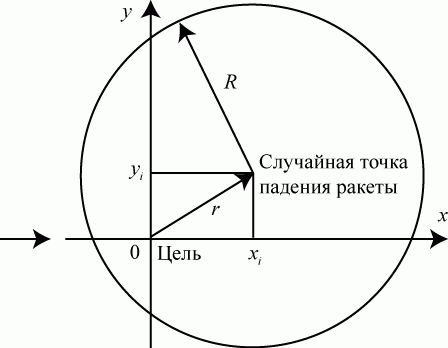
Рис. 3.1. Иллюстрация к нанесению удара
Первая последовательность соответствует распределению ![]() , вторая -
, вторая - ![]() . Матожидания
. Матожидания ![]() ,
,
![]() взяты равными нулю, так как объект поражения (точка прицеливания) находится в начале координат, то есть имеет координаты
взяты равными нулю, так как объект поражения (точка прицеливания) находится в начале координат, то есть имеет координаты ![]() и
и ![]() .
.
Закон и характеристики случайных чисел ![]() и
и ![]() соответствуют закону рассеивания пуска ракет.
соответствуют закону рассеивания пуска ракет.
Моделирование
- Имитируем удар, то есть мысленно нанесем удар по объекту путем определения координат взрыва. В силу идентичности закона рассеивания и его характеристик с законами распределения случайных чисел такими координатами могут быть
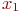 и
и 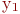 , взятые из последовательностей случайных чисел.
, взятые из последовательностей случайных чисел. - Вычислим расстояние
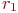 от места взрыва ракеты до цели:
от места взрыва ракеты до цели: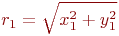
- Оценим результаты имитации удара, то есть установим факт поражения или непоражения объекта:
- если
 , то объект поражен;
, то объект поражен; - если
 , то объект непоражен.
, то объект непоражен.
- если
- Если объект поражен, запомним этот факт увеличением
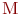 на единицу, то есть
на единицу, то есть 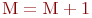 (в начале
(в начале 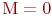 ).
). - Для нахождения вероятности поражения объекта повторим имитацию нанесения удара
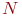 раз.
раз. - Оценим вероятность через частость поражения объекта:
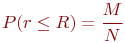
Возможность оценки вероятности частостью доказывается теоремой Я. Бернулли: при неограниченном числе однородных независимых опытов с практической достоверностью можно утверждать, что частота события будет сколь угодно мало отличаться от его вероятности в отдельном опыте (Бернулли Якоб 1 - самый старший из восьми представителей этой швейцарской семьи - выдающихся ученых).
Чем больше число ![]() (число реализаций, число испытаний, число прогонов модели), тем точнее будет оценка вероятности
(число реализаций, число испытаний, число прогонов модели), тем точнее будет оценка вероятности ![]() .
.
В рассмотренном примере 3.1 при ![]() ,
, ![]() ,
, ![]() оценки вероятностей
оценки вероятностей ![]() поражения цели при различном числе реализаций модели показаны в табл. 3.1.
поражения цели при различном числе реализаций модели показаны в табл. 3.1.
При ![]() , тех же характеристиках рассеивания и других радиусах поражения
, тех же характеристиках рассеивания и других радиусах поражения ![]() получим:
получим:
В одной из последующих тем мы установим количественную связь между числом реализаций модели ![]() , требуемой точностью и доверительной вероятностью результата моделирования, в данном случае оценки вероятности
, требуемой точностью и доверительной вероятностью результата моделирования, в данном случае оценки вероятности ![]() .
.
Данный пример иллюстрирует сущность метода имитационного моделирования , который заключается в следующем.
- Создается модель, поведение которой подчиняется тем же вероятностным законам, что и интересующий нас процесс.
- По известным законам распределения для отдельных характеристик процесса выбираются их случайные значения.
- Вычисляются параметры исхода процесса при случайных значениях характеристик, полученных на этапе 2, и запоминаются. Этапы 2 и 3 соответствуют одному статистическому испытанию.
- В результате статистических испытаний (повторений этапов 2 и 3) получают значений параметров исхода процесса. Вероятностные характеристики параметров исхода процесса получают в результате статистической обработки полученных случайных величин.
Статистическая обработка и оценка точности результатов моделирования основываются на предельных теоремах теории вероятностей: теореме Чебышева и теореме Бернулли.
Рассмотрим еще один пример.
Пример 3.2. Транспорт 1 с грузом отправился из пункта А в пункт С через пункт В. Одновременно из пункта D в пункт Е через пункт В отправился транспорт 2. Скорости движения транспортов распределены по нормальному закону с математическими ожиданиями ![]() и
и ![]() и стандартными отклонениями
и стандартными отклонениями ![]() и
и ![]()
Построить алгоритм имитационной модели (ИМ) с целью определения вероятности встречи транспортов 1 и 2 в пункте В. Расстояние от пункта А до пункта В ![]() а от пункта D до пункта В -
а от пункта D до пункта В - ![]() .Событие встречи считать состоявшимся, если их времена прибытия в пункт В либо равны, либо отличаются на величину, не превышающую
.Событие встречи считать состоявшимся, если их времена прибытия в пункт В либо равны, либо отличаются на величину, не превышающую ![]() .
.
Решение
Построим схему движения транспортов 1 и 2 (рис. 3.2).
Возьмем две последовательности нормально распределенных случайных чисел:
характеристики которых соответствуют матожиданиям и стандартным отклонениям скоростей движения транспортов 1 и 2.
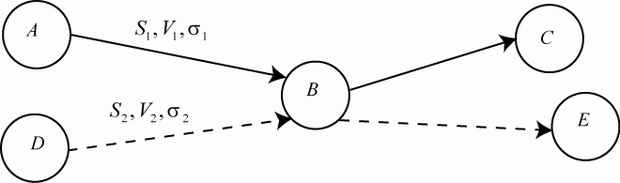
Рис. 3.2. Схема движения транспортов
- Имитируем движение транспортов 1 и 2 до пункта В со скоростями
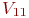 и
и 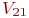 соответственно, взятыми из последовательностей нормально распределенных случайных чисел.
соответственно, взятыми из последовательностей нормально распределенных случайных чисел. - Вычислим время
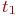 и
и 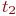 прибытия в пункт В транспортов 1 и 2 соответственно:
прибытия в пункт В транспортов 1 и 2 соответственно: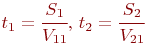
- Оценим результат имитации движения транспортов 1 и 2, т. е. установим факт наличия или отсутствия их встречи:
- если
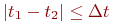 , встреча состоялась;
, встреча состоялась; - если
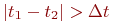 , встреча не состоялась.
, встреча не состоялась.
- если
- Если встреча состоялась, зафиксируем этот факт увеличением значения на
 , т. е.
, т. е. 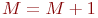 (вначале
(вначале 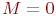 ).
). - Для нахождения вероятности встречи транспортов 1 и 2 повторим имитацию их движения раз.
Рассчитаем вероятность встречи:
Результаты моделирования при ![]() и характеристиках движения транспортов:
и характеристиках движения транспортов: ![]() ,
, ![]() ,
, ![]() :
:
Очевидно, изложенный процесс имитации легко может быть реализован на компьютере. Представим алгоритмы моделей примеров 3.1 и 3.2 схемами (рис. 3.3 и 3.4).
В рассмотренных примерах исследуются различные процессы. Но алгоритмы моделей этих процессов (для сравнения рядом с алгоритмом задачи 3.2 (рис. 3.3) показан и алгоритм задачи 3.1 (рис. 3.4) имеют общую, практически идентичную часть (блоки 1, 5…8, на рис. 3.3 и 3.4 они выделены) и часть, которая непосредственно имитирует исследуемый процесс (блоки 2… 4).
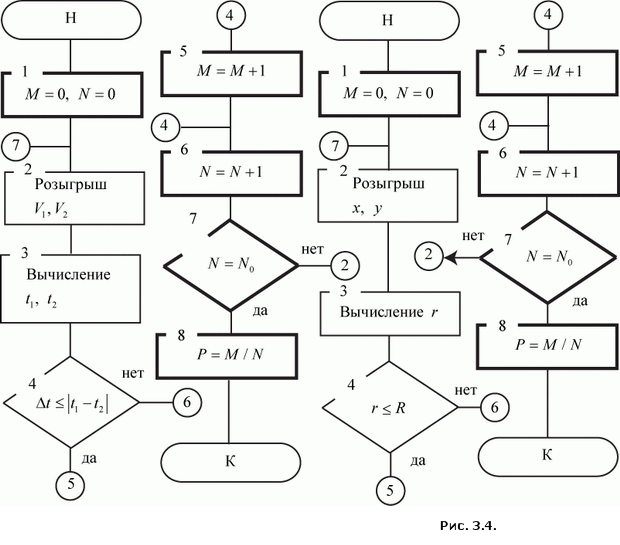
увеличить изображение
Рис. 3.3.
Подобное сходство и различие еще раз подтверждают сформулированную нами ранее сущность имитационного моделирования.
Пример 3.3. По объекту наносится не одиночный, а три последовательных ракетных удара. При поражении объекта любой ракетой пуски прекращаются. Остальные условия те же, что и в примере 3.1.
Алгоритм ИМ приведен на рис. 3.5. На нем выделены блоки 1, 8…11, выполняющие те же функции, что блоки 1, 5…8 в алгоритмах ИМ на рис. 3.3 и 3.4. Блоки 2…7 непосредственно имитируют нанесение удара по объекту, т. е. выполняют одну реализацию (один прогон модели). В блоке 2 переменной ![]() присваивается начальное число пусков ракет. Далее эта переменная используется для организации внутреннего цикла по числу пусков. После каждого пуска значение k уменьшается на 1 (блок 7). При
присваивается начальное число пусков ракет. Далее эта переменная используется для организации внутреннего цикла по числу пусков. После каждого пуска значение k уменьшается на 1 (блок 7). При ![]() (блок 3) реализация завершается. Завершается она также и при поражении объекта (блок 6). Но при этом предварительно значение переменной
(блок 3) реализация завершается. Завершается она также и при поражении объекта (блок 6). Но при этом предварительно значение переменной ![]() увеличивается на
увеличивается на ![]() . По завершении
. По завершении ![]() реализаций рассчитывается оценка математического ожидания вероятности поражения объекта тремя последовательными пусками ракет.
реализаций рассчитывается оценка математического ожидания вероятности поражения объекта тремя последовательными пусками ракет.
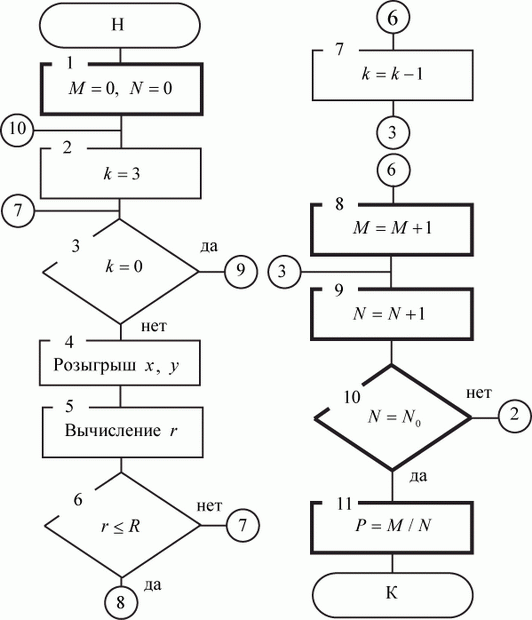
увеличить изображение
Рис. 3.5. Алгоритм модели нанесения удара тремя ракетами
Как отмечалось вначале, название метода - имитационное моделирование не очень удачно в том смысле, что несет в себе тавтологию: моделирование и есть имитация. Однако название прижилось. Очень часто метод называют статистическим моделированием из-за необходимости статистической обработки накапливаемого результата - в случае вероятностных операций.
Иногда статистическое моделирование называют "метод Монте-Карло", по городу, где процветает игра в рулетку, исход которой случаен и образуется своеобразным датчиком случайных исходов - рулеткой.
3.2. Общая характеристика метода имитационного моделирования
Имитационное моделирование представляет собой процесс построения и испытания некоторого моделирующего алгоритма, имитирующего поведение и взаимодействие исследуемой системы с учетом случайных входных воздействий и внешней среды.
Имитационная модель обладает самым главным свойством моделей вообще - она может быть объектом эксперимента, причем эксперимент проводится с моделью, представленной в виде компьютерной программы.
Имитационная модель отображает стохастический процесс смены дискретных состояний системы. При реализации модели на компьютере производится накопление статистических данных по показателям модели, которые являются предметом исследований. По окончании моделирования накопленная статистика обрабатывается, и результаты моделирования получаются в виде выборочных распределений исследуемых величин. Таким образом, математическая статистика и теория вероятностей являются математическими основами имитационного моделирования.
Имитационные модели могут быть реализованы средствами универсальных языков программирования (Паскаль, Си, Фортран и др.). Они предоставляют практически неограниченные возможности в разработке и отладке программ моделей. Однако, модель в виде программы на универсальном языке программирования часто непонятна исследователю. Ведь совершенно необязательно исследователь, специалист в конкретной предметной области должен знать тонкости программирования на каком-либо языке. Поэтому были созданы специализированные языки моделирования, которые существенно упрощают создание моделей и обработку результатов моделирования (Симпас, Симула, Арена, семейство языков GPSS и др.). Одна из наиболее распространенных систем моделирования GPSS World рассматривается в настоящем курсе.
Имитационная модель может представить объект практически любой сложности. Ограничениями могут служить лишь недостаточная квалификация исполнителя, а также требование адекватности модели и достижения очень большой точности результата. А это связано с получением статистических выборок большого объема, что ведет к необходимости получения большого числа реализаций модели и, следовательно, высокопроизводительных компьютеров.
Если сложность аналитической модели с усложнением моделируемого объекта возрастает с ускорением, как показано на рис. 3.6, то сложность имитационной модели, начиная с некоторого уровня ![]() растет незначительно.
растет незначительно.
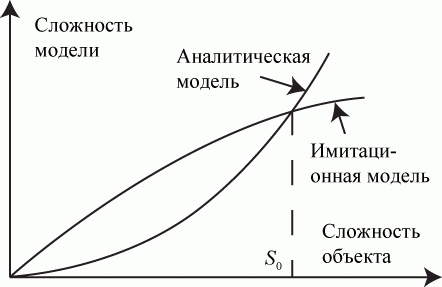
Рис. 3.6. Иллюстрация роста сложности моделей
К достоинствам имитационных моделей можно также отнести:
- простота алгоритма;
- малая связность алгоритма;
- устойчивость к случайным сбоям компьютера, так как при большом числе реализаций (прогонов) модели сбой в одной из них исказит статистику несущественно.
Недостатком имитационного моделирования является то, что решение, результат является численным, частным, справедливым только для конкретных значений исходных данных. Чтобы получить функциональные зависимости между параметрами исследуемого процесса (системы) потребуется сделать очень большое количество вариантов решений. Аналитическая же модель дает, как правило, функциональные зависимости. Если сложность задачи, требуемая точность решения, возможности математики и способности исследователя позволяют построить математическую аналитическую модель, то следует использовать ее.
Метод имитационного моделирования стал развиваться с появлением цифровых вычислительных машин, большой производительностью и памятью. Отметим, что именно необходимость широкого применения статистического моделирования является одним из существенных стимулов создания высокопроизводительных компьютеров.
Одной из основных целей имитационного моделирования является определение показателей эффективности различных операций. Показатели эффективности могут выступать в виде оценок характеристик случайных величин или процессов или вероятностей исхода операций. В первом случае - это время, расход ресурсов, численности противоборствующих сторон, расстояния и т. п. Во втором случае показатель эффективности выступает в качестве вероятности, например, достижения цели операции в заданный срок, исправного состояния техники и т. д.
3.3. Статистическое моделирование при решении детерминированных задач
Метод статистических испытаний может быть использован как численный метод решения математических задач. Именно в таком качестве он был применен в США в 1944 г. Джоном фон Нейманом при расчетах по созданию ядерного реактора.
Применение метода рассмотрим на примере вычисления некоторого интеграла.
Пример 3.4. Пусть ![]() ,
, ![]() . Полагаем, что функция
. Полагаем, что функция ![]() такова, что интеграл относится к "неберущимся".
такова, что интеграл относится к "неберущимся".
Требуется вычислить ![]() .
.
Решение
Представим функцию в координатах ![]() и
и ![]() как показано на рис. 3.7. Как известно, численное значение интеграла данного вида равно площади
как показано на рис. 3.7. Как известно, численное значение интеграла данного вида равно площади ![]() . Площадь
. Площадь ![]() состоит из множества элементарных площадок - точек. Количество точек в этой площади и будет численным значением искомого интеграла.
состоит из множества элементарных площадок - точек. Количество точек в этой площади и будет численным значением искомого интеграла.
Имитируем координаты каждой точки значениями ![]() и
и ![]() , принадлежащими равномерному распределению на участке
, принадлежащими равномерному распределению на участке ![]() :
:
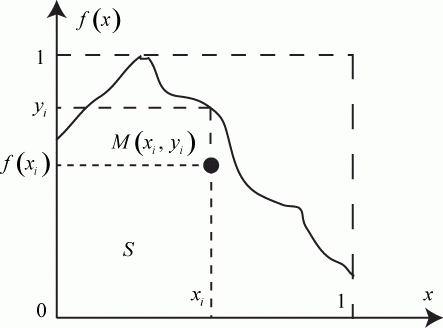
Рис. 3.7. Вычисление интеграла
Рассмотрим пару чисел ![]() . Вычислим
. Вычислим ![]() и сравним с
и сравним с ![]() . Если
. Если ![]() , то это означает, что точка
, то это означает, что точка ![]() принадлежит площади
принадлежит площади ![]() . Если
. Если ![]() , то это означает, что точка
, то это означает, что точка ![]() не принадлежит площади
не принадлежит площади ![]() .
.
Введем:
Число точек, попавших в границы ![]() равно
равно ![]() , где
, где ![]() - общее число точек, попавших в единичную площадь существования функции и аргумента. Отсюда следует:
- общее число точек, попавших в единичную площадь существования функции и аргумента. Отсюда следует:
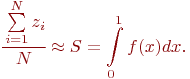
Чем больше будет элементарных площадей - точек, тем точнее будет вычислен интеграл. Приведенное решение примера справедливо для единичных областей существования функции и аргумента. Однако это несущественно, так как произвольные границы существования ![]() заменой переменных можно свести к единичным границам.
заменой переменных можно свести к единичным границам.
Известны статистические алгоритмы численного решения многократных интегралов.
Пример 3.5. Найти оценку ![]() интеграла
интеграла ![]() .
.
Решение
Область интегрирования ограничена линиями ![]() ,
, ![]() ,
, ![]() , т. е. принадлежит единичному квадрату (рис. 3.8).
, т. е. принадлежит единичному квадрату (рис. 3.8).
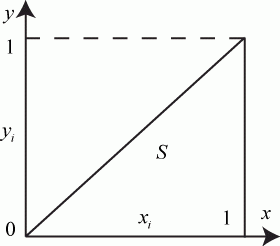
Рис. 3.8. Иллюстрация к примеру 3.5
Площадь области интегрирования (прямоугольного треугольника) ![]() Используем формулу
Используем формулу
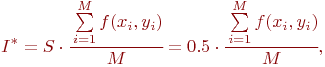
в которой ![]() - число случайных точек
- число случайных точек ![]() , принадлежащих области интегрирования. У этих точек
, принадлежащих области интегрирования. У этих точек ![]() . Если данное условие выполняется, то вычисляется
. Если данное условие выполняется, то вычисляется
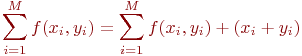
а число случайных точек ![]() увеличивается на
увеличивается на ![]() :
: ![]() .
.
Результаты моделирования приведены в табл. 3.2.
Из данных табл. 3.2 (верхние пять строк) видно, что с увеличением числа реализаций ![]() ошибка
ошибка ![]() в определении оценки интеграла
в определении оценки интеграла ![]() уменьшается и при
уменьшается и при ![]() становится равной нулю.
становится равной нулю.
| 10 | 1000 | 10000 | 100000 | 1000000 | |
| 5 | 500 | 5038 | 49658 | 500364 | |
| 4,773 | 487,695 | 5006,152 | 49533,242 | 500191,650 | |
| 0,477 | 0,488 | 0,497 | 0,499 | 0,500 | |
| 0,023 | 0,012 | 0,003 | 0,001 | 0 | |
| 6 | 503 | 4935 | 49833 | ||
| 5,025 | 494,593 | 4917,236 | 49802,019 | ||
| 0,419 | 0,492 | 0,498 | 0,500 | ||
| 0,081 | 0,008 | 0,002 | 0 |
В четырех нижних строках табл. 3.2 приведены результаты моделирования с другими начальными числами генераторов равномерно распределенных случайных чисел. Как видно, ошибка в оценке интеграла равна нулю уже при ![]() реализаций модели.
реализаций модели.
В заключение отметим, что имитационное (статистическое) моделирование целесообразно применять в случаях:
- когда нет законченной математической постановки задачи;
- когда нет аналитических методов решения сформулированной задачи;
- когда аналитические методы есть, но они не удовлетворяют требованиям точности и достоверности;
- когда аналитические методы есть, но их вычислительные процедуры сложны даже для компьютера;
- когда реализация известных процедур сталкивается с недостаточной математической подготовкой исследователя;
- когда исследователю нужно знать не только оценки искомых характеристик, но и динамику всего случайного процесса.
3.4. Моделирование равномерно распределенной случайной величины
Особое значение в статистическом моделировании имеет непрерывная равномерно распределенная случайная величина. Особая значимость этой случайной величины объясняется тем, что, во-первых, она сама по себе необходима для моделирования случайных процессов и величин и, во-вторых, случайные величины с другими законами распределения формируются на их основе.
Определение. Непрерывная случайная величина ![]() имеет равномерное распределение в интервале
имеет равномерное распределение в интервале ![]() , если ее плотность вероятности
, если ее плотность вероятности ![]() определяется так (рис. 3.9):
определяется так (рис. 3.9):
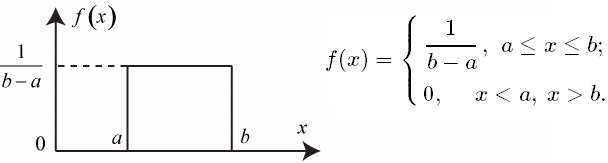
Рис. 3.9. Плотность вероятности равномерного распределения
Значения характеристик равномерного закона распределения:
- математическое ожидание
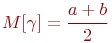 ;
; - дисперсия
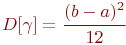 .
.
При моделировании часто используются случайные числа из интервала ![]() . Непрерывная случайная величина
. Непрерывная случайная величина ![]() равномерно распределена в интервале
равномерно распределена в интервале ![]() , если:
, если:
В этом случае ![]() .
.
Случайное число ![]() из интервала
из интервала ![]() легко преобразуется в случайное число
легко преобразуется в случайное число ![]() для интервала
для интервала ![]() :
:
Применительно к двоичным дробям случайное число из интервала ![]() представляет собой бесконечную дробь:
представляет собой бесконечную дробь:
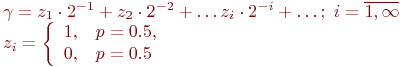
Очевидно, реализовать такую дробь в компьютере невозможно, так как разрядная сетка компьютера ограничена. В компьютере можно формировать дискретные последовательности случайных чисел, которые не могут отличаться друг от друга только на величину меньше ![]() (
( ![]() - число разрядов в сетке компьютера). То есть непрерывного, "теоретического" распределения на компьютерах получить нельзя. Если эти числа равновероятны, то такое распределение случайных чисел называют квазиравномерным.
- число разрядов в сетке компьютера). То есть непрерывного, "теоретического" распределения на компьютерах получить нельзя. Если эти числа равновероятны, то такое распределение случайных чисел называют квазиравномерным.
Заметим, что непрерывные случайные величины существуют только в теории. На практике все случайные величины дискретны и шаг дискретности равен наименьшей единице измерения.
Случайная величина ![]() , имеющая квазиравномерное распределение в интервале
, имеющая квазиравномерное распределение в интервале ![]() , принимает значения
, принимает значения
с вероятностями ![]() .
.
Можно показать, что эта случайная величина имеет характеристики:
| (2^n-1)}) |
Современные компьютеры имеют разрядность не менее 32. Следовательно, ![]() , а дисперсии тоже практически совпадают. Учитывая это, в дальнейшем квазиравномерное распределение будем называть равномерным и обозначать:
, а дисперсии тоже практически совпадают. Учитывая это, в дальнейшем квазиравномерное распределение будем называть равномерным и обозначать: ![]() .
.
Для формирования последовательности случайных чисел в компьютере может использоваться один из трех основных способов:
- аппаратный (физический);
- табличный (файловый);
- алгоритмический (программный).
Аппаратный способ. При этом способе случайные числа формируются специальным устройством. Источником случайных чисел чаще всего являются шумы в электронных приборах. Временные расстояния между шумовыми всплесками, превышающими подобранный уровень ограничения, фиксируются как случайные числа из распределения ![]() .
.
Преимущества такого способа:
- количество случайных чисел неограниченно;
- не требует затрат оперативной памяти;
- требует малые вычислительные ресурсы компьютера.
Однако, такой датчик (генератор) случайных чисел имеет существенные недостатки, которые в настоящее время исключили его из инженерной практики:
- трудность настройки;
- необходимость периодической проверки формируемой последовательности на соответствие закону распределения;
- обеспечение стабильности условий работы устройства - питания, влажности, температуры, старения приборов и элементов;
- при необходимости невозможно повторить эксперимент при одной и той же последовательности случайных чисел.
Табличный способ. Случайные числа в виде таблицы (файла) помещаются в оперативную или внешнюю память компьютера. Эти числа формируются заранее или берутся из соответствующего справочника. Достоинствами такого способа являются:
- числа требуют однократную проверку при формировании или недоверии источнику;
- можно повторять вычислительный эксперимент при одной и той же последовательности случайных чисел.
Недостатки же очень существенны:
- количество случайных чисел ограничено;
- файл занимает место в оперативной памяти компьютера;
- при размещении во внешней памяти обращение за случайными числами увеличивает время моделирования.
Алгоритмический способ. При этом способе случайные числа формируются с помощью специальных алгоритмов (формул) и реализующих их программ при каждом обращении моделирующего алгоритма за случайным числом. Достоинства способа:
- в настоящее время предлагается достаточно алгоритмов, генерирующих случайные числа, проверенных практикой и, следовательно, не нуждающихся в особых проверках;
- можно многократно воспроизвести одну и ту же последовательность;
- в памяти компьютера хранится только программа датчика (генератора), занимающая, как правило, малый объем;
- алгоритмический датчик может быть реализован и аппа-ратно, за счет чего существенно сокращается время формирования случайного числа и в целом время моделирования.
Недостатки:
- на формирование случайного числа при программной реализации датчика требуются затраты машинного времени;
- любой алгоритмический датчик может сгенерировать ограниченное количество неповторяющихся чисел.
В настоящее время практически везде применяются алгоритмические датчики случайных чисел (ДСЧ). Создание высокопроизводительных компьютеров существенно снижает роль первого недостатка (затраты машинного времени). Второй недостаток устраняется использованием в одной модели нескольких ДСЧ.
Алгоритмические датчики не обеспечивают получение теоретически "чистой" случайности чисел, так как их формирование идет по формулам. Вследствие этого, рано или поздно последовательность случайных чисел станет повторяться или выродится. Последнее означает, что, начиная с некоторого числа, все последующие числа будут равны нулю.
Поэтому алгоритмические датчики называют датчиками псевдослучайных чисел. Современные датчики вырабатывают числа, псевдослучайность которых практически неощутима.
Качество алгоритмического датчика оценивается тем, насколько полно он удовлетворяет следующим требованиям:
- закон распределения формируемых чисел должен быть равномерным (квазиравномерным);
- числа должны быть статистически независимыми;
- числа не должны повторяться;
- формирование чисел должно занимать минимальное машинное время и минимальный объем памяти.
Понимая, что алгоритмический ДСЧ выдает детерминированную, псевдослучайную последовательность квазиравномерно распределенных случайных чисел, в дальнейшем будем называть его датчиком случайных равномерно распределенных чисел.
Исторически первым таким датчиком является датчик, в котором был реализован так называемый "способ срединных квадратов". Сущность способа заключается в следующем:
- подбирается начальное число
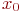 , например,
, например, 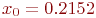 ;
; - вычисляется квадрат :
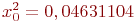 ;
; - первое случайное число
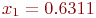 , то есть середина
, то есть середина 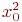 ;
; - вычисляется квадрат
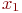 :
: 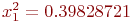 ;
; - второе случайное число
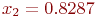 и т. д.
и т. д.
Такие ДСЧ теперь не используются: между числами имеется сильная корреляция, случайность отсутствует, при неудачно выбранном ![]() последовательность может быстро выродится, то есть
последовательность может быстро выродится, то есть ![]() при
при ![]() .
.
В настоящее время очень широкое распространение в практике моделирования получил мультипликативный метод формирования случайной последовательности:
где ![]() - произвольное нечетное число, неотрицательное;
- произвольное нечетное число, неотрицательное;
![]() - коэффициент,
- коэффициент, ![]() ,
, ![]() - любое целое положительное число;
- любое целое положительное число;
![]() - значение модуля. Для реализации на компьютере удобно
- значение модуля. Для реализации на компьютере удобно ![]() , где
, где ![]() - основание системы счисления (2 или 10),
- основание системы счисления (2 или 10), ![]() - число разрядов в случайном числе.
- число разрядов в случайном числе.
В этом случае взятие числа по модулю сводится к выделению ![]() младших разрядов произведения
младших разрядов произведения ![]() .
.
Алгоритм мультипликативного метода
- Выбрать
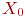 , например,
, например, 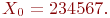
- Вычислить коэффициент
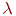 . Пусть
. Пусть 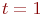 , тогда
, тогда 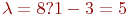 .
. - Выбрать модуль
 . Пусть система счисления десятичная (
. Пусть система счисления десятичная ( 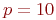 ), разрядность случайных чисел
), разрядность случайных чисел  .
. - Вычислить произведение
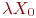 :
: 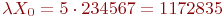 .
. - Найти остаток от деления по модулю :
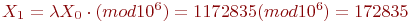 .
. - Найти число последовательности случайных чисел из интервала
 :
: 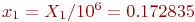 .
. - Присвоить
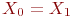 и перейти к п. 4.
и перейти к п. 4.
Рассмотренный метод обеспечивает приемлемое качество случайных чисел в смысле равномерности распределения и их независимости, а также простой реализации на компьютере.
Применяется и немного более сложный алгоритм:
где ![]() - неотрицательное целое число.
- неотрицательное целое число.
Такой метод называется конгруэнтно-мультипликативным. При удачном подборе дополнительного параметра ![]() корреляция
корреляция
формируемых чисел может быть несколько уменьшена по сравнению с мультипликативным методом.
3.5. Моделирование случайной величины с произвольным законом распределения
В основе моделирования случайных величин с произвольными законами распределения вероятностей лежит, как правило, метод обратной функции.
В этом методе используется следующая теорема.
Теорема. Если случайная величина ![]() имеет плотность распределения вероятностей
имеет плотность распределения вероятностей ![]() , то распределение случайной величины
, то распределение случайной величины
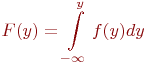 | (y)dy) |
равномерно в интервале ![]() , т. е.
, т. е.
По определению, ![]() является функцией распределения случайной величины
является функцией распределения случайной величины ![]() .
.
Теорема может быть проиллюстрирована графиками, представленными на рис. 3.10.
Обозначим: ![]() -
- ![]() -е число из
-е число из ![]() ,
, ![]() -
- ![]() -е случайное число из произвольного распределения.
-е случайное число из произвольного распределения.
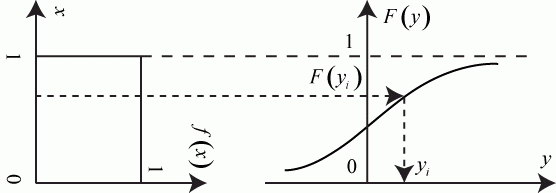
Рис. 3.10. Иллюстрация к методу обратной функции Из (3.1) следует:

Моделировать равномерно распределенное случайное число ![]() мы уже умеем. Нужно найти неизвестное
мы уже умеем. Нужно найти неизвестное ![]() , находящееся в верхнем пределе интегрирования.
, находящееся в верхнем пределе интегрирования.
Относительно ![]() ыражение принимает вид:
ыражение принимает вид:
Отсюда и название - "метод обратной функции".
Пример 3.6. Получить формулу для моделирования случайных
чисел, распределенных по экспоненциальному закону, с параметром ![]() (матожиданием
(матожиданием ![]() ).
).
Плотность ![]() и функция
и функция ![]() этого распределения имеют вид (рис. 3.11):
этого распределения имеют вид (рис. 3.11):
Решение
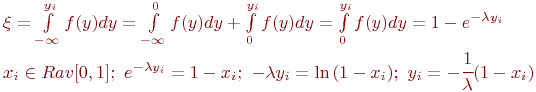
Поскольку случайная величина ![]() имеет равномерное распределение в интервале
имеет равномерное распределение в интервале ![]() , как и
, как и ![]() , то справедливо:
, то справедливо:
Примеров подобного аналитического преобразования случайного числа ![]() в случайное число из произвольного распределения немного, так как для многих законов распределения, встречающихся в практике моделирования, интеграл (3.1) относится к неберущимся, а численные методы решения увеличивают затраты машинного времени.
в случайное число из произвольного распределения немного, так как для многих законов распределения, встречающихся в практике моделирования, интеграл (3.1) относится к неберущимся, а численные методы решения увеличивают затраты машинного времени.
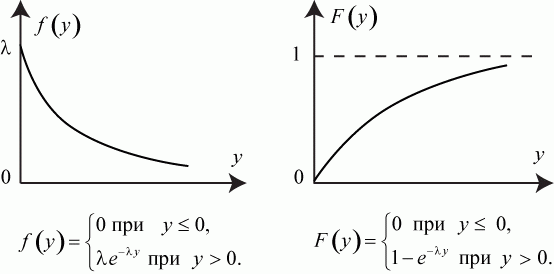
Рис. 3.11. Плотность и функция экспоненциального распределения
Поэтому в современных системах моделирования применяется приближенный метод обратной функции, основанный на кусочно-линейной аппроксимации функции распределения моделируемой случайной величины.
Суть метода заключается в следующем.
Требуемый закон распределения случайной величины размещается в памяти компьютера в виде координат функции распределения. Каждая координата состоит из случайного числа ![]() и соответствующего значения функции распределения
и соответствующего значения функции распределения ![]()
Чем больше координат, тем точнее будет моделирование. Приемлемая точность обеспечивается заданием 20…30 координат.
При обращении за очередным случайным числом нужного закона распределения сначала генерируется случайное число из ![]() Это число сравнивается со значениями
Это число сравнивается со значениями ![]() .
.
При совпадении выдается соответствующее случайное число ![]() .
.
Если нет совпадения, то случайное число ![]() вычисляется из подобия треугольников, как показано на рис. 3.12.
вычисляется из подобия треугольников, как показано на рис. 3.12.
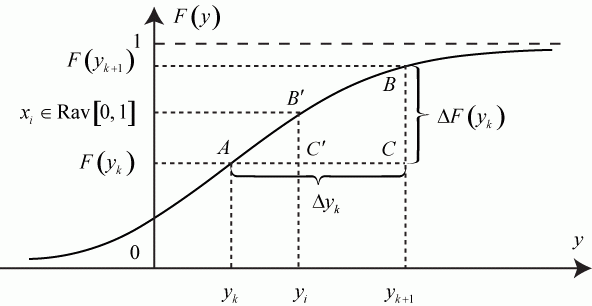
Рис. 3.12. Иллюстрация к методу кусочно-линейной аппроксимации
Из подобия треугольников ABC и AB'C' следует:
Отсюда по ![]() находится значение
находится значение ![]() .
.
Значительную роль в моделировании играет случайная величина, имеющая нормальное распределение. Метод обратной функции в аналитическом виде здесь неприемлем, так как интеграл (3.1) неберущийся, а его численное решение громоздко.
Для генерации случайных чисел, подчиненных нормальному распределению, применяется метод обратной функции с кусочно-линейной аппроксимацией, а также метод, основанный на центральной предельной теореме (ЦПТ) теории вероятностей.
Как известно, ЦПТ дает теоретическое объяснение подтвержденному практикой наблюдению: если исход случайного события определяется большим числом случайных факторов, и влияние каждого фактора мало, то такой случайный исход хорошо аппроксимируется нормальным распределением. Эта теорема имеет много формулировок. Одна из наиболее практичных для целей моделирования случайных последовательностей - теорема Леви-Линдеберга.
Теорема. Случайная величина
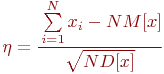
где ![]() - сумма
- сумма ![]() случайных чисел одного и того же распределения с матожиданием
случайных чисел одного и того же распределения с матожиданием ![]() и дисперсией
и дисперсией ![]() при
при ![]() асимптотически стремится к нормальному распределению с
асимптотически стремится к нормальному распределению с ![]() и дисперсией
и дисперсией ![]() .
.
Удобно случайные числа ![]() брать из рассмотренного датчика
брать из рассмотренного датчика ![]() . В этом случае
. В этом случае ![]()
![]() .
.
Хорошее приближение к нормальному распределению получается уже при числе ![]() Каждое случайное число при
Каждое случайное число при ![]() генерируется так:
генерируется так:
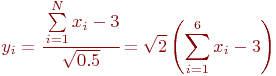
Недостаток способа состоит в том, что он не экономичен, так как для генерирования одного случайного числа ![]() требуется шесть случайных чисел из распределения
требуется шесть случайных чисел из распределения ![]() .
.
В ряде случаев применяют датчики с числом ![]() . Тогда
. Тогда
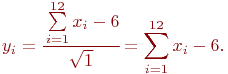
Если датчик случайных чисел нормального распределения выдает стандартную последовательность чисел с ![]() ,
, ![]() , то пересчет на произвольное значение характеристик выполняется так:
, то пересчет на произвольное значение характеристик выполняется так:
где ![]() - требуемое значение матожидания;
- требуемое значение матожидания;
![]() - требуемое значение среднего квадратического отклонения;
- требуемое значение среднего квадратического отклонения;
![]() - случайное число из нормального распределения с математическим ожиданием
- случайное число из нормального распределения с математическим ожиданием ![]() и средним квадратическим отклонением
и средним квадратическим отклонением ![]() .
.
В современных системах моделирования имеются встроенные датчики, позволяющие непосредственного задавать нужную случайную величину с требуемыми значениями характеристик. Однако если исследователя эти возможности не удовлетворяют (например, по точности представления функции распределения вероятностей), то он может задать требуемый закон распределения самостоятельно.
3.6. Моделирование единичного события
Под единичным событием мы будем понимать смену состояний одного элемента (системы), причем состояний всего два: оборудование исправно - неисправно, канал СМО свободен - занят, цель поражена - не поражена и т. п.
Переход из одного состояния в другое - случайный. В любой момент времени система находится в одном состоянии с вероятностью ![]() , в другом - с вероятностью
, в другом - с вероятностью ![]() .
.
Цель моделирования: имитировать состояние такого элемента.
Теорема. Пусть некоторое событие ![]() свершается с вероятностью
свершается с вероятностью ![]() . Это может быть отказ техники, поступление сообщения, уничтожение цели и т. п.
. Это может быть отказ техники, поступление сообщения, уничтожение цели и т. п.
Моделью свершения такого единичного события A является попадание значения ![]() случайной величины
случайной величины ![]() , равномерно распределенной в интервале
, равномерно распределенной в интервале ![]() , в числовой интервал
, в числовой интервал ![]() .
.
Доказател ьство Как известно
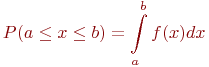
Для ![]()
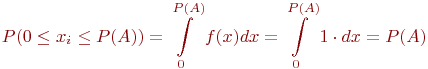
так как ![]() для
для ![]() на интервале
на интервале ![]() .
.
Пример 3.7. Пусть вероятность состояния элемента ![]() В
В ![]() -ой реализации случайное число
-ой реализации случайное число ![]() равно
равно ![]() Это означает, что в данной
Это означает, что в данной ![]() -ой реализации модели событие A не свершилось (рис. 3.13). Естественно, одна реализация ни о чем не говорит. Реальная ситуация будет отображена на множестве реализаций и чем их больше, тем точнее.
-ой реализации модели событие A не свершилось (рис. 3.13). Естественно, одна реализация ни о чем не говорит. Реальная ситуация будет отображена на множестве реализаций и чем их больше, тем точнее.
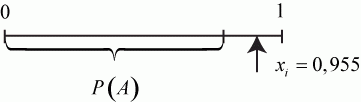
Рис. 3.13. Событие A не произошло
Фрагмент алгоритма имитации в модели единичного случайного события приведен на рис. 3.14.
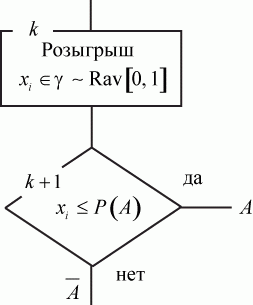
Рис. 3.14. Фрагмент алгоритма имитации единичного события
3.7. Моделирование полной группы несовместных событий
Элемент системы (или система в целом) может находиться во многих (больше двух) несовместных состояниях. Известны вероятности нахождения системы в этих состояниях. Например, средство вооружения может находиться:
- в боеготовом состоянии с вероятностью
 ;
; - в неисправном состоянии и ремонтироваться силами своего расчета, вероятность этого состояния
 ;
; - ремонтироваться в мастерской части -
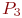 ;
; - ремонтироваться на заводе -
 Очевидно, что
Очевидно, что 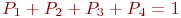 .
.
Такие и аналогичные события называются полной группой несовместных событий.
Алгоритм моделирования основан на следующей теореме.
Теорема. В полной группе несовместных событий моделью свершения события ![]() , происходящего с вероятностью
, происходящего с вероятностью ![]() , является попадание значения
, является попадание значения ![]() в отрезок, равный
в отрезок, равный ![]() , числовой шкалы
, числовой шкалы ![]() , где
, где ![]() - число несовместных событий (рис. 3.15):
- число несовместных событий (рис. 3.15):
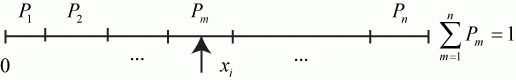
Рис. 3.15. Событие A_{m} произошло
Доказател ьство
Введем численные обозначения концов отрезков ![]() по нарастанию:
по нарастанию:
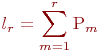
В этом случае, согласно теореме, условием свершения события ![]() является:
является:
Следовательно
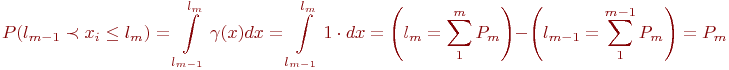
Такой способ моделирования несовместных событий обычно называют определением исходов по жребию.
Алгоритм, реализующий способ определения исходов по жребию, может быть построен тремя вариантами, представленными на рис. 3.16.
Первый вариант (рис. 3.16а) применяется тогда, когда число возможных исходов невелико и не равно степени по основанию два.
На рис. 3.16б алгоритм построен по способу половинных сечений для четырех исходов.
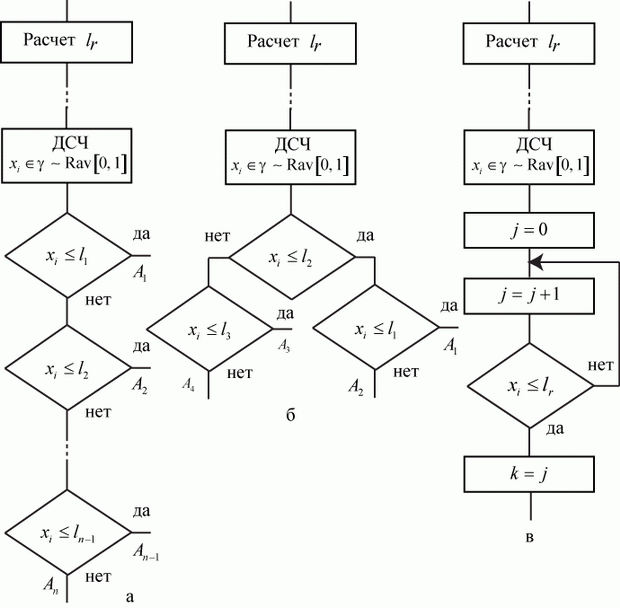
увеличить изображение
Рис. 3.16. Варианты алгоритма определения исходов по жребию
Третий вариант алгоритма (рис. 3.16в) в цикле определяет исход (событие), номер которого присваивается переменной ![]() . Далее этот номер используется для организации нужной работы алгоритма. Применение данного алгоритма будет показано в главе 6 (п. 6.7 и п. 6.8).
. Далее этот номер используется для организации нужной работы алгоритма. Применение данного алгоритма будет показано в главе 6 (п. 6.7 и п. 6.8).
Пример 3.8. Канал передачи данных может находиться в одном из четырех несовместных состояниях:
![]() - исправен и свободен,
- исправен и свободен, ![]() ;
;
![]() - исправен и занят,
- исправен и занят, ![]() ;
;
![]() - неисправен,
- неисправен, ![]() ;
;
![]() - подавлен помехами,
- подавлен помехами, ![]()
Решение
Представим необходимые для определения исходов по жребию данные табл. 3.3.
| Вероятности | Событие | |||
|---|---|---|---|---|
| Вероятности событий | 0,15 | 0,4 | 0,25 | 0,2 |
| Суммарные вероятности ( | 0,15 | 0,55 | 0,8 | 1,0 |
| Номера интервалов ( | 1 | 2 | 3 | 4 |
Предположим, что при выполнении ![]() -ой реализации датчик равномерно распределенных случайных чисел
-ой реализации датчик равномерно распределенных случайных чисел ![]() сгенерировал
сгенерировал ![]() Путем последовательных сравнений определяется, что
Путем последовательных сравнений определяется, что ![]() . Значит в данной реализации канал находится в состоянии
. Значит в данной реализации канал находится в состоянии ![]() - исправен и занят.
- исправен и занят.
3.8. Моделирование совместных независимых событий
Рассмотрим моделирование совместных независимых событий.
Способ моделирования состоит в том, что совместные независимые события сводятся к одному сложному событию.
Для лучшего понимания и обозримости способа рассмотрим моделирование двух событий A и B. Увеличение числа событий ничего принципиально нового в моделирование не вносит.
Пусть независимые события A и B происходят с вероятностями ![]() и
и ![]() соответственно. Например, это могут быть отказы монитора и процессора компьютера.
соответственно. Например, это могут быть отказы монитора и процессора компьютера.
Моделирование такой ситуации может быть выполнено двумя способами:
- определение совместных исходов выбором по жребию;
- последовательная проверка исходов.
3.8.1. Определение совместных исходов по жребию
Прежде всего, по вероятностям ![]() и
и ![]() нужно определить вероятности возможных исходов, т. е. появления совместных независимых событий. Возможные исходы совместного события
нужно определить вероятности возможных исходов, т. е. появления совместных независимых событий. Возможные исходы совместного события ![]() и соответствующие вероятности
и соответствующие вероятности ![]() представлены в табл. 3.4.
представлены в табл. 3.4.
Совместное событие в ![]() -ой реализации определяется выбором исхода по жребию.
-ой реализации определяется выбором исхода по жребию.
Если случайное число ![]() при очередной реализации окажется, например, на участке
при очередной реализации окажется, например, на участке ![]() , то в данной реализации фиксируется свершение сложного события
, то в данной реализации фиксируется свершение сложного события ![]() . Если же окажется
. Если же окажется ![]() , то фиксируется событие
, то фиксируется событие ![]() . Алгоритм может быть построен по одному из приведенных на рис. 3.16 вариантов.
. Алгоритм может быть построен по одному из приведенных на рис. 3.16 вариантов.
3.8.2. Последовательная проверка исходов
Алгоритм способа последовательной проверки исходов приведен на рис. 3.17.
Рис. 3.17. Алгоритм последовательной проверки исходов
Проверку свершения каждого из совместных событий надо осуществлять разными случайными числами, так как события независимые. При первом способе достаточно одного случайного числа ![]() , но сравнений может быть больше. Кроме того, нужно предварительно рассчитывать вероятности возможных исходов.
, но сравнений может быть больше. Кроме того, нужно предварительно рассчитывать вероятности возможных исходов.
3.9. Моделирование совместных зависимых событий
Пусть события A и B имеют вероятности свершения ![]() и
и ![]() соответственно. Условная вероятность
соответственно. Условная вероятность ![]() известна.
известна.
Покажем способ моделирования совместных зависимых событий на примере.
Пример 3.9. При испытании нового автомата определены вероятности горизонтального и вертикального отклонений пробоин от точки прицеливания ![]() и
и ![]()
Вероятность отклонения пробоин по высоте относительно тех, которые уложились в пределы допустимого бокового отклонения, равна:
Соответствующий фрагмент модели приведен на рис. 3.18.
Рис. 3.18. Алгоритм моделирования совместных зависимых событий
Пример 3.10. В ремонтное подразделение поступают вышедшие из строя средства связи (СС). В каждом СС могут быть неисправными в любом сочетании блоки A, B, C . Вероятности выхода из строя блоков ![]() ,
, ![]() ,
, ![]() соответственно. Ремонт производится путем замены неисправных блоков исправными блоками. В момент поступления неисправного СС вероятности наличия исправных блоков
соответственно. Ремонт производится путем замены неисправных блоков исправными блоками. В момент поступления неисправного СС вероятности наличия исправных блоков ![]() ,
, ![]() ,
, ![]() соответственно. При отсутствии хотя бы одного из исправных блоков A, B, C ремонт неисправного СС не производится.
соответственно. При отсутствии хотя бы одного из исправных блоков A, B, C ремонт неисправного СС не производится.
Построить алгоритм имитационной модели с целью определения абсолютного и относительного количества отремонтированных СС с неисправными блоками A, B, C и A, B из общего количества R поступивших в ремонт СС.
Решение
Для имитации неисправных блоков СС и имитации наличия исправных блоков в ремонтном подразделении воспользуемся способом определения по жребию. Для этого рассчитаем вероятности исходов и сведем их в табл. 3.5 и 3.6 соответственно.
Так как нужно определить абсолютное и относительное количества отремонтированных СС, поступивших с неисправными блоками A, B и A, B, C , то нет смысла рассчитывать вероятности для других сочетаний неисправных и исправных блоков.
Алгоритм имитационной модели приведен на рис. 3.19.
В алгоритме приняты следующие обозначения:
![]() - заданное количество реализаций модели;
- заданное количество реализаций модели;
![]() - счетчик количества реализаций модели;
- счетчик количества реализаций модели; ![]() - счетчик числа отремонтированных СС за
- счетчик числа отремонтированных СС за ![]() реализаций модели;
реализаций модели;
![]() - абсолютное количество отремонтированных СС;
- абсолютное количество отремонтированных СС;
![]() - относительное количество отремонтированных СС.
- относительное количество отремонтированных СС.
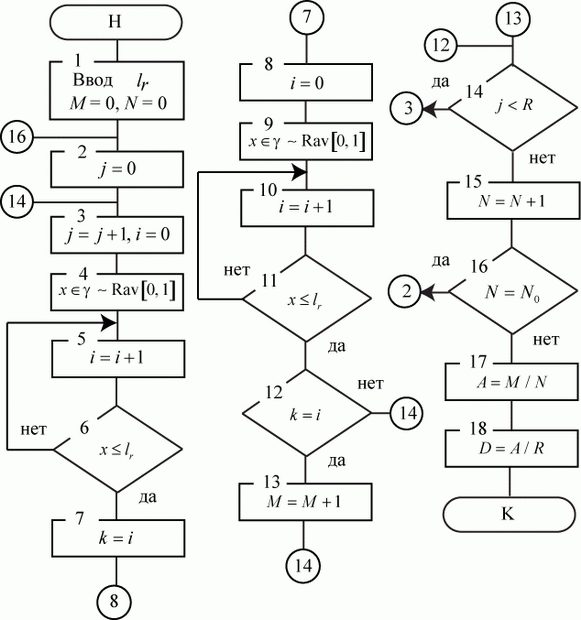
увеличить изображение
Рис. 3.19. Алгоритм модели функционирования системы ремонта
Согласно постановке задачи в блоках 3…7 по данным табл. 3.5 разыгрывается, с какими неисправными блоками поступает СС в ремонт. В результате розыгрыша определяется номер интервала (столбца табл. 3.5) и запоминается в переменной ![]() .
.
Аналогично в блоках 8…11 разыгрывается по данным табл. 3.6 наличие в ремонтном подразделении необходимых блоков для замены.
Если такие блоки имеются, т. е. выполняется условие ![]() в блоке 12, в счетчик
в блоке 12, в счетчик ![]() (блок 13) добавляется единица.
(блок 13) добавляется единица.
3.10. Классификация случайных процессов
Случайная величина ![]() зависящая от одного неслучайного вещественного аргумента
зависящая от одного неслучайного вещественного аргумента ![]() , называется случайным процессом.
, называется случайным процессом. ![]() является случайной величиной при каждом фиксированном
является случайной величиной при каждом фиксированном
значении аргумента. Обычно (во всяком случае, для процессов, протекающих в технических системах) в качестве вещественного аргумента выступает время, поэтому случайный процесс будем обозначать ![]() .
.
Определим два понятия, присущие случайным процессам: сечение и реализация (рис. 3.20).
Сечением случайного процесса ![]() называется случайная величина
называется случайная величина ![]() являющаяся значением случайного процесса в фиксированный момент времени
являющаяся значением случайного процесса в фиксированный момент времени ![]() .
.
Реализацией случайного процесса ![]() называется функция времени
называется функция времени ![]() описывающая течение процесса в некотором
описывающая течение процесса в некотором ![]() -м опыте.
-м опыте.
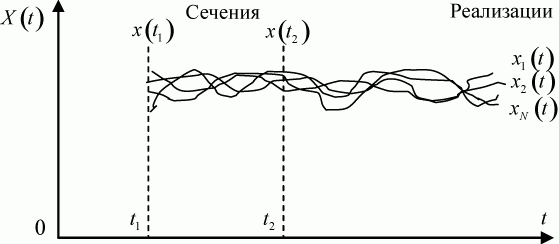
Рис. 3.20. Реализации и сечения случайного процесса
Случайный процесс ![]() и аргумент
и аргумент ![]() могут быть дискретными или непрерывными.
могут быть дискретными или непрерывными.
Очевидно, вследствие особенностей представления информации в компьютере моделью случайного процесса будет модель дискретной последовательности дискретного случайного процесса. Следовательно, чтобы смоделировать реальный случайный процесс, необходимо выполнить следующее:
- разбить интервал исследования на M временных точек
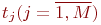 , которых должно быть столько, чтобы обеспечить необходимую точность воспроизведения исследуемого процесса;
, которых должно быть столько, чтобы обеспечить необходимую точность воспроизведения исследуемого процесса; - выполнить одну реализацию случайного процесса, то есть для каждого момента времени
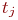 определить сечение, разыграв случайное число, обладающее характеристиками случайного процесса;
определить сечение, разыграв случайное число, обладающее характеристиками случайного процесса; - определить аналогичные сечения для каждой из реализаций случайного процесса (число выбирается таким, чтобы обеспечить необходимые точность и достоверность результатов).
Случайные процессы могут быть:
- стационарные;
- нестационарные.
На практике часто встречаются случайные процессы, у которых все реализации однородны в вероятностном смысле. То есть значения всех сечений представляют собой случайные числа, одинаково распределенные с одинаковыми матожиданиями и дисперсиями:
Такие процессы называют стационарными.
Что касается автокорреляционной функции ![]() , то ее значение в стационарном процессе зависит только от разности
, то ее значение в стационарном процессе зависит только от разности ![]() и не зависит от того, в каком месте временной оси находятся точки
и не зависит от того, в каком месте временной оси находятся точки ![]() и
и ![]() .
.
Для стационарного процесса нет необходимости определять искомые характеристики для всех ![]() сечений, а достаточно только для одного сечения
сечений, а достаточно только для одного сечения ![]() реализаций случайного процесса. То есть вместо
реализаций случайного процесса. То есть вместо ![]() измерений выполнить только
измерений выполнить только ![]() измерений. По данным этих измерений рассчитываются оценки
измерений. По данным этих измерений рассчитываются оценки ![]() и
и ![]() , которые в силу стационарности и являются оценками характеристик всего случайного процесса
, которые в силу стационарности и являются оценками характеристик всего случайного процесса ![]() и
и ![]() .
.
Если сечения случайного процесса неоднородны в вероятностном смысле, то такой процесс называется нестационарным.
В работе модели стационарного процесса может присутствовать и нестационарный период. Это разного рода переходные процессы. Например, характеристики начального периода работы модели нестационарные из-за того, что начальные установки характеристик процесса были не равны характеристикам, значения которых установятся в дальнейшем. Естественно, речь идет о средних значениях характеристик.
Важнейшим свойством случайного процесса является свойство эргодичности.
Свойство эргодичности заключается в том, что все реализации случайного процесса имеют одинаковые статистические характеристики. Отсюда следует, что одна реализация случайного процесса характеризует весь случайный процесс ![]() следовательно, для определения статистических характеристик процесса достаточно выполнить одну реализацию.
следовательно, для определения статистических характеристик процесса достаточно выполнить одну реализацию.
Обычно рассматривают свойство эргодичности по отношению к одной какой-либо характеристике случайного процесса. Относительно оценки матожидания свойство эргодичности формально выглядит так:
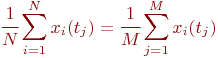
Свойством эргодичностиобладают многие случайные процессы и, в том числе, все стационарные.
Таким образом, можно сформулировать определение эргодиче-ского процесса.
Случайный процесс ![]() называется эргодическим, если его основные характеристики
называется эргодическим, если его основные характеристики ![]() и
и ![]() могут быть получены не только усреднением по множеству реализаций, но и усреднением по времени одной реализации.
могут быть получены не только усреднением по множеству реализаций, но и усреднением по времени одной реализации.
Например, при изучении флуктуационного шума радиоприемников, представляющего собой стационарный случайный процесс, достаточно ограничиться измерением сечений в течение заданного времени ![]() в одном конкретном образце. Результаты, полученные при обработке данных измерений, могут быть распространены на все идентичные радиоприемники.
в одном конкретном образце. Результаты, полученные при обработке данных измерений, могут быть распространены на все идентичные радиоприемники.
3.11. Способы продвижения модельного времени
При реализации имитационной модели используются обычно три представления времени:
- реальное время системы, функционирование которой имитируется;
- модельное время, по которому организуется синхронизация событий в модели;
- машинное время имитации, отражающее затраты ресурса времени компьютера.
Время в компьютерной модели принципиально не может протекать непрерывно. В компьютере в каждый момент времени выполняется одна команда. Но даже отдельные события реального процесса, протекающие, скажем, одновременно и мгновенно, в имитационной модели представляются цепочкой команд, на выполнение которых тратится машинное время.
Следовательно, время в модели, то есть модельное время (МВ), продвигается дискретно, скачками.
Продвижение времени в модели может быть организовано двумя способами:
- продвижение модельного времени с фиксированным переменным шагом
 ;
; - продвижение модельного времени до очередного события (по принципу
 ).
).
Сущность первого способа поясним временными диаграммами, показанными на рис. 3.21.
На диаграммах а…г показаны моменты смены дискретных состояний элементами 1…4 системы. На диаграмме д - временная последовательность смены состояний системой. На диаграмме е - точки модельного времени, то есть время смены состояний системы, показанных на диаграмме д.
Так как моменты модельного времени на диаграмме е не связаны с моментами появления событий а…г, то имитационная модель с фиксированным шагом продвижения времени искажает действительные процессы в системе: разновременные события представляются одновременными, моменты свершения событий фиксируются, как правило, с опозданием. Уменьшая величину ![]() , можно уменьшить искажение действительного процесса. Однако это приводит к увеличению затрат машинного времени, особенно, если интервалы между сменами состояний в среднем больше, чем
, можно уменьшить искажение действительного процесса. Однако это приводит к увеличению затрат машинного времени, особенно, если интервалы между сменами состояний в среднем больше, чем ![]() .
.
На диаграмме ж рис. 3.20 демонстрируется сущность второго способа. Она заключается в том, что модельное время сдвигается вперед не на фиксированную величину ![]() , а точно до времени наступления самого раннего из очередных событий - на
, а точно до времени наступления самого раннего из очередных событий - на ![]() .
.
Видно, что недостатки, присущие первому способу, здесь исключены: события рассматриваются и моделируются в моменты их свершения, и одновременно (события a1,г1), если у них одинаковое время появления. Промежутки времени, когда в модели "ничего не происходит", пропускаются без особых затрат машинного времени. Эти пропуски все равно учитываются в модельном времени.
увеличить изображение
Рис. 3.21. Временная диаграмма работы модели
Однозначных рекомендаций по выбору того или иного способа продвижения модельного времени нет. Из общих рассуждений можно установить, что, если смена состояний в моделируемой системе происходит регулярно и часто, нет ограничений на расход машинного времени, то продвижение модельного времени фиксированными шагами ![]() вполне приемлемо.
вполне приемлемо.
Если же смена состояний происходит редко и нерегулярно, кроме того, предъявляются повышенные требования к точности моделирования, то целесообразней второй способ продвижения модельного времени - скачками до ближайшего по времени события.
Мы рассмотрели способы продвижения модельного времени при так называемом последовательном (квазипараллельном) имитационном моделировании, характерным признаком которого является наличие централизованного списка событий и глобальных часов модельного времени. Обычно в таких имитационных моделях исследуемого процесса устанавливаются (или определяются) реальные затраты времени в масштабе, который устанавливает сам исследователь. Как правило, эти затраты безотносительны к естественному движению времени, которое обычно называют "реальным", хотя правильнее называть его естественным или натуральным.
Однако встречаются имитационные модели, которые предназначены для работы в реальном (естественном) масштабе времени. Это, например, некоторые типы тренажеров, работающие в интерактивном режиме с человеком. Заметим, что и в этом случае модельное время продвигается скачками - способом ![]() или
или ![]() . Следовательно, возникает проблема синхронизации модельного времени с естественным временем.
. Следовательно, возникает проблема синхронизации модельного времени с естественным временем.
Существует также понятие распределенного имитационного моделирования. Источниками его развития являются: модели, требующие для своего выполнения большого количества вычислительных ресурсов, военные приложения и компьютерные игры с использованием Интернет.
Под распределенным имитационным моделированием понимается распределенное выполнение единой программы имитационной модели на мультипроцессорной или мультикомпьютерной системе.
Последовательная имитационная модель может быть выполнена на параллельной вычислительной технике. Достижение выигрыша во времени возможно за счет параллельного выполнения событий, запланированных на один и тот же момент модельного времени. При распределенном моделировании параллельно выполняются события, запланированные в различных отрезках модельного времени.
Целью использования распределенного моделирования для военных приложений является интеграция отдельно разработанных моделей в единое модельное окружение. Примером могут быть тренажеры для обучения и имитации сценариев военных действий.
Другим примером являются модели инфраструктур, объединяющие экономические, экологические, транспортные и другие подмодели. Такие подмодели могут исполняться на географически распределенных гетерогенных мультикомпьютерных системах.
Пример 3.11. На узел связи поступают заявки на передачу сообщений. Интервалы времени поступления заявок подчинены показательному закону с математическим ожиданием ![]() . На узле связи имеются два канала передачи данных. При поступлении очередной заявки в интервале времени
. На узле связи имеются два канала передачи данных. При поступлении очередной заявки в интервале времени ![]() вероятности того,
вероятности того,
что каналы А и В будут свободны, соответственно равны ![]() и
и ![]() . При поступлении заявок после времени
. При поступлении заявок после времени ![]() вероятности того, что каналы А и В будут свободны, соответственно равны
вероятности того, что каналы А и В будут свободны, соответственно равны ![]() и
и ![]() . Сообщение передаётся по любому свободному каналу. Если оба канала заняты, заявка теряется.
. Сообщение передаётся по любому свободному каналу. Если оба канала заняты, заявка теряется.
Построить алгоритм имитационной модели "Обработка запросов на узле связи" с целью определения абсолютного и относительного числа обслуженных заявок из их общего количества, поступивших на узел связи за время ![]() ,
, ![]() .
.
Решение
В ранее рассмотренных постановках задач отсутствовала динамика или фактор времени. Например, просто указывалось, что поступает такое-то количество заявок, а за какое время и с какими интервалами - неизвестно. Настоящая постановка задачи отличается тем, что в нее введена динамика - определены интервалы времени поступления заявок, подчиненные показательному закону.
Алгоритм модели приведен на рис. 3.22.
увеличить изображение
Рис. 3.22. Алгоритм модели "Обработка запросов на узле связи"
В алгоритме модели:
![]() - суммарное количество заявок, поступивших за
- суммарное количество заявок, поступивших за ![]() реализаций модели;
реализаций модели;
![]() - текущее модельное время;
- текущее модельное время;
![]() - заданное количество реализаций модели;
- заданное количество реализаций модели;
![]() - счетчик текущего числа реализаций модели;
- счетчик текущего числа реализаций модели;
![]() - суммарное число обслуженных заявок за
- суммарное число обслуженных заявок за ![]() реализаций;
реализаций;
![]() - абсолютное число обслуженных заявок;
- абсолютное число обслуженных заявок;
![]() - относительное число обслуженных заявок.
- относительное число обслуженных заявок.
В связи с введением фактора времени следует обратить внимание на то, что алгоритм модели содержит два цикла: первый,
внутренний определяется временем моделирования ![]() (блок 15), а второй, внешний - количеством реализаций модели
(блок 15), а второй, внешний - количеством реализаций модели ![]() (блок 17).
(блок 17).
Алгоритм модели относительно прост. Но если увеличить количество элементов и различных процессов системы, ввести их динамику, например, обслуживания заявок, то алгоритм модели усложнится. Для построения имитационных моделей функционирования сложных систем "лобовой" подход неприемлем.
Далее мы рассмотрим способы, позволяющие в некотором роде унифицировать построение моделей сложных систем с продвижением в них модельного времени по принципу ![]() или
или ![]() , а также до ближайшего события.
, а также до ближайшего события.
3.12. Модель противоборства двух сторон
Имитационную модель, в которой продвижение модельного времени реализовано с фиксированным шагом, рассмотрим на примере огневого противоборства группировок A и В. Аналитическое моделирование такой операции мы рассмотрели в предыдущей теме. Однако мы снимаем условие многочисленности группировок, так как оно теперь несущественно.
Для начала, чтобы не загромождать алгоритм модели, введем два ограничения:
- вероятность поражения цели одним выстрелом
 ;
; - вероятность одновременного поражения двумя средствами друг друга пренебрежимо мала.
Впоследствии мы убедимся, что в имитационной модели рассматриваемого боя эти ограничения могут быть сняты.
Моделирование проводится с целью определения средних численностей группировок на любой момент боя, в частности, на фиксированный момент времени ![]() .
.
Учебная задача состоит в том, чтобы изучить структуру конкретного алгоритма, в котором продвижение модельного времени реализовано с фиксированным шагом ![]() .
.
Введем обозначения:
![]() - первоначальные численности группировок;
- первоначальные численности группировок;
![]() - текущие значения численностей группировок
- текущие значения численностей группировок ![]() и
и ![]() соответственно;
соответственно;
![]() - число оставшихся средств каждой из сторон в конце
- число оставшихся средств каждой из сторон в конце ![]() -го интервала моделирования (после
-го интервала моделирования (после ![]() -ой реализации модели);
-ой реализации модели);
![]() - текущее число реализаций модели;
- текущее число реализаций модели;
![]() - заданное число реализаций модели случайного процесса;
- заданное число реализаций модели случайного процесса;
![]() - текущее время;
- текущее время;
![]() - длительность интервала моделирования;
- длительность интервала моделирования;
![]() - средние за
- средние за ![]() реализаций модели численности оставшихся средств сторон в конце каждого интервала моделирования:
реализаций модели численности оставшихся средств сторон в конце каждого интервала моделирования:
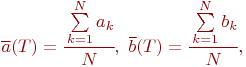
![]() - переменные счета средств сторон
- переменные счета средств сторон ![]() и
и ![]() соответственно .
соответственно .
Идея построения имитационной модели состоит в реализации модели противоборства ![]() раз и фиксации остатков сторон после каждой реализации. По выполнении
раз и фиксации остатков сторон после каждой реализации. По выполнении ![]() реализаций будут определены оценки численностей сторон
реализаций будут определены оценки численностей сторон ![]() .
.
Определим величину ![]() . На выбор величины
. На выбор величины ![]() влияют два противоречивых требования:
влияют два противоречивых требования:
- на протяжении отрезка времени не должно происходить много событий, так как они будут зафиксированы как одновременные, что исказит исследуемый реальный процесс;
- на протяжении отрезка времени должно произойти хотя бы одно событие, иначе будет много "пустых" прогонов модели, что увеличит машинное время.
С учетом приведенных выше требований разобьем интервал моделирования ![]() на равные отрезки
на равные отрезки ![]() такие, чтобы каждое огневое средство любой из сторон могло выстрелить не более одного раза.
такие, чтобы каждое огневое средство любой из сторон могло выстрелить не более одного раза.
Например, скорострельность средств поражения стороны ![]()
![]() , а средств стороны
, а средств стороны ![]() . Так как
. Так как ![]() , то
, то ![]() следует выбрать исходя из условия
следует выбрать исходя из условия ![]() .
.
Алгоритм имитации противоборства сторон состоит из четырех модулей:
 - установка начальных условий;
- установка начальных условий; - продвижение модельного времени;
- продвижение модельного времени; - формирование результата заданной точности;
- формирование результата заданной точности; - имитация противоборства сторон.
- имитация противоборства сторон.
Блок-схема алгоритма имитации противоборства двух сторон показана на рис. 3.23.
Модуль установки начальных условий ( ![]() ). Он состоит из трех блоков 1… 3.
). Он состоит из трех блоков 1… 3.
Блок 1 - установка начальных условий на весь процесс моделирования: число реализаций ![]() модели, интервал исследования
модели, интервал исследования ![]() , величина временного шага
, величина временного шага ![]() , установка в нуль ячеек
, установка в нуль ячеек ![]()
Блок 2 - установка начальных условий на очередную реализацию процесса: восстановление численностей сторон ![]() и исходного времени
и исходного времени ![]() .
.
Блок 3 - установка начальных условий на очередной отрезок ![]() модельного времени: подготовка перебора
модельного времени: подготовка перебора ![]() средств
средств
поражения каждой стороны.
Модуль продвижения модельного времени ( ![]() ). Состоит из двух блоков 4..5.
). Состоит из двух блоков 4..5.
Блок 4 - продвижение модельного времени на очередной временной отрезок ![]() .
.
Блок 5 - проверка условия окончания очередной реализации модели ![]() .
.
Модуль формирования результата и обеспечения заданной точности ( ![]() ). Состоит из блоков 6…9.
). Состоит из блоков 6…9.
Блок 6 - накопление суммы остатков средств каждой стороны за текущее количество интервалов моделирования (реализаций модели).
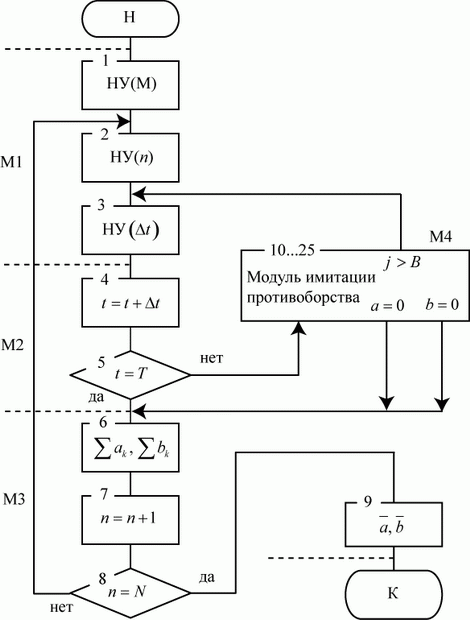
увеличить изображение
Рис. 3.23. Блок-схема алгоритма модели противоборства двух сторон
Блок 7 - счетчик числа реализаций модели ( ![]() ) .
) .
Блок 8 - осуществляет контроль над выполнением заданного числа реализаций модели. Число реализаций модели определяется, исходя из заданных точности и достоверности результатов моделирования.
Блок 9 - формирование конечного результата моделирования.
В данном случае - ![]() и
и ![]() .
.
При необходимости определяются и другие статистические характеристики.
Модуль имитации противоборства сторон ( ![]() ). Этот модуль - основной. Если структура предыдущих модулей, в общем-то, стандартна, то реализация данного модуля носит функционально-индивидуальный характер. Модуль включает блоки 10…25. Блок-схема алгоритма модуля представлена на рис. 3.24.
). Этот модуль - основной. Если структура предыдущих модулей, в общем-то, стандартна, то реализация данного модуля носит функционально-индивидуальный характер. Модуль включает блоки 10…25. Блок-схема алгоритма модуля представлена на рис. 3.24.
Каждое средство противоборствующих сторон идентифицируется его номером. Номера средств стороны ![]() -
- ![]() , средств стороны
, средств стороны ![]() -
- ![]() .
.
Блок 10 - выбор очередного средства стороны ![]() :
: ![]() .
.
Блок 11 - проверка: все ли средства стороны ![]() получили право на выстрел? Если
получили право на выстрел? Если ![]() , то управление передается блоку 18 для имитации выстрелов средствами стороны
, то управление передается блоку 18 для имитации выстрелов средствами стороны ![]() . В противном случае управление передается блоку 12.
. В противном случае управление передается блоку 12.
Блок 12 - проверка: боеспособно ли выбранное средство? Состояние средств сторон ![]() и
и ![]() определяют переменные
определяют переменные ![]() и
и ![]() :
:
Если окажется ![]() , то управление передается блоку 10 для
, то управление передается блоку 10 для
выбора очередного средства стороны ![]() . Иначе - переход к блоку 13.
. Иначе - переход к блоку 13.
Блок 13 - выбор цели из средств стороны ![]() . Выбор цели может быть организован либо случайной, либо детерминированной процедурами. Самый простой способ: последовательная проверка средств стороны
. Выбор цели может быть организован либо случайной, либо детерминированной процедурами. Самый простой способ: последовательная проверка средств стороны ![]() с выбором первого непораженного средства.
с выбором первого непораженного средства.
Блок 14 - проверка выбранной цели: не уничтожена ли она была на предыдущих этапах данной реализации модели? Если ![]() , то переход к блоку 13 для выбора непораженной цели.
, то переход к блоку 13 для выбора непораженной цели.
Иначе - переход к блоку 15 для имитации выстрела.
Выстрел - одиночное событие со случайным исходом. Моделью такого события является известная нам конструкция из двух блоков 15 и 15.1.
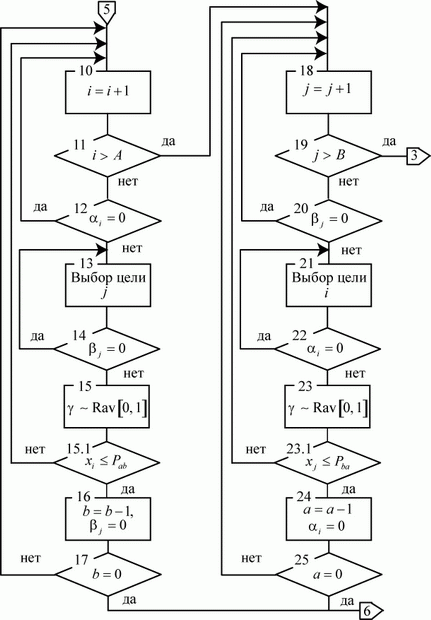
увеличить изображение
Рис. 3.24. Блок-схема алгоритма модуля противоборства двух сторон
Блок 15 - обращение к ДСЧ за равномерно распределенным случайным числом ![]() .
.
Блок 15.1 - проверка результата выстрела. Если ![]() , цель поражена и управление передается блоку 16 для фиксации этого факта. Если
, цель поражена и управление передается блоку 16 для фиксации этого факта. Если ![]() , то промах и управление передается блоку 10 для выбора очередного стреляющего средства стороны
, то промах и управление передается блоку 10 для выбора очередного стреляющего средства стороны ![]() .
.
Блок 16 - уменьшение числа средств стороны ![]() :
: ![]() и установка признака состояния пораженного средства:
и установка признака состояния пораженного средства: ![]() .
.
Блок 17 - не уничтожена ли вся группировка ![]() ? Если да, то данная реализация модели заканчивается и управление передается блоку 6 для фиксации оставшихся боеспособных средств стороны
? Если да, то данная реализация модели заканчивается и управление передается блоку 6 для фиксации оставшихся боеспособных средств стороны ![]() . Если нет, то управление передается блоку 10 для выбора очередного средства стороны
. Если нет, то управление передается блоку 10 для выбора очередного средства стороны ![]() и т. д.
и т. д.
После предоставления права на выстрел всем средствам стороны ![]() соответствующее право дается средствам стороны
соответствующее право дается средствам стороны ![]() - переход из блока 11 в блок 18.
- переход из блока 11 в блок 18.
Функции блоков 18… 25 попарно одинаковы с функциями блоков 10…17, изменены только обозначения - вместо ![]() указано
указано ![]() , вместо
, вместо ![]() , вместо
, вместо ![]() и т. д.
и т. д.
По окончании перебора всех средств стороны ![]() и, если не зафиксировано полное уничтожение средств стороны
и, если не зафиксировано полное уничтожение средств стороны ![]() , управление передается блоку 3 для моделирования очередного скачка времени на величину
, управление передается блоку 3 для моделирования очередного скачка времени на величину ![]() .
.
Примерная диаграмма изменения численностей сторон ![]() и
и ![]() в
в ![]() -й реализации на интервале
-й реализации на интервале ![]() показана на рис. 3.25.
показана на рис. 3.25.
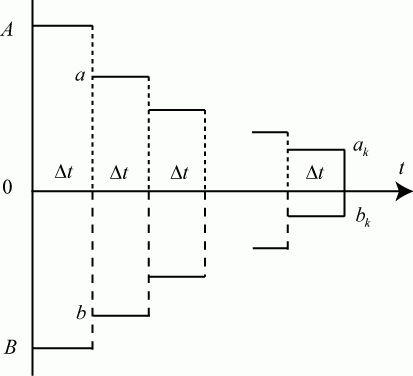
Рис. 3.25. Диаграмма изменения численности сторон
3.13. Модель противоборства как процесс блуждания по решетке
Итак, чтобы построить имитационную модель, надо скопировать и описать в виде программы элементарные действия процесса и соединить их в нужной последовательности. Такое прямолинейное моделирование, в общем, понятно и естественно.
Однако, иногда можно увидеть совсем неожиданную аналогию (структурную или функциональную) между исследуемым процессом и некоторым другим, на первый взгляд ничего не имеющим общего с оригиналом. Имитационная модель этого нового процесса может оказаться проще и, тем не менее, позволит определить искомые характеристики.
В частности, для исследования процесса противоборства двух сторон таким "дублером" может быть процесс "блуждания частицы по решетке".
Рассмотрим, как перемещение некоторого объекта по решетке становится аналогом, моделью противоборства двух сторон, если целью моделирования является определение оценок численностей сторон в конце операции - интервала исследования.
Противоборствуют две стороны: ![]() и
и ![]() .
.
Первоначальные численности сторон: ![]() и
и ![]() .
.
Текущие численности сторон: ![]() и
и ![]() ;
; ![]() ,
, ![]() .
.
Время "жизни" каждого средства случайно, имеет экспоненциальное распределение с параметрами ![]() и
и ![]() сторон
сторон ![]() и
и ![]() .
.
Обе стороны образуют единую систему ![]() . В ходе боя численности сторон изменяются (уменьшаются) или остаются неизменными. Мы это трактуем как переход системы из одного состояния в другое:
. В ходе боя численности сторон изменяются (уменьшаются) или остаются неизменными. Мы это трактуем как переход системы из одного состояния в другое: ![]() или
или ![]() и т. д.
и т. д.
Граф состояний такой системы имеет вид двумерной целочисленной решетки с однонаправленными связями. Переходу системы из одного состояния в другое можно поставить в соответствие случайное блуждание некоторой частицы по решетчатой структуре. Отсюда и название моделирующей абстракции.
Граф состояний приведен на рис. 3.26.
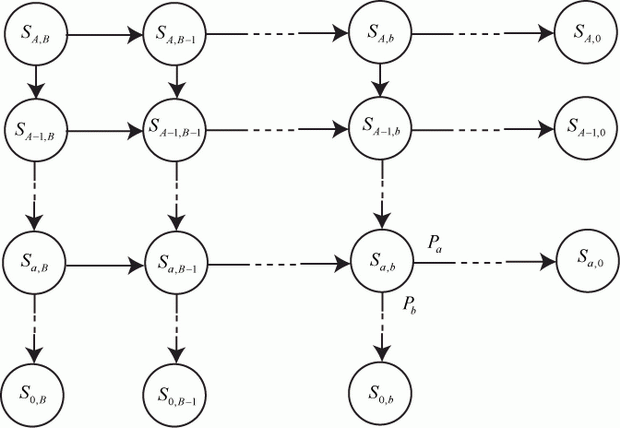
увеличить изображение
Рис. 3.26. Граф состояний моделируемой системы противоборства Исходное состояние системы S_{a,b} .
Стороны ведут взаимоуничтожающий огонь. В предположении ординарности потока событий, переводящего систему из одного состояния в другое, система из состояния ![]() может перейти только лишь в состояние
может перейти только лишь в состояние ![]() или
или ![]() (или остаться в прежнем состоянии
(или остаться в прежнем состоянии ![]() ). Очевидно, направления переходов в графе - решетке только вправо или вниз.
). Очевидно, направления переходов в графе - решетке только вправо или вниз.
Процесс противоборства заканчивается при полном уничтожении средств одной из сторон, т. е. при переходе в состояние ![]() или
или ![]() а также по окончании временного интервала исследования
а также по окончании временного интервала исследования ![]() . Так заканчивается одна,
. Так заканчивается одна, ![]() -я реализация процесса противоборства. Зафиксировав остатки средств сторон
-я реализация процесса противоборства. Зафиксировав остатки средств сторон ![]() и
и ![]() и усреднив их за
и усреднив их за ![]() реализаций, найдем решение поставленной задачи - определение оценок численностей сторон на момент окончания операции.
реализаций, найдем решение поставленной задачи - определение оценок численностей сторон на момент окончания операции.
Продвижение времени в модели - фиксированными шагами ![]() . Величина
. Величина ![]() такова, чтобы на этом временном участке происходило не более одного события.
такова, чтобы на этом временном участке происходило не более одного события.
Суммарные интенсивности огня сторон ![]() и
и ![]() зависят от численностей их боеспособных средств и равны
зависят от численностей их боеспособных средств и равны ![]() и.
и.
Следовательно, вероятности уничтожения одного из средств (перехода системы в очередное состояние) равны:
Эти приближенные равенства тем точнее, чем меньше ![]() .
.
Блок схема алгоритма ИМ противоборства двух сторон, построенная способом "блуждания частицы по решетке" представлена на рис. 3.27.
Блоки 1 и 2 - установка начальных условий на весь процесс моделирования и на каждую очередную реализацию.
Блок 3 - расчет вероятностей ![]() и
и ![]() .
.
Блоки 4…10 - определение исхода противоборства на очередном временном отрезке ![]() . Если
. Если ![]() , то свершилось событие
, то свершилось событие ![]() , иначе - проверка условия
, иначе - проверка условия ![]() ? Если это условие выполняется, то свершилось событие
? Если это условие выполняется, то свершилось событие ![]() , если не выполняется, то пораженных средств не оказалось. Вероятность этого события
, если не выполняется, то пораженных средств не оказалось. Вероятность этого события ![]() равна
равна ![]() .
.
Блоки 11… 16 аналогичны соответствующим блокам предыдущей имитационной модели противоборства двух сторон (см. рис. 3.22).
Сравним обе рассмотренные модели противоборства двух сторон.
Последняя заметно проще. Упрощение связано с тем, что в ней не моделируется поведение каждого отдельного средства, а рассматривается поведение системы в целом.
Однако, первую модель несложно развить, например, учесть неоднородность средств в каждой группировке, указав соответствующие значения ![]() и
и ![]() .
.
Последняя модель таких возможностей не имеет.
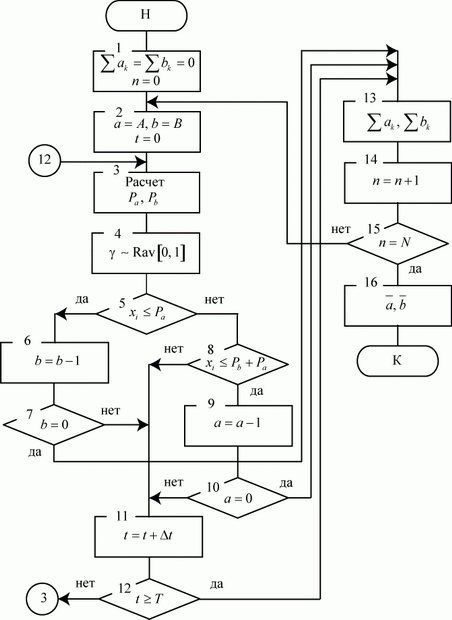
увеличить изображение
Рис. 3.27. Блок-схема модели "блуждание частицы по решетке"
3.14. Типовая схема имитационной модели с продвижением времени по событиям
Уточним понятие события.
Под событием будем понимать смену состояния системы.
Виды событий:
- выход из строя технических средств;
- восстановление работоспособности техники;
- поступление сообщения на узел связи;
- начало передачи сообщения;
- конец передачи сообщения;
- уничтожение цели и т. п.
Вид события связан с типом элемента, сменяющего свои состояния. Смена состояний системой есть объединение смен состояний ее элементов.
Будем считать, что событие совершается в конкретный момент времени мгновенно.
Вообще-то событие - смена состояния - совершается за некоторый отрезок времени. Но в интересующих нас процессах длительность смены состояний много меньше времени нахождения системы в каком-либо состоянии, поэтому длительностью события можно пренебречь.
Каждому событию соответствует пространственно-временная точка ![]() , где
, где ![]() - момент свершения события;
- момент свершения события; ![]() - тип элемента системы, сменившего состояние;
- тип элемента системы, сменившего состояние; ![]() - вид или номер события этого элемента.
- вид или номер события этого элемента.
Различают события активные и пассивные.
Активное событие - это смена состояния элемента под воздействием присущих ему внутренних причин.
Например, отказ техники - активное событие, так как оно определяется износом или скрытыми дефектами. Конец передачи сообщения по каналу связи - активное событие, так как при прочих равных условиях оно определяется быстродействием передающей аппаратуры.
Пассивное событие - событие, возникшее под воздействием активного события.
Например:
- начало передачи сообщения по каналу связи, так как оно зависит от другого активного состояния - поступления сообщения на узел связи;
- изменение числа устройств, ожидающих ремонта. Увеличение численности зависит от поступления неисправных устройств в мастерскую; уменьшение - от освобождения мастерской; и др.
В одном и том же элементе системы могут происходить активные и пассивные события. Например:
- начало решения задачи на компьютере - событие пассивное, так как оно происходит от другого события: поступления запроса на решение;
- завершение решения - событие активное, так как оно зависит от внутренних свойств компьютера (производительности);
- поступление заявок на обслуживание в очередь и покидание очереди - события пассивные, но уход из очереди "нетерпеливых" заявок - события активные.
Обычно элемент, в котором происходит активное событие, называют активным, пассивное событие - пассивным.
Основу имитационной модели системы с продвижением модельного времени по событиям составляют модели активных событий. Пассивные события моделируются просто, если выявлены их причинно-следственные отношения с активными событиями.
Множество точек ![]() представляет собой поведение системы во времени. Множество точек
представляет собой поведение системы во времени. Множество точек ![]() активных событий называется списком событий.
активных событий называется списком событий.
Список событий может быть сформирован либо перед началом моделирования, либо формироваться в ходе моделирования. На рис. 3.20 список событий представлен диаграммой ж.
Имитационная модель с продвижением времени по событиям любой системы состоит из следующих функциональных модулей:
- модуль установки начальных условий;
- модуль продвижения модельного времени;
- модули реакции;
- модуль обеспечения заданной точности и достоверности;
- модуль формирования результата моделирования.
Модуль установки начальных условий.
Модуль устанавливает значения разного рода констант, например, заданное число ![]() реализаций модели, критерий завершения интервала моделирования
реализаций модели, критерий завершения интервала моделирования ![]() и др., а также элементы списка событий
и др., а также элементы списка событий ![]() - все или только начальные для каждого вида события.
- все или только начальные для каждого вида события.
Если в предыдущем способе продвижения модельного времени на фиксированные промежутки ![]() модуль состоял из трех блоков установки начальных условий, то здесь достаточно двух: установка начальных условий на весь процесс моделирования (
модуль состоял из трех блоков установки начальных условий, то здесь достаточно двух: установка начальных условий на весь процесс моделирования ( ![]() ) и установка начальных условий на каждую реализацию (
) и установка начальных условий на каждую реализацию ( ![]() ).
).
Модуль продвижения модельного времени. Его функции: выбор в списке событий момента времени свершения очередного,
ближайшего события ![]() , и фиксация очередного момента модельного времени:
, и фиксация очередного момента модельного времени:
Модули реакции. Представляют собой программы, имитирующие действия соответствующих активных событий и связанных с ними пассивных событий. Модулей реакции столько, сколько возможно в системе активных событий. Подключение того или иного модуля реакции происходит в соответствии с значениями ![]() и
и ![]() .
.
Помимо имитации событий в модулях реакции могут выполняться следующие действия:
- фиксация текущих значений параметров, интересующих исследователя, так называемых числовых атрибутов, и, возможно, их текущая статистическая обработка;
- подсчет числа свершившихся событий данного вида;
- прогноз времени свершения
 , очередного события данного вида и занесение этого времени в список событий (если список событий формируется в ходе моделирования). Прогноз осуществляется с помощью соответствующего датчика случайных чисел, адекватно имитирующего временные интервалы между событиями.
, очередного события данного вида и занесение этого времени в список событий (если список событий формируется в ходе моделирования). Прогноз осуществляется с помощью соответствующего датчика случайных чисел, адекватно имитирующего временные интервалы между событиями.
Модуль обеспечения заданной точности и достоверности ведет подсчет числа реализаций модели ![]() . При достижении
. При достижении ![]() моделирование заканчивается.
моделирование заканчивается.
Модуль формирования результата. Выполняет окончательную статистическую обработку данных моделирования и обеспечивает отображение результата в данном виде.
Взаимодействие модулей показано на рис. 3.28.
Переход на соответствующий модуль реакции ![]() ,
, ![]() и т. д. происходит по значению индекса
и т. д. происходит по значению индекса ![]() текущего значения
текущего значения ![]() .
.
увеличить изображение
Рис. 3.28. Блок-схема модели с продвижением времени по событиям
Безусловный выход из любого модуля реакции - в блок выбора очередного значения ![]() модуля продвижения времени.
модуля продвижения времени.
В общий цикл предлагаемой структуры моделирующего алгоритма удобно вписывается определение конца интервала исследования ![]() и момента конца моделирования (
и момента конца моделирования ( ![]() ) . Для этого вся система интерпретируется как один обобщенный активный элемент, имеющий два состояния: включен и выключен.
) . Для этого вся система интерпретируется как один обобщенный активный элемент, имеющий два состояния: включен и выключен.
В списке событий этому обобщенному элементу соответствует одна пространственно-временная точка ![]() . Здесь
. Здесь ![]() - начальная точка отсчета интервала исследования, обычно
- начальная точка отсчета интервала исследования, обычно ![]() . Когда в процессе работы моделирующего алгоритма окажется, что
. Когда в процессе работы моделирующего алгоритма окажется, что ![]() , управление будет передано специальному модулю реакции
, управление будет передано специальному модулю реакции ![]() , который зафиксирует конец текущей реализации
, который зафиксирует конец текущей реализации ![]() .
.
Этот модуль также в случае ![]() передаст управление блоку (
передаст управление блоку ( ![]() ) на выполнение очередной реализации, а в случае выполнения
) на выполнение очередной реализации, а в случае выполнения ![]() - модулю формирования результатов.
- модулю формирования результатов.
Ранее было отмечено, что некоторые элементы в зависимости от состояния могут быть активными либо пассивными.
В случае перехода такого элемента в пассивное состояние надо
исключить возможность выбора его блоком "Выбор ![]() ". Для этого в список событий записывается время
". Для этого в список событий записывается время ![]() его переключения на свой модуль реакции. В этом случае модуль продвижения времени никогда не найдет этой временной точки, так как интервал исследования будет заканчиваться раньше.
его переключения на свой модуль реакции. В этом случае модуль продвижения времени никогда не найдет этой временной точки, так как интервал исследования будет заканчиваться раньше.
Но когда этот элемент вновь станет активным, время его активного события ![]() , должно быть занесено в список событий.
, должно быть занесено в список событий.
3.15. Имитационная модель системы массового обслуживания
Рассмотрим имитационную модель СМО следующего вида:
- многофазная;
- многоканальная;
- с несколькими неоднородными потоками заявок на обслуживание;
- разомкнутая;
- абсолютно надежная;
- с очередями неограниченной емкости на всех фазах обслуживания.
СМО такого вида показана на рис. 3.29.
На рис. 3.29:
![]() - источники потоков заявок на обслуживание;
- источники потоков заявок на обслуживание;
![]() - каналы обслуживания;
- каналы обслуживания;
![]() - число фаз;
- число фаз;
![]() - число каналов в каждой фазе;
- число каналов в каждой фазе;
![]() - очереди заявок на входах соответствующих фаз.
- очереди заявок на входах соответствующих фаз.
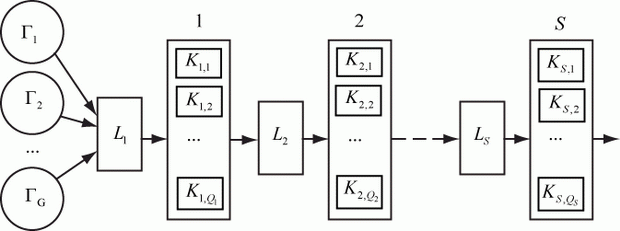
увеличить изображение
Рис. 3.29. Многофазная СМО
Такой СМО может быть, например, сборочный цех радиоэлектронного предприятия. Из нескольких цехов ( ![]() ) поступают готовые блоки для сборки изделия. Сначала они поступают на диспетчерские посты, на которых происходит оформление соответствующей документации. После этого блоки направляются на сборочные участки.
) поступают готовые блоки для сборки изделия. Сначала они поступают на диспетчерские посты, на которых происходит оформление соответствующей документации. После этого блоки направляются на сборочные участки.
Диспетчеризация - первая фаза обслуживания.
Сборка изделий - вторая фаза обслуживания.
Затем идет стендовый контроль и регулировка - это третья фаза обслуживания.
Четвертая фаза - приемка готового изделия (например, военная приемка)
Далее может быть упаковка изделия - пятая фаза.
Упакованные изделия поступают в транспортное подразделение для отправки - это шестая фаза.
На каждом из этих шести участков работают инженеры, техники, наладчики, контролеры, упаковщики. В силу различного рода случайностей на входе каждой фазы могут образовываться очереди комплектующих блоков, непроверенных изделий, готовых изделий. А также могут быть простои работников, что в терминах СМО трактуется как очереди свободных каналов.
Вернемся к общей постановке задачи.
Целью моделирования является определение показателей исхода операции массового обслуживания на временном интервале ![]() . Например, оценка относительной пропускной способности СМО, среднее количество заявок в очередях, коэффициент использования каналов в каждой фазе и др.
. Например, оценка относительной пропускной способности СМО, среднее количество заявок в очередях, коэффициент использования каналов в каждой фазе и др.
Проанализируем элементы СМО.
- Входные потоки заявок на обслуживание
Поступление заявок на вход первой фазы - событие активное.
Следовательно, в модели должны быть предусмотрены модули реакции на это событие. Каждый поток обслуживает свой модуль реакции, значит, модулей реакции этого типа должно быть столько, сколько имеется потоков заявок, то есть
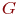 . Моменты поступления заявок имитируются соответствующими генераторами (датчиками) случайных интервалов между заявками потоков
. Моменты поступления заявок имитируются соответствующими генераторами (датчиками) случайных интервалов между заявками потоков  .
. - Каналы обслуживания
Каждый канал имеет два состояния: свободен или занят. Переход в состояние "занят" - событие пассивное, так как определяется поступлением заявки. Переход в состояние "свободен" - событие активное, оно определяется внутренними свойствами канала, например, производительностью. Следовательно, в модели должны быть модули реакции на освобождение каналов. И этих модулей должно быть столько, сколько имеется в нашей СМО каналов:
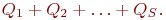
- Очереди заявок на обслуживание на входах фаз
Эти элементы СМО - пассивные, число состояний неограниченно.
- Очереди свободных каналов в каждой фазе обслуживания
Эти элементы СМО также пассивные, число состояний равно числу каналов в каждой фазе.
- Обобщенный элемент "СМО в целом"
Характеризуется одним активным событием - завершение интервала исследования
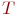 . Следовательно, для обработки этого события в модели предусматривается один специальный модуль реакции.
. Следовательно, для обработки этого события в модели предусматривается один специальный модуль реакции.
Изменения состояний считаем мгновенными. Общее число модулей реакции в рассматриваемой модели должно быть:
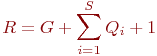
При большом числе входных потоков и каналов обслуживания количество модулей реакции будет значительным, и модель будет труднообозримой, громоздкой. Однако структуру модели можно существенно упростить, назначив однородным активным событиям по одному модулю реакции. Или: освобождение любого канала вызывает обращение к другому общему модулю реакции. Естественно, на входе таких универсальных модулей реакции должен присутствовать блок настройки на конкретное активное состояние объединенной группы.
Строить же общий модуль реакции на освобождение всех каналов СМО нецелесообразно, так как освобождение каналов последней фазы СМО требует действий, заметно отличающихся от тех, которые необходимо выполнить при освобождении каналов не последней фазы.
Таким образом, имитационная модель СМО будет иметь всего четыре модуля реакции:
- модуль реакции на поступление заявки (А);
- модуль реакции на освобождение канала не последней фазы (В);
- модуль реакции на освобождение канала последней фазы (С);
- модуль реакции на завершение интервала исследования - реакция на изменение состояния обобщенным элементом "СМО в целом".
Блок-схема имитационной модели СМО состоит из общей части и модулей реакции. Общая часть имеет стандартный вид и была рассмотрена ранее. Структура общей части определяется способом продвижения модельного времени по событиям. Она показана на рис. 3.30.
Блок 1 - установка начальных условий на весь процесс моделирования. Вводятся константы ![]() ,
, ![]() , указываются число источников заявок, число каналов. Счетчик числа реализаций
, указываются число источников заявок, число каналов. Счетчик числа реализаций ![]() устанавливается в нуль (или в
устанавливается в нуль (или в ![]() - в зависимости от того, как организован счет реализаций модели). Указываются данные планирования эксперимента с моделью и др.
- в зависимости от того, как организован счет реализаций модели). Указываются данные планирования эксперимента с моделью и др.
Блок 2 - установка начальных условий на очередную реализацию модели. Текущее время, счетчики числа поступивших и обслуженных заявок устанавливаются в нуль. Каналы обслуживания и очереди к ним устанавливаются в исходные состояния (установки исходных состояний определяются требованиями к исследованию) и др.
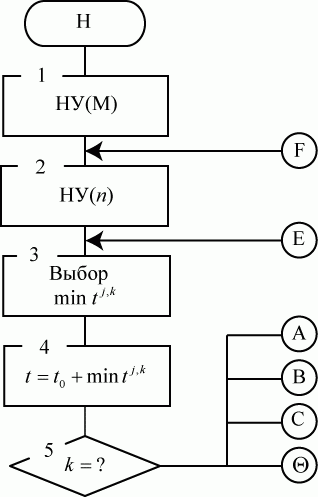
Рис. 3.30. Блок схема имитационной модели СМО
Наборы исходных данных ![]() и
и ![]() определяются конкретным назначением моделируемой СМО и характером последующих экспериментов.
определяются конкретным назначением моделируемой СМО и характером последующих экспериментов.
Блоки 3, 4 реализуют продвижение времени по событиям.
Блок 5 - выбор модуля реакции. В зависимости от индекса ![]() пространственно временной точки
пространственно временной точки ![]() передает управление соответствующему модулю реакции -
передает управление соответствующему модулю реакции - ![]() ,
, ![]() ,
, ![]() или
или ![]()
В рассматриваемой модели элементы СМО имеют только два состояния, одно из которых является начальным. Поэтому индекс ![]() не имеет смысла.
не имеет смысла.
Рассмотрим состав и функционирование модулей реакции.
Допустим, что в рассматриваемый момент времени свершилось активное событие - поступление заявки от одного из источников. Блок 5 передает управление модулю реакции А.
Блок-схема алгоритма модуля реакции ![]() приведена рис. 3.31.
приведена рис. 3.31.
Блок А5 - блок настройки. Обеспечивает доступ к ДСЧ, ячейкам и т. д. модуля, предназначенным для обслуживания конкретного потока заявок, которому принадлежит поступившая заявка.
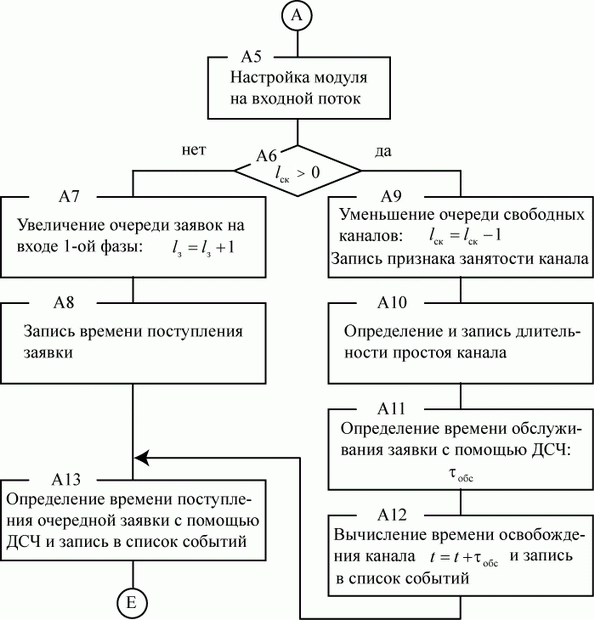
увеличить изображение
Рис. 3.31. Блок-схема алгоритма модуля реакции А
Блок А6 - проверка наличия свободных каналов первой фазы. Количество свободных каналов в очереди обозначено: ![]() .
.
Если все каналы заняты ![]() , управление передается блоку А7. Если свободные каналы есть
, управление передается блоку А7. Если свободные каналы есть ![]() , управление передается блоку А9.
, управление передается блоку А9.
Блок А7 - размещение поступившей заявки в соответствующей очереди первой фазы ![]() . Текущее содержимое этой очереди обозначено как
. Текущее содержимое этой очереди обозначено как ![]() .
.
Блок А8 - запоминание времени постановки заявки в очередь и передача управления блоку А13.
Правая ветвь алгоритма (см. рис. 3.30) выполняет действия, связанные с постановкой заявки на обслуживание.
Блок А9 - имитация загрузки одного из свободных каналов поступившей заявкой. Очередь свободных каналов уменьшается на ![]() (
( ![]() ) . Выбранному каналу присваивается признак занятости -
) . Выбранному каналу присваивается признак занятости - ![]() . У свободных каналов этот признак равен
. У свободных каналов этот признак равен ![]() .
.
Блок А10 - определение и запоминание длительности простоя канала. Накопление времени простоя необходимо, например, для определения коэффициента занятости канала на интервале исследования.
Блок А11 - имитация времени обслуживания заявки.
Случайное время обслуживания ![]() формируется обращением к соответствующему датчику случайных чисел.
формируется обращением к соответствующему датчику случайных чисел.
Блок А12 - прогноз времени окончания обслуживания ![]() и занесение новой пространственно-временной точки в список событий.
и занесение новой пространственно-временной точки в список событий.
Блок А13 - прогноз момента времени поступления очередной заявки. Соответствующий датчик случайных чисел выдает длительность случайного временного интервала между заявками данного типа. Момент поступления очередной заявки вычисляется как ![]() . Полученная таким образом пространственно-временная точка заносится в список событий.
. Полученная таким образом пространственно-временная точка заносится в список событий.
Управление передается в точку Е - блоку 3 для определения очередного ближайшего события.
Если очередным ближайшим событием окажется освобождение канала не последней фазы, то блок 5 передает управление модулю реакции В, имитирующему действия в СМО при свершении этого активного события.
Блок-схема алгоритма модуля реакции В представлена на рис. 3.32.
Модуль В имеет две функции. Во-первых, попытаться загрузить освободившийся канал заявкой из очереди на входе фазы, в которой находится освободившийся канал. Во-вторых, имитировать продвижение заявки, освободившей канал, в следующую фазу обслуживания.
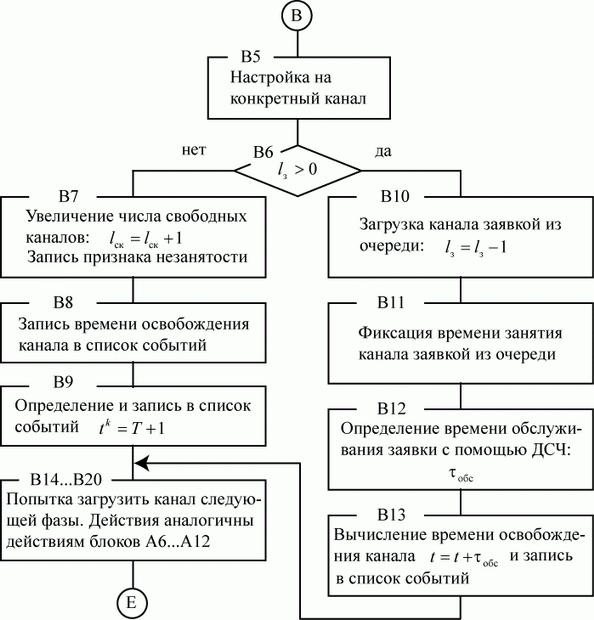
увеличить изображение
Рис. 3.32. Блок-схема алгоритма модуля реакции В
Блок В5 - настройка модуля на освободившийся канал конкретной фазы.
Каждая фаза обслуживания имеет свою очередь заявок на входе, свою очередь свободных каналов и, возможно, свои датчики случайных чисел. Поэтому не будем вводить для них новые обозначения, оставим те, которые были использованы при описании модуля А.
Блок В6. Проверка: есть ли в очереди на входе фазы заявки, ожидающие обслуживания ( ![]() ) ? Если есть, то освободившийся
) ? Если есть, то освободившийся
канал должен быть немедленно загружен (блоки 10… 13). Если нет, то канал должен быть переведен в режим ожидания (блоки В7…В9).
Блок В7. Очередь свободных каналов увеличивается на ![]() (
( ![]() ) . Признак занятости канала устанавливается в нуль.
) . Признак занятости канала устанавливается в нуль.
Блок В8. Запоминание момента освобождения канала.
Блок В9. Перевод освободившегося канала в пассивное состояние. Для этого пространственно-временной точке ![]() , относящейся к освободившемуся каналу, присвоить значение времени,
, относящейся к освободившемуся каналу, присвоить значение времени,
превышающего интервал исследования ![]() , то есть
, то есть ![]() . Это значение
. Это значение ![]() заносится в список событий. Управление передается блоку В14.
заносится в список событий. Управление передается блоку В14.
Блоки В14…В20 моделируют размещение заявки, освободившей канал, в следующей фазе обслуживания. Функции и взаимные связи этих блоков аналогичны блокам А6 … А12, рассмотренным ранее:
Блок 20 передает управление блоку 3 для идентификации очередного активного события. Этим событием может быть поступление заявки от какого-либо источника на вход первой фазы или окончание обслуживания заявки каким-либо каналом. В этих случаях управление будет снова передано модулям реакции ![]() или
или ![]() .
.
Если же очередным активным событием окажется освобождение канала последней фазы, то управление передается модулю реакции С (рис. 3.33).
Блок С5 - настройка на соответствующий канал последней фазы. Аналогичен блоку В5.
Блоки С6…С13 - загрузка освободившегося канала ожидающей заявкой, если таковая есть на входе последней фазы. Функции и взаимосвязи блоков аналогичны блокам В6…В13. Блок С6 соответствует блоку В6, блок С7 - блоку В7 и т. д. по одинаковым номерам.
Блок С14 формирует числовые атрибуты заявок, покидающих СМО. Такими атрибутами могут быть: суммарное время обслуживания заявки на всех фазах, суммарное время ожидания в очередях, число обслуживаний без ожидания и др. Атрибуты запоминаются и управление передается блоку 2.

Рис. 3.33. Блок-схема алгоритма модуля реакции С
Если очередное значение ![]() , что означает окончание интервала исследования работы СМО, управление передается модулю реакции
, что означает окончание интервала исследования работы СМО, управление передается модулю реакции ![]() (рис. 3.34).
(рис. 3.34).
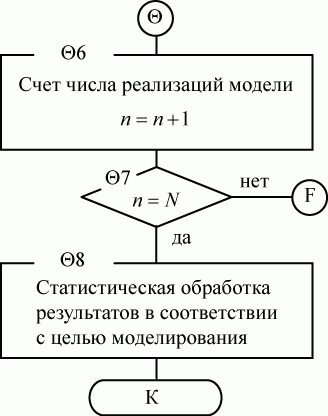
Рис. 3.34. Блок-схема алгоритма модуля реакции \Theta
Построить имитационную модель с продвижением времени можно и по-другому. Однако рассмотренная структура модели обладает важными достоинствами:
- Моделирующий алгоритм нагляден и прост, что существенно упрощает программирование и, особенно, отладку модели, а также изучение готовых моделей.
- Рассмотренная структура алгоритма позволяет параллельно разрабатывать модель по отдельным модулям и, следовательно, сокращать время на ее создание.
Облегчены корректировка и развитие модели. Например, в рассмотренной модели СМО легко учесть выход из строя и восстановление каналов обслуживания. Для этого надо добавить два модуля реакции: один - на возникновение отказа, другой - на восстановление работоспособности. Оба эти события рассматриваются как активные, если неисправность возникает из-за внутренних дефектов оборудования, а восстановление является результатом усилий обслуживающего персонала, входящего в состав СМО.
Вопросы для самоконтроля
- Что такое имитационная статистическая модель? Сравните ее с аналитической моделью.
- Назначение датчиков случайных чисел (генераторов) в имитационном моделировании.
- Принцип формирования случайных чисел в алгоритмических датчиках случайных чисел.
- Почему случайные числа, формируемые в компьютере, являются псевдослучайными квазиравномерными?
- Формирование случайных величин с произвольными законами распределения вероятностей методом обратной функции.
- Формирование равномерно распределенных случайных чисел на произвольном отрезке
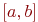 .
. - Формирование нормально распределенных случайных чисел с произвольными значениями
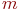 и
и  .
. - Найти методом обратной функции процедуру розыгрыша непрерывной случайной величины, распределенной по закону Ре-лея, заданного плотностью вероятности
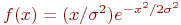 при
при  ;
; 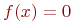 при
при  .
. - Найти процедуру розыгрыша случайной величины, распределенной по закону Вейбулла, заданного плотностью вероятности
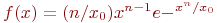 при
при  ;
; 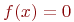 при
при  .
. - Создать программу мультипликативного датчика равномерно распределенных случайных чисел для 64-разрядной сетки:
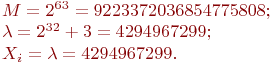
Определить период повторения случайных чисел.
- Усовершенствуйте алгоритм имитационной модели (рис. 3.5) так, чтобы можно было определять не только оценку математического ожидания вероятности поражения объекта, но оценку математического ожидания расхода ракет.
- Способ моделирования единичных событий.
- Способы моделирования полной группы несовместных событий.
- Три способа моделирования совместных независимых событий.
- Моделирование совместных зависимых событий.
- Стационарный и нестационарный случайные процессы.
- Эргодический и неэргодический случайные процессы.
- Способы продвижения модельного времени в имитационной модели.
- Какие виды времени различают при имитационном моделировании?
- Что понимается под распределенным имитационным моделированием? Сравните его с последовательным имитационным моделированием.
- Что значит квазипараллельное моделирование?
- Модель противоборства, назначение блоков. Признаки окончания одной реализации.
- Поясните прием моделирования противоборства двух сторон методом "блуждания по решетке".
- Понятие активного и пассивного элемента в модели СМО.
- Блок-схема имитационной модели СМО.
- Модули реакции в модели СМО.
- Достоинства структуры модели СМО.
Лекция 4. Планирование экспериментов
Создание модели - акт необходимый при анализе и синтезе сложных систем, но далеко не конечный. Модель - не цель исследователя, а только инструмент для проведения исследований, инструмент эксперимента. В первых темах мы достаточно полно раскрыли афоризм: "Модель есть объект и средство эксперимента".
Эксперимент должен быть информативен, то есть давать всю нужную информацию, которой следует быть полной, точной, достоверной. Но она должна быть получена приемлемым способом. Это означает, что способ должен удовлетворять экономическим, временным и, возможно, другим ограничениям. Такое противоречие разрешается с помощью рационального (оптимального) планирования эксперимента.
Теория планирования эксперимента сложилась в шестидесятые годы двадцатого века благодаря работам выдающегося английского математика, биолога, статистика Рональда Айлмера Фишера (1890-1962 гг.). Одно из первых отечественных изданий: Федоров В. В. Теория оптимального эксперимента. 1971 г. Несколько позже сложилась теория и практика планирования имитационных экспериментов, элементы которых рассматриваются в настоящей теме.
4.1. Сущность и цели планирования эксперимента
Итак, как мы уже знаем, модель создается для проведения на ней экспериментов. Будем считать, что эксперимент состоит из наблюдений, а каждое наблюдение - из прогонов ( реализаций ) модели.
Для организации экспериментов наиболее важно следующее.
- Простота повторений условий эксперимента.
- Возможность управления экспериментом, включая его прерывание и возобновление.
- Легкость изменения условий проведения эксперимента (воздействий внешней среды).
- Исключение корреляции между последовательностями данных, снимаемых в процессе эксперимента с моделью.
- Определением временного интервала исследования модели (
 ).
).
Компьютерный эксперимент с имитационной моделью обладает преимуществами перед натурным экспериментом по всем этим позициям.
Что же такое компьютерный (машинный) эксперимент?
Компьютерный эксперимент представляет собой процесс использования модели с целью получения и анализа интересующей исследователя информации о свойствах моделируемой системы.
Эксперимент требует затрат труда и времени и, следовательно, финансовых затрат. Чем больше мы хотим получить информации от эксперимента, тем он дороже.
Средством достижения приемлемого компромисса между максимумом информации и минимумом затрат ресурсов является план эксперимента.
План эксперимента определяет:
- объем вычислений на компьютере;
- порядок проведения вычислений на компьютере;
- способы накопления и статистической обработки результатов моделирования.
Планирование экспериментов имеет следующие цели:
- сокращение общего времени моделирования при соблюдении требований к точности и достоверности результатов;
- увеличение информативности каждого наблюдения;
- создание структурной основы процесса исследования.
Таким образом, план эксперимента на компьютере представляет собой метод получения с помощью эксперимента необходимой информации.
Конечно, можно проводить исследования и по такому плану: исследовать модель во всех возможных режимах, при всех возможных сочетаниях внешних и внутренних параметров, повторять каждый эксперимент десятки тысяч раз - чем больше, тем точнее!
Очевидно, пользы от такой организации эксперимента мало, полученные данные трудно обозреть и проанализировать. Кроме того, большими будут затраты ресурсов, а они всегда ограничены.
Весь комплекс действий по планированию эксперимента разделяют на две самостоятельные функциональные части:
- стратегическое планирование;
- тактическое планирование.
Стратегическое планирование - разработка условий проведения эксперимента, определение режимов, обеспечивающих наибольшую информативность эксперимента.
Тактическое планирование обеспечивает достижение заданных точности и достоверности результатов.
4.2. Элементы стратегического планирования экспериментов
Формирование стратегического плана выполняется в так называемом факторном пространстве. Факторное пространство - это множество внешних и внутренних параметров, значения которых исследователь может контролировать в ходе подготовки и проведения эксперимента.
Объектами стратегического планирования являются:
- выходные переменные (отклики, реакции, экзогенные переменные);
- входные переменные (факторы, эндогенные переменные);
- уровни факторов.
Математические методы планирования экспериментов основаны на так называемом кибернетическом представлении процесса проведения эксперимента (рис. 4.1).
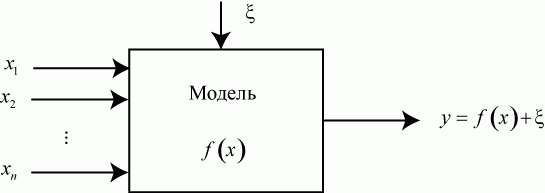
Рис. 4.1. Кибернетическое представление эксперимента
На рис. 4.1:
![]() - входные переменные, факторы;
- входные переменные, факторы;
![]() - выходная переменная (реакция, отклик);
- выходная переменная (реакция, отклик);
![]() - ошибка, помеха, вызываемая наличием случайных факторов;
- ошибка, помеха, вызываемая наличием случайных факторов;
![]() - оператор, моделирующий действие реальной системы, определяющий зависимость выходной переменной
- оператор, моделирующий действие реальной системы, определяющий зависимость выходной переменной ![]() от факторов
от факторов ![]()
Иначе: ![]() - модель процесса, протекающего в системе.
- модель процесса, протекающего в системе.
Первой проблемой, решаемой при стратегическом планировании, является выбор отклика (реакции), то есть определение, какие величины нужно измерять во время эксперимента, чтобы получить искомые ответы. Естественно, выбор отклика зависит от цели исследования.
Например, при моделировании информационно-поисковой системы может интересовать исследователя время ответа системы на запрос. Но может интересовать такой показатель как максимальное число обслуженных запросов за интервал времени. А может, то и другое. Измеряемых откликов может быть много: ![]() В дальнейшем будем говорить об одном отклике
В дальнейшем будем говорить об одном отклике ![]()
Второй проблемой стратегического планирования является выбор (определение) существенных факторов и их сочетаний, влияющих на работу моделируемого объекта. Факторами могут быть питающие напряжения, температура, влажность, ритмичность поставок комплектующих и многое другое. Обычно число факторов велико и чем меньше мы знакомы с моделируемой системой, тем большее, нам кажется, число их влияет на работу системы. В теории систем приводится так называемый принцип Парето:
- 20% факторов определяют 80% свойств системы;
- 80% факторов определяют 20% свойств системы. Следовательно, надо уметь выделять существенные факторы. А
это достигается достаточно глубоким изучением моделируемого объекта и протекающих в нем процессов.
Факторы могут быть количественными и (или) качественными.
Количественные факторы - это те, значения которых числа. Например, интенсивности входных потоков и потоков обслуживания, емкость буфера, число каналов в СМО, доля брака при изготовлении деталей и др.
Качественные факторы - дисциплины обслуживания (LIFO, FIFO и др.) в СМО, "белая сборка", "желтая сборка" радиоэлектронной аппаратуры, квалификация персонала и т. п.
Фактор должен быть управляемым. Управляемость фактора - это возможность установки и поддержания значения фактора постоянным или изменяющимся в соответствии с планом эксперимента. Возможны и неуправляемые факторы, например, влияние внешней среды.
К совокупности воздействующих факторов предъявляются два основных требования:
- совместимость;
- независимость.
Совместимость факторов означает, что все комбинации значений факторов осуществимы.
Независимость факторов определяет возможность установления значения фактора на любом уровне независимо от уровней других факторов.
В стратегических планах факторы обозначают латинской буквой ![]() , где индекс
, где индекс ![]() указывает номер (тип) фактора. Встречаются и такие обозначения факторов:
указывает номер (тип) фактора. Встречаются и такие обозначения факторов: ![]() и т. д.
и т. д.
Третьей проблемой стратегического планирования является выбор значений каждого фактора, называемых уровнями фактора.
Число уровней может быть два, три и более. Например, если в качестве одного из факторов выступает температура, то уровнями могут быть: 80o С, 100o С, 120o С.
Для удобства и, следовательно, удешевления эксперимента число уровней следует выбирать поменьше, но достаточное для удовлетворения точности и достоверности эксперимента. Минимальное число уровней - два.
С точки зрения удобства планирования эксперимента целесообразно устанавливать одинаковое число уровней у всех факторов. Такое планирование называют симметричным.
Анализ данных эксперимента существенно упрощается, если назначить уровни факторов, равноотстоящие друг от друга. Такой план называется ортогональным. Ортогональность плана обычно достигают так: две крайние точки области изменения фактора выбирают как два уровня, а остальные уровни располагают так, чтобы они делили полученный отрезок на две части.
Например, диапазон питающего напряжения 30…50 В на пять уровней будет разбит так: 30 В, 35 В, 40 В, 45 В, 50 В.
Эксперимент, в котором реализуются все сочетания уровней всех факторов, называется полным факторным экспериментом (ПФЭ).
План ПФЭ предельно информативен, но он может потребовать неприемлемых затрат ресурсов.
Если отвлечься от компьютерной реализации плана эксперимента, то число измерений откликов (реакций) модели ![]() при ПФЭ равно:
при ПФЭ равно:
где ![]() - число уровней
- число уровней ![]() -го фактора,
-го фактора, ![]() ;
; ![]() - число факторов эксперимента.
- число факторов эксперимента.
Величина ![]() определяет структуру стратегического плана, то есть количество наблюдений (информационных точек).
определяет структуру стратегического плана, то есть количество наблюдений (информационных точек).
При машинной реализации ПФЭ в каждом наблюдении (информационной точке) нужно выполнить определенное число прогонов (реализаций) модели, чтобы обеспечить заданную точность и достоверность значений откликов. Определение числа прогонов модели является предметом тактического планирования.
Обозначим число прогонов в каждом наблюдении ![]() . Тогда для симметричного ПФЭ общее число
. Тогда для симметричного ПФЭ общее число ![]() необходимых прогонов модели равно:
необходимых прогонов модели равно:
Пример 4.1. Планируется провести компьютерный эксперимент, в котором на отклик модели влияют три фактора. Для каждого фактора установлены три уровня. Требования по точности и достоверности требуют 6000 прогонов модели на каждом уровне (для каждого наблюдения). Время одного прогона модели равно 2 с.
Оценить затраты времени на проведение компьютерного эксперимента.
Решение
Исходные данные: ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Число прогонов модели: ![]() .
.
Затраты времени : ![]() .
.
Ранее на рис. 4.1 был показан оператор преобразования - математическая модель процесса ![]() В некоторых исследованиях, если
В некоторых исследованиях, если ![]() - имитационная модель процесса, требуется вместо
- имитационная модель процесса, требуется вместо
нее получить так называемую "вторичную модель" в виде аналитической зависимости. В дальнейшем "вторичная модель" может быть использована на практике или в других исследованиях. В таких случаях математическая модель формируется по данным эксперимента методом регрессионного анализа, что будет предметом нашего рассмотрения в следующей теме.
4.3. Стандартные планы
Многие планы экспериментов в настоящее время стандартизованы. Они имеются в справочниках, математических пакетах программ и системах моделирования. Однако исследователь должен быть готов к модификации имеющихся планов и приспособлению их к специфическим условиям конкретных задач.
С полным факторным экспериментом мы уже знакомы. Это, как отмечалось ранее, самый информативный план, понятный по структуре, но и самый неэкономичный. Поэтому ПФЭ применяют, когда число факторов невелико. В приведенном примере 4.1 при ![]() ,
, ![]() ,
, ![]() ,
, ![]() затраты времени на проведение компьютерного эксперимента ожидаются в 106 часов. Поэтому актуальной становится проблема более или менее обоснованного сокращения плана эксперимента (числа наблюдений). Способов сокращения плана и, следовательно, уменьшения затрат времени на проведение экспериментов, много, но все они, в конечном счете, основаны на пренебрежении эффектами парных, тройных и более взаимодействий факторов. Естественно, это снижает точность моделирования, но во многих случаях допустимо.
затраты времени на проведение компьютерного эксперимента ожидаются в 106 часов. Поэтому актуальной становится проблема более или менее обоснованного сокращения плана эксперимента (числа наблюдений). Способов сокращения плана и, следовательно, уменьшения затрат времени на проведение экспериментов, много, но все они, в конечном счете, основаны на пренебрежении эффектами парных, тройных и более взаимодействий факторов. Естественно, это снижает точность моделирования, но во многих случаях допустимо.
Рассмотрим несколько примеров.
Пример 4.2. Необходимо провести эксперимент с моделью, имеющей три двухуровневых фактора, с целью построения математической модели ("вторичной модели") процесса в виде:
Уравнение имеет восемь коэффициентов, следовательно, достаточно провести восемь наблюдений. Это уравнение соответствует
ПФЭ типа ![]() .
.
Полный факторный эксперимент дает возможность определить не только коэффициенты ![]() , соответствующие так называемым линейным эффектам (их также называют главными), но и коэффициенты
, соответствующие так называемым линейным эффектам (их также называют главными), но и коэффициенты ![]() , соответствующие всем эффектам взаимодействия факторов, а также свободный член
, соответствующие всем эффектам взаимодействия факторов, а также свободный член ![]() .
.
Эффекты взаимодействия двух и более факторов проявляются, если влияние каждого из них на отклик зависит от уровней, на которых установлены другие факторы.
Теперь допустим, что число наблюдений в эксперименте, равное восьми, неприемлемо и план надо сократить.
Вполне естественно предположить, что эффекты взаимодействия оказывают на реакцию системы существенно меньшее влияние, чем линейные, или даже отсутствуют вовсе, если факторы обладают свойством независимости.
Исключим их и тогда модель процесса (уравнение отклика, уравнение реакции, "вторичная модель") принимает вид:
Теперь число неизвестных коэффициентов ![]() сократилось вдвое и число необходимых наблюдений для их определения стало равно четырем.
сократилось вдвое и число необходимых наблюдений для их определения стало равно четырем.
Что это за наблюдения?
Четыре наблюдения достаточны для проведения ПФЭ при двух
факторной модели ![]() . Этими факторами, например, могут быть
. Этими факторами, например, могут быть ![]() или другая двухфакторная комбинация из трех факторов.
или другая двухфакторная комбинация из трех факторов.
Уровни третьего фактора ![]() получают из первых двух с помощью, так называемого генерирующего соотношения:
получают из первых двух с помощью, так называемого генерирующего соотношения:
Поскольку факторы двухуровневые, то в общем виде уровни принято обозначать так:
- верхний уровень: +1;
- нижний уровень: -1.
Новый, сокращенный план эксперимента называют полурепликой и обозначают ![]() План приведен в табл. 4.1.
План приведен в табл. 4.1.
Единичный столбец ![]() обеспечивает вычисление свободного члена
обеспечивает вычисление свободного члена ![]() в модели процесса.
в модели процесса.
Таким же образом можно проводить дальнейшее сокращение планов типа ![]() получая четверть реплики
получая четверть реплики ![]() и более мелкие реплики.
и более мелкие реплики.
Естественно, такое сокращение числа экспериментов приводит к "огрублению" коэффициентов ![]() Следовательно, полученную модель процесса
Следовательно, полученную модель процесса ![]() нужно проверять на адекватность, используя для этого "сэкономленные" наблюдения.
нужно проверять на адекватность, используя для этого "сэкономленные" наблюдения.
Рассмотренное планирование является основой и составной частью для разработки более сложных - несимметричных многоуровневых планов.
Не менее часто целью экспериментов является проверка разного рода гипотез о природе сравниваемых объектов. Например, однородны ли выходы двух систем в смысле законов распределения, характеристик этих законов. Поскольку обработка данных эксперимента ведется методами дисперсионного анализа, то и планы в данном случае называются планами дисперсионного анализа. Сущность дисперсионного анализа мы рассмотрим в следующей теме.
Планы дисперсионного анализа могут быть полные, если используются все возможные сочетания условий (аналогично ПФЭ), и неполные, которые применяются тогда, когда полные планы оказываются громоздкими и неэкономичными. Сокращение планов происходит, как и ранее, за счет исключения некоторых сочетаний факторов (взаимодействий) и уровней случайным или традиционным образом.
Наиболее популярными из неполных планов является симметричный план "латинский квадрат" или его вариации. Этот план целесообразно применять, когда из всех существенных факторов можно выделить один доминирующий (самый существенный).
В планах дисперсионного анализа часто факторы обозначают латинскими буквами ![]() , а уровни - индексами при соответствующих факторах:
, а уровни - индексами при соответствующих факторах: ![]()
Пример 4.3. Построить план "латинский квадрат" симметричного трехфакторного четырехуровневого эксперимента. Доминирующий фактор ![]() .
.
Решение
Исходные данные: ![]() .
.
Введем обозначения факторов и уровней:
![]() - уровни доминирующего фактора
- уровни доминирующего фактора ![]() ;
;
![]() - уровни фактора
- уровни фактора ![]() ;
;
![]() - уровни фактора
- уровни фактора ![]() .
.
План приведен в табл. 4.2.
В этом плане число наблюдений ![]() В полном плане их было бы
В полном плане их было бы ![]() Сокращение произошло за счет исключения некоторых комбинаций:
Сокращение произошло за счет исключения некоторых комбинаций: ![]() ,
, ![]() и др.
и др.
Заметим, что план может быть и несимметричным. В этом случае вместо квадрата будет прямоугольник. И еще: выделение доминирующего фактора не является существенным, то есть, внутри квадрата можно располагать уровни любого из действующих факторов.
В практике планирования экспериментов встречаются и такие неполные планы: один из факторов меняет свои значения при фиксированных значениях других. То есть исследуется поочередно влияние каждого фактора в отдельности.
Иногда применяются и так называемые рандомизированные планы. В таких планах сочетания факторов и уровней для каждого прогона модели выбираются случайно. Вид случайности и объем выборки определяется исследователем.
4.4. Формальный подход к сокращению общего числа прогонов
Рассмотренные способы сокращения общего числа прогонов носят эвристический (субъективный) характер. Они осуществлялись за счет исключения каких-то комбинаций уровней факторов.
Однако во многих случаях исследователь имеет свободу действий в выборе числа факторов ![]() числа уровней
числа уровней ![]() и числа прогонов
и числа прогонов ![]() модели в одном наблюдении. Каждый из этих аргументов в конкретной ситуации по-разному влияет на общее число прогонов модели
модели в одном наблюдении. Каждый из этих аргументов в конкретной ситуации по-разному влияет на общее число прогонов модели ![]()
Исследуем эти влияния.
Как нам уже известно, общее число прогонов (реализаций) модели равно:
Рассмотрим относительное влияние аргументов ![]() на число реализаций
на число реализаций ![]() .
.
Сначала нужно получить выражения для вычисления скоростей изменения функции ![]() при изменении одного аргумента и неизменных остальных аргументах. Для этого последовательно найдем частные производные первого порядка от функции
при изменении одного аргумента и неизменных остальных аргументах. Для этого последовательно найдем частные производные первого порядка от функции ![]() по этим аргументам:
по этим аргументам:
Теперь сравним попарно полученные производные:
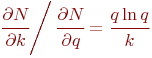
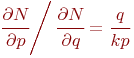
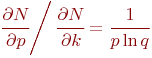
Из соотношений 1 и 2 следует: если ![]() и
и ![]() , то наибольшее влияние на число
, то наибольшее влияние на число ![]() оказывает изменение числа уровней
оказывает изменение числа уровней ![]() .
.
Из соотношений 3 и 1 следует: если ![]() и
и ![]() , то наибольшее влияние на число
, то наибольшее влияние на число ![]() оказывает изменение числа факторов
оказывает изменение числа факторов ![]() .
.
Из соотношений 2 и 3 следует: если ![]() и
и ![]() , то наибольшее влияние на число
, то наибольшее влияние на число ![]() оказывает изменение числа реализаций модели на каждом уровне факторов (на каждом наблюдении).
оказывает изменение числа реализаций модели на каждом уровне факторов (на каждом наблюдении).
Рассмотренный формальный подход к сокращению числа реализаций не совсем корректен, так как функция общего числа прогонов ![]() носит не непрерывный, а дискретный характер. Тем не менее, такой подход применяется с последующим округлением результатов до целых чисел.
носит не непрерывный, а дискретный характер. Тем не менее, такой подход применяется с последующим округлением результатов до целых чисел.
Покажем применение формального подхода сокращения реализаций на примере.
Пример 4.4. На вход модели объекта действуют четыре трехуровневых фактора ![]() В каждом наблюдении предполагаются восемь прогонов модели
В каждом наблюдении предполагаются восемь прогонов модели ![]() Полный факторный эксперимент потребует
Полный факторный эксперимент потребует ![]() прогонов или 81 наблюдение. Такие затраты ресурсов неприемлемы.
прогонов или 81 наблюдение. Такие затраты ресурсов неприемлемы.
Требуется определить, какой из аргументов ![]() следует уменьшить, чтобы достичь наиболее существенного уменьшения числа реализаций
следует уменьшить, чтобы достичь наиболее существенного уменьшения числа реализаций ![]() .
.
Решение
Подготовим данные для сравнений:
Соблюдается условие:
![]() , так как
, так как ![]()
Следовательно, наибольшее влияние на изменение ![]() оказывает изменение числа уровней
оказывает изменение числа уровней ![]() .
.
Уменьшим ![]() на единицу:
на единицу: ![]() . В этом случае при ПФЭ потребуется выполнить
. В этом случае при ПФЭ потребуется выполнить ![]() прогонов или 16 наблюдений, то есть в пять раз меньше.
прогонов или 16 наблюдений, то есть в пять раз меньше.
Варьирование факторов на двух уровнях встречается часто и решение ![]() будет приемлемо, если нет обстоятельств, не устраивающих это решение.
будет приемлемо, если нет обстоятельств, не устраивающих это решение.
4.5. Элементы тактического планирования
Основной задачей тактического планирования является обеспечение результатам компьютерного эксперимента заданных точности и достоверности.
Рассмотрим случай, когда имитационная модель строилась для определения характеристик некоторых случайных величин.
Такими случайными величинами могут быть:
- время обслуживания заявки в СМО;
- численности противоборствующих сторон;
- расход боеприпасов;
- время наработки на отказ технического устройства и др. Из характеристик случайных величин, как правило, интересуют среднее значение (матожидание), дисперсия и характеристика связи случайных величин - коэффициент корреляции.
Характеристику случайной величины будем обозначать греческой буквой ![]() .
.
С помощью имитационного моделирования точное значение ![]() определить нельзя, так как число
определить нельзя, так как число ![]() реализаций модели конечно. При конечном числе реализаций модели определяется приближенное значение характеристики. Обозначим это приближение
реализаций модели конечно. При конечном числе реализаций модели определяется приближенное значение характеристики. Обозначим это приближение ![]()
Приближенное значение ![]() называют оценка соответствующей характеристики: оценкой матожидания, оценкой дисперсии, оценкой коэффициента корреляции.
называют оценка соответствующей характеристики: оценкой матожидания, оценкой дисперсии, оценкой коэффициента корреляции.
Точностью характеристики ![]() называют величину
называют величину ![]() в отношении
в отношении
где ![]() - матожидание случайной величины.
- матожидание случайной величины.
Величина ![]() представляет собой абсолютное значение ошибки в определении значения искомой характеристики.
представляет собой абсолютное значение ошибки в определении значения искомой характеристики.
Достоверность оценки характеристики ![]() называют вероятность
называют вероятность ![]() того, что заданная точность достигается:
того, что заданная точность достигается:
Достоверность характеризует повторяемость, устойчивость эксперимента и трактуется так: если для оценки ![]() использовать величину
использовать величину ![]() то в среднем на каждые 1000 применений этого правила в
то в среднем на каждые 1000 применений этого правила в ![]() случаев величина
случаев величина ![]() будет отличаться от
будет отличаться от ![]() на величину меньше
на величину меньше ![]() .
.
В ряде случаев целесообразно пользоваться понятием относительной точности ![]()
В этом случае достоверность оценки имеет вид:
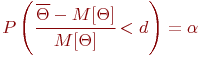
4.6. Точность и количество реализаций модели при определении средних значений параметров
Найдем функциональную связь точности е и достоверности а с количеством реализаций модели, когда в качестве показателей эффективности выступают матожидание и дисперсия некоторой случайной величины (времени, расстояния и т. п.).
4.6.1. Определение оценки матожидания
Найдем искомую связь для случая, когда целью эксперимента является определение оценки матожидания некоторой случайной величины.
В ![]() прогонах модели получены независимые значения интересующего нас показателя эффективности:
прогонах модели получены независимые значения интересующего нас показателя эффективности:
В качестве оценки матожидания возьмем выборочное среднее (среднее арифметическое):
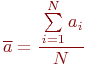
В последующей теме мы покажем, что оценка такого вида является наилучшей.
Согласно центральной предельной теореме, если значения ![]() независимы и имеют конечные дисперсии одного порядка, то при большом числе слагаемых
независимы и имеют конечные дисперсии одного порядка, то при большом числе слагаемых ![]() случайная величина
случайная величина ![]() имеет практически нормальное распределение с матожиданием и дисперсией соответственно:
имеет практически нормальное распределение с матожиданием и дисперсией соответственно:
где ![]() - дисперсия искомой случайной величины
- дисперсия искомой случайной величины ![]()
Следовательно, справедливо
где ![]() - интеграл вероятности.
- интеграл вероятности.
В некоторых изданиях под интегралом вероятности понимают несколько иное выражение, поэтому целесообразно пользоваться интегралом Лапласа, который связан с интегралом вероятности
так: ![]() .
. ![]() - интеграл Лапласа. Из приведенного следует:
- интеграл Лапласа. Из приведенного следует:
Сравнивая это выражение с выражением (4.1), имеем:

Интеграл Лапласа табулирован, следовательно, задаваясь значением достоверности ![]() , определяется аргумент
, определяется аргумент ![]() .
.
Итак, искомая связь между точностью ![]() , достоверностью
, достоверностью ![]() и числом реализаций модели получена:
и числом реализаций модели получена:
Из выражений (4.2) следует:
- увеличение точности на порядок (уменьшение ошибки на порядок) потребует увеличения числа реализаций на два порядка;
- число необходимых реализаций модели
 не зависит от величины искомого параметра
не зависит от величины искомого параметра  а от дисперсии
а от дисперсии 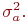
Достоверность результата ![]() указана значением аргумента функции Лапласа
указана значением аргумента функции Лапласа ![]() . Связь значения
. Связь значения ![]() с
с ![]() находится из таблицы значений функции (интеграла) Лапласа. Наиболее употребительные соответствия
находится из таблицы значений функции (интеграла) Лапласа. Наиболее употребительные соответствия ![]() и
и ![]() приведены в табл. 4.3.
приведены в табл. 4.3.
| | 0.8 | 0.85 | 0.9 | 0.95 | 0.99 | 0.995 | 0.999 |
|---|---|---|---|---|---|---|---|
| | 1.28 | 1.44 | 1.65 | 1.96 | 2.58 | 2.81 | 3.30 |
Чтобы пользоваться формулами (4.2), нужно знать дисперсию ![]() . Очень редки случаи, когда значение дисперсии известно до эксперимента, поэтому возможны два способа предварительного определения дисперсии.
. Очень редки случаи, когда значение дисперсии известно до эксперимента, поэтому возможны два способа предварительного определения дисперсии.
Первый способ. Иногда заранее известен размах значений искомой случайной величины:
В предположении нормального распределения случайной величины ![]() , можно с использованием "правила трех сигм" получить приближенную оценку
, можно с использованием "правила трех сигм" получить приближенную оценку ![]() :
:
Второй способ. Надо воспользоваться оценкой дисперсии. Для этого необходимо выполнить предварительный прогон модели в количестве ![]() реализаций. С использованием полученного ряда
реализаций. С использованием полученного ряда ![]() , найдем оценку дисперсии:
, найдем оценку дисперсии:
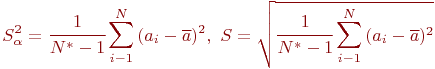
Здесь ![]() - среднеарифметическое значение по
- среднеарифметическое значение по ![]() измерениям. И в этом случае формулы (4.2) имеют вид:
измерениям. И в этом случае формулы (4.2) имеют вид:
Вычисленную дисперсию ![]() подставим в формулу для определения
подставим в формулу для определения ![]() . Если окажется
. Если окажется ![]() то моделирование должно быть продолжено до выполнения
то моделирование должно быть продолжено до выполнения ![]() реализаций. Если же
реализаций. Если же ![]() , то моделирование заканчивается. Необходимая точность
, то моделирование заканчивается. Необходимая точность ![]() оценки случайной величины
оценки случайной величины ![]() (искомого показателя эффективности) при заданной достоверности
(искомого показателя эффективности) при заданной достоверности ![]() достигнута.
достигнута.
Если в технических условиях задана относительная точность ![]() , то формулы (4.3) принимают вид:
, то формулы (4.3) принимают вид:
Значение ![]() определяется на основании
определяется на основании ![]() прогонов модели. Все дальнейшие расчеты аналогичны только что рассмотренным аналитическим выражениям.
прогонов модели. Все дальнейшие расчеты аналогичны только что рассмотренным аналитическим выражениям.
Вышеприведенные рассуждения и выражения были справедливы в предположении нормального закона распределения случайной величины ![]() . Если в этом есть сомнение, то для определения связи
. Если в этом есть сомнение, то для определения связи ![]() ,
, ![]() и
и ![]() можно воспользоваться неравенством Чебышева П. Ф.:
можно воспользоваться неравенством Чебышева П. Ф.:
С учетом направления знаков неравенств получим:
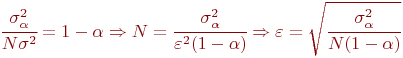
Также как и в предыдущих случаях вместо неизвестной дисперсии ![]() следует использовать ее оценку
следует использовать ее оценку ![]() , вычисленную по данным
, вычисленную по данным ![]() прогонов модели. И еще: обратим внимание, что в данном случае достоверность
прогонов модели. И еще: обратим внимание, что в данном случае достоверность ![]() участвует в формулах в явном виде.
участвует в формулах в явном виде.
Итак, в выражениях (4.3) мы вместо неизвестной дисперсии ![]() используем ее оценку
используем ее оценку ![]() . В этом случае вместо аргумента функции Лапласа
. В этом случае вместо аргумента функции Лапласа ![]() надо использовать параметр распределения Стьюдента
надо использовать параметр распределения Стьюдента ![]() , значения которого зависят не только от уровня достоверности
, значения которого зависят не только от уровня достоверности ![]() , но и от числа так называемых степеней свободы
, но и от числа так называемых степеней свободы ![]() . Здесь, как и прежде,
. Здесь, как и прежде, ![]() - число прогонов модели. Вообще-то, при
- число прогонов модели. Вообще-то, при ![]() распределение Стьюдента стремится к нормальному распределению, но при малом числе прогонов модели
распределение Стьюдента стремится к нормальному распределению, но при малом числе прогонов модели ![]() заметно отличается от
заметно отличается от ![]() .
.
Для практических целей значения ![]() можно взять из табл. 4.4.
можно взять из табл. 4.4.
Из табл. 4.4 видно, что при ![]() значения
значения ![]() и
и ![]() практически совпадают. Но при меньших значениях
практически совпадают. Но при меньших значениях ![]() следует пользоваться величиной
следует пользоваться величиной ![]() .
.
| | | ||||
|---|---|---|---|---|---|
| 0.8 | 0.9 | 0.95 | 0.99 | 0.999 | |
| 10 | 1.37 | 1.81 | 2.23 | 3.17 | 4.6 |
| 20 | 1.33 | 1.73 | 2.1 | 2.85 | 3.73 |
| 30 | 1.31 | 1.7 | 2.04 | 2.75 | 3.65 |
| 40 | 1.3 | 1.68 | 2.02 | 2.7 | 3.55 |
| 60 | 1.3 | 1.67 | 2.0 | 2.67 | 3.41 |
| 120 | 1.29 | 1.66 | 1.98 | 2.62 | 3.37 |
4.6.2. Определение оценки дисперсии
Мы научились находить оценку матожидания ![]() некоторой случайной величины
некоторой случайной величины ![]() с заданными точностью и достоверностью.
с заданными точностью и достоверностью.
Теперь рассмотрим задачу определения оценки дисперсии ![]() случайной величины
случайной величины ![]() также с заданными точностью и достоверностью.
также с заданными точностью и достоверностью.
Опустим вывод и приведем окончательный вид формул для расчета ![]() и
и ![]() :
:
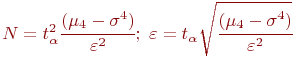
где ![]() - эмпирический центральный момент четвертого порядка:
- эмпирический центральный момент четвертого порядка:
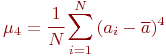
Неизвестное значение ![]() заменяется оценкой
заменяется оценкой ![]() , как было рассмотрено ранее.
, как было рассмотрено ранее.
Если определяемая случайная величина имеет нормальное распределение, то ![]() и выражения для
и выражения для ![]() и
и ![]() принимают вид:
принимают вид:
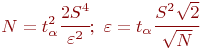
Как и ранее при малых значениях ![]() (
( ![]() ) следует использовать параметр распределения Стьюдента
) следует использовать параметр распределения Стьюдента ![]() .
.
Из сопоставления (4.3) и (4.4) следует, что одно и то же количество реализаций модели обеспечит разное значение ошибки ![]() при оценке матожидания случайной величины
при оценке матожидания случайной величины ![]() и ее дисперсии - при одинаковой достоверности. И иначе: одинаковую точность определения оценок матожидания и дисперсии случайного параметра при одинаковой достоверности обеспечит разное число реализаций модели.
и ее дисперсии - при одинаковой достоверности. И иначе: одинаковую точность определения оценок матожидания и дисперсии случайного параметра при одинаковой достоверности обеспечит разное число реализаций модели.
Пример 4.5. В результате предварительных прогонов модели ![]() определена оценка дисперсии
определена оценка дисперсии ![]() .
.
Определить число реализаций модели ![]() и
и ![]() для определения оценок матожидания и дисперсии случайной величины
для определения оценок матожидания и дисперсии случайной величины ![]() соответственно с точностью
соответственно с точностью ![]() и достоверностью
и достоверностью ![]()
Решение
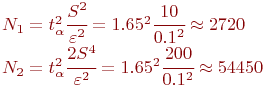
4.7. Точность и количество реализаций модели при определении вероятностей исходов
Мы рассматриваем случай, когда в качестве показателя эффективности выступает вероятность свершения (или не свершения) какого-либо события, например, поражения цели, выхода из строя техники, завершения комплекса работ в заданное время и др.
В качестве оценки вероятности ![]() события
события ![]() выступает частота его свершения:
выступает частота его свершения:
где ![]() - число реализаций модели;
- число реализаций модели;
![]() - число свершений данного события.
- число свершений данного события.
Использование частоты ![]() в качестве оценки искомой вероятности
в качестве оценки искомой вероятности ![]() основано на теореме Я. Бернулли, которую в данном случае можно в формализованном виде записать так:
основано на теореме Я. Бернулли, которую в данном случае можно в формализованном виде записать так:
Точность и достоверность этой оценки связаны уже с известным определением достоверности:
Задача сводится к нахождению такого количества реализаций ![]() чтобы оценка
чтобы оценка ![]() отличалась от искомого значения
отличалась от искомого значения ![]() менее, чем на
менее, чем на ![]() с заданной достоверностью. Здесь, как и ранее,
с заданной достоверностью. Здесь, как и ранее, ![]() - абсолютное значение, характеризующее точность оценки.
- абсолютное значение, характеризующее точность оценки.
Для нахождения функциональной связи между точностью, достоверностью и числом реализаций модели введем переменную ![]() - результат исхода
- результат исхода ![]() -й реализации модели:
-й реализации модели:
Тогда частота свершения события (оценка искомой вероятности) будет определяться следующим выражением:
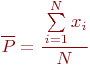
Величина ![]() - случайная и дискретная. Она при таком задании
- случайная и дискретная. Она при таком задании ![]() имеет биномиальное распределение (распределение Бернулли) с характеристиками:
имеет биномиальное распределение (распределение Бернулли) с характеристиками:
- матожидание

- дисперсия
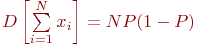
Из этого следует:
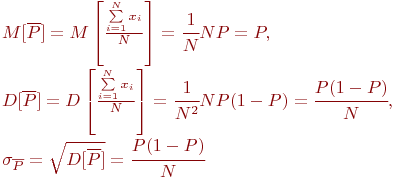
В теории вероятностей есть теорема Лапласа (частный случай центральной предельной теоремы), сущность которой состоит в том, что при больших значениях числа реализаций ![]() биномиальное распределение достаточно хорошо согласуется с нормальным распределением.
биномиальное распределение достаточно хорошо согласуется с нормальным распределением.
Следовательно, можно записать:
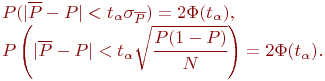
Следуя рассуждениям, приведенным ранее, получим искомые формулы:
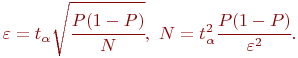
Как и ранее, ![]() - аргумент функции Лапласа,
- аргумент функции Лапласа, 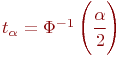
Если априорные сведения хотя бы о порядке искомой вероятности ![]() неизвестны, то использование значения абсолютной ошибки
неизвестны, то использование значения абсолютной ошибки ![]() может не иметь смысла. Например, может быть так, что исследователь задал значение абсолютной ошибки
может не иметь смысла. Например, может быть так, что исследователь задал значение абсолютной ошибки ![]() , а искомое значение вероятности оказалось
, а искомое значение вероятности оказалось ![]() . Очевидно, явное несоответствие. Поэтому целесообразно оперировать относительной погрешностью:
. Очевидно, явное несоответствие. Поэтому целесообразно оперировать относительной погрешностью: ![]()
В этом случае формулы (4.5) принимают вид:
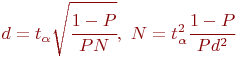
Из формул (4.6) следует, что при определении оценок малых вероятностей с приемлемо высокой точностью необходимо выполнить очень большое число реализаций модели. При отсутствии высокопроизводительного компьютера применение статистического моделирования становится проблематичным.
Пример 4.6. Вероятность ![]()
Определить число реализаций модели и затраты машинного времени для оценки данной вероятности с относительной точностью ![]() и достоверностью
и достоверностью ![]() На выполнение одной реализации модели требуется 5 сек.
На выполнение одной реализации модели требуется 5 сек.
Решение
Из табл. 4.3 находим ![]() . Относительная точность
. Относительная точность ![]() .
.
Если на выполнение одной реализации требуется 5 сек, то затраты машинного времени составят ![]()
В формулах (4.5) и (4.6) для вычисления ![]() или
или ![]() присутствует та же неопределенность, которую мы обсуждали ранее: вычисления требуют знания вероятности
присутствует та же неопределенность, которую мы обсуждали ранее: вычисления требуют знания вероятности ![]() , а она до эксперимента неизвестна. Эта неопределенность снимается так.
, а она до эксперимента неизвестна. Эта неопределенность снимается так.
Выполняется предварительно ![]() прогонов модели. Обычно
прогонов модели. Обычно ![]() По данным этих прогонов вычисляют ориентировочное значение оценки вероятности
По данным этих прогонов вычисляют ориентировочное значение оценки вероятности ![]() , которую и подставляют в формулу вместо вероятности
, которую и подставляют в формулу вместо вероятности ![]() .
.
Если окажется ![]() , моделирование следует продолжить до выполнения
, моделирование следует продолжить до выполнения ![]() реализаций.
реализаций.
Если окажется ![]() то моделирование заканчивается. При этом если
то моделирование заканчивается. При этом если ![]() то следует определить действительную точность
то следует определить действительную точность ![]() или
или ![]() для
для ![]() реализаций. Очевидно, в этом случае достигнутая точность будет выше заданной (ошибка меньше заданной)
реализаций. Очевидно, в этом случае достигнутая точность будет выше заданной (ошибка меньше заданной)
Но более удобно рассчитывать число реализаций на так называемый наихудший случай.
Вернемся к формуле (4.5)
Анализ формулы показывает, что число реализаций модели в зависимости от вероятности ![]() изменяется от
изменяется от ![]() (при
(при ![]() ) до
) до ![]() (при
(при ![]() ), проходя через максимум. Максимальное значение
), проходя через максимум. Максимальное значение ![]() принимает при
принимает при ![]() :
:
То есть наибольшее число реализаций модели будет тогда, когда искомая вероятность равна ![]() .
.
В этом случае число реализаций определяется так:
Если в результате моделирования окажется, что искомая вероятность значительно отличается от 0,5 (в любую сторону), то точность моделирования будет выше заданной (ошибка ![]() меньше). Для определения этой точности следует воспользоваться уже известной формулой (4.5), но при
меньше). Для определения этой точности следует воспользоваться уже известной формулой (4.5), но при ![]()
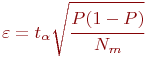
Пример 4.7. Сервер обрабатывает запросы, поступающие с автоматизированных рабочих мест (АРМ) с интервалами, распределенными по экспоненциальному закону со средним значением ![]() Вычислительная сложность запросов распределена по нормальному закону с математическим ожиданием
Вычислительная сложность запросов распределена по нормальному закону с математическим ожиданием ![]() и среднеквадратическим отклонением
и среднеквадратическим отклонением ![]() Производительность сервера по обработке запросов
Производительность сервера по обработке запросов ![]()
Построить алгоритм имитационной модели с целью определения вероятности обработки запросов за время ![]() Исследовать зависимость вероятности обработки запросов от интервалов их поступления, вычислительной сложности и производительности сервера.
Исследовать зависимость вероятности обработки запросов от интервалов их поступления, вычислительной сложности и производительности сервера.
Решение
Для построения алгоритма имитационной модели введем следующие идентификаторы:
![]() - текущее время поступления запроса;
- текущее время поступления запроса;
![]() - интервал поступления запросов;
- интервал поступления запросов;
![]() - текущее время окончания обработки запроса;
- текущее время окончания обработки запроса;
![]() - время обработки запроса;
- время обработки запроса;
![]() - счетчик количества прогонов модели (реализаций);
- счетчик количества прогонов модели (реализаций);
![]() - вероятность обработки запросов;
- вероятность обработки запросов;
![]() - счетчик количества обработанных запросов;
- счетчик количества обработанных запросов;
![]() - заданное количество прогонов модели (реализаций);
- заданное количество прогонов модели (реализаций);
![]() - количество запросов за
- количество запросов за ![]() прогонов модели;
прогонов модели;
![]() - время моделирования.
- время моделирования.
Алгоритм модели приведен на рис. 4.2.
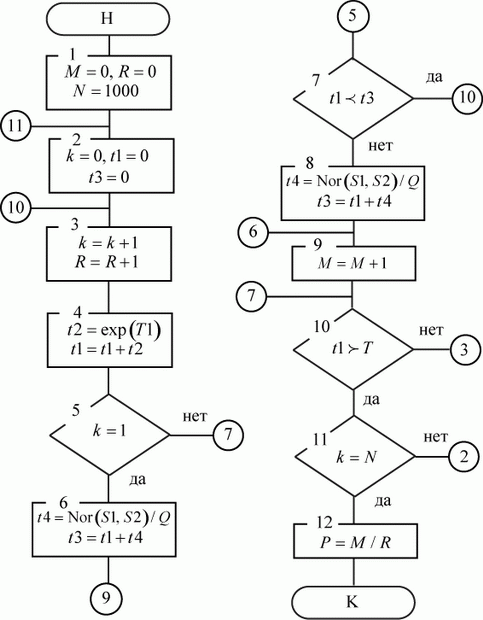
увеличить изображение
Рис. 4.2. Алгоритм модели обработки запросов сервером
Выберем интервалы варьирования уровней факторов.
![]() - средний интервал поступления запросов.
- средний интервал поступления запросов.
Для изменения математического ожидания и среднеквадрати-ческого отклонения целесообразно ввести коэффициент, принимающий два значения, например, ![]() и
и ![]() . Тогда
. Тогда ![]() ,
, ![]() ,
, ![]() - производительность сервера.
- производительность сервера.
В соответствии с интервалами варьирования представим уровни факторов таблицей (табл. 4.5). В табл. 4.5 индексы н и в - нижний и верхний уровни факторов соответственно.
Составим план факторного эксперимента:
| № | | | | | |
|---|---|---|---|---|---|
| | | ||||
| 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | -1 | -1 | -1 | 0.375 | 0.375 |
| 2 | -1 | -1 | +1 | 0.584 | 0.583 |
| 3 | -1 | +1 | -1 | 0.166 | 0.167 |
| 4 | -1 | +1 | +1 | 0.32 | 0.319 |
| 5 | +1 | -1 | -1 | 0.64 | 0.642 |
| 6 | +1 | -1 | +1 | 0.809 | 0.808 |
| 7 | +1 | +1 | -1 | 0.376 | 0.375 |
Проведем эксперимент. Выполним первое наблюдение при ![]() прогонов модели. Получим вероятность обработки запросов
прогонов модели. Получим вероятность обработки запросов ![]() . Занесем ее в табл. 4.5 (строка 1, столбец 5) Зададимся точностью
. Занесем ее в табл. 4.5 (строка 1, столбец 5) Зададимся точностью ![]() и доверительной вероятностью
и доверительной вероятностью ![]() . По таблице значений функции Лапласа найдем ее аргумент
. По таблице значений функции Лапласа найдем ее аргумент ![]() (см. табл. 4.3).
(см. табл. 4.3).
Рассчитаем требуемое количество прогонов модели при ![]() и
и ![]() :
:
При расчете числа прогонов для "худшего случая" (а такой вариант возможен, так как в табл. 4.6 мы видим, что есть ![]() ) получим:
) получим:
4.8. Точность и количество реализаций модели при зависимом ряде данных
До сих пор мы предполагали, что выходные данные модели образуют ряд значений ![]() , статистически независимых и принадлежащих одному закону распределения. Однако это не всегда так.
, статистически независимых и принадлежащих одному закону распределения. Однако это не всегда так.
Пусть, например, целью статистического моделирования будет определение матожидания времени пребывания заявки в очереди ![]() одноканальной системы массового обслуживания.
одноканальной системы массового обслуживания.
В результате эксперимента с моделью будет получен ряд значений ![]() , которые заведомо статистически зависимы:
, которые заведомо статистически зависимы:
при большом времени ожидания ![]() -й заявки значение
-й заявки значение ![]() , не может быть малым, если обе заявки находились одновременно в очереди. Связь точности оценки
, не может быть малым, если обе заявки находились одновременно в очереди. Связь точности оценки ![]() , среднего времени ожидания
, среднего времени ожидания ![]() с количеством реализаций
с количеством реализаций ![]() в этом случае выглядит иначе, чем было рассмотрено ранее. Мы рассмотрим метод определения точности и количества реализаций для статистически зависимых последовательностей - откликов модели, в основе которого лежит так называемый регенеративный анализ.
в этом случае выглядит иначе, чем было рассмотрено ранее. Мы рассмотрим метод определения точности и количества реализаций для статистически зависимых последовательностей - откликов модели, в основе которого лежит так называемый регенеративный анализ.
Допустим, что в результате эксперимента с имитационной моделью получен ряд значений ![]() , приведенный в табл. 4.7.
, приведенный в табл. 4.7.
Здесь ![]() - порядковый номер поступающих заявок.
- порядковый номер поступающих заявок.
Обратим внимание на то, что заявка 1 застает канал обслуживания свободным: ее время ожидания в очереди равно нулю. Такая же ситуация возникла для заявок 4, 6 и 11. Период занятости и простоя канала обслуживания образуют цикл его работы. В табл. 4.7 можно выделить три таких цикла, в которые входят следующие наборы обслуженных заявок:
- цикл 1 - заявки 1, 2, 3;
- цикл 2 - заявки 4, 5;
- цикл 3 - заявки 6, 7, 8, 9, 10.
Заявка 11 является началом нового цикла 4 и т. д.
Начала каждого цикла неотличимы друг от друга - заявка поступает на обслуживание без ожидания. Говорят так: система восстанавливается (регенерируется) к началу каждого цикла, следовательно, поведение системы в очередном цикле не зависит от ее поведения в предыдущих циклах.
Введем обозначения:
![]() - сумма времен ожидания
- сумма времен ожидания ![]() -го цикла,
-го цикла, ![]() ;
;
![]() - количество заявок, образующих
- количество заявок, образующих ![]() -й цикл. Для данных, приведенных в табл. 4.5:
-й цикл. Для данных, приведенных в табл. 4.5:
Таким образом, мы получили пары чисел - независимых и одинаково распределенных:
Заметим, что числа ![]() и
и ![]() между собой зависимы.
между собой зависимы.
Целью дальнейших рассуждений является определение оценки
матожидания времени пребывания заявки в очереди ![]() , отличающееся от
, отличающееся от ![]() на величину не более
на величину не более ![]() при заданной достоверности
при заданной достоверности ![]() . Так как
. Так как
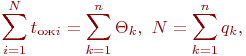
где ![]() - число циклов, то оценка матожидания времени пребывания заявки в очереди определяется так:
- число циклов, то оценка матожидания времени пребывания заявки в очереди определяется так:
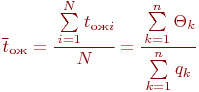
Разделим числитель и знаменатель на число циклов ![]() и получим:
и получим:
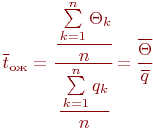
В соответствии с центральной предельной теоремой оценка длительности цикла ![]() при числе циклов
при числе циклов ![]() есть случайная величина, распределенная по нормальному закону с математическим ожиданием и дисперсией соответственно:
есть случайная величина, распределенная по нормальному закону с математическим ожиданием и дисперсией соответственно:
где ![]() - дисперсия, представляющая собой сумму дисперсий зависимых между собой случайных величин
- дисперсия, представляющая собой сумму дисперсий зависимых между собой случайных величин ![]() и
и ![]() .
.
Следовательно, имеет место уже знакомое нам выражение
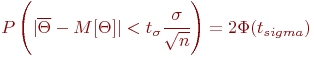
Если ![]() - граничное значение ошибки для оценки
- граничное значение ошибки для оценки ![]() , то очевидно граничное значение ошибки для оценки
, то очевидно граничное значение ошибки для оценки ![]() равно
равно ![]()
Тогда ![]() . Из этого следует:
. Из этого следует:
Коэффициент ![]() , как и ранее, характеризует достоверность оценки
, как и ранее, характеризует достоверность оценки ![]() и является аргументом функции Лапласа:
и является аргументом функции Лапласа:
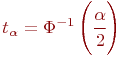
Значения ![]() и
и ![]() до эксперимента неизвестны. Их ориентировочные значения должны быть определены по данным предварительных прогонов модели в количестве
до эксперимента неизвестны. Их ориентировочные значения должны быть определены по данным предварительных прогонов модели в количестве ![]() реализаций циклов. Обычно
реализаций циклов. Обычно ![]()
Оценку дисперсии ![]() обозначим
обозначим ![]() Она вычисляется так:
Она вычисляется так:
Здесь:
![]() - оценка дисперсии
- оценка дисперсии ![]() ;
;
![]() - оценка дисперсии
- оценка дисперсии ![]() ;
;
![]() - корреляционный момент случайных величин
- корреляционный момент случайных величин ![]() и
и ![]() ;
;
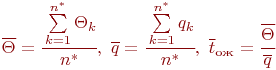
И, наконец, необходимое число циклов будет определено:
Если окажется ![]() , то моделирование продолжается до достижения
, то моделирование продолжается до достижения ![]() циклов. Если же окажется
циклов. Если же окажется ![]() то моделирование заканчивается и, если необходимо, дается оценка достигнутой точности.
то моделирование заканчивается и, если необходимо, дается оценка достигнутой точности.
Признак конца моделирования: ![]() или количество обслуженных СМО заявок
или количество обслуженных СМО заявок ![]() .
.
4.9. Проблема начальных условий
К тактическому планированию эксперимента относится и решение так называемой проблемы начальных условий.
В отличие от реальной системы модель работает прогонами - для накопления нужной статистики. Поэтому при каждом новом прогоне модели требуется какое-то время, чтобы установился стационарный режим, характеристики которого интересуют исследователя.
То есть начальные условия искажают характеристики стационарного режима.
Например, моделируется функционирование направления связи. В установившемся режиме входной буфер направления имеет среднее заполнение поступившими, но не обработанными пока сообщениями. Но перед каждым очередным прогоном в модели устанавливаются нулевые начальные условия.
Или еще: вероятность обслуживания заявки в СМО имеет какое-то стационарное значение. Но в начальный момент эта вероятность равна нулю.
Следовательно, начальные установки регистрируемого параметра (показателя эффективности и др.) искажают результат.
Для устранения ошибок, вызываемых не соответствующей установкой начальных условий, возможно применение следующих мер:
- Ставить начальные условия, близкие значениям стационарного режима, то есть модель разрабатывается так, что условия функционирования системы типичны с самого начала.
- Увеличить интервал исследования (
 ) так, чтобы он стал значительно больше предполагаемого времени установления стационарного режима.
) так, чтобы он стал значительно больше предполагаемого времени установления стационарного режима. - Отбросить информацию, снимаемую в промежутке времени от пуска (
 ) до установившихся стационарных значений, и продолжить моделирование, собирая статистику, на которую уже не влияют нетипичные ситуации.
) до установившихся стационарных значений, и продолжить моделирование, собирая статистику, на которую уже не влияют нетипичные ситуации.
Первый подход требует от разработчика знания типичных условий работы и умения внести в модель эти условия. В моделях сложных систем это вряд ли выполнимо.
При втором подходе требуется слишком долгое моделирование до наступления такого состояния, когда исчезает влияние собранных неверных данных. Стоимость такого моделирования для сложных систем может оказаться слишком высокой, что делает этот подход нежелательным.
Третий подход оказывается наиболее удобным. Нужно на определенной стадии моделирования отбросить статистику с последующим продолжением моделирования без каких-либо модификаций модели. Такой подход используется в ряде систем моделирования. Заметим, однако, что время установки стационарных значений в модели трудно определить до эксперимента.
Все эти приемы могут уменьшить влияние переходных процессов в модели на результаты эксперимента, однако свести его к нулю не могут.
Вопросы для самоконтроля
- Что понимается под компьютерным экспериментом?
- Каковы цели планирования экспериментов?
- Что такое стратегическое и тактическое планирование?
- Что понимается под кибернетическим представлением эксперимента?
- Что такое реакция или отклик системы?
- Что такое факторы и уровни факторов?
- Приведите вариант классификации факторов.
- Симметричный факторный эксперимент.
- Полный факторный эксперимент (ПФЭ).
- Как определяется количество информационных точек в ПФЭ? В симметричном ПФЭ?
- Пути сокращения затрат на проведение эксперимента.
- Дайте определение точности и достоверности оценки характеристики случайной величины.
- Как получено выражение, связывающее точность и достоверность оценки с числом реализаций модели?
- Способы априорного определения оценки дисперсии.
- Как получено выражение
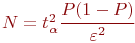 ? Что означают аргументы этого выражения?
? Что означают аргументы этого выражения? - Способы априорного определения вероятности
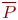 .
. - В результате прогонов имитационной модели ожидается получить три случайных показателя со следующими характеристиками:

Определить требуемое количество
реализаций модели для достижения требуемой точности и достоверности. - В чем состоит проблема начальных условий, и каковы пути ее разрешения?
Лекция 5. Обработка результатов имитационного эксперимента
Современные системы имитационного моделирования предоставляют возможность выполнять автоматически стандартную обработку результатов моделирования:
- определение характеристик случайных параметров, главным образом, их матожиданий и дисперсий;
- фиксация минимальных и максимальных значений исследуемых величин;
- частотное распределение результатов измерений (построение гистограмм);
- расчет коэффициентов использования объектов модели и др.
Часто инженеру приходится выполнять более сложную обработку:
- определение функциональных или статистических зависимостей между исследуемыми величинами;
- выявление существенных или несущественных факторов, участвующих в эксперименте;
- сравнение случайных параметров процесса с целью определения значимости расхождения или совпадения их характеристик и др.
В наиболее развитых системах моделирования предусмотрены средства, обеспечивающие выполнение этих обработок. Но в любом случае инженер должен понимать сущность обработки, уметь правильно готовить исходные данные, грамотно интерпретировать результаты обработки. При наличии альтернатив обоснованно выбирать метод обработки и, при необходимости, разрабатывать соответствующие процедуры.
5.1. Характеристики случайных величин и процессов
В результате эксперимента с имитационной статистической моделью, состоящего из ![]() наблюдений, мы получаем
наблюдений, мы получаем ![]() значений исследуемой случайной величины
значений исследуемой случайной величины ![]() :
:
По этим данным нужно дать всестороннее описание величины a.
Определить случайную величину - это значит определить ее характеристики. В общем случае:
где ![]() - оценка характеристики случайной величины. Под характеристикой понимают следующее.
- оценка характеристики случайной величины. Под характеристикой понимают следующее.
Во-первых, это характеристика величины:
- матожидание (среднее арифметическое);
- медиана (срединное значение);
- мода (наиболее вероятное значение);
- среднее геометрическое и др.
В рамках задач, характерных для нашей профессии, наиболее актуальным является матожидание. Как известно, матожидание определяет центр рассеивания случайной величины, наиболее полно отмечающее ее положение на числовой оси. Будем обозначать матожидание случайной величины ![]() так:
так: ![]() .
.
Во-вторых, это характеристики рассеивания:
- дисперсия (матожидание квадрата отклонения случайной величины a );
- среднее квадратическое отклонение (квадратный корень из дисперсии); иногда целесообразно пользоваться этой характеристикой, так как она имеет размерность самой случайной величины;
- размах (
 ).
).
В-третьих, это характеристика связи между случайными величинами (корреляция); степень связи определяется величиной коэффициента корреляции ![]() . В случайном процессе связь между значениями случайной функции в моменты времени
. В случайном процессе связь между значениями случайной функции в моменты времени ![]() ,
, ![]() определяет коэффициент автокорреляции
определяет коэффициент автокорреляции ![]()
В-четвертых, это характеристика закона распределения вероятностей случайной величины в виде плотности или функции распределения: ![]() или
или ![]() .
.
5.2. Требования к оценкам характеристик
Ограниченное число реализаций модели не позволяет точно определить значения этих характеристик, а только приближенно,
то есть так называемые оценки характеристик \Theta . Степень приближения оценок ![]() зависит от методов их вычислений (формул). Поскольку
зависит от методов их вычислений (формул). Поскольку ![]() , где
, где ![]() - случайные значения искомого параметра, то величина
- случайные значения искомого параметра, то величина ![]() - случайная со своими значениями матожидания, дисперсии и т. п.
- случайная со своими значениями матожидания, дисперсии и т. п.
Как правило, математическая статистика может предложить разные формулы для вычисления оценки одной и той же характеристики. Следовательно, оценки могут быть более или менее точными или даже вовсе непригодными при имитационном моделировании.
Чтобы оценка наилучшим образом представляла искомую характеристику, нужно, чтобы она обладала следующими свойствами:
- несмещенностью;
- состоятельностью;
- эффективностью.
Несмещенность. Это свойство означает, что оценка не содержит систематической ошибки. Т. е., математическое ожидание оценки совпадает с действительным значением характеристики ![]() :
:
Состоятельность. Это свойство означает, что оценка ![]() приближается сколь угодно близко к истинному значению характеристики
приближается сколь угодно близко к истинному значению характеристики ![]() по мере увеличения объема выборки, т. е. увеличения числа реализаций модели. Формально это свойство записывают так:
по мере увеличения объема выборки, т. е. увеличения числа реализаций модели. Формально это свойство записывают так:
при ![]() и любом
и любом ![]() .
.
Именно это свойство являлось определяющим при нахождении количественной связи между точностью, достоверностью оценок и числом реализаций модели.
Эффективность. Это свойство означает, что из всех несмещенных и состоятельных оценок следует предпочесть ту, у которой разброс значений меньше. Иначе: эффективной оценкой характеристики случайной величины называют ту, которая имеет наименьшую дисперсию:
![]() - число возможных оценок.
- число возможных оценок.
В исследовании свойств оценок большая заслуга принадлежит англичанину Рональду А. Фишеру. Основные результаты он получил в 1912 г., когда ему было 22 года.
5.3. Оценка характеристик случайных величин и процессов
Наиболее используемые оценки характеристик приведены в табл. 5.1.
| Характеристика | Оценка | Среднее квадратическое отклонение оценки |
|---|---|---|
| Матожидание | 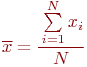 | |
| Дисперсия | ||
| Среднее квадратическое отклонение | 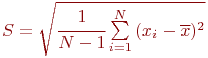 | |
| Вероятность события | ||
| Коэффициент корреляции | 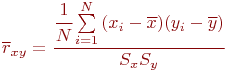 |
Все оценки несмещенные, состоятельные, эффективные.
Проблемами оценок занимался и Абрагам Вайльд, американский математик австрийского происхождения.
Приведем для иллюстрации два примера.
Пример 5.1. Оценка матожидания случайной величины ![]() - среднее арифметическое
- среднее арифметическое
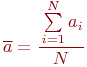
является несмещенной, состоятельной и эффективной.
Оценка в виде медианы не является эффективной, так как дисперсия в этом случае
в ![]() раз больше дисперсии
раз больше дисперсии ![]() , равной, как известно,
, равной, как известно, ![]()
Пример 5.2. Выборочная дисперсия случайной величины ![]()
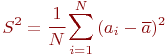
состоятельна, эффективна, но смещена. Смещение образовалось из-за того, что вместо неизвестного ![]() в формуле стоит оценка
в формуле стоит оценка ![]()
Несмещенная оценка имеет вид:
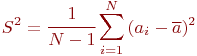
Иногда формулы для вычисления оценок матожидания и дисперсии используют в рекуррентной форме:
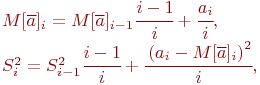
где ![]() - оценки матожидания и дисперсии, вычисленные по данным
- оценки матожидания и дисперсии, вычисленные по данным ![]() и (
и ( ![]() ) реализаций имитационной модели.
) реализаций имитационной модели.
Приведенные в табл. 5.1 ,формулы соответствуют нормальному закону распределения вероятностей исследуемой величины.
При исследовании случайного процесса ![]() весь временной интервал
весь временной интервал ![]() представляется последовательностью из
представляется последовательностью из ![]() временных точек
временных точек ![]() ,
, ![]() , в каждой из которых измеряется значение сечения
, в каждой из которых измеряется значение сечения ![]() . Индекс
. Индекс ![]() - номер реализации случайного процесса,
- номер реализации случайного процесса, ![]() .
.
Полученные данные образуют матрицу сечений размером ![]() , что и является моделью исследуемого процесса (табл. 5.2).
, что и является моделью исследуемого процесса (табл. 5.2).
Совокупность сечений в каждой временной точке ![]() (столбец матрицы), представляет собой случайные числа некоторой случайной величины в общем случае со своими законами распределения, матожиданиями, дисперсиями:
(столбец матрицы), представляет собой случайные числа некоторой случайной величины в общем случае со своими законами распределения, матожиданиями, дисперсиями:
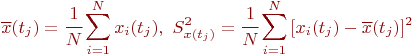
При решении практических задач последовательности этих оценок матожиданий и дисперсий, определенных в точках ![]() , достаточно полно представляют моделируемый случайный процесс. Оценки матожиданий
, достаточно полно представляют моделируемый случайный процесс. Оценки матожиданий ![]() и дисперсий
и дисперсий ![]() можно аппроксимировать подходящими кривыми в предположении непрерывности процесса.
можно аппроксимировать подходящими кривыми в предположении непрерывности процесса.
Иногда исследователя интересует связь сечений случайного процесса между собой. Степень зависимости между сечениями определяет автокорреляционная функция. Оценка ее имеет вид:
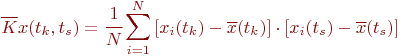 | (t_s)]) |
где ![]() и
и ![]() - значения сечений в точках
- значения сечений в точках ![]() и
и ![]() соответственно
соответственно ![]() -й реализации;
-й реализации;
![]() и
и ![]() - оценки матожиданий совокупности сечений в точках
- оценки матожиданий совокупности сечений в точках ![]() и
и ![]() соответственно.
соответственно.
Данные расчета значений автокорреляционной функции ![]() ,
, ![]() ,
, ![]() помещают в таблицу, которая и является табличным определением ее. В случае необходимости данные таблицы могут быть представлены подходящей аппроксимирующей кривой.
помещают в таблицу, которая и является табличным определением ее. В случае необходимости данные таблицы могут быть представлены подходящей аппроксимирующей кривой.
Пример таблицы значений ![]() для случайного процесса,
для случайного процесса,
определенного пятью сечениями ![]() , показан в табл. 5.3.
, показан в табл. 5.3.
Очевидно, что рассчитывать все значения ![]() для заполнения таблицы (в данном примере их 25) не надо, так как значения
для заполнения таблицы (в данном примере их 25) не надо, так как значения ![]() при
при ![]() ("северо-западная диагональ") представляют собой значения соответствующих дисперсий. И
("северо-западная диагональ") представляют собой значения соответствующих дисперсий. И ![]() , что исключает необходимость расчета половины оставшихся значений коэффициентов автокорреляционной функции, расположенных выше или ниже упомянутой диагонали.
, что исключает необходимость расчета половины оставшихся значений коэффициентов автокорреляционной функции, расположенных выше или ниже упомянутой диагонали.
5.4. Гистограмма
Одной из задач моделирования может быть определение закона распределения вероятностей исследуемой случайной величины и количественных значений его характеристик.
Аналогом, моделью плотности распределения вероятности случайной величины является гистограмма, которую можно построить (аналитически или графически) по данным имитационного моделирования.
Гистограмма (рис. 5.1) строится так.
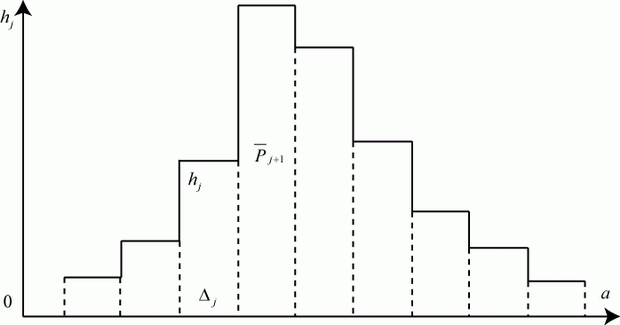
Рис. 5.1. Гистограмма
В результате ![]() реализаций модели получен ряд случайных значений исследуемого параметра
реализаций модели получен ряд случайных значений исследуемого параметра ![]() :
: ![]() . Весь диапазон значений
. Весь диапазон значений ![]() разбивается на
разбивается на ![]() интервалов (разрядов). Числовой диапазон каждого интервала обозначим
интервалов (разрядов). Числовой диапазон каждого интервала обозначим ![]() ,
, ![]() . Обычно все числовые диапазоны одинаковые:
. Обычно все числовые диапазоны одинаковые: ![]() .
.
Для каждого интервала подсчитываем число значений ![]() , попавших в него -
, попавших в него - ![]() .
.
На каждом интервале строят прямоугольник с высотой ![]() :
:
Площадь каждого прямоугольника гистограммы равна относительной частоте ![]() :
:
По выбору числа интервалов ![]() существуют разные эмпирические рекомендации, например:
существуют разные эмпирические рекомендации, например:
Чем больше ![]() и
и ![]() , а меньше
, а меньше ![]() , тем ближе гистограмма совпадает с некоторым теоретическим распределением. Доказал это Валерий Иванович Гливенко - известный отечественный математик.
, тем ближе гистограмма совпадает с некоторым теоретическим распределением. Доказал это Валерий Иванович Гливенко - известный отечественный математик.
На основе очертания гистограммы делается предположение (выдвигается гипотеза) о совпадении полученного эмпирического распределения вероятностей с тем или иным теоретическим - нормальным, экспоненциальным, Вейбулла и т. д. Затем выполняется проверка этой гипотезы с помощью критериев согласия.В курсе высшей математики рассматриваются некоторые (критерий Колмогорова, критерий Смирнова и др.), наиболее популярными считают критерий хи-квадрат - критерий Пирсона, предложенный в 1903 г.
Оценки матожидания и дисперсии можно получить по данным гистограммы:
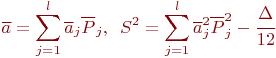
где ![]() - среднее значение каждого интервала;
- среднее значение каждого интервала;
![]() - оценка по каждому интервалу;
- оценка по каждому интервалу;
![]() - поправка Шеппарда.
- поправка Шеппарда.
5.4. Элементы дисперсионного анализа. Критерий Фишера
Приведем понятия, которые используем в дальнейшем. В математической статистике (а это основной математический аппарат обработки результатов моделирования) широко используется понятие гипотезы.
Гипотезой называется предположение о:
- законах распределения вероятностей случайных величин;
- значениях характеристик случайных величин;
- совпадении законов распределения двух и более случайных величин и др.
Обычно исходную гипотезу называют нулевой и обозначают ![]() Противоположное утверждение называют конкурирующей гипотезой и обозначают
Противоположное утверждение называют конкурирующей гипотезой и обозначают ![]()
Гипотеза подвергается проверке. Смысл этой проверки в том, чтобы принять или отклонить ее с допустимым минимальным риском. При этом возможны ошибки:
- забраковать проверяемую гипотезу, если она верна, что соответствует так называемой ошибке первого рода ;
- принять проверяемую гипотезу, когда она не верна,значит совершить ошибку второго рода.
Правило, которому принимается суждение об истинности или ложности основной гипотезы ![]() называют критерием проверки или критерием согласия.
называют критерием проверки или критерием согласия.
В практике моделирования и обработки экспериментальных данных очень часто необходимо решать проблему подтверждения или опровержения гипотезы о принадлежности двух или более выборок одной генеральной совокупности.
К такой проблеме приводят такие задачи:
- сравнительная оценка различных технологических процессов по их производительности, точности, экономичности;
- сравнение конструктивных особенностей приборов, машин, средств вооружения и др.
Признаки, по которым проводится сравнительная оценка, часто не являются детерминированными, обладают рассеиванием. Например, точность никогда не может быть абсолютной, так как измерительные приборы всегда несут в себе ошибку.
Наиболее общим и часто применяемым на практике методом сравнения качеств объектов является дисперсионный анализ.
Сущность дисперсионного анализа состоит в проверке гипотезы о тождественности выборочных дисперсий одной и той же генеральной дисперсии.
Почему исследователей интересует сравнение именно дисперсий, а не каких-либо других характеристик? Заметим, что есть методики сравнения, например, матожиданий и др., но они не обладают такой общностью, как дисперсионный анализ.
А дело в том, что дисперсия характеризует важные конструкторские и технологические показатели как:
- точность приборов;
- рассеивание точек попадания при стрельбе и др.
И еще дисперсионный анализ одновременно решает проблему проверки гипотезы о равенстве средних значений выборок.
Задача сравнения дисперсий сводится к проверке исходной гипотезы (нулевой гипотезы ![]() ) о принадлежности двух выборок
) о принадлежности двух выборок
одной и той же генеральной совокупности.
Для проверки гипотезы о равенстве дисперсий нужно иметь независимую функцию, вычислимую по данным эксперимента.
Такой функцией является функция Фишера (распределение Фишера, F -распределение), определяемая так:
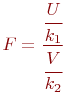
где ![]() и
и ![]() случайные величины, имеющие распределение
случайные величины, имеющие распределение ![]() ;
;
![]() и
и ![]() соответствующие степени свободы случайных величин
соответствующие степени свободы случайных величин ![]() и
и ![]() соответственно,
соответственно, ![]() ,
, ![]() ;
;
![]() и
и ![]() - количество испытаний (объемы выборок).
- количество испытаний (объемы выборок).
Почему ![]() является мерой сравнения дисперсий? А потому, что дисперсии, являясь суммой квадратов ошибок, имеют распределение
является мерой сравнения дисперсий? А потому, что дисперсии, являясь суммой квадратов ошибок, имеют распределение ![]() .
.
Распределение хи-квадрат определяется следующим образом:
где ![]() - число степеней свободы,
- число степеней свободы, ![]() - число Эйлера (2,71…),
- число Эйлера (2,71…), ![]() - гамма-функция.
- гамма-функция.
График плотности F -распределения показан на рис. 5.2.
Итак, случайная величина
где ![]() и
и ![]() - несмещенные оценки дисперсий, полученных из независимых выборок, взятых из нормальных совокупностей, имеет распределение Фишера ( F -распределение).
- несмещенные оценки дисперсий, полученных из независимых выборок, взятых из нормальных совокупностей, имеет распределение Фишера ( F -распределение).
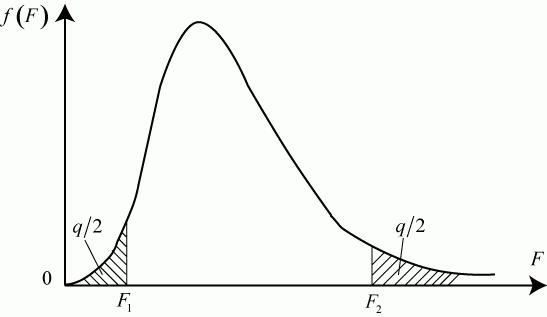
Рис. 5.2. График плотности F -распределения
Величина F - случайна, поэтому судить однозначно по ее величине о подтверждении или опровержении гипотезы об однородности исследуемых выборок нельзя.
Поэтому вводится ![]() уровень значимости, численно равный вероятности неприемлемых отклонений от принятой гипотезы. Области неприемлемых значений
уровень значимости, численно равный вероятности неприемлемых отклонений от принятой гипотезы. Области неприемлемых значений ![]() показаны на рис. 5.2 штриховкой. Граничные точки допустимых значений
показаны на рис. 5.2 штриховкой. Граничные точки допустимых значений ![]() определяются точками
определяются точками ![]() и
и ![]() , соответствующих вероятностям
, соответствующих вероятностям ![]() .
.
Если вычисленное по данным эксперимента значение ![]() попадает в область между точками
попадает в область между точками ![]() и
и ![]() :
:
то принятая гипотеза не опровергается.
Заметим, что случайная величина
также имеет F -распределение со степенями свободы ![]() и
и ![]() соответственно. Следовательно, вероятность попадания числа
соответственно. Следовательно, вероятность попадания числа ![]() в левую критическую область равна:
в левую критическую область равна:
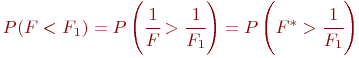
Отсюда следует, что левая критическая точка F -распределения соответствует правой критической точке ![]() -распределения. Т. е. правые точки распределений
-распределения. Т. е. правые точки распределений ![]() и
и ![]() определяют левую и правую точки
определяют левую и правую точки ![]() и
и ![]() . Поэтому в таблицах представлены только правые
. Поэтому в таблицах представлены только правые ![]() критические точки F -распределения.
критические точки F -распределения.
В таблицах значения ![]() приведены в зависимости от
приведены в зависимости от ![]() , числа степеней свободы
, числа степеней свободы ![]() и
и ![]() .
.
Обычно при вычислении ![]() в числитель отношения
в числитель отношения ![]() ставят значение большей дисперсии.
ставят значение большей дисперсии.
Итак, при ![]() принятая гипотеза не опровергается, при
принятая гипотеза не опровергается, при ![]() - не подтверждается.
- не подтверждается.
Пример 5.3. В часть поступили две буссоли. Первая из них при измерении пять раз одного и того же угла показала дисперсию ![]() . По результатам семи измерений второй буссолью того же угла получена дисперсия
. По результатам семи измерений второй буссолью того же угла получена дисперсия ![]() .
.
Однотипны ли буссоли? Одинаковы ли они по точности измерения углов? Выдвинем и проверим гипотезу об их однотипности для уровня значимости ![]()
Решение
По таблицу F -распределения для степеней свобод ![]() , соответствующей большей дисперсии, и
, соответствующей большей дисперсии, и ![]() , соответствующей меньшей дисперсии, и уровню значимости
, соответствующей меньшей дисперсии, и уровню значимости ![]() , находим
, находим ![]() .
.
Так как ![]() , то для уровня значимости
, то для уровня значимости ![]() гипотеза об одинаковости буссолей не опровергается.
гипотеза об одинаковости буссолей не опровергается.
Итак: чем меньше уровень значимости ![]() , тем меньше вероятность забраковать проверяемую гипотезу, когда она верна, т. е. совершить ошибку первого рода.
, тем меньше вероятность забраковать проверяемую гипотезу, когда она верна, т. е. совершить ошибку первого рода.
Но с уменьшением уровня значимости (увеличения ![]() ) расширяется область допустимых ошибок, что приводит к увеличению вероятности принятия неверного решения,т. е. совершения ошибки второго рода.
) расширяется область допустимых ошибок, что приводит к увеличению вероятности принятия неверного решения,т. е. совершения ошибки второго рода.
В заключение изложенного отметим, что как бы ни был велик объем статистического материала ![]() и
и ![]() критерий Фишера (впрочем, как и любой другой) не может дать абсолютно достоверный ответ о справедливости или несправедливости проверяемой гипотезы, так как мы оперируем случайными числами.
критерий Фишера (впрочем, как и любой другой) не может дать абсолютно достоверный ответ о справедливости или несправедливости проверяемой гипотезы, так как мы оперируем случайными числами.
То есть, опровержение гипотезы ни в коем случае не означает категорического, логического опровержения гипотезы при ![]() , равно как и подтверждение гипотезы при
, равно как и подтверждение гипотезы при ![]() не означает категорического доказательства ее справедливости. Не исключено, что в том и в другом случае решение может оказаться ошибочным.
не означает категорического доказательства ее справедливости. Не исключено, что в том и в другом случае решение может оказаться ошибочным.
Суждение о подтверждении или отклонении выдвинутой гипотезы высказывается с определенной степенью достоверности.
Среди инженеров бытует шутливое изречение: статистика, как фонарный столб на улице: света дает мало, но при случае на него можно опереться.
Но свет-то дает! И другой альтернативы нет.
5.6. Критерий Вилькоксона
Как и в предыдущем случае решается следующая задача. Имеются две серии независимых наблюдений однородных случайных величин ![]() и
и ![]() , причем значения
, причем значения ![]() и
и ![]() дают различные значения средних
дают различные значения средних ![]() или (и) различные рассеивания. Возникает вопрос: можно ли считать эти расхождения существенными или расхождения зависят от случайных выборок?
или (и) различные рассеивания. Возникает вопрос: можно ли считать эти расхождения существенными или расхождения зависят от случайных выборок?
Простой в употреблении и вполне приемлемый по точности критерий для проверки гипотезы о тождественности функций распределения ![]() и
и ![]() предложил в середине прошлого века Вилькоксон. Критерий назван его именем.
предложил в середине прошлого века Вилькоксон. Критерий назван его именем.
Рассматривается нулевая гипотеза: ![]() . Конкурирующая гипотеза:
. Конкурирующая гипотеза: ![]() .
.
Критерий основан на подсчете числа инверсий. Инверсии определяются так.
Измеренные значения ![]() и
и ![]() ,
, ![]() располагаются в общую последовательность в порядке возрастания их значений. Пусть это будет, например, так:
располагаются в общую последовательность в порядке возрастания их значений. Пусть это будет, например, так:
где ![]() - члены, принадлежащие первой выборке;
- члены, принадлежащие первой выборке;
![]() - члены второй выборки. Эта последовательность - не убывающая, содержащая
- члены второй выборки. Эта последовательность - не убывающая, содержащая ![]() чисел,
чисел, ![]() - количество чисел последовательности
- количество чисел последовательности ![]() ,
, ![]() - последовательности
- последовательности ![]() .
.
Если гипотеза ![]() верна, то достаточно очевидно, что числа из обеих последовательностей хорошо перемешиваются. Степень перемешивания определяется числом инверсий членов первой последовательности относительно второй. Если в упорядоченной общей последовательности некоторому
верна, то достаточно очевидно, что числа из обеих последовательностей хорошо перемешиваются. Степень перемешивания определяется числом инверсий членов первой последовательности относительно второй. Если в упорядоченной общей последовательности некоторому ![]() предшествует одно значение
предшествует одно значение ![]() , это означает, что имеет место одна инверсия.
, это означает, что имеет место одна инверсия.
Если некоторому ![]() предшествуют
предшествуют ![]() значений
значений ![]() , то это значение
, то это значение ![]() имеет
имеет ![]() инверсий.
инверсий.
Для нашего примера член ![]() имеет одну инверсию с
имеет одну инверсию с ![]() ; член
; член ![]() - тоже одну с
- тоже одну с ![]() ; член
; член ![]() имеет четыре инверсии (с
имеет четыре инверсии (с ![]() ); член
); член ![]() имеет шесть инверсий (с
имеет шесть инверсий (с ![]() ).
).
Таким образом, общее число инверсий:
Показано, что случайная величина ![]() уже при
уже при ![]() и
и ![]() дает хорошее приближение к нормальному распределению с матожиданием и дисперсией:
дает хорошее приближение к нормальному распределению с матожиданием и дисперсией:
При уровне значимости ![]() и нормальности распределения
и нормальности распределения ![]() вероятность попадания значения
вероятность попадания значения ![]() в критическую область (что означает не подтверждение нулевой гипотезы) равна:
в критическую область (что означает не подтверждение нулевой гипотезы) равна:
Отсюда следует, что левая критическая граница и правая критическая граница (рис. 5.3) равны соответственно:
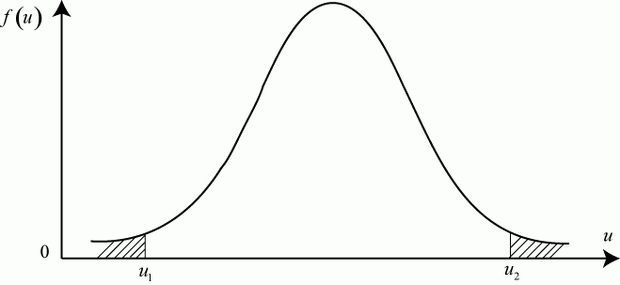
Рис. 5.3. Левая и правая критические границы функции /(и) Значение t _{\alpha }определяется так:
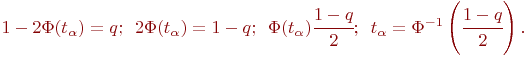
![]() - функция Лапласа, с которой мы встречались ранее, она табулирована. Наиболее актуальные соответствия уровней значимости
- функция Лапласа, с которой мы встречались ранее, она табулирована. Наиболее актуальные соответствия уровней значимости ![]() и аргументов функции Лапласа
и аргументов функции Лапласа ![]() указаны в табл. 5.4
указаны в табл. 5.4
Пример 5.4. С целью проверки адекватности модели центра коммутации сообщений измерено время задержки передачи сообщений на модели центра и непосредственно на самом центре. Результаты измерений сведены в табл. 5.5.
| | 0,8 | 1,9 | 3,0 | 3,5 | 3,8 | 2,5 | 1,7 | 0,9 | 1,0 | 2,3 |
|---|---|---|---|---|---|---|---|---|---|---|
| | 1,4 | 2,1 | 3,1 | 3,6 | 2,7 | 1,8 | 1,1 | 0,2 | 1,6 | 2,8 |
Последовательность ![]() - отклики модели,
- отклики модели, ![]() - данные, измеренные на центре. Проверка адекватности модели состоит в проверке нулевой гипотезы, то есть в том, что данные измерений идентичны в статистическом смысле. Решение
- данные, измеренные на центре. Проверка адекватности модели состоит в проверке нулевой гипотезы, то есть в том, что данные измерений идентичны в статистическом смысле. Решение
Составим в порядке возрастания общую последовательность времен задержек ![]() и
и ![]() (табл. 5.6).
(табл. 5.6).
| | | | | | | | | | |
|---|---|---|---|---|---|---|---|---|---|
| 0,2 | 0,8 | 0,9 | 1,0 | 1,1 | 1,4 | 1,6 | 1,7 | 1,8 | 1,9 |
| | | | | | | | | | |
| 2,1 | 2,3 | 2,5 | 2,7 | 2,8 | 3,0 | 3,1 | 3,5 | 3,6 | 3,8 |
Расчет числа инверсий для ![]() :
:
Расчет характеристик:

Примем уровень значимости ![]() . Тогда
. Тогда ![]()
Правая критическая точка:
Левая критическая точка:
Проверка гипотезы ![]() :
:
Гипотеза об идентичности распределений времен ожиданий в модели и в объекте не опровергается.
В заключение отметим, что при малых ![]() и
и ![]() (
( ![]() ) для критерия Вилькоксона составлены таблицы критических точек
) для критерия Вилькоксона составлены таблицы критических точек ![]() и
и ![]() для различных уровней значимости
для различных уровней значимости ![]() . Эти таблицы приводятся в широко известных изданиях, например, Б. Л. ван дер Варден "Математическая статистика", Б. В. Гнеденко и др. "Математические методы в теории надежности".
. Эти таблицы приводятся в широко известных изданиях, например, Б. Л. ван дер Варден "Математическая статистика", Б. В. Гнеденко и др. "Математические методы в теории надежности".
5.7. Однофакторный дисперсионный анализ
В современной жизни - военной и гражданской часто возникают проблемы, решение которых требует научного обоснования.
Однотипны ли патроны для конкретного образца стрелкового вооружения, выпускаемые на разных заводах?
Однородны ли, например, автоматы, выпускаемые на разных заводах?
Здесь в качестве исследуемого фактора выступают заводы. Разные, но однотипные по назначению - варианты фактора, которые можно трактовать как уровни факторов.
Аналогичная задача возникает при сравнении однотипных изделий, вырабатываемых с применением различных технологий. Здесь подлежит анализу фактор - технология производства.
Эти и подобные задачи являются задачами однофакторного дисперсионного анализа (ОДА).
Иногда возможны задачи одновременного исследования влияния двух и более факторов. Например, чем объяснить рассеивание попаданий в цель: конструкторскими особенностями стрелкового вооружения, выпущенного на разных заводах, или различиями в подготовке стрелков?
Исследованием влияния факторов и занимается факторный дисперсионный анализ.
Мы рассмотрим ОДА, наиболее актуальный анализ на практике. Теория рассматривает и многофакторный дисперсионный анализ. В нем процедуры подобны тем, которые мы рассмотрим в ОДА. Усложняются только расчеты и при необходимости, зная ОДА, овладеть методикой многофакторного дисперсионного анализа, не составит труда.
Эксперимент для выполнения ОДА состоит в накоплении результатов измерений контролируемого параметра (угла, расстояния, наработки на отказ некоторого изделия и т. д.) при каждом варианте исследуемого фактора.
Введем обозначения:
![]() - число вариантов фактора;
- число вариантов фактора;
![]() - число измерений при каждом варианте;
- число измерений при каждом варианте;
![]() - результат каждого измерения;
- результат каждого измерения;
![]() - номер варианта фактора;
- номер варианта фактора;
![]() - номер измерения.
- номер измерения.
Схема эксперимента заключается в следующем.
Производится ![]() измерений контролируемого параметра при
измерений контролируемого параметра при ![]() вариантах фактора.
вариантах фактора.
В принципе, число измерений может быть разным для каждого варианта фактора. Ход дальнейших рассуждений от этого не меняется.
Результаты эксперимента сводятся в таблицу (табл. 5.7).
Вопрос: влияют ли варианты фактора на точность измерений? Или, говоря языком математической статистики, являются результаты ![]() измерений выборкой одной генеральной совокупности, или нет? Если да, то варианты фактора несущественны, если нет, то существенны.
измерений выборкой одной генеральной совокупности, или нет? Если да, то варианты фактора несущественны, если нет, то существенны.
Будем исходить из следующей нулевой гипотезы:
- наблюдения каждого варианта независимы;
- наблюдения каждого варианта имеют нормальное распределение;
- имеют одинаковую дисперсию
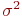 ;
; - имеют одинаковые центры рассеивания.
Очевидно, если систематические ошибки вариантов не одинаковы, следует ожидать повышенного рассеивания выборочных средних ![]() .
.
Для подтверждения или отрицания выдвинутой нулевой гипотезы об идентичности вариантов фактора проведем дисперсионный анализ.
Общее среднее арифметическое по всем ![]() измерениям:
измерениям:
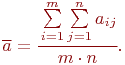
Сумма квадратов отклонений по всем ![]() измерений, то есть по данным всего эксперимента:
измерений, то есть по данным всего эксперимента:
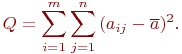
Эту сумму квадратов отклонений можно разложить на два независимых слагаемых:
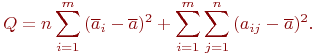
Обозначим:
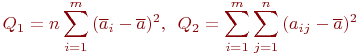
Что такое ![]() и
и ![]()
![]() - сумма квадратов отклонений между вариантами фактора, так как
- сумма квадратов отклонений между вариантами фактора, так как ![]() - среднее значение измеренного параметра
- среднее значение измеренного параметра ![]() -го варианта фактора;
-го варианта фактора;
![]() - характеризует отклонения внутри каждого варианта.
- характеризует отклонения внутри каждого варианта.
Если принятая гипотеза о равенстве центров рассеивания ![]() и дисперсий
и дисперсий ![]() верна, тогда все
верна, тогда все ![]() наблюдений значений
наблюдений значений ![]() можно рассматривать как выборку из одной и той же нормальной совокупности с очевидной несмещенной оценкой дисперсии:
можно рассматривать как выборку из одной и той же нормальной совокупности с очевидной несмещенной оценкой дисперсии:
Можно показать, что величина
имеющая распределение ![]() со степенями свободы
со степенями свободы ![]() , является оценкой дисперсии
, является оценкой дисперсии ![]()
И величина
имеющая распределение ![]() со степенями свободы
со степенями свободы ![]() , также является оценкой дисперсии
, также является оценкой дисперсии ![]() .
.
Из сказанного следует, что критерий
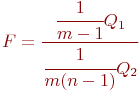
при нашей гипотезе и независимости ![]() и
и ![]() (это можно доказать) имеет F -распределение с
(это можно доказать) имеет F -распределение с ![]() и
и ![]() степенями свободы.
степенями свободы.
А дальше мы уже знаем, как поступить:
- выбираем уровень значимости
 ;
; - вычисляем число
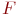 ;
; - из таблицы по величине
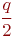 находим
находим 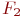 .
.
Если окажется
то есть мы попали в область маловероятных значений ![]() , то выдвинутая гипотеза не подтверждается.А это значит, что варианты фактора не однотипны. Но если
, то выдвинутая гипотеза не подтверждается.А это значит, что варианты фактора не однотипны. Но если
то гипотеза об однородности вариантов фактора подтверждается, конечно, в рамках допустимого риска.
Пример 5.5. Необходимо проверить однотипность патронов к автомату Калашникова, изготовленных на трех заводах.
Для получения необходимых для дисперсионного анализа данных автомат закрепили в специальном станке и сделали из него по 50 выстрелов патронами каждого завода. По результатам стрельбы измерялись радиальные отклонения пробоин от точки прицеливания.
Результаты измерений приведены в табл. 5.8.
| Заводы | Эксперименты и отклонения, см | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | … | 26 | 27 | … | 49 | 50 | |
| № 1 | 3 | 2 | 1 | … | 4 | 3 | … | 1 | 3 |
| № 2 | 2 | 0 | 4 | … | 3 | 2 | … | 2 | 3 |
| № 3 | 2 | 3 | 3 | … | 1 | 0 | … | 1 | 5 |
Решение
Проверяем исходную гипотезу: патроны, выпускаемые на трех разных заводах, баллистически однотипны.
При выборе уровня значимости ![]() исходим из того, что более опасна ошибка второго рода - подтвердить ошибочный выбор. Примем
исходим из того, что более опасна ошибка второго рода - подтвердить ошибочный выбор. Примем ![]() .
.
Число вариантов фактора: ![]()
Число измерений: ![]() .
.
При вычислениях опустим очевидные элементарные арифметические детали.
Средние отклонения пробоин при стрельбе патронами заводов № 1, № 2, № 3 равны соответственно:
Среднее отклонение по 150 выстрелам:
Средний квадрат расхождений между вариантами факторов:
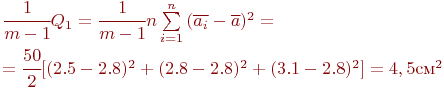
Число степеней свободы: ![]() .
.
Средний квадрат расхождений внутри вариантов:
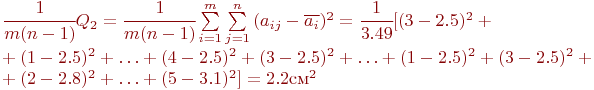
Число степеней свободы:
Расчет F -критерия:
По табл. П.2 при ![]() верхних пределов уклонения величины
верхних пределов уклонения величины ![]() и имеющихся степенях свободы 2 и 147 находим
и имеющихся степенях свободы 2 и 147 находим ![]() . Величина
. Величина ![]() определена при
определена при ![]() , так как табличные значения при
, так как табличные значения при ![]() не определены. Нетрудно убедиться, что такое приближение вполне допустимо.
не определены. Нетрудно убедиться, что такое приближение вполне допустимо.
Поскольку ![]() , делаем вывод о том, что выдвинутая гипотеза об однотипности партий патронов, выпускаемых тремя разными заводами, не опровергается (в пределах принятого уровня значимости).
, делаем вывод о том, что выдвинутая гипотеза об однотипности партий патронов, выпускаемых тремя разными заводами, не опровергается (в пределах принятого уровня значимости).
5.8. Выявление несущественных факторов
Большое количество факторов усложняет и снижает эффективность эксперимента. Среди этого множества могут быть и несущественные факторы. Исключение их упростило бы эксперимент, не снижая его информативности.
Несущественный фактор выявляется так.
Выполняются первый эксперимент из ![]() наблюдений с учетом проверяемого фактора и второй эксперимент также из
наблюдений с учетом проверяемого фактора и второй эксперимент также из ![]() наблюдений - без него. В обоих случаях фиксируются отклики
наблюдений - без него. В обоих случаях фиксируются отклики ![]() . Делается предположение, что обе выборки принадлежат одной генеральной совокупности, то есть, что проверяемый фактор - несущественный (это нулевая гипотеза). Дальнейшие рассуждения должны либо не опровергнуть эту гипотезу, либо посчитать ее недостаточно обоснованной.
. Делается предположение, что обе выборки принадлежат одной генеральной совокупности, то есть, что проверяемый фактор - несущественный (это нулевая гипотеза). Дальнейшие рассуждения должны либо не опровергнуть эту гипотезу, либо посчитать ее недостаточно обоснованной.
Итак, получены две последовательности откликов, в которой ![]() и
и ![]() - значения откликов в
- значения откликов в ![]() -м наблюдении при наличии и отсутствии проверяемого фактора соответственно:
-м наблюдении при наличии и отсутствии проверяемого фактора соответственно:
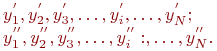
Согласно принятой гипотезе эти последовательности имеют одинаковые матожидания ![]() и дисперсии
и дисперсии ![]() .
.
Рассмотрим случайную величину ![]() , реализациями которой является последовательность случайных чисел
, реализациями которой является последовательность случайных чисел
При независимости ![]() и достаточно большом числе наблюдений
и достаточно большом числе наблюдений ![]() согласно центральной предельной теореме:
согласно центральной предельной теореме:
Очевидно:
Как отделить случайные отклонения ![]() от нуля от тех, которые мы будем считать не подтверждающими принятую гипотезу?
от нуля от тех, которые мы будем считать не подтверждающими принятую гипотезу?
Такое разделение осуществляется по следующему правилу: если вычисленная величина ![]() окажется маловероятной, в рамках нормального распределения и данном среднеквадратическом отклонении
окажется маловероятной, в рамках нормального распределения и данном среднеквадратическом отклонении ![]() , то такое отклонение
, то такое отклонение ![]() от нуля считается не соответствующим принятой гипотезе.
от нуля считается не соответствующим принятой гипотезе.
Эту малую вероятность называют уровнем значимости и обозначают ![]() . Обычно
. Обычно ![]() - в зависимости от степени опасности совершения ошибки первого или второго рода.
- в зависимости от степени опасности совершения ошибки первого или второго рода.
На графике плотности распределения ![]() уровень значимости
уровень значимости ![]() показан заштрихованным участком (рис. 5.4).
показан заштрихованным участком (рис. 5.4).
Для нормального закона распределения случайной величины ![]() вероятность превышения
вероятность превышения ![]() некоторого значения определяется известным выражением:
некоторого значения определяется известным выражением:
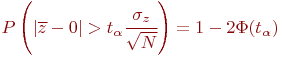
где ![]() - функция Лапласа.
- функция Лапласа.
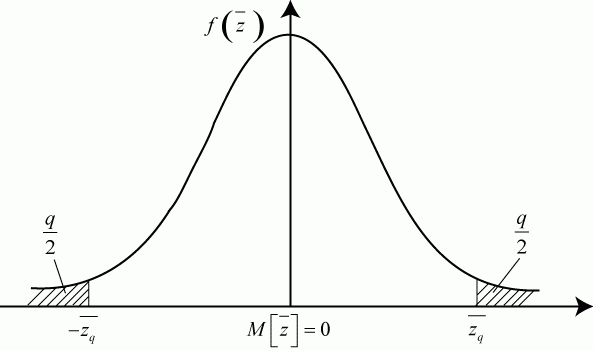
Рис. 5.4. Плотность распределения функции f(z) Следовательно:
- граничное значение
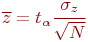
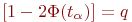
Аргумент функции Лапласа ![]() находим из соответствующего справочника согласно
находим из соответствующего справочника согласно 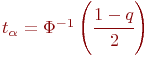 и, как было указано ранее,
и, как было указано ранее, ![]()
Из изложенного следует:
- если
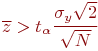 , принятая гипотеза о несущественности проверяемого фактора не подтверждается;
, принятая гипотеза о несущественности проверяемого фактора не подтверждается; - если
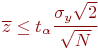 , принятая гипотеза не опровергается (в рамках принятого уровня значимости ).
, принятая гипотеза не опровергается (в рамках принятого уровня значимости ).
Обычно величина ![]() неизвестна, поэтому следует использовать ее оценку
неизвестна, поэтому следует использовать ее оценку ![]() :
:
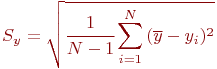
Оценку ![]() и ряд значений
и ряд значений ![]() можно получить из данных первого эксперимента (
можно получить из данных первого эксперимента ( ![]() ) или второго (
) или второго ( ![]() ), так как в силу рассматриваемой гипотезы они идентичны. Однако следует помнить, что если
), так как в силу рассматриваемой гипотезы они идентичны. Однако следует помнить, что если ![]() то вместо аргумента функции Лапласа
то вместо аргумента функции Лапласа ![]() надо брать
надо брать ![]() - аргумент функции Стьюдента.
- аргумент функции Стьюдента.
Пример 5.6. Исследуется зависимость времени пребывания заявки в системе массового обслуживания от дисциплины выборки заявок из очереди: LIFO или FIFO. Проведены два эксперимента. Первый эксперимент из ![]() наблюдений с дисциплиной FIFO и второй эксперимент также из
наблюдений с дисциплиной FIFO и второй эксперимент также из ![]() наблюдений с дисциплиной LIFO.
наблюдений с дисциплиной LIFO.
Решение
Выдвигается гипотеза о несущественности влияния на время пребывания заявки в системе массового обслуживания изменения дисциплины FIFO на LIFO.
Результаты измерений и вычислений:
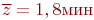 ,
, 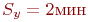 ;
;- для уровня значимости
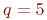 ,
, 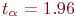
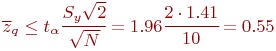
Так как ![]() то гипотеза не подтверждается. Для времени пребывания заявки в очереди в системе массового обслуживания не безразлично, какая дисциплина выборки заявок из очереди применена.
то гипотеза не подтверждается. Для времени пребывания заявки в очереди в системе массового обслуживания не безразлично, какая дисциплина выборки заявок из очереди применена.
В заключение отметим, что рассмотренную проблему можно решать и методом однофакторного анализа. Однако если ![]() (при сравнении двух выборок) целесообразно использовать изложенный метод.
(при сравнении двух выборок) целесообразно использовать изложенный метод.
5.9. Сущность корреляционного анализа
Часто при исследовании объекта или его модели необходимо наблюдать за характеристиками двух и более случайных величин. Например, за двумя откликами одного эксперимента. При этом может возникнуть вопрос: есть ли связь между этими случайными величинами? Существенна или несущественна эта связь, если она есть?
Корреляционный анализ - это совокупность методов обнаружения зависимости (корреляции) между двумя или более случайными признаками или процессами.
Под корреляцией будем понимать статистическую зависимость между двумя случайными величинами, не имеющую, вообще говоря, строго функционального характера.
Заметим, что корреляционный анализ не позволяет определить вид функциональной связи между случайными величинами, а только наличие или отсутствие предполагаемой связи, например, линейной, параболической, экспоненциальной и т. д. В рамках этого учебного пособия мы ограничимся рассмотрением гипотезы о наличии линейной корреляции.
Определение вида функциональной связи между величинами рассматривается в регрессионном анализе, элементы которого и практическое использование будут рассмотрены в следующем п. 5.10.
Название "корреляционный анализ" происходит от латинского слова correlatio - согласование, связь, соотношение, взаимосвязь. Термин впервые введен Гальтоном (Galton) в 1888 г.
Обычно исследуют парную корреляцию, то есть зависимость между двумя случайными величинами (процессами), хотя возможны и более сложные ситуации, когда необходимо обнаружить наличие или отсутствие связей между тремя или более случайными величинами.
Мы ограничимся исследованием парной корреляции.
Как известно, связь между двумя случайными величинами можно описать с помощью двумерной функции распределения. Однако такое описание часто очень сложно, а для практических целей можно удовлетвориться определением зависимостей средних значений.
Итак, целью имитационного эксперимента является определение характеристик двух случайных величин ![]() и
и ![]() . Например:
. Например:
| | |
|---|---|
| Средний балл успеваемости учебной группы по математике | Средний балл выполнения упражнения по стрельбе |
| Рассеивание точки падения заряда по дальности | Рассеивание точки падения заряда по боковому отклонению |
| Вес курсантов (студентов). | Успеваемость по физподготовке. |
Необходимо проверить: есть ли связь между величинами ![]() и
и ![]() ?
?
Проверка наличия (или отсутствия) связи - корреляции - между случайными величинами выполняется так.
Проводится два эксперимента, каждый - с соответствующей моделью. В каждом эксперименте - ![]() наблюдений (напоминаем, что компьютерный эксперимент состоит из наблюдений, а наблюдение - из реализаций (прогонов) модели, число которых рассчитывается с учетом требуемой точности и достоверности получаемых результатов моделирования). В результате экспериментов получаются два множества значений измеряемых параметров
наблюдений (напоминаем, что компьютерный эксперимент состоит из наблюдений, а наблюдение - из реализаций (прогонов) модели, число которых рассчитывается с учетом требуемой точности и достоверности получаемых результатов моделирования). В результате экспериментов получаются два множества значений измеряемых параметров ![]() и
и ![]() :
: ![]() и
и ![]() ,
, ![]() .
.
Из этих множеств формируются пары:
Каждая пара интерпретируется как координаты случайной точки в системе координат ![]() ,
, ![]() .
.
Первичное исследование можно провести графически. Возможны следующие варианты размещения точек на графиках (рис. 5.5).
Корреляция - важное понятие. Научитесь визуально определять по расположению данных, насколько тесно они коррелированны.
Говорят, что две переменные положительно коррелированны, если при увеличении значений одной переменной увеличиваются значения другой переменной (рис. 5.5б).
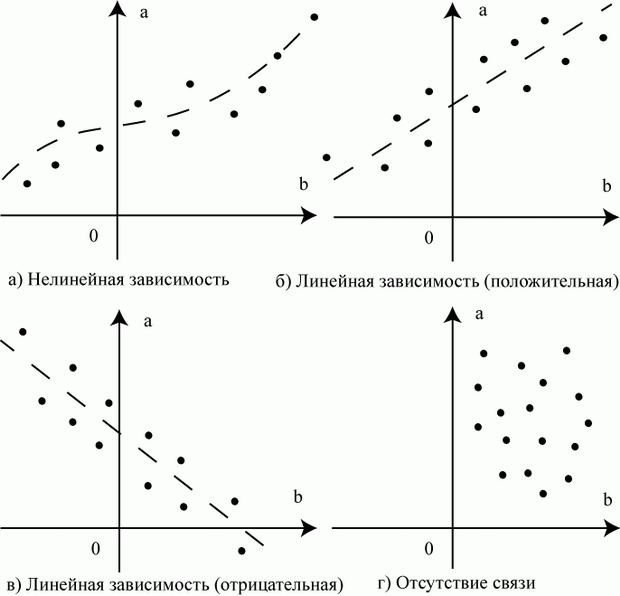
Рис. 5.5. Графическое исследование корреляции
Две переменные отрицательно коррелированны, если при увеличении одной переменной другая переменная уменьшается (рис. 5.5в).
Отсутствие корреляции - совместного поведения переменных - обнаруживается хаотическим нагромождением точек, исключающим проведение какой-либо аппроксимирующей линии (см. рис. 5.5г).
Но такое качественное исследование недостаточно. Необходимо иметь количественную оценку степени корреляции между величинами ![]() и
и ![]() .
.
Если совместное распределение вероятностей случайных величин ![]() и
и ![]() нормальное, то количественной характеристикой степени линейной связи между ними является коэффициент корреляции r (введен Пирсоном (Pearson), 1896 г.):
нормальное, то количественной характеристикой степени линейной связи между ними является коэффициент корреляции r (введен Пирсоном (Pearson), 1896 г.):
Если ![]() , то между
, то между ![]() и
и ![]() линейная независимость.
линейная независимость.
Равенство ![]() свидетельствует о наличии однозначной функциональной связи между
свидетельствует о наличии однозначной функциональной связи между ![]() и
и ![]() , то есть
, то есть ![]() .
.
При ![]() между
между ![]() и
и ![]() существует стохастическая связь, причем, чем ближе коэффициент корреляции
существует стохастическая связь, причем, чем ближе коэффициент корреляции ![]() к единице, тем эта связь сильнее. Стохастическая связь означает, что при изменении
к единице, тем эта связь сильнее. Стохастическая связь означает, что при изменении ![]() имеется лишь тенденция к изменению
имеется лишь тенденция к изменению ![]() .
.
Коэффициент корреляции ![]() определяется по данным эксперимента, следовательно, можно определить только его оценку
определяется по данным эксперимента, следовательно, можно определить только его оценку ![]() . В качестве оценки
. В качестве оценки ![]() принят выборочный коэффициент корреляции:
принят выборочный коэффициент корреляции:
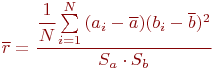
где ![]() оценки математических ожиданий и
оценки математических ожиданий и ![]() и
и ![]() ;
;
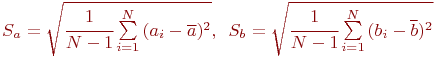 - оценки среднеквадратических отклонений
- оценки среднеквадратических отклонений ![]() и
и ![]()
Выборочный коэффициент корреляции ![]() , так же как и теоретический, принимает значения:
, так же как и теоретический, принимает значения: ![]() .
.
Если ![]() , то наблюдается положительная корреляция (см. рис. 5.5б). Если
, то наблюдается положительная корреляция (см. рис. 5.5б). Если ![]() - отрицательная корреляция (см. рис. 5.5в). Если
- отрицательная корреляция (см. рис. 5.5в). Если ![]() - линейная корреляция отсутствует (но не исключена нелинейная). Если
- линейная корреляция отсутствует (но не исключена нелинейная). Если ![]() , то между случайными величинами существует жесткая функциональная связь.
, то между случайными величинами существует жесткая функциональная связь.
Заметим, что рассматриваемый коэффициент корреляции ![]() определяет степень линейной связи между случайными величинами
определяет степень линейной связи между случайными величинами ![]() и
и ![]() . Эта корреляция наиболее популярна, поэтому часто, когда говорят о корреляции, имеют в виду именно корреляцию Пирсона.
. Эта корреляция наиболее популярна, поэтому часто, когда говорят о корреляции, имеют в виду именно корреляцию Пирсона.
Однако этот линейный коэффициент корреляции не является пригодным для оценки нелинейной связи, если таковая присутствует. При нелинейной зависимости степень связи между случайными величинами устанавливается более сложными характеристиками, например, корреляционным отношением (К. Пирсон).
Числитель выражения (5.1) иногда называют ковариацией - ![]() .
.
Если случайные величины ![]() и
и ![]() независимы, они и не коррелированны
независимы, они и не коррелированны ![]() . Но некоррелированность
. Но некоррелированность ![]() и
и ![]() не всегда свидетельствует об их независимости. Но если
не всегда свидетельствует об их независимости. Но если ![]() и
и ![]() имеют нормальное распределение, то условие
имеют нормальное распределение, то условие ![]() является необходимым и достаточным условием независимости этих величин.
является необходимым и достаточным условием независимости этих величин.
И еще. Наличие корреляции между случайными величинами ![]() и
и ![]() не всегда свидетельствует об их взаимосвязи. Дело в том, что при независимости
не всегда свидетельствует об их взаимосвязи. Дело в том, что при независимости ![]() и
и ![]() каждая из них в отдельности зависит от некоторого случайного фактора
каждая из них в отдельности зависит от некоторого случайного фактора ![]() , но эта зависимость нами не замечена.
, но эта зависимость нами не замечена.
Поэтому хорошим тоном после вычисления корреляций является построение диаграмм рассеяния, которые позволяют понять, действительно ли между двумя исследуемыми переменными имеется связь.
Оценка коэффициента корреляции должна быть определена с требуемыми точностью и достоверностью, которые зависят от числа реализаций модели. Найдем эту связь.
В предположении нормальности распределения ![]() можно написать:
можно написать:
С выражение (5.2) мы уже знакомы. Здесь:
![]() - точное значение коэффициента корреляции;
- точное значение коэффициента корреляции;
![]() - среднеквадратическое отклонение случайной величины
- среднеквадратическое отклонение случайной величины ![]() ;
;
![]() - аргумент функции Лапласа
- аргумент функции Лапласа ![]()
Обычно среднеквадратическое отклонение ![]() неизвестно, поэтому нужно брать ее оценку.
неизвестно, поэтому нужно брать ее оценку.
При больших выборках ![]() оценка среднеквадратического отклонения
оценка среднеквадратического отклонения ![]() :
:
Из (5.2) следует:
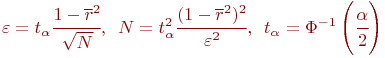
![]() - абсолютная величина ошибки.
- абсолютная величина ошибки.
Предварительное определение ![]() осуществляется по данным пробного эксперимента в количестве
осуществляется по данным пробного эксперимента в количестве ![]() реализаций модели.
реализаций модели.
На основании изложенного и в силу случайного характера исследуемых величин ![]() и
и ![]() мы можем утверждать лишь следующее: истинное значение коэффициента корреляции
мы можем утверждать лишь следующее: истинное значение коэффициента корреляции ![]() лежит в пределах
лежит в пределах
с заданной достоверностью ![]() .
.
В заключение отметим, что если совместное распределение случайных величин ![]() и
и ![]() не является нормальным, то оценка
не является нормальным, то оценка ![]() коэффициента корреляции может выступать в качестве ориентировочной оценки степени тесноты связи
коэффициента корреляции может выступать в качестве ориентировочной оценки степени тесноты связи ![]() и
и ![]() .
.
Пример 5.7 [2]. Для оценки конструкции нового крупнокалиберного пулемета было произведено 96 выстрелов по щиту, отстоявшему на расстоянии 300 метров.
Результаты отклонений попаданий от точки прицеливания (боковые ![]() , по высоте
, по высоте ![]() ) объединены в десятисантиметровые диапазоны и сведены в таблицу (табл. 5.9).
) объединены в десятисантиметровые диапазоны и сведены в таблицу (табл. 5.9).
Для оценки конструктивных особенностей пулемета необходимо узнать: есть ли какая-то связь между боковыми отклонениями и отклонениями по высоте.
Решение
Ответ на поставленный вопрос может дать коэффициент корреляции. Предварительно заметим, что группировка измерений в десятисантиметровые диапазоны вносит некоторую ошибку в дальнейшие расчеты, однако можно показать, что при данной группировке ошибка несущественна.
В табл. 5.9 указаны не реальные отклонения, а центры диапазонов (-25…-15, -15…-5, -5…5 и т. д.).
| | Боковые отклонения | Всего | ||||||
|---|---|---|---|---|---|---|---|---|
| -20 | -10 | 0 | 10 | 20 | 30 | 40 | ||
| -50 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 3 |
| -40 | 0 | 1 | 1 | 1 | 2 | 0 | 0 | 5 |
| -30 | 1 | 1 | 3 | 5 | 2 | 1 | 0 | 13 |
| -20 | 1 | 3 | 7 | 3 | 2 | 2 | 0 | 18 |
| -10 | 0 | 2 | 6 | 10 | 3 | 0 | 0 | 21 |
| 0 | 0 | 1 | 6 | 6 | 6 | 1 | 1 | 21 |
| 10 | 0 | 0 | 3 | 3 | 3 | 1 | 0 | 10 |
| 20 | 0 | 1 | 1 | 2 | 1 | 0 | 0 | 5 |
| Всего | 2 | 9 | 28 | 30 | 21 | 5 | 1 | 96 |
Для определения коэффициента корреляции понадобятся следующие характеристики:
![]() , ковариация
, ковариация ![]() .
.
Все эти характеристики вычисляются по данным измеренных отклонений боковых ![]() и по высоте
и по высоте ![]() .
.
Для примера, расчет ![]() :
:
Результаты расчета остальных характеристик:
Теперь оценка коэффициента корреляции:
Среднеквадратическое отклонение этой оценки:
Из-за малого количества выстрелов оценка ![]() определена с ошибкой, которая в предположении о нормальном распределении случайной величины
определена с ошибкой, которая в предположении о нормальном распределении случайной величины ![]() и достоверности, например,
и достоверности, например, ![]() (
( ![]() ) равна:
) равна:
Отсюда следует, что истинное значение коэффициента корреляции ![]() лежит в пределах:
лежит в пределах:
Обнаружена небольшая линейная зависимость отклонений боковых и по высоте. Баллистики, отвергая непосредственную корреляцию между отклонениями ![]() и
и ![]() , объясняют значение
, объясняют значение ![]() влиянием конструктивных особенностей пулемета. Обнаружена также систематическая ошибка в прицеле:
влиянием конструктивных особенностей пулемета. Обнаружена также систематическая ошибка в прицеле: ![]() ,
, ![]() .
.
5.10. Обработка результатов эксперимента на основе регрессии
Часто целью исследования является определение функциональной связи между факторами и откликом (реакцией модели) по данным, полученным при экспериментах с моделью объекта или непосредственно с объектом. Такая цель достигается регрессионным анализом значений факторов ![]() и отклика
и отклика ![]() .
.
Под регрессией в теории вероятностей и математической статистике понимают зависимость среднего значения какой-либо величины от некоторой другой (других) величины. Регрессионный анализ - это совокупность методов построения и исследования регрессионной зависимости между величинами (в нашем случае между факторами и откликом) по статистическим данным. Статистические данные накапливаются при проведении эксперимента.
Формальная схема эксперимента выглядит так (рис. 5.6).
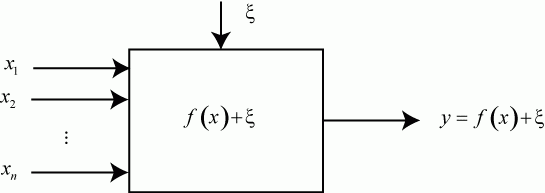
Рис. 5.6. Формальная схема эксперимента
Прямоугольник представляет исследуемый объект или его математическую модель. Обозначения на рис. 5.6:
![]() - значения факторов,
- значения факторов, ![]() ;
;
![]() - случайный фактор, помеха. Будем считать, что эта случайная величина имеет нормальное распределение с матожиданием
- случайный фактор, помеха. Будем считать, что эта случайная величина имеет нормальное распределение с матожиданием ![]() . Влияние помехи на отклик аддитивное, то есть ее случайные значения прибавляются к значениям отклика;
. Влияние помехи на отклик аддитивное, то есть ее случайные значения прибавляются к значениям отклика;
![]() - искомая функциональная зависимость между факторами и откликом.
- искомая функциональная зависимость между факторами и откликом.
Отклик ![]() - величина случайная.
- величина случайная. ![]() представляет собой среднее значение отклика (так как
представляет собой среднее значение отклика (так как ![]() ):
): ![]() .
.
Исследуемый объект представляется как "черный ящик", никаких предположений о виде функции ![]() нет. Поэтому представим ее в виде аппроксимирующего полинома:
нет. Поэтому представим ее в виде аппроксимирующего полинома:
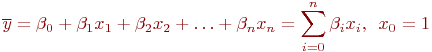
Этот полином получил название уравнения регрессии, а коэффициенты ![]() - коэффициенты регрессии. От точности подбора коэффициентов регрессии зависит точность представления
- коэффициенты регрессии. От точности подбора коэффициентов регрессии зависит точность представления ![]() .
.
Коэффициенты ![]() определяются путем обработки полученных в ходе эксперимента варьируемых значений факторов и откликов.
определяются путем обработки полученных в ходе эксперимента варьируемых значений факторов и откликов.
Однако из-за ограниченного числа наблюдений точные значения ![]() получить нельзя, будут найдены их оценки
получить нельзя, будут найдены их оценки ![]() :
:
Поэтому уравнение регрессии принимает вид:
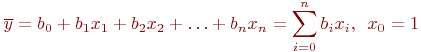
Вообще-то метку над ![]() теперь надо бы изменить, так как вместо
теперь надо бы изменить, так как вместо ![]() в уравнении теперь стоят
в уравнении теперь стоят ![]() , но мы этого делать не будем, чтобы не загромождать изложение новыми значками.
, но мы этого делать не будем, чтобы не загромождать изложение новыми значками.
В уравнении регрессии могут участвовать и так называемые "совместные эффекты" ( ![]() и т. п.) или степени значений факторов (
и т. п.) или степени значений факторов ( ![]() и т. п.). Совместные эффекты и степени факторов можно обозначать обобщенным фактором. Например, уравнение регрессии
и т. п.). Совместные эффекты и степени факторов можно обозначать обобщенным фактором. Например, уравнение регрессии
можно представить так:
Итак, для определения выражения ![]() надо:
надо:
- выбрать степень аппроксимирующего полинома - уравнения регрессии;
- определить коэффициенты регрессии.
Выбор уравнения регрессии обычно начинают с линейной модели. Например, для двухфакторного эксперимента ее вид:
Если окажется, что такая аппроксимация дает неприемлемые отклонения при сравнении с экспериментальными точками отклика y , то модель усложняется, например, так:
![]() или
или
![]() и т.д.
и т.д.
Коэффициенты регрессии ![]() для выбранного уравнения определяются из условия минимума суммы квадратов ошибок, вычисленных по все экспериментальным точкам. Это делается так. Введем обозначения:
для выбранного уравнения определяются из условия минимума суммы квадратов ошибок, вычисленных по все экспериментальным точкам. Это делается так. Введем обозначения:
![]() - значение
- значение ![]() -го фактора в наблюдении номер
-го фактора в наблюдении номер ![]() ;
;
![]() - значение отклика в
- значение отклика в ![]() -м наблюдении;
-м наблюдении;
![]() - значение отклика, вычисленное по принятому уравнению регрессии и данным
- значение отклика, вычисленное по принятому уравнению регрессии и данным ![]() .
.
Очевидно, сумма квадратов ошибок между экспериментальными значениями ![]() и вычисленными по уравнению регрессии
и вычисленными по уравнению регрессии ![]() для всех
для всех ![]() наблюдений равна:
наблюдений равна:
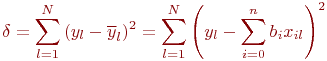
Для определения минимума ошибки ?возьмем частные производные от ![]() по всем неизвестным коэффициентам регрессии
по всем неизвестным коэффициентам регрессии ![]() ,
, ![]() и приравняем их нулю:
и приравняем их нулю:
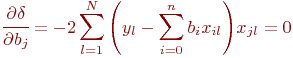
Нетрудно убедиться, что это условие минимума, а не максимума. Очевидно:
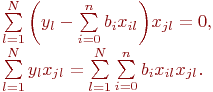
Для лучшей наглядности выделим неизвестные коэффициенты регрессии и получим:
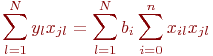
Выражение (5.3) представляет собой систему из ![]() уравнений для нахождения
уравнений для нахождения ![]() неизвестных коэффициентов регрессии
неизвестных коэффициентов регрессии ![]() , которые окончательно определят выбранное уравнение регрессии.
, которые окончательно определят выбранное уравнение регрессии.
Нахождение коэффициентов регрессии справедливо при следующих допущениях:
- Случайный фактор
 имеет нормальное распределение с матожиданием
имеет нормальное распределение с матожиданием 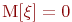 .
. - Результаты наблюдений
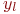 - независимые нормально распределенные случайные величины. Если это не соблюдается, то следует измерять другой отклик, удовлетворяющий этому условию, но функционально связанный с исследуемым откликом
- независимые нормально распределенные случайные величины. Если это не соблюдается, то следует измерять другой отклик, удовлетворяющий этому условию, но функционально связанный с исследуемым откликом 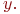
- Точность наблюдений (количество реализаций модели) не меняется от наблюдения к наблюдению.
- Точность наблюдения
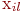 должна быть выше точности
должна быть выше точности 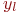 .
.
Пример 5.8. На модели объекта проведен однофакторный эксперимент из пяти наблюдений, результаты которого сведены в таблицу (табл. 5.10).
Найти функциональную связь фактора с откликом ![]()
| Фактор и отклики | Наблюдение | | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 0 | 0,5 | 1,0 | 1,5 | 2,0 | 5 | |
| 7,0 | 4,8 | 2,8 | 1,4 | 0 | 16 | |
| 0 | 2,4 | 2,8 | 2,1 | 0 | 7,3 | |
Решение
Примем, что кроме управляемого фактора ![]() при проведении эксперимента на объект воздействует случайный фактор, распределенный по нормальному закону с математическим ожиданием
при проведении эксперимента на объект воздействует случайный фактор, распределенный по нормальному закону с математическим ожиданием ![]() . Также предположим, что эта связь - линейная, следовательно, уравнение регрессии нужно определять в виде:
. Также предположим, что эта связь - линейная, следовательно, уравнение регрессии нужно определять в виде:
Неизвестных коэффициентов два: ![]() и
и ![]() . Запишем (5.3) в виде двух уравнений для
. Запишем (5.3) в виде двух уравнений для ![]() и в каждом из них разложим суммы по индексу
и в каждом из них разложим суммы по индексу ![]() :
:
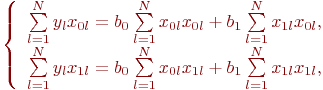
Так как ![]() , получим:
, получим:
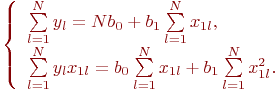
Подставим данные эксперимента из табл. 5.10 в систему (5.4):
Решим систему из двух уравнений и получим: ![]() ,
, ![]() .
.
Следовательно, искомое уравнение регрессии:
Доверительные границы для истинных значений ![]() и
и ![]() примера 5.8 определяются как обычно:
примера 5.8 определяются как обычно:
где ![]() - аргумент распределения Стьюдента;
- аргумент распределения Стьюдента; ![]() - среднеквадратические отклонения величин
- среднеквадратические отклонения величин ![]() и
и ![]() соответственно.
соответственно.
Значения ![]() определяются из таблицы распределения Стьюдента для
определяются из таблицы распределения Стьюдента для ![]() степеней свободы и задаваемом уровне достоверности
степеней свободы и задаваемом уровне достоверности ![]() . Пусть
. Пусть ![]() , тогда
, тогда ![]() .
.
Значения ![]() находятся по формулам:
находятся по формулам:
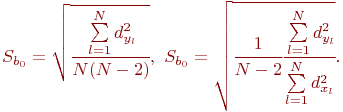
Данные для вычисления ![]() ,
, ![]() представлены в табл. 5.11.
представлены в табл. 5.11.
| | | | | | | | |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 1,0 | 1,0 | 7,0 | 6,68 | -0,32 | 0,1024 |
| 2 | 0,5 | 0,5 | 0,25 | 4,8 | 4,94 | 0,14 | 0,0196 |
| 3 | 1,0 | 0 | 0 | 2,8 | 3,2 | 0,40 | 0,16 |
| 4 | 1,5 | -0,5 | 0,25 | 1,4 | 1,46 | 0,06 | 0,0036 |
| 5 | 2,0 | -1,0 | 1,0 | 0 | 0,28 | 0,28 | 0,0784 |
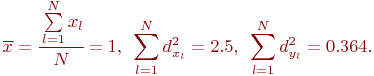
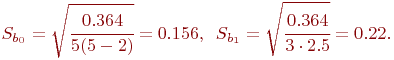
С уровнем достоверности ![]()
Большой размах доверительных границ объясняется малым числом наблюдений в данном эксперименте.
Доверительные границы для y принимают разные значения в зависимости от значений факторов [33].
На практике часто ограничиваются обобщенными оценками адекватности построенной модели: величиной среднего абсолютного отклонения
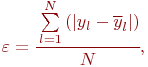
или (и) величиной среднеквадратической ошибки на единицу веса
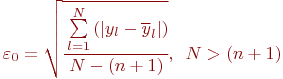
Весом или степенью свободы эксперимента называют разность ![]() между числом наблюдений
между числом наблюдений ![]() и числом коэффициентов регрессии
и числом коэффициентов регрессии ![]()
Предположим, что линейная модель ![]() недостаточно точно отображает связь между фактором
недостаточно точно отображает связь между фактором ![]() и откликом
и откликом ![]() .
.
Введем в рассмотрение более сложную нелинейную модель:
Для определения коэффициентов регрессии ![]() обозначим
обозначим ![]() и получим двухфакторную линейную модель:
и получим двухфакторную линейную модель:
В этом случае уравнение (5.3) раскрывается так:
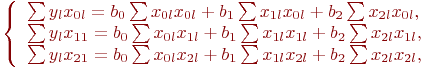
В уравнениях принято: ![]()
Так как ![]() ,
, ![]() , то система принимает вид:
, то система принимает вид:
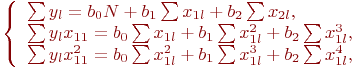
Подставим значения фактора и отклика из табл. 5.10:
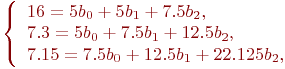
Решим систему из трех уравнений с тремя неизвестными и получим: ![]() .
.
Таким образом, получено новое уравнение регрессии:
По значениям ![]() и
и ![]() нетрудно убедиться в том, что нелинейная модель более точно отображает моделируемый процесс (см. табл. 5.10), чем линейная.
нетрудно убедиться в том, что нелинейная модель более точно отображает моделируемый процесс (см. табл. 5.10), чем линейная.
В рассмотренном примере ошибка модели определялась по тем же данным, по которым и была определена сама модель. Однако при сокращенных планах экспериментов (см. п. 4.3) можно выполнить все или часть "сэкономленных" наблюдений для получения так называемых проверочных данных, которые и использовать для вычисления ошибки ![]() или
или ![]() . В этом случае оценка адекватности модели будет более объективна, хотя число наблюдений в эксперименте увеличивается, и экономии их не будет.
. В этом случае оценка адекватности модели будет более объективна, хотя число наблюдений в эксперименте увеличивается, и экономии их не будет.
По уравнению регрессии можно сделать ориентировочную оценку чувствительности отклика к изменению того или иного фактора. Например, в уравнении ![]() влияние фактора
влияние фактора ![]() на отклик незначительно по сравнению с другими, так как коэффициент
на отклик незначительно по сравнению с другими, так как коэффициент ![]() намного меньше остальных коэффициентов.
намного меньше остальных коэффициентов.
В программном пакете MS Excel есть функция "Регрессия", которая может выполнить всесторонний регрессионный анализ данных компьютерного эксперимента.
Пример 5.9. В ремонтное подразделение поступают вышедшие из строя средства связи (СС) с интервалами времени, подчиненными показательному закону с математическим ожиданием ![]() . В каждом СС могут быть неисправными в любом сочетании блоки A, B, C с вероятностями
. В каждом СС могут быть неисправными в любом сочетании блоки A, B, C с вероятностями ![]() ,
, ![]() ,
, ![]() соответственно. Ремонтное подразделение ремонтирует СС путем замены неисправных блоков исправными блоками. В момент поступления неисправного СС в ремонтное подразделение вероятности наличия в нем исправных блоков
соответственно. Ремонтное подразделение ремонтирует СС путем замены неисправных блоков исправными блоками. В момент поступления неисправного СС в ремонтное подразделение вероятности наличия в нем исправных блоков ![]() соответственно
соответственно ![]() . Наличие и замена блока
. Наличие и замена блока ![]() обязательно при любом сочетании неисправных блоков.
обязательно при любом сочетании неисправных блоков.
Построить имитационную модель "Система ремонта" с целью определения вероятности ремонта СС с неисправными блоками ![]() ,
, ![]() и
и ![]() ,
, ![]() ,
, ![]() за время
за время ![]() . По результатам эксперимента получить уравнение регрессии, связывающее вероятность ремонта СС с вероятностями
. По результатам эксперимента получить уравнение регрессии, связывающее вероятность ремонта СС с вероятностями ![]() .
.
Решение
Постановка примера 5.9 аналогична постановке примера 3.8. Отличие состоит в том, что введен фактор времени - интервалы поступления неисправных СС. Это учтено в модели, при разработке которой использовался алгоритм примера 3.8 (см. рис. 3.18).
Для построения уравнения регрессии введем обозначения:
![]() - отклик модели, вероятность ремонта СС с неисправными блоками
- отклик модели, вероятность ремонта СС с неисправными блоками ![]() и
и ![]() за время
за время ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() .
.
Исходные данные и результаты эксперимента с моделью в количестве 32 наблюдений приведены в табл. 5.12. По этим данным функция "Регрессия" из MS Excel сформировала искомое уравнение:
| № отклика | | | | | | |
|---|---|---|---|---|---|---|
| 1 | 0,088 | 0,3 | 0,55 | 0,5 | 0,2 | 0,65 |
| 2 | 0,127 | 0,3 | 0,55 | 0,5 | 0,2 | 0,95 |
| 3 | 0,303 | 0,3 | 0,55 | 0,5 | 0,8 | 0,65 |
| 4 | 0,442 | 0,3 | 0,55 | 0,5 | 0,8 | 0,95 |
| 5 | 0,099 | 0,3 | 0,55 | 0,9 | 0,2 | 0,65 |
| 6 | 0,146 | 0,3 | 0,55 | 0,9 | 0,2 | 0,95 |
| 7 | 0,317 | 0,3 | 0,55 | 0,9 | 0,8 | 0,65 |
| 8 | 0,46 | 0,3 | 0,55 | 0,9 | 0,8 | 0,95 |
| 9 | 0,116 | 0,3 | 0,85 | 0,5 | 0,2 | 0,65 |
| 10 | 0,167 | 0,3 | 0,85 | 0,5 | 0,2 | 0,95 |
| 11 | 0,445 | 0,3 | 0,85 | 0,5 | 0,8 | 0,65 |
| 12 | 0,653 | 0,3 | 0,85 | 0,5 | 0,8 | 0,95 |
| 13 | 0,12 | 0,3 | 0,85 | 0,9 | 0,2 | 0,65 |
| 14 | 0,175 | 0,3 | 0,85 | 0,9 | 0,2 | 0,95 |
| 15 | 0,452 | 0,3 | 0,85 | 0,9 | 0,8 | 0,65 |
| 16 | 0,66 | 0,3 | 0,85 | 0,9 | 0,8 | 0,95 |
| 17 | 0,118 | 0,3 | 0,55 | 0,5 | 0,2 | 0,65 |
| 18 | 0,173 | 0,9 | 0,55 | 0,5 | 0,2 | 0,95 |
| 19 | 0,336 | 0,9 | 0,55 | 0,5 | 0,8 | 0,65 |
| 20 | 0,486 | 0,9 | 0,55 | 0,5 | 0,8 | 0,95 |
| 21 | 0,158 | 0,9 | 0,55 | 0,9 | 0,2 | 0,65 |
| 22 | 0,228 | 0,9 | 0,55 | 0,9 | 0,2 | 0,95 |
| 23 | 0,373 | 0,9 | 0,55 | 0,9 | 0,8 | 0,65 |
| 24 | 0,544 | 0,9 | 0,55 | 0,9 | 0,8 | 0,95 |
| 25 | 0,127 | 0,9 | 0,85 | 0,5 | 0,2 | 0,65 |
| 26 | 0,184 | 0,9 | 0,85 | 0,5 | 0,2 | 0,95 |
| 27 | 0,457 | 0,9 | 0,85 | 0,5 | 0,8 | 0,65 |
| 28 | 0,67 | 0,9 | 0,85 | 0,5 | 0,8 | 0,95 |
| 29 | 0,137 | 0,9 | 0,85 | 0,9 | 0,2 | 0,65 |
| 30 | 0,201 | 0,9 | 0,85 | 0,9 | 0,2 | 0,95 |
| 31 | 0,471 | 0,9 | 0,85 | 0,9 | 0,8 | 0,65 |
| 32 | 0,689 | 0,9 | 0,85 | 0,9 | 0,8 | 0,95 |
Кроме вычисленных оценок коэффициентов регрессии функция "Регрессия" выдает также результаты регрессионного анализа (табл. 5.13): вычисленные значения откликов ![]() , разность между ними и измеренными в эксперименте в каждом наблюдении
, разность между ними и измеренными в эксперименте в каждом наблюдении ![]() , среднеквадратические ошибки в определении коэффициентов регрессии
, среднеквадратические ошибки в определении коэффициентов регрессии ![]() и откликов при определенных значениях факторов
и откликов при определенных значениях факторов ![]() и некоторые другие.
и некоторые другие.
| Коэффициенты | Стандартная ошибка | t-статистика | |
|---|---|---|---|
| -0,52287 | 0,083821 | -6,23787 | |
| Переменная | 0,044568 | 0,034409 | 1,295248 |
| Переменная | 0,270679 | 0,068279 | 3,964334 |
| Переменная | 0,048634 | 0,051209 | 0,949722 |
| Переменная | 0,559089 | 0,034139 | 16,37673 |
| Переменная | 0,387762 | 0,068279 | 5,679123 |
| Наблюдение | Предсказанное Y | Остатки | Стандартные остатки |
| 1 | 0,027558 | 0,060442 | 1,141425 |
| 2 | 0,143886 | -0,01689 | -0,31889 |
| 3 | 0,363011 | -0,06001 | -1,13329 |
| 4 | 0,47934 | -0,03734 | -0,70515 |
| 5 | 0,047011 | 0,051989 | 0,981781 |
| 6 | 0,16334 | -0,01734 | -0,32746 |
| 7 | 0,382465 | -0,06547 | -1,23628 |
| 8 | 0,498794 | -0,03879 | -0,7326 |
| 9 | 0,108761 | 0,007239 | 0,136697 |
| 10 | 0,22509 | -0,05809 | -1,09701 |
| 11 | 0,444215 | 0,000785 | 0,014822 |
| 12 | 0,560544 | 0,092456 | 1,745995 |
| 13 | 0,128215 | -0,00822 | -0,15514 |
| 14 | 0,244544 | -0,06954 | -1,31331 |
| 15 | 0,463669 | -0,01167 | -0,22036 |
| 16 | 0,579998 | 0,080002 | 1,510813 |
| 17 | 0,027558 | 0,090442 | 1,707963 |
| 18 | 0,170627 | 0,002373 | 0,044804 |
| 19 | 0,389752 | -0,05375 | -1,01509 |
| 20 | 0,506081 | -0,02008 | -0,37922 |
| 21 | 0,073752 | 0,084248 | 1,590978 |
| 22 | 0,190081 | 0,037919 | 0,716081 |
| 23 | 0,409206 | -0,03621 | -0,68374 |
| 24 | 0,525535 | 0,018465 | 0,348706 |
| 25 | 0,135502 | -0,00850 | -0,16057 |
| 26 | 0,251831 | -0,06783 | -1,28096 |
| 27 | 0,470956 | -0,01396 | -0,26356 |
| 28 | 0,587285 | 0,082715 | 1,56204 |
| 29 | 0,154956 | -0,01796 | -0,33909 |
| 30 | 0,271285 | -0,07028 | -1,3273 |
| 31 | 0,490410 | -0,01941 | -0,36655 |
| 32 | 0,606739 | 0,082261 | 1,553472 |
Пример 5.10. На узел связи поступают заявки на передачу сообщений. Интервалы времени поступления заявок подчинены показательному закону с математическим ожиданием ![]() . На узле связи имеются два канала передачи данных. При поступлении очередной заявки в интервале времени
. На узле связи имеются два канала передачи данных. При поступлении очередной заявки в интервале времени ![]() вероятности того, что каналы
вероятности того, что каналы ![]() и
и ![]() будут свободны, соответственно равны
будут свободны, соответственно равны ![]() и
и ![]() . При поступлении заявок после времени
. При поступлении заявок после времени ![]() вероятности того, что каналы
вероятности того, что каналы ![]() и
и ![]() будут свободны, соответственно равны
будут свободны, соответственно равны ![]() и
и ![]() .
Сообщение передаётся по любому свободному каналу. Если оба канала заняты, заявка теряется.
.
Сообщение передаётся по любому свободному каналу. Если оба канала заняты, заявка теряется.
Построить имитационную модель "Обработка запросов на узле связи" с целью определения абсолютного и относительного числа потерянных заявок из их общего количества, поступивших на узел связи за время ![]() ,
, ![]() . Получить уравнение регрессии, связывающее относительную долю обслуженных заявок с интервалами их поступления и вероятностями
. Получить уравнение регрессии, связывающее относительную долю обслуженных заявок с интервалами их поступления и вероятностями ![]()
Решение
Имитационная модель построена в соответствии с алгоритмом (см. рис. 3.21). Для построения уравнения регрессии введем обозначения:
![]() - отклик модели, вероятность ремонта СС с неисправными блоками
- отклик модели, вероятность ремонта СС с неисправными блоками ![]() ,
, ![]() и
и ![]() ,
, ![]() ,
, ![]() за время
за время ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий вероятность
- фактор, представляющий вероятность ![]() ;
;
![]() - фактор, представляющий интервалы поступления заявок
- фактор, представляющий интервалы поступления заявок ![]() .
.
Исходные данные и результаты эксперимента приведены в табл. 5.14. Для регрессионного анализа также использовалась функция "Регрессия" MS Excel. Получено искомое уравнение:
| Номер отклика | | | | | | |
|---|---|---|---|---|---|---|
| 1 | 0,405 | 0,5 | 0,7 | 0,3 | 0,3 | 1 |
| 2 | 0,406 | 0,5 | 0,7 | 0,3 | 0,3 | 9 |
| 3 | 0,09 | 0,5 | 0,7 | 0,3 | 0,9 | 1 |
| 4 | 0,09 | 0,5 | 0,7 | 0,3 | 0,9 | 9 |
| 5 | 0,195 | 0,5 | 0,7 | 0,7 | 0,3 | 1 |
| 6 | 0,195 | 0,5 | 0,7 | 0,7 | 0,3 | 9 |
| 7 | 0,06 | 0,5 | 0,7 | 0,7 | 0,9 | 1 |
| 8 | 0,06 | 0,5 | 0,7 | 0,7 | 0,9 | 9 |
| 9 | 0,38 | 0,5 | 0,9 | 0,3 | 0,3 | 1 |
| 10 | 0,38 | 0,5 | 0,9 | 0,3 | 0,3 | 9 |
| 11 | 0,65 | 0,5 | 0,9 | 0,3 | 0,9 | 1 |
| 12 | 0,65 | 0,5 | 0,9 | 0,3 | 0,9 | 9 |
| 13 | 0,17 | 0,5 | 0,9 | 0,7 | 0,3 | 1 |
| 14 | 0,17 | 0,5 | 0,9 | 0,7 | 0,3 | 9 |
| 15 | 0,035 | 0,5 | 0,9 | 0,7 | 0,9 | 1 |
| 16 | 0,0348 | 0,5 | 0,9 | 0,7 | 0,9 | 9 |
| 17 | 0,375 | 0,9 | 0,7 | 0,3 | 0,3 | 1 |
| 18 | 0,376 | 0,9 | 0,7 | 0,3 | 0,3 | 9 |
| 19 | 0,06 | 0,9 | 0,7 | 0,3 | 0,9 | 1 |
| 20 | 0,06 | 0,9 | 0,7 | 0,3 | 0,9 | 9 |
| 21 | 0,165 | 0,9 | 0,7 | 0,7 | 0,3 | 1 |
| 22 | 0,165 | 0,9 | 0,7 | 0,7 | 0,3 | 9 |
| 23 | 0,03 | 0,9 | 0,7 | 0,7 | 0,9 | 1 |
| 24 | 0,0301 | 0,9 | 0,7 | 0,7 | 0,9 | 9 |
| 25 | 0,37 | 0,9 | 0,9 | 0,3 | 0,3 | 1 |
| 26 | 0,37 | 0,9 | 0,9 | 0,3 | 0,3 | 9 |
| 27 | 0,055 | 0,9 | 0,9 | 0,3 | 0,9 | 1 |
| 28 | 0,055 | 0,9 | 0,9 | 0,3 | 0,9 | 9 |
| 29 | 0,16 | 0,9 | 0,9 | 0,7 | 0,3 | 1 |
| 30 | 0,16 | 0,9 | 0,9 | 0,7 | 0,3 | 9 |
| 31 | 0,025 | 0,9 | 0,9 | 0,7 | 0,9 | 1 |
| 32 | 0,025 | 0,9 | 0,9 | 0,7 | 0,9 | 9 |
Результаты регрессионного анализа, аналогичные рассмотренным в примере 5.9 (табл. 5.13), приведены в табл. 5.15.
| Коэффициенты | Стандартная ошибка | t-статистика | |
|---|---|---|---|
| 0,526135 | 0,211881 | 2,483165 | |
| Переменная | -0,23277 | 0,112257 | -2,0735 |
| Переменная | 0,289906 | 0,224514 | 1,291259 |
| Переменная | -0,48314 | 0,112257 | -4,30387 |
| Переменная | -0,25334 | 0,074838 | -3,38522 |
| Переменная | 1,48E-05 | 0,005613 | 0,002645 |
| Наблюдение | Предсказанное Y | Остатки | Стандартные остатки |
| 1 | 0,391756 | 0,013244 | 0,113864 |
| 2 | 0,391875 | 0,014125 | 0,12144 |
| 3 | 0,23975 | -0,14975 | -1,28748 |
| 4 | 0,239869 | -0,14987 | -1,2885 |
| 5 | 0,1985 | -0,0035 | -0,03009 |
| 6 | 0,198619 | -0,00362 | -0,03111 |
| 7 | 0,046494 | 0,013506 | 0,116121 |
| 8 | 0,046613 | 0,013387 | 0,1151 |
| 9 | 0,449738 | -0,06974 | -0,59957 |
| 10 | 0,449856 | -0,06986 | -0,60059 |
| 11 | 0,297731 | 0,352269 | 3,02865 |
| 12 | 0,29785 | 0,35215 | 3,027629 |
| 13 | 0,256481 | -0,08648 | -0,74353 |
| 14 | 0,2566 | -0,0866 | -0,74455 |
| 15 | 0,104475 | -0,06948 | -0,59732 |
| 16 | 0,104594 | -0,06979 | -0,60006 |
| 17 | 0,29865 | 0,07635 | 0,656423 |
| 18 | 0,298769 | 0,077231 | 0,664 |
| 19 | 0,146644 | -0,08664 | -0,74492 |
| 20 | 0,146763 | -0,08676 | -0,74595 |
| 21 | 0,105394 | 0,059606 | 0,512468 |
| 22 | 0,105513 | 0,059487 | 0,511447 |
| 23 | -0,04661 | 0,076612 | 0,65868 |
| 24 | -0,04649 | 0,076594 | 0,658519 |
| 25 | 0,356631 | 0,013369 | 0,114939 |
| 26 | 0,35675 | 0,01325 | 0,113918 |
| 27 | 0,204625 | -0,14963 | -1,28641 |
| 28 | 0,204744 | -0,14974 | -1,28743 |
| 29 | 0,163375 | -0,00338 | -0,02902 |
| 30 | 0,163494 | -0,00349 | -0,03004 |
| 31 | 0,011369 | 0,013631 | 0,117195 |
| 32 | 0,011488 | 0,013512 | 0,116174 |
Вопросы для самоконтроля
- Что понимают под характеристикой случайных величин и процессов?
- Что такое несмещенная оценка характеристики случайной величины? Состоятельная? Эффективная?
- Что характеризует гистограмма? Правило построения гистограммы.
- В чем состоит сущность дисперсионного анализа?
- Что такое ошибки первого рода и второго рода при оценке гипотез?
- Что такое F - распределение и почему оно является мерой сравнения дисперсий случайных величин?
- Для чего используется критерий Вилькоксона?
- В чем состоит методика выявления несущественных факторов?
- Назначение корреляционного анализа.
- Назначение регрессионного анализа.
- Представьте графически виды корреляции между двумя переменными.
- Составьте систему уравнений для определения коэффициентов регрессии модели вида:
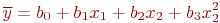
- Для линейной и нелинейной моделей, полученных в п. 5.12, вычислить и сравнить ошибки
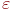 и
и  .
. - С объектом проведено
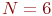 экспериментов. Данные экспериментов приведены в таблице:
экспериментов. Данные экспериментов приведены в таблице:
Построить линейную математическую модель функционирования объекта вида:
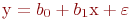 . Расчеты провести в таблице. Проверьте адекватность модели при абсолютной точности 0,2.
. Расчеты провести в таблице. Проверьте адекватность модели при абсолютной точности 0,2.
Лекция 6. Моделирование в GPSS World
6.1. Основы построения и принципы функционирования языка имитационного моделирования
Модель разрабатывается на языке GPSS и состоит из операторов, а объект " Модель " создается при помощи встроенного текстового редактора. Объект " Процесс моделирования " - это результат трансляции модели. Далее процесс моделирования запускается с помощью команд GPSS. По завершении моделирования, как правило, автоматически создается объект " Отчет ".
Текстовый объект ( текстовый файл GPSS World) предназначен для упрощения разработки больших моделей и создания библиотеки исходных текстов. То есть модель может быть разделена на наборы операторов, представляющие собой отдельные текстовые файлы, а затем объектом "Процесс моделирования" собрана из них. Объект "Процесс моделирования" может также создавать новые текстовые файлы с фрагментами модели, результатами моделирования, а также считывать и записывать данные в текстовые файлы.
GPSS World предназначена для имитационного моделирования систем с дискретными и непрерывными процессами. Языком моделирования в ней является язык GPSS, улучшенный встроенным языком программирования низкого уровня PLUS. Язык GPSS построен в предположении, что модель сложной системы можно представить совокупностью элементов и логических правил их взаимодействия в процессе функционирования моделируемой системы. Набор абстрактных элементов, называемых объектами, небольшой. Также набор логических правил ограничен и может быть описан стандартными операциями. Комплекс программ, описывающих функционирование объектов и выполняющих логические операции, является основой для создания программной модели.
Кроме этого комплекса в составе GPSS World имеется программа- планировщик, выполняющая следующие функции:
- обеспечение продвижения по заданным разработчиком маршрутам динамических объектов, называемых транзактами ;
- планирование событий, происходящих в модели, путем регистрации времени наступления каждого события и выполнения их в нарастающей временной последовательности;
- регистрация статистической информации о функционировании модели;
- продвижение модельного времени в процессе моделирования системы.
Чтобы обеспечить правильную последовательность обработки событий во времени, имеются системные часы, хранящие значения абсолютного модельного времени
Объекты в моделируемой системе предназначены для различных целей. Совершенно не обязательно, чтобы в одной модели участвовали все типы объектов. Необходимо лишь наличие блоков и транзактов, иначе модель работать не будет.
Объекты подразделяются на 7 категорий и 15 типов, которые представлены в табл. 6.1.
| Категории | Типы объектов |
|---|---|
| Динамическая | Транзакты |
| Операционная | Блоки |
| Аппаратная | Одноканальные устройства, памяти (многоканальные |
| устройства), логические ключи (переключатели) | |
| Вычислительная | Переменные, функции, генераторы случайных чисел |
| Статистическая | Очереди, таблицы |
| Запоминающая | Ячейки, матрицы ячеек |
| Группирующая | Числовые группы, группы транзактов, списки |
Рассмотрим назначение объектов GPSS.
Динамическими объектами являются транзакты, которые создаются в определенных точках модели, продвигаются планировщиком через блоки, а затем уничтожаются. Транзакты являются аналогами единиц - потоков в реальной системе. Они могут представлять собой различные элементы даже в одной модели. С каждым транзактом связаны параметры, которые используются для конкретных данных. Каждый транзакт может иметь любое число параметров. Параметры нумеруются или им даются имена. Номера параметров и имена используются для ссылок на значения, присвоенные параметрам. Транзактам может присваиваться приоритет.Приоритет определяет предпочтение, которое получает транзакт, когда он и другие транзакты претендуют на один и тот же ресурс.
Объекты аппаратной категории - это абстрактные элементы, на которые может быть декомпозирована реальная система. Воздействуя на эти объекты, транзакты могут изменять их состояние и влиять на движение других транзактов. К объектам этого типа относятся одноканальные устройства, памяти (многоканальные устройства) и логические ключи.
Одноканальные устройства (ОКУ) представляют собой оборудование, которое в любой момент времени может быть занято только одним транзактом. Например, один канал передачи данных, одноканальный ремонтный орган, один станок изготовления деталей, одно транспортное средство.
Многоканальные устройства (МКУ) предназначены для имитации оборудования, осуществляющего параллельную обработку. Они могут быть использованы одновременно несколькими тран-зактами. МКУ можно использовать в качестве аналога, например, многоканального ремонтного органа, нескольких каналов связи.
Для моделирования такого оборудования, как переключатели, имеющие только два состояния, в GPSS используются логические ключи.
Операционные объекты, т. е. блоки, задают логику функционирования модели системы и определяют пути движения транзактов между объектами аппаратной категории. В блоках могут происходить события четырех основных типов:
- создание или уничтожение транзактов;
- изменение числового атрибута объекта;
- задержка транзакта на определенный период времени;
- изменение маршрута движения транзакта в модели. Версия GPSS, реализованная в системе GPSS World, содержит 53 типа блоков.
В зависимости от назначения блоки подразделяются на несколько групп.
- Блоки, осуществляющие модификацию атрибутов транзактов:
- генерирование и уничтожение транзактов GENERATE, SPLIT, TERMINATE, ASSEMBLE ;
- временная задержка ADVANCE ;
- синхронизация движения двух MATCH и нескольких GATHER транзактов;
- изменение приоритета транзакта PRIORITY ;
- изменение параметров транзактов ASSIGN, INDEX, MARK, PLUS.
- Блоки, изменяющие последовательность движения транзактов (блоки передачи управления): DISPLACE, TRANSFER, LOOP, TEST, GATE.
- Блоки, связанные с группирующей категорией: ADOPT, ALTER, EXAMINE, JOIN, REMOVE, SCAN.
- Блоки, описывающие объекты аппаратной категории:
- одноканальные устройства (технические средства) SEIZE, RELEASE, PREEMPT, RETURN, FUNAVAIL, FAVAIL ;
- многоканальные устройства (памяти) ENTER, LEAVE, SAVAIL, SUNAVAIL ;
- ключи (логические переключатели) LOGIC.
- Блоки, сохраняющие необходимые значения для дальнейшего использования: SAVEVALUE, MSAVEVALUE.
- Блоки для получения статистических результатов:
- очереди QUEUE, DEPART ;
- таблицы TABULATE.
- Блоки для организации списка пользователя: LINK, UNLINK.
- Блоки для организации ввода-вывода:
- открытие/закрытие файла: OPEN / CLOSE ;
- считывание/запись в файл: READ / WRITE ;
- установка позиции текущей строки: SEEK.
- Специальные блоки: BUFFER, COUNT, EXECUTE, INTEGRATION, SELECT, TRACE, UNTRACE.
Вычислительная категория служит для описания таких ситуаций в процессе моделирования, когда связи между компонентами моделируемой системы посредством процессом наиболее просто и компактно выражаются в виде математических (аналитических и логических) соотношений. Для этих целей в качестве объектов вычислительной категории введены арифметические и булевы переменные и функции.
Переменные представляют собой сложные выражения, которые включают константы, системные числовые атрибуты (СЧА), библиотечные арифметические функции, арифметические и логические операции.
Выражения могут применяться в переменных и операторах GPSS. При применении в переменных выражения определяются командами GPSS. При применении в операторах GPSS выражения определяются как часть языка PLUS.
Каждому объекту соответствуют атрибуты, описывающие его состояние в данный момент времени. Они доступны для использования в течение всего процесса моделирования и называются системными числовыми атрибутами (СЧА). Например, объект вычислительной категории - генератор случайных чисел имеет СЧА RNn - число, вычисляемое генератором равномерно распределенных случайных чисел номер n ; у объекта динамической категории - транзакта СЧА: PR - приоритет обрабатываемого в данный момент транзакта; Pi - значение i -го параметра активного транзакта и др. Всего в GPSS World имеется свыше 50 СЧА.
Булевы переменные позволяют пользователю проверять в одном блоке GPSS одновременно несколько условий, исходя из состояния или значения этих условий и их атрибутов.
С помощью функций пользователь может производить вычисления непрерывных или дискретных функциональных зависимостей между аргументом функции (независимая величина) и зависимым значением функции.
Кроме библиотечных арифметических функций GPSS World имеет 24 встроенных генератора случайных чисел.
Объекты запоминающей категории обеспечивают обращения к сохраняемым значениям. Ячейки сохраняемых величин и матрицы ячеек сохраняемых величин используются для сохранения некоторой числовой информации. Любой активный транзакт может произвести запись информации в эти объекты. Впоследствии записанную в эти объекты информацию может считать любой транзакт. Матрицы могут иметь до шести измерений.
К статистическим объектам относятся очереди и таблицы. В любой системе движение потока транзактов может быть задержано из-за недоступности устройств. В этом случае задержанные транзакты ставятся в очередь - еще один тип объектов GPSS. Учет этих очередей составляет одну из основных функций планировщика. Планировщик автоматически накапливает определенную статистику относительно устройств и очередей. Кроме этого пользователь может собирать дополнительную статистическую информацию, указав специальные точки в модели.
Для облегчения табулирования статистической информации в GPSS предусмотрен специальный объект - таблица. Таблицы используются для получения выборочных распределений некоторых случайных величин. Таблица состоит из частотных классов (диапазонов значений), куда заносится число попаданий конкретного числового атрибута в каждый, тот или иной, частотный класс. Для каждой таблицы вычисляется также математическое ожидание и среднеквадратическое отклонение.
К группирующей категории относятся три типа объектов: числовая группа, группа транзактов и списки.
При моделировании транзакты хранятся в списках. Существует пять видов списков, только в одном из которых в любой момент времени может находиться транзакт:
- текущих событий;
- будущих событий;
- задержки ОКУ или МКУ;
- отложенных прерываний ОКУ;
- пользователя.
Одноканальное устройство имеет:
- список отложенных прерываний - список транзактов, ожидающих занятия ОКУ по приоритету;
- список прерываний - список транзактов, обслуживание которых данным ОКУ было прервано;
- список задержки - список транзактов, ожидающих занятия ОКУ в порядке приоритета;
- список повторных попыток - список транзактов, ожидающих изменения состояния ОКУ.
Многоканальное устройство имеет:
- список задержки - список транзактов в порядке приоритета, ожидающих возможность занять освободившиеся каналы МКУ;
- список повторных попыток - список транзактов, ожидающих изменения состояния МКУ.
Список пользователя содержит транзакты, удаленные пользователем из списка текущих событий и помещенные в список пользователя как временно неактивные. Списки пользователя используются для организации очередей с дисциплинами, отличными от дисциплины "первым пришел - первым обслужен".
6.2. Построение моделей с устройствами
Для представления собственно обслуживания используются определенные элементы. Такими элементами могут быть либо люди, либо какие-то предметы. Независимо от этого подобные элементы в GPSS называют объектами аппаратной категории, к которой относят одноканальные (ОКУ) и многоканальные устройства (МКУ) и логические ключи.
Рассмотрение методов построения моделей с устройствами начнем с имитации функционирования ОКУ.
При моделировании возможны следующие режимы организации функционирования ОКУ:
- занятие ОКУ и его освобождение;
- прерывание обслуживания ОКУ;
- недоступность ОКУ и восстановление доступности. Прежде чем сразу рассматривать блоки, моделирующие ОКУ,
вспомним, что потоки, существующие в реальных системах, в моделях имитируют транзакты. Поэтому сначала узнаем, как вводятся транзакты в модель и как выводятся из нее. А так как построение самых простейших моделей невозможно без некоторых блоков GPSS, такие блоки будут также рассмотрены.
6.2.1. Организация поступления транзактов в модель и удаления транзактов из нее
6.2.1.1. Поступление транзактов в модель
GENERATE - это блок, через который транзакты входят в модель. Блок GENERATE имеет следующий формат записи:
GENERATE [A],[B],[C],[D],[E]
Скобки [ ] означают, что данный операнд является необязательным. Не существует ограничений на число различных блоков GENERATE в одной модели.
Интервалы времени между последовательными появлениями транзактов блока GENERATE называют интервалом поступления. Все разработчики должны задавать спецификацию распределения интервалов времени поступления в блоке GENERATE. Информация, необходимая для этого, задается операндами А и B. Все возможные виды распределения интервалов времени поступления в GPSS делят на равномерно распределенные и все другие виды распределения.
Операнд А - средний интервал времени между последовательными поступлениями транзактов в модель.
Операнд B - задает модификатор, который изменяет значения интервала генерации транзактов по сравнению с интервалом, указанным операндом А. Есть два типа модификаторов: модификатор-интервал и модификатор-функция.
С помощью модификатора-интервала задается равномерный закон распределения времени между генерацией транзактов.
Операнды А и B могут быть именем, положительным числом, выражением в скобках или непосредственно СЧА.
При вычислении разности значений (А-В), заданных операндами А и B, получается нижняя граница интервала, а при вычислении суммы (А+В) - верхняя граница. После генерации очередного транзакта выбирается число из полученного интервала, это и будет значение времени, через которое следующий транзакт выйдет из блока GENERATE.
Когда операнды А и B задают в виде констант ( B - модификатор-интервал), они должны быть неотрицательными числами, т. е. интервал времени может быть выражен числами, например, 4.1,…,12.7. Предположим, что транзакт входит в модель - блок GENERATE - в момент модельного времени 25.6. После того, как этот транзакт попадет в следующий блок модели, планировщик GPSS разыграет случайное значение из распределения интервалов времени, равного ![]() .
.
Пусть разыгранным значением будет число 9.7. Тогда планировщик планирует приход следующего транзакта в блок GENERATE в момент времени 25.6+9.7=35.3.
Можно выбрать для розыгрыша генератор равномерно распределенных случайных чисел. Это устанавливается на странице " Random Numbers " ( Случайные числа ) в журнале настроек модели. Нужно выбрать Edit/Settings ( Правка/Настройка ) и страницу " Random Numbers " ( Случайные числа ), на которой в поле ввода " GENERATE " ввести номер генератора - любое положительное целое число. По умолчанию используется генератор равномерно распределенных случайных чисел номер 1.
Операнды А и В не обязательно должны быть заданы. Когда один или оба операнда не указаны, по умолчанию предполагается их нулевое значение. Например, А=16.4, В=0. Поскольку операнд В=0, то интервалы времени распределены равномерно, ![]() , т. е. интервал времени поступления равен 16.4. Это пример того, как может быть задано детерминированное значение интервалов времени.
, т. е. интервал времени поступления равен 16.4. Это пример того, как может быть задано детерминированное значение интервалов времени.
Более сложные интервалы времени поступления транзактов (не по равномерному закону) могут быть заданы с использованием модификатора-функции или встроенных генераторов случайных чисел. Под действием модификатора-функции значение операнда А умножается на значение функции, заданной операндом В.
При любом способе вычисления интервала времени значение операнда В не должно превышать значения операнда А, в противном случае в блоке GENERATE может быть получен отрицательный интервал времени, который вызовет останов по ошибке "Отрицательное время задержки".
Рассмотрим три дополнительных операнда: С - смещение интервалов, D - ограничитель, Е - уровень приоритета.
Смещение интервалов (первоначальная задержка) С - это момент времени, в который в блоке GENERATE должен появиться первый транзакт. После этого первого прихода все остальные приходы транзактов возникают в соответствии с распределением интервалов времени, задаваемых операндами А и B. Операнд С можно использовать как для ускорения, так и для замедления прихода первого транзакта или для указания прихода в нужный момент времени. Начальная задержка может быть меньше, равна или больше среднего времени, заданного операндом А. Когда операнд С не используется, интервалы генерирования определяются операндами А и B (они не оказывают влияния на задержку). Операнд С может быть таким же как и операнды А и B.
Операнд D задает граничное значение общего числа транзак-тов, которые могут войти в модель через данный блок GENERATE в течение времени моделирования. Когда это число достигнуто, данный блок GENERATE перестает быть активным. Если не определено граничное значение (операнд D не используется), блок GENERATE остается активным в течение всего времени моделирования, т. е. по умолчанию ограничения на количество создаваемых транзактов нет.
Операнд Е устанавливает класс приоритета каждого из транзак-тов, входящих в модель через данный блок GENERATE. Для задания приоритетов c целью повышения эффективности работы GPSS World рекомендуется использовать последовательность целых чисел 0, 1, 2, 3,… вместо, например, 37, 43, 88, 122,... Чем выше число, тем выше приоритет. Если операнд Е не используется, по умолчанию приоритет генерируемых данным блоком GENERATE транзактов равен нулю.
Операнды D и Е могут задаваться также как и операнды А, B и С, но при этом принимать значения только целых положительных и целых чисел соответственно.
В любом блоке GENERATE должен быть обязательно задан либо операнд А, либо операнд D. Нельзя использовать в качествеоперанда параметры транзактов. Необходимо также помнить, что транзакт не должен входить в блок GENERATE. Если транзакт пытается это делать, возникает ошибка выполнения. Приведем примеры записи блоков GENERATE:
- с операндом А
GENERATE 38.6 GENERATE X$IntPostTran GENERATE MX$VrPost(3,6) GENERATE V$Prom GENERATE (Exponential(11,0,X$Mat)) GENERATE IntPostTran
- с операндами А и B
GENERATE 73.25,X$Otk GENERATE X$Sredne,FN2 GENERATE Sredne,FN4 GENERATE (V$Post+7.1),FN$Mod
- с операндами А и C
GENERATE 7.3,,4.1 GENERATE 7.3,,X$VrSm GENERATE V$IntP,,MX2(X$Stroka,X$Stolbez) GENERATE (Normal(3,X$Sre,X$SreOtk)),,Sme
- с операндами А, B, E
GENERATE 13.3,2.8,,,1 GENERATE (Normal(8,X$Sr,X$SrOtk)),Post,,1 GENERATE V$IntPostTran,(V1-12.3),,12
Приведенные примеры демонстрируют различные способы задания операндов блока GENERATE. Однако при этом нужно помнить следующее.
В начальный момент времени в каждом блоке GENERATE производится подготовка к выходу одного транзакта. На этой стадии модель еще полностью не инициализирована для выполнения, т. е. не все переменные получили значения. Но описанные в блоке GENERATE, должны быть уже определены - инициализированы. Поэтому в модели блоку GENERATE должны предшествовать команды определения EQU, INITIAL, FUNCTION, VARIABLE, FVARIABLE. Это делается для того, чтобы СЧА в блоке GENERATE, который ссылается на них, давали нужные для ввода транзактов в модель результаты.
Например:
SrIntPost EQU 47.2
StanOtkl EQU 28.6
INITIAL X$KolTrans,43
. . .
GENERATE SrIntPost,StOtk,,X$KolTransКак видно из примера, блоку GENERATE предшествуют присвоения командой EQU именам числовых значений и командой INITIAL начального значения сохраняемой ячейке с именем Kol-Trans.
6.2.1.2. Удаление транзактов из модели и завершение моделирования
Транзакты удаляются из модели, попадая в блок TERMINATE (завершить).
Блоки TERMINATE всегда позволяют войти всем транзактам, которые пытаются это сделать. В модели может быть любое число блоков TERMINATE. Блок имеет следующий формат записи:
TERMINATE [A]
Значением операнда А является число единиц, на которое блок TERMINATE уменьшает содержимое счетчика завершения, определяющего момент окончания моделирования. Операнд А может быть именем, положительным целым числом, выражением в скобках, СЧА или СЧА*<параметр>. По умолчанию значение операнда А равно нулю. В этом случае транзакт уничтожается, а значение счетчика завершения не меняется.
Счетчик завершения представляет собой ячейку памяти с именем TG1, которая хранит положительное целое число. Это число записывается в ячейку TG1 командой START в начале процесса моделирования.
В процессе моделирования транзакты попадают в блок TERMINATE и в соответствии со значением операнда А вычитают определенное число из счетчика завершения. При достижении содержимым счетчика нуля моделирование завершается. В модели может быть много блоков TERMINATE, но счетчик завершения только один.
Когда пользователь подготавливает модель, он задает время моделирования, указывая в операторе START значение счетчика завершения. Поскольку пути прохождения транзактов в модели имеют различный физический смысл, каждый блок TERMINATE может либо уменьшать, либо не уменьшать содержимое счетчика завершения.
Рассмотрим пример, в котором блок TERMINATE и команда START используются для управления временем моделирования. Предположим, что разработчик выбрал в качестве единицы времени 1 мин. Он хочет промоделировать поведение системы в течение 10 часов, затем моделирование должно быть закончено. За единицу модельного времени возьмем 1 мин, тогда время моделирования равно 10*60=600 единицам.
Любая модель на GPSS состоит из одного или нескольких сегментов. Для управления временем моделирования разработчик (см. блок-диаграмму):
- включает в модель сегмент из блоков GENERATE и TERMINATE ;
- в блоке TERMINATE в качестве операнда А использует 1 ;
- во всех прочих блоках TERMINATE модели использует операнд А по умолчанию (однако возможны и другие варианты, т. е. и в других блоках TERMINATE операнд А может быть 1 ).
В процессе моделирования транзакты, которые двигаются в других сегментах модели, время от времени выводятся из модели в других блоках TERMINATE, но они не оказывают воздействия на счетчик завершения. В момент модельного времени 600 транзакт в приведенном выше сегменте попадает в блок GENERATE и сразу же переходит в следующий блок TERMINATE.
Поскольку операнд А блока содержит 1, то из счетчика завершения вычитается 1. Предположим, что в команде START было указано число 10, т. е. десять прогонов модели, и в счетчик завершений записано число 10: TG1 = 10. После первого вычитания содержимое ячейки TG1 = 9, т. е. не равно нулю. Поэтому моделирование продолжается. После десяти прогонов, т. е. вычитания десяти единиц, TG1 = 0. Планировщик прекращает моделирование.
Команда START используется для запуска процесса моделирования. Она имеет следующий формат записи:
START A,[B],C,[D]
Операнд А задает значение счетчика завершения, определяющего момент окончания прогона модели. Может быть только целым положительным числом. Операнд B - операнд вывода статистики. Он может быть NP ("нет вывода данных") либо опущен. При задании NP стандартный отчет не выводится. По умолчанию выводится стандартный отчет. Операнд С не используется и сохранен для совместимости с описаниями ранних версий GPSS. Операнд D определяет необходимость вывода содержимого списков событий. Если операнд D указать любым положительным целым числом, например, 1, то списки текущих и будущих событий включаются в стандартный отчет и выводятся. Если операнд D опущен, то по умолчанию списки в стандартном отчете не выводятся.
Команду START можно сразу указывать в конце программы модели при ее подготовке и в таком виде записывать на магнитный носитель. Тогда после трансляции модели, т. е. создания объекта "процесс моделирования", сразу начинается моделирование. Этот же оператор можно вводить в программу модели в интерактивном режиме.
Однако может возникнуть необходимость завершить моделирование не по истечении какого-то времени, а после обработки определенного количества транзактов, имитирующих, например, изготовленные детали, переданные по каналу связи сообщения и т. д. В этом случае сегмент задания времени моделирования не нужен. Для организации такого способа завершения моделирования необходимо сделать следующее. В блоках TERMINATE, которые выводят из модели транзакты, имеющие смысл тех же изготовленных деталей или переданных сообщений, указать число, на которое уменьшается счетчик завершения моделирования. В команде START также указать число, деление которого на указанное в блоке TERMINATE число даст требуемое количество изготовленных деталей или переданных сообщений. Например, требуется завершить моделирование после изготовления 100 деталей. В модели это может быть так:
. . . TERMINATE 1 . . . TERMINATE 1 . . . TERMINATE START 100
Блоков TERMINATE, которые выводят из модели транзакты, соответствующие изготовленным деталям, может быть несколько. Все эти блоки должны иметь 1 в качестве операнда А. У остальных блоков TERMINATE, если они есть в модели, операнд А должен быть опущен.
Итак, транзакты введены в модель. Но аналоги транзактов - элементы потоков в реальных системах имеют различные характеристики. Рассмотрим, как эти же характеристики присваиваются транзактам.
6.2.1.3. Изменение значений параметров транзактов
Каждый транзакт может иметь любое число параметров. Интерпретация смысла параметров произвольная. В момент генерации транзактов все его параметры нулевые (только те, которые используются в модели). Блок ASSIGN является основным средством для задания значений параметров транзактов.
Формат записи:
ASSIGN A,B,[C]
Операндом А задается номер параметра, которому присваивается значение. Операнд А может быть именем, положительным целым числом, выражением в скобках, СЧА, СЧА*параметр и следующими за ними знаками + (если нужно увеличить), - (если нужно уменьшить).
Операнд B определяет значение, которое следует добавить, вычесть или которым следует заменить значение в параметре, заданном операндом А. Если такой параметр не существует, то он создается со значением, равным 0. Операнд B может быть таким же как и операнд А, кроме того, числом и строкой.
Операнд С задает номер модификатора-функции. При использовании операнда С значение операнда B умножается на значение модификатора-функции. Полученное произведение становится значением, которое изменяет значение параметра, заданного операндом А. Следует отметить, что операнд С определяет номер функции или ее имя (не нужно использовать СЧА FN или FN$ перед ним). Если используется СЧА FN, например, FN3, вычисляется функция номер 3 GPSS. Полученный результат используется
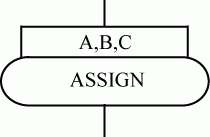
для определения второй функции GPSS, которая также вычисляется и ее значение умножается на значение операнда B. Приведем примеры записи блока ASSIGN:
ASSIGN 1,754.3 ASSIGN 4+,Q5 ASSIGN 3-,5.85,7 ASSIGN Name,"Plan" ASSIGN Tr1-,(Normal(32,Sred,SrOtkl),Expdis
В первом примере параметру 1 присваивается 754.3. Во втором примере к значению параметра 4 прибавляется значение длины текущей очереди номер 5. В третьем примере из значения параметра 3 вычитается произведение 5.85 на вычисленное значение функции номер 7. В четвертом примере параметру с именем Name присваивается строка Plan. В пятом примере вычисляются выражение в скобках и функция с именем Expdis, перемножаются и полученное произведение вычитается из значения параметра с именем Tr1.
6.2.2. Занятие и освобождение одноканального устройства
В GPSS элементами, которые требуют обслуживания, являются транзакты. Они перемещаются в модели от блока к блоку. Если в какой-то момент активности транзакт занимает ОКУ, то для этого он входит (или пытается войти) в соответствующий блок, описывающий это ОКУ. Блок должен обладать следующими свойствами:
- если ОКУ уже используют, транзакт не может войти в блок и должен ждать в очереди;
- если ОКУ не используют, транзакт может войти в блок, статус ОКУ изменяется на "занято".
Блок, обладающий этими свойствами, является блоком SEIZE (занято). Вход транзакта в блок SEIZE моделирует занятие ОКУ.
После обслуживания (блок, имитирующий обслуживание, будет рассмотрен в п. 6.2.3) вход того же транзакта в другой блок моделирует освобождение ОКУ. Назначением этого блока является изменение состояния ранее занятого ОКУ с "занято" в "незанято". Этим блоком является блок RELEASE (освободить).
Форматы блоков:
SEIZE A RELEASE A
В обоих блоках операнд А - это имя занимаемого (освобождаемого) ОКУ. Может быть именем, положительным целым числом, выражением в скобках, СЧА, СЧА*параметр. Планировщик автоматически обеспечивает возникновение транзактов и ОКУ, когда этого требует логика модели. В то время как транзакты находятся в модели временно, ОКУ, используемые в модели, существуют постоянно в течение всего процесса моделирования. Прежде чем освободить ОКУ, транзакт может пройти через неограниченное число блоков. Например:
SEIZE Can . . . RELEASE Can
Если ОКУ с именем Can не занято, активный транзакт занимает его. Если ОКУ занято, транзакт помещается в список задержки данного ОКУ позади транзактов с таким же приоритетом. Этот транзакт не входит в блок SEIZE. Транзакту также отказывается во входе в блок SEIZE, если ОКУ с именем CAN находится в недоступном состоянии (режим недоступности ОКУ рассматривается в п. 4.2).
ОКУ, как уже отмечалось, может иметь имя или номер. В данном случае разрешается записывать вместо операнда А номер непосредственно без предварительного присвоения его имени командой EQU. Например:
SEIZE 5 . . . RELEASE 5
Блоки SEIZE и RELEASE при необходимости создания других версий модели могут переопределяться. Для этого они должны иметь метки (не путайте с операндами А этих блоков).
6.2.3. Имитация обслуживания посредством задержки во времени
Обычно транзакт занимает ОКУ для того, чтобы немедленно начать на нем обслуживание, которое длится некоторый промежуток модельного времени. В течение этого времени транзакт должен прекратить двигаться по модели. Только по истечении времени обслуживания он должен попасть в блок RELEASE для освобождения ОКУ.
Для задержки транзакта в течение некоторого интервала модельного времени используется блок ADVANCE. Чаще всего этот интервал задается случайной переменной. Как и при использовании блока GENERATE информация, необходимая для описания соответствующего времени обслуживания и его распределения, задается операндами А и B. Формат записи блока ADVANCE следующий:
ADVANCE A,[B]
Здесь А - среднее время обслуживания, а B - способ модификации операнда А. Каждый из операндов А и B может быть именем, числом, выражением в скобках, СЧА или СЧА*параметр.
Как и в блоке GENERATE, модификаторы могут быть двух типов: модификатор-интервал и модификатор-функция, т. е. блок ADVANCE вычисляет время задержки (приращения модельного времени) такими же способами.
Если задан только операнд А, он вычисляется и используется в качестве времени задержки. Например:
ADVANCE (Normal(12,X$Sredn,X$SreOtk))
Время задержки распределено по нормальному закону со средним значением и среднеквадратическим отклонением, предварительно записанными командой INITIAL в сохраняемые ячейки с именами Sredn и SreOtk соответственно. Для генератора нормального распределения источником случайных чисел, равномерно распределенных в интервале [0, 1], является генератор номер 12.
При задании операндов А и B, и B не определяет функцию, оба операнда вычисляются (если они не константы) и в качестве времени задержки выбирается случайное число, равномерно распределенное в интервале (А-В, А+В). Для розыгрыша может быть выбран любой генератор равномерно распределенных случайных чисел. Делается это так же, как и при выборе генератора для блока GENERATE. Только номер генератора на странице "Random Numbers" (Случайные числа) в журнале настроек модели нужно указать в поле ввода ADVANCE. По умолчанию используется генератор случайных чисел номер 1. Например
ADVANCE 56.7,23.2
В данном примере входящий транзакт задерживается на время, равномерно распределенное в интервале от 33.5 до 79.9.
Так же, как и в блоке GENERATE, при любых способах вычисления времени задержки значение операнда B не должно превышать значение операнда А. Если в приведенном выше примере операнд B взять равным 56.8, в процессе моделирования произойдет останов по ошибке "Отрицательное приращение времени".
Для задания времени задержки по другому закону, отличному от равномерного, в операнде B записывается модификатор-функция. При обращении к функции определяется некоторое число - значение функции. Оно умножается на значение операнда А. Результат используется как время задержки. Например:
ADVANCE Ring,FN$Exper
В примере вычисляется значение функции с именем Exper и умножается на значение переменной пользователя Ring, которой предварительно должно быть присвоено числовое значение командой EQU.
Как отмечалось ранее, в блоке GENERATE можно использовать функции и арифметические переменные, предварительно определенные командами FUNCTION и VARIABLE или FVARIABLE. Но в этих командах не должны были быть ссылки на параметры транзактов, так как транзактов еще нет. В операндах блока ADVANCE ссылки на параметры транзактов возможны. Естественно, что этим параметрам пользователем должны быть предварительно присвоены соответствующие значения. Например:
ADVANCE P1 ADVANCE (Exponental(7,0,MX$Sred(P2,P$Stolb))) ADVANCE SrIntPost,FN*2
В первом примере транзакт задерживается на время, равное значению параметра 1. Во втором примере время задержки определяется по экспоненциальному закону. При этом среднее значение выбирается из элемента матрицы, номера строки и столбца которого содержатся в параметре 2 и параметре с именем Stolb соответственно. Для генератора экспоненциального распределения источником равномерно распределенных случайных чисел в интервале [0, 1] является генератор номер 7 (RN7).
В третьем примере время задержки находится как произведение значения переменной пользователя SrIntPost и вычисленного значения функции, номер которой содержится в параметре 2 активного транзакта.
Блок ADVANCE никогда не препятствует входу транзакта. Любое число транзактов может находиться в этом блоке одновременно.
Приведем пример использования блоков SEIZE, ADVANCE и RELEASE (см. блок-диаграмму).
Транзакт, войдя в блок SEIZE, займет ОКУ с символическим именем Rем1, задержится там благодаря блоку ADVANCE на 21±7 единиц времени и затем покинет его. После того, как транзакт войдет в блок RELEASE, планировщик попытается продвинуть транзакт в следующий блок модели, и следующий транзакт попытается использовать ОКУ, называемое Rем1.
Блок ADVANCE можно располагать в любых местах модели, а не только между блоками SEIZE и RELEASE.
Время задержки может быть также равным нулю. Если время равно нулю, транзакт в блоке ADVANCE не задерживается и переходит в следующий блок.
6.2.4. Проверка состояния одноканального устройства
Представим себе, что в какой-либо системе, модель которой вы собираетесь разработать, имеются, например, два канала передачи данных - два ОКУ. Естественно, что если один канал занят, то выясняется: свободен ли второй канал? Если он не занят, надо попытаться передать по этому каналу. Но как проверить состояние каналов в модели?
В GPSS World блок GATE используется для определения состояния устройств без изменения их состояния.
Формат записи:
GATE X A,[B]
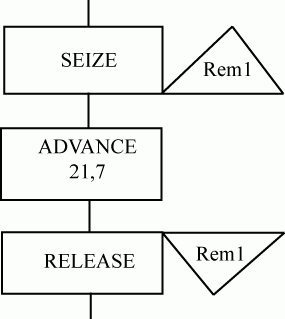
Блок GATE работает в двух режимах:
- отказа во входе;
- разрешении во входе и альтернативном выходе.
При работе в режиме отказа блок GATE не пропускает транзакты, если соответствующий объект не находится в требуемом состоянии. Если же поставленное в блоке GATE условие удовлетворяется, то активный транзакт входит в него и затем переходит к следующему по порядку блоку. Операнд А определяет имя или номер ОКУ.
Условие задается одним из следующих условных операторов X, связанных с ОКУ:
NU - ОКУ, заданное операндом А, свободно;
U - ОКУ, заданное операндом А, занято.
Как видно, тип проверяемого объекта неявно задается условным оператором (позже мы рассмотрим применение блока GATE для проверки и других объектов аппаратной категории).
Операнд B содержит номер следующего блока для входящего транзакта, когда условный оператор имеет значение "ложь". Операнды А и B могут быть именем, положительным целым числом, выражением в скобках, СЧА, СЧА*параметр. Если операнд B не используется, то проверка проводится в режиме отказа. Если результат этой проверки не будет "истина", то транзакт помещается в список повторных попыток проверяемого объекта. Когда состояние любого из объектов меняется, заблокированный транзакт снова активизируется, повторяется проверка заданного блоком GATE условия. Если это условие выполняется, транзакту разрешается войти в блок GATE и далее перейти к следующему по порядку блоку. Например:
GATE U Zrk GATE NU (FN$Expert+4) GATE NU Bat,Oper
В первом примере блок GATE не пропустит транзакт при условии незанятости ОКУ с именем Zrk. Во втором случае - когда занято ОКУ, номер которого определяется как результат вычисления и последующего округления выражения в скобках FN$Expert+4. В третьем примере в случае занятости ОКУ с именем Вat транзакт будет направлен к блоку с именем Oper.
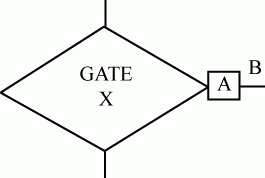
Следует отметить, что несмотря на удобство применения блока GATE, в некоторых случаях это может привести при отсутствии операнда B к увеличению машинного времени за счет проведения проверок для заблокированных транзактов. Уменьшение числа проверок и исключение из проверяемых тех транзактов, для которых вряд ли когда-нибудь результат проверки будет истинным, может быть организовано с помощью блоков LINK и UNLINK. Методы применения этих блоков будут рассмотрены позже.
Для проверки состояния различных объектов, в том числе и ОКУ, можно использовать также булевы переменные и блок TEST.
6.2.5. Методы сбора статистики в имитационной модели
6.2.5.1. Регистратор очереди
В GPSS объекты типа "очередь" вводятся для сбора статистических данных. Эта статистика должна дать ответы на вопросы:
- Сколько раз транзакты приходили в очередь?
- Сколько пришедших транзактов фактически присоединились к очереди (задержались) и сколько их сразу без задержки заняло ОКУ?
- Каково было максимальное значение длины очереди?
- Среднее число ожидающих транзактов в очереди?
- Каково было среднее время ожидания тех транзактов, которым пришлось ждать?
GPSS обеспечивает возможность сбора такой статистики с помощью средства, называемого регистратором очереди. При использовании регистратора очереди в тех точках модели, где ресурсы ограничены, планировщик начинает автоматически собирать статистику, описывающую ожидание (если оно есть), возникающее в этих точках. Регистраторы очередей различают заданием имен. Условия задания имен те же, что и у устройств. Разработчик вносит регистратор очереди в модель с помощью пары взаимодополняющих блоков QUEUE (стать в очередь) и DEPART (покинуть очередь).
Формат записи блока QUEUE следующий:
QUEUE A,[B]
Блок QUEUE увеличивает длину очереди. Операнд А задает номер или имя очереди, к длине которой добавляются единицы.
Операнд B определяет число единиц, на которое увеличивается текущая длина очереди. Если операнд B не используется, то прибавляется единица.
Рассмотрим примеры записи блока QUEUE.
QUEUE RemQ
Увеличивает длину очереди RemQ на единицу при входе каждого транзакта.
QUEUE Р14,Р1
Увеличивает длину очереди, номер или имя которой задан в параметре Р14 транзакта, на число единиц, заданных в параметре Р1.
Формат записи блока DEPART имеет вид:
DEPART A,[B]
Блок DEPART служит для уменьшения длины очереди. Операнд А задает номер или имя очереди, длину которой надо уменьшить. Операнд B задает число единиц, на которое уменьшается длина очереди. Это число не должно превышать текущую длину очереди. Если операнд B не используется, то по умолчанию длина очереди уменьшается на 1. Операнды А и B в блоках QUEUE и DEPART могут быть именем, положительным целым числом, выражением в скобках, СЧА или СЧА*параметр.
Приведем примеры записи блока DEPART.
DEPART RemQ
Уменьшает длину очереди RemQ на единицу. DEPART V3,(V4+3.7)
Операнды А и B заданы арифметической переменной V3 и выражением в скобках, которое также содержит арифметическую переменную V4. При входе транзакта в блок DEPART переменная и выражение в скобках вычисляются и округляются. После этого длина очереди, номер которой есть значение переменной V3, уменьшается на значение выражения в скобках (V4+3.7).
Очереди, как и ОКУ, разрешается записывать вместо операнда А номер без предварительного присвоения его имени командой EQU. Например:
QUEUE 5 … DEPART 5
Рассмотрим использование блоков QUEUE и DEPART в модели на примере представленной блок-диаграммы. Ожидание может возникнуть ввиду занятости ОКУ с именем Rem1. Для сбора статистики об ожидании введем регистратор очереди и дадим ему имя RemQ.
Если транзакт вошел в сегмент в момент, когда ОКУ Rem1 не занято, транзакт входит в блок QUEUE. Далее транзакт пытается войти в блок SEIZE и, поскольку Rem1 свободно, эта попытка оказывается успешной. Состояние Rem1 меняется на "занято", и далее транзакт сразу попадает в блок DEPART. Выполняется соответствующая подпрограмма и транзакт попадает в блок ADVANCE, где задерживается на некоторое время, вычисленное в соответствии с распределением ![]() .
.
Предположим теперь, что ОКУ Rem1 находится в занятом состоянии и следующий транзакт входит в сегмент модели. Он проходит в блок QUEUE и получает далее отказ, поскольку Rem1 находится в занятом состоянии. Транзакт перестает двигаться, оставаясь в блоке QUEUE.
Позднее, когда транзакт, находящийся на обслуживании в устройстве, покидает его, ожидающий транзакт опять попытается войти в блок SEIZE. На этот раз попытка окажется успешной. Двигаясь дальше, транзакт войдет в блок DEPART, уменьшая значение счетчика содержимого очереди на 1 (по умолчанию, так как операнд B не используется).
Длина очереди не может быть отрицательной. Если такое произойдет, происходит останов по ошибке "Запрещенная попытка сделать содержимое очереди отрицательным".
Останов по ошибке "Недопустимое отрицательное число в операторе GPSS. Operand B." происходит и тогда, когда при создании очереди делается попытка уменьшить ее длину.
Например:
QUEUE Server,3
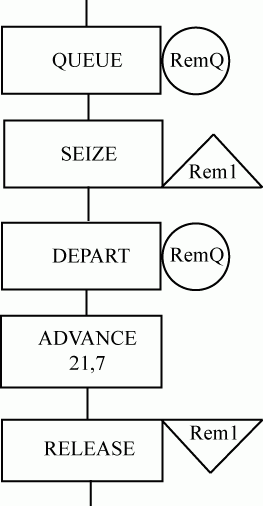
6.2.5.2. Статистические таблицы
Для получения плотности распределения, ее интегральных относительных частот, среднего значения и стандартного отклонения некоторых аргументов, которыми могут быть СЧА (например, времени нахождения транзакта в модели или задержки в ее отдельных частях, длин очередей, содержимого МКУ, коэффициентов использования устройств и т. д.), используются статистические таблицы TABLE и QTABLE.
Команда описания таблицы TABLE имеет следующий формат:
Name TABLE A,B,C,D
Команда определяет аргумент, а также число и ширину частотных интервалов (классов). Метка Name определяет имя таблицы.
Операндом А задается аргумент таблицы - элемент данных, чье частотное распределение будет табулироваться. Операнд может быть именем, выражением в скобках или СЧА.
Операндом B задается верхний предел первого частотного интервала.
Операнд С задает ширину частотного интервала - разницу между верхней и нижней границей каждого частотного класса.
Операнды B и С могут быть числами или strinq.
Операндом D задается число частотных интервалов (положительное целое число).
Для сбора данных транзакт должен войти в блок TABULATE с тем же именем таблицы, которое определено в блоке TABLE. Блок помещается в ту точку модели, которая соответствует исследуемому объекту.
Блок TABULATE имеет следующий формат:
TABULATE A,[B]
Операндом А задается имя таблицы, в которую табулируется значение аргумента.
Операндом B ( весовой коэффициент ) задается число единиц, которые должны быть занесены в тот частотный интервал, в который попало значение аргумента. Если операнд B отсутствует, то по умолчанию эта величина равна 1.
Операнды А и B могут быть именем, выражением в скобках, СЧА или СЧА*параметр. Кроме того, операнд А может быть только положительным целым числом, а операнд B - положительным числом. Например,
VrRem TABLE P$ReaLvs,8.2,5.5,10
. . .
TABULATE VrRemОператором TABLE описывается таблица с именем VrRem. Аргументом таблицы является СЧА P$ReaLvs с верхним пределом первого интервала 8.2, шириной 5.5 и числом интервалов 10. Каждое значение табулируемого аргумента P$ReaLvs, меньшее или равное 8.2, увеличивает частоту первого частотного класса таблицы на 1. Если аргумент таблицы не попадает в первый частотный класс, класс определяется делением значения аргумента на операнд С оператора TABLE. Например, значение P$ReaLvs равно 30.25. Тогда 30.25/5.5=5.5 и будет увеличена на 1 частота шестого класса. Если аргумент A таблицы больше B+C#D=8.2+5.5#10= =63.2, изменен будет на 1 последний (десятый) класс. Одновременно корректируются текущие значения СЧА таблицы: счетчик входов в таблицу ТС, среднее время ожидания ТВ и стандартное отклонение времени ожидания TD. Собранная в таблице статистика выводится в стандартный отчет.
При использовании в операнде B блока TABULATE весового коэффициента, например:
TABULATE VrRem,3
последний будет добавляться к значению частоты частотного класса. Весовой коэффициент применяется также для среднего и стандартного отклонения, что равносильно нескольким входам в блок TABULATE.
Таким образом, команда TABLE вместе с блоком TABULATE служат для табулирования любого СЧА.
Кроме таблиц TABLE могут использоваться Q -таблицы, являющиеся средством получения распределения только времени пребывания транзакта в очереди. Формат команды описания Q -таблицы такой же, как и TABLE. Отличие состоит в том, что операндом А задается имя очереди. Назначение операндов B, С, D такое же, что и в команде описания TABLE. Операнд B может быть нулем или положительным числом. Для создания в модели такой таблицы ее нужно предварительно определить с помощью команды QTABLE формата:
Name QTABLE A,B,C,D
Например:
VTime QTABLE Dlina,18.2,4.3,6
Dlina - имя очереди к устройству, а не СЧА, как в случае использования TABLE.
При прохождении транзакта через блоки QUEUE и DEPART его время ожидания фиксируется, и к счетчику частотного интервала таблицы, в который попало это время, добавляется 1. Одновременно в таблице накапливается информация для вычисления среднего значения и среднеквадратического отклонения времени ожидания. Следует обратить внимание, что при использовании QTABLE информация в таблицу заносится автоматически при входе транзакта в блоки QUEUE и DEPART и никаких специальных мер, т. е. блока TABULATE, при этом не требуется. По окончании моделирования собранная в таблице информация также выводится в стандартном отчете GPSS.
6.2.6. Методы изменения маршрутов движения транзактов в модели
Для изменения маршрутов движения транзактов в модели применяются блоки DISPLACE, LOOP, GATE, TEST и TRANSFER. Здесь мы рассмотрим методы применения блоков TRANSFER и DISPLACE.
6.2.6.1. Блок TRANSFER
Блок TRANSFER (передать) предназначен для передачи входящего в него транзакта в любой другой блок модели. Он имеет следующий формат:
TRANSFER [A],[B],[C],[D]
Все режимы блока TRANSFER, кроме безусловного, выборочные, т. е. отличаются друг от друга способом выбора очередного блока, к которому должен быть направлен активный транзакт. Операнд А задает этот режим выбора. Существуют следующие девять режимов работы блока TRANSFER:
- , (по умолчанию) - безусловный;
- - статистический, выбор случайным образом одного из двух блоков;
- ВОТН - последовательный выбор одного из двух блоков;
- ALL - последовательный выбор одного из нескольких блоков;
- PICK - выбор случайным образом одного из нескольких блоков;
- FN - функциональный;
- P - параметрический;
- SBR - подпрограммный;
- SIM - одновременный.
Операнд А может принимать указанные выше значения, а также может быть именем, положительным целым числом, выражением в скобках, СЧА, СЧА*параметр.
Операнды B и С задают возможные значения номеров следующих блоков или их положение. Они могут быть такими же, как и операнд А. Использование этих значений будет описано ниже при рассмотрении указанных выше режимов работы. Если операнд B опущен, то планировщик записывает вместо него номер блока, следующего за блоком TRANSFER.
Рассмотрим режимы безусловной передачи и статистической передачи блока TRANSFER, как наиболее часто используемые в моделях.
Режим безусловной передачи. B режиме безусловной передачи операнд А не используется. Операнд B указывает имя блока, в который транзакт должен попытаться войти. Блок TRANSFER не может отказать транзакту во входе.
Например:
TRANSFER ,Oper
После входа транзакт сразу же пытается войти в блок с меткой Oper. Если этот блок отказывает во входе, транзакт остается в блоке TRANSFER.
Рассмотрим еще один пример использования безусловного режима блока TRANSFER. Пусть требуется поток обслуженных транзактов перед удалением из модели разделить на четыре составляющие. Первый параметр каждого транзакта имеет одно из четырех присвоенных ранее значений: 1, 2, 3 или 4. Вначале для разделения потока используем блок TEST.
. . .
TEST E P1,1,Met2
Met2 TERMINATE
TEST E P1,2,Met3
TERMINATE
Met3 TEST E P1,3,Met4
TERMINATE
Met4 TERMINATE
Теперь этот же фрагмент модели перепишем с использованием блока TRANSFER.
. . .
Met1 TRANSFER ,(Met1+P1)
TERMINATE
TERMINATE
TERMINATE
TERMINATEВ блоке TRANSFER в качестве операнда B указано выражение в скобках. При входе активного транзакта выражение вычисляется, т. е. к номеру, который присвоен планировщиком блоку с меткой Met1, прибавляется значение первого параметра. В итоге получается номер блока, к которому и направляется транзакт.
Режим статистической передачи. Когда операнд А используется и не является зарезервированным словом, блок TRANSFER работает в режиме передачи транзакта в один из двух блоков случайным образом.
Значение операнда А, записываемого после точки, рассматривается как трехзначное число, показывающее (в долях от тысячи), какая доля входящих в блок транзактов должна быть направлена в блок С. Остальные транзакты направляются в блок B или к следующему по номеру блоку, если операнд B опущен.
Числовое значение операнда А может быть задано любым СЧА. При этом возможны следующие случаи:
- значение операнда А меньше или равно нулю;
- значение операнда А равно или больше 1 000 ;
- значение операнда А больше нуля, но меньше 1 000.
Если вычисленное значение операнда А меньше или равно нулю, то будет производиться безусловная передача транзакта к блоку B. Если значение операнда А больше или равно 1 000, то будет осуществляться безусловная передача транзакта к блоку С. В третьем случае блок TRANSFER работает в обычном режиме.
Например:
TRANSFER .P5,,Rrw
Трехзначное число, записанное в параметре 5 транзакта, входящего в блок TRANSFER, интерпретируется как вероятность (в долях от тысячи) того, что транзакт будет передаваться блоку Rrw, а в остальных случаях - следующему блоку, так как операнд B не используется.
Режим статистической передачи удобно использовать, например, в таких случаях. При моделировании работы цеха по производству деталей известно, что 12,5% изготовленных деталей бракуется. В модели это можно реализовать так:
. . . TRANSFER .125,Sam,Wzw . . .
Транзакты, имитирующие изготовленные в цехе детали, в 12,5% случаев будут направлены к блоку с
меткой Wzw, а в остальных 87,5% случаях - к блоку с меткой Sam.
Можно указать генератор - источник случайных чисел. Для этого нужно выбрать Edit/Settings ( Правка/Настройки ). Затем выбрать страницу Random Numbers ( Случайные числа ) и ввести номер генератора в поле ввода, отмеченное TRANSFER. После инсталляции по умолчанию используется генератор номер 1.
6.2.6.2. Блок DISPLACE
Блок DISPLACE предназначен для нахождения любого тран-закта и перемещения его к новому блоку. Блок DISPLACE имеет формат:
DISPLACE A,B,[C],[D]
Операнд А - номер транзакта, который нужно переместить.
Операнд B - метка блока, к которому перемещается транзакт, указанный операндом А.
Операнд С - номер параметра перемещаемого транзакта, в который записывается оставшееся до конца его обслуживания время, если он находился в списке будущих событий.
Операнд D - метка альтернативного блока для транзакта.
Операнды А, B, С и D могут быть именем, положительным целым числом, выражением в скобках, СЧА или СЧА*параметр. Например:
DISPLACE (P2+32),Term3,Ostatok,Met2
Операнд А указан выражением в скобках. Это выражение вычисляется и округляется до целого. Полученный результат является номером транзакта, который следует переместить. Далее блок DISPLACE отыскивает этот транзакт. При этом возможны случаи:
- транзакт есть в модели, и не находится в списке будущих событий;
- транзакт есть в модели, и находится в списке будущих событий;
- транзакта с нужным номером нет в модели. В первом случае транзакт перемещается к блоку с меткой
Term3. Во втором случае определяется время, оставшееся до его повторного ввода в процесс моделирования, и записывается в параметр с именем Ostatok. Если параметра с таким именем нет, он создается. Транзакт также перемещается к блоку с меткой Term3. В третьем случае, т. е. когда в модели нет транзакта с нужным номером, активный транзакт, вошедший в блок DISPLACE, направляется к блоку с меткой Met2. Если операнда D нет, активный транзакт переходит к следующему блоку.
Когда транзакт перемещается к новому блоку, он исключается из списков:
- будущих событий;
- отложенных прерываний (для прерывающих транзактов);
- задержки (в порядке приоритета);
- пользователя;
- повторных попыток. И не исключается из списков:
- текущих событий;
- прерываний (для прерванных транзактов);
- групп.
При перемещении прерванные выполнения в устройствах не сбрасываются.
Это означает, что перемещаемый транзакт продолжает занимать устройство. Следовательно, если необходимо, нужно освободить устройство.
Пример использования блока DISPLACE приведен в п. 6.8.2.
6.2.7. Прерывание функционирования одноканального устройства
Если на входе ОКУ образуется очередь, выбор транзакта для ОКУ занятия после его освобождения происходит:
- в порядке поступления (FIFO) - для транзактов с равными приоритетами;
- с учетом приоритета, указанного операндом Е блока GENERATE.
При этом очередной транзакт с большим приоритетом ждет окончания обслуживания предыдущего транзакта независимо от его приоритета. Приоритет учитывается только в образующейся очереди. В ней транзакты выстраиваются в приоритетном порядке.
Такой режим функционирования ОКУ организуется блоками SEIZE и RELEASE, рассмотренными в п. 6.2.2.
Однако может возникнуть необходимость смоделировать ситуацию, когда очередной транзакт должен занять ОКУ, прервав обслуживание предыдущего транзак-та. Такое прерывание называется "захватом" ОКУ и моделируется блоком PREEMPT (захватить). Формат блока:
PREEMPT A,[B],[C],[D],[E]
Операнд А - имя или номер захватываемого ОКУ.
Когда ОКУ свободно (см. блок-диаграмму), блок PREEMPT работает также, как и блок SEIZE.
При занятом ОКУ блок PREEMPT функционирует либо в приоритетном режиме, либо в режиме прерывания. Режимы определяются операндом B:
- PR - приоритетный;
- по умолчанию ( B не используется) - режим прерывания.
6.2.7.1. Прерывание в приоритетном режиме
В приоритетном режиме прервать обслуживание предыдущего (обслуживаемого) транзакта, т. е. "захватить" ОКУ, может только транзакт с большим приоритетом. Если приоритет претендующего на занятие ОКУ транзакта равен или ниже приоритета обслуживаемого транзакта, он помещается в список задержки ОКУ последним в своем приоритете.
Что делать с транзактом, обслуживание которого прерывается? Это определяют операнды С, D и Е.
Операнд С - имя или номер блока, куда должен быть направлен прерванный транзакт.
Операнд Е при значении RE определяет режим удаления прерванного транзакта.
Операнд D - номер параметра прерванного транзакта, в который записывается оставшееся до завершения обслуживания время.
Операнды А, С, D и Е могут быть именем, положительным целым числом, выражением в скобках, СЧА или СЧА*параметр.
Транзакт, захвативший ОКУ, освобождает его от захвата вхождением в блок RETURN.Формат блока:
RETURN A
Операнд А - имя или номер освобождаемого ОКУ. Например:
RETURN Rem1
Освободить от захвата ОКУ Rem1.
Применение блоков PREEMPT и RETURN показано в п. 6.5.5.
6.2.7.2. Прерывание в режиме "захвата"
В режиме "захвата", если ОКУ уже используется, активный транзакт помещается в список отложенных прерываний или "захватывает" ОКУ. Прерывание обслуживания сразу, а не помещение транзакта в список, происходит тогда, когда список отложенных прерываний пуст и обслуживаемый транзакт сам не является "захватчиком".
Транзактам из списка отложенных прерываний предоставляется право занять ОКУ ранее, чем прерванным транзактам или транзак-там из списка задержки ОКУ.
6.2.7.3. Проверка состояния одноканального устройства, функционирующего в приоритетном режиме
Проверка состояния ОКУ в приоритетном режиме может проводиться блоком GATE, а также с использованием булевой переменной и блока TEST.
Рассмотрим проверку состояния ОКУ блоком GATE.
Условие проверки задается одним из следующих условных операторов Х:
- I - ОКУ, заданное операндом А, прервано;
- NI - ОКУ, заданное операндом А, не прервано.
Например:
GATE I Stan GATE NI (V$Rasp-3) GATE I Print,Udal GATE I *1
В первом примере блок GATE пропустит транзакт, когда ОКУ Stan будет прервано. Во втором примере транзакт пройдет к следующему блоку, когда не прервано ОКУ, номер которого определяется как результат вычисления и последующего округления до целого выражения в скобках ( V$Rasp-3 ). В третьем примере в случае прерывания ОКУ Print транзакт будет направлен к блоку с меткой Udal.
В первом и втором примерах блок GATE работает в режиме отказа во входе в случае невыполнения условия. Здесь также остается справедливым замечание, сделанное в п. 6.2.4: отсутствие операнда В может привести к увеличению машинного времени моделирования. Однако в некоторых случаях такой режим, наверное, можно использовать.
6.2.8. Недоступность одноканального устройства
Для моделирования неисправностей ОКУ и других ситуаций в GPSS World предусмотрены блоки, реализующие недоступность и доступность ОКУ. При использовании этих блоков статистика ОКУ не искажается. Здесь имеется в виду следующее. Для моделирования, например, неисправностей можно использовать и режим прерывания ( PREEMPT ). Однако при этом транзакты, вызывающие прерывания (имитирующие отказы ОКУ), учитываются в статистике, как и транзакты, обслуженные при исправном функционировании ОКУ. А это неправильно, вследствие чего и искажается статистика ОКУ.
6.2.8.1. Перевод в недоступное состояние и восстановление доступности
Недоступность ОКУ моделируется блоком FUNAVAIL (символ F означает ОКУ, UNAVAIL - недоступный). При использовании этого блока статистика ОКУ не искажается.
Формат блока:
FUNAVAIL A,[B],[C],[D],[E],[F],[G],[H]
Блок делает недоступным ОКУ с именем или номером, указываемым операндом А (см. блок-диаграмму).
Все транзакты, обрабатываемые блоком FUNAVAIL, разделяются на три класса, которые и определяют назначение операндов:
- транзакт, занимающий ОКУ (по SEIZE или PREEMPT ) в момент перевода его в недоступное состояние (операнды B, C, D );
- ранее прерванные транзакты, находящиеся в списке прерываний (операнды E, F );
- транзакты, находящиеся в списке отложенных прерываний и в списке задержки ОКУ (операнды G, H ).
Операндом B задаются режимы обработки транзакта, занимающего ОКУ в момент перевода его в недоступноcть:
- СО - режим продолжения: продолжить обработку занимающего ОКУ транзакта во время недоступности;
- RE - режим удаления: удалить и направить занимающий ОКУ транзакт к блоку, метка которого должна быть указана операндом С;
- по умолчанию - прервать обработку и поместить в список прерываний ОКУ; после восстановления доступности этот транзакт может занять ОКУ и "дообслужиться".
Операнд С - метка блока, в который будет направлен в режиме удаления транзакт, занимавший ОКУ в момент перевода его в недоступное состояние.
Операнд D - номер или имя параметра транзакта, занимавшего ОКУ в момент перевода его в недоступное состояние; если он будет удален (режим RE ), т. е. исключен из СБС, в этот параметр будет записано время, оставшееся удаленному транзакту до конца обслуживания.
Операндом Е задаются режимы обработки транзактов, находящихся к моменту перевода ОКУ в недоступное состояние в списке прерываний, т. е. тех транзактов, обслуживание которых на данном ОКУ было ранее прервано:
- СО - режим продолжения: продолжить работу ОКУ во время недоступности - обслуживать транзакты из списка прерываний;
- RE - режим удаления: удалить и направить транзакты из списка прерываний к новому блоку, метка которого должна быть указана операндом F ;
- по умолчанию - оставить ранее прерванные транзакты в списке прерываний ОКУ и запретить им занимать его во время недоступности.
Операнд F указывает метку блока, к которому будут направлены транзакты из списка прерываний ОКУ, из-за чего они не могут находиться в СБС, поэтому для них нет возможности занесения в их параметры времени, оставшегося до конца обслуживания.
Операнд F может использоваться и тогда, когда отсутствует операнд E (по умолчанию). В этом случае для перемещенных к новому блоку транзактов прерывание обслуживания сохраняется.
Операндом G задаются режимы обработки транзактов, находящихся к моменту перевода ОКУ в недоступное состояние в списке отложенных прерываний, т. е. ожидающих выполнения с прерыванием, и в списке задержки:
- СО - режим продолжения: продолжить работу ОКУ во время недоступности - обслуживать транзакты из списка отложенных прерываний и списка задержки;
- RE - режим удаления: удалить и направить транзакты из списка отложенных прерываний и списка задержки к новому блоку, метка которого должна быть указана операндом H ;
- по умолчанию - оставить транзакты в списке отложенных прерываний и списке задержки ОКУ и запретить им занимать его во время недоступности.
Операндом H указывается метка нового блока, к которому в режиме удаления ( RE ) направляются транзакты из списка отложенных прерываний и списка задержки. Когда операнд G не используется, нельзя использовать и операнд H.
Недоступность ОКУ сохраняется до тех пор, пока транзакт, вызвавший переход в недоступное состояние, не войдет в блок
FAVAIL A
Блок FAVAIL изменяет состояние ОКУ на доступное, т. е. восстанавливает обычный режим вхождения транзактов в ОКУ. Все транзакты, ожидающие доступного состояния ОКУ, указанного операндом А, активизируются и могут попытаться занять его.
Применение блоков FUNAVAIL и FAVAIL показано в п. 6.7.5.
6.2.8.2. Проверка состояний недоступности и доступности одноканального устройства
Проверка состояния ОКУ в режиме недоступности проводится блоком GATE. Формат блока см. п. 6.2.4.
Условие проверки задается одним из следующих условных операторов Х:
FNV - ОКУ, заданное операндом А, недоступно ;
FV - ОКУ, заданное операндом А, доступно.
Например:
GATE FNV Stan GATE FV (FN$Rasp-X$Col) GATE FNV Print,Udal
В первом примере блок GATE пропустит транзакт, когда ОКУ Stan будет недоступно.
Во втором примере транзакт пройдет к следующему блоку, когда доступно ОКУ, номер которого определяется как результат вычисления и последующего округления до целого выражения в скобках (FN$Rasp-X$Col).
В третьем примере в случае доступности ОКУ Print, т. е. не выполнения заданного в блоке GATE условия, транзакт будет направлен к блоку с меткой Udal.
В первом и втором примерах блок GATE работает в режиме отказа, если условия не выполняются. Здесь также остается справедливым замечание, сделанное в п. 6.2.4: отсутствие операнда В может привести к увеличению времени моделирования.
6.2.9. Сокращение машинного времени и изменение дисциплин обслуживания методом применения списков пользователя
При движении по модели транзакты могут быть заблокированы, например, как отмечалось ранее, при проверке состояния ОКУ блоками GATE и TEST. Если заблокированные транзакты находятся в списке текущих событий (СТС), то при большом их количестве планировщик расходует много времени на просмотр СТС с целью выбора очередного транзакта для продвижения.
Для экономии машинного времени заблокированные транзакты целесообразно помещать в списки пользователя и оставлять их там до тех пор, пока не будут выполнены условия, позволяющие дальнейшее продвижение этих транзактов. Кроме того, этим предоставляется возможность организовать различные дисциплины очередей, отличающиеся от дисциплины FIFO, реализованной в списке текущих событий.
Список пользователя представляет собой некоторый буфер, в который могут временно помещаться транзакты, выведенные из СТС. В отличие от списков текущих и будущих событий тран-закты вводятся в список пользователя и выводятся из него не автоматически, а по решению пользователя в соответствии с логикой модели при помощи специальных блоков.
Для ввода транзактов в список пользователя служит блок LINK (ввести в список), который может быть использован в режимах:
- условном;
- безусловном.
6.2.9.1. Ввод транзактов в список пользователя в безусловном режиме
В безусловном режиме, блок LINK имеет формат записи: [имя] LINK A,B
Операндом А задается имя или номер списка пользователя, в который безусловно помещается транзакт, вошедший в блок LINK.
Операнд B определяет, в какое место списка пользователя следует поместить вошедший транзакт. Допустимые значения:
- FIFO - транзакт помещается в конец списка;
- LIFO - транзакт помещается в начало списка;
- PR - транзакты помещаются по убыванию приоритета;
- Р - транзакты помещаются позади тех транзактов, значения соответствующего параметра которых меньше (в порядке возрастания значения параметра);
- М1 - транзакты помещаются в порядке возрастания относительного времени их пребывания в модели.
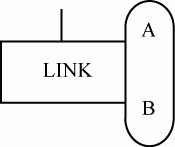
В качестве операнда B могут использоваться и другие СЧА, кроме указанных ранее СЧА транзактов: арифметическая переменная, функция, а также выражение в скобках. В этом случае выполняется вычисление указанного операндом B для активного транзакта и для всех остальных транзактов, уже находящихся в списке пользователя, начиная с начала очереди. После этого производится упорядочивание транзактов в списке пользователя по убыванию вычисленного значения. Например, блок
LINK 3,FIFO
помещает транзакты в конец списка пользователя с номером 3 в порядке их поступления в блок. Блок
LINK Otst,P$Pol
помещает транзакты в список пользователя с именем Otst, упорядочивая их по возрастанию значения параметра с именем Pol.
Условия, при которых транзакт помещается в список пользователя, в безусловном режиме проверяются средствами, предусмотренными разработчиком модели. Например, направить транзакт в список пользователя в случае занятости ОКУ можно так, как показано ниже.
. . .
GATE NU Rem1,Wait
SEIZE Rem1
. . .
Wait LINK Otst,FIFO
. . .Если ОКУ Rem1 занято, блок GATE не впускает транзакт в блок SEIZE, а направляет его в блок LINK с именем Wait, и тран-закт вводится в конец списка пользователя с именем Otst.
В том же фрагменте модели список пользователя можно разместить и иначе.
. . .
GATE U Rem1,Met1
LINK Otst,FIFO
Met1 SEIZE Rem1
. . .Здесь ОКУ Rem1 проверяется на занятость. Если ОКУ занято, транзакт проходит к следующему блоку LINK и помещается в список пользователя с именем Otst. В случае незанятости ОКУ, транзакт направляется к блоку SEIZE с меткой Met1 и занимает свободное ОКУ.
В только что рассмотренных примерах предполагается, что список пользователя неограничен, т. е. в него может помещаться любое количество транзактов. При моделировании реальных систем список пользователя может использоваться для имитации, например, входного накопителя, емкость которого, как правило, ограничена. Это ограничение можно реализовать следующим образом.
Emk EQU 10
. . .
GATE NU Rem1,Wait
SEIZE Rem1
. . .
Wait TEST L CH$Otst,Emk,Term1
LINK Otst,LIFOЕсли ОКУ Rem1 занято, то блок GATE не впускает транзакт в блок SEIZE, а направляет его в блок TEST с меткой Wait, находящийся перед блоком LINK. Если текущее содержимое списка пользователя с именем Otst меньше заданной емкости Emk, тран-закт проходит в список пользователя, в противном случае направляется к блоку с меткой Term1.
Приведем еще возможный вариант этого же фрагмента модели.
Emk EQU 10
. . .
GATE U Rem1,Met1
TEST L CH$Otst,Emk,Term1
LINK Otst,LIFO
Met1 SEIZE Rem1Если ОКУ Rem1 занято, блок GATE пропускает транзакт к блоку TEST. Если текущее содержимое списка пользователя с именем Otst меньше заданной емкости Emk, транзакт проходит в список пользователя, в противном случае направляется к блоку с меткой Term1. Если ОКУ незанято, транзакт направляется к блоку SEIZE с меткой Met1 и занимает свободное ОКУ Rem1.
6.2.9.2. Вывод транзактов из списка пользователя в условном режиме
Для вывода одного или нескольких транзактов из списка пользователя и помещения их обратно в список текущих событий служит блок UNLINK (вывести из списка), имеющий следующий формат:
[имя] UNLINK X A,B,C,[D],[E],[F]
Операндом А указывается имя или номер списка пользователя.
Операнд B - метка блока, в который переходят выведенные из списка пользователя транзакты.
Операндом С указывается число выводимых транзактов или ключевое слово ALL для вывода всех находящихся в списке транзактов. По умолчанию, т. е. когда не используется операнд С, берется слово ALL.
Операнды D и E вместе с условным оператором Х определяют способ и условия вывода транзактов из списка пользователя. Значения оператора Х те же, что и в блоке TEST. В случае, когда условный оператор Х должен использоваться, но не указан, по умолчанию он принимает значение Е (равенство). Если операнды D и Е не используются, не указывается и условный оператор Х. В этом случае транзакты выводятся с начала списка, а количество выводимых транзактов определяется обязательным операндом С.
Операнд D может быть:
- булевой переменной;
- номером параметра транзакта;
- ключевым словом BACK.
Если операнд D является булевой переменной, операнд Е и оператор Х не используются. Булева переменная вычисляется относительно транзакта, находящегося в списке пользователя. Если результат не нуль, т. е. условие вывода выполняется, транзакт выводится. Количество выводимых транзактов определяется операндом С. Однако выведено может быть и меньше, чем указано операндом С: по числу не нулевых результатов вычисления булевой переменной. Кроме того и транзактов в списке пользователя может быть меньше, чем указано операндом С.
Если операндом D указано ключевое слово BACK, также операнд Е и условный оператор Х не используются, а транзакты выводятся с конца списка в количестве, определяемом обязательным операндом С.
Если операнд D не булева переменная и не ключевое слово BACK, должны быть указаны операнд Е и условный оператор Х. Операнд D вычисляется относительно транзакта, находящегося в списке пользователя, и используется в качестве номера параметра, значение которого сравнивается с результатом вычисления операнда Е.
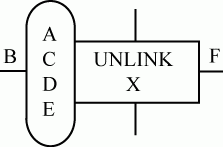
Если операнд D задает параметр, а операнд Е не используется, значение параметра транзакта из списка пользователя сравнивается со значением такого же параметра выводящего транзакта. Если они равны, транзакт выводится из списка пользователя. И в этом случае количество выводимых транзактов определяется операндом С.
Операндом F указывается имя блока, куда переходит транзакт, выходящий из блока UNLINK, если из списка пользователя не выведен ни один транзакт. Если операнд F не используется, выходящий транзакт переходит в следующий блок независимо от количества выведенных транзактов.
Например, блок
UNLINK 4,Apd,1
выводит из списка пользователя с номером 4 один транзакт с начала списка и направляет его в блок с меткой Apd. Блок
UNLINK Otst,Mars,1,BACK
выводит из списка пользователя с именем Otst один транзакт с конца списка и направляет его в блок с меткой Mars. Блок
UNLINK E P$Wiw,App1,ALL,App2,P$App2,App3
выводит из списка пользователя, номер которого записан в параметре Wiw выводящего транзакта, и направляет в блок с меткой App1 все транзакты, содержимое параметра App2 которых равно содержимому одноименного параметра выводящего транзакта. Если таких параметров в списке не окажется, выводящий транзакт будет направлен в блок с меткой Аpp3, в противном случае - к следующему блоку.
Примеры применения списков пользователя (блоков LINK и UNLINK ) показаны в п. 6.3 и 6.7.
6.2.10. Построение моделей систем с многоканальными устройствами и переключателями
Два или более обслуживающих устройств могут быть промоделированы на GPSS двумя или более ОКУ, располагаемыми рядом, т. е. параллельно. Так нужно поступать, когда отдельные устройства являются разнородными, т. е. характеризуются различными свойствами, например, различной интенсивностью обслуживания.
Однако часто различные параллельно работающие устройства являются однородными. GPSS представляет для моделирования однородных параллельных устройств специальное средство, именуемое многоканальным устройством. МКУ может быть использовано несколькими транзактами одновременно. Ограничений на число МКУ в модели нет. Для различия им дают имена.
МКУ определяется до его использования командой STORAGE. Формат команды:
Name STORAGE A
Name - имя МКУ. Символическому имени может быть поставлен в соответствие номер командой EQU. Это необходимо, если требуется обращаться к нескольким МКУ в блоках SELECT и COUNT или в других случаях. Операнд А может быть только целым положительным числом. Иные способы задания емкости вызывают ошибку.
В модели можно организовать функционирование МКУ в двух режимах:
- занятие и освобождение МКУ;
- недоступность МКУ.
6.2.10.1. Занятие многоканального устройства и его освобождение
Занятие и освобождение МКУ имитируется блоками ENTER (войти) и LEAVE (выйти). Форматы блоков:
ENTER A,[B] LEAVE A,[B]
Операнд А в обеих блоках используется для указания имени, соответствующего МКУ. Операнд B задает число устройств (элементов памяти), которое должно быть занято в блоке ENTER или освобождено в блоке LEAVE. По умолчанию операнд В = 1. При В = 0 блок считается неработоспособным.
Когда транзакт входит в блок ENTER, операнд А используется для нахождения МКУ с указанным именем. Если такого МКУ нет, происходит останов по ошибке "Обращение к несуществующей памяти". Если МКУ существует и задан операнд B, он вычисляется, округляется до целого и полученный результат используется для оценки свободной емкости. Транзакт может войти в блок ENTER, если МКУ находится в доступном состоянии и достаточно емкости для выполнения запроса. В противном случае транзакт помещается в список задержки устройства в соответствии с приоритетом.
Когда транзакт входит в блок ENTER (см. блок-диаграмму), планировщик выполняет следующие действия:
- увеличивает на 1 счетчик входов МКУ;
- увеличивает на значение операнда B (по умолчанию на 1 ) текущее содержимое МКУ;
- уменьшает на значение операнда B (по умолчанию на 1 ) доступную емкость МКУ.
Если транзакт при входе в блок ENTER запрашивает больше устройств (элементов памяти), чем определено командой STORAGE, т. е. ее операнд А меньше операнда B блока ENTER, возникает ошибка "Запрос элементов памяти превышает ее общую емкость".
МКУ никогда не может быть удалено из текущей модели, даже если команда STORAGE удаляется из рабочей программы. МКУ можно переопределить, т. е. изменить емкость другой командой STORAGE с тем же самым именем. Например:
Batr STORAGE 18
Повторное описание:
Batr STORAGE 24
Имитация обслуживания транзакта в течение какого-то промежутка времени также осуществляется блоком ADVANCE.
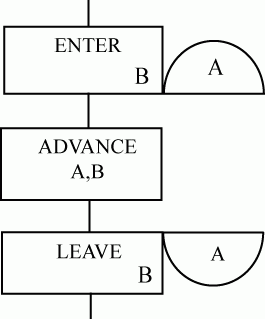
Пример 1.
Nak STORAGE 20
. . .
ENTER Nak,2
ADVANCE 120,40
LEAVE Nak,2
. . .Командой STORAGE определяется МКУ с именем Nak емкостью 20 единиц. При входе транзакта в блок ENTER занимается 2 единицы и столько же освобождается в блоке LEAVE при выходе из МКУ.
Пример 2.
Nak STORAGE 20 . . . ENTER Nak,21 ADVANCE 120,40 LEAVE Nak,2 . . .
При входе транзакта в блок ENTER произойдет останов по ошибке, так как транзакт будет пытаться занять больше каналов (21), чем определено (20) командой STORAGE. То же самое произойдет, если при выходе из блока LEAVE транзакт будет пытаться освободить каналов больше, чем определено командой STORAGE.
Пример 3.
Pun1 EQU 1 Pun2 EQU 2 Pun3 EQU 3 Pun1 STORAGE 6 Pun2 STORAGE 5 Pun3 STORAGE 3 . . . ENTER *1 ADVANCE MX$NorVr(P2,P3) LEAVE *1 . . .
В данном примере определены три МКУ с именами Pun1, Pun2, Pun3 и емкостями 6, 5 и 3 соответственно. Именам командами EQU поставлены в соответствие номера 1, 2 и 3.
Предполагается, что при входе транзакта в блок ENTER в его первом параметре (ссылка *1) содержится какой-либо один из трех номеров. Согласно этому номеру и занимается МКУ, а затем освобождается. Операнд B в блоках ENTER и LEAVE не используется, поэтому транзактом занимается и освобождается одна единица емкости МКУ.
Ранее (см. табл. 6.1) для МКУ был употреблен термин "память". Это связано с тем, что блоки ENTER и LEAVE могут быть использованы для имитации функционирования запоминающих устройств, например, оперативного или внешних устройств памяти. В этом случае в качестве операнда B этих блоков может быть использован один из параметров транзакта, имитирующего, например, сообщение, содержащий количество занимаемых (освобождаемых) ячеек памяти. Пример такого использования блоков ENTER и LEAVE приведен в 6.7.5.
6.2.10.2. Перевод многоканального устройства в недоступное состояние и восстановление его доступности
Недоступность МКУ моделируется блоком SUNAVAIL (символ S означает МКУ, UNAVAIL - недоступный). Формат блока:
SUNAVAIL A
Операнд А - имя или номер МКУ, может быть именем, положительным целым числом, выражением в скобках, СЧА, СЧА*параметр.
Например:
SUNAVAIL Batr
Когда транзакт входит в этот блок, МКУ Batr становится недоступным. Если при переводе в недоступное состояние в МКУ находились транзакты, т. е. текущее содержимое МКУ не равнялось нулю, то обслуживание этих транзак-тов продолжается, пока текущее содержимое не станет равным нулю.
Транзакты, которые пытаются занять МКУ во время нахождения его в недоступном состоянии, не входят в блок ENTER и помещаются в список задержки МКУ.
Нахождение в недоступном состоянии продолжается до тех пор, пока транзакт не войдет в блок SAVAIL.
Формат блока:
SAVAIL A
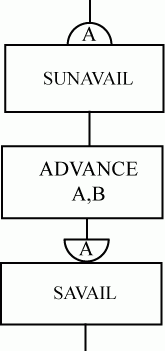
Операнд А - имя или номер МКУ. Может быть таким же, как операнд А в блоке SUNAVAIL.
Если в момент перевода МКУ в доступное состояние в его списке задержки были транзакты, им предоставляется возможность занять МКУ в соответствии с дисциплиной "first-fit-with-skip" (первый подходящий с пропусками).
Транзакты, которым будет отказано в занятии МКУ, остаются в его списке задержки.
6.2.10.3. Проверка состояния многоканального устройства
Состояние МКУ, как и состояние ОКУ, проверяется блоком GATE такого же формата
GATE X A,[B]
Отличие состоит в значениях условного оператора Х, которые могут быть следующими:
- SE - МКУ, заданное операндом А, пусто;
- SF - МКУ, заданное операндом А, заполнено;
- SNE - МКУ, заданное операндом А, не пусто;
- SNF - МКУ, заданное операндом А, не заполнено;
- SNV - МКУ, заданное операндом А, не доступно;
- SV - МКУ, заданное операндом А, доступно. Блок GATE также работает в двух режимах:
- отказа во входе;
- разрешении во входе и альтернативном выходе.
Например:
GATE SNF Can,Met5
Если МКУ с именем Can не заполнено, т. е. имеются свободные каналы (элементы памяти), заданное в блоке GATE условие выполняется, и транзакт будет направлен к следующему блоку. Если МКУ заполнено, транзакт будет направлен к блоку с меткой Met5.
Блок GATE позволяет только определить состояние не заполненности МКУ, т. е. наличие свободных каналов, но достаточно ли их для удовлетворения запроса, он не определяет.
Для проверки состояния МКУ могут также использоваться булева переменная и блок TEST [5]. Их использование позволяет расширить возможности по осуществлению проверок состояния, а также сократить машинное время, так как в одном блоке с помощью булевой переменной может проверяться сразу несколько условий.
6.2.10.4. Моделирование переключателей
Для моделирования такого оборудования как переключатели, имеющие только два состояния, в GPSS используются логические ключи. Логический ключ может находиться в одном из двух состояний:
- включен ( ON или 1 );
- выключен ( OFF или 0 ). В зависимости от состояния ключа изменяется направление движения транзактов.
Логический ключ моделируется блоком LOGIC. Формат блока:
LOGIC X A
Операнд А - имя или номер логического ключа. Может быть именем, положительным целым числом, выражением в скобках, СЧА или СЧА*параметр.
Логический оператор Х - состояние логического ключа устанавливается в зависимости от следующих его значений:
- S - ключ, заданный операндом А, включается;
- R - ключ, заданный операндом А, выключается;
- I - логический ключ инвертируется, т. е. состояние его меняется на противоположное, например, если был включен, будет выключен.
Состояние логического ключа проверяется также блоком GATE. Блок GATE имеет такой же формат, как и при проверке состояний ОКУ и МКУ, и два режима работы:
GATE X A,[B]
Операнд А - имя или номер проверяемого ключа. Может быть именем, положительным целым числом, выражением в скобках, СЧА или СЧА*параметр.
Операнд B - метка блока, к которому будет направлен тран-закт при невыполнения условия, заданного оператором Х.
Условный оператор может принимать значения:
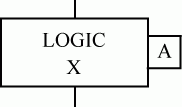
- LS - равен 1, если логический ключ, заданный операндом А, включен; 0 - если выключен;
- LR - равен 1, если логический ключ, заданный операндом А, выключен; 0 - если включен.
6.3. Решение прямой и обратной задач в системе моделирования
При имитационном моделировании с использованием специальных инструментальных средств, например, GPSS World, в общем случае решаются две задачи. Назовем их прямой и обратной.
Прямая задача заключается в нахождении оценки математического ожидания какого-либо параметра моделируемой системы при заданном времени ее функционирования.
Обратная задача состоит в определении оценки математического ожидания времени функционирования моделируемой системы, за которое какой-либо ее показатель достигает заданного значения.
Решение этих задач, особенно обратной задачи, имеет свои особенности. Рассмотрим эти особенности на примере.
6.3.1. Постановка прямой и обратной задач
Пример 6.1. Сервер обрабатывает запросы, поступающие с автоматизированных рабочих мест (АРМ) с интервалами, распределенными по показательному закону со средним значением T1= 2 мин. Вычислительная сложность запросов распределена по нормальному закону с математическим ожиданием S1 = 6 x 107 оп и среднеквадратическим отклонением S2 = 2*105 Производительность сервера Q = 6*105 оп /c. В случае занятости сервера поступающий запрос теряется.
Сервер представляет собой однофазную систему массового обслуживания разомкнутого типа с отказами.
Прямая задача.Построить имитационную модель для определения оценки математического ожидания количества запросов (дальше - количества запросов), обработанных сервером за время функционирования T = 1 час, и оценки математического ожидания вероятности обработки запросов (дальше - вероятности обработки запросов).
Обратная задача.Построить имитационную модель для определения оценки математического ожидания времени (дальше - времени обработки), за которое будет обработано сервером N запросов, и оценки математического ожидания вероятности обработки запросов.
6.3.2. Решение прямой задачи
Рассчитаем количество прогонов, которые нужно выполнить в каждом наблюдении, т. е. проведем так называемое тактическое планирование эксперимента. Пусть результаты моделирования (вероятность обработки запросов) нужно получить с доверительной вероятностью ![]() и точностью
и точностью ![]() . Расчет проведем для худшего случая, т. е. при вероятности
. Расчет проведем для худшего случая, т. е. при вероятности ![]() так как до эксперимента
так как до эксперимента ![]() неизвестно:
неизвестно:
В модели для имитации источника запросов следует использовать блок GENERATE, для имитации сервера как одноканального устройства - блоки SEIZE и RELEASE, для имитации обработки запросов - блок ADVANCE.
В модели должны быть следующие элементы:
- задание исходных данных;
- описание арифметических выражений;
- сегмент имитации поступления и обработки запросов;
- сегмент задания времени моделирования и расчета результатов моделирования.
Серверу дадим имя Server. Для вывода из модели транзактов, имитирующих обработанные и потерянные запросы, используем блоки TERMINATE с метками ObrZap и PotZap соответственно. Для счета количества всех запросов используем метку KolZap.
6.3.2.1. Блок-диаграмма модели
Построим блок-диаграмму модели для решения прямой задачи, т. е. сегмент имитации поступления и обработки запросов и сегмент задания времени моделирования и расчета результатов моделирования (рис. 6.1).
Блок-диаграмма представляет собой набор стандартных блоков [5]. Она строится так. Из множества блоков выбирают нужные и далее выстраивают их в диаграмму для того, чтобы в процессе функционирования модели они как бы взаимодействовали друг с другом. Диаграмма сопровождается необходимыми комментариями. Использование блоков при построении моделей зависит от логических схем работы реальных систем, моделируемых на ЭВМ.
Теперь приступим к написанию программы модели.
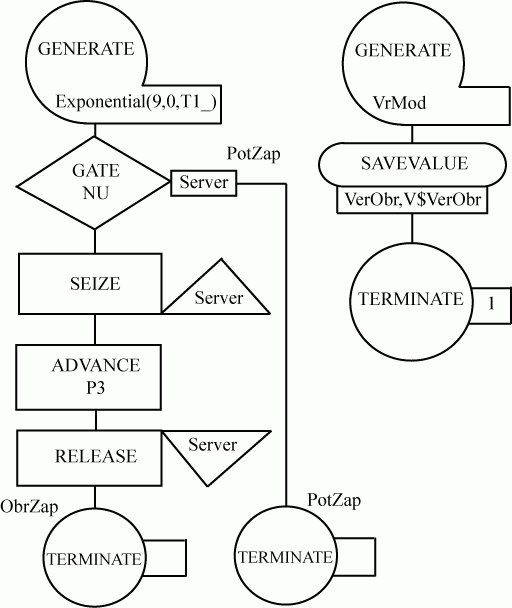
Рис. 6.1. Блок-диаграмма модели
6.3.2.2. Программа модели
Для задания исходных данных используем переменные пользователя. Они задаются с помощью команды EQU. Переменным пользователя даны такие же имена, как и в постановке задачи, но добавлен знак подчеркивания. Например, T1_, S1_ и т. д. Время моделирования зададим переменной пользователя VrMod.
Арифметическая переменная для расчета времени обработки VrObr запроса на сервере:
VrObr VARIABLE (Normal(2,S1_#Koef,S2_#Koef))/Q_
Переменная пользователя Koef введена для удобства изменения (пропорционального изменения) характеристик нормального закона распределения, которому подчиняется вычислительная сложность запросов. Особенно целесообразно использование этой переменной при проведении экспериментов. Примеры применения приведены в главе 7.
Вероятность обработки VerObr запросов на сервере будем определять как отношение количества обработанных N$ObrZap запросов к количеству всего поступивших N$KolZap запросов:
VerObr VARIABLE N$ObrZap/N$KolZap
В арифметическом выражении VerObr, например, N$ObrZap - системный числовой атрибут - количество транзактов, вошедших в блок с меткой ObrZap, а N$KolZap - количество транзактов, вошедших в блок с меткой KolZap.
Все необходимое для написания программы модели имеется. Напишем программу решения прямой задачи.
; Обработка запросов сервером. Прямая задача ; Задание исходных данных T1_ EQU 120 ; Средний интервал поступления запросов, с S1_ EQU 60000000 ; Среднее значение вычислительной сложности запросов, оп S2_ EQU 200000 ; Стандартное отклонение вычислительной сложности запросов, оп Q_ EQU 600000 ; Среднее значение производительности сервера, оп/с Koef EQU 1 ; Коэффициент изменения характеристик нормального распределения VrObr VARIABLE (Normal(2,(S1_#Koef),(S2_#Koef))/Q_ VerObr VARIABLE N$ObrZap/N$KolZap VrMod EQU 3600 ; Время моделирования, 1 ед. мод. времени = 1 с. ; Сегмент имитации обработки запросов GENERATE (Exponential(1,0,T1_)) ; Источник запросов KolZap GATE NU Server,PotZap ; Свободен ли сервер? Если да, то SEIZE Server ; занять сервер ADVANCE V$VrObr ; Имитация обработки запроса RELEASE Server ; Освободить сервер ObrZap TERMINATE ; Обработанные запросы PotZap TERMINATE ; Потерянные запросы ; Сегмент задания времени моделирования и расчета результатов GENERATE VrMod TEST L X$Prog,TG1,Met1 ; Если X$Prog < TG1, SAVEVALUE Prog,TG1 ; то X$Prog = TG1 Met1 TEST E TG1,1,Met2 ; Если TG1 = 1, то SAVEVALUE VerObr, V$VerObr ; расчет и сохранение в ячейке VerObr вероятности обработки запросов SAVEVALUE Res,(INT(N$ObrZap/X$Prog)) ; расчет и сохранение в ячейке Res количества обработанных запросов Met2 TERMINATE 1 START 1000,NP ; Прогоны до установившегося режима RESET ; Сброс накопленной статистики START 9604 ; Количество прогонов модели
При расчете количества обработанных запросов
SAVEVALUE Res,(INT(N$ObrZap/X$Prog))
в арифметическом выражении N$ObrZap/X$Prog используется число прогонов. В арифметическом выражении указано не явное число прогонов, а в виде содержимого ячейки X$Prog. Число прогонов заносится предварительно в эту ячейку по завершении первого прогона модели, но до того момента, когда из счетчика завершений TG1 будет вычтена первая единица. В этом случае арифметическое выражение не зависит от числа прогонов, которое может меняться на различных этапах создания и эксплуатации модели, в том числе и в зависимости от исходных данных, а также от точности и достоверности результатов моделирования. Поскольку количество обработанных запросов не может быть дробным числом, то для получения целого числа, записываемого в ячейку Res, используется процедура INT из встроенной библиотеки.
Для уменьшения машинного времени расчет искомых показателей производится не после каждого прогона, а после завершения последнего прогона, т. е. когда содержимое счетчика завершений будет равно единице ( TG1 = 1 ).
6.3.2.3. Ввод текста программы модели, исправление ошибок и проведение моделирования
- Запустите GPSS World.
- Закройте окно напоминания о необходимости обновления "Заметок". Откроется главное меню.
- Для ввода текста GPSS World имеет текстовый редактор. Откройте окно текстового редактора. Для этого выберите в меню File / New и в появившемся меню выберите Model. Нажмите Ok.
- Наберите текст программы модели, т. е. создайте объект "Модель". При вводе текста следует использовать клавишу [Tab]. Например, после набора Т1_ нужно нажать клавишу [Tab]. Интервалы табуляции установлены по умолчанию.
- После ввода текста программы модели создайте объект "Процесс моделирования", представляющий собой оттранслированный объект "Модель". Для трансляции объекта "Модель" выберите Command / Creat e Simulation. По этой команде транслятор GPSS проверяет текст программы модели на наличие синтаксических ошибок.
- При наличии синтаксических ошибок транслятор в окне JOURNAL выдаст список сообщений об ошибках трансляции. Перейдите к п. 7. При отсутствии ошибок в окне JOURNAL появится сообщение Model Translation Begun. Ready. Перейдите к п. 9.
- Исправьте ошибки. Для поиска ошибок в тексте программы модели и их исправления используйте команду Search / Next Error. При первом выполнении этой команды курсор мыши помещается в строке текста модели с ошибкой. После исправления первой ошибки вновь используйте команду Search / Next Error и т.д. столько раз, сколько ошибок в тексте программы.
- После исправления ошибок перейдите к п.5.
- Сохраните модель. Для этого выберите в главном меню File / Save As. Дайте модели имя Модель процессов изготовления изделий и нажмите Ok.
- Откликом в данной модели является вероятность обработки запросов сервером. Рассчитаем количество прогонов модели при среднеквадратическом отклонении для худшего случая при точности
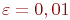 , и доверительной вероятности
, и доверительной вероятности 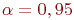 :
: - Запустите модель. Для этого в главном меню выберите Command / Start и в диалоговом окне вместо 1 наберите 9604. Нажмите Ok.
- При наличии логических ошибок для их поиска в тексте программы модели и исправления используйте команду Search / Goto Line столько раз, сколько ошибок указано в окне JOURNAL. Там же (в окне JOURNAL ) указаны номера строк с ошибками.
- При отсутствии логических ошибок в модели по окончании ее работы система GPSS World автоматически создает стандартный отчет, который появится в окне Report. В окне будут содержаться следующие данные:
- об именах объектов модели;
- блоках модели;
- ОКУ и МКУ;
- очередях;
- сохраняемых величинах.
В результате решения прямой задачи получим, что за один час сервером будет обработано N=16 запросов, а вероятность обработки составит VerObr = 0,546. Если не использовать процедуру INT - выделения целого числа с отбрасыванием дробной части, будет обработано 16,345 запроса.
6.3.3. Решение обратной задачи
Для решения обратной задачи возьмем количество запросов, ожидаемое время обработки которых нужно определить, N =16 - результат решения прямой задачи.
Программа модели приведена ниже.
; Обработка запросов сервером. Обратная задача ; Задание исходных данных T1_ EQU 120 ; Средний интервал поступления запросов, с S1_ EQU 60000000 ; Среднее значение вычислительной сложности запросов, оп S2_ EQU 200000 ; Стандартное отклонение вычислительной сложности запросов, оп Q_ EQU 600000 ; Среднее значение производительности сервера, оп/c Koef EQU 1 ; Коэффициент изменения характеристик нормального распределения Koef1 EQU 1 ; Коэффициент учета дробной части N_ EQU 16 ; Количество запросов ; Сегмент имитации обработки запросов GENERATE (Exponential(1,0,T1_)) ; Источник запросов KolZap GATE NU Server,PotZap ; Свободен ли сервер? Если да, то SEIZE Server ; занять сервер ADVANCE ((Normal(2,(S1_#Koef),(S2_#Koef)))/Q_) ; Имитация обработки запроса RELEASE Server ; Освободить сервер TRANSFER ,ObrZap ; Запрос отправляется в сегмент завершения моделирования PotZap TERMINATE ; Потерянные запросы ; Сегмент организации завершения моделирования и расчета результатов ObrZap TEST L X$Prog,TG1,Met1 ; Если X$Prog < TG1, SAVEVALUE Prog,TG1 ; то X$Prog = TG1 SAVEVALUE NZap,0 ; Обнуление счетчика обработанных запросов Met1 SAVEVALUE NZap+,1 ; Счет количества обработанных запросов TEST E X$NZap,N_,Ter1 ; Если X$NZap = N_, то TEST E TG1,1,Met2 ; если TG1 = 1, то SAVEVALUE VerObr,(N$ObrZap/N$KolZap) ; расчет и сохранение в ячейке VerObr вероятности обработки запросов SAVEVALUE TimeNZap,((AC1-X$AC2)/(X$Prog#Koef1)) ;расчет и сохранение в ячейке TimeNZap времени обработки запросов SAVEVALUE AC2,AC1 ; Запомнить абсолютное модельное время в ячейке АС2 Met2 SAVEVALUE NZap,0 ; Обнуление счетчика обработанных запросов TERMINATE 1 Ter1 TERMINATE START 1000,NP ; Прогоны до установившегося режима RESET ; Сброс накопленной статистики START 9604 ; Количество прогонов модели
При решении обратной задачи один прогон определяется заданным количеством запросов N_, а не временем моделирования. Для этого организован счетчик обработанных запросов в виде сохраняемой ячейки NZap. Как только содержимое X$NZap = N_, из счетчика завершений вычитается единица.
Для расчета времени обработки заданного количества запросов используется арифметическое выражение (AC1-X$AC2)/X$Prog. В состав этого выражения входят абсолютное модельное время АС1 и опять количество прогонов. Запоминается количество прогонов также как и при решении прямой задачи.
Кроме этого, в арифметическом выражении есть сохраняемая ячейка X$AC2. Дело в том, что команда RESET не влияет на абсолютное модельное время АС1. Время же выполнения 1000 прогонов до установившегося режима не должно участвовать в расчете. Поэтому оно запоминается, а затем вычитается из абсолютного модельного времени выполнения 1000 + 9604 = 10604 прогонов. Количество прогонов до установившегося режима может быть и другим.
В результате моделирования получим время обработки 16 запросов 3523,658 с.
Фрагмент из отчета моделирования приведен ниже:
SAVEVALUE RETRY VALUE PROG 0 9604.000 NZAP 0 0 VEROBR 0 0.546 TIMENZAP 0 3523.658
А почему не 3600 с? Ведь это же время моделирования было задано при решении прямой задачи. Потому что мы отбросили дробную часть, т. е. взяли 16, а не 16,345. Как же поступить, чтобы учесть и отброшенную дробную часть? Ведь в счетчике фиксируются обработанные запросы только целыми числами, а не дробными?
Для учета десятых долей дробной части зададим N_ = 163, т. е. увеличим в 10 раз. Это нужно учесть и в арифметическом выражении: ((AC1-X$AC2)/(X$Prog#Koef1)). Переменной пользователя Koef1 задается значение 10. По завершении моделирования получим 3586,504. Этот результат уже ближе к 3600.
Для учета сотых долей дробной части зададим N_ = 1634, а Koef1 = 100. Получим 3595,399 с.
Вероятность обработки запросов во всех случаях практически одна и та же, т. е. 0,546. Однако время моделирования существенно возрастает: 4 с, 39 с и 6 мин 29 c, т. е. в 10 и 100 раз соответственно.
В примере решения обратной задачи также показано, что арифметические выражения можно не описывать отдельно до блоковой части программы вместе с заданием исходных данных (как в модели прямой задачи), а сразу записывать в соответствующих блоках, заключив в скобки (скобки можно и не ставить, но лучше это делать).
Например (см. сегмент организации завершения моделирования и расчета результатов):
ADVANCE ((Normal(2,(S1_#Koef),(S2_#Koef)))/Q_) ; Розыгрыш времени обработки запроса SAVEVALUE VerObr,(N$ObrZap/N$KolZap)) ; Расчет вероятности обработки запросов SAVEVALUE TimeNZap,((AC1-X$AC2)/(X$Prog#Koef1)) ;Расчет среднего времени обработки запросов
6.4. Пример построения моделей с ОКУ, МКУ и списками пользователя
6.4.1. Модель процесса изготовления изделий на предприятии. Прямая задача
6.4.1.1. Постановка задача
Предприятие имеет ![]() цехов, производящих
цехов, производящих ![]() типов блоков, т. е. каждый цех производит блоки одного типа. Интервалы выпуска блоков
типов блоков, т. е. каждый цех производит блоки одного типа. Интервалы выпуска блоков ![]() - случайные. Из
- случайные. Из ![]() типов блоков собирается одно изделие.
типов блоков собирается одно изделие.
Перед сборкой каждый тип блоков проверяется на ![]() соответствующих постах. Длительности контроля одного блока
соответствующих постах. Длительности контроля одного блока ![]() случайные. На каждом посту бракуется
случайные. На каждом посту бракуется ![]() блоков соответственно. Эти блоки в дальнейшем процессе сборки не участвуют и удаляются с постов контроля.
блоков соответственно. Эти блоки в дальнейшем процессе сборки не участвуют и удаляются с постов контроля.
Прошедшие контроль, т. е. не забракованные блоки поступают на один из ![]() пунктов сборки. На каждом пункте сборки одновременно собирается только одно изделие. Сборка начинается только тогда, когда имеются все необходимые
пунктов сборки. На каждом пункте сборки одновременно собирается только одно изделие. Сборка начинается только тогда, когда имеются все необходимые ![]() блоков различных типов. Время сборки
блоков различных типов. Время сборки ![]() случайное.
случайное.
После сборки изделие поступает на один из ![]() стендов выходного контроля. На одном стенде одновременно проверяется только одно изделие. Время проверки
стендов выходного контроля. На одном стенде одновременно проверяется только одно изделие. Время проверки ![]() случайное. По результатам проверки бракуется
случайное. По результатам проверки бракуется ![]() изделий.
изделий.
Забракованное изделие направляется в цех сборки, где неработоспособные блоки заменяются новыми. Время замены ![]() случайное. После замены блоков изделие вновь поступает на один из стендов выходного контроля.
случайное. После замены блоков изделие вновь поступает на один из стендов выходного контроля.
Прошедшие стенд выходного контроля изделия поступают в отдел приемки. Время приемки ![]() одного изделия случайное. По результатам приемки бракуется
одного изделия случайное. По результатам приемки бракуется ![]() изделий, которые направляются вновь на стенд выходного контроля. Принятые приемкой изделия направляются на склад предприятия.
изделий, которые направляются вновь на стенд выходного контроля. Принятые приемкой изделия направляются на склад предприятия.
6.4.1.2. Исходные данные

6.4.1.3. Задание на исследование
Разработать имитационную модель процесса изготовления изделий на предприятии.
Вариант 1 .Исследовать влияние интервалов выпуска блоков из цехов, времени сборки и проверки на стенде выходного контроля (табл. 6.2) на количество принятых приемкой изделий в течение недели (40 часов). Результаты моделирования необходимо получить с точностью ![]() и доверительной вероятностью
и доверительной вероятностью ![]()
- В табл. 6.2 идентификаторы факторов указаны такими, какими они приняты в программе модели. Факторы T2_ и T4_ соответствуют
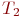 и
и 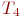 .
. - Изменение параметров равномерного (
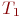 ,
, 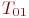 ,
, 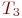 ,
, 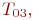 в модели Т1, Т01, Т3, Т03 соответственно) и нормального (
в модели Т1, Т01, Т3, Т03 соответственно) и нормального ( 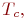
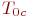 ,
,  ,
,  , в модели Тс, Т0с, Тpr, Т0pr соответственно) законов распределения производится изменением значений коэффициентов K1_, K3_, Kc_, Kpr_ соответственно. В этом случае среднее значение и сред-неквадратическое отклонение изменяются пропорционально соответствующему коэффициенту, например, T1_#K1_, T01_#K1_.
, в модели Тс, Т0с, Тpr, Т0pr соответственно) законов распределения производится изменением значений коэффициентов K1_, K3_, Kc_, Kpr_ соответственно. В этом случае среднее значение и сред-неквадратическое отклонение изменяются пропорционально соответствующему коэффициенту, например, T1_#K1_, T01_#K1_.
Вариант 2. При исходных данных, указанных в п. 6.4.1.2, исследовать влияние качества изготовления блоков и сборки изделий (табл. 6.3) на количество принятых приемкой изделий в течение недели (40 часов).
| Уровни факторов | Факторы | |||||
|---|---|---|---|---|---|---|
| q11_ | q12_ | q13_ | q14_ | q2_ | q4_ | |
| Нижний | 0.4 | 8 | 0.6 | 10 | 0.5 | 0.7 |
| Верхний | 1.6 | 20 | 1.4 | 24 | 1.5 | 1.3 |
Сделать выводы о работе подразделений предприятия и необходимых мерах по повышению их эффективности.
Результаты моделирования необходимо получить с точностью ![]() и доверительной вероятностью (достоверностью)
и доверительной вероятностью (достоверностью) ![]()
6.4.1.4. Уяснение задачи на исследование
Предприятие при изготовлении блоков и сборки из них изделий может быть представлено как многофазная многоканальная разомкнутая система массового обслуживания с ожиданием, так как оно имеет все ее элементы (рис. 6.2):
- поток изготовленных цехами блоков;
- очереди блоков на посты контроля и пункты сборки;
- очереди изделий на стенды контроля и пункт приемки;
- одноканальное устройство обслуживания (пункт приемки);
- многоканальные устройства обслуживания (посты контроля, стенды выходного контроля, пункты сборки);
- потоки забракованных блоков;
- выходные потоки готовых изделий.
Для имитации МКУ следует использовать блоки ENTER и LEAVE, для ОКУ - SEIZE и RELEASE. Для имитации ОКУ, а в данном случае это пункт приема изделий, можно также использовать МКУ, описав его командой STORAGE с емкостью 1. Тогда при увеличении количества пунктов приема собранных изделий нужно будет только изменить команду STORAGE, записав в ней вместо 1 новое значение емкости МКУ.
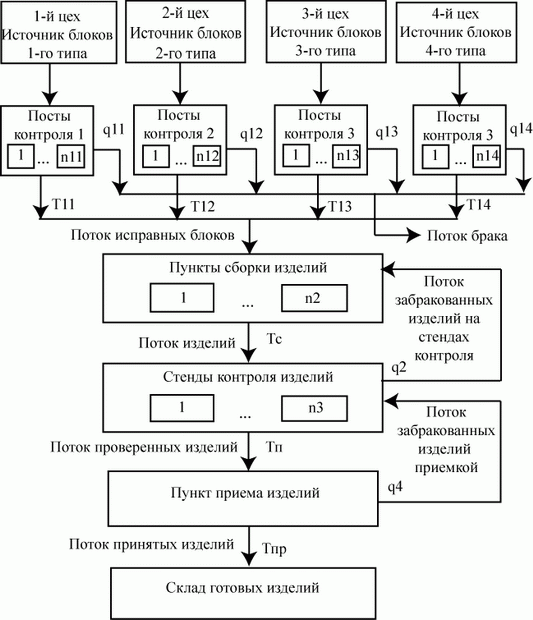
увеличить изображение
Рис. 6.2. Предприятие как система массового обслуживания
Для исходных данных в программе модели возьмем те же идентификаторы, что и в постановке задачи, но для предотвращения случаев совпадения с зарезервированными символами GPSS World добавим символ подчеркивания.
Например, q11_, n1_. Сделаем это для отличия от зарезервированных символов GPSS World: q - системный числовой атрибут, означающий очередь, n -используется в качестве ссылки при определении количества транзактов, вошедших в какой-либо блок программы. Добавление символа подчеркивания предотвратит ошибку, которая в противном случае будет выявлена на этапе создания объекта "Процесс моделирования". Другие идентификаторы будем вводить по мере уяснения задачи, а также в ходе разработки блок-диаграммы и программы модели.
Для моделирования необходимо привести в соответствие время протекания реального процесса изготовления блоков и сборки изделий на предприятии и в модели. Это осуществляется введением масштабного коэффициента, например, если для условий рассматриваемой задачи его взять равным 1, а в реальном процессе измерять время в минутах, то 1 мин будет соответствовать 1 ед. мод. вр. Тогда время моделирования VrMod = 60 # 40 = 2400 ед. мод. вр. Временные параметры изготовления и контроля блоков, сборки, контроля и приемки изделий даны в минутах, поэтому при выбранном масштабном коэффициенте 1 они не изменятся.
В модели, как процесса, протекающего в СМО (см. рис. 6.2), необходимо иметь:
- задание исходных данных;
- сегмент имитации работы цеха 1 без постов контроля;
- сегмент имитации работы цеха 2 без постов контроля;
- сегмент имитации работы цеха 3 без постов контроля;
- сегмент имитации работы цеха 4 без постов контроля;
- сегмент имитации работы постов контроля блоков;
- сегмент имитации сборки изделий;
- сегмент имитации работы стендов выходного контроля;
- сегмент имитации работы приемки;
- сегмент задания времени моделирования и расчета результатов моделирования.
6.4.1.5. Блок-диаграмма модели
Модели функционирования систем на GPSS, как уже было показано в п. 6.3.2.1, могут быть первично описаны в виде блок-диаграмм.
При этом отдельные элементы модели и модель в целом имеют достаточно различимое подобие. Для получения такого вывода сравните рис. 6.2 и 6.3: состав и блок-диаграмму модели функционирования предприятия.
Это подобие может быть также усилено разработчиком за счет продуманного на этапе разработки разделения исследуемого объекта на элементы, на процессы, протекающие в них, а модели - на сегменты.
Однако возможно и другое. В данном примере в каждом цехе имеются свои посты контроля блоков. Поэтому, казалось, в модели должны были бы быть сегменты, имитирующие работу цеха и его постов контроля. По предложенному же составу модели видно, что в нее входят сегменты, имитирующие работу каждого из цехов без постов контроля, и сегмент имитации работы всех постов контроля. Т. е. как бы все посты контроля блоков объединены в отдельное подразделение предприятия, но функциональное предназначение соответствующих постов контроля осталось прежним.
Объединение сделано в интересах частичной универсальности модели. Предположим, количество цехов увеличилось. В первом случае нужно было бы добавлять сегменты имитации работы цехов и постов контроля, т. е. количество блоков в модели увеличилось бы. Во втором случае добавляются только сегменты имитации работы цехов и необходимые исходные данные. При этом сегмент имитации функционирования постов контроля блоков изделий остается неизменным.
Списки пользователя применяются для имитации работы складов готовых блоков. Предполагается наличие такого склада у каждого цеха.
Для розыгрыша брака блоков и изделий используется блок TRANSFER в статистическом режиме.
Обратите внимание, что в сегменте имитации сборки изделий блок TEST используется в режиме, который рекомендуется избегать вследствие того, что проверяемое условие может не выполниться. Однако здесь этого не должно быть, так как в противном случае будут отсутствовать готовые блоки для сборки изделий. По мере готовности блоков условие обязательно выполняется и блоки - транзакты направляются на сборку. Первые три транзакта уничтожаются, а четвертый транзакт имитирует собранное из четырех блоков изделие. Он направляется для проверки работоспособности на пункт приема изделий.
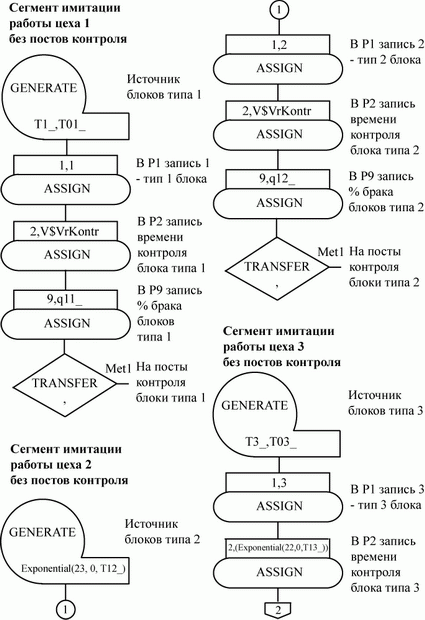
увеличить изображение
Рис. 6.3. Блок-диаграмма модели (лист 1)
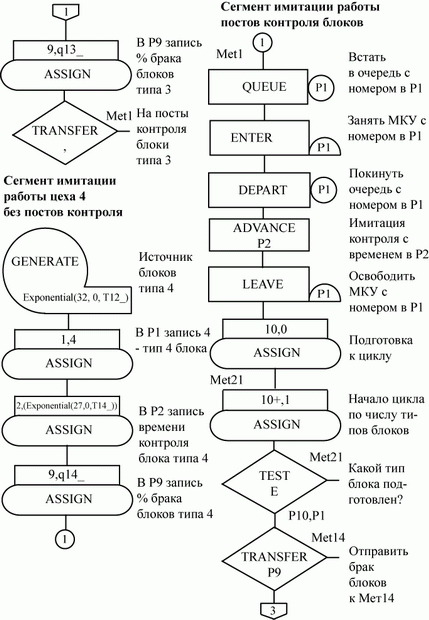
увеличить изображение
Рис. 6.3. Блок-диаграмма модели (продолжение, лист 2)
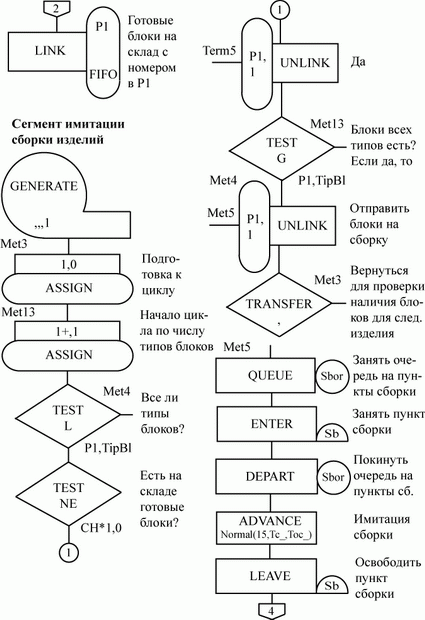
увеличить изображение
Рис. 6.3. Блок-диаграмма модели (продолжение, лист 3)
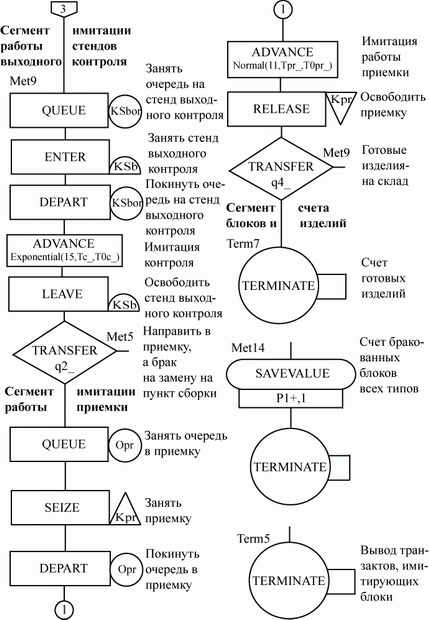
увеличить изображение
Рис. 6.3. Блок-диаграмма модели (продолжение, лист 4)
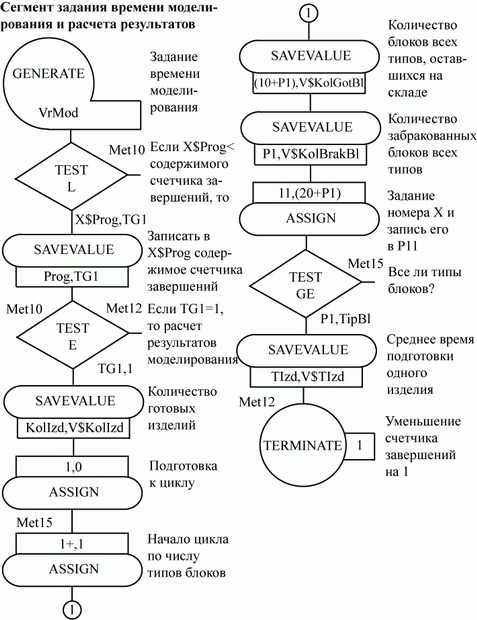
увеличить изображение
Рис. 6.3. Блок-диаграмма модели (окончание, лист 5)
6.4.1.6. Программа модели
Программа модели построена в соответствии с блок-диаграммой (см. рис. 6.3). В ней, кроме, как уже отмечалось, раскрытия методов использования ОКУ, МКУ и списков пользователя демонстрируется применение номеров МКУ вместо их имен.
Этот метод дает возможность иметь в модели один сегмент имитации работы постов контроля блоков вместо подобного сегмента для каждого цеха, т. е. сократить число блоков в модели.
Обратите внимание, что в программе присвоение номеров именам МКУ указывается в самом начале и только потом, не обязательно следом, определение МКУ командой STORAGE. Если вы построите программу так, что поменяете порядок: вначале определение МКУ командой STORAGE, а потом - присвоение командой EQU номеров именам МКУ, то на этапе выполнения программы модели возникнет ошибка: "Обращение к несуществующей памяти". На этапе создания объекта "Процесс моделирования" ошибка изменение этого порядка не обнаруживается.
; Модель функционирования предприятия. Прямая задача ; Замена имен МКУ номерами Kontr1 EQU 1 Kontr2 EQU 2 Kontr3 EQU 3 Kontr4 EQU 4 ; Задание исходных данных q11_ EQU 0.02 ; Доля брака блоков на постах n11 q12_ EQU 0.03 ; Доля брака блоков на постах n12 q13_ EQU 0.04 ; Доля брака блоков на постах n13 q14_ EQU 0.06 ; Доля брака блоков на постах n14 q2_ EQU 0.05 ; Доля брака изделий на пункте вых. контроля q4_ EQU 0.03 ; Доля забракованных изделий приемкой TipBl EQU 4 ; Максимальное количество типов блоков VrMod EQU 2400 ; Время моделирования, 1 ед. мод. вр. = 1 мин T1_ EQU 19 ; Средний интервал выпуска блоков типа 1 T01_ EQU 6 ; Стандартное отклонение времени выпуска блоков типа 1 T2_ EQU 11 ; Средний интервал выпуска блоков типа 2 T3_ EQU 15 ; Средний интервал выпуска блоков типа 3 T03_ EQU 8 ; Стандартное отклонение времени выпуска блоков типа 3 T4_ EQU 18 ; Средний интервал выпуска блоков типа 4 T11_ EQU 12 ; Среднее время контроля на постах n11 T011_ EQU 6 ; Стандартное отклонение времени контроля на постах n11 T12_ EQU 16 ; Среднее время контроля на постах n12 T13_ EQU 21 ; Среднее время контроля на постах n13 T14_ EQU 17 ; Среднее время контроля на постах n14 Tc_ EQU 22 ; Среднее время сборки изделия T0c_ EQU 2 ; Стандартное отклонение времени сборки изделия Tp_ EQU 15 ; Среднее время проверки изделия Tpr_ EQU 18 ; Среднее время приема изделия T0pr_ EQU 2 ; Стандартное отклонение времени приема изделия ; Коэффициенты изменения параметров законов распределения K1_ EQU 1 ; Коэффициент изменения T1_ и T01_ K2_ EQU 1 ; Коэффициент изменения T2_ и T02_ K3_ EQU 1 ; Коэффициент изменения T3_ и T03_ K4_ EQU 1 ; Коэффициент изменения T4_ и T04_ Kc_ EQU 1 ; Коэффициент изменения Tс_ и T0с_ Kp_ EQU 1 ; Коэффициент изменения Tp_ и T0p_ Kpr_ EQU 1 ; Коэффициент изменения Tpr_ и T0pr_ ; Задание количества пунктов сборки и постов контроля Sbor STORAGE 2 ; Количество пунктов сборки Kontr1 STORAGE 3 ; Количество постов n11 Kontr2 STORAGE 2 ; Количество постов n12 Kontr3 STORAGE 2 ; Количество постов n13 Kontr4 STORAGE 2 ; Количество постов n14 Kontsb STORAGE 2 ; Количество стендов выходного контроля ; Описание арифметических выражений KolIzd VARIABLE INT(N$Term7/X$prog) ; Количество готовых изделий KolGotBl VARIABLE (INT(CH*1/X$Prog)) ; Количество готовых блоков всех типов, оставшихся на складах KolBrBl VARIABLE (INT(X*1/X$Prog)) ; Количество забракованных блоков всех типов TIzd VARIABLE (AC1/X$Prog)/X$KolIzd ; Среднее время подготовки одного изделия ;Сегмент имитации работы цеха 1 без постов контроля GENERATE (T1_#K1_),(T01_#K1_) ASSIGN 1,1 ; Код 1 в параметре 1 транзакта - тип 1 блока ASSIGN 2,((T11_-T01_)+2#T011_#(RN27/1000)) ; Розыгрыш времени контроля и запись в Р2 ASSIGN 9,q11_ ; Запись в Р9 доли брака блоков после постов контроля TRANSFER ,Met1 ; Сегмент имитации работы цеха 2 без постов контроля GENERATE (Exponential(32,0,(T2_#K2_))) ASSIGN 1,2 ; Код 2 в параметре 1 транзакта - тип 2 блока ASSIGN 2,(Exponential(23,0,T12_)) ; Розыгрыш времени контроля и запись в Р2 ASSIGN 9,q12_ ; Запись в Р9 доли брака блоков после постов контроля TRANSFER ,Met1 ; Сегмент имитации работы цеха 3 без постов контроля GENERATE (T3_#K3_),(T03_#K3_) ASSIGN 1,3 ; Код 3 в параметре 1 транзакта - тип 3 блока ASSIGN 2,(Exponential(22,0,T13_)) ; Розыгрыш времени контроля и запись в Р2 ASSIGN 9,q13_ ; Запись в Р9 доли брака блоков после постов контроля TRANSFER ,Met1 ; Сегмент имитации работы цеха 4 без постов контроля GENERATE (Exponential(32,0,(T4_#K4_))) ASSIGN 1,4 ; Код 4 в параметре 1 транзакта - тип 4 блока ASSIGN 2,(Exponential(22,0,T14_)) ; Розыгрыш времени контроля и запись в Р2 ASSIGN 9,q14_ ; Запись в Р9 доли брака блоков после постов контроля ; Сегмент имитации работы постов контроля блоков Met1 QUEUE P1 ; Встать в очередь с номером в Р1 ENTER P1 ; Занять МКУ с номером в Р1 DEPART P1 ; Покинуть очередь с номером в Р1 ADVANCE P2 ; Имитация контроля с временем в Р2 LEAVE P1 ; Освободить МКУ с номером в Р1 ASSIGN 10,0 ; Подготовка к циклу Met21 ASSIGN 10+,1 ; Начало цикла по числу типов блоков TEST E P10,P1,Met21 ; Какой тип блока подготовлен? TRANSFER P9,,Met14 ; Отправить брак блоков к Met14 LINK P1,FIFO ; Готовые блоки на склад с номером в Р1 ; Сегмент имитации сборки изделий GENERATE ,,,1 Met3 ASSIGN 1,0 ; Подготовка к циклу Met13 ASSIGN 1+,1 ; Начало цикла по числу типов блоков TEST L P1,TipBl,Met4 ; Все ли типы блоков? TEST NE CH*1,0 ; Есть на складе готовые блоки? UNLINK P1,Term5,1 ; Да TEST G P1,TipBl,Met13 ; Блоки всех типов есть? Если да, Met4 UNLINK P1,Met5,1 ; то, отправить блоки на сборку TRANSFER ,Met3 ; Вернуться для проверки наличия всех типов блоков для следующего изделия Met5 QUEUE Sbor ; Занять очередь на пункты сборки ENTER Sb ; Занять пункт сборки DEPART Sbor ; Освободить очередь на пункт сборки ADVANCE (Normal(15,(Tc_#Kc_),(T0c_#Kc_))) ; Имитация сборки LEAVE Sb ; Освободить пункт сборки ; Сегмент имитации работы стендов выходного контроля Met9 QUEUE KSbor ; Занять очередь на стенд выходного контроля ENTER KSb ; Занять стенд выходного контроля DEPART KSbor ; Освободить очередь на стенд выходного контроля ADVANCE (Exponential(11,0,(Tp_#Kp_))) ; Имитация работы стенда выходного контроля LEAVE KSb ; Освободить стенд выходного контроля TRANSFER q2_,,Met5 ; Направить в приемку, а брак - для замены на пункт сборки ; Сегмент имитации работы приемки QUEUE Opr ; Занять очередь на пункт приемки SEIZE KPr ; Занять пункт приемки DEPART Opr ; Освободить очередь пункта приемки ADVANCE (Normal(11,(Tpr_#Kpr_),(T0pr_#Kpr_))) ; Имитация работы приемки RELEASE KPr ; Освободить пункт приемки TRANSFER q4_,,Met9 ; Готовые изделия - на склад ; Сегмент счета блоков и изделий Term7 TERMINATE ; Количество готовых изделий Met14 SAVEVALUE P1+,1 ; Количество брака блоков всех типов TERMINATE Term5 TERMINATE ; Задание времени моделирования и расчет результатов моделирования GENERATE VrMod ; Задание времени моделирования TEST L X$Prog,TG1,Met10 ; Если X$Prog< содержимого счетчика завершений, то SAVEVALUE Prog,TG1 ; записать в X$Prog содержимое счетчика завершений Met10 TEST E TG1,1,Met12 ; Если содержимое счетчика завершений равно 1, то расчет результатов моделирования SAVEVALUE KolIzd,V$KolIzd ; Количество готовых изделий ASSIGN 1,0 ; Подготовка к циклу Met15 ASSIGN 1+,1 ; Начало цикла по числу типов блоков SAVEVALUE (10+P1),V$KolGotBl ; Количество готовых блоков всех типов, оставшихся на складах SAVEVALUE P1,V$KolBrBl ; Количество забракованных блоков всех типов ASSIGN 11,(20+P1) ; Задание номера Х и запись его в Р11 TEST GE P1,TipBl,Met15 ; Все ли типы блоков? SAVEVALUE TIzd,V$TIzd ; Среднее время подготовки одного изделия Met12 TERMINATE 1
Отладьте модель. Выполните моделирование, указав в команде START 1000 прогонов. В отчете, фрагмент которого приведен ниже,
SAVEVALUE RETRY VALUE KOLIZD 0 122.000 TIZD 0 19.512
найдите, что за 40 часов подготовлено 122 изделия, а среднее время подготовки одного изделия ? 20 мин (19,51 мин).
После изучения материала главы 7 вернитесь к данной задаче и проведите два отсеивающих эксперимента (дисперсионных анализа). Для первого эксперимента используйте данные, приведенные в табл. 6.2, а для второго - в табл. 6.3.
При необходимости внесите в эти данные свои изменения. По результатам экспериментов сделайте выводы.
6.4.2. Модель процесса изготовления изделий на предприятии. Обратная задача
6.4.2.1. Постановка задачи
Постановка задачи аналогична постановке задачи п. 6.4.1.1 при тех же исходных данных (п. 6.4.1.2).
Отличие состоит в том, что нужно построить имитационную модель для определения оценки математического ожидания времени, за которое будет изготовлено предприятием N изделий, и оценки математического ожидания времени изготовления одного изделия. Поэтому в исходных данных нет времени моделирования, а вводится переменная пользователя N_ - количество изделий, время изготовления которых нужно оценить.
6.4.2.2. Программа модели
В программе модели те же сегменты (п. 6.4.1.6), только вместо сегмента задания времени моделирования и расчета результатов включен сегмент организации завершения моделирования и расчета результатов моделирования.
Один прогон наблюдения завершается подготовкой N_ изделий, т. е. поступлением их на склад. Поэтому соответствующие этим изделиям транзакты не выводятся сразу из модели, как в прямой задаче, а поступают в сегмент организации завершения моделирования и расчета результатов моделирования.
В блоке
Met10 SAVEVALUE NIzd+,1
подсчитывается количество подготовленных изделий. Если это количество равно N_, т. е. выполняется условие
TEST E X$NIzd,N_,Term5
фиксируется один прогон.
С целью сокращения машинного времени расчет результатов моделирования производится один раз по накопленной статистике за все прогоны. Программа, как и в п. 6.3.2.2, построена так, чтобы расчет результатов моделирования не требовал ее изменения при различном числе прогонов, задаваемом пользователем.
Ниже приведена программа обратной задачи.
; Модель функционирования предприятия. Обратная задача ; Замена имен МКУ номерами Kontr1 EQU 1 ; Замена имени МКУ Kontr1 номером Kontr2 EQU 2 ; Замена имени МКУ Kontr2 номером Kontr3 EQU 3 ; Замена имени МКУ Kontr3 номером Kontr4 EQU 4 ; Замена имени МКУ Kontr4 номером ; Задание исходных данных q11_ EQU 0.02 ; Доля забракованных блоков на постах n11 q12_ EQU 0.03 ; Доля забракованных блоков на постах n12 q13_ EQU 0.04 ; Доля забракованных блоков на постах n13 q14_ EQU 0.06 ; Доля забракованных блоков на постах n14 q2_ EQU 0.05 ; Доля брака изделий на пункте выходного контроля q4_ EQU 0.03 ; Доля забракованных изделий приемкой TipBl EQU 4 ; Максимальное количество типов блоков, изготавливаемых цехами T1_ EQU 19 ; Средний интервал выпуска блоков типа 1 T01_ EQU 6 ; Стандартное отклонение времени выпуска блоков типа 1 T2_ EQU 11 ; Средний интервал выпуска блоков типа 2 T3_ EQU 15 ; Средний интервал выпуска блоков типа 3 T03_ EQU 8 ; Стандартное отклонение времени выпуска блоков типа 3 T4_ EQU 18 ; Средний интервал выпуска блоков типа 4 T11_ EQU 12 ; Среднее время контроля на постах n11 T011_ EQU 6 ; Стандартное отклонение времени контроля на постах n11 T12_ EQU 16 ; Среднее время контроля на постах n12 T13_ EQU 21 ; Среднее время контроля на постах n13 T14_ EQU 17 ; Среднее время контроля на постах n14 Tc_ EQU 22 ; Среднее время сборки изделия T0c_ EQU 2 ; Стандартное отклонение времени сборки изделия Tp_ EQU 15 ; Среднее время проверки изделия Tpr_ EQU 18 ; Среднее время приема изделия T0pr_ EQU 2 ; Стандартное отклонение времени приема изделия N_ EQU 122 ; Количество изделий, которое необходимо подготовить ; Задание количества пунктов сборки и контроля Sbor STORAGE 2 ; Количество пунктов сборки Kontr1 STORAGE 3 ; Количество постов n11 Kontr2 STORAGE 2 ; Количество постов n12 Kontr3 STORAGE 2 ; Количество постов n13 Kontr4 STORAGE 2 ; Количество постов n14 Kontsb STORAGE 2 ; Количество пунктов сборки ; Сегмент имитации работы цеха 1 без постов контроля GENERATE T1_,T01_; Источник блоков типа 1 ASSIGN 1,1 ; Код 1 в параметре 1 транзакта - тип 1 блока ASSIGN 2,((T11_-T011_)+2#T011_#(RN27/1000)) ; Розыгрыш времени контроля и запись в Р2 ASSIGN 9,q11_ ; Запись в Р9 доли брака блоков после постов контроля TRANSFER ,Met1 ; Сегмент имитации работы цеха 2 без постов контроля GENERATE (Exponential(32,0,T2_)); Источник блоков типа 2 ASSIGN 1,2 ; Код 2 в параметре 1 транзакта - тип 2 блока ASSIGN 2,(Exponential(23,0,T12_)) ; Розыгрыш времени контроля и запись в Р2 ASSIGN 9,q12_ ; Запись в Р9 доли брака блоков после постов контроля TRANSFER ,Met1 ; Сегмент имитации работы цеха 3 без постов контроля GENERATE T3_,T03_ ; Источник блоков типа 3 ASSIGN 1,3 ; Код 3 в параметре 1 транзакта - тип 3 блока ASSIGN 2,(Exponential(22,0,T13_)) ; Розыгрыш времени контроля и запись в Р2 ASSIGN 9,q13_ ; Запись в Р9 доли брака блоков после постов контроля TRANSFER ,Met1 ; Сегмент имитации работы цеха 4 без постов контроля GENERATE (Exponential(32,0,T4_)) ; Источник блоков типа 4 ASSIGN 1,4 ; Код 4 в параметре 1 транзакта - тип 4 блока ASSIGN 2,(Exponential(22,0,T14_)) ; Розыгрыш времени контроля блока и запись в Р2 ASSIGN 9,q14_ ; Запись в Р9 доли брака блоков после постов контроля ; Сегмент имитации работы постов контроля блоков Met1 QUEUE P1 ; Встать в очередь с номером в Р1 ENTER P1 ; Занять МКУ с номером в Р1 DEPART P1 ; Покинуть очередь с номером в Р1 ADVANCE P2 ; Имитация контроля качества блока с временем контроля в Р2 LEAVE P1 ; Освободить МКУ с номером в Р1 ASSIGN 10,0 ; Подготовка к циклу Met21 ASSIGN 10+,1 ; Начало цикла по числу типов блоков TEST E P10,P1,Met21 ; Какой тип блока подготовлен? TRANSFER P9,,Met14 ; Отправить брак блоков к Met14 LINK P1,FIFO ; Готовые блоки на склад с номером в Р1 ; Сегмент имитации сборки изделий GENERATE ,,,1 Met3 ASSIGN 1,0 ; Подготовка к циклу Met13 ASSIGN 1+,1 ; Начало цикла по числу типов блоков TEST L P1,TipBl,Met4 ; Все ли типы блоков? TEST NE CH*1,0 ; Есть на складе готовые блоки? UNLINK P1,Term5,1 ; Да TEST G P1,TipBl,Met13 ; Блоки всех типов есть? Если да, Met4 UNLINK P1,Met5,1 ; то отправить блоки на сборку TRANSFER ,Met3 ; Вернуться для проверки наличия всех типов блоков для следующего изделия Met5 QUEUE Sbor ; Занять очередь на пункты сборки ENTER Sb ; Занять пункт сборки DEPART Sbor ; Освободить очередь на пункт сборки ADVANCE (Normal(15,Tc_,T0c_)) ; Имитация сборки LEAVE Sb ; Освободить пункт сборки ; Cегмент имитации работы стендов выходного контроля Met9 QUEUE KSbor ; Занять очередь на стенд выходного контроля ENTER KSb ; Занять стенд выходного контроля DEPART KSbor ; Освободить очередь на стенд выходного контроля ADVANCE (Exponential(11,0,Tp_)) ; Имитация работы стенда выходного контроля LEAVE KSb ; Освободить стенд выходного контроля TRANSFER q2_,,Met5 ; Направить изделие в приемку, а брак -на замену на пункт сборки ; Сегмент имитации работы приемки QUEUE Opr ; Занять очередь на пункт приемки SEIZE KPr ; Занять пункт приемки DEPART Opr ;Освободить очередь пункта приемки ADVANCE (Normal(11,Tpr_,T0pr_)) ; Имитация работы приемки RELEASE KPr ; Освободить пункт приемки TRANSFER q4_,,Met9 ; Готовые изделия - на склад ; Сегмент организации завершения моделирования и расчета результатов моделирования TEST L X$Prog,TG1,Met10 ; Если X$Prog< содержимого счетчика завершений, то SAVEVALUE Prog,TG1 ; записать в X$Prog содержимое счетчика завершений - количество прогонов из TG1 SAVEVALUE NIzd,0 Met10 SAVEVALUE NIzd+,1 ; Счет и сохранение в ячейке NIzd количества принятых приемкой изделий TEST E X$NIzd,N_,Term5 ; Если принято N_изделий, зафиксировать один прогон TEST E TG1,1,Met12 ; Если содержимое счетчика завершений равно 1, то расчет результатов моделирования ASSIGN 1,0 ; Подготовка к циклу Met15 ASSIGN 1+,1 ; Начало цикла по числу типов блоков SAVEVALUE (10+P1),(INT(CH*1/X$Prog)) ; Количество готовых блоков всех типов, оставшихся на складах SAVEVALUE P1,(INT(X*1/X$Prog)) ; Количество забракованных блоков всех типов ASSIGN 11,(20+P1) ; Задание номера сохраняемой ячейки и запись его в Р11 TEST GE P1,TipBl,Met15 ; Все ли типы блоков для подготовки изделия имеются на складах цехов? SAVEVALUE TIzd,((AC1/X$Prog)/60) ; Расчет и сохранение в ячейке TIzd времени подготовки N_изделий, час SAVEVALUE STIzd,((X$TIzd/N_)#60) ; Расчет и сохранение в ячейке STIzd среднего времени подготовки одного изделия, мин Met12 SAVEVALUE NIzd,0 ; Обнуление X$NIzd - подготовка к очередному прогону TERMINATE 1 Met14 SAVEVALUE P1+,1 ; Количество брака блоков всех типов TERMINATE Term5 TERMINATE ; Вывод вспомогательных транзактов
Отладьте модель. Запустите модель, указав в команде START 1000 прогонов. По окончании моделирования в отчете, фрагмент которого приведен ниже,
SAVEVALUE RETRY VALUE TIZD 0 39.438 STIZD 0 19.396
получите, что среднее время подготовки N_=122 изделий составляет 40 ч (39,438) при среднем времени подготовки одного изделия 20 мин (19,396). Как видно, эти результаты согласуются с исходными данными и результатами решения прямой задачи.
Результаты решения обратной задачи можно проверить. Найдите в самом начале отчета
START TIME END TIME BLOCKS FACILITIES STORAGES 0.000 2366280.440 74 1 6
Разделите END TIME (абсолютное модельное время АС1) на количество прогонов и минут в одном часе, т. е. на 60 000, получите ?40 ч.
Теперь в программе модели укажите командой EQU количество изделий N_=244:
N_ EQU 244
Выполните моделирование, указав, как и в предыдущем случае, в команде START 1000 прогонов. Из отчета
видно, что время подготовки, как и число изделий, увеличивается в два раза при неизменном времени изготовления одного изделия.
Сделайте выводы: влияет ли стохастичность, как и при решении прямой задачи, на результаты моделирования.
6.5. Уменьшение числа объектов в модели
6.5.1. Постановка задачи
Автоматическая телефонная станция (АТС) обслуживает ![]() телефонных аппаратов (ТА) первой категории (ТА1),
телефонных аппаратов (ТА) первой категории (ТА1), ![]() ТА второй категории (ТА2) и имеет
ТА второй категории (ТА2) и имеет ![]() выходов в сеть связи. Интервал времени
выходов в сеть связи. Интервал времени ![]() между звонками с ТА1 случайный. Вероятность звонка с i-го ТА1
между звонками с ТА1 случайный. Вероятность звонка с i-го ТА1 ![]() Вероятность того, что при этом для разговора потребуется внешняя линия связи
Вероятность того, что при этом для разговора потребуется внешняя линия связи ![]() соединение с ТА2
соединение с ТА2 ![]() При этом может быть занята любая свободная линия связи, а вероятность звонка на
При этом может быть занята любая свободная линия связи, а вероятность звонка на ![]() -й ТА2
-й ТА2 ![]() Длительность
Длительность ![]() разговора с ТА1 случайная.
Время
разговора с ТА1 случайная.
Время ![]() ожидания при занятости ТА или внешних линий связи случайное. Вероятность того, что ТА2 не ответит,
ожидания при занятости ТА или внешних линий связи случайное. Вероятность того, что ТА2 не ответит, ![]() При этом время
При этом время ![]() случайное.
случайное.
Интервал времени ![]() между звонками с ТА2 случайный. Вероятность звонка с
между звонками с ТА2 случайный. Вероятность звонка с ![]() -го ТА2
-го ТА2 ![]() Вероятности того, что при этом для разговора потребуются внешняя линия связи
Вероятности того, что при этом для разговора потребуются внешняя линия связи ![]() соединение с ТА1
соединение с ТА1 ![]() Для разговора может быть занята любая свободная внешняя линия связи, а вероятность звонка на
Для разговора может быть занята любая свободная внешняя линия связи, а вероятность звонка на ![]() -й ТА1
-й ТА1 ![]() Длительность
Длительность ![]() разговора с ТА2 случайная. Время
разговора с ТА2 случайная. Время ![]() при занятости ТА или внешних линий связи случайное.
Вероятность того, что ТА1 не ответит,
при занятости ТА или внешних линий связи случайное.
Вероятность того, что ТА1 не ответит, ![]() При этом время
При этом время ![]() также случайное.
также случайное.
Звонки с ТА1 обладают абсолютным приоритетом по отношению к звонкам с ТА2 при занятости внешнего выхода в сеть связи. Поэтому, если при поступлении с ТА1 заявки на разговор по внешнему выходу все внешние выходы будут заняты разговорами также с ТА1, прерывания разговоров не происходит и заявка считается потерянной. Если же некоторые внешние выходы будут заняты разговорами с ТА2, после ![]() один из этих разговоров прерывается (теряется) и начинается разговор по этому выходу с ТА1.
один из этих разговоров прерывается (теряется) и начинается разговор по этому выходу с ТА1.
6.5.2. Исходные данные

6.5.3. Задание на исследование
Разработать имитационную модель функционирования АТС. Исследовать зависимость вероятности разговоров абонентами ТА1 от интервалов времени T1, T2, времени t1, t2 разговоров и вероятностей р5 и р10 ответа на звонки абонентов ТА2 и ТА1 соответственно.
Результаты моделирования необходимо получить с точностью ![]() и доверительной вероятностью (достоверностью) \alpha = 0,99.
и доверительной вероятностью (достоверностью) \alpha = 0,99.
6.5.4. Блок-диаграмма модели
Модель функционирования АТС должна иметь:
- задание исходных данных;
- сегмент имитации телефонных разговоров с ТА1;
- сегмент имитации телефонных разговоров с ТА2;
- сегмент задания времени моделирования и расчета результатов моделирования.
Телефоны и внешние выходы в модели нужно представить ОКУ, а заявки на разговоры - транзактами. Казалось бы, что в целях сокращения программы модели нужно использовать МКУ, однако МКУ не дает возможности идентифицировать каждый свой канал. Что касается сокращения, то этого можно достичь и с ОКУ.
В программе п. 6.5.1.6 (сегмент имитации работы постов контроля) был продемонстрирован метод сокращения блоков модели за счет замены имен МКУ номерами. Язык GPSS не позволяет сразу, без объявления имен МКУ, использовать номера.
Но для одноканального устройства это возможно. Дадим, используя переменные пользователя, номера ОКУ, предварительно не указывая их имена:
- ТА1 - 1 … N1_ ;
- ТА2 - (N1_+1) … (N1_+N2_) ;
- внешние выходы - (N1_+N2_+1) … (N1_+N2_+N3_).
Нумерацию будем использовать в блок-диаграмме и программе модели. За счет этого при увеличении числа ТА1, ТА2 и внешних выходов программа модели не потребует внесения каких-либо изменений.
Конечно, можно также определить арифметические выражения для вычисления (N1_+N2_), (N1_+N2_+N3_) и затем ссылаться на них в программе модели, например:
Num1 VARIABLE N1_+N2_ Num2 VARIABLE N1_+N2_+N3_
В больших моделях этот вариант предпочтителен. Для лучшего понимания построения модели ее сегменты разделены на части, реализующие самостоятельные функции. Сегмент имитации телефонных разговоров с ТА1:
- определение номера звонящего ТА1;
- поиск свободного внешнего выхода;
- поиск внешнего выхода, занятого ТА2;
- прерывание разговора с ТА2;
- имитация ведения разговора с ТА1 без прерывания разговора с ТА2;
- определение номера ТА2, на который звонят с ТА1;
- имитация разговора между абонентами ТА1 и ТА2. Сегмент имитации телефонных разговоров абонентами ТА2:
- определение номера звонящего ТА2;
- поиск свободного внешнего выхода;
- имитация ведения разговора с ТА2;
- определение номера ТА1, на который звонят с ТА2;
- имитация разговора абонентов ТА2 и ТА1.
В программе демонстрируется возможность GPSS описания и использования в одной и той же модели ОКУ, функционирующего в различных режимах:
- занятия и освобождения устройства (режим FIFO);
- прерывания работы устройства.
Для имитации прерывания телефонных разговоров абонентов ТА2 звонками абонентов с ТА1 используются блоки PREEMPT и RETURN.
Блок-диаграмма модели представлена ниже (рис. 6.4).
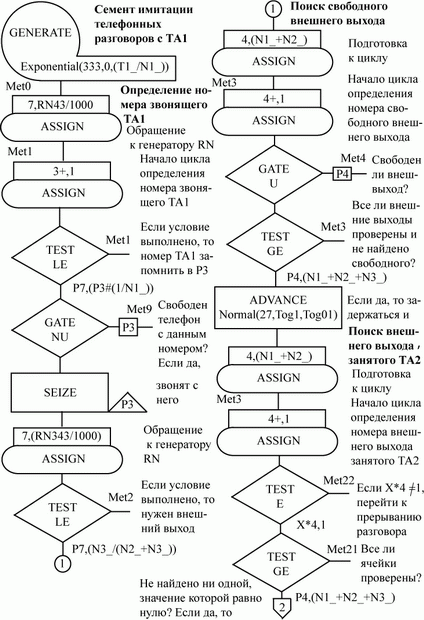
увеличить изображение
Рис. 6.4. Блок-диаграмма модели АТС (лист 1)
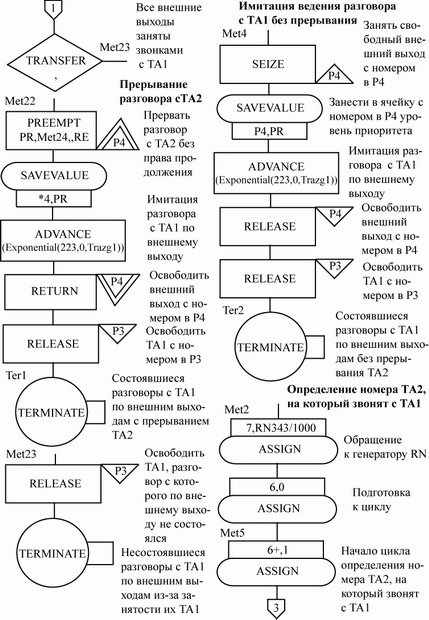
увеличить изображение
Рис. 6.4. Блок-диаграмма модели АТС (продолжение, лист 2)
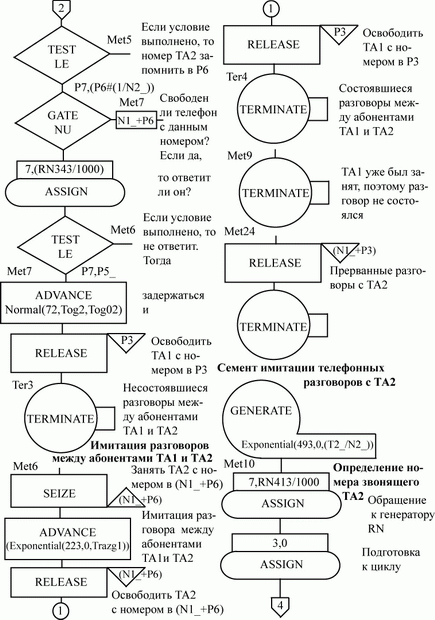
увеличить изображение
Рис. 6.4. Блок-диаграмма модели АТС (продолжение, лист 3)
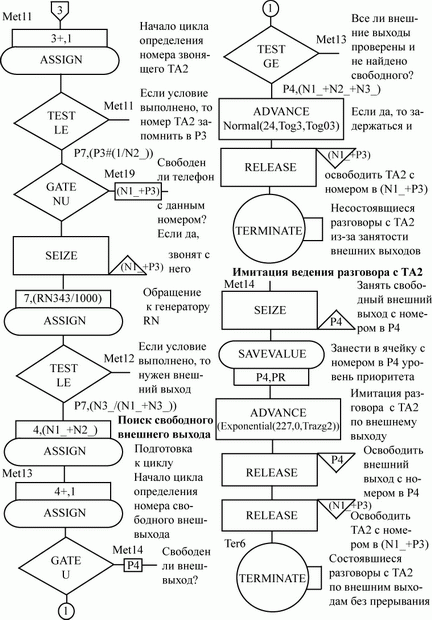
увеличить изображение
Рис. 6.4. Блок-диаграмма модели АТС (продолжение, лист 4)
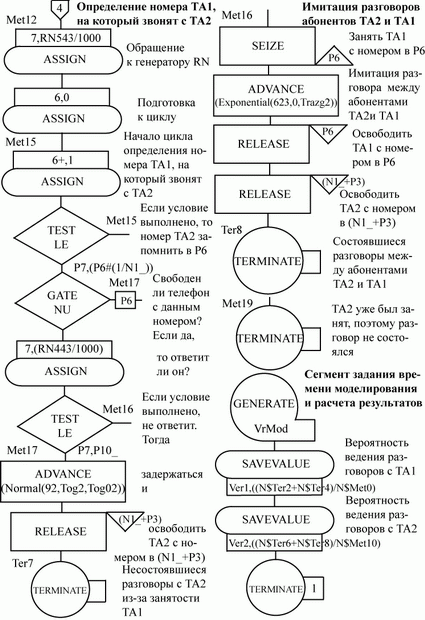
увеличить изображение
Рис. 6.4. Блок-диаграмма модели АТС (окончание, лист 5)
6.5.5. Программа модели
В программе модели для задания исходных данных используются переменные пользователя. Значения им присваиваются командой EQU. Это позволяет проводить эксперименты с использованием встроенных генераторов, так как факторы в них должны быть только переменными пользователя.
Рассмотрим работу сегмента имитации телефонных разговоров с ТА1.
Генератор этого сегмента вводит в модель транзакты со средним интервалом времени (T1_/ N1_ ). Поскольку звонки с ТА1 имеют абсолютный приоритет, то блоком GENERATE транзактам присваивается приоритет 1. Генератор сегмента имитации телефонных разговоров с ТА2 вводит в модель транзакты с нулевым приоритетом.
После ввода транзакта в модель, имитирующего заявку на звонок, производится определение номера звонящего ТА1. Группа событий - звонки с ТА1 - рассматривается как полная группа несовместных событий. Три варианта алгоритмов розыгрыша таких событий рассматривались ранее (п. 3.7). В модели реализован алгоритм розыгрыша в цикле, что делает его независимым при изменении количества телефонных аппаратов.
Определенный в результате розыгрыша номер ТА1 заносится в параметр Р3 транзакта. Однако возможно, что с этого телефона уже звонят. Поэтому блоком GATE производится проверка: свободен ли ТА1 с данным номером? Если нет, заявка теряется.
Если телефон свободен, то далее определяется: куда звонок? На ТА2 или требуется внешний выход? Ответ на этот вопрос находится розыгрышем единичного события (см. п. 3.6).
Пусть требуется внешний выход. Поиск свободного внешнего выхода производится в цикле от номера (N1_+ N2_)+1) до номера ( N1_+ N2_+ N3_). Предположим, что найден свободный
внешний выход, номер которого занесен в параметр Р4. Тогда последовательностью блоков, начиная с метки Мет4, имитируется ведение разговора с ТА1 без прерывания разговора по внешнему выходу с ТА2. После занятия свободного выхода в сохраняемую ячейку с тем же номером, что и номер занятого внешнего выхода, заносится уровень приоритета, в данном случае это 1.
Разговор с ТА1 по внешнему выходу состоялся. Транзакт выводится из модели блоком TERMINATE с меткой Ter2.
Вернемся к поиску свободного внешнего выхода. Пусть все внешние выходы заняты. Далее отыскивается внешний выход, занятый разговором с ТА2. Поиск производится также в цикле от номера (N1_+ N2_) +1 до номера ( N1_+ N2_+ N3_). Однако при этом проверяется содержимое сохраняемых ячеек с такими же номерами, как и номера внешних выходов. Если содержимое проверяемой ячейки равно 1, то внешний выход занят ТА1. Если все внешние выходы заняты ТА1, т. е. во всех проверяемых сохраняемых ячейках 1, заявка на звонок теряется - транзакт отправляется на метку Мет23.
Пусть найден внешний выход, занятый ТА2, т. е. в соответствующей сохраняемой ячейке 0. Транзакт переходит к последовательности блоков, начинающихся с метки Мет22. Эта последовательность имитирует прерывание разговора с ТА2 и ведение разговора с ТА1 по внешнему выходу. По окончании разговора тран-закт выводится из модели блоком TERMINATE с меткой Ter1.
Возвратимся к последовательности блоков, разыгрывающей номер ТА1, с которого поступает заявка на звонок. Пусть теперь требуется не внешний выход, а нужно позвонить одному из абонентов ТА2. В этом случае транзакт направляется к последовательности блоков, начинающейся с метки Мет2. Эта последовательность имитирует определение номера ТА2, на который звонят с ТА1. Номер ТА2 разыгрывается также, как и ранее рассмотренный розыгрыш номера ТА1. После определения номера ТА2 проверяется: свободен ли ТА2 с данным номером? Если не свободен, фиксируется несостоявшийся разговор выводом транзакта из модели блоком TERMINATE с меткой Ter3. Если же ТА2 свободен, транзакт направляется к последовательности блоков, начинающейся с метки Мет6. Эти блоки имитируют ведение разговора абонентами ТА1 и ТА2. По окончании разговора транзакт выводится из модели блоком TERMINATE с меткой Ter4.
Сегмент имитации телефонных разговоров с ТА2 отличается от только что рассмотренного тем, что в нем отсутствует последовательность блоков, имитирующей прерывание разговоров с ТА2 заявками на разговор с ТА1 при отсутствии свободных внешних выходов.
; Модель функционирования автоматической телефонной станции ; Задание исходных данных VrMod EQU 3600 ; Время моделирования, 1 ед. мод. вр. = 1 с N1_ EQU 10 ; Количество ТА1 N2_ EQU 20 ; Количество ТА2 N3_ EQU 3 ; Количество внешних выходов T1_ EQU 40 ; Время для расчета интервалов между звонками с ТА1 T2_ EQU 50 ; Время для расчета интервалов между звонками с ТА2 Tog1 EQU 3.5 ; Среднее время ожидания при занятости внешних линий Tog01 EQU 0.5 ; Среднеквадратическое отклонение времени ожидания Tog2 EQU 3 ; Среднее время ожидания при звонке с ТА1 на ТА2 Tog02 EQU 0.5 ; Среднеквадратическое отклонение времени ожидания Tog3 EQU 2.5 ; Среднее время ожидания при занятости внешних линий Tog03 EQU 0.4 ; Среднеквадратическое отклонение времени ожидания Tog4 EQU 2 ; Среднее время ожидания при звонке с ТА2 на ТА1 Tog04 EQU 0.3 ; Среднеквадратическое отклонение времени ожидания Trazg1 EQU 3 ; Среднее время разговора с ТА1 Trazg2 EQU 5 ; Среднее время разговора с ТА2 P5_ EQU 0.7 ; Вероятность того, что ТА2 не ответит P10_ EQU 0.3 ; Вероятность того, что ТА1 не ответит ; Сегмент имитации телефонных разговоров с ТА1 GENERATE (Exponential(333,0,(T1_/N1_))),,,,1 ; Определение номера звонящего ТА1 Met0 ASSIGN 7,(RN43/1000) ; Обращение к генератору RN Met1 ASSIGN 3+,1 ; Начало цикла определения номера звонящего ТА1 TEST LE P7,(P3#(1/N1_)),Met1 ; Если условие выполнено, то номер ТА1 запомнить в Р3 GATE NU P3,Met9 ; Свободен ли телефон с данным номером? Если да, SEIZE P3 ; то звонят с него ASSIGN 7,(RN343/1000) ; Обращение к генератору RN TEST LE P7,(N3_/(N2_+N3_)),Met2 ; Если условие выполнено, то нужен внешний выход ; Поиск свободного внешнего выхода ASSIGN 4,(N1_+N2_) ; Подготовка к циклу Met3 ASSIGN 4+,1 ; Начало цикла определения номера свободного внешнего выхода GATE U P4,Met4 ; Свободен ли внешний выход? TEST GE P4,(N1_+N2_+N3_),Met3 ; Все ли внешние выходы проверены и не найдено свободного? ADVANCE Tog1,Tog01 ; Если да, то задержаться и ; Поиск внешнего выхода, занятого ТА2 ASSIGN 4,(N1_+N2_) ; подготовка к циклу Met21 ASSIGN 4+,1 ; Начало цикла определения номера внешнего выхода, занятого ТА2 TEST E X*4,1,Met22 ; Равно ли значение сохраняемой ячейки 1? Если нет, то перейти к прерыванию разговора TEST GE P4,(N1_+N2_+N3_),Met21 ; Все ли сохраняемые ячейки проверены? Не найдено ни одной, значение которой равно 0? Если да, то TRANSFER ,Met23 ; все внешние выходы заняты звонками с ТА1 ; Прерывание разговора с ТА2 Met22 PREEMPT P4,PR,Met24,,RE ; Прервать разговор с ТА2 по внешнему выходу без права продолжения SAVEVALUE *4,PR ; Сохранить PR в ячейке с номером в Р4 ADVANCE (Exponential(222,0,Trazg1)) ; Имитация разговора с ТА1 по внешнему выходу RETURN P4 ; Освободить внешний выход с номером в Р4 RELEASE P3 ; Освободить ТА1 с номером в Р3 Ter1 TERMINATE ; Состоявшиеся разговоры с ТА1 по внешним выходам с прерыванием разговоров с ТА2 Met23 RELEASE P3 ; Освободить ТА1, разговор с которого по внешнему выходу не состоялся TERMINATE ; Несостоявшиеся разговоры с ТА1 по внешним выходам из-за занятости их ТА1 ; Имитация ведения разговоров с ТА1 без прерывания Met4 SEIZE P4 ; Занять свободный внешний выход с номером в Р4 SAVEVALUE P4,PR ; Занести в ячейку с номером в Р4 уровень приоритета ADVANCE (Exponential(222,0,Trazg1)) ; Имитация разговора с ТА1 RELEASE P4 ; Освободить внешний выход с номером в Р4 RELEASE P3 ; освободить ТА1 с номером в Р3 Ter2 TERMINATE ; Состоявшиеся разговоры с ТА1 по внешним выходам ; Определение номера ТА2, на который звонят с ТА1 Met2 ASSIGN 7,(RN343/1000) ; Обращение к генератору RN ASSIGN 6,0 ; Подготовка к циклу Met5 ASSIGN 6+,1 ; Начало цикла определения номера ТА2, на который звонят с ТА1 TEST LE P7,(P6#(1/N2_)),Met5 ; Если условие выполнено, то номер ТА2 запомнить в Р6 GATE NU (N1_+P6),Met7 ; Свободен ли телефон с данным номером? Если да, ASSIGN 7,(RN343/1000) ; то ответит ли он? TEST LE P7,P5_,Met6 ; Если условие выполнено, то не ответит. Тогда Met7 ADVANCE Tog2,Tog02 ; задержаться и RELEASE P3 ; освободить ТА1 с номером в Р3 Ter3 TERMINATE ; Несостоявшиеся разговоры между абонентами ТА1 и ТА2 ; Имитация разговоров абонентов ТА1 и ТА2 Met6 SEIZE (N1_+P6) ; Занять ТА2 с номером в (N1_+Р6) ADVANCE (Exponential(222,0,Trazg1)) ; Имитация разговора между абонентами ТА1 и ТА2 RELEASE (N1_+P6) ; Освободить ТА2 с номером в (N1_+Р6) RELEASE P3 ; Освободить ТА1 с номером в Р3 Ter4 TERMINATE ; Состоявшиеся разговоры между абонентами ТА1 и ТА2 Met9 TERMINATE ; ТА1 уже был занят, поэтому разговор не состоялся Met24 RELEASE (N1_+P3) ; Прерванные разговоры с ТА2 TERMINATE ; Сегмент имитации телефонных разговоров с ТА2 GENERATE (Exponential(493,0,(T2_/N2_))) ; Определение номера звонящего ТА1 Met10 ASSIGN 7,(RN413/1000) ; Обращение к генератору RN ASSIGN 3,0 ; Подготовка к циклу Met11 ASSIGN 3+,1 ; Начало цикла определения номера звонящего ТА2 TEST LE P7,(P3#(1/N2_)),Met11 ; Если условие выполнено, то номер ТА2 запомнить в Р3 GATE NU (N1_+P3),Met19 ; Свободен ли телефон с данным номером? Если да, SEIZE (N1_+P3) ; то звонят с него ; Поиск свободного внешнего выхода ASSIGN 7,(RN343/1000) ; Обращение к генератору RN TEST LE P7,(N3_/(N1_+N3_)),Met12 ; Если условие выполнено, то нужен внешний выход ASSIGN 4,(N1_+N2_) ; Подготовка к циклу Met13 ASSIGN 4+,1 ; Начало цикла определения номера свободного внешнего выхода GATE U P4,Met14 ; Свободен ли внешний выход? TEST GE P4,(N1_+N2_+N3_),Met13 ; Все ли внешние выходы проверены и не найдено свободного выхода? ADVANCE Tog3,Tog03 ; Если да, то задержаться и RELEASE (N1_+P3) ; Освободить телефон с номером (N1_+P3) Ter5 TERMINATE ; Несостоявшиеся разговоры с ТА2 из-за занятости внешних выходов Met14 SEIZE P4 ; Занять свободный внешний выход SAVEVALUE P4,PR ; Запомнить приоритет абонента, ведущего разговор ADVANCE (Exponential(222,0,Trazg2)) ; Имитация разговора между абонентами ТА2 по внешним выходам RELEASE P4 ; Освободить внешний выход RELEASE (N1_+P3) ; Освободить ТА2 Ter6 TERMINATE ; Состоявшиеся разговоры с ТА2 по внешним выходам ; Определение номера ТА1, на который звонят с ТА2 Met12 ASSIGN 7,(RN343/1000) ; Обращение к генератору RN ASSIGN 6,0 ; Подготовка к циклу Met15 ASSIGN 6+,1 ; Начало цикла определения номера ТА1, на который звонят с ТА2 TEST LE P7,(P6#(1/N1_)),Met15 ; Если условие выполнено, то номер ТА1 запомнить в Р6 GATE NU P6,Met17 ; Свободен ли телефон с данным номером? Если да, ASSIGN 7,(RN343/1000) ; то ответит ли он? TEST LE P7,P10_,Met16 ; Если условие выполнено, то не ответит. Тогда Met17 ADVANCE (Normal(211,Tog2,Tog02)) ; задержаться и RELEASE (N1_+P3) ; освободить телефон с номером N1_+P3 Ter7 TERMINATE ; Несостоявшиеся разговоры с ТА2 из-за занятости ТА1 ; Имитация разговоров абонентов ТА2 и ТА1 Met16 SEIZE P6 ; Занять ТА1 с номером в Р6 ADVANCE (Exponential(222,0,Trazg2)) ; Имитация разговора между абонентами ТА2 и ТА1 RELEASE P6 ; Освободить ТА1 с номером в Р6 RELEASE (N1_+P3) ; Освободить ТА2 с номером N1_+P3 Ter8 TERMINATE ; Состоявшиеся разговоры между абонентами ТА2 и ТА1 Met19 TERMINATE ; Сегмент задания времени моделирования и расчета результатов моделирования GENERATE VrMod ; Задание времени моделирования TEST E TG1,1,Met20 ; Если содержимое счетчика завершений равно 1, то рассчитать SAVEVALUE Ver1,((N$Ter2+N$Ter4)/N$Met0) ; Вероятность ведения разговоров с ТА1 SAVEVALUE Ver2,((N$Ter6+N$Ter8)/N$Met10) ; Вероятность ведения разговоров с ТА2 Met20 TERMINATE 1 ; Фиксация очередного прогона
Приведем результаты моделирования, полученные после 1000 прогонов.
SAVEVALUE RETRY VALUE VER1 0 0.614 VER2 0 0.396
Вероятность ведения разговоров с ТА2 Ver2 = 0,396 меньше, чем Ver1 = 0,614. Одним из факторов, влияющим на это, является вероятность P10_ = 0,7 того, что абонент ТА1 на звонок абонента ТА2 не ответит.
Оставим без изменений все исходные данные, установим лишь равную вероятность не ответа на звонки абонентами обеих категорий P10_ = P5_ = 0,3.
По окончании моделирования получим:
SAVEVALUE RETRY VALUE VER1 0 0.584 VER2 0 0.625
6.6. Применение матриц, функций и изменение версий модели
В условиях рыночных отношений производственная и финансовая деятельность организаций сложна и динамична, что требует применения динамических моделей практически во всех вариантах методик проведения реинжиниринга бизнес-процессов.
Накопление опыта в области компьютерного моделирования позволило выделить четыре группы бизнес процессов, обладающих спецификой в отношении построения динамических моделей: процессы реализации проектов, процессы производства, процессы распределения и процессы предоставления услуг.
Процессы предоставления услуг - наиболее распространенная область применения динамических моделей. Такие процессы характерны для организаций, предоставляющих услуги по средствам связи, сервис-центров (рестораны, агентства, поликлиники, ремонтные мастерские и т. п.) и предприятий торговли.
Рассмотрим разработку и реализацию подобных моделей в системе моделирования GPSS World на примере бизнес-процесса предоставления услуг по средствам связи.
6.6.1. Постановка задачи бизнес-процесса
На дежурстве находятся n1 средств связи (СС) n2 типов (n21 + n22 + … + n2n2 = n2) в течение n3 часов.
Каждое СС может в любой момент времени выйти из строя. В этом случае его заменяют резервным, причем либо сразу, либо по мере его появления. Тем временем, вышедшие из строя СС ремонтируют, после чего содержат в качестве резервного. Всего количество резервных СС - n4.
Ремонт неисправных СС производят n5 мастеров. Время T1, T2, …, Tn2 ремонта случайное и зависит от типа СС, но не зависит от того, какой мастер это СС ремонтирует. Интервалы времени T21, T22, …, T2n2 между отказами находящихся на дежурстве СС случайные.
Прибыль от СС, находящихся на дежурстве, составляет S1 денежных единиц в час. Почасовой убыток при отсутствии на дежурстве одного СС - S2 денежных единиц. Оплата мастера за ремонт неисправного СС - S31, S32, …, S3n2 денежных единиц в час. Затраты на содержание одного резервного СС составляют S4 денежных единиц в час.
Исследовать через промежутки времени ![]() (пять недель) влияние на ожидаемую прибыль различного количества резервных СС и мастеров.
(пять недель) влияние на ожидаемую прибыль различного количества резервных СС и мастеров.
Определить абсолютные величины и относительные коэффициенты ожидаемой прибыли для каждого промежутка времени. Результаты моделирования (относительный коэффициент прибыли) необходимо получить с точностью ![]() и доверительной вероятностью
и доверительной вероятностью ![]() .
.
Сделать выводы об использовании СС, мастеров по промежуткам времени ![]() и необходимых мерах по совершенст вованию бизнес-процесса.
и необходимых мерах по совершенст вованию бизнес-процесса.
Вариант исходных данных приведен в программе модели (п. 6.6.3).
6.6.2. Уяснение задачи
Уясним задачу на разработку имитационной модели, предварительно разработав структуру системы предоставления услуг связи (рис. 6.5).
Видно, что система предоставления услуг связи представляет собой многофазную многоканальную систему массового обслуживания замкнутого типа.
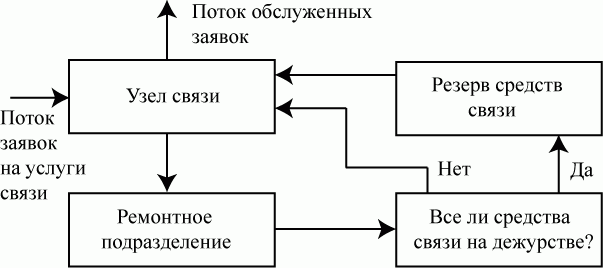
Рис. 6.5. Структура системы предоставления услуг связи
Какие ограничения в системе?
- Число мастеров-ремонтников в ремонтном подразделении.
- Максимальное число СС, одновременно находящихся на дежурстве.
- Максимальное число резервных СС.
- Общее число СС в системе.
Для моделирования двух первых ограничений используем МКУ, а для третьего и четвертого ограничений - транзакты.
Модель бизнес-процесса должна состоять из следующих сегментов:
- описание арифметических выражений;
- сегмент имитации постановки на дежурство СС;
- сегмент имитации функционирования системы дежурства СС;
- сегмент имитации функционирования ремонтного подразделения;
- сегмент задания времени моделирования и вычисления результатов моделирования;
- расчет ожидаемой прибыли;
- сегмент переопределения блоков - изменения версий модели.
Сегмент переопределения блоков модели необходим для изменения версий модели, т. е. изменения количества резервных СС и мастеров-ремонтников в ремонтном подразделении, а также номеров строк и столбцов матриц, в которые записываются результаты моделирования.
6.6.3. Программа модели
Предполагается, что количество типов СС в системе предоставления услуг связи может изменяться от одного до максимального значения n1_. Программа модели построена для n1_ =5.
Для хранения результатов моделирования используются матрицы. В целях придания неизменности программы модели при варьировании количеством типов СС матрицы должны быть пронумерованы. Однако GPSS World при описании матриц командой MATRIX не позволяет вместо имени указывать число. Матрицы нужно вначале описать, дав им имена, а затем пронумеровать.
Результаты моделирования для одного типа СС хранятся в трех матрицах, например, для СС типа 1 ( СС1 ) с идентификаторами:
- Prib1 - матрица ожидаемой прибыли СС1 ;
- KPr1 - матрица коэффициентов прибыли СС1 ;
- KZen1 - матрица коэффициентов использования СС1.
Значит, аналогичных матриц будет пятнадцать. Да плюс еще матрица KRem коэффициентов использования мастеров - ремонтников. Именам этим шестнадцати матрицам даны номера.
Три матрицы для хранения суммарных результатов моделирования для СС всех типов не нумеровались:
- Pribil - матрица суммарной прибыли;
- SrKPrib - матрица средних коэффициентов прибыли СС всех типов;
- SrKIsp - матрица коэффициентов использования СС всех типов.
Именам пяти МКУ СС1_, СС2_, СС3_, СС4_ и СС5_, имитирующим по типам СС, находящиеся на дежурстве, даны номера 1 … 5. Это позволяет сократить число блоков в модели за счет того, что вместо пяти (в данном варианте модели) сегментов имитации постановки на дежурство СС используется один сегмент.
Для записи исходных данных (количества СС всех типов (в том числе и резервных), среднего времени наработки до отказа и среднего времени восстановления по типам СС, дохода по типам от одного СС, находящегося на дежурстве, убытка по типам при отсутствии одного СС на дежурстве, стоимости по типам одного резервного СС) используются функции KolSS, KollSSRes, NarOtk, SrVrRem, S1_, S2_, S3_ соответственно. По сравнению с использованием матриц для записи этих же данных программа модели сокращается на двадцать пять строк.
В начале работы модели генератор сразу вырабатывает количество транзактов, равное соответствующему количеству типов СС, и перестает быть активным.
Далее блоками SAVEVALUE и ASSIGN в параметр 1 каждого из транзактов последовательно заносятся коды 1 … n1_ - признак типа СС.
Затем каждый из транзактов с помощью блока SPLIT расщепляется (копируется, размножается) по количеству СС (с учетом резервных) соответствующего типа. После расщепления транзакты в соответствии с типом СС сразу занимают все каналы МКУ, имитирующие нахождение СС на дежурстве.
Вышедшее из строя СС снимается с дежурства, поступает в ремонтное подразделение - транзакт либо занимает свободный канал МКУ Rem, если такой есть, либо при отсутствии свободного канала помещается в список задержки этого МКУ - список тран-зактов, ожидающих возможность занять освободившиеся каналы МКУ.
После ремонта СС отправляется либо сразу на дежурство, либо в резерв. В обоих случаях транзакт направляется на метку Met1. Здесь также транзакт либо занимает свободный канал, либо помещается в список задержки МКУ, соответствующего типу СС.
Ниже приводится программа только (в целях сокращения) для моделирования случая три мастера-ремонтника, а резервных СС2 - четыре, пять и шесть. Количество типов СС - n1_ = 4.
; Модель бизнес-процесса ; Задание номеров матрицам Prib1 EQU 1 ; Матрица ожидаемой прибыли СС1 KPr1 EQU 2 ; Матрица коэффициентов прибыли СС1 KZen1 EQU 3 ; Матрица коэффициентов использования СС1 Prib2 EQU 4 ; Матрица ожидаемой прибыли СС2 KPr2 EQU 5 ; Матрица коэффициентов прибыли СС2 KZen2 EQU 6 ; Матрица коэффициентов использования СС2 Prib3 EQU 7 ; Матрица ожидаемой прибыли СС3 KPr3 EQU 8 ; Матрица коэффициентов прибыли СС3 KZen3 EQU 9 ; Матрица коэффициентов использования СС3 Prib4 EQU 10 ; Матрица ожидаемой прибыли СС4 KPr4 EQU 11 ; Матрица коэффициентов прибыли СС4 KZen4 EQU 12 ; Матрица коэффициентов использования СС4 Prib5 EQU 13 ; Матрица ожидаемой прибыли СС5 KPr5 EQU 14 ; Матрица коэффициентов прибыли СС5 KZen5 EQU 15 ; Матрица коэффициентов использования СС5 KRem EQU 16 ; Матрица коэффициентов использования Rem ; Задание номеров МКУ, имитирующих дежурство СС CC1_ EQU 1 ; Задание номера МКУ СС1 CC2_ EQU 2 ; Задание номера МКУ СС2 CC3_ EQU 3 ; Задание номера МКУ СС3 CC4_ EQU 4 ; Задание номера МКУ СС4 CC5_ EQU 5 ; Задание номера МКУ СС5 ; Задание матриц Prib1 MATRIX ,3,5 ; Матрица ожидаемой прибыли СС1 KPr1 MATRIX ,3,5 ; Матрица коэффициентов прибыли СС1 KZen1 MATRIX ,3,5 ; Матрица коэффициентов загрузки СС1 Prib2 MATRIX ,3,5 ; Матрица ожидаемой прибыли СС2 KPr2 MATRIX ,3,5 ; Матрица коэффициентов прибыли СС2 KZen2 MATRIX ,3,5 ; Матрица коэффициентов загрузки СС2 Prib3 MATRIX ,3,5 ; Матрица ожидаемой прибыли СС3 KPr3 MATRIX ,3,5 ; Матрица коэффициентов прибыли СС3 KZen3 MATRIX ,3,5 ; Матрица коэффициентов загрузки СС3 Prib4 MATRIX ,3,5 ; Матрица ожидаемой прибыли СС4 KPr4 MATRIX ,3,5 ; Матрица коэффициентов прибыли СС4 KZen4 MATRIX ,3,5 ; Матрица коэффициентов загрузки СС4 Prib5 MATRIX ,3,5 ; Матрица ожидаемой прибыли СС5 KPr5 MATRIX ,3,5 ; Матрица коэффициентов прибыли СС5 KZen5 MATRIX ,3,5 ; Матрица коэффициентов загрузки СС5 KRem MATRIX ,3,5 ; Матрица коэффициентов загрузки Rem Pribil MATRIX ,3,5 ; Матрица суммарной прибыли SrKPrib MATRIX ,3,5 ; Матрица коэффициентов прибыли СС всех типов SrKIsp MATRIX ,3,5 ; Матрица коэффициентов загрузки СС всех типов KolSS MATRIX ,2,5 ; Матрица количества СС всех типов NarOtk MATRIX ,1,5 ; Матрица среднего времени наработки до отказа по типам СС, час SrVrRem MATRIX ,1,5 ; Матрица среднего ремонта по типам СС, час ; Определение МКУ по числу СС, находящихся на дежурстве CC1_ STORAGE 35 ; Емкость МКУ по количеству СС1 CC2_ STORAGE 100 ; Емкость МКУ по количеству СС2 CC3_ STORAGE 60 ; Емкость МКУ по количеству СС3 CC4_ STORAGE 45 ; Емкость МКУ по количеству СС4 CC5_ STORAGE 60 ; Емкость МКУ по количеству СС5 Rem STORAGE 3 ; Емкость МКУ по числу мастеров-ремонтников ; Исходные данные VrMod EQU 200 ; Время моделирования, 1 ед. мод. вр. = 1 час Stroka EQU 1 ; Номер строки матрицы Stolbez EQU 1 ; Номер столбца матрицы n1_ EQU 5 ; Количество типов СС StoMast FUNCTION P1,D5 ; Стоимость работы одного мастера 1,17/2,18/3,16/4,20/5,21 KolSS FUNCTION P1,D5 ; Количество по типам СС, находящихся на дежурстве 1,55/2,100/3,60/4,45/5,60 KolSSRes FUNCTION P1,D5 ; Количество по типам резервных СС 1,2/2,4/3,4/4,3/5,4 NarOtk FUNCTION P1,D5 ; Среднее время наработки до отказа по типам СС, час 1,373/2,301/3,482/4,325/5,470 SrVrRem FUNCTION P1,D5 ; Среднее время ремонта по типам СС 1,6.5/2,4.2/3,2.8/4,3/5, 5.5 S1_ FUNCTION P1,D5 ; Доход по типам от одного СС, находящегося на дежурстве 1,20/2,24.2/3,32.8/4,23/5, 25.5 S2_ FUNCTION P1,D5 ; Убыток по типам при отсутствии одного СС на дежурстве 1,32/2,34.2/3,37/4,31/5,32.5 S3_ FUNCTION P1,D5 ; Стоимость по типам содержания одного резервного СС 1,21/2,24.2/3,28/4,26/5, 25.5 ; Арифметические выражения для расчета показателей DoxMax VARIABLE VrMod#FN$S1_#FN$KolSS ; Максимальный доход от дежурства СС Ubitok VARIABLE VrMod#FN$KolSS#(1-SR*1/1000)#FN$S2_ ; Убыток от отсутствия на дежурстве СС DoxPol VARIABLE X$DoxMax-X$Ubitok ; Полученный доход от дежурства СС StoRem VARIABLE (VrMod#SM$Rem#FN$StoMast)#(SR$Rem/1000) ; Стоимость ремонта неисправных СС ZatrResSS VARIABLE FN$S3_#FN$KolSSRes#VrMod ; Затраты на содержание резервных СС SumPrib VARIABLE X$DoxPol-(X$StoRem+X$ZatrResSS) ; Прибыль KoefPr VARIABLE MX*3(Stroka,Stolbez)/X$DoxMax ; Коэффициент прибыли ; Сегмент имитации постановки на дежурство СС GENERATE ,,,n1_ SAVEVALUE TipSS+,1 ; Код 1 ... n2_ - признак СС1 ... CCn1 в X$TipSS ASSIGN 1,X$TipSS ; Код 1 ... n2_ - признак СС1 ...CCn2_ в P1 SPLIT (FN$KolSS+FN$KolSSRes-1) ; Число СС + резервные СС ; Сегмент имитации дежурства СС Met1 ENTER P1 ; Встать на дежурство СС типа с номером в Р1 ADVANCE (Exponential(30,0,FN$NarOtk)) ; Имитация выхода из строя СС LEAVE P1 ; Снятие с дежурства из-за выхода из строя СС типа, номер которого в Р1 ; Сегмент имитации работы ремонтного подразделения ENTER Rem ; Занять одного мастера ADVANCE (Exponential(31,0,FN$SrVrRem)) ; Имитация ремонта LEAVE Rem ; Конец ремонта TRANSFER ,Met1 ; Направить исправное СС на дежурство или в резерв ; Сегмент задания времени моделирования и расчета результатов GENERATE VrMod TEST E TG1,1,Met2 Met23 ASSIGN 1+,1 ; Начало цикла изменения типов СС SAVEVALUE DoxMax,V$DoxMax ; Максимально возможный доход от дежурства СС SAVEVALUE Ubitok,V$Ubitok ; Убыток SAVEVALUE DoxPol,V$DoxPol ; Полученный доход от дежурства СС SAVEVALUE StoRem,V$StoRem ; Затраты на ремонт SAVEVALUE ZatrResSS,V$ZatrResSS ; Затраты на резервные СС SAVEVALUE SumPrib,V$SumPrib ; Суммарная прибыль ASSIGN 2,(P1#3) ASSIGN 3,(P2-2) MSAVEVALUE *3,Stroka,Stolbez,X$SumPrib ; Прибыль по типу СС MSAVEVALUE Pribil+,Stroka,Stolbez,X$SumPrib ; Суммарная прибыль по СС всех типов ASSIGN 4,V$KoefPr ; Коэфициент прибыли по типам СС в Р4 ASSIGN 3,(P2-1) MSAVEVALUE *3,Stroka,Stolbez,P4 ; Коэфициент прибыли по типам СС MSAVEVALUE SrKPrib+,Stroka,Stolbez,(P4/n1_) ; Средний коэффициент прибыли по СС всех типов MSAVEVALUE *2,Stroka,Stolbez,(SR*1/1000) ; Коэффициент использования CC MSAVEVALUE SrKIsp+,Stroka,Stolbez,(SR*1/(1000#n1_)) ; Средний коэффициент использования CC всех типов TEST GE P1,n1_,Met23 MSAVEVALUE 16,Stroka,Stolbez,(SR$Rem/1000); Коэффициент использования Rem SAVEVALUE TipSS,0 Met2 TERMINATE 1 START 1000,NP ; Недели 1-5: Резервных СС2=4, мастеров=3 ; Сегмент переопределения блоков - изменения версий модели Stolbez EQU 2 RESET START 1000,NP ; Недели 6-10: Резервных СС2=4, масте-ров=3 Stolbez EQU 3 RESET START 1000,NP ; Недели 11-15: Резервных СС2=4, мас-теров=3 Stolbez EQU 4 RESET START 1000,NP ; Недели 16-20: Резервных СС2=4, мас-теров=3 Stolbez EQU 5 RESET START 1000,NP ; Недели 21-25: Резервных СС2=4, мас-теров=3 KolSSRes FUNCTION P1,D5 ; Количество резервных СС2 1,2/2,5/3,4/4,4/5,4 Stroka EQU 2 Stolbez EQU 1 RESET START 1000,NP ; Недели 1-5: Резервных СС2=5, мастеров=3 Stolbez EQU 2 RESET START 1000,NP ; Недели 6-10: Резервных СС2=5, мастеров=3 Stolbez EQU 3 RESET START 1000,NP ; Недели 11-15: Резервных СС2=5, мастеров=3 Stolbez EQU 4 RESET START 1000,NP ; Недели 16-20: Резервных СС2=5, мастеров=3 Stolbez EQU 5 RESET START 1000,NP ; Недели 21-25: Резервных СС2=5, мастеров=3 KolSSRes FUNCTION P1,D5 ; Количество резервных СС2 1,2/2,6/3,4/4,5/5,4 Stroka EQU 3 Stolbez EQU 1 RESET START 1000,NP ; Недели 1-5: Резервных СС2=6, мастеров=3 Stolbez EQU 2 RESET START 1000,NP ; Недели 6-10: Резервных СС2=6, мастеров=3 Stolbez EQU 3 RESET START 1000,NP ; Недели 11-15: Резервных СС2=6, мастеров=3 Stolbez EQU 4 RESET START 1000,NP ; Недели 16-20: Резервных СС2=6, мастеров=3 Stolbez EQU 5 RESET START 1000 ; Недели 21-25: Резервных СС2=6, мастеров=3
В программе, кроме методов применения матриц и функций, показывается метод изменения версий модели. Изменение версий модели производится переопределением соответствующих блоков. Переопределяться не могут блоки GENERATE. Для переопределения блоков, описывающих ОКУ и МКУ, они должны иметь метки. Однако одного переопределения блоков недостаточно. В GPSS World изменение версий модели достигается также за счет использования команд RESET и CLEAR.
В рассматриваемом примере в процессе моделирования необходимо собирать статистику по отрезкам времени \Delta T. То есть предшествующую статистику нужно сбросить, но оставить неизменными условия функционирования системы.
Сброс в ноль статистики без удаления транзактов из процесса моделирования осуществляет команда RESET. Команда RESET не имеет операндов:
RESET
Команда также не сбрасывает генераторы случайных чисел, ячейки и матрицы ячеек, не влияет на абсолютное модельное время и нумерацию транзактов. Относительное модельное время (после последней команды RESET ) устанавливается равным нулю. Таким образом, с помощью команды RESET обеспечивается удобное средство сбора статистических данных в типичных условиях функционирования систем.
После того как для данной версии модели выполнено моделирование в течение заданного числа отрезков времени \Delta T (в примере - пять), нужно изменить версию модели и провести моделирование сначала.
Изменение версии в данной модели производится переопределением функции KolSSRes, т. е. изменением количества резервных СС2, например:
KolSSRes FUNCTION P1,D5 ; Количество резервных СС2 1,2/2,5/3,4/4,4/5,4
Процесс моделирования в исходное состояние возвращает команда CLEAR. Формат записи команды:
CLEAR [A]
Операнд А может быть ON либо OFF. По умолчанию - ON.
Команда CLEAR сбрасывает всю накопленные статистические данные, удаляет все транзакты из процесса моделирования и заполняет все блоки GENERATE первым транзактом. ОКУ и МКУ становятся доступными, устанавливаются в незанятое состояние. Содержимое всех блоков становится нулевым. Генераторы случайных чисел не сбрасываются.
Если в команде CLEAR операнд А равен OFF, то сохраняемые ячейки, матрицы и логические ключи остаются без изменений. Поэтому в модели в команде CLEAR используется операнд А, равный OFF, так как нужно сохранить результаты моделирования для предыдущей версии модели.
Однако при этом нужно иметь в виду те ячейки, начальные значения которых должны быть нулевыми в новой версии модели. Необходимо предусмотреть в программе блоки приведения таких ячеек в исходное состояние. В данной модели это показано на примере сохраняемой ячейки TipSS. Если эту ячейку не привести в нулевое состояние, процесс моделирования второй версии будет остановлен по ошибке "Обращение к несуществующей памяти".
Поскольку накопленные и сохраненные в матрицах результаты моделирования нет необходимости выводить на каждом отрезке \Delta T, то в команде START используется операнд B, равный ON. В последней команде START операнд B не используется. Поэтому стандартный отчет выдается после завершения моделирования. В рассматриваемом примере - после пятнадцати наблюдений.
Ниже показан фрагмент журнала с информацией о ходе моделирования. В первых пяти наблюдениях (первой версии модели) команда RESET не влияет на абсолютное модельное время, которое растет от 0 до 1 000 000 единиц модельного времени.
После переопределения (формирования второй версии модели) выполняется команда CLEAR и абсолютное модельное время вновь изменяется от 0 до 1 000 000 единиц модельного времени.
06/05/08 17:29:10 Model Translation Begun. 06/05/08 17:29:10 Ready. 06/05/08 17:29:10 Simulation in Progress. 06/05/08 17:29:15 The Simulation has ended. Clock is 200000.000000. 06/05/08 17:29:15 Simulation in Progress. 06/05/08 17:29:19 The Simulation has ended. Clock is 400000.000000. 06/05/08 17:29:19 Simulation in Progress. 06/05/08 17:29:24 The Simulation has ended. Clock is 600000.000000. 06/05/08 17:29:24 Simulation in Progress. 06/05/08 17:29:28 The Simulation has ended. Clock is 800000.000000. 06/05/08 17:29:28 Simulation in Progress. 06/05/08 17:29:32 The Simulation has ended. Clock is 1000000.000000. 06/05/08 17:29:33 Simulation in Progress. 06/05/08 17:29:37 The Simulation has ended. Clock is 200000.000000. 06/05/08 17:29:37 Simulation in Progress. 06/05/08 17:29:41 The Simulation has ended. Clock is 400000.000000. 06/05/08 17:29:41 Simulation in Progress. … 06/05/08 17:30:17 Reporting in Rem_SS_2.59.1 - REPORT Window.
Для включения в формируемый стандартный отчет матриц необходимо при открытом объекте "Модель" выполнить команду:
Edit/Settings/Reports/Matrices/Применить/Ok
Результаты моделирования после 1000 прогонов приведены ниже. Но опять же в целях сокращения - для СС1 и СС всех типов.
| MATRIX | RETRY | INDICES | VALUE |
|---|---|---|---|
| PRIB1 | 0 | ||
| 1 1 | 181586.183 | ||
| 1 2 | 181251.160 | ||
| 1 3 | 179584.944 | ||
| 1 4 | 181774.706 | ||
| 1 5 | 182291.154 | ||
| 2 1 | 180844.964 | ||
| 2 2 | 181435.896 | ||
| 2 3 | 181478.223 | ||
| 2 4 | 179347.815 | ||
| 2 5 | 179178.486 | ||
| 3 1 | 178683.512 | ||
| 3 2 | 178136.334 | ||
| 3 3 | 179139.261 | ||
| 3 4 | 181934.517 | ||
| 3 5 | 179655.938 | ||
| KPR1 | 0 | ||
| 1 1 | .825 | ||
| 1 2 | .823 | ||
| 1 3 | .816 | ||
| 1 4 | .826 | ||
| 1 5 | .828 | ||
| 2 1 | .822 | ||
| 2 2 | .824 | ||
| 2 3 | .824 | ||
| 2 4 | .815 | ||
| 2 5 | .814 | ||
| 3 1 | .812 | ||
| 3 2 | .809 | ||
| 3 3 | .814 | ||
| 3 4 | .826 | ||
| 3 5 | .816 | ||
| KZEN1 | 0 | ||
| 1 1 | .943 | ||
| 1 2 | .942 | ||
| 1 3 | .937 | ||
| 1 4 | .943 | ||
| 1 5 | .945 | ||
| 2 1 | .941 | ||
| 2 2 | .942 | ||
| 2 3 | .942 | ||
| 2 4 | .936 | ||
| 2 5 | .936 | ||
| 3 1 | .935 | ||
| 3 2 | .933 | ||
| 3 3 | .936 | ||
| 3 4 | .944 | ||
| 3 5 | .937 | ||
| 3 5 | .601 | ||
| KREM | 0 | ||
| 1 1 | .981 | ||
| 1 2 | .982 | ||
| 1 3 | .984 | ||
| 1 4 | .978 | ||
| 1 5 | .981 | ||
| 2 1 | .983 | ||
| 2 2 | .982 | ||
| 2 3 | .982 | ||
| 2 4 | .984 | ||
| 2 5 | .982 | ||
| 3 1 | .985 | ||
| 3 2 | .984 | ||
| 3 3 | .984 | ||
| 3 4 | .979 | ||
| 3 5 | .982 | ||
| PRIBIL | 0 | ||
| 1 1 | 1111897.023 | ||
| 1 2 | 1110398.484 | ||
| 1 3 | 1102062.813 | ||
| 1 4 | 1113459.610 | ||
| 1 5 | 1114232.258 | ||
| 2 1 | 1105731.875 | ||
| 2 2 | 1107881.589 | ||
| 2 3 | 1111610.502 | ||
| 2 4 | 1098478.153 | ||
| 2 5 | 1097605.578 | ||
| 3 1 | 1094679.743 | ||
| 3 2 | 1091129.285 | ||
| 3 3 | 1096084.094 | ||
| 3 4 | 1107311.254 | ||
| 3 5 | 1097609.762 | ||
| SRKPRIB | 0 | ||
| 1 1 | .844 | ||
| 1 2 | .843 | ||
| 1 3 | .837 | ||
| 1 4 | .846 | ||
| 1 5 | .846 | ||
| 2 1 | .839 | ||
| 2 2 | .840 | ||
| 2 3 | .843 | ||
| 2 4 | .833 | ||
| 2 5 | .832 | ||
| 3 1 | .829 | ||
| 3 2 | .826 | ||
| 3 3 | .830 | ||
| 3 4 | .839 | ||
| 3 5 | .831 | ||
| SRKISP | 0 | ||
| 1 1 | .954 | ||
| 1 2 | .953 | ||
| 1 3 | .948 | ||
| 1 4 | .954 | ||
| 1 5 | .955 | ||
| 2 1 | .956 | ||
| 2 2 | .957 | ||
| 2 3 | .959 | ||
| 2 4 | .952 | ||
| 2 5 | .951 | ||
| 3 1 | .955 | ||
| 3 2 | .953 | ||
| 3 3 | .956 | ||
| 3 4 | .962 | ||
| 3 5 | .957 |
6.7. Моделирование неисправностей одноканальных устройств
6.7.1. Постановка задачи
На вычислительный комплекс коммутации сообщений (ВККС) поступают сообщения от ![]() абонентов с интервалами времени
абонентов с интервалами времени ![]() . Сообщения могут быть
. Сообщения могут быть ![]() категорий с вероятностями
категорий с вероятностями ![]() ) и вычислительными сложностями их обработки
) и вычислительными сложностями их обработки ![]() операций (оп) соответственно. Вычислительные сложности случайные. ВККС имеет входной накопитель емкостью
операций (оп) соответственно. Вычислительные сложности случайные. ВККС имеет входной накопитель емкостью ![]() байт для хранения сообщений, ожидающих передачи. Сообщения 1-й категории обладают относительным приоритетом по отношению к сообщениям остальных категорий при обработке на ВККС. В буфере сообщения размещаются в соответствии с приоритетом.
байт для хранения сообщений, ожидающих передачи. Сообщения 1-й категории обладают относительным приоритетом по отношению к сообщениям остальных категорий при обработке на ВККС. В буфере сообщения размещаются в соответствии с приоритетом.
ВККС обрабатывает сообщения с производительностью ![]() оп/с. После обработки сообщения передаются по
оп/с. После обработки сообщения передаются по ![]() каналам связи. Скорость передачи
каналам связи. Скорость передачи ![]() бит/с. Сообщения 1-й категории обладают абсолютным приоритетом по отношению к сообщениям других категорий. Поэтому если после обработки сообщения все
бит/с. Сообщения 1-й категории обладают абсолютным приоритетом по отношению к сообщениям других категорий. Поэтому если после обработки сообщения все ![]() каналов связи заняты передачей сообщений 1-й категории, обработанное сообщение помещается в накопитель каналов связи, если в нем есть место, иначе - теряется. Если же по какому-либо каналу передается сообщение другой категории, происходит прерывание передачи этого сообщения и передается сообщение 1-й категории. Емкость накопителя каналов связи ограничена
каналов связи заняты передачей сообщений 1-й категории, обработанное сообщение помещается в накопитель каналов связи, если в нем есть место, иначе - теряется. Если же по какому-либо каналу передается сообщение другой категории, происходит прерывание передачи этого сообщения и передается сообщение 1-й категории. Емкость накопителя каналов связи ограничена ![]() сообщениями.
сообщениями.
ВККС и каналы связи имеют конечную надежность. Интервалы времени ![]() и
и ![]() между отказами ВККС и каналов связи случайные. Длительности восстановления
между отказами ВККС и каналов связи случайные. Длительности восстановления ![]() и
и ![]() ВККС и каналов связи случайные. При отказе канала связи передаваемые сообщения 1-й категории сохраняются в накопителе каналов, если в нем есть место. При выходе из строя ВККС с вероятностью
ВККС и каналов связи случайные. При отказе канала связи передаваемые сообщения 1-й категории сохраняются в накопителе каналов, если в нем есть место. При выходе из строя ВККС с вероятностью ![]() все сообщения в накопителе ВККС и накопителе каналов связи сохраняются, обрабатываемое сообщение теряется, а прием ВККС и передача сообщений по каналам связи прекращается. Все поступающие в это время сообщения теряются.
все сообщения в накопителе ВККС и накопителе каналов связи сохраняются, обрабатываемое сообщение теряется, а прием ВККС и передача сообщений по каналам связи прекращается. Все поступающие в это время сообщения теряются.
6.7.2. Исходные данные

6.7.3. Задание на исследование
Разработать имитационную модель функционирования ВККС. Исследовать влияние емкостей входных накопителей, интервалов времени ![]() и вероятностей
и вероятностей ![]() и
и ![]() на вероятности передачи сообщений по категориям и в целом через ВККС в течение двух часов. Провести дисперсионный и регрессионный анализы. Сделать выводы о загруженности элементов ВККС и необходимых мерах по повышению эффективности его функционирования.
на вероятности передачи сообщений по категориям и в целом через ВККС в течение двух часов. Провести дисперсионный и регрессионный анализы. Сделать выводы о загруженности элементов ВККС и необходимых мерах по повышению эффективности его функционирования.
Результаты моделирования необходимо получить с точностью ![]() и доверительной вероятностью
и доверительной вероятностью ![]() .
.
6.7.4. Уяснение задачи
Представим систему, имитационную модель которой предстоит разработать, схемой (рис. 6.6).
Видно, что ВККС - это многофазная многоканальная система массового обслуживания разомкнутого типа. На рис. 6.6 показаны средства GPSS World, которые будут использованы для моделирования элементов ВККС.
В структуре системы выделен блок контроля состояний ВККС, каналов связи ( GATE ) и их накопителей ( TEST ).
В модели сообщения следует представить транзактами, ВККС и каналы связи - одноканальными устройствами. Так как количество каналов связи может быть любым, то целесообразно идентифицировать их не именами, а номерами. Тогда в ходе моделирования для указания номеров этих устройств нужно будет использовать параметр транзакта, например, номер четыре, предварительно записав в него номер устройства.
Для имитации накопителей будет использоваться список пользователя, т. е. блоки LINK и UNLINK. Но так как емкость накопителя ВККС определяется в байтах, а список пользователя не позволяет вести в них учет, следует ввести сохраняемую ячейку и в ней вести учет текущей емкости накопителя. Также примем, что объем накопителя, занимаемый сообщением, равен его вычислительной сложности.
Для моделирования неисправностей ВККС и каналов связи нужно использовать блоки FUNAVAIL и F AVAIL. В этом случае статистика ОКУ не будет искажена, как это могло быть при использовании блоков PREEMPT и RETURN.
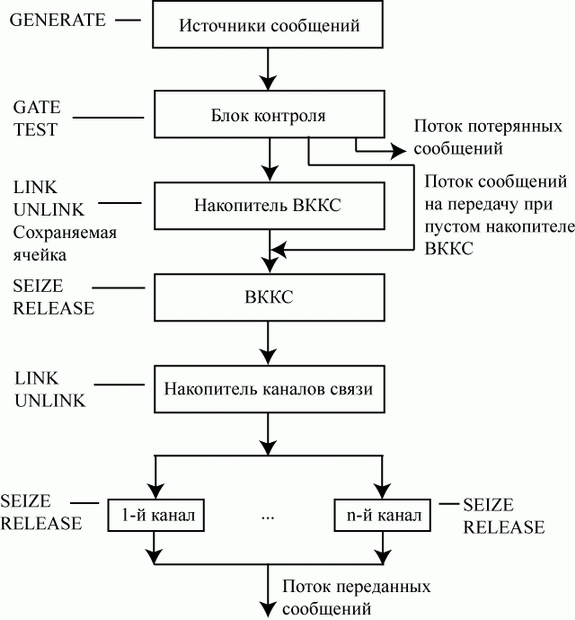
увеличить изображение
Рис. 6.6. ВККС как система массового обслуживания
6.7.5. Программа модели
Программа модели согласно декомпозиции ВККС (рис. 6.6) должна иметь:
- задание исходных данных;
- описание арифметических выражений;
- сегмент имитации поступления сообщений от источников;
- сегмент имитации работы накопителя 1 и ВККС;
- сегмент имитации работы накопителя 2 и каналов связи;
- сегмент имитации отказов ВККС;
- сегмент имитации отказов каналов связи;
- сегмент счета переданных и потерянных сообщений и расчета вероятностей передачи сообщений;
- сегмент задания времени моделирования.
Программа модели функционирования ВККС приведена ниже.
; Модель функционирования ВККС ; Задание исходных данных VrMod EQU 7200 ; Время моделирования, 1 ед. мод. вр. = 1с NCan EQU 3 ; Число каналов n1_ EQU 6 ; Количество источников сообщений MaxKat EQU 3 ; Максимальное число категорий сообщений T_ EQU 118.4 ; Средний интервал времени поступления сообщений от источника Q EQU 3600 ; Производительность ВККС, оп/c V_ EQU 5000 ; Скорость передачи, бит/с Pc_ EQU 0.7 ; Вероятность потери сообщений при отказе ВККС L1_ EQU 2500000 ; Емкость накопителя ВККС, байт L2_ EQU 5 ; Емкость накопителя каналов связи, сообщений TOtk1 EQU 3600 ; Среднее время между отказами ВККС TOtk2 EQU 1800 ; Среднее время между отказами каналов TVost1 EQU 3.7 ; Среднее время восстановления ВККС TVost2 EQU 4.2 ; Среднее время восстановления каналов ; Описание функций, задающих исходные данные Kat FUNCTION RN34,D3 ; Вероятности видов категорий .3,1/.5,2/1,3 S_ FUNCTION P1,D3 ; Средние вычислительные сложности сообщений (длины), оп (байт) по категориям 1,53000/2,86000/3,66000 So_ FUNCTION P1,D3 ; Среднеквадратические отклонения вычис- лительных сложностей (длин) сообщений, оп (байт) по категориям 1,6100/2,5000/3,7000 ; Арифметические выражения вычисления DL VARIABLE INT(NORMAL(114,FN$S_,FN$So_)) ; Длин (вычислительных сложностей) сообщений VrPer VARIABLE (P2/V_)#8 ; Времени передачи сообщения VrObr VARIABLE P2/Q_ ; Времени обработки сообщения ; Сегмент имитации поступления сообщений от источников GENERATE (Exponential(11,0,(T_/n1_))) ; Источники сообщений ; Розыгрыш категории сообщения и счета сообщений Met4 ASSIGN 1,FN$Kat ; Запись в Р1 кода категории и счет сообщений всех категорий ASSIGN 10,(P1+MaxKat) ; Запись в Р10 номера Х для счета поступающих сообщений по категориям ASSIGN 11,(P10+MaxKat) ; Запись в Р11 номера Х для счета переданных сообщений по категориям ASSIGN 12,(P11+MaxKat) ; Запись в Р12 номера Х для счета потерянных сообщений по категориям ASSIGN 13,(P12+MaxKat) ; Запись в Р13 номера Х для записи вероятности переданных сообщений по категориям ASSIGN 14,(P13+MaxKat) ; Запись в Р14 номера Х для записи вероятности потерянных сообщений по категориям SAVEVALUE P10+,1 ; Cчет поступающих сообщений по категориям ; Розыгрыш характеристик сообщений Met02 ASSIGN 2,V$DL ; Занесение в Р2 длины (вычислительной сложности) сообщения ASSIGN 3,V$VrPer ; Занесение в Р3 времени передачи сообщения ASSIGN 8,V$VrObr ; Занесение в Р8 времени обработки сообщения ASSIGN 7,0 ; Код 0 в Р7 - признак попадания сообщения в накопитель TEST E P1,1,Met111 ; Если сообщение 1 категории, то PRIORITY 1 ; сообщению 1 категории - высокий приоритет ;Сегмент имитации работы накопителя 1 и ВККС Met111 GATE FV Vkks,Met5 ; Проверка ВККС на исправность GATE U Vkks,Met17 ; Проверка ВККС на занятость TEST LE P2,(L1_-X$TEmk),Met5 ; Есть ли место в накопителе ВККС? SAVEVALUE TEmk+,P2 ; Увеличение текущей емкости накопителя на длину сообщения LINK SVkks,PR ; Поместить сообщение в накопитель ВККС Met17 ASSIGN 7,1 ; Признак: сообщение поступило на ВККС, минуя накопитель Met14 SEIZE Vkks ; Занять ВККС ADVANCE P8 ; Имитация обработки RELEASE Vkks ; Освобождение ВККС TEST E P7,0,Met18 ; Если Р7 =0, то SAVEVALUE TEmk-,P2 ; уменьшить текущую емкость накопителя ВККС на длину обработанного сообщения Met18 UNLINK SVkks,Met111,1 ; Очередное сообщение из накопителя ВККС послать на обработку ; Сегмент имитации работы накопителя 2 и каналов связи Met15 ASSIGN 4,NCan ; Подготовка к циклу Met16 GATE FV P4,Met23 ; Начало цикла поиска исправного и свободного канала. ;Исправен ли канал? Если да, то GATE U P4,Met21 ; занят ли канал? Если нет, на Met21-занять канал TEST E X*4,1,Met61 ; Если канал занят сообщением низкого приоритета, то прервать Met23 LOOP 4,Met16 ; Все ли каналы просмотрены? Если нет, продолжить поиск TEST L CH$SCan_,L2_,Met5 ; Есть ли место в накопителе каналов? LINK SCan_,PR ; Сообщение в накопитель каналов Met21 SEIZE P4 ; Занять канал с номером в Р4 SAVEVALUE P4,P1 ; Занести код категории в ячейку с номером в Р4 ADVANCE P3 ; Имитация передачи сообщения RELEASE P4 ; Освобождение канала с номером в Р4 UNLINK SCan_,Met15,1 ; Очередное сообщение из накопителя каналов на передачу TRANSFER ,Met10 ; Счет переданных сообщений ; Имитация передачи по каналам с прерыванием Met61 SAVEVALUE P4,P1 ; Занести PR в ячейку с номером в Р4 PREEMPT P4,PR,Met62 ; Занять канал с номером в Р4 ADVANCE P3 ; Имитация передачи сообщения RETURN P4 ; Освобождение канала с номером в Р4 UNLINK SCan_,Met15,1 ; Очередное сообщение из накопителя каналов на передачу TRANSFER ,Met10 ; Счет переданных сообщений Met62 RELEASE P4 ; Освободить канал с номером в Р4 TRANSFER ,Met15 ; Отправить в накопитель каналов ;Сегмент имитации отказов ВККС GENERATE ,,,1 Met49 ADVANCE (Exponential(237,0,TOtk1)) ; Розыгрыш времени до очередного отказа ASSIGN 1,(RN35/1000) ; Обращение к датчику RN TEST LE P1,Pc_,Met50 ; Все ли сообщения в накопителях теряются? Met51 FUNAVAIL Vkks,RE,Met115 ; Перевод ВККС в неисправное состояние ADVANCE (Exponential(237,0,TVost1)) ; Имитация восстановления FAVAIL Vkks ; Перевод ВККС в исправное состояние TRANSFER ,Met49 ; Отправить для розыгрыша очередного отказа Met115 RELEASE Vkks ; Освобождение ВККС прерванным сообщением TEST E P7,0,Met5 ; Если Р7=0, то SAVEVALUE TEmk-,P2 ; уменьшить текущую емкость накопителя ВККС на длину потерянного сообщения TRANSFER ,Met5 ; Отправить для счета потерь Met50 UNLINK SVkks,Met5,ALL ; Потеря всех сообщений из накопителя ВККС UNLINK SCan_,Met5,ALL ; Потеря всех сообщений из накопителя каналов SAVEVALUE TEmk,0 ; Значение текущей емкости =0 TRANSFER ,Met51 ; Отправить для перевода ВККС в неисправное состояние ;Сегмент имитации отказов каналов связи GENERATE ,,,NCan ; Число транзактов - по числу каналов связи SAVEVALUE NumCan+,1 ; Записать в X$NumCan последовательно 1, 2, ..., NCan ASSIGN 4,X$NumCan ; Записать в Р4 последовательно 1, 2, ..., NCan Met19 ADVANCE (Exponential(237,0,TOtk2)) ; Розыгрыш времени до очередного отказа GATE FV P4,Met19 FUNAVAIL P4,RE,Met112 ; Перевод канала в неисправное состояние ADVANCE (Exponential(237,0,TVost2)) ; Имитация восстановления канала FAVAIL P4 ; Перевод в исправное состояние TRANSFER ,Met19 ; Отправить для розыгрыша очередного отказа Met112 RELEASE P4 ; Освобождение канала с номером 1 TEST E P1,1,Met5 ; Если сообщение 1 категории, то TRANSFER ,Met15 ; отправить на повторную передачу ; Сегмент счета переданных и потерянных сообщений и расчет вероятностей передачи сообщений Met10 SAVEVALUE P11+,1 ; Cчет и сохранение в ячейке с номером в Р11 переданных сообщений всего и по категориям SAVEVALUE P13,(X*11/X*10) ; Расчет и сохранение в ячейке с номером в Р13 вероятностей передачи по категориям ; SAVEVALUE VPerS,(N$Met10/N$Met4) ; Расчет и сохранение в ячейке VPerS вероятностей передачи сообщений всех категорий TERMINATE Met5 SAVEVALUE P12+,1 ; Cчет и сохранение в ячейке с номером в Р12 потерянных сообщений всего и по категориям SAVEVALUE P14,(X*12/X*10) ; Расчет и сохранение в ячейке с номером в Р14 вероятностей потери сообщений по категориям ; SAVEVALUE VPotS,(N$Met5/N$Met4) ; Расчет и сохранение в ячейке VPotS вероятностей потерь сообщений всех категорий TERMINATE ;Задание времени моделирования GENERATE VrMod ; Задание времени моделирования TERMINATE 1
Для задания исходных данных использованы команда EQU и функции.
Арифметические выражения введены для расчета вычислительных сложностей сообщений, времени их обработки и передачи. Поскольку вычислительная сложность определяется количеством операций, которое не может быть дробным, то для перевода в целое используется встроенная функция INT.
Рассмотрим работу блоковой части модели.
Так как интервалы времени поступления сообщений от источников одинаковы, то блок GENERATE вводит транзакты - сообщения в модель со средним значением интервала (T_/n1_ ).
Предполагается, что число категорий сообщений может изменяться от единицы до определенного максимального значения, поэтому программа модели построена так, чтобы не подвергаться коррекции в таком случае.
Для этого в сегмент имитации поступления сообщений от источников включена последовательность блоков, разыгрывающих категории сообщений. Категория сообщения записывается в параметр Р1 транзакта. Для счета всех поступивших сообщений и в последующем переданных и потерянных сообщений по категориям в параметры Р10…Р14 транзакта записываются номера сохраняемых ячеек. В параметр Р10 записывается номер (Р1+MaxKat), в параметры Р11…Р14 записываются те, которые отличаются в указанной последовательности на максимальное число категорий MaxKat, задаваемое в исходных данных.
Пусть MaxKat = 5. Тогда в зависимости от того, что в Р1:
- Р1 = 1; Р10 = 4; Р11 = 7; Р12 = 10; Р13 = 13; Р14 = 16 ;
- Р1 = 2; Р10 = 5; Р11 = 8; Р12 = 11; Р13 = 14; Р14 = 17 ;
- Р1 = 3; Р10 = 6; Р11 = 9; Р12 = 12; Р13 = 15; Р14 = 18.
Таким образом, распределение номеров сохраняемых ячеек не зависит от количества категорий сообщений.
После счета поступающих сообщений по категориям в сохраняемых ячейках с номерами в параметре Р10 производится розыгрыш и запись характеристик сообщений: вычислительной сложности, времени обработки и времени передачи по описанным ранее арифметическим выражениям. Характеристики записываются в параметры Р2, Р8 и Р3 соответственно.
Если сообщение первой категории, ему присваивается приоритет 1. Все сообщения отправляются на сегмент имитации работы накопителя 1 и ВККС.
Здесь вначале ВККС проверяется на исправность и занятость.
Если ВККС неисправен, сообщение теряется. Транзакт направляется на метку Мет5. Здесь учитывается потерянное сообщение, и рассчитываются вероятности потерь по категориям и в целом по всем категориям. После этого транзакт выводится из модели.
Если ВККС исправен, но занят, проверяется возможность сохранения сообщения в накопителе 1 SVkks. Если достаточно свободной емкости, сообщение помещается в накопитель 1. Его текущая занятая емкость TEmk увеличивается на длину сообщения. Если свободной емкости недостаточно, сообщение теряется. Транзакт направляется на метку Мет5. Здесь выполняются те же действия, что и при возникновении неисправности ВККС.
Если ВККС исправен и свободен, т. е. накопитель 1 пуст, тран-закт направляется на метку Мет17. В параметр Р7 заносится 1 - признак поступления сообщения на обработку, минуя накопитель 1. Транзакт занимает ВККС. После обработки при Р7 = 1 транзакт направляется на Мет18 для вывода очередного сообщения из накопителя 1 (если оно есть) для обработки на ВККС. Выводящий же транзакт - обработанное сообщение направляется в сегмент имитации работы накопителя 2 и каналов связи.
Поиск канала для передачи сообщения организован в цикле Максимально возможное повторение в цикле равно числу каналов связи.
Для организации в модели циклов предназначен блок LOOP. Он имеет следующий формат:
LOOP A,B
Операнд А - параметр транзакта или параметр цикла, в котором содержится число повторений какого-либо участка модели.
Операнд B - метка блока, с которого начинается цикл.
Операнды А и B могут быть именем, положительным целым числом, выражением в скобках, СЧА или СЧА*параметр.
Например, в данной модели блок LOOP используется так:
Met15 ASSIGN 4,NCan ; Подготовка к циклу Met16 GATE FV P4,Met23 ; Начало цикла поиска исправного и свободного канала ; Исправен ли канал? Если да, то GATE U P4,Met21 ; занят ли канал? Если нет, на Met21-занять канал TEST E X*4,1,Met61 ; Если канал занят сообщением низкого приоритета, то прервать Met23 LOOP 4,Met16 ; Все ли каналы просмотрены? Если нет, продолжить поиск
Блок с меткой Мет16 является началом цикла, т. е. расположен раньше блока LOOP. Когда транзакт, пройдя участок модели, начинающийся блоком с меткой Мет16, войдет в блок LOOP, значение его параметра - параметра номер четыре транзакта уменьшается на 1. Если это значение не равно нулю, транзакт переходит к блоку с меткой Мет16, т. е. цикл повторяется. Если же после вычитания 1 значение параметра цикла равно нулю, следовательно, выполнено заданное число повторений, транзакт переходит к следующему блоку.
Если в результате поиска находится исправный и свободный канал, транзакт направляется на Мет21 и занимает канал, номер которого содержится в его параметре Р4 (ссылка *4). После имитации передачи транзакт входит в блок UNLINK для вывода очередного сообщения из накопителя 2 на передачу. Выводящий же транзакт - переданное сообщение направляется на метку Мет10. Здесь учитывается переданное сообщение, рассчитываются вероятности передачи сообщений отдельно по категориям и в целом по всем категориям.
Если просмотрены все каналы связи и не найдено свободного канала для передачи сообщения не первой категории, проверяется возможность помещения этого сообщения в накопитель Scan_. При отсутствии свободного места в накопителе Scan_ сообщение теряется, и транзакт направляется на метку Мет5 для учета и вывода из модели.
Если при передаче сообщения первой категории, обладающего абсолютным приоритетом по отношению к сообщениям других категорий, в результате поиска не найдено свободного канала или занятого передачей сообщений более низких приоритетов, сообщение также теряется, как и в предыдущем случае.
Если же обнаружен канал, занятый передачей сообщения более низкого приоритета, транзакт направляется на метку Мет61. Происходит прерывание сообщения низкого приоритета. Прерванное сообщение направляется на метку Мет15 для проверки возможности размещения его в накопителе каналов связи Scan_. Переданное сообщение выводит из накопителя каналов связи на передачу очередное сообщение и направляется на метку Мет10 для счета.
Теперь рассмотрим сегменты имитации отказов.
Начнем с сегмента имитации отказов ВККС. ВККС в модели представлен ОКУ с именем Vkks. Блок GENERATE вырабатывает один транзакт и становится неактивным. Далее имитация отказов организуется в цикле. Такой метод позволяет уменьшить количество транзактов в модели, сократить машинное время. Ведь можно было бы сделать так, чтобы GENERATE вводил в модель транзакт для имитации каждого отказа ВККС, а блок TERMINATE выводил его после имитации восстановления.
Блоком ADVANCE с меткой Мет49 разыгрывается время до очередного отказа. Затем: все ли сообщения в накопителе теряются? Если да, транзакт направляется на Мет50. Из накопителей SVkks и Scan_ выводятся и теряются все имевшиеся там сообщения. Обнуляется текущая емкость TEmk накопителя SVkks и транзакт направляется к метке Мет51 для перевода ВККС в неисправное (недоступное) состояние. После восстановления транзакт направляется на метку Мет49 для розыгрыша очередного отказа.
Если же не все сообщения теряются, а только те, которые обрабатываются ВККС, он переводится в неисправное состояние. Обрабатываемое сообщение удаляется, и транзакт направляется на метку Мет115.
Если сообщение перед обработкой помещалось в накопитель SVkks, его емкость уменьшается на длину потерянного сообщения. Транзакт направляется на метку Мет5 для счета и уничтожения.
Каналы связи в модели представлены несколькими ОКУ, работающими параллельно. Следовательно, они будут независимо друг от друга выходить из строя. Поэтому блок GENERATE вырабатывает сразу количество транзактов, равное количеству каналов связи NCan_. Далее эти транзакты в соответствии с номером канала, записанным в параметр Р1 каждого из NCan_ транзактов, имитируют выход каналов связи из строя. Предполагается, что время восстановления канала связи значительно меньше времени между его предыдущим и последующим отказами.
После 1000 прогонов получим следующие результаты моделирования:
| SAVEVALUE | RETRY | VALUE |
|---|---|---|
| 1 | 0 | 1.000 |
| 2 | 0 | 1.000 |
| 3 | 0 | 1.000 |
| 4 | 0 | 1094993.000 |
| 5 | 0 | 729783.000 |
| 6 | 0 | 1823763.000 |
| 7 | 0 | 519429.000 |
| 8 | 0 | 320633.000 |
| 9 | 0 | 811566.000 |
| 10 | 0 | 575561.000 |
| 11 | 0 | 409149.000 |
| 12 | 0 | 1012190.000 |
| 13 | 0 | 0.474 |
| 14 | 0 | 0.439 |
| 15 | 0 | 0.445 |
| 16 | 0 | 0.526 |
| 17 | 0 | 0.561 |
| 18 | 0 | 0.555 |
| TEMK | 0 | 2498959.000 |
| VPERS | 0 | 0.453 |
| VPOTS | 0 | 0.547 |
6.8. Моделирование неисправностей многоканальных устройств
6.8.1. Постановка задачи
Ранее отмечалось, что осуществить имитацию выхода МКУ из строя, при котором все транзакты, находившиеся в МКУ на обслуживании, теряются, блоками SUNAVAIL и SAVAIL невозможно. Рассмотрим, как это можно осуществить с применением блока DISPLACE на следующем примере.
Многоканальная СМО с отказами без очереди. СМО имеет конечную надежность. При выходе СМО из строя заявки, находившиеся на обслуживании, теряются. Новые заявки на обслуживание не принимаются.
6.8.2. Программа модели
; Модель многоканальной СМО конечной надежности ; Определение МКУ и булевых переменных Emk EQU 7 Zap EQU 2 Sist STORAGE 7 Kont1 BVARIABLE SV$Sist'AND'((7-S$Sist)>=Zap) Kont2 BVARIABLE SE$Sist ; Сегмент имитации поступления и обслуживания заявок GENERATE 2,,,7 ; Источник заявок Met12 TEST E BV$Kont1,1,Met1 ; Есть ли место в МКУ? SAVEVALUE KolPovt,(INT(Emk/Zap)) ENTER Sist,Zap ; Занять МКУ ; Учет номеров транзактов, занявших МКУ ASSIGN KolPovt,X$KolPovt ; Запись в параметр цикла Met5 TEST E X*KolPovt,0,Met4 ; Есть ли в списке место? SAVEVALUE P$KolPovt,XN1 ; Да, записать номер транзакта TRANSFER ,Met6 ; Выйти из цикла Met4 LOOP KolPovt,Met5 ; Повторить или конец цикла ; Met6 ADVANCE 5 ; Имитация обслуживания LEAVE Sist,Zap ; Освободить МКУ ; Учет номеров транзактов, освободивших МКУ ASSIGN KolPovt,X$KolPovt ; Запись в параметр цикла Met8 TEST E X*KolPovt,XN1,Met7 ; Есть ли этот номер транзакта? SAVEVALUE P$KolPovt,0 ; Да, тогда удалить TRANSFER ,Met9 ; Выйти из цикла Met7 LOOP KolPovt,Met8 ; Повторить или конец цикла Met9 TERMINATE 1 ; Обслуженные заявки Met1 TERMINATE 1 ; Потерянные заявки ; Сегмент имитации неисправностей GENERATE ,,,1 Met2 ADVANCE 7.5 ; Интервал отказов SUNAVAIL Sist ; Перевод в недоступность ; Удаление транзактов из МКУ ASSIGN KolPovt,X$KolPovt ; Запись в параметр цикла Met10 TEST NE X*KolPovt,0,Met11 ; Есть ли транзакт в МКУ DISPLACE X*KolPovt,Met3 ; Да, тогда удалить SAVEVALUE P$KolPovt,0 ; Снять с учета Met11 LOOP KolPovt,Met10 ; Повторить или конец цикла TEST E BV$Kont2,1 ; МКУ пуст? ADVANCE 1 ; Да, тогда ремонтируем SAVAIL Sist ; Перевод в доступность TRANSFER ,Met2 Met3 LEAVE Sist,2 ; Освободить МКУ TERMINATE 1 ; Удаленные из МКУ транзакты
В данной модели кроме блока DISPLACE показывается также применение булевых переменных.
Булевы переменные с использованием всего лишь одного блока дают возможность принимать решения в зависимости от состояния и значения атрибутов многих объектов GPSS. Булева переменная представляет собой логическое выражение, составленное из различных СЧА, в том числе и других булевых переменных.
Булева переменная определяется командой BVARIABLE.
Формат команды:
Name BVARIABLE A
Name - имя булевой переменной, которое также, как и имя арифметической переменной, по желанию пользователя командой EQU может быть заменено номером.
Операнд А - логическое выражение.
В выражении можно использовать арифметические и логические операторы. Результат преобразуется в целое значение 0, если равен нулю, или в целое значение 1, если отличен от нуля.
Логические операторы связаны с объектами аппаратной категории и используются для определения состояния этих объектов.
Имеются следующие логические операторы:
- FVj равен 1, если устройство j доступно, иначе - 0 ;
- FIj равен 1, если устройство j обслуживает прерывание, иначе - 0 ;
- SFj равен 1, если МКУ j заполнено полностью, иначе - 0 ;
- SEj равен 1, если МКУ j пусто, иначе - 0 ;
- SVj равен 1, если МКУ j доступно, иначе - 0 ;
- LSj равен 1, если логический ключ j включен, иначе - 0. Под j понимается номер или имя.
Например:
Oky BVARIABLE FV$Rem1 Can3 BVARIABLE SF$Usel Prov1 BVARIABLE SV$Pusk Prov2 BVARIABLE LS2
В первом примере булева переменная Oky равна 1, если устройство Rem1 доступно, и - 0, если не доступно. Во втором примере булева переменная Can3 равна 1, если МКУ Usel заполнено полностью. В третьем примере булева переменная Prov1 равна 1, если МКУ Pusk доступно. В четвертом примере булева переменная Prov2 равна 1, если логический ключ номер 2 включен.
Операторы отношения производят алгебраическое сравнение операндов. Например:
Prov1 BVARIABLE V$VseAvt'G'16 Prov2 BVARIABLE Q5$'LE'P3 Prov3 BVARIABLE MX$Plan(Stroka,Stolbez)'GE'P2
Булева переменная Prov1 равна 1, если переменная VseAvt больше 16, иначе равна 0. Во втором примере булева переменная Prov2 равна 1, если текущая длина очереди номер 5 меньше или равна значению параметра 3 транзакта. В третьем примере булева переменная Prov3 равна 1, если значение определенного элемента матрицы Plan больше или равно значению параметра 2.
Булевых операторов два: OR - ИЛИ и AND - И. Оператор ИЛИ проверяет выполнение хотя бы одного из условий, а оператор И требует выполнения обоих условий. Например:
Con1 BVARIABLE FI$Rem"OR"SF4 Con2 BVARIABLE FI$Rem"AND"SF$Pogr Con3 BVARIABLE (V3'G'7)"AND"(FN$Rav"OR"LS7)
Булева переменная Con1 равна 1, если выполняется одно из условий: устройство Rem обслуживает прерывание или память номер 4 не заполнена. Булева переменная Con2 равна 1, если выполняются оба условия: устройство Rem обслуживает прерывание и память с именем Pogr не заполнена. В третьем примере переменная Con3 равна 1, если выполняются оба условия: значение переменной номер 3 больше 7 и логический ключ номер 7 включен.
Скобки в третьем примере нужны только для задания определенных булевых соотношений. Скобки следует использовать только в тех случаях, когда они необходимы.
Если булева переменная задается СЧА, как например
Stan BVARIABLE V$TreAvt
то вычисляется значение арифметической переменной с именем TreAvt и если оно отлично от нуля - значение булевой переменной Stan будет равно 1, в противном случае - 0.
Рассмотрим работу модели.
Блок GENERATE с интервалами две единицы модельного времени генерирует семь транзактов. Следующий за ним блок TEST проверяет МКУ Sist на исправность (доступность) и наличия в нем свободных каналов, достаточных для удовлетворения запроса. Если булева переменная Kont1 равна 1, транзакт пропускается и занимает МКУ Sist. Но перед этим вычисляется и заносится целое число INT(Emk/Zap) = INT(7/2)=3 в сохраняемую ячейку с именем KolPovt, которое определяет, сколько транзактов может одновременно находится в МКУ.
После выхода транзакта из блока ENTER начинает работать сегмент учета номеров транзактов, занявших МКУ. Блоком ASSIGN в параметр с именем KolPovt - параметр цикла - заносится число, находящееся в сохраняемой ячейке с именем KolPovt. Далее в цикле, тело которого начинается с блока TEST с меткой Met5 и заканчивается блоком LOOP с меткой Met4, находится свободное место в списке для записи номера транзакта. Свободное место определяется блоком TEST как равенство нулю значения какой-либо одной из трех сохраняемых ячеек Х1, Х2 или Х3 (по числу транзактов, одновременно находящихся в МКУ). Такая ячейка всегда есть и блоком SAVEVALUE в нее записывается номер занявшего МКУ транзакта. А так как сохраняемых ячеек, значения которых равны нулю, может быть несколько (особенно вначале работы модели), после записи номера транзакта осуществляется выход из цикла.
Транзакт направляется к блоку ADVANCE с меткой Met6 и входит в него. Имитируется обслуживание заявки. После обслуживания транзакт освобождает МКУ Sist, пройдя блок LEAVE.
Начинает работать сегмент учета номеров транзактов, освободивших МКУ. Его работа аналогична рассмотренной ранее работе сегмента учета номеров транзактов, занявших МКУ. Отличие состоит в том, что отыскивается сохраняемая ячейка Х1, Х2 или Х3, которая содержит номер обслуженного транзакта. Найденная ячейка обнуляется, т. е. обслуженный транзакт снимается с учета. Так как номер записывается только в одну ячейку, то после ее обнуления осуществляется выход из цикла, тело которого начинается с блока TEST с меткой Met8 и заканчивается блоком LOOP с меткой Met7.
Теперь рассмотрим работу модели при возникновении неисправности МКУ. Транзакт, инициирующий неисправность, после задержки блоком ADVANCE сегмента имитации неисправностей, входит в блок SUNAVAIL, который переводит МКУ Sist в недоступное (неисправное) состояние.
Далее начинается работа сегмента удаления транзактов из МКУ. Суть ее заключается в следующем. В цикле, также организованном с помощью блока LOOP, просматривается список номеров транзактов, занявших МКУ. Если значение какой-либо сохраняемой ячейки Х1, Х2 или Х3 не равно нулю, значит в ней записан номер транзакта, находящегося в данный момент в МКУ. Блоком DISPLACE этот транзакт перемещается к блоку LEAVE с меткой Met3, освобождает МКУ и выводится из модели.
После удаления из МКУ всех транзактов, транзакт - инициатор неисправности входит в следующий за блоком LOOP с меткой Met11 блок TEST. Так как МКУ Sist пусто (булева переменная Kont2 равна нулю), блок TEST пропускает этот транзакт в блок ADVANCE и начинается имитация восстановления работоспособности МКУ.
Результаты моделирования представлены в табл. 6.4.
Из результатов следует, что обслужены только две заявки (первый и шестой транзакты). Пять заявок не обслужены: пятый тран-закт поступил, когда МКУ было неисправным, а третий и четвертый, седьмой и восьмой транзакты потеряны: в моменты возникновения неисправностей ( t = 7,5 и t =16 соответственно) они находились в МКУ.
| События | Транзакты | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 3 | 4 | 5 | 6 | 7 | 8 | |
| Вход в модель | 2 | 4 | 6 | 8 | 10 | 12 | 14 |
| Занятие МКУ | 2 | 4 | 6 | 10 | 12 | 14 | |
| В МКУ транзакты | 1 | 1,3 | 1,3,4 | 6 | 6,7 | 6,7,8 | |
| Удаление | 7.5 | 7.5 | 16 | 16 | |||
| Освобождение МКУ | 7 | 7.5 | 7.5 | 15 | 16 | 16 | |
| Вывод из модели | 7 | 7.5 | 7.5 | 8 | 15 | 16 | 16 |
Коэффициент использования ( Util.) МКУ Sist равен 0,375. Он рассчитывается по формуле:
где ![]() - число транзактов, занимавших МКУ за время Т моделирования;
- число транзактов, занимавших МКУ за время Т моделирования;
![]() - число каналов МКУ (емкость);
- число каналов МКУ (емкость);
![]() - число каналов, занимаемых i - м транзактом;
- число каналов, занимаемых i - м транзактом;
![]() - промежуток времени, в течение которого
- промежуток времени, в течение которого ![]() - м транзактом было занято
- м транзактом было занято ![]() каналов, рассчитывается как
каналов, рассчитывается как
![]() и
и ![]() - абсолютное модельное время занятия и освобождения соответственно
- абсолютное модельное время занятия и освобождения соответственно ![]() каналов МКУ.
каналов МКУ.
Для рассматриваемого примера п. 6.8.1 (см. табл. 6.4) имеем:
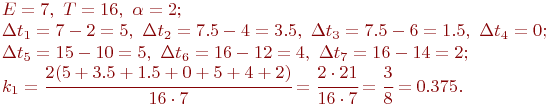
Таким образом, коэффициент использования МКУ рассчитан с учетом времени занятия его полностью обработанными транзак-тами и временем, затраченным на обработку тех транзактов, обслуживание которых было прервано.
Если в результате моделирования требуется определить коэффициент использования МКУ без учета удаленных из него тран-зактов, т. е. транзактов, обслуживание которых было прервано, пользователь может это сделать самостоятельно. Для этого нужно знать, сколько заявок будет обслужено полностью. Введем в модель следующие строки:
KIsp VARIABLE (Zap#N$Met9#5)/(Emk#16) SAVEVALUE KIsp,V$KIsp
Получим ![]() .
.
Вопросы для самоконтроля
- Перечислите категории объектов GPSS World.
- Какие реальные объекты моделируются транзактом?
- Назовите блок, генерирующий транзакты, его формат и назначение операндов.
- Раскройте понятие одноканального устройства (ОКУ), режимы его работы. Напишите операторы, описывающие ОКУ; назначение операндов.
- Раскройте понятие многоканального устройства (МКУ), режимы его работы. Напишите операторы, описывающие МКУ; назначение операндов.
- Назовите блоки, обеспечивающие получение статистических результатов.
- Назначение и формат операторов LINK и UNLINK.
- Что такое системные числовые атрибуты?
- Как описывается в модели арифметическое выражение? Приведите примеры.
- Как организовать в модели сохранение какой-либо величины?
- Что такое прямая и обратная задачи имитационного моделирования?
- Назовите виды списков для хранения транзактов.
- Назовите виды списков ОКУ и МКУ.
- Структура модели на языке GPSS и ее представление в виде блок-диаграмм.
- Назначение, сходство и различие команд CLEAR и RESET.
- Назовите блоки, изменяющие последовательность движения транзактов (блоки передачи управления).
- Приведите пример фрагмента модели, с введением которого арифметические выражения расчета результатов моделирования не требуют корректировки при изменении количества прогонов.
- Какими методами можно уменьшить машинное время моделирования?
- Измените условия примера 6.1 так, чтобы сервер стал однофазной системой массового обслуживания с ожиданием разомкнутого типа (добавьте входной накопитель емкостью на L сообщений). В соответствии с этим откорректируйте программу модели решения прямой задачи (п. 6.3.1). Запустите модель и получите результаты.
- Откорректируйте так же, как и в вопросе 6.19, программу модели решения обратной задачи (п. 6.3.2). В качестве количества запросов, время обработки которых нужно оценить, используйте результат моделирования, полученный при решении прямой задачи. Запустите модель. Получив результаты, сделайте выводы об особенностях решения прямой и обратной задач. Выясните, учитывается ли стохастичность при решении обратной задачи.
- В каких отношениях должны быть средние значения и среднеквадратические отклонения равномерного и нормального распределений? К чему приводят несоблюдения этих отношений?
- Какими средствами GPSS World можно представлять исходные данные в программе модели?
- Внесите изменения в исходные данные модели процесса изготовления изделий на предприятии (п. 6.5.1.2, прямая задача): количество цехов, а значит и количество различных типов блоков, выпускаемых цехами, из которых собирается одно изделие, равно шести (
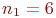 ) . Откорректируйте в соответствии с этим программу модели. Дополните по своему усмотрению необходимыми исходными данными. Сравните результаты моделирования с результатами, полученными при
) . Откорректируйте в соответствии с этим программу модели. Дополните по своему усмотрению необходимыми исходными данными. Сравните результаты моделирования с результатами, полученными при 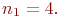
- Проделайте то же самое, что и при ответе на вопрос 6.23, с моделью процесса изготовления изделий на предприятии (обратная задача). Количество изделий, время подготовки которых нужно оценить, возьмите из ответа на вопрос 6.23.
- Какими методами можно сократить количество блоков в программе модели?
- Приведите примеры организации циклов средствами GPSS World. Назовите достоинства и недостатки.
- Приведите пример розыгрыша в имитационной модели группы несовместных независимых событий средствами GPSS World.
- Приведите варианты организации счета, например, сообщений по видам и в целом средствами GPSS World.
- Приведите примеры имитации средствами GPSS World неисправностей одноканальных устройств.
- Какими средствами GPSS World можно организовать изменение версий модели?
- Измените постановку задачи процесса изготовления изделий на предприятии (п. 6.4.1.1, прямая задача) так, чтобы на откорректированной в соответствии с этими изменениями модели можно было исследовать зависимость дохода (в условных единицах) предприятия от качества изготовления блоков и других факторов.
Лекция 7. Организация компьютерных экспериментов
GPSS World имеет все необходимые средства, которые позволяют провести:
- дисперсионный анализ (отсеивающий эксперимент);
- регрессионный анализ (оптимизирующий эксперимент);
- собственный эксперимент пользователя. Рассмотрение возможностей GPSS World по проведению компьютерных экспериментов начнем с дисперсионного анализа.
7.1. Дисперсионный анализ (отсеивающий эксперимент). Прямая задача
Сущность этого эксперимента состоит в проведении многофакторного дисперсионного анализа с целью выявления степени влияния различных факторов и их комбинаций (взаимодействий) на значение целевой функции (функции отклика, представленной в виде уравнения регрессии).
Пример 7.1. В условиях примера 6.1 (прямая задача) требуется исследовать зависимость вероятности обработки запросов от трех факторов, например, при следующих их минимальных и максимальных значениях (табл. 7.1):
Для проведения дисперсионного анализа нужно воспользоваться созданным в п. 6.3.1 объектом "Модель". В программе модели удалите последние три строки:
START 1000,NP ; Прогоны до установившегося режима RESET ; Сброс накопленной статистики START 9604 ; Количество прогонов модели
Откройте модель Прямая задача. Выберите Edit / Insert Experiment / Screening … ( Правка / Вставить эксперимент / Отсеивающий … ).
Откроется диалоговое окно Screening Experiment Generator ( Генератор отсеивающего эксперимента ) (рис. 7.1).
Рис. 7.1. Диалоговое окно (незаполненное) Screening Experiment Generator (Генератор отсеивающего эксперимента)
Приступите к заполнению полей диалогового окна.
В поля Experiment Name ( Имя эксперимента ) и Run Procedure Name ( Имя процедуры запуска ) введите, например, Dis_Server и Dis_Server_Run соответственно (рис. 7.2).
Имена эксперименту и процедуре запуска эксперимента дает пользователь.
Рис. 7.2. Диалоговое окно (заполненное) Screening Experiment Generator (Генератор отсеивающего эксперимента)
Дальше расположена группа полей Factors ( Факторы ). В рассматриваемом примере определяется вероятность обработки запросов, поступающих на сервер. Факторы, влияние которых необходимо исследовать, были определены нами ранее (см. табл. 7.1).
В GPSS World максимальное количество факторов, влияние которых на функцию отклика можно исследовать посредством дисперсионного анализа, равно шести.
Для каждого фактора необходимо выбрать два уровня - нижний и верхний. Рекомендуется выбирать уровни, значительно отстоящие друг от друга. Это необходимо для получения также значительно отличающихся откликов.
Введите ранее выбранные факторы, начиная с фактора А. В поле Name ( User Variable ) ( Имя ( Переменная пользователя )) введите имя фактора, в поля Value1 и Value2 - его нижний и верхний уровни соответственно. После ввода всех факторов для дальнейшей работы будем иметь факторы А, В и С.
Ниже идет группа Fraction ( Часть полного эксперимента ). Эксперимент, проводимый в GPSS World, может быть полным факторным экспериментом (ПФЭ) или дробным факторным экспериментом (ДФЭ). Группа Fraction ( Часть дробного эксперимента ) позволяет это задавать, т. е. позволяет провести стратегическое планирование эксперимента, цель которого, как вам известно, является определение количества наблюдений и сочетаний уровней факторов в них для получения наиболее полной и достоверной информации о поведении системы.
Установке ПФЭ соответствует кнопка Full, для ДФЭ в 1/2 от ПФЭ - Half, в 1/4 - Quarter, в 1/8 - Eight, в 1/16 - Sixteen.
Установите пока Half ( 1/2 ). Справа под Run Count появится число 4, так как 22 =4. Это количество наблюдений, которое необходимо сделать. Количество прогонов в каждом наблюдении будет указано позже.
В поле Expression ( Выражение ) группы Result ( Результат ) введите выражение, по которому вычисляется вероятность обработки запросов: N$ObrZap/N$KolZap.
После группы Result ( Результат ) расположены два флажка, позволяющие выбирать опции.
При выборе опции Generate Run Procedure вместе с экспериментом создается стандартная процедура запуска, которую пользователь может корректировать согласно своим требованиям.
Выбор второй опции Load F11 with CONDUCT Command закрепляет команду CONDUCT за функциональной клавишей F11. Тогда после создания объекта "Процесс моделирования" для запуска эксперимента нужно только нажать функциональную клавишу F11. Выберите обе опции.
Перед созданием эксперимента необходимо изучить группы смешивания с целью осуществления стратегического планирования эксперимента. Для этого нужно нажать кнопку Alias Groups ( Группы смешивания ). Появится диалоговое окно Alias Groups ( Группы смешивания ) (рис. 7.3).
При изучении групп смешивания необходимо вначале найти отсутствующие факторы, а затем факторы, которые неразличимы, так как находятся в одной группе смешивания. Например, взаимодействие факторов А и В - АВ.
Из рис. 7.3 видно, что отсутствующих факторов нет. Факторы А, В и С находятся в различных группах смешивания по два фактора в каждом. Невозможно будет судить об эффектах, т. е. о влиянии на отклик взаимодействий двух факторов. В некоторых случаях этого будет достаточно.
Нажмите кнопку Cancel ( Отмена ).
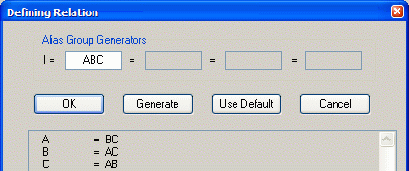
Рис. 7.3. диалоговое окно Alias Groups (Группы смешивания)
В диалоговом окне Screening Experiment Generator ( Генератор отсеивающего эксперимента ) в группе Fraction ( Часть дробного эксперимента ) установите Full ( ПФЭ ). Под Run Count появится число 8.
Обратите внимание, что кнопка Alias Groups ( Группы смешивания ) при установке полного факторного эксперимента Full ( ПФЭ ) не будет активной.
Теперь необходимо создать Plus - операторы и вставить их в нижнюю часть модели Прямая задача. Для этого нажмите кнопку Insert Experiment ( Вставить эксперимент ), расположенную в левой нижней части диалогового окна Screening Experiment Generator ( Генератор отсеивающего эксперимента ).
Так как была выбрана опция Generate Run Procedure, то создана стандартная процедура запуска. Появится ее диалоговое окно, дающее возможность пользователю изменить процедуру запуска согласно своим требованиям.
Введите через пробел после слова PROCEDURE указанное ранее имя процедуры Dis_Server_Run, оставив в скобках ( Run_Number ), без изменения (рис. 7.4).
Перейдите, пользуясь клавишами вверх-вниз, в конец процедуры запуска. Там в разделе Set up your own run conditions ( Задайте свои условия наблюдения ) имеются две команды START, между которыми находится команда RESET (рис. 7.5).
Поясним назначение этих команд.
Для получения достоверной статистики существуют три подхода (см. п. 4.9). В генераторе экспериментов использован третий подход.
Рис. 7.4. Диалоговое окно стандартной процедуры запуска
Рис. 7.5. Условия стандартной процедуры запуска по умолчанию
Первой командой START
DoCommand("START 100,NP"); /*Get past the Startup Period. */определяется количество прогонов в неустоявшемся режиме.
Подразумевается, что если моделирование выполняется долго, то система приходит в стационарное состояние. Сколько времени следует вести моделирование, чтобы достичь стационарного состояния? Часто ответ на этот вопрос можно получить из опыта экспериментирования с моделью. Команда RESET служит для этого. Она сбрасывает в ноль накопленную на неустоявшемся режиме статистику без удаления транзактов из процесса моделирования. Второй командой START
DoCommand("START 1000,NP"); /*Run the Simulation. */определяется количество прогонов в наблюдении, т. е. количество прогонов, которое было определено ранее при тактическом планировании эксперимента: N=9604. Измените 1000 на 9604 (рис. 7.6).
Корректировка процедуры запуска возможна до и после того, как она будет добавлена к объекту "Модель". После корректировки нажмите Ok. Сгенерированный Plus - эксперимент представлен ниже. Изучите его. Это необходимо для создания собственных экспериментов.
Рис. 7.6. Условия стандартной процедуры запуска после корректировки
В начале автоматически сгенерированного эксперимента определяется и инициализируется в неопределенное состояние ( UNSPECIFIED ) матрица результатов. Далее имеются Plus - операторы, которые для каждого из наблюдений определяют сочетания уровней факторов. В рассматриваемом примере таких сочетаний восемь.
Plus - эксперимент содержит также вызов Plus - процедуры запуска. Процедура запуска осуществляет связь между генерируемым экспериментом и процессом моделирования. Она вызывается столько раз, сколько требуется сделать наблюдений. Так как процедура запуска вызывается Plus - экспериментом, ей разрешается вызывать библиотечную процедуру DoCommand и, следовательно, выполнять RMULT, CLEAR, RESET и многие другие команды GPSS. Поэтому все команды, необходимые для определения условий наблюдения, следует помещать в процедуру запуска.
Для сохранения матрицы результатов при обнулении переменных перед очередным наблюдением используется команда CLEAR OFF. Для изменения начального числа генератора случайных чисел в каждом наблюдении процедуре передается номер запуска.
****************************************************
* Dis_Server *
* Факторный отсеивающий эксперимент *
****************************************************
Dis_Server_Results MATRIX ,2,2,2
INITIAL Dis_Server_Results,UNSPECIFIED
Dis_Server_NextRunNumber EQU 0
EXPERIMENT Dis_Server() BEGIN
/* Наблюдение 1 */
T1_ = 60;
Koef = 0.5;
Q_ = 300000;
IF (StringCompare(DataType(Dis_Server_Results[1,1,1]),
"UNSPECIFIED")'E'0)
THEN BEGIN
/* Установить начальное значение переменной количества наблюдений */
Dis_Server_NextRunNumber = 1;
/* Записать данные наблюдения и запустить процесс моделирования*/
Dis_Server_GetResult();
Dis_Server_Results[1,1,1] = N$ObrZap/N$KolZap;
END;
/* Наблюдение 2 */
T1_ = 60;
Koef = 0.5;
Q_ = 700000;
IF (StringCompare(DataType(Dis_Server_Results[1,1,2]),
"UNSPECIFIED")'E'0)
THEN BEGIN
/* Записать данные наблюдения и запустить процесс моделирования */
Dis_Server_GetResult();
Dis_Server_Results[1,1,2] = N$ObrZap/N$KolZap;
END;
/* Наблюдения 3 - 7 для краткости пропущены */
/* Наблюдение 8 */
T1_ = 180;
Koef = 1.5;
Q_ = 700000;
IF (StringCompare(DataType(Dis_Server_Results[2,2,2]),
"UNSPECIFIED")'E'0)
THEN BEGIN
/* Записать данные наблюдения и запустить процесс моделирования */
Dis_Server_GetResult();
Dis_Server_Results[2,2,2] = N$ObrZap/N$KolZap;
END;
/* Эффекты смешивания в дробном факторном эксперименте */
SE_Effects(Dis_Server_Results,"I");
END;
*******************************************************
* Процедура запуска наблюдения *
*******************************************************
PROCEDURE Dis_Server_GetResult() BEGIN
/* Выполнить указанное число прогонов и записать результаты. */
/* Факторы для этого наблюдения уже были определены. */
TEMPORARY CurrentYield,ShowString,CommandString;
/* Вызов процедуры запуска */
Dis_Server_Run(Dis_Server_NextRunNumber);
CurrentYield = N$ObrZap/N$KolZap;
ShowString = PolyCatenate("Run ",String(Dis_Server_NextRunNumber),
". ", "" );
ShowString = PolyCatenate(ShowString," Yield=",String(CurrentYield),
". ");
ShowString = PolyCatenate(ShowString," T1_=",String(T1_), ";" );
ShowString = PolyCatenate(ShowString," Koef=",String(Koef), ";" );
ShowString = PolyCatenate(ShowString," Q_=",String(Q_), ";" );
CommandString = PolyCatenate("SHOW """,ShowString,
"""", "" );
DoCommand(CommandString);
Dis_Server_NextRunNumber = Dis_Server_NextRunNumber + 1;
RETURN CurrentYield;
END;
*******************************************************
* Процедура запуска *
*******************************************************
PROCEDURE Dis_Server_Run(Run_Number) BEGIN
DoCommand("CLEAR OFF"); /* Использовать OFF для сохранения результата. */
/* Увеличьте число команд RMULT, если у вас большее число ГСЧ. */
/* Задать новые случайные числа всем потокам случайных чисел. */
TEMPORARY CommandString;
/* Вычислить, прежде чем перейти к DoCommand. */
CommandString = Catenate("RMULT ",Run_Number#111);
/* DoCommand контролирует строку в глобальном контексте. */
DoCommand(CommandString);
/* Установить собственные условия наблюдения. */
DoCommand("START 100,NP"); /* Пройти неустоявшийся режим. */
DoCommand("RESET"); /* Начать период измерений. */
DoCommand("START 9604,NP"); /* Провести моделирование. */
END;Проведем эксперимент. Для вызова эксперимента предназначена команда CONDUCT. Однако за функциональной клавишей [F11] была закреплена соответствующая команда CONDUCT ( Edit / Settings / Function Keys ( Правка / Настройки / Функциональные клавиши ).
Проведите трансляцию, т. е. создайте объект "Процесс моделирования", для чего нажмите [Ctrl]+[Alt]+[S] или выполните команду Command / Create Simulation ( Команда / Создать процесс моделирования ).
При отсутствии ошибок в сгенерированном эксперименте в окне Journal ( Журнал ) появится сообщение (рис. 7.7), свидетельствующее об отсутствии ошибок.
Теперь нажмите функциональную клавишу [F11]. Эксперимент начинает работать.
В ходе выполнения сгенерированного эксперимента автоматически создается отчет, который по готовности записывается в окно Journal ( Журнал ) объекта "Процесс моделирования". Фрагмент отчета для четырех наблюдений ( Run1 … Run4 ) показан на рис. 7.8. В отчете содержатся Yield - целевая функция и значения факторов, при которых получение значение целевой функции.
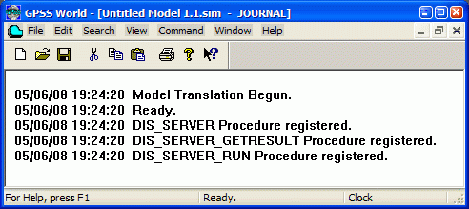
Рис. 7.7. Окно Journal (Журнал) с сообщением об успешном создании объекта "Процесс моделирования"
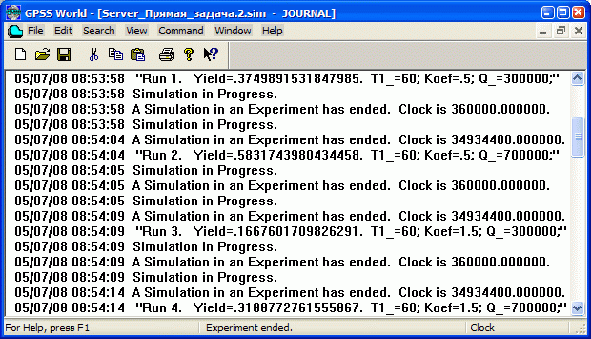
Рис. 7.8. Окно Journal (Журнал) с отчетами по каждому наблюдению
Так как эксперимент включает 8 наблюдений по 9604 прогонов в каждом из них, то будет выдано 8 отчетов (на рис. 7.8 в целях сокращения показаны только первые четыре отчета). Окончательные результаты моделирования после статистической обработки будут выведены в виде таблицы Anova (рис. 7.9).
В таблице каждый фактор и взаимодействие факторов представлены отдельной строкой. В каждой строке для всех эффектов указаны коэффициенты, с которыми они входят в целевую функцию (столбец Effect ), а для главных эффектов (А, В, С) - суммы квадратов отклонений, аналогичных величинам Q 1 (см. п. 5.7) - столбец Sum of Squares.
В столбце Degrees of Freedom приведены степени свободы соответствующих измерений.
В столбце F-for Only Main Effects - вычисленные значения F-статистик для главных эффектов, а в столбце Critical Value of F (p=0,05) - соответствующие критические значения F - распределения для уровня значимости 50%.
В строке Error показаны остаточная составляющая дисперсии (аналогичная Q 2 в п. 5.7) и соответствующая степень свободы.
В строке Total - общая сумма квадратов ошибок по всему эксперименту.
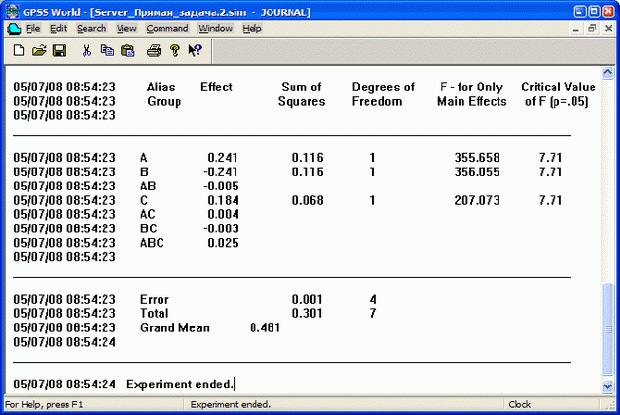
увеличить изображение
Рис. 7.9. Результаты дисперсионного анализа
В строке Greand - среднее значение результата исследования (в примере - вероятности) по данным всего эксперимента.
Чем больше значение F-статистики ( F-for Only Main Effects ), тем сильнее эффект. Эффект, а, следовательно, и фактор, считается значимым, если превышает критическое значение ( Critical Value of F ( p=.05 )).
В данном примере факторы А, В и С являются значимыми, так как их F-статистики больше критического значения, равного 7.71.
Наибольший эффект на вероятность обработки запросов оказывают факторы В и А, так как они имеют самые большие и близкие статистики (356,055 и 355.658 соответственно). Обратите внимание, что эффекты факторов А и В противоположны.
Таким образом, по результатам моделирования можно сделать вывод, что при данном потоке и характеристике сервера вероятность обработки запросов в среднем составляет 0,481, т. е. вероятность потерь запросов составляет 0,519. Для уменьшения потерь запросов нужно продолжить исследование каждого значимого фактора и в первую очередь факторов В и А, как наиболее существенных.
7.2. Регрессионный анализ (оптимизирующий эксперимент). Прямая задача
Дисперсионный анализ (отсеивающий эксперимент) показывает силу влияния каждого фактора на наблюдаемую переменную (отклик). Однако оптимизация и количественный прогноз поведения систем часто являются основными задачами моделирования. В GPSS World решение таких задач возможно посредством проведения регрессионного анализа (оптимизирующего эксперимента).
Оптимизация моделируемого процесса состоит в определении таких значения уровней факторов, при которых показатель эффективности процесса достигает максимального значения (или минимального - в зависимости от смысла показателя эффективности).
В общем случае показатель эффективности представляется уравнением регрессии
где ![]() - значения уровней факторов процесса;
- значения уровней факторов процесса; ![]() -количество управляемых факторов.
-количество управляемых факторов.
Оптимизация многофакторного, особенно нелинейного уравнения регрессии, задача не простая, и для ее решения разработан ряд численных методов. Наиболее эффективен при компьютерном моделировании так называемый метод поверхностей, при котором уравнение регрессии трактуется как уравнение поверхности в многофакторном пространстве. Оптимальное решение в этом случае составляют координаты из значений факторов вершины (или впадины) этой поверхности. Поиск оптимума осуществляется последовательными изменениями (шагами) значений уровней факторов в направлении, на котором обнаруживается улучшение показателя эффективности. Такой метод реализован в GPSS World.
Пользователь задает исходные условия, а GPSS World автоматически создает план и проводит с поверхностью отклика эксперимент, который отыскивает оптимальное значение. В ходе эксперимента GPSS World пытается подобрать либо линейную модель, либо модель второго порядка (включая двухфакторные взаимодействия).
Рассмотрим на примере проведение регрессионного анализа (оптимизирующего эксперимента).
Пример 7.2. В условиях примера 6.1 провести регрессионный анализ результатов моделирования. При этом вычислительную сложность обработки запросов сервером взять распределенной не по нормальному, а по экспоненциальному закону, т. е. в программе модели примера 6.1 удалить строку
S2_ EQU 200000 ; Стандартное отклонение вычислительной сложности запросов, оп
а строку с блоком ADVANCE заменить строкой:
ADVANCE ((Exponential(32,0,S_))/Q_) ; Имитация обработки запроса
Откройте модель примера 6.1. Сохраните как Reg_Server. Внесите рекомендованные изменения.
Выберите Edit / Insert Experiment / Optimising … ( Правка / вставить эксперимент / Оптимизирующий … ). Откроется диалоговое окно Optimizing Experiment Generator ( Генератор оптимизирующего эксперимента ).
Введите имена факторов и значения уровней (рис. 7.10).
В поле Expression ( Выражение ) группы Result ( Результат ) введите выражение, по которому рассчитывается результат наблюдения:
(N$ObrZap/N$KolZap)
Оптимизирующий эксперимент нужно ограничить пределами. Группа полей Movement ( Пределы перемещения ) позволяет ограничить перемещение локальной экспериментальной области. Если это возможно, необходимо ввести пределы изменения для каждого фактора эксперимента. Другой способ ограничить поиск - задание величины Redirection Limit ( Предел изменения направления ). Это значение устанавливает предел на количество изменений направления движения эксперимента по факторному пространству.
Введите в поля эти данные, приведенные на рис. 7.10.
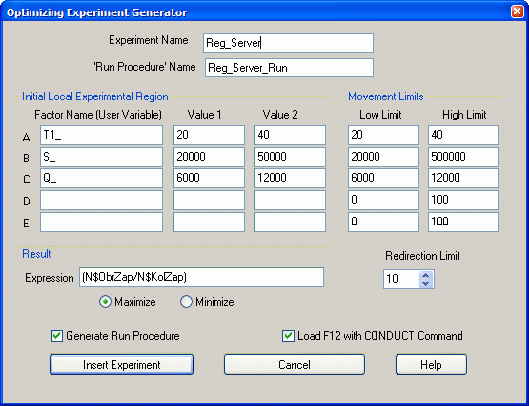
Рис. 7.10. Диалоговое окно Optimizing Experiment Generator (Генератор оптимизирующего эксперимента)
Далее, так как вероятность обработки запросов должна быть максимальной, оставьте Maximize. Также установите флажки, позволяющие выбрать опции Generate Run Procedure и Load F12 with CONDUCT Command. Назначение этих опций такое же, как и в генераторе отсеивающего эксперимента. Только после создания объекта "Процесс моделирования" для запуска эксперимента нужно нажать функциональную клавишу [ F12 ], а не [ F11 ].
Все необходимые данные введены в соответствующие поля. Нажмите кнопку Insert Experiment ( Вставить эксперимент ). Так как GPSS World было указано сгенерировать процедуру запуска, то появится диалоговое окно, позволяющее отредактировать ее так же, как и в генераторе отсеивающего эксперимента. После корректировки нажмите Ok. Автоматически сгенерированные Plus-операторы появятся в нижней части модели.
Для запуска эксперимента сначала создайте, нажав [ Ctrl ]+[ Alt ]+[ S ], объект "Процесс моделирования". При успешном завершении появится соответствующее сообщение (рис. 7.11).
Рис. 7.11. Сообщение об успешном создании объекта "Процесс моделирования" для проведения регрессионного анализа
После такого сообщения нажмите функциональную клавишу [ F12 ]. Эксперимент начнет выполняться. В окно Journal ( Журнал ) процесса моделирования будут выводиться отчеты о состоянии и результатах каждого наблюдения.
По отчетам можно узнать о перемещении локальной экспериментальной области. Plus-эксперимент пытается переместить локальную экспериментальную область так, чтобы она включала в себя оптимальные условия. Если это происходит, или, если достигнут предел изменения направления или предел перемещения, эксперимент заканчивается.
Когда перемещение останавливается, в окно Journal ( Журнал ) также выводятся результаты проверки критерия адекватности и уравнение подобранной (найденной) поверхности отклика. Затем, если это еще не сделано, Plus-эксперимент пытается проверить прогнозируемые оптимальные условия, запустив процесс моделирования для них.
Результаты регрессионного анализа (оптимизирующего эксперимента), после 209 наблюдений, приведены на рис. 7.12.
Заметим, что это на 201 наблюдение больше, чем при проведении дисперсионного анализа (отсеивающего эксперимента) (п. 7.1). Оптимум не находится в локальной экспериментальной области.
Рис. 7.12. Результаты оптимизирующего эксперимента
Полученное уравнение поверхности отклика имеет вид:
Оптимальное значение вероятности обработки запросов сервером составляет 0.973068.
При проведении оптимизирующего эксперимента важным является задание локальной экспериментальной области. Значения факторов, указанные исследователем, формируют начальную точку эксперимента. От этого зависит достижение его цели, заключающейся:
- в получении оптимального значения в пределах локальной области;
- выполнении подтверждающего прогона;
- выводе модели, которая была использована.
Следует иметь в виду, что цель получения математической модели в оптимизирующем эксперименте достигается не всегда.
7.3. Дисперсионный анализ (отсеивающий эксперимент). Обратная задача
7.3.1. Постановка задачи
Изготовление в цехе детали начинается через случайное время ![]() Выполнению операций предшествует подготовка. Длительность подготовки зависит от качества заготовки, из которой будет сделана деталь. Всего различных видов заготовок
Выполнению операций предшествует подготовка. Длительность подготовки зависит от качества заготовки, из которой будет сделана деталь. Всего различных видов заготовок ![]() Время подготовки подчинено экспоненциальному закону. Частота появления различных заготовок и средние значения времени их подготовки заданы табл. 7.2 дискретного распределения:
Время подготовки подчинено экспоненциальному закону. Частота появления различных заготовок и средние значения времени их подготовки заданы табл. 7.2 дискретного распределения:
Для изготовления детали последовательно выполняются ![]() операций, продолжительностями
операций, продолжительностями ![]() соответственно. После каждой операции в течение времени
соответственно. После каждой операции в течение времени ![]() следует контроль. Время выполнения операций и контроля - случайное. Контроль не проходят
следует контроль. Время выполнения операций и контроля - случайное. Контроль не проходят ![]() деталей соответственно.
деталей соответственно.
Забракованные детали поступают на пункт окончательного контроля и проходят на нем проверку в течение случайного времени ![]() . В результате из общего количества не прошедших контроль деталей
. В результате из общего количества не прошедших контроль деталей ![]() идут в брак, а оставшиеся
идут в брак, а оставшиеся ![]() деталей подлежат повторному выполнению операций, после которых они не прошли контроль. Если деталь во второй раз не проходит контроль, она окончательно бракуется.
деталей подлежат повторному выполнению операций, после которых они не прошли контроль. Если деталь во второй раз не проходит контроль, она окончательно бракуется.
7.3.2. Исходные данные

7.3.3. Задание на исследование
Разработать имитационную модель процесса изготовления в цехе деталей.
Вариант 1. Исследовать влияние качества выполнения операций ![]() на время изготовления
на время изготовления ![]() деталей (табл. 7.3). Результаты моделирования необходимо получить с точностью
деталей (табл. 7.3). Результаты моделирования необходимо получить с точностью ![]() мин и доверительной вероятностью
мин и доверительной вероятностью ![]() .
.
Вариант 2. Исследовать влияние интервалов времени ![]() поступления заготовок и времени
поступления заготовок и времени ![]() выполнения операций 1, 2, 3 соответственно на время подготовки
выполнения операций 1, 2, 3 соответственно на время подготовки ![]() деталей (табл. 7.4). Результаты моделирования также необходимо получить с точностью
деталей (табл. 7.4). Результаты моделирования также необходимо получить с точностью ![]() мин и доверительной вероятностью
мин и доверительной вероятностью ![]() .
.
Модель должна также позволять определять относительное количество готовых и забракованных деталей, среднее время изготовления одной детали. Сделать выводы о загруженности пунктов выполнения операций и необходимых мерах по сокращению времени изготовления деталей.
7.3.4. Уяснение задачи на исследование
Процесс изготовления в цехе деталей представляет собой процесс, протекающий в многофазной разомкнутой системе массового обслуживания с ожиданием (рис. 7.13).
Представим, что подготовка заготовки и операции 1, 2 и 3 производятся на станках - ОКУ 1, 2, 3 и 4 соответственно. Пункт окончательного контроля можно также представить ОКУ. Необходимые для их имитации средства GPSS приведены на рис. 7.13.
Время подготовки заготовки и время выполнения операций даны в мин. Возьмем 1 ед. мод. вр. = 1мин. Для расчета количества прогонов модели примем, что среднее квадратическое отклонение времени изготовления ![]() деталей
деталей ![]() . Тогда
. Тогда
увеличить изображение
Рис. 7.13. Цех как система массового обслуживания
Программа модели обратной задачи приведена ниже.
7.3.5. Программа модели
; Модель изготовления деталей. Обратная задача ; Задание исходных данных Tn_ EQU 35 ; Среднее время между поступлениями заготовок T1 EQU 30 ; Среднее время выполнения 1-й операции, мин T2 EQU 25 ; Среднее время выполнения 2-й операции, мин T3 EQU 35 ; Среднее время выполнения 3-й операции, мин To3 EQU 6 ; Среднеквадратическое отклонение времени выполнения 3-й операции, мин Tk1 EQU 4 ; Среднее время контроля после 1-й операции, мин Tk2 EQU 5 ; Среднее время контроля после 2-й операции, мин Tk3 EQU 15 ; Среднее время контроля после 3-й операции, мин Tok3 EQU 2 ; Среднеквадратическое отклонение времени контроля после 3-й операции, мин Tk EQU 8 ; Среднее время окончательного контроля, мин q1_ EQU .12 ; Доля брака после 1-й операции q2_ EQU .15 ; Доля брака после 2-й операции q3_ EQU .10 ; Доля брака после 3-й операции q4_ EQU .80 ; Доля окончательного брака Det EQU 4 ; Количество деталей, которые нужно изготовить ; Описание функции времени подготовки заготовок для детали Pod FUNCTION RN10,D6 .05,10/.18,14/.34,21/.56,22/.85,28/1,25 ; Сегмент имитации изготовления деталей GENERATE (Exponential(1,0,Tn_)) ; Источник заготовок ; Подготовка заготовок для деталей QUEUE Pod ; Встать в очередь SEIZE Pod ; Начать подготовку заготовки DEPART Pod ; Покинуть очередь ADVANCE (Exponential(34,0,FN$Pod)) ; Имитация подготовки RELEASE Pod ; Закончить подготовку заготовки ; Имитация выполнения 1-й операции DCount ASSIGN 1,1 ; Код 1 в Р1-деталь проходит первый раз ASSIGN 2,1 ; Код 1 в Р2-признак 1-й операции Oper1 QUEUE P2 ; Встать в очередь SEIZE Konveer1 ; Начать первую операцию DEPART P2 ; Покинуть очередь ADVANCE (Exponential(23,0,T1)) ; Имитация 1-й операции RELEASE Konveer1 ; Закончить 1-ю операцию ADVANCE (Exponential(23,0,Tk1)) ; Контроль 1-й операции TRANSFER q1_,,Sboi ; Отправить брак на пункт контроля ; Имитация выполнения 2-й операции ASSIGN 2,2 ; Код 2 в Р2-признак 2-й операции Oper2 QUEUE P2 ; Встать в очередь SEIZE Konveer2 ; Начать вторую операцию DEPART P2 ; Покинуть очередь ADVANCE (Exponential(23,0,T2)) ; Имитация 2-й операции RELEASE Konveer2 ; Закончить 2-ю операцию ADVANCE (Exponential(23,0,Tk2)) ; Контроль 2-й операции TRANSFER q2_,,Sboi ; Отправить брак на пункт контроля ; Имитация выполнения 3-й операции ASSIGN 2,3 ; Код 3 в Р2-признак 3-й операции Oper3 QUEUE P2 ; Встать в очередь SEIZE Konveer3 ; Начать третью операцию DEPART P2 ; Покинуть очередь ADVANCE (Normal(20,(T3#K1),(To3#K1))) ; Имитация 3-й операции RELEASE Konveer3 ; Закончить 3-ю операцию ADVANCE (Normal(20,Tk3,Tok3)) ; Контроль 3-й операции TRANSFER q3_,,Sboi ; Отправить брак на пункт контроля TRANSFER ,Met2 ; Готовые детали ; Сегмент имитации работы пункта контроля Sboi QUEUE Kont ; Встать в очередь на пункт контроля SEIZE Kontr ; Занять пункт контроля DEPART Kont ; Покинуть очередь на пункт контроля ADVANCE (Exponential(23,0,Tk)) ; Окончательный контроль RELEASE Kontr ; Освободить пункт контроля TRANSFER q4_,,EndOper ; Отправить в окончательный брак TEST E P1,1,EndOper; Если второй раз, то в окончательный брак ASSIGN 1,2 ; Код 2 в Р1-деталь проходит второй раз Met1 TRANSFER ,(Met1+P2) TRANSFER ,Oper1 ; На повторное выполнение 1-й операции TRANSFER ,Oper2 ; На повторное выполнение 2-й операции TRANSFER ,Oper3 ; На повторное выполнение 3-й операции EndOper TERMINATE ; Счет брака ; Сегмент завершения моделирования и расчета результатов Met2 TEST L X$Prog,TG1,Met3 ; Если условие выполняется, то SAVEVALUE Prog,TG1 ; X$Prog=TG1 счетчику завершений SAVEVALUE NDet,0 ; Обнуление X$NDet Met3 SAVEVALUE NDet+,1 ; Счет количества готовых деталей TEST E X$NDet,Det,Ter1 ; Если готово Det деталей, зафиксировать один прогон TEST E TG1,1,Met4 ; Если содержимое счетчика завершений равно 1, то расчет результатов моделирования SAVEVALUE Brak,(INT(N$EndOper/X$Prog)) ; Количество забракованных деталей, шт. SAVEVALUE DoljaBrak,(X$Brak/(X$Brak+Det)) ; Общая доля брака SAVEVALUE DoljaDet,(Det/(X$Brak+Det)) ; Доля готовых деталей SAVEVALUE AC3,(AC1-X$AC2) SAVEVALUE TDet,((X$AC3/X$Prog)/60) ; Среднее время изготовления Det деталей, час SAVEVALUE SDet,((X$TDet/N_)#60) ; Среднее время изготовления одной детали, мин SAVEVALUE AC2,AC1 SAVEVALUE X$Prog,0 Met4 SAVEVALUE NDet,0 ; Обнуление X$NDet TERMINATE 1 ; Вычитание из счетчика завершений 1 Ter1 TERMINATE ; Вывод вспомогательных транзактов
Программа модели имеет достаточно подробный комментарий. Поэтому остановимся только на особенностях сегмента завершения моделирования и расчета результатов.
Поскольку результатом моделирования является оценка математического ожидания времени TDet изготовления Det деталей, то в ее вычислении используется абсолютное модельное время АС1 (системный числовой атрибут). При проведении дисперсионного анализа встроенный генератор эксперимента имеет две команды START, а между ними - команда RESET. Команда RESET не влияет на абсолютное модельное время. Поэтому АС1 будет суммой абсолютного модельного времени предварительных прогонов до установившегося режима, обозначим его АС2, и абсолютного модельного времени, пусть АС3, основных прогонов, в ходе которых собирается интересующая нас статистика. Нам для расчетов нужно АС3. Для его получения в программу введены строки:
SAVEVALUE AC3,(AC1-X$AC2) SAVEVALUE AC2,AC1
После предварительных прогонов в ячейке X$Prog сохранится указанное в первой команде START количество прогонов. Эта ячейка используется в первой строке рассматриваемого сегмента и ее содержимое должно быть равным нулю. В противном случае модель будет работать неверно. Для предотвращения ошибки введена строка:
SAVEVALUE X$Prog,0
7.3.6. Проведение экспериментов
Вначале проведите эксперимент согласно варианту 1 (см. п. 7.3.3 и рис. 7.14).
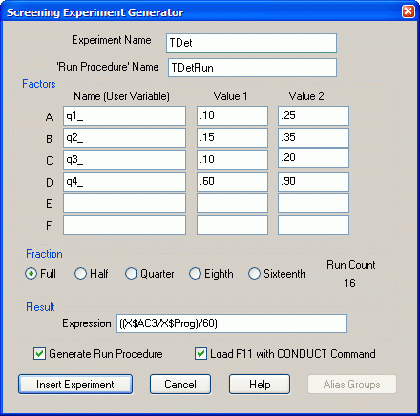
Рис. 7.14. Диалоговое окно (заполненное) Screening Experiment Generator (Генератор отсеивающего эксперимента)
Ранее (п. 4.9) отмечалось, что из трех подходов получения достоверной статистики наиболее удобен подход сброса статистики на определенном этапе моделирования с последующим его продолжением без модификации модели. Для реализации этого подхода в GPSS World имеется команда RESET.
Однако остается открытым вопрос: сколько нужно выполнить предварительных прогонов модели до сброса статистики?
Для получения ответа на этот вопрос проведите несколько экспериментов с моделью, меняя в каждом из них только количество предварительных прогонов модели.
В первой команде START генератора экспериментов укажите 20 прогонов. Во второй команде START - 170 прогонов, которые были определены ранее (п. 7.3.4). Результаты экспериментов - оценку матожидания времени TDet изготовления Det деталей - заносите в табл. 7.5.
| Оценка | Количество прогонов модели | ||||||
|---|---|---|---|---|---|---|---|
| 20 | 40 | 60 | 80 | 100 | 120 | 150 | |
| TDet | 3,988 | 3,975 | 4,007 | 4,024 | 3,986 | 3,995 | 4,044 |
Согласно табл. 7.5 изменяйте и количество прогонов модели. Для сокращения времени проведения экспериментов изменяйте их непосредственно в процедуре запуска генератора экспериментов.
По окончании экспериментов получите (табл. 7.5). Видно, что изменения результата моделирования столь малы, что ими для данной модели практически можно пренебречь.
Повторите эксперимент, указав, например, 100 предварительных прогонов. Получите результаты дисперсионного анализа, представленные на рис. 7.15.
Видно, что все четыре фактора существенные. Наибольшее влияние на функцию отклика оказывает фактор В, что вполне логично, так как из первых трех имеет наибольший верхний уровень, т. е. наибольшую долю брака. Ожидаемое время изготовления четырех деталей DET = 4 деталей составляет ТDet = 3,986 ч.
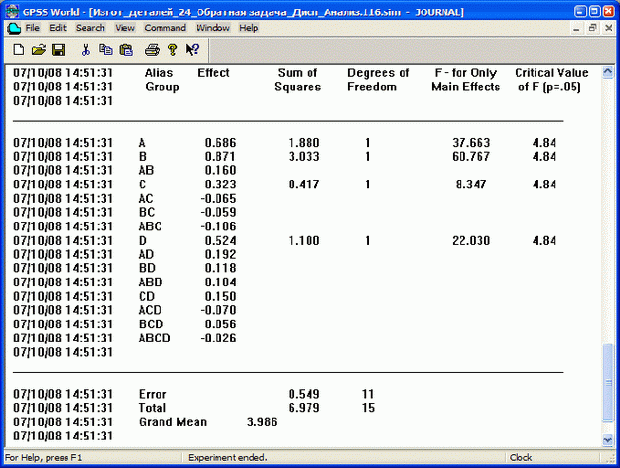
увеличить изображение
Рис. 7.15. Результаты отсеивающего эксперимента (вариант1)
Теперь проведите эксперимент согласно варианту 2 (см. п. 7.3.3) при том же количестве предварительных и основных прогонов. Получите (рис. 7.16), что ожидаемое время изготовления четырех деталей ТDet = 4,518 ч. Все факторы, кроме фактора D (время выполнения третьей операции), несущественные.
Уменьшите верхний уровень фактора D: возьмем, например, K1 = 1,5. Проведите эксперимент с новым значением фактора D. Получите, что время изготовления ТDet ожидается 3,992 ч, а все факторы можно считать практически не существенными.
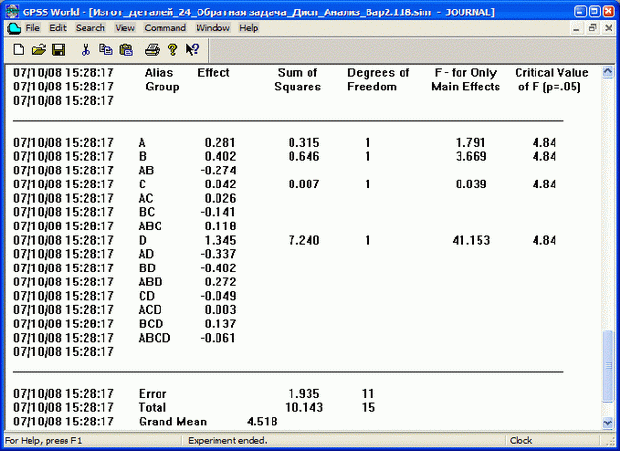
увеличить изображение
Рис. 7.16. Результаты отсеивающего эксперимента (вариант 2)
Вопросы для самоконтроля
- Что понимается под компьютерным экспериментом?
- Каковы цели стратегического и тактического планирования эксперимента?
- Какова цель и средства проведения дисперсионного анализа (отсеивающего эксперимента) в GPSS World?
- В каком виде выводятся результаты дисперсионного анализа? Дайте характеристику выводимых величин.
- Как изучить группы смешивания с целью осуществления стратегического планирования эксперимента?
- Какова цель и средства проведения оптимизирующего эксперимента в GPSS World?
- Дайте характеристику метода поверхности отклика.
- Как должны быть представлены в программе модели характеристики моделируемой системы, которые будут использоваться при проведении исследований с применением генераторов экспериментов?
- Можно ли при проведении отсеивающего или оптимизирующего эксперимента указывать, например, для нормального или равномерного распределения, по отдельности в качестве факторов среднее значение и среднеквадратическое отклонение? Если да, приведите примеры. Если нет, обоснуйте причину, к каким ошибкам это может приводить, как их избежать.
- Может ли пользователь изменять условия проведения отсеивающего и оптимизирующего экспериментов? Если да, какие?
- Измените условия примера 6.1 так, чтобы сервер стал однофазной системой массового обслуживания с ожиданием разомкнутого типа (добавьте входной накопитель емкостью на L сообщений). В соответствии с этим откорректируйте программу модели решения прямой задачи (п. 6.3.1). Проведите дисперсионный анализ. Исследуйте влияние на вероятность обработки запросов сервером четырех факторов: три указаны в табл. 6.1, а четвертый фактор - емкость входного накопителя сервера.
- В программу модели, измененную при ответе на вопрос 7.11, добавьте сегмент имитации сбоев сервера. Проведите дисперсионный анализ. Исследуйте влияние на вероятность обработки запросов сервером пяти факторов: четыре указаны в вопросе 7.11, а пятый фактор - среднее значение интервалов времени наработки на отказ.
- Проведите оптимизирующий эксперимент, используя те же факторы, что и в дисперсионном анализе (вопрос 7.11). Попробуйте получить регрессионную зависимость, изменяя, при необходимости, значения уровней факторов.
- Проведите оптимизирующий эксперимент согласно условиям варианта 1 (п. 6.4.1.3). Попробуйте получить регрессионную зависимость, изменяя, при необходимости, значения уровней факторов.
- Проведите оптимизирующий эксперимент согласно условиям варианта 2 (п. 6.4.1.3). Попробуйте получить регрессионную зависимость, изменяя, при необходимости, значения уровней факторов.
- Измените исходные данные задачи (п. 6.5.2): добавьте телефонные аппараты третьей категории (ТА3). Откорректируйте в соответствии с этим программу модели (п. 6.5.4). Проведите дисперсионный анализ. Исследуйте зависимость вероятностей разговоров абонентов ТА по категориям и в целом от интенсивности заявок на звонки и длительности ведения разговоров.
- Проведите оптимизирующий эксперимент по условиям вопроса 7.16. Попробуйте получить регрессионную зависимость, изменяя, при необходимости, значения уровней факторов.
- Проведите дисперсионный анализ согласно постановке п. 7.3.1. Но при этом решите прямую задачу, т. е. определите количество деталей, которое будет изготовлено за четыре часа. Для этого замените сегмент завершения моделирования и расчета результатов сегментом задания времени моделирования и расчета результатов:
GENERATE TMod ; Время моделирования TEST L X$Prog,TG1,Met11 ; Если условие выполняется, то SAVEVALUE Prog,TG1 ; X$Prog=TG1 содержимому счетчика завершений SAVEVALUE Prog1,TG1 ; X$Prog1=TG1 содержимому счетчика завершений Met11 TEST E TG1,1,Met12 ; Если содержимое счетчика завершений равно 1, то расчет результатов моделирования SAVEVALUE NDet,(INT(N$EndOper1/X$Prog1)) ; Количество готовых деталей, шт. SAVEVALUE Brak,(INT(N$EndOper/X$Prog1)) ; Количество забракованных деталей, шт. SAVEVALUE DoljaBrak,(X$Brak/(X$Brak+X$NDet)) ; Общая доля брака SAVEVALUE DoljaDet,(X$NDet/(X$Brak+X$NDet)) ; Доля готовых деталей SAVEVALUE TDet,((AC1-X$AC2)/N$EndOper1) ; Среднее время изготовления одной детали, мин SAVEVALUE AC2,AC1 SAVEVALUE Prog,0 Met12 TERMINATE 1
Остальную необходимую корректировку модели выполните самостоятельно.
Лекция 8. Разработка имитационных моделей в виде приложений с интерфейсом
8.1. Применение текстовых объектов и потоков данных
Модель представляет собой набор операторов, содержащихся в одном объекте "Модель" и в любом количестве необязательных текстовых объектов.
Текстовые объекты с наборами операторов модели подключаются к объекту "Модель" командой INCLUDE. Формат команды:
INCLUDE A
Операнд А - спецификация файла (полный путь доступа к файлу). Допустимые значения - String. Например:
INCLUDE "DanDon.txt" INCLUDE "D:\Primer\DanZad.txt"
В первом примере путь доступа к файлу не приводится, так как предполагается, что файл с указанным именем находится в папке модели. Во втором примере указан путь доступа к файлу.
Команда INCLUDE является срочной командой. При трансляции она заменяется файлом. Поэтому располагать в модели команду INCLUDE нужно там, где должны быть операторы или команды, содержащиеся в файле.
Все дополнительно вводимые файлы нумеруются транслятором целыми числами, начиная с 0. Номер 0 присваивается объекту-модели. Нескольким вводам одного файла также присваиваются уникальные номера, т. е. каждый ввод файла приводит к созданию отличающихся наборов блоков.
Команда INCLUDE допускает пять уровней вложенности файлов модели. Нельзя помещать команду INCLUDE в Plus-процедуру.
Операторы INCLUDE можно также закреплять за функциональными клавишами. Это позволяет одним нажатием клавиши объекту "Процесс моделирования" передать набор команд и (или) Plus-операторов, содержащихся в текстовом файле.
Текстовые объекты применяются и вместе с потоками данных. Потоки данных позволяют процессу моделирования считывать из файлов и записывать данные в файлы, а также создавать файлы результатов моделирования для последующего использования.
Поток данных - это последовательность текстовых строк, используемых процессом моделирования. Существуют два типа потоков данных:
- потоки ввода-вывода (I/O или "файловые" потоки) для доступа к файлам;
- потоки в памяти для тестирования или прямого доступа к внутренним данным.
Основной элемент потока данных - текстовая строка, которая является строкой печатных символов, включая пробелы.
Для обработки потоков данных существуют пять блоков GPSS World: OPEN, CLOSE, READ, WRITE, SEEK. Три из них - READ, WRITE, SEEK - выполняют операции только с одной отдельной строкой текста.
Перейдем к рассмотрению блоков обработки потоков данных.
8.1.1. Блок OPEN
Блок OPEN предназначен для инициализации потока данных. Формат блока:
OPEN A,[B],[C]
Операнд А - дескриптор потока данных. Операнд определяет тип потока данных. Он обрабатывается как строка. Если это нулевая строка, создается поток в памяти. Если это канальное имя, такое как "\pipe\mypipe", создается канальный поток. В противном случае создается поток ввода-вывода и предполагается, что операнд А является спецификацией файла.
Операнд В - номер потока данных, произвольное положительное число, задаваемое пользователем. Нумерация потоков введена с целью использования одновременно в одном процессе моделирования нескольких потоков данных. По умолчанию номер потока данных равен 1.
Операнд С - метка блока, в который направляется транзакт в случае ошибки инициализации потока данных. Коды ошибок:
- 0 - нет ошибки;
- 10 - длинное имя файла;
- 11 - ошибка чтения внешнего файла;
- 12 - во время попытки открыть файл был запрещен доступ к памяти.
OPEN ("Plan.txt"),3,Kon1
OPEN ("G\Model\NorPogr.txt")
OPEN ("")В первом примере открывается поток ввода-вывода, потоку присваивается номер 3 и в случае ошибки открытия активный транзакт направляется к блоку с меткой Kon1. Операндом А указан неполный путь доступа к файлу, поэтому подразумевается, что используется папка объекта "Процесс моделирования". Если файл с указанным именем не найден, то предполагается, что файл создается, и ошибка не возникает.
Во втором примере операндом А указан полный путь доступа к файлу, открываемому потоку ввода-вывода по умолчанию присваивается номер один. В случае ошибки открытия активный транзакт направляется к следующему по порядку блоку.
В третьем примере открывается поток в памяти.
8.1.2. Блок CLOSE
Блок CLOSE предназначен для закрытия потока данных. Формат блока:
CLOSE A,[B],[C]
Операнд А - номер или имя параметра транзакта, в который записывается код ошибки закрытия потока данных. Если такой параметр не существует, он создается.
Операнд В - номер закрываемого потока данных, по умолчанию равен 1, т. е. если операнд В не используется, закрывается поток номер один.
Операнд С - метка блока, в который направляется транзакт в случае ошибки закрытия потока данных. Коды ошибок:
- 0 - нет ошибки;
- 41 - запись файла на диск не произведена из-за ошибки ввода-вывода;
- 42 - файл не был открыт.
Например:
CLOSE Parm_Error,(P1+1)
В примере блок CLOSE закрывает поток данных, номер которого задан выражением в скобках. Это выражение вычисляется, округляется и используется в качестве номера потока данных (должен быть положительным целым числом).
Блок CLOSE для потоков ввода-вывода записывает данные из виртуальной памяти в дисковый файл.
8.1.3. Блок READ
Блок READ предназначен для считывания из потока данных текстовой строки. Формат блока:
READ A,[B],[C]
Операнд А - номер или имя параметра транзакта, в который записывается считанная из потока ввода или потока в памяти строка, находящаяся на позиции текущей строки. После считывания позиция текущей строки увеличивается на единицу. Если такой параметр активного транзакта не существует, он создается.
Операнд В - номер потока данных, из которого производится считывание. По умолчанию равен 1, т. е. если операнд В не используется, считывание производится из потока номер один.
Операнд С - метка блока, в который направляется транзакт в случае ошибки считывания. Если операнд С не используется, код ошибки все равно сохраняется. Для его получения нужно использовать блок CLOSE. Коды ошибок:
- 21 - во время попытки выполнить чтение был запрещен доступ к памяти;
- 22 - файл не был открыт.
Например:
READ Stroka_Text,4,Kon5
В примере блок READ считывает текстовую строку из потока данных номер 4 и записывает в параметр транзакта с именем Stro-ka_Text. Если текстовая строка считывается без ошибки, а параметр активного транзакта не существует, он создается. В случае ошибки строка не считывается и активный транзакт направляется к блоку с меткой Kon5.
8.1.4. Блок WRITE
Блок WRITE предназначен для передачи текстовой строки потоку данных. Формат блока:
WRITE A,[B],[C],[D]
Операнд А - текстовая строка, которая должна быть передана потоку данных.
Операнд В - номер потока данных, по умолчанию равен 1.
Операнд С - метка блока, в который направляется транзакт в случае ошибки записи. Коды ошибок:
- 0 - нет ошибки;
- 31 - во время попытки выполнить запись был запрещен доступ к памяти;
- 32 - файл не был открыт.
Операнд D - задает режим работы блока WRITE. Если операнд D не используется (по умолчанию) или равен ON, блок WRITE работает в режиме вставки. Если операнд D равен OFF - в режиме замены.
Режим вставки:
- все текстовые строки, находящиеся на или за позицией текущей строки, сдвигаются на одну позицию;
- если позиция текущей строки находится далеко за последней текстовой строкой, она устанавливается сразу после последней строки потока данных;
- копия новой текстовой строки помещается на позицию текущей строки;
- позиция текущей строки увеличивается на единицу. Режим замены:
- если позиция текущей строки находится далеко за последней текстовой строкой, все промежуточные позиции заполняются нулевыми текстовыми строками;
- текстовая строка, находящаяся на позиции текущей строки, удаляется;
- копия новой текстовой строки помещается на позицию текущей строки;
- позиция текущей строки увеличивается на единицу. Пример:
WRITE "INITIAL MX$TDon(1,1),420",5,Met3
В этом примере блок WRITE передает текстовую строку потоку данных с номером 5. Если происходит ошибка, активный транзакт переходит к блоку с меткой Met3. Иначе он переходит к следующему по порядку блоку. Если в данном случае поток данных является потоком вывода или потоком в памяти, запись производится в режиме вставки, так как операнд D не используется.
8.1.5. Блок SEEK
Блок SEEK устанавливает позицию текущей строки потока данных. Формат блока:
SEEK A,[B]
Операнд А - новая позиция текущей строки.
Операнд В - номер потока данных, по умолчанию равен 1.
Позиция текущей строки - это односвязный индекс, указывающий позицию следующей строки, которую необходимо считать или записать. Она не может быть меньше единицы. При попытке установить ее меньше единицы позиция текущей строки устанавливается равной единице.
31 - код ошибки: файл не был открыт.
Пример:
SEEK (Stroka+P1),(Potok+3)
В этом примере, когда транзакт входит в блок SEEK, операнд А вычисляется, округляется и используется как номер потока данных. Операнд В также вычисляется, округляется и используется как номер потока данных.
8.2. Разработка модели в GPSS World
8.2.1. Постановка задачи
На склад, имеющий 10 пунктов выгрузки, прибывают транспорта с материальными средствами (МС). В транспорте могут быть автомобили различной грузоподъемности. Всего количество типов автомобилей, отличающихся грузоподъемностью, которое может быть в транспорте, распределено по нормальному закону с математическим ожиданием 6 автомобилей и стандартным отклонением 1 автомобиль. Количество автомобилей одного типа в транспорте также распределено по нормальному закону с математическим ожиданием 11 автомобилей и стандартным отклонением 2 автомобиля. Интервалы времени прибытия транспортов распределены по экспоненциальному закону со средним значением 9 часов. Время разгрузки автомобиля зависит от его типа и подчиняется экспоненциальному закону. Среднее время выгрузки МС приведено в табл. 8.1. После выгрузки из тех же автомобилей вновь формируется транспорт.
Построить модель функционирования пунктов выгрузки в течение трех суток с целью определения среднего времени выгрузки транспортов и коэффициентов загрузки пунктов выгрузки при рациональной организации работ на складе.
| Характеристики | Тип автомобиля | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Среднее время выгрузки, мин | 8 | 10 | 12 | 7 | 6 | 9 | 11 | 5 | 13 | 10 |
Для имитации транспорта в целом и одного автомобиля следует использовать транзакты. Пункты выгрузки в модели будут представлять ОКУ.
8.2.2. Программа модели
; Модель разгрузки транспортов ; Задание исходных данных IntTp EQU 720 ; Средний интервал поступления транспортов MOTip EQU 6 ; Матожидание типов автомобилей в транспорте SOTip EQU 1 ; Стандартное отклонение типов автомобилей MatA EQU 11 ; Матожидание автомобилей одного типа SOtkA EQU 2 ; Стандартное отклонение автомобилей одного типа KolPun EQU 10 ; Количество пунктов выгрузки VrMod EQU 1440 ; Время моделирования ; Определение функций и булевых переменных SrVrA FUNCTION P3,D10 ; Среднее время выгрузки 1,8/2,10/3,12/4,7/5,6/6,9/7,11/8,5/9,13/10,10 TipAvt FUNCTION RN64,C2 ; Число типов автомобилей 0,1/1,7 ; Сегмент имитации поступления и обработки сообщений GENERATE (Exponential(33,0,IntTp)) ; Источник транспортов SAVEVALUE 1,0 ; Обнуление счетчика ASSIGN 5,AC1 ; Абсолютное модельное время входа транспорта ASSIGN 2,(INT(Normal(77,MOTip,SOTip)-1)) ;Число типов SPLIT *2 ; Транзактов - по числу типов автомобилей ASSIGN 2+,1 ; Запомнить число типов автомобилей ASSIGN 4,(INT(Normal(55,MatA,SOtkA)-1));Автомобили SPLIT *4 ; Транзактов - по числу автомобилей ASSIGN 4+,1 ; Запомнить число автомобилей одного типа TEST L X1,KolPun,Met1 ; Есть свободные пункты выгрузки? SAVEVALUE 1+,1 Met2 SELECT MIN 3,1,KolPun,,FR ; Выбор пункта с min загрузкой TEST NE P3,0,Met1 ; Есть пункты с min загрузкой? QUEUE P3 ; Встать в очередь SEIZE P3 ; Занять пункт выгрузки DEPART P3 ; Покинуть очередь ADVANCE (Exponential(73,0,FN$SrVrA)) ; Выгрузка RELEASE P3 ; Освободить АРМ UNLINK PunSb,Met2,1 ; Автомобиль на выгрузку ASSEMBLE *4 ; Собрать автомобили одного типа ASSEMBLE *2 ; Собрать автомобили всех типов ASSIGN 6,AC1 ; Время выхода транспорта SAVEVALUE VrVigS+,(P6-P5) ; Суммарное время выгрузки VigTr TERMINATE ; Выгруженные транспорта Met1 LINK PunSb,FIFO ; Автомобили, ожидающие выгрузки ; Сегмент задания времени моделирования GENERATE VrMod TEST NE N$VigTr,0,Met3 SAVEVALUE VrVig,(X$VrVigS/N$VigTr) ; Среднее время выгрузки Met3 TERMINATE 1
Замысел построения модели заключается в следующем. Блок GENERATE имитирует поступление транзактов. Один транзакт - один транспорт. Затем случайным образом определяется количество типов автомобилей в транспорте и заносится в параметр 2 транзакта. Исходный (порождающий) транзакт - транспорт копируется блоком SPLIT и результат копирования - число автомобилей различных типов в прибывшем транспорте копируется вторым блоком SPLIT. Результат копирования - число транзактов, равное числу автомобилей в транспорте. Число автомобилей одного типа заносится в параметр 4 всех транзактов, имитирующих автомобили данного типа.
Далее первые десять транзактов-автомобилей (по числу пунктов выгрузки) поступают на блок SELECT, остальные - в список пользователя с именем PunSb. По мере освобождения пунктов выгрузки из списка пользователя выводятся транзакты и направляются на блок SELECT с меткой Met2. Результат работы блока SELECT - номер пункта выгрузки с минимальным коэффициентом загрузки заносится в параметр 3 вошедшего транзакта. Если результатом поиска блока SELECT является P3=0, т. е. номер нужного блока не найден, то транзакт блоком TEST снова отправляется в список пользователя. При успешном поиске транзакт занимает соответствующий пункт выгрузки.
Разгруженные автомобили первым блоком ASSEMBLE сначала собираются по каждому типу автомобилей отдельно, а вторым блоком ASSEMBLE - по всем типам.
При входе транзакта-транспорта в модель и выходе из нее в параметры 5 и 6 записывается соответствующее модельное время. Оно используется для расчета времени разгрузки транспорта. Суммарное время разгрузки всех транспортов накапливается в ячейке VrVigS.
Для работы с GPSS-моделью можно создать в какой-либо другой системе программирования, например, Delphi, интерфейс, который должен позволять осуществлять ввод исходных данных и вывод результатов моделирования. Например, в приведенной программе модели разгрузки транспортов вводить посредством интерфейса характеристики, для ввода которых используется команда EQU, а также среднее время выгрузки из одного автомобиля. При этом, естественно, необходимо разработать процедуры, формирующие в Delphi соответствующие строки программы GPSS-модели. Сама GPSS-программа также потребует модификации, для проведения которой нужно будет использовать команду INCLUDE и рассмотренные в п. 8.1 блоки OPEN, CLOSE, READ, WRITE для работы с текстовыми объектами и потоками данных.
8.3. Создание стартовой формы приложения - имитационной модели
Работа над новым проектом начинается с создания стартовой формы - окна, которое появляется при запуске приложения.
При запуске Delphi автоматически создаётся новый проект. Вид экрана после запуска Delphi показан на рис. 8.1. Можно использовать этот проект для создания нового приложения. По умолчанию этот проект имеет название Project1.
Стартовая форма создается путем изменения свойств формы Forml (см. рис. 8.1) .Свойства формы определяют ее внешний вид: размер, положение на экране, текст заголовка, вид рамки. Свойства перечислены на вкладке Properties (свойства) окна Object Inspector.В левой колонке находятся имена свойств, а в правой - их значения.
Сначала надо изменить значение свойства Caption ( Заголовок ) - заменить Forml на Модель разгрузки транспортов. Для этого щелкнуть мышью в поле Caption.В результате этого в правой колонке, где находится текущее значение свойства - текст Forml, появляется курсор (рис. 8.2.).
Используя клавишу <Backspase>, надо удалить Forml и ввести Модель разгрузки транспортов.
Аналогичным образом можно установить значения свойств Height и Width, которые определяют высоту и ширину формы. Этим свойствам надо присвоить значения 530 и 715. Размер формы и элементов управления, а также положение формы на экране и элементов управления на поверхности формы задаются в пикселях, точках экрана.
При выборе некоторых свойств, например Color (цвет), которое определяет цвет фона формы, после значения свойств выводится значок выпадающего списка. В результате щелчка на нем появляется список допустимых значений свойства, из которого можно выбрать нужное значение (рис. 8.3).
При разработке формы Form1 имитационной модели оставим свойство Color неизменным.
увеличить изображение
Рис. 8.1. Вид экрана после запуска Delphi
Рис. 8.2. Установка значения свойства Caption посредством ввода
Рис. 8.3. Установка значения свойства выбором из списка
В поле значения свойства Font расположена командная кнопка с тремя точками, при нажатии на которую появляется стандартное диалоговое окно Windows выбора шрифта и его свойств (рис. 8.4). Для рассматриваемого примера выбран шрифт Times New Roman размером 10.
Большинство свойств определяют внешний вид формы. Свойство Name определяет имя формы, которое используется в программе для управления формой.
Ниже в табл. 8.2 приведены измененные свойства формы разрабатываемой имитационной модели. Остальные свойства формы оставлены без изменения и в таблице не приведены.
Рис. 8.4. Пример раскрытого списка уточняющих свойств свойства Font
| Свойство | Обозначение | Значение |
|---|---|---|
| Имя формы | Name | Form1 |
| Заголовок | Caption | Модель разгрузки транспортов |
| Высота | Height | 530 |
| Ширина | Width | 715 |
| Шрифт | Font. Name | Times New Roman |
| Размер шрифта | Font. Size | 10 |
Таблица содержит значения вложенных свойств: Name и Size. Перед именем вложенного свойства указывается имя свойства, его вмещающего. В данном случае имя вмещающего свойства Font. После установки значений свойств, перечисленных в табл. 8.2, форма должна выглядеть так, как изображено на рис. 8.5.
Создайте папки D:\ModRTr\Интерфей с и в последней сохраните проект. Чтобы сохранить проект, надо выполнить команду File/ Save Project As. Откроется окно Save Unit As. Выберите в нем и раскройте созданную ранее папку Интерфейс. В поле Имя файла введите имя программного модуля, например, Rasgruska, и щелкните кнопку Сохранить.
После этого щелчка в диалоговом окне Save Unit As появится диалоговое окно Save Project As. В поле имя файла введите, например, Rasgr_transporta и щелкните кнопку Сохранить.

Рис. 8.5. Вид формы имитационной модели после установки значений свойств
8.3 Добавление компонент в стартовую форму имитационной модели
8.3.1. Добавление полей редактирования
Программа имитационной модели должна получить от пользователя следующие исходные данные:
IntTp - средние значения интервалов поступления транспортов;
MOТip, SOTip - математическое ожидание MOТip и стандартное отклонение SOTip количества типов автомобилей в транспорте;
MatA, SOtkA - математическое ожидание MatA и стандартное отклонение SOtkA количества автомобилей одного типа в транспорте;
KolPun - количество пунктов выгрузки;
VrMod - время моделирования.
В Windows данные с клавиатуры вводятся в поля редактирования. Поэтому в данную форму надо добавить компоненты - семь полей редактирования.
В Delphi поля редактирования, командные кнопки, поля статического текста и прочие элементы управления, находящиеся в форме, называются компонентами (компоненты формы). В программе форма и компоненты рассматриваются как объекты. Этим можно объяснить то, что окно, в котором находятся свойства компонентов, называется Object Inspector.
Чтобы добавить к форме компонент, надо в палитре компонентов (рис. 8.6) щелкнуть на пиктограмме нужного компонента, и затем щелкнуть в той точке формы, где должен находиться правый верхний угол компонента. В результате в форме появляется компонент стандартного размера.

увеличить изображение
Рис. 8.6. Пиктограммы стандартной палитры компонентов
Добавить к форме компонент нужного размера, т. е. изменить его стандартный размер, можно так. После щелчка на палитре компонентов нужно поместить курсор мыши в ту точку формы, где должен находиться левый верхний угол компонента, нажать кнопку мыши и, удерживая ее нажатой, переместить курсор в точку, где должен быть правый нижний угол компонента, затем отпустить кнопку. В форме появится компонент нужного размера.
Добавьте в форму, перейдя на вкладку Standard (см. рис. 8.6), семь компонентов редактирования Edit. У компонента Edit пиктограмма .
Компонент формы, окруженный восемью маленькими квадратиками (см. на рис. 8.7 поле Edit1 ), называется выделенным (маркированным).Свойства маркированного компонента отображаются в окне Object Inspector.Ниже, в табл. 8.3, перечислены основные свойства компонента, называемого полем редактирования.
На рис. 8.7 представлен вид формы после добавления к ней семи полей редактирования Edit1 … Edit7.

увеличить изображение
Рис. 8.7. Форма имитационной модели с семью полями редактирования
Delphi позволяет легко изменить положение и размер компонента. Чтобы изменить положение компонента в форме, надо установить курсор мыши на изображение компонента, нажать левую кнопку мыши и, удерживая ее нажатой, переместить изображение границы компонента в нужную точку формы. Затем отпустить кнопку мыши.
| Свойство | Обозначение |
|---|---|
| Имя поля. Используется в программе для доступа к содержимому (тексту) поля | Name |
| Текст, находящийся в поле ввода-редактирования | Text |
| Расстояние от левой границы поля до левой границы формы | Left |
| Расстояние от верхней границы поля до верхней границы формы | Top |
| Высота поля | Height |
| Ширина поля | Width |
| Шрифт, используемый для отображения вводимого текста | Font |
| Признак наследования свойств шрифта родительской формы | ParentFont |
Чтобы изменить размер компонента, надо его маркировать (щелкнуть на изображении компонента), установить указатель мыши на один из квадратиков, помечающих границу компонента, нажать левую кнопку мыши и, удерживая ее нажатой, изменить положение границы компонента. При выполнении указанного действия высвечиваются размеры компонента, например, 97?21. При достижении нужного размера отпустить кнопку мыши.
Свойства компонента можно так же изменить в окне Object Inspector.Чтобы свойства компонента появились в данном окне, надо маркировать нужный компонент, или выбрать его имя из раскрывающегося списка объектов, кнопка раскрытия которого находится в верхней части окна Object Inspector (рис. 8.8).
Рис. 8.8. Окно Object Inspector с свойствами поля редактирования Edit1
В табл. 8.4 приведены свойства полей редактирования, предназначенных для ввода IntTp, MOТip, SOTip, MatA, SOtkA, KolPun, VrMod.
| Name | Edit1 | Edit2 | Edit3 | Edit4 | Edit5 | Edit6 | Edit7 |
|---|---|---|---|---|---|---|---|
| Text | |||||||
| Top | 30 | 60 | 90 | 30 | 60 | 90 | 120 |
| Left | 16 | 16 | 16 | 350 | 350 | 350 | 16 |
| Height | 21 | 21 | 21 | 21 | 21 | 21 | 21 |
| Width | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
8.3.2. Добавление меток
Помимо полей редактирования окно формы должно содержать поясняющий текст: краткие информационные сообщения, которые должны раскрывать порядок работы с программой модели.
Текст, находящийся в форме, называется меткой. Добавляется метка к форме точно так же, как и поле редактирования. Пиктограмма метки (большая буква А) находится в палитре компонентов перед пиктограммой поля редактирования (см. рис. 8.6). После того как метка добавлена, можно, используя окно Object Inspector,изменить ее свойства.
К форме разрабатываемого приложения надо добавить восемь меток. Все метки будут представлять собой информационные сообщения. Добавьте метки и установите значения их свойств согласно табл. 8.5. Форма разрабатываемого приложения будет иметь вид, представленный на рис. 8.9.
| Name | Labell | Label2 | Label3 | Label4 | Label5 | Label6 | Label7 | Label8 |
|---|---|---|---|---|---|---|---|---|
| Caption | ||||||||
| AutoSize | false | true | true | true | true | true | true | true |
| Top | 0 | 30 | 60 | 90 | 30 | 60 | 90 | 120 |
| Left | 140 | 70 | 70 | 70 | 410 | 410 | 410 | 70 |
| Wordwrap | true | true | true | true | true | true | True | true |
| ParentFont | false | true | true | true | true | true | true | true |
увеличить изображение
Рис. 8.9. Вид формы имитационной модели после добавления меток
Как видно по рис. 8.9, из полей редактирования необходимо удалить их имена Edit1…Edit7. На этом же рисунке указано свойство Caption для каждой метки - информационное сообщение. Например, для Labell: Введите исходные данные и нажмите кнопку ВВОД. Для Labell: Средний интервал поступления транспортов.
Свойство ParentFont метки Labell имеет значение false, поэтому свойство Font этой метки не наследует значения свойства Font "родителя", в данном случае основной формы. Это дает возможность установить свойства шрифта метки иные, чем у формы. У меток Label2…Label8 значение свойства ParentFont оставлено без изменения. Значит, они наследуют свойства Font "родителя".
Если свойство AutoSize (автоматический подгон размера) имеет значение true, Delphi автоматически устанавливает размеры метки в зависимости от количества символов текста метки, используемого шрифта и его размера. Если надо, чтобы метка представляла собой текст из нескольких строк, то свойству AutoSize надо присвоить значение false и вручную установить значения свойств, определяющих ее размер.
У меток Label2…Label8 свойству AutoSize установлено значение true, а у метки Label1 - false.
8.3.3. Добавление компонент для ввода и вывода данных, представленных в виде таблиц
Среднее время разгрузки одного автомобиля различных типов представлено табл. 8.1. Компонент StringGrid ( Строковая таблица ) используется для отображения информации в виде таблицы. Таблица представляет собой набор ячеек, расположенных в строках и столбцах. Ее содержимое задается двумерным массивом.
Значок компонента StringGrid находится на дополнительной ( Additional ) странице палитры компонентов. В разрабатываемую форму имитационной модели необходимо добавить два компонента. Один компонент для ввода табл. 8.1. В данной модели результаты моделирования целесообразно вывести таблицей. Поэтому нужен второй компонент StringGrid. Добавьте два компонента. Добавляются они также, как и другие компоненты.
Добавленные компоненты StringGrid имеют стандартные свойства. Delphi предоставляет разработчику возможность изменить эти свойства после добавления компонентов в форму.
В табл. 8.6 перечислены основные свойства компонента StringGrid.
| Свойство | Описание |
|---|---|
| Name | Имя компонента. Используется в программе для доступа к свойствам компонента |
| ColCount | Количество колонок таблицы |
| RowCount | Количество строк таблицы |
| Cells | Соответствующий таблице двумерный строковый массив. Если строки и столбцы нумеровать с нуля, то ячейке Cells соответствует Cells (i,j) |
| FixedCols | Количество зафиксированных слева столбцов таблицы. Они выделяются цветом и при горизонтальной прокрутке таблицы остаются на месте |
| FixedRows | Количество зафиксированных сверху строк таблицы. Они выделяются цветом и при вертикальной прокрутке таблицы остаются на месте |
| Options | Свойство используется для задания других атрибутов таблицы (табл. 8.7) |
| DefaultColWidth | Ширина столбцов таблицы |
| DefaultRowHeight | Высота строк таблицы |
| GridLineWidth | Ширина линий, ограничивающих ячейки таблицы |
| Left | Расстояние от левой границы поля таблицы до левой границы формы |
| Top | Расстояние от верхней границы поля таблицы до верхней границы формы |
| Height | Высота поля таблицы |
| Width | Ширина поля таблицы |
| Font | Шрифт, используемый для отображения содержимого ячеек таблицы |
| ParentFont | Признак наследования характеристик шрифта формы |
Из всех свойств следует обратить внимание на свойство Options. Свойство Options используется для задания многих атрибутов таблицы (компонента StringGrid ), которые описаны в табл. 8.7. На вкладке, показанной на рис. 8.10, перед свойством Options стоит знак " + ". При двойном нажатии на него появляется вкладка с вложенными свойствами свойства Options (рис. 8.10).
| Атрибут | Описание (для значения True ) |
|---|---|
| goFixedHorzLine | Горизонтальные линии фиксированы |
| goFixedVertLine | Вертикальные линии фиксированы |
| goHorzLine | Горизонтальные разделительные линии отображаются |
| goVertLine | Вертикальные разделительные линии отображаются |
| goRangeSelect | Можно выбирать несколько ячеек |
| goDrawFocusSelected | Текущая ячейка помечается цветом |
| goRowSizing | Возможно изменение размеров строк |
| goColSizing | Возможно изменение размеров столбцов |
| goRowMoving | Возможно перемещение строк |
| goColMoving | Возможно перемещение столбцов |
| goEditing | Возможно редактирование содержимого ячеек |
| goTabs | Возможно перемещение по ячейкам клавишами Tab и Shift-Tab |
| goThumbTracking | Содержимое таблицы скроллируется с помощью полос прокрутки |
Свойства, перечисленные в табл. 8.6 и табл. 8.7, после выделения (маркирования) соответствующей таблицы устанавливаются либо заданием какого - то числового значения, либо выбором True или False (рис. 8.10).
Для ввода данных табл. 8.1 необходимо изменить некоторые из свойств StringGrid. Например, для того, чтобы была возможность редактировать содержимое ячеек таблиц, нужно установить свойство goEditing True, а для перемещения курсора с помощью клавиш Tab и стрелок - свойство goTabs также установить True.
В табл. 8.8 приведены значения свойств обеих компонентов StringGrid, используемых моделью для ввода и вывода данных. Установите эти значения. Форма должна иметь вид, показанный на рис. 8.11. Введите также метки Label9 и Label10 (см. рис. 8.11).
Рис. 8.10. Вкладка свойства Options
| Свойство | Компоненты | |
|---|---|---|
| 1 | 2 | |
| Name | Tabl1 | Tabl2 |
| ColCount | 11 | 11 |
| RowCount | 2 | 5 |
| FixedCols | 1 | 1 |
| FixedRows | 1 | 1 |
| Options.goEditing | True | True |
| Options.goTabs | True | True |
| DefaultColWidth | 70 | 125 |
| DefaultRowHeight | 24 | 24 |
| GridLineWidth | 1 | 1 |
| goRowSizing | True | True |
увеличить изображение
Рис. 8.11. Вид формы после добавления компонентов StringGrid
Первая строка и первый столбец таблиц зафиксированы (см. рис. 8.11). Они используются в качестве заголовков таблиц. В рассматриваемом примере в первой строке первой таблицы это тип автомобиля (номера 1 … 10), во второй таблице - пункты выгрузки (также номера 1 … 10). Следует отметить, что можно было бы ввести в эти ячейки и наименования вместо порядковых номеров. Как это делается, покажем на примере ввода поясняющего текста в строки таблиц. Во вторую строку первой таблицы - Cells(0, 1) - введем: Время, мин. Во вторую таблицу: Cells(0, 1) - Коэф. загр.; Cells(0, 2) - Ср. время ; Cells(0, 3) - Макс. очер. Во время создания формы имитационной модели установить значения элементов Cells таблицы нельзя, так как элементы таблицы доступны только во время работы программы. Поэтому значения элементов Cells таблицы, соответствующие первой строке и первому столбцу обеих таблиц устанавливают процедуры FormActivate1 и FormActivate2 (текст их приведен ниже) во время активизации формы. В какой процедуре обработки события производится вызов указанных процедур, укажем позже.
procedure TForm1.FormActivate1(Sender: TObject);
var n1:integer;
begin
for n1:=1 to Tabl1.ColCount do
Tabl1.Cells[n1,0]:=IntToStr(n1);
Tabl1.Cells[0,1]:='Время, мин';
end;
procedure TForm1.FormActivate2(Sender: TObject);
var n1:integer;
begin
for n1:=1 to Tabl2.ColCount do
Tabl2.Cells[n1,0]:=IntToStr(n1);
Tabl2.Cells[0,1]:='Коэф.исп.пункт. разгр.';
Tabl2.Cells[0,2]:='Ср.вр.разгр.авт.,мин';
Tabl2.Cells[0,3]:='Макс.очер.на пун.разгр.';
Tabl2.Cells[0,4]:='Ср.вр.разгр.тран.,час';
end;8.3.4. Добавление командных кнопок
Для управления работой имитационной модели к форме надо добавить шесть командных кнопок (рис. 8.12).
В модели предусмотрен пример. При нажатии кнопки ПРИМЕР автоматически вводятся исходные данные, курсор устанавливается на кнопке МОДЕЛИРОВАНИЕ. Нажатием этой кнопки переходят к процессу моделирования.
увеличить изображение
Рис. 8.12. Стартовая форма имитационной модели
По окончании моделирования для вывода результатов нужно нажать кнопку ВЫВОД. Результаты моделирования появятся в нижней таблице.
Если производилось моделирование примера, а потом нужно выполнить моделирование с другими исходными данными, нажатием кнопки СБРОС можно удалить данные примера и ввести новые. Использование кнопки СБРОС удобно в том случае, если очередной ввод исходных данных требует большого количества изменений. После этого нажать кнопку ВВОД и нажатием кнопки МОДЕЛИРОВАНИЕ перейти к процессу моделирования, по завершении которого нажать кнопку ВЫВОД.
Нажатие на кнопку ВЫХОД ИЗ МОДЕЛИ приводит к завершению работы программы имитационной модели. Закрывается открытая форма приложения.
Кнопки добавляются в форму точно так же, как и другие компоненты. Пиктограмма командной кнопки _2U,находится на палитре стандартных компонентов (см. рис. 8.6). После добавления кнопок с помощью диалогового окна Object Inspector надо установить требуемые значения их свойств (табл. 8.9).
| Name | Button1 | Button2 | Button3 | Button4 | Button5 | Button6 |
|---|---|---|---|---|---|---|
| Caption | Ввод | Сброс | Моделирование | Выход из модели | Пример | Вывод |
| Top | 470 | 470 | 470 | 470 | 470 | 470 |
| Left | 176 | 96 | 256 | 528 | 16 | 424 |
| Height | 25 | 25 | 25 | 25 | 25 | 25 |
| Width | 75 | 75 | 161 | 169 | 75 | 75 |
После запуска программы курсор сразу автоматически устанавливается в поле редактирования Edit1 для ввода переменной Средний интервал поступления транспортов. Поэтому в форме указано, что надо сначала ввести данные, потом нажать кнопку ВВОД и только потом кнопку МОДЕЛИРОВАНИЕ.
8.4. События и процедуры обработки событий
8.4.1. События
Вид созданной формы подсказывает, как работает приложение. Очевидно, что пользователь должен ввести значения в поля редактирования, нажать ВВОД и потом щелкнуть кнопку МОДЕЛИРОВАНИЕ. Щелчок на изображении командной кнопки - это пример того, что в Windows называется событием.
Событие - это то, что происходит во время работы приложения. В Delphi у каждого события есть имя, например, щелчок кнопкой мыши это событие OnClick, двойной щелчок - событие onDblClick.
В табл. 8.10 приведены некоторые события Windows.
Реакцией на событие должно быть какое-либо действие. Например, реакцией на событие OnClick, произошедшее на кнопке МОДЕЛИРОВАНИЕ,должен быть переход к запуску имитационной модели. В Delphi реакция на событие реализуется как процедура обработки события.Таким образом, задача программиста состоит в написании необходимых процедур обработки событий.
Поскольку в форму добавлены пятнадцать компонентов, то необходимо разработать для них процедуры обработки событий.
Рассмотрим методику создания процедур обработки событий.
| Событие | Содержание |
|---|---|
| OnClick | Происходит при щелчке кнопкой мыши |
| OnDblClick | Происходит при двойном щелчке кнопкой мыши |
| OnEnter | Происходит перед тем, как элемент управления действительно получает фокус |
| OnError | Происходит, когда элемент контроля обнаруживает ошибку и не может вернуть информацию об ошибке вызывающей программе |
| OnExit | Происходит непосредственно перед тем, как элемент управления теряет фокус |
| OnKeyDown | Происходит при нажатии на клавишу. События OnKeyDown и OnKeyPress - это чередующиеся, повторяющиеся события, которые происходят до тех пор, пока не будет отпущена удерживаемая клавиша (в этот момент происходит событие OnKeyUp ) |
| OnKeyPress | Происходит, когда пользователь нажимает клавишу, которая генерирует печатаемый символ. Может происходить также при нажатии клавиши печатаемого символа с <Ctrl>. He происходит при нажатии клавиш <Tab>, <Enter>, клавиш перемещения курсора |
| OnKeyUp | Происходит при отпускании нажатой клавиши |
| OnMouseDown | Происходит при нажатии кнопки мыши |
| OnMouseMove | Происходит при перемещении мыши |
| OnMouseUp | Происходит при отпускании кнопки мыши |
8.4.2. Разработка процедур обработки событий для кнопок
Сначала следует на форме приложения щелчком мыши маркировать (выделить) компонент, для которого создается процедура обработки события. В нашем случае целесообразно начать разработку с процедуры кнопки ВВОД. Выделите ее.
Затем нужно выбрать вкладку Events (события) окна Object Inspector.В результате этих действий в окне Object Inspector появится вкладка со списком событий, которые способен воспринимать маркированный компонент, в данном случае - командная кнопка (рис. 8.13).
В левой колонке вкладки перечислены имена событий, на которые может реагировать маркированный объект. Если для события определена процедура обработки события, то в правой колонке, рядом с именем события выводится ее имя.
Чтобы создать процедуру обработки события, надо сделать двойной щелчок в поле имени процедуры обработки события. В результате открывается окно редактора кода (в Delphi кодом называется текст программы) с макетом процедуры обработки события (рис. 8.14).
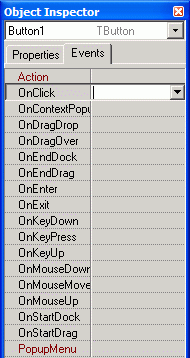
Рис. 8.13. Вкладка Events командной кнопки ВВОД (Button1)
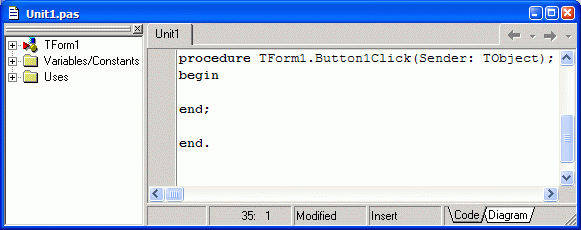
Рис. 8.14. Окно редактора кода с макетом процедуры обработки события, происходящего на кнопке Button1 (ВВОД)
Delphi автоматически присваивает процедуре обработки события имя. Имя процедуры обработки события состоит из двух частей. Первая часть идентифицирует форму, которой принадлежит объект, для которого создается процедура обработки события. Вторая часть имени идентифицирует сам объект и событие. В нашем случае имя формы - Form1, Button1 - имя командной кнопки ВВОД,а имя события - Click.
В окне редактора кода (см. рис. 8.14) между begin и end можно печатать инструкции Object Pascal, реализующие процедуру обработки события. Введите следующий программный код:
procedure TForm1.Button1Click(Sender: TObject);
begin
ProvVvod1;
begin
MOTip:=StrToFloat(Edit2.text);
SOTip:=StrToFloat(Edit3.text);
MatA:=StrToFloat(Edit4.text);
SOtkA:=StrToFloat(Edit5.text);
end;
if (SOTip*5)>MOTip then begin
MessageDlg('Стандартное отклонение SOTip'+#13
+'должно быть более чем в 5 раз меньше'+#13
+'математического ожидания MOTip',
mtWarning,[mbOk],0);
Edit3.SetFocus;
end
else if (SOtkA*)>MatA then begin
MessageDlg('Стандартное отклонение SOtkA'+#13
+'должно быть более чем в 5 раз меньше'+#13
+'математического ожидания MatA',
mtWarning,[mbOk],0);
Edit5.SetFocus;
end;
ProvVvod2; Tabl1.SetFocus;
end;В тексте процедуры выделено то, что сформировано Delphi. Остальное вводится разработчиком.
Обработка события при щелчке кнопки ВВОД происходит так. Вначале процедурой ProvVvod1 проверяется, все ли данные введены в поля редактирования. Если все данные введены, производится их перевод в вещественный тип.
В модели используются случайные числа, распределенные по нормальному закону. Поэтому далее производится проверка с целью предотвращения случаев неправильного задания стандартного отклонения. Оно должно быть в пять раз и более меньше математического ожидания.
Далее процедурой ProvVvod2 проверяется полнота ввода данных в первую таблицу StrinGrid. Создайте процедуры ProvVvod1, ProvVvod2 в разделе implementation программного модуля (.pas ).
procedure TForm1.ProvVvod1;
begin
begin
if (Edit1.text='') or (Edit2.text='')
or (Edit3.text='') or (Edit4.text='')
or (Edit5.text='') or (Edit6.text='')
or (Edit7.text='') then
MessageDlg('Необходимо задать все'+#13
+'исходные данные'+#13
+ 'в полях редактирования',
mtWarning,[mbOk],0);
end;
begin
if Edit1.text='' then Edit1.SetFocus;
if Edit2.text='' then Edit2.SetFocus;
if Edit3.text='' then Edit3.SetFocus;
if Edit4.text='' then Edit4.SetFocus;
if Edit5.text='' then Edit5.SetFocus;
if Edit6.text='' then Edit6.SetFocus;
if Edit7.text='' then Edit7.SetFocus;
end;
end;
procedure TForm1.ProvVvod2;
begin
begin
if (Tabl1.Cells[1,1]='') or (Tabl1.Cells[2,1]='') or (Tabl1.Cells[3,1]='')
or (Tabl1.Cells[4,1]='') or (Tabl1.Cells[5,1]='') or (Tabl1.Cells[6,1]='')
or (Tabl1.Cells[7,1]='') or (Tabl1.Cells[8,1]='') or (Tabl1.Cells[9,1]='')
or (Tabl1.Cells[10,1]='')
then
MessageDlg('Необходимо задать все'+#13
+'исходные данные в таблице',
mtWarning,[mbOk],0);
end;
Tabl1.SetFocus;
end;Объявите в интерфейсной части эти процедуры.
type TForm1 = class(TForm)
Edit1: TEdit;
…
procedure ProvVvod1;
procedure ProvVvod2;
privateПри нажатии кнопки СБРОС все поля редактирования и ячейки Tabl1 очищаются. Создайте обработчик этого события, программный код которого приведен ниже.
procedure TForm1.Button2Click(Sender: TObject);
var n1,n2:integer;
begin
Edit1.text:='';
Edit2.text:='';
Edit3.text:='';
Edit4.text:='';
Edit5.text:='';
Edit6.text:='';
Edit7.text:='';
for n1:=1 to 10 do
Tabl1.Cells[n1,1]:='';
for n2:=1 to 3 do
for n1:=1 to 10 do
Tabl2.Cells[n1,n2]:=''; Edit1.SetFocus;
end;Нажатием кнопки МОДЕЛИРОВАНИЕ производится переход к процессу моделирования. Создайте обработчик этого события согласно следующему программному коду.
procedure TForm1.Button3Click(Sender: TObject); begin
VivProgr;
WinExec('d:\ModRTr\GPSSW.exe',SW_RESTORE);
Button6.SetFocus;
end;При обработке этого события вначале выполняется процедура VivProgr, состоящая в свою очередь из четырех процедур VivProgr1, VivProgr2, VivProgr3 и VivProgr4. Они формирует следующие тестовые файлы с фрагментами программы GPSS:
- Progr1.txt для ввода данных командой EQU и посредством функции SrVrA (процедура VivProgr1 );
- Progr2.txt для ввода времени моделирования из поля редактирования Edit7 (процедура VivProgr2 );
- Progr3.txt - для вывода результатов моделирования в текстовый файл DanTabl211.txt (процедура VivProgr3 );
- Progr4.txt - для вывода результатов моделирования в текстовый файл DanTabl212.txt (процедура VivProgr4 );
- Progr5.txt - для вывода результатов моделирования в текстовый файл DanTabl213.txt (процедура VivProgr5 );
Создайте в разделе implementation программного модуля ( .pas ) программные коды шести процедур.
procedure TForm1.VivProgr;
begin
VivProgr1;
VivProgr2;
VivProgr3;
VivProgr4;
VivProgr5;
end;
procedure TForm1.VivProgr1;
var
f:TextFile;
begin
AssignFile(f,'d:\ModRTr\Progr1.txt');
Rewrite(f);
writeln(f,'IntTp EQU ',Edit1.text);
writeln(f,'MOTip EQU ',Edit2.text);
writeln(f,'SOTip EQU ',Edit3.text);
writeln(f,'MatA EQU ',Edit4.text);
writeln(f,'SOtkA EQU ',Edit5.text);
writeln(f,'KolPun EQU ',Edit6.text);
writeln(f,'VrMod EQU ',Edit7.text);
writeln(f,'SrVrA FUNCTION P3,D',(Tabl1.ColCount-1));
writeln(f,'1,',Tabl1.Cells[1,1],'/2,',Tabl1.Cells[2,1],'/3,',Tabl1.Cells[3,1],
'/4,',Tabl1.Cells[4,1],'/5,',Tabl1.Cells[5,1],'/6,',Tabl1.Cells[6,1],
'/7,',Tabl1.Cells[7,1],'/8,',Tabl1.Cells[8,1],'/9,',Tabl1.Cells[9,1],
'/10,',Tabl1.Cells[10,1]);
CloseFile(f);
end;
procedure TForm1.VivProgr2;
var
f:TextFile;
begin
AssignFile(f,'d:\ModRTr\Progr2.txt');
Rewrite(f);
writeln(f,'GENERATE ', StrToFloat(Edit7.text);
CloseFile(f);
end;
procedure TForm1.VivProgr3;
var
f:TextFile;
n1:integer;
begin
AssignFile(f,'d:\ModRTr\Progr3.txt');
Rewrite(f);
writeln(f,'OPEN ("DanTabl21.txt"),1,Kon1');
for n1:=1 to StrToInt(Edit6.text) do
writeln(f,'WRITE FR',n1,',,,OFF');
writeln(f,'Kon1 CLOSE Err1,1');
CloseFile(f);
end;
procedure TForm1.VivProgr4;
var
f:TextFile;
n1:integer;
begin
AssignFile(f,'d:\ModRTr\Progr4.txt');
Rewrite(f);
writeln(f,'OPEN ("DanTabl22.txt"),1,Kon2');
for n1:=1 to StrToInt(Edit6.text) do
writeln(f,'WRITE FT',n1,',,,OFF');
writeln(f,'Kon2 CLOSE Err1,1');
CloseFile(f);
end;
procedure TForm1.VivProgr5;
var
f:TextFile;
n1:integer;
begin
AssignFile(f,'d:\ModRTr\Progr5.txt');
Rewrite(f);
writeln(f,'OPEN ("DanTabl23.txt"),1,Kon3');
for n1:=1 to StrToInt(Edit6.text) do
writeln(f,'WRITE QM',n1,',,,OFF');
writeln(f,'WRITE X$VrVig',',,,OFF')
writeln(f,'Kon3 CLOSE Err1,1');
CloseFile(f);
end;Объявите в интерфейсной части программного модуля эти шесть процедур.
type TForm1 = class(TForm)
Edit1: TEdit;
…
procedure VivProgr;
procedure VivProgr1;
procedure VivProgr2;
procedure VivProgr3;
procedure VivProgr4;
procedure VivProgr5;
privateПосле выполнения процедуры VivProgr командой
WinExec('d:\ModRTr\GPSSW.exe',SW_RESTORE);запускается GPSS.exe. И далее пользователем - приложение Модель разгрузки транспортов. Курсор устанавливается на кнопке ВЫВОД.
Для обработки события - щелчка кнопки ВЫВОД - используйте следующий программный код:
procedure TForm1.Button6Click(Sender: TObject);
begin
FormActivate2(Sender);
VivRes1;
VivRes2;
VivRes3;
end;Обработка события начинается с выполнения процедуры FormActivate2(Sender). В результате этого вводятся заголовки в первую строку и в первый столбец второй таблицы. Затем последовательно выполняются процедуры VivRes1, VivRes2 и VivRes3, которые считывают результаты моделирования из файлов DanTabl211.txt, DanTabl212.txt и DanTabl213.txt соответственно и выводят их построчно во вторую таблицу.
Создайте обработчик события - щелчка кнопки ВЫВОД и в разделе implementation программного модуля ( .pas ) создайте процедуры FormActivate2(Sender) (см. п. 8.3.3), VivRes1, VivRes2 и VivRes3.
procedure TForm1.VivRes1;
var
f:TextFile;
n1:integer;
a:real;
begin
AssignFile(f, 'd:\ModRTr\DanTabl21.txt');
Reset(f);
for n1:=1 to (Tabl2.ColCount-1) do begin
read(f,a);
a:=Trunc(a);
a:=a/1000;
Tabl2.Cells[n1,1]:=FloatToStr(a);
end;
end;
procedure TForm1.VivRes2;
var
f:TextFile;
n1:integer;
a:real;
begin
AssignFile(f, 'd:\ModRTr\DanTabl22.txt');
Reset(f);
for n1:=1 to (Tabl2.ColCount-1) do begin
read(f,a);
a:=a*1000;
a:=Trunc(a);
a:=a/1000;
Tabl2.Cells[n1,2]:=FloatToStr(a);
end;
end;
procedure TForm1.VivRes3;
var
f:TextFile;
n1:integer;
a:real;
begin
AssignFile(f, 'd:\ModRTr\DanTabl23.txt');
Reset(f);
for n1:=1 to (Tabl2.ColCount-1) do
begin
read(f,a);
Tabl2.Cells[n1,3]:=FloatToStr(a);
end;
end;Объявите в интерфейсной части только что созданные четыре процедуры.
type TForm1 = class(TForm)
Edit1: TEdit;
…
procedure FormActivate2(Sender: TObject);
procedure VivRes1;
procedure VivRes2;
procedure VivRes3;
privateЗавершение работы с программой модели происходит при нажатии кнопки ВЫХОД ИЗ МОДЕЛИ. Результатом является закрытие формы приложения. Создайте обработчик этого события.
procedure TForm1.Button4Click(Sender: TObject);
begin
Form1.close;
end;8.4.3. Разработка процедур обработки событий для полей редактирования
В соответствии с видом формы имитационной модели сформулируем следующие требования к программе:
- в поля исходных данных модели допускается вводить только положительные числа, а ввод других символов программа должна блокировать;
- числа, вводимые в поля Edit3 и Edit5, не должны быть равны или больше чисел, вводимых в поля соответственно Edit2 и Edit4 (стандартное отклонение должно быть в пять раз и более меньше математического ожидания);
- во время ввода данных модели при нажатии на клавишу Enter курсор автоматически должен перемещаться в поле ввода следующего числа. Если клавиша Enter нажата во время ввода в поле Edit7, программа должна перейти к вводу в первую таблицу;
- при обнаружении ошибок при вводе в поля Edit3 или Edit5 курсор должен быть соответственно в одном из них;
- если в какое - то поле не введена хотя бы одна цифра (поле пустое) и нажата клавиша Enter, то возникает ошибка, о чем выдается сообщение, и ввод нужно повторить.
Чтобы программа удовлетворяла вышеприведенным требованиям, надо для каждого поля редактирования написать процедуру обработки события OnKeyPress, которая в зависимости от того, какую клавишу нажал пользователь, будет выполнять нужное действие.
Заготовка процедуры OnKeyPress для Edit1, генерируемая Delphi, выглядит следующим образом:
Procedure Tform1.Edit1KeyPress(Sender:Tobject; var Key:Char); begin end;
Заголовок процедуры Edit1KeyPress показывает, что процедура в качестве параметра получает символьную переменную Key. Эта переменная содержит символ, соответствующий нажатой клавише. Следует обратить внимание на то, что параметр принимается по ссылке (перед именем переменной стоит слово var ), поэтому процедура может изменить значение переменной. Символ, соответствующий нажатой клавише, появляется в поле редактирования после выполнения процедуры обработки события OnKeyPress, поэтому процедура обработки может заменить введенный символ или присвоением переменной Key значения Chr(0) запретить его появление в поле редактирования.
Ниже приведен программный код процедуры обработки события OnKeyPress в поле редактирования.
рrocedure TForm1.Edit1KeyPress(Sender:Tobject; var Key:Char);
begin
case Key of
'0'..'9',Chr(8):;
'-':Key:=Chr(0);
',':if pos(',',Edit1.text)<> then Key:=Chr(0);
Chr(13):Edit2.SetFocus
'.': begin
MessageDlg('Для отделения дробной части' +'числа'+#13
+'от целой используйте запятую', mtInformation, [mbOk],0);
Key:=Chr(0);
end;
else Key:=Chr(0);
end;
end;Процедура TForm1.Edit1KeyPress проверяет, какая клавиша нажата при вводе исходных данных в поле редактирования Edit1. Если нажата клавиша BackSprace, то процедура завершает свою работу и символ появляется в поле редактирования или стирается последний введённый символ. Если нажата запятая, то процедура проверяет, есть ли уже запятая в поле редактирования. Если есть, то ввод второй запятой блокируется. Если нажата клавиша "-", то ввод её тоже блокируется. Если нажата клавиша Enter, то применением метода SetFocus к полю редактирования Edit2 курсор перемещается в это поле.
Процедуры обработки события OnKeyPress полей редактирования отличаются только способом обработки нажатия клавиши Enter (в поле Edit1 Edit2.SetFocus, в поле Edit2 Edit3.SetFocus и т.д., а в поле Edit7
then
begin
FormActivate1(Sender);
Tabl1.SetFocus;
end;В остальном эти процедуры идентичны. Поэтому вместо написания процедур обработки события OnKeyPress для каждого поля редактирования можно написать одну общую процедуру, которая при нажатии Enter будет выбирать нужное действие в зависимости от того, в каком поле произошло событие. Получить информацию об источнике события можно проверкой значения параметра Sender.
Создайте в разделе implementation программный код процедур EditKeyPress и FormActivate1 (см. п. 8.3.3).
procedure TForm1.EditKeyPress(Sender: TObject; var Key: Char);
var
nak:string[20];
begin
if Sender=Edit1 then
nak:=Edit1.text
else if Sender=Edit2 then
nak:=Edit2.text
else if Sender=Edit3 then
nak:=Edit3.text
else if Sender=Edit4 then
nak:=Edit4.text
else if Sender=Edit5 then
nak:=Edit5.text
else if Sender=Edit6 then
nak:=Edit6.text
else nak:=Edit7.text;
case Key of
'0'..'9',Chr(8):;
'-':Key:=Chr(0);
',':if pos(',',nak) <>0 then Key:=Chr(0);
Chr(13):if Sender=Edit1
then Edit2.SetFocus
else if Sender=Edit2
then Edit3.SetFocus
else if Sender=Edit3
then Edit4.SetFocus
else if Sender=Edit4
then Edit5.SetFocus
else if Sender=Edit5
then Edit6.SetFocus
else if Sender=Edit6
then Edit7.SetFocus
else if Sender=Edit7
then
begin
FormActivate1(Sender);
Tabl1.SetFocus;
end;
'.':begin
MessageDlg('Для отделения дробной'
+'части от целой'+#13
+'используйте запятую',
mtInformation,[mbOk],0);
Key:=Chr(0);
end;
else Key:=Chr(0)
end;
end;Объявите в интерфейсной части:
type TForm1 = class(TForm) Edit1: TEdit; … procedure FormActivate1(Sender: TObject); private
Теперь выделите компонент Edit2 и на вкладке Events раскройте список. Из списка для onKeyPress щелчком установите EditKeyPress. Проделайте тоже для компонентов Edit3 … Edit7.
8.4.4. Модификация программы имитационной модели
Интерфейс приложения разработан. Согласно интерфейсу внесем изменения в исходную GPSS-модель (см. п. 8.2.2). Заменим строки программы с командой EQU и строки
SrVrA FUNCTION P3,D10 ; Среднее время выгрузки 1,26/2,20/3,30/4,25/5,15/6,18/7,28/8,32/9,23/10,30
командой
INCLUDE "Progr1.txt" ; Подключение файла
Модифицируем также сегмент задания времени моделирования.
;Сегмент задания времени моделирования INCLUDE "Progr2.txt" ; Подключение файла TEST E TG1,1,Met3 ; При TG1=1 - расчет результатов моделирования ; TEST NE N$VigTr,0,Met3 SAVEVALUE VrVig,((X$VrVigS/N$VigTr)/60) ; Среднее время выгрузки, час INCLUDE "Progr3.txt" ; Подключение файла INCLUDE "Progr4.txt" ; Подключение файла INCLUDE "Progr5.txt" ; Подключение файла Met3 TERMINATE 1
Разработка имитационной модели в виде приложения с интерфейсом завершена.
Отладьте приложение и перейдите к работе с ним.
8.5. Работа с приложением
Поместите в папку D:\ModRTr файл GPSS.exe и GPSS-модель ModRasgTr.gps. Нахождение файла Rasg_transporta.exe в этой же папке необязательно. Запустите Rasg_transporta.exe.
Нажмите кнопку ПРИМЕР. Автоматически будут введены данные, показанные на рис. 8.15.
Убедитесь, правильно ли выявляются ошибки, нахождение которых предусмотрено программным путем.
Проверьте, выполняется ли условие ввода характеристик нормального закона распределения случайных чисел. Измените в сторону увеличения любое из стандартных отклонений: введите в соответствующее поле редактирования, например, 4.2. Появится сообщение об ошибке (рис. 8.16): для отделения целой части от дробной нужно использовать запятую.
Нажмите OK. Повторите ввод числа с отделением его целой части от дробной части запятой в это же поле редактирования. Нажмите кнопку ВВОД. Появится предупреждение о другой ошибке (рис. 8.17). Нажмите OK и исправьте ошибку.
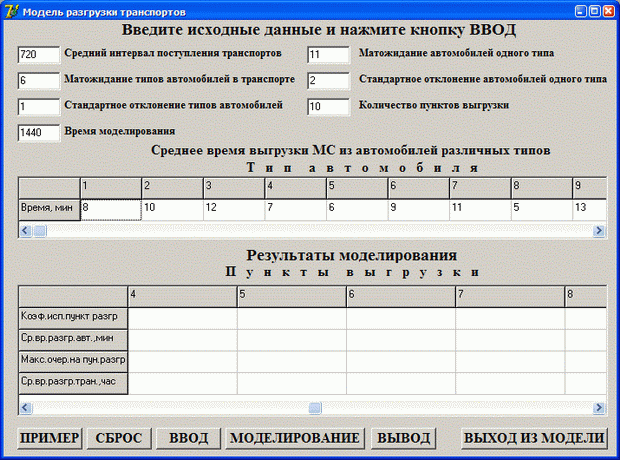
увеличить изображение
Рис. 8.15. Форма приложения с данными примера
Рис. 8.16. Сообщение об ошибке при вводе числа
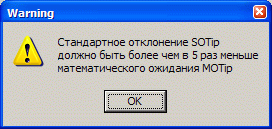
Рис. 8.17. Сообщение об ошибке при вводе стандартного отклонения
Далее удалите, например, количество пунктов разгрузки из поля редактирования и щелкните ВВОД. Появится предупреждение о том, что необходимо задать все исходные данные в полях редактирования (рис. 8.18). Щелкните OK и исправьте ошибку.
Теперь удалите, например, среднее время разгрузки автомобиля второго типа из первой таблицы и щелкните ВВОД. Появится предупреждение о том, что необходимо задать все исходные данные в полях редактирования (рис. 8.19). Щелкните OK, исправьте ошибку и нажмите ВВОД.
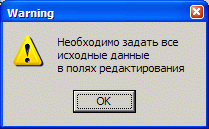
Рис. 8.18. Предупреждение о необходимости ввода всех данных в поля редактирования
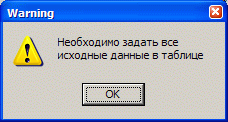
Рис. 8.19. Предупреждение о необходимости ввода всех данных в первую таблицу
Теперь ошибок ввода исходных данных нет. Щелкните кнопку МОДЕЛИРОВАНИЕ.
Выполните необходимые действия с GPSS-моделью. Закройте GPSS-exe и нажмите активную кнопку ВЫВОД. Во второй таблице появятся результаты моделирования (рис. 8.20):
- среднее время разгрузки автомобилей различных типов;
- коэффициенты использования пунктов разгрузки;
- максимальные очереди на пункты разгрузки;
- среднее время разгрузки одного транспорта.
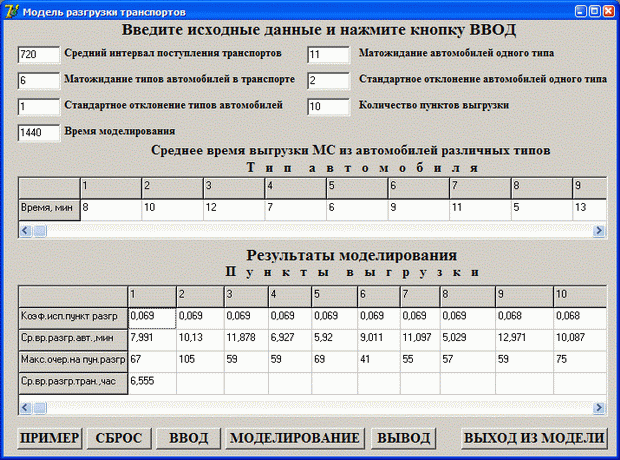
увеличить изображение
Рис. 8.20. Форма приложения с данными и результатами моделирования
Вопросы для самоконтроля
- Какова цель предназначения текстовых объектов и потоков данных?
- Какой командой подключаются текстовые объекты к объе-ту GPSS World "Модель"? Формат этой команды.
- Назначение и формат блока OPEN.
- Назначение и формат блока CLOSE.
- Назначение и формат блока READ.
- Назначение и формат блока WRITE.
- Назовите режимы работы блока WRITE и дайте им характеристику.
- Назначение и формат блока SEEK.
- Назначение и формат блока SELECT.
Дополнения
Дополнение. Приложения
Приложение 1
Таблица значений функции ![]()
| | | | | | | | |
|---|---|---|---|---|---|---|---|
| 0,00 | 0,0000 | 0,35 | 0,1368 | 0,70 | 0,2580 | 1,05 | 0,3531 |
| 0,01 | 0,0040 | 0,36 | 0,1406 | 0,71 | 0,2611 | 1,06 | 0,3554 |
| 0,02 | 0,0080 | 0,37 | 0,1443 | 0,72 | 0,2642 | 1,07 | 0,3577 |
| 0,03 | 0,0120 | 0,38 | 0,1480 | 0,73 | 0,2673 | 1,08 | 0,3599 |
| 0,04 | 0,0160 | 0,39 | 0,1517 | 0,74 | 0,2703 | 1,09 | 0,3621 |
| 0,05 | 0,0199 | 0,40 | 0,1554 | 0,75 | 0,2734 | 1,10 | 0,3643 |
| 0,06 | 0,0239 | 0,41 | 0,1591 | 0,76 | 0,2764 | 1,11 | 0,3665 |
| 0,07 | 0,0279 | 0,42 | 0,1628 | 0,77 | 0,2794 | 1,12 | 0,3686 |
| 0,08 | 0,0319 | 0,43 | 0,1664 | 0,78 | 0,2823 | 1,13 | 0,3708 |
| 0,09 | 0,0359 | 0,44 | 0,1700 | 0,79 | 0,2852 | 1,14 | 0,3729 |
| 0,10 | 0,0398 | 0,45 | 0,1736 | 0,80 | 0,2881 | 1,15 | 0,3739 |
| 0,11 | 0,0438 | 0,46 | 0,1772 | 0,81 | 0,2910 | 1,16 | 0,3770 |
| 0,12 | 0,0478 | 0,47 | 0,1808 | 0,82 | 0,2939 | 1,17 | 0,3790 |
| 0,13 | 0,0517 | 0,48 | 0,1844 | 0,83 | 0,2967 | 1,18 | 0,3810 |
| 0,14 | 0,0557 | 0,49 | 0,1879 | 0,84 | 0,2995 | 1,19 | 0,3830 |
| 0,15 | 0,0596 | 0,50 | 0,1915 | 0,85 | 0,3023 | 1,20 | 0,3849 |
| 0,16 | 0,0636 | 0,51 | 0,1950 | 0,86 | 0,3051 | 1,21 | 0,3869 |
| 0,17 | 0,0675 | 0,52 | 0,1985 | 0,87 | 0,3078 | 1,22 | 0,3883 |
| 0,18 | 0,0714 | 0,53 | 0,2019 | 0,88 | 0,3106 | 1,23 | 0,3907 |
| 0,19 | 0,0753 | 0,54 | 0,2054 | 0,89 | 0,3133 | 1,24 | 0,3925 |
| 0,20 | 0,0793 | 0,55 | 0,2088 | 0,90 | 0,3159 | 1,25 | 0,3944 |
| 0,21 | 0,0832 | 0,56 | 0,2123 | 0,91 | 0,3186 | 1,26 | 0,3962 |
| 0,22 | 0,0871 | 0,57 | 0,2157 | 0,92 | 0,3212 | 1,27 | 0,3980 |
| 0,23 | 0,0910 | 0,58 | 0,2190 | 0,93 | 0,3238 | 1,28 | 0,3997 |
| 0,24 | 0,0948 | 0,59 | 0,2224 | 0,94 | 0,3264 | 1,29 | 0,4015 |
| 0,25 | 0,0987 | 0,60 | 0,2257 | 0,95 | 0,3289 | 1,30 | 0,4032 |
| 0,26 | 0,1026 | 0,61 | 0,2291 | 0,96 | 0,3315 | 1,31 | 0,4049 |
| 0,27 | 0,1064 | 0,62 | 0,2324 | 0,97 | 0,3340 | 1,32 | 0,4066 |
| 0,28 | 0,1103 | 0,63 | 0,2357 | 0,98 | 0,3365 | 1,33 | 0,4082 |
| 0,29 | 0,1141 | 0,64 | 0,2389 | 0,99 | 0,3389 | 1,34 | 0,4099 |
| 0,30 | 0,1179 | 0,65 | 0,2422 | 1,00 | 0,3413 | 1,35 | 0,4115 |
| 0,31 | 0,1217 | 0,66 | 0,2454 | 1,01 | 0,3438 | 1,36 | 0,4131 |
| 0,32 | 0,1255 | 0,67 | 0,2486 | 1,02 | 0,3461 | 1,37 | 0,4147 |
| 0,33 | 0,1293 | 0,68 | 0,2517 | 1,03 | 0,3485 | 1,38 | 0,4162 |
| 0,34 | 0,1331 | 0,69 | 0,2549 | 1,04 | 0,3508 | 1,39 | 0,4177 |
| | | | | | | | |
|---|---|---|---|---|---|---|---|
| 1,40 | 0,4192 | 1,71 | 0,4564 | 2,04 | 0,4793 | 2,66 | 0,4961 |
| 1,41 | 0,4207 | 1,72 | 0,4573 | 2,06 | 0,4803 | 2,68 | 0,4963 |
| 1,42 | 0,4222 | 1,73 | 0,4582 | 2,08 | 0,4812 | 2,70 | 0,4965 |
| 1,43 | 0,4236 | 1,74 | 0,4591 | 2,10 | 0,4821 | 2,72 | 0,4967 |
| 1,44 | 0,4251 | 1,75 | 0,4599 | 2,12 | 0,4830 | 2,74 | 0,4969 |
| 1,45 | 0,4265 | 1,76 | 0,4608 | 2,14 | 0,4838 | 2,76 | 0,4971 |
| 1,46 | 0,4279 | 1,77 | 0,4616 | 2,16 | 0,4846 | 2,78 | 0,4973 |
| 1,47 | 0,4292 | 1,78 | 0,4625 | 2,18 | 0,4854 | 2,80 | 0,4974 |
| 1,48 | 0,4306 | 1,79 | 0,4633 | 2,20 | 0,4861 | 2,82 | 0,4976 |
| 1,49 | 0,4319 | 1,80 | 0,4641 | 2,22 | 0,4868 | 2,84 | 0,4977 |
| 1,50 | 0,4332 | 1,81 | 0,4649 | 2,24 | 0,4875 | 2,86 | 0,4979 |
| 1,51 | 0,4345 | 1,82 | 0,4656 | 2,26 | 0,4881 | 2,88 | 0,4980 |
| 1,52 | 0,4357 | 1,83 | 0,4664 | 2,28 | 0,4887 | 2,90 | 0,4981 |
| 1,53 | 0,4370 | 1,84 | 0,4671 | 2,30 | 0,4893 | 2,92 | 0,4982 |
| 1,54 | 0,4382 | 1,85 | 0,4678 | 2,32 | 0,4898 | 2,94 | 0,4984 |
| 1,55 | 0,4394 | 1,86 | 0,4686 | 2,34 | 0,4904 | 2,96 | 0,4985 |
| 1,56 | 0,4406 | 1,87 | 0,4693 | 2,36 | 0,4909 | 2,98 | 0,4986 |
| 1,57 | 0,4418 | 1,88 | 0,4699 | 2,38 | 0,4913 | 3,00 | 0,49865 |
| 1,58 | 0,4429 | 1,89 | 0,4706 | 2,40 | 0,4918 | 3,20 | 0,49931 |
| 1,59 | 0,4441 | 1,90 | 0,4713 | 2,42 | 0,4922 | 3,40 | 0,49966 |
| 1,60 | 0,4452 | 1,91 | 0,4719 | 2,44 | 0,4927 | 3,60 | 0,499841 |
| 1,61 | 0,4463 | 1,92 | 0,4726 | 2,46 | 0,4931 | 3,80 | 0,499928 |
| 1,62 | 0,4474 | 1,93 | 0,4732 | 2,48 | 0,4934 | 4,00 | 0,499968 |
| 1,63 | 0,4484 | 1,94 | 0,4738 | 2,50 | 0,4938 | 4,50 | 0,499997 |
| 1,64 | 0,4495 | 1,95 | 0,4744 | 2,52 | 0,4941 | 5,00 | 0,499999 |
| 1,65 | 0,4505 | 1,96 | 0,4750 | 2,54 | 0,4945 | ||
| 1,66 | 0,4515 | 1,97 | 0,4756 | 2,56 | 0,4948 | ||
| 1,67 | 0,4525 | 1,98 | 0,4761 | 2,58 | 0,4951 | ||
| 1,68 | 0,4535 | 1,99 | 0,4767 | 2,60 | 0,4953 | ||
| 1,69 | 0,4545 | 2,00 | 0,4772 | 2,62 | 0,4956 | ||
| 1,70 | 0,4554 | 2,02 | 0,4783 | 2,64 | 0,4959 |
Приложение 2
Критические точки распределения F Фишера
( ![]() - число степеней свободы большей дисперсии,
- число степеней свободы большей дисперсии,
![]() - число степеней свободы меньшей дисперсии)
- число степеней свободы меньшей дисперсии)
| Уровень значимости | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| | 2 | 4 | 6 | 8 | 10 | 12 | 20 | 24 | 150 |
| 2 | 19,00 | 19,25 | 19,33 | 19,37 | 19,39 | 19,41 | 19,44 | 19,45 | 19,49 |
| 4 | 6,94 | 6,39 | 6,16 | 6,04 | 5,96 | 5,91 | 5,80 | 5,77 | 5,65 |
| 6 | 5,14 | 4,53 | 4,28 | 4,15 | 4,06 | 4,00 | 3,87 | 3,84 | 2,97 |
| 8 | 4,46 | 3,84 | 3,58 | 3,44 | 3,34 | 3,28 | 3,15 | 3,12 | 2,58 |
| 10 | 4,1 | 3,48 | 3,22 | 3,07 | 2,97 | 2,91 | 2,77 | 2,74 | 2,34 |
| 12 | 3,88 | 3,26 | 3,00 | 2,80 | 2,76 | 2,69 | 2,54 | 2,50 | 2,18 |
| 14 | 3,74 | 3,11 | 2,85 | 2,70 | 2,60 | 2,53 | 2,39 | 2,35 | 2,06 |
| 16 | 3,63 | 3,01 | 2,74 | 2,59 | 2,49 | 2,42 | 2,28 | 2,24 | 1,97 |
| 18 | 3,55 | 2,93 | 2,66 | 2,51 | 2,41 | 2,34 | 2,19 | 2,15 | 1,89 |
| 20 | 3,49 | 2,87 | 2,60 | 2,45 | 2,35 | 2,28 | 2,12 | 2,08 | 1,82 |
| 22 | 3,44 | 2,82 | 2,55 | 2,4 | 2,30 | 2,23 | 2,07 | 2,03 | 1,78 |
| 24 | 3,40 | 2,78 | 2,51 | 2,36 | 2,26 | 2,18 | 2,02 | 1,98 | 1,74 |
| 26 | 3,37 | 2,74 | 2,47 | 2,32 | 2,22 | 2,15 | 1,99 | 1,95 | 1,71 |
| 28 | 3,34 | 2,71 | 2,44 | 2,29 | 2,19 | 2,12 | 1,96 | 1,91 | 1,68 |
| 150 | 3,06 | 2,43 | 2,16 | 2,00 | 1,89 | 1,82 | 1,64 | 1,59 | 1,33 |
| Уровень значимости | |||||||||
| | 2 | 4 | 6 | 8 | 10 | 12 | 20 | 24 | 120 |
| 2 | 99,01 | 99,25 | 99,33 | 99,36 | 99,40 | 99,42 | 99,45 | 99,46 | 99,49 |
| 4 | 18,00 | 15,98 | 15,21 | 14,80 | 14,54 | 14,37 | 14,02 | 13,63 | 13,56 |
| 6 | 10,92 | 9,15 | 8,47 | 8,10 | 7,87 | 7,72 | 7,40 | 7,31 | 6,97 |
| 8 | 8,65 | 7,01 | 6,37 | 6,03 | 5,82 | 5,67 | 5,36 | 5,28 | 4,95 |
| 10 | 7,56 | 5,99 | 5,39 | 5,06 | 4,85 | 4,71 | 4,41 | 4,33 | 4,00 |
| 12 | 6,93 | 5,41 | 4,82 | 4,50 | 4,30 | 4,16 | 3,86 | 3,78 | 3,45 |
| 14 | 6,51 | 5,03 | 4,46 | 4,14 | 3,94 | 3,80 | 3,51 | 3,43 | 3,09 |
| 16 | 6,23 | 4,77 | 4,20 | 3,89 | 3,69 | 3,55 | 3,25 | 3,18 | 2,85 |
| 18 | 6,01 | 4,58 | 4,01 | 3,71 | 3,51 | 3,37 | 3,07 | 3,00 | 2,66 |
| 20 | 5,85 | 4,43 | 3,87 | 3,56 | 3,37 | 3,23 | 2,94 | 2,26 | 2,52 |
| 22 | 5,72 | 4,31 | 3,76 | 3,45 | 3,26 | 3,12 | 2,83 | 2,75 | 2,40 |
| 24 | 5,61 | 4,22 | 3,67 | 3,36 | 3,17 | 3,03 | 2,74 | 2,66 | 2,31 |
| 26 | 5,53 | 4,14 | 3,6 | 3,29 | 3,09 | 2,96 | 2,66 | 2,59 | 2,23 |
| 28 | 5,45 | 4,07 | 3,53 | 3,23 | 3,03 | 2,90 | 2,60 | 2,52 | 2,17 |
| 120 | 4,79 | 3,48 | 2,96 | 2,66 | 2,47 | 2,34 | 2,04 | 1,95 | 1,53 |